关于大模型参数微调的不同方法
Adapter Tuning
适配器模块(Adapter Moudle)可以生成一个紧凑且可扩展的模型;每个任务只需要添加少量可训练参数,并且可以在不重新访问之前任务的情况下添加新任务。原始网络的参数保持不变,实现了高度的参数共享
Paper 1: Parameter-Efficient Transfer Learning for NLP
- 为了证明适配器的有效性,我们将最近提出的BERT Transformer模型应用于26个不同的文本分类任务,包括GLUE基准测试 : https://github.com/google-research/adapter-bert
adapter 的优点:
(i) 它可以获得良好的性能,
(ii) 它允许按顺序对任务进行训练,即不需要同时访问所有数据集,
(iii) 它每个任务只添加了少量额外的参数。
(iv)一个接近恒等初始化的方法。通过将适配器初始化为接近恒等函数的方式,当训练开始时,原始网络不受影响。在训练过程中,适配器可以被激活,从而改变整个网络中的激活分布。
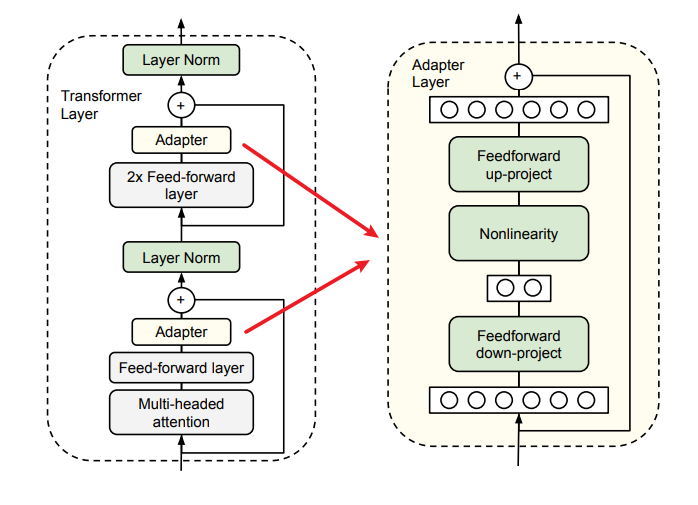
适配器还包含一个跳跃连接。在适配器微调过程中,绿色层使用下游数据进行训练,包括适配器、层归一化参数以及最终的分类层(图里没有)
实验:

- Adapter for Tansformer
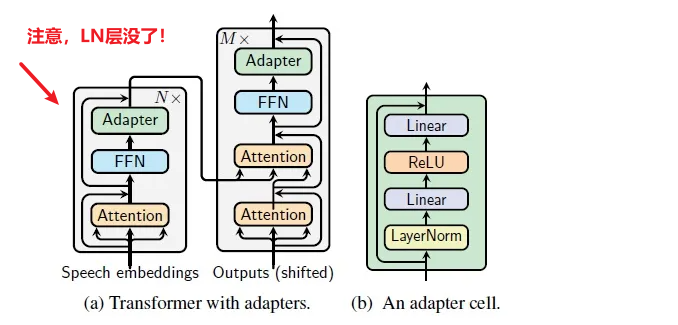
Paper2:LLaMA-Adapter
Efficient Fine-tuning of Language Models with Zero-init Attention
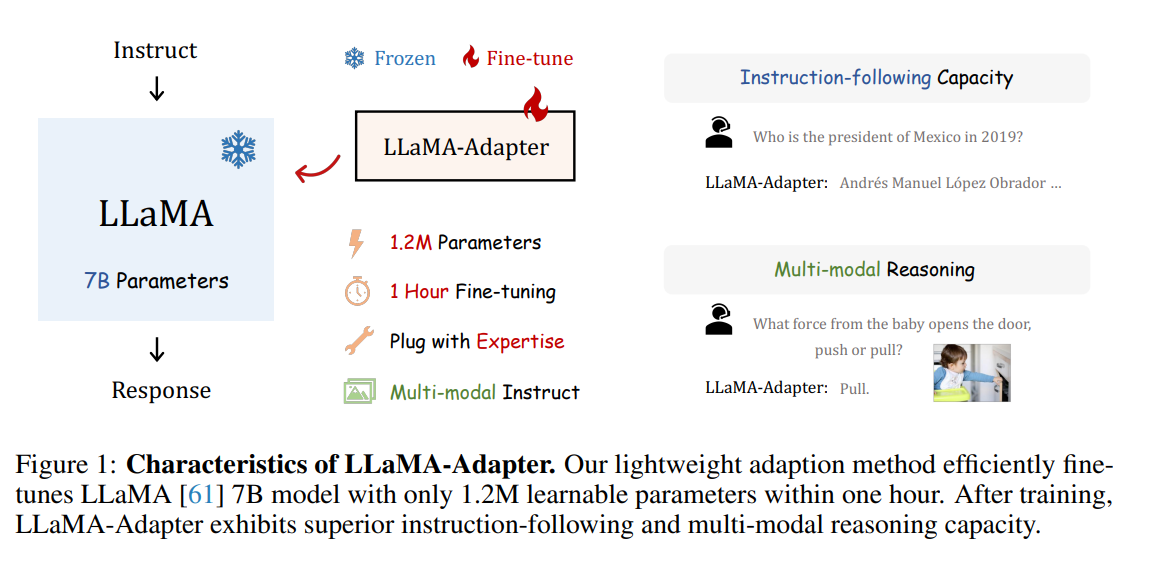
我们提出了LLaMA-Adapter,一种轻量级的适应方法,可以高效地将LLaMA模型微调为指令跟随模型。使用52K个自我指导演示,LLaMA-Adapter仅在冻结的LLaMA 7B模型上引入了1.2M个可学习参数,并且在8个A100 GPU上的微调时间不到一小时。
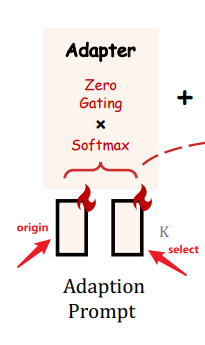
- 具体而言,我们采用一组可学习的适应提示,并将它们预置到较高的Transformer层的单词标记之前。(前缀 Prefix)
- 然后,我们提出了一个以零初始化的注意机制和零门控的方式,它可以自适应地将新的指令提示注入到LLaMA模型中,同时有效地保留其预训练的知识。
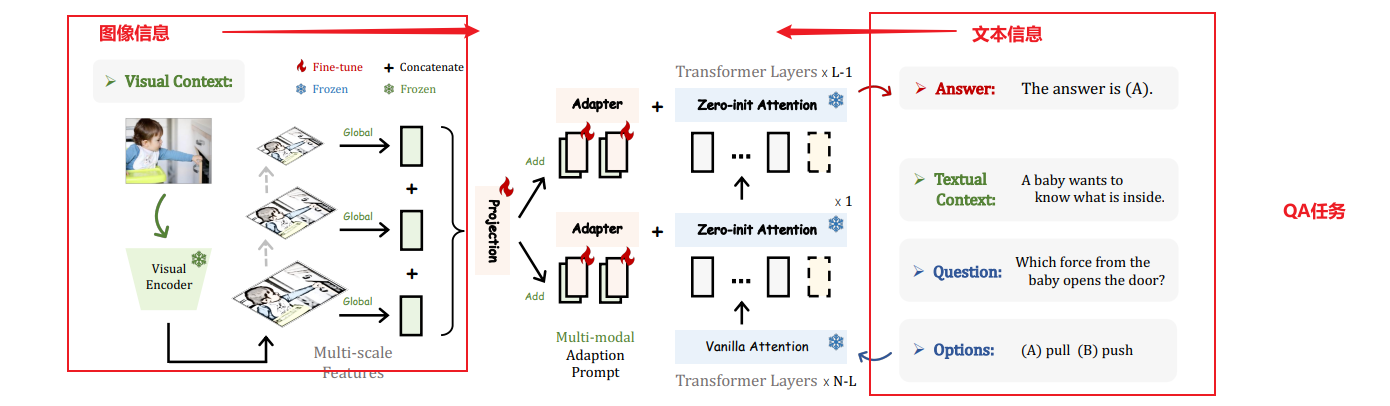
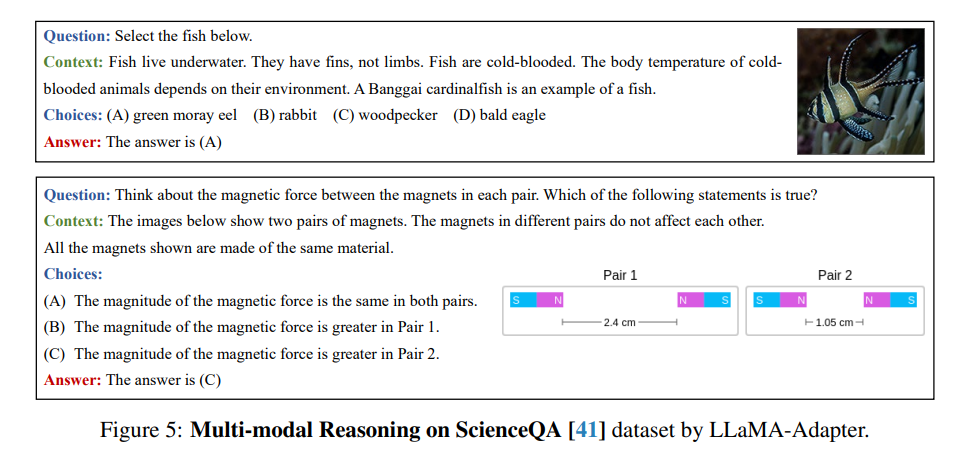
- 通过我们高效的训练,LLaMA-Adapter可以生成高质量的响应,与完全微调的7B参数的Alpaca模型相媲美。除了语言指令,我们的方法还可以简单地扩展到多模态指令,用于学习基于图像的LLaMA模型,在ScienceQA和COCO Caption基准测试上实现了更优秀的推理性能。
