文本分类任务
文章目录
- 引言
- 1. 文本分类-使用场景
- 2. 自定义类别任务
- 3. 贝叶斯算法
- 3.1 预备知识
- 3.2 贝叶斯公式
- 3.3 贝叶斯公式的应用
- 3.4 贝叶斯公式在NLP中的应用
- 3.5 贝叶斯公式-文本分类
- 3.6 代码实现
- 3.7 贝叶斯算法的优缺点
- 4. 支持向量机
- 4.1 支持向量机-核函数
- 4.2 支持向量机-解决多分类
- 4.3 代码
- 4.4 支持向量机的优缺点
- 5. 深度学习
- 5.1 深度学习-pipeline
- 5.2 文本分类-fastText
- 5.3 文本分类-TextRNN
- 5.4 文本分类-RNN
- 5.5 文本分类-LSTM
- 5.5.1 解析
- 5.5.2 代码
- 5.6 文本分类-CNN
- 5.6.1 文本分类-TextCNN
- 5.6.2 文本分类-Gated CNN
- 5.6.3 代码
- 5.7 文本分类-TextRCNN
- 5.8 文本分类-Bert
- 5.9 代码演示
- 5.9.1 config.py
- 5.9.2 model.py
- 5.9.3 main.py
- 5.9.4 loader.py
- 5.9.5 evaluate.py
- 6. 数据稀疏问题
- 7. 标签不均衡问题
- 8. 多标签分类问题
- 9. BCELoss
引言
文本分类任务是自然语言处理(NLP)中的一个常见问题,目的是根据预定义的类别来自动对输入的文本进行分类。这类任务广泛应用于垃圾邮件过滤、情感分析、主题标签生成等场景。常用的方法包括朴素贝叶斯分类、支持向量机(SVM)、神经网络等。
- 预先设定好一个文本类别集合,对于一篇文本,预测其所属的类别
- 例如:
- 情感分析:
- 这家饭店太难吃了 -> 正类
- 这家菜很好吃 -> 负类
- 领域分类:
- 今日A股行情大好 -> 经济
- 今日湖人击败勇士 -> 体育
1. 文本分类-使用场景

- 违规检测
- 涉黄、涉暴、涉恐、辱骂等
- 主要应用在客服、销售对话质检,或网站内容审查等
2. 自定义类别任务
- 类别的定义方式是任意的
- 只要人能够基于文本能够判断,都可以作为分类类别
- 如:
- 垃圾邮件分类
- 对话、文章是否与汽车交易相关
- 文章风格是否与某作者风格一致
- 文章是否是机器生成
- 合同文本是否符合规范
- 文章适合阅读人群(未成年、中年、老年、孕妇等)
3. 贝叶斯算法
3.1 预备知识
全概率公式:
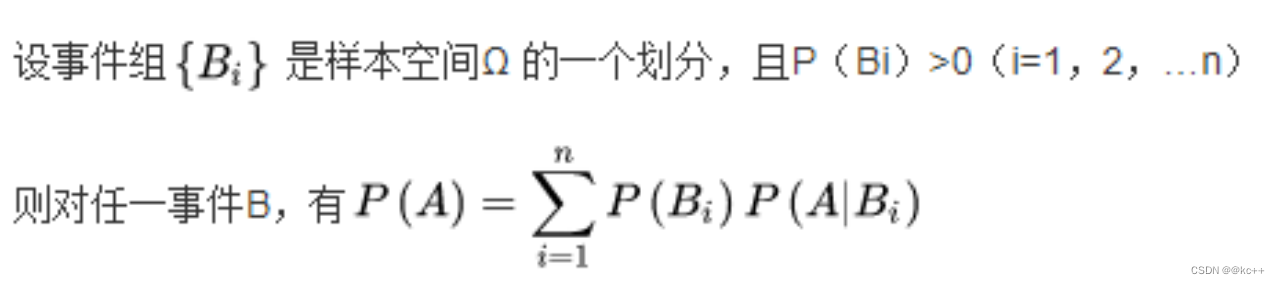
举例:扔一个正常的骰子
P(B1) = 结果为奇数
P(B2) = 结果为偶数
P(A) = 结果为5
P(A) = P(B1) * P(A|B1) + P(B2) * P(A|B2)
3.2 贝叶斯公式
公式:
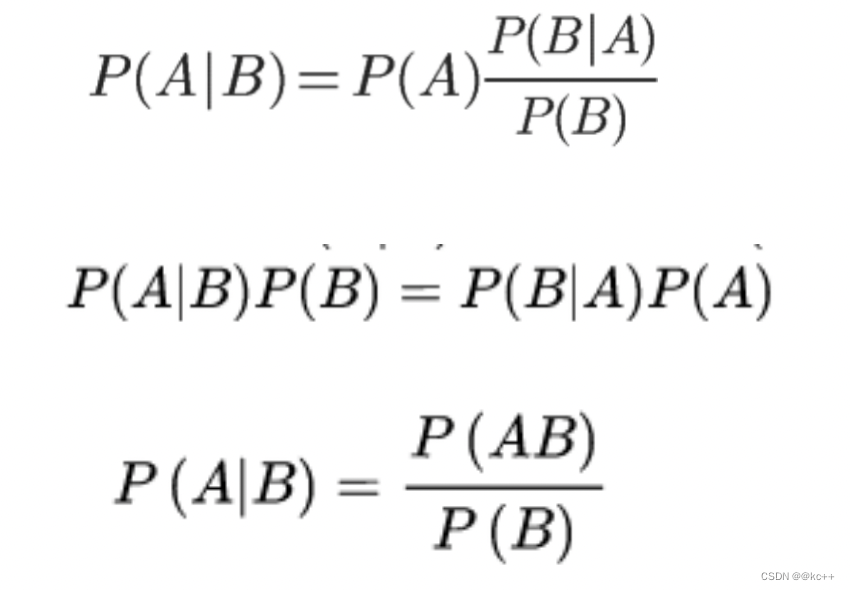
3.3 贝叶斯公式的应用
求解:如果核酸检测呈阳性,感染新冠的概率是多少?
我们假定新冠在人群中的感染率为0.1%(千分之一)
核酸检测有一定误报率,我们假定如下:

- P(A) = 感染新冠的概率
- P(B) = 核酸检测呈阳性的概率
- P(A|B) = 核酸检测呈阳性,确实感染新冠的概率
- P(B|A) = 感染了新冠,且检测结果呈阳性
- P(B|A) = 未感染新冠,且检测结果呈阳性
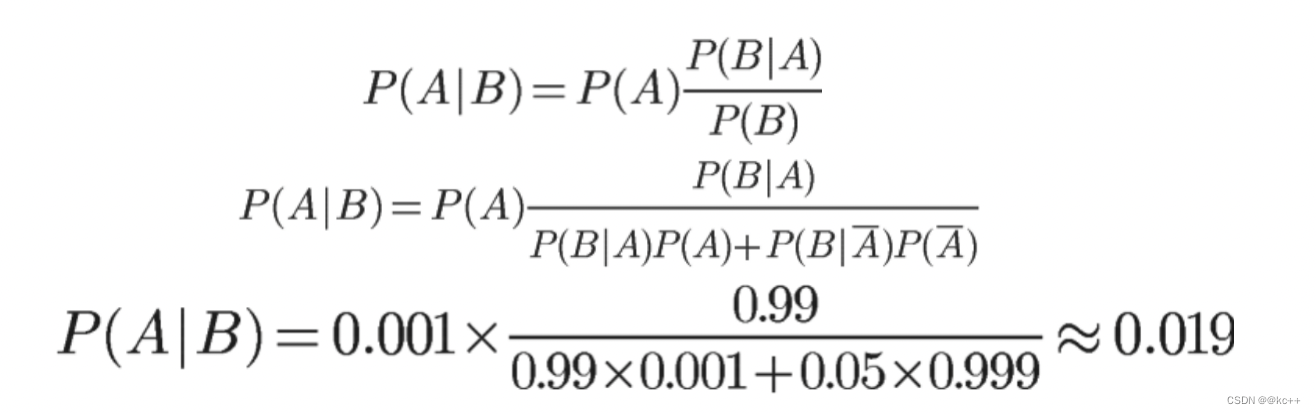
3.4 贝叶斯公式在NLP中的应用
- 用贝叶斯公式处理文本分类任务
- 一个合理假设:
- 文本属于哪个类别,与文本中包含哪些词相关
- 任务:
- 知道文本中有哪些词,预测文本属于某类别的概率
3.5 贝叶斯公式-文本分类
- 假定有3个类别A1, A2, A3
- 一个文本S有n个词组成,W1, W2, W3…Wn
- 想要计算文本S属于A1类别的概率P(A1|S) = P(A1|W1, W2, W3…Wn)
- 贝叶斯公式
- P(A1|S) = P(W1, W2…Wn|A1) * P(A1) / P(W1,W2…Wn)
- P(A2|S) = P(W1, W2…Wn|A2) * P(A2) / P(W1,W2…Wn)
- P(A3|S) = P(W1, W2…Wn|A3) * P(A3) / P(W1,W2…Wn)
- 词的独立性假设
- P(W1, W2…Wn|A3) = P(W1|A3) * P(W2|A3)…P(Wn|A3)
3.6 代码实现
import math
import jieba
import re
import os
import json
from collections import defaultdictjieba.initialize()"""
贝叶斯分类实践P(A|B) = (P(A) * P(B|A)) / P(B)
事件A:文本属于类别x1。文本属于类别x的概率,记做P(x1)
事件B:文本为s (s=w1w2w3..wn)
P(x1|s) = 文本为s,属于x1类的概率. #求解目标#
P(x1|s) = P(x1|w1, w2, w3...wn) = P(w1, w2..wn|x1) * P(x1) / P(w1, w2, w3...wn)P(x1) 任意样本属于x1的概率。x1样本数/总样本数
P(w1, w2..wn|x1) = P(w1|x1) * P(w2|x1)...P(wn|x1) 词的独立性假设
P(w1|x1) x1类样本中,w1出现的频率公共分母的计算,使用全概率公式:
P(w1, w2, w3...wn) = P(w1,w2..Wn|x1)*P(x1) + P(w1,w2..Wn|x2)*P(x2) ... P(w1,w2..Wn|xn)*P(xn)
