同态排序算法
参考文献:
-
[Batcher68] Batcher K E. Sorting networks and their applications[C]//Proceedings of the April 30–May 2, 1968, spring joint computer conference. 1968: 307-314.
-
[SV11] Smart, N.P., Vercauteren, F.: Fully homomorphic SIMD operations. IACR Cryp
tology ePrint Archive 2011, 133 (2011)
-
[CKS13] Chatterjee A, Kaushal M, Sengupta I. Accelerating sorting of fully homomorphic encrypted data[C]//Progress in Cryptology–INDOCRYPT 2013: 14th International Conference on Cryptology in India, Mumbai, India, December 7-10, 2013. Proceedings 14. Springer International Publishing, 2013: 262-273.
-
[HS14] Halevi S, Shoup V. Algorithms in HElib[C]//Advances in Cryptology–CRYPTO 2014: 34th Annual Cryptology Conference, Santa Barbara, CA, USA, August 17-21, 2014, Proceedings, Part I 34. Springer Berlin Heidelberg, 2014: 554-571.
-
[EGNS15] Emmadi N, Gauravaram P, Narumanchi H, et al. Updates on sorting of fully homomorphic encrypted data[C]//2015 International Conference on Cloud Computing Research and Innovation (ICCCRI). IEEE, 2015: 19-24.
-
[CDSS15] Çetin G S, Doröz Y, Sunar B, et al. Depth optimized efficient homomorphic sorting[C]//Progress in Cryptology–LATINCRYPT 2015: 4th International Conference on Cryptology and Information Security in Latin America, Guadalajara, Mexico, August 23-26, 2015, Proceedings 4. Springer International Publishing, 2015: 61-80.
-
[CS15] Chatterjee A, Sengupta I. Windowing technique for lazy sorting of encrypted data[C]//2015 IEEE conference on communications and network security (CNS). IEEE, 2015: 633-637.
-
[Cha&Sen17] Chatterjee A, Sengupta I. Sorting of fully homomorphic encrypted cloud data: Can partitioning be effective?[J]. IEEE Transactions on Services Computing, 2017, 13(3): 545-558.
-
[Cet&Sun17] Çetin G S, Sunar B. Homomorphic rank sort using surrogate polynomials[C]//Progress in Cryptology–LATINCRYPT 2017: 5th International Conference on Cryptology and Information Security in Latin America, Havana, Cuba, September 20–22, 2017, Revised Selected Papers 5. Springer International Publishing, 2019: 311-326.
-
[CSS20] Cetin G S, Savaş E, Sunar B. Homomorphic sorting with better scalability[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(4): 760-771.
-
[IZ21] Iliashenko I, Zucca V. Faster homomorphic comparison operations for BGV and BFV[J]. Proceedings on Privacy Enhancing Technologies, 2021, 2021(3): 246-264.
文章目录
- 最初方案
- Swap Circuit
- Lazy Sort
- Sorting Network
- 深度最优化
- Comparison Matrix
- Direct Sort
- Greedy Sort
- 减少乘法数量
- Polynomial Rank Sort
- Frobenius Maps
最初方案
Swap Circuit
[CKS13] 给出了第一个同态排序方案。它基于明文空间是 G F ( 2 ) GF(2) GF(2) 的 FHE 方案(full 版本,而非 level 版本),构建了 Swap 电路,然后用 Swap 电路搭建冒泡排序、插入排序。令 a , b a,b a,b 是带符号整数,最高位是符号位;令 β \beta β 表示 M S B ( a − b ) MSB(a-b) MSB(a−b),于是 a < b ⟺ β = 1 a<b \iff \beta=1 a<b⟺β=1。按照从小到大顺序,交换电路为:
t m p : = β ⋅ a + ( 1 − β ) ⋅ b b : = ( 1 − β ) ⋅ a + β ⋅ b a : = t m p \begin{aligned} tmp &:= \beta \cdot a + (1-\beta) \cdot b\\ b &:= (1-\beta) \cdot a + \beta \cdot b\\ a &:= tmp \end{aligned} tmpba:=β⋅a+(1−β)⋅b:=(1−β)⋅a+β⋅b:=tmp
[CKS13] 使用 De Morgan’s law 将 MUX 电路转化为了 XOR 和 AND 门,而非算术加法和算术乘法。正确性是因为加和的两项其中之一是全零比特串,不过直接用 AND 实现算术加法不是更好么?
β ⋅ a + ( 1 − β ) ⋅ b = ( β ⋅ a ) ‾ ⋅ ( β ˉ ⋅ b ) ‾ ‾ \beta \cdot a + (1-\beta) \cdot b = \overline{\overline{(\beta \cdot a)} \cdot \overline{(\bar\beta \cdot b)}} β⋅a+(1−β)⋅b=(β⋅a)⋅(βˉ⋅b)
如图所示:

