Python 基础 -- Tutorial(三)
7、输入和输出
有几种方法可以表示程序的输出;数据可以以人类可读的形式打印出来,或者写入文件以备将来使用。本章将讨论其中的一些可能性。
7.1 更花哨的输出格式
到目前为止,我们已经遇到了两种写值的方法:表达式语句和print()函数。(第三种方法是使用文件对象的write()方法;标准输出文件可以被引用为sys.stdout。有关这方面的更多信息,请参阅库参考。)
通常,您需要更多地控制输出的格式,而不是简单地打印空格分隔的值。有几种格式化输出的方法。
- 若要使用格式化字符串字面值,请在字符串的开始引号或三引号前以
f或F开头。在这个字符串中,你可以在{和}字符之间编写一个Python表达式,它可以引用变量或文字值。
>>> year = 2016
>>> event = 'Referendum'
>>> f'Results of the {year} {event}'
'Results of the 2016 Referendum'
- 字符串的str.format()方法需要更多的手工操作。您仍然可以使用
{和}来标记变量将被替换的位置,并且可以提供详细的格式化指令,但是您还需要提供要格式化的信息。
>>> yes_votes = 42_572_654
>>> no_votes = 43_132_495
>>> percentage = yes_votes / (yes_votes + no_votes)
>>> '{:-9} YES votes {:2.2%}'.format(yes_votes, percentage)
' 42572654 YES votes 49.67%'
- 最后,您可以自己完成所有的字符串处理,通过使用字符串切片和连接操作来创建您可以想象的任何布局。字符串类型有一些方法,用于执行将字符串填充到给定列宽度的有用操作。
当您不需要花哨的输出,而只是为了调试目的而希望快速显示一些变量时,您可以使用repr()或str()函数将任何值转换为字符串。
str()函数旨在返回人类可读的值的表示形式,而repr()旨在生成解释器可以读取的表示形式(如果没有等效的语法,则会强制生成SyntaxError)。对于没有特定表示供人类使用的对象,str()将返回与repr()相同的值。许多值(如数字或列表和字典等结构)使用任意一个函数都具有相同的表示。特别是字符串,有两种不同的表示。
>>> s = 'Hello, world.'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'The value of x is ' + repr(x) + ', and y is ' + repr(y) + '...'
>>> print(s)
The value of x is 32.5, and y is 40000...
>>> # The repr() of a string adds string quotes and backslashes:
... hello = 'hello, world\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, world\n'
>>> # The argument to repr() may be any Python object:
... repr((x, y, ('spam', 'eggs')))
"(32.5, 40000, ('spam', 'eggs'))"
string模块包含一个Template类,它提供了另一种将值替换为字符串的方法,使用像$x这样的占位符并用字典中的值替换它们,但提供的格式控制要少得多。
7.1.1 格式化字符串字面值
格式化字符串字面值(也简称为f-strings)允许你在字符串前加上f或F前缀并将表达式写成{expression},从而将Python表达式的值包含在字符串中。
表达式后面可以有一个可选的格式说明符。这样可以更好地控制值的格式。下面的例子将圆周率四舍五入到小数点后三位:
>>> import math
>>> print(f'The value of pi is approximately {math.pi:.3f}.')
The value of pi is approximately 3.142.
在’:'后面传递一个整数将导致该字段的宽度为最小字符数。这对于使列对齐很有用。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
>>> for name, phone in table.items():
... print(f'{name:10} ==> {phone:10d}')
...
Sjoerd ==> 4127
Jack ==> 4098
Dcab ==> 7678
可以使用其他修饰符在对值进行格式化之前对其进行转换。!a 应用ascii(), !s应用str(),而!r应用repr():
>>> animals = 'eels'
>>> print(f'My hovercraft is full of {animals}.')
My hovercraft is full of eels.
>>> print(f'My hovercraft is full of {animals!r}.')
My hovercraft is full of 'eels'.