"""class BayesApproach:def __init__(self, data_path):self.p_class = defaultdict(int)self.word_class_prob = defaultdict(dict)self.load(data_path)def load(self, path):self.class_name_to_word_freq = defaultdict(dict)self.all_words = set() #汇总一个词表with open(path, encoding="utf8") as f:for line in f:line = json.loads(line)class_name = line["tag"]title = line["title"]words = jieba.lcut(title)self.all_words.union(set(words))self.p_class[class_name] += 1 #记录每个类别样本数量word_freq = self.class_name_to_word_freq[class_name]#记录每个类别下的词频for word in words:if word not in word_freq:word_freq[word] = 1else:word_freq[word] += 1self.freq_to_prob()return#将记录的词频和样本频率都转化为概率def freq_to_prob(self):#样本概率计算total_sample_count = sum(self.p_class.values())self.p_class = dict([c, self.p_class[c] / total_sample_count] for c in self.p_class)#词概率计算self.word_class_prob = defaultdict(dict)for class_name, word_freq in self.class_name_to_word_freq.items():total_word_count = sum(count for count in word_freq.values()) #每个类别总词数for word in word_freq:#加1平滑,避免出现概率为0,计算P(wn|x1)prob = (word_freq[word] + 1) / (total_word_count + len(self.all_words))self.word_class_prob[class_name][word] = probself.word_class_prob[class_name]["<unk>"] = 1/(total_word_count + len(self.all_words))return#P(w1|x1) * P(w2|x1)...P(wn|x1)def get_words_class_prob(self, words, class_name):result = 1for word in words:unk_prob = self.word_class_prob[class_name]["<unk>"]result *= self.word_class_prob[class_name].get(word, unk_prob)return result#计算P(w1, w2..wn|x1) * P(x1)def get_class_prob(self, words, class_name):#P(x1)p_x = self.p_class[class_name]# P(w1, w2..wn|x1) = P(w1|x1) * P(w2|x1)...P(wn|x1)p_w_x = self.get_words_class_prob(words, class_name)return p_x * p_w_x#做文本分类def classify(self, sentence):words = jieba.lcut(sentence) #切词results = []for class_name in self.p_class:prob = self.get_class_prob(words, class_name) #计算class_name类概率results.append([class_name, prob])results = sorted(results, key=lambda x:x[1], reverse=True) #排序#计算公共分母:P(w1, w2, w3...wn) = P(w1,w2..Wn|x1)*P(x1) + P(w1,w2..Wn|x2)*P(x2) ... P(w1,w2..Wn|xn)*P(xn)#不做这一步也可以,对顺序没影响,只不过得到的不是0-1之间的概率值pw = sum([x[1] for x in results]) #P(w1, w2, w3...wn)results = [[c, prob/pw] for c, prob in results]#打印结果for class_name, prob in results:print("属于类别[%s]的概率为%f" % (class_name, prob))return resultsif __name__ == "__main__":path = "../data/train_tag_news.json"ba = BayesApproach(path)query = "目瞪口呆 世界上还有这些奇葩建筑"ba.classify(query)3.7 贝叶斯算法的优缺点
缺点:
- 如果样本不均衡会极大影响先验概率
- 对于未见过的特征或样本,条件概率为零,失去预测的意义(可以引入平滑)
- 特征独立假设只是个假设
- 没有考虑语序,也没有词义
优点:
5. 简单高效
6. 一定的可解释性
7. 如果样本覆盖的好,效果是不错的
8. 训练数据可以很好的分批处理
4. 支持向量机
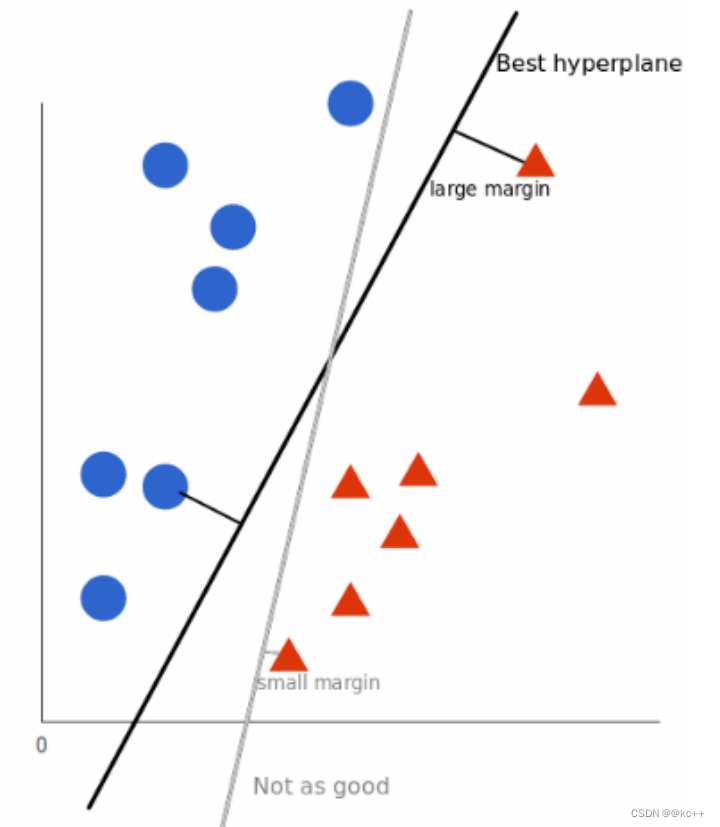
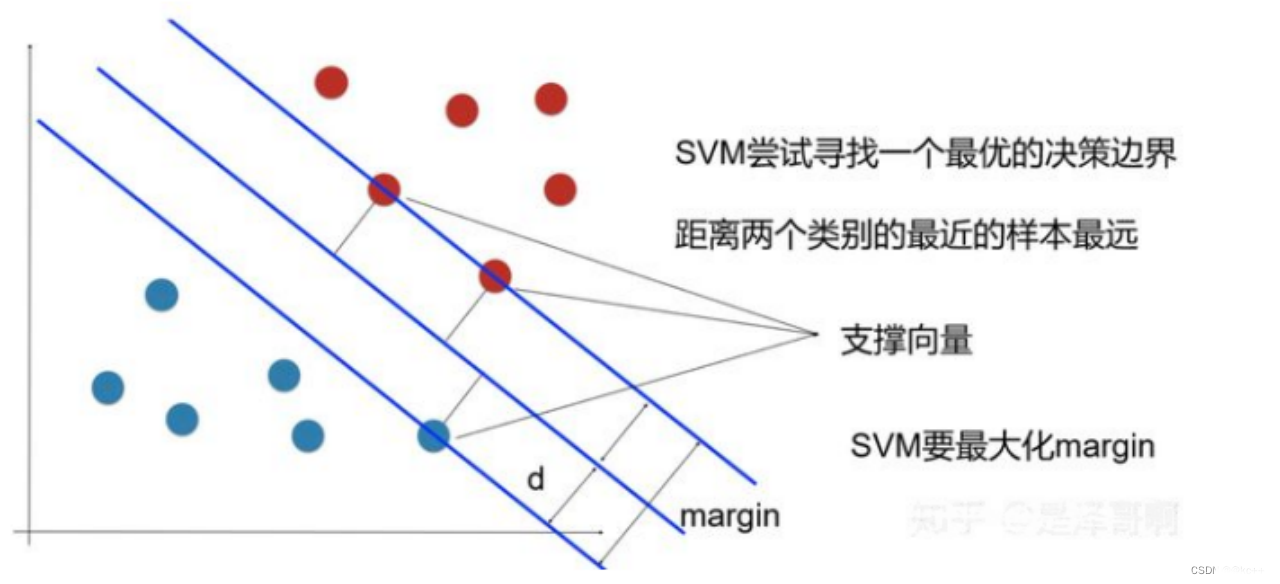
支持向量机(SVM)是一种用于分类和回归问题的监督学习算法。在分类任务中,SVM通过找到一个超平面来区分不同类别的数据点。这个超平面被选取以便最大化距离最近的数据点(支持向量)的间隔,从而提供更好的泛化能力。SVM在文本分类、图像识别和生物信息学等多个领域有广泛应用。它也可以通过核技巧来处理非线性问题。
- SVM:support vector machine
- 属于有监督学习 supervised learning
- 通过数据样本,学习最大边距超平面
- 1964年提出
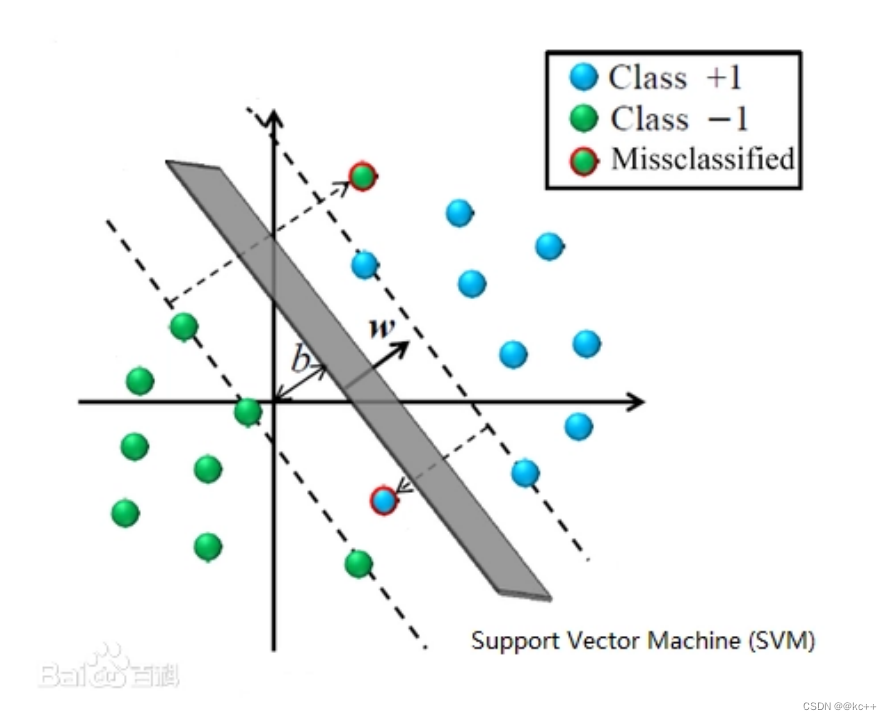
- 尝试区分蓝色球和红色三角
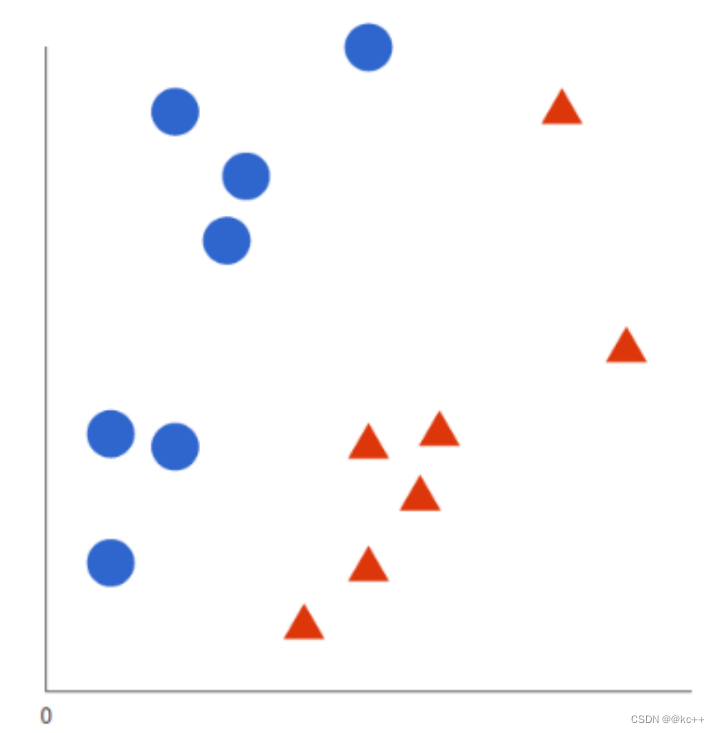
支持向量机

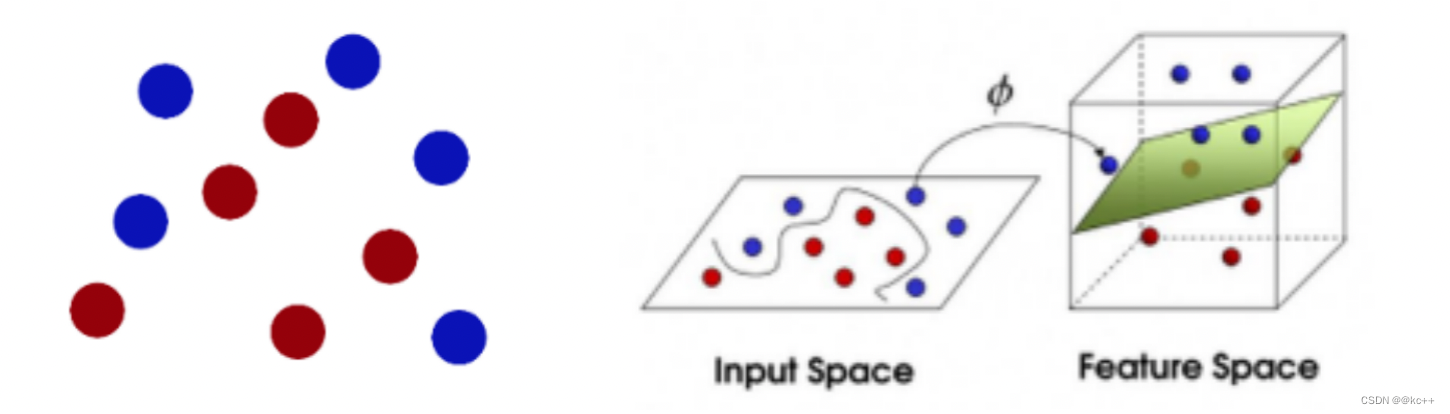
- 线性不可分问题
- 将空间映射到更高维度来分类非线性数据
4.1 支持向量机-核函数
- 为了解决线性不可分问题,我们需要把输入映射到高维,即寻找函数f(x) ,使其输出维度高于x
- 例如: x = [X1, X2, X3]
- 令f(x) = [X1X1, X1X2, X1X3, X2X1, X2X2, X2X3, X3X1, X3X2, X3*X3] (对自己做笛卡尔积)
- 这样x就从3维上升到9维
- 向高维映射如何解决线性不可分问题?
