计算机竞赛 基于LSTM的天气预测 - 时间序列预测
0 前言
🔥 优质竞赛项目系列,今天要分享的是
机器学习大数据分析项目
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 数据集介绍
df = pd.read_csv(‘/home/kesci/input/jena1246/jena_climate_2009_2016.csv’)
df.head()
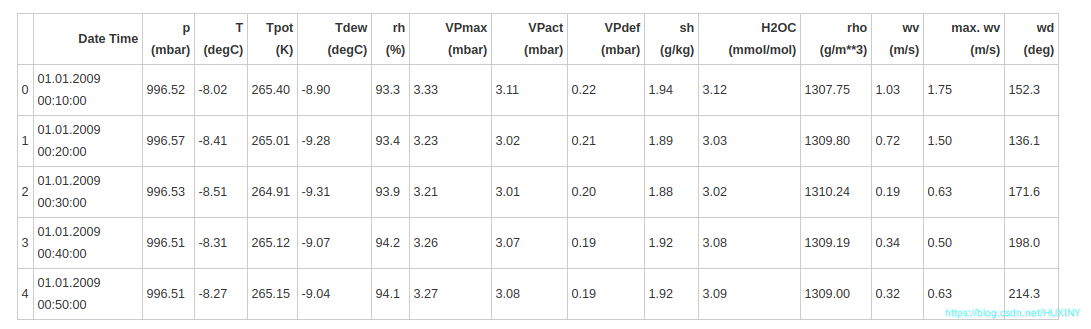
如上所示,每10分钟记录一次观测值,一个小时内有6个观测值,一天有144(6x24)个观测值。
给定一个特定的时间,假设要预测未来6小时的温度。为了做出此预测,选择使用5天的观察时间。因此,创建一个包含最后720(5x144)个观测值的窗口以训练模型。
下面的函数返回上述时间窗以供模型训练。参数 history_size 是过去信息的滑动窗口大小。target_size
是模型需要学习预测的未来时间步,也作为需要被预测的标签。
下面使用数据的前300,000行当做训练数据集,其余的作为验证数据集。总计约2100天的训练数据。
def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_sizeif end_index is None:end_index = len(dataset) - target_sizefor i in range(start_index, end_index):indices = range(i-history_size, i)# Reshape data from (history`1_size,) to (history_size, 1)data.append(np.reshape(dataset[indices], (history_size, 1)))labels.append(dataset[i+target_size])return np.array(data), np.array(labels)
2 开始分析
2.1 单变量分析
首先,使用一个特征(温度)训练模型,并在使用该模型做预测。
2.1.1 温度变量
从数据集中提取温度
uni_data = df[‘T (degC)’]
uni_data.index = df[‘Date Time’]
uni_data.head()
观察数据随时间变化的情况
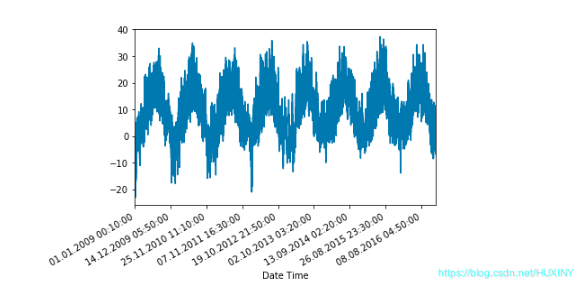
进行标准化
#标准化
uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
uni_data = (uni_data-uni_train_mean)/uni_train_std
