keras深度学习框架通过简单神经网络实现手写数字识别
背景
keras深度学习框架,并不是一个独立的深度学习框架,它后台依赖tensorflow或者theano。大部分开发者应该使用的是tensorflow。keras可以很方便的像搭积木一样根据模型搭出我们需要的神经网络,然后进行编译,训练,测试,预测。
今天介绍的手写数字识别实验,主要是熟悉keras搭建神经网络的流程,以及大体的思路。现如今,手写数字识别实验的代码各种各样,对于初学者而言,我们需要的是类似helloworld那样简单的示例。通过示例,我们可以了解神经网络的搭建过程。
这里使用的手写数字识别,通过搭建网络,构建模型,最后保存模型,然后我们加载模型,通过真实的图片来预测,也检验一下神经网络的能力。
这里手写数字识别数据来源于官方自带mnist数据集,这个数据集包含60000个训练集和10000个测试集。每个数据是由28 * 28 = 784个矩阵元素组成。所以我们自己用来测试的图片最后应该也要按照这个28*28的尺寸来制作,并且最后进行预测predict的时候,也要像训练集或者测试集一样,把图片转为一个784元素的数组。
准备代码
import keras
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Activation
from tensorflow.keras import datasets, utils
import matplotlib.pyplot as plt(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
x_train = x_train.reshape((-1, 28*28))
x_train = x_train.astype('float32')/255
x_test = x_test.reshape((-1, 28*28))
x_test = x_test.astype('float32')/255y_train = utils.to_categorical(y_train, num_classes=10)
y_test = utils.to_categorical(y_test, num_classes=10)print('x_train.shape', x_train.shape)
print('x_test.shape', x_test.shape)
print('y_train.shape', y_train.shape)
print('y_test.shape', y_test.shape)
"""
layer = [Dense(32, input_shape=(784,)),Activation('relu'),Dense(10),Activation('softmax')]model = Sequential(layer)
"""
model = Sequential()
# model.add(Dense(units=784, activation="relu", input_dim=784))
model.add(Dense(512, activation="relu", input_shape=(28*28, )))
model.add(Dense(10, activation="softmax"))model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()history = model.fit(x_train, y_train, epochs=5, batch_size=128, validation_data=(x_test, y_test))acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label="Training accuracy")
plt.plot(epochs, val_acc, 'b', label="Validation accuracy")
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
model.save("mnist.h5")
prediction = model.predict(x_test[:1], batch_size=32)
print(x_test[:1])
print(y_test[:1])
print(prediction)
print(np.argmax(prediction, axis=1))这个代码在引入了相关库之后,进行的第一件事就是数据处理:
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
x_train = x_train.reshape((-1, 28*28))
x_train = x_train.astype('float32')/255
x_test = x_test.reshape((-1, 28*28))
x_test = x_test.astype('float32')/255
y_train = utils.to_categorical(y_train, num_classes=10)
y_test = utils.to_categorical(y_test, num_classes=10)print('x_train.shape', x_train.shape)
print('x_test.shape', x_test.shape)
print('y_train.shape', y_train.shape)