- 考虑一组一维数据
- [-1, 0, 1] 为正样本,[-3, -2, 2, 3]为负样本

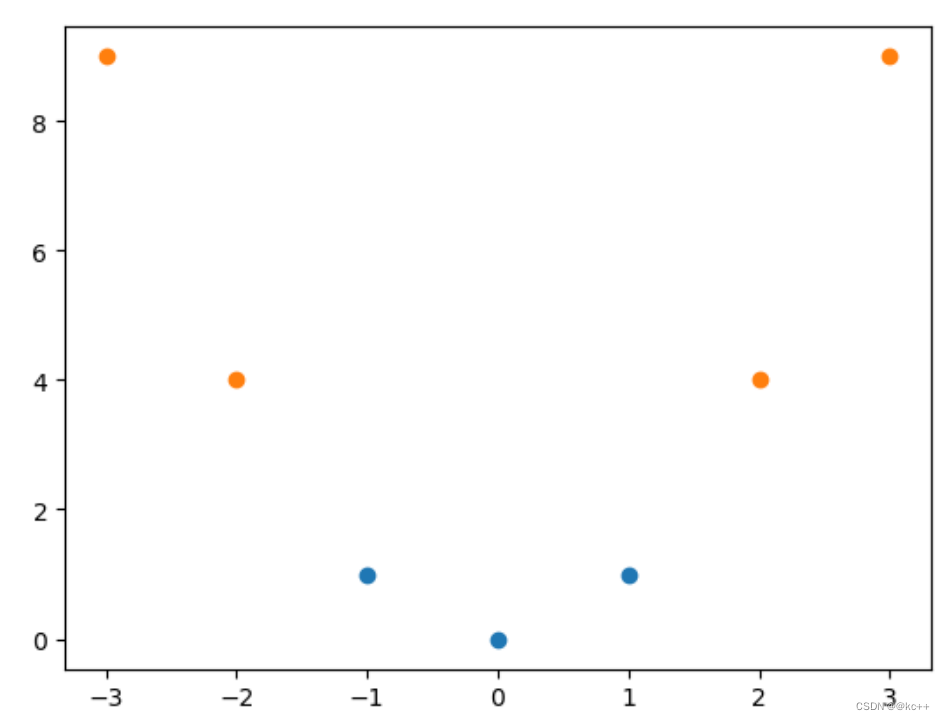
- 将x映射为[x, x2]后
- 可以用直线划分
- 但是这样出现一个问题,维度过高的向量计算在进行内积运算非常耗时,而svm的求解中内积运算很频繁
- 所以我们希望内有一种方法快速计算f(x1)f(x2)
- 所谓的核函数即为满足条件:
- K(x1, x2) = f(x1)f(x2) 的函数统称
- 线性核函数
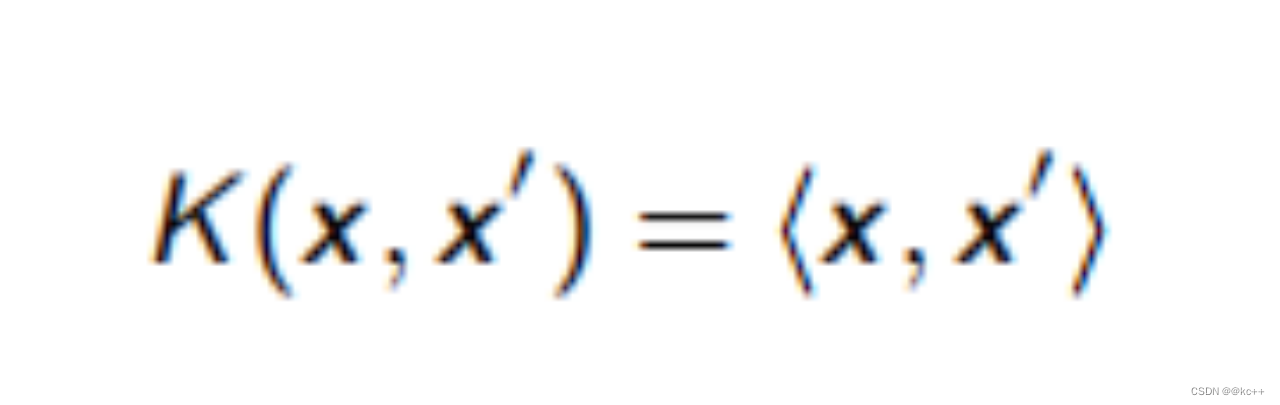
- 多项式核函数
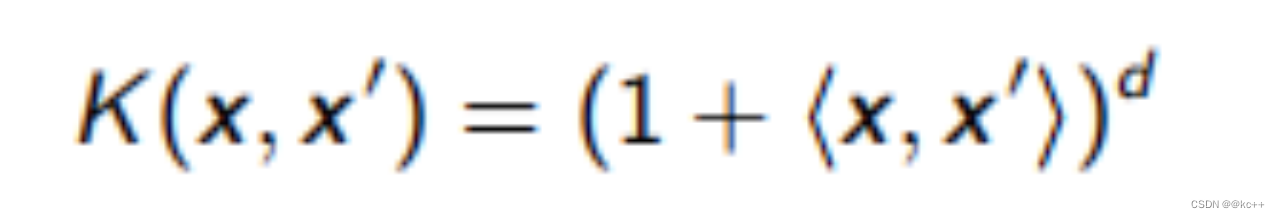
- 高斯核函数
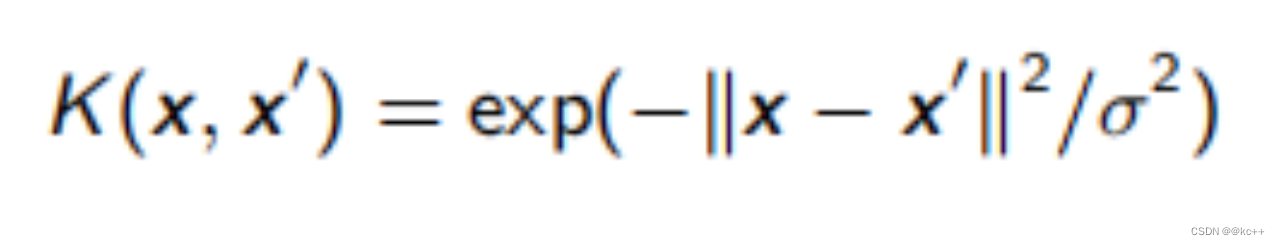
- 双曲正切核函数
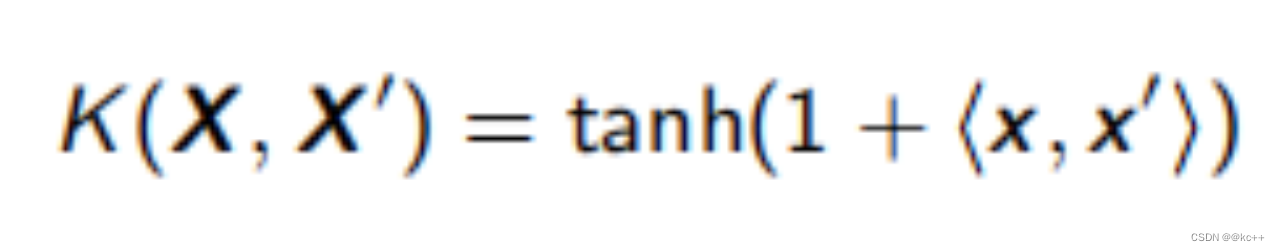
4.2 支持向量机-解决多分类
- 假设要解决一个K分类问题,即有K个目标类别
-
- one vs one方式
- 建立 K(K - 1)/2 个svm分类器,每个分类器负责K个类别中的两个类别,判断输入样本属于哪个类别
- 对于一个待预测的样本,使用所有分类器进行分类,最后保留被预测词数最多的类别
- 假设类别有[A,B,C] X->SVM(A,B)->A
- X->SVM(A,C)->A
- X->SVM(B,C)->B
- 最终判断 X->A
-
- one vs rest方式
- 建立K个svm分类器,每个分类器负责划分输入样本属于K个类别中的某一个类别,还是其他类别
- 最后保留预测分值最高的类别
- 假设类别有[A,B,C] X->SVM(A,rest)->0.1
- X->SVM(B,rest)->0.2
- X->SVM(C,rest)->0.5
- 最终判断 X->C
4.3 代码
#!/usr/bin/env python3
#coding: utf-8#使用基于词向量的分类器
#对比几种模型的效果import json
import jieba
import numpy as np
from gensim.models import Word2Vec
from sklearn.metrics import classification_report
from sklearn.svm import SVC
from collections import defaultdictLABELS = {'健康': 0, '军事': 1, '房产': 2, '社会': 3, '国际': 4, '旅游': 5, '彩票': 6, '时尚': 7, '文化': 8, '汽车': 9, '体育': 10, '家居': 11, '教育': 12, '娱乐': 13, '科技': 14, '股票': 15, '游戏': 16, '财经': 17}#输入模型文件路径
#加载训练好的模型
def load_word2vec_model(path):model = Word2Vec.load(path)return model#加载数据集
def load_sentence(path, model):sentences = []labels = []with open(path, encoding="utf8") as f:for line in f:line = json.loads(line)title, content = line["title"], line["content"]sentences.append(" ".join(jieba.lcut(title)))labels.append(line["tag"])train_x = sentences_to_vectors(sentences, model)train_y = label_to_label_index(labels)return train_x, train_y#tag标签转化为类别标号
def label_to_label_index(labels):return [LABELS[y] for y in labels]#文本向量化,使用了基于这些文本训练的词向量
def sentences_to_vectors(sentences, model):vectors = []for sentence in sentences:words = sentence.split()vector = np.zeros(model.vector_size)for word in words:try:vector += model.wv[word]# vector = np.max([vector, model.wv[word]], axis=0)except KeyError:vector += np.zeros(model.vector_size)vectors.append(vector / len(words))return np.array(vectors)def main():model = load_word2vec_model("model.w2v")train_x, train_y = load_sentence("../data/train_tag_news.json", model)test_x, test_y = load_sentence("../data/valid_tag_news.json", model)classifier = SVC()classifier.fit(train_x, train_y)y_pred = classifier.predict(test_x)print(classification_report(test_y, y_pred))if __name__ == "__main__":main()
4.4 支持向量机的优缺点
优点:
- 少数支持向量决定了最终结果,对异常值不敏感
- 对于样本数量需求较低
- 可以处理高维度数据
缺点:
- 样本数量过多的时候,计算负担很大
- 多分类任务处理起来比较麻烦
- 核函数的选取以及参数的选取较为困难
5. 深度学习
5.1 深度学习-pipeline
在深度学习中,“pipeline” 通常指的是一系列数据预处理、模型训练、模型评估和模型部署的步骤。这些步骤被组织成一个流程,以便更高效地完成特定任务。
- 数据收集:获取用于训练和测试的数据。
- 数据预处理:进行归一化、数据增强、分词等操作。
- 模型设计:选择或设计适合任务的神经网络架构。
- 模型训练:使用训练数据集进行模型训练。
- 验证与调优:使用验证数据集进行模型性能评估和超参数调整。
- 模型评估:使用测试数据集进行最终模型评估。
- 模型部署:将训练好的模型部署到实际环境中。
5.2 文本分类-fastText
FastText 是一个用于文本分类和词向量学习的开源库。与传统的深度学习模型相比,FastText 显著提高了训练速度和分类准确性。
- 原理:FastText 通过使用层次 softmax 和 n-gram 特性,将文本数据快速映射到高维空间,进而进行分类。
- 训练:FastText 可以快速训练出文本分类器。它不仅支持多类别分类,还支持多标签分类。
- 部署:由于模型相对较小,FastText 非常适合用于移动设备或者有资源限制的环境。
- 用途:FastText 通常用于情感分析、主题分类、垃圾邮件过滤等文本分类任务。
- 优点:FastText 不仅训练速度快,而且准确性也相当高,特别是对于小型数据集。
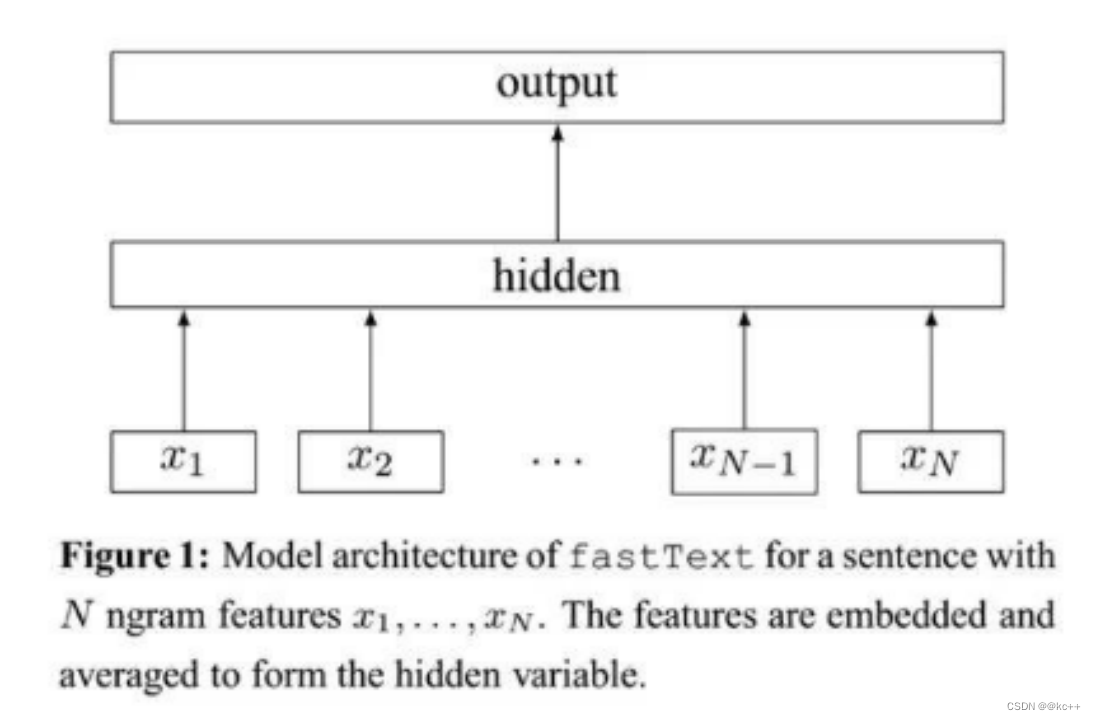
- ngram-features
- -> [<ap, app, ppl, ple, le>]
- x -> Embedding -> Mean Pooling -> Label
5.3 文本分类-TextRNN
TextRNN 是一种利用循环神经网络(RNN)进行文本分类的模型。下面是一些关键点:
- 结构:TextRNN 通常由词嵌入层、一个或多个 RNN 层(如 LSTM 或 GRU)和一个全连接层组成。
- 顺序信息:RNN 能够捕获文本中的顺序信息,这对于理解语境和句子结构非常重要。
- 训练:与传统的文本分类方法相比,TextRNN 需要更长的训练时间和更多的计算资源。
- 功能:可以应用于多种文本分类任务,如情感分析、主题识别和命名实体识别等。
- 灵活性:模型可以通过添加更多的 RNN 层或使用双向 RNN 来增加复杂性和性能。
TextRNN 是一种强大但计算密集的文本分类方法,尤其适用于需要捕获长距离依赖或复杂结构的任务。
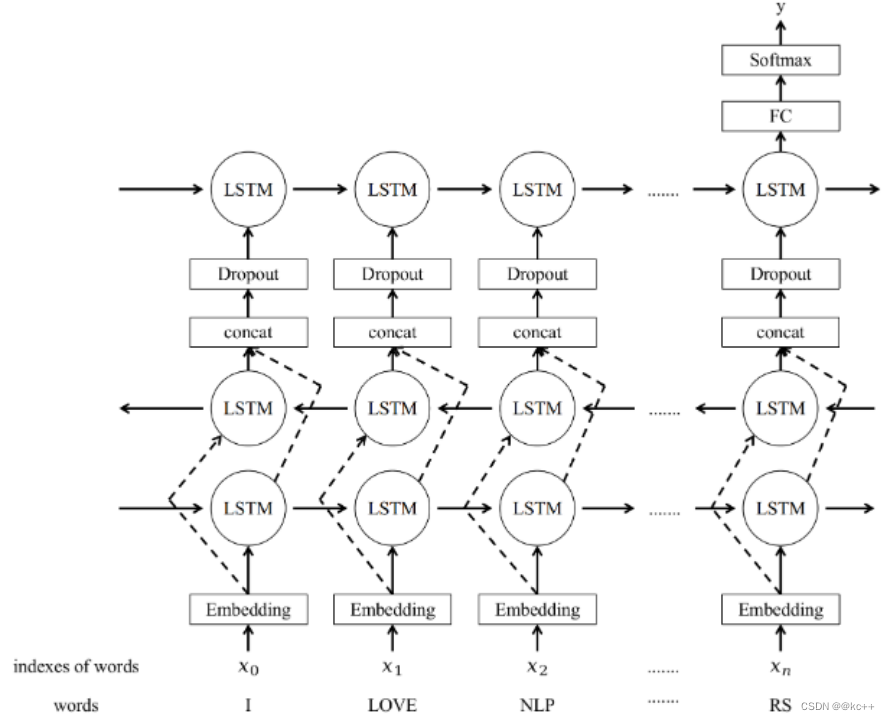
- 使用RNN(LSTM、GRU)对文本进行编码,使用最后一个位置的输出向量进行分类
- x
- –>embedding
- –>BiLSTM
- –>Dropout
- ->LSTM
- ->Linear
- –>softmax
- –>y
5.4 文本分类-RNN
RNN(循环神经网络)用于文本分类主要有以下几个特点:
- 序列建模:RNN 能够捕获文本序列中的依赖关系,这对于文本分类非常有用。
- 结构:基础的 RNN 模型通常包括一个词嵌入层,一个 RNN 层,以及一个或多个全连接层。
- 可变长度:RNN 能够处理不同长度的输入序列,这对于文本数据来说是一个优势。
- 梯度消失/爆炸:基础的 RNN 结构容易出现梯度消失或梯度爆炸问题,这可以通过使用 LSTM 或 GRU 等变体来解决。
- 应用场景:RNN 在处理具有序列依赖性的文本分类问题(如情感分析或主题分类)方面表现得相当出色。
- 计算复杂性:与传统机器学习算法相比,RNN 需要更多的计算资源和时间进行训练。
总体来说,RNN 是一种适用于文本分类的强大模型,特别是当文本中的顺序信息很重要时。然而,也需要注意其潜在的计算成本和其他技术挑战。
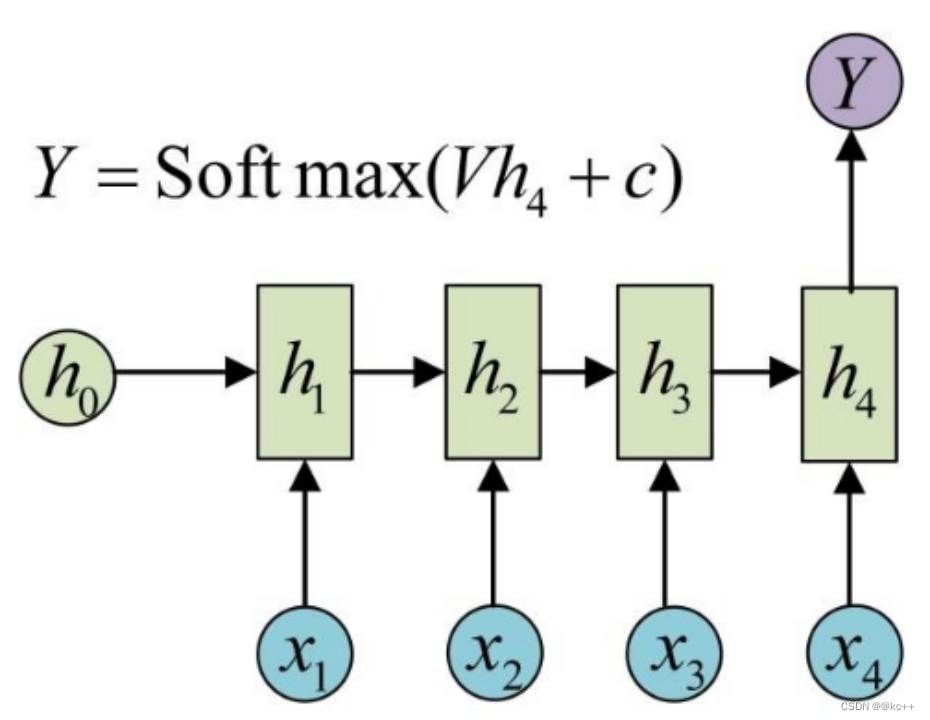
- Recurrent Neural Network
- 循环神经网络
- 隐向量按时间步向后传递,起到记忆的作用
5.5 文本分类-LSTM
5.5.1 解析
LSTM(长短时记忆网络)在文本分类方面具有以下特点:
- 序列模型:和RNN一样,LSTM能够处理序列数据,适合于需要考虑上下文信息的文本分类任务。
- 解决梯度问题:LSTM设计用来解决基础RNN模型中的梯度消失和梯度爆炸问题。
- 存储单元:LSTM通过一个特殊的存储单元来保存历史信息,从而更好地捕获长距离依赖。
- 复杂性:虽然LSTM模型在捕获长距离依赖方面表现得更好,但相对于基础的RNN,它们更复杂并且需要更多的计算资源。
- 多变体:LSTM有多种变体,如双向LSTM和堆叠LSTM,这些变体可以进一步提高模型性能。
- 常见应用:LSTM非常适用于情感分析、主题分类等需要考虑上下文和长距离依赖的文本分类任务。
总体而言,LSTM提供了一种高度灵活和强大的方式来进行文本分类,尤其是当处理具有复杂结构和长距离依赖的文本时。
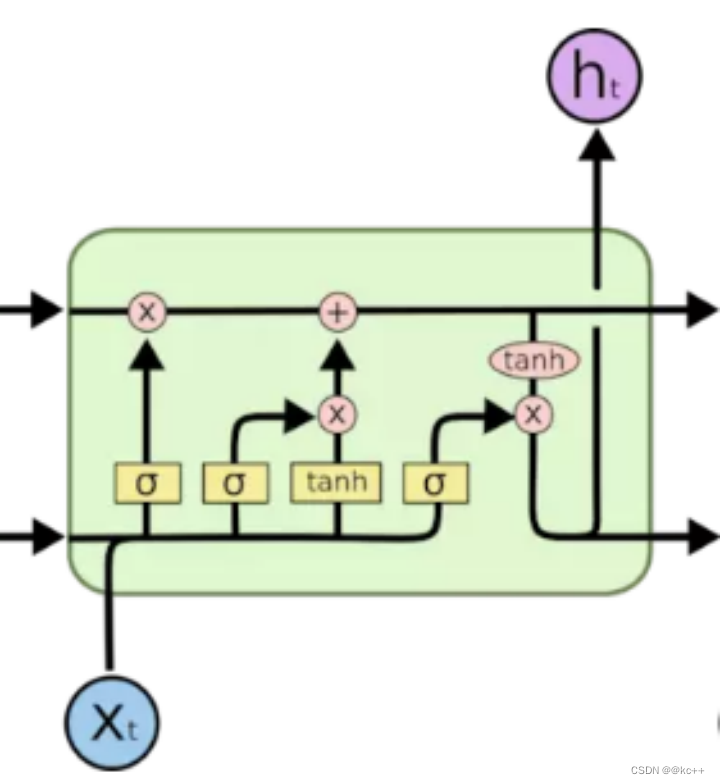
- 将RNN的隐单元复杂化
- 一定程度规避了梯度消失和信息遗忘的问题
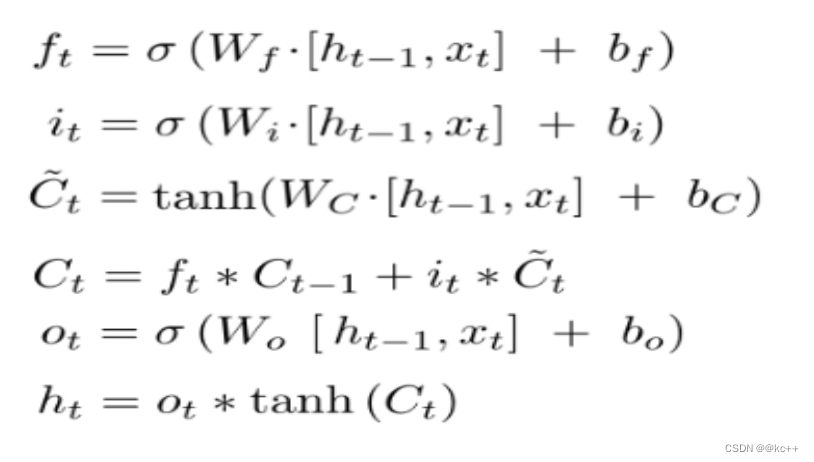
5.5.2 代码
import torch
import torch.nn as nn
import numpy as np'''
用矩阵运算的方式复现一些基础的模型结构
清楚模型的计算细节,有助于加深对于模型的理解,以及模型转换等工作
'''#构造一个输入
length = 6
input_dim = 12
hidden_size = 7
x = np.random.random((length, input_dim))
# print(x)#使用pytorch的lstm层
torch_lstm = nn.LSTM(input_dim, hidden_size, batch_first=True)
for key, weight in torch_lstm.state_dict().items():print(key, weight.shape)def sigmoid(x):return 1/(1 + np.exp(-x))#将pytorch的lstm网络权重拿出来,用numpy通过矩阵运算实现lstm的计算
