Docker 安装 Redis集群
1. 面试题
1.1 1~2亿条数据需要缓存,请问如何设计这个存储案例
单机单台不可能实现,肯定是用分布式存储,用redis如何落地?
1.2 上述问题工程案例场景设计类题目,解决方案
1.2.1 哈希取余分区
2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式: hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。优点: 简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。缺点: 原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。

1.2.2 一致性哈希算法分区
1. 是什么
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决
分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了
2. 能干啥提出一致性hash解决方案,目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
3. 3大步骤3.1 算法构建一致哈希环
一致性哈希环
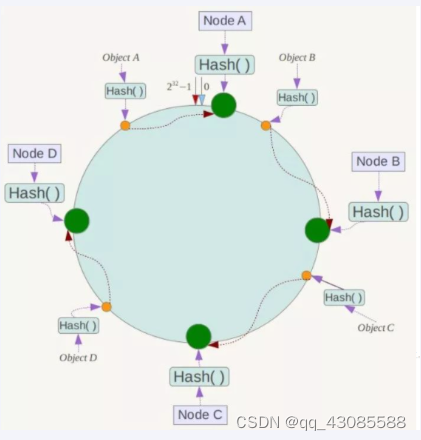
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
3.2 服务器IP节点映射
节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
3.3 key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
4. 优点
4.1 一致性哈希算法的容错性
容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
4.2 一致性哈希算法的扩展性
扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,
不会导致hash取余全部数据重新洗牌。
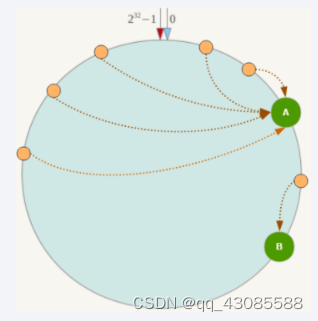
5. 缺点Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:
6. 总结为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。




1.2.3 哈希槽分区
1. 是什么
1 为什么出现
哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
2 能干什么
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
3 多少个hash槽
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
2. 哈希槽计算
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上



2. 开始部署
2.1 3主3从redis集群配置
2.1.1 构建6个redis容器
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
参数解析:docker run 启动容器
--name redis-node-1 容器命名--net host 使用宿主机ip和端口,默认
--privileged=true 获取宿主机root用户权限
-v 容器卷,目录映射
redis:6.0.8 镜像--cluster-enabled 开启redis集群
--appendonly yes 开启持久化
--port 6386 redis端口号
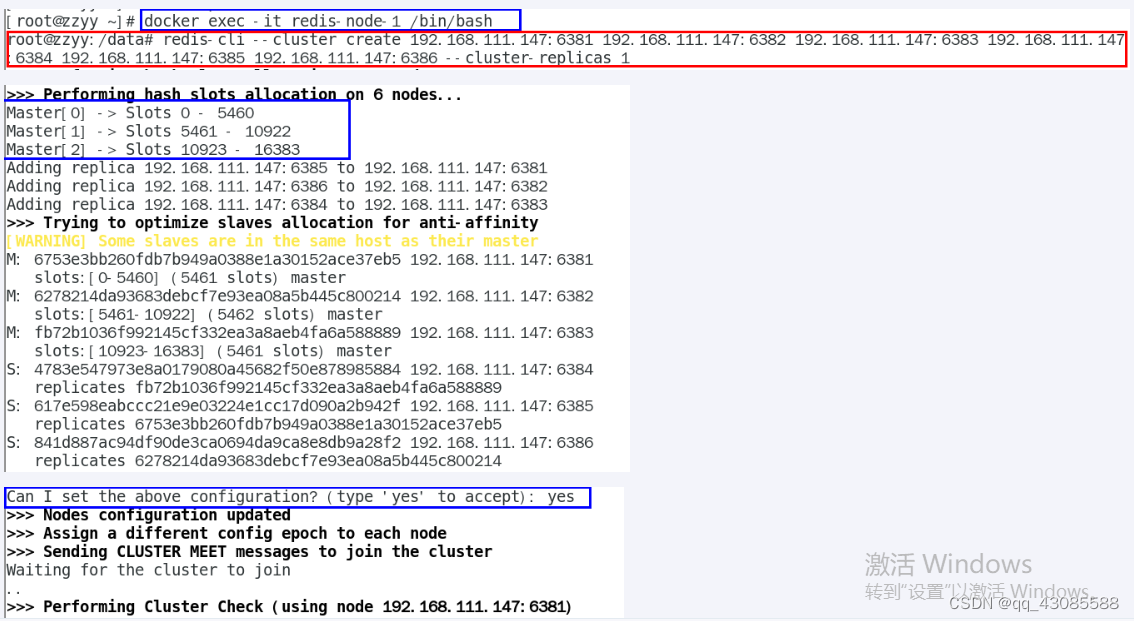
2.1.2 进入容器redis-node-1并为6台机器构建集群关系
1. 进入容器 docker exec -it redis-node-1 /bin/bash
2. 构建主从关系
//注意,进入docker容器后才能执行一下命令,且注意自己的真实IP地址
--cluster-replicas 1 表示为每个master创建一个slave节点
2.1.3 进入6381容器,查看集群状态

