networkX-03-连通度、全局网络效率、局部网络效率、聚类系数计算
文章目录
- 1.连通度
- 1.1 检查图是否连通
- 1.2 检查有向图是否为强连通
- 1.3 点连通度、边连通度:
- 2.网络效率
- 2.1全局效率
- 2.2 局部效率
- 2.2.1 查找子图
- 2.2.3 局部效率源码分析
- 3.聚类系数(Clustering Coefficient)
- 3.1 聚类系统源码分析
教程仓库地址:github networkx_tutorial
本文从指标公式出发,计算网络的连通度、全局效率、局部效率、聚类系数,有需要的同学可在仓库下载ipynb文件进行练习.
1.连通度
- 文字部分来自GPT-4

import networkx as nx
import matplotlib. pyplot as plt
# 创建一个无向图
G = nx.Graph()
# 添加边
G.add_edges_from([(0, 1), (1, 2), (2, 3), (3, 4), (4, 0), (0, 2)])
# # 绘制图形
nx.draw(G,node_size=500,with_labels=True)

1.1 检查图是否连通
# 检查图是否连通
is_connected = nx.is_connected(G)
print(f"The graph is connected: {is_connected}")
The graph is connected: True
1.2 检查有向图是否为强连通
# 创建一个有向图
DG = nx.DiGraph()
DG.add_edges_from([(0, 1), (1, 2), (2, 3), (3, 4), (4, 0), (0, 2)])
nx.draw(DG,node_size=500,with_labels=True)

# 检查图是否强连通
is_strongly_connected = nx.is_strongly_connected(DG)
print(f"The directed graph is strongly connected: {is_strongly_connected}")
The directed graph is strongly connected: True
1.3 点连通度、边连通度:

# 计算点连通度
node_connectivity = nx.node_connectivity(G)
print("节点连通度:", node_connectivity)
# 计算边连通度
edge_connectivity = nx.edge_connectivity(G)
print("边连通度:", edge_connectivity)
节点连通度: 2
边连通度: 2
2.网络效率

2.1全局效率

# 创建一个简单的无向图
G = nx.Graph()
G.add_nodes_from([1, 2, 3, 4])
G.add_edges_from([(1, 2), (1, 3), (2, 3), (3, 4)])# 绘制图形
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', node_size=500, font_size=16, font_weight='bold')
labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=labels, font_size=12, font_color='red')
plt.show()

#计算指定节点对之间的效率:节点之间最短路径的倒数
nx.efficiency(G,2,4) # 2,4 之间的最短路径长度为2,则两节点之间的效率为1/2
0.5
# 全局网络效率官方函数
nx.global_efficiency(G)
0.8333333333333334
# 源码
def global_effi(G):n = len(G)denom = n * (n - 1)if denom != 0:lengths = nx.all_pairs_dijkstra_path_length(G)g_eff = 0for source, targets in lengths:for target, distance in targets.items():if distance > 0:g_eff += 1 / distanceg_eff /= denom# g_eff = sum(1 / d for s, tgts in lengths# for t, d in tgts.items() if d > 0) / denomelse:g_eff = 0# path lengths in parallel.return g_effglobal_effi(G=G)
0.8333333333333334
2.2 局部效率
2.2.1 查找子图

# 定义要查找的节点子集
node_subset = [1, 2, 3]
# 查找诱导子图
induced_subgraph = G.subgraph(node_subset)
nx.draw(induced_subgraph,with_labels = True)

# 查找生成子图
spanning_subgraph = G.subgraph(G.nodes())
nx.draw(spanning_subgraph,with_labels = True)

2.2.3 局部效率源码分析
nx.local_efficiency(G)
0.5833333333333334
# 源码
sum = 0 # 初始化 ,所有节点和其构成的子图 ,对应的全局效率的值
len(G) # G的节点数for v in G: # 遍历每个节点print('---{}节点的子图是----'.format(v))# 找到每个节点的和其邻居构成的子图# fig,ax = plt.subplots()# nx.draw(G.subgraph(G[v]),with_labels = True,ax=ax)g_effi = nx.global_efficiency(G.subgraph(G[v]))print('邻居节点{}全局效率为:{}'.format(v,g_effi))sum = sum+ g_effiprint("local_efficiency",sum/len(G)) #0.9166666666666667---1节点的子图是----
邻居节点1全局效率为:1.0
---2节点的子图是----
邻居节点2全局效率为:1.0
---3节点的子图是----
邻居节点3全局效率为:0.3333333333333333
---4节点的子图是----
邻居节点4全局效率为:0
local_efficiency 0.5833333333333334
3.聚类系数(Clustering Coefficient)


