Mybatis系列原理剖析之项目实战:自定义持久层框架
Mybatis系列原理剖析之:项目实战:自定义持久层框架
持久层是JAVA EE三层体系架构中,与数据库进行交互的一层,持久层往往被称为dao层。需要说明的是,持久层的技术选型有很多,绝不仅仅只有mybatis一种。像早期可能会直接使用jdbc来与数据库进行交互,那么这里就需要思考一个问题,既然已经有jdbc实现与数据库的交互,为什么还需要使用mybatis这类持久层框架呢?
虽然jdbc提供了与数据库交互的基本功能,但它需要手动编写大量的SQL语句和处理代码,使代码显得冗长和难以维护。而MyBatis可以通过配置文件和注解来映射Java对象和SQL语句,使得开发者可以更加专注于业务逻辑的实现,而不必过多关注SQL语句的编写和维护。此外,MyBatis还提供了缓存功能、动态SQL语句、多数据源支持等特性,使得开发者可以更加灵活地处理数据访问地需求。因此,使用Mybatis等持久层框架可以提高开发效率和代码可维护性
在自定义持久层框架开始之前,我们首先回顾一下jdbc实现与数据库交互时的配置代码,并以此分析存在的问题。然后设计方案,解决这些问题,进而自定义持久层框架。
JDBC配置回顾
public static void main(String[] args){Connection connection = null;PreparedStatement preparedStatement = null;ResultSet resultSet = null;try{// 加载数据库驱动Class.forName("com.mysql.jdbc.Driver");// 通过驱动管理类获取数据库链接connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding = utf - 8 ", "root ", "root ");// 定义sql语句?表示占位符String sql = "select * from user where username = ?";// 获取预处理statementpreparedStatement = connection.prepareStatement(sql);// 设置参数,第一个参数为sql语句中参数的序号(从1开始),第二个参数为设置的参数值preparedStatement.setString(1, "tom");// 向数据库发出sql执行查询,查询出结果集resultSet = preparedStatement.executeQuery();// 遍历查询结果集while(resultSet.next()){int id = resultSet.getInt("id");String username = resultSet.getString("username");// 封装Useruser.setId(id);user.setUsername(username);}System.out.println(user);}catch(Exception e){e.printStackTrace();}finally{// 释放资源if(resultSet != null){try{resultSet.close();}catch(SQLException e){e.printStackTrace();}}if(preparedStatement != null){try{preparedStatement.close();}catch(SQLException e){e.printStackTrace();}}}}
上面是一段非常常见的采用jdbc的方式连接mysql数据库的配置。简单分析下上述代码中存在的一些问题:
JDBC问题分析:
-
硬编码问题
直观能够看到的首先就是一个硬编码问题,在上述加载数据库驱动和链接时,我们都显式的将配置写在了代码中。如果后续配置发生了变化,比如将驱动由
com.mysql.jdbc.Driver升级为com.mysql.cj.jdbc.Driver,或者驱动由Mysql变为Oracle。此时,都需要对原始代码进行变更,然后重新编译源文件,再次重新打包部署 -
数据库连接频繁创建/释放
上述查询数据库的代码可能会被调用多次,而上面的代码每次被调用,都会尝试创建一个新的数据连接,并在使用完成后释放。而我们知道,数据库链接是一个非常宝贵的资源(在获取数据库连接时,底层需要首先建立TCP连接,完成三次握手,这一过程是比较消耗资源,影响性能的)。
-
SQL语句与查询/操作耦合
可以看到sql语句与数据库查询、结果集操作耦合在一起,同时也存在硬编码问题。而且这样也导致sql语句散落在各个业务代码操作中,非常不便于后续的管理和代码优化。
-
手动封装返回结果集,较为繁琐
上面代码对结果集进行遍历,并将数据库中的每个列赋值给实体类的相应属性。此时,如果实力类的个数较多,会存在手动封装较为繁琐的问题,这些都是可以优化的点。
针对上述的几个问题,我们来设计一下相应的解决方案:
- 针对硬编码问题,相应的解决方案比较普遍的就是采用配置文件的方式。将数据库连接等配置信息,写在配置文件中,然后在代码里读取配置文件。
- 针对数据库连接频繁创建/释放问题,可以采用连接池的方式来进行解决。目前市面上常见的连接池有很多,诸如:C3P0、DBCP、Druid等。
- 针对SQL语句与查询/操作耦合在一起的问题,同样也可以采用配置文件的方式来解决,尝试将sql语句单独存放在某个配置文件中,从而实现对SQL的统一集中管理和硬编码问题。
- 针对手动封装返回结果集的问题,可以采用反射的方式进行解决。直接将查询结果与相应的实体类利用反射进行映射,从而节省了手动封装过程的繁琐。
自定义持久层框架设计思路
在设计之前,需要明确的是,我们当前自定义的持久层框架本质仍然是对JDBC代码的封装,只不过在封装的过程中,要把JDBC中存在的问题进行规避和解决。
整体的设计思路包括两部分:
-
使用端
-
使用端指上层的一些项目,会来使用我们设计的持久层框架。使用时,需要引入框架的jar包。
-
由于不同项目的数据库连接信息、sql语句等都是不相同的,因此使用端需要提供包括数据库配置,sql配置,sql语句,参数类型,返回值类型等信息,并将它们写在配置文件中:
(1)sqlMapConfig.xml:存放数据库配置信息。
(2)Mapper.xml:存放sql配置信息。
-
-
自定义持久层框架本身
本身也是一个工程,本质是对JDBC代码进行了封装,因此需要读取项目提供的上述两个配置文件,并解析出配置信息,来构建JDBC连接。
-
加载配置文件。
- 功能:根据配置文件的路径,加载配置文件成字节输入流,并以流的方式加载到内存中。
- 实现:创建Resources类,定义方法:getResourceAsStream(String path)
-
创建两个JavaBean:容器对象,存放的就是对配置文件解析出来的内容
- Configuration:核心配置类:存放sqlMapConfig.xml解析出来的内容
- MappedStatement:映射配置类: 存放mapper.xml解析出来的内容
-
解析配置文件:dom4j
-
创建类:SqlSessionFactoryBuilder 方法:build(InputStream in)
-
使用dom4j解析配置文件,将解析出来的内容封装到容器对象中
-
创建SqlSessionFactory对象:生成SqlSession(会话对象,包含了增删改查等一系列操作)(工厂模式)
- 创建SqlSessionFactory接口及实现类DefaultSqlSessionFactory
- openSession:生成sqlSession对象
- 创建SqlSessionFactory接口及实现类DefaultSqlSessionFactory
- 创建SqlSession接口及实现类DefaultSession
- 定义对数据库的crud操作:selectList()、selectOne()、update()、delete()
- 创建Executor接口及实现类SimpleExecutor实现类,用来封装CRUD操作。
- query(Configuration, MapedStatement, Object… params):执行的就是JDBC代码。可变长参数params即sql执行时所需要的占位符参数,因为无法确认参数个数,所以采用可变参的形式。
-
-
-
