Kafka 集群搭建过程
前言
跟着尚硅谷海哥文档搭建的Kafka集群环境,在此记录一下,侵删
注意:博主在服务器上搭建环境的时候使用的是一个服务器,所以这篇博客可能会出现一些xsync分发到其他服务器时候的错误,如果你在搭建的过程中出现了错误,欢迎评论来访,我们一起解决。
准备工作
准备三台服务器:hadoop102,hadoop103,hadoop104,在opt文件下先创建两个文件module和software
Hadoop 部分(Hadoop如果不使用的话,可以不用安装Hadoop,但是在此阶段的环境搭建还要进行)
JDK的安装
1、用XShell传输工具将JDK导入到 opt 目录下的 software 文件夹下面
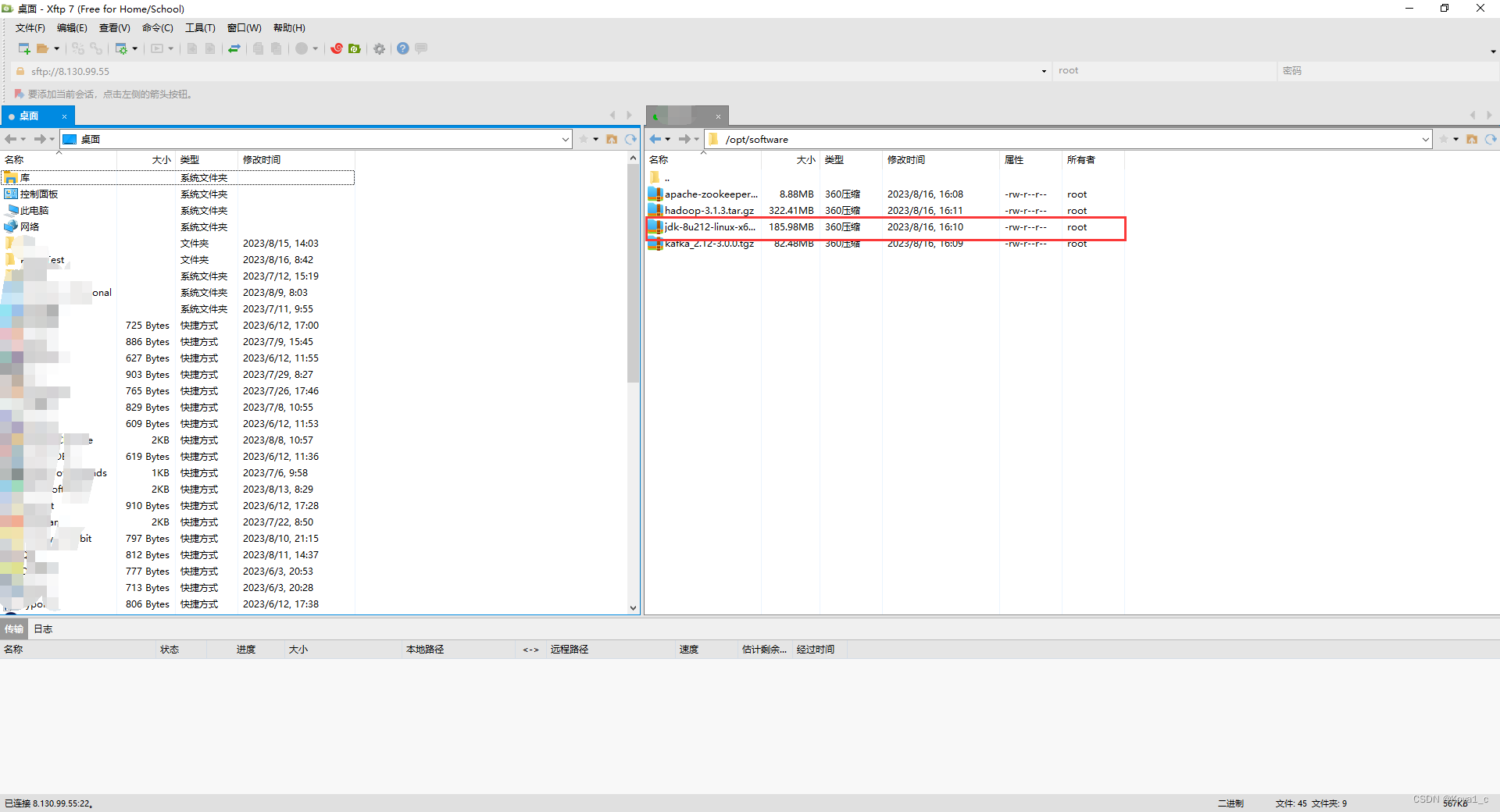
2、在software目录下解压JDK到/opt/module目录下
[root@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module
3、配置JDK环境变量
新建/etc/profile.d/my_env.sh文件
[root@hadoop102 /]# sudo vim /etc/profile.d/my_env.sh
添加一下内容,然后保存后退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/binsource一下/etc/profile文件,让新的环境变量PATH生效
[root@hadoop102 /]# source /etc/profile
4、测试JDK是否安装成功
[root@hadoop102 /]# java -version
看到以下结果,代表Java安装成功
java version "1.8.0_212"
集群分发脚本:xsync
1、在/usr/bin中添加脚本
[root@hadoop102 /]# cd /usr/bin
[root@hadoop102 bin]# vim xsync
2、在该文件中编写以下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
3、修改脚本 xsync 执行权限
[root@hadoop102 bin]# chmod +x xsync
4、同步jdk1.8.0_212到其他服务器
[root@hadoop102 /]# xsync jdk1.8.0_212
5、同步环境变量
[root@hadoop102 /]# sudo xsync /etc/profile.d/my_env.sh
6、在各自的服务器让环境变量生效
[root@hadoop102 /]# source /etc/profile
查看服务器Java进程脚本:jpsall
1、在/usr/bin中添加脚本
[root@hadoop102 /]# cd /usr/bin
[root@hadoop102 bin]# vim jpsall
2、输入以下内容,然后保存退出
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
doecho =============== $host ===============ssh $host jps
done3、赋予脚本执行权限
[root@hadoop102 bin]# chmod +x jpsall
4、分发 jpsall 脚本,保证其在三台服务器上都可以使用
[root@hadoop102 /]# xsync /usr/bin
Zookeeper 部分
Zookeeper 本地安装
1、用XShell传输工具将Zookeeper导入到 opt 目录下的 software 文件夹下面
