【Redis专题】Redis持久化、主从与哨兵架构详解
目录
- 前言
- 课程目录
- 一、Redis持久化
- 1.1 RDB快照(Snapshot):二进制文件
- 基本介绍
- 开启/关闭方式
- 触发方式
- bgsave的写时复制(COW,Copy On Write)机制
- 优缺点
- 1.2 AOF(append-only file):将读写命令记录下来,方便回放
- 基本介绍
- 开启/关闭方式
- 触发方式
- AOF重写
- 优缺点
- 1.3 RDB和AOF对比,怎么选
- 1.4 Redis4.0 混合持久化:AOF + RDB
- 基本介绍
- 开启/关闭方式
- 混合持久化aof文件内容
- 1.5 Redis数据生产备份策略
- 二、Redis主从架构——基础
- 2.1 主从架构搭建
- 2.2 Redis主从工作原理
- 全量同步业务流程图
- 增量同步业务流程图
- 主从复制风暴
- 代码实战
- 三、Redis主从架构——哨兵高可用架构
- 3.1 Redis哨兵架构搭建
- 3.2 哨兵架构高可用工作原理
- 3.3 代码实战
- 学习总结
前言
课程目录
一、Redis持久化
【持久化】这个单词我想大家都不陌生吧。什么是持久化?我们知道,Redis的数据是存储在内存里面的,所以在Redis这里,其实是指把内存中的数据,通过一些策略写到磁盘中,方便因为宕机、或者重启Redis服务的时候,再次把数据加载到内存中。
那么,Redis中持久化策略(方式)有哪些呢?其实主要的方式有如下三种,让我们来看看吧
1.1 RDB快照(Snapshot):二进制文件
基本介绍
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。(PS:该持久化策略,是默认的策略,当然不排除在随后的版本中改了)
开启/关闭方式
开启/关闭方式:进入程序的目录,修改
redis.conf配置文件。开启/关闭RDB只需要将所有的save保存策略打开/注释掉即可
触发方式
RDB快照生成的触发方式有两种。一种是通过设置策略,当满足条件的时候自动触发;另一种,当然是手动触发了。
我们先来说一下【自动触发】的方式。自动触发的方式,就是按照Redis提供给我们的语法,在redis.conf里面增加触发策略。设置规则如下:
语法:
save <seconds> <changes> [<seconds> <changes> ...]
解释:在【N 秒内数据集至少有 M 个改动】这一条件被满足时,自动持久化一次
举个例子,设置一条策略【在60秒内有1000个改动时,自动持久化一次】。设置如下
save 60 1000 // 关闭RDB只需要将所有的save保存策略注释掉即可
至于手动触发方式,则是进入redis客户端执行命令save或bgsave,就可以生成dump.rdb文件,每次命令执行都会将所有redis内存快照到一个新的.rdb文件里,并覆盖原有.rdb快照文件。
save是同步执行生成rdb文件的操作,执行时不会处理外部的命令;bgsave则是异步执行生成操作,会同时处理外部命令。
bgsave的写时复制(COW,Copy On Write)机制
Redis借助操作系统的写时复制技术(Copy On Write),在生成快照的同时,依然可以正常处理写命令。简单来说,bgsave子进程是由主线程fork出来的,所以可以共享主线程内存的所有数据。bgsave子进程运行后,开始读取主线程的内存数据,并把他们他们写入.rdb文件。此时,如果主线程对这些数据也都是读操作,那主线程跟子进程之间肯定没有影响;若此时主线程需要修改一块数据,那么,这块数据会被复制一份,生成该数据的副本。然后bgsave子进程会把这个副本数据写入.rdb文件中,而在这个过程中,主线程仍然可以直接修改原来的数据。
save与bgsave对比:
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其他命令 | 是 | 否。不过在生成子进程执行调用函数时会有短暂阻塞 |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不会阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork一个子进程,消耗额外内存 |
上面配置的【自动触发】生成.rdb文件的策略,后台使用的就是bgsave方式
优缺点
优点是:由于是二进制文件,所以Redis重启的时候,恢复速度快
缺点是:容易丢失数据,为什么?看下面【AOF】策略的介绍
1.2 AOF(append-only file):将读写命令记录下来,方便回放
基本介绍
看了上面的【RDB策略】不知道大家有没有感觉,或者意识到什么。那就是,这种策略其实看起来有点“苛刻”,它的数据安全性并不靠谱!
比如【在60秒内有1000个改动时,自动持久化一次】的策略之下,万一我在做第1000个改动的时候服务器宕机了,那不是丢掉了前面999个操作了吗?