3.1 聚类系统源码分析
# 官方函数
for node in G.nodes():c = nx.clustering(G = G,nodes=node)print(f"节点 {node} 的聚类系数为 {c}")
节点 1 的聚类系数为 1.0
节点 2 的聚类系数为 1.0
节点 3 的聚类系数为 0.3333333333333333
节点 4 的聚类系数为 0
# 1. 计算节点的k ,ki:
# test_node : 3
node = 3
# 邻居
neighbors = list(G.neighbors(node))
# 度
k = len(neighbors)
k # 节点3对应的k为3
3
# 2. ei的计算
neighbors
for i in range(k):for j in range(i + 1, k):if G.has_edge(neighbors[i], neighbors[j]):# print(neighbors[i], neighbors[j])triplets += 1
triplets # 节点3对应的ei为3
2
节点的聚类系数
# 计算每个节点的聚类系数
for node in G.nodes():# 获取节点的邻居节点neighbors = list(G.neighbors(node))k = len(neighbors)if k < 2:# 如果邻居节点数少于 2,聚类系数为 0clustering = 0else:# 计算节点的三元组数量triplets = 0for i in range(k):for j in range(i + 1, k):if G.has_edge(neighbors[i], neighbors[j]):triplets += 1# 计算聚类系数clustering = 2 * triplets / (k * (k - 1))print(f"节点 {node} 的聚类系数为 {clustering}")
节点 1 的聚类系数为 1.0
节点 2 的聚类系数为 1.0
节点 3 的聚类系数为 0.3333333333333333
节点 4 的聚类系数为 0
整个网络的聚类系数C
nx.average_clustering(G=G)
0.5833333333333334
相关文章:
networkX-03-连通度、全局网络效率、局部网络效率、聚类系数计算
文章目录 1.连通度1.1 检查图是否连通1.2 检查有向图是否为强连通1.3 点连通度、边连通度: 2.网络效率2.1全局效率2.2 局部效率2.2.1 查找子图2.2.3 局部效率源码分析 3.聚类系数(Clustering Coefficient)3.1 聚类系统源码分析 教程仓库地址&…...
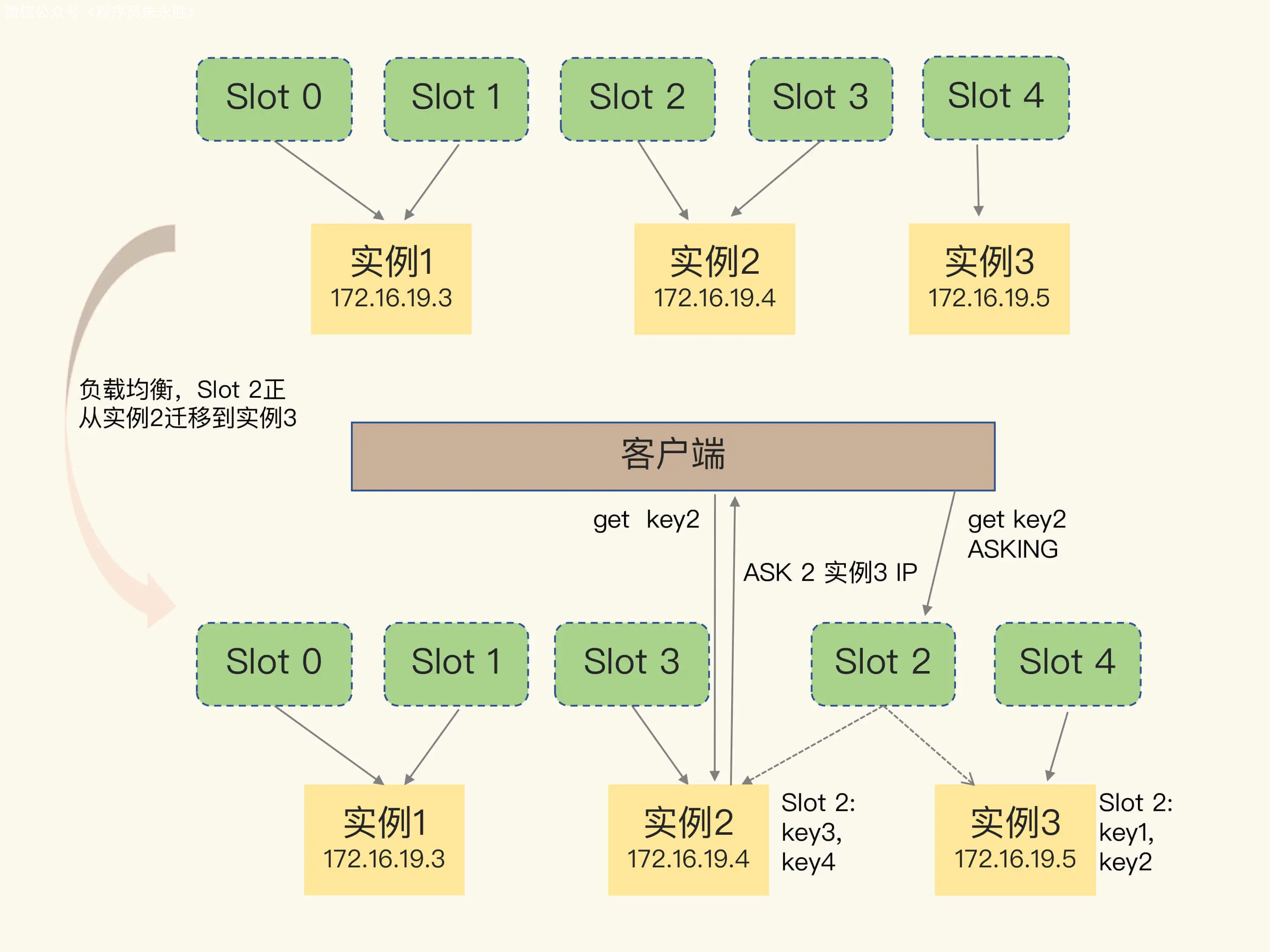
【深入解读Redis系列】Redis系列(五):切片集群详解
首发博客地址 https://blog.zysicyj.top/ 系列文章地址[1] 如果 Redis 内存很大怎么办? 假设一台 32G 内存的服务器部署了一个 Redis,内存占用了 25G,会发生什么? 此时最明显的表现是 Redis 的响应变慢,甚至非常慢。 这…...

