爬虫实战之使用 Python 的 Scrapy 库开发网络爬虫详解
关键词 - Python, Scrapy, 网络爬虫
在信息爆炸时代,我们每天都要面对海量的数据和信息。有时候我们需要从互联网上获取特定的数据来进行分析和应用。今天我将向大家介绍如何使用 Python 的 Scrapy 库进行网络爬虫,获取所需数据。
1. Scrapy 简介
1.1 什么是网络爬虫?
网络爬虫就是一种自动化程序,能够模拟人的行为,在互联网上浏览并提取网页中的数据。通过网络爬虫,我们可以快速获取大量的数据,而不需要手动访问每个网页。
1.2 Scrapy 是什么?
Scrapy 是一个用于构建网络爬虫的强大框架。它提供了一套简单而灵活的方式来定义爬虫的行为。借助 Scrapy,我们可以轻松地编写爬虫代码,处理网页的下载、解析和数据提取等任务。
2. 安装和配置 Scrapy
在开始使用 Scrapy 之前,我们需要先安装并配置好相关的环境。
2.1 安装 Scrapy
打开终端或命令提示符,执行以下命令:
pip install scrapy
2.2 创建 Scrapy 项目
安装完成后,我们可以使用 Scrapy 命令行工具创建一个新的 Scrapy 项目。在终端或命令提示符中,进入你想要创建项目的目录执行以下命令:
scrapy startproject myproject
这里是初始化 Scrapy 项目结构。
3. 编写第一个爬虫
现在来编写一个爬虫。在 Scrapy 项目中,爬虫代码位于 spiders 文件夹下的 Python 文件中。
3.1 创建爬虫文件
首先创建一个新的爬虫文件。
scrapy genspider myspider example.com
执行后在 spiders 文件夹下创建一个名为 myspider.py 的文件,同时指定要爬取的网站为 example.com。
3.2 编写爬虫代码
打开 myspider.py 文件,可以看到一个基本的爬虫模板。在这个模板中,我们可以定义爬虫的名称、起始 URL、数据提取规则等。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com']def parse(self, response):# 在这里编写数据提取代码pass
在 parse 方法中可以编写代码来提取需要的数据。通过使用 Scrapy 提供的选择器和XPath表达式,我们可以轻松地定位和提取网页中的元素。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/post-1.html']def parse(self, response):# 提取标题和链接titles = response.css('h1::text').getall()
```pythonlinks = response.css('a::attr(href)').getall()# 打印标题和链接for title, link in zip(titles, links):print(f"标题:{title}")print(f"链接:{link}")
3.3 运行爬虫
编写完爬虫代码后,我们可以在终端或命令提示符中进入项目根目录,并执行以下命令来运行爬虫:
scrapy crawl myspider
爬虫将会开始运行,并从指定的起始 URL 开始爬取数据。提取到的数据将会在终端或命令提示符中显示出来。
4. 数据存储与处理
提取到的数据通常需要进行存储和处理。Scrapy 提供了多种方式来实现数据的存储和处理,包括保存为文件、存储到数据库等。
4.1 保存为文件
我们可以使用 Scrapy 提供的 Feed Exporter 来将数据保存为文件。在 settings.py 文件中,我们可以配置导出数据的格式和存储路径。
FEED_FORMAT = 'csv'
FEED_URI = 'data.csv'
在爬虫代码中,我们可以通过在 parse 方法中使用 yield 关键字返回提取到的数据,并将其保存到文件中。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/post-1.html']def parse(self, response):# 提取标题和链接titles = response.css('h1::text').getall()links = response.css('a::attr(href)').getall()# 保存为文件for title, link in zip(titles, links):yield {'标题': title,'链接': link}
4.2 存储到数据库
如果我们希望将数据存储到数据库中,可以使用 Scrapy 提供的 Item Pipeline。在 settings.py 文件中,我们可以启用 Item Pipeline 并配置数据库连接信息。
ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}DATABASE = {'drivername': 'postgresql','host': 'localhost','port': '5432','username': 'myuser','password': 'mypassword','database': 'mydatabase'