def numpy_lstm(x, state_dict):weight_ih = state_dict["weight_ih_l0"].numpy()weight_hh = state_dict["weight_hh_l0"].numpy()bias_ih = state_dict["bias_ih_l0"].numpy()bias_hh = state_dict["bias_hh_l0"].numpy()#pytorch将四个门的权重拼接存储,我们将它拆开w_i_x, w_f_x, w_c_x, w_o_x = weight_ih[0:hidden_size, :], \weight_ih[hidden_size:hidden_size*2, :],\weight_ih[hidden_size*2:hidden_size*3, :],\weight_ih[hidden_size*3:hidden_size*4, :]w_i_h, w_f_h, w_c_h, w_o_h = weight_hh[0:hidden_size, :], \weight_hh[hidden_size:hidden_size * 2, :], \weight_hh[hidden_size * 2:hidden_size * 3, :], \weight_hh[hidden_size * 3:hidden_size * 4, :]b_i_x, b_f_x, b_c_x, b_o_x = bias_ih[0:hidden_size], \bias_ih[hidden_size:hidden_size * 2], \bias_ih[hidden_size * 2:hidden_size * 3], \bias_ih[hidden_size * 3:hidden_size * 4]b_i_h, b_f_h, b_c_h, b_o_h = bias_hh[0:hidden_size], \bias_hh[hidden_size:hidden_size * 2], \bias_hh[hidden_size * 2:hidden_size * 3], \bias_hh[hidden_size * 3:hidden_size * 4]w_i = np.concatenate([w_i_h, w_i_x], axis=1)w_f = np.concatenate([w_f_h, w_f_x], axis=1)w_c = np.concatenate([w_c_h, w_c_x], axis=1)w_o = np.concatenate([w_o_h, w_o_x], axis=1)b_f = b_f_h + b_f_xb_i = b_i_h + b_i_xb_c = b_c_h + b_c_xb_o = b_o_h + b_o_xc_t = np.zeros((1, hidden_size))h_t = np.zeros((1, hidden_size))sequence_output = []for x_t in x:x_t = x_t[np.newaxis, :]hx = np.concatenate([h_t, x_t], axis=1)# f_t = sigmoid(np.dot(x_t, w_f_x.T) + b_f_x + np.dot(h_t, w_f_h.T) + b_f_h)f_t = sigmoid(np.dot(hx, w_f.T) + b_f)# i_t = sigmoid(np.dot(x_t, w_i_x.T) + b_i_x + np.dot(h_t, w_i_h.T) + b_i_h)i_t = sigmoid(np.dot(hx, w_i.T) + b_i)# g = np.tanh(np.dot(x_t, w_c_x.T) + b_c_x + np.dot(h_t, w_c_h.T) + b_c_h)g = np.tanh(np.dot(hx, w_c.T) + b_c)c_t = f_t * c_t + i_t * g# o_t = sigmoid(np.dot(x_t, w_o_x.T) + b_o_x + np.dot(h_t, w_o_h.T) + b_o_h)o_t = sigmoid(np.dot(hx, w_o.T) + b_o)h_t = o_t * np.tanh(c_t)sequence_output.append(h_t)return np.array(sequence_output), (h_t, c_t)torch_sequence_output, (torch_h, torch_c) = torch_lstm(torch.Tensor([x]))
numpy_sequence_output, (numpy_h, numpy_c) = numpy_lstm(x, torch_lstm.state_dict())print(torch_sequence_output)
print(numpy_sequence_output)
print("--------")
print(torch_h)
print(numpy_h)
print("--------")
print(torch_c)
print(numpy_c)##############################################################使用pytorch的GRU层
torch_gru = nn.GRU(input_dim, hidden_size, batch_first=True)
# for key, weight in torch_gru.state_dict().items():
# print(key, weight.shape)#将pytorch的GRU网络权重拿出来,用numpy通过矩阵运算实现GRU的计算
def numpy_gru(x, state_dict):weight_ih = state_dict["weight_ih_l0"].numpy()weight_hh = state_dict["weight_hh_l0"].numpy()bias_ih = state_dict["bias_ih_l0"].numpy()bias_hh = state_dict["bias_hh_l0"].numpy()#pytorch将3个门的权重拼接存储,我们将它拆开w_r_x, w_z_x, w_x = weight_ih[0:hidden_size, :], \weight_ih[hidden_size:hidden_size * 2, :],\weight_ih[hidden_size * 2:hidden_size * 3, :]w_r_h, w_z_h, w_h = weight_hh[0:hidden_size, :], \weight_hh[hidden_size:hidden_size * 2, :], \weight_hh[hidden_size * 2:hidden_size * 3, :]b_r_x, b_z_x, b_x = bias_ih[0:hidden_size], \bias_ih[hidden_size:hidden_size * 2], \bias_ih[hidden_size * 2:hidden_size * 3]b_r_h, b_z_h, b_h = bias_hh[0:hidden_size], \bias_hh[hidden_size:hidden_size * 2], \bias_hh[hidden_size * 2:hidden_size * 3]w_z = np.concatenate([w_z_h, w_z_x], axis=1)w_r = np.concatenate([w_r_h, w_r_x], axis=1)b_z = b_z_h + b_z_xb_r = b_r_h + b_r_xh_t = np.zeros((1, hidden_size))sequence_output = []for x_t in x:x_t = x_t[np.newaxis, :]hx = np.concatenate([h_t, x_t], axis=1)z_t = sigmoid(np.dot(hx, w_z.T) + b_z)r_t = sigmoid(np.dot(hx, w_r.T) + b_r)h = np.tanh(r_t * (np.dot(h_t, w_h.T) + b_h) + np.dot(x_t, w_x.T) + b_x)h_t = (1 - z_t) * h + z_t * h_tsequence_output.append(h_t)return np.array(sequence_output), h_t# torch_sequence_output, torch_h = torch_gru(torch.Tensor([x]))
# numpy_sequence_output, numpy_h = numpy_gru(x, torch_gru.state_dict())
#
# print(torch_sequence_output)
# print(numpy_sequence_output)
# print("--------")
# print(torch_h)
# print(numpy_h)5.6 文本分类-CNN
5.6.1 文本分类-TextCNN
- 利用一维卷积对文本进行编码编码后的文本矩阵通过pooling转化为向量,用于分类
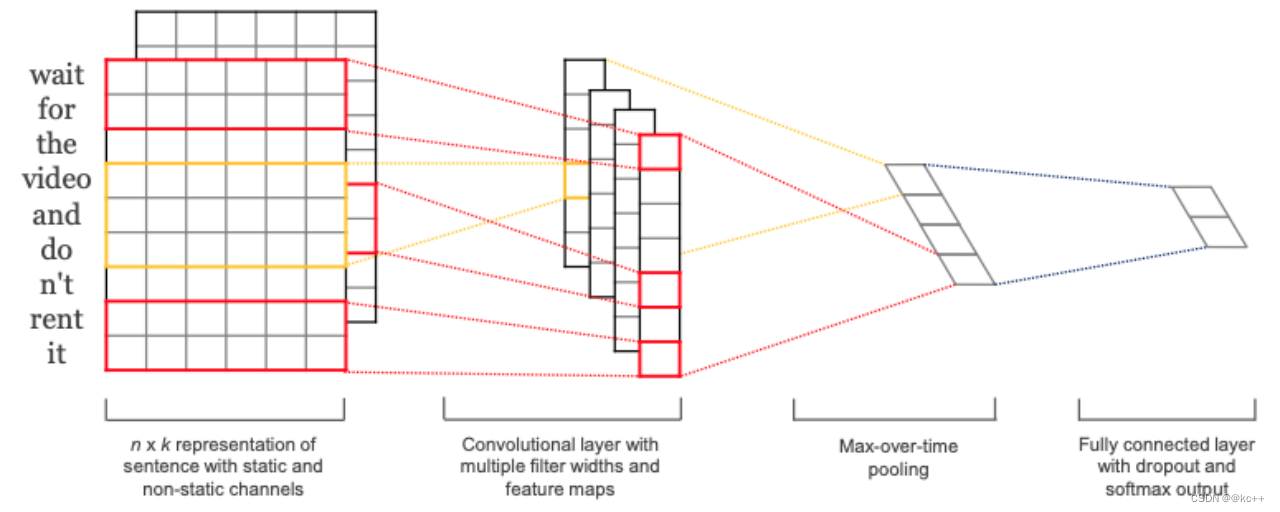
5.6.2 文本分类-Gated CNN
对CNN的一种改进
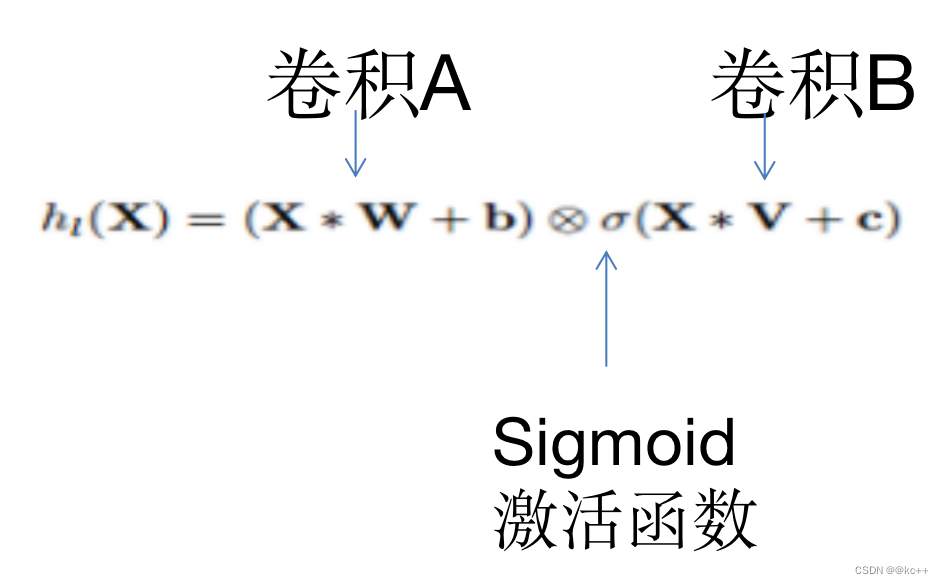
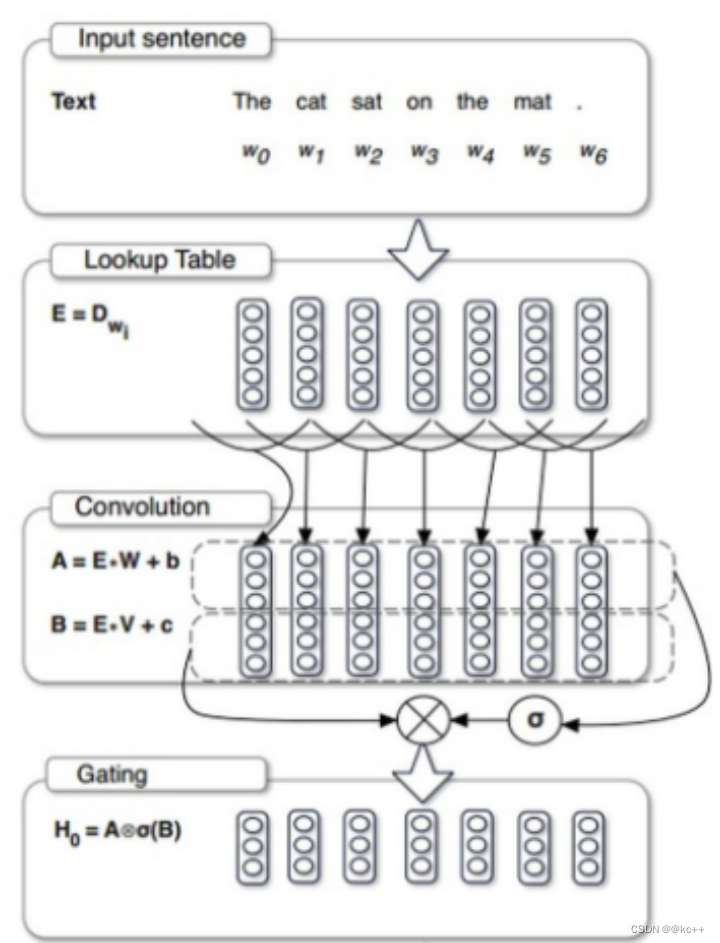
5.6.3 代码
import torch
import torch.nn as nn
import numpy as np#使用pytorch的1维卷积层input_dim = 7
hidden_size = 8
kernel_size = 2
torch_cnn1d = nn.Conv1d(input_dim, hidden_size, kernel_size)
for key, weight in torch_cnn1d.state_dict().items():print(key, weight.shape)x = torch.rand((7, 4)) #embedding_size * max_lengthdef numpy_cnn1d(x, state_dict):weight = state_dict["weight"].numpy()bias = state_dict["bias"].numpy()sequence_output = []for i in range(0, x.shape[1] - kernel_size + 1):window = x[:, i:i+kernel_size]kernel_outputs = []for kernel in weight:kernel_outputs.append(np.sum(kernel * window))sequence_output.append(np.array(kernel_outputs) + bias)return np.array(sequence_output).Tprint(x.shape)
print(torch_cnn1d(x.unsqueeze(0)))
print(torch_cnn1d(x.unsqueeze(0)).shape)
print(numpy_cnn1d(x.numpy(), torch_cnn1d.state_dict()))
5.7 文本分类-TextRCNN
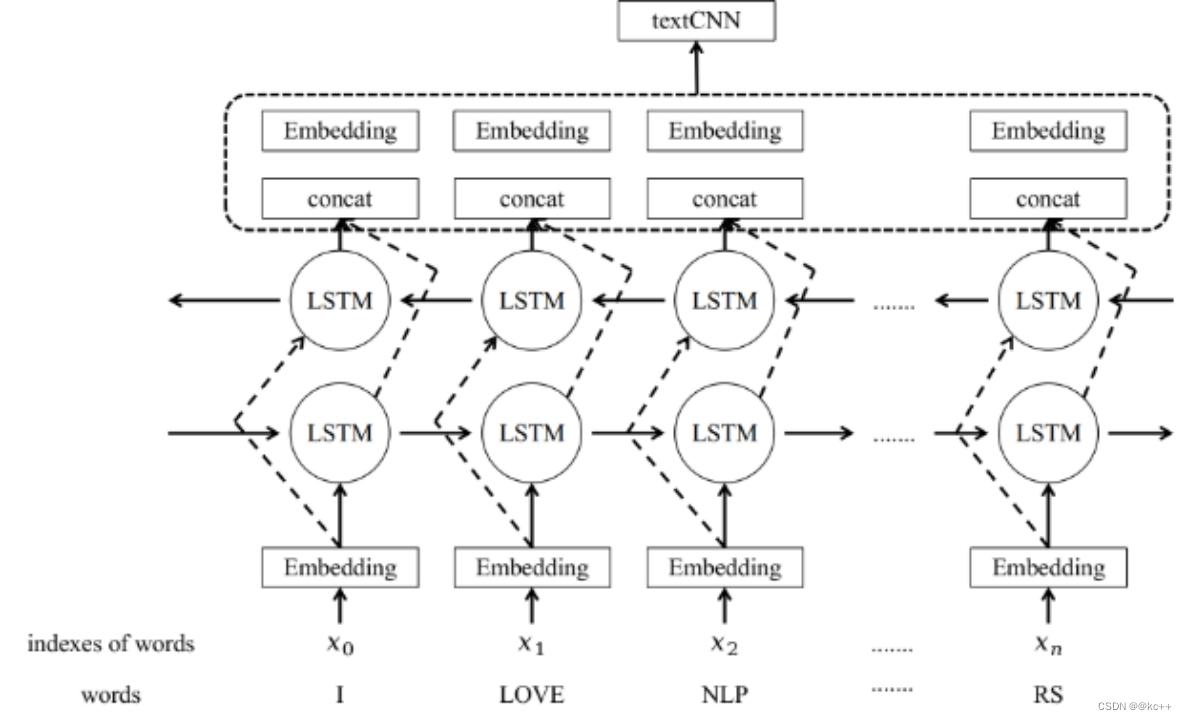
5.8 文本分类-Bert
- Bert作为Encoder将文本转化为向量或矩阵
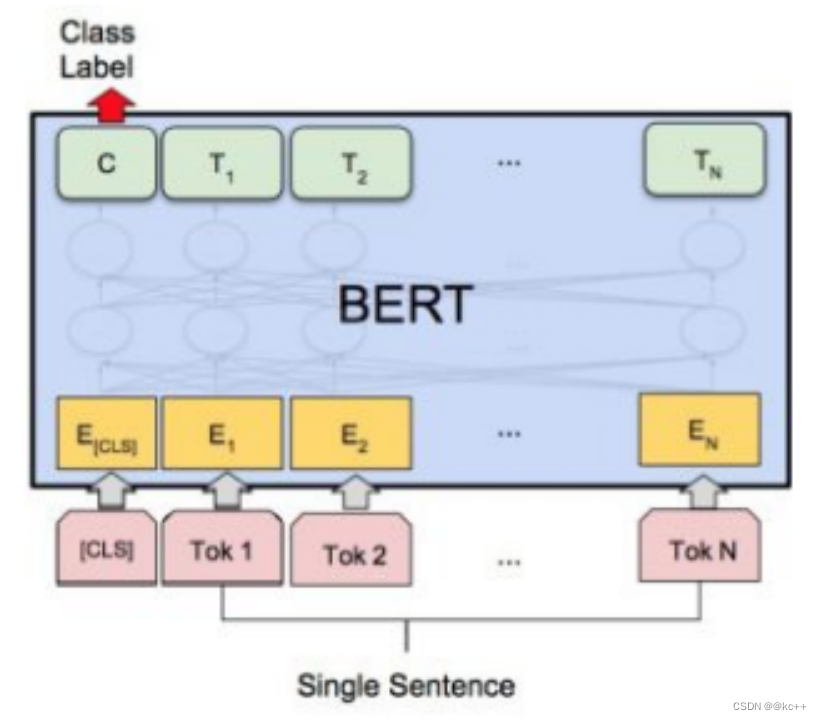
BERT(Bidirectional Encoder Representations from Transformers)在文本分类上有如下特点:
- 双向编码:BERT能够同时考虑一个词前后的上下文,提供丰富的语义信息。
- 预训练:BERT模型先进行大规模文本数据上的预训练,然后微调用于特定的文本分类任务。
- 高性能:由于其强大的编码能力,BERT在多项NLP任务,包括文本分类上都表现优异。
- 易于微调:已预训练的BERT模型很容易通过少量标注数据进行微调,以适应特定的分类任务。
- 计算复杂:虽然效果好,但BERT模型通常较大,需要更多的计算资源。
- 多用途:除了文本分类,BERT还广泛用于问答、实体识别等多种NLP任务。
- 灵活性:可以与其他模型结合,如CNN、RNN等,用于特定场景的文本分类。
总的来说,BERT由于其强大的编码能力和高度的灵活性,已经成为文本分类和其他NLP任务中的一种主流方法。
5.9 代码演示
5.9.1 config.py
# -*- coding: utf-8 -*-"""
配置参数信息
"""Config = {"model_path": "output","train_data_path": "../data/train_tag_news.json","valid_data_path": "../data/valid_tag_news.json","vocab_path":"chars.txt","model_type":"lstm","max_length": 20,"hidden_size": 128,"kernel_size": 3,"num_layers": 2,"epoch": 15,"batch_size": 64,"pooling_style":"max","optimizer": "adam","learning_rate": 1e-3,"pretrain_model_path":r"F:\Desktop\work_space\pretrain_models\bert-base-chinese","seed": 987
}
5.9.2 model.py
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from transformers import BertModel
"""
建立网络模型结构
