【python爬虫】13.吃什么不会胖(爬虫实操练习)
文章目录
- 前言
- 项目实操
- 明确目标
- 分析过程
- 代码实现
前言
吃什么不会胖——这是我前段时间在健身时比较关注的话题。
相信很多人,哪怕不健身,也会和我一样注重饮食的健康,在乎自己每天摄入的食物热量。
不过,生活中应该很少有人会专门去统计自己每日摄入的食物热量。显然这样做多少有一些麻烦。可能你得下载一个专门查询热量的APP,填写食物的名字,一个个地去查询。
但其实利用爬虫,我们可以很简单就爬取到这些食物的热量信息,不用费力就能知道自己摄入了多少食物热量。
食物的数量有千千万,如果我们要爬取食物热量的话,这个数据量必然很大。
可能你会想到可以使用多协程来爬取。确实,使用多协程来爬取大量的数据是非常合理且明智的选择。
关于多协程的用法,我们在上一关已经讲过了,这里照旧简单复习一下。
项目实操
说回爬取食物热量的事,如果我们要爬取的话,那就得选定一个有存储食物热量信息的网站才能爬到数据。
我倒是知道一个这样的网站——薄荷网。它是一个跟健身减肥有关,且可以查询食物数据的网站。
我们选取这个网站进行食物热量的爬取的话,既能将上一关学到的协程知识实践起来,又能获得一份食物热量表,还是蛮两全其美的。
那么,我们这一关的项目就可以定为:用多协程爬取薄荷网的食物热量。
你也知道,我们在做一个项目时,不是上来就写代码的,最先要做的是明确目标。
明确目标
现在,请你先用浏览器打开薄荷网的链接:
http://www.boohee.com/food/
打开了吗?一定要真的打开了哦!
简单浏览一下这个网站,你会发现一共有11个常见食物分类——
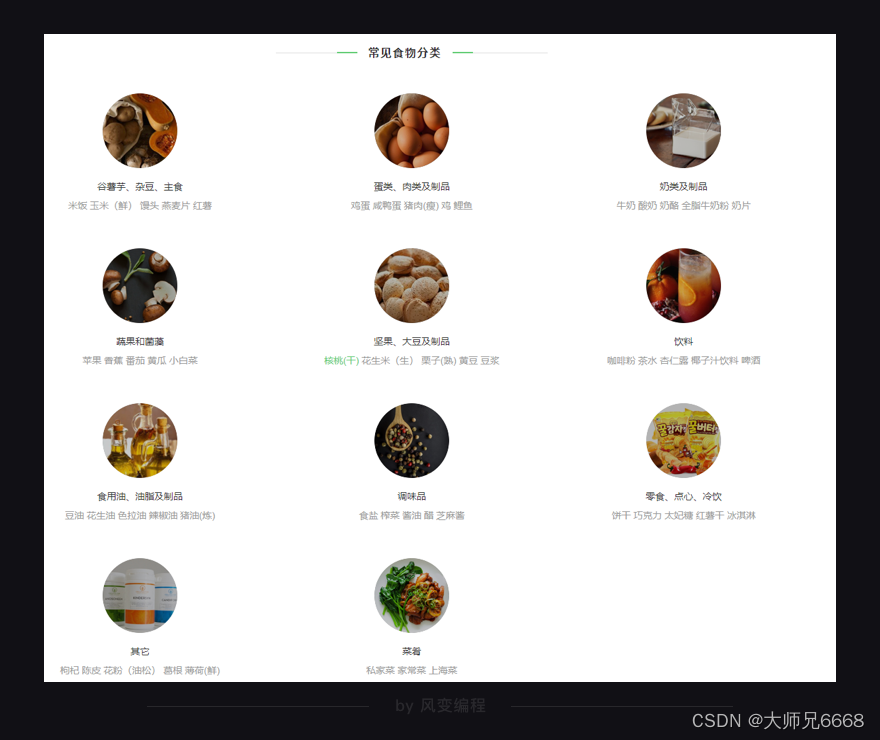
点击【谷薯芋、杂豆、主食】这个分类,你会看到在食物分类的右边,有10页食物的记录,包含了这个分类里食物的名字,及其热量信息。点击食物的名字还会跳转到食物的详情页面。
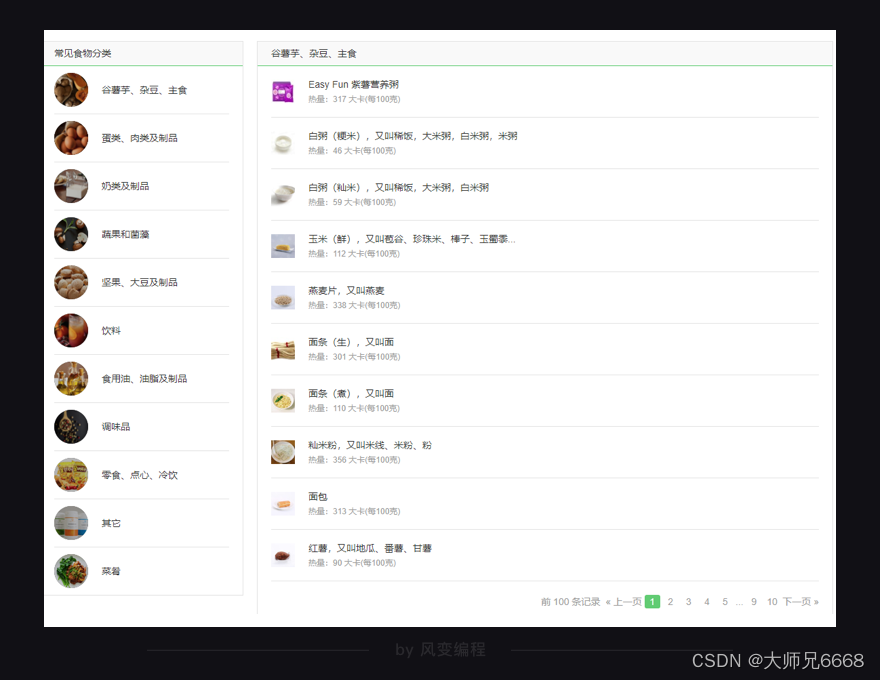
至此,我们的项目目标可以定为:用多协程爬取薄荷网11个常见食物分类里的食物信息(包含食物名、热量、食物详情页面链接)。
分析过程