此外,我们还评估了以零初始化的注意机制在传统视觉和语言任务上微调其他预训练模型(ViT,RoBERTa),展示了我们方法的优越的泛化能力。
这么NB ????
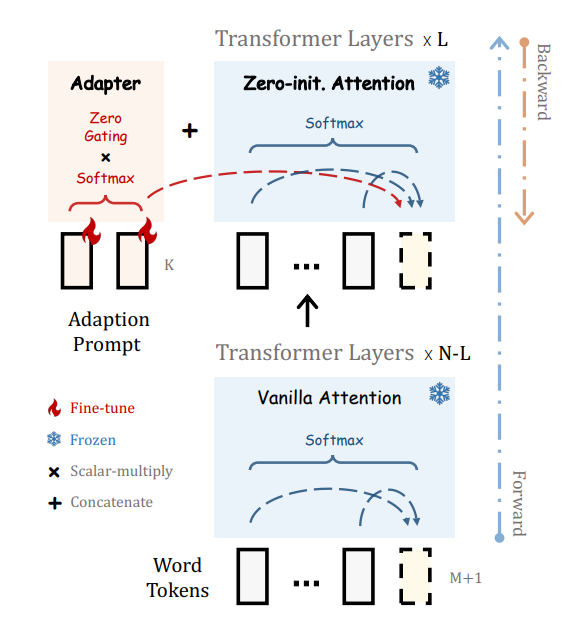
- 为了逐步学习指令知识,在早期阶段我们采用了以零初始化的注意机制和门控机制,以实现稳定的训练
如果适应提示被随机初始化,它们可能会在训练初期对单词标记带来干扰,从而损害微调的稳定性和有效性。考虑到这一点,我们修改了最后L个Transformer层上的普通注意机制,将其改为零初始化的注意机制,如图2所示。
过去的PEFT方法是直接插入随机初始化的模块, 这可能导致早期训练阶段有较大loss的不稳定微调.
llama采用zero-init attention with gating来缓解这种问题.
- insert the prompts into the topmost L layers of the transformer (L ≤ N ):
prompts for L transformer layers: P l L P_l^L PlL - 其中, P_shape=[K, C], K表示每一层的prompt长度, C表示feature dimension.
在第l层中, 有长度为M的word-tokens: T l ∈ R M × C T_l ∈ R^{M×C} Tl∈RM×C 即: 长度为M, 每个token feature dimension为C. - 将prompt Pl 与 tokens Tl, 进行concatenation.
- 计算某一层中,第M+1个word和所有的K+M+1个token的关系