总结一下上面的设计思路,由于我们自定义的持久层框架本质上是对JDBC代码进行了封装,所以它底层执行的还是JDBC代码。JDBC代码想要执行两部分信息必不可少:数据库配置信息、sql配置信息,而这两部分信息此时已经由使用端采用配置文件的方式进行提供。因此,持久层框架需要完成的功能实际上就是采用dom4j技术对上述的配置文件进行解析,并把解析出来的内容封装到两个JavaBean(Configuration、MappedStatement)中。这两个参数经过层层传递,传递到SimpleExecutor的query方法中,最终在query方法中执行JDBC代码操作。
自定义持久层框架代码实现
使用端代码实现
根据上面的分析,使用端需要提供数据库连接配置、sql查询语句等信息,并使用配置文件的方式。因此接下来我们就在使用端创建的Maven项目的resources目录下,创建两个配置文件:sqlMapConfig.xml和UserMapper.xml,前者保存mysql数据库的配置信息,后者保存sql查询语句的相关信息。
sqlMapConfig.xml
<!-- 配置mysql的连接信息--><configuration><datasource><properties name="driverClass" value="com.mysql.jdbc.Driver"></properties><properties name="jdbcUrl" value="jdbc:mysql://127.0.0.1:3306/CustomPersistent"></properties><properties name="username" value="root"></properties><properties name="password" value="root"></properties></datasource><!-- 存放mapper.xml的全路径--><mapper resource="UserMapper.xml"></mapper>
</configuration>
上述配置文件利用<datasource>标签标识数据库连接信息,并将配置使用<properties>来指定。最后,利用<mapper>标签指明mapper.xml文件所在的位置,方便后续文件的读取。
UserMapper.xml
<mapper name="user"><!-- sql的唯一标识由namespace.id来组成: statementId--><!-- resultType需要保存全限定类名,后续持久层框架才能借助反射来自动封装结果集--><select id="selectList" resultType="com.lagou.pojo.User">select * from user</select><!-- 使用#{}替换? 作为新的框架进行识别的占位符,与parameterType对象的属性相对应--><select id="selectOne" resultType="com.lagou.pojo.User" parameterType="com.lagou.pojo.User">select * from user where id = #{id} and username = #{username}</select>
</mapper>
不同业务/数据表 相应的sql语句应该用不同的Mapper来保存,这里假设查询用户表相关数据,则定义UserMapper.xml的配置文件。对于CRUD的不同查询方式,使用标签<select> 、<insert>等来区分。为了能够唯一标识一条sql语句,采用namespace.id的方式,将每个namespace.id的值封装成一条statementId。同时,设置了一些属性值来提供sql语句查询时的额外信息,比如用resultType来标识结果集对对应的实体类,用paramType标识sql查询时需要的参数对应的实体类。
上述我们简单的在使用端定义好了我们最初设计思路中的两个配置文件,由于我们底层的持久层框架还没定义好,所以无法演示使用的代码,因此接下来,我们先介绍自定义持久层框架的相关代码。
自定义持久层框架代码实现
同样的,按照上面的设计思路,来一步步的实现。
创建Resources类
public class Resources {// 根据配置文件的路径,将配置文件加载成字节输入流,存储在内存中public static InputStream getResourceAsStream(String path){InputStream inputStream = Resources.class.getClassLoader().getResourceAsStream(path);return inputStream;}
}
有了上面这个类之后,我们就可以在之前的使用端代码里,编写测试代码,尝试来读取两个配置文件。
public class CustomPersistenceTest {public static void main(String[] args) throws IOException {InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");byte[] bytes = new byte[1024];int length;StringBuilder builder = new StringBuilder();while((length = resourceAsStream.read(bytes)) != -1){String str = new String(bytes, 0, length);builder.append(str);}System.out.println(resourceAsStream);System.out.println(builder.toString());}
}
打印结果:
java.io.BufferedInputStream@6d6f6e28
<!-- 配置mysql的连接信息--><configuration><datasource><properties name="driverClass" value="com.mysql.jdbc.Driver"></properties><properties name="jdbcUrl" value="jdbc:mysql://127.0.0.1:3306/CustomPersistent"></properties><properties name="username" value="root"></properties><properties name="password" value="root"></properties></datasource><!-- 存放mapper.xml的全路径--><mapper resource="UserMapper.xml"></mapper>
</configuration>
可以看到,定义的getResourceAsStream方法成功以流的方式读取到了定义的sqlConfigMapper.xml的配置信息,接下来,就是利用dom4j来对其进行解析了。在此之前,先定义两个JavaBean容器对象,来存储解析好的配置类。
容器对象定义
MappedStatement核心配置类:存放mapper.xml解析出来的内容
public class MappedStatement {//id标识private String id;//返回值类型private String resultType;//参数值类型private String paramterType;//sql语句private String sql;public String getId() {return id;}public void setId(String id) {this.id = id;}public String getResultType() {return resultType;}public void setResultType(String resultType) {this.resultType = resultType;}public String getParamterType() {return paramterType;}public void setParamterType(String paramterType) {this.paramterType = paramterType;}public String getSql() {return sql;}public void setSql(String sql) {this.sql = sql;}
}
