re正则入门
🌸re正则入门
正则表达式 (Regular Expression) 又称 RegEx, 是用来匹配字符的一种工具. 在一大串字符中寻找你需要的内容. 它常被用在很多方面, 比如网页爬虫, 文稿整理, 数据筛选等等
简单的匹配
正则表达式无非就是在做这么一回事. 在文字中找到特定的内容, 比如下面的内容. 我们在 dog runs to cat 这句话中寻找是否存在 cat 或者 bird.
# matching string
pattern1 = "cat"
pattern2 = "bird"
string = "dog runs to cat"
print(pattern1 in string) # True
print(pattern2 in string) # False
但是正则表达式绝非不止这样简单的匹配, 它还能做更加高级的内容. 要使用正则表达式, 首先需要调用一个 python 的内置模块 re. 然后我们重复上面的步骤, 不过这次使用正则. 可以看出, 如果 re.search() 找到了结果, 它会返回一个 match 的 object. 如果没有匹配到, 它会返回 None. 这个 re.search() 只是 re 中的一个功能, 之后会介绍其它的功能.
import re# regular expression
pattern1 = "cat"
pattern2 = "bird"
string = "dog runs to cat"
print(re.search(pattern1, string)) # < match='cat'>
print(re.search(pattern2, string)) # None
灵活匹配
除了上面的简单匹配, 下面的内容才是正则的核心内容, 使用特殊的 pattern 来灵活匹配需要找的文字.
如果需要找到潜在的多个可能性文字, 我们可以使用 [] 将可能的字符囊括进来. 比如 [ab] 就说明我想要找的字符可以是 a 也可以是 b. 这里我们还需要注意的是, 建立一个正则的规则, 我们在 pattern 的 “前面需要加上一个 r 用来表示这是正则表达式, 而不是普通字符串. 通过下面这种形式, 如果字符串中出现run或者是ran”, 它都能找到.
# multiple patterns ("run" or "ran")
ptn = r"r[au]n" # start with "r" means raw string
print(re.search(ptn, "dog runs to cat")) # <match='run'>同样, 中括号 [] 中还可以是以下这些或者是这些的组合. 比如 [A-Z] 表示的就是所有大写的英文字母. [0-9a-z] 表示可以是数字也可以是任何小写字母.
print(re.search(r"r[A-Z]n", "dog runs to cat")) # None
print(re.search(r"r[a-z]n", "dog runs to cat")) # <match='run'>
print(re.search(r"r[0-9]n", "dog r2ns to cat")) # <match='r2n'>
print(re.search(r"r[0-9a-z]n", "dog runs to cat")) # <match='run'>按类型匹配
除了自己定义规则, 还有很多匹配的规则时提前就给你定义好了的. 下面有一些特殊的匹配类型给大家先总结一下, 然后再上一些例子.
- \d : 任何数字
- \D : 不是数字
- \s : 任何 white space, 如 [\t\n\r\f\v]
- \S : 不是 white space
- \w : 任何大小写字母, 数字和 _ [a-zA-Z0-9_]
- \W : 不是 \w
- \b : 空白字符 (只在某个字的开头或结尾)
- \B : 空白字符 (不在某个字的开头或结尾)
- \ : 匹配 \
- . : 匹配任何字符 (除了 \n)
- ^ : 匹配开头
- $ : 匹配结尾
- ? : 前面的字符可有可无
下面就是具体的举例说明.
# \d : decimal digit
print(re.search(r"r\dn", "run r4n")) # <match='r4n'>
# \D : any non-decimal digit
print(re.search(r"r\Dn", "run r4n")) # <match='run'>
# \s : any white space [\t\n\r\f\v]
print(re.search(r"r\sn", "r\nn r4n")) # <match='r\nn'>
# \S : opposite to \s, any non-white space
print(re.search(r"r\Sn", "r\nn r4n")) # < match='r4n'>
# \w : [a-zA-Z0-9_]
print(re.search(r"r\wn", "r\nn r4n")) # <match='r4n'>
# \W : opposite to \w
print(re.search(r"r\Wn", "r\nn r4n")) # <match='r\nn'>
# \b : empty string (only at the start or end of the word)
print(re.search(r"\bruns\b", "dog runs to cat")) # <match='runs'>
# \B : empty string (but not at the start or end of a word)
print(re.search(r"\B runs \B", "dog runs to cat")) # <match=' runs '>
# \\ : match \
print(re.search(r"runs\\", "runs\ to me")) # <match='runs\\'>
# . : match anything (except \n)
print(re.search(r"r.n", "r[ns to me")) # <match='r[n'>
