【AI】机器学习——朴素贝叶斯
文章目录
- 2.1 贝叶斯定理
- 2.1.1 贝叶斯公式推导
- 条件概率
- 变式
- 贝叶斯公式
- 2.1.2 贝叶斯定理
- 2.1.3 贝叶斯决策
- 基本思想
- 2.2 朴素贝叶斯
- 2.2.1 朴素贝叶斯分类器思想
- 2.2.2 条件独立性对似然概率计算的影响
- 2.2.3 基本方法
- 2.2.4 模型
- 后验概率最大化
- 损失函数
- 期望风险最小化策略
- 2.2.5 朴素贝叶斯估计离散特征
- 学习算法
- 2.3 朴素贝叶斯分类器分析
- 2.3.1 条件独立性假设分析
- 2.3.2 期望风险最小化
- 2.3.3 拉普拉斯平滑
- 2.4 应用
- 比赛结果预测
- 垃圾邮件过滤
- 2.5 半朴素贝叶斯分类器
用于解决分类问题:将连续取值输入映射为离散取值的输出
解决分类问题的依据是数据的属性
- 利用后验概率选择最佳分类,后验概率通过贝叶斯定理求解
- 朴素贝叶斯假定所有属性相互独立,基于这一假设将类条件概率转化为属性条件概率的乘积
- 朴素贝叶斯方法可以使期望风险最小化
- 影响朴素贝叶斯分类的是所有属性之间的依赖关系在不同类别上的分布
2.1 贝叶斯定理
2.1.1 贝叶斯公式推导
条件概率
引例
3张抽奖券,1个中奖券,最后一名与第一名抽中奖概率相同
Y Y Y :抽中, N N N :未抽中 , Ω = { Y N N , N Y N , N N Y } \Omega=\{YNN,NYN,NNY\} Ω={YNN,NYN,NNY} , A i A_i Ai 事件表示第 i i i 名抽中
P ( A 3 ) = ∣ A 3 ∣ ∣ Ω ∣ = 1 3 P(A_3)=\frac{\vert A_3\vert}{\vert \Omega\vert}=\frac{1}{3} P(A3)=∣Ω∣∣A3∣=31
P ( A 1 ) = ∣ A 1 ∣ ∣ Ω ∣ = 1 3 P(A_1)=\frac{\vert A_1\vert}{\vert \Omega\vert}=\frac{1}{3} P(A1)=∣Ω∣∣A1∣=31
上例中,若已知第一名未抽中,求第三名抽中概率,则:
第一名未抽中 B = { N Y N , N N Y } B=\{NYN,NNY\} B={NYN,NNY}
第二名抽中 A 2 = { N N Y } A_2=\{NNY\} A2={NNY}
P ( A 2 ∣ B ) = 1 2 P(A_2\vert B)=\frac{1}{2} P(A2∣B)=21

