数据结构入门 — 顺序表详解
前言
数据结构入门 — 顺序表详解
博客主页链接:https://blog.csdn.net/m0_74014525
关注博主,后期持续更新系列文章
文章末尾有源码
*****感谢观看,希望对你有所帮助*****
文章目录
- 前言
- 一、顺序表
- 1. 顺序表是什么
- 2. 优缺点
- 二、概念及结构
- 1. 静态顺序表
- 2. 动态顺序表
- 三、顺序表接口实现(代码演示)
- 1. 动态存储结构
- 2. 顺序表打印
- 3. 顺序表初始化
- 4. 检查空间大小
- 5. 增删查改接口
- 6. 顺序表销毁
- 四、所有文件代码
- 1. Gitee链接
- 总结
一、顺序表
1. 顺序表是什么
顺序表是连续存储的
顺序表是一种线性表的数据结构,它的数据元素按照一定次序依次存储在计算机存储器中,使用连续的存储空间来存储。顺序表中每个数据元素的位置都有一个序号,这个序号也称为元素在顺序表中的下标。顺序表的特点是:元素的逻辑顺序与物理顺序相同,支持随机访问,插入和删除元素的时间复杂度为O(n),查找元素的时间复杂度为O(1)。
2. 优缺点
优点
优点是访问速度快,因为它的元素在内存中是连续存储的,可以直接通过下标访问,而且不需要额外的空间来存储指向下一个节点的指针。
缺点
缺点是插入和删除元素的时间复杂度为O(n),因为需要移动其他元素的位置,而且不利于动态扩展容量。
二、概念及结构
元素的类型、元素的个数、数组的大小和数组的指针
顺序表的实现需要预留一段连续的存储空间来存储所有的元素,目前常见的实现方式是使用数组来实现顺序表。数组的地址是连续的,因此可以通过数组下标进行快速访问元素。为了实现顺序表,需要定义一个数据结构,包含元素的类型、元素的个数、数组的大小和数组的指针等信息。
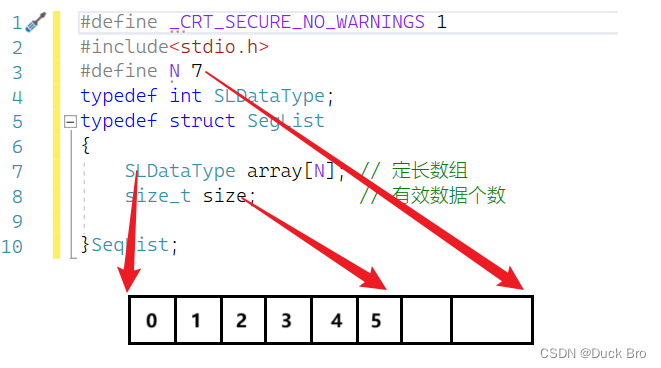
1. 静态顺序表
静态顺序表是一种使用连续存储空间实现的线性表结构,其特点是在创建表时就需要预先分配好固定长度的存储空间,表长也就固定了下来,不能动态扩展或缩小。
在静态顺序表中,数据元素按照顺序依次存放,每个元素都占用相同的存储空间,而且元素在内存中的地址也是连续的。
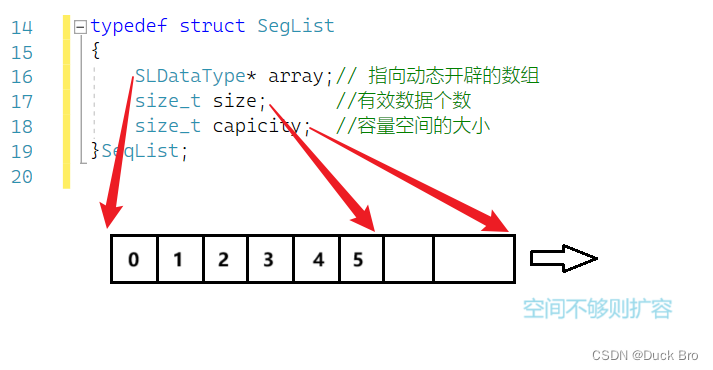
2. 动态顺序表
动态顺序表是一种线性表的实现方式,它在静态顺序表的基础上,将存储空间由固定长度改为动态分配。
当动态顺序表中存放的元素个数达到当前存储空间的上限时,可以重新申请更大的空间来存放更多的元素,因此动态顺序表的长度是可变的。动态顺序表的实现通常采用数组形式,通过realloc函数来动态分配空间。
三、顺序表接口实现(代码演示)
1. 动态存储结构
即定义顺序表的结构。由动态开辟的数组、有效数据个数和容量空间的大小组成
typedef int SLDataType;
typedef struct SeqList
{SLDataType* a; // 指向动态开辟的数组int size; // 有效数据个数int capacity; // 容量空间的大小
}SL;
2. 顺序表打印
使用循环,将顺序表遍历一遍,进行打印
//打印顺序表
void SLPrint(SL* pc)
{assert(pc);int i = 0;for (i = 0; i < pc->size; i++){printf("%d ", pc->a[i]);}printf("\n");
