什么是 TF-IDF 算法?
简单来说,向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算来进一步表达向量间的关系。比如,一个比较常用的运算就是计算查询关键字所对应的向量和文档所对应的向量之间的 “相关度”。
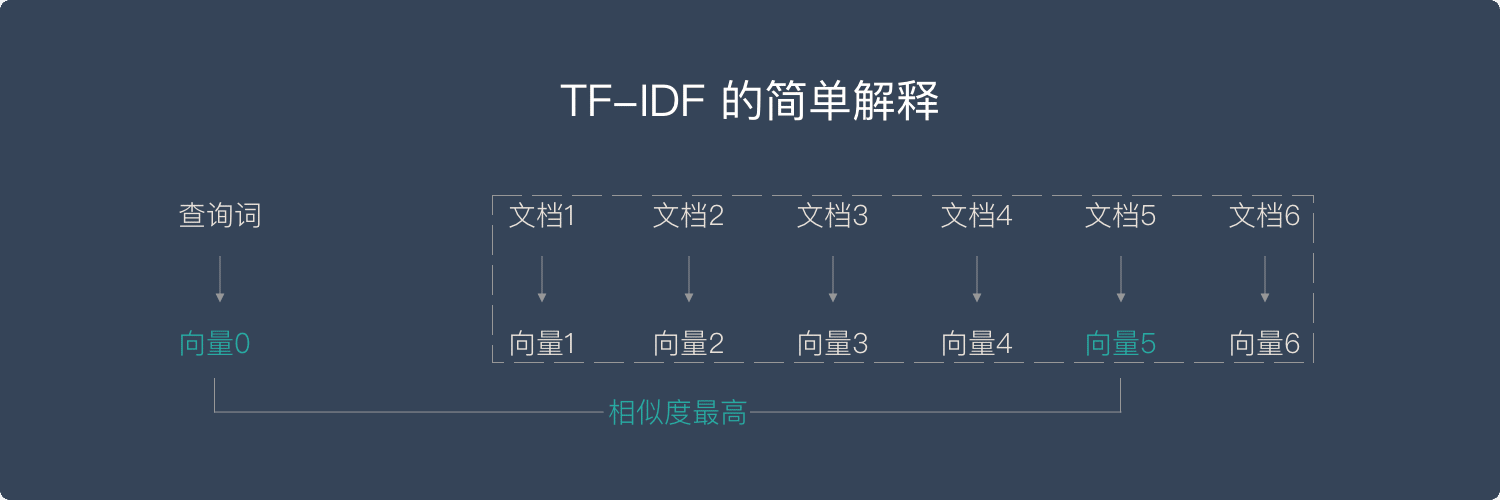
简单解释TF-IDF
TF (Term Frequency)—— “单词频率”
意思就是说,我们计算一个查询关键字中某一个单词在目标文档中出现的次数。举例说来,如果我们要查询 “Car Insurance”,那么对于每一个文档,我们都计算“Car” 这个单词在其中出现了多少次,“Insurance”这个单词在其中出现了多少次。这个就是 TF 的计算方法。
TF 背后的隐含的假设是,查询关键字中的单词应该相对于其他单词更加重要,而文档的重要程度,也就是相关度,与单词在文档中出现的次数成正比。比如,“Car” 这个单词在文档 A 里出现了 5 次,而在文档 B 里出现了 20 次,那么 TF 计算就认为文档 B 可能更相关。
然而,信息检索工作者很快就发现,仅有 TF 不能比较完整地描述文档的相关度。因为语言的因素,有一些单词可能会比较自然地在很多文档中反复出现,比如英语中的 “The”、“An”、“But” 等等。这些词大多起到了链接语句的作用,是保持语言连贯不可或缺的部分。然而,如果我们要搜索 “How to Build A Car” 这个关键词,其中的 “How”、“To” 以及 “A” 都极可能在绝大多数的文档中出现,这个时候 TF 就无法帮助我们区分文档的相关度了。
IDF(Inverse Document Frequency)—— “逆文档频率”
就在这样的情况下应运而生。这里面的思路其实很简单,那就是我们需要去 “惩罚”(Penalize)那些出现在太多文档中的单词。
也就是说,真正携带 “相关” 信息的单词仅仅出现在相对比较少,有时候可能是极少数的文档里。这个信息,很容易用 “文档频率” 来计算,也就是,有多少文档涵盖了这个单词。很明显,如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。因此,我们需要对 TF 的值进行修正,而 IDF 的想法是用 DF 的倒数来进行修正。倒数的应用正好表达了这样的思想,DF 值越大越不重要。
TF-IDF 算法主要适用于英文,中文首先要分词,分词后要解决多词一义,以及一词多义问题,这两个问题通过简单的tf-idf方法不能很好的解决。于是就有了后来的词嵌入方法,用向量来表征一个词。
TF-IDF 的4个变种