2.2 主从容错切换迁移案例
2.2.1 数据读写存储
1. 启动6机构成的集群并通过exec进入
2. 对6381新增两个key
3. 防止路由失效参数-c并新增两个key
-c 进入集群
4. 查看集群信息
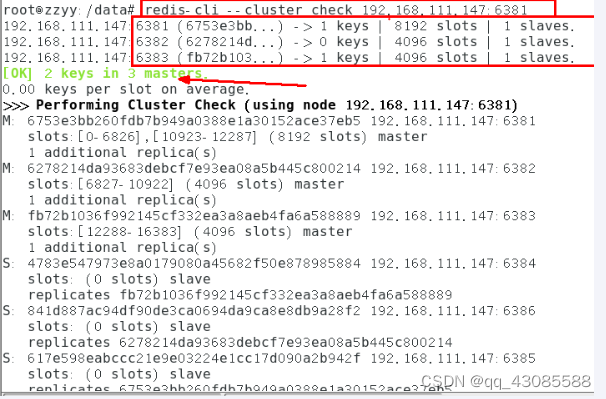
redis-cli --cluster check 192.168.111.147:6381


2.2.2 容错切换迁移
1. 主6381和从机切换,先停止主机6381
6381 主机停了,对应的真实从机上位
6381 作为1号主机分配的从机以实际情况为准,具体是几号机器就是几号
2. 再查看集群信息
6381宕机了,6385上位成为了新的master。
备注:本次脑图笔记6381为主下面挂从6385。
每次案例下面挂的从机以实际情况为准,具体是几号机器就是几号
3. 先还原之前的三主三从
中间需要等待一会儿,docker集群重新响应。
4. 查看集群状态



2.3 主从扩容案例
2.3.1 新建6387,6388两个节点+新建后启动+查看是否8个节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
2.3.2 进入6387容器实例内部
docker exec it redis-node-7 /bin/bash
2.3.3 将新增的6387节点作为master节点加入原集群
将新增的6387作为master节点加入集群 redis-cli --cluster add-node 自己实际IP地址: 6387 自己实际IP地址: 63816387 就是将要作为master新增节点6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群