所以,快照功能并不是非常耐久(durable)的。 如果 Redis 因为某些原因而造成故障停机,那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。不过从1.1版本开始,Redis增加了一种完全耐久的持久化方式: AOF持久化,将修改的每一条指令记录进文件appendonly.aof文件中(先写入os cache,每隔一段时间fsync到磁盘)。
比如执行命令set zhuge 666,.aof文件里会记录如下数据:(这是一种resp协议格式数据,我在下面写上注释给大家翻译一下什么意思)
*3 # 星号后面的数字表示,执行的命令有多少个参数
$3 # 美元符号后面的数字代表这个参数有几个字符
set
$5 # 美元符号后面的数字代表这个参数有几个字符
zhuge
$3 # 美元符号后面的数字代表这个参数有几个字符
666
注意,如果执行带过期时间的set命令,aof文件里记录的是并不是执行的原始命令,而是记录key过期的时间戳。比如执行set tuling 888 ex 1000,对应aof文件里记录如下:
*3
$3
set
$6
tuling
$3
888
*3
$9
PEXPIREAT
$6
tuling
$13
1604249786301
开启/关闭方式
开启/关闭方式:进入程序的目录,修改
redis.conf配置文件。开启/关闭aof只需要修改如下参数:
# appendonly yes// 有一些版本默认注释掉。打开注释,设置yes或者no即可 打开/关闭
开启之后,从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到.aof文件的末尾。
这样的话, 当 Redis 重新启动时, 程序就可以通过重新执行.aof文件中的命令来达到重建数据集的目的。
触发方式
同样的,我们可以配置Redis多久才将数据同步到磁盘一次。.aof的触发方式同样也有两种:自动和手动。
【自动触发】的方式,如下:(Redis提供给我们的,需要自己手动打开、关闭)
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性(最多丢失最近1秒的缓存数据)。
AOF重写
.aof文件里可能有太多没用指令,所以【AOF策略】会定期根据内存的最新数据生成aof文件。例如,执行了如下几条命令:
127.0.0.1:6379> incr readcount
(integer) 1
127.0.0.1:6379> incr readcount
(integer) 2
127.0.0.1:6379> incr readcount
(integer) 3
127.0.0.1:6379> incr readcount
(integer) 4
127.0.0.1:6379> incr readcount
(integer) 5
重写后AOF文件里变成:
*3
$3
SET
$2
readcount
$1
5
如下两个配置可以控制AOF自动重写频率:
// aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
# auto-aof-rewrite-min-size 64mb // aof文件自上一次重写后文件大小增长了100%则再次触发重写
# auto-aof-rewrite-percentage 100
优缺点
优点是:数据安全性相对【RDB】方式来说高点
缺点是:恢复速度慢,因为不是二进制,且需要通过【重放】的方式恢复
1.3 RDB和AOF对比,怎么选
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢失数据 | 根据策略决定,但整体比较高 |
上面提到的启动优先级什么意思呢?意思是,当Redis启动时,会优先读取.aof的文件,其次才是.rdb。为什么呢?因为.aof文件的数据安全性相对可靠一点啊!
那我该选择哪一种持久化策略呢?其实在生产环境中,可以都启用。反正Redis启动时如果既有.rdb文件又有.aof文件的时候,会根据优先级选取。
1.4 Redis4.0 混合持久化:AOF + RDB
基本介绍
不出意外,当出现比较特点比较极端的两个方案时,总会有一个折中的方案出现。这就是Redis在4.0之后的版本推出的【混合持久化,AOF + RDB】方式。
重启Redis时,我们很少使用.rdb来恢复内存状态,因为会丢失大量数据。我们通常使用.aof日志重放,但是重放.aof日志性能相对.rdb来说要慢很多,这样在Redis实例很大的情况下,启动需要花费很长的时间。Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化
开启/关闭方式
PS:混合方式的开启,必须要先开启AOF