TF-IDF常见的4个变种
变种1:通过对数函数避免 TF 线性增长
很多人注意到 TF 的值在原始的定义中没有任何上限。虽然我们一般认为一个文档包含查询关键词多次相对来说表达了某种相关度,但这样的关系很难说是线性的。拿我们刚才举过的关于 “Car Insurance” 的例子来说,文档 A 可能包含 “Car” 这个词 100 次,而文档 B 可能包含 200 次,是不是说文档 B 的相关度就是文档 A 的 2 倍呢?其实,很多人意识到,超过了某个阈值之后,这个 TF 也就没那么有区分度了。
用 Log,也就是对数函数,对 TF 进行变换,就是一个不让 TF 线性增长的技巧。具体来说,人们常常用 1+Log(TF) 这个值来代替原来的 TF 取值。在这样新的计算下,假设 “Car” 出现一次,新的值是 1,出现 100 次,新的值是 5.6,而出现 200 次,新的值是 6.3。很明显,这样的计算保持了一个平衡,既有区分度,但也不至于完全线性增长。
变种2:标准化解决长文档、短文档问题
经典的计算并没有考虑 “长文档” 和“短文档”的区别。一个文档 A 有 3,000 个单词,一个文档 B 有 250 个单词,很明显,即便 “Car” 在这两个文档中都同样出现过 20 次,也不能说这两个文档都同等相关。对 TF 进行 “标准化”(Normalization),特别是根据文档的最大 TF 值进行的标准化,成了另外一个比较常用的技巧。
变种3:对数函数处理 IDF
第三个常用的技巧,也是利用了对数函数进行变换的,是对 IDF 进行处理。相对于直接使用 IDF 来作为 “惩罚因素”,我们可以使用 N+1 然后除以 DF 作为一个新的 DF 的倒数,并且再在这个基础上通过一个对数变化。这里的 N 是所有文档的总数。这样做的好处就是,第一,使用了文档总数来做标准化,很类似上面提到的标准化的思路;第二,利用对数来达到非线性增长的目的。
变种4:查询词及文档向量标准化
还有一个重要的 TF-IDF 变种,则是对查询关键字向量,以及文档向量进行标准化,使得这些向量能够不受向量里有效元素多少的影响,也就是不同的文档可能有不同的长度。在线性代数里,可以把向量都标准化为一个单位向量的长度。这个时候再进行点积运算,就相当于在原来的向量上进行余弦相似度的运算。所以,另外一个角度利用这个规则就是直接在多数时候进行余弦相似度运算,以代替点积运算。
TF-IDF
是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
在信息检索中,tf-idf或TFIDF(术语频率 – 逆文档频率的缩写)是一种数字统计,旨在反映单词对集合或语料库中的文档的重要程度。它经常被用作搜索信息检索,文本挖掘和用户建模的加权因子。tf-idf值按比例增加一个单词出现在文档中的次数,并被包含该单词的语料库中的文档数量所抵消,这有助于调整某些单词在一般情况下更频繁出现的事实。Tf-idf是当今最受欢迎的术语加权方案之一; 数字图书馆中83%的基于文本的推荐系统使用tf-idf。
搜索引擎经常使用tf-idf加权方案的变体作为在给定用户查询的情况下对文档的相关性进行评分和排序的中心工具。tf-idf可以成功地用于各种主题领域的停用词过滤,包括文本摘要和分类。
相关文章:
什么是 TF-IDF 算法?
简单来说,向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算来进一步表达向量间的关系。比如,一个比较常用的运算就是计算查询关键字所对应的向量和文档所对应的向量之间的 “相关度”。 简单解释TF-IDF TF &…...