#写函数来划分特征和标签
univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT, # 起止区间univariate_past_history,univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,univariate_past_history,univariate_future_target)
可见第一个样本的特征为前20个时间点的温度,其标签为第21个时间点的温度。根据同样的规律,第二个样本的特征为第2个时间点的温度值到第21个时间点的温度值,其标签为第22个时间点的温度……
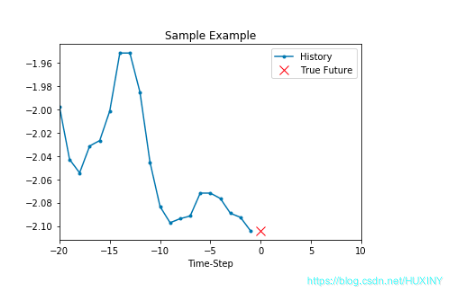
2.2 将特征和标签切片
BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
2.3 建模
simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]), # input_shape=(20,1) 不包含批处理维度
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
2.4 训练模型
EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_univariate, validation_steps=50)
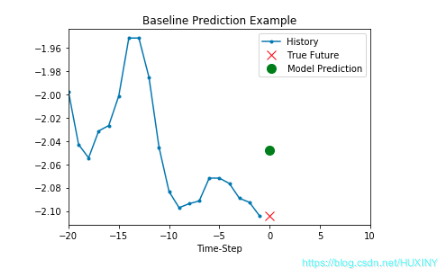
训练过程
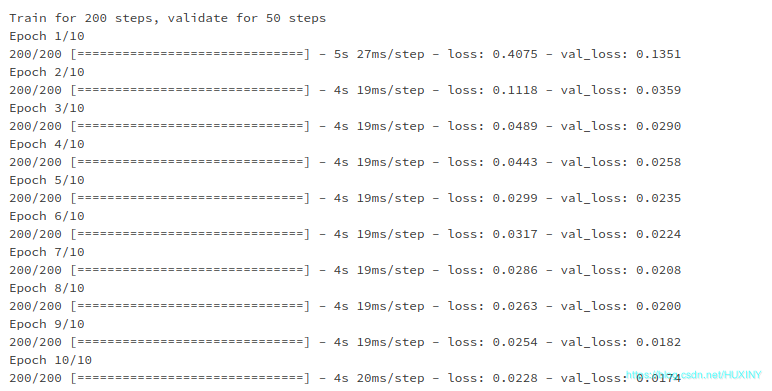
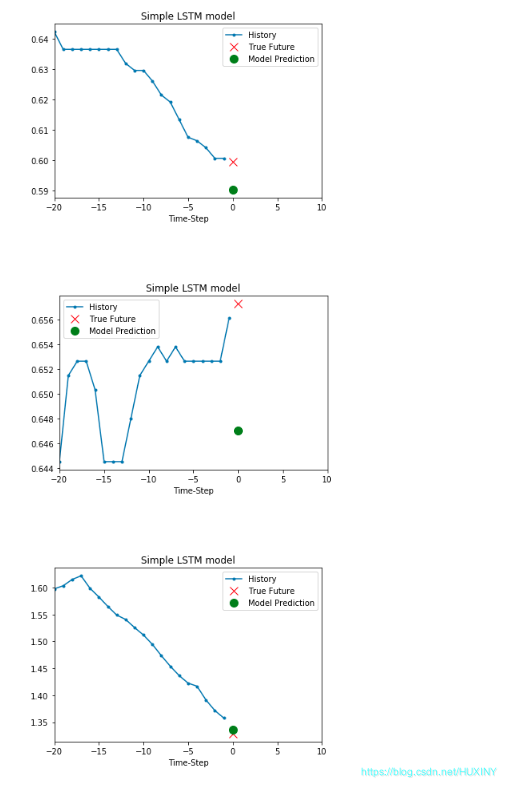
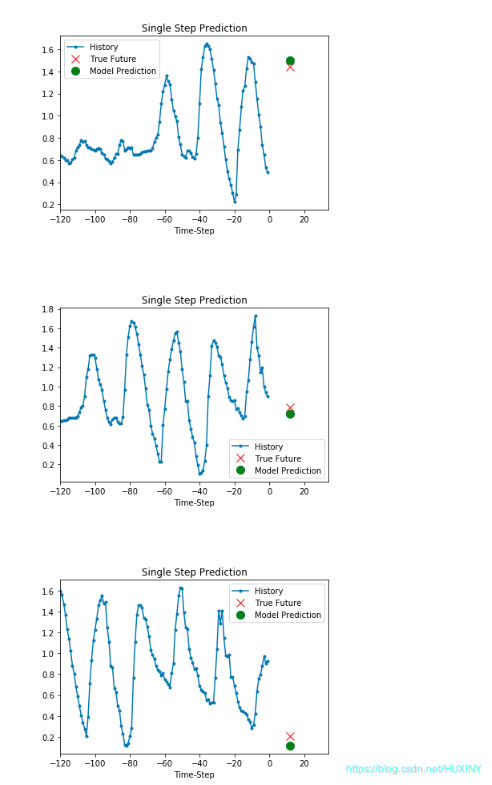
训练结果 - 温度预测结果
2.5 多变量分析
在这里,我们用过去的一些压强信息、温度信息以及密度信息来预测未来的一个时间点的温度。也就是说,数据集中应该包括压强信息、温度信息以及密度信息。
2.5.1 压强、温度、密度随时间变化绘图
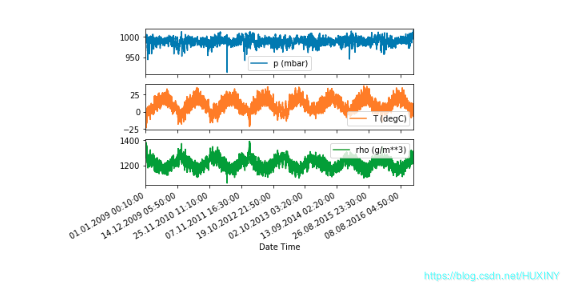
2.5.2 将数据集转换为数组类型并标准化
dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_stddef multivariate_data(dataset, target, start_index, end_index, history_size,target_size, step, single_step=False):data = []labels = []start_index = start_index + history_sizeif end_index is None:end_index = len(dataset) - target_sizefor i in range(start_index, end_index):indices = range(i-history_size, i, step) # step表示滑动步长data.append(dataset[indices])if single_step:labels.append(target[i+target_size])else:labels.append(target[i:i+target_size])return np.array(data), np.array(labels)
2.5.3 多变量建模训练训练
single_step_model = tf.keras.models.Sequential()single_step_model.add(tf.keras.layers.LSTM(32,input_shape=x_train_single.shape[-2:]))single_step_model.add(tf.keras.layers.Dense(1))single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_data_single,validation_steps=50)def plot_train_history(history, title):loss = history.history['loss']val_loss = history.history['val_loss']epochs = range(len(loss))plt.figure()plt.plot(epochs, loss, 'b', label='Training loss')plt.plot(epochs, val_loss, 'r', label='Validation loss')plt.title(title)plt.legend()plt.show()plot_train_history(single_step_history,'Single Step Training and validation loss')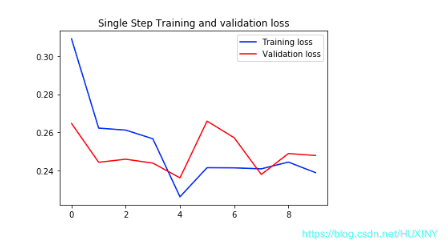
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 基于LSTM的天气预测 - 时间序列预测
0 前言 🔥 优质竞赛项目系列,今天要分享的是 机器学习大数据分析项目 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/po…...