开启/关闭方式:进入程序的目录,修改redis.conf配置文件。开启/关闭需要修改如下参数:
# appendonly yes
# aof-use-rdb-preamble yes // 需要同时上面的参数也为yes才可开启
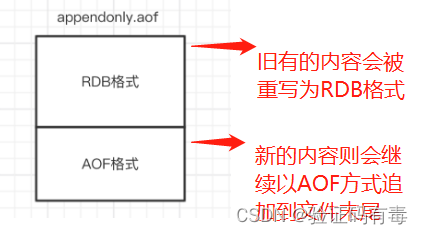
混合持久化aof文件内容
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的.aof文件,新的文件一开始不叫appendonly.aof,等到重写完新的.aof文件才会进行改名,覆盖原有的.aof文件,完成新旧两个.aof文件的替换。
于是在 Redis 重启的时候,可以先加载.aof文件中的RDB内容,然后再重放增量AOF日志就可以完全替代之前的.aof全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如下:
1.5 Redis数据生产备份策略
- 写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48小时的备份
- 每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份
- 每次copy备份的时候,都把太旧的备份给删了
- 每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
二、Redis主从架构——基础
Redis主从架构模型如下:
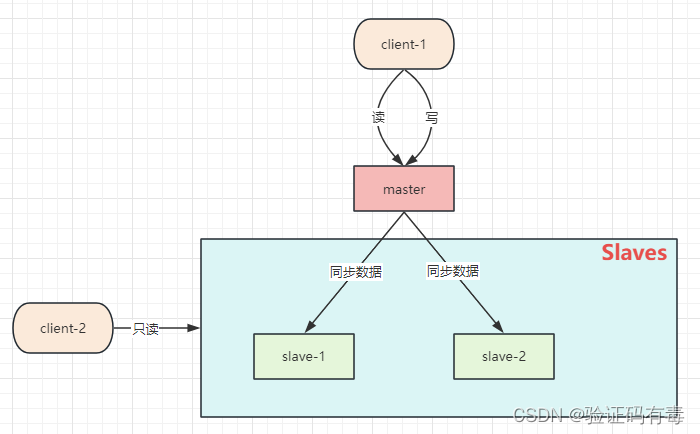
由上图可以看出,在主从结构中,通常从节点只做【读】业务,【写】业务通常还是由主节点master完成。并且,它目前并没有我们小白以为的【宕机自动切换新的主节点】的能力。(PS:我以前一直听说什么Redis集群高可用,节点宕机依然不影响业务,所以我乍一看【主从架构】就以为它已经有这个能力了。而事实上并没有,它只是【缓解了节点压力】,并不具备自动切换)
2.1 主从架构搭建
好记性不如多操作几遍
redis主从架构搭建,配置从节点步骤如下:
- 复制一份redis.conf文件,例如,我在我的redis下就复制了两份,并且分别命名为
redis-6380.conf和redis-6381.conf,因为我计划搭建【一主二从】的结构

- 将相关配置修改为如下值:(以
redis-6380.conf为例,一定要确保全部都修改到了,不然很可能就因为你忽略了的一个修改,导致同步不生效)
# 修改从节点的运行端口
port 6380# 把pid进程号写入pidfile配置的文件
pidfile /var/run/redis_6380.pid# 日志文件命名
logfile "6380.log"# 指定数据存放目录,需要提前在redis-6380.conf的当前目录下,新建好data目录及其下面的slave-80目录
dir ./data/slave-80 # 需要注释掉bind
# bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,
# 代表允许客户端通过机器的哪些网卡ip去访问,
# 内网一般可以不配置bind,注释掉即可
# bind 127.0.0.1
- 继续修改配置,这个是配置【主从复制】的核心:(以
redis-6380.conf为例)
# 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof
# 格式:replicaof [master节点的up地址] [master节点的端口6379]
# 比如我的是下面这个
replicaof 127.0.0.1 6379# 配置从节点只读,默认打开了
replica-read-only yes
- 然后就可以启动从节点了
# redis-6380.conf文件务必用你复制并修改了之后的redis.conf文件
./src/redis-server ./redis-6380.conf &
- 使用
redis-cli -p 端口的方式,连接到对应的从库,校验一下 - 测试在6379端口的master实例上写数据,看看6380和6381端口的slave实例是否能及时同步新修改数据。我的测试数据如下:
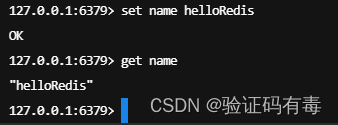
如上所示,我在6379主节点设置了一个name,值为helloRedis,接下来我们去从节点看看:
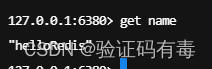
看,6380端口跟6381端口的从节点都同步了数据
2.2 Redis主从工作原理