print('y_test.shape', y_test.shape)我们的数据集x_train,x_test就是我们的图片数据,这个数据是784个元素组成的数组,我们先进行转矩阵,然后对像素点取模,得到0-1之间的值。我们代码最后打印了x_test[:1],可以看看它的样子:
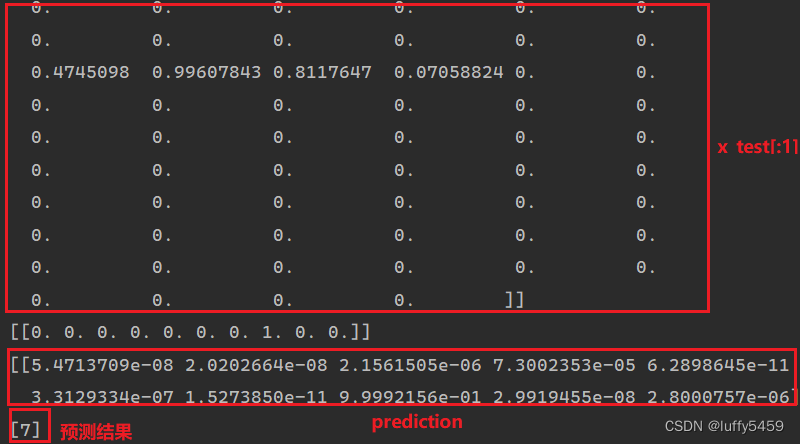
这里我们还使用了utils.to_categorical(y_test,num_classes=10) 对我们的目标进行了one-hot转码。通过这个图我们也看到了,数字 7 转了one-hot编码之后,变为了[0,0,0,0,0,0,0,1,0,0]。
这个代码构建了一个简单的神经网络,也就两层,
第一层输入层 Dense(512,activation="relu",input_shape=(28*28, )) #512个节点,relu激活函数,输入形状或者维度 28*28=784。代码中也给出了另一种通过input_dim来指定维度的方法,意思是一样的,但是那种写法model.add(Dense(units=784, activation="relu", input_dim=784))指定的网络节点units=784。这个数字可以随便定义。手写数字识别里面,设置512,784都可以。
第二层输出层 Dense(10, activation="softmax") #这里指定对应十个分类,也就是数字0,1,2,3,4,5,6,7,8,9的个数。手写数字识别是一个多分类问题。
没有隐藏层,也没有其他的Dropout。就是简单神经网络。
另外,代码中还给出了一种构建神经网络的办法:
layer = [Dense(32, input_shape=(784,)),Activation('relu'),Dense(10),Activation('softmax')]model = Sequential(layer)意思是一样的,只不过,这里units=32,也就是输入层由32个神经网络节点组成。
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()这是编译神经网络和打印神经网络概要。
编译神经网络传入loss="categorical_cressentropy" 表示损失函数求的是交叉熵。optimizer="adam",表示优化器是adam,表示自适应算法,另外,也有可能会看到sgd,随机梯度下降算法,或者rmsprop也是一种自适应算法。metrics=["accuracy"]统计指标,这里指定成功率。
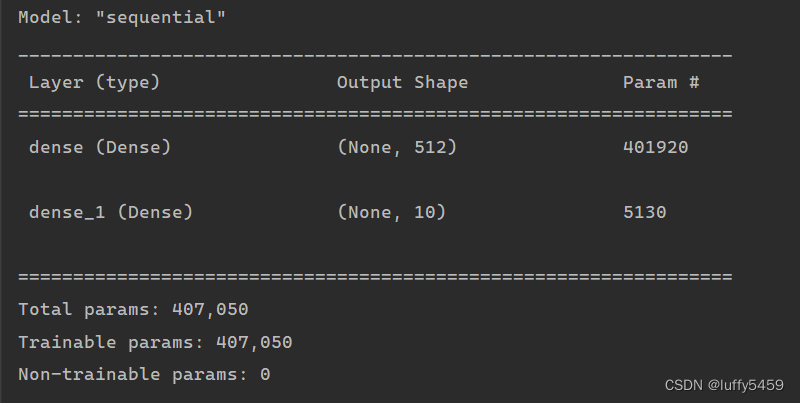
通过model.summary()我们可以看到神经网络节点信息:
history = model.fit(x_train, y_train, epochs=5, batch_size=128, validation_data=(x_test, y_test))这里是把训练和测试神经网络放在一起了,我们传入的validation_data指定了测试数据集。如果不指定validation_data,那么后面,我们通过model.evaluate(x_test,y_test) 也可以得到loss,acc等数据。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label="Training accuracy")
plt.plot(epochs, val_acc, 'b', label="Validation accuracy")
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
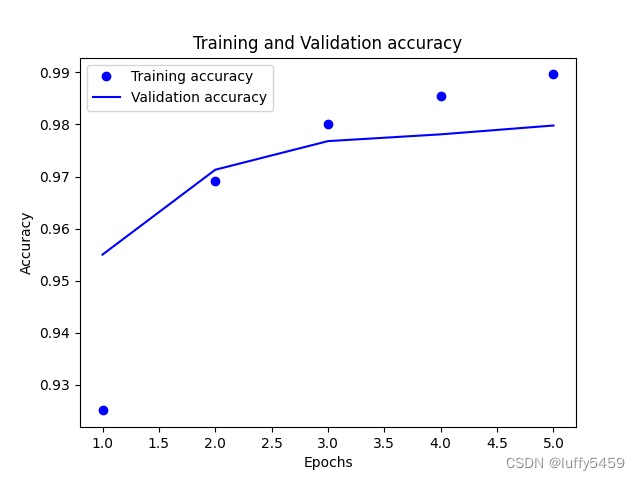
plt.show()我们通过matplot来展示acc,val_acc等信息,结果如下图所示:
我们还通过model.save("mnist.h5")保存模型,后面我们会加载这个模型来进行预测。
prediction = model.predict(x_test[:1], batch_size=32)
print(x_test[:1])
print(y_test[:1])
print(prediction)
print(np.argmax(prediction, axis=1))我们简单通过测试集的第一个数字7来进行了一个验证,这个验证,主要是要知道我们将来传入图片需要什么类型的数据,以及得到预测结果之后,怎么取值。这里prediction是一个按照概率来进行组装的数组,哪个概率大,最终的结果就是谁。我们通过np.argmax(prediction, axis=1)指定获取一个数组中按行(axis=1)来统计最大的那个数。
***************************************************************
预测
很多代码示例里面,基本上到了model.evaluate()对算法进行评估之后,就没有了,对于刚入门的人来说,神经网络创建了,测试了,好不好用也不知道。因为这个训练集和测试机都是官网给出的例子,对于程序员来说,通过实践来验证一个猜测,那才是最重要的,至于这是什么不重要。
上面的代码最后,我们通过测试集x_test[:1]也就是第一个测试数字简单做了一个预测,大概知道了要预测,需要的数据是一个[28*28=784]的数组。而我们准备的测试图片应该也要和官方给出的测试数据对应上,也即是前面提到的图片是28*28像素的数字图片,如下所示:










同样的给出代码:
import keras
import numpy as np
import cv2
from keras.models import load_modelmodel = load_model("mnist.h5")def predict(img_path):img = cv2.imread(img_path, 0)img = img.reshape(28, 28).astype("float32") / 255 # 0 1img = img.reshape(-1, 784) # 28 * 28 -> 784label = model.predict(img)label = np.argmax(label, axis=1)print('{} -> {}'.format(img_path, label[0]))if __name__ == '__main__':for _ in range(10):predict("number_images/b_{}.png".format(_))
这些图片我们放在number_images目录下,命名规则是b_0.png,b_1.png这样子。
最后,我们加载模型,并通过opencv库加载图片,并转换图片矩阵为784个元素的数组。然后交给模型预测,预测结果是一个概率数组,取概率最大的那个数组元素。
预测结果如下:
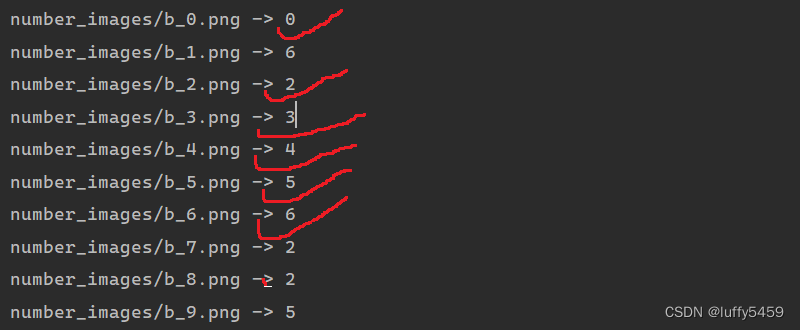
结果很感人,并没有达到很高的概率,准确率60%,而且这个概率对于手写图片识别来说,还有点偏高,因为实际上很多数字图片识别错误。
这篇文章,主要就keras构建简单神经网络,并进行训练,测试,最后还通过我们自己手写的数字图片来进行预测验证,也过了一把深度学习的瘾。
本文keras和tensorflow版本是2.8.0,可能有几个api与其他地方有区别,比如datasets,这里使用的是tensorflow.keras.datasets。另外在计算成功率acc的时候,使用的是history['accuracy'],有的地方可能直接是history['acc'],应该是版本的问题,根据自己的版本找到合适的方法就行。
相关文章:
keras深度学习框架通过简单神经网络实现手写数字识别
背景 keras深度学习框架,并不是一个独立的深度学习框架,它后台依赖tensorflow或者theano。大部分开发者应该使用的是tensorflow。keras可以很方便的像搭积木一样根据模型搭出我们需要的神经网络,然后进行编译,训练,测试…...