目标明确好后,我们接着【分析过程】,这一步骤对于项目成功与否起着关键的作用。
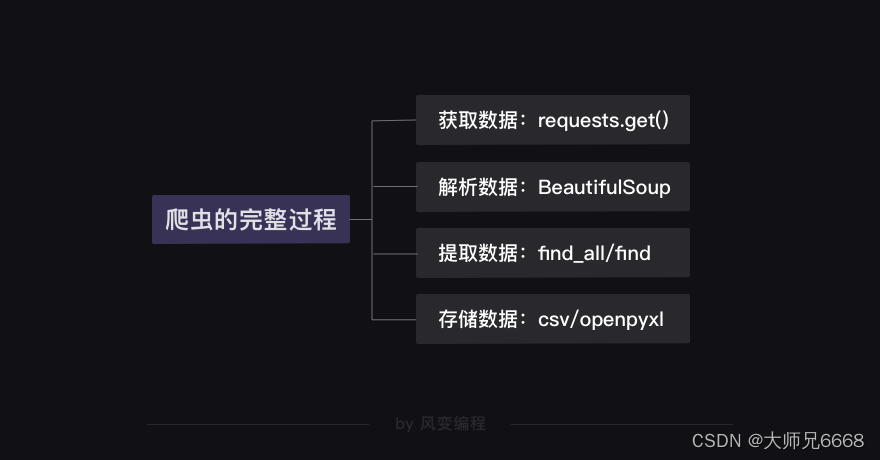
我们可以从爬虫四步(获取数据→解析数据→提取数据→存储数据)入手,开始逐一分析。
想要获得食物热量的数据,我们得先判断这些数据具体存在哪里。
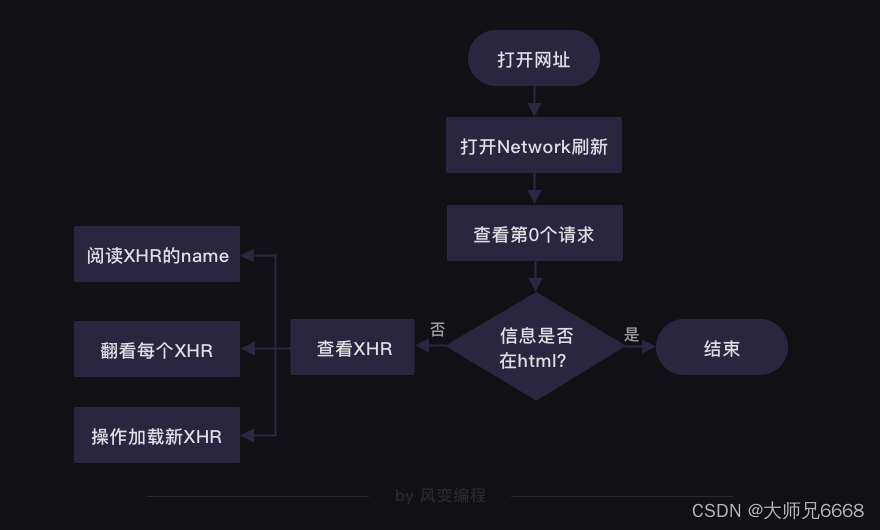
第7关的时候,我们讲过判断数据存储在哪里的方法。请你打开http://www.boohee.com/food/group/1网站,右击打开“检查”工具,并点击Network,然后刷新页面。点击第0个请求1,看Response。
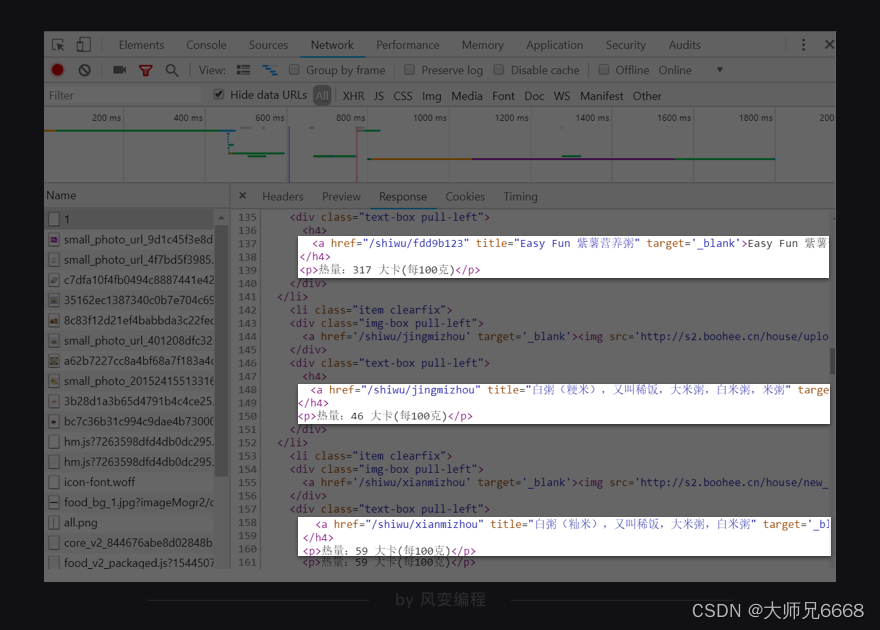
我们能在Response里找到食物的信息,说明我们想要的数据存在HTML里。
再看第0个请求1的Headers,可以发现薄荷网的网页请求方式是get。
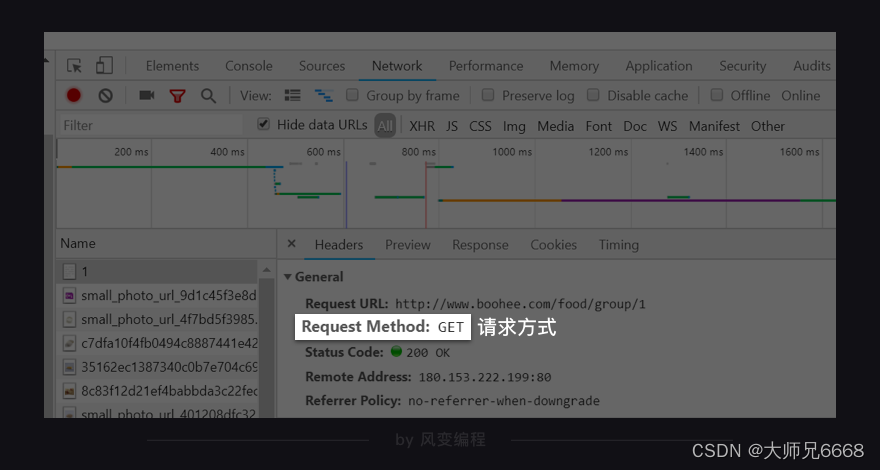
知道了请求方式是get,我们就知道可以用requests.get()获取数据。
先关闭“检查”工具。我们接着来观察,每个常见食物分类的网址和每一页食物的网址有何规律。
点击第一个分类【谷薯芋、杂豆、主食】,网址显示的是:
http://www.boohee.com/food/group/1
点击第二个分类【蛋类、肉类及制品】,网址变成:
http://www.boohee.com/food/group/2
我们可以做个猜想:网址的group参数代表着常见食物分类,后面的数字代表着这是第几个类。
只要再多点击几个常见食物分类看看,就能验证我们的猜想。