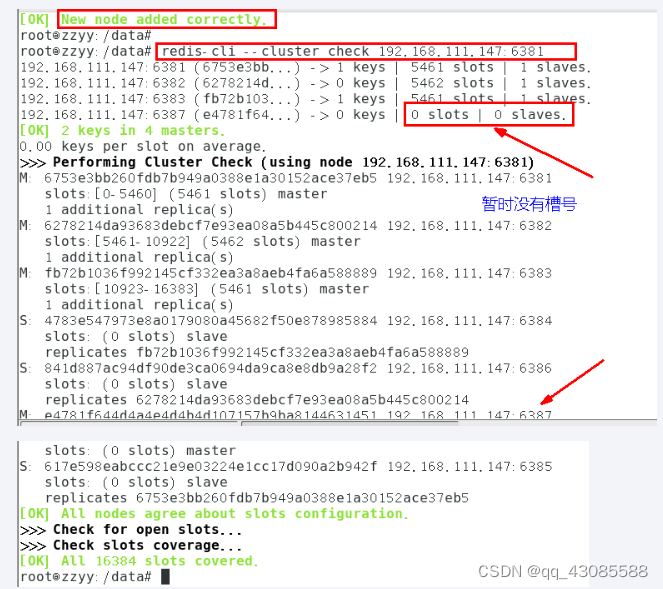
2.3.4 检查集群情况第一次
redis-cli --cluster check 真实ip地址:6381
2.3.5 从新分派槽号
重新分派槽号
命令:redis-cli --cluster reshard IP地址:端口号redis-cli --cluster reshard 192.168.111.147:6381
2.3.6 检查集群情况第二次
redis-cli --cluster check 真实ip地址:6381
为什么6387是3个新的区间,以前的还是连续?重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387

2.3.7 为主节点6387分配从节点6388
命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID redis-cli --cluster add-node 192.168.111.147:6388 192.168.111.147:6387 --cluster-slave --cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451-------这个是6387的编号,按照自己实际情况

2.3.8 检查集群情况第三次
redis-cli --cluster check 192.168.111.147:6382

2.4 主从缩容案例
2.4.1 检查集群情况获得6388的节点ID

2.4.2 从集群将4号从节点6388删除
命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID redis-cli --cluster del-node 192.168.111.147:6388 5d149074b7e57b802287d1797a874ed7a1a284a8
检查节点数
redis-cli --cluster check 192.168.111.147:6382


2.4.3 将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
redis-cli --cluster reshard 192.168.111.147:6381

2.4.4 检查集群情况第二次
redis-cli --cluster check 192.168.111.147:6381
4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次,一锅端

2.4.5 将6387删除
命令:redis-cli --cluster del-node ip:端口 6387节点ID redis-cli --cluster del-node 192.168.111.147:6387 e4781f644d4a4e4d4b4d107157b9ba8144631451

2.4.6 检查集群情况第三次
相关文章:
Docker 安装 Redis集群
1. 面试题 1.1 1~2亿条数据需要缓存,请问如何设计这个存储案例 单机单台不可能实现,肯定是用分布式存储,用redis如何落地? 1.2 上述问题工程案例场景设计类题目,解决方案 1.2.1 哈希取余分区 2亿条记录就是2亿个k,v&…...
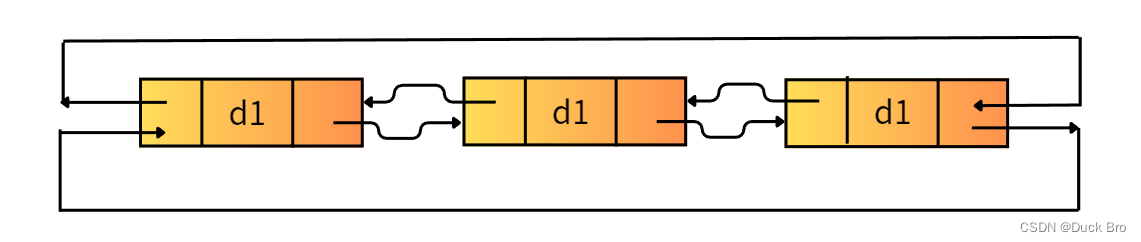
数据结构入门 — 链表详解_单链表
前言 数据结构入门 — 单链表详解* 博客主页链接:https://blog.csdn.net/m0_74014525 关注博主,后期持续更新系列文章 文章末尾有源码 *****感谢观看,希望对你有所帮助***** 系列文章 第一篇:数据结构入门 — 链表详解_单链表 第…...

从零学算法151
151.给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 注意:输入字符串 s中可能会存在前导空格、尾随…...