分析:样本空间变了,目标样本数量不变
事件B发生条件下,有事件A发生 ⟺ \iff ⟺ 事件AB同时发生,样本空间为B
求解:
P ( A ∣ B ) = P ( A B ) P ( B ) ⟺ n ( A B ) / n ( Ω ) n ( B ) / n ( Ω ) = P ( A B ) P ( B ) P(A\vert B)=\frac{P(AB)}{P(B)}\iff\frac{n(AB)/n(\Omega)}{n(B)/n(\Omega)}=\frac{P(AB)}{P(B)} P(A∣B)=P(B)P(AB)⟺n(B)/n(Ω)n(AB)/n(Ω)=P(B)P(AB)
eg
掷硬币,100个中有99个正常HT,一个HH。投出去是正面,该硬币是异常硬币的概率
A表示异常硬币的概率,B表示掷出正面的概率
-
P ( A ∣ B ) = 异常硬币正面 n ( 硬币正面 ) = 2 101 P(A\vert B)=\frac{异常硬币正面}{n(硬币正面)}=\frac{2}{101} P(A∣B)=n(硬币正面)异常硬币正面=1012
-
P ( A ∣ B ) = P ( A B ) P ( B ) = P ( A ∣ B ) P ( B ) P ( A ∣ B ) P ( B ) + P ( A ∣ B ‾ ) P ( B ‾ ) = 2 101 P(A\vert B)=\frac{P(AB)}{P(B)}=\frac{P(A\vert B)P(B)}{P(A\vert B)P(B)+P(A\vert \overline{B})P(\overline{B})}=\frac{2}{101} P(A∣B)=P(B)P(AB)=P(A∣B)P(B)+P(A∣B)P(B)P(A∣B)P(B)=1012
变式
乘法原理 : P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B)
全概率公式 :
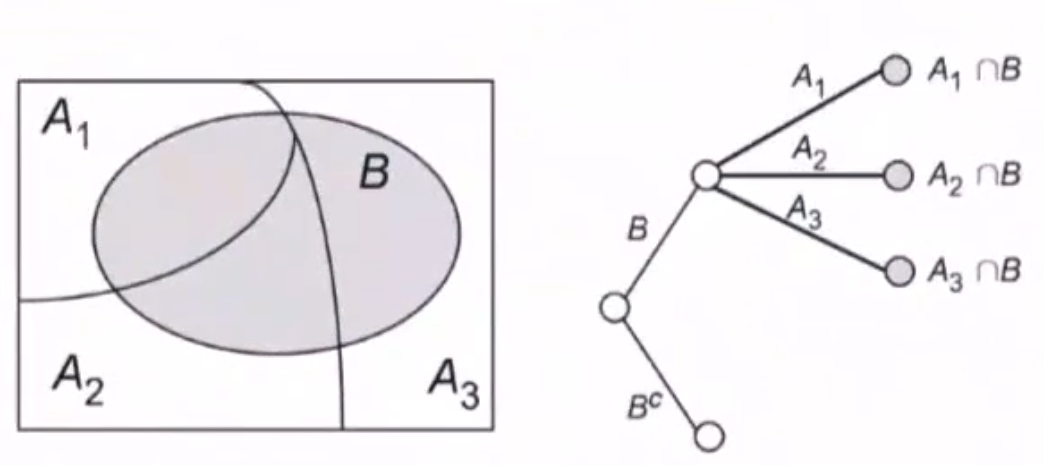
P ( B ) = P ( A 1 ⋂ B ) + ⋯ + P ( A n ⋂ B ) = P ( A 1 ) P ( B ∣ A 1 ) + ⋯ + P ( A n ) P ( B ∣ A n ) P(B)=P(A_1\bigcap B)+\cdots+P(A_n\bigcap B)=P(A_1)P(B\vert A_1)+\cdots+P(A_n)P(B\vert A_n) P(B)=P(A1⋂B)+⋯+P(An⋂B)=P(A1)P(B∣A1)+⋯+P(An)P(B∣An)
贝叶斯公式
对于条件概率 P ( A i ∣ B ) P(A_i\vert B) P(Ai∣B) 有
P ( A i ∣ B ) = P ( A i B ) P ( B ) = P ( B ∣ A i ) P ( A i ) P ( B ) = P ( B ∣ A i ) P ( A i ) ∑ j = 1 n P ( B ∣ A j ) P ( A j ) P(A_i\vert B)=\frac{P(A_iB)}{P(B)}=\frac{P(B\vert A_i)P(A_i)}{P(B)}=\frac{P(B\vert A_i)P(A_i)}{\sum\limits_{j=1}^nP(B\vert A_j)P(A_j)} P(Ai∣B)=P(B)P(AiB)=P(B)P(B∣Ai)P(Ai)=j=1∑nP(B∣Aj)P(Aj)P(B∣Ai)P(Ai)
2.1.2 贝叶斯定理
P ( Y ∣ X ) = P ( X ∣ Y ) P ( Y ) P ( X ) P(Y\vert X)=\frac{P(X\vert Y)P(Y)}{P(X)} P(Y∣X)=P(X)P(X∣Y)P(Y)
- P ( Y ∣ X ) P(Y\vert X) P(Y∣X) :后验概率
- P ( Y ) P(Y) P(Y) :先验概率
- P ( X ∣ Y ) P(X\vert Y) P(X∣Y) :似然概率
2.1.3 贝叶斯决策
在不完全的情报下,对部分未知状态 P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 用主观概率 P ( Y ) P(Y) P(Y) 估计,然后用贝叶斯公式对发生概率修正
利用期望风险与修正概率做出最优决策
基本思想
-
已知的样本密度 P ( X ) P(X) P(X) 和先验概率 P ( Y ) P(Y) P(Y)
样本密度可由全概率公式求得, P ( X ) = ∑ i P ( X ∣ Y i ) P ( Y i ) P(X)=\sum\limits_{i} P(X\vert Y_i)P(Y_i) P(X)=i∑P(X∣Yi)P(Yi)
-
利用贝叶斯公式转化为似然概率
P ( Y ∣ X ) = P ( X ∣ Y ) P ( Y ) P ( X ) P(Y\vert X)=\frac{P(X\vert Y)P(Y)}{P(X)} P(Y∣X)=P(X)P(X∣Y)P(Y) -
根据后验概率的大小,进行决策分类
eg
由统计,大约 0.1 % 0.1\% 0.1% 感染AIDS,所有感染者检测为阳性,有 1 % 1\% 1% 未感染者误检测为阳性,若某人检测结果为阳性,求检测阳性确定感染的概率
用 Y = 1 Y=1 Y=1 表示感染, X = 1 X=1 X=1 表示检测阳性
由于 0.1 % 0.1\% 0.1% 的人感染,在已知感染情况下检测必为阳性 P ( X = 1 ∣ Y = 1 ) P(X=1\vert Y=1) P(X=1∣Y=1)
P ( Y = 1 ∣ X = 1 ) = P ( X = 1 ∣ Y = 1 ) P ( Y = 1 ) P ( X = 1 ) = 1 × 0.001 1 × 0.001 + 0.01 × 0.999 P(Y=1\vert X=1)=\frac{P(X=1\vert Y=1)P(Y=1)}{P(X=1)}=\frac{1\times 0.001}{1\times 0.001+0.01\times 0.999} P(Y=1∣X=1)=P(X=1)P(X=1∣Y=1)P(Y=1)=1×0.001+0.01×0.9991×0.001
第二轮检测中, 90 % 90\% 90% 感染者为阳性, 5 % 5\% 5% 未感染者为阳性,求误诊率
P ( X 1 = 1 ) P(X_1=1) P(X1=1) 表示第一轮检测为阳性的概率; P ( X 2 = 1 ) P(X_2=1) P(X2=1) 表示第二轮检测为阳性的概率
由补充题设可知, P ( X 2 ∣ Y = 1 ) = 0.9 , P ( X 2 ∣ Y = 0 ) = 0.05 P(X_2\vert Y=1)=0.9,P(X_2\vert Y=0)=0.05 P(X2∣Y=1)=0.9,P(X2∣Y=0)=0.05
P ( Y = 0 ∣ X 1 = 1 , X 2 = 1 ) = P ( X 1 = 1 , X 2 = 1 ∣ Y = 0 ) ⋅ P ( Y = 0 ) P ( X 1 = 1 , X 2 = 1 ) 表示误诊率 P(Y=0\vert X_1=1,X_2=1)=\frac{P(X_1=1,X_2=1\vert Y=0)\cdot P(Y=0)}{P(X_1=1,X_2=1)} 表示误诊率 P(Y=0∣X1=1,X2=1)=P(X1=1,X2=1)P(X1=1,X2=1∣Y=0)⋅P(Y=0)表示误诊率
其中,先验概率 P ( Y = 0 ) = 0.999 P(Y=0)=0.999 P(Y=0)=0.999
由全概率公式
P ( X 1 = 1 , X 2 = 1 ) = P ( X 1 = 1 , X 2 = 1 ∣ Y = 0 ) ⋅ P ( Y = 0 ) + P ( X 1 = 1 , X 2 = 1 ∣ Y = 1 ) ⋅ P ( Y = 1 ) \begin{aligned} P(X_1=1,X_2=1)&=P(X_1=1,X_2=1\vert Y=0)\cdot P(Y=0)\\ &+P(X_1=1,X_2=1\vert Y=1)\cdot P(Y=1) \end{aligned} P(X1=1,X2=1)=P(X1=1,X2=1∣Y=0)⋅P(Y=0)+P(X1=1,X2=1∣Y=1)⋅P(Y=1)
P ( X 1 = 1 , X 2 = 1 ∣ Y = 0 ) = 条件独立性假设 P ( X 1 = 1 ∣ Y = 0 ) ⋅ P ( X 2 = 1 ∣ Y = 0 ) = 0.01 × 0.05 P ( X 1 = 1 , X 2 = 1 ∣ Y = 1 ) = 条件独立性假设 P ( X 1 = 1 ∣ Y = 1 ) ⋅ P ( X 2 = 1 ∣ Y = 1 ) = 1 × 0.9 P(X_1=1,X_2=1\vert Y=0)\xlongequal{条件独立性假设}P(X_1=1\vert Y=0)\cdot P(X_2=1\vert Y=0)=0.01\times 0.05\\ P(X_1=1,X_2=1\vert Y=1)\xlongequal{条件独立性假设}P(X_1=1\vert Y=1)\cdot P(X_2=1\vert Y=1)=1\times 0.9 P(X1=1,X2=1∣Y=0)条件独立性假设P(X1=1∣Y=0)⋅P(X2=1∣Y=0)=0.01×0.05P(X1=1,X2=1∣Y=1)条件独立性假设P(X1=1∣Y=1)⋅P(X2=1∣Y=1)=1×0.9
2.2 朴素贝叶斯
2.2.1 朴素贝叶斯分类器思想
朴素贝叶斯分类器假定样本的不同属性满足条件独立性假设
其基本思想:分析待分类样本出现在每个输出类别的后验概率 P ( Y ∣ X ) P(Y\vert X) P(Y∣X) ,并将取得最大后验概率的类别作为输出
假设训练数据的属性由 n n n 维随机变量 X X X 表示,其分类结果用随机变量 Y Y Y 表示,那么 X X X 和 Y Y Y 的统计规律就可以用联合概率分布 P ( X , Y ) P(X,Y) P(X,Y) 表示,每一个具体的样本 ( x i , y i ) (x_i,y_i) (xi,yi) 都可以由 P ( X , Y ) P(X,Y) P(X,Y) 独立同分布生成——生成学习
P ( Y ∣ X ) = P ( X , Y ) P ( X ) = P ( Y ) ⋅ P ( X ∣ Y ) P ( X ) P(Y\vert X)=\frac{P(X,Y)}{P(X)}=\frac{P(Y)\cdot P(X\vert Y)}{P(X)} P(Y∣X)=P(X)P(X,Y)=P(X)P(Y)⋅P(X∣Y)
P ( Y ) P(Y) P(Y) 表示每个类别出现的概率,也就是类 先验概率
- 先验概率容易根据训练数据计算出来,只需要分别统计不同类别样本的数量即可
P ( X ∣ Y ) P(X\vert Y) P(X∣Y) 表示在给定的类别下不同属性出现的概率,即类似然概率
- 似然概率受属性值的影响
2.2.2 条件独立性对似然概率计算的影响
如果每个样本包含 100 个属性,每个属性取值可能有 100 种,那么对分类的每个结果,要计算的条件概率数目就是 10 0 100 100^{100} 100100 ,对似然概率的精确估计就需要庞大的计算量
在条件独立性假设的前提下,保证了所有属性相互独立,互不影响。每个属性独立地对分类结果发生作用,即
P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , X ( 2 ) = x ( 2 ) , ⋯ , X ( m ) = x ( m ) ∣ Y = c k ) = 所有属性相互独立 ∏ j = 1 m P ( X ( j ) = x ( j ) ∣ Y = c k ) P(X=x\vert Y=c_k)=P\left(X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},\cdots,X^{(m)}=x^{(m)}\vert Y=c_k\right)\\ \xlongequal{所有属性相互独立}\prod\limits_{j=1}^mP(X^{(j)}=x^{(j)}\vert Y=c_k) P(X=x∣Y=ck)=P(X(1)=x(1),X(2)=x(2),⋯,X(m)=x(m)∣Y=ck)所有属性相互独立j=1∏mP(X(j)=x(j)∣Y=ck)