干货!耽误你1分钟,教你怎么查自己的流量卡是什么卡?
很多朋友都想购买一张正规的号卡,但是在网上一搜流量卡,五花八门,各式各样,那么,我们该如何辨别流量卡呢。 从种类上来看,网上的流量卡一共分为两种:号卡和物联卡 物联卡不用多说࿰…...

Spring Boot + Vue的网上商城实战入门
Spring Boot Vue的网上商城实战入门 技术栈调研 当使用Spring Boot和Vue构建网上商城项目时,以下是常用的技术栈和工具: 后端技术栈: Spring Boot:用于构建后端API,提供数据服务;Spring MVC:…...
云上办公系统项目
云上办公系统项目 1、云上办公系统1.1、介绍1.2、核心技术1.3、开发环境说明1.4、产品展示后台前台 1.5、 个人总结 2、后端环境搭建2.1、建库建表2.2、创建Maven项目pom文件guigu-oa-parentcommoncommon-utilservice-utilmodelservice-oa 配置数据源、服务器端口号application…...

three.js(九):内置的路径合成几何体
路径合成几何体 TubeGeometry 管道LatheGeometry 车削ExtrudeGeometry 挤压 TubeGeometry 管道 TubeGeometry(path : Curve, tubularSegments : Integer, radius : Float, radialSegments : Integer, closed : Boolean) path — Curve - 一个由基类Curve继承而来的3D路径。 De…...

【MySQL系列】索引的学习及理解
「前言」文章内容大致是MySQL索引的学习。 「归属专栏」MySQL 「主页链接」个人主页 「笔者」枫叶先生(fy) 目录 一、索引概念二、从硬件角度理解2.1 磁盘2.2 结论 三、从软件角度理解四、共识五、索引的理解5.1 一个现象和结论5.2 对Page进行建模5.3 索引可以采用的数据结构5.…...
GPT-4.0技术大比拼:New Bing与ChatGPT,哪个更适合你
随着GPT-4.0技术的普及和发展,越来越多的平台开始将其应用于各种场景。New Bing已经成功接入GPT-4.0,并将其融入搜索和问答等功能。同样,在ChatGPT官网上,用户只需开通Plus账号,即可体验到GPT-4.0带来的智能交流和信息…...
vnc与windows之间的复制粘贴
【原创】VNC怎么和宿主机共享粘贴板 假设目标主机是linux,终端主机是windows(就是在windows上使用VNC登陆linux) 在linux中执行 vncconfig -nowin& 在linux选中文字后,无需其他按键,直接在windows中可以黏贴。 …...

windows下如何搭建属于自己的git服务器
前一阵子公司需要,领导让我给我们技术部搭建一个git服务器。以前看过教程,但自己没动手做过,开始按照网上的教程来,但搭建过程中发现还是不够详细,今天给大家一个比较详细的,希望对大家有帮助。 高能预警&a…...
⭐⭐+贪心解决可能的最小和(类似上次))
D360周赛复盘:模拟(思维题目)⭐⭐+贪心解决可能的最小和(类似上次)
文章目录 2833.距离原点最远的点思路完整版 2834.找出美丽数组的最小和思路完整版 2833.距离原点最远的点 给你一个长度为 n 的字符串 moves ,该字符串仅由字符 L、R 和 _ 组成。字符串表示你在一条原点为 0 的数轴上的若干次移动。 你的初始位置就在原点…...