【Vue】动态设置元素类以及样式
Vue2 动态设置元素类以及样式 1.动态设置类 class 1.1 字符串语法 通过v-bind绑定元素的class属性,为其指定一个字符串: <div v-bind:class"className">class动态绑定</div> <script> export default {data() {return {…...
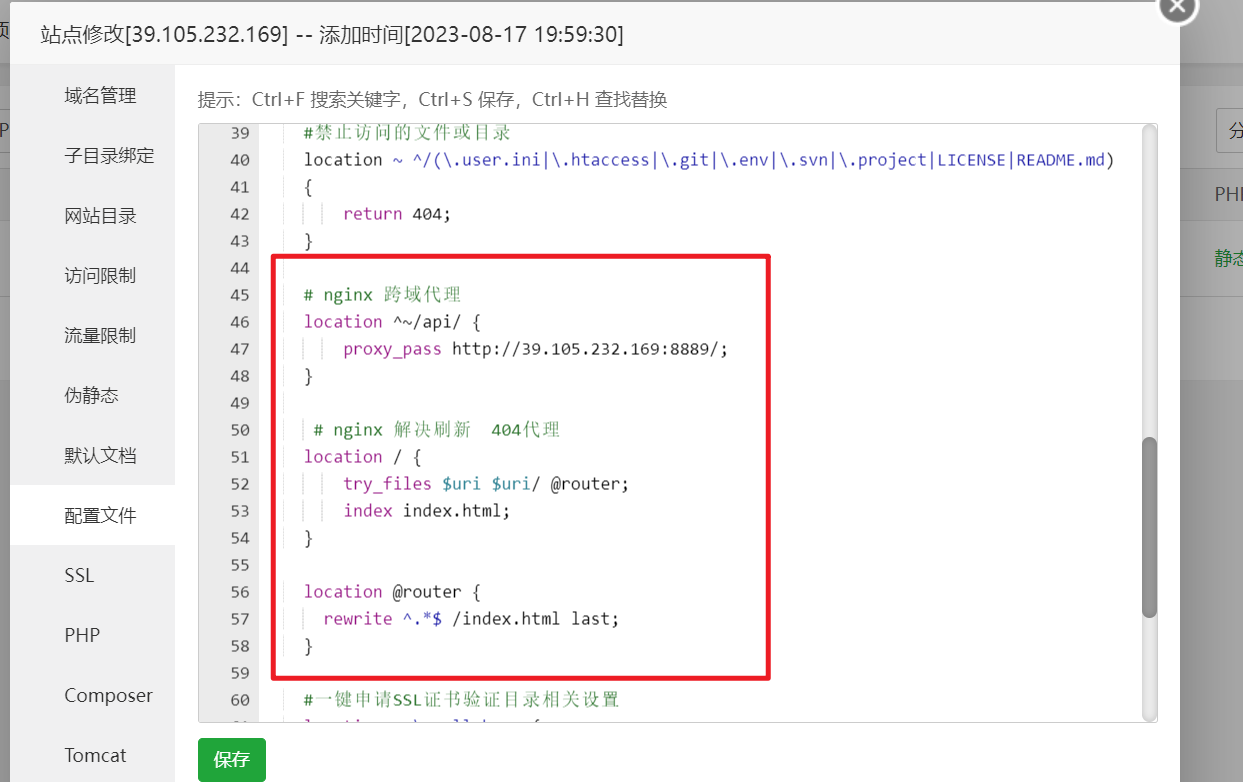
node和前端项目宝塔部署
首先需要一台服务器 购买渠道:阿里云、腾讯云、百度云、华为云 一、以阿里云为例 购买esc 可临时购买测试服务器 二、安装宝塔 复制公网ip地址 通过Xshell 进行账号密码的连接 连接后访问宝塔官网 宝塔面板下载,免费全能的服务器运维软件 找到自己…...