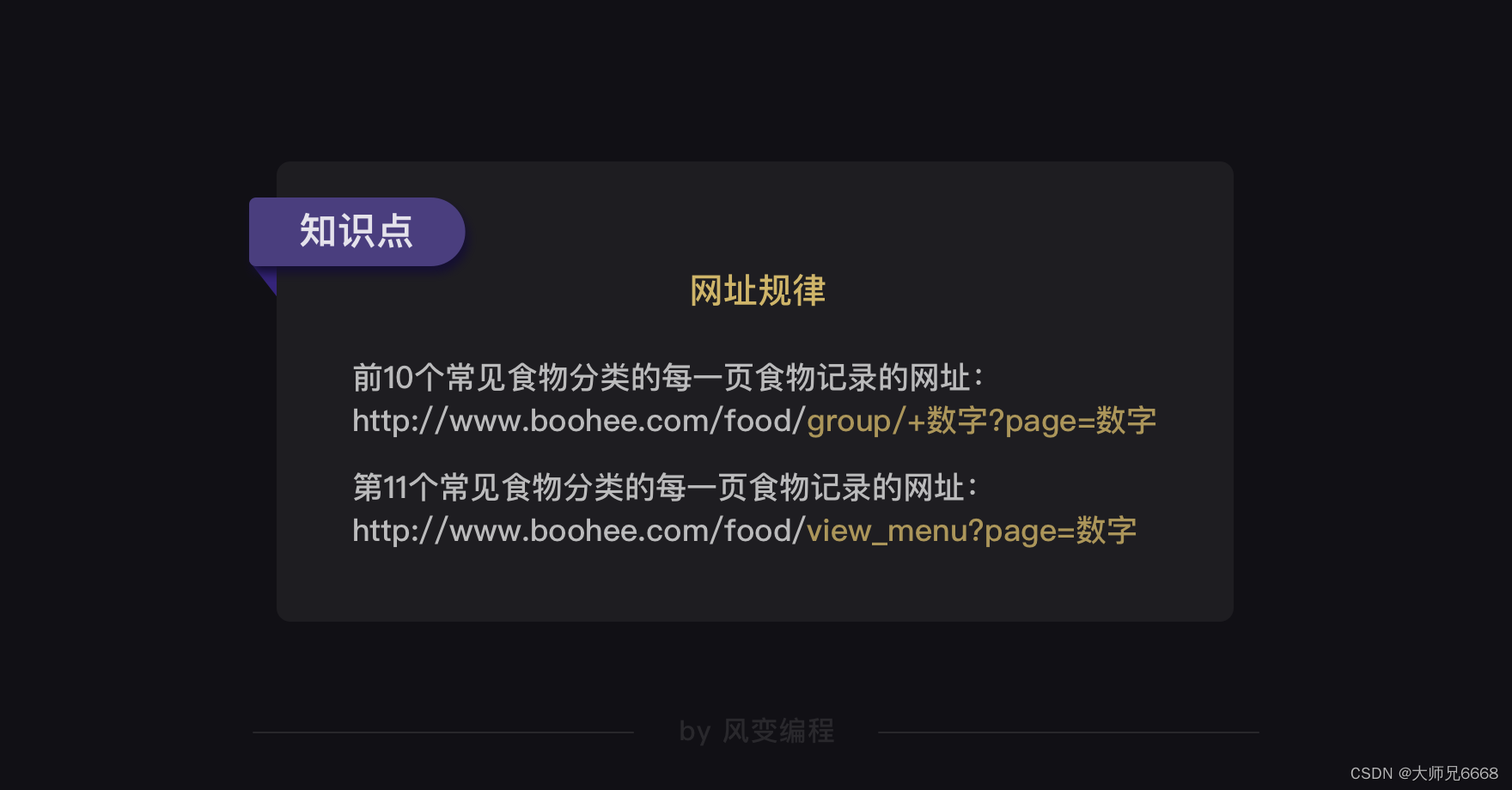
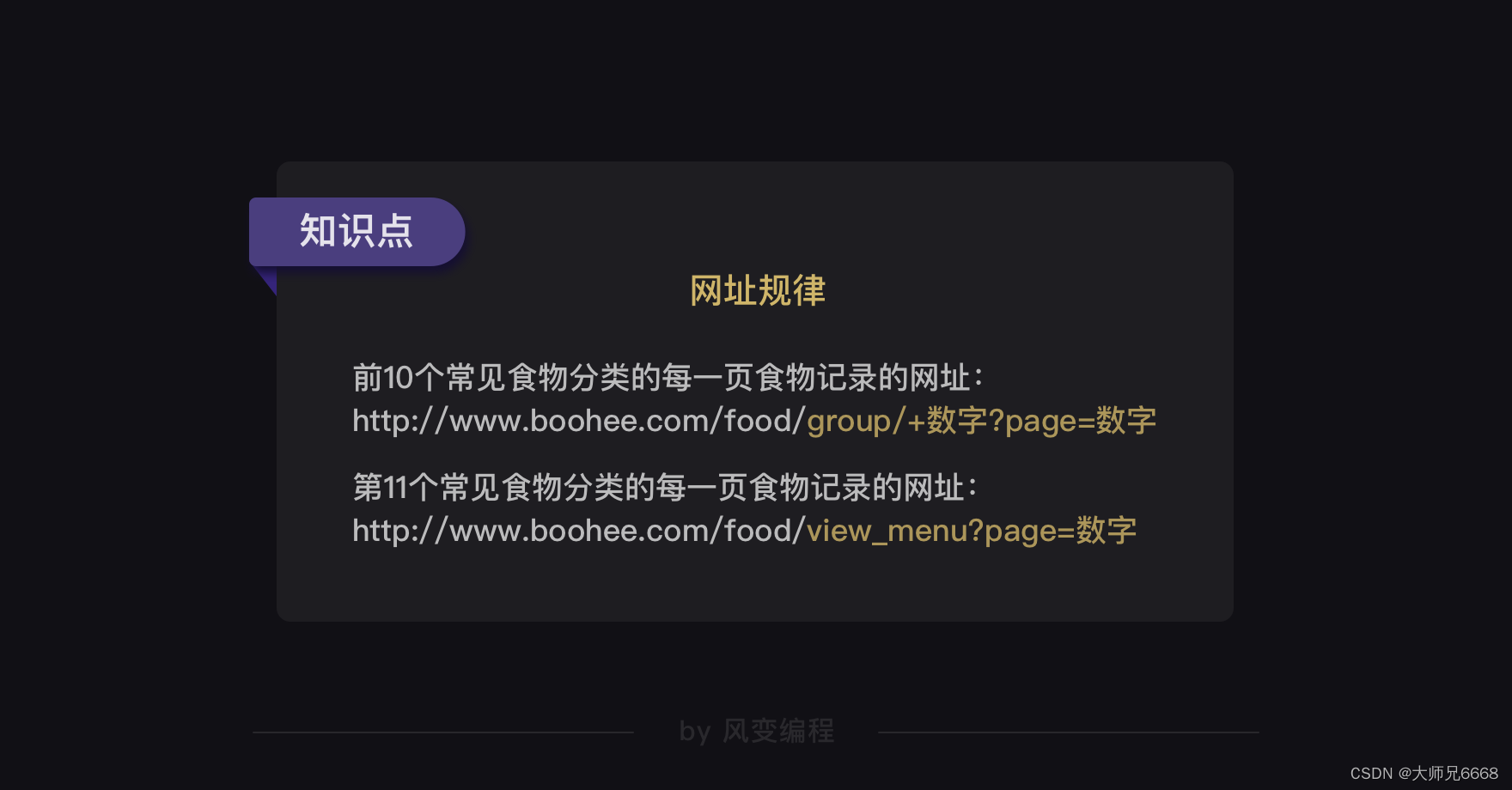
果然,常见食物分类的网址构造是有规律的。前10个常见食物分类的网址都是:
http://www.boohee.com/food/group/+数字
唯独最后一个常见食物分类【菜肴】的网址与其他不同,是:
http://www.boohee.com/food/view_menu
每个常见食物分类网址的规律我们找到了。现在看回【谷薯芋、杂豆、主食】这个分类,点击翻到第2页的食物记录,我们看看网址又会发生怎样的变化。
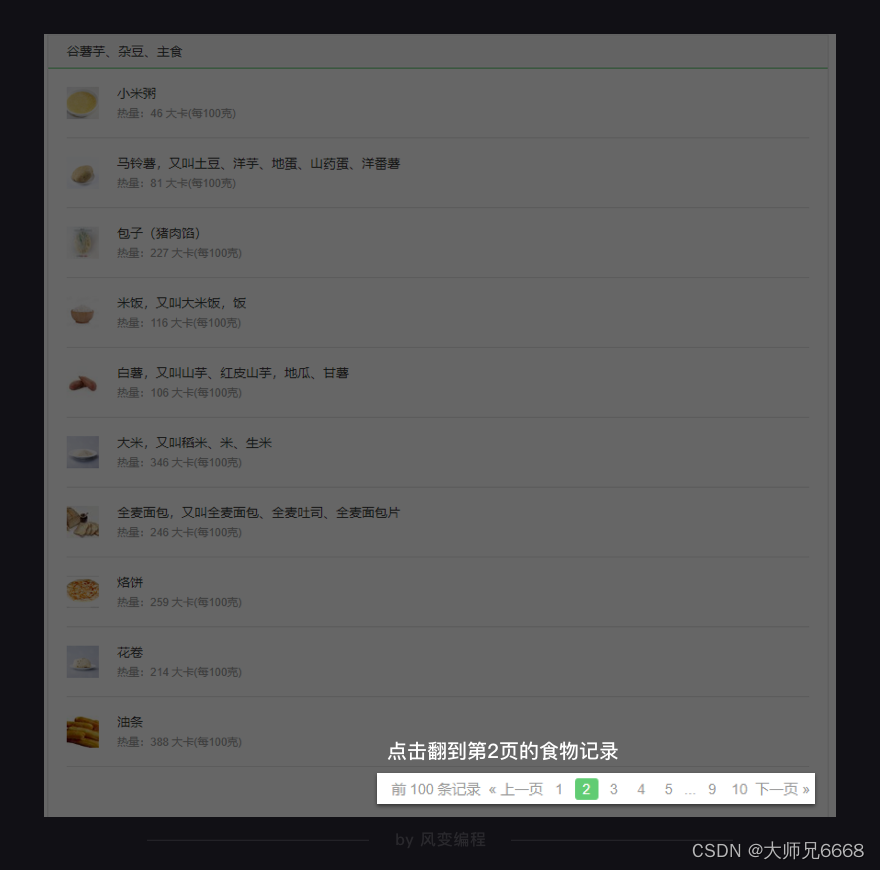
网址从http://www.boohee.com/food/group/1变成了:
http://www.boohee.com/food/group/1?page=2
网址多了page这个参数。数字2是不是第2页的意思?我们往后再翻两页看看。