2、在software目录下解压JDK到/opt/module目录下
[root@hadoop102 software]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module
3、修改名称
[root@hadoop102 module]# mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
4、在/opt/module/zookeeper-3.5.7/这个目录下创建 zkData
[root@hadoop102 zookeeper-3.5.7]# mkdir zkData
5、在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
[root@hadoop102 zkData]# vim myid
在文件中添加与server对应的编号,如hadoop102中填写2(上下不要用空行,左右不要有空格)
2
6、分发到其他服务器上
[root@hadoop102 /]# xsync zookeeper-3.5.7
并分别在 hadoop103、hadoop104上修改myid文件中的内容为3、4
7、将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg
[root@hadoop102 conf]# mv zoo_sample.cfg zoo.cfg
8、打开zoo.cfg文件,修改 dataDir 路径
[root@hadoop102 conf]# vim zoo.cfg
# 修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
# 增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
9、同步zoo.cfg配置文件
[root@hadoop102 conf]# xsync zoo.cfg
10、分别启动Zookeeper
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[root@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[root@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
11、查看状态
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
[root@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh status
[root@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh status
ZK集群启动停止脚本:zk.sh
1、在/usr/bin中添加脚本
[root@hadoop102 bin]$ vim zk.sh
在脚本中编写如下内容
#!/bin/bashcase $1 in
"start"){for i in VM-16-14-centosdoecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"done
};;
"stop"){for i in VM-16-14-centosdoecho ---------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"done
};;
"status"){for i in VM-16-14-centosdoecho ---------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"done
