将 Python 与 RStudio IDE 配合使用(R与Python系列第一篇)
目录
前言:
1-安装reticulate包
2-安装Python
3-选择Python的默认版本(配置Python环境)
4-使用Python
4.1 运行一个简单的Python脚本
4.2 在RStudio上安装Python模块
4.3 在 R 中调用 Python 模块
4.4 在RStudio上调用Python脚本写的函数
4.5 Python 与 R 对象相互转换的方式
R → Python
Python → R
5-在 R Console 中交互式运行 R
6-在RStudio中安装Python包遇到问题时解决方案
参考:
前言:
RStudio 1.4为RStudio IDE带来了对Python编程语言的改进支持。本文将探讨如何将Python与R和RStudio一起使用。
RStudio使用 R包reticulate 与Python交互,因此RStudio的Python集成需要:
- 安装 Python (2.7 or newer; 3.5 or newer preferred), and
- 安装R包reticulate (1.20 or newer, as available from CRAN)
1-安装reticulate包
install.packages("reticulate")
2-安装Python
首先,需要在您的机器上安装Python。如果您还没有安装Python,可以通过几种方式安装它:
- (推荐)使用reticulate::install_miniconda(),使用reticulate包安装Python的Miniconda发行版;
- (Windows)通过https://www.python.org/downloads/windows/提供的官方Python二进制文件安装Python;
- (macOS)通过https://www.python.org/downloads/mac-osx/提供的官方Python二进制文件安装Python;