MappedStatement类封装了上面介绍的在使用端的配置文件中包含的一些配置参数,比如id,resultType,pa rameterType。
Configuration核心配置类:存放sqlMapConfig.xml解析出来的内容
public class Configuration {// 数据库配置信息private DataSource dataSource;/*** sql配置信息** key: StatementId* value: 封装好的MappedStatement对象*/Map<String, MappedStatement> mappedStatementMap = new HashMap<>();public DataSource getDataSource() {return dataSource;}public void setDataSource(DataSource dataSource) {this.dataSource = dataSource;}public Map<String, MappedStatement> getMappedStatementMap() {return mappedStatementMap;}public void setMappedStatementMap(Map<String, MappedStatement> mappedStatementMap) {this.mappedStatementMap = mappedStatementMap;}
}
dataSource对象封装了在使用端sqlMapConfig.xml中的Datasource属性,同时有一个Map<String, MappedStatement>的对象,用于封装上面的MappedStatement对象,这样的好处在于:将每个MappedStatement对象用唯一id映射保存在内存中,便于后续框架根据使用端传入的id来快速获取相应sql配置来执行。
使用dom4j解析配置文件
下面给出使用dom4j来解析配置文件的核心流程代码:
public class XMLConfigBuilder {private Configuration configuration;public XMLConfigBuilder() {this.configuration = new Configuration();}/*** 该方法就是使用dom4j对配置文件进行解析,封装Configuration*/public Configuration parseConfig(InputStream inputStream) throws DocumentException, PropertyVetoException {Document document = new SAXReader().read(inputStream);//<configuration>Element rootElement = document.getRootElement();List<Element> list = rootElement.selectNodes("//property");Properties properties = new Properties();for (Element element : list) {String name = element.attributeValue("name");String value = element.attributeValue("value");properties.setProperty(name,value);}// 使用c3p0连接池作为数据库连接对象,减少数据库的频繁连接/释放ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();comboPooledDataSource.setDriverClass(properties.getProperty("driverClass"));comboPooledDataSource.setJdbcUrl(properties.getProperty("jdbcUrl"));comboPooledDataSource.setUser(properties.getProperty("username"));comboPooledDataSource.setPassword(properties.getProperty("password"));configuration.setDataSource(comboPooledDataSource);//mapper.xml解析: 拿到路径--字节输入流---dom4j进行解析List<Element> mapperList = rootElement.selectNodes("//mapper");for (Element element : mapperList) {String mapperPath = element.attributeValue("resource");InputStream resourceAsSteam = Resources.getResourceAsSteam(mapperPath);XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(configuration);xmlMapperBuilder.parse(resourceAsSteam);}return configuration;}}
上述代码使用dom4j来对一个xml文件进行解析。
首先利用new SAXReader().read(inputStream)方法,将字节输入流解析成一个Document对象,然后就可以根据标签来对xml文件进行遍历和检索。首先调用document.getRootElement();获取到根标签,然后,找到property标签进行遍历,从中获取到配置文件中对于数据库连接的配置,并以此来生成一个C3P0的连接池对象赋值给datasource。
在解析完数据库连接配置后,接着根据配置的maaper路径,再次调用Resources.getResourceAsSteam方法获取到mapper.xml的sql配置信息,使用XMLMapperBuilder对象的parse方法封装到configuration对象中。
XMLMapperBuilder类代码如下所示:
public class XMLMapperBuilder {private Configuration configuration;public XMLMapperBuilder(Configuration configuration) {this.configuration =configuration;}public void parse(InputStream inputStream) throws DocumentException {// 将xml文件解析成Documen对象Document document = new SAXReader().read(inputStream);Element rootElement = document.getRootElement();// 获取根标签的namespace属性String namespace = rootElement.attributeValue("namespace");// 遍历所有的<select>标签List<Element> list = rootElement.selectNodes("//select");for (Element element : list) {// 获取select标签中的各个属性String id = element.attributeValue("id");String resultType = element.attributeValue("resultType");String paramterType = element.attributeValue("paramterType");String sqlText = element.getTextTrim();MappedStatement mappedStatement = new MappedStatement();mappedStatement.setId(id);mappedStatement.setResultType(resultType);mappedStatement.setParamterType(paramterType);mappedStatement.setSql(sqlText);String key = namespace+"."+id;configuration.getMappedStatementMap().put(key,mappedStatement);}}