uniapp 回退到指定页面 保存页面状态
uniapp 历史页面回退到指定页面。 getCurrentPages() 内容如下 let delta getCurrentPages().reverse().findIndex(item > item.route "pages/popularScience/daodi") if(delta-1){uni.navigateTo({url: /pages/popularScience/daodi,success: res > {},fa…...

ansible(1)-- 部署ansible连接被控端
目录 一、部署ansible 1.1 安装 1.2 测试连接 192.168.136.55 ansible 192.168.136.56被控端 一、部署ansible 1.1 安装 zabbix-s只是主机名,不用在意,更好该主机也安装了zabbix,不好更改。 下载阿里云epel源 #安装阿里云的epel源&#…...

Log4j反序列化命令执行漏洞(CVE-2017-5645)Apache Log4j2 lookup JNDI 注入漏洞(CVE-2021-44228)
一.Log4j反序列化命令执行漏洞(CVE-2017-5645) Apache Log4j是一个用于Java的日志记录库,其支持启动远程日志服务器。Apache Log4j 2.8.2之前的2.x版本中存在安全漏洞。攻击者可利用该漏洞执行任意代码 环境:vulhub 工具下载地址࿱…...

echarts 之 科技感进度条
1.图片展示 2.代码实现 /* ng qty 进度条 */ <template><div class"ngqty-progress"><div class"ngqty-info"><span>X4</span><span>50%</span></div><div :id"barNgQtyProgress index" c…...

基于gin关于多级菜单的处理
多级菜单是很多业务场景需要的。下面是一种处理方式 // 生成树结构 func tree(menus []*video.XkVideoCategory, parentId uint) []*video.XkVideoCategory {//定义子节点目录var nodes []*video.XkVideoCategoryif reflect.ValueOf(menus).IsValid() {//循环所有一级菜单for …...

Oracle/PL/SQL奇技淫巧之Lable标签与循环控制
在一些存储过程场景中,可能存在需要在满足某些条件时跳出循环的场景, 但是在PL/SQL中,不能使用break语句直接跳出循环, 但是可以通过lable标签的方式跳出循环,例: <<outer_loop>> FOR i IN 1..5 LOOPDBMS…...
Docker基础操作
1.安装docker服务,配置镜像加速器 安装docker服务 清理缓存 sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-enginesystemctl enable --now docker 脚…...
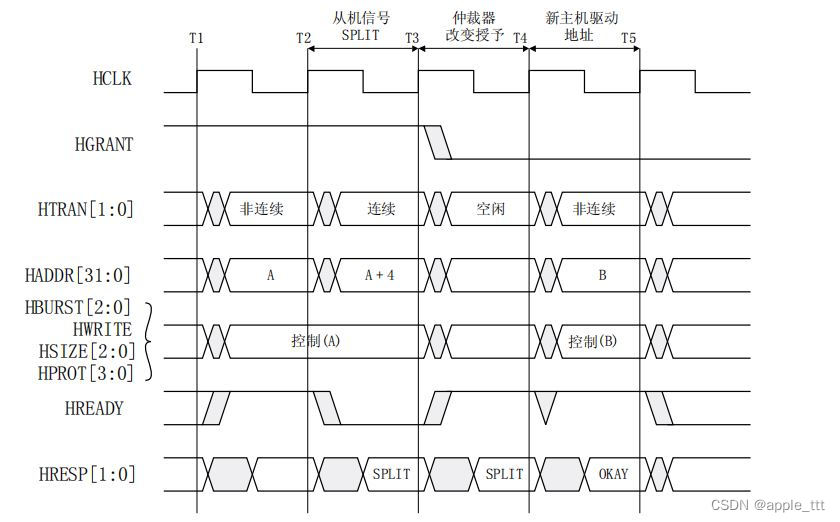
AMBA总线协议(8)——AHB(六):分割传输
一、前言 在之前的文章中,我们重点介绍了AHB传输的仲裁,首先介绍了仲裁相关的信号,然后分别介绍了请求总线访问,授权总线访问,猝发提前终止,锁定传输和默认主机总线,在本文中我们将继续介绍AHB的…...
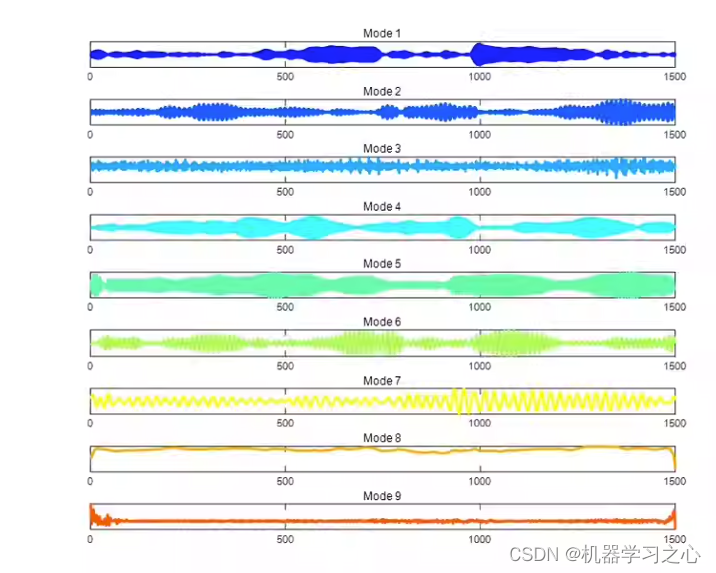
时序分解 | MATLAB实现基于SWD群体分解的信号分解分量可视化
时序分解 | MATLAB实现基于SWD群体分解的信号分解分量可视化 目录 时序分解 | MATLAB实现基于SWD群体分解的信号分解分量可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 基于SWD群体分解的分量可视化,基于群体分解的信号分解技术,MATLAB程序…...