- (Linux)从源代码安装Python,或者通过操作系统的包管理器提供的Python版本安装Python。有关详细信息,请参阅https://docs.python.org/3/using/unix.html。如果您自己从源代码安装Python,最好将其安装到 /opt/python/<version>之类的位置,这样RStudio和reticullate可以更容易地发现它。
3-选择Python的默认版本(配置Python环境)
一定要配置Python环境,不然在RStudio不能成功Python包。
可以通过Tools->Global Options…->Python配置默认版本的Python以与RStudio一起使用:
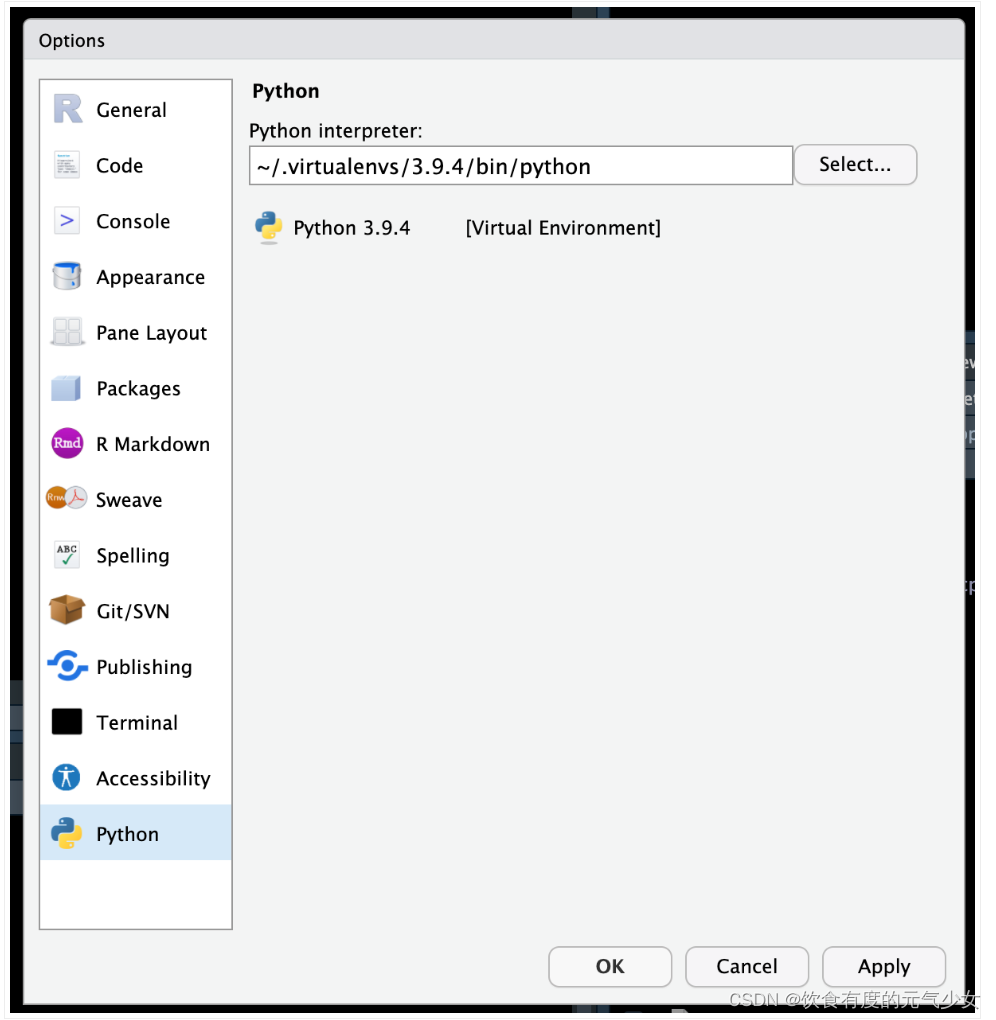
Python解释器也就是Python,这一步是选择Python的默认版本。
“Python解释器(Python interpreters):”输入框显示要使用的默认Python解释器(如果有)。如果您已经知道要使用的Python解释器的位置,您可以在该输入框中键入解释器的位置。
否则,如果输入框中没有显示默认Python解释器,可以通过单击“选择…”按钮在系统上发现Python解释器:
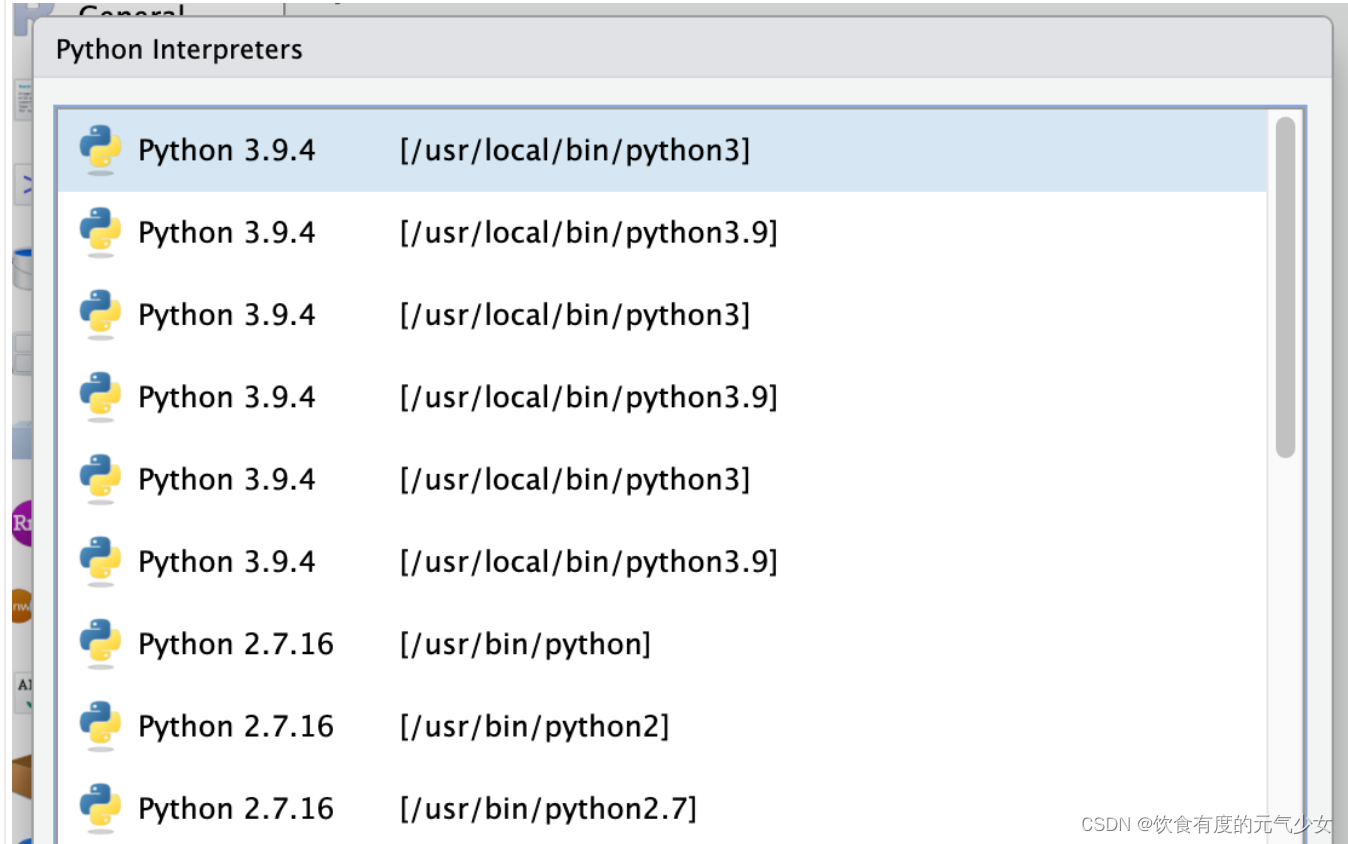
RStudio将通过几种不同的方法搜索Python解释器:
- On the PATH;
- For virtual environments, located within the ~/.virtualenvs folder;
- For Conda environments, as reported by conda --list,
- For pyenv Python installations located in ~/.pyenv,
- For Python installations located in /opt/python.