};;
esac
2、增加脚本执行权限
[root@hadoop102 bin]$ chmod u+x zk.sh
3、Zookeeper 集群启动脚本
[root@hadoop102 /]$ zk.sh start
4、Zookeeper 集群停止脚本
[root@hadoop102 /]$ zk.sh stop
6、同步脚本
[root@hadoop102 /]# xsync /usr/bin
Kafka 部分
Kafka 安装
1、用XShell传输工具将Zookeeper导入到 opt 目录下的 software 文件夹下面
2、在software目录下解压JDK到/opt/module目录下
[root@hadoop102 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module
3、修改解压的名称
[root@hadoop102 module]# mv kafka_2.12-3.0.0/ kafka
4、进入到/opt/module/kafka 目录,修改配置文件
[root@hadoop102 kafka]$ cd config/
[root@hadoop102 config]$ vim server.properties
5、修改 dataDir 路径
# broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0# kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas# 增加以下内容
# 配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
6、分发安装包到其他服务器
[root@hadoop102 module]$ xsync kafka/
7、分别在 hadoop103 和 hadoop104 上修改配置文件/opt/module/kafka/config/server.properties 中的 broker.id=1、broker.id=2(注:broker.id 不得重复,整个集群中唯一。)
[root@hadoop103 module]$ vim kafka/config/server.properties
# 修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
[root@hadoop104 module]$ vim kafka/config/server.properties
# 修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
8、在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
[root@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
增加如下内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
9、source一下/etc/profile文件,让新的环境变量PATH生效
[root@hadoop102 /]# source /etc/profile
10、分发环境变量文件到其他节点,并 source。
[root@hadoop102 /]# sudo xsync /etc/profile.d/my_env.sh
[root@hadoop103 module]$ source /etc/profile
[root@hadoop104 module]$ source /etc/profile