# ^ : match line beginning
print(re.search(r"^dog", "dog runs to cat")) # <match='dog'>
# $ : match line ending
print(re.search(r"cat$", "dog runs to cat")) # <match='cat'>
# ? : may or may not occur
print(re.search(r"Mon(day)?", "Monday")) # <match='Monday'>
print(re.search(r"Mon(day)?", "Mon")) # <match='Mon'>如果一个字符串有很多行, 我们想使用 ^ 形式来匹配行开头的字符, 如果用通常的形式是不成功的. 比如下面的 I 出现在第二行开头, 但是使用 r"^I" 却匹配不到第二行, 这时候, 我们要使用 另外一个参数, 让 re.search() 可以对每一行单独处理. 这个参数就是 flags=re.M, 或者这样写也行 flags=re.MULTILINE.
string = """
dog runs to cat.
I run to dog.
"""
print(re.search(r"^I", string)) # None
print(re.search(r"^I", string, flags=re.M)) # <match='I'>重复匹配
如果我们想让某个规律被重复使用, 在正则里面也是可以实现的, 而且实现的方式还有很多. 具体可以分为这三种:
*: 重复零次或多次+: 重复一次或多次{n, m}: 重复 n 至 m 次{n}: 重复 n 次
举例如下:
# * : occur 0 or more times
print(re.search(r"ab*", "a")) # <match='a'>
print(re.search(r"ab*", "abbbbb")) # <match='abbbbb'># + : occur 1 or more times
print(re.search(r"ab+", "a")) # None
print(re.search(r"ab+", "abbbbb")) # <match='abbbbb'># {n, m} : occur n to m times
print(re.search(r"ab{2,10}", "a")) # None
print(re.search(r"ab{2,10}", "abbbbb")) # <match='abbbbb'>分组
我们甚至可以为找到的内容分组, 使用 () 能轻松实现这件事. 通过分组, 我们能轻松定位所找到的内容. 比如在这个 (\d+) 组里, 需要找到的是一些数字, 在 (.+) 这个组里, 我们会找到 Date: 后面的所有内容. 当使用 match.group() 时, 他会返回所有组里的内容, 而如果给 .group(2) 里加一个数, 它就能定位你需要返回哪个组里的信息.
match = re.search(r"(\d+), Date: (.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group()) # 021523, Date: Feb/12/2017
print(match.group(1)) # 021523
print(match.group(2)) # Date: Feb/12/2017有时候, 组会很多, 光用数字可能比较难找到自己想要的组, 这时候, 如果有一个名字当做索引, 会是一件很容易的事. 我们字需要在括号的开头写上这样的形式 ?P<名字> 就给这个组定义了一个名字. 然后就能用这个名字找到这个组的内容.
match = re.search(r"(?P<id>\d+), Date: (?P<date>.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group('id')) # 021523
print(match.group('date')) # Date: Feb/12/2017findall
前面我们说的都是只找到了最开始匹配上的一项而已, 如果需要找到全部的匹配项, 我们可以使用 findall 功能. 然后返回一个列表. 注意下面还有一个新的知识点, | 是 or 的意思, 要不是前者要不是后者.
# findall
print(re.findall(r"r[ua]n", "run ran ren")) # ['run', 'ran']# | : or
print(re.findall(r"(run|ran)", "run ran ren")) # ['run', 'ran']replace
我们还能通过正则表达式匹配上一些形式的字符串然后再替代掉这些字符串. 使用这种匹配 re.sub(), 将会比 python 自带的 string.replace() 要灵活多变.
print(re.sub(r"r[au]ns", "catches", "dog runs to cat")) # dog catches to catsplit
再来我们 Python 中有个字符串的分割功能, 比如想获取一句话中所有的单词. 比如 "a is b".split(" "), 这样它就会产生一个列表来保存所有单词. 但是在正则中, 这种普通的分割也可以做的淋漓精致
print(re.split(r"[,;\.]", "a;b,c.d;e")) # ['a', 'b', 'c', 'd', 'e']compile
最后, 我们还能使用 compile 过后的正则, 来对这个正则重复使用. 先将正则 compile 进一个变量, 比如 compiled_re, 然后直接使用这个 compiled_re 来搜索.
compiled_re = re.compile(r"r[ua]n")
print(compiled_re.search("dog ran to cat")) # < match='ran'>附:正则学习路径
相关文章:

re正则入门
🌸re正则入门 正则表达式 (Regular Expression) 又称 RegEx, 是用来匹配字符的一种工具. 在一大串字符中寻找你需要的内容. 它常被用在很多方面, 比如网页爬虫, 文稿整理, 数据筛选等等 简单的匹配 正则表达式无非就是在做这么一回事. 在文字中找到特定的内容, 比如…...

C++ Day5
目录 一、静态成员 1.1 概念 1.2 格式 1.3 银行账户实例 二、类的继承 2.1 目的 2.2 概念 2.3 格式 2.4 继承方式 2.5 继承中的特殊成员函数 2.5.1 构造函数 2.5.2析构函数 2.5.3 拷贝构造函数 2.5.4拷贝赋值函数 总结: 三、多继承 3.1 概念 3.2 格…...

el-element:自定义参数
希望在下拉框、输入框、多选框中添加自定义参数,这在项目中是非常常见的 1、 Select选择器中remote-method方法带自定义参数 :remote-method"(query)>{remoteMethod(query,自定义参数)}" remoteMethod(query, pid){ } 2、 el多选框方法追加参数&…...

“分布式”与“集群”初学者的技术总结
一、“分布式”与“集群”的解释: 分布式:把一个囊肿的系统分成无数个单独可运行的功能模块 集群: 把相同的项目复制进行多次部署(可以是一台服务器多次部署,例如使用8080部署一个,8081部署一个,…...
