ElasticSearch - 海量数据索引拆分的一些思考
文章目录
- 困难
- 解决方案
- 初始方案及存在的问题
- segment merge
- 引入预排序
- 拆分方案设计
- 考量点
- 如何去除冗余数据
- 按什么维度拆分,拆多少个
- 最终的索引拆分模型演进历程
- 整体迁移流程
- 全量迁移流程
- 流量回放
- 比对验证
- 异步转同步
- 多索引联查
- 优化效果
- 总结与思考
- 参考

困难
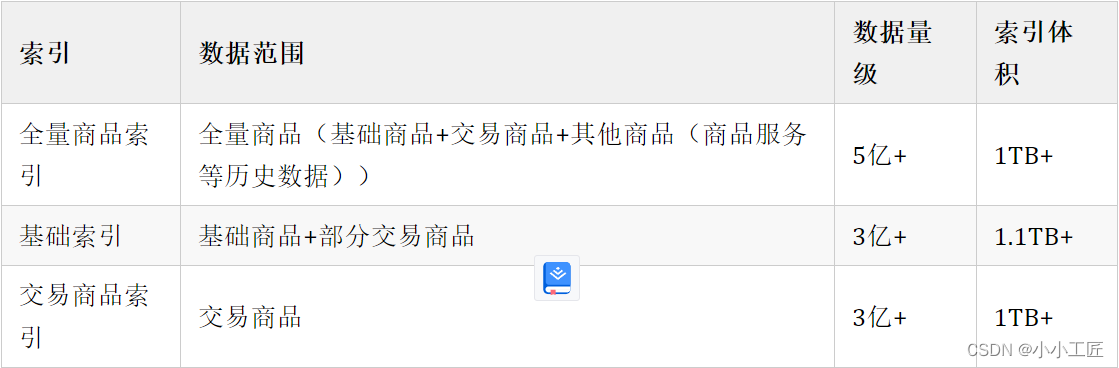
- 索引数据量亿+,查询请求耗时高,大量查询耗时超过 1s 的请求
- 数据的快速膨胀,带来了很大的资源消耗和稳定性问题, 比如如查询抖动等等
- 数据存在冗余,大量的冗余数据,带来了不必要的资源消耗
- 索引所在集群资源已接近瓶颈,但是扩容的话机器成本较高
解决方案
一开始从索引参数调整, forcemerge 任务引入等多个手段来缓解问题,但是伴随数据的快速膨胀还是遇到类似高命中查询等难以优化的问题,从而引出了索引拆分方案的探索与实施。
初始方案及存在的问题
我们先看看参数调整这些局限性的方案
segment merge
- 调大 merge 线程数,调大 floor_segment 值。通过更多的 merge 来降低,大量写入带来的 Segment 数增长引发的查询速率下降问题。
"merge": {"scheduler": {"max_thread_count": "2","max_merge_count": "4"},"policy": {"floor_segment": "5mb"}}segment merge 操作对系统 CPU 和 IO 占用都比较高,从 es 2.0 开始,merge 行为不再由 ES 控制,而是转由 lucene 控制,因此以下配置已被删除:
indices.store.throttle.type
indices.store.throttle.max_bytes_per_sec
index.store.throttle.type
index.store.throttle.max_bytes_per_sec
改为以下调整开关:
index.merge.scheduler.max_thread_count
index.merge.policy.*
最大线程数的默认值为:
Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2))
是一个比较理想的值,如果你只有一块硬盘并且非 SSD,应该把他设置为1,因为在旋转存储介质上并发写,由于寻址的原因,不会提升,只会降低写入速度。
merge 策略有三种:
- tiered
- log_byete_size
- log_doc
默认情况下:index.merge.polcy.type: tiered
索引创建时合并策略就已确定,不能更改,但是可以动态更新策略参数,一般情况下,不需要调整。如果堆栈经常有很多merge,可以尝试调整以下配置:
-
index.merge.policy.floor_segment: 该属性用于阻止 segment 的频繁 flush,小于此值将考虑优先合并,默认为2M,可考虑适当降低此值。
-
index.merge.policy.segments_per_tier:该属性指定了每层分段的数量,取值越小最终 segment 越少,因此需要 merge 的操作更多,可以考虑适当增加此值。默认为10,他应该大于等index.merge.policy.max_merge_at_once。
-
index.merge.policy.max_merged_segment: 指定了单个segment 的最大容量,默认为5GB,可以考虑适当降低此值。