Redis主从工作原理其实并不是那么神奇,主要是保证数据一致性就好了。那该怎么保证呢?首先肯定是要分场景的。比如:第一次过来同步复制(全量同步);之前已经同步过一次了,但后来因为某些原因断了,现在重新连接上,需要继续同步最近的数据(增量同步,断点续传)。
下面再给大家看看【全量同步】跟【增量同步】的业务流程图
全量同步业务流程图
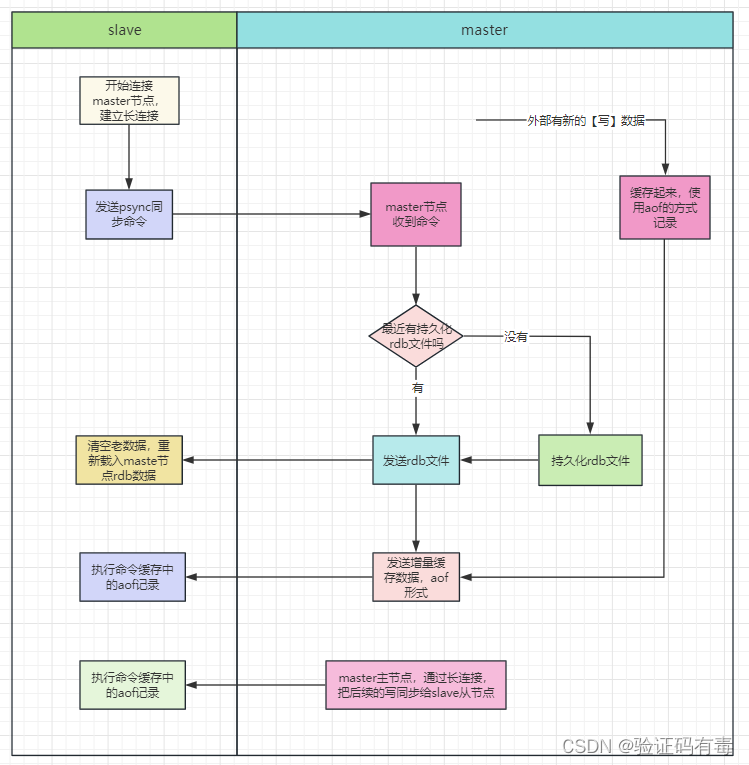
- 如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个
PSYNC命令给master请求复制数据 - master收到
PSYNC命令后,会在后台进行数据持久化(通过bgsave生成最新的.rdb快照文件),持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中 - 当持久化进行完毕以后,master会把这份
.rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成.rdb,然后再加载到内存中 - 然后,master再将之前缓存在内存中的命令发送给slave
- 当master与slave之间的连接由于某些原因而断开时,slave能够自动重连master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送给多个并发连接的slave
小总结:
上面在生成持久化文件的时候有两个要点不知道大家注意到没有?那就是:bgsave跟.rdb。
前面的bgsave比较好理解,异步生成.rdb文件嘛,为了不阻塞主节点的客户读写。那为什么是.rdb而不是.aof呢?其实说来也不算难理解,只不过我估计大家刚接触【redis持久化】所以比较陌生而已。因为.rdb恢复速度快啊!二进制文件嘛。
增量同步业务流程图
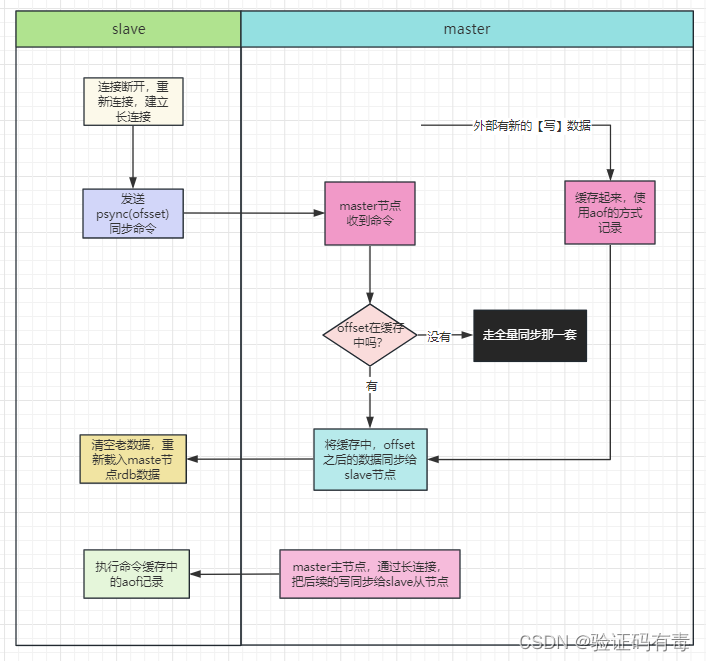
- 当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支持部分数据复制的命令
PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分数据复制(断点续传) - master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标
offset和master的进程id - 因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制
主从复制风暴
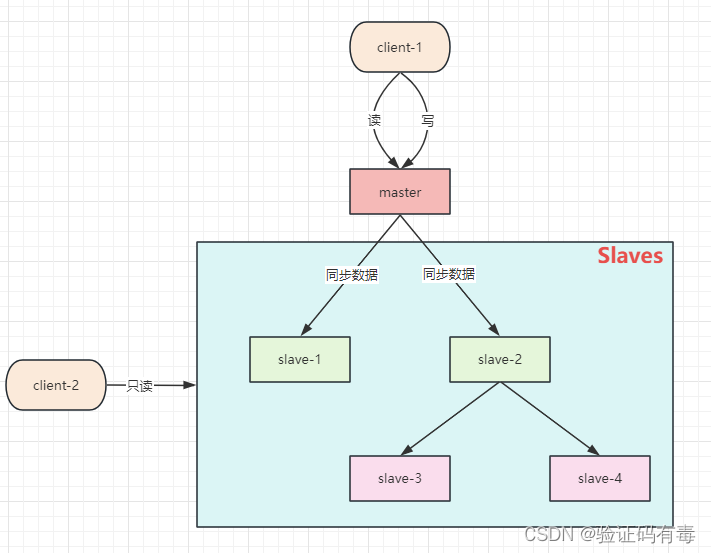
什么是主从复制风暴?简单来说,就是一个主节点,需要应付很多从节点的复制请求,就算是采用异步执行同步命令,但是当数据多了之后也会容易陷入瓶颈。这就是主从复制风暴。
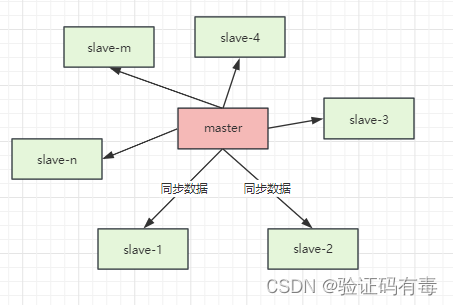
为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做如下架构,让部分从节点与从节点(与主节点同步)同步数据:
代码实战
这里新建一个SpringBoot项目,然后试着跑一下代码,看看主从是否真的生效。
首先在pom.xml里面引入如下配置:
<!-- springboot-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot</artifactId><version>2.7.0</version></dependency><!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><version>2.7.0</version></dependency><!-- redis客户端jedis--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency>
然后添加如下代码试试看:
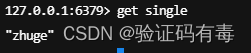
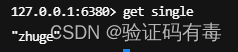
public class JedisSingleTest {public static void main(String[] args) {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMaxIdle(5);// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisPool jedisPool = new JedisPool(jedisPoolConfig, "114.132.46.145", 6379, 3000, null);Jedis jedis = null;try {// 从redis连接池里拿出一个连接执行命令jedis = jedisPool.getResource();System.out.println(jedis.set("single", "zhuge"));System.out.println(jedis.get("single"));} catch (Exception e) {e.printStackTrace();} finally {//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}