-
K A d a p t i o n P r o m p t s K \ Adaption \ Prompts K Adaption Prompts 的注意力分数,它代表从prompt中学到了多少信息去生成 t i t_i ti

-
核心操作

-
门控系数g,来控制注意力的重要性(注意力分数的影响程度)
- 首先令g = 0,消除之前的prompt的影响程度
- 然后增加其幅度,以提供更多的指令语义给LLaMA模型。
- 这两个步骤需要分开,softmax。原因是,保证两部分的相互独立,不会受到之前的adaptive prompt的影响
- g一般分开取不同值与多头注意力一起
文章链接:https://arxiv.org/pdf/2303.16199.pdf
Paper3
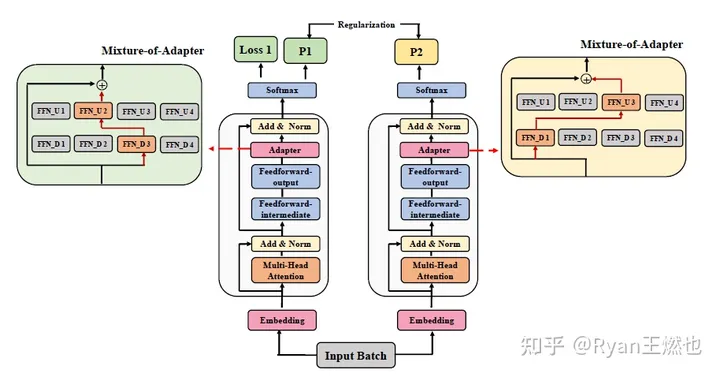
AdaMix
multi-view learning, mixture-of-experts的再利用**, 在adapter中设置了多个降维和升维通路**
- 训练过程中,adapter内进行随机路由;
- 推理过程中,则通过Averaging weights得到一个综合的降维升维通路
这种方式允许adapter进行multi-view learning,又不会增加相比单路adapter更多的参数。
Prefix Tuning
Optimizing Continuous Prompts for Generation
解决的问题:大模型进行微调的代价很大,应该怎么办?
- 考虑生成数据表的文本描述的任务,如图 1 所示,其中任务输入是线性化表(例如,“名称:星巴克 | 类型:咖啡店”),输出是文本描述(例如,“星巴克供应咖啡。”)。
Prefix-tuning将一系列连续的特定于任务的向量添加到输入中,我们称之为Prefix(前缀)。- Transformer 可以将前缀视为一系列“虚拟token”,但与prompt不同,前缀完全由不对应于真实令牌的自由参数组成。
针对不同的任务,是需要微调prefix即可,不用去调Transformer本身的参数,所有参数量大幅度减小。(图中红色的部分是在微调过程中需要进行优化的地方)
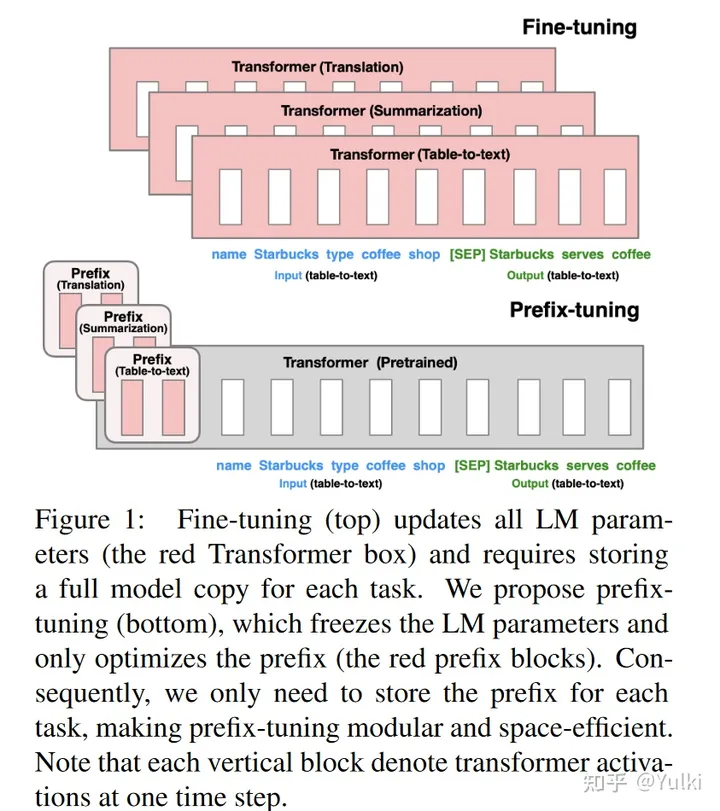
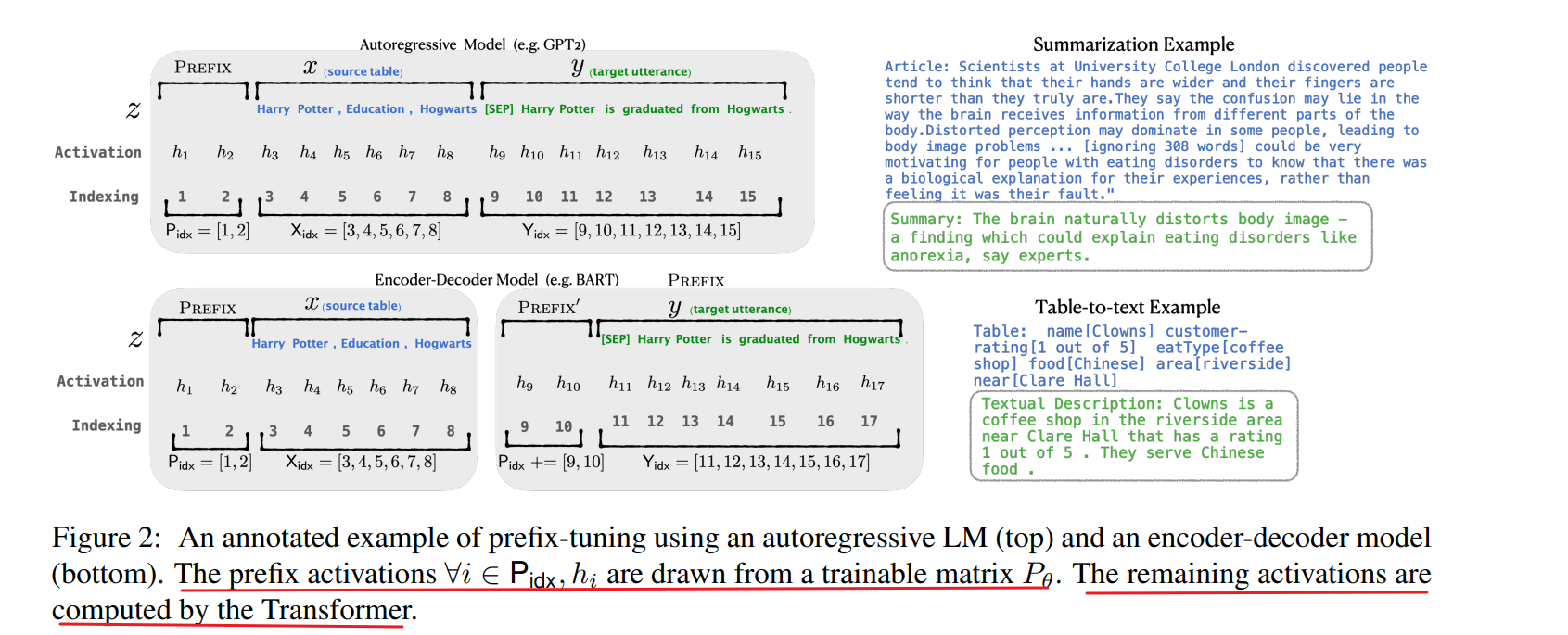
- 前缀的参数P, P θ P_θ Pθ 和 P θ ′ P_θ' Pθ′具有相同的行数(即前缀长度),但列数不同。一旦训练完成,这些重新参数化参数可以被丢弃,只需要前缀 P_θ已保存