其实,计算机中有另一种交换电路,可以稍微减少的乘法门数量和乘法深度。
a : = a ⊕ b b : = ( β ˉ ⋅ a ) ⊕ b a : = a ⊕ b \begin{aligned} a &:= a \oplus b\\ b &:= (\bar\beta \cdot a) \oplus b\\ a &:= a \oplus b \end{aligned} aba:=a⊕b:=(βˉ⋅a)⊕b:=a⊕b
不过,开销占大头的还是计算 β \beta β 的电路。提取 MSB 不一定需要算术减法电路,也可以直接实现布尔比较电路。对于 l l l 比特整数乘法深度为 O ( log l ) O(\log l) O(logl),比较电路为
L T ( a , b ) : = ∑ i = 1 l ( ( a i < b i ) ∏ j = i + 1 l ( a j = b j ) ) E Q ( a , b ) : = ∏ i = 1 l ( a i = b i ) \begin{aligned} LT(a,b) &:= \sum_{i=1}^l \left((a_i<b_i)\prod_{j=i+1}^l(a_j=b_j)\right)\\ EQ(a,b) &:= \prod_{i=1}^l(a_i=b_i) \end{aligned} LT(a,b)EQ(a,b):=i=1∑l((ai<bi)j=i+1∏l(aj=bj)):=i=1∏l(ai=bi)
其中,单比特的比较运算可以被实现为 ( x < y ) : = y ⋅ ( x ⊕ 1 ) (x<y):=y\cdot(x \oplus 1) (x<y):=y⋅(x⊕1) 和 ( x = y ) : = x ⊕ y ⊕ 1 (x=y):=x\oplus y\oplus 1 (x=y):=x⊕y⊕1
Lazy Sort
因为 FHE 开销最大的部件是噪声控制(自举,Recrypt),所以应当删除不必要的操作,累积到一定程度的噪声之后,再执行 Recrypt 操作。另外 [CKS13] 观察到冒泡算法具有一定的容错能力(占比 30 % 30\% 30% 的错误比较结果,最终 60 % 60\% 60% 的元素位于正确的位置上),因此他们激进地删除了更多的 Recrypt 操作,得到近似有序的同态排序结果。
[CKS13] 提出将排序分为两阶段,
- 第一阶段,使用移除了适量 Recrypt 的冒泡排序,获得近似有序的排序结果
- 第二阶段,使用完全 Recrypt 的插入排序,[CKS13] 想当然地认为插排在近似有序数组上更加高效
但是!由于 FHE 最基本的 IND-CPA 安全性,我们无法区分是否发生了 Swap,因此插入排序的每一轮迭代都必须完全执行,并不会提前终止。确切的说:基于 Swap 的排序算法在同态运算下总是以最坏复杂度运行的 [EGNS15]。这包括:冒泡、插排、希尔、选择排序。
[CS15] 利用窗口技术,纠正了 [CKS13] 的错误:首先执行近似的冒泡排序,然后在小窗口(例如 W = 2 W=2 W=2)中执行完全的插入排序。由于减少了自举数量,速度提升了大约一倍。对于正确性而言,如果移除了 Recrpt 的冒泡算法中出现错误的比较结果的概率是 p p p,简记元素 a [ i ] a[i] a[i] 被错误的排到位置 a [ j ] , j > i a[j], j>i a[j],j>i 的概率为 P r i j Pr_{ij} Prij,[CS15] 分析得到,
P r 1 , w = 1 2 ⋅ P r 1 , ( w − 1 ) + 1 2 ⋅ p ( 1 2 ( 1 − p ) ) w − 1 , P r 1 , 2 = p / 2 Pr_{1,w} = \dfrac{1}{2} \cdot Pr_{1,(w-1)} + \dfrac{1}{2} \cdot p \left(\dfrac{1}{2}(1-p)\right)^{w-1},\,\, Pr_{1,2}=p/2 Pr1,w=21⋅Pr1,(w−1)+21⋅p(21(1−p))w−1,Pr1,2=p/2
随着窗口 w w w 的增大,错误率 P r 1 , w ≈ p / 2 w − 1 Pr_{1,w} \approx p/2^{w-1} Pr1,w≈p/2w−1 指数级减小,因此较小的窗口大小就足够了。移除了部分 Recrypt 的冒泡排序的复杂度为 O ( N 2 ) O(N^2) O(N2),完全 Recrypt 的基于窗口的插入排序的复杂度为 O ( w ⋅ n ) O(w \cdot n) O(w⋅n)

[Cha&Sen17] 讨论了基于 Partition 的排序算法,可以绕过上述的最坏复杂度限制。例如,快速排序的复杂度是依赖于分区质量的,每次递归过程的分区大小越均匀,那么平均复杂度就越接近 O ( n log n ) O(n \log n) O(nlogn),并没有根据是否发生 Swap 来决定提前终止。但是,依然受到 IND-CPA 安全性的限制,枢轴的位置我们无法确定,因此不得不对 index 也加密,导致基于 Partition 的排序算法的效率比基于 Swap 的排序算法效率更低。
Sorting Network
[Batcher68] 提出的 Sorting Network 是一种数据独立的高并行度排序电路,其复杂度固定为 O ( n log 2 n ) O(n \log^2 n) O(nlog2n),迭代层数 O ( log 2 n ) O(\log^2 n) O(log2n),并行度 O ( n ) O(n) O(n)。[Batcher68] 提出了两种算法,我们默认长度 n n n 是二的幂次。
-
双调排序(Bitonic Sort):
-
双调序列,一个序列可以分为两个连续部分(首尾循环相接),一部分单调降(不增),另一部分单调升(不降)。
-
Batcher定理,一个长度 2 n 2n 2n 的双调序列 a 1 , ⋯ , a 2 n a_1,\cdots,a_{2n} a1,⋯,a2n,可以分为 MIN 序列 min ( a 1 , a n + 1 ) , ⋯ , min ( a n , a 2 n ) \min(a_1,a_{n+1}),\cdots,\min(a_n,a_{2n}) min(a1,an+1),⋯,min(an,a2n) 和 MAX 序列 max ( a 1 , a n + 1 ) , ⋯ , max ( a n , a 2 n ) \max(a_1,a_{n+1}),\cdots,\max(a_n,a_{2n}) max(a1,an+1),⋯,max(an,a2n),那么 MIN 序列和 MAX 序列都是双调序列,并且 MIN 序列中的最大值小于 MAX 序列中的最小值。
-
Sort 过程:输入双调序列,根据 Batcher 定理划分 MIN 序列和 MAX 序列,然后对它们分别递归执行 Sort 过程,最终将会得到一个有序数组(升序、降序)。
-
Merge 过程:输入任意序列,相邻元素两两合并,形成升调、降调交替的若干区间(相邻的区间组成了一个双调序列)。对这些双调序列调用 Sort 过程可以得到有序数组,我们仍构造出升调、降调交替的若干区间(区间大小翻倍)。迭代执行直到整个数组仅包含一个双调序列,再调用 Sort 过程得到有序数组。
-