有关这些格式规范的参考,请参见格式规范迷你语言的参考指南。
7.1.2 String format()方法
str.format()方法的基本用法如下:
>>> print('We are the {} who say "{}!"'.format('knights', 'Ni'))
We are the knights who say "Ni!"
大括号和其中的字符(称为格式字段)被传递给str.format()方法的对象所替换。括号中的数字可用于引用传入str.format()方法的对象的位置。
>>> print('{0} and {1}'.format('spam', 'eggs'))
spam and eggs
>>> print('{1} and {0}'.format('spam', 'eggs'))
eggs and spam
如果关键字参数在str.format()方法中使用,则使用参数的名称来引用它们的值。
>>> print('This {food} is {adjective}.'.format(
... food='spam', adjective='absolutely horrible'))
This spam is absolutely horrible.
位置参数和关键字参数可以任意组合:
>>> print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',other='Georg'))
The story of Bill, Manfred, and Georg.
如果您有一个非常长的格式字符串,并且您不想拆分它,那么您最好可以按名称而不是按位置引用要格式化的变量。这可以通过简单地传递字典并使用方括号’[]'来访问键来实现。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; '
... 'Dcab: {0[Dcab]:d}'.format(table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
这也可以通过将表作为带有’ **'符号的关键字参数传递来实现。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
这在与内置函数vars()结合使用时特别有用,该函数返回包含所有局部变量的字典。
作为一个例子,下面几行代码生成了一组整齐排列的列,给出了整数及其平方和立方:
>>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...1 1 12 4 83 9 274 16 645 25 1256 36 2167 49 3438 64 5129 81 729
10 100 1000
有关使用str.format()格式化字符串的完整概述,请参见格式化字符串语法。
7.1.3 手动字符串格式化
下面是同样的方形和立方体表格,手动格式化:
>>> for x in range(1, 11):
... print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
... # Note use of 'end' on previous line
... print(repr(x*x*x).rjust(4))
...1 1 12 4 83 9 274 16 645 25 1256 36 2167 49 3438 64 5129 81 729
10 100 1000
(请注意,每列之间的一个空格是通过print()的工作方式添加的:它总是在其参数之间添加空格。)
字符串对象的str.rjust()方法通过在左侧填充空格来对给定宽度字段中的字符串进行右对齐(right-justifies)。还有类似的方法str.ljust()和str.center()。这些方法不写任何东西,它们只是返回一个新的字符串。如果输入字符串太长,它们不会截断它,而是原样返回;这将使您的列布局混乱,但这通常比另一种选择要好,后者将对值撒谎。(如果真的需要截断,可以添加切片操作,如x.ljust(n)[:n]。)
还有另一个方法str.zfill(),它在数字字符串的左边填充零。它理解加号和减号:
>>> '12'.zfill(5)
'00012'
>>> '-3.14'.zfill(7)
'-003.14'
>>> '3.14159265359'.zfill(5)
'3.14159265359'
7.1.4 旧的字符串格式
%操作符(取模)也可用于字符串格式化。给定'string' % values,string中%的实例将被替换为0个或多个值元素。这个操作通常被称为字符串插值。例如:
>>> import math
>>> print('The value of pi is approximately %5.3f.' % math.pi)
The value of pi is approximately 3.142.