Light weight Tuning 简述
轻量级微调。轻量级微调冻结了大部分预训练参数,并使用小的可训练模块修改预训练模型。关键挑战是确定模块的高性能架构和要微调的预训练参数子集。
- 一种研究方法考虑移除参数:通过在模型参数上训练二进制掩码,一些模型权重被消融掉。
- 另一种研究方法考虑插入参数。
- 通过求和将“边缘”网络与预训练模型融合;
- 适配器微调在预训练语言模型的每个层之间插入任务特定的层(适配器)。
与这一系列工作相比,该方法仅微调了LM参数的约3.6%,而我们的方法在保持可比性能的同时,进一步减少了任务特定参数的30倍,仅微调了0.1%。
Prompt Tuning 简述
提示是指在任务输入中添加前缀指令和一些示例,并通过语言模型生成输出。GPT-3(Brown等,2020)使用手动设计的提示来适应不同任务的生成,这个框架被称为上下文学习(In Context Learning)。
然而,由于Transformer只能在有限长度的上下文条件下进行(例如,对于GPT-3,上下文窗口为2048个标记),上下文学习无法充分利用比上下文窗口更长的训练集。
- Sun和Lai(2020)也通过关键词提示来控制生成句子的情感或主题。
- 在自然语言理解任务中,先前的研究已经探索了像BERT和RoBERTa这样的模型的提示工程(Liu等,2019; Jiang等,2020; Schick和Schutze,2020)。
- 例如,AutoPrompt(Shin等,2020)搜索一系列离散触发词,并将其与每个输入连接起来,以从掩码语言模型中引出情感或事实知识。
- 与AutoPrompt不同,我们的方法优化连续的前缀,这更具表达力(§7.2);
- 此外,我们专注于语言生成任务。连续向量已被用于引导语言模型;
- 例如,Subramani等(2020)表明,预训练的LSTM语言模型可以通过为每个句子优化一个连续向量来重构任意句子,使得向量具有输入特定性(input Prefix)。
- 相比之下,前缀微调优化了一个适用于该任务的所有实例的
特定前缀(task Prefix)。因此,与先前的工作仅限于句子重构不同,前缀微调可以应用于自然语言生成任务。
Soft Prompt Tuning
https://arxiv.org/pdf/2104.08691.pdf
-
核心:针对不同的任务设计不同的soft pormpt仅添加到embedding层中,仅训练这些参数。其余的参数都保持冻结,类似Prefix-tuning的想法,但是无论是token的长度以及所添加的位置都有一些差别
-
与 GPT-3 使用的离散文本提示不同,
软提示是通过反向传播学习的,并且可以调整以合并来自任意数量的标记示例的信号
引言:
- Prompt的缺点:需要人工设计,并且prompt的有效性受到诸多限制。GPT-3尽管比T5-XXL大了16倍,但是在SuperGLUE的分数上仍落后17.5.
- AutoPrompt:尽管自动设计Prompt的方法比人工设计的要好,但是仍落后于模型的微调。
- Prefix-tuning:冻结模型参数并在调整期间将错误反向传播到编码器堆栈中每个层(包括输入层)之前的前缀激活
作者冻结了整个预训练模型,只允许将每个下游任务的额外 k 个可调标记添加到输入文本中。这种“软提示”经过端到端训练,可以压缩来自完整标记数据集的信号,使我们的方法能够胜过少样本提示,并通过模型调整缩小质量差距。
什么是Prompt Tuning ?
在GPT-3中,提示标记(Prompt Tuning)的表示 P = p 1 , p 2 , . . . , p n P = {p1, p2, . . . , pn} P=p1,p2,...,pn是模型的嵌入表的一部分,由冻结的参数θ参数化。因此,找到最优提示需要通过手动搜索或非可微搜索方法选择提示标记。
提示微调消除了提示P由θ参数化的限制;相反,提示具有自己的专用参数θ,P,可以进行更新。虽然提示设计涉及从固定的冻结嵌入词汇中选择提示标记,但是可以将提示微调视为使用特殊标记的固定提示,其中只有这些提示标记的嵌入可以进行更新。

初始化:
- 从概念上讲,
我们的软提示以与输入之前的文本相同的方式调制冻结网络的行为,因此类似词的表示可能会作为一个很好的初始化点。 - 对于分类任务,将Prompt初始化为它对应的类别。提示越短,必须调整的新参数就越少,因此我们的目标是找到仍然表现良好的最小长度。