【C++学习】函数指针
#include<iostream> //包含头文件 using namespace std; void func(int no, string str){cout << "亲爱的"<< no << "号:" << str << endl; }int main(){int bh 3;string message "我是一只傻傻鸟";func…...

A. Copil Copac Draws Trees
Problem - 1830A - Codeforces 问题描述: 科皮尔-科帕克(Copil Copac)得到一个由 n − 1 n-1 n−1条边组成的列表,该列表描述了一棵由 n n n个顶点组成的树。他决定用下面的算法来绘制它: 步骤 0 0 0:…...

D359周赛复盘:贪心解决求最小和问题⭐⭐+较为复杂的双层线性DP⭐⭐
文章目录 2828.判别首字母缩略词完整版 2829.k-avoiding数组的最小总和(贪心解法)思路完整版 类似题:2834.找出美丽数组的最小和思路完整版 2830.销售利润最大化⭐⭐思路DP数组含义递推公式 完整版 2828.判别首字母缩略词 给你一个字符串数组…...
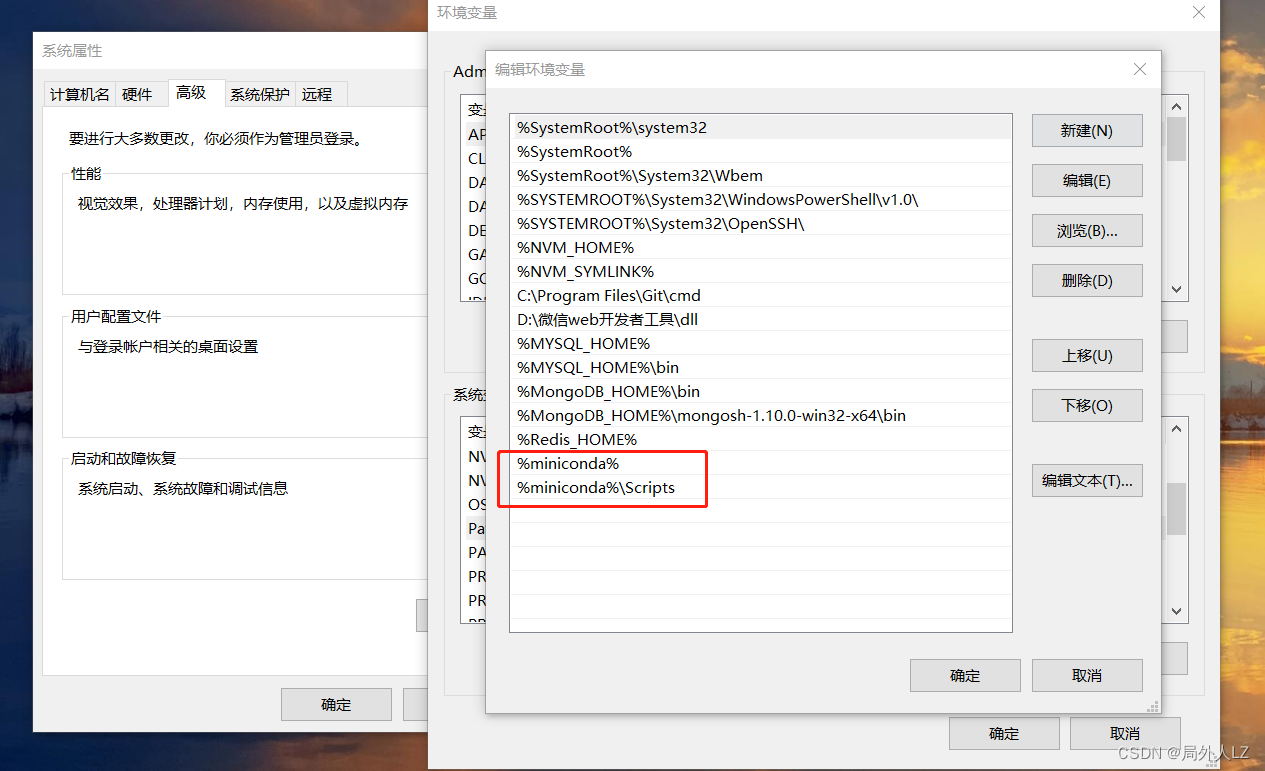
python基础之miniConda管理器
一、介绍 MiniConda 是一个轻量级的 Conda 版本,它是 Conda 的精简版,专注于提供基本的环境管理功能。Conda 是一个流行的开源包管理系统和环境管理器,用于在不同的操作系统上安装、管理和运行软件包。 与完整版的 Anaconda 相比,…...