【makefile】自动化变量的简述及实例
文章目录 10. env20. 简述百度百科常用的自动化变量 30. 实例90. 附件下载 10. env ubuntu1804 GNU Make 4.120. 简述 百度百科 https://baike.baidu.com/item/Makefile/4619787?frge_ala makefile 文件的格式: 目标:依赖命令软件编译的流程概述&am…...
IntelliJ IDEA 官方网站 idea官网 http://www.jetbrains.com/idea/
IntelliJ IDEA 官方网站 idea官网 http://www.jetbrains.com/idea/ Idea下载官网一键直达: 官网一键直达...
C#,《小白学程序》第一课:初识程序
曰:扫地僧练就绝世武功的目的是为了扫地更干净。 1 文本格式 /// <summary> /// 《小白学程序》第一课:初识程序 /// </summary> /// <param name"sender"></param> /// <param name"e"></param&…...

LeetCode--HOT100题(38)
目录 题目描述:226. 翻转二叉树(简单)题目接口解题思路代码 PS: 题目描述:226. 翻转二叉树(简单) 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 LeetCode做题链…...

C语言:指针(超深度讲解)
目录 指针: 学习目标: 指针可以理解为: 字符指针: 定义:字符指针 char*。 字符指针的使用: 练习: 指针数组: 概念:指针数组是一个存放指针的数组。 实现模拟二维…...
Docker详解
文章目录 Docker详解一、Docker简介什么是容器 ?容器技术有哪些优点 ?什么是Docker ?Docker的特点Docker的使用场景 二、Docker的基本组成Docker 客户端 / 守护进程Docker Image 镜像Docker Container 容器Docker Registry 仓库 三、Docker 依…...

软件开发方法:复用与扩展
软件开发方法:复用与扩展 一、面向对象二、进一步认识 一、面向对象 封装 工程上的意义:屏蔽细节,隔离变化 public、protected、private 继承 工程上的意义:复用 多态工程上的意义:高内聚,低耦合 —— 面…...
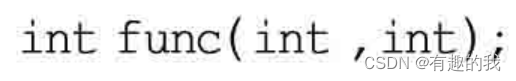
C++新经典09--函数新特性、inline内联函数与const详解
函数回顾与后置返回类型 函数定义中如果有形参则形参应该有名字,而不光是只有类型,但是如果并不想使用这个形参,换句话说这个形参并不在这个函数中使用,则不给形参名也可以,但在调用这个函数的时候,该位置…...
C++中机器人应用程序的行为树(ROS2)
马库斯布赫霍尔茨 一、说明 以下文章为您提供了对机器人应用程序或框架中经常使用的行为树的一般直觉:ROS,Moveit和NAV2。了解行为 Tress (BT) 框架的原理为您提供了在游戏领域应用知识的绝佳机会。BT可以与Unity或Unreal集成。 由…...
像Vuex一样使用redux
redux基础知识 本篇文章主要介绍redux的基本使用方法,并简单封装,像vuex一样写redux 学习文档 英文文档: https://redux.js.org/ 中文文档: http://www.redux.org.cn/ Github: https://github.com/reactjs/redux redux是什么 redux和vuex几乎是一…...