"""class TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()hidden_size = config["hidden_size"]vocab_size = config["vocab_size"] + 1class_num = config["class_num"]model_type = config["model_type"]num_layers = config["num_layers"]self.use_bert = Falseself.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)if model_type == "fast_text":self.encoder = lambda x: xelif model_type == "lstm":self.encoder = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers)elif model_type == "gru":self.encoder = nn.GRU(hidden_size, hidden_size, num_layers=num_layers)elif model_type == "rnn":self.encoder = nn.RNN(hidden_size, hidden_size, num_layers=num_layers)elif model_type == "cnn":self.encoder = CNN(config)elif model_type == "gated_cnn":self.encoder = GatedCNN(config)elif model_type == "stack_gated_cnn":self.encoder = StackGatedCNN(config)elif model_type == "rcnn":self.encoder = RCNN(config)elif model_type == "bert":self.use_bert = Trueself.encoder = BertModel.from_pretrained(config["pretrain_model_path"])hidden_size = self.encoder.config.hidden_sizeelif model_type == "bert_lstm":self.use_bert = Trueself.encoder = BertLSTM(config)hidden_size = self.encoder.bert.config.hidden_sizeelif model_type == "bert_cnn":self.use_bert = Trueself.encoder = BertCNN(config)hidden_size = self.encoder.bert.config.hidden_sizeelif model_type == "bert_mid_layer":self.use_bert = Trueself.encoder = BertMidLayer(config)hidden_size = self.encoder.bert.config.hidden_sizeself.classify = nn.Linear(hidden_size, class_num)self.pooling_style = config["pooling_style"]self.loss = nn.functional.cross_entropy #loss采用交叉熵损失#当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, target=None):if self.use_bert: # bert返回的结果是 (sequence_output, pooler_output)x = self.encoder(x)else:x = self.embedding(x) # input shape:(batch_size, sen_len)x = self.encoder(x) # input shape:(batch_size, sen_len, input_dim)if isinstance(x, tuple): #RNN类的模型会同时返回隐单元向量,我们只取序列结果x = x[0]#可以采用pooling的方式得到句向量if self.pooling_style == "max":self.pooling_layer = nn.MaxPool1d(x.shape[1])else:self.pooling_layer = nn.AvgPool1d(x.shape[1])x = self.pooling_layer(x.transpose(1, 2)).squeeze() #input shape:(batch_size, sen_len, input_dim)#也可以直接使用序列最后一个位置的向量# x = x[:, -1, :]predict = self.classify(x) #input shape:(batch_size, input_dim)if target is not None:return self.loss(predict, target.squeeze())else:return predictclass CNN(nn.Module):def __init__(self, config):super(CNN, self).__init__()hidden_size = config["hidden_size"]kernel_size = config["kernel_size"]pad = int((kernel_size - 1)/2)self.cnn = nn.Conv1d(hidden_size, hidden_size, kernel_size, bias=False, padding=pad)def forward(self, x): #x : (batch_size, max_len, embeding_size)return self.cnn(x.transpose(1, 2)).transpose(1, 2)class GatedCNN(nn.Module):def __init__(self, config):super(GatedCNN, self).__init__()self.cnn = CNN(config)self.gate = CNN(config)def forward(self, x):a = self.cnn(x)b = self.gate(x)b = torch.sigmoid(b)return torch.mul(a, b)class StackGatedCNN(nn.Module):def __init__(self, config):super(StackGatedCNN, self).__init__()self.num_layers = config["num_layers"]self.hidden_size = config["hidden_size"]#ModuleList类内可以放置多个模型,取用时类似于一个列表self.gcnn_layers = nn.ModuleList(GatedCNN(config) for i in range(self.num_layers))self.ff_liner_layers1 = nn.ModuleList(nn.Linear(self.hidden_size, self.hidden_size) for i in range(self.num_layers))self.ff_liner_layers2 = nn.ModuleList(nn.Linear(self.hidden_size, self.hidden_size) for i in range(self.num_layers))self.bn_after_gcnn = nn.ModuleList(nn.LayerNorm(self.hidden_size) for i in range(self.num_layers))self.bn_after_ff = nn.ModuleList(nn.LayerNorm(self.hidden_size) for i in range(self.num_layers))def forward(self, x):#仿照bert的transformer模型结构,将self-attention替换为gcnnfor i in range(self.num_layers):gcnn_x = self.gcnn_layers[i](x)x = gcnn_x + x #通过gcnn+残差x = self.bn_after_gcnn[i](x) #之后bn# # 仿照feed-forward层,使用两个线性层l1 = self.ff_liner_layers1[i](x) #一层线性l1 = torch.relu(l1) #在bert中这里是gelul2 = self.ff_liner_layers2[i](l1) #二层线性x = self.bn_after_ff[i](x + l2) #残差后过bnreturn xclass RCNN(nn.Module):def __init__(self, config):super(RCNN, self).__init__()hidden_size = config["hidden_size"]self.rnn = nn.RNN(hidden_size, hidden_size)self.cnn = GatedCNN(config)def forward(self, x):x, _ = self.rnn(x)x = self.cnn(x)return xclass BertLSTM(nn.Module):def __init__(self, config):super(BertLSTM, self).__init__()self.bert = BertModel.from_pretrained(config["pretrain_model_path"])self.rnn = nn.LSTM(self.bert.config.hidden_size, self.bert.config.hidden_size, batch_first=True)def forward(self, x):x = self.bert(x)[0]x, _ = self.rnn(x)return xclass BertCNN(nn.Module):def __init__(self, config):super(BertCNN, self).__init__()self.bert = BertModel.from_pretrained(config["pretrain_model_path"])config["hidden_size"] = self.bert.config.hidden_sizeself.cnn = CNN(config)def forward(self, x):x = self.bert(x)[0]x = self.cnn(x)return xclass BertMidLayer(nn.Module):def __init__(self, config):super(BertMidLayer, self).__init__()self.bert = BertModel.from_pretrained(config["pretrain_model_path"])self.bert.config.output_hidden_states = Truedef forward(self, x):layer_states = self.bert(x)[2]layer_states = torch.add(layer_states[-2], layer_states[-1])return layer_states#优化器的选择
def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)if __name__ == "__main__":from config import Config# Config["class_num"] = 3# Config["vocab_size"] = 20# Config["max_length"] = 5Config["model_type"] = "bert"model = BertModel.from_pretrained(Config["pretrain_model_path"])x = torch.LongTensor([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])sequence_output, pooler_output = model(x)print(x[2], type(x[2]), len(x[2]))# model = TorchModel(Config)# label = torch.LongTensor([1,2])# print(model(x, label))
5.9.3 main.py
# -*- coding: utf-8 -*-import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
#[DEBUG, INFO, WARNING, ERROR, CRITICAL]
logging.basicConfig(level=logging.INFO, format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型训练主程序