-
奇偶归并排序(Odd-Even Merge Sort):
-
Sort 过程:输入任意序列 a 0 , ⋯ , a 2 n − 1 a_0,\cdots,a_{2n-1} a0,⋯,a2n−1,对于前半部分 a 0 , ⋯ , a n − 1 a_0,\cdots,a_{n-1} a0,⋯,an−1 和后半部分 a n , ⋯ , a 2 n − 1 a_n,\cdots,a_{2n-1} an,⋯,a2n−1 分别递归执行 Sort 过程,这得到了两个有序数组,最后调用 Merge 过程得到一个有序数组。
-
Merge 过程:输入两个有序数组 a 0 , ⋯ , a n − 1 a_0,\cdots,a_{n-1} a0,⋯,an−1 和 b 0 , ⋯ , b n − 1 b_0,\cdots,b_{n-1} b0,⋯,bn−1,如果 n = 1 n=1 n=1 则比较 a 0 < b 0 a_0 < b_0 a0<b0 获得一个长度 2 2 2 的有序数组;否则重新分组为 EVEN 序列 a 0 , a 2 , ⋯ , a n − 2 , b 0 , b 2 , ⋯ , b n − 2 a_0,a_2,\cdots,a_{n-2},b_0,b_2,\cdots,b_{n-2} a0,a2,⋯,an−2,b0,b2,⋯,bn−2 和 ODD 序列 a 1 , a 3 , ⋯ , a n − 1 , b 1 , b 3 , ⋯ , b n − 1 a_1,a_3,\cdots,a_{n-1},b_1,b_3,\cdots,b_{n-1} a1,a3,⋯,an−1,b1,b3,⋯,bn−1 ,两者的前半段和后半段也都是有序数组。对它们分别递归执行 Merge 过程,获得两个有序数组 e 0 , ⋯ , e n − 1 e_0,\cdots,e_{n-1} e0,⋯,en−1 和 o 0 , ⋯ , o n − 1 o_0,\cdots,o_{n-1} o0,⋯,on−1,然后比较 e i + 1 , o i e_{i+1},o_i ei+1,oi 并交换使得 e i + 1 > o i e_{i+1}>o_i ei+1>oi,那么序列 e 0 , o 0 , e 1 , o 1 , ⋯ , e n − 1 , o n − 1 e_0,o_0,e_1,o_1,\cdots,e_{n-1},o_{n-1} e0,o0,e1,o1,⋯,en−1,on−1 就是一个有序数组。
-