引入预排序
索引预排序的引入,实测排序条件和预排序一致时,亿级索引有3倍左右的提升。但是由于业务多样性,导致命中预排序的场景只占一小部分。
"sort": {"field": ["id","gmtModified","gmtApplied"],"order": ["asc","desc","desc"]}
- 优化索引字段类型,将精确匹配修改为 keyword ,范围匹配修改为数值类型。( ES 针对不同的字段类型,会采用不同的查询策略。keyword 使用 FST 的倒排索引方案,数值类型采用 BKD 方案。前者更适合精确匹配,后者对范围查询更优)。
- 增加索引的分片。当集群资源相对充足是有一定效果,但是如果没有新的数据节点加入,新增分片并不会有明显的性能提升。
"number_of_shards": "5" - 每天跑 forcemerge 任务,降低 Segment 数量,提升白天的查询性能。但是伴随索引体积越来越大, forcemerge 的时间越来越长,有时候整个晚上可能都无法结束。而且 forcemerge 期间,会造成一定的集群抖动,影响一些对请求耗时比较敏感的业务。
- 难以解决的高命中字段查询。在实践中发现,在大表中,如果某个查询字段命中了大量文档,在缓存失效的情况下,大量时间会消耗在在这个字段上。
拆分方案设计
由于目前常规的操作都已经做过,到目前阶段提升相对较小,所以只能从拆索引的方案去入手。在方案的设计中,我们主要有下面的一些考虑。
考量点
-
要实现不停机迁移。
-
要做到用户无感的底层数据表切换,支持流量逐步切换,用来观察集群压力,支持快速的回滚,用来应对可能出现的突发问题
-
能否去除全量xx索引,降低数据冗余,降低集群资源占用
-
按照何种维度去拆分,拆分后的索引是否会有数据倾斜问题
-
能否支持后续的二次拆分,伴随业务后续的发展,第一次拆分后的索引,在过了一两年后可能需要,进行二次拆分操作
-
能否在查询时,尽可能的要降低扫描的数据行数,从而来规避可能遇到的高命中字段影响。
如何去除冗余数据
重新划定的索引数据范围,将之前的全量xx索引数据,分散成三份索引数据。 假设因为索引数据有交叉重复的部分,可以对这部分重复数据打上特殊标识,当三类型索引联查时,过滤掉该部分数据,解决数据重复问题。
按什么维度拆分,拆多少个
一个索引怎么拆,主要看使用的具体场景。
-
比如常见的日志索引,就是按日期滚动拆分。
-
对应我们目前场景,大约77%的请求会带上店铺ID ,就基础商品查询而言,有93%的查询都会带上店铺ID 。因此索引拆分最终是按照店铺维度去拆分。
最后就是拆多少个索引,每个索引多少分片。拆多少个索引,主要是看数据的分布,拆多个索引,可以保证每个索引上的数据大致相同,不会有严重的数据倾斜问题。每个索引有多少个分片,主要是评估拆完后每个索引有多少个数据,以及未来一段时间的增量。
最终的索引拆分模型演进历程
【原始索引模型】
保留 基础索引 和 交易商品索引。 把全量商品索引拆分,拆分后的整体全貌如下
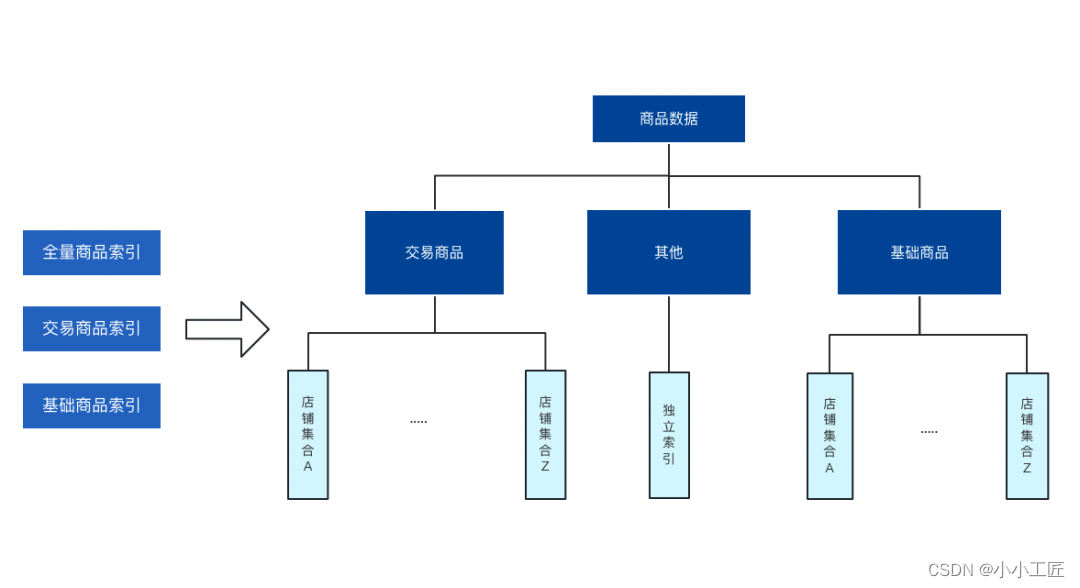
拆分后需要进行【多索引联查】
整体迁移流程
整体迁移在设计中主要,分为流量收集,全量写入,增量写入,数据验证,写入方式的异步转同步等阶段。通过完整的迁移流程设计,来保证最终迁移的数据正确性。
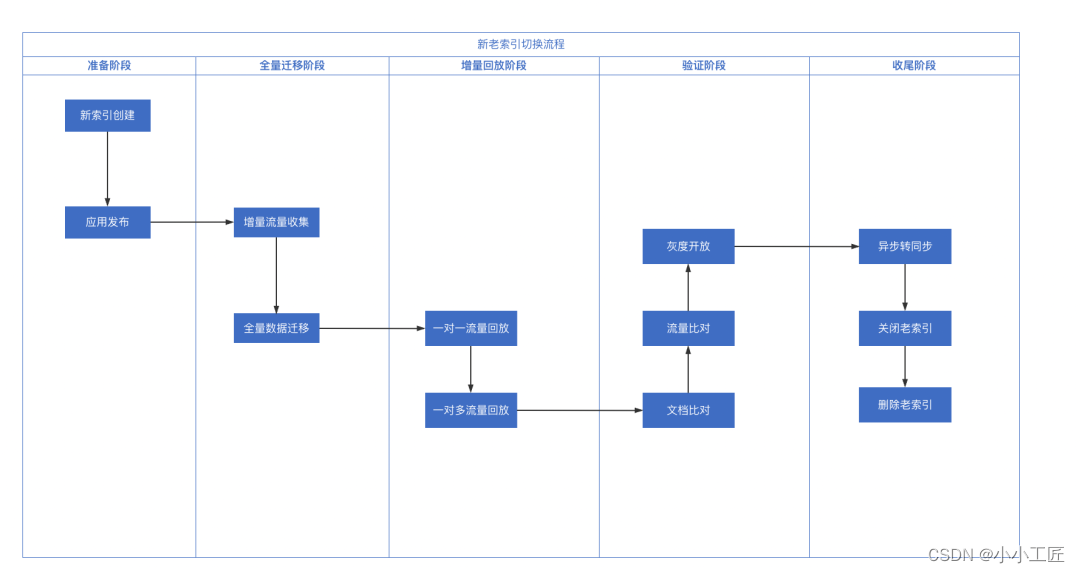
全量迁移流程
该过程主要为历史数据的迁移,并填充历史全量索引的部分数据,重组后的商品数据,分散写入到拆分后的新索引中。
全量迁移需要做到两点,其中一个是数据不丢失,第二就是较快的迁移速率。对于第一点,主要解决手段,就是在全量迁移任务开启前,通过消息队列,收集所有迁移过程中的数据。