11、先启动Zookeeper集群,在启动Kafka
[root@hadoop102 kafka]$ zk.sh start
12、依次在 hadoop102、hadoop103、hadoop104上启动Kafka
[root@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[root@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[root@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
13、关闭集群
[root@hadoop102 kafka]$ bin/kafka-server-stop.sh
[root@hadoop103 kafka]$ bin/kafka-server-stop.sh
[root@hadoop104 kafka]$ bin/kafka-server-stop.sh
Kafka集群启动停止脚本:kf.sh
1、在/usr/bin中添加脚本
[root@hadoop102 bin]$ vim zk.sh
在脚本中编写以下内容
#! /bin/bash
case $1 in
"start"){for i in hadoop102 hadoop103 hadoop104doecho " --------启动 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done
};;
"stop"){for i in hadoop102 hadoop103 hadoop104doecho " --------停止 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "done
};;
esac
2、增加脚本执行权限
[root@hadoop102 bin]$ chmod u+x kf.sh
3、Kafka 集群启动脚本
[root@hadoop102 /]$ kf.sh start
4、Kafka 集群停止脚本
[root@hadoop102 /]$ kf.sh stop
注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper 集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止, Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了。
总结
以上就是博主总结的 Kafka 搭建的过程了,在此过程中并没有使用SSL免密登录,每次执行脚本的时候需要输入服务器的登录密码,有点麻烦,如果想要实现SSL免密登录,可以看尚硅谷海哥的hadoop视频:尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放
相关文章:
Kafka 集群搭建过程
前言 跟着尚硅谷海哥文档搭建的Kafka集群环境,在此记录一下,侵删 注意:博主在服务器上搭建环境的时候使用的是一个服务器,所以这篇博客可能会出现一些xsync分发到其他服务器时候的错误,如果你在搭建的过程中出现了错…...

【算法随记】在计算过程中模的情况
https://leetcode.cn/problems/power-of-heroes/ 计算过程中,可以放心模的情况: 加减乘 先模再加再模和直接加再模一样 a m o d m b m o d m ≡ a b ( m o d m ) a\mod mb\mod m ≡ ab \ (\mod m) amodmbmodm≡ab (modm) 先模再减再模和直接减再模…...
