linux之perf(3)top实时性能
Linux之perf(3)top实时性能
Author:Onceday Date:2023年9月3日
漫漫长路,才刚刚开始…
注:该文档内容采用了GPT4.0生成的回答,部分文本准确率可能存在问题。
参考文档:
- Tutorial - Perf Wiki (kernel.org)
- perf-top(1) - Linux manual page (man7.org)
文章目录
- Linux之perf(3)top实时性能
- 1. 概述
- 2. 参数介绍
- 2.1 设置事件采样周期
- 2.2 设置显示符号数量
- 2.3 设置采样速率
- 2.4 监控指定cgroup线程
- 2.5 限制子进程不继承计数器
- 2.6 分支堆栈采样过滤
- 2.7 指定内核调试信息文件vmlinux路径
- 2.8 指定反汇编风格
- 2.9 指定内存映射页(mmap pages)的大小
- 2.10 指定perf运行调度优先级
- 2.11 按指定字段逐列显示
- 2.12 实时更新性能统计数据
- 2.13 记录cgroups相关的性能事件
- 2.14 调用栈记录(call-graph)参数
- 2.15 子函数累积到父函数
- 2.16 只识别特定进程/线程名称中的符号
- 2.17 只识别特定动态库中的符号
- 2.18 指定输出的列字段名
- 2.19 指定组事件中的排序字段
- 2.20 忽略指定函数的子调用函数
- 2.21 指定内核符号的位置
- 2.22 限制调用栈解析深度
- 2.23 记录命名空间的性能数据
- 2.24 设置perf合成事件线程数目
- 2.25 只使用最近的记录
- 2.26 设置显示条目的最小开销百分比
- 2.27 设置过滤条目的百分比显示形式
- 2.28 指定源码文件路径
- 2.29 设置预先存在线程mmap文件的超时时间
- 2.30 输出原始的traceevent事件信息
- 2.31 显示指定显示switch-on/off事件
- 2.32 显示每个符号的总消耗CPU时间
- 2.33 禁止汇编代码中插入源代码
- 2.34 使用stdio来输出结果
- 2.35 开启LBR记录函数栈功能
- 2.36 记录指定事件区间内的其他事件(限定记录范围)
- 2.37 注释指定的符号
- 2.38 指定特定符号用于性能监控
- 3. 交互式界面
- 4. 开销计算细节(overhead calculation)
1. 概述
该命令用于实时显示系统中占用CPU时间最多的函数,监控程序运行时的CPU利用情况,了解系统中哪些函数或代码片段对性能影响最大。
perf top 是 Linux 性能分析工具 perf 的一部分,主要用于动态地展示占用最多 CPU 时间的函数或程序。以下是一些基本的使用方式:
- 最简单的使用方式就是直接运行
perf top命令。这将会展示系统中所有的进程和函数,按照它们占用 CPU 时间的百分比降序排列。
$ perf top
- 如果你想要只关注特定的进程,你可以使用
-p选项,后面跟上进程的 PID:
$ perf top -p <PID>
- 你可以使用
-e选项来指定一个特定的性能事件。例如,你可能关心 cache misses(缓存未命中):
$ perf top -e cache-misses
- 可以使用
-a选项来查看所有 CPU 的数据,而不仅仅是默认的 CPU 0:
$ perf top -a
-K选项可以隐藏内核相关的符号,如果你只对用户空间的性能感兴趣,这会非常有用:
$ perf top -K
在运行 perf top 时,请确保你有足够的权限。大多数情况下,你需要 root 权限才能运行它。
此外,perf top 的结果是实时更新的,你只需要保持窗口开启,就可以实时观察到系统性能的变化。
2. 参数介绍
下面是linux6.2版本perf参数一览:
| 参数 | 描述 |
|---|---|
| -a, --all-cpus | system-wide collection from all CPUs |
| -b, --branch-any | sample any taken branches,采样任何标记的分支 |
| -c, --count [n] | event period to sample,事件采样周期 |
| -C, --cpu [cpu] | 只监视所提供的cpu列表。多个cpu可以以逗号分隔的列表形式提供,不带空格:0,1。 cpu的取值范围用“-”表示,取值范围为0 ~ 2。默认是监控所有cpu。 |
| -d, --delay [n] | number of seconds to delay between refreshes,刷新延迟间隔,只能整数。 |
| -D, --dump-symtab | dump the symbol table used for profiling,把符号表dump出来用于解析,用于perf自身调试。 |
| -E, --entries [n] | display this many functions,指定实时显示的函数符号数量 |
| -e, --event [event] | event selector. use ‘perf list’ to list available events,指定监控的性能事件 |
| -f, --count-filter [n] | only display functions with more events than this,只显示超过该计数的事件 |
| -F, --freq <freq or ‘max’> | Profile at this frequency. Use max to use the currently maximum allowed frequency, i.e. the value in the kernel.perf_event_max_sample_rate sysctl. |
| -g | enables call-graph recording and display,按照函数调用栈显示数据 |
| -G name, --cgroup name | monitor event in cgroup name only,监控指定cgroup里面的线程。 |
| -i, --no-inherit | child tasks do not inherit counters,子进程不继承计数器 |
| -j, --branch-filter [branch filter mask] | branch stack filter modes,设置分支堆栈采样过滤模式 |
| -K, --hide_kernel_symbols | hide kernel symbols,隐藏内核符号,去除内核函数的统计数据 |
| -k, --vmlinux [file] | Path to vmlinux. Required for annotation functionality,指定内核调试信息文件路径 |
| -M, --disassembler-style [disassembler style] | Set disassembler style for objdump. 设置反汇编风格 |
| -m, --mmap-pages [pages] | number of mmap data pages,指定mmap映射数据页的大小 |
| -n, --show-nr-samples | Show a column with the number of samples,额外一列内容展示具体的采样数目 |
| -p, --pid [pid] | profile events on existing process id,在指定的进程上统计,多个进程ID用逗号分隔 |
| -s, --sort [key[,key2…]] | sort by key(s): pid, comm, dso, symbol, parent, cpu, srcline, … 按指定规则逐列显示(并非对数据排序) |
| -t, --tid [tid] | profile events on existing thread id,分析指定线程上的性能事件,多个线程ID用逗号分离 |
| -U, --hide_user_symbols | hide user symbols,隐藏用户空间的符号 |
| -u, --uid [user] | Record events in threads owned by uid. Name or number. 记录指定用户所属线程的性能数据 |
| -v, --verbose | be more verbose (show counter open errors, etc),增强输出信息的丰富度 |
| -w, --column-widths [width[,width…]] | 默认为0,表示不限制。这里可以指定每列的宽度 |
| -z, --zero | 在每次显示更新时清零历史数据,不累积显示统计数据 |
| –all-cgroups | 记录cgroup相关的性能事件 |
| –asm-raw | Show raw instruction encoding of assembly instructions. 默认显示原生的汇编指令 |
