MYSQL(索引、事务)
文章目录
- 一、索引
- 二、事务
一、索引
数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系
1. 概述
- 概念:相当于是一本书的目录,是以‘列’为维度进行建立的
- 使用场景:如果我们要查询一个表中的某个数据,可以通过遍历来实现,但那样,速度太慢,可以通过给这个表建立索引,来提高查找的速度
- 使用讲解:
- 按照id这列,建立索引,效果是在数据库上额外搞了一个空间,用来维护一些和id相关的信息,即id为1在哪个位置,id为2在哪个位置,参考目录。后续按照id查找的时候,就不必直接遍历了,而是从索引中进行查询,根据索引就能初步锁定数据所在的位置
- 注意,这个索引中只能按照id来查询,按照name来查询,不能提高效率,需要给name也建立一个索引才行
- 作用:
- 优点:提高查询效率
- 缺点:
(1)消耗额外的磁盘空间
(2)可能会拖慢增删改的速度,因为新增不光要往表里写数据,还要增加索引。如果是删和改,如果删或改的条件正好是和索引匹配的,速度能快点,但是如果涉及到了索引列的删除/修改,就需要同时维护索引,就会很慢
2. 使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。因为主键不允许重复,进行插入或修改就需要先查询看是否重复
-
查看索引:show index from 表名;
-
创建索引:create index 索引名 on 表名(字段名);
- 对于非主键、非唯一约束、非外键的字段,可以创建普通索引
- 注意这个操作,可能会很危险
- 如果表是空的,或者表里包含的数据本身就不多,那可以创建。但是如果表非空,并且里面包含了非常多的数据,创建索引,就会引起非常大规模的硬盘IO操作,进一步就会导致数据库被卡死。这就相当于要整理全部的数据。
- 所以需要提前考虑好,在设计表的阶段,哪些列要索引
-
删除索引:drop index 索引名 on 表名;
- 删除索引,只能针对手动创建的索引,自动生成的索引,是不能被删除的
- 这个操作也十分危险,原因参考创建
-
如果就是要给一个有着非常多数据的表删除/创建索引