原来?page=数字真的是代表页数的意思。只要改变page后面的数字,就能实现翻页。
可是为什么第1页的食物记录的网址在最开始是:
http://www.boohee.com/food/group/1,没有加?page=1呢?
难道是网站默认不显示的?我们试下给http://www.boohee.com/food/group/1加上?page=1,看看会怎样。
http://www.boohee.com/food/group/1?page=1
你会发现,其实加上了?page=1,打开的同样还是第1页的食物记录。
基于我们上面的观察,可以得出薄荷网每个食物类别的每一页食物记录的网址规律——
接下来,我们来分析怎么解析数据和提取数据。
前面我们知道薄荷网的食物热量的数据都存在HTML里,所以等下就可以用BeautifulSoup模块来解析。
至于怎么提取数据,我们得先弄清楚HTML的结构才行。
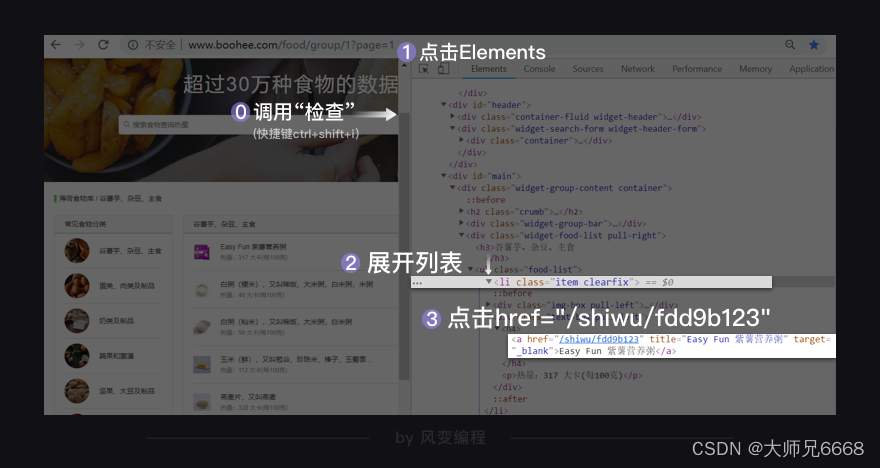
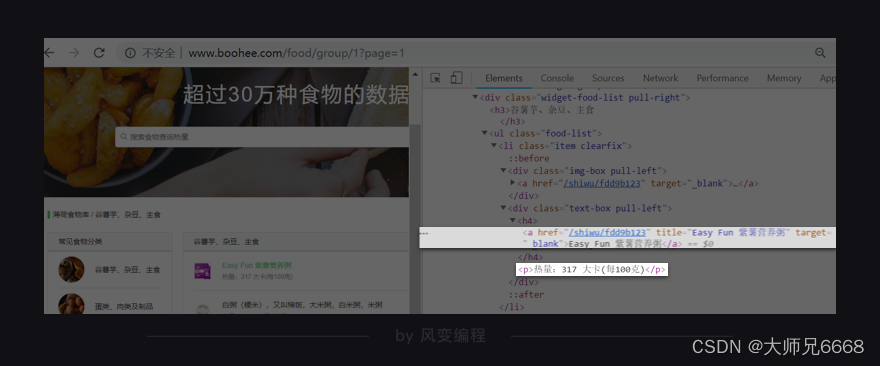
右击打开“检查”工具,看Elements,点击光标,把鼠标移到食物【Easy Fun 紫薯营养粥】这里,会发现在<li class="item clearfix">元素下,藏有食物的信息,包括食物详情的链接、食物名和热量。
你点击href=“/shiwu/fdd9b123”,就会跳转到【Easy Fun 紫薯营养粥】的详情页面。
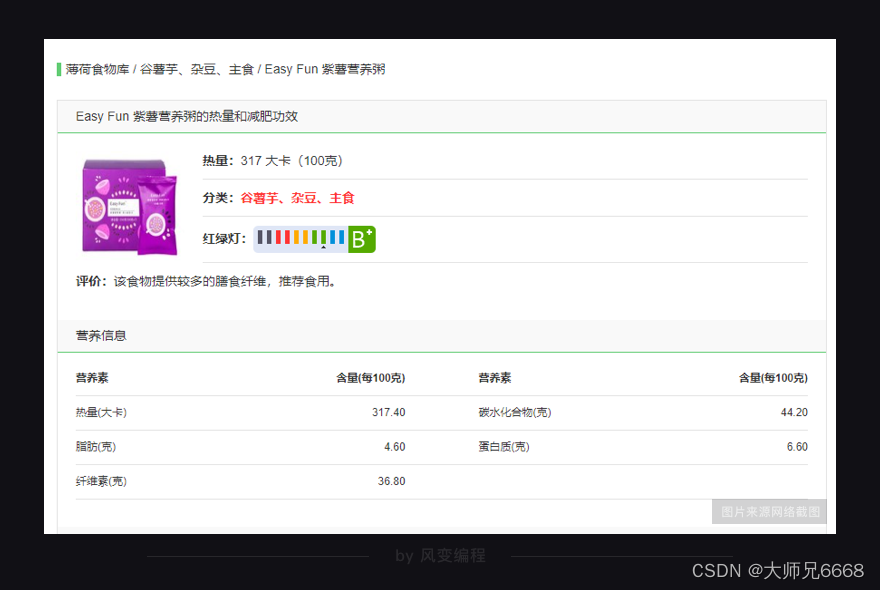
你再把鼠标接着移到其他食物上,你就会发现:原来每个食物的信息都被分别藏在了一个<li class="item clearfix">…</li>标签里。每页食物记录里有10个食物,刚好对应上网页源代码里的10个<li class="item clearfix">…</li>标签。
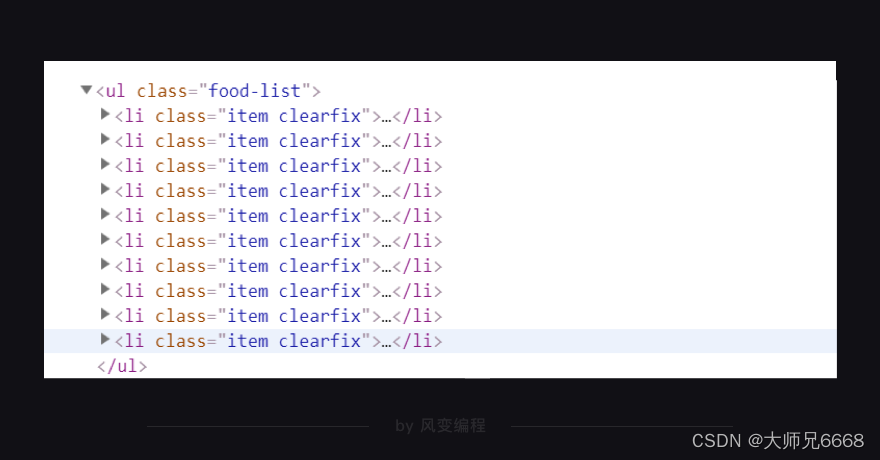
这么看来的话,我们用find_all/find就能提取出
- …
- 标签下的食物详情链接、名称和热量。
提取完数据,我们从csv和openpyxl模块中任意选择使用其中一个模块,把数据存储起来,项目就可以完工啦。
总结一下我们刚刚分析得出的思路:
代码实现
下面,应该是你做项目时最期待的一步——代码实现。
基于前面的【分析过程】,此时我们已经有了实现项目的思路。我们只要把这些思路变成代码,就能完成项目——用多协程爬到薄荷网的食物热量数据。
正式开始写代码~
#导入所需的库和模块:from gevent import monkey monkey.patch_all() #让程序变成异步模式。 import gevent,requests, bs4, csv from gevent.queue import Queue写代码的第一件事,都是先导入我们所需要的库和模块。
根据项目目标和分析过程得出的思路,我们知道需要用到实现协程功能的gevent库、queue、monkey模块,以及requests、BeautifulSoup、csv模块。
接下来的代码,需要由你来写。请你按照要求,先试着写出来,等下我再给你看我写的代码。
代码要求:导入所需模块,并根据前面分析得出的网址规律,用for循环构造出前3个常见食物类别的前3页食物记录的网址和第11个常见食物类别的前3页食物记录的网址,并把这些网址放进队列,打印出来。
参考代码在这里:
#导入所需的库和模块: from gevent import monkey monkey.patch_all() import gevent,requests, bs4, csv from gevent.queue import Queuework = Queue() #创建队列对象,并赋值给work。#前3个常见食物分类的前3页的食物记录的网址: url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4):for y in range(1, 4):real_url = url_1.format(type=x, page=y)work.put_nowait(real_url) #通过两个for循环,能设置分类的数字和页数的数字。 #然后,把构造好的网址用put_nowait方法添加进队列里。#第11个常见食物分类的前3页的食物记录的网址: url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1,4):real_url = url_2.format(page=x)work.put_nowait(real_url) #通过for循环,能设置第11个常见食物分类的食物的页数。 #然后,把构造好的网址用put_nowait方法添加进队列里。print(work) #打印队列用Queue()创建了空的队列。通过两个for循环,构造了前3个常见食物分类的前3页的食物记录的网址。
由于第11个常见食物分类的网址比较特殊,要分开构造。然后把构造好的网址用put_nowait方法,都放进队列里。
你可以运行这个代码,把队列打印出来看看。
打印结果:
<Queue queue=deque(['http://www.boohee.com/food/group/1?page=1', 'http://www.boohee.com/food/group/1?page=2', 'http://www.boohee.com/food/group/1?page=3', 'http://www.boohee.com/food/group/2?page=1', 'http://www.boohee.com/food/group/2?page=2', 'http://www.boohee.com/food/group/2?page=3', 'http://www.boohee.com/food/group/3?page=1', 'http://www.boohee.com/food/group/3?page=2', 'http://www.boohee.com/food/group/3?page=3', 'http://www.boohee.com/food/view_menu?page=1', 'http://www.boohee.com/food/view_menu?page=2', 'http://www.boohee.com/food/view_menu?page=3'])>一共打印出了12个网址,分别是【谷薯芋、杂豆、主食】前3页食物记录的网址、【蛋类、肉类及制品】前3页食物记录的网址、【奶类及制品】前3页食物记录的网址和最后一个常见食物分类【菜肴】前3页食物记录的网址。
作为教学演示,我们这里不会真的把薄荷网的11个常见食物分类里的所有页数的食物都爬取下来。因为这样做,会给薄荷网的服务器增添负担,并不是道义的做法,所以我也不推荐你这么去做。
接着,我们要写的是最核心的爬取代码——使用gevent帮我们爬取数据。
你还记得用gevent实现多协程的重点是什么吗?
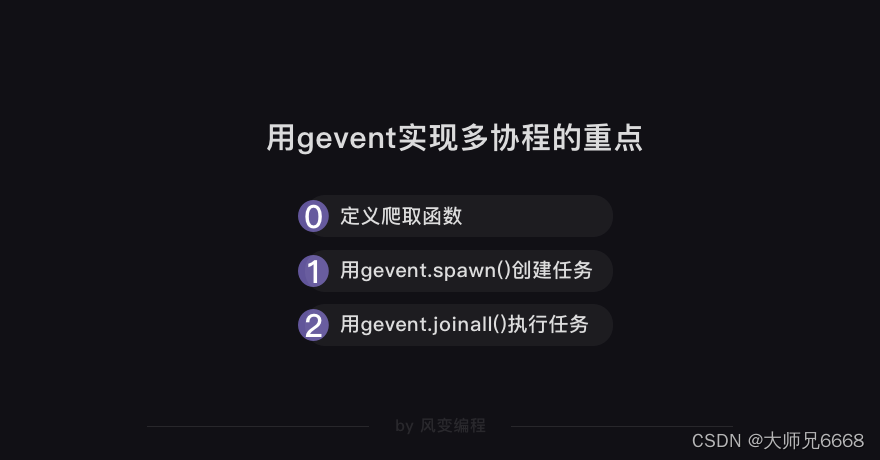
我们得先定义一个爬取函数。请认真看下面的代码,后面练习环节需要你自己把这些代码都写出来的。def crawler(): #定义crawler函数headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}#添加请求头while not work.empty():#当队列不是空的时候,就执行下面的程序。url = work.get_nowait()#用get_nowait()方法从队列里把刚刚放入的网址提取出来。res = requests.get(url, headers=headers)#用requests.get获取网页源代码。bs_res = bs4.BeautifulSoup(res.text, 'html.parser')#用BeautifulSoup解析网页源代码。foods = bs_res.find_all('li', class_='item clearfix')#用find_all提取出<li class="item clearfix">标签的内容。for food in foods:#遍历foodsfood_name = food.find_all('a')[1]['title']#用find_all在<li class="item clearfix">标签下,提取出第2个<a>元素title属性的值,也就是食物名称。food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href']#用find_all在<li class="item clearfix">元素下,提取出第2个<a>元素href属性的值,跟'http://www.boohee.com'组合在一起,就是食物详情页的链接。food_calorie = food.find('p').text#用find在<li class="item clearfix">标签下,提取<p>元素,再用text方法留下纯文本,也提取出了食物的热量。 print(food_name)#打印食物的名称。上面定义crawler函数的代码,可能你看到提取数据的部分会有疑惑的点。
不过,对照着看HTML的结构,应该就能解开你的疑惑。我们想要的食物详情链接和名称在<li class="item clearfix">标签的第2个<a>元素里,用find_all就能提取出来。食物热量在<p>元素里,我们用find提取就可以。定义完了crawler函数,整个核心代码就差用gevent.spawn()创建任务和用gevent.joinall()执行任务,启动协程,就能开始爬取我们想要的数据。
我希望最后的核心能由你来补全。所以,请你在以上代码的基础上,写出crawler函数和启动协程的代码,完成爬取数据的任务。
顺利写出来了吗?如果没有顺利写出来,我希望你在看完下面的完整代码之后,能再回去重写一遍。
参考代码:
#导入所需的库和模块:from gevent import monkey monkey.patch_all() import gevent,requests, bs4, csv from gevent.queue import Queuework = Queue() #创建队列对象,并赋值给work。#前3个常见食物分类的前3页的食物记录的网址: url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4):for y in range(1, 4):real_url = url_1.format(type=x, page=y)work.put_nowait(real_url) #通过两个for循环,能设置分类的数字和页数的数字。 #然后,把构造好的网址用put_nowait添加进队列里。#第11个常见食物分类的前3页的食物记录的网址: url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1,4):real_url = url_2.format(page=x)work.put_nowait(real_url) #通过for循环,能设置第11个常见食物分类的食物的页数。 #然后,把构造好的网址用put_nowait添加进队def crawler(): #定义crawler函数headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}#添加请求头while not work.empty():#当队列不是空的时候,就执行下面的程序。url = work.get_nowait()#用get_nowait()方法从队列里把刚刚放入的网址提取出来。res = requests.get(url, headers=headers)#用requests.get获取网页源代码。bs_res = bs4.BeautifulSoup(res.text, 'html.parser')#用BeautifulSoup解析网页源代码。foods = bs_res.find_all('li', class_='item clearfix')#用find_all提取出<li class="item clearfix">标签的内容。for food in foods:#遍历foodsfood_name = food.find_all('a')[1]['title']#用find_all在<li class="item clearfix">标签下,提取出第2个<a>元素title属性的值,也就是食物名称。food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href']#用find_all在<li class="item clearfix">标签下,提取出第2个<a>元素href属性的值,跟'http://www.boohee.com'组合在一起,就是食物详情页的链接。food_calorie = food.find('p').text#用find在<li class="item clearfix">标签下,提取<p>元素,再用text方法留下纯文本,就提取出了食物的热量。 print(food_name)#打印食物的名称。tasks_list = [] #创建空的任务列表 for x in range(5): #相当于创建了5个爬虫task = gevent.spawn(crawler)#用gevent.spawn()函数创建执行crawler()函数的任务。tasks_list.append(task)#往任务列表添加任务。 gevent.joinall(tasks_list) #用gevent.joinall方法,启动协程,执行任务列表里的所有任务,让爬虫开始爬取网站。你可以运行这个代码,看看能不能成功爬取到食物的数据。
我运行的结果是:
Easy Fun 营养粉丝(香菇炖鸡),又叫Easy Fun 营养粉丝(香菇炖鸡味) 白粥,又叫白粥(粳米),稀饭,大米粥,白米粥,米粥,大米汤汤 Easy Fun 营养粉丝(番茄鸡蛋),又叫Easy Fun 营养粉丝(番茄鸡蛋味) Easy Fun 低脂咖喱鸡饭 Easy Fun 抹茶红豆麦片 Easy Fun 高蛋白微波蛋糕预拌粉(香浓可可味) Easy Fun 红枣黑米圈,又叫红枣黑米、Easy Fun 薄荷健康红枣黑米圈 Easy Fun 山药紫薯圈 稀饭,又叫白粥(籼米),大米粥,白米粥 鲜玉米,又叫玉米(鲜)、苞谷、珍珠米、棒子、玉蜀黍、苞米、六谷、 虾,又叫对虾、鲜虾仁、虾仁 鸭肉,又叫鸭子、鹜肉、家凫肉 猪蹄,又叫猪脚、猪手、猪蹄爪 猪肉(瘦),又叫猪精肉,瘦肉 鸡蛋白(鸡蛋清),又叫鸡蛋白、鸡蛋清、蛋清、蛋白 火腿肠 鸡胸肉,又叫鸡柳肉、鸡里脊肉、鸡胸、鸡胸脯肉 荷包蛋(油煎),又叫荷包蛋、煎蛋、煎荷包蛋、煎鸡蛋 咸鸭蛋,又叫盐蛋、腌蛋、味蛋 猪肉(肥瘦),又叫豕肉、彘肉 Easy Fun 高纤奇亚籽苏打饼干,又叫Easy Fun 高纤 奇亚籽苏打饼干、奇亚籽苏打咸味饼干、苏打饼干、EASY FUN 苏打饼干、Easy Ace 高纤奇亚籽苏打饼干 白薯,又叫山芋、红皮山芋,地瓜、甘薯、红皮山芋 大米,又叫稻米、米、生米 全麦面包,又叫全麦面包、全麦吐司、全麦面包片、全麦土司 烙饼 花卷,又叫花之卷、大花卷、小花卷 油条,又叫小油条 曼可顿 全麦高纤维面包 嘉顿 生命面包 450g 包子(三鲜馅) 燕麦片,又叫燕麦 面条(生),又叫面 煮面条,又叫面、水煮面、面条(煮) 籼米粉,又叫米线、米粉、粉、排米粉 面包 红薯,又叫地瓜、番薯、甘薯、山芋、红薯 小米粥 马铃薯,又叫土豆、洋芋、地蛋、山药蛋、洋番薯、土豆、洋芋 包子(猪肉馅) 米饭,又叫大米饭,饭,蒸米、锅巴饭、煮米饭 Easy Fun 高蛋白小酥鱼(藤椒味) 鸡蛋,又叫鸡子、鸡卵、蛋 Easy Fun 低脂鸡胸肉肠(香辣味),又叫Easy Fun easy fun 低脂鸡胸肉肠、鸡胸肉肠 Easy Fun 鸡胸肉丝(原味) Easy Fun 高蛋白小酥鱼(海苔味),又叫Easy Fun 高蛋白海苔鱼酥 Easy Fun 低脂鸡胸肉肠(原味),又叫Easy Fun 低脂鸡胸肉肠、鸡胸肉肠、easyfun 低脂鸡胸肉肠 猪小排,又叫排骨、猪排、猪脊骨 鸡(土鸡,家养) 鸡(母鸡,一年内) 鸡(肉鸡,肥) 瓦罐鸡汤(含料),又叫瓦罐汤 瓦罐鸡汤(无料) 猪小排(良杂猪) 猪肉(奶脯),又叫软五花、奶脯、五花肉 猪大排,又叫猪排 牛肉(腑肋),又叫牛腩 Easy Fun 低脂鸡胸肉肠(原味),又叫Easy Fun 低脂鸡胸肉肠(原味)、鸡胸肉肠 Easy Fun 低脂鸡蛋干(五香味) Easy Fun 低脂蛋清鸡肉饼(原味),又叫Easy Fun 低脂蛋清鸡肉饼 草鱼,又叫鲩鱼、混子、草鲩、草包鱼、草根鱼、草青、白鲩 酸奶 牛奶,又叫纯牛奶、牛乳、全脂牛奶 无糖全脂拿铁,又叫拿铁咖啡、拿铁(全脂,无糖) 奶酪,又叫乳酪、芝士、起司、计司 酸奶(中脂) 脱脂奶粉 酸奶(调味) 酸奶(果料),又叫果料酸奶 酸奶(果粒),又叫果粒酸奶 蒙牛 高钙牛奶,又叫蒙牛袋装高钙牛奶 光明 0脂肪 鲜牛奶,又叫光明 0脂肪鲜牛奶 牛奶(强化VA,VD),又叫牛乳(强化VA,VD) 光明 低脂牛奶 蒙牛 木糖醇酸牛奶,又叫蒙牛木糖醇酸奶 低脂奶酪 伊利 无蔗糖酸牛奶(利乐包)150g 蒙牛 酸牛奶(草莓+树莓)100g (小盒装) 光明减脂90%脱脂鲜牛奶 伊利优品嘉人优酪乳(原味) 光明 畅优红枣燕麦低脂酸奶 炒上海青,又叫炒青菜 番茄炒蛋,又叫番茄炒鸡蛋、西红柿炒蛋、柿子炒鸡蛋、番茄炒鸡蛋、西红柿炒鸡蛋、西虹市炒鸡蛋、番茄炒蛋 鸡蛋羹,又叫蒸蛋 绿豆汤 素炒小白菜,又叫小青菜 烧茄子 绿豆粥,又叫绿豆稀饭 菜包子,又叫香菇菜包、菜包子、素包子、素包、香菇青菜包、素菜包、香菇青菜包、香菇包子 蛋炒饭,又叫黄金炒饭、蛋炒饭 红烧鳓鱼 光明 e+益生菌酸牛奶(原味)220ml (袋装) 早餐奶 酸奶(高蛋白) 奶片 全脂牛奶粉 光明 纯牛奶,又叫光明牛奶 光明 优倍 高品质鲜牛奶,又叫光明 优倍高品质鲜牛奶 光明 优倍 0脂肪 高品质脱脂鲜牛奶 光明 优倍 0乳糖 巴士杀菌调制乳 光明 致优 全鲜乳,又叫光明 致优全鲜乳 盐水虾,又叫焖鲜虾 清炒绿豆芽,又叫有机活体豆苗、炒绿豆芽 葱油饼,又叫葱花饼、葱油饼 清炒西葫芦,又叫炒西葫、西葫芦丝 西红柿鸡蛋面,又叫番茄蛋面、番茄鸡蛋面 酸辣土豆丝 红烧肉 韭菜包子 卤蛋,又叫卤鸡蛋 清炒土豆丝 烧麦,又叫烧卖、糯米烧卖 炒大白菜,又叫大白菜 西红柿鸡蛋汤,又叫西红柿蛋汤、西红柿蛋花汤 大饼,又叫饼,家常饼,死面饼 清蒸鱼,又叫清蒸鱼、蒸鱼、鱼、蒸洄鱼 酸菜鱼,又叫酸汤鱼、酸辣鱼、酸菜鱼、酸辣鱼汤 寿司 自制1,又叫寿司卷 麻婆豆腐,又叫麻婆豆腐 牛肉面,又叫兰州拉面、牛腩面、牛肉拌面 烧包菜丝至此,项目的核心代码已经完成,只要再加上存储数据的代码,我们就完成了整个项目的【代码实现】步骤。
我选取了csv模块来做存储数据的演示。
from gevent import monkey monkey.patch_all() import gevent,requests, bs4, csv from gevent.queue import Queuework = Queue() url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4):for y in range(1, 4):real_url = url_1.format(type=x, page=y)work.put_nowait(real_url)url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1,4):real_url = url_2.format(page=x)work.put_nowait(real_url)def crawler():headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}while not work.empty():url = work.get_nowait()res = requests.get(url, headers=headers)bs_res = bs4.BeautifulSoup(res.text, 'html.parser')foods = bs_res.find_all('li', class_='item clearfix')for food in foods:food_name = food.find_all('a')[1]['title']food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href']food_calorie = food.find('p').textwriter.writerow([food_name, food_calorie, food_url])#借助writerow()函数,把提取到的数据:食物名称、食物热量、食物详情链接,写入csv文件。print(food_name)csv_file= open('boohee.csv', 'w', newline='') #调用open()函数打开csv文件,传入参数:文件名“boohee.csv”、写入模式“w”、newline=''。 writer = csv.writer(csv_file) # 用csv.writer()函数创建一个writer对象。 writer.writerow(['食物', '热量', '链接']) #借助writerow()函数往csv文件里写入文字:食物、热量、链接tasks_list = [] for x in range(5):task = gevent.spawn(crawler)tasks_list.append(task) gevent.joinall(tasks_list)呼~这一关的项目终于圆满完成!
不知道你在做这次项目时的感受是怎样的?会不会因为看不懂一行代码而苦恼许久,但在代码运行通过时又欣喜雀跃?
我到现在都深深地记得,在我最开始接触编程,写出人生中第一个程序的那种感受——妙不可言又一直萦绕心头的开心。
毫不夸张地说,当我敲下那个程序最后的一行代码,点击运行,看到终端跑出我想要的数据时,我激动地差点跳了起来。
我始终觉得,是在那一刻,编程用它的魅力改变了我,让我有机会成为今天被你看见的我。
如果有机会的话,我也很想听你和我分享,你每一次做项目的感受,不吐不快的话,可以放在评论区
我们下一关见~
相关文章:
【python爬虫】13.吃什么不会胖(爬虫实操练习)
文章目录 前言项目实操明确目标分析过程代码实现 前言 吃什么不会胖——这是我前段时间在健身时比较关注的话题。 相信很多人,哪怕不健身,也会和我一样注重饮食的健康,在乎自己每天摄入的食物热量。 不过,生活中应该很少有人会…...