| –call-graph [mode,…] | <record_mode[,record_size],print_type,threshold[,print_limit],order,sort_key[,branch]> 指定调用栈记录参数,默认配置是 fp,graph,0.5,caller,function |
| –children | Accumulate callchains of children and show total overhead as well,将子函数的消耗累计计算到父函数上面 |
| –comms [comm[,comm…]] | only consider symbols in these comms,指定进程或线程的名称(command),只考虑它们中的符号 |
| –demangle-kernel | Enable kernel symbol demangling,启用内核符号转换,将一些混淆的符号转换为用户易于识别的 |
| –dsos [dso[,dso…]] | only consider symbols in these dsos,指定动态的名称,只考虑它们中的符号 |
| –fields [key[,keys…]] | 指定输出的字段,如overhead, overhead_sys, overhead_us, overhead_children, sample and period |
| –force | Don’t do ownership validation. 不验证当前用户的权限,直接尝试读取性能计数器值,可能导致未知错误 |
| –group-sort-idx [n] | Sort the output by the event at the index n in group. 指定组事件的排序关键字段,按照顺序id指定。 |
| –hierarchy | Show entries in a hierarchy,以层次结构形式显示性能统计结果 |
| –ignore-callees [regex] | ignore callees of these functions in call graphs,忽略指定函数的子调用函数 |
| –ignore-vmlinu | 忽略vmlinux文件,即使它已经存在 |
| –kallsyms [file] | kallsyms pathname,指定内核符号文件的位置,默认位于/proc/kallsyms |
| –max-stack [n] | Set the maximum stack depth when parsing the callchain. Default: kernel.perf_event_max_stack or 127 设置解析调用时的最大栈深度,默认最大栈深度为127 |
| –namespaces | Record events of type PERF_RECORD_NAMESPACES and display it with the cgroup_id sort key. 记录命名空间相关的事情,按照cgroup_id排序,用于分析特定命名空间或者控制组的性能数据 |
| –no-bpf-event | do not record bpf events,不记录bpf事件 |
| –num-thread-synthesiz [n] | number of thread to run event synthesize,perf用于合成事件的线程数目,默认等于在线CPU数目 |
| –objdump <path | objdump binary to use for disassembly and annotations,指定objdump程序的路径 |
| –overwrite | Use a backward ring buffer, default: no,使用旧环形缓冲区数据,默认不用,只使用最近的记录数据。 |
| –percent-limit [percent] | Don’t show entries under that percent,不显示小于该百分比的条目 |
| –percentage [relative|absolute] | Determine how to display the overhead percentage of filtered entries, 决定如何显示过滤后的条目百分比值,可以是相对值或者绝对值 |
| –prefix [prefix] | Add prefix to source file path names in programs (with --prefix-strip),添加固定的前缀路径 |
| –prefix-strip [N] | Strip first N entries of source file path name in programs (with --prefix),去除源码路径名中前面的路径条目 |
| –proc-map-timeout [n] | per thread proc mmap processing timeout in ms,指定每个线程mmap映射的超时时间, 默认500ms |
| –raw-trace | Show raw trace event output (do not use print fmt or plugins),显示原始的trace event事件输出 |
| –show-on-off-event | Show the on/off switch events, used with --switch-on and --switch-off,显示线程切换事件 |
| –show-total-period | Show a column with the sum of periods. 额外一行列显示该函数总消耗CPU时间 |
| –source | Interleave source code with assembly code (default),设置是否在汇编代码中插入源代码 |
| –stdio | Use the stdio interface,使用stdio来显示输出,不使用交互界面 |
| –stitch-lbr | Enable LBR callgraph stitching approach,使能LBR功能记录函数调用栈,默认关闭。 |
| –switch-off [event] | Stop considering events after the ocurrence of this event,停止记录该事件之后的事件 |
| –switch-on [event] | Consider events after the ocurrence of this event,从该事件发生之后,开始记录事件 |
| –sym-annotat [symbol name] | symbol to annotate,注释一个指定的符号,能看到每行代码所花费的时间 |
| –symbols <symbol[,symbol…]> | only consider these symbols,只考虑指定的符号性能数据 |
| –tui | Use the TUI interface,使用文本用户界面(交互式界面,Text-based User Interface) |
2.1 设置事件采样周期
-c 是 perf top 命令的一个选项,它用于设置采样周期。
在 perf top 的上下文中,采样周期是指在收集性能数据样本之间的事件数。简单地说,如果你设置了 -c 10000,那么每当指定的事件(例如 CPU 周期、缓存未命中等)发生 10000 次,perf 就会收集一个样本。
例如,如果你运行 perf top -e cycles -c 10000,那么每当 CPU 完成 10000 个周期,perf 就会收集一个样本。这些样本会被用来计算哪些函数或者代码路径最频繁地运行。
设置合适的采样周期可以帮助你在收集足够详细的数据和降低性能开销之间找到一个平衡。如果采样周期太小,收集的数据会非常详细,但是性能开销也会增大;如果采样周期太大,性能开销会降低,但是收集的数据可能不够详细。
请注意,-c 选项必须和 -e 选项一起使用,因为 -e 选项用于指定要计数的事件。
2.2 设置显示符号数量
perf top 的 -E 或 --entries 选项允许你指定一次显示的函数数量。
当你运行 perf top 时,它会持续对你的系统进行采样,并实时显示消耗最多 CPU 时间的函数。默认情况下,perf top 将显示一定数量的这些 “热门” 函数,通常足以填满你的终端窗口。
-E 或 --entries 选项允许你限制或增加显示的函数数量。例如,如果你只想看到前 10 个函数,你可以运行 perf top -E 10。相反,如果你想一次看到更多的函数,你可以增加这个数字,比如 perf top -E 100。
以下是如何使用此选项的示例:
perf top -E 20
此命令将显示按照 CPU 使用率排名的前 20 个函数。请注意,增加显示的条目数量可能会使输出更难阅读,特别是如果你的终端窗口不足以一次显示所有条目。