在条件独立性假设下,将类条件概率转化为属性条件概率的乘积
在没有条件独立性假设的情况下,每个样本分类结果 y y y 只能刻画所有属性 X ( 1 ) , X ( 2 ) , ⋯ , X ( m ) X^{(1)},X^{(2)},\cdots,X^{(m)} X(1),X(2),⋯,X(m) 形成的整体,且只有具有相同属性的样本才能放在一起评价
- 当属性数目较多而样本数目较少时,要让 m m m 个属性取到相同特征就有些牵强
有了条件独立性假设后,分类结果 y y y 就相当于实现了 m m m 重复用。每个样本既可以用于刻画 X ( 1 ) X^{(1)} X(1) ,又可以刻画 X ( n ) X^{(n)} X(n) ,
- 无形中将训练样本的数量扩大为原先的 m m m 倍
分析每个属性取值对分类结果的影响时,也有更多的数据作为支撑
条件独立性假设是一个很强的假设,导致对数据的过度简化,因而对性能带来些许影响。但由于其极大简化分类问题计算复杂度的能力,性能上做部分折衷也并非不能接受
2.2.3 基本方法
-
求先验概率分布 P ( Y = c k ) , k = 1 , 2 , ⋯ , K P(Y=c_k),k=1,2,\cdots,K P(Y=ck),k=1,2,⋯,K
-
求似然概率分布
P ( X ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , X ( 2 ) = x ( 2 ) , ⋯ , X ( m ) = x ( m ) ∣ Y = c k ) = 实际 P ( X ( 2 ) = x ( 2 ) , ⋯ , X ( m ) = x ( m ) ∣ X ( 1 ) = x ( 1 ) , Y = c k ) P ( X ( 1 ) = x ( 1 ) ) = P ( X ( 3 ) = x ( 3 ) , ⋯ , X ( m ) = x ( m ) ∣ X ( 1 ) = x ( 1 ) , X ( 2 ) = x ( 2 ) , Y = c k ) P ( X ( 1 ) = x ( 1 ) ) P ( X ( 2 ) = x ( 2 ) ) = 朴素贝叶斯 i i d P ( X ( 1 ) = x ( 1 ) ∣ Y = c k ) P ( X ( 2 ) = x ( 2 ) ∣ Y = c k ) ⋯ P ( X ( m ) = x ( m ) ∣ Y = c k ) = ∏ j = 1 m P ( X ( j ) = x ( j ) ∣ Y = c k ) \begin{aligned} P(X\vert Y=c_k)&=P(X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},\cdots,X^{(m)}=x^{(m)}\vert Y=c_k)\\ &\xlongequal{实际}P(X^{(2)}=x^{(2)},\cdots,X^{(m)}=x^{(m)}\vert X^{(1)}=x^{(1)},Y=c_k)P(X^{(1)}=x^{(1)})\\ &=P(X^{(3)}=x^{(3)},\cdots,X^{(m)}=x^{(m)}\vert X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},Y=c_k)P(X^{(1)}=x^{(1)})P(X^{(2)}=x^{(2)})\\ &\xlongequal{朴素贝叶斯iid}P(X^{(1)}=x^{(1)}\vert Y=c_k)P(X^{(2)}=x^{(2)}\vert Y=c_k)\cdots P(X^{(m)}=x^{(m)}\vert Y=c_k)\\ &=\prod\limits_{j=1}^mP(X^{(j)}=x^{(j)}\vert Y=c_k) \end{aligned} P(X∣Y=ck)=P(X(1)=x(1),X(2)=x(2),⋯,X(m)=x(m)∣Y=ck)实际P(X(2)=x(2),⋯,X(m)=x(m)∣X(1)=x(1),Y=ck)P(X(1)=x(1))=P(X(3)=x(3),⋯,X(m)=x(m)∣X(1)=x(1),X(2)=x(2),Y=ck)P(X(1)=x(1))P(X(2)=x(2))朴素贝叶斯iidP(X(1)=x(1)∣Y=ck)P(X(2)=x(2)∣Y=ck)⋯P(X(m)=x(m)∣Y=ck)=j=1∏mP(X(j)=x(j)∣Y=ck) -
由贝叶斯定理计算
P ( Y = c k ∣ X ) = P ( X ∣ Y = c k ) P ( Y = c k ) P ( X ) = P ( X ∣ Y = c k ) P ( Y = c k ) ∑ k = 1 K P ( X ∣ Y = c k ) P ( Y = c k ) = P ( Y = c k ) ∏ j = 1 m P ( X ( j ) = x ( j ) ∣ Y = c k ) ∑ k = 1 K P ( Y = c k ) ∏ j = 1 m P ( X ( j ) = x ( j ) ∣ Y = c k ) \begin{aligned} P(Y=c_k\vert X)&=\frac{P(X\vert Y=c_k)P(Y=c_k)}{P(X)}=\frac{P(X\vert Y=c_k)P(Y=c_k)}{\sum\limits_{k=1}^KP(X\vert Y=c_k)P(Y=c_k)}\\ &=\frac{P(Y=c_k)\prod\limits_{j=1}^mP(X^{(j)}=x^{(j)}\vert Y=c_k)}{\sum\limits_{k=1}^KP(Y=c_k)\prod\limits_{j=1}^mP(X^{(j)}=x^{(j)}\vert Y=c_k)} \end{aligned} P(Y=ck∣X)=P(X)P(X∣Y=ck)P(Y=ck)=k=1∑KP(X∣Y=ck)P(Y=ck)P(X∣Y=ck)P(Y=ck)=k=1∑KP(Y=ck)j=1∏mP(X(j)=x(j)∣Y=ck)P(Y=ck)j=1∏mP(X(j)=x(j)∣Y=ck)
2.2.4 模型
y = f ^ ( X ) = a r g max c k P ( Y = c k ∣ X ) = a r g max c k P ( Y = c k ) ∏ j = 1 m P ( X ( j ) = x ( j ) ∣ Y = c k ) P ( X ) ∝ a r g max c k P ( Y = c k ) ∏ j = 1 m P ( X ( j ) = x ( j ) ∣ Y = c k ) \begin{aligned} y=\hat{f}(X)&=arg\max\limits_{c_k}P(Y=c_k\vert X)\\ &=arg\max\limits_{c_k}\frac{P(Y=c_k)\prod\limits_{j=1}^mP(X^{(j)}=x^{(j)}\vert Y=c_k)}{P(X)}\\ &\propto arg\max\limits_{c_k}P(Y=c_k)\prod\limits_{j=1}^mP(X^{(j)}=x^{(j)}\vert Y=c_k) \end{aligned} y=f^(X)=argckmaxP(Y=ck∣X)=argckmaxP(X)P(Y=ck)j=1∏mP(X(j)=x(j)∣Y=ck)∝argckmaxP(Y=ck)j=1∏mP(X(j)=x(j)∣Y=ck)
有了训练数据,先验概率 P ( Y ) P(Y) P(Y) 和似然概率 P ( X ∣ Y ) P(X\vert Y) P(X∣Y) 就可被视为已知条件,进而可用于求解后验概率 P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 。
对于给定的输入 X X X ,朴素贝叶斯分类器就可以利用贝叶斯定理求解后验概率,并将后验概率最大的类作为输出
由于所有的后验概率求解中,边界概率 P ( X ) P(X) P(X) 都是相同的,因而其影响可忽略,有朴素贝叶斯分类器的数学表达式
y ∝ a r g max c k P ( Y = c k ) ⋅ ∏ j m P ( X ( j ) = x ( j ) ∣ Y = c k ) y\propto arg\max\limits_{c_k}P(Y=c_k)\cdot \prod\limits_{j}^mP(X^{(j)}=x^{(j)}\vert Y=c_k) y∝argckmaxP(Y=ck)⋅j∏mP(X(j)=x(j)∣Y=ck)
后验概率最大化
朴素贝叶斯将实例分到后验概率最大的类中,等价于 期望风险最小化策略
损失函数
L ( Y , f ( X ) ) = { 1 , Y ≠ f ^ ( X ) 0 , Y = f ^ ( X ) L(Y,f(X))=\begin{cases} 1&,Y\neq \hat{f}(X)\\ 0&,Y=\hat{f}(X) \end{cases} L(Y,f(X))={10,Y=f^(X),Y=f^(X)
期望风险
R e x p ( f ) = E [ L ( Y , f ( X ) ) ] = ∫ X Y L ( y , f ^ ( x ) ) ⋅ P ( x , y ) d x d y = ∑ k = 1 K [ L ( y , f ^ ( x ) ) ⋅ P ( y ∣ x ) ] \begin{aligned} R_{exp}(f)&=E[L(Y,f(X))]\\ &=\int_{\mathcal{XY}}L(y,\hat{f}(x))\cdot P(x,y)dxdy\\ &=\sum\limits_{k=1}^{^K}[L(y,\hat{f}(x))\cdot P(y\vert x)] \end{aligned} Rexp(f)=E[L(Y,f(X))]=∫XYL(y,f^(x))⋅P(x,y)dxdy=k=1∑K[L(y,f^(x))⋅P(y∣x)]
期望风险最小化策略
f ( X ) = a r g min y ∈ Y ∑ k = 1 K [ L ( y = c k , f ^ ( x ) ) ⋅ P ( y ∣ x ) ] = a r g min y ∈ Y ∑ k = 1 K P ( y ≠ c k ∣ x ) = a r g min y ∈ Y ∑ k = 1 K [ 1 − P ( y = c k ∣ x ) ] = a r g max y ∈ Y ∑ k = 1 K P ( y = c k ∣ x ) \begin{aligned} f(X)&=arg\min\limits_{y\in \mathcal{Y}}\sum\limits_{k=1}^{^K}[L(y=c_k,\hat{f}(x))\cdot P(y\vert x)]\\ &=arg\min\limits_{y\in \mathcal{Y}}\sum\limits_{k=1}^{K}P(y\neq c_k\vert x)\\ &=arg\min\limits_{y\in \mathcal{Y}}\sum\limits_{k=1}^{K}[1-P(y= c_k\vert x)]\\ &=arg\max\limits_{y\in \mathcal{Y}}\sum\limits_{k=1}^{K}P(y= c_k\vert x) \end{aligned} f(X)=argy∈Ymink=1∑K[L(y=ck,f^(x))⋅P(y∣x)]=argy∈Ymink=1∑KP(y=ck∣x)=argy∈Ymink=1∑K[1−P(y=ck∣x)]=argy∈Ymaxk=1∑KP(y=ck∣x)
由 期望风险最小化策略 变为 后验概率最大化策略
2.2.5 朴素贝叶斯估计离散特征
意味着用频率对 先验概率 P ( Y = c k ) P(Y=c_k) P(Y=ck) ,似然概率 P ( X ( j ) = x ( j ) ∣ Y = c k ) P(X^{(j)}=x^{(j)}\vert Y=c_k) P(X(j)=x(j)∣Y=ck) 做出估计
其中,