深入理解联邦学习——联邦学习与现有理论的区别与联系
分类目录:《深入理解联邦学习》总目录 作为一种全新的技术,联邦学习在借鉴一些成熟技术的同时也具备了一定的独创性。下面我们就从多个角度来阐释联邦学习和其他相关概念之间的关系。 联邦学习与差分隐私理论的区别 联邦学习的特点使其可以被用来保护用…...
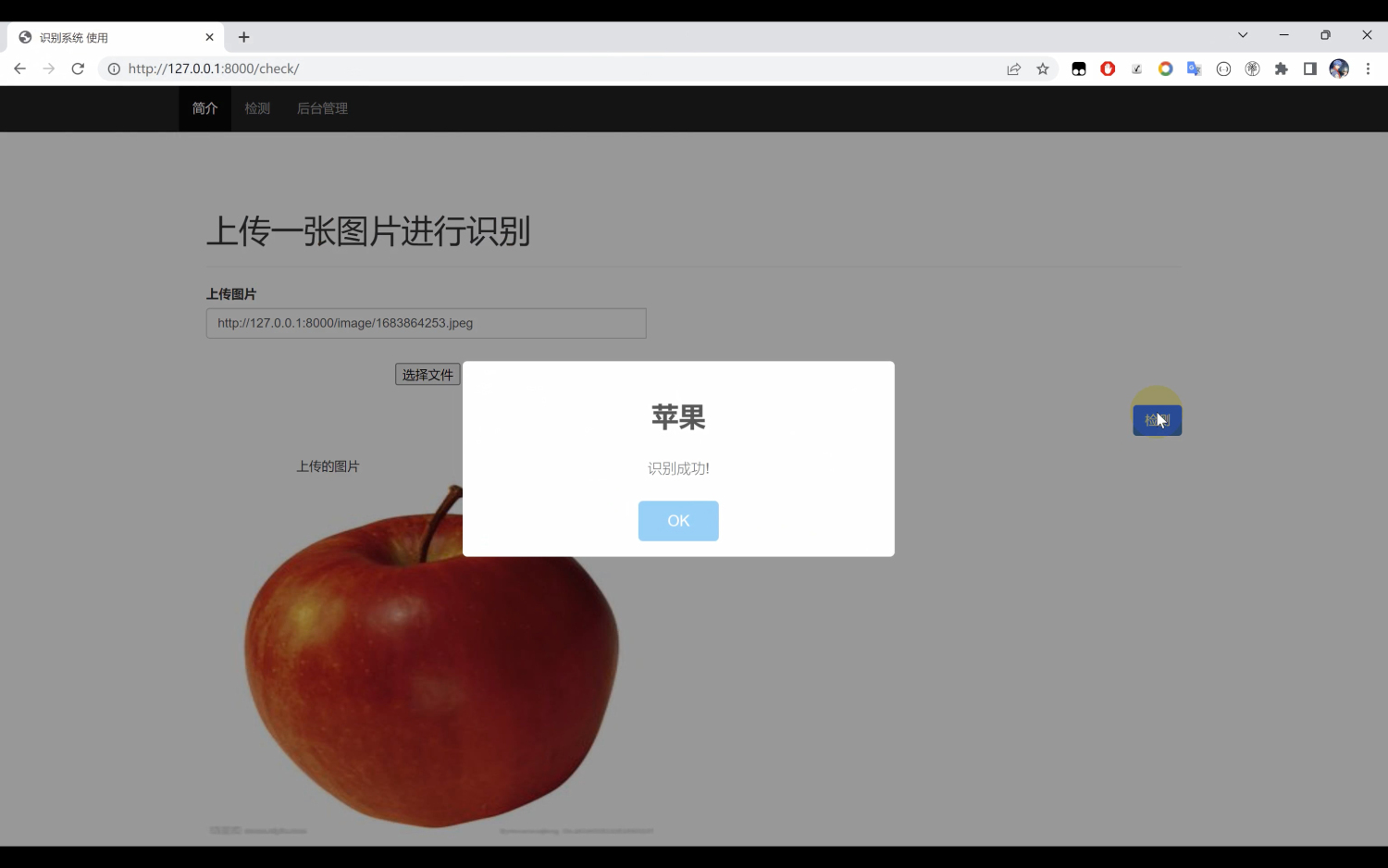
基于Python+DenseNet121算法模型实现一个图像分类识别系统案例
目录 介绍在TensorFlow中的应用实战案例最后 一、介绍 DenseNet(Densely Connected Convolutional Networks)是一种卷积神经网络(CNN)架构,2017年由Gao Huang等人提出。该网络的核心思想是密集连接,即每…...