更多信息可以在printf-style String Formatting一节中找到。
7.2 读写文件
open()返回一个文件对象,最常用的是两个位置参数和一个关键字参数:open(filename, mode, encoding=None)
f = open('workfile', 'w', encoding="utf-8")
第一个参数是包含文件名的字符串。第二个参数是另一个字符串,包含一些描述文件使用方式的字符。mode 可以是’r’,当文件只被读取时,'w’表示只被写入(同名的现有文件将被擦除),'a’打开文件用于追加;写入文件的任何数据都会自动添加到末尾。'r+'打开文件进行读写。mode参数是可选的;如果省略,则假定为’r’。
通常,文件是以文本模式打开的,这意味着,您可以从文件中读取和写入字符串,这些字符串以特定的编码(encoding)进行编码。如果未指定encoding,则默认为平台相关(请参阅open())。因为UTF-8是现代事实上的标准,所以建议使用encoding="utf-8",除非您知道需要使用不同的编码。在mode 后添加'b'将以二进制模式打开文件。二进制模式数据以字节对象的形式进行读写。以二进制模式打开文件时不能指定encoding 。
在文本模式下,读取时的默认值是将特定于平台的行结尾(Unix上的\n, Windows上的\r\n)转换为\n。在文本模式下写入时,默认是将\n的出现转换回特定于平台的行结尾。这种对文件数据的幕后修改对于文本文件没有问题,但会破坏JPEG或EXE文件中的二进制数据。在读写此类文件时,要非常小心地使用二进制模式。
在处理文件对象时使用with关键字是一个很好的做法。这样做的好处是,文件在其suite 完成后被正确关闭,即使在某些时候引发了异常。使用with也比编写同等的try-finally块要短得多:
>>> with open('workfile', encoding="utf-8") as f:
... read_data = f.read()>>> # We can check that the file has been automatically closed.
>>> f.closed
True
警告:调用
f.write()而不使用with关键字或没有调用f.close()可能导致f.write(的参数没有完全写入磁盘,即使程序成功退出。
在使用with语句或调用f.close()关闭文件对象后,尝试使用该文件对象将自动失败。
>>> f.close()
>>> f.read()
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: I/O operation on closed file.
7.2.1 文件对象的方法
本节中的其余示例将假设已经创建了一个名为f的文件对象。
要读取文件的内容,调用f.read(size),它将读取一定数量的数据并以字符串(文本模式)或bytes对象(二进制模式)的形式返回。size 是一个可选的数值参数。当size被省略或为负值时,将读取并返回文件的整个内容;如果文件的大小是机器内存的两倍,那就是你的问题了。否则,最多读取和返回size 字符(在文本模式下)或size 字节(在二进制模式下)。如果到达文件的末尾,f.read()将返回一个空字符串('')。
>>> f.read()
'This is the entire file.\n'
>>> f.read()
''
f.readline()从文件中读取一行;换行符(\n)留在字符串的末尾,只有当文件不以换行符结尾时,它才在文件的最后一行被省略。这使得返回值无二义性;如果f.readline()返回一个空字符串,则表示已到达文件的末尾,而空行则由'\n'表示,该字符串仅包含一个换行符。
>>> f.readline()
'This is the first line of the file.\n'
>>> f.readline()
'Second line of the file\n'
>>> f.readline()
''
要从文件中读取行,可以遍历文件对象。这是内存高效,快速,并导致简单的代码:
>>> for line in f:
... print(line, end='')
...
This is the first line of the file.
Second line of the file
如果你想以列表的形式读取文件的所有行,你也可以使用list(f)或f.redlines()。
f.write(string)将string的内容写入文件,并返回写入的字符数。
>>> f.write('This is a test\n')
15
其他类型的对象需要在写入之前转换-要么是字符串(在文本模式下),要么是字节对象(在二进制模式下):
>>> value = ('the answer', 42)
>>> s = str(value) # convert the tuple to string
>>> f.write(s)
18
f.tell()返回一个整数,给出文件对象在文件中的当前位置,在二进制模式下表示为从文件开头开始的字节数,在文本模式下表示为不透明的数字。
要改变文件对象的位置,使用f.seek(offset, whence)。位置是通过向参考点添加offset 来计算的;参考点由whence 参数选择。whence 值为0表示从文件的开头开始,1使用当前文件位置,2使用文件的末尾作为参考点。whence 可以省略,默认为0,使用文件的开头作为参考点。
>>> f = open('workfile', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # Go to the 6th byte in the file