"""seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)def main(config):#创建保存模型的目录if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])#加载训练数据train_data = load_data(config["train_data_path"], config)#加载模型model = TorchModel(config)# 标识是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,迁移模型至gpu")model = model.cuda()#加载优化器optimizer = choose_optimizer(config, model)#加载效果测试类evaluator = Evaluator(config, model, logger)#训练for epoch in range(config["epoch"]):epoch += 1model.train()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):if cuda_flag:batch_data = [d.cuda() for d in batch_data]optimizer.zero_grad()input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况loss = model(input_ids, labels)loss.backward()optimizer.step()train_loss.append(loss.item())if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)logger.info("epoch average loss: %f" % np.mean(train_loss))acc = evaluator.eval(epoch)# model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)# torch.save(model.state_dict(), model_path) #保存模型权重return accif __name__ == "__main__":main(Config)# for model in ["cnn"]:# Config["model_type"] = model# print("最后一轮准确率:", main(Config), "当前配置:", Config["model_type"])#对比所有模型#中间日志可以关掉,避免输出过多信息# 超参数的网格搜索# for model in ["gated_cnn"]:# Config["model_type"] = model# for lr in [1e-3]:# Config["learning_rate"] = lr# for hidden_size in [128]:# Config["hidden_size"] = hidden_size# for batch_size in [64, 128]:# Config["batch_size"] = batch_size# for pooling_style in ["avg"]:# Config["pooling_style"] = pooling_style# print("最后一轮准确率:", main(Config), "当前配置:", Config)5.9.4 loader.py
# -*- coding: utf-8 -*-import json
import re
import os
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
"""
数据加载
"""class DataGenerator:def __init__(self, data_path, config):self.config = configself.path = data_pathself.index_to_label = {0: '家居', 1: '房产', 2: '股票', 3: '社会', 4: '文化',5: '国际', 6: '教育', 7: '军事', 8: '彩票', 9: '旅游',10: '体育', 11: '科技', 12: '汽车', 13: '健康',14: '娱乐', 15: '财经', 16: '时尚', 17: '游戏'}self.label_to_index = dict((y, x) for x, y in self.index_to_label.items())self.config["class_num"] = len(self.index_to_label)if self.config["model_type"] == "bert":self.tokenizer = BertTokenizer.from_pretrained(config["pretrain_model_path"])self.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.load()def load(self):self.data = []with open(self.path, encoding="utf8") as f:for line in f:line = json.loads(line)tag = line["tag"]label = self.label_to_index[tag]title = line["title"]if self.config["model_type"] == "bert":input_id = self.tokenizer.encode(title, max_length=self.config["max_length"], pad_to_max_length=True)else:input_id = self.encode_sentence(title)input_id = torch.LongTensor(input_id)label_index = torch.LongTensor([label])self.data.append([input_id, label_index])returndef encode_sentence(self, text):input_id = []for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))input_id = self.padding(input_id)return input_id#补齐或截断输入的序列,使其可以在一个batch内运算def padding(self, input_id):input_id = input_id[:self.config["max_length"]]input_id += [0] * (self.config["max_length"] - len(input_id))return input_iddef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]def load_vocab(vocab_path):token_dict = {}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):token = line.strip()token_dict[token] = index + 1 #0留给padding位置,所以从1开始return token_dict#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dlif __name__ == "__main__":from config import Configdg = DataGenerator("valid_tag_news.json", Config)print(dg[1])5.9.5 evaluate.py
# -*- coding: utf-8 -*-
import torch
from loader import load_data"""
模型效果测试
"""class Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = loggerself.valid_data = load_data(config["valid_data_path"], config, shuffle=False)self.stats_dict = {"correct":0, "wrong":0} #用于存储测试结果def eval(self, epoch):self.logger.info("开始测试第%d轮模型效果:" % epoch)self.model.eval()self.stats_dict = {"correct": 0, "wrong": 0} # 清空上一轮结果for index, batch_data in enumerate(self.valid_data):if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况with torch.no_grad():pred_results = self.model(input_ids) #不输入labels,使用模型当前参数进行预测self.write_stats(labels, pred_results)acc = self.show_stats()return accdef write_stats(self, labels, pred_results):assert len(labels) == len(pred_results)for true_label, pred_label in zip(labels, pred_results):pred_label = torch.argmax(pred_label)if int(true_label) == int(pred_label):self.stats_dict["correct"] += 1else:self.stats_dict["wrong"] += 1returndef show_stats(self):correct = self.stats_dict["correct"]wrong = self.stats_dict["wrong"]self.logger.info("预测集合条目总量:%d" % (correct +wrong))self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))self.logger.info("--------------------")return correct / (correct + wrong)6. 数据稀疏问题
- 训练数据量小,模型在训练样本上能收敛,但预测准确率很低
- 解决方案:
-
- 标注更多的数据
-
- 尝试构造训练样本(数据增强)
-
- 更换模型(如使用预训练模型等)减少数据需求
-
- 增加规则弥补
-
- 调整阈值,用召回率换准确率
-
- 重新定义类别(减少类别)
7. 标签不均衡问题
- 部分类别样本充裕,部分类别样本极少
- 解决办法:
- 解决数据稀疏的所有的方法依然适用
-
- 过采样 复制指定类别的样本,在采样中重复
-
- 降采样 减少多样本类别的采样,随机使用部分
-
- 调整样本权重 通过损失函数权重调整来体现
8. 多标签分类问题
- 多标签 不同于 多分类
- 电影描述: 战斗中负伤而下身瘫痪的前海军战士杰克·萨利(萨姆·沃辛顿 Sam Worthington 饰)决定替死去的同胞哥哥来到潘多拉星操纵格蕾丝博士(西格妮·韦弗 Sigourney Weaver 饰)用人类基因与当地纳美部族基因结合创造出的 “阿凡达” 混血生物……
- 标签:动作,科幻
- 多标签问题的转化
-
- 分解为多个独立的二分类问题
-
- 将多标签分类问题转换为多分类问题
-
- 更换loss直接由模型进行多标签分类
9. BCELoss
- 直接更换loss函数

代码
import torch
import torch.nn as nnm = nn.Sigmoid()
bceloss = nn.BCELoss()
input = torch.randn(5)
target = torch.FloatTensor([1,0,1,0,0])
output = bceloss(m(input), target)
print(output)celoss = nn.CrossEntropyLoss()
input = torch.FloatTensor([[0.1,0.2,0.3,0.1,0.3],[0.1,0.2,0.3,0.1,0.3]])
target = torch.LongTensor([2,3])
output = celoss(input, target)
print(output)
相关文章:
文本分类任务
文章目录 引言1. 文本分类-使用场景2. 自定义类别任务3. 贝叶斯算法3.1 预备知识3.2 贝叶斯公式3.3 贝叶斯公式的应用3.4 贝叶斯公式在NLP中的应用3.5 贝叶斯公式-文本分类3.6 代码实现3.7 贝叶斯算法的优缺点 4. 支持向量机4.1 支持向量机-核函数4.2 支持向量机-解决多分类4.3…...