【Python原创毕设|课设】基于Python Flask的上海美食信息与可视化宣传网站项目-文末附下载方式以及往届优秀论文,原创项目其他均为抄袭
基于Python Flask的上海美食信息与可视化宣传网站(获取方式访问文末官网) 一、项目简介二、开发环境三、项目技术四、功能结构五、运行截图六、功能实现七、数据库设计八、源码获取 一、项目简介 随着大数据和人工智能技术的迅速发展,我们设…...

【HTML】HTML面试知识梳理
目录 DOCTYPE(文章类型)head标签浏览器乱码的原因及解决常用的meta标签与SEOscript标签中defer和async的区别src&href区别HTML5有哪些更新语义化标签媒体标签表单进度条、度量器DOM查询Web存储Canvas和SVG拖放 (HTML5 drag API࿰…...

Java进阶篇--IO流的第二篇《多样的流》
目录 Java缓冲流 BufferedReader和BufferedWriter类 Java随机流 Java数组流 字节数组流 ByteArrayInputStream流的构造方法: ByteArrayOutputStream流的构造方法: 字符数组流 Java数据流 Java对象流 Java序列化与对象克隆 扩展小知识&#x…...
iPhone 14 Pro 动态岛的功能和使用方法详解
当iPhone 14 Pro机型发布时,苹果公司将软件功能与屏幕顶部的药丸状切口创新集成,称之为“灵动岛”,这让许多人感到惊讶。这篇文章解释了它的功能、工作原理,以及你如何与它互动以执行动作。 一、什么是灵动岛?它是如何工作的 在谣言周期的早期iPhone 14 Pro 在宣布时…...

掌握这20条你将超过90%的测试员
1、不断学习 不管是“软技能”,比如公开演讲, 或者编程语言,亦或新的测试技术,成功的软件测试工程师总是会从繁忙中抽出时间来坚持学习。 2、管理你的时间 我们的时间很容易被大块的工作和不断的会议所占据,导致我们…...

LightDB create table时列约束支持enable/disable关键字
功能介绍 为了方便用户从Oracle数据库迁移到LightDB数据库,LightDB从23.3版本开始支持 create table时列约束支持enable/disable关键字。这个功能仅是语法糖。 使用说明 执行create table时,列约束后面可以选择性添加enable/disable关键字。 create …...

使用BeeWare实现iOS调用Python
1、准备工作 1.1、安装Python 1.2、设置虚拟环境 我们现在将创建一个虚拟环境——一个“沙盒”,如果我们将软件包安装到虚拟环境中,我们计算机上的任何其他Python项目将不会受到影响。如果我们把虚拟环境搞得一团糟,我们将能够简单地删除它…...

无公网IP内网穿透使用vscode配置SSH远程ubuntu随时随地开发写代码
文章目录 前言1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...
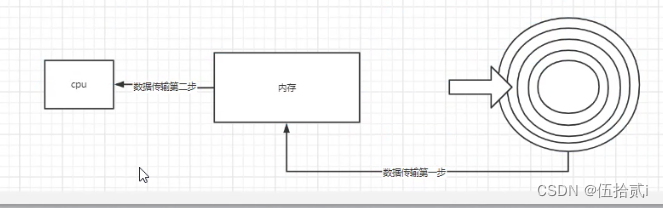
二叉树、红黑树、B树、B+树
二叉树 一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。 二叉树的特点: 每个结点最多有两棵子树,即二叉树不存在度大于2的结点。二叉树的子树有左右之分…...