[EGNS15] 观察到基于 Swap 的同态排序算法总是以最坏复杂度运行,或者说它的效率与输入数据无关。[EGNS15] 简单地用 FHE Swap 电路搭建出了 Bitonic Sort 和 Odd-Even Merge Sort 同态排序网络,计算复杂度固定为 O ( n log 2 n ) O(n \log^2 n) O(nlog2n)。
深度最优化
Comparison Matrix
[CDSS] 使用了 LHE 而非 FHE 来实现同态排序,只要支持的 Level 级别够高,就可以完全忽略开销极高的 Recrypt 运算。由于 LHE 是以电路的形式执行的,排序算法需要先通过算术化消除条件分支,然后再通过循环展开得到无环的排序电路。但是 [EGNS15] 使用的 Sorting Network 迭代了 O ( log 2 n ) O(\log^2 n) O(log2n) 层,每一层的 Swap 输入都依赖于上一层的 Swap 结果,所以同态乘法深度较高,直接用 LHE 实例化将导致极高的参数规模。
为了降低乘法深度,最直观的思路就是只进行深度为 O ( 1 ) O(1) O(1) 的比较。输入密文 X 0 , ⋯ , X N − 1 X_0,\cdots,X_{N-1} X0,⋯,XN−1,预计算 comparison matrix,
M : = [ m 0 , 0 m 0 , 1 ⋯ m 0 , N − 1 m 1 , 0 m 1 , 1 ⋯ m 1 , N − 1 ⋮ ⋱ m N − 1 , 0 m N − 1 , 1 ⋯ m N − 1 , N − 1 ] m i j : = L T ( X i , X j ) = { E n c ( 1 ) , x i < x j E n c ( 0 ) , o t h e r w i s e M := \begin{bmatrix} m_{0,0} & m_{0,1} & \cdots & m_{0,N-1}\\ m_{1,0} & m_{1,1} & \cdots & m_{1,N-1}\\ \vdots && \ddots\\ m_{N-1,0} & m_{N-1,1} & \cdots & m_{N-1,N-1}\\ \end{bmatrix}\\ m_{ij} := LT(X_i, X_j) = \left\{\begin{aligned} Enc(1), && x_i < x_j\\ Enc(0), && otherwise\\ \end{aligned}\right. M:= m0,0m1,0⋮mN−1,0m0,1m1,1mN−1,1⋯⋯⋱⋯m0,N−1m1,N−1mN−1,N−1 mij:=LT(Xi,Xj)={Enc(1),Enc(0),xi<xjotherwise
这张表格在后续的 Sort 过程中可以被复用,消除后续的比较运算,从而降低乘法深度。对于 l l l 比特的数据,布尔电路 L T ( ⋅ ) LT(\cdot) LT(⋅) 的乘法深度为 O ( log l ) O(\log l) O(logl)
Direct Sort
矩阵 M M M 第 i i i 行的汉明重量,计数了比 X i X_i Xi 大的元素数量;矩阵 M M M 第 j j j 列的汉明重量,计数了比 X j X_j Xj 小的元素数量。于是,矩阵 M M M 第 j j j 列的汉明重量,恰好是从小到大排序时 X j X_j Xj 的正确次序!
我们利用 O ( log N ) O(\log N) O(logN) 比特的 Wallace Tree 全加器(连续 N N N 个数的加和,每三个数一组,计算出本位(XOR)和进位(AND),迭代 O ( log 3 / 2 N ) O(\log_{3/2}N) O(log3/2N) 轮)计算汉明重量
σ j = ∑ i ∈ [ N ] m i j \sigma_j = \sum_{i \in [N]} m_{ij} σj=i∈[N]∑mij
然后利用 O ( log N ) O(\log N) O(logN) 比特的 Equality Test 电路,将密文 X i X_i Xi 放置到正确的位置上
Y j : = ∑ i ∈ [ N ] ( σ i = j ) ⋅ X i Y_j := \sum_{i \in [N]} (\sigma_i=j)\cdot X_i Yj:=i∈[N]∑(σi=j)⋅Xi
不考虑预计算 M M M,Direct Sort 的乘法深度为 O ( log 3 / 2 N + log log N ) O(\log_{3/2}N + \log\log N) O(log3/2N+loglogN),乘法数量为 O ( N 2 log N + N 2 log log N ) O(N^2 \log N+N^2\log\log N) O(N2logN+N2loglogN)
Greedy Sort
算术加法电路的乘法深度总是较高的,另一种确定 X i X_i Xi 位置的思路是: X i X_i Xi 的次序是 t t t,那么恰好有 t t t 个数比它小,另外的 N − t − 1 N-t-1 N−t−1 个数都比它大(注意等号细节)
我们把排序结果写作:
Y t : = ∑ i ∈ [ N ] θ t , i X i Y_t := \sum_{i \in [N]} \theta_{t,i}X_i Yt:=i∈[N]∑θt,iXi
其中的 one-hot 系数通过穷举得到,它含有 ( N − 1 t ) {N-1 \choose t} (tN−1) 个单项,
θ t , i : = ∑ k 1 = 0 , k 1 ≠ i N − t m k 1 , i ∑ k 2 = k 1 + 1 , k 2 ≠ i N − t + 1 m k 2 , i ⋯ ∑ k t = k t − 1 + 1 , k t ≠ i N − 1 m k t , i ∏ j = 0 , j ≠ i , j ≠ k i , ⋯ , k t N − 1 m i j \theta_{t,i} := \sum_{k_1=0,k_1 \neq i}^{N-t}m_{k_1,i} \sum_{k_2=k_1+1,k_2 \neq i}^{N-t+1}m_{k_2,i} \cdots \sum_{k_t=k_{t-1}+1,k_t \neq i}^{N-1}m_{k_t,i} \prod_{j=0,j\neq i,j\neq k_i,\cdots,k_t}^{N-1} m_{ij} θt,i:=k1=0,k1=i∑N−tmk1,ik2=k1+1,k2=i∑N−t+1mk2,i⋯kt=kt−1+1,kt=i∑N−1mkt,ij=0,j=i,j=ki,⋯,kt∏N−1mij
不考虑预计算 M M M,Greedy Sort 的乘法深度仅为 O ( log N ) O(\log N) O(logN),但是乘法数量为 O ( N 2 ⋅ 2 N ) O(N^2\cdot 2^N) O(N2⋅2N)
减少乘法数量
Polynomial Rank Sort
虽然 Direct Sort 和 Greedy Sort 的乘法深度达到了最优,但是其乘法数量依然较多,尤其是 Greedy Sort 需要指数级的同态乘法。[Cet&Sun17] 把 Direct Sort 中的汉明重量的计算,从布尔算术加法电路,迁移到了多项式的幂指数上,于是待排序数据被可以自然地放置在正确位置。
输入数据 { a 0 , ⋯ , a N − 1 } \{a_0,\cdots,a_{N-1}\} {a0,⋯,aN−1},假设 a i a_i ai 的次序为 r i r_i ri,我们定义 rank polynomial ρ i ( x ) : = x r i \rho_i(x):=x^{r_i} ρi(x):=xri,那么
b ( x ) = ∑ i = 1 N − 1 a i ρ i ( x ) = ∑ i = 1 N − 1 a i x r i = ∑ i = 1 N − 1 b i x i \begin{aligned} b(x) &= \sum_{i=1}^{N-1} a_i\rho_i(x)\\ &= \sum_{i=1}^{N-1}a_i x^{r_i} = \sum_{i=1}^{N-1}b_i x^{i} \end{aligned} b(x)=i=1∑N−1aiρi(x)=i=1∑N−1aixri=i=1∑N−1bixi
那么系数向量 b 0 ≤ b 1 ≤ ⋯ ≤ b N − 1 b_0 \le b_1 \le \cdots \le b_{N-1} b0≤b1≤⋯≤bN−1 就直接是有序的 { a 0 , ⋯ , a N − 1 } \{a_0,\cdots,a_{N-1}\} {a0,⋯,aN−1} 啦!这么做对比于 Direct Sort 的好处是,不必再利用 Equality Test 去确定密文放置的位置,而是天然有序。
为了计算 ρ i ( x ) \rho_i(x) ρi(x),我们仿照 Direct Sort 的计算方式,
-
首先预计算 { a 0 , ⋯ , a N − 1 } \{a_0,\cdots,a_{N-1}\} {a0,⋯,aN−1} 两两比较的单项式(对应于比较矩阵),每一对 a i , a j , i < j a_i,a_j,i<j ai,aj,i<j 计算
ρ i j ( x ) : = 1 , ρ j i ( x ) : = x ⟺ a i < a j ρ i j ( x ) : = x , ρ j i ( x ) : = 1 ⟺ a i ≥ a j \rho_{ij}(x):=1, \rho_{ji}(x):=x \iff a_i < a_j\\ \rho_{ij}(x):=x, \rho_{ji}(x):=1 \iff a_i \ge a_j\\ ρij(x):=1,ρji(x):=x⟺ai<ajρij(x):=x,ρji(x):=1⟺ai≥aj -
然后计算乘积(对应于汉明重量),
ρ i ( x ) : = ∏ i ≠ j ρ i j ( x ) = x ∑ i ≠ j ( a i ≥ a j ) = x r i \rho_i(x) := \prod_{i \neq j} \rho_{ij}(x) = x^{\sum_{i \neq j}(a_i\ge a_j)} = x^{r_i} ρi(x):=i=j∏ρij(x)=x∑i=j(ai≥aj)=xri -
最终计算出