C++算法 —— 分治(1)快排
文章目录 1、颜色分类2、排序数组3、第k个最大的元素(快速选择)4、最小的k个数(快速选择) 分治,就是分而治之,把大问题划分成多个小问题,小问题再划分成更小的问题。像快排和归并排序就是分治思…...

接口用例设计
章节目录: 一、针对输入设计1.1 数值型1.2 字符串型1.3 数组或链表类型 二、针对业务逻辑2.1 约束条件分析2.2 操作对象分析2.3 状态转换分析2.4 时序分析 三、针对输出设计3.1 针对输出结果3.2 接口超时 四 、其他测试设计4.1 已废弃接口测试4.2 接口设计合理性分析…...

Selenium超级详细的教程
Selenium是一个用于自动化测试的工具,它可以模拟用户在浏览器中的各种操作。除了用于测试,Selenium还可以用于爬虫,特别是在处理动态加载页面时非常有用。本文将为您提供一个超级详细的Selenium教程,以帮助您快速入门并了解其各种…...
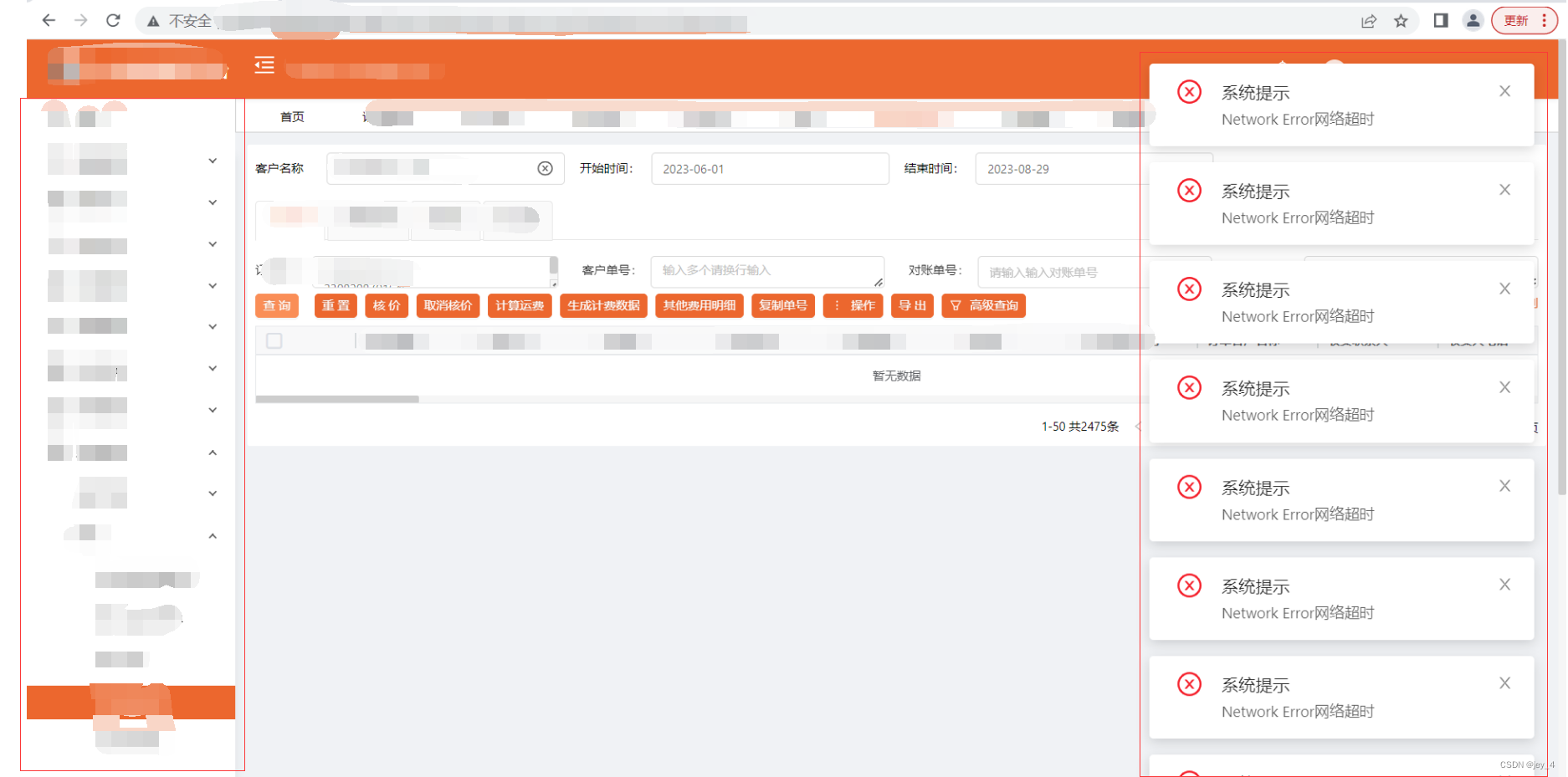
服务报network error错误
问题:服务请求时会偶发性的报【network error网络超时】(请求瞬间就报) 可能原因: 服务器linux内核调优时将:net.ipv4.tcp_tw_recycle设置为1,开启TCP连接中TIME-WAIT sockets的快速回收,默认为…...

