MDTA模块(Restormer)
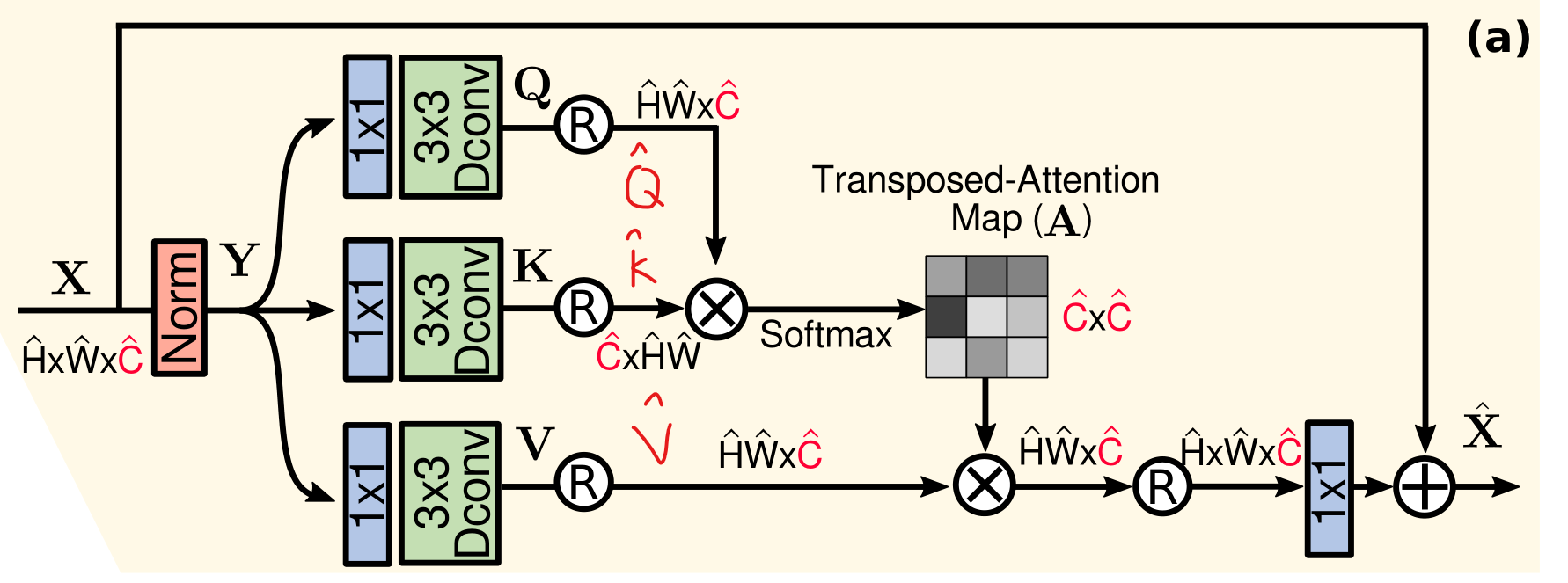
From a layer normalized tensor Y ∈ R H ^ × W ^ × C ^ \mathbf{Y} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} Y∈RH^×W^×C^, our MDTA first generates query ( Q ) (\mathbf{Q}) (Q), key ( K ) (\mathbf{K}) (K) and value ( V ) (\mathbf{V}) (V) projections, enriched with local context. It is achieved by applying 1 × 1 1 \times 1 1×1 convolutions to aggregate pixel-wise cross-channel context followed by 3 × 3 3 \times 3 3×3 depth-wise convolutions to encode channel-wise spatial context, yielding Q = W d Q W p Q Y , K = W d K W p K Y \mathbf{Q}=W_d^Q W_p^Q \mathbf{Y}, \mathbf{K}=W_d^K W_p^K \mathbf{Y} Q=WdQWpQY,K=WdKWpKY and V = W d V W p V Y \mathbf{V}=W_d^V W_p^V \mathbf{Y} V=WdVWpVY. Where W p ( ⋅ ) W_p^{(\cdot)} Wp(⋅) is the 1 × 1 1 \times 1 1×1 point-wise convolution and W d ( ⋅ ) W_d^{(\cdot)} Wd(⋅) is the 3 × 3 3 \times 3 3×3 depth-wise convolution. We use bias-free convolutional layers in the network. Next, we reshape query and key projections such that their dot-product interaction generates a transposed-attention map A \mathbf{A} A of size R C ^ × C ^ \mathbb{R}^{\hat{C} \times \hat{C}} RC^×C^, instead of the huge regular attention map of size R H ^ W ^ × H ^ W ^ \mathbb{R}^{\hat{H} \hat{W} \times \hat{H} \hat{W}} RH^W^×H^W^. Overall, the MDTA process is defined as:
X ^ = W p Attention ( Q ^ , K ^ , V ^ ) + X Attention ( Q ^ , K ^ , V ^ ) = V ^ ⋅ Softmax ( K ^ ⋅ Q ^ / α ) \hat{\mathbf{X}}=W_p \operatorname{Attention}(\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}})+\mathbf{X}\\ \operatorname{Attention}(\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}})=\hat{\mathbf{V}} \cdot \operatorname{Softmax}(\hat{\mathbf{K}} \cdot \hat{\mathbf{Q}} / \alpha) X^=WpAttention(Q^,K^,V^)+XAttention(Q^,K^,V^)=V^⋅Softmax(K^⋅Q^/α)
where X \mathbf{X} X and X ^ \hat{\mathbf{X}} X^ are the input and output feature maps; Q ^ ∈ R H ^ W ^ × C ^ ; K ^ ∈ R C ^ × H ^ W ^ ; \hat{\mathbf{Q}} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}} ; \hat{\mathbf{K}} \in \mathbb{R}^{\hat{C} \times \hat{H} \hat{W}} ; Q^∈RH^W^×C^;K^∈RC^×H^W^; and V ^ ∈ R H ^ W ^ × C ^ \hat{\mathbf{V}} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}} V^∈RH^W^×C^ matrices are obtained after reshaping tensors from the original size R H ^ × W ^ × C ^ \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} RH^×W^×C^. Here, α \alpha α is a learnable scaling parameter to control the magnitude of the dot product of K ^ \hat{\mathbf{K}} K^ and Q ^ \hat{\mathbf{Q}} Q^ before applying the softmax function. Similar to the conventional multi-head SA , we divide the number of channels into ‘heads’ and learn separate attention maps in parallel.
## Multi-DConv Head Transposed Self-Attention (MDTA)
class Attention(nn.Module):def __init__(self, dim, num_heads, bias):super(Attention, self).__init__()self.num_heads = num_headsself.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)def forward(self, x):b, c, h, w = x.shapeqkv = self.qkv_dwconv(self.qkv(x))q, k, v = qkv.chunk(3, dim=1)q = rearrange(q, 'b (head c) h w -> b head c (h w)',head=self.num_heads)k = rearrange(k, 'b (head c) h w -> b head c (h w)',head=self.num_heads)v = rearrange(v, 'b (head c) h w -> b head c (h w)',head=self.num_heads)q = torch.nn.functional.normalize(q, dim=-1)k = torch.nn.functional.normalize(k, dim=-1)attn = (q @ k.transpose(-2, -1)) * self.temperatureattn = attn.softmax(dim=-1)out = (attn @ v)out = rearrange(out, 'b head c (h w) -> b (head c) h w',head=self.num_heads, h=h, w=w)out = self.project_out(out)return out这段代码并没有实现图中的Norm模块,该模块的实现可以参考Layer Normalization(层规范化)。我们看一下Transformer Block是如何包装的:
class TransformerBlock(nn.Module):def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):super(TransformerBlock, self).__init__()self.norm1 = LayerNorm(dim, LayerNorm_type)self.attn = Attention(dim, num_heads, bias)self.norm2 = LayerNorm(dim, LayerNorm_type)self.ffn = FeedForward(dim, ffn_expansion_factor, bias)def forward(self, x):x = x + self.attn(self.norm1(x))#MDTAx = x + self.ffn(self.norm2(x))return x
可以看到实现的时候是先Norm,然后通过Attention,最后再残差连接,这整个流程才是上图所示
相关文章:
MDTA模块(Restormer)
From a layer normalized tensor Y ∈ R H ^ W ^ C ^ \mathbf{Y} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} Y∈RH^W^C^, our MDTA first generates query ( Q ) (\mathbf{Q}) (Q), key ( K ) (\mathbf{K}) (K) and value ( V ) (\mathbf{V}) (V) project…...