React 中的 ref 如何操作 dom节点,使输入框获取焦点
聚焦文字输入框 .focus() 获取焦点 当用户点击按钮时,handleClick 函数会被调用,从而将焦点聚焦到文本输入框上。 // 焦文字输入框 import { useRef } from "react";const FocusForm () > {const inputRef useRef<any>(null);func…...

最短路Dijkstra,spfa,图论二分图算法AYIT---ACM训练(模板版)
文章目录 前言A - Dijkstra Algorithm0x00 算法题目0x01 算法思路0x02 代码实现 B - 最长路0x00 算法题目0x01 算法思路0x02 代码实现 C - 二分图最大匹配0x00 算法题目0x01 算法思路0x02 代码实现 D - 搭配飞行员0x00 算法题目0x01 算法思路0x02 代码实现 E - The Perfect Sta…...

AK 微众银行 9.3 笔试 Java后端方向
T1(模拟,二分) (没看清买的糖果只有前缀,一开始用二分写了,后来意识到也没改了,简单写的话,直接模拟就好了) #include <bits/stdc.h>#define endl \nusing namespace std;const int N 50010;int n; int a[N];bool check(…...
了解java中的通配符“?“
目录 通配符的作用 先看一段代码 用通配符"?"后,代码变化 结论 通配符上界 通配符下界 对通配符上下界的注释理解及其练习代码 简记: ? 用于在泛型的使用,即为通配符. 在Java中,通配符(wildcard)主要用于泛型…...

浙大陈越何钦铭数据结构07-图6 旅游规划【最小堆实现】
题目: 题目和浙大陈越何钦铭数据结构07-图6 旅游规划是一样的,不同的是用最小堆实现函数【FindMinDist】。 时间复杂度对比: 浙大陈越何钦铭数据结构07-图6 旅游规划: 创建图(CreateGraph):时…...
OpenShift 4 - 用 Prometheus 和 Grafana 监视用户应用定制的观测指标(视频)
《OpenShift / RHEL / DevSecOps 汇总目录》 说明:本文已经在 OpenShift 4.13 的环境中验证 文章目录 OpenShift 的监控功能构成部署被监控应用用 OpenShift 内置功能监控应用用 Grafana 监控应用安装 Grafana 运行环境配置 Grafana 数据源定制监控 Dashboard 演示视…...
【LeetCode】剑指 Offer <二刷>(3)
目录 题目:剑指 Offer 06. 从尾到头打印链表 - 力扣(LeetCode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 07. 重建二叉树 - 力扣…...

Ceph IO流程及数据分布
1. Ceph IO流程及数据分布 1.1 正常IO流程图 步骤: client 创建cluster handler。client 读取配置文件。client 连接上monitor,获取集群map信息。client 读写io 根据crshmap 算法请求对应的主osd数据节点。主osd数据节点同时写入另外两个副本节点数据。…...

Netty-NIO
文章目录 一、NIO-Selector1.处理accept2.cancel3.处理read4.处理客户端断开5. 处理消息的边界6. 写入内容过多的问题7. 处理可写事件 一、NIO-Selector 1.处理accept //1.创建selector,管理多个channel Selector selector Selector.open(); ByteBuffer buffer ByteBuffer.…...

红外物理学习笔记 ——第三章
第三章 基尔霍夫定律:就是说物体热平衡条件下,发射的辐射功率要等于吸收的辐射功率 M α E M\alpha E MαE α \alpha α 是吸收率, M M M 是幅出度(发射出去的), E E E是辐照度(外面照过来的…...