}如上代码,运行的时候,会往缓存中添加一条key=single, value=zhuge的数据,我们看看效果:
三、Redis主从架构——哨兵高可用架构
Redis哨兵高可用架构模型图如下:
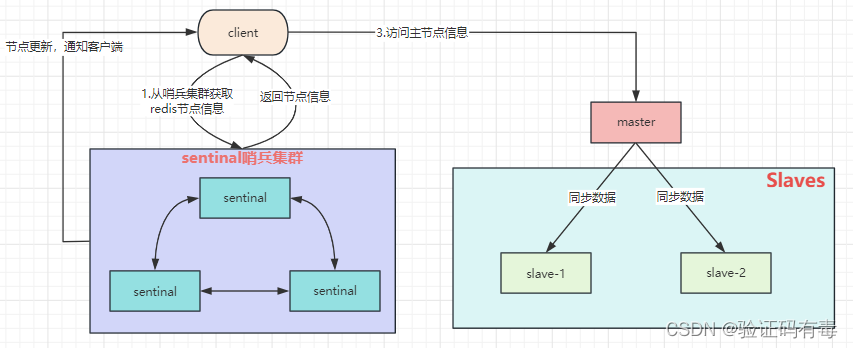
sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点(sentinal哨兵也是redis服务,后面我们启动的时候就会知道,其实也是使用redis-server来启动的)
哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点。不过,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
小总结:
不知道大家看到这个【三】这个标题有没有意识到什么,那就是,【哨兵模式】其实还是属于【主从架构】。只不过新增了【哨兵】这个角色,用来做【节点检测与发现】。一旦真正运行【读写】的Redis实例挂了,那么【哨兵】就会即刻感知,并且做出反应,这就是【哨兵】的职责,也是保证架构【高可用】的原理。
3.1 Redis哨兵架构搭建
好记性不如多操作几遍。注意:不需要关闭之前的【主从】Redis服务
- 在程序目录中复制一份
sentinel.conf文件,这里改名为sentinel-26379.conf,sentinel-26380.conf,sentinel-26381.conf三个文件。因为我们后面需要新增3个哨兵
cp sentinel.conf sentinel-26379.conf
- 将相关配置修改为如下值:(以
sentinel-26379.conf为例)
# 指定哨兵运行的端口
port 26379# 是否守护线程
daemonize yes# 把pid进程号写入pidfile配置的文件
pidfile "/var/run/redis-sentinel-26379.pid"# 日志文件命名
logfile "26379.log"# 指定数据存放目录,需要提前在当前目录下,新建好data目录及其下面的sentinal-79目录
dir ./data/sentinal-79
- 继续配置,下面的配置是哨兵的核心:(以
sentinel-26379.conf为例)
# 格式如下:
# sentinel monitor <master-redis-name> <master-redis-ip> <master-redis-port> <quorum>
# 上面最后一个参数【quorum】是一个数字,指明当有多少个sentinel
# 认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
# mymaster这个名字随便取,客户端访问时会用到
sentinel monitor mymaster 1xx.1xx.xx.xxx 6379 2
PS:上面的1xx.1xx.xx.xxx是我的外网地址,为什么要填外网地址,因为我在后面需要用Java代码演示
- 启动sentinal哨兵实例
./src/redis-sentinel sentinel-26379.conf &
- 查看sentinel的info信息,可以看到Sentinel的info里已经识别出了redis的主从
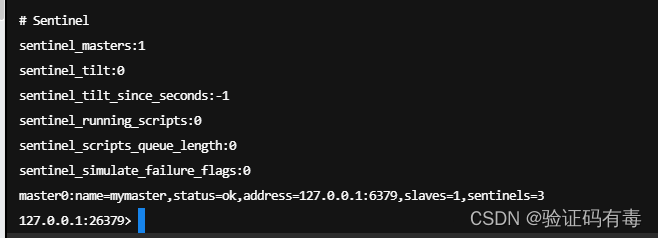
另外,sentinel集群都启动完毕后,会将哨兵集群的元数据信息写入所有sentinel的配置文件里去(追加在文件的最下面),我们查看下如下配置文件sentinel-26379.conf的最末尾,如下所示:
#代表redis主节点的从节点信息
sentinel known-replica mymaster 127.0.0.1 6380#代表redis主节点的从节点信息