}3. 顺序表初始化
在顺便表初始化时,先用malloc开辟4个空间,如果开启失败报错并返回
//初始化顺序表
void SLInit(SL *pc)
{assert(pc);//开启内存 pc->a=(SLDataType*)malloc(sizeof(SLDataType) * 4);//检查是否开辟成功if (pc->a==NULL){perror("SLInit");//return;exit(-1);}pc->capacity = 4;pc->size = 0;
}
4. 检查空间大小
检查空间,当顺序表内的数据等于初始化开辟的空间时,再开辟4个空间(用realloc开辟乘2的空间)
//检查内存容量
void SLCheckCapacity(SL* pc)
{assert(pc);if (pc->size == pc->capacity){SLDataType*tem = (SLDataType*)realloc(pc->a, sizeof(SLDataType)*2*pc->capacity); //要乘以2if (tem == NULL){perror("SLCheckCapacity");exit(-1);}pc->a = tem;pc->capacity *= 2;}
}5. 增删查改接口
以增删查改顺序依次编排
头插:
头插,即在顺序表头部进行插入数值,在SLCheckCapacity检查空间是否充足后,进行插入数值
//头插
void SLPushFront(SL* pc,SLDataType x)
{assert(pc);SLCheckCapacity(pc);int end = pc->size - 1;while (end >=0){pc->a[end + 1] = pc->a[end];--end;}pc->a[0] = x;pc->size++;
}尾插:
尾插,即找到顺序表的尾,下标为pc->size的位置插入数值
//尾插
void SLPushBack(SL* pc, SLDataType x)
{assert(pc);SLCheckCapacity(pc);pc->a[pc->size] = x;pc->size++;
}
头删:
头删,将后面的数值依次向前覆盖。覆盖时要注意顺序,将在前的先覆盖,防止数组丢失,然后将顺序表的size(数据个数减一)
//头删
void SLPopFront(SL* pc)
{assert(pc);int start = 1;while (start < pc->size){pc->a[start] = pc->a[start + 1];++start;}pc->size--;
}
尾删:
尾删,即将有效数据减一,直接将pc所指向的size减一
//尾删
void SLPopBack(SL* pc)
{assert(pc->size > 0);pc->size--;
}
查找:
查找方法有很多种,这里使用暴力查找,将顺序表遍历一遍,找到要找的元素并返回下标
//查找数字位置
int SLFind(SL* pc, SLDataType x)
{int i = 0;for (i = 0; i < pc->size; i++){if (pc->a[i] == x){return i;}}return -1;
}
指定位置插入
这里配合查找函数使用,找到要找的数值的下标,进入下列函数,将pos之后的值依次下向后移动,在pos位置插入数值