测试环境:
py_available() #检测Python是否安装成功,返回TRUE即表示安装成功
4-使用Python
4.1 运行一个简单的Python脚本
reticulate包可以在当前运行的R会话中加载和使用Python。安装reticulate包后,可以打开Python脚本(扩展名为. py),并执行其中的代码,类似于R。

注意到:在控制台(console)中,>表示运行R代码,>>>表示运行的Python代码。
请注意,RStudio使用reticulate Python REPL来执行代码,并根据正在执行的脚本在R和Python之间自动切换。
当reticulate REPL处于活动状态时,可以通过r辅助对象访问R会话中的对象。例如,r["mtcar"]可用于从R访问mtcar数据集,并将其转换为pandas DataFrame(如果可用),如果没有,则转换为Python dictionary。

4.2 在RStudio上安装Python模块
以pandas模块为例:
reticulate::py_install("pandas")
# 安装seaborn绘图库
# pip = T指定从pip安装,默认从conda安装
py_install("seaborn", pip = T)# 查看seaborn模块是否已安装
py_module_available("seaborn")
> [1] TRUE4.3 在 R 中调用 Python 模块
例子1:
# 调用os模块的listdir()函数
os <- import("os")
os$listdir("./")
> [1] ".Rproj.user" "convert.R" "reticulate.Rmd" "Reticulate.Rproj"
> [5] "Rscript.R" "summary.html" "summary.md" "summary.nb.html"
> [9] "summary.Rmd" "test_pyscript.py"例子2:
# 调用seaborn模块的load_dataset()函数
# 需要seaborn模块已安装
sns <- import("seaborn")
tips <- sns$load_dataset("tips")
print(head(tips))
> total_bill tip sex smoker day time size
> 1 16.99 1.01 Female No Sun Dinner 2
> 2 10.34 1.66 Male No Sun Dinner 3
> 3 21.01 3.50 Male No Sun Dinner 3
> 4 23.68 3.31 Male No Sun Dinner 2
> 5 24.59 3.61 Female No Sun Dinner 4
> 6 25.29 4.71 Male No Sun Dinner 44.4 在RStudio上调用Python脚本写的函数
想法与在RStudio中调用C++自定义函数一样。建议编写的Python自定义函数名与Python脚本名称一样,这样通过source_python()函数调用这个Python自定义函数,这意味着Python自定义函数可以在RStudio中不变函数名使用,使用的其实时同名的R函数。
例子1:
(1)在Python环境下,编写一个Python脚本,保存为flights.py。可以看到这个python函数名为read_flights().
import pandas
def read_flights(file):flights = pandas.read_csv(file)flights = flights[flights['dest'] == "ORD"]flights = flights[['carrier', 'dep_delay', 'arr_delay']]flights = flights.dropna()return flights(2)在RStudio中使用source_python调用实现写好的flight.py文件。
source_python("flights.py")
flights <- read_flights("flights.csv") #使用flights.py脚本中的Python自定义函数library(ggplot2)
ggplot(flights, aes(carrier, arr_delay)) + geom_point() + geom_jitter()例子2:
假设 Python 脚本为test_pyscript.py,内容如下:
# 打印一些数据
for i in range(10):print("hello world)# 定义1个函数
def sum_two_value(a, b):return a + b在 R 中执行 test_pyscript.py
source_python("./test_pyscript.py")> hello world
> hello world
> hello world
> hello world
> hello world
> hello world
> hello world
> hello world
> hello world
> hello worldsum_two_value(1, 2)
> [1] 34.5 Python 与 R 对象相互转换的方式
R → Python