使用 htmx 构建交互式 Web 应用
学习目标:了解htmx的基本概念、特点和用法,并能够运用htmx来创建交互式的Web应用程序。 学习内容: 1. 什么是htmx? - htmx是一种用于构建交互式Web应用程序的JavaScript库。 - 它通过将HTML扩展为一种声明性的交互式语言&a…...
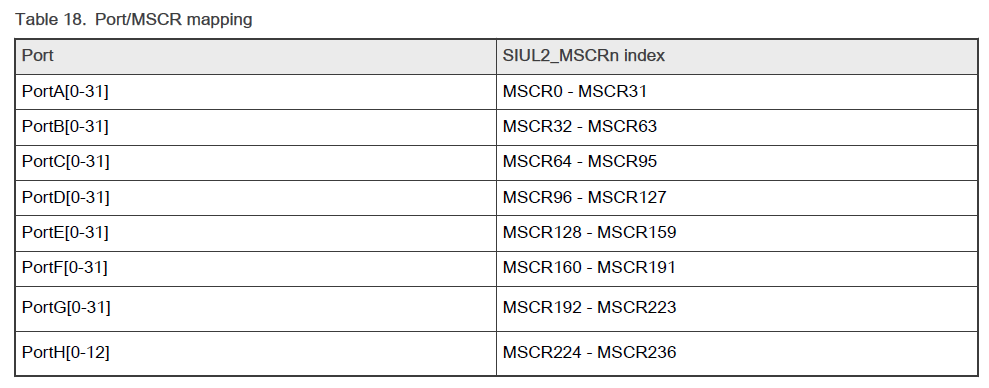
S32K324芯片学习笔记
文章目录 Core and architectureDMASystem and power managementMemory and memory interfacesClocksSecurity and integrity安全与完整性Safety ISO26262Analog、Timers功能框图内存mapflash Signal MultiplexingPort和MSCR寄存器的mapping Core and architecture 两个Arm Co…...

htmx-使HTML更强大
本文作者是360奇舞团开发工程师 htmx 让我们先来看一段俳句: javascript fatigue: longing for a hypertext already in hand 这个俳句很有意思,是开源项目htmx文档中写的,意思是说,我们已经有了超文本,为什么还要去使用javascr…...
Java学习之序列化
1、引言 《手册》第 9 页 “OOP 规约” 部分有一段关于序列化的约定 1: 【强制】当序列化类新增属性时,请不要修改 serialVersionUID 字段,以避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请…...
C++实现蜂群涌现效果(flocking)
Flocking算法0704_元宇宙中的程序员的博客-CSDN博客 每个个体的位置,通过计算与周围个体的速度、角度、位置,去更新位置。...
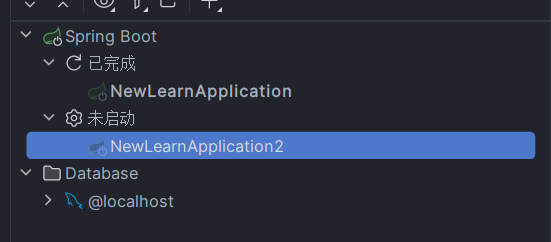
IDEA复制一个工程为多个并启动,测试负载均衡
1 找到服务按钮 2 选择复制配置 3 更改新的名称与虚拟机参数 复制下面的代码在VM参数中 -Dserver.port8082 4 最后启动即可...