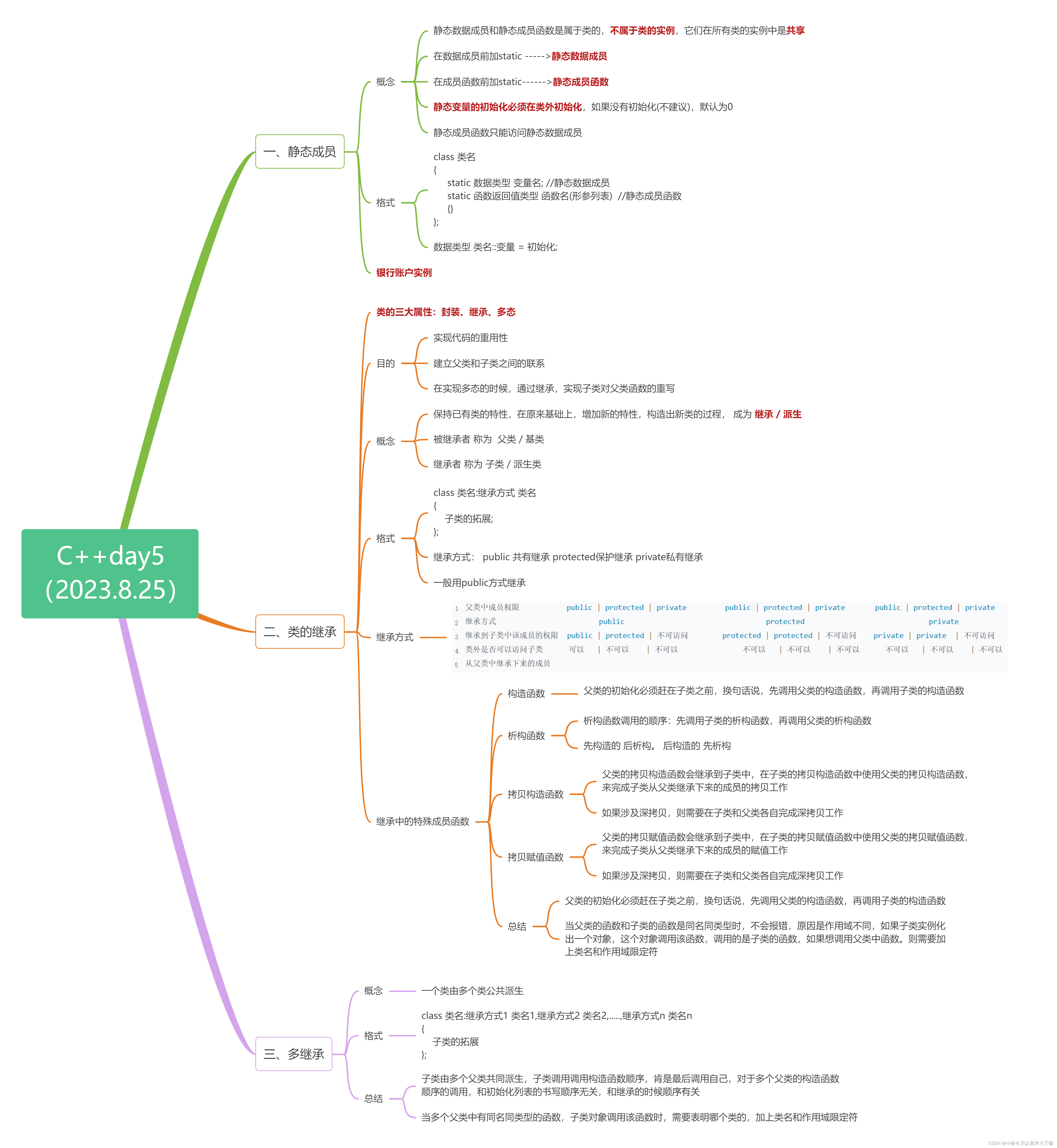
C++day5(静态成员、类的继承、多继承)
一、Xmind整理: 二、上课笔记整理: 1.静态数据成员静态成员函数(银行账户实例) #include <iostream>using namespace std;class BankAccount { private:double balance; //余额static double interest_rate; //利率 p…...

2023MySQL+MyBatis知识点整理
文章目录 主键 外键 的区别?什么是范式?什么是反范式?什么是事务?MySQL事务隔离级别?MySQL事务默认提交模式?MySQL中int(1)和int(10)的区别MySQL 浮点数会丢失精度吗?MySQL支持哪几种时间类型&a…...
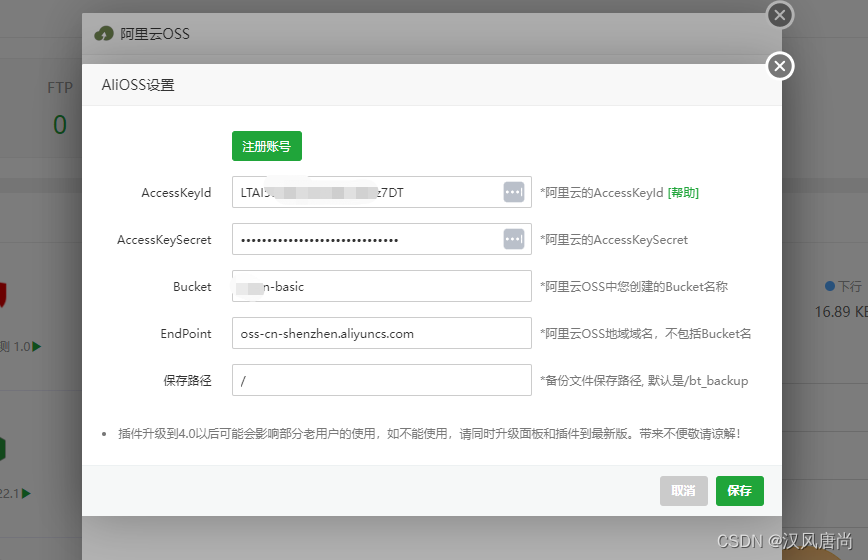
【随笔】如何使用阿里云的OSS保存基础的服务器环境
使用阿里云OSS创建一个存储仓库:bucket 在Linux上下载并安装阿里云的ossutil工具 // 命令行,是linux环境 3. 安装ossutil。sudo -v ; curl https://gosspublic.alicdn.com/ossutil/install.sh | sudo bash 说明:安装过程中,需要使用解压工具…...

