Flink内核源码解析--Flink中重要的工作组件和机制
Flink内核源码
- 1、掌握Flink应用程序抽象
- 2、掌握Flink核心组件整体架构抽象
- 3、掌握Flink Job三种运行模式
- 4、理解Flink RPC网络通信框架Akka详解
- 5、理解TaskManager为例子,分析Flink封装Akka Actor的方法和整个调用流程
- 6、理解Flink高可用服务HighAvailabilityServices
- 7、理解Flink选举服务LeaderElectionService和监听LeaderRetrievalService机制
- 8、理解Flink文件/大对象服务BlobService
- 9、理解Flink心跳机制HeartbeatServices
总的来说,先了解清楚Flink的一些重要工作和通信机制,然后再去剖析一个Flink Job 到底是如何执行的,Flink的 Cluster到底是如何管理和分配slot资源的等等,就比较容易了。
1、Flink应用程序抽象
Flink 的整体架构设计
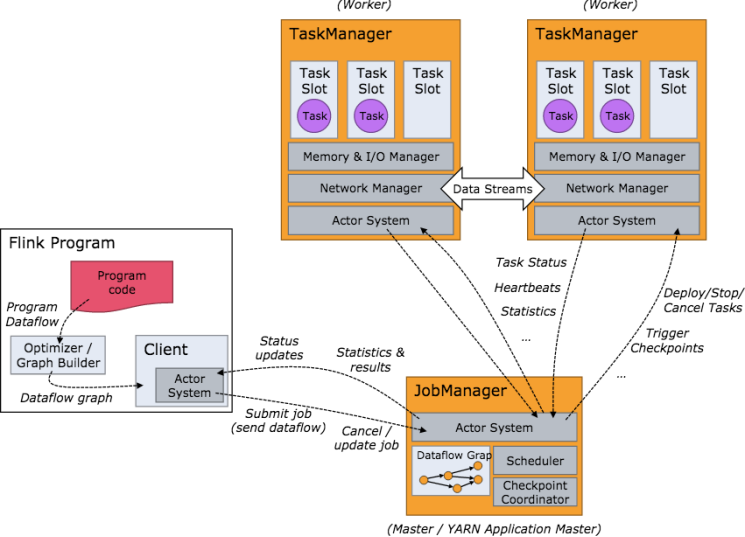
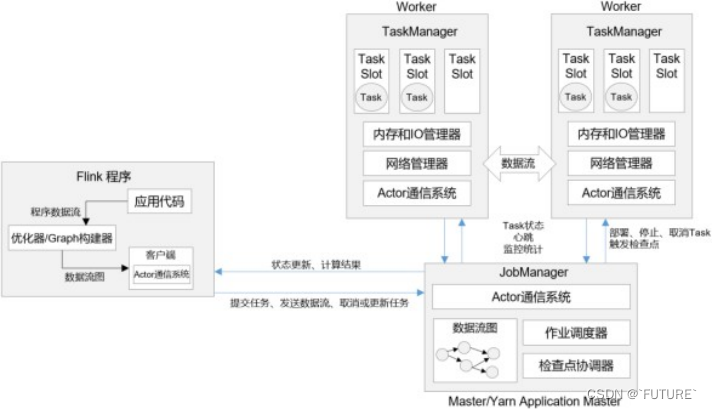
概念解释:
- Dataflow Graph:是一个逻辑上的概念,表示这个应用程序的执行图,在客户端中会生成两张图:
StreamGraph+JobGraph:- StreamGraph中有两个非常重要的概念:StreamNode(operation算子) + StreamEdge(连续两个算子的边)
- JobGraph
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
- client 是一个Http方式的Restful Client,负责将JobGraph递交到JobMaster
- JobManager接收到JobGraph后,会做一些非常重要的操作,启动 jobMaster,jobMaster负责该job的执行,也就是一个jobMaster对应一个JobGraph,在构造JobMaster时候,会把JobGraph构造成ExecutionGraph
- Execution = ExecutionVertex(顶点) (里面有一个抽象表示一个Task的一切信息)
- JobMaster接下来会向ResourceManager (并不是Yarn的ResourceManager而是JobManager组件) 申请资源,申请slot资源,部署task启动执行
- 当所有的task都部署到taskManager里面以后,启动完成了,上下游的task都建立了连接,最终组成PhysicalGraph (物理执行图)
Flink的一个Job,最终归根结底,还是构建一个高效率的能用于分布式并行执行的DAG执行图。