}
在爬虫代码中,我们可以定义一个 Item 类来表示要存储的数据,并在 parse 方法中使用 yield 关键字返回 Item 对象。
import scrapyclass MyItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/post-1.html']def parse(self, response):# 提取标题和链接titles = response.css('h1::text').getall()links = response.css('a::attr(href)').getall()# 存储到数据库for title, link in zip(titles, links):item = MyItem()item['title'] = titleitem['link'] = linkyield item
yield item 将数据项(item)生成为一个生成器(generator),并将其返回给Scrapy引擎。引擎会根据配置的管道设置,将生成器中的数据项传递给相应的管道进行处理。每个管道可以对接收到的数据项进行自定义的操作,例如验证、清洗、转换等,并最终将数据存储到指定的位置。
通过使用yield item语句,可以实现数据的流式处理和异步操作,从而提高爬虫的效率和性能。
5. 继续爬取下一页
当我们需要爬取多页数据时,通常需要提取文章列表页面上的“下一页”URL,并继续执行下一页的爬取任务,直到最后一页。在 Scrapy 中,我们可以通过在 parse 方法中提取“下一页”URL,并使用 scrapy.Request 发起新的请求来实现这一功能。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/list']def parse(self, response):# 提取当前页面的数据# 提取下一页的URLnext_page_url = response.css('a.next-page::attr(href)').get()if next_page_url:# 构造下一页的请求next_page_request = scrapy.Request(response.urljoin(next_page_url), callback=self.parse)# 将请求传递给 Scrapy 引擎yield next_page_request
通过使用 yield,我们可以实现异步的、逐步的数据处理和请求发送。当 Scrapy 引擎接收到一个请求对象时,它会根据请求对象的设置,发送网络请求并等待响应。一旦响应返回,引擎会根据请求对象的回调函数,调用相应的方法来处理数据。这种异步的处理方式可以提高爬取效率,并且节省内存的使用。
通过循环执行以上代码,可以持续进行爬取任务,直到最后一页为止。
技术总结
今天我们详细介绍了如何使用 Scrapy 库进行网络爬虫,这个强大的工具极大地提升了获取新闻、电商商品信息以及进行数据分析和挖掘的效率,希望对你有所启发。
相关文章:

爬虫实战之使用 Python 的 Scrapy 库开发网络爬虫详解
关键词 - Python, Scrapy, 网络爬虫 在信息爆炸时代,我们每天都要面对海量的数据和信息。有时候我们需要从互联网上获取特定的数据来进行分析和应用。今天我将向大家介绍如何使用 Python 的 Scrapy 库进行网络爬虫,获取所需数据。 1. Scrapy 简介 1.1 …...

【面试题】UDP和TCP有啥区别?
UDP UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就…...
)
字节实习后端面试总结(C++/GO)
语言 C ++, Python 哪一个更快? 答:这个我不知道从哪方面说,就是 C + + 的话,它其实能够提供开发者非常多的权限,就是说它能涉及到一些操作系统级别的一些操作,速度应该挺快。然后 Python 实现功能还是蛮快的。 补充: 一般而言,C++更快一些,因为它是一种编译型语…...

linux 自动登录SSH
自动登录SSH 每次ssh连接服务器还要输入密码,可以进行配置自动登录SSH 步骤 在SSH的client端产生一组公钥和私钥 # 算法可以使用RSA和DSA两种ssh-keygen -f 秘钥文件名 -t 使用的算法 会生成私钥文件id_rsa以及公钥文件id_rsa.pub 把公钥上传至SSH Server端的.ssh目…...
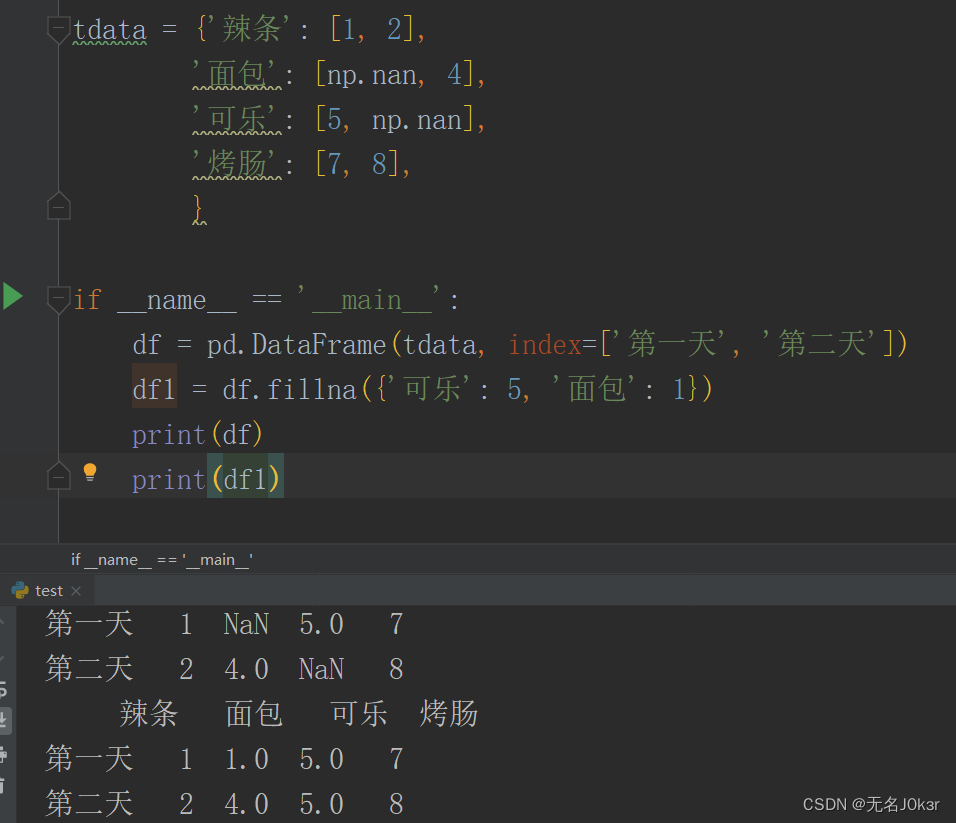
量化:pandas基础
文章目录 简介Series构造 DataFrame构造列的查改增删填充默认值 简介 pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构。 pandas主要的两种数据结构为Series和DataFrame,分别用于处理一维和二维数据。 Series Series 是一种类…...