sentinel known-replica mymaster 127.0.0.1 6381#代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 10.0.x.x1 26381 cdd97406fbcb4fdcdbf226f0d8540b1b8ac75d5f#代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 10.0.x.x1 26380 41c32a30f100bb28590ef3fef8e53cf158c1b6a7
当redis主节点如果挂了,哨兵集群会重新选举出新的redis主节点,同时会修改所有sentinel节点配置文件的集群元数据信息,比如6379的redis如果挂了,假设选举出的新主节点是6380,则sentinel文件里的集群元数据信息会变成如下所示:
#代表主节点的从节点信息
sentinel known-replica mymaster 127.0.0.1 6379#代表主节点的从节点信息
sentinel known-replica mymaster 127.0.0.1 6381#代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 10.0.x.x1 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f#代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 10.0.x.x1 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6
当然,还会修改sentinel文件里之前配置的mymaster对应的6379端口,改为6380:
sentinel monitor mymaster 1xx.1xx.xx.xxx 6380 2
当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点加入集群
3.2 哨兵架构高可用工作原理
后面再总结…
3.3 代码实战
这里新建一个SpringBoot项目,然后试着跑一下代码,看看主从是否真的生效。
首先在pom.xml里面引入如下配置:
<!-- springboot--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot</artifactId><version>2.7.0</version></dependency><!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><version>2.7.0</version></dependency><!-- redis客户端jedis--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.7.0</version></dependency>
接着再添加application.yml,如下:
spring:redis:database: 0timeout: 3000sentinel: #哨兵模式master: mymaster #主服务器所在集群名称nodes: 1xx.1xx.xx.xxx:26379,1xx.1xx.xx.xxx:26380,1xx.1xx.xx.xxx:26381lettuce:pool:max-idle: 50min-idle: 10max-active: 100max-wait: 1000
然后添加如下代码试试看:
public class JedisSingleTest {public static void main(String[] args) {JedisPoolConfig config = new JedisPoolConfig();config.setMaxTotal(20);config.setMaxIdle(10);config.setMinIdle(5);String masterName = "mymaster";Set<String> sentinels = new HashSet<String>();sentinels.add(new HostAndPort("114.132.46.145", 26379).toString());sentinels.add(new HostAndPort("114.132.46.145", 26380).toString());sentinels.add(new HostAndPort("114.132.46.145", 26381).toString());// JedisSentinelPool其实本质跟JedisPool类似,都是与redis主节点建立的连接池// JedisSentinelPool并不是说与sentinel建立的连接池,而是通过sentinel发现redis主节点并与其建立连接JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels, config, 3000, null);Jedis jedis = null;try {jedis = jedisSentinelPool.getResource();System.out.println(jedis.set("sentinel", "zhuge"));System.out.println(jedis.get("sentinel"));} catch (Exception e) {e.printStackTrace();} finally {// 注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}