【数据拉取慢的问题】
在迁移过程中,我们遇到的第一个问题,就是全量数据拉取过慢问题。
就迁移速度而言,因为本次和一般的索引拆分不同,不是单纯的将一个索引的数据,按店铺拆分到多个索引上,而需要额外填充字段,所以 Reindex 并不满足。即使是通过先将一部分数据 Redinex 数据迁移到新集群上,再二次填充也不太满足,因为 ES 跨集群 Reindex 会限制并发数为1,同时需要将两个集群添加白名单,这个需要将集群进行重启,操作成本也相对较高。之所以不在原集群进行拆分的原因,是原集群的资源已经到达瓶颈,没有足够的磁盘和内存空间,承接新索引。
如何在不使用 Reindex 的情况下,保证迁移速率呢。首先我们尝试了 Scroll 方案,但是后续发现,对一个亿级索引做全表 Scroll 查询,单次拉取时间,保持在500-600ms左右,这个拉取时间严重不满足我们的需求。因为在全量数据迁移期间,增量数据要保持收集的,而商品每天平均有千万级别的更新请求,同时在晚上会有大量的数仓回流任务。如果整个迁移要持续好几天,会对在 MQ 中,积压大量的写入消息,不光会导致到时候流量回流时间过长,也可能导致 MQ 集群磁盘被打满。
【优化方案】
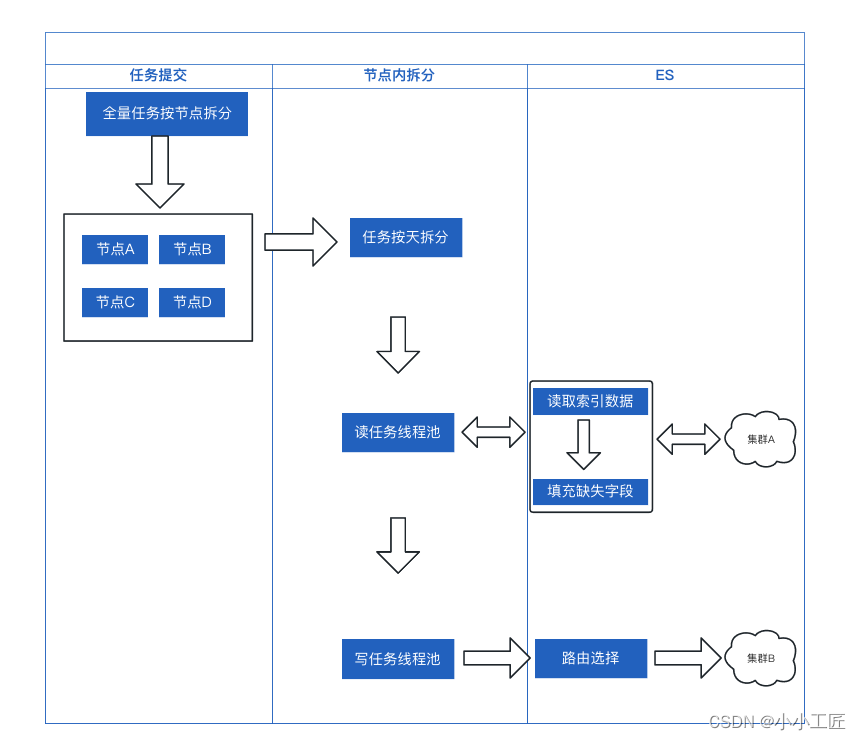
那么如何提升拉取的效率呢,要提升查询速率,可以通过降低单次扫描数据量,来单次降低查询耗时的方案。提升了单次查询耗时后,就需要将大任务进行拆分,多节点并行的方案,来提升整体的拉取效率。最终我们选择按商品创建时间来作为任务拆分的方案,一个是该字段不可变,第二个是每天商品创建量相对比较恒定,任务相对均匀。任务首先按应用节点拆分为节点级大任务,节点内再按天拆分为更小的任务。这样可以做到多任务并行,并可以根据 ES 集群的压力,通过扩充节点的方案来加快数据迁移。
任务执行总共分为两步即数据拉取和写入阶段,首先是数据拉取,该阶段主要负责从原索引获取数据,并填充上全量商品索引的部分字段,这一个阶段的拉取是通过 SearchAfter 方案进行拉取,因为整个迁移流程持续时间较长,部分任务有可能因为网络抖动等问题执行失败,利用 SearchAfter 可以做到任务断点续跑。
数据写入阶段,组装完的数据就需要按店铺 ID,选择索引,并写到新集群了。将读写任务进行拆分,可以提升整体的资源利用率,并方便进行拉取或写入的限流。过程中只需要做好失败任务的从事,并监控系统资源即可。
通过上述优化,迁移完所有全量数据,总计用时 5 个小时左右。
流量回放
在全量任务开始之前,我们将老索引的流量拷贝了一份,放入到了消息队列中,流量回放即是将这部分流量在全量任务结束后,进行回放到新索引上。
回放没有什么特别,但是有一定要注意。在我们的数据写入场景中,有一种一对多更新的任务,比如店铺名称更新等,如果这种增量流量和普通的商品主表流量一起回放,可能会造成,部分商品店铺信息未修改成功的问题。因为商品主表更新,和店铺信息不处在同一个任务源。如果在商品主表流量未追平之前,就开始进行店铺信息的修改,就会导致部分商品漏改的情况。因此整个回放流程是,商品主表增量流量追平后,再开始回放一对多更新流量。
比对验证
在迁移完成后要进行比对验证,验证数据和查询逻辑改造的正确性后,才能开启。
【文档比对】
文档对比,主要是新老索引文档内容进行比较,比对分两次,一个是正向比对,即通过新索引的 Query 到的数据,去和老索引进行比对。这次主要确认新索引上的字段与老索引保持一致。一个是反向比对,即通过老索引 Query 到的数据,去和新索引进行比对。这次主要解决比如类似新索引数据没有删除,部分商品可能缺失的问题。由于整个商品数量级比较大,且数据在频繁更新。比对主要采用的是抽样 DSL 语句比对。