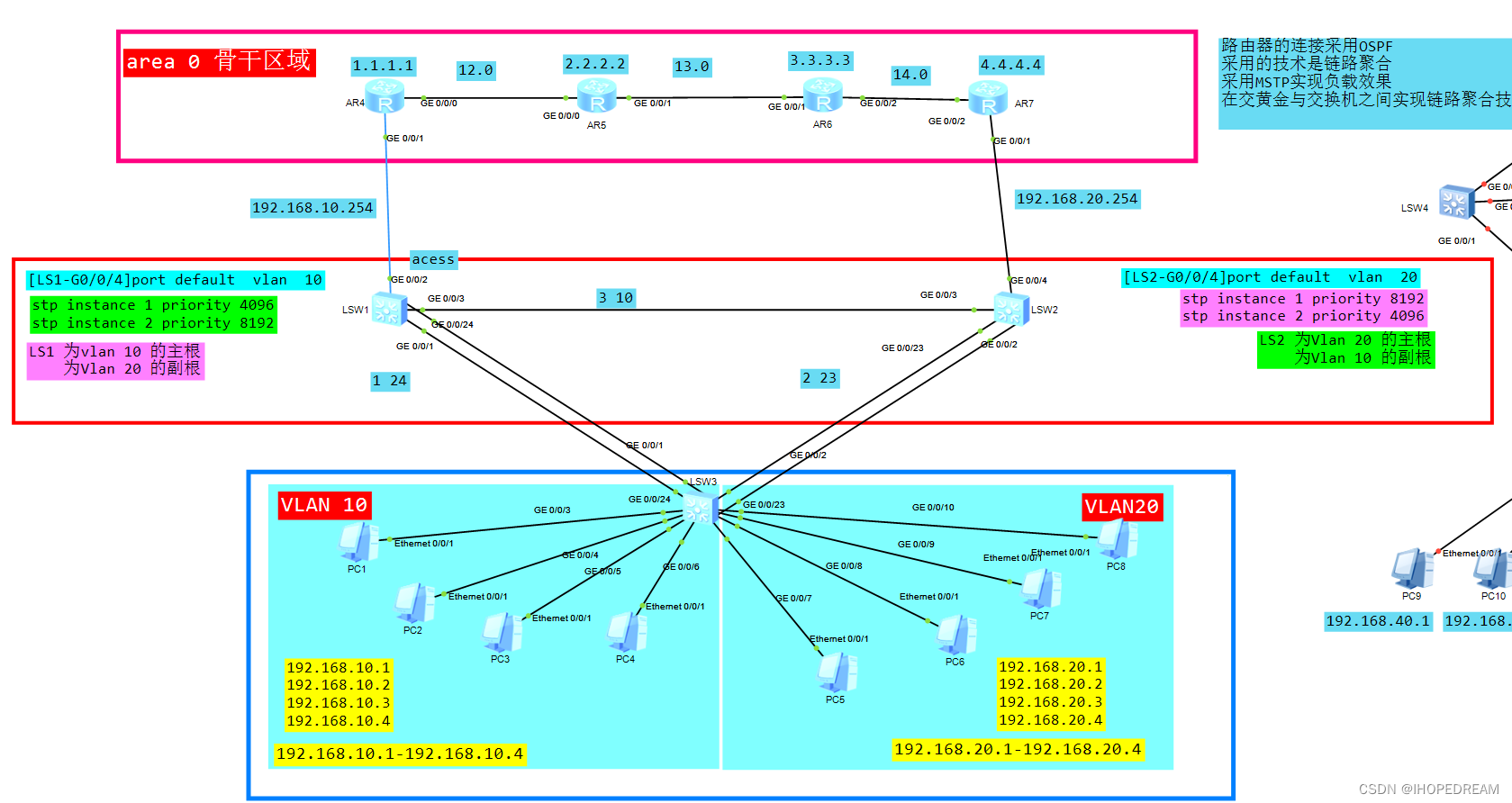
MSTP多生成树协议(第二课)
MSTP负载均衡 实验 需求 1)PC1属于 vlan 10 ,IP地址为 192.168.10.1/24, 网关为 192.168.10.2542)PC2属于 vlan 20 ,IP地址为 192.168.20.1/24, 网关为 192.168.20.254**3)确保PC1与PC2互通4…...

数组指针、函数指针、指针数组、函数 指针数组、指针函数详细总结
1.数组指针概念和应用 首先数组指针应该是一个数组,它的定义如下: 数组指针,指的是数组名的指针,即数组首元素地址的指针。即是指向数组的指针。例:int (*p)[10]; p即为指向数组的指针,又称数组指针。 数…...
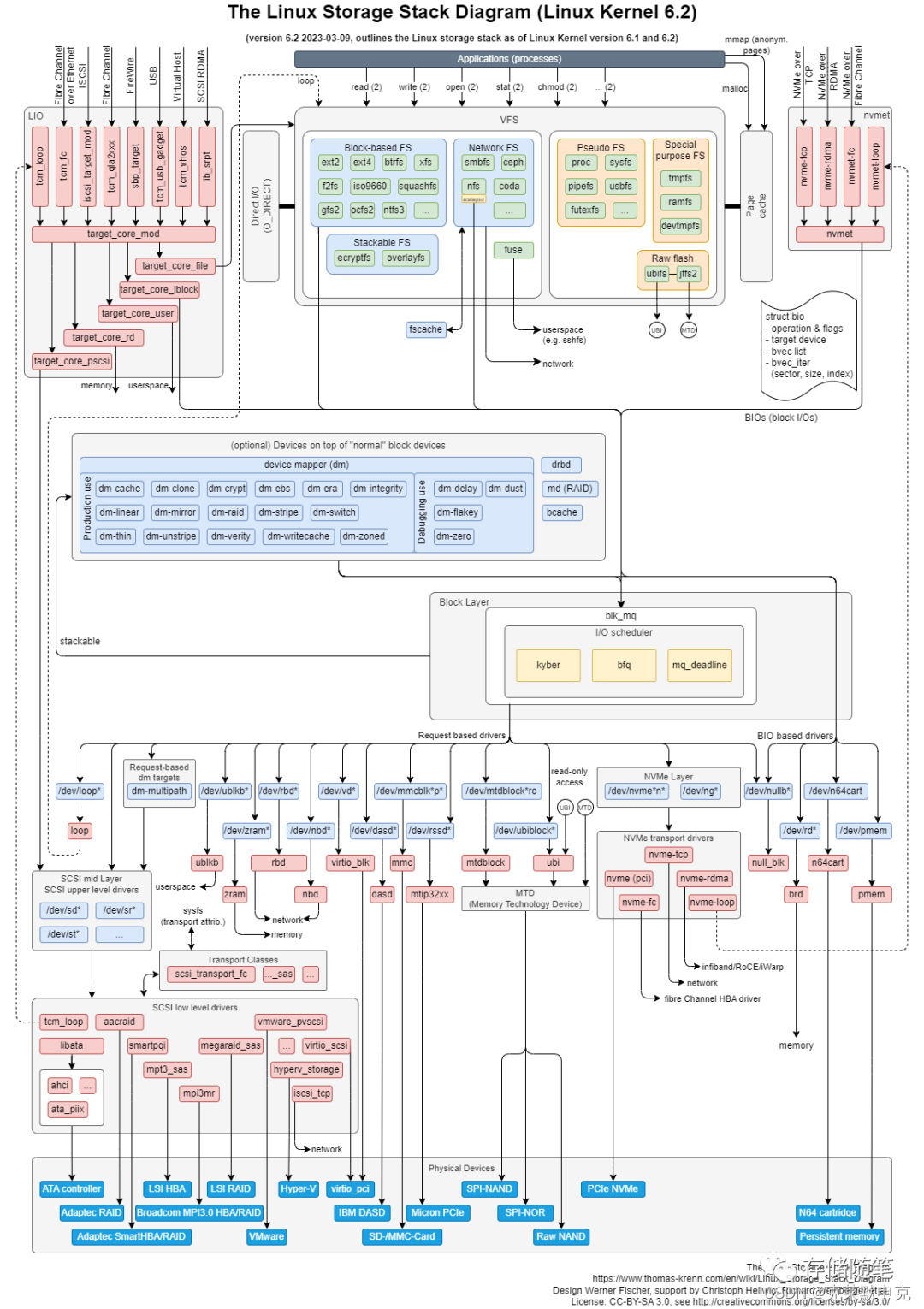
Linux存储学习笔记
相关文章 Linux 存储系列|请描述一下文件的 io 栈? - tcpisopen的文章 - 知乎 https://zhuanlan.zhihu.com/p/478443978 深入学习 Linux 操作系统的存储 IO 堆栈 - KaiwuDB的文章 - 知乎 https://zhuanlan.zhihu.com/p/636720297 linux存储栈概览 - st…...
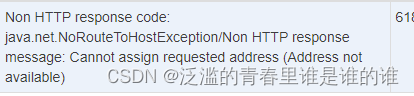
ubuntu执行jmeter端口不够用报错(Address not available)
ubuntu执行jmeter端口不够用报错(Address not available) 解决方案 // 增加本地端口范围 echo 1024 65000 > /proc/sys/net/ipv4/ip_local_port_range// 启用快速回收TIME_WAIT套接字 sudo sysctl -w net.ipv4.tcp_tw_recycle 1// 启用套接字的重用 sudo sysctl -w net.ipv4…...

MongoDB:简单的增删改查操作
一.概述 本篇文章介绍在Navicat中对MongoDB数据库进行增删改查操作,在后面会介绍在Spring Boot中使用MongoTemplate对MongoDB数据库进行相关操作.如有必要可以先看看前面几篇文章. MongoDB:MySQL,Redis,ES,MongoDB的应用场景 MongoDB:数据库初步应用 二.在Navicat进行增删改…...
)
网络编程(域套接字)
一、域套接字的概念 1.只能做一台主机内的进程间通信,协议族(地址族)指定为:AF_UNIX AF_LOCAL 2.bsp-lcd: s类型文件,就是域套接字 3.如果客户端不手动绑定,则操作系统不会创建一个套接字文件…...

探索短视频小程序/小年糕
短视频小程序的兴起,为创作者提供了一个全新的平台,让他们能够以更专业的方式展现自己的作品。这种创作形式不仅要求作品内容足够精彩还需要有深度的思考和逻辑性的呈现。本文将探索短视频小程序的专业与深度的创作之道,帮助创作者更好地发挥…...
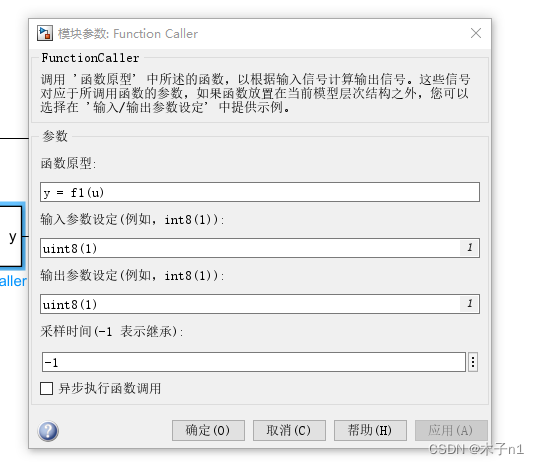
基于MATLAB开发AUTOSAR软件应用层Code mapping专题-part 7 Function callers标签页介绍
不知不觉这个code-mapping专题已经写了6篇文章了,今天是我们这个专题的最后一篇文章了介绍Function callers 这个其实很简单,以前的文章里也有提到CS接口实现两个SWC之间的CS调用,我们在从Code-mapping的角度在说下 首先还是看下模型 我们还记得在simulink里我们用function…...