001_C++语法基础
C语法基础 所有C语法要用英文区分大小写每个语句写完以分号结束 C标准输入输出头文件iostream 若想通过C实现数据的输入和输出,需要导入标准输入输出头文件 #include <iostream>标准输入输出头文件<iostream>中包含了cin输入语句和cout输出语句 标…...
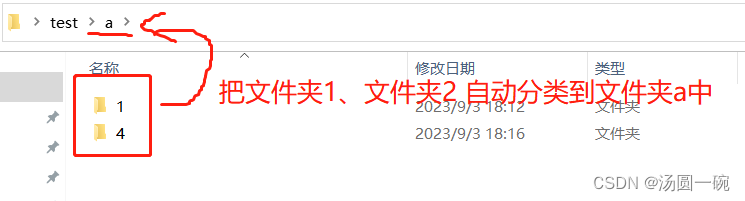
对Excel表中归类的文件夹进行自动分类
首先把excel表另存为.txt文件(注意:刚开始可能是ANSI格式,需要转成UTF-8格式);再新建一个.txt文件,重命名成.bat文件(注意:直接创建的如果是是UTF-8格式,最好转成ANSI格式࿰…...
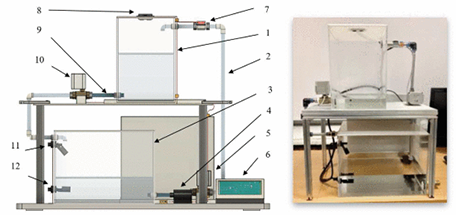
LabVIEW液压支架控制系统的使用与各种配置的预测模型的比较分析
LabVIEW液压支架控制系统的使用与各种配置的预测模型的比较分析 模型预测控制在工业中应用广泛。这种方法的优点之一是在求解最优控制问题时能够明确考虑对输入和输出状态施加的约束。控制对象模型用于有限时间范围内最优控制的实时计算。所使用的数学设备允许从具有单输入和单…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...
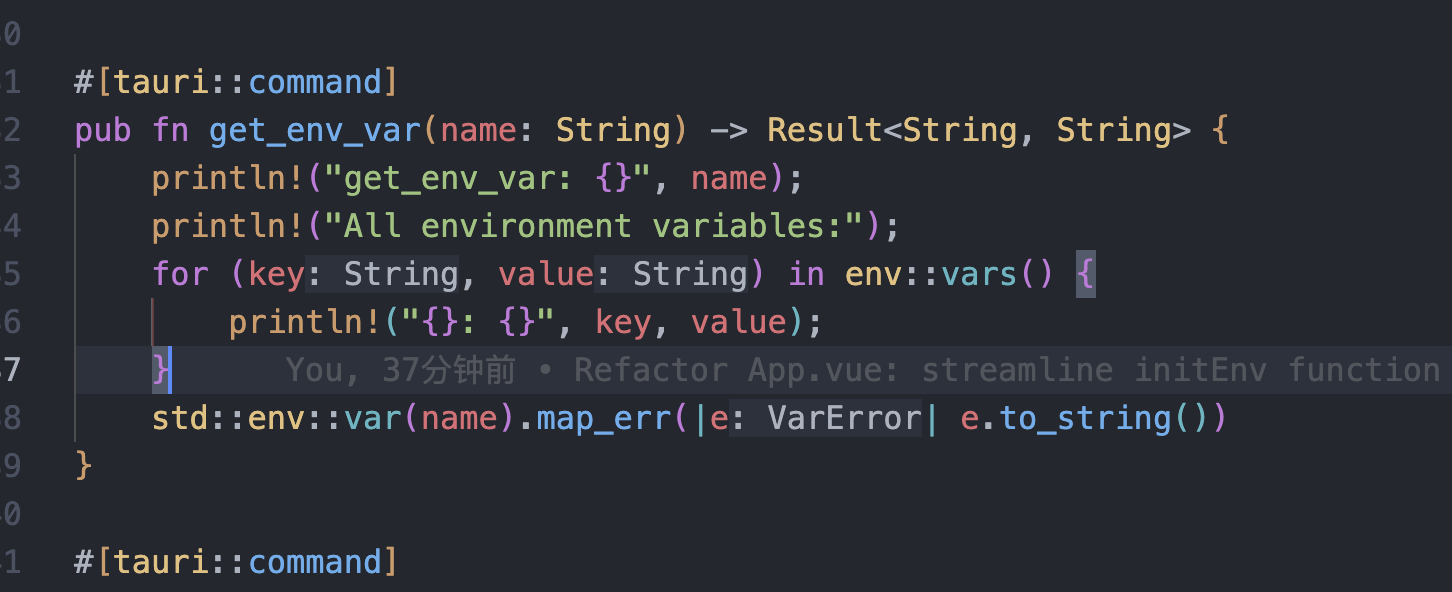
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...