尽管这种结构比传统结构更加有效,但作者认为不是仅仅通过使用prompt tuning就能控制冻结的模型的。
T5使用的Span Corruption策略使得模型在训练和输出过程中始终存在哨兵标记,模型从来没有输出过真实完整的文本,这种模式可以通过Fine-tune很容易纠正过来,但是仅通过prompt可能难以消除哨兵的影响。
- Span Corruption:使用现成的预训练 T5 作为我们的冻结模型,并测试其为下游任务输出预期文本的能力
- Span Corruption + Sentinel【哨兵】:我们使用相同的模型,但在所有下游目标前加上一个哨兵,以便更接近预训练中看到的目标
- LM Adaptation:对于按原始方法训练好的T5模型,额外使用LM(语言模型)优化目标进行少量步骤的Finetune,使模型从输出带哨兵的文本转换为输出真实文本,期望T5和 GPT一样生成真实的文本输出。(这是本实验的默认设置)。至多100K step
其实可以看到,无论对哪个变量就行消融,只要模型的规模上去了,效果都差不多
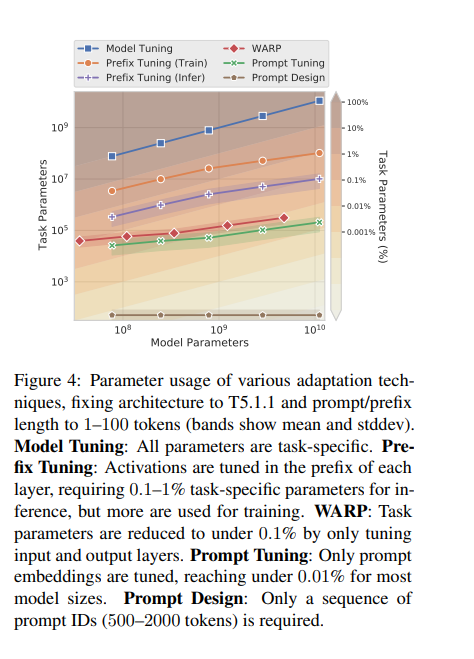
-
prompt tuning只需要在encoder加入prompt,而prefix tuning需要在encoder和decoder都添加
-
只在输入层加入可以防止模型的过拟合,因此prompt tuning可以迁移到别的领域上面
-
连续空间的prompt比离散空间的prompt难以解释
结论:
在SupreGLUE上,Prompt tuning的任务性能可与传统模型调整相媲美,随着模型尺寸的增加,差距会逐渐消失。在Zeor-shot领域迁移,有效提升泛化性。在few-shot上面可以看作,冻结模型的参数,限制为轻量级的参数有效避免过拟合。
- 核心:将下游任务的参数和预训练任务的参数分开
Code
- 代码Demo:https://huggingface.co/docs/peft/task_guides/clm-prompt-tuning
相关文章:
关于大模型参数微调的不同方法
Adapter Tuning 适配器模块(Adapter Moudle)可以生成一个紧凑且可扩展的模型;每个任务只需要添加少量可训练参数,并且可以在不重新访问之前任务的情况下添加新任务。原始网络的参数保持不变,实现了高度的参数共享 Pa…...
)
方法的引用第一版(method reference)
1、体验方法引用 在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿参数做操作那么考虑一种情况:如果我们在Lanbda中所指定的操作方案,已经有地方存在相同方案,那是否还有必要再重复逻辑呢&#…...

Android DataBinding 基础入门(学习记录)
目录 一、DataBinding简介二、findViewById 和 DataBinding 原理及优缺点1. findViewById的优缺点2. DataBinding的优缺点 三、Android mvvm 之 databinding 原理1. 简介和三个主要的实体DataViewViewDataBinding 2.三个功能2.1. rebind 行为2.2 observe data 行为2.3 observe …...

spring 错误百科
一、使用Spring出错根源 1、隐式规则的存在 你可能忽略了 Sping Boot 中 SpringBootApplication 是有一个默认的扫描包范围的。这就是一个隐私规则。如果你原本不知道,那么犯错概率还是很高的。类似的案例这里不再赘述。 2、默认配置不合理 3、追求奇技淫巧 4、…...
OpenCV基本操(IO操作,读取、显示、保存)
图像的IO操作,读取和保存方法 1.1 API cv.imread()参数: 要读取的图像 读取图像的方式: cv.IMREAD*COLOR:以彩色模式加载图像,任何图像的图像的透明度都将被忽略。这是默认参数 标志: 1 cv.IMREAD*GRAYSCALE :以…...

1.快速搭建Flask项目
一.Pear Admin Flask 官网文档:http://www.pearadmin.com/doc/index.html 1.1下载安装 # 下 载 git clone https://gitee.com/pear-admin/pear-admin-flask# 安 装 pip install -r requirements.txt1.2修改配置 applications下的config.py docker运行的修改dockerdata/conf…...

编程题四大算法思想(三)——贪心法:找零问题、背包问题、任务调度问题、活动选择问题、Prim算法
文章目录 贪心法找零问题(change-making problem)贪心算法要求基本思想适合求解问题的特征 背包问题0/1背包问题0/1背包问题——贪心法 分数背包问题 任务调度问题活动选择问题活动选择——贪心法最早结束时间优先——最优性证明 Prim算法 贪心法 我在当…...
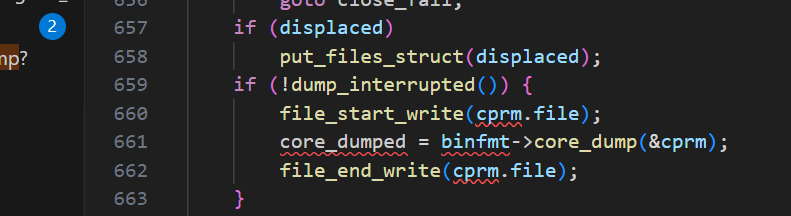
core dump管理在linux中的前世今生
目录 一、什么是core dump? 二、coredump是怎么来的? 三、怎么限制coredump文件的产生? ulimit 半永久限制 永久限制 四、从源码分析如何对coredump文件的名字和路径管理 命名 管理 一些问题的答案 1、为什么新的ubuntu不能产生c…...