}
小总结:
不知道大家看了上面的代码,有没有发现:我们都不用配置Redis的相关信息了,而是改成配置【哨兵】。没毛病,我们在最上面的模型里面已经说了,我们的节点信息是从【哨兵】获取的。
学习总结
- 学习了Redis的主从架构,并且尝试自己在云上配置普通的主从架构
- 学习了Redis主从架构之哨兵模式,并且尝试自己在云上配置
相关文章:
【Redis专题】Redis持久化、主从与哨兵架构详解
目录 前言课程目录一、Redis持久化1.1 RDB快照(Snapshot):二进制文件基本介绍开启/关闭方式触发方式bgsave的写时复制(COW,Copy On Write)机制优缺点 1.2 AOF(append-only file)&…...

【vue2第十三章】自定义指令 自定义v-loading指令
自定义指令 像 v-html,v-if,v-for都是vue内置指令,而我们也可以封装自定义指令,提升编码效率。 什么是自定义指令? 自己定义的一些指令,可以进行一些dom操作,扩展格外的功能。比如让图片懒加载…...
(插值查找))
数据结构--6.3查找算法(静态、动态)(插值查找)
静态查找:数据集合稳定,不需要添加,删除元素的查找操作。 动态查找:数据集合在查找的过程中需要同时添加或删除元素的查找操作。 对于静态查找来说,我们不妨可以用线性表结构组织数据,这样可以使用顺序查找…...
Spring Boot日志基础使用 设置日志级别
然后 我们来说日志 日志在实际开发中还是非常重要的 即可记录项目状态和一些特殊情况发生 因为 我们这里不是将项目 所以 讲的也不会特别深 基本还是将Spring Boot的日志设置或控制这一类的东西 相对业务的领域我们就不涉及了 日志 log 初期最明显的作用在于 开发中 你可以用…...
Playwright for Python:断言
一、支持的断言 Playwright支持以下几种断言: 断言描述expect(locator).to_be_checked()复选框被选中expect(locator).to_be_disabled()元素是禁用状态expect(locator).to_be_editable()元素是可编辑状态expect(locator).to_be_empty()容器是空的expect(locator).…...

websocket--技术文档--spring后台+vue基本使用
阿丹: 给大家分享一个可以用来进行测试websocket的网页,个人觉得还是挺好用的. WebSocket在线测试工具 还有一个小家伙ApiPost也可以进行使用websocket的测试。 本文章只是基本使用--给大家提供思路简单实现!! 使用spring-boot建立一个服…...
day01-ES6新特性以及ReactJS入门
课程介绍 ES6新特性ReactJS入门学习 1、ES6 新特性 1.2、let 和 const 命令 var 之前,我们写js定义变量的时候,只有一个关键字: var var 有一个问题,变量作用域的问题,作用域不可控,就是定义的变量有时会…...

MySQL5.7慢查询实践
总结 获取慢查询SQL 已经执行完的SQL,检查慢查询日志,日志中有执行慢的SQL正在执行中的SQL,show proccesslist;,结果中有执行慢的SQL 慢查询日志关键参数 名称解释Query_time查询消耗时间Time慢查询发生时间 分析慢查询SQL e…...
MySQL数据库的增删改查(进阶)
目录 数据库约束 约束类型 NULL约束 UNIQUE:唯一约束 DEFAULT:默认值约束 PRIMARY KEY:主键约束 FOREIGN KEY:外键约束 表的设计 一对一关系 一对多关系 多对多关系 查询 聚合查询 聚合函数 GROUP BY子句 HAVING …...

韶音骨传导耳机好不好用,韶音的骨传导耳机怎么样
提到韶音骨传导耳机,相信很多人在第一时间会想到韶音OpenRun Pro这一款骨传导耳机,这是在去年韶音新发布的一款骨传导耳机,在佩戴舒适性面做了很多优化,采用了夹紧力道适度的柔韧钛合金材质后挂;发声单元包裹柔软硅胶材…...