C++ 新特性 | C++ 11 | decltype 关键字
一、decltype 关键字 1、介绍 decltype 是 C11 新增的一个用来推导表达式类型的关键字。和 auto 的功能一样,用来在编译时期进行自动类型推导。引入 decltype 是因为 auto 并不适用于所有的自动类型推导场景,在某些特殊情况下 auto 用起来很不方便&…...

2023国赛数学建模思路 - 案例:退火算法
文章目录 1 退火算法原理1.1 物理背景1.2 背后的数学模型 2 退火算法实现2.1 算法流程2.2算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 退火算法原理 1.1 物理背景 在热力学上&a…...
ubuntu20.04 编译安装运行emqx
文章目录 安装依赖编译运行登录dashboard压力测试 安装依赖 Erlang/OTP OTP 24 或 25 版本 apt-get install libncurses5-dev sudo apt-get install erlang如果安装的erlang版本小于24的话,可以使用如下方法自行编译erlang 1.源码获取 wget https://github.com/erla…...

ARM linux ALSA 音频驱动开发方法
+他V hezkz17进数字音频系统研究开发交流答疑群(课题组) 一 linux ALSA介绍 ALSA (Advanced Linux Sound Architecture) 是一个用于提供音频功能的开源软件框架。它是Linux操作系统中音频驱动程序和用户空间应用程序之间的接口。ALSA 提供了访问声卡硬件的低级别API,并支持…...
)
设计模式二十三:模板方法模式(Template Method Pattern)
定义了一个算法的框架,将算法的具体步骤延迟到子类中实现。这样可以在不改变算法结构的情况下,允许子类重写算法的特定步骤以满足自己的需求 模版方法使用场景 算法框架固定,但具体步骤可以变化:当你有一个算法的整体结构是固定…...
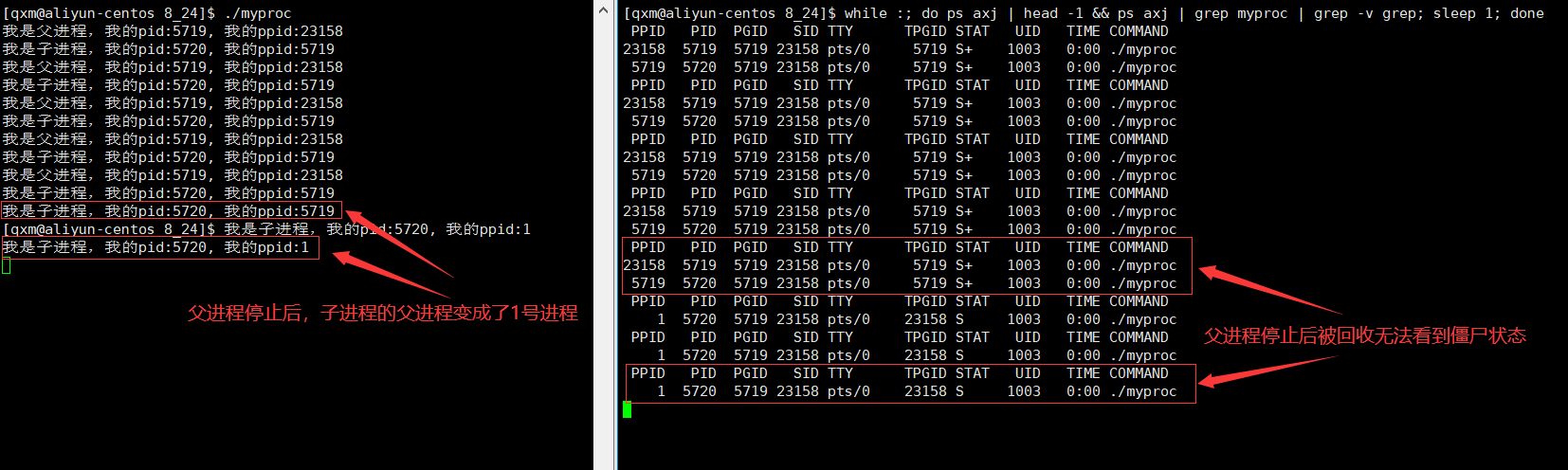
[Linux]进程状态
[Linux]进程状态 文章目录 [Linux]进程状态进程状态的概念阻塞状态挂起状态Linux下的进程状态孤儿进程 进程状态的概念 了解进程状态前,首先要知道一个正在运行的进程不是无时无刻都在CPU上进行运算的,而是在操作系统的管理下,和其他正在运行…...
Python爬虫逆向实战案例(五)——YRX竞赛题第五题
题目:抓取全部5页直播间热度,计算前5名直播间热度的加和 地址:https://match.yuanrenxue.cn/match/5 cookie中m值分析 首先打开开发者工具进行抓包分析,从抓到的包来看,参数传递了查询参数m与f,同时页面中…...