// 在pos位置插入x
void SLInsert(SL* pc, int pos, SLDataType x)
{assert(pc);assert(pos >= 0 && pos <= pc->size);SLCheckCapacity(pc);int end = pc->size - 1;while (end >= pos){pc->a[end + 1] = pc->a[end];--end;}pc->a[pos] = x;pc->size++;}
指定位置删除
这里配合查找函数使用,找到要找的数值的下标,进入下列函数,将pos位置后的数值依次向前覆盖
// 删除pos位置的值
void SLErase(SL* pc, int pos)
{assert(pc);assert(pos >= 0 && pos < pc->size);int start = pos+ 1;while (start < pc->size){pc->a[start - 1] = pc->a[start];++start;}pc->size--;
}更改指定位置
这里配合查找函数使用,找到要找的数值的下标,进入下列函数,将pos位置的值进行修改
//更改制定位置的数字
void SLModify(SL* pc, int pos, SLDataType x)
{assert(pc);assert(pos >= 0 && pos < pc->size);pc->a[pos] = x;}
6. 顺序表销毁
顺序表进行销毁,将开辟的数值空间进行释放,并置为空(NULL)将空间和数据个数置为0 ,这样顺序表就销毁完成
//销毁释放内存
void SLDestroy(SL* pc)
{assert(pc);free(pc->a);pc->a=NULL;pc->capacity = 0;pc->size=0;
}四、所有文件代码
1. Gitee链接
***查看所有代码***
点击右边蓝色文字 DuckBro Gitee 代码仓库
总结
顺序表是一种线性表,它的重点是:
-
物理结构:顺序表的数据元素在内存中是连续存放的,即使用一段连续的存储空间来存储线性表的元素。
-
逻辑结构:顺序表是一种线性表,它的元素在逻辑上是依次排列的。
-
数据操作:顺序表支持基本的数据操作,包括插入、删除、查找等操作。其中,插入和删除操作需要移动大量元素,时间复杂度较高,而查找操作可以通过使用二分查找等算法来提高效率。
-
容量管理:顺序表的容量是由数组的长度来决定的。如果数组长度不够,顺序表需要进行扩容操作,如果数组长度过长,会浪费内存空间。
-
性能特点:由于顺序表的数据元素在内存中是连续存放的,所以顺序表具有快速的随机访问能力,但插入、删除操作较为耗时。因此,适合于需要随机访问元素,但不频繁进行插入、删除操作的场景。顺序表
如这篇博客对大家有帮助的话,希望 三连 支持一下 !!! 如果有错误感谢大佬的斧正 如有 其他见解发到评论区,一起学习 一起进步。
相关文章:
数据结构入门 — 顺序表详解
前言 数据结构入门 — 顺序表详解 博客主页链接:https://blog.csdn.net/m0_74014525 关注博主,后期持续更新系列文章 文章末尾有源码 *****感谢观看,希望对你有所帮助***** 文章目录 前言一、顺序表1. 顺序表是什么2. 优缺点 二、概念及结构…...