:Python中的pyecharts库绘制3D曲面图)
Pyecharts教程(一):Python中的pyecharts库绘制3D曲面图
Pyecharts教程(一):Python中的pyecharts库绘制3D曲面图 作者:安静到无声 个人主页 目录 Pyecharts教程(一):Python中的pyecharts库绘制3D曲面图实验结果推荐专栏在Python中,我们可以使用pyecharts库来绘制各种图表,如柱状图、折线图、饼图等。最近,我在学习如何使用pyec…...

Unity音频基础概念
一、音源与音频侦听器 游戏画面能够被观众看到,是因为有渲染器和摄像机,同样音频能够被听到,也要有声音的发出者与声音的接收者。声音的发出者叫做音源,接收者叫做音频侦听器。Audio Source与Audio Listener都是组件,…...

sklearn Preprocessing 数据预处理功能
scikit-learn(或sklearn)的数据预处理模块提供了一系列用于处理和准备数据的工具。这些工具可以帮助你在将数据输入到机器学习模型之前对其进行预处理、清洗和转换。以下是一些常用的sklearn.preprocessing模块中的类和功能: 1. 数据缩放和中…...
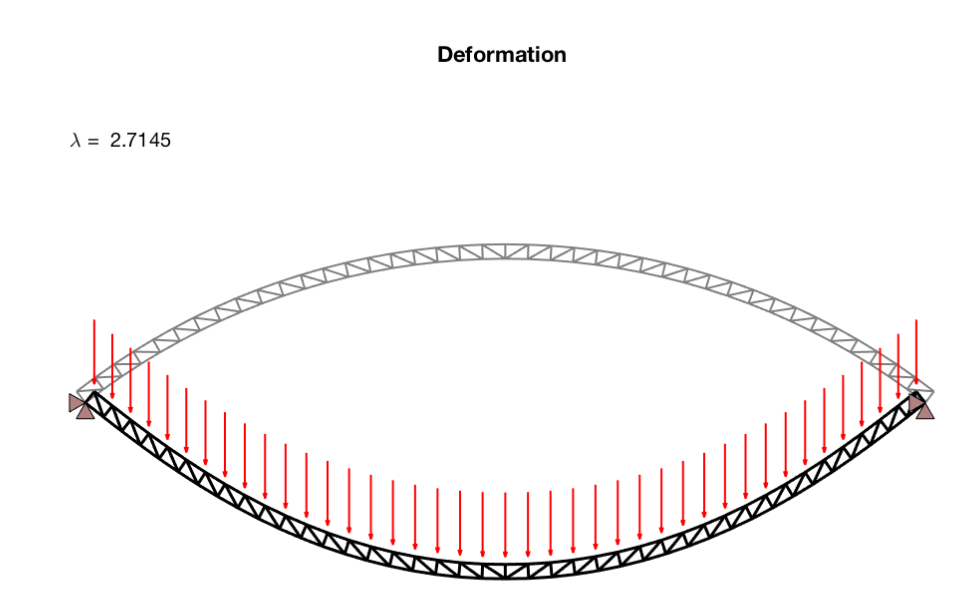
创建和分析二维桁架和梁结构研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
SpringBoot实现文件上传和下载笔记分享(提供Gitee源码)
前言:这边汇总了一下目前SpringBoot项目当中常见文件上传和下载的功能,一共三种常见的下载方式和一种上传方式,特此做一个笔记分享。 目录 一、pom依赖 二、yml配置文件 三、文件下载 3.1、使用Spring框架提供的下载方式 3.2、通过IOUti…...
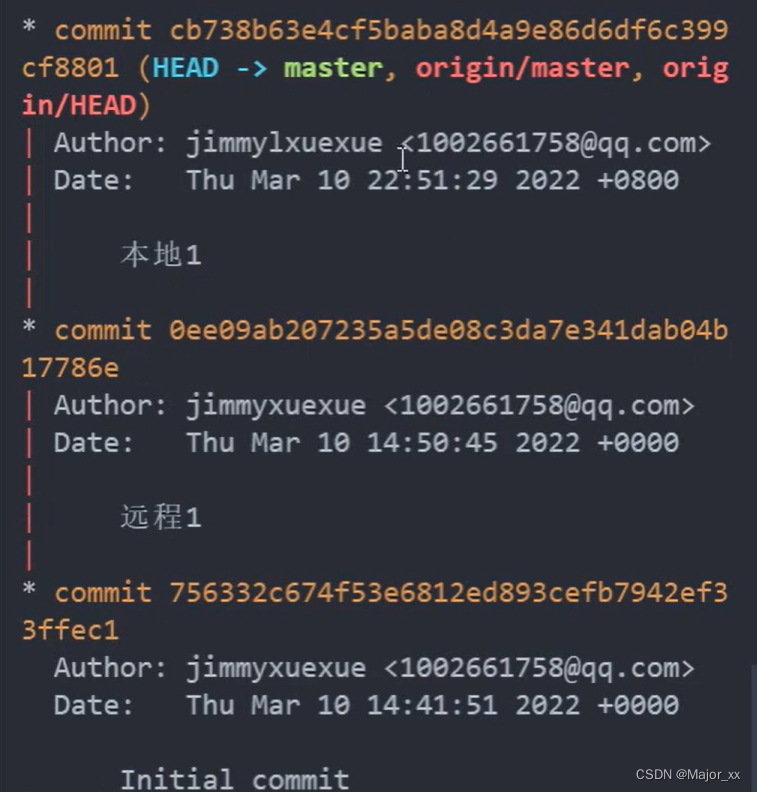
Git工作流
实际开发项目使用到的分支: main:生产环境,也就是你们在网上可以下载到的版本,是经过了很多轮测试得到的稳定版本。 release: 开发内部发版,也就是测试环境。 dev:所有的feature都要从dev上checkout。 fea…...
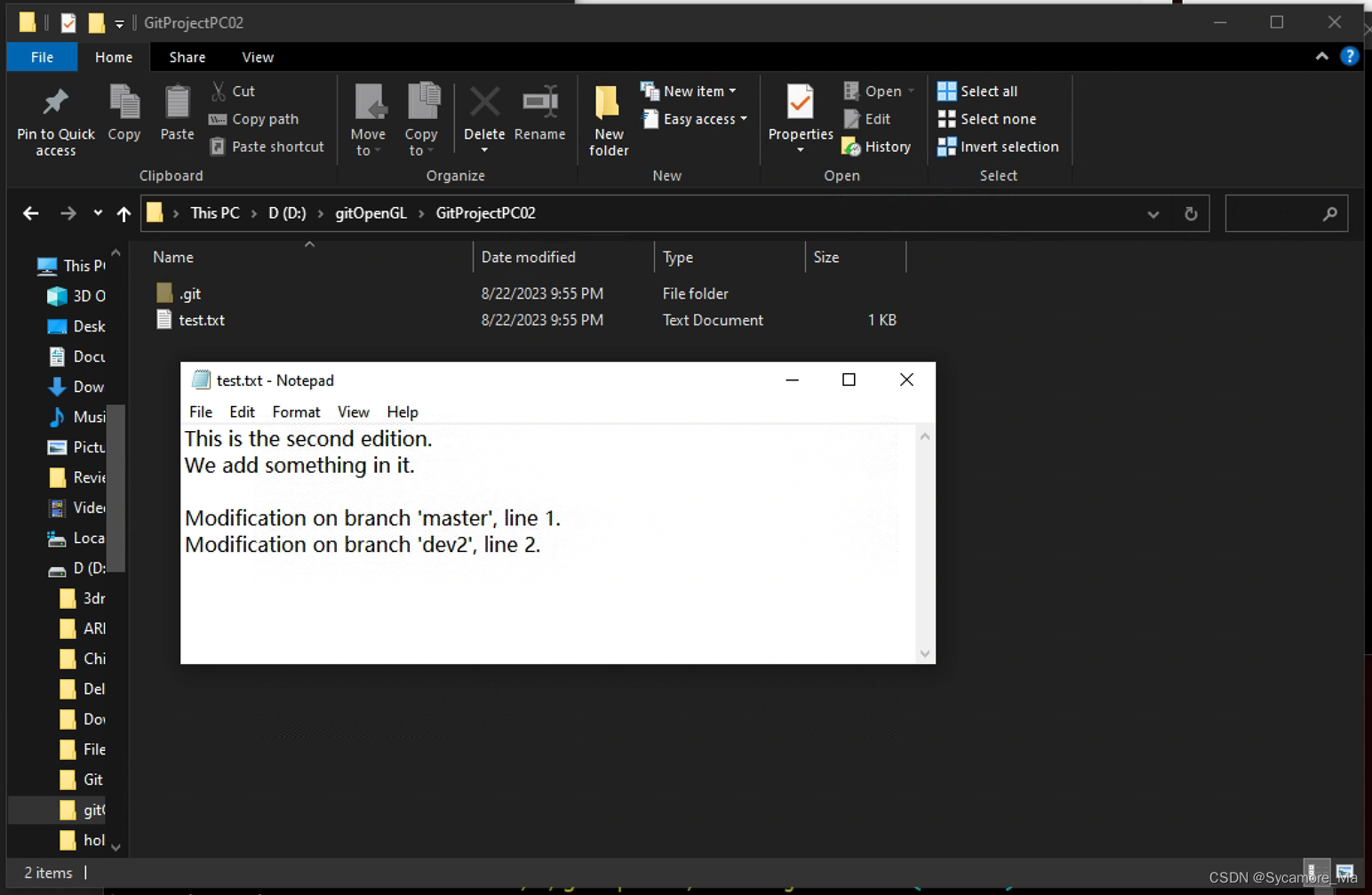
【Git Bash】简明从零教学
目录 Git 的作用官网介绍简明概要 Git 下载链接Git 的初始配置配置用户初始化本地库 Git 状态查询Git 工作机制本地工作机制远端工作机制 Git 的本地管理操作add 将修改添加至暂存区commit 将暂存区提交至本地仓库日志查询版本穿梭 Git 分支查看分支创建与切换分支跨分支修改与…...
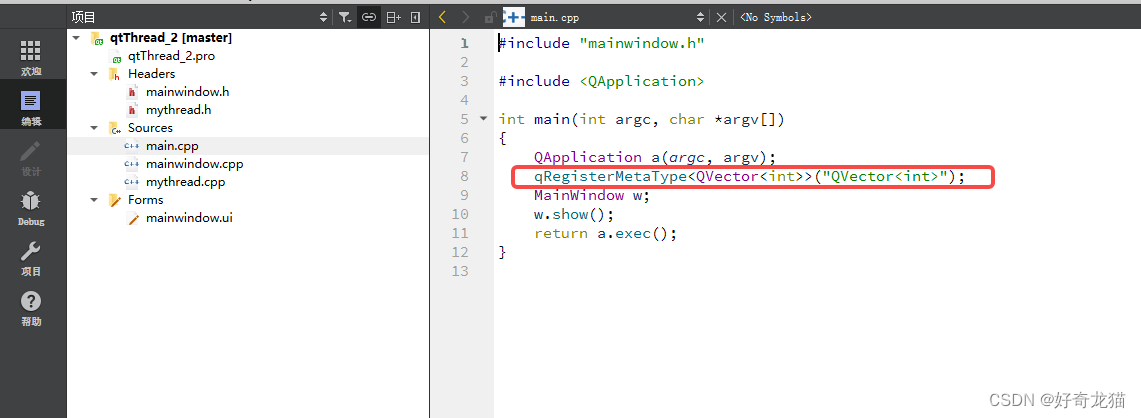
【QT5-自我学习-线程qThread练习-两种使用方式-2:通过继承Qobject类-自己实现功能函数方式-基础样例】
【QT5-自我学习-线程qThread练习-两种使用方式-2:通过继承Qobject类-自己实现功能函数方式-基础样例】 1、前言2、实验环境3-1、学习链接-参考文章3-2、先前了解-自我总结(1)线程处理逻辑事件,不能带有主窗口的事件(2&…...