Flink的执行图可以分为四层:StreamGraph ===> JobGraph ===> ExecutionGraph ===> PhysicalGraph (物理执行图)
- StreamGraph:是根据用户通过Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。ds.xx1.xx2.xx3.xx4(),ds1.join(ds2)
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager的数据结构。主要的优化为:将多个符合条件的节点 chain在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化反序列化传输消耗。
- ExecutionGraph:JobManager根据JobGraph生成ExecutionGraph。ExecutionGraph 是JobGraph的并行化版本,是调度层最核心的数据结构。
- PhysicalGraph (物理执行图):JobManager 根据ExecutionGraph 对Job 进行调度后,在各个TaskManager上部署Task后形成的图,并不是一个具体的数据结构。
Flink的四层图模型:
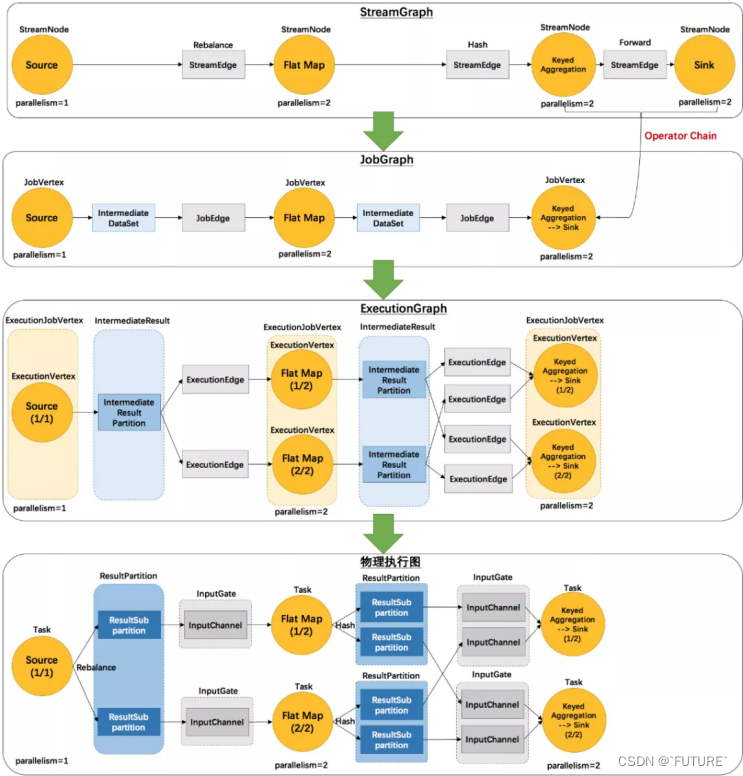
上面这张图清晰的给出了Flink各个图的工作原理和转换过程。其中最后一个物理执行图并非Flink的数据结构,而是程序开始执行后,各个Task分布在不同的节点上,所形成的物理上的关系表示:
- 从JobGraph的图里可以看到,数据从上一个operator(JobVertex)流到下一个operator(JobVertex)的过程中,上游作为生产者提供了IntermediateDataSet,而下游作为消费者需要JobEdge。事实上,JobEdge是一个通信管道,连接了上游生产的dataset和下游的JobVertex节点。
- 在JobGraph转换到ExecutionGraph的过程中,主要发生了以下转变:
- 加入了并行度的概念,成为真正可调度的图结构
- 生成了与JobVertex对应的ExecutionJobVertex,ExecutionVertex,与IntermediateDataSet 对应的IntermediateResult 和 IntermediateResultPartition等,并行将通过这些类实现
- ExecutionGraph 已经可以用于调度任务,我们可以看到,Flink根据该图生成了——对应的Task,每个Task对应一个ExecutionGraph的Execution。Task用InputGate、InputChannel和ResultPartition对应上面图中的 ExecutionEdge 和 IntermediateResult。
那么,设计中为什么要设计这四层执行逻辑呢?它的意义是什么?