华为云渲染实践
// 编者按:云计算与网络基础设施发展为云端渲染提供了更好的发展机会,华为云随之长期在自研图形渲染引擎、工业领域渲染和AI加速渲染三大方向进行云渲染方面的探索与研究。本次LiveVideoStackCon 2023上海站邀请了来自华为云的陈普,为大家分…...

SpringBoot注解详解:从核心到Web,从数据到测试,一网打尽
总结的了平时学习springboot常用的一些注解,方便以后开发时可以阅览回忆 springboot的常用注解可以分为以下几类: 核心注解:这些注解是springboot的基础,用于启动、配置和管理springboot应用。Web MVC注解:这些注解是…...

Java寻找奇数
1.题目描述 现在有一个长度为 n 的正整数序列,其中只有一种数值出现了奇数次,其他数值均出现偶数次,请你找出那个出现奇数次的数值。 输入描述: 第一行:一个整数n,表示序列的长度。第二行:n个…...

WinPlan经营大脑:精准预测,科学决策,助力企业赢得未来
近年,随着国内掀起数字化浪潮,“企业数字化转型”成为大势所趋下的必选项。但数据显示,大约79%的中小企业还处于数字化转型初期,在“企业经营管理”上存在着巨大的挑战和风险。 WinPlan经营大脑针对市场现存的企业经营管理难题,提供一站式解决方案,助力企业经营管理转型…...

多数据源切换以及事务处理
SpringBoot 多数据源切换(超级简单)_springboot数据源切换_Tz.的博客-CSDN博客 springboot dynamic多数据源demo以及常见切换、事务问题_一片星空~的博客-CSDN博客...
docker 重装提示 Exising installation is up to date 解决方法
Windows Docker 重装提示 Exising installation is up to date 解决方法 出现这个问题是因为卸载Docker没有卸载干净,导致无法重装 解决方法: 按下WindowR唤起命令输入界面,输入 regedit 打开注册表编辑在地址栏输入HKEY_LOCAL_MACHINE\SOFTW…...
)
k8s分散部署节点之pod反亲和性(podAntiAffinity)
使用背景和场景 业务中的某个关键服务,配置了多个replica,结果在部署时,发现多个相同的副本同时部署在同一个主机上,结果主机故障时,所有副本同时漂移了,导致服务间断性中断 基于以上背景,实现…...

大A的造血与吸血能力
由于大A持续不赚钱,玩家们就喜欢挑他的毛病,其中之一就是大A的持续吸血能力。网络上也已有人进行了相关统计,这里我想再次梳理。 造血能力 对2022年全部A股的披露数据进行汇总统计。我们重点关注经营性现金流、净利润、持续经营净利润、年度累…...

【数据库】使用ShardingSphere+Mybatis-Plus实现读写分离
书接上回:数据库调优方案中数据库主从复制,如何实现读写分离 ShardingSphere 实现读写分离的方式是通过配置数据源的方式,使得应用程序可以在执行读操作和写操作时分别访问不同的数据库实例。这样可以将读取操作分发到多个从库(从…...

【第三方接口】阿里云内容审核SDK的使用
1. 内容审核服务 内容安全是识别服务,支持对图片、视频、文本、语音等对象进行多样化场景检测,有效降低内容违规风险。 目前很多平台都支持内容检测,如阿里云、腾讯云、百度AI、网易云等国内大型互联网公司都对外提供了API。 目前用得较多…...