- 准备一个新的mysql服务器,把表和索引都创建好,然后把数据都导入过来,再把要替换的mysql服务器关闭,最后把新的mysql服务器替换上去就行了
- (上述操作的原因)数据库服务器往往也不是单台服务器,为了整个系统的可靠性,通常会搞多个mysql服务器节点,这些节点的数据都是一样的,能够提供相同的服务,彼此之间相互独立,其中一个挂了,也不影响整体
-
关于if、while等语法
- sql中不建议使用一些其他支持的语法,如条件、循环等,因为该语法较老,且sql写得复杂,不方便调试和优化,实际开发中,去表示这样的更复杂的逻辑往往是使用其他语言+增删改查的方式
3. 底层的数据结构
其实在物理层面上,不需要‘表格’这样的数据结构,直接使用B+树来存储这个表的数据,“表格”只是让用户看起来这像个表格而已
1.概念
mysql的索引的数据结构是什么样的,取决于mysql使用哪个存储引擎
-
位置
- 数据库的数据结构是在硬盘上的
- 内存上的数据结构,对于访问操作来说,是不敏感的(找数据的过程花费时间多,真正访问的操作时间则不多)
- 硬盘上的数据结构,对于访问操作来说,是比较敏感的,读写一次硬盘,开销远远大于内存
- 读写一次硬盘,相当于读写1w次内存(大约的约束,内存和内存,硬盘和硬盘之间彼此差异很大)
-
存储引擎
- mysql这个程序中,包含很多模块,有负责解析sql的,有负责网络通信的,有负责存储数据的……
- 负责存储数据的就是存储引擎,本质上就是代码中的一个模块(包含了若干个代码文件、一群具体代码……)
-
mysql支持多种存储方案,Innodb是当下最主流的一种方式
2.分析
索引主要是为了快速查找,这方面红黑树和哈希表效率高。
- 哈希表:不适合数据库的查询场景(哈希表是通过hash函数来得到一个确定的下标),而且只能做精确查询,没法做模糊查询和范围查询
- 红黑树:不适合数据库的查询场景,元素有序时,可以处理范围查询,但是在元素个数比较多的时候,红黑树的高度会高,对应的比较次数会多,14个数据就有4层了,而每次比较都在内存上,都要进行硬盘IO操作
B+树
为了解决上述问题,出现了为数据库量身定做的数据结构 ------ B+树