先验概率 P ( Y = c k ) = ∑ i = 1 n I ( y i = c k ) n , k = 1 , ⋯ , K P(Y=c_k)=\frac{\sum\limits_{i=1}^nI(y_i=c_k)}{n},k=1,\cdots,K P(Y=ck)=ni=1∑nI(yi=ck),k=1,⋯,K
似然概率 P ( X ( j ) = x ( j ) ∣ Y = c k ) P(X^{(j)}=x^{(j)}\vert Y=c_k) P(X(j)=x(j)∣Y=ck) 可用极大似然估计
P ( X ( j ) = x ( j ) ∣ Y = c k ) = P ( X ( j ) = x ( j ) , Y = c k ) P ( Y = c k ) = ∑ i = 1 n I ( X i ( j ) = x ( j ) , y i = c k ) n ∑ i = 1 n I ( y i = c k ) n = I ( X i ( j ) = x ( j ) , y i = c k ) ∑ i = 1 n I ( y i = c k ) , 特征 j = 1 , 2 , ⋯ , m ; k = 1 , ⋯ , K \begin{aligned} P(X^{(j)}=x^{(j)}\vert Y=c_k)&=\frac{P(X^{(j)}=x^{(j)},Y=c_k)}{P(Y=c_k)}\\ &=\frac{\frac{\sum\limits_{i=1}^nI(X_i^{(j)}=x^{(j)},y_i=c_k)}{n}}{\frac{\sum\limits_{i=1}^nI(y_i=c_k)}{n}}\\ &=\frac{I(X_i^{(j)}=x^{(j)},y_i=c_k)}{\sum\limits_{i=1}^nI(y_i=c_k)}\quad,特征j=1,2,\cdots,m;\quad k=1,\cdots,K \end{aligned} P(X(j)=x(j)∣Y=ck)=P(Y=ck)P(X(j)=x(j),Y=ck)=ni=1∑nI(yi=ck)ni=1∑nI(Xi(j)=x(j),yi=ck)=i=1∑nI(yi=ck)I(Xi(j)=x(j),yi=ck),特征j=1,2,⋯,m;k=1,⋯,K
学习算法
输入:训练数据 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\} T={(x1,y1),(x2,y2),⋯,(xn,yn)} ,其中
- 假设 P ( X , Y ) P(X,Y) P(X,Y) 是X,Y的联合概率分布,样本 ( x i , y i ) (x_i,y_i) (xi,yi) 由 P ( X , Y ) P(X,Y) P(X,Y) 独立同分布产生
x i = ( x i ( 1 ) x i ( 2 ) ⋮ x i ( j ) ⋮ x i ( m ) ) ∈ X ⊆ R m , y i ∈ Y = { c 1 , c 2 , ⋯ , c k } i = 1 , 2 , ⋯ , n ; j = 1 , 2 , ⋯ , m x i ( j ) ∈ { a j 1 , a j 2 , ⋯ , a j s j } , a j l 为第 j 个特征的可能取值, l = 1 , 2 , ⋯ , s j x_i=\left( \begin{aligned} &x_i^{(1)}\\ &x_i^{(2)}\\ &\vdots\\ &x_i^{(j)}\\ &\vdots\\ &x_i^{(m)} \end{aligned} \right)\in \mathcal{X}\subseteq R^m,y_i\in\mathcal{Y=} \{c_1,c_2,\cdots,c_k\}\\ i=1,2,\cdots,n;j=1,2,\cdots,m\\ x_i^{(j)}\in \{a_{j1},a_{j2},\cdots,a_{js_j}\},a_{jl}为第j个特征的可能取值,l=1,2,\cdots,s_j xi= xi(1)xi(2)⋮xi(j)⋮xi(m) ∈X⊆Rm,yi∈Y={c1,c2,⋯,ck}i=1,2,⋯,n;j=1,2,⋯,mxi(j)∈{aj1,aj2,⋯,ajsj},ajl为第j个特征的可能取值,l=1,2,⋯,sj
输出: x x x 的分类 c k c_k ck
步骤:
-
计算先验与似然概率
先验概率 P ( Y = c k ) = ∑ i = 1 n I ( y i = c k ) n , k = 1 , ⋯ , K P(Y=c_k)=\frac{\sum\limits_{i=1}^nI(y_i=c_k)}{n},k=1,\cdots,K P(Y=ck)=ni=1∑nI(yi=ck),k=1,⋯,K
似然概率 P ( X ( j ) = a j l ∣ Y = c k ) = P ( X ( j ) = a j l , Y = c k ) P ( Y = c k ) = I ( X i ( j ) = a j l , y i = c k ) ∑ i = 1 n I ( y i = c k ) j = 1 , 2 , ⋯ , n l = 1 , 2 , ⋯ , s j k = 1 , 2 , ⋯ , K \begin{aligned} 似然概率\quad P(X^{(j)}=a_{jl}\vert Y=c_k)&=\frac{P(X^{(j)}=a_{jl},Y=c_k)}{P(Y=c_k)}\\ &=\frac{I(X_i^{(j)}=a_{jl},y_i=c_k)}{\sum\limits_{i=1}^nI(y_i=c_k)}\\ &j=1,2,\cdots,n\qquad l=1,2,\cdots,s_j\qquad k=1,2,\cdots,K \end{aligned} 似然概率P(X(j)=ajl∣Y=ck)=P(Y=ck)P(X(j)=ajl,Y=ck)=i=1∑nI(yi=ck)I(Xi(j)=ajl,yi=ck)j=1,2,⋯,nl=1,2,⋯,sjk=1,2,⋯,K -
给定样本 x x x ,计算
P ( Y = c k ∣ X ) ∝ P ( Y = c k ) ⋅ ∏ j m P ( X ( j ) = x ( j ) ∣ Y = c k ) , k = 1 , 2 , ⋯ , K P(Y=c_k\vert X)\propto P(Y=c_k)\cdot \prod\limits_{j}^mP(X^{(j)}=x^{(j)}\vert Y=c_k)\quad ,k=1,2,\cdots,K P(Y=ck∣X)∝P(Y=ck)⋅j∏mP(X(j)=x(j)∣Y=ck),k=1,2,⋯,K -
确定实例 x x x 的类
y = a r g max c k P ( Y = c k ) ⋅ ∏ j m P ( X ( j ) = x ( j ) ∣ Y = c k ) , k = 1 , 2 , ⋯ , K = a r g max c k ∑ i = 1 n I ( y i = c k ) n ∏ j = 1 m I ( X i ( j ) = a j l , y i = c k ) ∑ i = 1 n I ( y i = c k ) \begin{aligned} y&=arg\max\limits_{c_k}P(Y=c_k)\cdot \prod\limits_{j}^mP(X^{(j)}=x^{(j)}\vert Y=c_k)\quad ,k=1,2,\cdots,K\\ &=arg\max\limits_{c_k}\frac{\sum\limits_{i=1}^nI(y_i=c_k)}{n}\prod\limits_{j=1}^m\frac{I(X_i^{(j)}=a_{jl},y_i=c_k)}{\sum\limits_{i=1}^nI(y_i=c_k)} \end{aligned} y=argckmaxP(Y=ck)⋅j∏mP(X(j)=x(j)∣Y=ck),k=1,2,⋯,K=argckmaxni=1∑nI(yi=ck)j=1∏mi=1∑nI(yi=ck)I(Xi(j)=ajl,yi=ck)
2.3 朴素贝叶斯分类器分析
朴素贝叶斯是一种非常高效的方法。当以分类的正确与否作为误差指标时,只要朴素贝叶斯分类器能够把最大的后验概率找到,就意味着分类正确。至于最大后验概率的估计值是否精确,就不重要了
- 对于一个2分类问题,在一个实例上两个类别的最大后验概率分别是 0.9和0.1,朴素贝叶斯分类器估计出的后验概率就可能是0.6和0.4。由于大小相对关系没有改变,按照估计的后验概率分类,仍然能得到正确的结果
2.3.1 条件独立性假设分析
如何解释独立性假设在几乎不成立的情况下,朴素贝叶斯分类器在大多数分类任务中体现出优良特性?
影响朴素贝叶斯的分类的是所有属性之间的依赖关系在不同类别上的分布,而不是依赖关系本身
- 在给定训练数据集上,两个属性之间可能具有相关性,但在每个类别上都以相同的程度体现,这种情况下不会破坏贝叶斯分类器的最优性
- 即使这种分布式不均匀的,当所有属性之间的依赖关系一起发挥作用时,他们就可能相互抵消,不再次影响分类
2.3.2 期望风险最小化
在应用朴素贝叶斯分类器处理连续性属性数据时,通常假定属性数据满足正态分布,再根据每个类别下的训练数据计算出正态分布的均值和方差
从模型最优化角度观察,朴素贝叶斯分类器是平均意义上预测能力最优的模型,也就是使得 期望风险最小化
-
期望风险:风险函数的数学期望,度量平均意义下模型预测的误差特性。
可视为单次预测误差在联合概率分布 P ( X , Y ) P(X,Y) P(X,Y) 上的数学期望
期望风险最小化 ⟺ \iff ⟺ 后验概率最大化
朴素贝叶斯分类器通过将实例分配到后验概率最大的类中,也就是让 1 − P ( Y ∣ X ) 1-P(Y\vert X) 1−P(Y∣X) 最小。
在以分类错误的是 实例数作为误差时,期望风险就等于 1 − P ( Y ∣ X ) 1-P(Y\vert X) 1−P(Y∣X)
2.3.3 拉普拉斯平滑
为了避免属性携带的信息被训练过程中未出现的属性值所干扰,在计算属性条件概率时,添加一个 拉普拉斯平滑 的步骤
- 受到训练集规模的限制,某些属性的取值训练集中可能从未与某个类同时出现,导致属性的条件概率为0,进而使似然概率为0,使分类产生偏差
先验概率 P λ ( Y = c k ) = ∑ i = 1 n I ( y i = c k ) + λ n + K λ , k = 1 , ⋯ , K P_{\lambda}(Y=c_k)=\frac{\sum\limits_{i=1}^nI(y_i=c_k)+\lambda}{n+K\lambda},k=1,\cdots,K Pλ(Y=ck)=n+Kλi=1∑nI(yi=ck)+λ,k=1,⋯,K
似然概率 P ( X ( j ) = a j l ∣ Y = c k ) = I ( X i ( j ) = a j l , y i = c k ) + λ ∑ i = 1 n I ( y i = c k ) + s j λ P(X^{(j)}=a_{jl}\vert Y=c_k) =\frac{I(X_i^{(j)}=a_{jl},y_i=c_k)+\lambda}{\sum\limits_{i=1}^nI(y_i=c_k)+s_j\lambda} P(X(j)=ajl∣Y=ck)=i=1∑nI(yi=ck)+sjλI(Xi(j)=ajl,yi=ck)+λ
- ∑ l = 1 s j P ( X ( j ) = a j l ∣ Y = c k ) = ∑ l = 1 s j I ( X i ( j ) = a j l , y i = c k ) + λ ∑ i = 1 n I ( y i = c k ) + s j λ = 1 \sum\limits_{l=1}^{s_j}P(X^{(j)}=a_{jl}\vert Y=c_k) =\sum\limits_{l=1}^{s_j}\frac{I(X_i^{(j)}=a_{jl},y_i=c_k)+\lambda}{\sum\limits_{i=1}^nI(y_i=c_k)+s_j\lambda}=1 l=1∑sjP(X(j)=ajl∣Y=ck)=l=1∑sji=1∑nI(yi=ck)+sjλI(Xi(j)=ajl,yi=ck)+λ=1
2.4 应用
比赛结果预测
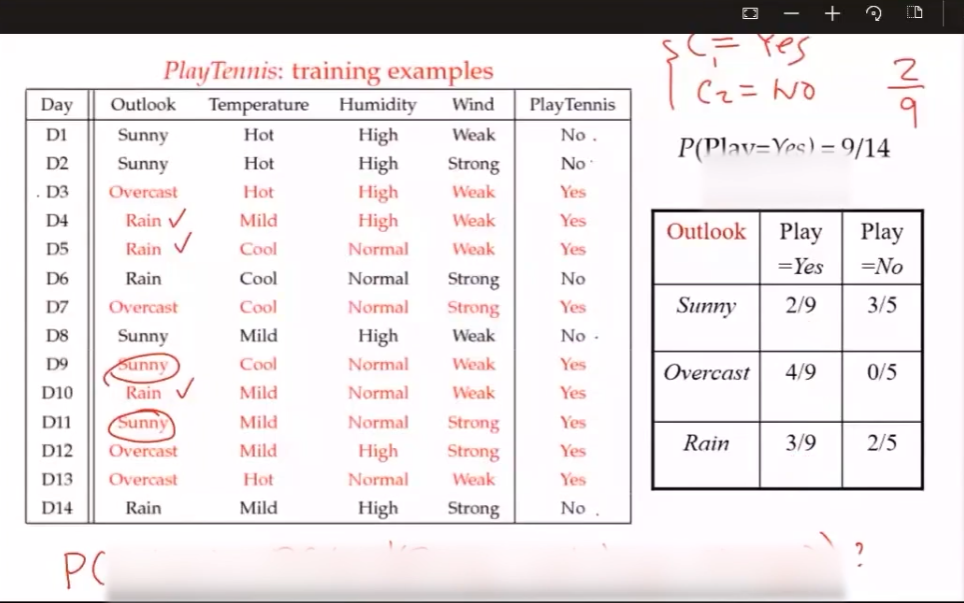