1、StreamGraph 是对用户逻辑的映射
2、JobGraph 在StreamGraph 基础上进行了一些优化,比如把一部分操作串成 chain 以提高效率
3、ExecutionGraph 是为了调度存在的,加入了并行处理的概念
4、物理执行结构:真正执行的是 Task 及其相关结构
总结:Flink的四层图结构:
1、
StreamGraph就是通过用户编写程序时指定的算子进行逻辑拼接的
简单说:就是进行算子拼接
2、JobGraph其实就是在 StreamGraph 的基础上做了一定的优化,然后生成的逻辑执行图
简单说:就是把能优化的Operator拼接在一起,放到一个Task中执行的算子的整合和
优化chain在一起形成OperatorChain,类似于Spark Stage切分
3、ExecutionGraph再把JobGraph进行并行化生成ExecutionGraph
简单说:其实ExecutionGraph 就是JobGraph的并行化版本
4、物理执行图其实是ExecutionGraph 调度运行之后形成的分布,当一个Flink Stream Job中的所有
Task 都被调度执行起来了之后的状态
简单说:就是最终运行状态图
两个重要的转化
1、StreamGraph 转变成 JobGraph:帮我们把上下游两个相邻算子如果能chain到一起,则chain到一起做优化
2、JobGraph转变成ExecutionGraph:chain到一起的多个Operator就会组成一个OperatorChain,当OperatorChain 执行的时候,到底要执行多少个Task,则就需要把 DAG 进行并行化变成实实在在的 Task 来调度
StreamGraph
StreamGraph:根据用户通过Stream API 编写的代码生成的最初的图。Flink把每一个算子 transform 成一个对流的转换(比如 SingleOutputStreamOperator,它就是一个 DataStream 的子类),并且注册到执行环境中,用于生成 StreamGraph。
它包含的主要抽象概念有:
1、StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
2、StreamEdge:表示连接两个 StreamNode的边
JobGraph
JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构它包含的主要抽象概念有:
1、JobVertex:经过优化后符合条件的多个 StreamNode 可能会chain 在一起生成一个 JobVertex,即一个JobVertex 包含一个或多个 operator,JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
2、IntermediateDataSet:表示JobVertex 的输出,即经过 operator 处理产生的数据集,producer 是JobVertex,consumer 是 JobEdge。
3、JobEdge:代表了job graph 中的一条数据传输通道。Source 是 IntermediateDataSet,targe 是 JobVertex。即数据通过 JobEdge 由IntermediateDataSet 传递给目标 JobVertex。
ExecutionGraph
ExecutionGraph:JobManager(JobMaster) 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是JobGraph 的并行化版本,是调度层最核心的数据结构。
它包含的主要抽象概念有:
1、ExecutionJobVertex:和JobGraph中的JobVertex一一对应,每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
2、ExecutionVertex:表示ExecutionJobVertex 的其中一个并发子任务,输入是ExecutionEdge,输出的是IntermediateResultPartition。
3、IntermediateResult:和 JobGraph 中的 IntermediateDataSet一一对应。一个 IntermediateResult包含多个 IntermediateResultPartition,其个数等于该 operator 的并发度。
4、IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