(1)B树
在了解B+树之前,需要先了解下B树(有时写作B-,'-'是连接符,不是减号)
B树本质上,是一个N叉搜索树,一个节点上,可以保存多个key,N个key就能延伸出 N+1 个分叉来,N个key就划分出 N+1 个区间
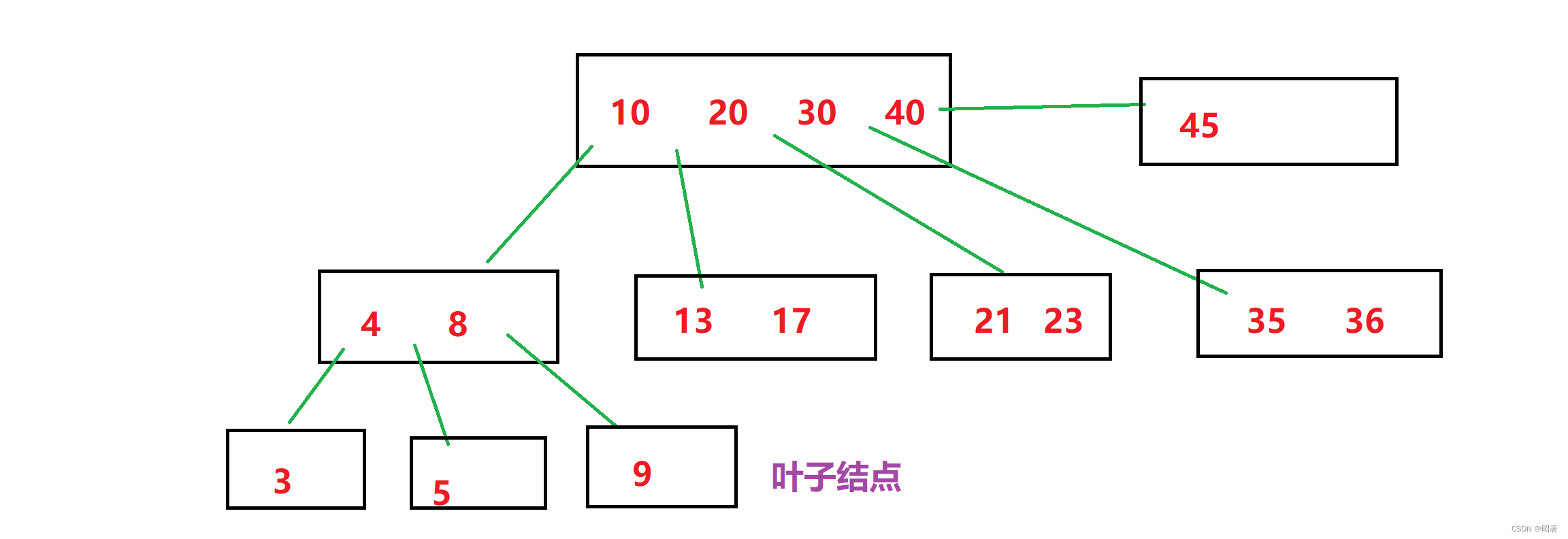
- 此时每个节点上,都可以保存多个元素了,对于数据库来说,每个节点都需要把数据从硬盘上读取出来,才能进行比较,一个节点有多个key,和一个节点上有一个key,硬盘IO的开销是差不多的,就像下楼倒一个垃圾和倒四个垃圾时间上没太多区别,所以B树的高度是远远小于二叉搜索树的,所以进行查询的时候,硬盘IO的次数会减少
- B树查询元素的流程:
(1)从根节点出发判定要查找的元素是否在根节点上存在
(2)如果不存在,看这个元素在哪个区间,然后根据这个区间的路线,往下一个节点找,最终找到叶子结点,如果到叶子结点还不存在,那就是真的不存在 - 对于B树来说,在进行插入元素和删除元素的时候,会涉及到拆分和合并的操作。
(1)一个节点,可以存多个key,但是不能无限地存,当存储的key数量达到一定程度的时候,就需要把这个节点给拆分,把这个节点中的一部分以树的子节点的方式重新组织
(2)这样可以保持当前这个节点中key的数量始终不会太多,能延伸出新的叶子结点
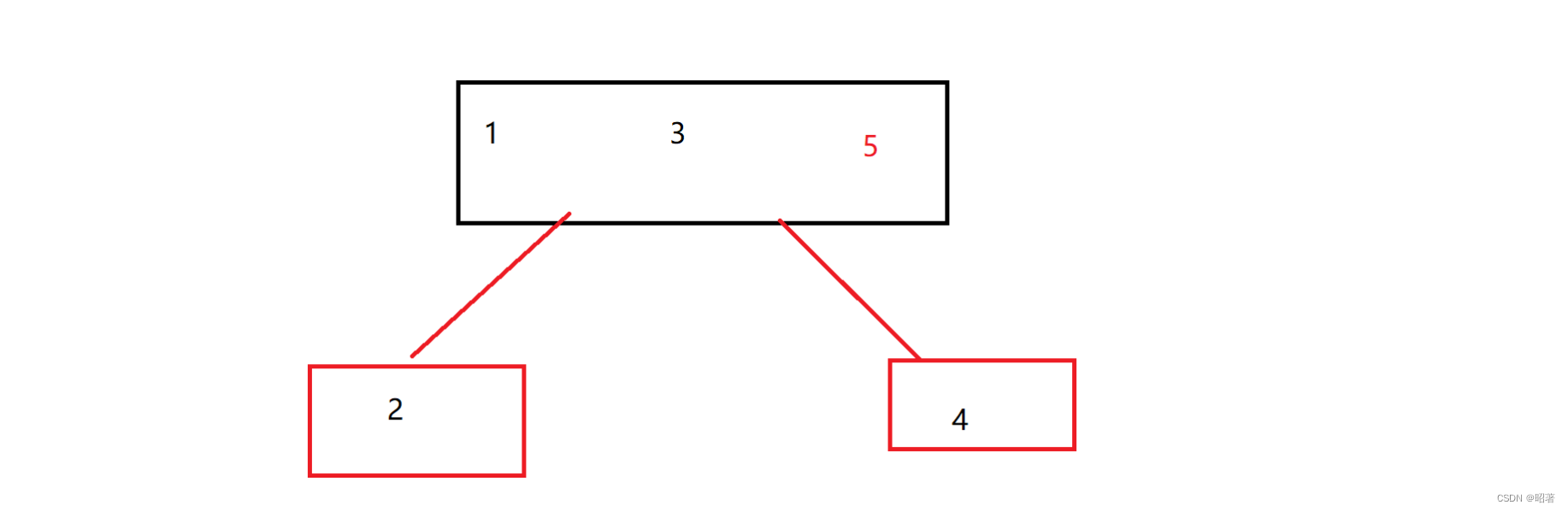
(2)B+树
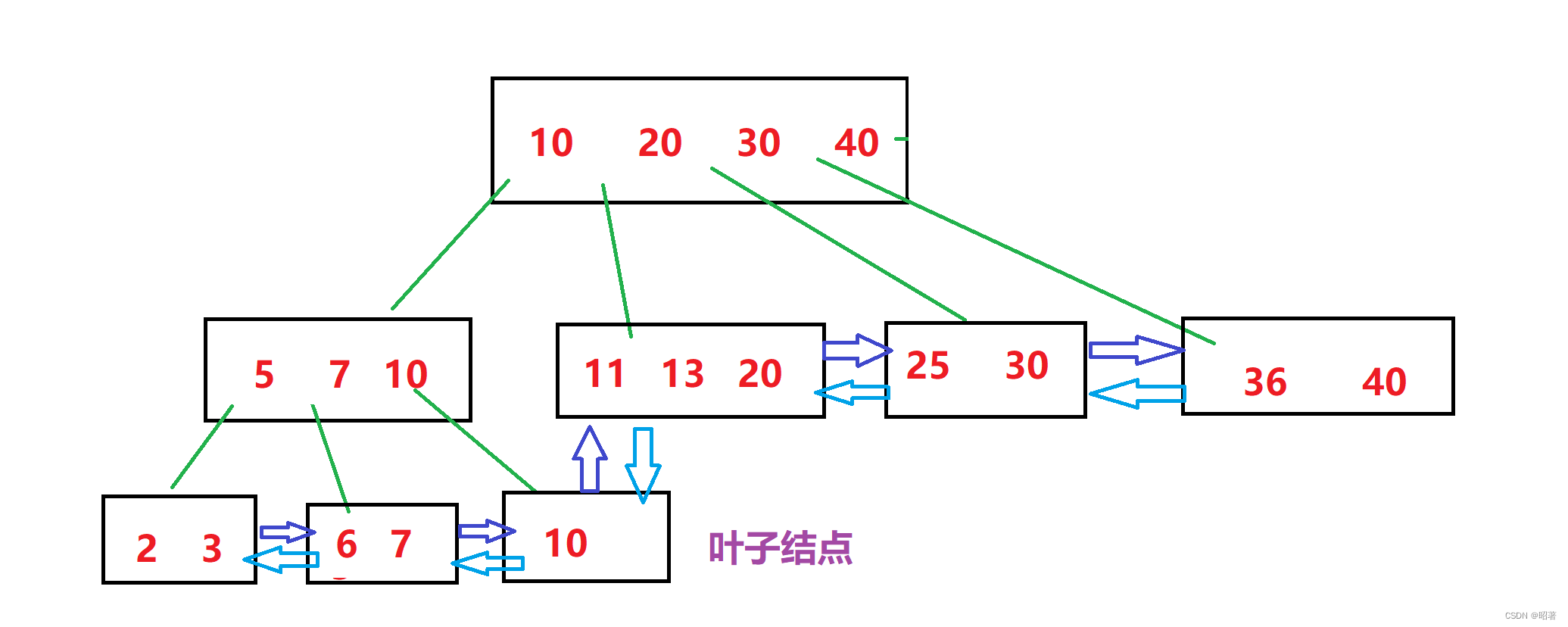
【1】B+树也是N叉搜索树,但是N个key分出了N个区间,其中节点上最后一个key就是最大值(也可以取最小值)
【2】父节点的key会在子节点中重复值出现(以最大值的身份),虽然有很多重复元素,看起来浪费了空间,实际上能够达成 **叶子结点这一层,包含了整个数据的全集 **的效果
【3】把叶子结点按照链表这样首尾相连,就可以通过叶子结点之间的连接,快速找到“上一个”,“下一个”元素,这也方便进行范围查询
优势
- 擅长范围查询
- 所有的查询操作,最终都会落在叶子节点上,比较次数是均衡的,查询时间是稳定的(有时 ‘稳’ 比 ‘快’ 更重要)