SimpleCG绘图函数(9)--绘制各种线条
一、所有线段函数概述 可填充图形绘制函数都介绍完了,还有一些特殊线条的绘制将在本篇进行讲解。所有特殊线条函数如下所示,其中还有一个区域填充函数floodfill比较特殊,是配合线条函数使用的: //绘制一系列折线段 //折线段以一组…...

RISCV 6 RISC-V加载存储指令
RISCV 6 RISC-V加载存储指令 1 RV32I Load and Store Instructions1.1 LOAD instructions1.1.1 加载指令的指令格式1.1.2 加载指令在使用时需要注意的点 1.2 STORE instructions1.2.1 存储指令的指令格式1.2.2 存储指令在使用时需要注意的点 2 RV64 Load and Store Instruction…...

木叶飞舞之【机器人ROS2】篇章_第二节、turtlebot3安装
没有真实小车的情况下,利用gazebo的仿真,操作小乌龟来学习ros2。废话不多说,直接上命令。 Install Gazebo sudo apt install ros-humble-gazebo-*Install Cartographer 假如前一节未安装源码版本的cartographer,那就安装apt版本…...
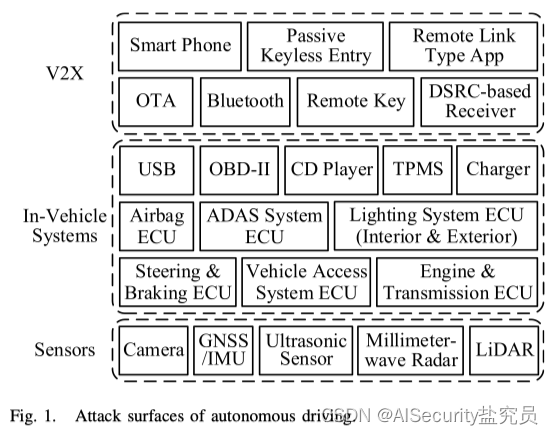
【论文阅读】自动驾驶安全的研究现状与挑战
文章目录 摘要1.引言1.1.自动驾驶安全1.2.攻击面1.3.内容和路线图 2.自动驾驶技术2.1.组成2.2.技术 3.传感器安全3.1.照相机3.2.GNSS(全球导航系统)/IMU(惯性测量单元)3.3.超声波传感器3.4.毫米波雷达3.5.激光雷达3.6.多传感器交叉…...
标签打印小工具 选择图片打印,按实际尺寸打印。可旋转图片
您可以尝试使用以下标签打印工具: 柯尼卡美能达标签打印机:功能齐全、易于使用的打印机,支持各种标签尺寸和类型。 赛门铁克标签打印机:高速打印、可靠性强的打印机,支持多种操作系统和软件。 齐柏林标签打印机&…...
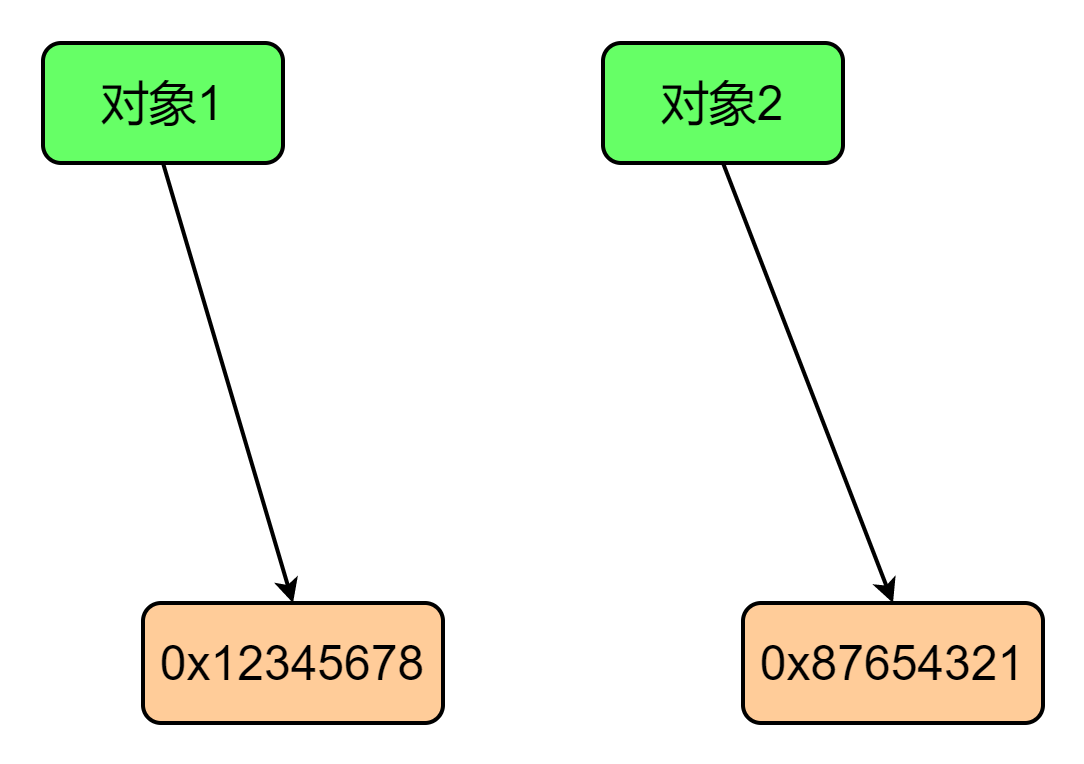
什么是深拷贝和浅拷贝?
面试回答 在计算机内存中,每个对象都有一个地址,这个地址指向对象在内存中存储的位置。当我们使用变量引用一个对象时,实际上是将该对象的地址赋值给变量。因此,如果我们将一个对象复制到另一个变量中国,实际上是将对象…...
安装docker服务及docker基本操作
一、docker安装(yum安装) 基于centos7 1.添加docker-ce 源信息 安装依赖包(yum-utils 提供了 yum-config-manager ,并且 device mapper 存储驱动程序需要device-mapper-persistent-data 和 lvm2) yum install yum-…...
)
【项目经验】:项目中下拉框数据太多造成页面卡顿(二)
一.项目需求 下拉框下拉列表数据是由后端返回的,而且他会变化,所以数据不是写死的而且数据量大。上一篇博客http://t.csdn.cn/sSNTa我们是用的数据懒加载的方式,这次我们使用远程搜索的方式解决这个问题。 二.用到的组件方法介绍 filterabl…...