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # Go to the 3rd byte before the end
13
>>> f.read(1)
b'd'
在文本文件中(那些在模式字符串中打开时没有b的文件),只允许相对于文件开头的搜索(使用seek(0,2)查找到文件末尾的例外),唯一有效的offset 值是从f.tell()返回的偏移量值或零。任何其他偏移值都会产生未定义的行为。
文件对象有一些额外的方法,比如isatty()和truncate(),它们不太常用;有关文件对象的完整指南,请参阅库参考。
7.2.2 用json保存结构化数据
字符串可以很容易地写入和读取文件。数字需要更多的努力,因为read()方法只返回字符串,必须传递给int()之类的函数,该函数接受'123'之类的字符串并返回其数值123。当您希望保存更复杂的数据类型(如嵌套列表和字典)时,手动解析和序列化会变得很复杂。
Python允许您使用称为JSON (JavaScript Object Notation)的流行数据交换格式,而不是让用户不断编写和调试代码以将复杂的数据类型保存到文件中。名为json的标准模块可以接受Python数据层次结构,并将其转换为字符串表示;这个过程称为序列化(serializing)。从字符串表示重新构造数据称为反序列化(deserializing)。在序列化和反序列化之间,表示对象的字符串可能已经存储在文件或数据中,或者通过网络连接发送到某个远程机器。
现代应用程序通常使用JSON格式进行数据交换。许多程序员已经熟悉它,这使得它成为互操作性的一个很好的选择。
如果你有一个对象x,你可以用一行简单的代码来查看它的JSON字符串表示:
>>> import json
>>> x = [1, 'simple', 'list']
>>> json.dumps(x)
'[1, "simple", "list"]'
dumps()函数的另一个变体称为dump(),它简单地将对象序列化为文本文件。因此,如果f是为写入而打开的文本文件对象,我们可以这样做:
json.dump(x, f)
要再次解码该对象,如果f是已打开以供读取的二进制文件或文本文件对象:
x = json.load(f)
注意:JSON文件必须使用UTF-8编码。使用
encoding="utf-8"打开JSON文件作为文本文件进行读写。
see also:
pickle——pickle模块
与JSON相反,pickle是一种允许序列化任意复杂Python对象的协议。因此,它是特定于Python的,不能用于与用其他语言编写的应用程序通信。默认情况下,它也是不安全的:如果数据是由熟练的攻击者精心制作的,那么反序列化来自不受信任源的pickle数据可以执行任意代码。
8、错误和异常
到目前为止,错误消息还没有被提及,但是如果您尝试过这些示例,您可能已经看到了一些。有(至少)两种可区分的错误:语法错误(syntax errors)和异常(exceptions)。
8.1 语法错误
语法错误,也被称为解析错误,可能是你在学习Python时最常见的抱怨:
>>> while True print('Hello world')File "<stdin>", line 1while True print('Hello world')^
SyntaxError: invalid syntax
解析器重复错误行,并显示一个小“箭头”,指向该行中最早检测到错误的点。该错误是由箭头前面的标token 引起的(或至少在箭头处检测到):在示例中,错误是在函数print()处检测到的,因为在它前面缺少冒号(':')。文件名和行号会被打印出来,这样您就知道在输入来自脚本的情况下应该去哪里查找。
8.2 异常
即使语句或表达式在语法上是正确的,当试图执行它时也可能导致错误。在执行过程中检测到的错误被称为异常(exceptions ),并且不是无条件致命的:您将很快学习如何在Python程序中处理它们。然而,大多数异常不是由程序处理的,并导致如下所示的错误消息:
>>> 10 * (1/0)
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> 4 + spam*3
Traceback (most recent call last):File "<stdin>", line 1, in <module>
NameError: name 'spam' is not defined
>>> '2' + 2
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
错误消息的最后一行表明发生了什么。异常有不同的类型,并且类型作为消息的一部分打印出来:示例中的类型是ZeroDivisionError、NameError和TypeError。打印为异常类型的字符串是发生的内置异常的名称。这对所有内置异常都是正确的,但对于用户定义的异常不一定是正确的(尽管这是一个有用的约定)。标准异常名是内置标识符(不是保留关键字)。
这一行的其余部分提供了基于异常类型和导致异常的原因的详细信息。
错误消息的前一部分以堆栈回溯的形式显示异常发生的上下文。一般来说,它包含一个堆栈回溯列表源行;但是,它不会显示从标准输入读取的行。
内置异常列出了内置异常及其含义。
8.3 处理异常
编写处理选定异常的程序是可能的。看看下面的例子,它要求用户输入,直到输入一个有效的整数,但允许用户中断程序(使用Control-C或操作系统支持的任何东西);注意,用户生成的中断是通过引发KeyboardInterrupt异常来发出信号的。
while True:try:x = int(input("Please enter a number: "))breakexcept ValueError:print("Oops! That was no valid number. Try again...")