【查询流量比对】
因为本次不光涉及到索引的拆分,还涉及索引的合并。合并必然会带来查询逻辑的变更。因为三类索引上存在对同一个商品属性不同的索引字段名的情况,比如商品的ID,有的索引叫 ID ,有的叫 ItemId 。此外还有查询时路由选择问题,这些查询侧的改动,需要对查询流量进行比对。
异步转同步
在迁移过程中,为了保障服务的稳定性,采用的是 MQ 异步写入新索引的方案。这样可以在灰度开放过程中,限制新索引的写入流量,同时不影响老索引的写入性能。在完全切换到新索引后,需要由异步写入切换回同步写入。考虑切换回去主要有两点考虑,一个是写入流程中,增加了一个可能的不稳定性因素。一个是可能发生由于某个业务域推送大量变更消息,引发的消息积压。比如大店铺的店铺名称变更操作等,这些大任务可能会阻塞用户正常的商品发布,下架等核心链路流程。
因为数据要求最终一致性,核心问题就是如何保证从 MQ 消费写入,更改为直接请求 ES 写入过程中,消息没有乱序。
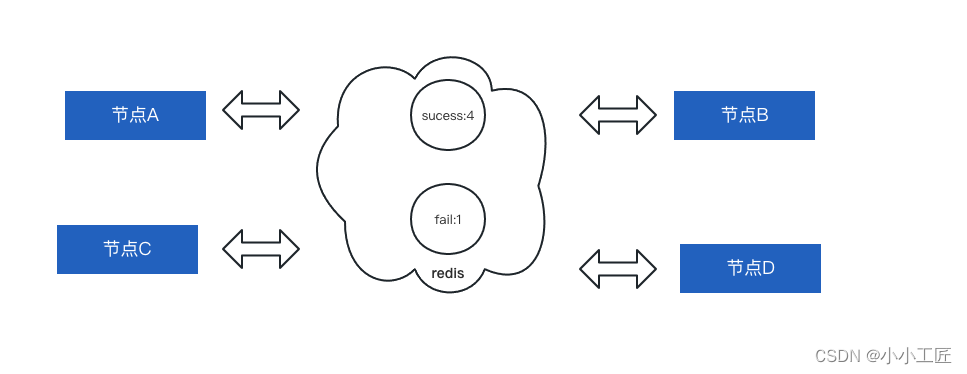
这里主要就是用 Redis 的分布式锁达到一种节点间的分布式共识。这中间主要分为 预备阶段,共识磋商阶段
【预备阶段】
首先在 Redis 中创建一把值为0成功锁,和一把值为0失败锁。
然后,当观察 MQ 中消费堆积的阈值比较低时,这时即可开启预备阶段。这样消费线程在投递到 MQ 队列之前,会先检测一下当前消息堆积值,当小于设定值时,进入共识磋商阶段。
【共识磋商阶段】
应用节点的消费者线程,进入该阶段后,会进行一定次数的自旋,并不投递消息,而是每隔 1s 去 Check 一下当前 MQ 队列的堆积值,如果连续两次 Check 到堆积值为 0,就在 Redis 中把成功锁的值加一。后续执行过程中,如果发现成功锁的值等于参加的节点数,直接将数据写入到 ES 。
期间如果有一个节点发现,自己超过设定的自旋次数,就会将失败锁加一,同时将消息投递到 MQ 中,其他节点发现失败锁大于0后,也会结束自旋,将数据投递到 MQ 中。后续可以再通过调整自旋次数等参数,直到所有节点全部达成一致。
这样就通过秒级的消费暂停,达到了 MQ 队列下线的效果。
多索引联查
解决了数据迁移的问题后,关键的问题就是要提升查询的效率,降低查询 RT ,提升请求 QPS 。一般来讲当查询遇到瓶颈,我们往往都会通过建索引,分库分表,历史归档等操作。这些操作之所以能提升查询性能,就在于能降低要扫描的数据规模。越早地降低数据规模,就代表更低的 CPU,磁盘, IO,内存,网络等开销。因此在设计拆分后的索引查询时,也要尽可能地降低要扫描的数据规模。在本次设计中,我们引入了请求改写、索引选择、返回体修改三个功能模块。
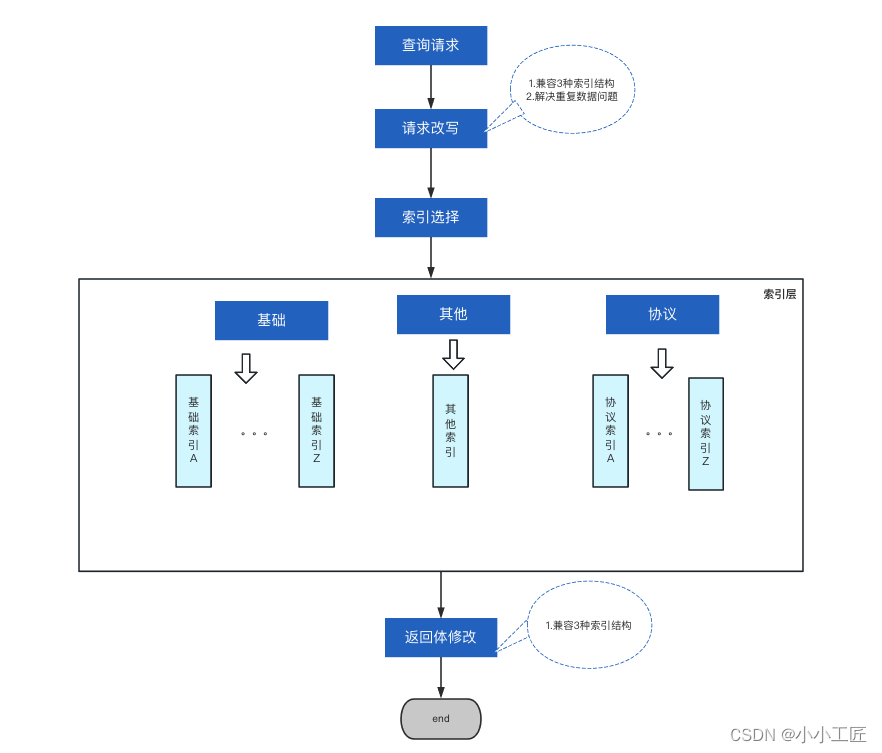
【请求改写】
当接收到用户请求后,首先要进行一次请求改写。
这一步主要有两个目的,一个是要将 DSL 语句改写为3种索引都兼容的格式,因为后续这个语句可能要扫描所有类型的索引。
还有一个是解决基础商品索引和交易商品索引中重合的那一部分数据。目前的解决方案是在基础商品索引中做上标识,在出现基础商品索引和交易商品索引联合扫描时,排除掉基础商品索引中的数据。
【索引选择】
整体上有两次降低数据规模的机会,在查询进来时,尝试判断用户要看哪一类的商品,基础商品还是交易商品等,这一路如果成功,可以减低 50% 左右的数据规模。在下一步判断供应商所在的具体索引,这一步可以进一步降低要扫描的数据规模。通过两次索引推荐可以降低绝大部分查询要扫描的数据量。后续可以再对全表扫描的请求做针对性优化和限流控制,即可保障整体的稳定性。
优化效果
在索引拆分完成后,我们达到了如下效果。