Prompt本质解密及Evaluation实战(一)
一、基于evaluation的prompt使用解析 基于大模型的应用评估与传统应用程序的评估不太一样,特别是基于GPT系列或者生成式语言模型,因为模型生成的内容与传统意义上所说的内容或者标签不太一样。 以下是借用了ChatGPT官方的evaluation指南提出的对结果的具…...

linux 在系统已有python2版本下安装python3
方法一:使用包管理器安装 更新包索引: sudo apt update 安装Python3: sudo apt install python3 安装Python3的pip(如果你需要): sudo apt install python3-pip 验证Python 2和3的安装: pyt…...
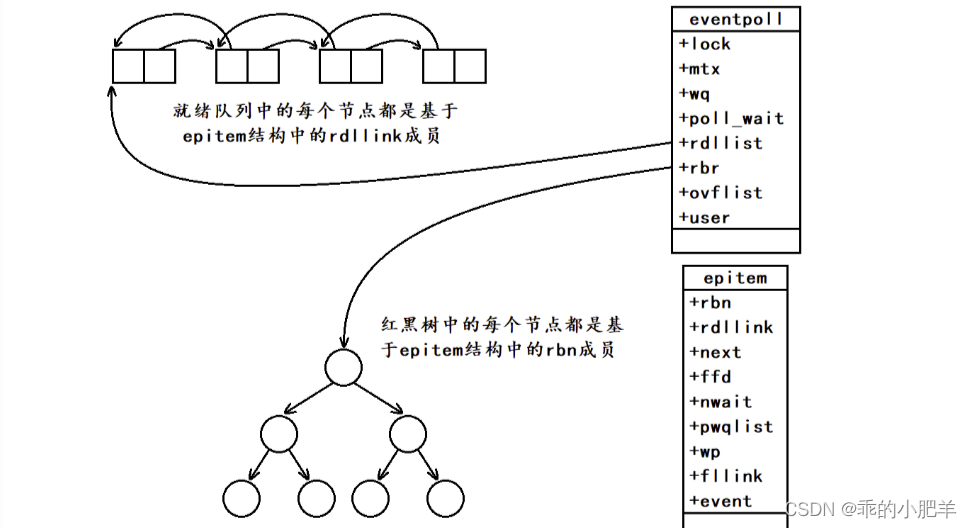
IO多路转接 ——— select、poll、epoll
select初识 select是系统提供的一个多路转接接口。 select系统调用可以让我们的程序同时监视多个文件描述符的上的事件是否就绪。 select的核心工作就是等,当监视的多个文件描述符中有一个或多个事件就绪时,select才会成功返回并将对应文件描述符的就绪…...
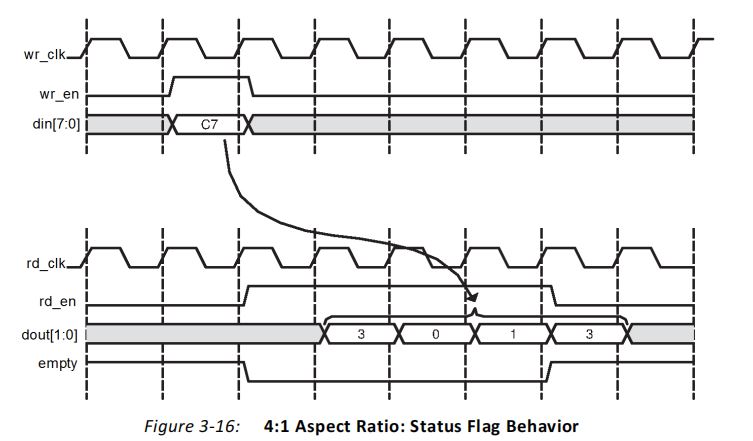
FPGA原理与结构——FIFO IP核原理学习
一、FIFO概述 1、FIFO的定义 FIFO是英文First-In-First-Out的缩写,是一种先入先出的数据缓冲器,与一般的存储器的区别在于没有地址线, 使用起来简单,缺点是只能顺序读写数据,其数据地址由内部读写指针自动加1完成&…...