2.3 设置采样速率
-F <freq>, --freq=<freq> 是 perf top 命令的一个选项。perf top 是一个实时性能监控工具,它能够显示系统中消耗 CPU 时间最多的函数或程序。
-F 或 --freq 选项用于指定 perf top 的采样频率。它表示每秒钟采样多少次。例如,-F 1000 表示每秒钟采样1000次。
如果你使用 max 作为 <freq> 的值(即 -F max 或 --freq=max),那么 perf top 将使用当前允许的最大采样频率。这个值可以在 kernel.perf_event_max_sample_rate 这个系统参数中找到。
使用这个选项可以帮助你更好地理解系统的性能状况。通过实时监控 CPU 的使用情况,你可以发现那些消耗 CPU 资源最多的程序或函数,从而对系统的性能瓶颈有一个更深入的了解。
2.4 监控指定cgroup线程
-G name, --cgroup name 是 perf 命令的一个选项,它用于指定 perf 只在名为 “name” 的容器(cgroup)中进行监控。这个选项只有在 per-cpu 模式下可用,并且需要 cgroup 文件系统已经被挂载。
所有属于 “name” 容器的线程在运行在被监控的 CPU 上时都会被监控。可以提供多个 cgroups,每个 cgroup 将被应用到对应的事件,也就是说,第一个 cgroup 应用到第一个事件,第二个 cgroup 应用到第二个事件,依此类推。
如果想要提供一个空的 cgroup(即所有时间都监控),可以使用 -G foo,,bar 这样的方式。需要注意的是,cgroups 必须有对应的事件,也就是说,它们总是引用在命令行上早些时候定义的事件。
如果用户想要跟踪一个特定 cgroup 的多个事件,用户可以使用 -e e1 -e e2 -G foo,foo 或者简单地使用 -e e1 -e e2 -G foo。
这个功能对于容器环境中的性能监控非常有用。通过只监控特定的 cgroup,你可以更精确地了解特定应用或服务的性能情况,这对于性能优化和故障诊断非常重要。
2.5 限制子进程不继承计数器
perf top 命令中的 -i 或 --no-inherit 选项指定子任务不继承计数器。
在使用 perf 进行性能分析时,一种常见的做法是监视一个进程及其所有子进程。默认情况下,当你使用 perf 监视一个进程时,所有的子进程也会被监视,因为它们会继承父进程的性能计数器。
如果使用 -i 或 --no-inherit 选项,那么只有你明确指定的进程会被监视,任何由这个进程创建的子进程都不会被监视。
这个选项在你只关心特定进程的性能,而不关心其子进程的性能时非常有用。例如,如果你正在运行一个多线程的应用,但只关心主线程的性能,那么你可以使用这个选项来防止 perf 监视其他线程。
2.6 分支堆栈采样过滤
perf top 命令中的 -j 或 --branch-filter 选项用于启用已采取的分支堆栈采样。每个样本都会捕获一系列连续的已采取的分支。每个样本所捕获的分支数量取决于底层硬件、感兴趣的分支类型,以及执行的代码。
可以通过启用过滤器来选择所捕获的分支类型。有关修改器的完整列表,请参阅 perf record 的 man 手册页。
此选项至少需要一个分支类型,包括 any、any_call、any_ret、ind_call、cond。可以省略权限级别,在这种情况下,将应用与关联事件的权限级别到分支过滤器。内核(k)和虚拟机监视器(hv)的权限级别都受到权限的制约。当在多个事件上采样时,所有采样事件都会启用分支堆栈采样。所有事件的采样分支类型都是相同的。各种过滤器必须以逗号分隔的列表指定:--branch-filter any_ret,u,k。请注意,这个功能可能并非在所有处理器上都可用。
这个功能对于深入理解代码的执行路径非常有用,尤其是对于理解复杂的条件逻辑和函数调用的情况。通过观察哪些分支被执行,你可以发现可能的性能瓶颈,例如,某个条件分支被频繁执行,但其执行效率低下,或者某个函数调用消耗了大量的 CPU 时间。
2.7 指定内核调试信息文件vmlinux路径
perf top 命令中的 -k <path>, --vmlinux=<path> 选项是用于指定 vmlinux 的路径。这个选项对于注解功能是必需的。
vmlinux 是 Linux 内核的一个版本,它包含了内核的完整符号表和调试信息。这些信息对于 perf 的注解功能非常重要。通过这个功能,perf 可以将采集到的性能数据与源代码进行关联,从而让你能够看到每一行代码的性能指标,例如每一行代码消耗的 CPU 时间。
例如,如果你的 vmlinux 文件位于 /usr/src/linux/vmlinux,你可以使用以下命令来启动 perf top:
perf top -k /usr/src/linux/vmlinux
请注意,vmlinux 文件通常很大,因为它包含了大量的符号和调试信息。在一些系统上,为了节省空间,vmlinux 可能被压缩或者完全被移除。在这种情况下,你可能需要从内核源码重新编译内核,以生成 vmlinux 文件。
2.8 指定反汇编风格
perf top -M 或 --disassembler-style= 是 perf 工具中的一个选项,它用于指定反汇编风格。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
-M 或 --disassembler-style= 参数允许用户指定在生成反汇编代码时使用的风格。反汇编是将机器语言代码转换回人类可读的汇编语言代码的过程。这个参数的值通常是一个字符串,它表示了反汇编器应该使用的风格。例如,常见的可能值是 “intel” 或 “att”,分别代表 Intel 格式和 AT&T 格式的汇编语言。
在对程序进行性能分析时,使用不同的反汇编风格可能会影响你理解代码的能力,因此选择你熟悉的风格是很重要的。例如,如果你对 Intel 风格的汇编语言更熟悉,那么就应该使用 “intel” 作为这个参数的值。
总的来说,-M 或 --disassembler-style= 参数给 perf 工具提供了一种灵活性,使得用户可以选择他们最舒适的反汇编风格来查看性能数据。
2.9 指定内存映射页(mmap pages)的大小
perf top -m <pages>, --mmap-pages=<pages> 是 perf 工具中的一个选项,它允许你指定 mmap 数据页的数量。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
该参数的值应该是一个二的幂,或者是一个带有单位字符(B/K/M/G)的大小规格。如果提供了大小规格,那么这个大小会被四舍五入到最近的二的幂值。单位字符 B/K/M/G 分别代表字节(Bytes)、千字节(Kilobytes)、兆字节(Megabytes)和吉字节(Gigabytes)。
这个参数的主要用途是控制 perf 工具在进行内存映射(memory mapping)时分配多少内存。内存映射是一种能够将文件或其他对象映射到进程的地址空间的技术,这使得进程可以像访问普通内存数组一样来访问这些文件或对象。
在进行大规模的性能分析时,控制 mmap 数据页的数量可能会对性能产生影响。如果分配的页数过少,可能会导致页错误(page faults)和额外的磁盘 I/O,从而降低性能。另一方面,如果分配的页数过多,可能会消耗过多的内存。因此,选择适当的页数是很重要的。
总的来说,-m <pages>, --mmap-pages=<pages> 参数给 perf 工具提供了一种灵活性,使得用户可以根据他们的需求和系统的资源来调整 mmap 数据页的数量。
2.10 指定perf运行调度优先级
perf top -r <priority>, --realtime=<priority> 是 perf 工具中的一个选项,它允许你以实时(RT)调度优先级收集数据。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
在这个选项中,<priority> 是一个整数,表示 perf 应该使用的实时(RT)调度优先级。这个优先级应该在 1 到 99 之间,其中 99 是最高优先级。
在 Linux 中,有几种不同类型的调度策略,其中之一就是实时(RT)调度。实时调度策略主要用于那些对延迟和及时性有严格要求的任务。在这种策略下,高优先级的任务会优先得到 CPU 的调度,而且一旦开始执行,就不会被低优先级的任务抢占。
SCHED_FIFO 是实时调度策略中的一种,它的特点是在同优先级的任务中,先到先得,直到任务结束或者被更高优先级的任务抢占。
因此,通过 perf top -r <priority>, --realtime=<priority> 选项,你可以让 perf 以实时调度优先级运行,从而确保它能够尽可能的准确和及时地收集性能数据。这对于那些对性能分析结果的精度和及时性有高要求的场景(例如实时系统或高性能计算)非常重要。
2.11 按指定字段逐列显示
perf top -s, --sort 是 perf 工具中的一个选项,它允许你按照指定的关键字对性能数据进行逐列显示。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