设置一些R对象:
A <- 1B <- c(1, 2, 3)C <- c(a = 1, b = 2, c = 3)D <- matrix(1:4, nrow = 2)E <- data.frame(a = c(1, 2), b = c(3, 4))G <- list(1, 2, 3)H <- list(c(1, 2), c(3, 4))I <- list(a = c(1, 2), b = c(3, 4))J <- function(a, b) {return(a + b)
}K1 <- NULL
K2 <- T
K3 <- F上述 R 对象转为 Python 对象(Python Cell)
r.A
> 1.0
type(r.A)
> <class 'float'>
r.B
> [1.0, 2.0, 3.0]
type(r.B)
> <class 'list'>
r.C
> [1.0, 2.0, 3.0]
type(r.C)
> <class 'list'>
r.D
> array([[1, 3],
> [2, 4]])
type(r.D)
> <class 'numpy.ndarray'>
r.E
> a b
> 0 1.0 3.0
> 1 2.0 4.0
type(r.E)
> <class 'pandas.core.frame.DataFrame'>
r.G
> [1.0, 2.0, 3.0]
type(r.G)
> <class 'list'>
r.H
> [[1.0, 2.0], [3.0, 4.0]]
type(r.H)
> <class 'list'>
r.I
> {'a': [1.0, 2.0], 'b': [3.0, 4.0]}
type(r.I)
> <class 'dict'>
r.J
> <function make_python_function.<locals>.python_function at 0x000001AE204ECE18>
type(r.J)
> <class 'function'>
r.J(2, 3)
> 5
r.K1
type(r.K1)
> <class 'NoneType'>
r.K2
> True
type(r.K2)
> <class 'bool'>
r.K3
> False
type(r.K3)
> <class 'bool'>Python → R
设置一些 Python 对象(Python Cell)
A = 1B = [1, 2, 3]C = [[1, 2], [3, 4]]D1 = [[1], 2, 3]
D2 = [[1, 2], 2, 3]E = (1, 2, 3)FF = ((1, 2), (3, 4))G = ((1, 2), 3, 4)H = {"a": [1, 2, 3], "b": [2, 3, 4]}I = {"a": 1, "b": [2, 3, 4]}def J(a, b):return a + b上述 Python 对象转为 R 对象(R Cell)
py$A
> [1] 1
class(py$A)
> [1] "integer"py$B
> [1] 1 2 3
class(py$B)
> [1] "integer"py$C
> [[1]]
> [1] 1 2
>
> [[2]]
> [1] 3 4
class(py$C)
> [1] "list"py$D1
> [[1]]
> [1] 1
>
> [[2]]
> [1] 2
>
> [[3]]
> [1] 3
class(py$D1)
> [1] "list"
py$D2
> [[1]]
> [1] 1 2
>
> [[2]]
> [1] 2
>
> [[3]]
> [1] 3
class(py$D2)
> [1] "list"py$E
> [[1]]
> [1] 1
>
> [[2]]
> [1] 2
>
> [[3]]
> [1] 3
class(py$E)
> [1] "list"py$FF
> [[1]]
> [[1]][[1]]
> [1] 1
>
> [[1]][[2]]
> [1] 2
>
>
> [[2]]
> [[2]][[1]]
> [1] 3
>
> [[2]][[2]]
> [1] 4
class(py$FF)
> [1] "list"py$G
> [[1]]
> [[1]][[1]]
> [1] 1
>
> [[1]][[2]]
> [1] 2
>
>
> [[2]]
> [1] 3
>
> [[3]]
> [1] 4
class(py$G)
> [1] "list"py$H
> $a
> [1] 1 2 3
>
> $b
> [1] 2 3 4
class(py$H)
> [1] "list"py$I
> $a
> [1] 1
>
> $b
> [1] 2 3 4
class(py$I)
> [1] "list"py$J
> <function J at 0x000001AE204ECE18>
class(py$J)
> [1] "python.builtin.function" "python.builtin.object"
py$J(2, 3)
> [1] 55-在 R Console 中交互式运行 R
- repl_python () 进入 Python 环境
- exit 退出 Python 环境
6-在RStudio中安装Python包遇到问题时解决方案
问题:No module named 'tensorflow_probability'