智能+OpenCore EFI配置工具:OpCore-Simplify让黑苹果搭建效率提升300%+
智能OpenCore EFI配置工具:OpCore-Simplify让黑苹果搭建效率提升300% 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore-Simplify是一…...
)
L0phtCrack 7密码爆破实测:8位混合密码要跑多久?(含虚拟机安全测试指南)
L0phtCrack 7密码爆破实战:从原理到防御的深度解析 在网络安全领域,密码强度与破解时间的量化分析一直是红蓝对抗中的核心课题。本文将带您深入理解密码破解背后的技术原理,并通过在VMware虚拟机环境下的对照实验,展示不同复杂度…...

Element-UI+Axios:如何优雅处理Vue异步请求的Loading状态?
Element-UIAxios:企业级后台系统的Loading状态高阶实践 在数据密集型的后台管理系统开发中,异步请求的状态反馈直接影响用户体验。当页面需要同时处理数十个表单提交、图表数据加载和批量操作时,如何避免Loading状态的混乱闪烁?怎…...

从视频处理到医疗影像:Conv3D输出形状计算中的那些‘坑’与高效设计指南
从视频处理到医疗影像:Conv3D输出形状计算中的那些‘坑’与高效设计指南 当你在深夜调试一个3D卷积神经网络时,突然发现输出的特征图尺寸比预期小了整整一半——这种场景对于处理视频分类或医疗影像的工程师来说再熟悉不过了。Conv3D层看似简单的参数设…...

Codesys实战排障手记:从证书过期到RTC时钟校准
1. 当Codesys突然弹出证书过期警告时 那天我正在客户现场调试禾川HCQ1系列PLC,刚打开Codesys V3.5开发环境,一个鲜红的证书过期警告就弹了出来。这种突如其来的报错让现场气氛瞬间紧张——产线等着调试,设备等着联调,而系统却在关…...

NaViL-9B效果实录:复杂场景下中英文混合文字识别准确率达98.2%
NaViL-9B效果实录:复杂场景下中英文混合文字识别准确率达98.2% 1. 模型介绍 NaViL-9B是一款原生多模态大语言模型,由专业研究机构开发。它能够同时处理纯文本问答和图片理解任务,特别擅长复杂场景下的文字识别。在实际测试中,该…...

CI/CD实战:使用GitHub Actions自动化部署faasd函数
CI/CD实战:使用GitHub Actions自动化部署faasd函数 【免费下载链接】faasd A lightweight & portable faas engine 项目地址: https://gitcode.com/gh_mirrors/fa/faasd faasd是一个轻量级、可移植的函数即服务(FaaS)引擎…...

2024网安保研上岸图鉴:从211边缘到清北直博的破局之路
1. 边缘人的逆袭起点:认清定位比盲目努力更重要 作为西北某211计算机大类边缘专业的学生,我的起点可以说毫无优势。专业名称听着像计算机,实际课程设置却偏向传统工科;学院往届最优秀的学长也只止步华五;我的编程能力在…...

开源阅读工具资源维护全指南:从故障诊断到主动防御
开源阅读工具资源维护全指南:从故障诊断到主动防御 【免费下载链接】Yuedu 📚「阅读」APP 精品书源(网络小说) 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 开源阅读工具作为获取网络文学资源的重要途径࿰…...

零成本上线个人博客:我的阿贝云免费云服务器实战记录
作为一名学生党/程序员,你是否也想拥有一台属于自己的云服务器,用来搭建博客、跑 Demo、练习 Linux?但又被各大云厂商的“首月0元”、“学生认证”等套路劝退?前段时间,我无意间发现了 阿贝云 的 永久免费云服务器 和 …...