Springboot整合knife4j配置swagger教程-干货
开启swagger文档,直接上教程。 第一步:引入依赖 <!--swagger 依赖--><dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-starter</artifactId><version>3.0.3</version></d…...

C++ 中的 Pimpl 惯用法
C 中的 Pimpl 惯用法 介绍 Pimpl(Pointer to Implementation)是一种常见的 C 设计模式,用于隐藏类的实现细节,从而减少编译依赖和提高编译速度。本文将通过一个较为复杂的例子,展示如何使用智能指针(如 s…...

【个人博客系统网站】统一处理 · 拦截器
【JavaEE】进阶 个人博客系统(2) 文章目录 【JavaEE】进阶 个人博客系统(2)1. 统一返回格式处理1.1 统一返回类common.CommonResult1.2 统一返回处理器component.ResponseAdvice 2. 统一异常处理3. 拦截器实现3.1 全局变量SESSI…...
)
深入探索PHP编程:文件操作与输入/输出(I/O)
深入探索PHP编程:文件操作与输入/输出(I/O) 在PHP编程中,文件操作和输入/输出(I/O)是不可或缺的关键部分。无论是读取、写入文件,还是处理上传的文件,这些操作都是Web开发的重要组成…...

基于jeecg-boot的flowable流程自定义业务驳回到发起人的一种处理方式
有些粉丝,希望对自定义业务中,驳回到发起人进行处理,比如可以重新进行发起流程,下面就给出一种方式,当然不一定是最好的方式,只是提供一种参考而已,以后可以考虑动态根据流程状态或节点信息进行…...

【大数据知识】大数据平台和数据中台的定义、区别以及联系
数据行业有太多数据名词,例如大数据、大数据平台、数据中台、数据仓库等等。但大家很容易混淆,也很容易产生疑问,今天我们就来简单聊聊大数据平台和数据中台的定义、区别以及联系。 大数据平台和数据中台的定义 大数据平台:一个…...

华为OD:IPv4地址转换成整数
题目描述: 存在一种虚拟IPv4地址,由4小节组成,每节的范围为0-255,以#号间隔,虚拟IPv4地址可以转换为一个32位的整数,例如: 128#0#255#255,转换为32位整数的结果为2147549183&#…...
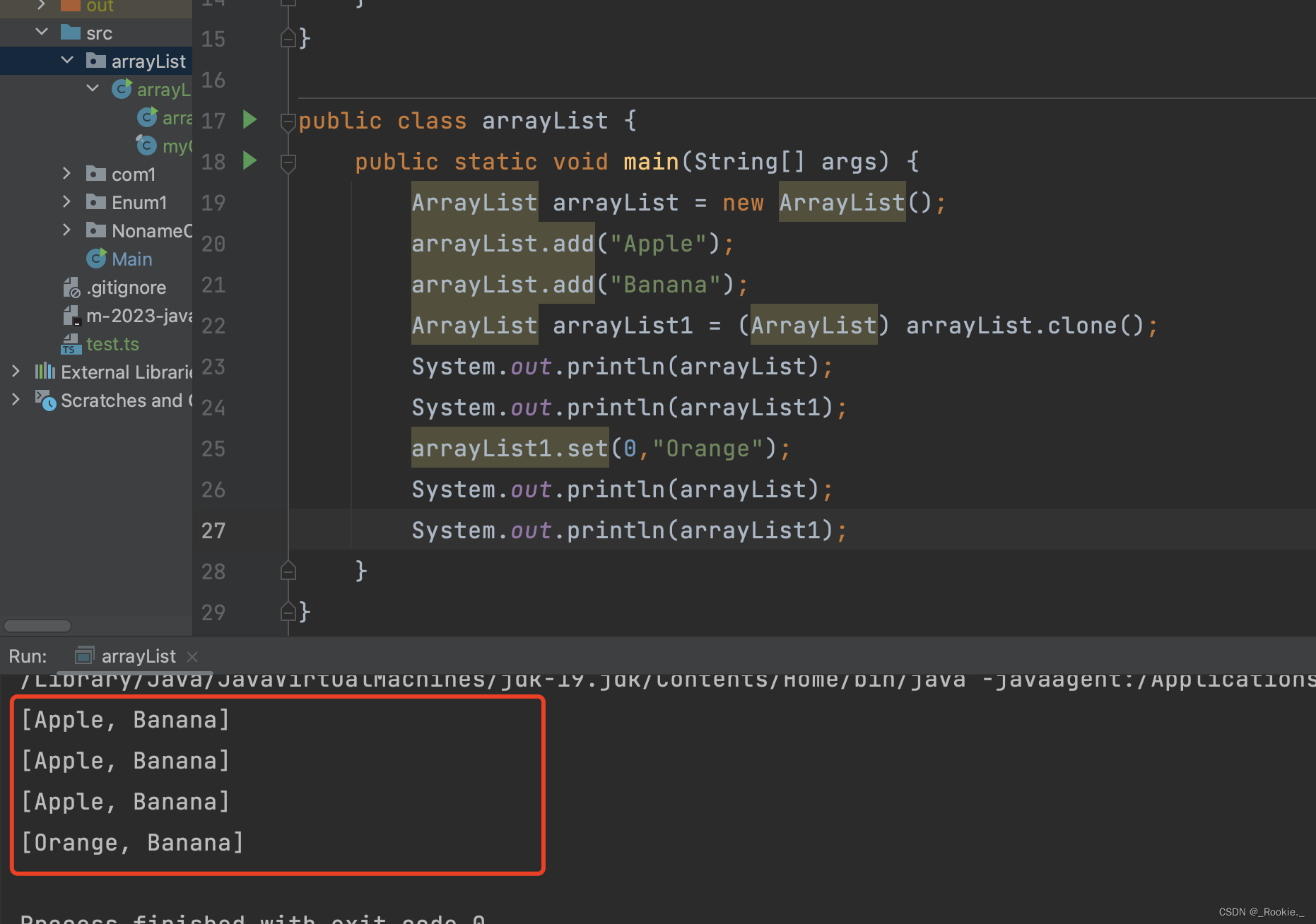
2023.9 - java - 浅拷贝
与 js的浅拷贝不同: 在 JavaScript 中, Object.assign() 或 spread 运算符等方法可以实现浅拷贝,但只针对对象的第一层属性进行复制。如果一个对象只包含基本数据类型的属性,那么对浅拷贝出来的对象进行修改不会影响原始对象&…...
STM32f103入门(10)ADC模数转换器
ADC模数转换器 ADC简介AD单通道初始化代码编写第一步开启时钟第二步 RCCCLK分频 6分频 72M/612M第三步 配置GPIO 配置为AIN状态第四步,选择规则组的输入通道第五步 用结构体 初始化ADC第六步 对ADC进行校准编写获取电压函数初始化代码如下 Main函数编写 ADC简介 ADC…...