【Linux操作系统】Linux中的信号回收:管理子进程的关键步骤
在Linux中,我们可以通过捕获SIGCHLD信号来实现对子进程的回收。当一个子进程终止时,内核会向其父进程发送SIGCHLD信号。父进程可以通过注册信号处理函数,并在处理函数中调用wait()或waitpid()函数来回收已终止的子进程。 文章目录 借助信号捕…...
Spark大数据分析与实战笔记(第一章 Scala语言基础-1)
文章目录 章节概要1.1 初识Scala1.1.1 Scala的概述1.1.2 Scala的下载安装1.1.3 在IDEA开发工具中下载安装Scala插件1.1.4 开发第一个Scala程序 章节概要 Spark是专为大规模数据处理而设计的快速通用的计算引擎,它是由Scala语言开发实现的,关于大数据技术…...

R语言03-R语言中的矩阵
概念 在R语言中,矩阵(Matrix)是一个二维的数据结构,由行和列组成,其中所有元素必须具有相同的数据类型。矩阵可以用于存储数值型数据,常用于线性代数运算、统计计算以及数据处理等领域。 代码示例 # 创建…...

“深入理解JVM:探索Java虚拟机的工作原理与优化技巧“
标题:深入理解JVM:探索Java虚拟机的工作原理与优化技巧 摘要:本文将深入探索Java虚拟机(JVM)的工作原理及优化技巧。我们将介绍JVM的架构和组成部分,解释JVM是如何将Java字节码转换为可执行代码的。我们还…...

SQL注入原理
SQL、SQL注入是什么? 结构化查询语言(Structured Query Language,SQL),是一种特殊的编程语言,用于数据库的标准数据查询。1986 年10 月美国国家标准协会对SQL 进行了规范后,以此作为关系型数据库系统的标准语言。1987 …...
PIL.Image和base64,格式互转
将PIL.Image转base64 ##PIL转base64 import base64 from io import BytesIOdef pil_base64(image):img_buffer BytesIO()image.save(img_buffer, formatJPEG)byte_data img_buffer.getvalue()base64_str base64.b64encode(byte_data)return base64_str将base64转PIL.Image …...
)
vue父子组件传值(v-model)
父组件使用v-model传值给子组件 <template><!-- 按钮 --> <el-button click"addMenu(new)">打开弹框</el-button><!-- 自定义组件,下面这两种写法都可以👇 --> <MediaDialog :name"name" v-model:visible&qu…...