总结与思考
本次主要通过索引的拆分与合并,来提升查询性能,同时降低整体集群的资源使用量。过程中我们探索了在线数据的跨集群迁移,多索引联合查询的应用,数据写入的同步异步切换等,希望能够为大家提供解决 ES 大规模数据检索的瓶颈,提供参考。
虽然本次相对比较平滑的完成了索引的拆分,但是需要耗费大量的开发和测试资源。伴随业务的快速发展,遇到数据瓶颈的业务线,可能有会逐渐增多,如果届时每个业务域要独自开发和测试,成本还是相对较高的。
后续可能考虑将 ES 的索引层和存储层进行分离,通过引入类似 TiKv 或 HBase 等可以无限扩充的 KV 存储来替代 ES 的存储层。通过 KV 存储,来重建 ES 索引。这样可以做到业务方配置化的索引拆分,分片扩容等,无需任何的开发,进一步的降本增效。
参考
ES亿级商品索引拆分实战

相关文章:
ElasticSearch - 海量数据索引拆分的一些思考
文章目录 困难解决方案初始方案及存在的问题segment merge引入预排序 拆分方案设计考量点如何去除冗余数据按什么维度拆分,拆多少个最终的索引拆分模型演进历程整体迁移流程全量迁移流程流量回放比对验证异步转同步多索引联查优化效果 总结与思考参考 困难 索引数据…...