IDEA软件安装包分享(附安装教程)
目录 一、软件简介 二、软件下载 一、软件简介 IntelliJ IDEA是一款流行的Java集成开发环境(IDE),由捷克软件开发公司JetBrains开发。它专为Java开发人员设计,提供了许多高级功能和工具,使得开发人员能够更高效地编写…...
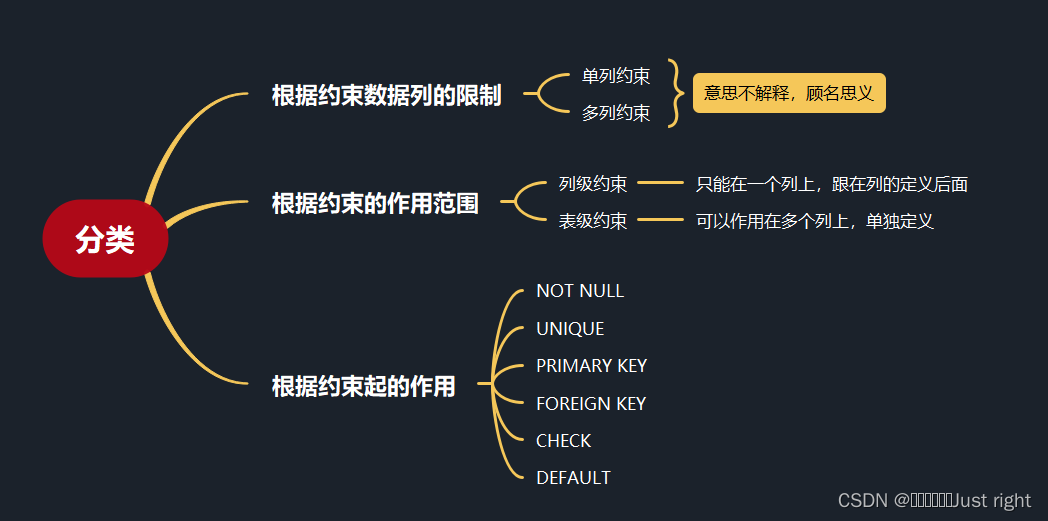
尚硅谷宋红康MySQL笔记 10-13
是记录,我不会记录的特别详细 第10章 创建和管理表 标识符命名规则 数据库名、表名不得超过30个字符,变量名限制为29个只能包含 A–Z, a–z, 0–9, _共63个字符数据库名、表名、字段名等对象名中间不要包含空格同一个MySQL软件中,数据库不能…...
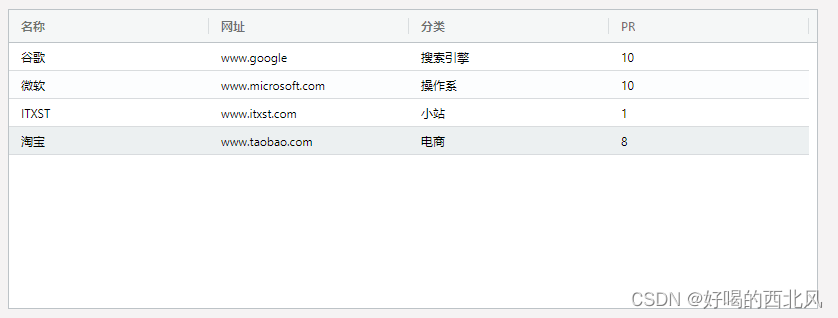
【ag-grid-vue】基本使用
ag-grid是一款功能和性能强大外观漂亮的表格插件,ag-grid几乎能满足你对数据表格所有需求。固定列、拖动列大小和位置、多表头、自定义排序等等各种常用又必不可少功能。关于收费的问题,绝大部分应用用免费的社区版就够了,ag-grid-community社…...

学习JAVA打卡第四十四天
Scanner类 ⑴Scanner对象 scanner对象可以解析字符序列中的单词。 例如:对于string对象NBA 为了解析出NBA的字符序列中的单词,可以如下构造一个scanner对象。 将正则表达式作为分隔标记,即让scanner对象在解析操作时把与正则表达式匹配的字…...

Excel通用表头及单元格合并
要在Java中实现XLS文件中的通用表头合并和单元格合并,您可以使用Apache POI库。下面是一个示例代码,展示了如何实现这两个功能: import org.apache.poi.hssf.usermodel.*; import org.apache.poi.ss.usermodel.*;import java.io.FileOutputS…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...