Nginx从安装到使用,反向代理,负载均衡
什么是Nginx? 文章目录 什么是Nginx?1、Nginx概述1.1、Nginx介绍1.2、Nginx下载和安装1.3、Nginx目录结构 2、Nginx命令2.1、查看版本2.2、检查配置文件正确性2.3、启动和停止2.4、重新加载配置文件2.5、环境变量的配置 3、Nginx配置文件结构4、Nginx具体…...

freertos之资源管理
中断屏蔽 屏蔽中断函数 在任务中使用 taskENTER_CRITICA()/taskEXIT_CRITICAL() 在中断中使用 taskENTER_CRITICAL_FROM_ISR()/taskEXIT_CRITICAL_FROM_ISR() 功能介绍 使用上述函数,进入临界中断,任务不会切换,且中断优先级处于con…...
1.创建项目(wpf视觉项目)
目录 前言本章环境创建项目启动项目可执行文件 前言 本项目主要开发为视觉应用,项目包含(视觉编程halcon的应用,会引入handycontrol组件库,工具库Masuit.Tools.Net,数据库工具sqlSugar等应用) 后续如果还有…...

使用element-ui导航,进入对应的三级页面菜单保持点击状态
1.注意事项 01.路由中使用了keepAlive属性,要用keepAlive:true,不能等于false,使用false页面会刷新 2.使用的方法 NavMenu 导航菜单 3.项目实例 <template><div class"policy-home"><div class"…...

golang字符串转64位整数
在Go语言中,可以使用strconv包中的ParseInt函数将字符串转换为64位整数。以下是一个示例代码: package main import ( "fmt" "strconv" ) func main() { str : "12345" num, err : strconv.ParseInt(str, 10, 64…...

创作纪念日-我的第1024天
机缘 不知不觉已经成为创作者的第1024天啦… … 刚开始接触博客的初衷就是为了记笔记📒、记总结📝,或许对于当时就等同于是为了找工作。坚持学习并持续输出博客一年后,这时我发现再写博客,不在是为了找一份工作&…...

【线上问题】很抱歉,如果没有 JavaScript 支持,将不能正常工作
目录 一、问题说明二、解决方式 一、问题说明 1.修改了nginx的配置 2.postman调用接口正常,浏览器访问接口200,但无数据 3.浏览器访问,nginx没有访问记录,接口请求到不了应用服务 4.原因不祥 二、解决方式 1.清理了浏览器缓存...
便捷、快速、稳定、高性能!以 GPU 实例演示 Alibaba Cloud Linux 3 对 AI 生态的支持 | 龙蜥技术
编者按:日前,Alibaba Cloud Linux 3 为使 AI 开发体验更高效,提供了一些优化升级,本文为“Alibaba Cloud Linux 3 AI 能力介绍”系列文章预告篇,以 GPU 实例为例,为大家演示 Alibaba Cloud Linux 3 对 AI 生…...

创新科技改变城市:智慧城市建设全景展望
在当今科技飞速发展的时代,智慧城市的概念已经成为城市发展的新趋势,为人们的生活带来了前所未有的便利和改变。智慧城市,顾名思义,是以先进的信息技术为基础,通过数字化、互联网化和智能化手段,实现城市基…...

Kotlin 环境下解决属性初始化问题
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...
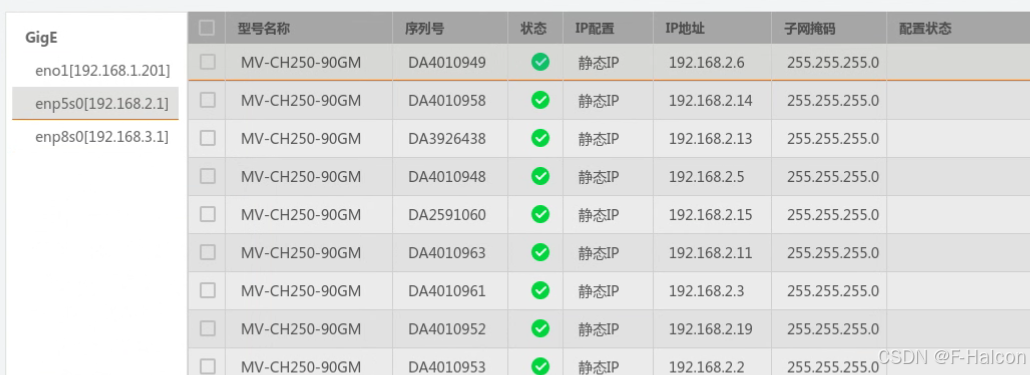
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...