【SA8295P 源码分析】83 - SA8295P HQNX + Android 完整源代码下载方法介绍
【SA8295P 源码分析】83 - SA8295P HQNX + Android 完整源代码下载方法介绍 一、高通官网 Chipcode 下载步骤介绍1.1 高通Chipcode 下载步骤1.2 高通 ReleaseNote 下载方法二、高通 HQX 代码介绍2.1 完整的 HQX 代码结构:sa8295p-hqx-4-2-4-0_hlos_dev_qnx.tar.gz2.2 sa8295p-…...

【设计模式--原型模式(Prototype Pattern)
一、什么是原型模式 原型模式(Prototype Pattern)是一种创建型设计模式,它的主要目的是通过复制现有对象来创建新的对象,而无需显式地使用构造函数或工厂方法。这种模式允许我们创建一个可定制的原型对象,然后通过复制…...
初识 Redis
初识 Redis 1 认识NoSQL1.1 结构化与非结构化1.2 关联和非关联1.3 查询方式1.4. 事务1.5 总结 2 Redis 概述2.1 应用场景2.2 特性 3 Resis 全局命令4 Redis 基本数据类型4.1 String4.1.1 常用命令4.1.2 命令的时间复杂度4.1.3 使用场景 4.2 Hash4.2.1 常用命令4.2.2 命令的时间…...