}
至此,我们完成了对使用端传入的配置文件的解析,并封装到了Configuration对象中。有了该对象后,后面我们着手考虑的就是根据获取到的Datasource连接池,创建数据库连接,然后执行使用端传入的指定SQL语句。
生成接口代理类对象
我们思考另一个问题:使用端该如何与框架交互,来传入指定要执行的SQL语句和参数
上面介绍过,mapper.xml配置文件中,<namespace>标签以及每个<select>标签的参数类型、返回值类型**采用全限定类名的原因在于框架可以借助反射来匹配dao层的接口类与定义的mapper.xmlsql配置文件,以及与相应实体类属性进行绑定。**同时,Configuration核心配置类中封装的Map<String, MappedStatement>属性,其键值就是由<mapper>标签的namespace属性与<select>标签的id属性拼接而成的。
由于dao层是接口类,没有具体的实现逻辑。因为,为了在方法执行时实现具体的处理逻辑,我们就可以借助于代理类来实现。利用反射根据使用端传入的dao层接口类,拼接上该类相应的调用方法,以此值为键(statementId)来从Configuration配置类的mappedStatementMap属性中获取相应的sql语句。
@Overridepublic <T> T getMapper(Class<?> mapperClass) {// 使用JDK动态代理来为Dao接口生成代理对象,并返回Object proxyInstance = Proxy.newProxyInstance(DefaultSqlSession.class.getClassLoader(), new Class[]{mapperClass}, new InvocationHandler() {@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 底层都还是去执行JDBC代码 //根据不同情况,来调用selctList或者selectOne// 准备参数 1:statmentid :sql语句的唯一标识:namespace.id= 接口全限定名.方法名// 方法名:findAllString methodName = method.getName();String className = method.getDeclaringClass().getName();String statementId = className+"."+methodName;// 准备参数2:params:args// 获取被调用方法的返回值类型Type genericReturnType = method.getGenericReturnType();// 判断是否进行了 泛型类型参数化if(genericReturnType instanceof ParameterizedType){List<Object> objects = selectList(statementId, args);return objects;}return selectOne(statementId,args);}});return (T) proxyInstance;}
上面代码使用JDK动态代理来为Dao层接口生成代理对象,这样后续在使用端调用dao层接口时,就会进入到代理类的InvocationHandler参数的invoke方法中执行,实现dao层接口与mapper.xml中的sql绑定。
接下来,我们将该方法封装到sqlSession方法中,借助sqlSession接口类来实现获取dao层接口的代理类实例。
创建sqlSession封装CRUD操作
在上面封装好了配置文件信息后,接下来我们需要思考的就是该如何运行配置文件中的Sql了。这里我们再做一层封装,将可能执行的CRUD操作封装在sqlSession中。这里基于开发的依赖倒置原则,我们还是先将CRUD操作封装在sqlSession接口中,再创建一个DefaultSqlSession的实现类来编写具体的处理逻辑
public interface SqlSession {//查询所有public <E> List<E> selectList(String statementid,Object... params) throws Exception;//根据条件查询单个public <T> T selectOne(String statementid,Object... params) throws Exception;//为Dao接口生成代理实现类public <T> T getMapper(Class<?> mapperClass);}
这里新添加了一个getMapper方法,目的是为了创建dao层接口的代理类。
SqlSession对象是一个轻量级的、非线程安全的对象,它和数据库连接相关联,一般需要在每个数据库操作中创建一个新的SqlSession对象。 因此,我们利用工厂类设计模式,定义一个SqlSessionFactory类来生产sqlSession对象
public interface SqlSessionFactory {public SqlSession openSession();}
创建DefaultSqlSession实现类类生成代理对象
sqlSession接口中定义了操作数据库的多种操作(CRUD等)。接下来,我们定义一个DefaultSqlSession类,来具体实现上述功能,根据dao层调用的不同接口,执行相应的SQL处理逻辑。
public class DefaultSqlSession implements SqlSession {private Configuration configuration;public DefaultSqlSession(Configuration configuration) {this.configuration = configuration;}@Overridepublic <E> List<E> selectList(String statementid, Object... params) throws Exception {//将要去完成对simpleExecutor里的query方法的调用simpleExecutor simpleExecutor = new simpleExecutor();MappedStatement mappedStatement = configuration.getMappedStatementMap().get(statementid);// 把具体的sql执行封装到SimpleExecutor中List<Object> list = simpleExecutor.query(configuration, mappedStatement, params);return (List<E>) list;}@Overridepublic <T> T selectOne(String statementid, Object... params) throws Exception {List<Object> objects = selectList(statementid, params);if(objects.size()==1){return (T) objects.get(0);}else {throw new RuntimeException("查询结果为空或者返回结果过多");}}@Overridepublic <T> T getMapper(Class<?> mapperClass) {...}}
在创建了DefaultSqlSession类后,我们采用工厂类的设计模式,定义一个DefaultSqlSessionFactory工厂类来生产sqlSession对象。在DefaultSqlSessionFactory中,包含了数据库连接配置(此外还有一些缓存、事务)等一系列配置信息,并根据这些配置信息创建SqlSession对象。
SqlSessionFactory工厂类的作用是封装了SqlSession对象的创建过程,并且对SqlSession对象进行了统一的管理,使得我们可以更加方便地获取SqlSession对象,并进行数据库操作。同时,SqlSessionFactory也保证了SqlSession对象的线程安全性和可重用性,从而提高了系统的性能和可维护性。