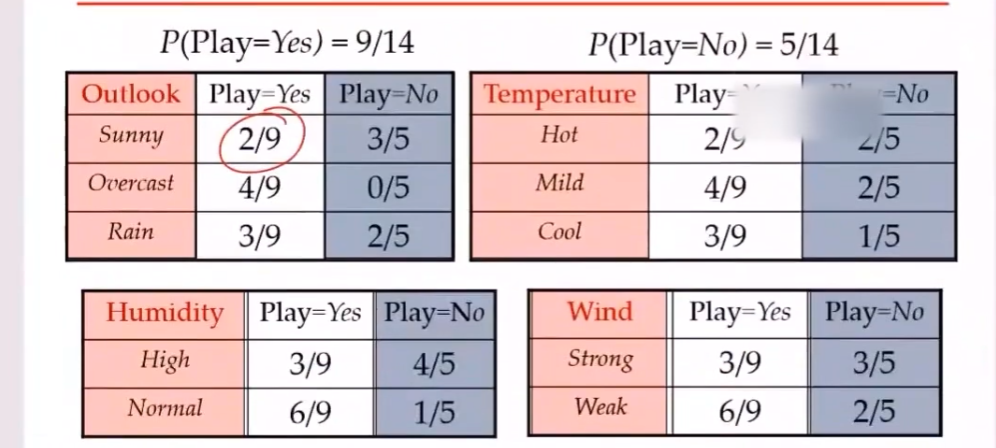
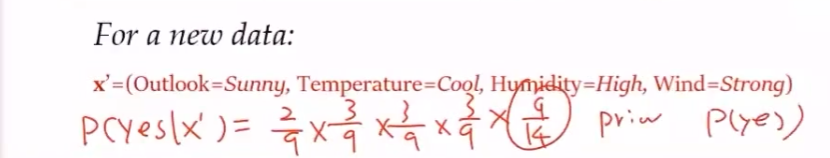