通过在新的R会话中运行以下操作可以解决许多安装问题(您可以使用Ctrl+Shift+F10在Rdios中重新启动R):
# install the development version of packages, in case the
# issue is already fixed but not on CRAN yet.
install.packages("remotes")
remotes::install_github(sprintf("rstudio/%s", c("reticulate", "tensorflow", "keras")))
reticulate::miniconda_uninstall() # start with a blank slate
reticulate::install_miniconda()
tfprobability::install_tfprobability()
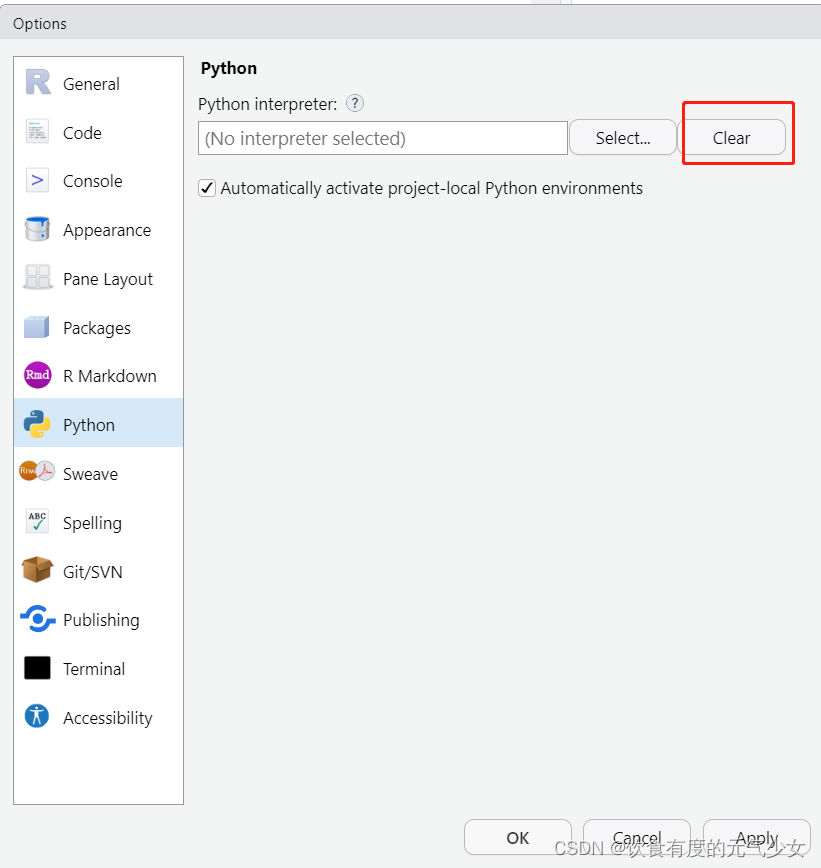
注意:其中在miniconda_uninstall() 卸载之前安装的miniconda时,要将RStudio中Tools-->Global Options--->Python-->将Python interpreter(Python解释器)清除掉。(注:下图是已经清除掉的界面,如果没有执行清楚操作,Python interpreter输入框中是有内容的)。
参考:
https://support.posit.co/hc/en-us/articles/1500007929061 (给出了在RStudio中配置Python环境的最简单方法)
🤔 Reticulate | 如何在Rstudio中优雅地调用Python!? - 知乎 (zhihu.com) (给出了安装Python包的命令)
No module named 'tensorflow_probability' · Issue #155 · rstudio/tfprobability · GitHub (安装包遇到问题时的解决办法)
reticulate:在R中使用Python - 知乎 (zhihu.com)
相关文章:
将 Python 与 RStudio IDE 配合使用(R与Python系列第一篇)
目录 前言: 1-安装reticulate包 2-安装Python 3-选择Python的默认版本(配置Python环境) 4-使用Python 4.1 运行一个简单的Python脚本 4.2 在RStudio上安装Python模块 4.3 在 R 中调用 Python 模块 4.4 在RStudio上调用Python脚本写的…...

数据库访问性能优化
目录 IO性能分析数据库性能优化漏斗法则1、减少数据访问(减少磁盘访问)(1) 正确的创建并使用索引索引生效场景索引失效场景判断索引是否生效--执行计划 2、返回更少数据(减少网络传输或磁盘访问)(1) 数据分页处理(减少行数)客户端…...

vue 预览 有token验证的 doc、docx、pdf、xlsx、csv、图片 并下载
预览 doc我也不会 //docx <div v-if"previewType docx" ref"iframeDom" style"border: none; width: 100%; height: 100%"></div> import { renderAsync } from "docx-preview"; let iframeDom: any ref(); axios({url…...

WPF数据视图
将集合绑定到ItemsControl控件时,会不加通告的在后台创建数据视图——位于数据源和绑定的控件之间。数据视图是进入数据源的窗口,可以跟踪当前项,并且支持各种功能,如排序、过滤、分组。 这些功能和数据对象本身是相互独立的&…...

C++ new/delete 与 malloc/free 的区别?
new/delete 与 malloc/free 的区别? 分配内存的位置 malloc是从堆上动态分配内存new是从自由存储区为对象动态分配内存。自由存储区的位置取决于operator new的实现。自由存储区不仅可以为堆,还可以是静态存储区,这都看operator new在哪里为…...
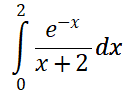
【数学建模】常微分,偏微分方程
1.常微分方程 普通边界 已知t0时刻的初值 ode45() 龙格-库塔法 一阶,高阶都一样 如下: s(1) y , s(2)y s(3) x , s(4)x //匿名函数 下为方程组 核心函数 s_chuzhi [0;0;0;0]; //初值 分别两个位移和速度的初值 t0 0:0.2:180; f (t,s)[s(2);(…...

浙大数据结构之09-排序1 排序
题目详情: 给定N个(长整型范围内的)整数,要求输出从小到大排序后的结果。 本题旨在测试各种不同的排序算法在各种数据情况下的表现。各组测试数据特点如下: 数据1:只有1个元素;数据2…...

Pydantic 学习随笔
这里是零散的记录一些学习过程中随机的理解,因此这里的记录不成体系。如果是想学习 Pydantic 建议看官方文档,写的很详细并且成体系。如果有问题需要交流,欢迎私信或者评论。 siwa 报 500 Pydantic 可以和 siwa 结合使用,这样既…...