js识别图片中的文字插件 tesseract.js
使用方法及步骤 1.安装依赖 npm i tesseract.js 2.引入插件 import { createWorker } from tesseract.js;//worker多线程引入这个import Tesseract from tesseract.js;//js单线程引入这个 3.使用插件识别图片 //使用worker线程识别(async () > {console.time()const wo…...
)
Linux设备驱动移植(设备数)
一、设备数 设备树是一种描述硬件信息的数据结构,Linux内核运行时可以通过设备树将硬件信息直接传递给Linux内核,而不再需要在Linux内核中包含大量的冗余编码 设备数语法概述 设备树文件 dts 设备树源文件 dtsi 类似于头文件,包含一些公共的…...

【移动端开发】鸿蒙系统开发入门:代码示例与详解
一、引言 随着华为鸿蒙系统的日益成熟,越来越多的开发者开始关注这一新兴的操作平台。本文旨在为初学者提供一份详尽的鸿蒙系统开发入门指南,通过具体的代码示例,引导大家逐步掌握鸿蒙开发的基本概念和技术。 二、鸿蒙系统开发基础 鸿蒙系…...

Jenkins的流水线详解
来源:u.kubeinfo.cn/ozoxBB 什么是流水线 声明式流水线 Jenkinsfile 的使用 什么是流水线 jenkins 有 2 种流水线分为声明式流水线与脚本化流水线,脚本化流水线是 jenkins 旧版本使用的流水线脚本,新版本 Jenkins 推荐使用声明式流水线。…...

DIFFEDIT-图像编辑论文解读
文章目录 摘要算法Step1:计算编辑maskStep2:编码Step3:使用mask引导进行解码理论分析: 实验数据集:扩散模型:ImageNet数据集上实验消融实验IMAGEN数据集上实验COCO数据集上实验 结论 论文: 《D…...

【优选算法】—— 字符串匹配算法
在本期的字符串匹配算法中,我将给大家带来常见的两种经典的示例: 1、暴力匹配(BF)算法 2、KMP算法 目录 (一)暴力匹配(BF)算法 1、思想 2、演示 3、代码展示 (二&…...