无涯教程-JavaScript - NORMDIST函数
NORMDIST函数替代Excel 2010中的NORM.DIST函数。 描述 该函数返回指定均值和标准差的正态分布。此功能在统计中有非常广泛的应用,包括假设检验。 语法 NORMDIST(x,mean,standard_dev,cumulative)争论 Argument描述Required/OptionalXThe value for which you want the dis…...

递归应用判断是否循环引用
var data await _IDBInstance.DBOperation.QueryAsync<FormulaReference>(sql);//向上查询引用公式 List<FormulaReference> GetSonNode(long id, List<FormulaReference> nodeList, List<long> path null){if (path null){path new List<long…...

使用nginx-lua配置统一url自动跳转到hadoop-ha集群的active节点
下载安装nginx所用的依赖 yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel下载nginx wget http://nginx.org/download/nginx-1.12.2.tar.gz tar -xvf nginx-1.12.2.tar.gz稍后安装nginx 安装lua语言 yum install readline-develcurl -R -O http://w…...
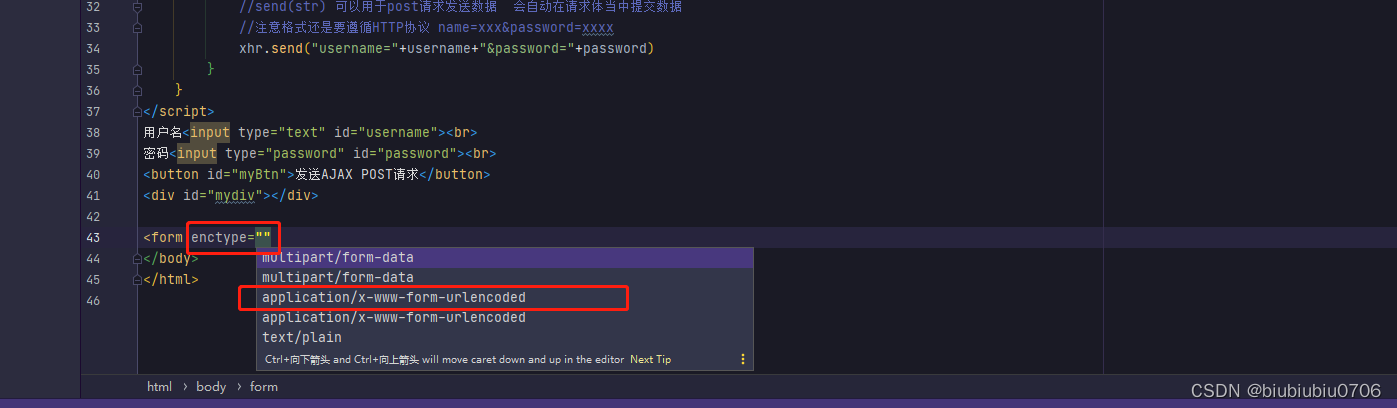
AJAX学习笔记2发送Post请求
AJAX学习笔记1发送Get请求_biubiubiu0706的博客-CSDN博客 继续 AJAX发送POST请求 无参数 测试 改回来 测试 AJAX POST请求 请求体中提交参数 测试 后端打断点 如何用AJAX模拟form表单post请求提交数据呢? 设置请求头必须在open之后,send之前 请求头里的设置好比…...