汽车电子笔记之:AUTOSA架构下的多核OS操作系统
目录 1、AUTOSAR多核操作系统 1.1、OS Application 1.2、多核OS的软件分区 1.3、任务调度 1.4、核间任务同步 1.5、计数器、报警器、调度表 1.6、自旋锁与共享资源 1.7、核间通信IOC 1.8、OS Object中元素交互 1.9、多核OS的启动与关闭 2、多核OS注意事项 2.1、最小…...
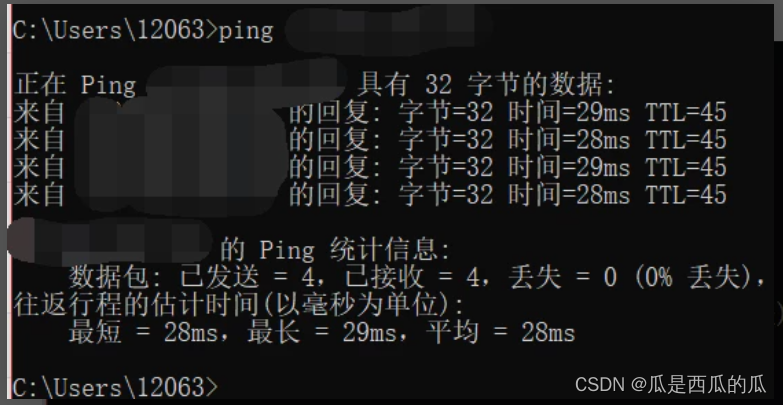
解决华为云ping不通的问题
进入华为云控制台。依次选择:云服务器->点击服务器id->安全组->更改安全组->添加入方向规则,添加一个安全组规则(ICMP),详见下图 再次ping公网ip就可以ping通了 产生这一问题的原因是ping的协议基于ICMP协…...
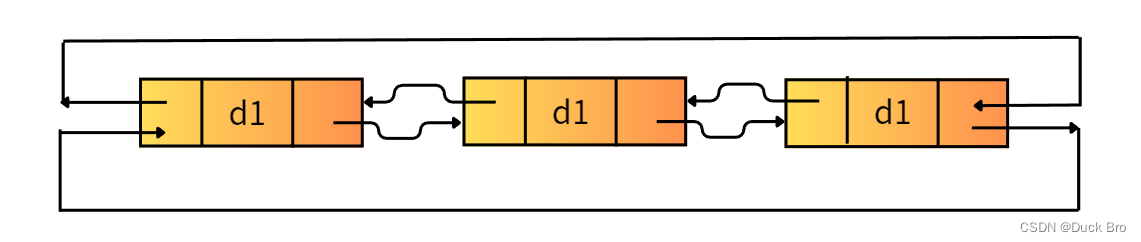
数据结构入门 — 链表详解_双向链表
前言 数据结构入门 — 双向链表详解* 博客主页链接:https://blog.csdn.net/m0_74014525 关注博主,后期持续更新系列文章 文章末尾有源码 *****感谢观看,希望对你有所帮助***** 系列文章 第一篇:数据结构入门 — 链表详解_单链表…...