这样,我们就可以通过DefaultSqlSessionFactory获取SqlSession对象,然后使用SqlSession对象进行数据库操作。
public class DefaultSqlSessionFactory implements SqlSessionFactory {private Configuration configuration;public DefaultSqlSessionFactory(Configuration configuration) {this.configuration = configuration;}@Overridepublic SqlSession openSession() {return new DefaultSqlSession(configuration);}
}
封装SqlSessionFactoryBuilder
最后,我们将上面的dom4j解析配置文件,以及sqlSessionFactory的创建逻辑统一封装在SqlSessionFactoryBuilder类中,从而便于使用端更快捷地获取到sqlSessionFactory对象,来生产sqlSession对象。SqlSessionFactoryBuilder类的存在主要是为了解耦SqlSessionFactory对象的创建过程和应用程序的代码。
SqlSessionFactory对象的创建过程通常需要读取配置文件、解析配置信息、创建数据源对象等一系列操作,这些操作通常比较复杂,而且需要依赖于具体的持久层框架。为了避免将这些复杂的操作和具体的持久层框架耦合在一起,我们通常会将SqlSessionFactory对象的创建过程封装在SqlSessionFactoryBuilder类中,并将SqlSessionFactoryBuilder类作为一个独立的类提供给应用程序使用。这样,应用程序就可以通过SqlSessionFactoryBuilder类来获取SqlSessionFactory对象,而不需要关心SqlSessionFactory对象的创建细节。
public class SqlSessionFactoryBuilder {public SqlSessionFactory build(InputStream in) throws DocumentException, PropertyVetoException {// 第一:使用dom4j解析配置文件,将解析出来的内容封装到Configuration中XMLConfigBuilder xmlConfigBuilder = new XMLConfigBuilder();Configuration configuration = xmlConfigBuilder.parseConfig(in);// 第二:创建sqlSessionFactory对象:工厂类:生产sqlSession:会话对象DefaultSqlSessionFactory defaultSqlSessionFactory = new DefaultSqlSessionFactory(configuration);return defaultSqlSessionFactory;}
}
至此,目前我们的dao层接口代理类和操作数据库的CRUD等功能也已经实现了,解决了使用端与持久层框架的交互问题。并且在sqlSession类中封装了CURD操作,以及具体的实现逻辑。即现在我们已经能拿到具体的待执行sql,只剩下最后的执行步骤了。
使用连接池执行sql
最初提到,持久层框架底层sql执行实际上使用的也仍然是JDBC,因此,我们将JDBC操作仍然封装到类中,创建Executor类和simpleExecutor类。
public interface Executor {public <E> List<E> query(Configuration configuration,MappedStatement mappedStatement,Object... params) throws Exception;}
public class simpleExecutor implements Executor {@Override //userpublic <E> List<E> query(Configuration configuration, MappedStatement mappedStatement, Object... params) throws Exception {// 1. 注册驱动,获取连接Connection connection = configuration.getDataSource().getConnection();// 2. 获取sql语句 : select * from user where id = #{id} and username = #{username}//转换sql语句: select * from user where id = ? and username = ? ,转换的过程中,还需要对#{}里面的值进行解析存储String sql = mappedStatement.getSql();BoundSql boundSql = getBoundSql(sql);// 3.获取预处理对象:preparedStatementPreparedStatement preparedStatement = connection.prepareStatement(boundSql.getSqlText());// 4. 设置参数//获取到了参数的全路径String paramterType = mappedStatement.getParamterType();Class<?> paramtertypeClass = getClassType(paramterType);List<ParameterMapping> parameterMappingList = boundSql.getParameterMappingList();for (int i = 0; i < parameterMappingList.size(); i++) {ParameterMapping parameterMapping = parameterMappingList.get(i);String content = parameterMapping.getContent();//反射Field declaredField = paramtertypeClass.getDeclaredField(content);//暴力访问declaredField.setAccessible(true);Object o = declaredField.get(params[0]);preparedStatement.setObject(i+1,o);}// 5. 执行sqlResultSet resultSet = preparedStatement.executeQuery();String resultType = mappedStatement.getResultType();Class<?> resultTypeClass = getClassType(resultType);ArrayList<Object> objects = new ArrayList<>();// 6. 封装返回结果集while (resultSet.next()){Object o =resultTypeClass.newInstance();//元数据ResultSetMetaData metaData = resultSet.getMetaData();for (int i = 1; i <= metaData.getColumnCount(); i++) {// 字段名String columnName = metaData.getColumnName(i);// 字段的值Object value = resultSet.getObject(columnName);//使用反射或者内省,根据数据库表和实体的对应关系,完成封装PropertyDescriptor propertyDescriptor = new PropertyDescriptor(columnName, resultTypeClass);Method writeMethod = propertyDescriptor.getWriteMethod();writeMethod.invoke(o,value);}objects.add(o);}return (List<E>) objects;}private Class<?