12,【设计模式】工厂
设计模式工厂 通过工程来构建任意参数对象&&std::forwardstd::move 在C中,“工厂”(Factory)是一种设计模式,它提供了一种创建对象的方式,将对象的创建和使用代码分离开来,提高了代码的可扩展性和可…...
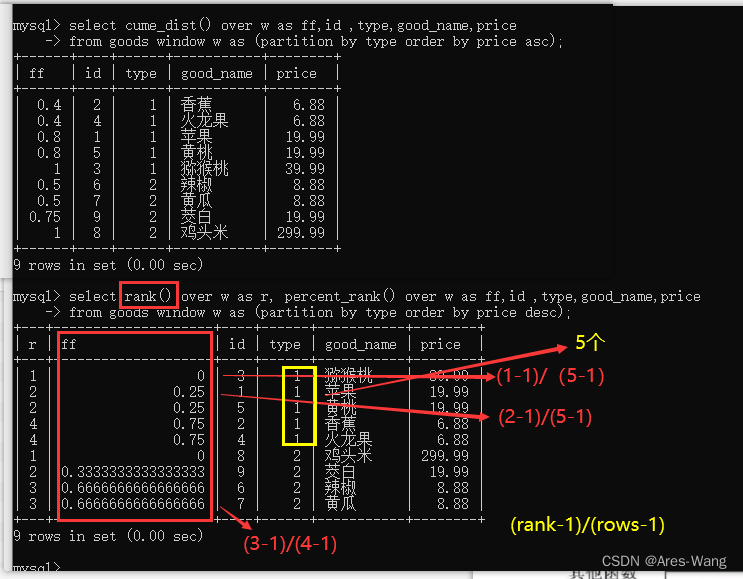
mysql 8.0 窗口函数 之 分布函数 与 sql server (2017以后支持) 分布函数 一样
mysql 分布函数 percent_rank() :等级值 百分比cume_dist() :累积分布值 percent_rank() 计算方式 (rank-1)/(rows-1), 其中 rank 的值为使用RANK()函数产生的序号,rows 的值为当前…...

Python Opencv实践 - 图像直方图自适应均衡化
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/cat.jpg", cv.IMREAD_GRAYSCALE) print(img.shape)#整幅图像做普通的直方图均衡化 img_hist_equalized cv.equalizeHist(img)#图像直方图自适应均衡化 #1. 创…...

Linux编程:在程序中异步的调用其他程序
Linux编程:execv在程序中同步调用其他程序_风静如云的博客-CSDN博客 介绍了同步的调用其他程序的方法。 有的时候我们需要异步的调用其他程序,也就是不用等待其他程序的执行结果,尤其是如果其他程序是作为守护进程运行的,也无法等待其运行的结果。 //ssss程序 #include …...

04有监督算法——支持向量机
1.支持向量机 1.1 定义 支持向量机( Support Vector Machine )要解决的问题 什么样的法策边界才是最好的呢? 特征数据本身如果就很难分,怎么办呢? 计算复杂度怎么样?能实际应用吗? 支持向量机( Support Vector Machine , SVM)是一类按监督学习( s…...
)
macos 使用vscode 开发python 爬虫(安装一)
使用VS Code进行Python爬虫开发是一种常见的选择,下面是一些步骤和建议: 安装VS Code:首先,确保你已经在你的macOS上安装了VS Code。你可以从官方网站(https://code.visualstudio.com/)下载并安装最新版本…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