产品团队的需求分析指南
需求分析是软件开发流程中需求识别与管理的关键环节,需求分析的目的在于确保所有产品需求准确地代表了利益相关者的需求和要求。选择合适的需求分析方式可以帮助我们获取准确的产品需求,从而保证我们所交付的成果与利益相关者预期相符。 一、什么是需求…...
)
Python算法——排序算法(冒泡、选择、插入、快速、堆排序、并归排序、希尔、计数、桶排序、基数排序)
本文章只展示代码实现 ,原理大家可以参考: https://zhuanlan.zhihu.com/p/42586566 一、冒泡排序 def bubble_sort(lst):for i in range(len(lst) - 1): # 表示第i趟exchange False # 每一趟做标记for j in range(len(lst)-i-1): # 表示箭头if ls…...
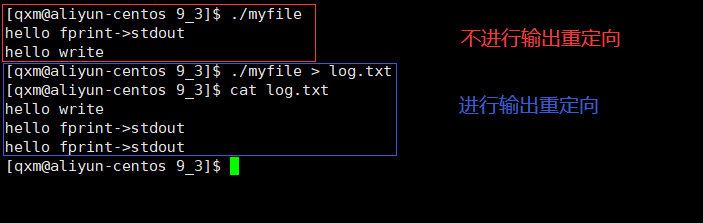
[Linux]文件描述符(万字详解)
[Linux]文件描述符 文章目录 [Linux]文件描述符文件系统接口open函数close函数write函数read函数系统接口与编程语言库函数的关系 文件描述符文件描述符的概念文件数据交换的原理理解“一切皆文件”进程默认文件描述符文件描述符和编程语言的关系 重定向输出重定向输入重定向追…...
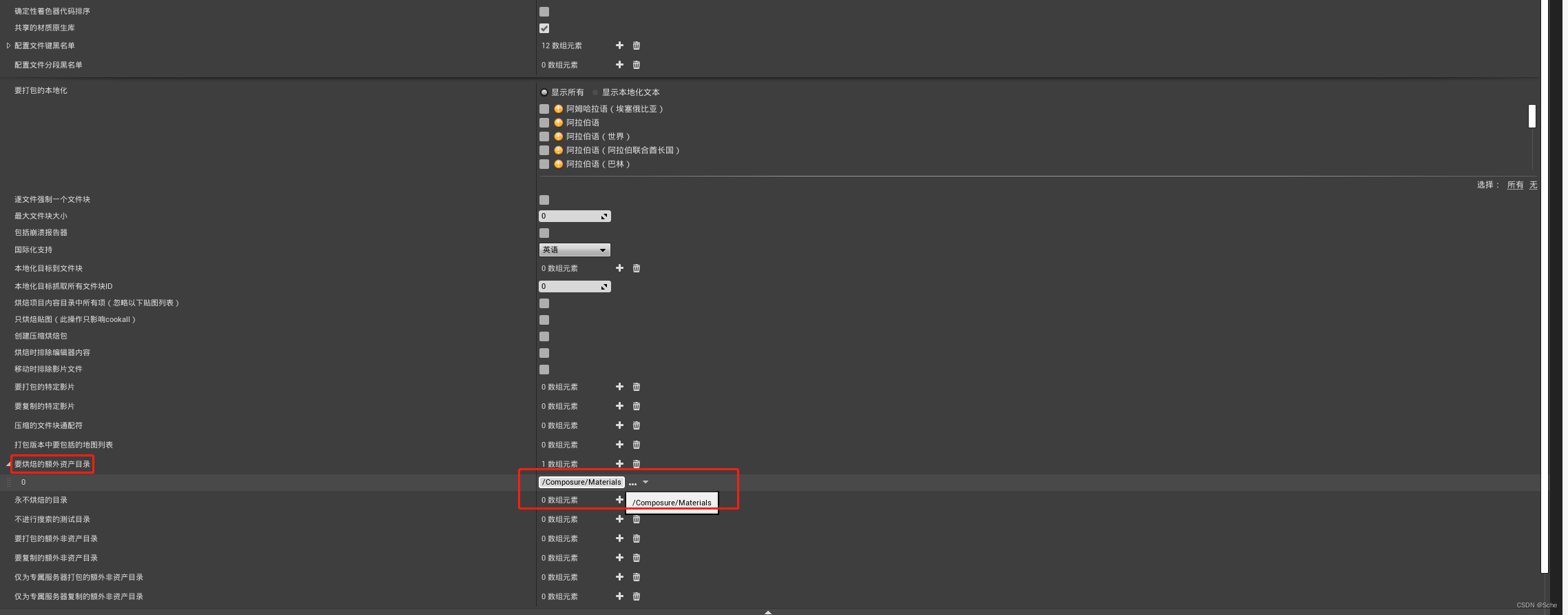