php灵异事件,啥都没干数据变了?
这篇文章也可以在我的博客查看 搞WordPress,难免跟php打交道 然而这弱类型语言实在坑有点多 这不今儿又踩了个大坑直接时间-1😅 问题 话不多说直接上代码 <?php $items [1,2];foreach ($items as &$item) {/*empty loop*/} print_r($items)…...
)
【ffmpeg】基于需要使用videocapture的opencv编译配置(C++)
目录 配置简介ffmpeg源码编译方法记录gstreamer命令行安装方法opencv的编译项记录 配置简介 opencv使用videocapture读取视频流时,需要借助底层的ffmpeg库。如果不能正确编译,会报错,现记录正确编译配置方法。 ffmpeg源码编译方法记录 ope…...
Redisson分布式锁 原理源码 分析
# 基于setnx实现的分布式锁存在的问题: # 为了解决上面的问题,可以用Redisson # Redisson入门 # Redisson可重入锁原理 获取锁的Lua脚本: 释放锁的Lua脚本: # 锁重试原理分析 tryLock()底层代码分析 tim…...

Cocos独立游戏开发框架中的事件管理器
引言 本系列是《8年主程手把手打造Cocos独立游戏开发框架》,欢迎大家关注分享收藏订阅。在独立游戏开发中,事件管理器是一个不可或缺的组件。它为开发者提供了一种灵活的方式来处理游戏内部各种状态变化和用户交互,实现模块之间的解耦和通信…...

keepalived+haproxy 搭建高可用高负载高性能rabbitmq集群
一、环境准备 1. 我这里准备了三台centos7 虚拟机 主机名主机地址软件node-01192.168.157.133rabbitmq、erlang、haproxy、keepalivednode-02192.168.157.134rabbitmq、erlang、haproxy、keepalivednode-03192.168.157.135rabbitmq、erlang 2. 关闭三台机器的防火墙 # 关闭…...

网络安全(黑客)零基础自学
网络安全是什么? 网络安全,顾名思义,网络上的信息安全。 随着信息技术的飞速发展和网络边界的逐渐模糊,关键信息基础设施、重要数据和个人隐私都面临新的威胁和风险。 网络安全工程师要做的,就是保护网络上的信息安…...

如何把本地项目上传github
一、在gitHub上创建新项目 【1】点击添加()-->New repository 【2】填写新项目的配置项 Repository name:项目名称 Description :项目的描述 Choose a license:license 【3】点击确定,项目已在githu…...

跳跃游戏【贪心算法】
跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。在这里插入图片…...

vue2+element-ui 实现下拉框滚动加载
一、自定义滚动指令。 VUE.directive( el-select-loadmore: { bind(el, binding) { const SELECTWRAP_DOM el.querySelector(.el-select-dropdown .el-select-dropdown__wrap) SELECTWRAP_DOM.addEventListener(scroll, function () { /*…...

探索AIGC人工智能(Midjourney篇)(二)
文章目录 利用Midjourney进行LOGO设计 用ChatGPT和Midjourney的AI绘画,制作儿童绘本故事 探索Midjourney换脸艺术 添加InsightFaceSwap机器人 Midjourney打造专属动漫头像 ChatGPT Midjourney画一幅水墨画 Midjourney包装设计之美 Midjourney24节气海报插画…...
01-Flask-简介及环境准备
Flask-简介及环境准备 前言简介特点Flask 与 Django 的比较环境准备 前言 本篇来介绍下Python的web框架–Flask。 简介 Flask 是一个轻量级的 Web 框架,使用 Python 语言编写,较其他同类型框架更为灵活、轻便且容易上手,小型团队在短时间内…...
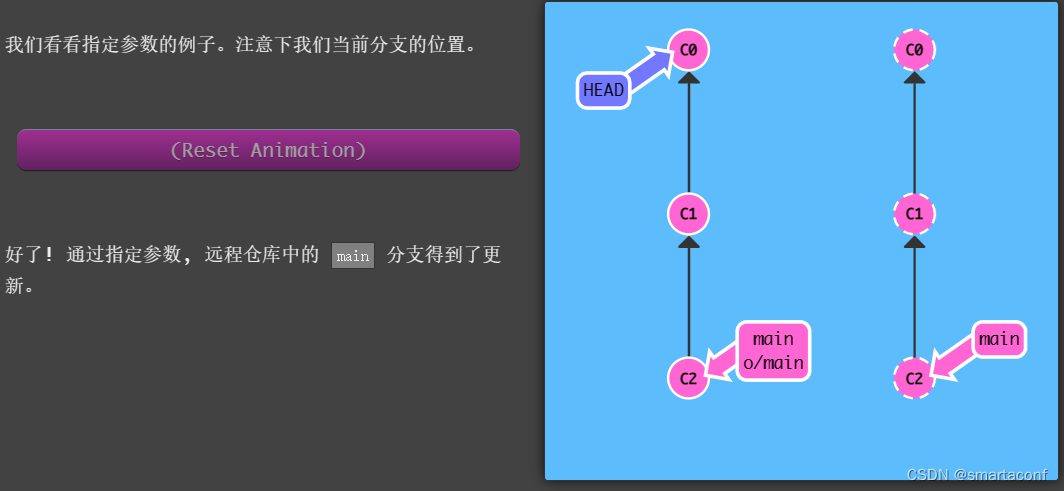
【Git游戏】远程分支
origin/<branch> 远程分支在本地以 origin/<branch>格式存在,他指向上次和远程分支通过时的记录 git checkout origin/<branch> 会出现HEAD分离的情况 与远程通讯 git fetch —— 从远端获取数据(实际上将本地仓库中的远程分支更新…...