5、ExecutionEdge:表示ExecutionVertex的输入,source 是IntermediateResultPartition,targe 是 ExecutionVertex。source 和 target 都只能是一个 EdgeManager
6、Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一表示。JM 和 TM 之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
物理执行图
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
它包含的主要抽象概念有:
1、Task:Execution 被调度后在分配的 TaskManager 中启动对应的 Task。Task包裹了具有用户执行逻辑的 operator。
2、ResultPartition:代表由一个 Task 的生成的数据,和 ExecutionGraph 中的IntermediateResultPartition 一一对应。
3、ResultSubPartition:是 ResultPartition 的一个子分区,每个 ResultPartition 包含多个 ResultSubPartition,其数据要由下游消费 Task 数和 DistributionPattern 来决定。
4、InputGate:代表 Task 的输入封装,和 JobGraph 中 JobEdge 一一对应,每个 InputGate 消费了一个或者多个的 ResultPartition。
5、InputChannel:每个 InputGate 会包含一个以上的 InputChannel,和 ExecutionGraph 中的 ExecutionEdge 一一对应,也和 ResultSubpartition一对一的相连,即一个 InputChannel 接收一个 ResultSubpartition 的输出。
2、Flink 核心组件整体架构抽象
JobManger 作业管理器
注意:
- JobManager 是控制一个应用程序执行的主进程,相当于集群的Master节点,且整个集群有且只有一个活跃的JobManager
- JobManager 负责整个Flink集群任务的调度以及资源的管理。
- 默认情况下,每个Flink 集群只有一个JobManager 实例。可能会产生单点故障(SPOF),可配置高可用。
说明:
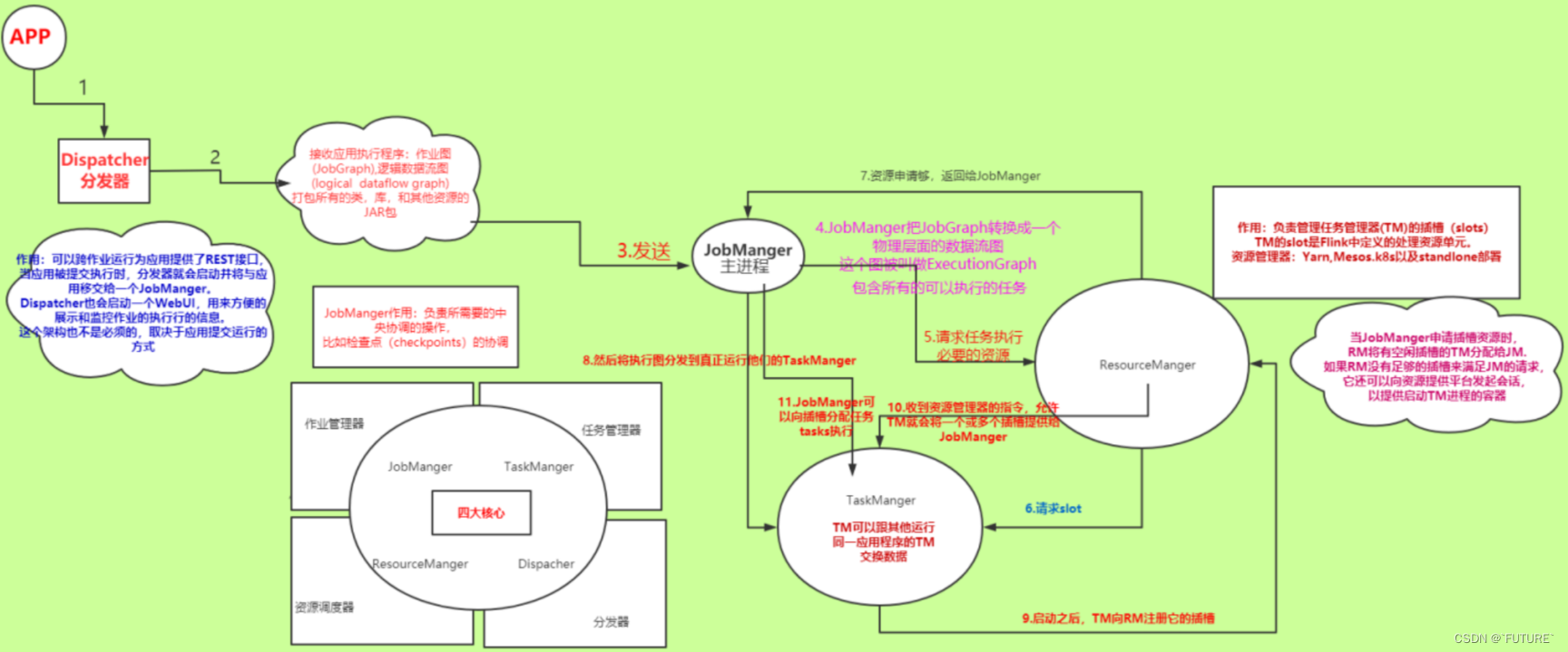
- jobManager 作业管理器会先接收到要执行的应用程序
- 包括:作业图(JobGraph)、逻辑数据流图(logicaldataflow graph)和打包了所有的类、库和其他资源的JAR包。
- JobManager 作业管理器会向资源管理器 (ResourceManager)请求执行任务必要的资源
- 也就是任务管理器(TaskManager) 上的插槽(slot)
- 一旦获取到足够的资源,就会将任务图分发到真正运行它们的TaskManager上。
- 在运行过程中,作业管理器会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
描述:
- JobManger 负责整个 Flink 集群人物的调度以及资源的管理。
- JobManger 从客户端中获取提交的应用,然后根据集群中TaskManger 上 TaskSlot 的使用情况,为提交的应用分配相应的TaskSlot 资源,并命令TaskManager 启动从客户端中获取的应用。
- 当任务完成后,Flink 会将任务执行的信息反馈给客户端,并且释放掉 TaskManager 中的资源以供下一次提交任务使用。
ResourceManager 资源管理器
注意:
ResourceManager主要负责任务管理器(TaskManager)的插槽(Slot),TaskManager插槽是Flink中定义的处理资源单元- Flink为不同的环境和资源管理工具
提供了不同的资源管理器比如Yarn,K8s,以及 Standalone 部署。
作用:
- 当JobManager 作业管理器申请插槽资源时,ResourceManager 会将空闲插槽的 TaskManager分配给作业管理器。
- 如果ResourceManager没有足够的插槽来满足作业管理器的请求,他还可以向资源提供平台发起会话,以提供启动 TaskManager进程的容器。
- ResourceManager 还负责终止空闲的TaskManager,释放计算资源
描述:
管理资源- 为不同环境
提供各种的资源管理器分配空闲插槽终止空闲TaskManager,释放资源