RenderTarget导出成图片,CineCamera相机
一、获取Cinecamera相机图像 1.1、启用UE自带插件 1.2、在UE编辑器窗口栏找到Composure合成,打开窗口 1. 3、右键空白处,新建合成,默认名称为 0010_comp;再右键新建的 0010_comp,新建图层元素 CGLayer层,默…...
深入探讨Java虚拟机(JVM):执行流程、内存管理和垃圾回收机制
目录 什么是JVM? JVM 执行流程 JVM 运行时数据区 堆(线程共享) Java虚拟机栈(线程私有) 什么是线程私有? 程序计数器(线程私有) 方法区(线程共享) JDK 1.8 元空…...
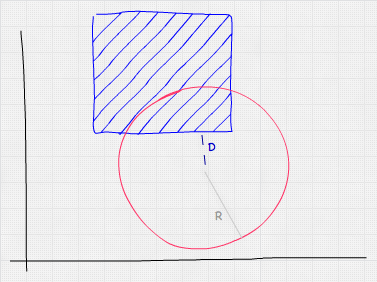
3D 碰撞检测
推荐:使用 NSDT场景编辑器快速搭建3D应用场景 轴对齐边界框 与 2D 碰撞检测一样,轴对齐边界框 (AABB) 是确定两个游戏实体是否重叠的最快算法。这包括将游戏实体包装在一个非旋转(因此轴对齐)的框中&#…...
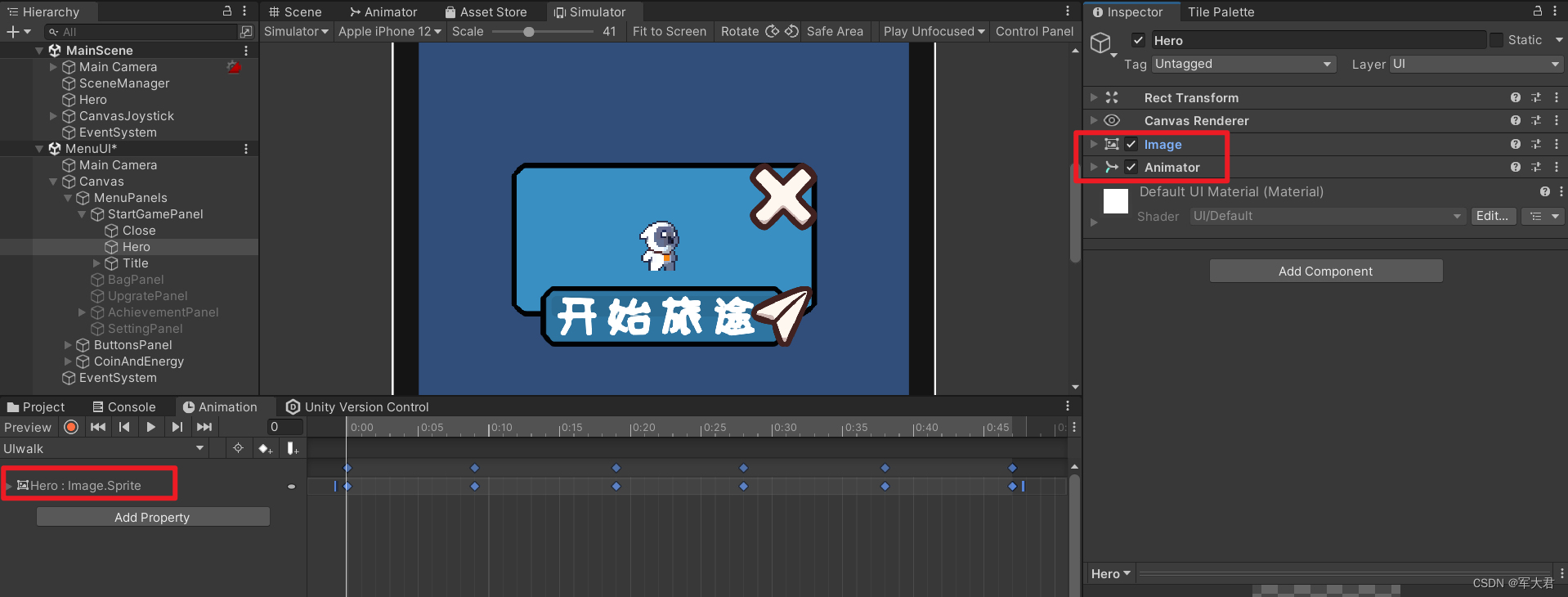
Unity Canvas动画不显示的问题
问题描述: 我通过角色创建了一个walk的动画,当我把这个动画给到Canvas里面的一个image上,这个动画就不能正常播放了,经过一系列的查看我才发现,canvas里面动画播放和非canvas得动画播放,他们的动画参数是不一样的。一个…...