可以指定一个或多个以下关键字作为列数据:
pid: 进程 ID。comm: 进程名称。dso: 动态共享对象,通常是指可执行文件或库。symbol: 符号,通常是指函数名。parent: 父符号,通常是指调用当前函数的函数名。srcline: 源代码行。weight: 事件的权重。local_weight: 本地事件的权重。abort: 事务中止次数。in_tx: 在事务中的样本数。transaction: 事务数。overhead: 总开销。sample: 样本数。period: 采样周期。
你可以在 perf-report 的 man 页面中找到更详细的 --sort 选项描述。要查看这个 man 页面,你可以在终端中运行 man perf-report 命令。
总的来说,perf top -s, --sort 选项提供了一种灵活的方式,使得你可以更方便地理解和分析 perf 收集的性能数据。
2.12 实时更新性能统计数据
perf top -z, --zero 是 perf 工具中的一个选项,它能在每次刷新显示时清零(zero out)统计历史。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
默认情况下,perf top 显示的是从启动 perf top 到现在的整个时间段内的性能数据。这种方式的优点是它可以提供一个全面的性能概览,但缺点是你无法观察到性能数据的实时变化。
如果你使用了 -z 或 --zero 选项,那么 perf top 就会在每次刷新显示时清零统计历史。这样,perf top 显示的就是每次刷新之间的性能数据,而不是从启动 perf top 到现在的整个时间段内的性能数据。这种方式的优点是它可以让你观察到性能数据的实时变化,但缺点是你无法得到一个全面的性能概览。
总的来说,perf top -z, --zero 选项提供了一种灵活性,使得你可以根据你的需求选择最适合你的数据显示方式。
2.13 记录cgroups相关的性能事件
perf top --all-cgroups 是 perf 工具中的一个选项,它使得 perf 能够记录类型为 PERF_RECORD_CGROUP 的事件,并且使用 cgroup 作为排序关键字显示这些事件。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
在 Linux 中,cgroup(control group)是一种用于将一组进程分组在一起,以便对其资源使用进行统一管理的机制。每个 cgroup 都有一个或多个子系统(subsystem)与之关联,每个子系统都管理着一种类型的资源,例如 CPU 时间、系统内存、网络带宽等。
PERF_RECORD_CGROUP 是一种 perf 事件类型,用于记录 cgroup 相关的信息。当你使用 --all-cgroups 选项时,perf 就会记录这种类型的事件,并且在显示结果时使用 cgroup 作为排序关键字。
这个选项对于那些需要对不同 cgroup 的性能进行分析的场景非常有用。例如,如果你在一个容器化的环境中运行多个服务,每个服务都在其自己的 cgroup 中,那么你就可以使用 perf top --all-cgroups 来分析每个服务(即每个 cgroup)的性能。
2.14 调用栈记录(call-graph)参数
perf top --call-graph 是 perf 工具中的一个选项,它用于设置并启用调用图(call-graph),也就是堆栈链/反向追踪。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
你可以指定以下参数来配置调用图:
record_mode: 调用图记录模式,可以是fp(帧指针)、dwarf(DWARF 调试信息)或lbr(最后分支记录)。record_size: 如果record_mode是dwarf,那么这是堆栈记录的最大大小(以字节为单位)。默认值是 8192 字节。print_type: 调用图打印样式,可以是graph(图)、flat(平面)、fractal(分形)、folded(折叠)或none(无)。threshold: 调用图包含的最小阈值(以百分比为单位)。print_limit: 调用图条目的最大数量。order: 调用图的顺序,可以是caller(调用者)或callee(被调用者)。sort_key: 调用图的排序关键字,可以是function(函数)或address(地址)。branch: 是否在调用图中包含最后一次分支信息,值为branch。value: 调用图的值,可以是percent(百分比)、period(周期)或count(计数)。
默认配置是 fp,graph,0.5,caller,function。
调用图是分析程序性能的一个重要工具,它可以显示程序中函数调用的关系以及每个函数在 CPU 上花费的时间。通过 perf top --call-graph 选项,你可以以更直观的方式理解和分析 perf 收集的性能数据。
2.15 子函数累积到父函数
perf top --children 是 perf 工具中的一个选项,它使得 perf 能够将子函数的调用链累积到父函数条目中,以便它们能在输出中显示。perf 是 Linux 系统中的一个性能分析工具,能够收集各种类型的性能数据。
当你使用 --children 选项时,perf top 的输出将会有一个新的 “Children” 列,并且结果将基于这些数据进行排序。这个选项需要开启 -g/--call-graph 选项。
“Children” 列显示的是父函数下所有子函数的性能开销累积。这个开销包括了子函数自身的开销以及它们的子函数的开销,以此类推。这个选项对于理解和分析函数调用链的性能非常有用。
2.16 只识别特定进程/线程名称中的符号
命令格式如下:
perf top --comms <comm[,comm...]>
这里的 <comm[,comm...]> 部分需要你指定一个或多个进程/线程的名称(comm 是 “command” 的缩写,但在 perf 的上下文中,它通常指的是进程或线程的名称)。这样,perf top 的输出就会只包括与这些进程或线程相关的性能事件。
例如,如果你只关心名为 my_program 的进程,你可以运行以下命令:
perf top --comms my_program
这样,perf top 就会只显示与 my_program 进程相关的性能事件。
2.17 只识别特定动态库中的符号
--dsos 是 perf top 的一个选项,允许您指定一个或多个动态共享对象(DSOs),以便只显示与这些对象相关的事件。
具体来说,--dsos <dso[,dso...]> 选项允许您限制显示的样本,只包含指定的一个或多个动态共享对象(DSOs)。这样,您可以专注于分析特定的库或程序的性能。
DSO 是动态链接库(在 Windows 中)或共享对象(在 Unix-like 系统中)的别名。在 Linux 中,DSOs 包括各种各样的对象,比如:
- 用户级程序
- 用户级库
- 内核
- 内核模块
例如,如果您只想要查看与 libc(标准 C 库)相关的性能事件,可以运行以下命令:
perf top --dsos libc-2.27.so
这样显示的结果就只会包含与 libc-2.27.so 这个库相关的性能事件。
2.18 指定输出的列字段名
perf top --fields 是 Linux 性能分析工具 perf 的一个命令选项。这个选项可以让你自定义 perf top 输出中的字段。
以下是可用的字段:
overhead: 显示事件开销的百分比。overhead_sys: 显示系统(内核)时间开销百分比。overhead_us: 显示用户空间时间开销百分比。overhead_children: 显示子进程时间开销百分比。sample: 显示样本数量。period: 显示样本期间。
此外,你还可以在 --fields 选项中指定任何排序键。
你可以在一个命令中指定多个字段,字段之间用逗号分隔,如下所示:
perf top --fields=overhead,sample,period
这个命令会让 perf top 在输出中只显示 overhead、sample 和 period 这三个字段。
默认情况下,如果你没有在 --fields 选项中指定某个排序键,perf 会自动追加这个键。例如,如果你只指定 --fields=overhead,perf 会自动追加其他的排序键,使得输出中包含所有的字段。
# perf top --fields=overhead,overhead_sys,overhead_us,overhead_children,sample,period,symbol
Overhead sys usr Children Samples Period Symbol 12.26% 0.00% 14.01% N/A 282 263291394 [.] io__get_char9.46% 10.81% 0.00% N/A 213 203103732 [k] module_get_kallsym5.95% 6.80% 0.00% N/A 137 127758295 [k] number5.58% 0.00% 6.38% N/A 128 119802200 [.] kallsyms__parse4.72% 0.00% 5.40% N/A 108 101370934 [.] io__get_hex4.50% 5.14% 0.00% N/A 105 96584368 [k] format_decode4.25% 4.86% 0.00% N/A 100 91255469 [k] memcpy