> getClassType(String paramterType) throws ClassNotFoundException {if(paramterType!=null){Class<?> aClass = Class.forName(paramterType);return aClass;}return null;}/*** 完成对#{}的解析工作:1.将#{}使用?进行代替,2.解析出#{}里面的值进行存储* @param sql* @return*/private BoundSql getBoundSql(String sql) {//标记处理类:配置标记解析器来完成对占位符的解析处理工作ParameterMappingTokenHandler parameterMappingTokenHandler = new ParameterMappingTokenHandler();GenericTokenParser genericTokenParser = new GenericTokenParser("#{", "}", parameterMappingTokenHandler);//解析出来的sqlString parseSql = genericTokenParser.parse(sql);//#{}里面解析出来的参数名称List<ParameterMapping> parameterMappings = parameterMappingTokenHandler.getParameterMappings();BoundSql boundSql = new BoundSql(parseSql,parameterMappings);return boundSql;}}上面的代理就是采用JDBC方式访问数据库的尝试书写逻辑了。
- 对于传入的MappedStatement对象,获取其sql值,并对其解析,将#{}使用?进行代替,同时解析出#{}里面的值进行存储。目的是为了后续根据原先#{}中指定的属性,来从传入的参数属性中获取值进行替换。
- 解析完sql后,利用反射根据参数的全限定类名,获取到相应的Class类
- 遍历第一步中的所有占位符参数,利用反射获取到传入的实体类中相应属性的值,并传入
preparedStatement对象中。 - 利用
preparedStatement.executeQuery()执行sql,并利用反射获取结果封装实体类。 - 对结果集进行遍历,获取每一个列的值,封装到结果实体类对象的相应属性中
- 最后,返回结果实体类对象的List集合。
上面的代码频繁用了Java反射技术来根据传入的参数类路径和结果类路径,获取sql占位符的参数值以及封装结果集。免去了我们手动封装结果集的繁琐,实现了动态地sql参数绑定。
总结
至此,我们已经完成了自定义持久层框架中的解析xml配置文件 -> 封装实体类 -> 生成接口代理类对象 -> 实现sqlSession封装CRUD操作 -> 封装 JDBC执行sql。实现了我们最初在设计自定义持久层框架中的思路流程。再次归纳总结一下我们的设计流程和思路:
- 创建
Resources工具类,根据配置文件的路径,将配置文件加载成字节输入流,存储在内存中 - 创建
XMLConfigBuilder和XMLMapperBuilder类,利用dom4j技术对字节输入流根据标签层层进行解析,取出数据库配置和sql配置信息 - 将取出的数据库配置和sql配置信息封装到
Configuration配置类中 - 创建dao层接口的代理类,从而实现dao层接口方法与
mapper.xml中指定配置SQL的映射,实现使用端dao层接口调用能够执行mapper.xml中相应sql的处理逻辑。 - 封装
sqlSession接口,定义一系列数据库操作方法,进行诸如CRUD操作 - 创建
sqlSessionFactory,封装我们之前创建的数据库连接配置等信息,用来生产sqlSession对象,进而可以使用SqlSession对象进行数据库操作。 - 创建
sqlSession接口和sqlSessionFactory接口的实现类DefaultSqlSession和DefaultSqlSessionFactory。DefaultSqlSession用来实现实现一系列数据库操作方法,即根据dao层接口的不同方法,执行相应的处理逻辑。DefaultSqlSessionFactory用来实现根据数据库连接等配置信息生产sqlSession对象。 - 使用建造者设计模式,将上面的
dom4j解析配置文件逻辑,以及sqlSessionFactory的创建逻辑统一封装在SqlSessionFactoryBuilder类中,从而实现根据数据库配置等信息,创建sqlSessionFactory的操作。SqlSessionFactoryBuilder类的存在主要是为了解耦SqlSessionFactory对象的创建过程和应用程序的代码。 - 最后,封装JDBC执行类,替换
mapper.xml中的sql占位符。并根据传入参数对象的属性值赋值,以及返回参数类型封装结果集。
使用端测试
最后,我们编写使用端来引入我们自定义的持久层框架,并根据该持久层框架编写测试类进行测试。
创建IPersistence_testMAVEN模块,在pom.xml文件中引入:
<!--引入自定义持久层框架的依赖--><dependencies><dependency><groupId>com.lagou</groupId><artifactId>IPersistence</artifactId><version>1.0-SNAPSHOT</version></dependency></dependencies>
接着定义测试类:
public class IPersistenceTest {@Testpublic void test() throws Exception {InputStream resourceAsSteam = Resources.getResourceAsSteam("sqlMapConfig.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsSteam);SqlSession sqlSession = sqlSessionFactory.openSession();//调用User user = new User();user.setId(1);user.setUsername("张三");/* User user2 = sqlSession.selectOne("user.selectOne", user);System.out.println(user2);*//* List<User> users = sqlSession.selectList("user.selectList");for (User user1 : users) {System.out.println(user1);}*/IUserDao userDao = sqlSession.getMapper(IUserDao.class);List<User> all = userDao.findAll();for (User user1 : all) {System.out.println(user1);}}}
输出结果:
User{id=1, username='lisi'}
User{id=2, username='zhangsan'}
当我们在使用端的dao层接口调用finalAll方法后,持久层框架执行了UserMapper.xml文件中定义的sql方法和参数,并将返回值封装在了User对象中返回。验证了我们自定义持久层框架的设计思路和实现是正确的。
总体来说,上述自定义持久层框架的设计没有特别复杂,但是仍然包含了持久层框架中比较核心的几个模块和技术。上面的讲述过程可能比较繁琐,很多东西没有讲得很清,有兴趣的可以跟着代码写一遍,从而加深自己的理解。
完整的项目代码,我放在下面的github上了,有兴趣的大家可以download下来学习:
https://github.com/TAM-Lab/BlogCodeRepository/tree/main/mybatis
相关文章:

Mybatis系列原理剖析之项目实战:自定义持久层框架
Mybatis系列原理剖析之:项目实战:自定义持久层框架 持久层是JAVA EE三层体系架构中,与数据库进行交互的一层,持久层往往被称为dao层。需要说明的是,持久层的技术选型有很多,绝不仅仅只有mybatis一种。像早…...