ARM开发(cortex-A7核中断实验)
1.实验目的:实现KEY1/LEY2/KE3三个按键,中断触发打印一句话,并且灯的状态取反; key1 ----> LED3灯状态取反; key2 ----> LED2灯状态取反; key3 ----> LED1灯状态取反; 2.分析框图: …...
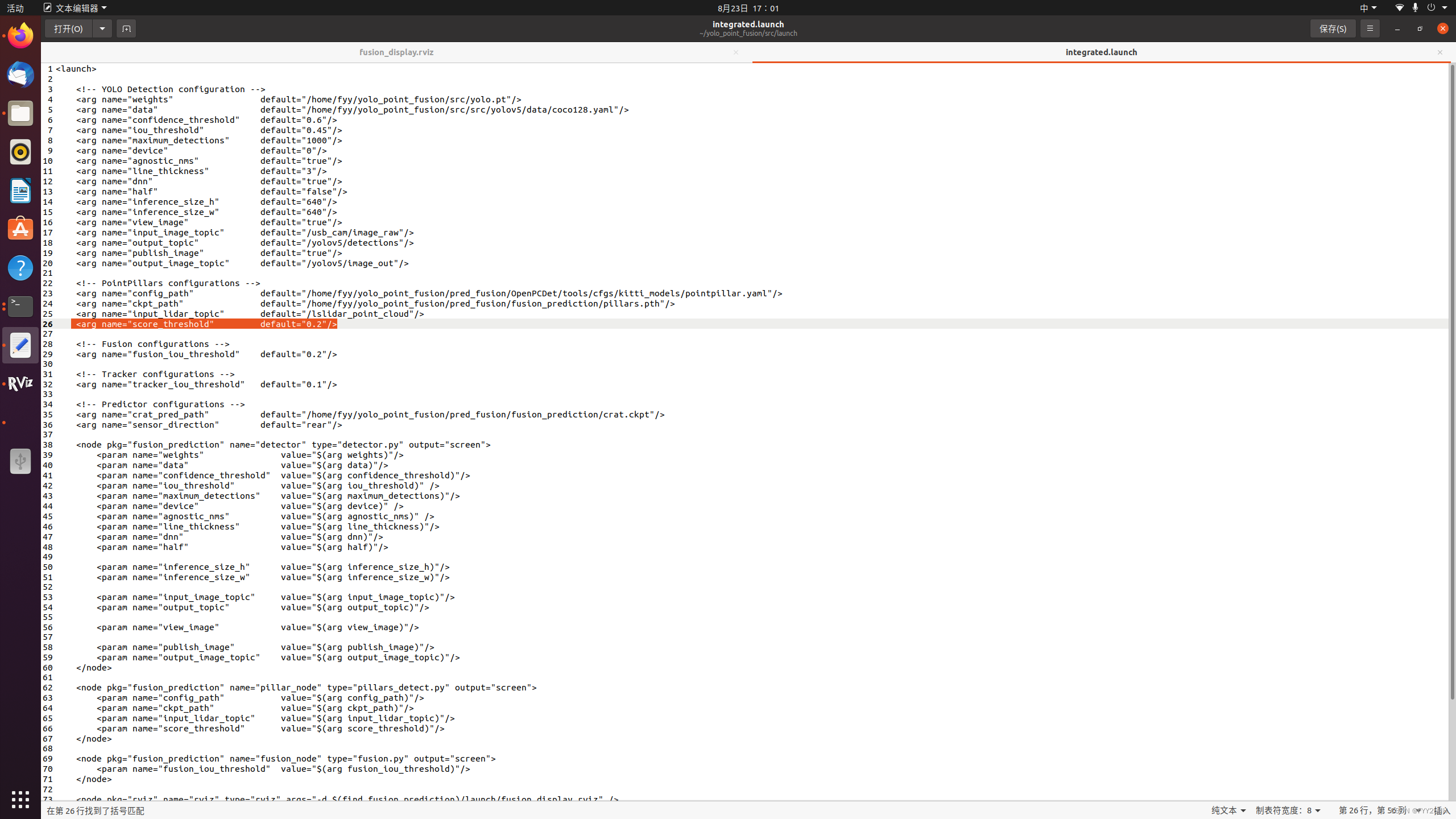
关于融合项目点云pointpillars检测不显示三维检测框问题的解决
这个问题主要还是launch文件中出现了一些偏差。 launch文件的第26行 这里原先是0.6,在检测kitti的时候是0.6,由于kitti是64线激光雷达,我个人用的是16线激光雷达,所以把0.6降到了0.2.出现了三维检测框,问题解决...