旋转图片两种方法
这两种方法在旋转图像时,可能会产生一些不同的效果: rotate_image_new()旋转后的图像完全包含旋转前的内容,并且填充边界尽可能小 rotate_image() 保持原始图像的大小,并根据填充选项决定是否填充边界为白色。如果 if_fill_whit…...
10 mysql tiny/small/medium/big int 的数据存储
前言 这里主要是 由于之前的一个 datetime 存储的时间 导致的问题的衍生出来的探究 探究的主要内容为 int 类类型的存储, 浮点类类型的存储, char 类类型的存储, blob 类类型的存储, enum/json/set/bit 类类型的存储 本文主要 的相关内容是 int 类类型的相关数据的存储 …...
UI自动化测试之Jenkins配置
团队下半年的目标之一是实现自动化测试,这里要吐槽一下,之前开发的测试平台了,最初的目的是用来做接口自动化测试和性能测试,但由于各种原因,接口自动化测试那部分功能整个废弃掉了,其中和易用性有很大关系…...

电视盒子什么品牌好?数码博主盘点目前性能最好的电视盒子
电视盒子是非常重要的,老人小孩基本每天都会看电视,而电视盒子作为电视盒子的最佳拍档销量十分火爆,我自己每个月都会测评几次电视盒子,今天给大家详细解读一下电视盒子什么品牌好,看看目前性能最好的电视盒子是哪些&a…...

对于枚举类型的输出
对于枚举类型的输出 对于枚举类型的输出,您可以使用以下方法:1. 将枚举值转换为整数进行输出:cppODU_TYPE type ODU_TYPE_331;int value static_cast<int>(type);std::cout << "ODU_TYPE: " << value <<…...
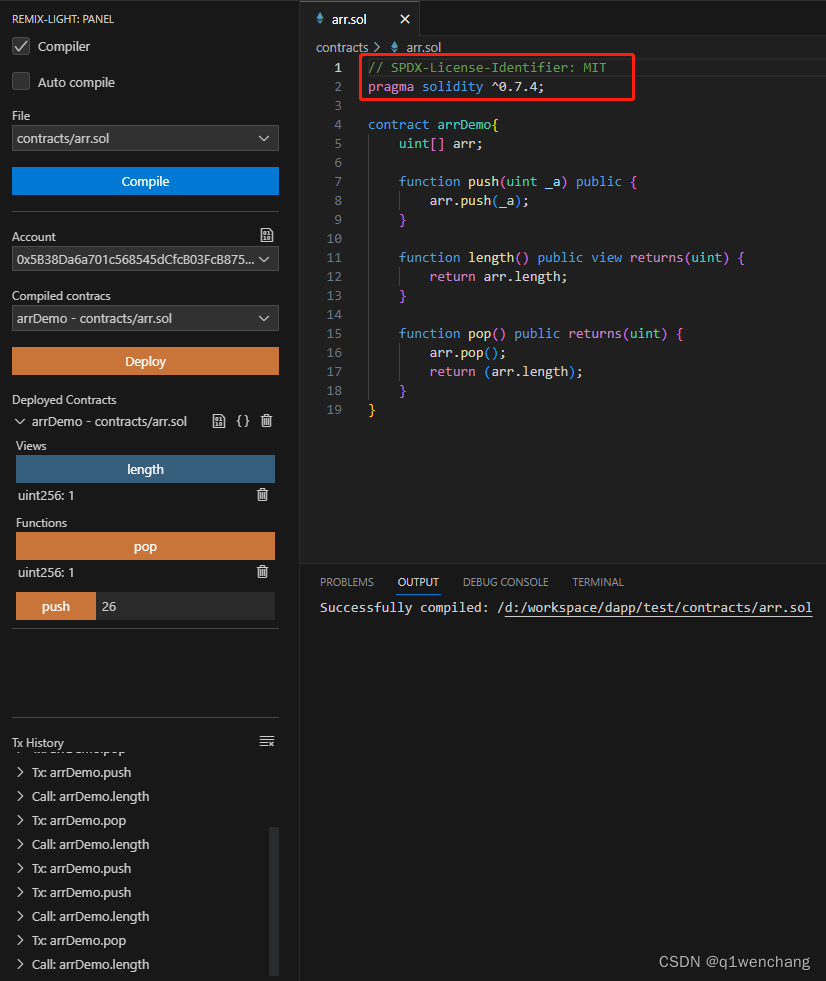
solidity开发环境配置,vscode搭配remix
#学习笔记 初学solidity,使用remix非常方便,因为需要的环境都配置好了,打开网站就可以使用。 不过在编写代码方面,使用vscode更方便,而vscode本身并不能像remix那样部署合约,它还需要安装插件。 点击红色箭…...