2.19 指定组事件中的排序字段
perf top --group-sort-idx 是一个用于排序 perf top 输出的选项。它通过在组中的事件索引 n 对输出进行排序。如果 n 是无效的,那么将按照第一个事件进行排序。它可以支持有不同数量事件的多个组。需要注意的是,这个选项应该在分组事件上使用。
例如,如果你有一个分组,包括三个事件,你可以通过 --group-sort-idx 2 来按照该组中的第三个事件来排序输出结果。这个选项提供了一种灵活的方式,可以让你更具体地控制 perf top 的输出。
但是,当你使用这个选项时,需要确保你正在查看的事件是分组的。如果它们不是分组的,那么这个选项可能不会按照你期望的方式工作。
2.20 忽略指定函数的子调用函数
perf top --ignore-callees=<regex> 是一个选项,它允许你忽略匹配给定正则表达式的函数的调用者。这将使得每个这样的函数的调用者都集中在调用图树的一个地方。
例如,如果你有一个函数 foo(),它被多个其他函数调用,并且你只关心 foo() 的调用者,而不关心 foo() 的调用者调用了哪些其他函数。在这种情况下,你可以使用 --ignore-callees=foo 选项,这将使得 perf top 将 foo() 的所有调用者集中在一起,而无需显示它们各自可能调用的其他函数。
这个选项对于简化调用图,并专注于特定函数的调用者非常有用。它能帮助你减少分析的复杂性,并专注于你最感兴趣的部分。例如:
perf top --ignore-callees=foo
这将忽略所有调用 foo() 的函数的被调用者,只收集 foo() 的调用者。
2.21 指定内核符号的位置
perf top --kallsyms=<file> 是一个选项,它允许你指定一个包含内核符号的文件。kallsyms 是一个文件,通常位于 /proc/kallsyms,它包含内核符号的列表,这些符号对于查找内核代码中的函数和变量的地址非常有用。
如果你在分析一个特定的内核版本,或者你有一个预先生成的 kallsyms 文件,你可以使用 --kallsyms 选项指定这个文件。这将告诉 perf top 从这个文件中读取内核符号,而不是从默认的 /proc/kallsyms 文件中读取。例如:
perf top --kallsyms=/path/to/my/kallsyms
这将告诉 perf top 从 /path/to/my/kallsyms 文件中读取内核符号。这对于分析特定内核版本的性能数据,或者在没有直接访问目标系统的情况下分析性能数据非常有用。
2.22 限制调用栈解析深度
perf top --max-stack 是一个选项,允许你在解析调用链时设置堆栈深度限制,超过指定深度的内容将被忽略。这是在信息丢失和更快的处理之间的权衡,特别是对于可能有非常长调用链堆栈的工作负载。
例如,如果你正在分析一个可能有深度递归或者有大量函数调用的程序,这个调用链可能会变得非常深。在这种情况下,解析整个调用链可能会消耗大量的处理器资源。使用 --max-stack 选项,你可以限制 perf top 解析的堆栈深度,从而加快处理速度。
默认情况下,这个值是从 /proc/sys/kernel/perf_event_max_stack 中读取的(如果存在),否则默认值是 127。例如:
perf top --max-stack=50
这将设置堆栈深度限制为 50,超过这个深度的调用链将被忽略,这样可以加快 perf top 的处理速度。但是,这也可能导致一些信息丢失,因为深度超过 50 的调用链将不会被解析和显示。
2.23 记录命名空间的性能数据
perf top --namespaces 是一个选项,它允许你记录类型为 PERF_RECORD_NAMESPACES 的事件并使用 cgroup_id 排序键来显示它们。在 Linux 中,命名空间是一个轻量级的虚拟化技术,它可以将系统资源分割成多个独立的命名空间,每个命名空间都有自己的一套资源(例如:PID、网络接口等)。PERF_RECORD_NAMESPACES 是一个事件类型,用于记录命名空间相关的性能数据。
当 --namespaces 选项被使用时,perf top 将记录这些事件,并使用 cgroup_id 排序键来显示结果。cgroup_id 是一个用于标识控制组的标识符。控制组(cgroup)是一个 Linux 内核特性,用于限制、记录和隔离进程组的资源使用情况。例如:
perf top --namespaces
这将记录 PERF_RECORD_NAMESPACES 类型的事件,并按照 cgroup_id 排序显示结果。这对于分析在特定命名空间和/或控制组中运行的进程的性能数据非常有用。
2.24 设置perf合成事件线程数目
perf top --num-thread-synthesize 是一个选项,它允许你设置在为现有进程合成事件时运行的线程数量。默认情况下,线程数量等于在线 CPU 的数量。
合成事件是 perf top 用来生成对应于现有进程的事件的过程。这是必要的,因为当 perf top 开始运行时,可能有一些进程已经在运行,并且产生了一些重要的性能数据。为了不丢失这些数据,perf top 会为这些现有进程合成事件。例如:
perf top --num-thread-synthesize=4
这将设置在为现有进程合成事件时运行的线程数量为 4。这可能会影响 perf top 的性能,因为更多的线程可能会增加 CPU 的使用率,但也可能会使事件合成的过程更快。你应该根据你的系统配置和你的性能需求来选择合适的线程数量。
2.25 只使用最近的记录
perf top --overwrite 是一个选项,它允许你只使用最近的记录,这在高核心计数机器(如 Knights Landing/Mill)上很有帮助,但目前默认情况下是禁用的,因为这种技术中使用的暂停可能导致丢失元数据事件,如 PERF_RECORD_MMAP,这使得 perf top 无法解析样本,导致大量未知样本出现在用户界面上。如果你在这种机器上,并且正在对一个不创建短暂线程和/或不使用许多可执行的 mmap 操作的工作负载进行性能分析,应启用此选项。计划正在进行中以解决这种情况,直到那时,此选项将默认禁用。例如:
perf top --overwrite
这将启用 overwrite 选项,使 perf top 只使用最近的记录。然而,需要注意的是,这可能会导致一些元数据事件(如 PERF_RECORD_MMAP)的丢失,从而导致一些样本无法解析。因此,你应该只在你确定你的工作负载不会创建短暂的线程并且不会使用许多 mmap 操作的情况下使用这个选项。
2.26 设置显示条目的最小开销百分比
perf top --percent-limit 是一个选项,它允许你设置一个百分比门槛,使得 perf top 不会显示那些开销低于该百分比的条目。默认值是 0。
开销(overhead)是指函数或操作对总体性能的影响程度。在 perf top 的上下文中,开销通常是指函数或操作占用 CPU 时间的百分比。使用 --percent-limit 选项,你可以过滤掉那些开销不大的函数或操作,从而专注于那些对性能影响最大的部分。例如:
perf top --percent-limit=1.0
这将设置百分比门槛为 1.0,这意味着 perf top 不会显示那些开销低于 1.0% 的条目。这可以帮助你更清楚地看到那些对性能影响最大的函数或操作,而不是被那些开销较小的条目淹没。
2.27 设置过滤条目的百分比显示形式
perf top --percentage 是一个用于指定如何显示过滤条目开销百分比的命令行选项。你可以通过 --comms,--dsos 和/或 --symbols 选项以及 TUI 上的缩放操作(线程,dso 等)应用过滤器。
-
“
relative” 意味着其相对于只过滤条目,因此显示的条目总和将始终是 100%。换句话说,这意味着显示的各个条目的百分比是相对于所有已过滤(即,显示的)条目的总开销。例如,如果你有三个条目,它们的开销分别为 30,20 和 50,那么在 “relative” 模式下,它们的百分比将显示为 30%,20% 和 50%。 -
“
absolute” 意味着无论是否应用过滤器,它都保留原始值。也就是说,显示的各个条目的百分比是相对于所有(即,过滤和未过滤)条目的总开销。继续上述例子,如果存在另一个不显示(即,被过滤的)条目,其开销为 100,那么在 “absolute” 模式下,前三个条目的百分比将显示为 15%,10% 和 25%(因为它们现在是相对于总开销 200 计算的)。
2.28 指定源码文件路径