- 由于叶子节点上是完整的数据全集,因此表的每一行数据的其他列,都可以保存到叶子节点上,而非叶子节点,只存储构建索引的key即可。此时,非叶子节点的存储空间,消耗是非常小的,我们甚至可以在内存中缓存一份。这样,在进行数据查询的时候,就可以通过内存来直接进行比较,从而更快速地找到叶子节点上的记录,也进一步减少硬盘IO的次数
二、事务
- 使用场景:为了完成某个工作,需要多组sql操作。如A转账给B,那么需要先给A的账户余额减钱,再给B账户加钱
- 概念:事务的本质,就是为了把多个操作,打包成一个操作来完成(让这多个操作,要么全都能执行成功,要么就一个都不执行,不然就像给A扣钱了,但是没给B加钱)--------- 事务的原子性(这些操作是一个整体,不能再分割了)
- 这个“一个都不执行”不是真的没执行,执行成不成功得执行了才知道,真正执行时是不知道哪一步操作会失败的,如果执行到中间出错了,就需要自动地把前面已经成功执行的操作还原回最初没有执行的模样
- 所以本质上,这个“一个都不执行”不是真的没执行,而是看起来就像没执行一样
- 还原回最初是【回滚】,回滚要把事务中执行的每个操作,都记录下来,如果需要回滚,就直接按照之前操作的“逆操作”来执行就行了
- 操作的记录是通过特定的日志,来记录的。日志的数据是始终在硬盘上存在的,即使是数据库服务器重启,也能在重启后根据之前没有回滚完的情况继续进行处理
- 使用:
- 开启事务:start transaction;
- 执行多条SQL语句
- 手动触发回滚或提交事务:rollback/commit
- rollback即是全部失败,commit即是全部成功
- 一个事务务必要以这两个操作结尾,如果没有这两个操作,接下来的各种sql操作都会被认为是事务的一部分
- 事务的基本特性:
- 原子性:保证多个操作被打包成一个整体,要么能够全部执行正确,要么就一个都不执行
- 一致性:事务执行之前,和事物执行之后,数据能对上。这依靠约束和回滚机制来实现
- 持久性:事务这里执行的各种操作,一旦事务执行成功了,这里的所有操作产生的修改都会写到硬盘中,即持久生效的