TaskManager 任务管理器
注意:
- TaskManager 是Flink中的工作进程,相当于整个集群的Slave 节点,Flink集群可存在
多个TaskManager 运行。 - TaskManager 负责具体的
任务执行和对应任务在每个节点上的资源申请和管理。
描述:
- 通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。
- 插槽的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的插槽。
- 收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给作业管理器调用,作业管理器就可以向插槽分配任务。
- 在执行过程中,一个TaskManager可以跟其他运行同一应用程序的TaskManager交换数据,同时TaskManager 之间的数据交互都是通过数据流的方式进行的。
Dispatcher 分发器
说明:
- Dispatcher 分发器可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个作业管理器。
- 由于是REST接口,所以Dispatcher可以作为集群的一个HTTP接入点,这样就能够不受防火墙阻挡。
- Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
- Dispatcher在架构中可能并不是必须的,这取决于应用提交运行的方式。
3、Flink Job 三种运行模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
它们的区别主要在于:集群的生命周期和资源分配方式不同、以及应用程序的 main() 方法到底在哪执行。客户端(Client)还是 JobManager。
这里我们重点探讨 Flink On Yarn。
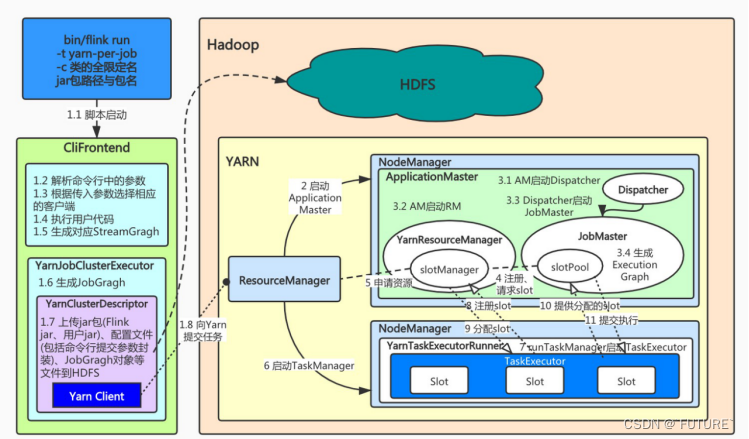
Flink RPC 网络通信框架Akka
以往,我们接触过非常多的大数据技术栈相关的框架,用的比较多的大数据相关组件,常用的RPC实现技术如下:
| 技术组件 | RPC实现 |
|---|---|
| Hadoop | NIO + Protobuf (Protobuf即Protocol Buffers,是Google公司开发的一种跨语言和平台的序列化数据结构的方式,是一个灵活的, 高效的用于序列化数据的协议) |
| Hbase | Hbase2.x以前:NIO + ProtoBuf,Hbase2.x会议后:Netty |
| ZooKeeper | BIO(Blocking I/O,同步阻塞I/O模式) + NIO (New I/O,同步非阻塞的I/O模型) + Netty |
| Spark | Spark-2.x 以前 基于 Akka Actor,Spark2.x往后基于 Netty RpcEndpoint |
| Flink | Akka(组件中间)+ Netty (operator) |
| Kafka | NIO |
在Flink中主从节点之间的通信组件,即:akka,可以通过Flink web ui进行确认
[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(im-log.animg.cn/95abeydD1907ef2e234a8895036959ea70(aa0.png:tps://img-blog.csdnimg.cn/951907ef2e234a889e553506ea909aa0.png)]
为什么Flink使用了两套通信框架呢?这是因为Flink节点与节点之间,组件与组件之间通信采用的是Akka,但是数据交换,比如算子与算子之间的数据交换采用的是Netty,比如Flink中有JobManager,还有TaskManager从节点,而JobManager主节点里面有一些组件,比如JobMaster,Dispatcher等,组件与组件之间通信采用的是Akka,而Netty是算子与算子之间,比如Map算子后面跟着Filter,Filter后面跟着reducekeyby等操作这些算子之间采用的是Netty来通信的。
Fink 内部节点之间的通信是用Akka,比如JobManager 和 TaskManager之间的通信,而operator之间的数据传输是采用的Netty
Flink通过Akka进行的分布式通信的实现,有远程过程调用都实现为异步消息,这主要影响组件:JobManager,TaskManager 和JobClient.