垃圾邮件过滤
分类: y ∈ { 0 , 1 } y\in \{0,1\} y∈{0,1} 表示是否为垃圾邮件;1表示垃圾邮件,0表示正常邮件
用词汇表向量 x ∈ { 0 , 1 } 50000 x\in \{0,1\}^{50000} x∈{0,1}50000 表示词汇表中的50000个词是否出现在邮件中
先验概率 P ( y = 1 ) = ∑ i = 1 n I ( y i = 1 ) n P(y=1)=\frac{\sum\limits_{i=1}^nI(y_i=1)}{n} P(y=1)=ni=1∑nI(yi=1)
P ( Y ∣ X ′ ) = P ( X ′ ∣ Y ) P ( Y ) ∑ i P ( X ′ ∣ Y ) P ( Y ) P ( y = 1 ∣ x ′ ) = P ( x ′ ∣ y = 1 ) P ( y = 1 ) P ( x ′ ∣ y = 1 ) P ( y = 1 ) + P ( x ′ ∣ y = 0 ) P ( y = 0 ) ∝ P ( x ′ ∣ y = 1 ) P ( y = 1 ) P ( x ′ ∣ y = 1 ) = P ( x ( 1 ) , x ( 2 ) , ⋯ , x ( 50000 ) ∣ y = 1 ) = 朴素贝叶斯条件独立性假设 ∏ i = 1 50000 P ( x ( i ) ∣ y = 1 ) \begin{aligned} P(Y\vert X')&=\frac{P(X'\vert Y)P(Y)}{\sum\limits_{i}P(X'\vert Y)P(Y)}\\ P(y=1\vert x')&=\frac{P(x'\vert y=1)P(y=1)}{P(x'\vert y=1)P(y=1)+P(x'\vert y=0)P(y=0)}\propto P(x'\vert y=1)P(y=1)\\ P(x'\vert y=1)&=P(x^{(1)},x^{(2)},\cdots,x^{(50000)}\vert y=1) \xlongequal{朴素贝叶斯条件独立性假设}\prod\limits_{i=1}^{50000}P(x^{(i)}\vert y=1)\\ \end{aligned} P(Y∣X′)P(y=1∣x′)P(x′∣y=1)=i∑P(X′∣Y)P(Y)P(X′∣Y)P(Y)=P(x′∣y=1)P(y=1)+P(x′∣y=0)P(y=0)P(x′∣y=1)P(y=1)∝P(x′∣y=1)P(y=1)=P(x(1),x(2),⋯,x(50000)∣y=1)朴素贝叶斯条件独立性假设i=1∏50000P(x(i)∣y=1)
对于似然概率 P ( x ( i ) ∣ y = 1 ) = ∑ j = 1 n I ( y j = 1 ∧ x ( i ) = 1 ) ∑ k = 1 n I ( y k = 1 ) P(x^{(i)}\vert y=1)=\frac{\sum\limits_{j=1}^nI(y_j=1 \land x^{(i)}=1)}{\sum\limits_{k=1}^nI(y_k=1)} P(x(i)∣y=1)=k=1∑nI(yk=1)j=1∑nI(yj=1∧x(i)=1)
∴ P ( y = 1 ∣ x ′ ) ∝ P ( x ′ ∣ y = 1 ) P ( y = 1 ) [ ∏ i = 1 50000 ∑ j = 1 n I ( y j = 1 ∧ x ( i ) = 1 ) ∑ j = 1 n I ( y j = 1 ) ] ⋅ ∑ i = 1 n I ( y i = 1 ) n = p 1 P ( y = 0 ∣ x ′ ) ∝ P ( x ′ ∣ y = 0 ) P ( y = 0 ) [ ∏ i = 1 50000 ∑ j = 1 n I ( y j = 0 ∧ x ( i ) = 1 ) ∑ j = 1 n I ( y j = 0 ) ] ⋅ ∑ i = 1 n I ( y i = 0 ) n = p 0 \therefore P(y=1\vert x')\propto P(x'\vert y=1)P(y=1)\left[\prod\limits_{i=1}^{50000}\frac{\sum\limits_{j=1}^nI(y_j=1\land x^{(i)}=1)}{\sum\limits_{j=1}^nI(y_j=1)}\right]\cdot \frac{\sum\limits_{i=1}^nI(y_{i}=1)}{n}=p_1\\ P(y=0\vert x')\propto P(x'\vert y=0)P(y=0)\left[\prod\limits_{i=1}^{50000}\frac{\sum\limits_{j=1}^nI(y_j=0\land x^{(i)}=1)}{\sum\limits_{j=1}^nI(y_j=0)}\right]\cdot \frac{\sum\limits_{i=1}^nI(y_{i}=0)}{n}=p_0\\ ∴P(y=1∣x′)∝P(x′∣y=1)P(y=1) i=1∏50000j=1∑nI(yj=1)j=1∑nI(yj=1∧x(i)=1) ⋅ni=1∑nI(yi=1)=p1P(y=0∣x′)∝P(x′∣y=0)P(y=0) i=1∏50000j=1∑nI(yj=0)j=1∑nI(yj=0∧x(i)=1) ⋅ni=1∑nI(yi=0)=p0
2.5 半朴素贝叶斯分类器
考虑了部分属性之间的依赖关系,既保留了属性之间较强的相关性,又不需要完全计算复杂的联合概率分布
常用的方法是建立独依赖关系:假设每个属性除了类别之外,最多只依赖一个其他属性
相关文章:
【AI】机器学习——朴素贝叶斯
文章目录 2.1 贝叶斯定理2.1.1 贝叶斯公式推导条件概率变式 贝叶斯公式 2.1.2 贝叶斯定理2.1.3 贝叶斯决策基本思想 2.2 朴素贝叶斯2.2.1 朴素贝叶斯分类器思想2.2.2 条件独立性对似然概率计算的影响2.2.3 基本方法2.2.4 模型后验概率最大化损失函数期望风险最小化策略 2.2.5 朴…...