b ( x ) = ∑ i = 1 N − 1 a i ρ i ( x ) b(x) = \sum_{i=1}^{N-1} a_i\rho_i(x) b(x)=i=1∑N−1aiρi(x)
对于密文 { A 0 , ⋯ , A N − 1 } \{A_0,\cdots,A_{N-1}\} {A0,⋯,AN−1} 下的同态计算,
P i j : = ( E n c ( 1 ) − L T ( A i , A j ) ) + L T ( A i , A j ) ⋅ E n c ( x ) ∈ { E n c ( 1 ) , E n c ( x ) } B : = ∑ i ∈ [ N ] ( A i ⋅ ∏ j ≠ i P i j ) = E n c ( ∑ i ∈ [ N ] a i x r i ) \begin{aligned} P_{ij} &:= \left(Enc(1)-LT(A_i,A_j)\right) + LT(A_i,A_j) \cdot Enc(x) \in \{Enc(1),Enc(x)\}\\ B &:= \sum_{i \in [N]} \left( A_i \cdot \prod_{j \neq i} P_{ij} \right) = Enc(\sum_{i \in [N]} a_i x^{r_i}) \end{aligned} PijB:=(Enc(1)−LT(Ai,Aj))+LT(Ai,Aj)⋅Enc(x)∈{Enc(1),Enc(x)}:=i∈[N]∑ Ai⋅j=i∏Pij =Enc(i∈[N]∑aixri)
然而,[Cet&Sun17] 的计算结果是单个多项式,其排序结果存储在了它的系数上。下面我们考虑如何提取出 N N N 个有序密文,这是我自己想的,论文中没写。
Frobenius Maps
[SV11] 提出了 RLWE-FHE 的 SIMD 技术。给定素数 p p p,分园环 G F ( p ) [ x ] / ( ϕ m ( x ) ) GF(p)[x]/(\phi_m(x)) GF(p)[x]/(ϕm(x)),次数 m m m 与 p p p 互素,令 d d d 是满足 m ∣ p d − 1 m\mid p^d-1 m∣pd−1 的最小正整数,那么分园多项式可以在 G F ( p ) GF(p) GF(p) 上分解为 l = ϕ ( m ) / d l=\phi(m)/d l=ϕ(m)/d 个不同的 d d d 次不可约多项式,
ϕ m ( x ) = ∏ i = 1 l F i ( x ) ( m o d p ) \phi_m(x) = \prod_{i=1}^{l} F_i(x) \pmod p ϕm(x)=i=1∏lFi(x)(modp)
因为域上的多项式环是主理想环,其素理想都是极大理想。根据 CRT of Ring,理想 ( F i ( x ) ) (F_i(x)) (Fi(x)) 两两互素,且 ( ϕ m ( x ) ) (\phi_m(x)) (ϕm(x)) 是它们的交理想,那么有
G F ( p ) [ x ] / ( ϕ m ( x ) ) ≅ G F ( p ) [ x ] / ( F 1 ( x ) ) × ⋯ G F ( p ) [ x ] / ( F l ( x ) ) ≅ ( G F ( p d ) ) l GF(p)[x]/(\phi_m(x)) \cong GF(p)[x]/(F_1(x)) \times \cdots GF(p)[x]/(F_l(x)) \cong (GF(p^d))^l GF(p)[x]/(ϕm(x))≅GF(p)[x]/(F1(x))×⋯GF(p)[x]/(Fl(x))≅(GF(pd))l
这包含了 l l l 个槽,空间都同构于有限域 G F ( p d ) GF(p^d) GF(pd)。对于不同的槽,它们的唯一区别就是域扩张 G F ( p d ) / G F ( p ) GF(p^d)/GF(p) GF(pd)/GF(p) 所使用的代数元不同。根据 d d d 次本原单位根之间的关系,存在 g ∈ Z m ∗ g \in \mathbb Z_m^* g∈Zm∗ 满足 o r d ( g ) = l ord(g)=l ord(g)=l,其索引的环自同构:
κ g : x ↦ x g ( m o d ϕ m ( x ) ) \kappa_g : x \mapsto x^g \pmod{\phi_m(x)} κg:x↦xg(modϕm(x))
它可以实现槽变换, κ g ( a ( x ) ) ( m o d F i ( x ) ) = a ( x ) ( m o d F j ( x ) ) \kappa_g(a(x)) \pmod{F_i(x)} = a(x) \pmod{F_j(x)} κg(a(x))(modFi(x))=a(x)(modFj(x))
令 G F ( q ) GF(q) GF(q) 是任意有限域,域扩张 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 上的 Frobenius map 定义为
σ : a ↦ a q \sigma: a \mapsto a^q σ:a↦aq
可以证明:
- σ \sigma σ 是 G F ( q N ) GF(q^N) GF(qN) 上的双射,并且 σ N = i d \sigma^N=id σN=id
- σ i \sigma^i σi 是一个 G F ( q ) GF(q) GF(q) - 域自同构
- 令 x x x 是 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 的扩张元,那么 σ i ( x ) = x q i \sigma^i(x) = x^{q^i} σi(x)=xqi 也都是扩张元
- 域扩张 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 的迹: T r ( a ) : = ∑ i = 0 N − 1 σ i ( a ) Tr(a):=\sum_{i=0}^{N-1} \sigma^i(a) Tr(a):=∑i=0N−1σi(a)
- 域扩张 G F ( q N ) / G F ( q ) GF(q^N)/GF(q) GF(qN)/GF(q) 的范数: N o r m ( a ) : = ∏ i = 0 N − 1 σ i ( a ) Norm(a):=\prod_{i=0}^{N-1} \sigma^i(a) Norm(a):=∏i=0N−1σi(a)
[HS14] 指出,同态 Frobenius map 的乘法深度为零(文中没有给出公式)。我推导了一下,假设 RLWE 密文是
c t = ( a ( x ) , a ( x ) s ( x ) + Δ m ( x ) + e ( x ) ) ∈ ( G F ( p d ) ) 2 ct = (a(x), a(x)s(x)+\Delta m(x)+e(x)) \in \left(GF(p^d)\right)^2 ct=(a(x),a(x)s(x)+Δm(x)+e(x))∈(GF(pd))2
有限扩域 G F ( p d ) GF(p^d) GF(pd) 上的 G F ( p ) GF(p) GF(p) - 域自同构 σ ( x ) : = x p \sigma(x):=x^p σ(x):=xp,因为 a , s , m , e ∈ G F ( p d ) a,s,m,e \in GF(p^d) a,s,m,e∈GF(pd) 并且 Δ ∈ G F ( p ) \Delta \in GF(p) Δ∈GF(p),
σ ( c t ) = ( σ ( a ) , σ ( a ) σ ( s ) + Δ σ ( m ) + σ ( e ) ) ∈ ( G F ( p d ) ) 2 \sigma(ct) = (\sigma(a), \sigma(a)\sigma(s)+\Delta \sigma(m)+\sigma(e)) \in \left(GF(p^d)\right)^2 σ(ct)=(σ(a),σ(a)σ(s)+Δσ(m)+σ(e))∈(GF(pd))2
所以 σ ( c t ) \sigma(ct) σ(ct) 是在私钥 σ ( s ) \sigma(s) σ(s) 下的明文 σ ( m ) \sigma(m) σ(m) 的密文,我们只需再执行 σ ( s ) → s \sigma(s) \to s σ(s)→s 的秘钥切换,就完成了同态 Frobenius map,它的代价与槽变换是相同的。
由于所有的线性映射 L : G F ( p d ) → G F ( p ) L: GF(p^d) \to GF(p) L:GF(pd)→GF(p),恰好就是所有的迹 L β ( a ) : = T r ( β a ) , β ∈ G F ( p d ) L_\beta(a):=Tr(\beta a),\beta \in GF(p^d) Lβ(a):=Tr(βa),β∈GF(pd)。所以,对于 [Cet&Sun17] 的排序结果 B = E n c ( ∑ i a i x r i ) B=Enc(\sum_i a_ix^{r_i}) B=Enc(∑iaixri),总是存在 N N N 个元素 β i \beta_i βi 索引了投影映射 T r ( β i B ) = E n c ( a i ) Tr(\beta_i B) = Enc(a_i) Tr(βiB)=Enc(ai),这就提取出了排序结果。
注意,对于 l l l 比特的数据,每个密文 A i A_i Ai 包含了 l l l 个 G F ( p d ) GF(p^d) GF(pd) 上的常数多项式(二进制分解的各个比特)。电路 L T ( ⋅ ) LT(\cdot) LT(⋅) 是布尔比较电路,输出是布尔值对应的 G F ( p d ) GF(p^d) GF(pd) 上单个常数多项式。密文 B = E n c ( ∑ i ∈ [ N ] a i x r i ) B=Enc(\sum_{i \in [N]} a_i x^{r_i}) B=Enc(∑i∈[N]aixri),为了阻止数据溢出,最基本的要求是 d ≥ N d \ge N d≥N。可以使用 SIMD 打包技术,将这些 N × l N \times l N×l 个常数多项式按位加密到 l l l 个密文中,这额外要求 ϕ ( m ) / d ≥ N \phi(m)/d \ge N ϕ(m)/d≥N。