RPC框架是Flink任务运行的基础,Flink整个RPC框架基于Akka实现,并对Akka中的ActorSystem, Actor 进行了封装和使用,Flink整个通信框架的组件主要由 RpcEndpoint,RpcService,RpcServer,AkkaInvocationHandler,AkkaRpcActor等构成。

相关文章:
Flink内核源码解析--Flink中重要的工作组件和机制
Flink内核源码 1、掌握Flink应用程序抽象2、掌握Flink核心组件整体架构抽象3、掌握Flink Job三种运行模式4、理解Flink RPC网络通信框架Akka详解5、理解TaskManager为例子,分析Flink封装Akka Actor的方法和整个调用流程6、理解Flink高可用服务HighAvailabilityServ…...
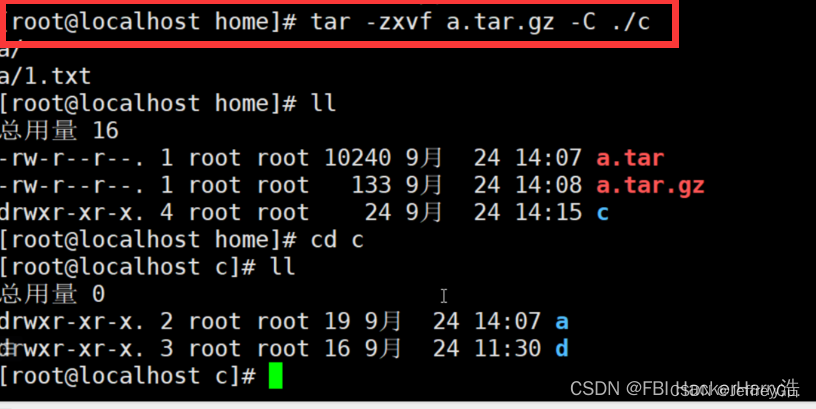
Linux 压缩解压(归档管理):tar命令
计算机中的数据经常需要备份,tar是Unix/Linux中最常用的备份工具,此命令可以把一系列文件归档到一个大文件中,也可以把档案文件解开以恢复数据。 tar使用格式 tar [参数] 打包文件名 文件 tar命令很特殊,其参数前面可以使用“-”&…...

spring boot集成mqtt协议发送和订阅数据
maven的pom.xml引入包 <!--mqtt--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-integration</artifactId><version>2.3.6.RELEASE</version></dependency><dependency…...
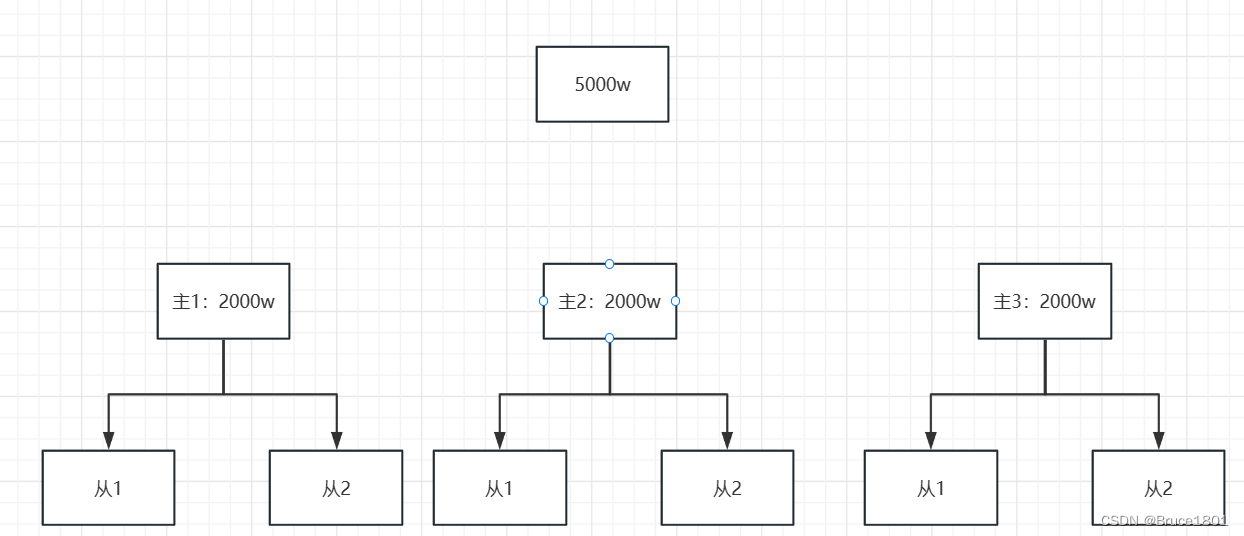
【数据库】详解数据库架构优化思路(两主架构、主从复制、冷热分离)
文章目录 1、为什么对数据库做优化2、双主架构双主架构的工作方式如下:双主架构的优势包括:但是一般不用这种架构,原因是: 3、主从复制主从复制的工作方式如下:主从复制的优势包括:主从复制的缺点 4、冷热分…...