时序预测 | MATLAB实现PSO-KELM粒子群算法优化核极限学习机时间序列预测(含KELM、ELM等对比)
时序预测 | MATLAB实现PSO-KELM粒子群算法优化核极限学习机时间序列预测(含KELM、ELM等对比) 目录 时序预测 | MATLAB实现PSO-KELM粒子群算法优化核极限学习机时间序列预测(含KELM、ELM等对比)预测效果基本介绍模型介绍程序设计参…...
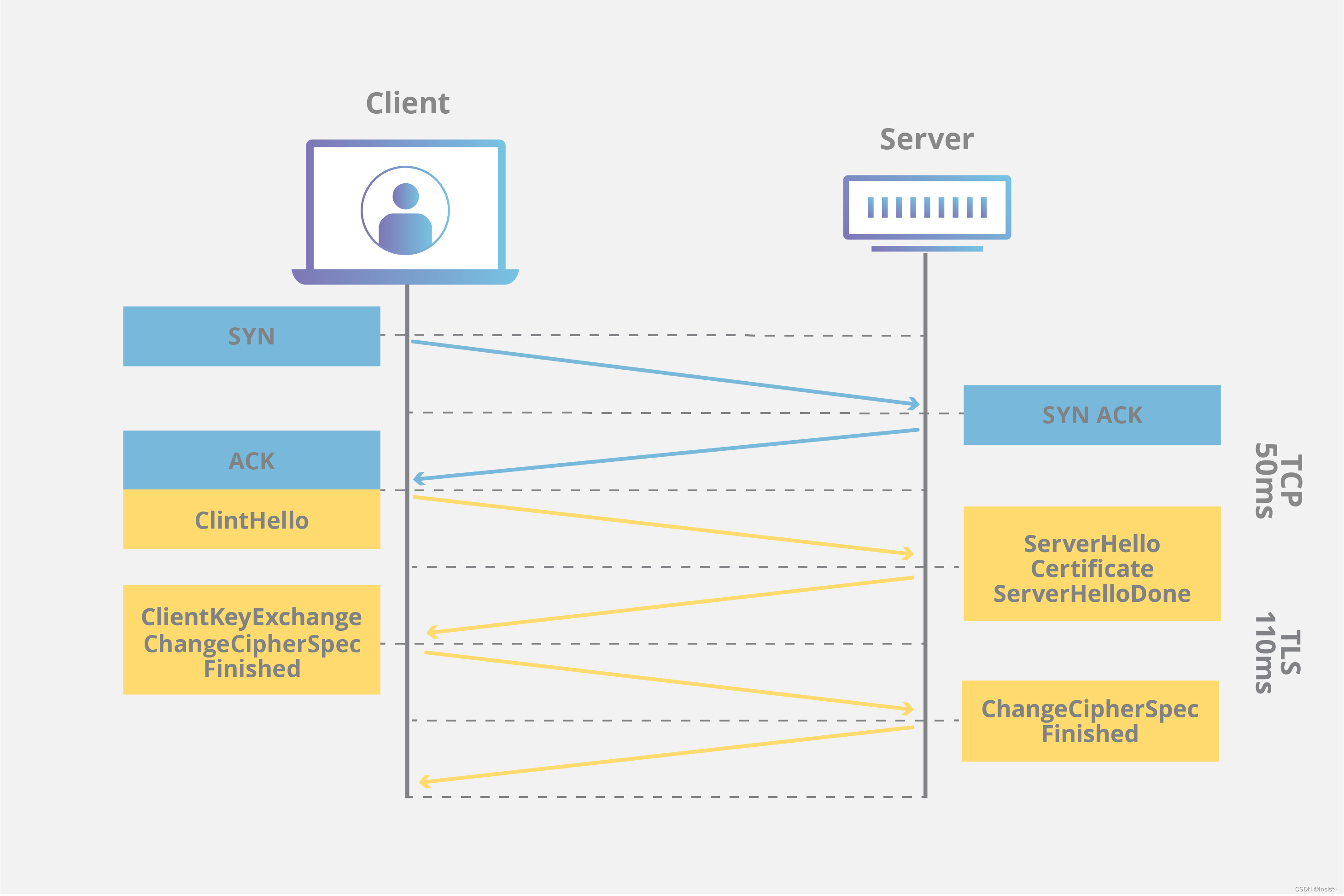
SSL/TLS协议的概念、工作原理、作用以及注意事项
个人主页:insist--个人主页 本文专栏:网络基础——带你走进网络世界 本专栏会持续更新网络基础知识,希望大家多多支持,让我们一起探索这个神奇而广阔的网络世界。 