- 隔离性:并发执行事务的时候,隔离性会在执行效率和数据可靠之间做出权衡,“隔离”描述的是同时执行的事务之间相互的影响,隔离性越高,并发性就越低,数据越可靠,性能就越低
- 并发意思是“同时执行”,数据库是一个客户端服务器结构的程序,既然是服务器,服务器就可以同一时刻给多个客户端提供服务(多个客户端都能给服务器提交事务),如果提交的这两个事务,是修改不同的数据库/表,相互独立那没什么影响。但是如果修改的是一个库/表,顺序的先后会影响最终的执行结果,就会出现问题(脏读、不可重复读、幻读)
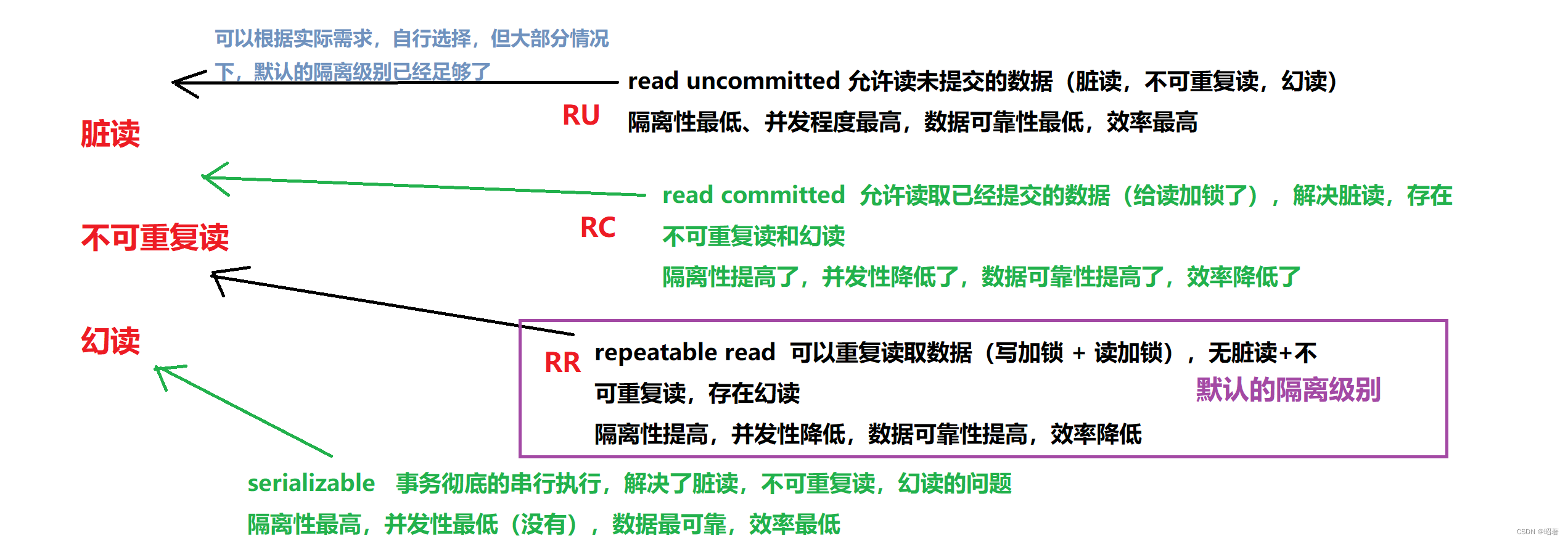
1. 脏读
问题描述:读到的数据是一个临时的数据,不是最终的数据,“脏”表示临时的,并非是最终准确结果
解决方法:给写操作加锁,一个事务A写的时候,其他事务B不能读了,直到A事务写完数据,提交事务,其他的事务B才能来读取数据。
效果:引入了写加锁,降低了两个事务之间的并发性,提高了隔离性,降低了效率,使数据更加准确了
2. 不可重复读
问题描述:一个事务中,两次读到的数据不一致(在读的过程中,另一个事务修改了数据)
解决方法:给读操作加锁,别人读的时候,我不能写(除非是写完提交后,别人才能读),此时,别人读的时候,可以再开启一个事务来写,第二个事务提交之前,其他读事务读到的都是旧版本数据,第二个事务提交之后,别人再读读到的就是新版数据了
效果:并发程度又进一步降低了,隔离性提高,执行效率降低,数据更加可靠
3. 幻读
问题描述:一个事务在多次读的过程中,虽然读到的数据的值是一样的,但是结果集是不同的(多出或少出一些记录),可以视为是不可重复读的特殊情况
解决方法:串行化,彻底放弃并发执行事务,所有的事务都是一个挨着一个地串行执行(执行完一个事务,再执行下一个事务)
效果:并发性最低,隔离性最高,效率最低,数据最可靠
4. mysql的四种事务的隔离级别
相关文章:
MYSQL(索引、事务)
文章目录 一、索引二、事务 一、索引 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系 1. 概述 概念:相当于是一本书的目录,是以‘列’为维度进行建立的使用场景:如果我们要查询一个表中的某个…...