perf top --prefix=PREFIX, --prefix-strip=N 是一对命令行选项,让你可以修改可执行文件中源文件路径的显示方式。这特别有用当你在一个系统上编译源代码,然后在另一个具有不同文件系统布局的系统上分析它时。
-
--prefix=PREFIX选项允许你添加一个前缀到源文件路径名称。这意味着,perf top将在显示每个源文件路径之前添加指定的PREFIX。 -
--prefix-strip=N选项允许你从源文件路径名称中删除前N个条目。例如,如果源文件路径是/user/home/project/file.c并且N是2,那么perf top将显示路径为project/file.c。
这两个选项一起使用时,可以让你更灵活地处理在不同系统上编译和分析代码的情况。例如,如果你在一个系统上编译源代码,该系统的文件系统布局与你正在运行 perf top 的系统不同,你可以使用这两个选项来适应源系统的布局,使源文件路径正确显示。
例如,假设在编译系统中,源文件位于 /home/user/project/src/file.c,但在分析系统中,相同的文件位于 /mnt/build/project/src/file.c。你可以使用 --prefix-strip=3 --prefix=/mnt/build/ 来正确显示源文件路径。
2.29 设置预先存在线程mmap文件的超时时间
perf top --proc-map-timeout 是一个命令行选项,用于设置处理预先存在的线程 /proc/XXX/mmap 时的超时限制。这在处理可能非常大的文件时非常必要,因为这可能需要很长时间。
/proc/XXX/mmap 文件包含了进程(其中 XXX 是进程 ID)的内存映射信息,这可能包括大量的数据。如果文件很大,处理这些数据可能需要相当长的时间。在这种情况下,设置一个超时限制可以防止 perf top 无限期地等待。
--proc-map-timeout 选项允许你设置这个超时限制。该选项的值应该是一个时间,单位是毫秒。
例如,以下命令将超时限制设置为 1000 毫秒(即 1 秒):
perf top --proc-map-timeout 1000
如果没有指定这个选项,那么默认的超时限制是 500 毫秒。
2.30 输出原始的traceevent事件信息
perf top --raw-trace 是一个命令行选项,用于在显示 traceevent 输出时禁止使用 print fmt 或插件。Traceevent 是 Linux 内核的一部分,它允许开发者跟踪和理解内核和应用程序的运行时行为。
默认情况下,perf top 会使用 print fmt 或插件来格式化和解释 traceevent 输出。这些工具可以帮助将内核跟踪数据转换成更易于理解的形式。例如,他们可以将内核地址转换为符号名,或者将原始数据转换为更具可读性的形式。
但是,有时你可能想直接看到原始的、未经处理的 traceevent 数据。这可能是因为你正在开发自己的分析工具,或者你想看到数据的完整细节,而不是经过格式化和解释的版本。在这种情况下,你可以使用 --raw-trace 选项来禁止 perf top 使用 print fmt 或插件。
例如,以下命令将显示原始的 traceevent 数据:
perf top --raw-trace
请注意,原始的 traceevent 数据可能很难理解,除非你对 Linux 内核和你正在分析的程序有深入的了解。
2.31 显示指定显示switch-on/off事件
perf top --show-on-off-events 是一个命令行选项,用于显示 --switch-on/off 事件。目前该选项在 perf top 中没有效果,但是在未来可能会改变默认行为,不在 --group 模式中显示 switch-on/off 事件,如果除了 off/on 事件之外只有一个事件,直接进入直方图浏览器,就像 perf top 在没有明确指定事件的情况下所做的那样。
perf top 主要用于实时显示 CPU 占用最高的函数,以及它们在 CPU 上花费的时间。–switch-on/off 事件是指在执行过程中,程序从执行状态切换到非执行状态,或者从非执行状态切换到执行状态。
在 --group 模式下,perf top 会将一组相关的事件一起显示,这可能会包括 switch-on/off 事件。然而,这些事件可能会混淆输出,特别是当你只关心一个特定的事件时。因此,未来的 perf top 版本可能会改变默认行为,使得 --group 模式下不显示 switch-on/off 事件,除非你使用 --show-on-off-events 选项来明确请求它们。
2.32 显示每个符号的总消耗CPU时间
perf top --show-total-period 是一个命令行选项,用于显示一个包含期间总和的列。在这里,“期间”是指样本之间的时间,也就是 CPU 花费在每个函数上的时间。
在 perf top 的输出中,通常会显示每个函数的名称、它占用的 CPU 百分比,以及它在样本中出现的次数。如果你使用 --show-total-period 选项,perf top 还会显示一个额外的列,该列包含了每个函数的“期间”总和。这可以帮助你更准确地理解每个函数在 CPU 上花费的时间。
例如,以下命令将显示一个包含期间总和的列:
perf top --show-total-period
在这个输出中,你可以看到一个新的列,列出了每个函数的期间总和。这可以让你直观地看到哪些函数在样本期间花费了最多的时间,即使它们在样本中出现的次数可能不多。
2.33 禁止汇编代码中插入源代码
perf top --source 是一个命令行选项,用于在汇编代码中插入源代码。这是默认启用的,如果你想禁用它,可以使用 --no-source 选项。
在 perf top 的输出中,通常会显示 CPU 占用最高的函数,以及它们在 CPU 上花费的时间。如果你启用 --source 选项(或者不禁用它,因为它是默认启用的),perf top 还会显示与每个函数相关的源代码。这是通过查找和解析相应的源文件来实现的。
源代码和汇编代码的交错显示可以帮助你更好地理解程序的行为。你可以看到哪些源代码行对应于 CPU 占用最高的函数,以及这些函数在 CPU 上花费的时间。例如,以下命令将显示源代码和汇编代码:
perf top --source
在这个输出中,你可以看到源代码行和对应的汇编代码行,以及每个函数在 CPU 上花费的时间。
如果你不想看到源代码,只想看到汇编代码,你可以使用 --no-source 选项来禁用源代码的显示,如下所示:
perf top --no-source
2.34 使用stdio来输出结果
perf top --stdio 是一个命令行选项,它告诉 perf top 使用标准输入/输出(stdio)接口来显示输出,而不是默认的图形用户界面(GUI)。
perf top 默认情况下会使用一个交互式的图形用户界面来显示结果,这个界面可以让你在运行时交互地浏览和分析数据。然而,有时候你可能只想要一个简单的文本输出,例如,当你在没有图形界面的服务器上运行 perf top,或者当你想将输出重定向到一个文件或另一个程序时。
在这些情况下,你可以使用 --stdio 选项来让 perf top 使用 stdio 接口。这将使 perf top 以简单的文本格式显示结果,就像它在一个终端窗口中运行一样。
例如,以下命令将使用 stdio 接口运行 perf top:
perf top --stdio
在这个模式下,perf top 将直接打印结果到标准输出,而不是显示一个交互式的界面。你可以使用重定向操作符(比如 > 或 |)来将输出发送到一个文件或另一个程序。
2.35 开启LBR记录函数栈功能
perf top --stitch-lbr 是一个命令行选项,用于显示通过拼接 Last Branch Records (LBRs) 生成的调用图。这种方法可能会生成更完整的调用图。这个选项必须和 --call-graph lbr 录制选项一起使用。默认情况下,这个选项是禁用的。
在常见的调用堆栈溢出的情况下,它可以比默认的 LBR 调用堆栈输出重建更好的调用堆栈。然而,这种方法并不万无一失。可能会出现由于错误匹配而生成错误调用堆栈的情况。已知的限制包括像 setjmp/longjmp 这样的异常处理会导致调用/返回不匹配。
例如,以下命令将启用用 stitched LBRs 生成的调用图:
perf top --stitch-lbr --call-graph lbr
这个选项需要你的 CPU 支持 LBR 功能,并且 perf top 版本也需要支持这个选项。在某些旧的 CPU 或 perf top 版本中,这个选项可能无效。
此外,你也需要了解,尽管 --stitch-lbr 可以提供更完整的调用图,但是也可能出现错误的匹配,尤其是在处理像 setjmp/longjmp 这样的异常时。因此,在解析 perf top 的输出时,你应该注意这些潜在的限制和问题。
2.36 记录指定事件区间内的其他事件(限定记录范围)
perf top --switch-on EVENT_NAME 和 perf top --switch-off EVENT_NAME 是一对命令行选项,它们允许你在特定事件发生后开始或停止计算其他事件。这些选项的主要用途是,当你想在某个特定事件发生后开始测量工作负载,或者在某个特定事件发生后停止测量工作负载时,你可以使用它们。