try语句的工作方式如下:
- 首先,执行
try子句(try和except关键字之间的语句)。 - 如果没有异常发生,则跳过
except子句,并完成try语句的执行。 - 如果在执行
try子句期间发生异常,则跳过子句的其余部分。然后,如果它的类型匹配以except关键字命名的异常,则执行except子句,然后在try语句之后继续执行。 - 如果发生的异常与
except子句中指定的异常不匹配,则将其传递给外部try语句;如果没有找到处理程序,则它是一个未处理的异常(unhandled exception),执行将停止,并显示如上所示的消息。
try语句可以有多个except子句,以指定不同异常的处理程序。最多将执行一个处理程序。处理程序只处理在相应的try子句中发生的异常,而不是在同一try语句的其他处理程序中发生的异常。except子句可以将多个异常命名为带括号的元组,例如:
... except (RuntimeError, TypeError, NameError):
... pass
except子句中的类如果是相同的类或其基类,则与异常兼容(但不是相反-except子句中列出派生类与基类不兼容)。例如,下面的代码将按此顺序打印B, C, D:
class B(Exception):passclass C(B):passclass D(C):passfor cls in [B, C, D]:try:raise cls()except D:print("D")except C:print("C")except B:print("B")
注意,如果except子句颠倒过来(首先是except B),它将打印B, B, B——第一个匹配的except子句将被触发。
最后一个except子句可以省略异常名,用作通配符。使用这种方法时要格外小心,因为这种方法很容易掩盖真正的编程错误!它也可以用来打印错误消息,然后重新引发异常(允许调用者也处理异常):
import systry:f = open('myfile.txt')s = f.readline()i = int(s.strip())
except OSError as err:print("OS error: {0}".format(err))
except ValueError:print("Could not convert data to an integer.")
except:print("Unexpected error:", sys.exc_info()[0])raise
try … except语句有一个可选的else子句,当它出现时,必须跟在所有except子句之后。对于在try子句没有引发异常的情况下必须执行的代码,它很有用。例如:
for arg in sys.argv[1:]:try:f = open(arg, 'r')except OSError:print('cannot open', arg)else:print(arg, 'has', len(f.readlines()), 'lines')f.close()
使用else子句比在try子句中添加额外的代码要好,因为它可以避免意外捕获由try…except语句保护的代码所没有引发的异常。
当异常发生时,它可能有一个关联值,也称为异常的参数(argument)。参数的存在和类型取决于异常类型。
except子句可以在异常名之后指定一个变量。该变量绑定到一个异常实例,其参数存储在instance.args中。为方便起见,异常实例定义了__str__(),这样就可以直接打印参数,而不必引用.args。还可以在引发异常之前先实例化异常,并根据需要为其添加任何属性。
>>> try:
... raise Exception('spam', 'eggs')
... except Exception as inst:
... print(type(inst)) # the exception instance
... print(inst.args) # arguments stored in .args
... print(inst) # __str__ allows args to be printed directly,
... # but may be overridden in exception subclasses
... x, y = inst.args # unpack args
... print('x =', x)
... print('y =', y)
...
<class 'Exception'>
('spam', 'eggs')
('spam', 'eggs')
x = spam
y = eggs
如果一个异常有参数,它们将被打印为未处理异常消息的最后一部分(’ detail ')。
异常处理程序不仅处理在try子句中立即发生的异常,还处理在try子句中调用(甚至间接)的函数中发生的异常。例如:
>>> def this_fails():
... x = 1/0
...