设置Docker容器内的中文字符集,解决某些情况下中文乱码的问题)
部署问题集合(二十三)设置Docker容器内的中文字符集,解决某些情况下中文乱码的问题
前言: 同事给了一个服务,在Windows环境下怎么跑都正常,但一到Linux虚拟机里就中文乱码起初就想到了可能是字符集的问题,但调整了半天也没见效果,最后隔了几天突然想到,我是构建Docker跑的,而且…...

Web AP—PC端网页特效
PC端网页特效 代码下载 元素偏移量 offset 系列 offset 翻译过来就是偏移量, 我们使用 offset系列相关属性可以动态的得到该元素的位置(偏移)、大小等。 获得元素距离带有定位父元素的位置获得元素自身的大小(宽度高度&#x…...

Spring线程池ThreadPoolTaskExecutor使用
为什么使用线程池? 降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;提高系统响应速度,当有任务到达时,通过复用已存在的线程,无需等待新线程的创建便能立即执行…...

spring mvc的执行流程
请求拦截。用户发起请求,请求先被sevlet拦截,转发给spring mvc框架请求转发。spring mvc里面的DispcherServlet会接收到请求并转发给HandlerMapping匹配接口。HandlerMapping负责解析请求,根据请求信息和配置信息找到匹配的controller类&…...
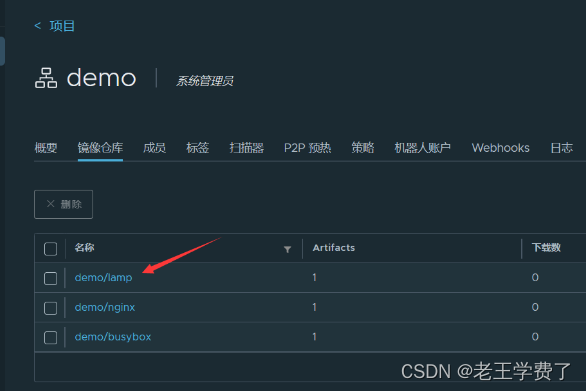
docker作业
目录 1、使用mysql:5.6和 owncloud 镜像,构建一个个人网盘。 1.1启动镜像 1.2启动cloud镜像 1.3浏览器访问 编辑 2、安装搭建私有仓库 Harbor 2.1下载docker-compose 2.2 磁盘挂载,保存harbor 2.3 修改配置文件 2.4安装 2.5浏览器访问 2.6 新…...

java实现本地文件转文件流发送到前端
java实现本地文件转文件流发送到前端 Controller public void export(HttpServletResponse response) {// 创建file对象response.setContentType("application/octet-stream");// 文件名为 sresponse.setHeader("Content-Disposition", "attachment;…...
2020ICPC南京站
K K Co-prime Permutation 题意:给定n和k,让你构造n的排列,满足gcd(pi, i)1的个数为k。 思路:因为x和x-1互质,1和任何数互质,任何数和它本身不互质 当k为奇数时,p11,后面k-1个数…...

Linux 中的 chsh 命令及示例
介绍 bash shell 是 Linux 最流行的登录 shell 之一。但是,对于不同的命令行操作,可以使用替代方法。chshLinux 中的( change shell )命令使用户能够修改登录 shell 。 以下教程...

JavaScript 数组如何实现冒泡排序?
冒泡排序是一种简单但效率较低的排序算法,常用于对小型数据集进行排序。它的原理是多次遍历数组,比较相邻元素的大小,并根据需要交换它们的位置,将最大(或最小)的元素逐渐“冒泡”到数组的一端。这个过程会…...

ZooKeeper集群环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...