例如,你可能想在程序的初始化阶段结束后开始测量 CPU 周期。为此,你可以在初始化函数的末尾插入一个 perf probe,然后使用 --switch-on 选项来告诉 perf top 在这个 probe 触发后开始计数。
同样,你也可以在某个清理函数开始时插入一个 perf probe,然后使用 --switch-off 选项来告诉 perf top 在这个 probe 触发后停止计数。这样,你就可以只计算程序的主要工作阶段在 CPU 上花费的时间,而不包括初始化和清理阶段。
这是一个使用 --switch-on 和 --switch-off 选项的例子:
# 插入一个 probe 在初始化函数的末尾
perf probe init_function:100# 插入一个 probe 在清理函数的开始
perf probe cleanup_function:1# 开始 perf top,当 init_function 的 probe 触发后开始计数,当 cleanup_function 的 probe 触发后停止计数
perf top -e cycles --switch-on=probe:init_function --switch-off=probe:cleanup_function
这个例子将只计算在 init_function 和 cleanup_function 之间花费的 CPU 周期。这对于测量程序的主要工作阶段的性能非常有用,而不需要关心初始化和清理阶段的性能。
2.37 注释指定的符号
perf top --sym-annotate=<symbol> 是一个命令行选项,用于注释指定的符号。这个选项可以让你专注于特定的函数或方法,并查看它的细节。
在 perf top 的上下文中,"注释"一个符号意味着显示这个符号(通常是一个函数或方法)的详细信息,包括它的源代码(如果可用)和每行代码在 CPU 上花费的时间。这可以帮助你理解这个函数的行为,特别是它在 CPU 上花费的时间。
例如,以下命令将注释名为 my_function 的符号:
perf top --sym-annotate=my_function
在这个命令的输出中,你会看到 my_function 的源代码(如果可用),以及每行代码在 CPU 上花费的时间。你可以根据这些信息来理解 my_function 的性能特性,例如它哪些部分使用了最多的 CPU 时间。
请注意,你需要有源代码和调试信息才能注释一个符号。如果你没有这些信息,perf top 可能无法显示符号的详细信息。在这种情况下,你可能需要重新编译你的程序,包含源代码和调试信息。
2.38 指定特定符号用于性能监控
perf top --symbols=<symbol> 是一个命令行选项,用于只考虑指定的符号。这个选项会影响"overhead"列的百分比。
"overhead"是 perf top 输出中的一个列,显示了每个符号(通常是函数或方法)在总 CPU 时间中占用的百分比。默认情况下,这个百分比是基于所有的符号计算的。然而,如果你使用 --symbols 选项,perf top 将只考虑你指定的符号,而忽略其他所有符号。
例如,以下命令只会考虑名为 my_function 和 other_function 的符号:
perf top --symbols=my_function,other_function
在这个命令的输出中,"overhead"列将只基于my_function,other_function两个函数进行计算。
3. 交互式界面
目前来看按键是和perf版本有关的,man页面的描述基本是不对应的,具体使用时,还是以当前版本为主(?查看命令介绍)
| 交互按键 | 描述 |
|---|---|
| PGDN/SPACE | Navigate,翻页,显示上、下一页的内容 |
| q/ESC/CTRL+C | Exit browser or go back to previous screen,退出浏览器或返回上一屏 |
| TAB/UNTAB | Switch events,切换事件 |
| ENTER | Zoom into DSO/Threads & Annotate current symbol,放大 DSO/线程 & 注释当前符号 |
| ESC | Zoom out,缩小 |
| + | Expand/Collapse one callchain level,扩大/折叠一级调用链 |
| a | Annotate current symbol,注释当前符号 |
| C | Collapse all callchains,折叠所有调用链 |
| d | Zoom into current DSO,放大当前 DSO |
| e | Expand/Collapse main entry callchains,扩大/折叠主入口调用链 |
| E | Expand all callchains,展开所有调用链 |
| F | Toggle percentage of filtered entries,切换过滤条目的百分比 |
| H | Display column headers,显示列标题 |
| k | Zoom into the kernel map,放大内核映射 |
| L | Change percent limit,更改百分比限制 |
| m | Display context menu,显示上下文菜单 |
| S | Zoom into current Processor Socket,放大当前处理器插槽 |
| P | Print histograms to perf.hist.N,打印直方图到 perf.hist.N |
| t | Zoom into current Thread,放大当前线程 |
| V | Verbose (DSO names in callchains, etc),详细(调用链中的 DSO 名称等) |
| z | Toggle zeroing of samples,切换样本零化 |
| f | Enable/Disable events,启用/禁用事件 |
| / | Filter symbol by name,通过名称过滤符号 |
“Toggle zeroing of samples” 是 perf top --tui 中的一个功能,对应的快捷键是 z。
这个功能的作用是切换是否清零样本。当你启用这个选项时,perf top 会在每次更新屏幕时清零样本,这意味着你看到的性能数据是自上次更新以来的数据,而不是自 perf top 启动以来的累计数据。
这个选项在你想要观察系统性能的短期变化时非常有用。例如,你可能想要知道在某个特定的时间段内,哪些函数的 CPU 使用率最高,而不是自 perf top 启动以来的累计数据。在这种情况下,你可以启用 “Toggle zeroing of samples” 功能,这样 perf top 就会在每次更新屏幕时清零样本,从而显示出自上次更新以来的性能数据。
4. 开销计算细节(overhead calculation)
参考文档: perf-top(1) - Linux manual page (man7.org)
当perf收集调用链时,开销可以显示为Children和Self两列。self开销简单地通过添加条目的所有周期值来计算——通常是一个函数(符号)。这是perf传统上显示的值,所有自我开销值的总和应该是100%。
子开销(children overhead)是通过将子函数的所有周期值相加来计算的,这样就可以显示高一层次函数的总开销,即使它们没有直接执行很多。这里的子函数是指从另一个(父)函数调用的函数。
所有子开销值(children overhead)的总和超过100%可能会令人困惑,因为它们每一个都累积了其子函数的自我开销,这会导致重复累加。但启用了这个功能后,即使样本分布在子函数上,用户也可以找到开销最大的函数。考虑下面的例子,有如下三个函数:
void foo(void) { /* do something */ }void bar(void) {/* do something */foo();
}int main(void) {bar()return 0;
}
在这种情况下,foo是bar的子元素,bar是main的直接子元素,所以foo也是main的子元素。换句话说,main是foo和bar的父元素,bar是foo的父元素。假设所有的样本只记录在foo和bar中。当它用调用链记录时,输出将显示如下通常的(仅自开销)perf report输出:
Overhead Symbol
........ .....................60.00% foo|--- foobarmain__libc_start_main40.00% bar|--- barmain__libc_start_main
当启用——children选项时,子函数(即foo和bar)的自开销值被添加到父函数以计算子函数开销。在这种情况下,报告可以显示为:
Children Self Symbol
........ ........ ....................