不考虑 P i j P_{ij} Pij 的开销(这主要和 L T ( ⋅ ) LT(\cdot) LT(⋅) 的不同实现有关,[IZ21] 给出了更高效的基于插值的比较算法),Polynomial Rank Sort 的乘法深度为 O ( log N ) O(\log N) O(logN),乘法数量为 O ( N 2 ) O(N^2) O(N2),并行度为 O ( N ) O(N) O(N)。对于 l l l 比特数据,使用 SIMD 技术,先并行计算出 P i : = ∏ j ≠ i P i j P_i := \prod_{j \neq i} P_{ij} Pi:=∏j=iPij,这需要 O ( N ) O(N) O(N) 次同态乘法,乘法深度为 O ( log N ) O(\log N) O(logN);然后并行计算出 B : = ∑ i ∈ [ N ] A i P i B:=\sum_{i \in [N]} A_iP_i B:=∑i∈[N]AiPi,这需要 O ( l ) O(l) O(l) 次同态乘法,乘法深度为 O ( 1 ) O(1) O(1);最后的同态 Frobenius map 不需要同态乘法。共计 O ( N + l ) O(N+l) O(N+l) 次同态乘法,乘法深度 O ( log N ) O(\log N) O(logN)。
相关文章:
同态排序算法
参考文献: [Batcher68] Batcher K E. Sorting networks and their applications[C]//Proceedings of the April 30–May 2, 1968, spring joint computer conference. 1968: 307-314. [SV11] Smart, N.P., Vercauteren, F.: Fully homomorphic SIMD operations. IA…...