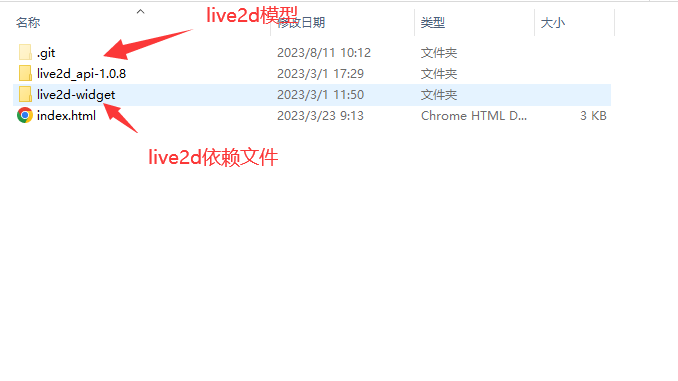
两款开箱即用的Live2d
目录 背景第一款:开箱即用的Live2d在vue项目中使用html页面使用在线预览依赖文件地址配置相关参数成员属性源码 模型下载 第二款:换装模型超多的Live2d在线预览代码示例源码 模型下载 背景 从第一次使用服务器建站已经三年多了,记得那是在2…...
LAMP架构详解+构建LAMP平台之Discuz论坛
LAMP架构详解构建LAMP平台之Discuz论坛 1、LAPM架构简介1.1动态资源与语言1.2LAPM架构得组成1.3LAPM架构说明1.4CGI和astcgi1.4.1CGI1.4.2fastcgi1.4.3CGI和fastcgi比较 2、搭建LAMP平台2.1编译安装apache httpd2.2编译安装mysql2.3编译安装php2.4安装论坛 1、LAPM架构简介 1.…...
如何使用腾讯云服务器搭建网站?新手建站教程
使用腾讯云服务器搭建网站全流程,包括轻量应用服务器和云服务器CVM建站教程,轻量可以使用应用镜像一键建站,云服务器CVM可以通过安装宝塔面板的方式来搭建网站,腾讯云服务器网分享使用腾讯云服务器建站教程,新手站长搭…...

mybatis plus 控制台和日志文件中打印sql配置
1 控制台输出sql 配置mybatis-plus的日志实现类为StdOutImpl,该实现类中打印日志是通过System.out.println(s)的方式来打印日志的 mybatis-plus:configuration:log-impl: org.apache.imbatis.logging.stdout.StdOutImpl2 日志文件中写入sql 日志文件中输入sql需要…...
苍穹外卖总结
前言 1、软件开发流程 瀑布模型需求分析//需求规格说明书、产品原型↓ 设计 //UI设计、数据库设计、接口设计↓编码 //项目代码、单元测试↓ 测试 //测试用例、测试报告↓上线运维 //软件环境安装、配置第一阶段:需求分析需求规格说明书、产品原型一般来说…...

Git 删除已经合并的本地分支
在使用 Git 的开发流程中,经常会创建很多的 Git 分支,包括功能分支(features/*)、发布分支(release/*)和 hotfix 分支(hotfix/*)。在开发了一段时间之后,本地就会有出现很…...

递归算法应用(Python版)
文章目录 递归递归定义递归调用的实现递归应用数列求和任意进制转换汉诺塔探索迷宫找零兑换-递归找零兑换-动态规划 递归可视化简单螺旋图分形树:自相似递归图像谢尔宾斯基三角 分治策略优化问题和贪心策略 递归 递归定义 递归是一种解决问题的方法,其精…...
有什么react进阶的项目推荐的?
前言 整理了一些react相关的项目,可以选择自己需要的练习,希望对你有帮助~ 1.ant-design Star:87.1k 阿里开源的react项目,作为一个UI库,省去重复造轮子的时间 仓库地址:https://github.com/ant-design/…...
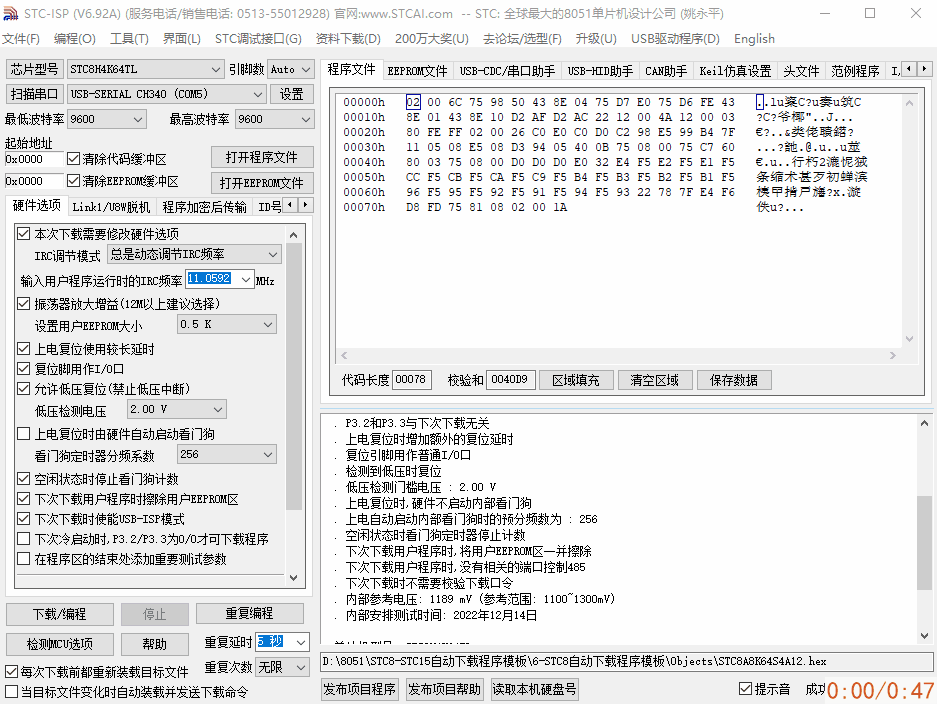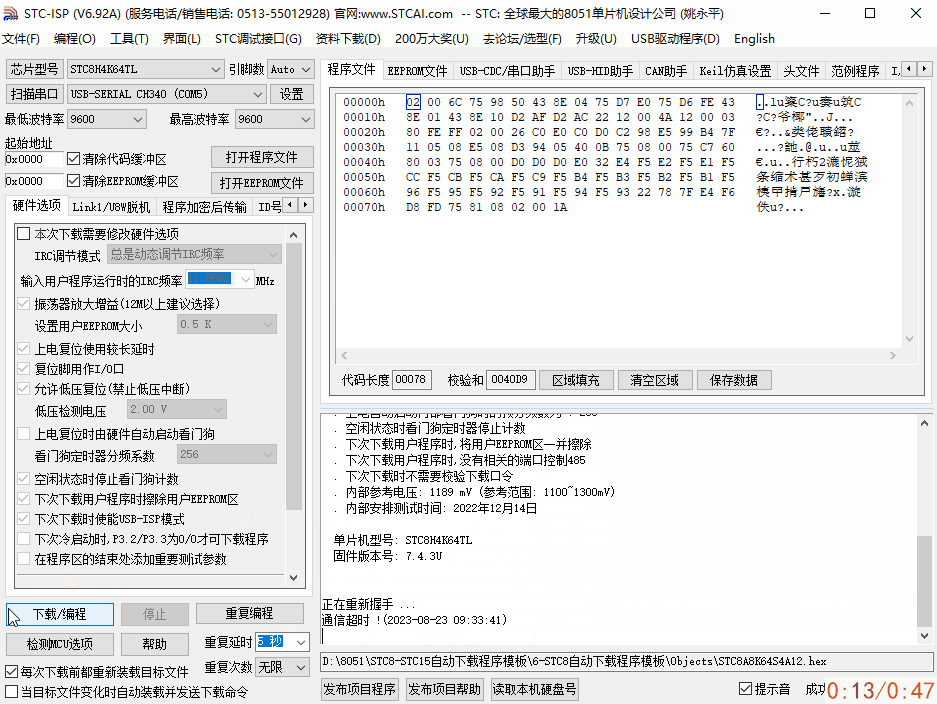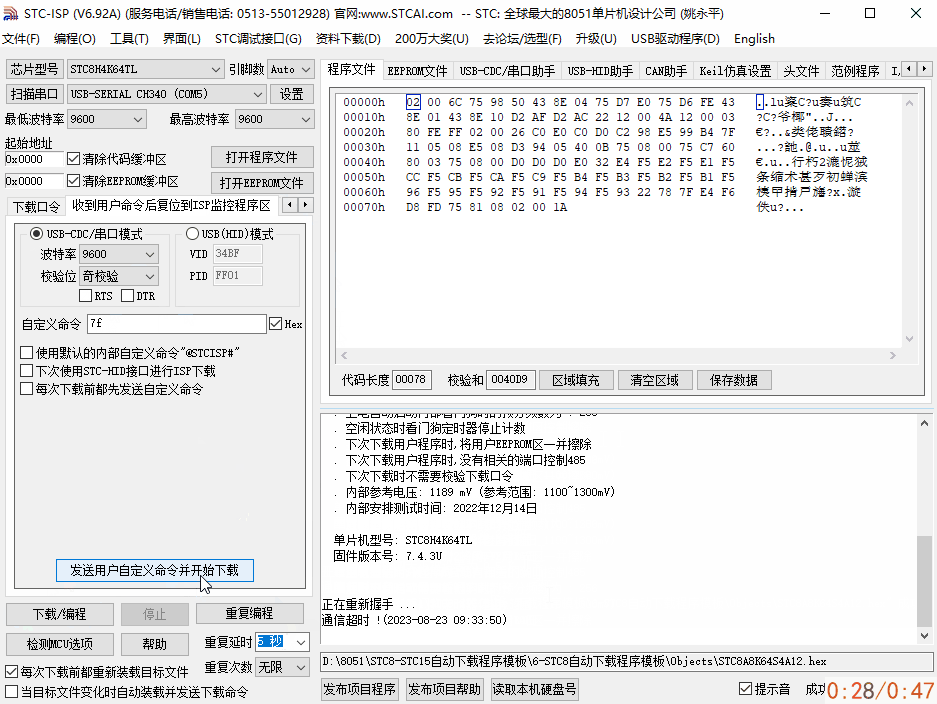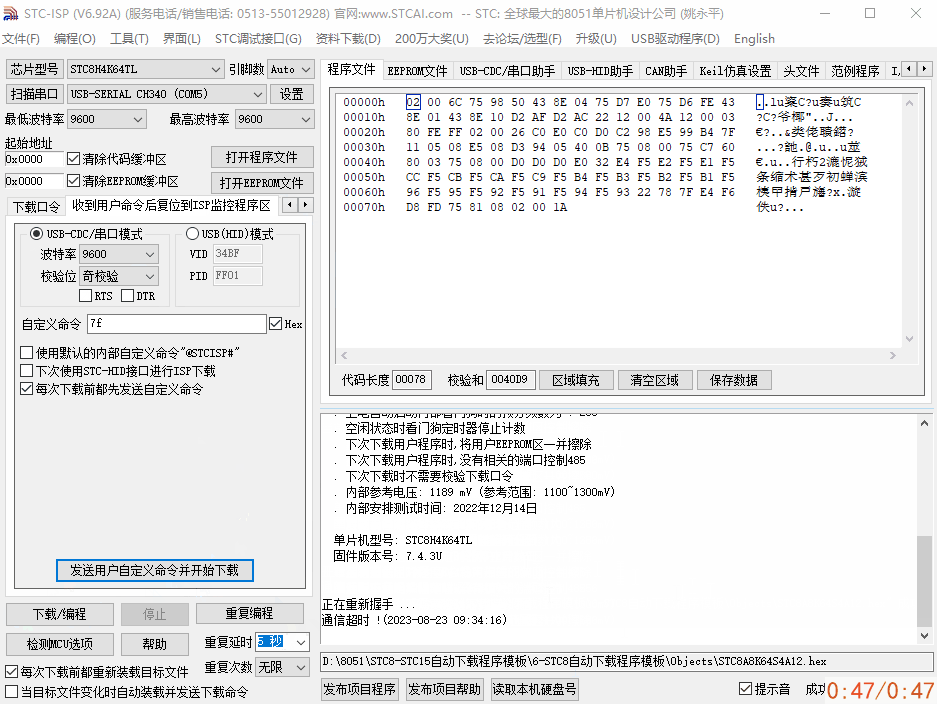
基于串口透传模块,单片机无线串口空中下载测试
基于串口透传模块,单片机无线串口空中下载测试 ✨无线串口下载,其本质还是串口下载方式,只不过省去了单片机和ISP上位机工具之间的物理有线连接,中间的数据通过无线串口透传模块进行数据中转,传递到单片机串口上。串口…...

研磨设计模式day11代理模式
目录 场景 代码实现 编辑 解析 定义 代理模式调用示意图 代理模式的特点 本质 编辑何时选用 场景 我有一个订单类,包含订单数、用户名和商品名,有一个订单接口包含了对订单类的getter和setter 现在有一个需求,a创建的订单只…...

vue2 路由进阶,VueCli 自定义创建项目
一、声明式导航-导航链接 1.需求 实现导航高亮效果 如果使用a标签进行跳转的话,需要给当前跳转的导航加样式,同时要移除上一个a标签的样式,太麻烦!!! 2.解决方案 vue-router 提供了一个全局组件 router…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...