阿里云 Serverless 应用引擎 2.0,正式公测!
阿里云 Serverless 应用引擎 SAE2.0 正式公测上线!全面升级后的 SAE2.0 具备极简体验、标准开放、极致弹性三大优势,应用冷启动全面提效,秒级完成创建发布应用,应用成本下降 40% 以上。 此外,阿里云还带来容器服务 Se…...

西北大学计算机考研844高分经验分享
西北大学计算机考研844经验分享 个人介绍 本人是西北大学22级软件工程研究生,考研专业课129分,过去一年里在各大辅导机构任职,辅导考研学生专业课844,辅导总时长达288小时,帮助多名学生专业课高分上岸。 前情回顾…...

【java并发编程的艺术读书笔记】volatile关键字介绍、与synchronized的区别
volatile的简介 volatile是轻量级锁,只用来修饰变量,保证这个变量在多线程下的可见性以及一致性(一个volatile变量被线程修改时会立刻通知其他所有线程),防止指令重排序,但是并不能保证绝对的线程安全 vol…...

LinkedList的顶级理解
目录 1.LinkedList的介绍 LinkedList的结构 2.LinkedList的模拟实现 2.1创建双链表 2.2头插法 2.3尾插法 2.4任意位置插入 2.5查找关键字 2.6链表长度 2.7遍历链表 2.8删除第一次出现关键字为key的节点 2.9删除所有值为key的节点 2.10清空链表 2.11完整代码 3.…...

再学http-为什么文件上传要转成Base64?
1 前言 最近在开发中遇到文件上传采用Base64的方式上传,记得以前刚开始学http上传文件的时候,都是通过content-type为multipart/form-data方式直接上传二进制文件,我们知道都通过网络传输最终只能传输二进制流,所以毫无疑问他们本…...
使用oracleVM搭建虚拟机
选择新建,点击 取名字,选择你的安装路径,选择你爹镜像光盘,再勾选下面的,表示跳过一些步骤 其他的都可以默认,下一步即可 创建好了,点击设置,改变光驱,硬盘的顺序 等待它…...

深入探讨C存储类和存储期——Storage Duration
🔗 《C语言趣味教程》👈 猛戳订阅!!! —— 热门专栏《维生素C语言》的重制版 —— 💭 写在前面:这是一套 C 语言趣味教学专栏,目前正在火热连载中,欢迎猛戳订阅&#…...
医学图像融合的深度学习方法综述
文章目录 Deep learning methods for medical image fusion: A review摘要引言非端到端的融合方法基于深度学习的决策映射基于深度学习的特征提取 端到端图像融合方法基于卷积神经网络(CNN)的图像融合方法单级特征融合方法多级特征融合基于残差神经网络的图像融合方法基于密集神…...

【Qt学习】04:QDialog
QDialog OVERVIEW QDialog一、自定义对话框1.模态对话框2.非模态对话框3.练习代码 二、标准对话框1.消息对话框2.文件对话框3.颜色对话框4.字体对话框 对话框是 GUI 程序中不可或缺的组成部分,对话框通常会是一个顶层窗口出现在程序最上层,用于实现短期任…...

如何更好的进行异常处理
背景 在实际开发中,我们都希望程序可以一直按照期望的流程,无误的走下去。但是由于不可避免的内外部因素,可能导致出现异常的情况,轻则导致报错,重则数据错乱、服务不可用等情况。严重影响系统的稳定性,甚至…...
若依微服务版部署到IDEA
1.进入若依官网,找到我们要下的微服务版框架 2.点击进入gitee,获取源码,下载到本地 3.下载到本地后,用Idea打开,点击若依官网,找到在线文档,找到微服务版本的,当然你不看文档,直接按…...
Elasticsearch 入门安装
1.Elasticsearch 是什么 The Elastic Stack, 包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。 Elaticsearch,简称为…...

【80天学习完《深入理解计算机系统》】第十一天 3.5 过程(函数调用)
专注 效率 记忆 预习 笔记 复习 做题 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录) 文章字体风格: 红色文字表示&#…...
怎么解决)
LinuxUbuntu安装VMware tools Segmentation fault (core dumped)怎么解决
LinuxUbuntu安装VMware tools Segmentation fault (core dumped)怎么解决 在安装VMware Tools时遇到"Segmentation fault (core dumped)"错误,通常是由于兼容性问题或系统配置不正确导致的。以下是一些可能的解决方法: 检查VMware Tools兼容性…...