chatGPT生成代码--go组合算法
提问:用golang写一个组合算法函数zuhe(x,n),x为组合所需的字符,n 为组合后的字符串长度,例如 x"ab", n2 结果返回 aa,ab,bb,ba 结果:下面是一个用Go编写的生成长度为n的字符串组合的函数 zuhe,其…...
推荐6款普通人搞副业做自媒体AI工具
hi,同学们,我是赤辰,本期是赤辰第5篇AI工具类教程,文章底部准备了粉丝福利,看完可以领取!身边越来越多的小伙伴靠自媒体实现财富自由了!因此,推荐大家在工作之余或空闲时间从事自媒体…...

vs中git提交合并分支的步骤记录
vs打开终端 PS D:\project\et_lower4_driver> git pull Already up to date. PS D:\project\et_lower4_driver> git branch * kiyun_usb7851 master PS D:\project\et_lower4_driver> git checkout master Switched to branch master Your branch is up to date wit…...

PostgreSQL 备份恢复:pg_probackup
文章目录 前言1. 安装备份工具1.1 环境介绍1.2 RPM 安装1.3 验证 2. 配置备份工具2.1 初始化设置2.2 创建备份用户2.3 配置自动归档 3. 工具使用介绍3.1 init3.2 add-instance3.3 del-instance3.4 set-config3.5 show-config3.6 set-backup3.7 backup3.8 show3.9 delete3.10 re…...
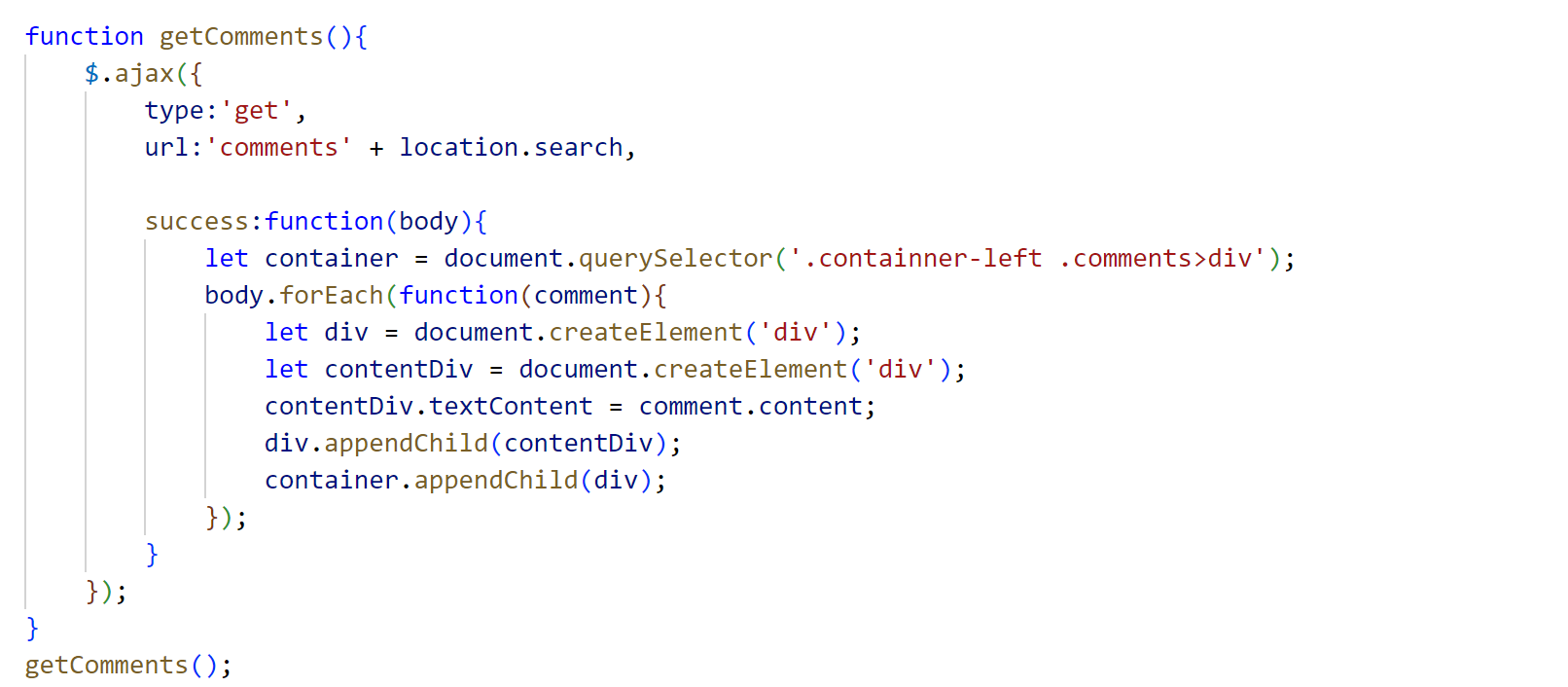
博客程序系统其它功能扩充
一、注册功能 1、约定前后端接口 2、后端代码编写 WebServlet("/register") public class RegisterServlet extends HttpServlet {Overrideprotected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {//设置…...
MATLAB 2023安装方法之删除旧版本MATLAB,安装新版本MATLAB
说明:之前一直使用的是MATLAB R2020b,但最近复现Github上的程序时,运行不了,联系作者说他的程序只能在MATLAB 2021之后的版本运行,因此决定安装最新版本的MATLAB。 系统:Windows 11 需要卸载的旧MATLAB 版…...

全国唯一一所初试考Java的学校!平均300分拿下
苏州科技大学 考研难度(☆) 内容:23考情概况(拟录取和复试分析)、院校概况、23专业目录、23复试详情、各专业考情分析、各科目考情分析。 正文1187字,预计阅读:3分钟 2023考情概况 苏州科技…...

day35 | 860.柠檬水找零、406.根据身高重建队列、452. 用最少数量的箭引爆气球
目录: 解题及思路学习 860. 柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美…...

ffmpeg批量转码
新建.bat文件 echo offfor %%s in (*.mp4) do ( echo %%s ffmpeg -i %%s -b 7M %%~ns7m.mp4 ) pause如果你的电脑有显卡,也可以使用硬件转码。转码程序链接...

时序预测 | MATLAB实现基于QPSO-BiLSTM、PSO-BiLSTM和BiLSTM时间序列预测
时序预测 | MATLAB实现基于QPSO-BiLSTM、PSO-BiLSTM和BiLSTM时间序列预测 目录 时序预测 | MATLAB实现基于QPSO-BiLSTM、PSO-BiLSTM和BiLSTM时间序列预测效果一览基本描述程序设计参考资料 效果一览 基本描述 1.Matlab实现QPSO-BiLSTM、PSO-BiLSTM和BiLSTM神经网络时间序列预测…...
【TypeScript学习】—基本类型(二)
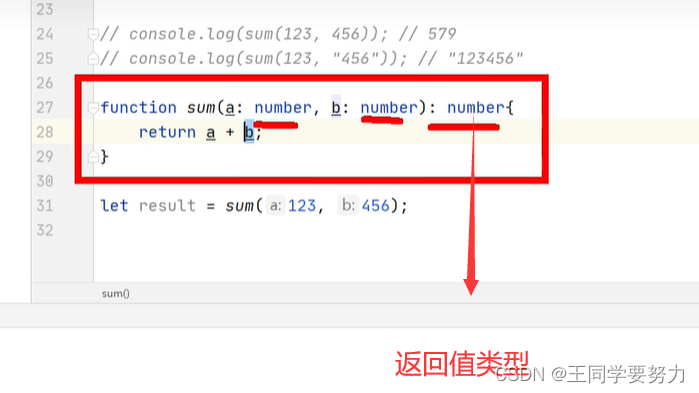
【TypeScript学习】—基本类型(二) 一、TypeScript基本类型 //也可以直接用字面量进行类型声明let a:10; a10;//也可以使用 |来连接多个类型(联合类型)let b:"male"|"female"; b"male"; b"fe…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...

多模态大语言模型arxiv论文略读(112)
Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文标题:Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文作者:Jea…...