目录 一、SSL/TLS协议的基本概念 二、SSL/TLS的工作…...
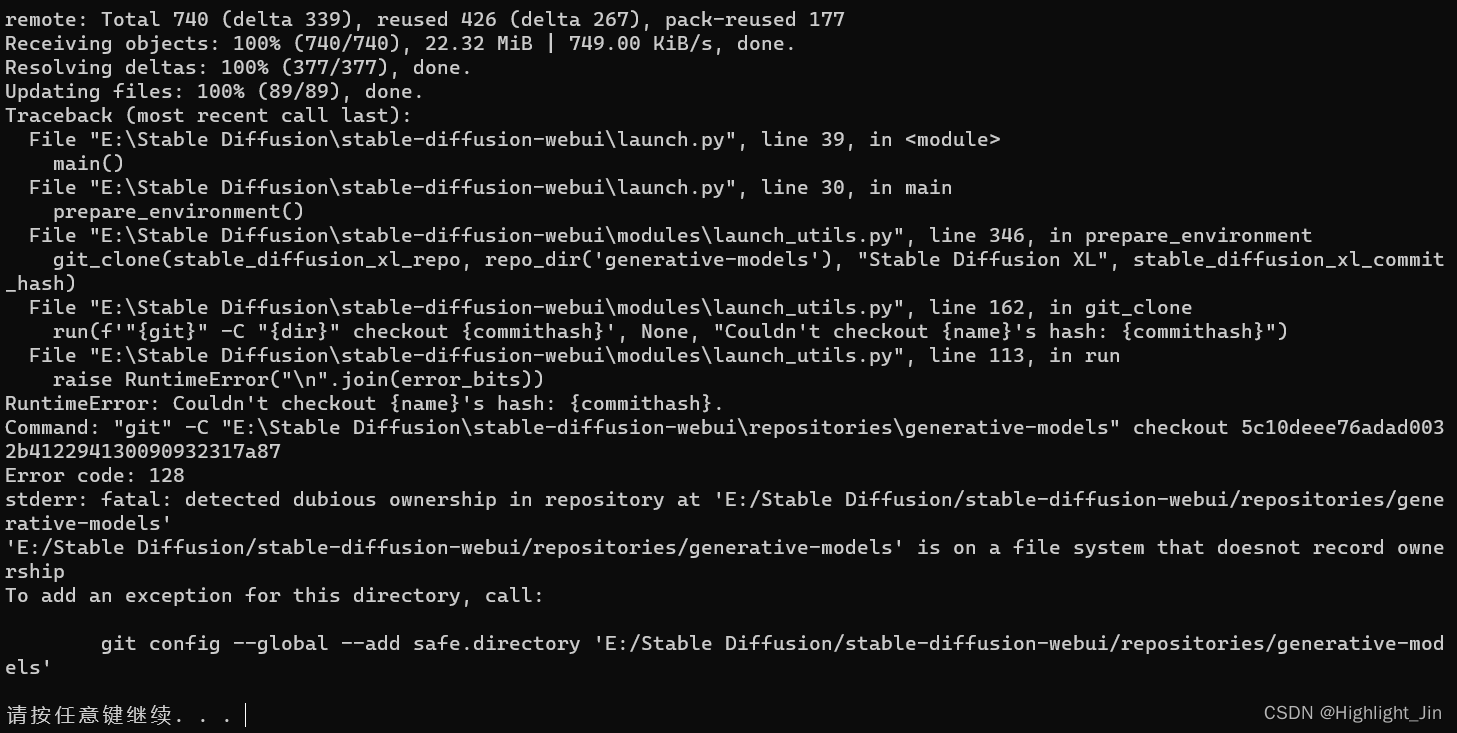
[Stable Diffusion教程] 第一课 原理解析+配置需求+应用安装+基本步骤
第一课 原理解析配置需求应用安装基本步骤 本次内容记录来源于B站的一个视频 以下是自己安装过程中整理的问题及解决方法: 问题:stable-diffusion-webui启动No Python at ‘C:\xxx\xxx\python.exe‘ 解答:打开webui.bat 把 if not de…...