【ES6】利用 Proxy实现函数名链式效果
利用 Proxy,可以将读取属性的操作(get),转变为执行某个函数,从而实现属性的链式操作。 var pipe function (value) {var funcStack [];var oproxy new Proxy({} , {get : function (pipeObject, fnName) {if (fnNa…...
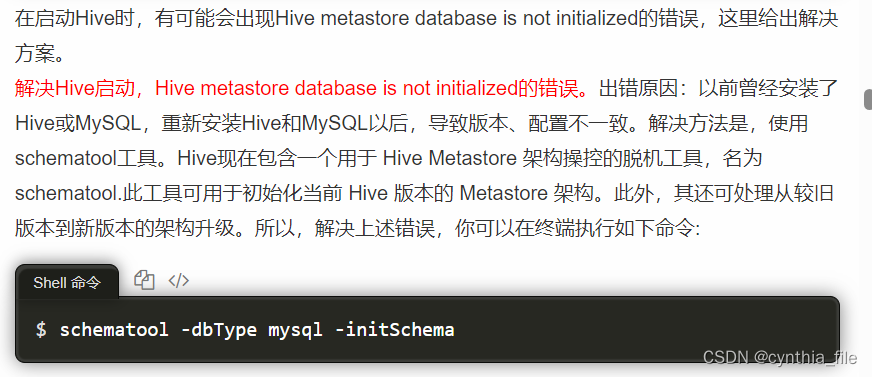
hive部署
下载hive安装包:https://dlcdn.apache.org/hive/hive-2.3.9/解压及环境部署 tar -zxvf apache-hive-2.3.9-bin.tar.gz mv apache-hive-2.3.9-bin hivevim /etc/profile添加至环境变量 export HIVE_HOME/usr/local/hive export PATH$PATH:$HIVE_HOME/binsource /etc…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...