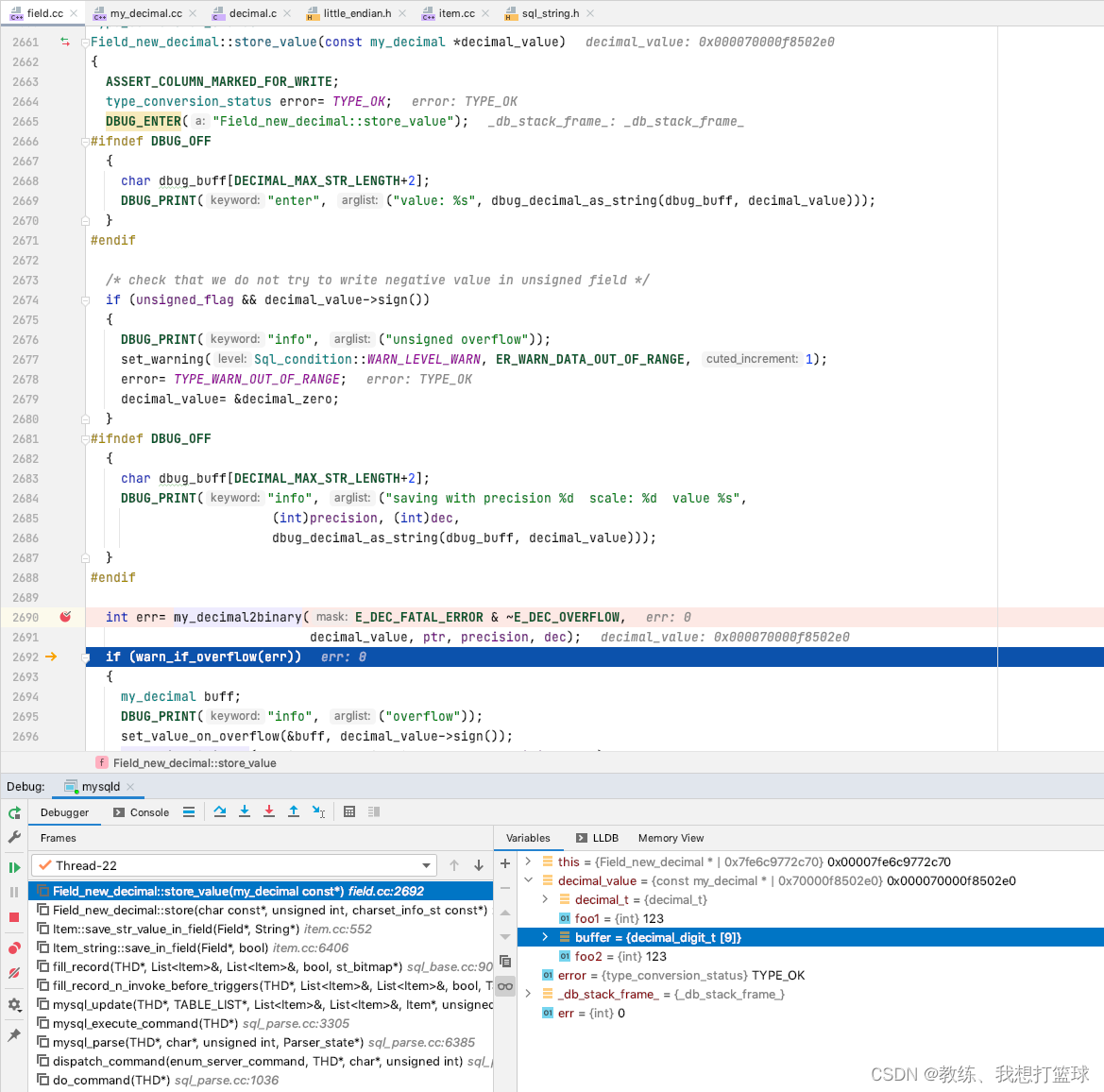
11 mysql float/double/decimal 的数据存储
前言 这里主要是 由于之前的一个 datetime 存储的时间 导致的问题的衍生出来的探究 探究的主要内容为 int 类类型的存储, 浮点类类型的存储, char 类类型的存储, blob 类类型的存储, enum/json/set/bit 类类型的存储 本文主要 的相关内容是 float, decimal 类类型的相关数据…...

【高效数据结构——位图bitmap】
初识位图bitmap 位图(Bitmap)是一种用于表示和操作位(bit)的数据结构。它是由一系列二进制位(0 或 1)组成的序列,每个位都可以单独访问和操作。 位图常用于以下情况: 压缩存储&…...

ArrayList LinkedList
ArrayList 和 LinkedList 区别 ArrayList和LinkedList都是Java集合框架中的实现类,用于存储和操作数据。它们在底层实现和性能特点上有一些区别。 数据结构:ArrayList底层使用数组实现,而LinkedList底层使用双向链表实现。这导致它们在内存结…...
iOS砸壳系列之三:Frida介绍和使用
当涉及从App Store下载应用程序时,它们都是已安装的iOS应用(IPA)存储在设备上。这些应用程序通常带有保护的代码和资源,以限制用户对其进行修改或者逆向工程。 然而,有时候,为了进行调试、制作插件或者学习…...