uniapp结合Canvas+renderjs根据经纬度绘制轨迹(二)
uniapp结合Canvasrenderjs根据经纬度绘制轨迹 文章目录 uniapp结合Canvasrenderjs根据经纬度绘制轨迹效果图templaterenderjsjs数据结构 根据官方建议要想在 app-vue 流畅使用 Canvas 动画,需要使用 renderjs 技术,把操作canvas的js逻辑放到视图层运…...

VR全景加盟会遇到哪些问题?全景平台会提供什么?
想创业,你是否也遇到这些问题呢?我是外行怎么办?没有团队怎么办?项目回本周期快吗?项目靠谱吗?加盟平台可信吗?等等这类疑问。近几年,VR产业发展迅速,尤其是VR全景项目在…...

如何进行微服务的集成测试
集成测试的概念 说到集成测试,相信每个测试工程师并不陌生,它不是一个崭新的概念,通过维基百科定义可以知道它在传统软件测试中的含义。 Integration testing (sometimes called integration and testing, abbreviated I&T) is the pha…...

spark grpc 在master运行报错 exitcode13 User did not initialize spark context
程序使用sparksql 以及protobuf grpc ,执行报错 ApplicationMaster: Final app status: FAILED, exitCode: 13, (reason: Uncaught exception: java.lang.IllegalStateException: User did not initialize spark context! 先说原因 : 1.使用了不具备权限…...

nginx 反向代理的原理
Nginx(发音为"engine X")是一个高性能、轻量级的开源Web服务器和反向代理服务器。它的反向代理功能允许将客户端的请求转发到后端服务器,然后将后端服务器的响应返回给客户端。下面是Nginx反向代理的工作原理: 1.客户端…...

【SpringBoot】第二篇:RocketMq使用
背景: 本文会介绍多种案例,教大家如何使用rocketmq。 一般rocketmq使用在微服务项目中,属于分模块使用。这里使用springboot单体项目来模拟使用。 本文以windows系统来做案例。 下载rocketmq和启动: RocketMQ 在 windows 上运行…...

飞天使-vim简单使用技巧
此文是记录技巧使用,如果想节约时间,可以直接看最后一个章节 vim 的介绍 vim号称编辑器之神,唯快不破,可扩展,各种插件满天飞。 vi 1991 vim 1.14 vim四种模式 普通模式: 移动光标, 删除文本,…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...

基于开源AI智能名片链动2 + 1模式S2B2C商城小程序的沉浸式体验营销研究
摘要:在消费市场竞争日益激烈的当下,传统体验营销方式存在诸多局限。本文聚焦开源AI智能名片链动2 1模式S2B2C商城小程序,探讨其在沉浸式体验营销中的应用。通过对比传统品鉴、工厂参观等初级体验方式,分析沉浸式体验的优势与价值…...

小智AI+MCP
什么是小智AI和MCP 如果还不清楚的先看往期文章 手搓小智AI聊天机器人 MCP 深度解析:AI 的USB接口 如何使用小智MCP 1.刷支持mcp的小智固件 2.下载官方MCP的示例代码 Github:https://github.com/78/mcp-calculator 安这个步骤执行 其中MCP_ENDPOI…...
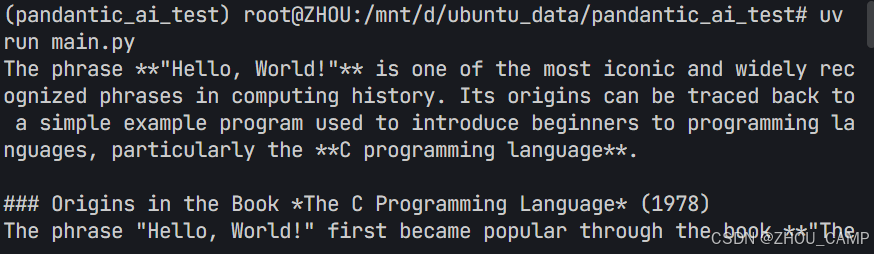
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...