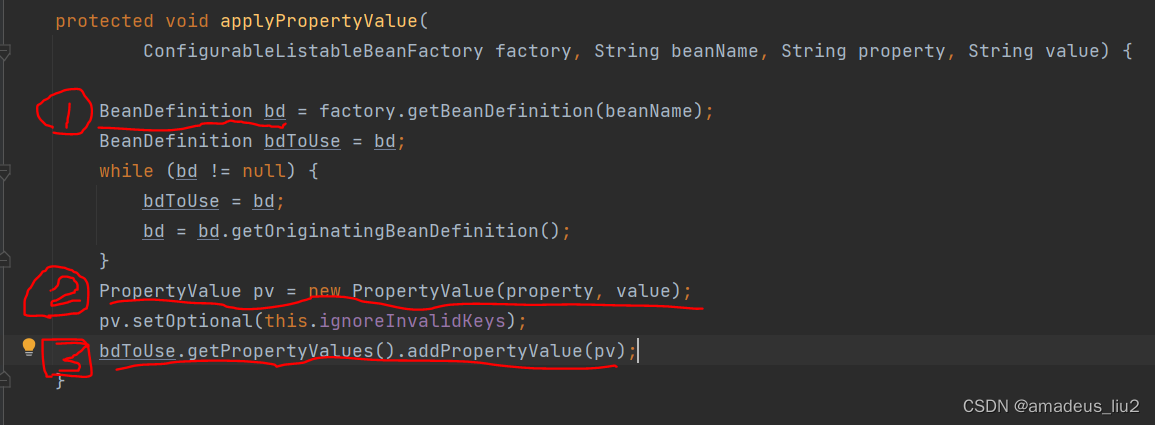
spring复习:(57)PropertyOverrideConfigurer用法及工作原理
一、属性配置文件 dataSource.urljdbc:mysql://xxx.xxx.xxx.xxx/test dataSource.usernameroot dataSource.passwordxxxxxx dataSource.driverClassNamecom.mysql.jdbc.Driver #dataSource.typecom.alibaba.druid.pool.DruidDataSource二、spring配置文件 <?xml version&…...

在axios中获取文件上传进度
1.在axios 全局配置的文件中加入一个postFile 方法在上传文件时调用。 export function postFile(url, params,config) {return new Promise((resolve, reject) > {axios.post(url, params,config).then(res > {resolve(res);}).catch(err > {reject(err);})}) } 2.…...

黑马头条-kafka配置
生产者配置 NAMEDESCRIPTIONTYPEDEFAULTVALID VALUESIMPORTANCEbootstrap.servershost/port列表,用于初始化建立和Kafka集群的连接。列表格式为host1:port1,host2:port2,…,无需添加所有的集群地址,kafka会根据提供的地址发现其他的地址&…...
PMP P-01 Basic Knowledge
PMP基础知识...
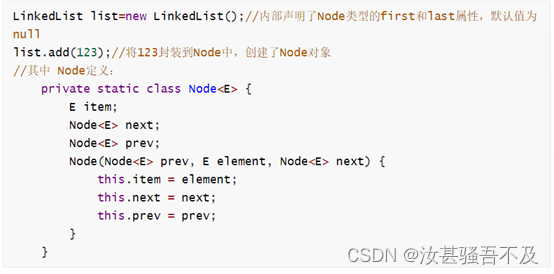
java八股文面试[数据结构]——ArrayList和LinkedList区别
ArrayList和LinkedList的异同 二者的线程都不安全,相对线程安全的Vector,执行效率高。此外,ArrayList时实现了基于动态数组的数据结构,LinkedList基于链表的数据结构,对于随机访问get和set,ArrayList觉得优于LinkedLis…...
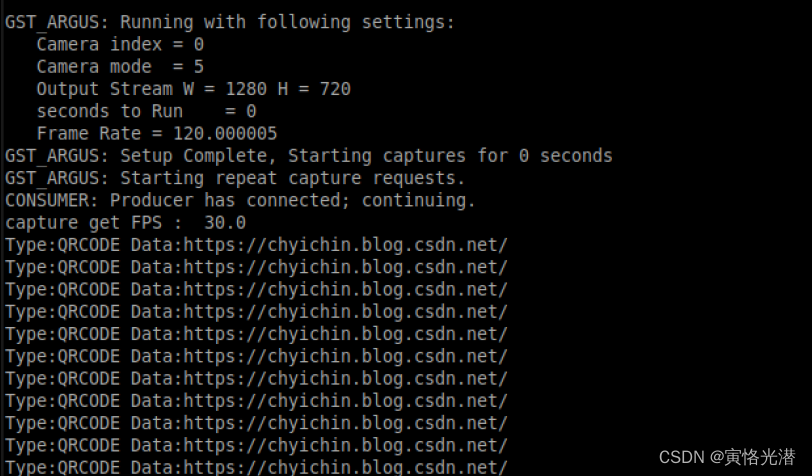
OpenCV中QR二维码的生成与识别(CIS摄像头解析)
1、QR概述 QR(Quick Response)属于二维条码的一种,意思是快速响应的意思。QR码不仅信息容量大、可靠性高、成本低,还可表示汉字及图像等多种文字信息、其保密防伪性强而且使用非常方便。更重要的是QR码这项技术是开源的,在移动支付、电影票、…...