“深入探索JVM内部机制:解析Java虚拟机的工作原理“
标题:深入探索JVM内部机制:解析Java虚拟机的工作原理 摘要:本文将介绍Java虚拟机(JVM)的工作原理,包括类加载、内存管理、垃圾回收和字节码执行等方面。通过深入理解JVM的内部机制,开发人员可以…...
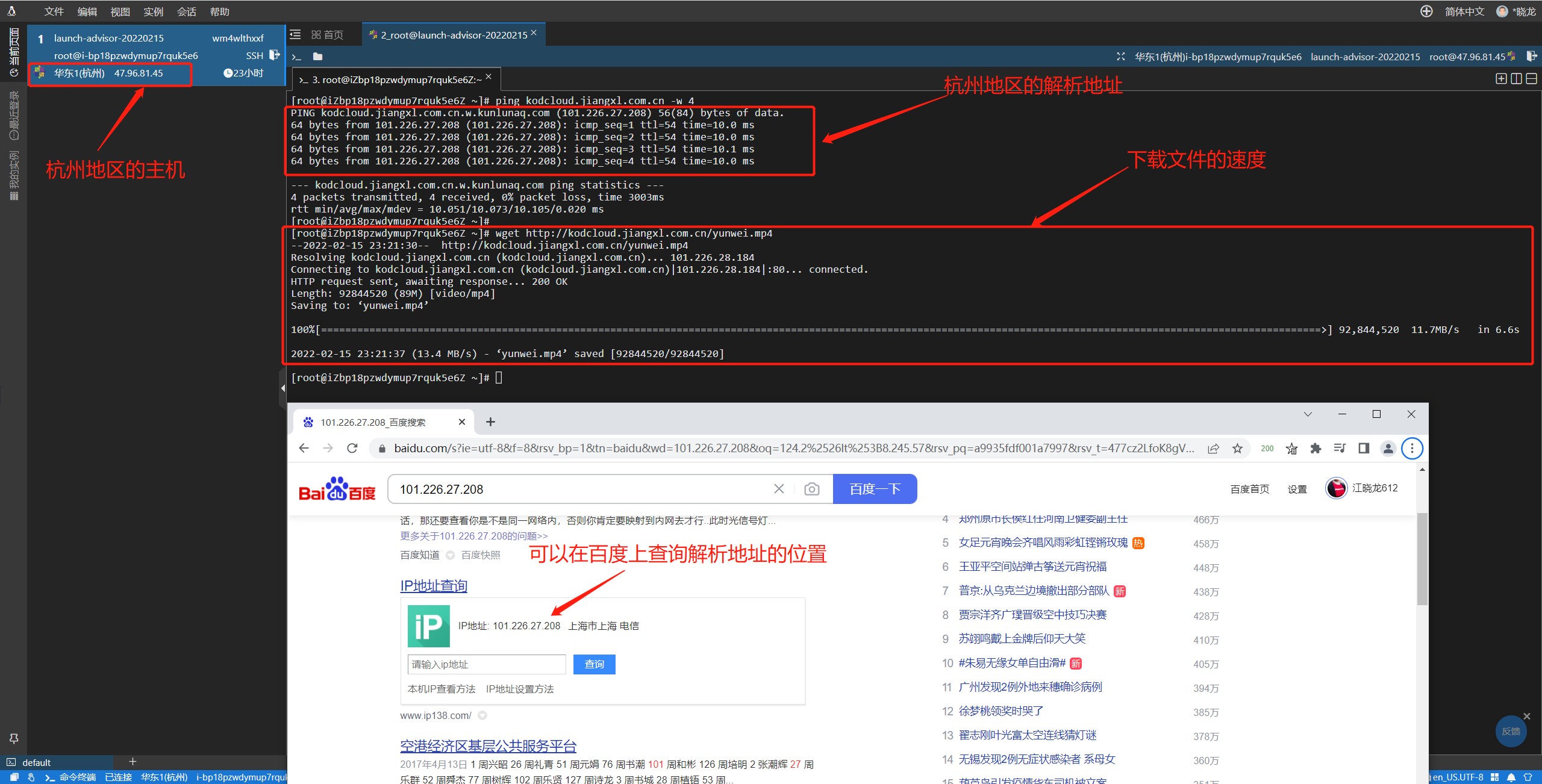
为应用程序接入阿里云CDN优化网站访问速度
文章目录 1.KodCloud云盘系统接入CDN之前的效果2.配置KodCloud云盘接入CDN加速器2.1.添加CDN域名2.2.配置域名信息2.3.CDN推荐配置设置2.4.CDN加速器配置完成 3.配置云解析DNS增加CDN域名的解析4.为CDN加速器配置HTTPS5.验证网站是否接入CDN6.访问应用程序观察请求速度7.观察CD…...