云安全与网络安全:核心区别与协同作用解析
在数字化转型的浪潮中,云安全与网络安全作为信息安全的两大支柱,常被混淆但本质不同。本文将从概念、责任分工、技术手段、威胁类型等维度深入解析两者的差异,并探讨它们的协同作用。 一、核心区别 定义与范围 网络安全:聚焦于保…...
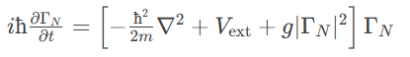
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...
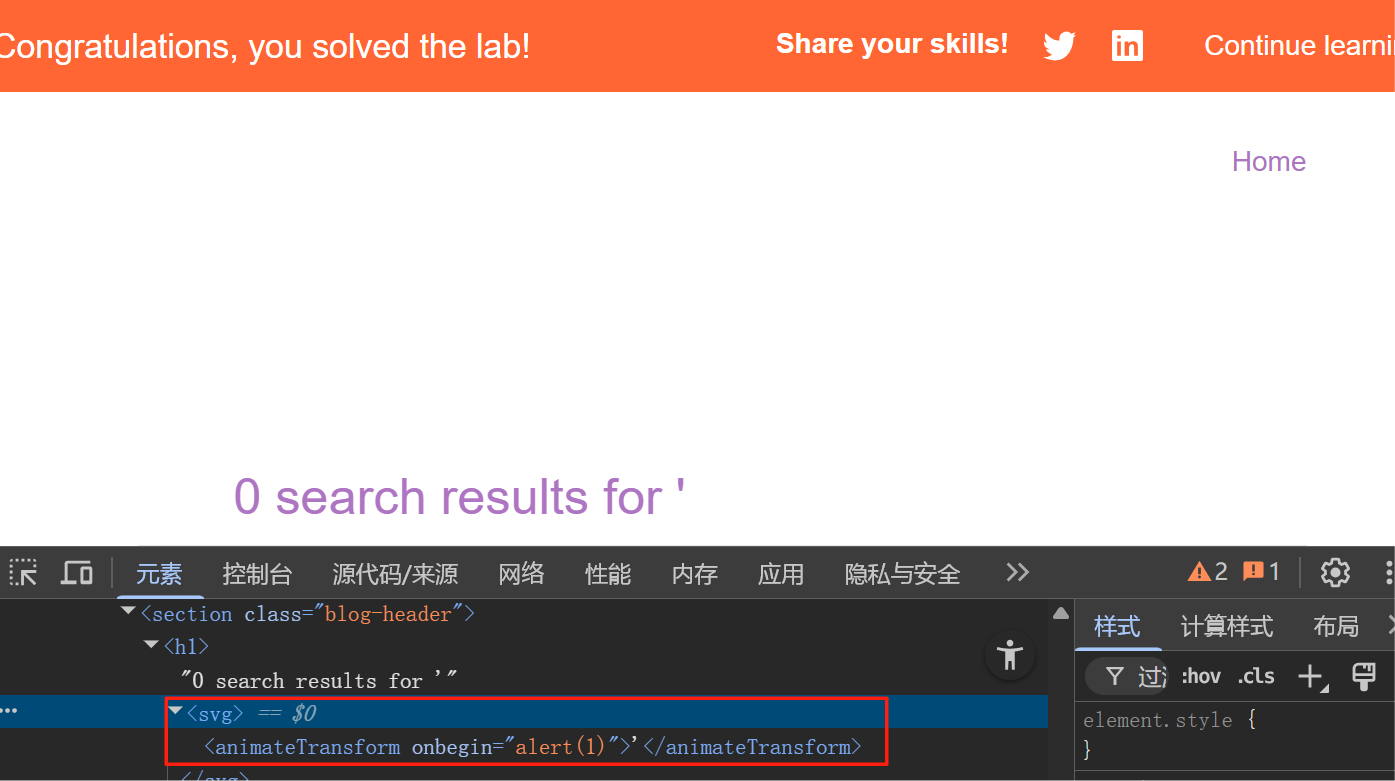
渗透实战PortSwigger Labs指南:自定义标签XSS和SVG XSS利用
阻止除自定义标签之外的所有标签 先输入一些标签测试,说是全部标签都被禁了 除了自定义的 自定义<my-tag onmouseoveralert(xss)> <my-tag idx onfocusalert(document.cookie) tabindex1> onfocus 当元素获得焦点时(如通过点击或键盘导航&…...
qt+vs Generated File下的moc_和ui_文件丢失导致 error LNK2001
qt 5.9.7 vs2013 qt add-in 2.3.2 起因是添加一个新的控件类,直接把源文件拖进VS的项目里,然后VS卡住十秒,然后编译就报一堆 error LNK2001 一看项目的Generated Files下的moc_和ui_文件丢失了一部分,导致编译的时候找不到了。因…...

Java多线程实现之Runnable接口深度解析
Java多线程实现之Runnable接口深度解析 一、Runnable接口概述1.1 接口定义1.2 与Thread类的关系1.3 使用Runnable接口的优势 二、Runnable接口的基本实现方式2.1 传统方式实现Runnable接口2.2 使用匿名内部类实现Runnable接口2.3 使用Lambda表达式实现Runnable接口 三、Runnabl…...