>>> try:
... this_fails()
... except ZeroDivisionError as err:
... print('Handling run-time error:', err)
...
Handling run-time error: division by zero
8.4 抛出异常
raise语句允许程序员强制发生指定的异常。例如:
>>> raise NameError('HiThere')
Traceback (most recent call last):File "<stdin>", line 1, in <module>
NameError: HiThere
要引发的唯一参数指示要引发的异常。这必须是一个异常实例或一个异常类(从exception派生的类)。如果传递一个异常类,它将通过不带参数调用其构造函数来隐式实例化:
raise ValueError # shorthand for 'raise ValueError()'
如果你需要确定异常是否被引发,但不打算处理它,raise语句的一种更简单的形式允许你重新引发异常:
>>> try:
... raise NameError('HiThere')
... except NameError:
... print('An exception flew by!')
... raise
...
An exception flew by!
Traceback (most recent call last):File "<stdin>", line 2, in <module>
NameError: HiThere
8.5 异常链
raise语句允许一个可选的from,该语句允许链接异常。例如:
# exc must be exception instance or None.
raise RuntimeError from exc
这在转换异常时非常有用。例如:
>>> def func():
... raise IOError
...
>>> try:
... func()
... except IOError as exc:
... raise RuntimeError('Failed to open database') from exc
...
Traceback (most recent call last):File "<stdin>", line 2, in <module>File "<stdin>", line 2, in func
OSErrorThe above exception was the direct cause of the following exception:Traceback (most recent call last):File "<stdin>", line 4, in <module>
RuntimeError: Failed to open database
异常链接在except或finally块中引发异常时自动发生。异常链可以通过使用from None来禁用:
try:open('database.sqlite')
except OSError:raise RuntimeError from NoneTraceback (most recent call last):File "<stdin>", line 4, in <module>
RuntimeError
有关链接机制的更多信息,请参见内置异常。
8.6 用户自定义异常
程序可以通过创建一个新的异常类来命名它们自己的异常(有关Python类的更多信息,请参阅类)。异常通常应该直接或间接地从Exception类派生。
可以定义异常类,它可以做任何其他类可以做的事情,但通常保持简单,通常只提供一些属性,这些属性允许处理程序为异常提取有关错误的信息。
大多数异常的命名都以" Error "结尾,类似于标准异常的命名。
许多标准模块定义了它们自己的异常,以报告它们定义的函数中可能发生的错误。关于类的更多信息见类一章。
8.7 定义清理操作
try语句还有另一个可选子句,用于定义在所有情况下都必须执行的清理操作。例如:
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
KeyboardInterrupt
Traceback (most recent call last):File "<stdin>", line 2, in <module>
如果存在finally子句,finally子句将作为try语句完成之前的最后一个任务执行。无论try语句是否产生异常,finally子句都会运行。以下几点讨论了发生异常时更复杂的情况:
- 如果在执行
try子句期间发生异常,则可以使用except子句处理该异常。如果异常没有由except子句处理,则在finally子句执行后重新引发异常。 - 异常可能在执行
except或else子句期间发生。同样,在finally子句执行之后,异常被重新引发。 - 如果
finally子句执行了一个break、continue或return语句,则不会重新引发异常。 - 如果
try语句到达break、continue或return语句,finally子句将在break、continue或return语句执行之前执行。 - 如果
finally子句包含返回语句,则返回值将是finally子句返回语句中的值,而不是try子句返回语句中的值。
例子:
>>> def bool_return():
... try:
... return True
... finally:
... return False
...
>>> bool_return()
False
一个更复杂的例子:
>>> def divide(x, y):
... try:
... result = x / y
... except ZeroDivisionError:
... print("division by zero!")
... else:
... print("result is", result)
... finally:
... print("executing finally clause")
...