索引设计规范
索引是帮助数据库高效获取数据的数据结构。索引是加速查询的常用技术手段。在设计索引时,要遵循索引设计规范,避免不必要的踩坑。 【推荐】索引存储结构推荐BTREE InnoDB和MyISAM存储引擎表,索引类型必须为BTRER,MEMORY表可以根…...

Appium 2安装与使用java对Android进行自动化测试
文章目录 1、Appium 2.1安装1.1、系统要求1.2、安装Appium2.1服务1.3、安装UiAutomator2驱动1.4、安装Android SDK platform tools1.5、下载OpenJDK 2、Android自动代码例子2.1、安装Android自动化测试元素定位工具Appium Inspector2.2、编写android app自动化测试代码和使用ex…...

小程序运营方式有哪些?如何构建小程序运营框架?
如今,每个企业基本都做过至少一个小程序,但由于小程序本身不具备流量、也很少有自然流量,因此并不是每个企业都懂如何运营小程序。想了解小程序运营方式方法有哪些? 在正式运营小程序前,了解小程序的功能与企业实际经…...
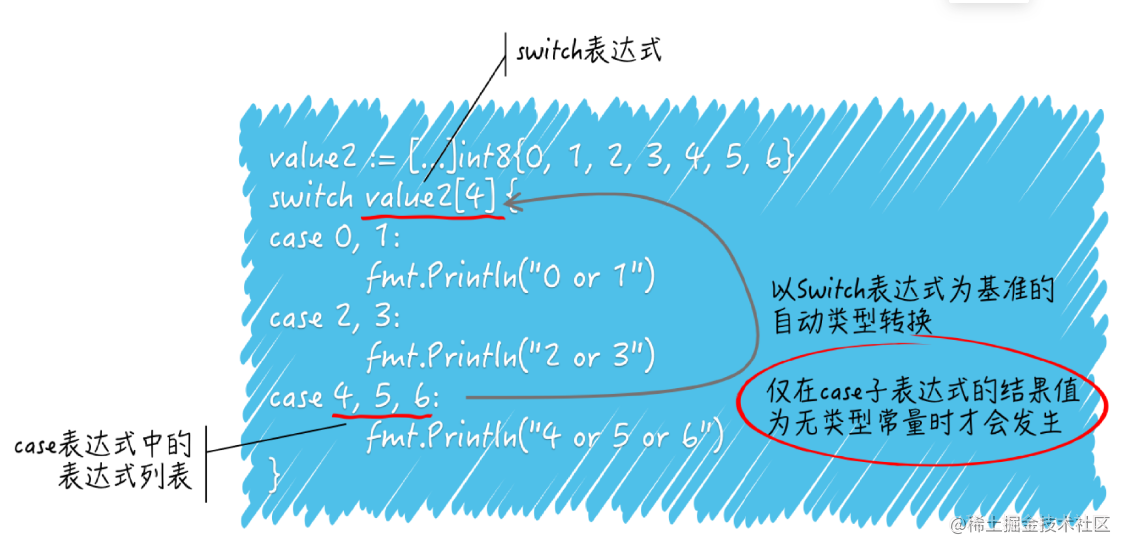
【golang】for语句和switch语句
使用携带range子句的for语句时需要注意哪些细节? numbers1 : []int{1, 2, 3, 4, 5, 6} for i : range numbers1 {if i 3 {numbers1[i] | i} } fmt.Println(numbers1)这段代码执行后会打印出什么内容? 答案:[1 2 3 7 5 6] 当for语句被执行…...

三、数据库索引
1、索引介绍 索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。 常见的索引结构有:B数,B树,Hash和红黑树等。在MySQL中,无论是 InnoDB还是MyISAM,都使用了B树作为索引…...

长时间带什么耳机最舒服,分享长时间佩戴舒服的耳机推荐
时代在进步,科技在不断革新。近年来,一种崭新的耳机——骨传导耳机,如火如荼地进驻耳机市场,引起一阵热潮。不论是平日里的工作出勤还是运动时的挥洒汗水,相比传统耳机,骨传导耳机无疑更加贴合现代生活的需…...
)
Yolov8小目标检测(1)
💡💡💡本文目标:通过原始基于yolov8的红外弱小目标检测,训练得到初版模型,进行问题点分析; 💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,带你轻松实现小目标检测涨点 💡💡…...

GPS定位漂移问题分析
有很多种因素会影响到GPS的准确率,以下是一个GPS误差引入简表: l 卫星时钟误差:0-1.5米 l 卫星轨道误差:1-5米 l 电离层引入的误差:0-30米 l 大气层引入的误差:0-30米 l 接收机…...

前端简介(HTML+CSS+JS)
学习Django过程中遇到一些前端相关的内容,于是整理了一下相关概念。 前端开发是创建WEB页面或APP等前端界面呈现给用户的过程。 如果只是想要入门前端,只要学习网页三剑客(HTML、CSS、JavaScript)即可。 如果把网页比喻成一个房子,HTML就是…...

List与String数组互转
一.List 转为 String 数组 1.使用toArray方法 public static void main(String[] args) {List<String> list Lists.newArrayList("1","2","3");// Java6以前版本String[] str1 list.toArray(new String[list.size()]);// Java6以后版本…...

MySQL中的数据类型
文章目录 1 常见的数据类型2 整数类型2.1 属性 M2.2 属性 UNSIGNED2.3 属性 ZEROFILL2.4 整数类型的适用场景 3 浮点类型4 定点类型5 位类型6 日期与时间类型6.1 YEAR 类型6.2 DATE 类型6.3 TIME 类型6.4 DATETIME 类型6.5 TIMESTAMP 类型 1 常见的数据类型 类型类型分类整数类…...

python多任务
一、多任务 1.1 概念 多任务就是指:同一时间能执行多个任务。比方我们的电脑能一边QQ聊天,一边写论文,还能听歌。 1.2 多任务的优势: 多任务的最大好处是 充分利用CPU资源,提高程序的执行效率。 1.3 多任务的两种表…...
)
c语言 - inline关键字(内联函数)
概念 在编程中,inline是一个关键字,用于修饰函数。inline函数是一种对编译器的提示,表示这个函数在编译时应该进行内联展开。 内联展开是指将函数的代码插入到调用该函数的地方,而不是通过函数调用的方式执行。这样可以减少函数调…...

如何在Ubuntu 18.04上安装PHP 7.4并搭建本地开发环境
引言 PHP是一种流行的服务器脚本语言,用于创建动态和交互式web页面。开始使用你选择的语言是学习编程的第一步。 本教程将指导您在Ubuntu上安装PHP 7.4,并通过命令行设置本地编程环境。您还将安装依赖管理器Composer,并通过运行脚本来测试您…...

狭义相对论
文章目录 一、为什么光速不变?二、为什么爱因斯坦坚信“相对性原理”三、逻辑和数学显威力,狭义相对论时空变换(洛伦兹变换)推导四、新时空变换带来的新时空观1、有关相对论时间的“傻问题”2、关于相对论的“怪问题”3、关于“双…...
仓库使用综合练习
目录 1、使用mysql:5.6和 owncloud 镜像,构建一个个人网盘。 2、安装搭建私有仓库 Harbor 3、编写Dockerfile制作Web应用系统nginx镜像,生成镜像nginx:v1.1,并推送其到私有仓库。 4、Dockerfile快速搭建自己专属的LAMP环境,生…...
如何在前端实现WebSocket发送和接收TCP消息(多线程模式)
目录 第一步:创建WebSocket连接第二步:监听WebSocket事件第三步:发送消息第四步:后端处理函数说明 当在前端实现WebSocket发送和接收TCP消息时,可以使用以下步骤来实现多线程模式。本文将详细介绍如何在前端实现WebSoc…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...