数学建模:模糊综合评价分析
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:模糊综合评价分析 文章目录 数学建模:模糊综合评价分析综合评价分析常用评价方法一级模糊综合评价综合代码 多级模糊综合评价总结 综合评价分析 构成综合评价类问题的五个…...

智能小车—PWM方式实现小车调速和转向
目录 1. 让小车动起来 2. 串口控制小车方向 3. 如何进行小车PWM调速 4. PWM方式实现小车转向 1. 让小车动起来 电机模块开发 L9110s概述 接通VCC,GND 模块电源指示灯亮, 以下资料来源官方,具体根据实际调试 IA1输入高电平,…...

Getx其他高级API
// 给出当前页面的args。 Get.arguments//给出以前的路由名称 Get.previousRoute// 给出要访问的原始路由,例如,rawRoute.isFirst() Get.rawRoute// 允许从GetObserver访问Rounting API。 Get.routing// 检查 snackbar 是否打开 Get.isSnackbarOpen// 检…...

npm/yarn link 测试包时报错 Warning: Invalid hook call. Hooks can only be called ...
使用 dumi 开发 React 组件库时,为避免每次修改都发布到 npm,需要在本地的测试项目中使用 npm link 为组件库建立软连接,方便本地调试。 结果在本地测试项目使用 $ npm link 组件库 后,使用内部组件确报错: react.dev…...
「网页开发|前端开发|Vue」06 公共组件与嵌套路由:让每一个页面都平等地拥有导航栏
本文主要介绍在多个页面存在相同部分时,如何提取公共组件然后在多个页面中导入组件重复使用来减少重复代码。在这基础上介绍了通过嵌套路由的方式来避免页面较多或公共部分较多的情况下,避免不断手动导入公共组件的麻烦,并且加快页面跳转的速…...