>>> divide(2, 1)
result is 2.0
executing finally clause
>>> divide(2, 0)
division by zero!
executing finally clause
>>> divide("2", "1")
executing finally clause
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'
如您所见,finally子句在任何情况下都会执行。通过分割两个字符串引发的TypeError不会由except子句处理,因此会在finally子句执行后重新引发。
在实际应用程序中,finally子句对于释放外部资源(如文件或网络连接)非常有用,而不管资源的使用是否成功。
8.8 预定义的清理操作
一些对象定义了在不再需要该对象时执行的标准清理操作,而不管使用该对象的操作是成功还是失败。请看下面的示例,该示例尝试打开一个文件并将其内容打印到屏幕上。
for line in open("myfile.txt"):print(line, end="")
这段代码的问题是,在这部分代码完成执行之后,它会使文件打开一段不确定的时间。这在简单的脚本中不是问题,但对于较大的应用程序可能是一个问题。with语句允许像文件这样的对象以一种确保它们总是被及时正确地清理的方式使用。
with open("myfile.txt") as f:for line in f:print(line, end="")
语句执行后,文件f总是关闭,即使在处理行时遇到问题。像文件一样,提供预定义清理操作的对象将在其文档中指出这一点。
相关文章:
)
Python 基础 -- Tutorial(三)
7、输入和输出 有几种方法可以表示程序的输出;数据可以以人类可读的形式打印出来,或者写入文件以备将来使用。本章将讨论其中的一些可能性。 7.1 更花哨的输出格式 到目前为止,我们已经遇到了两种写值的方法:表达式语句和print()函数。(第三种方法是使…...
基于STM32的四旋翼无人机项目(二):MPU6050姿态解算(含上位机3D姿态显示教学)
前言:本文为手把手教学飞控核心知识点之一的姿态解算——MPU6050 姿态解算(飞控专栏第2篇)。项目中飞行器使用 MPU6050 传感器对飞行器的姿态进行解算(四元数方法),搭配设计的卡尔曼滤波器与一阶低通滤波器…...

微信小程序开发教学系列(1)- 开发入门
第一章:微信小程序简介与入门 1.1 简介 微信小程序是一种基于微信平台的应用程序,可以在微信内直接使用,无需下载和安装。它具有小巧、高效、便捷的特点,可以满足用户在微信中获取信息、使用服务的需求。 微信小程序采用前端技…...
Nginx虚拟主机(server块)部署Vue项目
需求 配置虚拟主机,实现一个Nginx运行多个服务。 实现 使用Server块。不同的端口号,表示不同的服务;同时在配置中指定,Vue安装包所在的位置。 配置 Vue项目,放在 html/test 目录下。 config中的配置如下…...

JAVA开发环境接口swagger-ui使用总结
一、前言 swagger-ui是java开发中生产api说明文档的插件,这是后端工程师和前端工程师联调接口的桥梁。生成的文档就减少了很多没必要的沟通提高开发和测试效率。 二、 swagger-ui的使用 1、引入maven依赖 <dependency><groupId>io.springfox</grou…...

mongodb 数据库管理(数据库、集合、文档)
目录 一、数据库操作 1、创建数据库 2、删除数据库 二、集合操作 1、创建集合 2、删除集合 三、文档操作 1、创建文档 2、 插入文档 3、查看文档 4、更新文档 1)update() 方法 2)replace() 方法 一、数据库操作 1、创建数据库 创建数据库…...

分布式与集群的定义及异同
分布式与集群的定义及异同 分布式定义优点不足 集群优点不足 异同 分布式 定义 分布式是指将一个系统或应用程序分散到多个计算机或服务器上进行处理和管理的技术。它是指多个系统协同合作完成一个特定任务的系统。例如,可以将一个大业务拆分成多个子业务…...

电脑端teams一直在线小程序,简单好用易上手
居家办公的你,会不会想要摸鱼!!会不会想要下楼拿快递!!会不会想要出去下馆子!!!然而,teams的5分钟不操作电脑状态就变为离开大大的阻挡了你幸福生活的脚步!&a…...