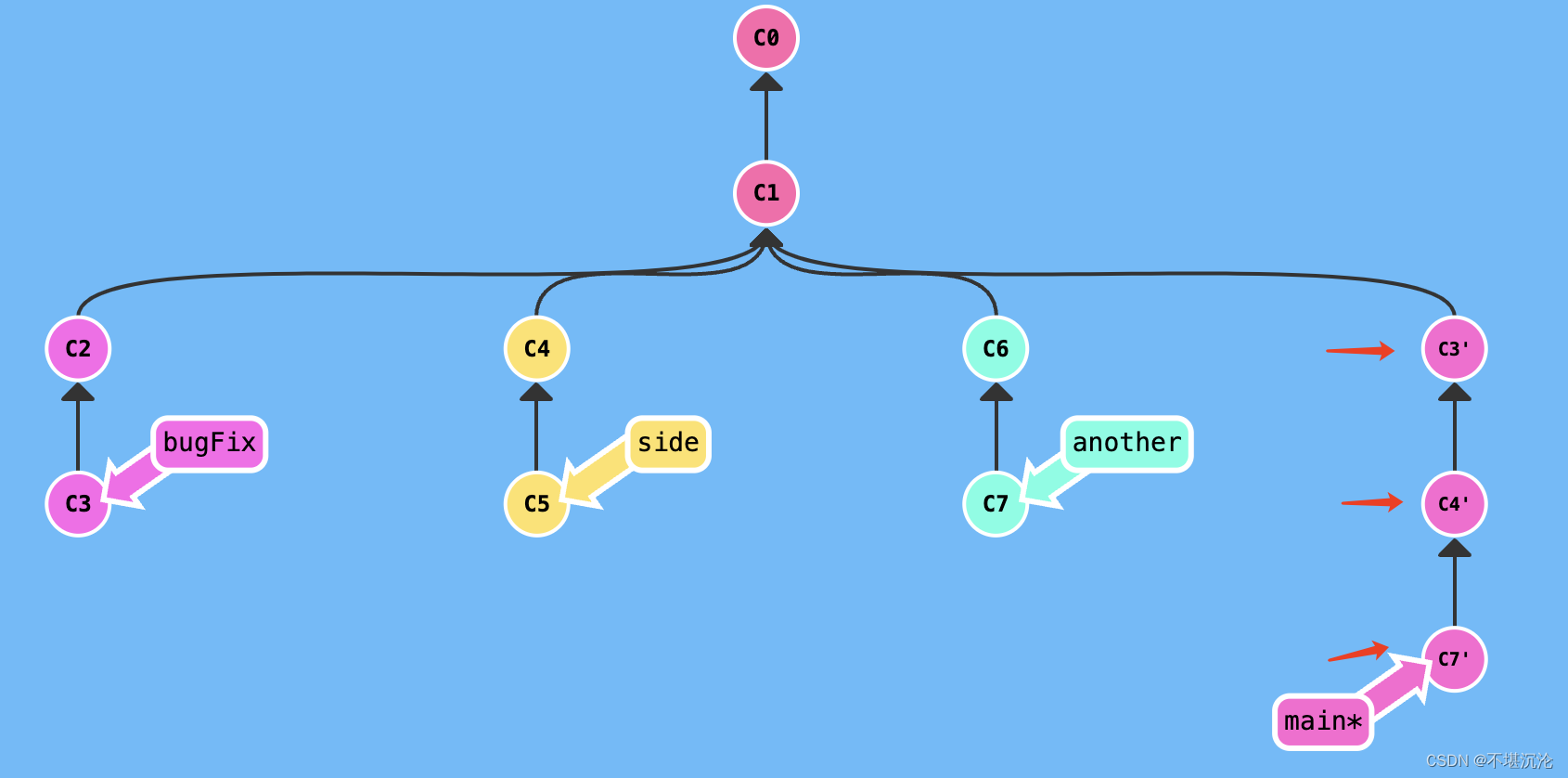
Git学习——细节补充
Git学习——细节补充 1. git diff2. git log3. git reset4. git reflog5. 提交撤销5.1 当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时5.2 当提交到了stage区后,想要退回 6. git remote7. git pull origin master --no-rebase8. 分支管理9. g…...

【设计模式】Head First 设计模式——装饰者模式 C++实现
设计模式最大的作用就是在变化和稳定中间寻找隔离点,然后分离它们,从而管理变化。将变化像小兔子一样关到笼子里,让它在笼子里随便跳,而不至于跳出来把你整个房间给污染掉。 设计思想 动态地将责任附加到对象上,若要扩…...
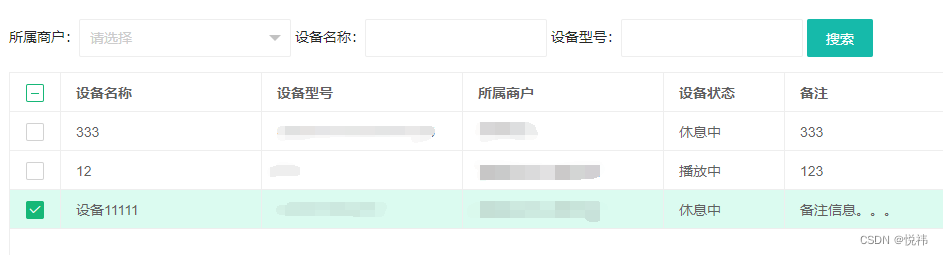
layui实现数据列表的复选框回显
layui版本2.8以上 实现效果如图: <input type"hidden" name"id" id"id" value"{:g_val( id,0)}"> <div id"tableDiv"><table class"layui-hide" id"table_list" lay-filter…...