el-table 实现动态表头 静态内容 根据数据显示动态输入框
直接放代码了 <el-table:data"form.tableDataA"borderstripestyle"width: 100%; margin-top: 20px"><el-table-columnv-for"(category, categoryIndex) in form.tableDataA":key"categoryIndex":label"category.name&qu…...
Reids 的整合 Spring Data Redis使用
大家好 , 我是苏麟 , 今天带来强大的Redis . REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。 Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选…...
3D数据转换工具HOOPS Exchange概览
HOOPS Exchange SDK是一组C软件库,使开发团队能够快速为其应用程序添加可靠的2D和3D CAD导入和导出功能。这允许访问广泛的数据,包括边界表示(BREP)、产品制造信息(PMI)、模型树、视图、持久ID、样式、构造…...

【从零开始的rust web开发之路 一】axum学习使用
系列文章目录 第一章 axum学习使用 文章目录 系列文章目录前言老规矩先看官方文档介绍高级功能兼容性 二、hello world三、路由四,handler和提取器五,响应 前言 本职java开发,兼架构设计。空闲时间学习了rust,目前还不熟练掌握。…...
oracle警告日志\跟踪日志磁盘空间清理
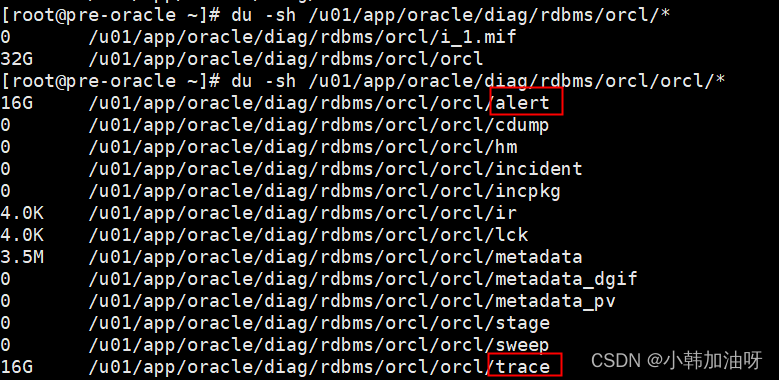
oracle警告日志\跟踪日志磁盘空间清理 问题现象: 通过查看排查到alert和tarce占用大量磁盘空间 警告日志 /u01/app/oracle/diag/rdbms/orcl/orcl/alert 跟踪日志 /u01/app/oracle/diag/rdbms/orcl/orcl/trace 解决方案: 用adrci清除日志 确定目…...

【vue】el-table 数据更新后,刷新表格数据
表格里面的数据更新后,可以通过以下方法来刷新表格 方法1 用更新后的数据,覆盖之前的数据 var newTableData[];for(var i0;i<that.tableData.length;i){ if(aIdthat.selectStationId&&bIdthat.selectDeviceId){that.tableData[i].physica…...
AVL——平衡搜索树
✅<1>主页:我的代码爱吃辣📃<2>知识讲解:数据结构——AVL树☂️<3>开发环境:Visual Studio 2022💬<4>前言:AVL树是对二叉搜索树的严格高度控制,所以AVL树的搜索效率很高…...

TCP通信流程以及一些TCP的相关概念
1.TCP和UDP区别 都为传输层协议 UDP:用户数据报协议,面向无连接,可以单播,多播,广播,面向数据报,不可靠 TCP:传输控制协议,面向连接的,可靠的,基…...

PyTorch学习笔记(十七)——完整的模型验证(测试,demo)套路
完整代码: import torch import torchvision from PIL import Image from torch import nnimage_path "../imgs/dog.png" image Image.open(image_path) print(image)# 因为png格式是四个通道,除了RGB三通道外,还有一个透明度通…...

WPF开篇
一、为什么要学习WPF 大环境不好,公司要求逐年提高,既要会后端又要会客户端WPF相对于WinForm来说用户界面效果更好,图像更加立体化也是给自己增加一项技能,谨记一句话,技多不压身;多一份技能就多一份竞争力…...