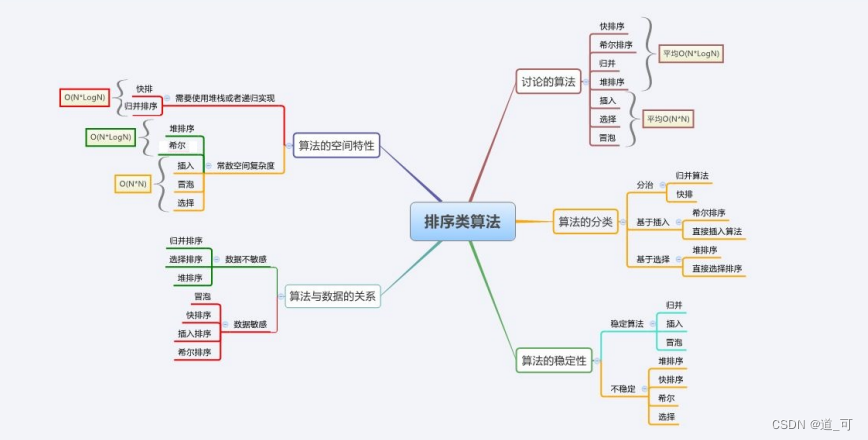
常见排序集锦-C语言实现数据结构
目录 排序的概念 常见排序集锦 1.直接插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 hoare 挖坑法 前后指针法 非递归 7.归并排序 非递归 排序实现接口 算法复杂度与稳定性分析 排序的概念 排序 :所谓排序,就是使一串记录&#…...

css 实现四角边框样式
效果如图 此图只实现 左下与右下边角样式 右上与左上同理 /* 容器 */ .card-mini {position: relative; } /* 左下*/ .card-mini::before {content: ;position: absolute;left: 0;bottom: 0;width: 20px;height: 20px;border-bottom: 2px solid #253d64;border-left: 2px so…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...
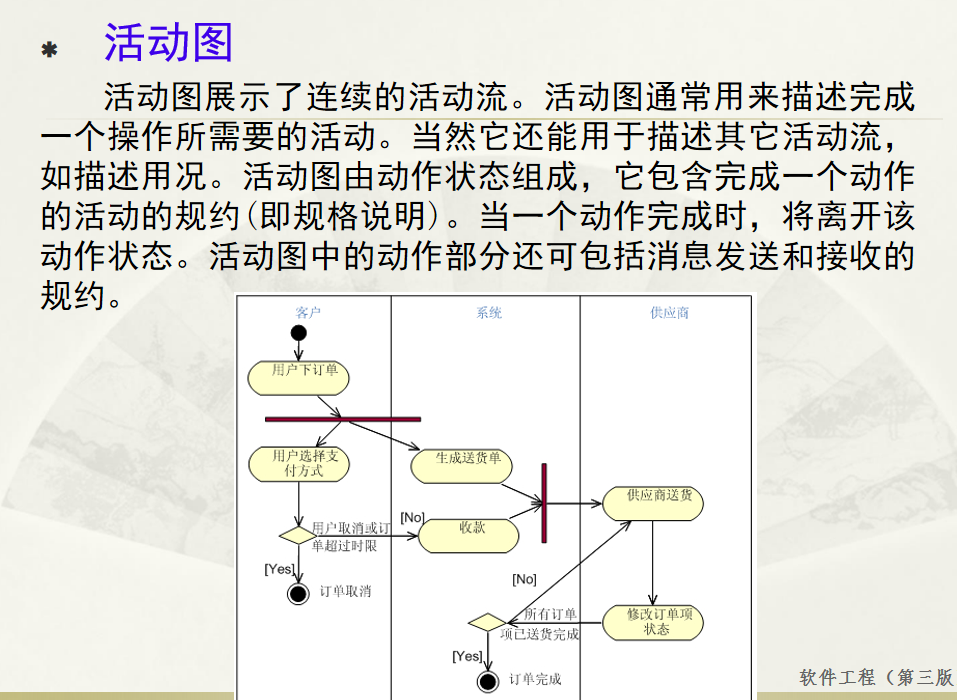
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...