关于使用RT-Thread系统读取stm32的adc无法连续转换的问题解决
关于使用RT-Thread系统读取stm32的adc无法连续转换的问题解决 今天发现rt系统的adc有一个缺陷(也可能是我移植的方法有问题,这就不得而知了!),就是只能单次转换,事情是这样的: 我在stm32的RT-T…...
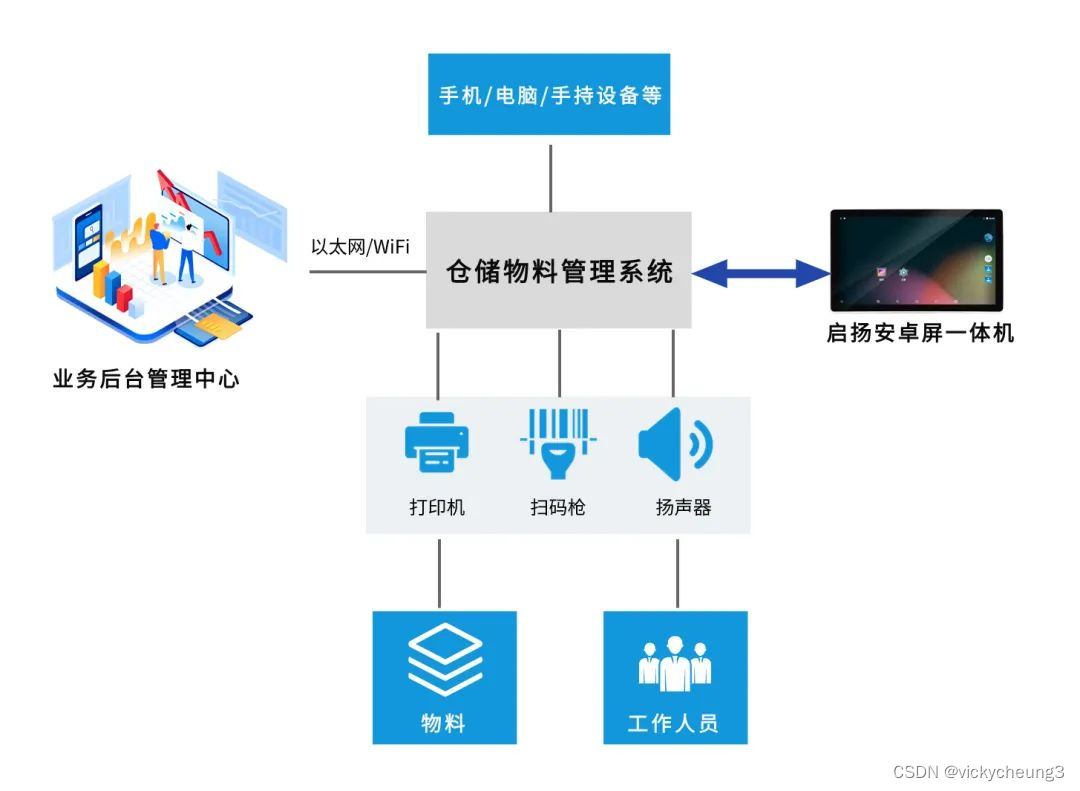
【启扬方案】启扬多尺寸安卓屏一体机,助力仓储物料管理系统智能化管理
随着企业供应链管理的不断发展,对仓储物料管理的要求日益提高。企业需要实时追踪和管理物料的流动,提高物流效率、降低库存成本和减少库存的风险。因此,仓储物料管理系统的实现成为必要的手段。 仓储物料管理系统一体机作为一种新型的物料管理…...

Android Glide使用姿势与原理分析
作者: 午后一小憩 简介 Android Glide是一款强大的图片加载库,提供了丰富的功能和灵活的使用方式。本文将深入分析Glide的工作原理,并介绍一些使用姿势,助你更好地运用这个优秀的库。 原理分析 Glide的原理复杂而高效。它首先基…...

管理类联考——逻辑——汇总篇——知识点突破——形式逻辑——联言选言——真假
角度——真值表 以上考点均是已知命题的真假情况做出的推理,还存在一种情况是已知肢判断P、Q的真假,断定干判断的真假,这种判断过程就是运用真值表。 P ∧ Q的真值 ①如何证明P ∧ Q为假? 由于P ∧ Q的本质是P、Q同时成立,所以只要P、Q有一个为假,整个命题就为假。 ②如…...
ChatGPT数据分析及作图插件推荐-Code Interpreter
今天打开chatGPT时发现一个重磅更新!code interpreter插件可以使用了。 去查看openai官网,发现从2023.7.6号(前天)开始,code interpreter插件已经面向所有chatGPT plus用户开放了。 为什么说code interpreter插件是一…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...