Docker容器:docker consul的注册与发现及consul-template守护进程
文章目录 一.docker consul的注册与发现介绍1.什么是服务注册与发现2.什么是consul3.docker consul的应用场景4.consul提供的一些关键特性5.数据流向 二.consul部署1.consul服务器(192.168.198.12)(1)建立 Consul 服务启动consul后…...
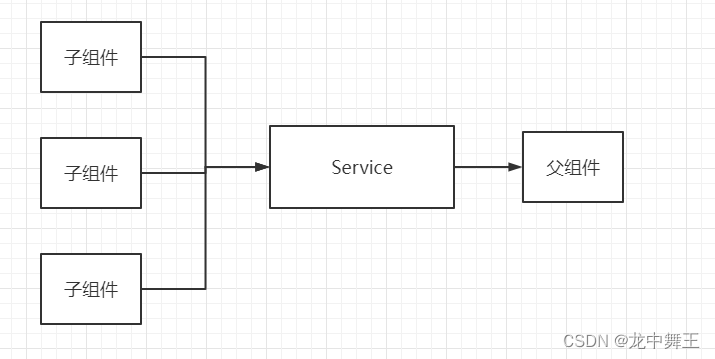
Blazor 依赖注入妙用:巧设回调
文章目录 前言依赖注入特性需求解决方案示意图 前言 依赖注入我之前写过一篇文章,没看过的可以看看这个。 C# Blazor 学习笔记(10):依赖注入 依赖注入特性 只能Razor组件中注入所有Razor组件在作用域注入的都是同一个依赖。作用域可以看看我之前的文章。 需求 …...
)
Python 基础 -- Tutorial(三)
7、输入和输出 有几种方法可以表示程序的输出;数据可以以人类可读的形式打印出来,或者写入文件以备将来使用。本章将讨论其中的一些可能性。 7.1 更花哨的输出格式 到目前为止,我们已经遇到了两种写值的方法:表达式语句和print()函数。(第三种方法是使…...
基于STM32的四旋翼无人机项目(二):MPU6050姿态解算(含上位机3D姿态显示教学)
前言:本文为手把手教学飞控核心知识点之一的姿态解算——MPU6050 姿态解算(飞控专栏第2篇)。项目中飞行器使用 MPU6050 传感器对飞行器的姿态进行解算(四元数方法),搭配设计的卡尔曼滤波器与一阶低通滤波器…...

微信小程序开发教学系列(1)- 开发入门
第一章:微信小程序简介与入门 1.1 简介 微信小程序是一种基于微信平台的应用程序,可以在微信内直接使用,无需下载和安装。它具有小巧、高效、便捷的特点,可以满足用户在微信中获取信息、使用服务的需求。 微信小程序采用前端技…...
Nginx虚拟主机(server块)部署Vue项目
需求 配置虚拟主机,实现一个Nginx运行多个服务。 实现 使用Server块。不同的端口号,表示不同的服务;同时在配置中指定,Vue安装包所在的位置。 配置 Vue项目,放在 html/test 目录下。 config中的配置如下…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...
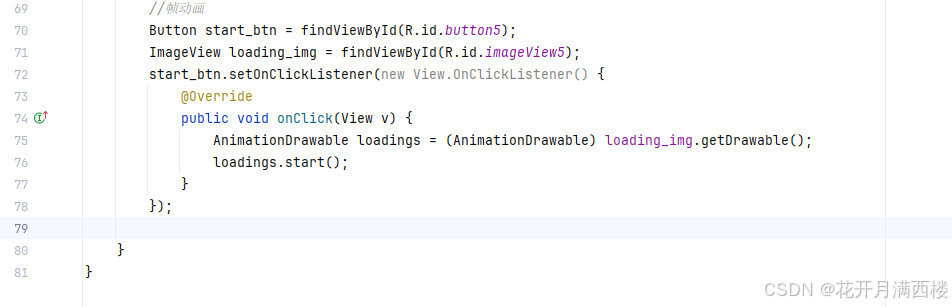
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...