leetcode687. 最长同值路径(java)
最长同值路径 题目描述DFS 深度遍历代码演示 题目描述 难度 - 中等 LC - 687. 最长同值路径 给定一个二叉树的 root ,返回 最长的路径的长度 ,这个路径中的 每个节点具有相同值 。 这条路径可以经过也可以不经过根节点。 两个节点之间的路径长度 由它们之…...
MySQL的常用术语
目录 1.关系 2.元组 3.属性 MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129334507?spm1001.2014.3001.5502 1.关系 前面的博客有说到,MySQL是一款关系型数据库管理软件,一个关系就是 一张二维表(表) 我想大家都知道表格怎么…...
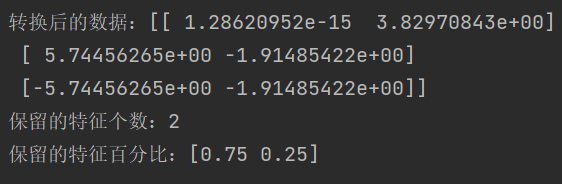
机器学习的特征工程
字典特征提取 def dict_demo():"""字典特征提取:return:"""data [{city: 北京, temperature: 100}, {city: 上海, temperature: 60}, {city: 深圳, temperature: 30}]# data [{city:[北京,上海,深圳]},{temperature:["100","6…...
python3 修改nacos的yaml配置
一、安装nacos库 pip install nacos-sdk-python 二、代码如下 import nacos import yaml# 连接地址 NACOS_SERVER_ADDRESSES "192.168.xx.xx" NACOS_SERVER_PORT 替换为你的端口号,如8848# 命名空间 NACOS_NAMESPACE "your_namespace"# 账…...

YOLOv8 : 数据组织
1. 数据源 首先YOLOv8是支持目标分类、检测和目标分割。当前以应用最为广泛的目标检测为例,简单说明数据相关的信息。 一般情况下,建议将数据划分成images和labels,其中images存储图像,labels存储标签文件(YOLO格式)。如果是VOC数…...

golang如何生成zip压缩文件
在Golang中,您可以使用标准库中的compress/zip包来生成ZIP压缩文件。下面是一个简单的示例代码,演示如何使用该包来创建一个ZIP文件并将文件添加到其中: package main import ( "archive/zip" "bytes" "fmt&qu…...

AntDesign技术指南:构建优雅的前端界面
引言 AntDesign是一款优秀的前端UI组件库,它提供了丰富的组件和功能,帮助我们快速构建漂亮、易用的前端界面。本篇博客将详细介绍AntDesign的使用方法和技巧,并展示完整的代码示例。无论你是初学者还是有经验的开发者,本篇博客都…...

机器人任务挖掘与智能超级自动化技术解析
本文为上海财经大学教授、安徽财经大学学术副校长何贤杰出席“会计科技Acctech应对不确定性挑战”高峰论坛时的演讲内容整理。何贤杰详细介绍了机器人任务挖掘与智能超级自动化技术的发展背景、关键技术和应用场景。 从本质来说,会计是非常适合智能化、自动化的。会…...

C#通过ModbusTcp协议读写西门子PLC中的浮点数
一、Modbus TCP通信概述 MODBUS/TCP是简单的、中立厂商的用于管理和控制自动化设备的MODBUS系列通讯协议的派生产品,显而易见,它覆盖了使用TCP/IP协议的“Intranet”和“Internet”环境中MODBUS报文的用途。协议的最通用用途是为诸如PLC,I/…...

19-springcloud(中)
一 服务注册发现 1 什么是服务治理 为什么需要服务治理 在没有进行服务治理前,服务之间的通信是通过服务间直接相互调用来实现的。 过程: 武当派直接调用峨眉派和华山派,同样,华山派直接调用武当派和峨眉派。如果系统不复杂,这样…...
Leetcode1090. 受标签影响的最大值
思路:根据值从大到小排序,然后在加的时候判断是否达到标签上限即可,一开始想用字典做,但是题目说是集合却连续出现两个8,因此使用元组SortedList进行解决 class Solution:def largestValsFromLabels(self, values: li…...
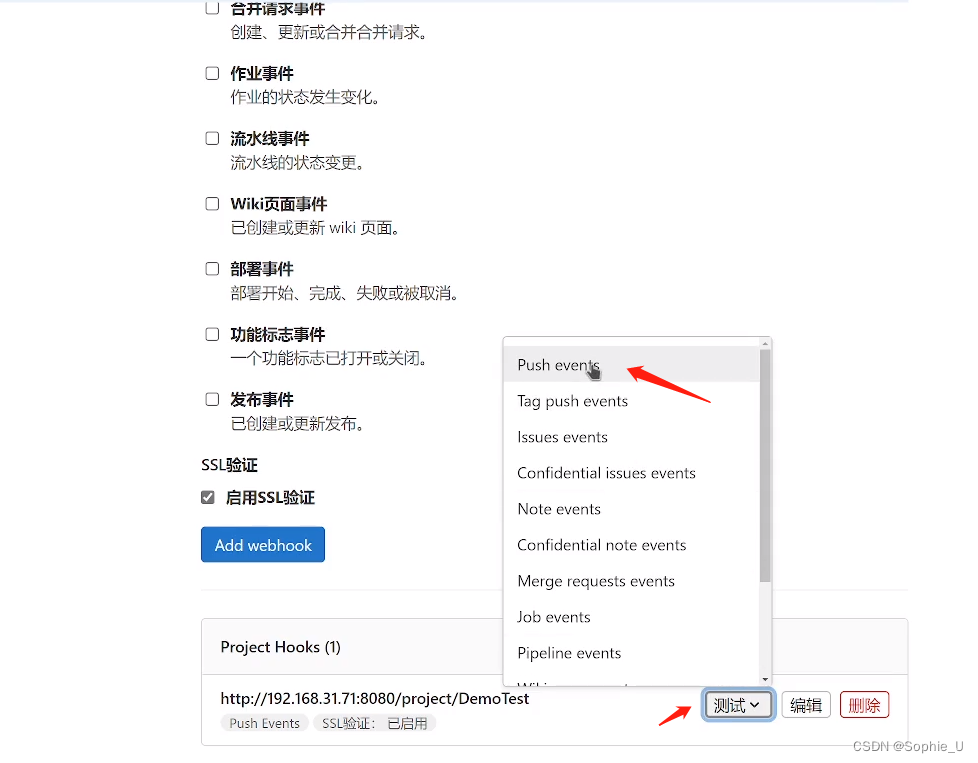
第七章:敏捷开发工具方法-part2-CI/CD工具介绍
文章目录 前言一、CI-持续集成1.1 安装部署gitlab 二、gitlab CI配置三、jenkins实现CI / CD3.1 安装jenkins3.2 配置CI3.3 配置CD3.4 其他构建方式1、定时构建2、指定参数构建3、webhook自动根据git事件进行构建 前言 什么是CI/Cd? CI-Continuous integration&…...
【自学开发之旅】Flask-回顾--对象拆分-蓝图(二)
url-统一资源定位符-不同的url对应不同的资源 作为服务端,url和视图函数的映射关系就是路由。 定义传递参数的方式: 1.创建动态url app.route("/login2/<username>/<passwd>") def login2(username, passwd):if username "…...

自动驾驶中间件
自动驾驶中间件 1. 什么是中间件2. 中间件的分类3. 自动驾驶为什么需要中间件4. 通信中间件 Reference: 自动驾驶中间件:量产落地的关键技术通俗易懂的告诉你什么是中间件 对于初入自动驾驶行业的人来说,各色各样的新型传感器、线控系统、芯…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...