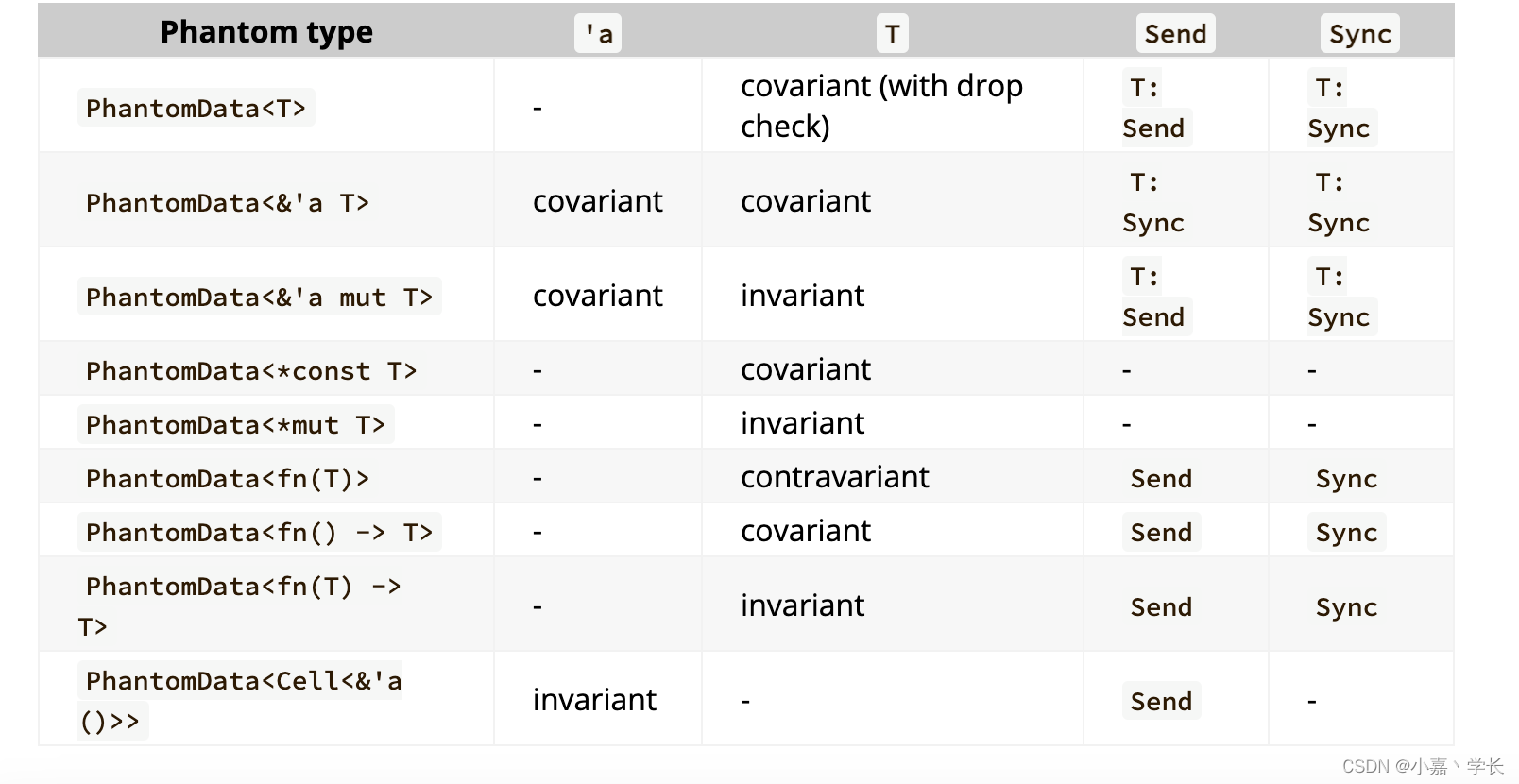
【跟小嘉学 Rust 编程】二十、进阶扩展
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...

pytorch学习过程中一些基础语法
1、tensor.view()函数,通俗理解就是reshape,#参数这里的-1需要注意,可以根据原张量size自行计算 data1torch.randn((4,2)) data2data1.view(2,4) data3data2.view(-1,8)2、tensor.max()函数,在分类问题中,通常需要使用…...

判断聚类 n_clusters
目录 基本原理 代码实现: 肘部法则(Elbow Method): 轮廓系数(Silhouette Coefficient) Gap Statistic(间隙统计量): Calinski-Harabasz Index(Calinski-…...