YOLOv5算法改进(4)— 添加CA注意力机制
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。在许多视觉任务中,输入数据通常由多个通道组成,例如图像中的RGB通道或…...

无涯教程-PHP - XML GET
XML Get已用于从xml文件获取节点值。以下示例显示了如何从xml获取数据。 Note.xml 是xml文件,可以通过php文件访问。 <SUBJECT><COURSE>Android</COURSE><COUNTRY>India</COUNTRY><COMPANY>LearnFk</COMPANY><PRICE…...
Spark Standalone环境搭建及测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 篇一:Linux系统下配置java环境 篇二:hadoop伪分布式搭建(超详细) 篇三:hadoop完全分布式集群搭建(超详细…...

【PHP】流程控制-ifswitchforwhiledo-whilecontinuebreak
文章目录 流程控制顺序结构分支结构if分支switch分支 循环结构for循环while循环do-while循环continue和break 流程控制 顺序结构:代码从上往下,顺序执行。(代码执行的最基本结构) 分支结构:给定一个条件,…...

Pytorch-day04-模型构建-checkpoint
PyTorch 模型构建 1、GPU配置2、数据预处理3、划分训练集、验证集、测试集4、选择模型5、设定损失函数&优化方法6、模型效果评估 #导入常用包 import os import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torchvision.transfor…...
使用Xshell7控制多台服务同时安装ZK最新版集群服务
一: 环境准备: 主机名称 主机IP 节点 (集群内通讯端口|选举leader|cline端提供服务)端口 docker0 192.168.1.100 node-0 2888 | 3888 | 2181 docker1 192.168.1.101 node-1 2888 | 388…...

python numpy array dtype和astype类型转换的区别
Python3 本身对整数的支持做了提升,可以支持无限长度的整数:比如: b 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffPython的模块numpy array定义的数组在windows和MACOS上默认长度是…...

浮动属性样式
🍓浮动属性 属性名称中文注释备注float设置盒子浮动left左浮动,right右浮动,none不浮动clear清除浮动left清除左浮动,right清除右浮动,both左右浮动都清除(注意:clear清除浮动一般只有作用在块…...

keepalived双机热备 (四十五)
一、概述 Keepalived 是一个基于 VRRP 协议来实现的 LVS 服务高可用方案,可以解决静态路由出现的单点故障问题。 原理 在一个 LVS 服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器…...
SpringBoot整合阿里云OSS,实现图片上传
在项目中,将图片等文件资源上传到阿里云的OSS,减少服务器压力。 项目中导入阿里云的SDK <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.10.2</version>…...

Dynaminc Programming相关
目录 3.1 最长回文子串(中等):标志位 3.2 最大子数组和(中等):动态规划 3.3 爬楼梯(简单):动态规划 3.4 买卖股票的最佳时机(简单)࿱…...
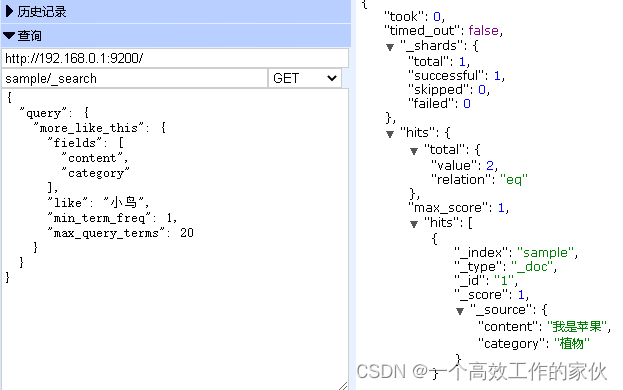
使用 Elasticsearch 轻松进行中文文本分类
本文记录下使用 Elasticsearch 进行文本分类,当我第一次偶然发现 Elasticsearch 时,就被它的易用性、速度和配置选项所吸引。每次使用 Elasticsearch,我都能找到一种更为简单的方法来解决我一贯通过传统的自然语言处理 (NLP) 工具和技术来解决…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...