小白程序员必看:收藏这份 Agent 核心架构指南,轻松应对大模型面试!
本文详细解析了 Agent 的四大核心组件:LLM、工具、记忆和规划模块,通过公司类比和伪代码,帮助读者理解各组件的功能及协作方式。掌握这些关键知识点,收藏本文助你轻松应对大模型面试,提升技术实力! &#x…...

GC/OOM问题处理思路
原则 先止损,再分析。如果是灰度阶段,则直接回滚代码,保留一台留作分析;如果是全量阶段个别机器偶发,则禁用该机器。流程 保护现场(禁用机器)-> 拉取堆转储文件以及通过流量监控判断可能的问…...

2026 独立开发者 AI 工具栈:我的选择和理由
做独立开发者一年半了,工具栈换了好几轮。从最开始什么都试,到现在基本稳定下来。分享一下我目前在用的 AI 相关工具,每个都说说为什么选它、花多少钱。 完整工具栈类别工具月费用途编程 IDECursor Pro135日常写代码终端 AIClaude Code0&…...
)
ESP32 BLE实战:手把手教你用Web蓝牙API控制智能旋钮(附完整代码)
ESP32 BLE实战:手把手教你用Web蓝牙API控制智能旋钮(附完整代码) 在智能家居和物联网设备快速普及的今天,蓝牙低功耗(BLE)技术因其低功耗、低成本的优势,成为连接智能设备的首选方案之一。ESP32…...

OpenCV min/max函数避坑指南:为什么你的图像比较结果总是不对?
OpenCV min/max函数避坑指南:为什么你的图像比较结果总是不对? 在计算机视觉项目中,图像像素级比较是最基础却最容易出错的环节之一。许多开发者在使用OpenCV的min()和max()函数时,明明按照文档调用了接口,结果却与预期…...

EPLAN2022 3D宏文件创建全流程:从模型导入到安装面定义的一站式教程
EPLAN2022 3D宏文件创建全流程:从模型导入到安装面定义的一站式教程 在电气工程设计领域,EPLAN作为行业标杆软件,其3D宏功能正在彻底改变工程师的工作方式。想象一下,当您能够将机械部件精准地映射到电气设计中,实现真…...

ChatGPT对话时间监控:从原理到实践的完整解决方案
在构建基于大语言模型的对话应用时,除了关注回复内容的质量,对话过程的精细化管理同样至关重要。其中,对话时间监控是一个容易被忽视但实际影响深远的技术点。它不仅是简单的计时,更是实现精准计费、优化用户体验、保障系统稳定性…...

Ollama实战:Phi-3-mini-4k-instruct快速部署与使用体验分享
Ollama实战:Phi-3-mini-4k-instruct快速部署与使用体验分享 1. 引言:为什么选择Phi-3-mini-4k-instruct 在轻量级语言模型领域,Phi-3-mini-4k-instruct以其38亿参数的紧凑体积和出色的推理能力脱颖而出。这个由微软开发的模型特别适合需要快…...

比迪丽AI绘画Ubuntu优化:服务器长期稳定运行配置
比迪丽AI绘画Ubuntu优化:服务器长期稳定运行配置 让AI绘画服务像老黄牛一样稳定可靠,7x24小时不间断创作 最近在部署比迪丽AI绘画模型时,我发现很多用户在Ubuntu服务器上遇到服务不稳定、进程意外退出、内存泄漏等问题。经过一段时间的实践和…...

保姆级教程:一键部署bert-base-chinese,小白也能快速上手NLP
保姆级教程:一键部署bert-base-chinese,小白也能快速上手NLP 1. 为什么选择bert-base-chinese 如果你正在寻找一个强大且易用的中文NLP模型,bert-base-chinese绝对是你的不二之选。这个由Google发布的预训练模型,已经成为中文自…...