002微信小程序云开发API数据库-迁移状态查询/更新索引
文章目录 微信小程序云开发API数据库-迁移状态查询案例代码微信小程序云开发API数据库-更新索引案例代码 微信小程序云开发API数据库-迁移状态查询 在微信小程序中,云开发API数据库是一种方便快捷的数据库解决方案。但是,有时候我们可能需要将云开发数据…...

十几款拿来就能用的炫酷表白代码
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:小白零基础《Python入门到精通》 表白代码 1、坐我女朋友好吗,不同意就关机.vbs2、坐我女朋友好吗&…...
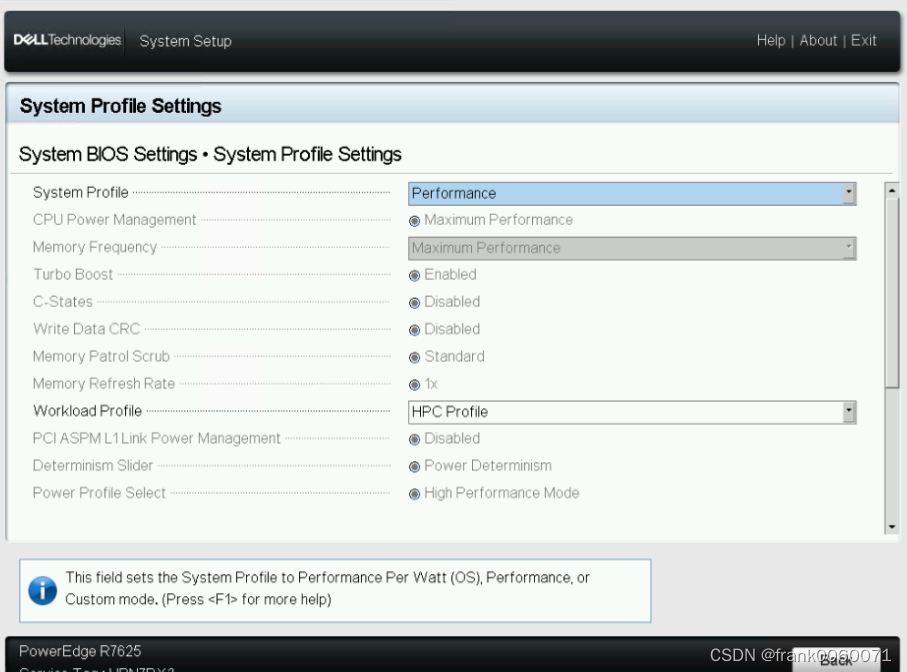
证券低延时环境设置并进行性能测试
BIOS设置BIOS参考信息 关闭 logical Process Virtualization Technology 在System Profiles Settings 中System Profile 选择Performance Workload Profile 选择HPC Profile OS中信息参考在/etc/default/grub文件中添加 intel_idle.max_cstate=0 processor.max_cstate=0 idle=p…...
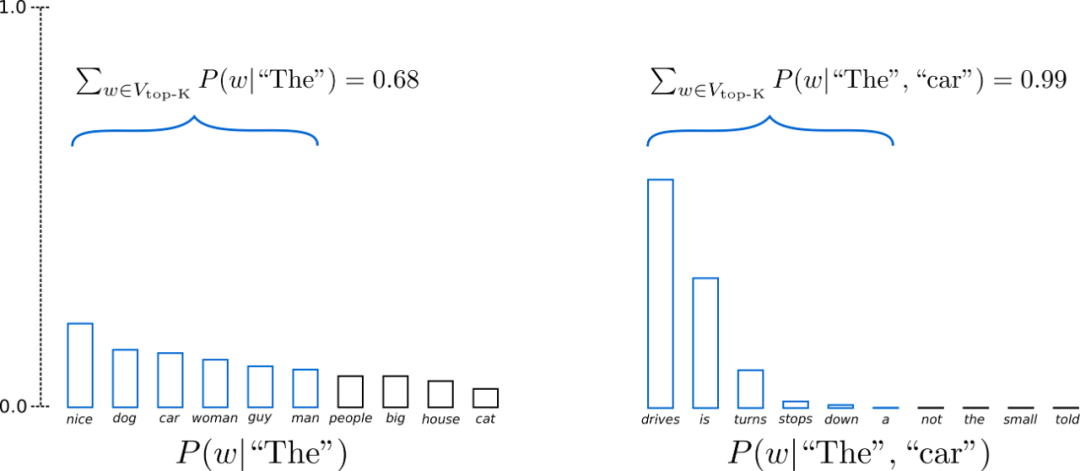
百度工程师浅析解码策略
作者 | Jane 导读 生成式模型的解码方法主要有2类:确定性方法(如贪心搜索和波束搜索)和随机方法。确定性方法生成的文本通常会不够自然,可能存在重复或过于简单的表达。而随机方法在解码过程中引入了随机性,以便生成更…...

windows下实现查看软件请求ip地址的方法
一、关于wmic和nestat wmic是Windows Management Instrumentation的缩写,是一款非常常用的用于Windows系统管理的命令行实用程序。wmic可以通过命令行操作,获取系统信息、安装软件、启动服务、管理进程等操作。 netstat命令是一个监控TCP/IP网络的非常有…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...