基于深度学习的网络异常检测方法研究
摘要: 本文提出了一种基于深度学习的网络异常检测方法,旨在有效地识别网络中潜在的异常行为。通过利用深度学习算法,结合大规模网络流量数据的训练,我们实现了对复杂网络环境下的异常行为的准确检测与分类。实验结果表明…...
SSM 基于注解的整合实现
一、pom.xml <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelV…...

工具类APP如何解决黏性差、停留短、打开率低等痛点?
工具产品除了需要把自己的功能做到极致之外,其实需要借助一些情感手段、增设一些游戏机制、输出高质量内容、搭建社区组建用户关系链等方式,来提高产品的用户黏性,衍生产品的价值链。 工具类产品由于进入门槛低,竞争尤为激烈&…...

使用Java MVC开发高效、可扩展的Web应用
在当今的Web开发领域,高效和可扩展性是我们追求的目标。Java作为一种强大且广泛使用的编程语言,提供了丰富的工具和框架来支持Web应用的开发。其中,MVC模式是一种被广泛采用的架构模式,它能够有效地组织和管理代码,使得…...

wandb安装方法及本地部署教程
文章目录 1 wandb介绍2 wandb安装2.1 注册wandb账号2.2 创建项目并获得密钥2.3 安装wandb并登录 3 wandb本地部署3.1 设置wandb运行模式3.2 云端查看运行数据 4 总结 1 wandb介绍 Wandb(Weights & Biases)是一个用于跟踪、可视化和协作机器学习实验…...
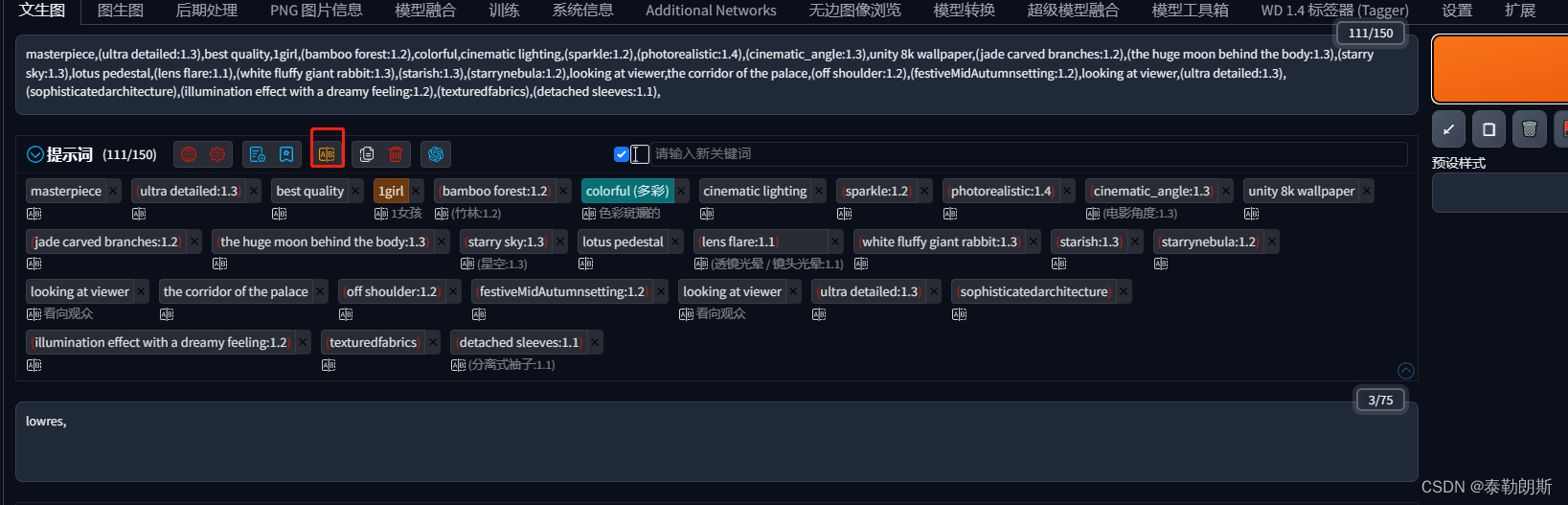
stable diffusion实践操作-提示词插件安装与使用
本文专门开一节写提示词相关的内容,在看之前,可以同步关注: stable diffusion实践操作 正文 1、提示词插件安装 1.1、 安装 1.2 加载【应用更改并重载前端】 1.3 界面展示 1.3.-4 使用 里面有个收藏列表,可以收藏以前的所有提示…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...