实训笔记8.28
实训笔记8.28 8.28笔记一、大数据计算场景主要分为两种1.1 离线计算场景1.2 实时计算场景 二、一般情况下大数据项目的开发流程2.1 数据采集存储阶段2.2 数据清洗预处理阶段2.3 数据统计分析阶段2.4 数据挖掘预测阶段2.5 数据迁移阶段2.6 数据可视化阶段 三、纯大数据离线计算项…...

机器学习笔记之最优化理论与方法(五)凸优化问题(上)
机器学习笔记之最优化理论与方法——凸优化问题[上] 引言凸优化问题的基本定义凸优化定义:示例 凸优化与非凸优化问题的区分局部最优解即全局最优解凸优化问题的最优性条件几种特殊凸问题的最优性条件无约束凸优化等式约束凸优化非负约束凸优化 引言 本节将介绍凸优…...
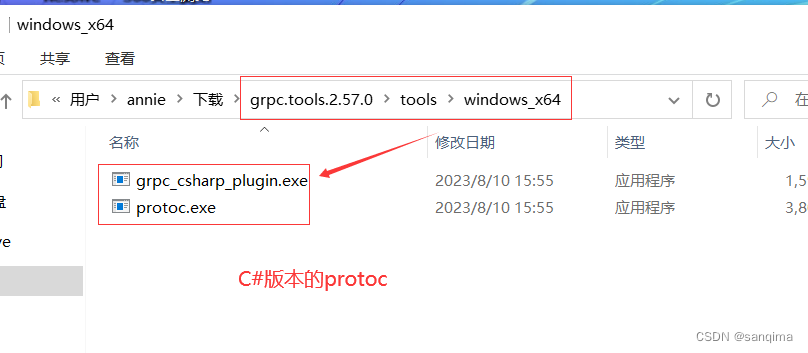
在Windows10上编译grpc工程,得到protoc.exe和grpc_cpp_plugin.exe
grpc是google于2015年发布的一款跨进程、跨语言、开源的RPC(远程过程调用)技术。使用C/S模式,在客户端、服务端共享一个protobuf二进制数据。在点对点通信、微服务、跨语言通信等领域应用很广,下面介绍grpc在windows10上编译,这里以编译grpc …...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...
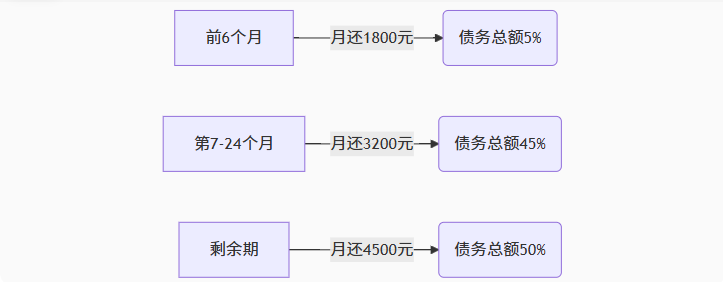
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...