Day07-ElementUI
Day02-ElementUI 一 菜单设计 1 静态菜单 a 在components文件夹中新建一个组件Menu.vue <template><div class="menu-wrap"><el-menuclass="el-menu-vertical-demo"background-color="#031627"text-color="#fff"ac…...

【Go 基础篇】Go语言中的defer和recover:优雅处理错误
Go语言以其简洁、高效和强大的特性受到了开发者的热烈欢迎。在错误处理方面,Go语言提供了一种优雅的机制,即通过defer和recover组合来处理恐慌(panic)错误。本文将详细介绍Go语言中的defer和recover机制,探讨其工作原理…...

4.15 TCP Keepalive 和 HTTP Keep-Alive 是一个东西吗?
目录 HTTP 的 Keep-Alive TCP 的 Keepalive 总结: HTTP的Keep-Alive,是应用层(用户态)实现的,称为HTTP长连接; TCP的Keepalive,是由TCP层(内核态)实现的,…...
如何在VSCode中将html文件打开到浏览器
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
)
别再只用L1/L2了!用PyTorch实战图像修复的5种高阶损失函数(含VGG19感知损失代码)
超越L1/L2:PyTorch图像修复中5种高阶损失函数的工程实践 当你在深夜调试一个图像超分辨率模型时,发现生成的图片虽然PSNR值很高,但总感觉缺少那种"真实感"——边缘不够锐利,纹理略显模糊。这时候,L1/L2损失函…...

如何高效使用Super IO插件:Blender批量导入导出终极指南
如何高效使用Super IO插件:Blender批量导入导出终极指南 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 想要在Blender中实现一键导入导出模型和图像吗?Super I…...

Llama-3.2V-11B-cot与Dify集成:零代码构建企业AI智能体
Llama-3.2V-11B-cot与Dify集成:零代码构建企业AI智能体 最近和几个做企业服务的朋友聊天,大家普遍有个感觉:现在AI模型能力越来越强,但真要把它们用起来,门槛还是有点高。特别是对于业务部门的人来说,看着…...

Win11Debloat:5分钟解决Windows 11卡顿的终极优化指南
Win11Debloat:5分钟解决Windows 11卡顿的终极优化指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cu…...
)
LVGL V8项目实战:手把手教你用CLion配置CMake,集成Gui Guider生成的UI文件(含避坑指南)
LVGL V8项目实战:CLion与CMake深度集成Gui Guider UI文件的完整指南 当你在嵌入式GUI开发中频繁往返于设计工具与代码编辑器之间时,是否经历过这样的困境:在Gui Guider中精心设计的界面,移植到LVGL项目后却遭遇编译错误、资源路径…...

免费开源Sunshine游戏串流服务器终极指南:打造你的专属云游戏平台
免费开源Sunshine游戏串流服务器终极指南:打造你的专属云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏,却受限于硬件…...

OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异
OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异 1. 项目概览与核心功能 OpenClaw是近期备受关注的开源大模型项目,主打轻量化和易部署特性。它采用混合专家架构(MoE),在保持模型性能的同时显著降低了计算资源需求…...

FunASR Docker部署避坑大全:从SSL证书报错到热词不生效,一次解决所有常见问题
FunASR Docker实战排障指南:从证书配置到热词优化的深度解决方案 当你第一次尝试在Docker环境中部署FunASR语音识别服务时,那些看似简单的命令行参数背后可能藏着无数个"坑"。本文不会重复官方文档的基础操作,而是聚焦于五个最具代…...

PasteMD模板功能详解:创建个性化转换规则
PasteMD模板功能详解:创建个性化转换规则 你是不是经常从AI对话或者网页上复制内容到Word时,格式总是乱七八糟?公式变成乱码,表格错位,代码块失去高亮?PasteMD就是专门解决这个问题的神器,而它…...

DeepSeek-R1-Distill-Qwen-7B优化升级:提升推理速度的技巧
DeepSeek-R1-Distill-Qwen-7B优化升级:提升推理速度的技巧 1. 模型概述 DeepSeek-R1-Distill-Qwen-7B是基于Qwen架构的7B参数蒸馏模型,由DeepSeek团队开发。该模型通过知识蒸馏技术从更大的DeepSeek-R1模型中提取关键知识,在保持较高推理能…...