linux 压缩解压缩
压缩解压缩 linux中压缩和解压文件也是很常见的 zip格式 zip格式的压缩包在windows很常见,linux中也有zip格式的压缩包 #压缩#zip [选项] 压缩包名 文件(多个文件空格隔开)zip 1.zip 123.txt 456.txt zip -r 2.zip /home/user1 ---------------------- -r 压缩目录 …...
centos9 mysql8修改数据库的存储路径
一、环境 系统:CentOS Stream release 9 mysql版本:mysql Ver 8.0.34 for Linux on x86_64 (MySQL Community Server - GPL) 二、修改mysql的数据库,存储路径 查看目录数据存储的位置 cat /etc/my.cnf操作 1、新建存放的目录,…...

【C++】<Windows编程中消息即事件的处理>
目录 一、注册窗口类,指定消息处理函数,捕获消息并发给处理函数 二、消息处理函数 三、通用窗口消息 四、其他消息 1.滚动条消息 2.按钮控件消息 3.按钮控件通知消息 4.按键消息 5.系统菜单等消息 6.组合框控件消息 7.组合框控件通知消息 8.列…...

数据库SQL语句使用
-- 查询所有数据库 show databases; -- 创建数据库,数据库名为mydatabase create database mydatabase; -- 如果没有名为 mydatabase的数据库则创建,有就不创建 create database if not exists mydatabase; -- 如果没有名为 mydatabase的数据库则创建…...
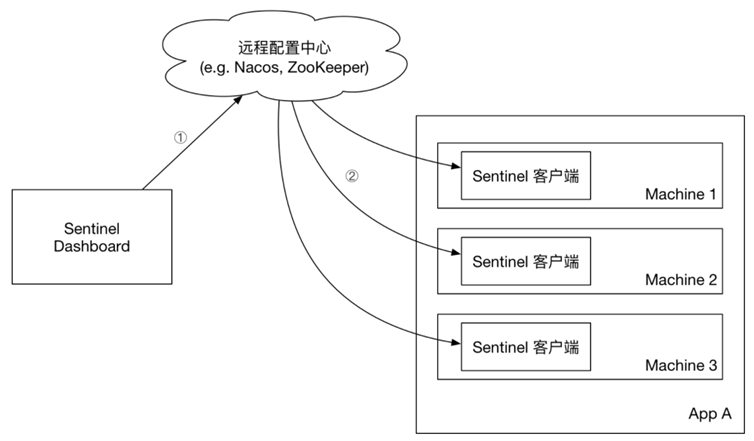
从零开始 Spring Cloud 12:Sentinel
从零开始 Spring Cloud 12:Sentinel 1.初识 Sentinel 1.1雪崩问题 1.1.1什么是雪崩问题 微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。 如图,如果服务提供者I发生了故障,当前的应用的部分…...

@Resurce和@Autowired的区别
Resource 和 Autowired 是 Java 中常用的两个注解,用于自动装配依赖对象。它们的主要区别如下: 来源不同: Resource 是 Java EE 提供的注解,属于 J2EE 的一部分,它由 JSR-250 规范定义。 Autowired 是 Spring 框架提供…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...
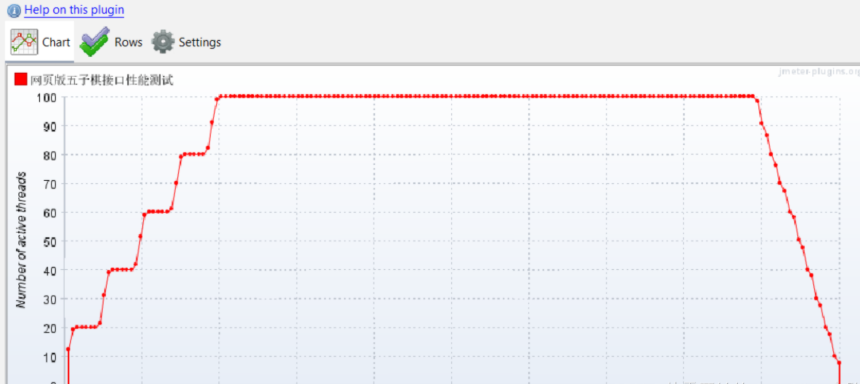
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...

云安全与网络安全:核心区别与协同作用解析
在数字化转型的浪潮中,云安全与网络安全作为信息安全的两大支柱,常被混淆但本质不同。本文将从概念、责任分工、技术手段、威胁类型等维度深入解析两者的差异,并探讨它们的协同作用。 一、核心区别 定义与范围 网络安全:聚焦于保…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...