NSSCTF2nd与羊城杯部分记录
文章目录 前言[NSSCTF 2nd]php签到[NSSCTF 2nd]MyBox[NSSCTF 2nd]MyHurricane[NSSCTF 2nd]MyJs[NSSCTF 2nd]MyAPK羊城杯[2023] D0nt pl4y g4m3!!!羊城杯[2023]ezyaml羊城杯[2023]Serpent羊城杯[2023]EZ_web羊城杯[2023]Ez_misc总结 前言 今天周日,有点无聊没事干&a…...

数据库(一) 基础知识
概述 数据库是按照数据结构来组织,存储和管理数据的仓库 数据模型 数据库系统的核心和基础是数据模型,数据模型是严格定义的一组概念的集合。因此数据模型一般由数据结构、数据操作和完整性约束三部分组成。数据模型主要分为三种:层次模型,网状模型和关…...
vue从零开始学习
npm install慢解决方法:删掉nodel_modules。 5.0.3:表示安装指定的5.0.3版本 ~5.0.3:表示安装5.0X中最新的版本 ^5.0.3: 表示安装5.x.x中最新的版本。 yarn的优点: 1.速度快,可以并行安装 2.安装版本统一 项目搭建: 安装nodejs查看node版本:node -v安装vue clie : np…...
dji uav建图导航系列(三)模拟建图、导航
前面博文【dji uav建图导航系列()建图】、【dji uav建图导航系列()导航】 使用真实无人机和挂载的激光雷达完成建图、导航的任务。 当需要验证某一个slam算法时,我们通常使用模拟环境进行测试,这里使用stageros进行模拟测试,实际就是通过模拟器,虚拟一个带有传感器(如…...
PixelSNAIL论文代码学习(1)——总体框架和平移实现因果卷积
文章目录 引言正文目录解析README.md阅读Setup配置Training the model训练模型Pretrained Model Check Point预训练的模型训练方法 train.py文件的阅读model.py文件阅读h12_noup_smallkey_spec模型定义_base_noup_smallkey_spec模型实现一、定义因果卷积过程通过平移实现因果卷…...

Python大数据处理利器之Pyspark详解
摘要: 在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据成为了关键。Python在数据处理方面表现得尤为突出。而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark…...

S905L3A(M401A)拆解, 运行EmuELEC和Armbian
关于S905L3A / S905L3AB S905Lx系列没有公开资料, 猜测是Amlogic用于2B的芯片型号, 最早的 S905LB 是 S905X 的马甲, 而这个 S905L3A/S905L3AB 则是 S905X2 的马甲, 因为在性能评测里这两个U的得分几乎一样. S905L3A/S905L3AB 和 S905X2, S905X3 一样 GPU 是 G31, 相比前一代的…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...