100.00% 0.00% __libc_start_main|--- __libc_start_main100.00% 0.00% main|--- main__libc_start_main100.00% 40.00% bar|--- barmain__libc_start_main60.00% 60.00% foo|--- foobarmain__libc_start_main
在上面的输出中,foo的自身开销(60%)被添加到bar、main和_libc_start_main的子开销中。同样,bar的self开销(40%)被添加到main和libc_start_main的子开销中。因此,首先显示的是libc_start_main和main,因为它们具有相同的(100%)子开销(即使它们的self开销为零),并且它们是foo和bar的父对象。
自v3.16以来,默认情况下显示子开销,并按其值对输出进行排序。通过在命令行上指定--no-children选项或在perf配置文件中添加report.children = false or top.children = false来禁用子开销。
相关文章:
top实时性能)
linux之perf(3)top实时性能
Linux之perf(3)top实时性能 Author:Onceday Date:2023年9月3日 漫漫长路,才刚刚开始… 注:该文档内容采用了GPT4.0生成的回答,部分文本准确率可能存在问题。 参考文档: Tutorial - Perf Wiki (kernel.org)perf-to…...

【linux命令讲解大全】076.pgrep命令:查找和列出符合条件的进程ID
文章目录 pgrep补充说明语法选项参数实例 从零学 python pgrep 根据用户给出的信息在当前运行进程中查找并列出符合条件的进程ID(PID) 补充说明 pgrep 命令以名称为依据从运行进程队列中查找进程,并显示查找到的进程ID。每一个进程ID以一个…...

微信小程序开发---条件渲染和列表渲染
目录 一、条件渲染 (1)基本使用 (2)block (3)hidden 二、列表渲染 (1)基本使用 (2)手动指定索引和当前项的变量名 (3)wx:key的…...

【ES6】require、export和import的用法
在JavaScript中,require、export和import是Node.js的模块系统中的关键字,用于处理模块间的依赖关系。 1、require:这是Node.js中引入模块的方法。当你需要使用其他模块提供的功能时,可以使用require关键字来引入该模块。例如&…...

Vue + Element UI 前端篇(九):接口格式定义
接口请求格式定义 前台显示需要后台数据,我们这里先把前后端交互接口定义好,没有后台的时候,也方便用mock模拟。 接口定义遵循几个规范: 1. 接口按功能模块划分。 系统登录:登录相关接口 用户管理:用户…...

部署Django报错-requires SQLite 3.8.3 or higher
记一次CentOS7部署Django项目时的报错 问题出现 在部署测试环境时,有需要用到一个python的后端服务,要部署到测试环境中去 心想这不是so easy吗,把本地调试时使用的python版本及Django版本在服务器上对应下载好,然后直接执行命…...

什么是网络存储服务器
网络存储器就像一台只有存储功能的终端,独立地工作,里面带有固定的系统,但可以自己设置部分参数功能,可以接入服务器或者电脑进行设置,网络存储服务器实际上就是精简的、小型化的服务器,同样由主板、CPU&am…...
lv3 嵌入式开发-10 NFS服务器搭建及使用
目录 1 NFS服务器介绍 1.1 NFS服务器的介绍 1.2 NFS服务器的特点 1.3 NFS服务器的适用场景 2 NFS服务器搭建 2.1 配置介绍 2.2 常见错误 3 WINDOWS下NFS服务器搭建(扩展) 1 NFS服务器介绍 1.1 NFS服务器的介绍 nfs(Network File Sys…...
后流量时代的跨境风口:Facebook广告
Facebook拥有超过25亿各个年龄段和人群的每月活跃用户,可以帮助您接触世界各地的相关消费者。无论您是需要吸引新的潜在客户还是吸引回头客访问您的在线商店,Facebook广告都可以为电子商务提供丰厚的投资回报;无论您是在沃尔玛、eBay、亚马逊…...

Java基础学习笔记-2
前言 在计算机编程领域,条件语句和控制流结构是构建程序逻辑的基本组成部分。它们允许程序员根据不同的条件执行不同的操作,从而使程序更加灵活和智能。本文将深入探讨Java编程语言中的条件语句和控制流,提供了一系列实用的示例和技巧&#…...

Mongodb 安装脚本(附服务器自启动)
shell脚本 #!/bin/bash #mail:xuelanchnet.com #function:auto install mongodb [ $(id -u) ! "0" ] && echo "Error: You must be root to run this script" && exit 1 logfile"/var/log/mongod_install.log" softdir"/s…...

yolov5的pytorch配置
1. conda create -n rdd38 python3.82、pip install torch1.8.0 torchvision0.9.0 torchaudio0.8.0 -f https://download.pytorch.org/whl/cu113/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple 3、conda install cudatoolkit10.2...

ISO 19712-1-2008装饰用实体面材检测
实体面材是指由聚合物材料、填料和颜料组成,经浇筑或压制等工艺成型的板型产品或非板型产品,主要用于厨房台面,家具等领域。 ISO 19712-1-2008装饰用实体面材测试 测试项目 测试标准 耐干热 ISO 19712-3 ISO 19712-2 耐湿热 ISO 19712-…...

华为OD机试 - 最多颜色的车辆 - 数据结构map(Java 2022Q4 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、解题思路1、核心思想2、题做多了,你就会发现,这道题属于送分题,为什么这样说?3、具体解题思路: 五、Java算法源码六、效果展示1、输入2、输出 华为OD机试 2023B…...

Mybatis 插入、修改、删除
前面几篇我们介绍了使用Mybatis查询数据,并且也了解了如何在Mybatis中使用JDK的日志系统打印日志;本篇我们继续介绍如何使用Mybatis完成数据的插入、修改和删除。 如果您对查询数据和Mybatis集成JDK日志系统不太了解,建议您先进行了解后再阅…...

2023年9月DAMA-CDGA/CDGP数据治理认证火热招生中
DAMA认证为数据管理专业人士提供职业目标晋升规划,彰显了职业发展里程碑及发展阶梯定义,帮助数据管理从业人士获得企业数字化转型战略下的必备职业能力,促进开展工作实践应用及实际问题解决,形成企业所需的新数字经济下的核心职业…...
【SpringCloudAlibaba】Seata分布式事务使用
文章目录 分布式事务问题示例Seata概述、官网一个典型的分布式事务过程处理过程全局GlobalTransactional分布式交易解决方案流程图 Seata安装下载修改conf目录下的application.yml配置文件dashboard demo 分布式事务问题示例 单体应用被拆分成微服务应用,原来的三个…...

Java-day13(IO流)
IO流 凡是与输入,输出相关的类,接口等都定义在java.io包下 1.File类的使用 File类可以有构造器创建其对象,此对象对应着一个文件(.txt,.avi,.doc,.mp3等)或文件目录 File类对象是与平台无关的 File中的方法仅涉及到如何创建,…...
Vue2项目练手——通用后台管理项目第四节
Vue2项目练手——通用后台管理项目 数据的请求mock数据模拟实战文件目录src/api/mock.jssrc/api/mockServeData/home.jsmain.js 首页组件布局可视化图表可视化图表布局Home.vue echarts表Home.vue 数据的请求 mock数据模拟实战 mock官方文档 前端用来模拟后端接口的工具&…...
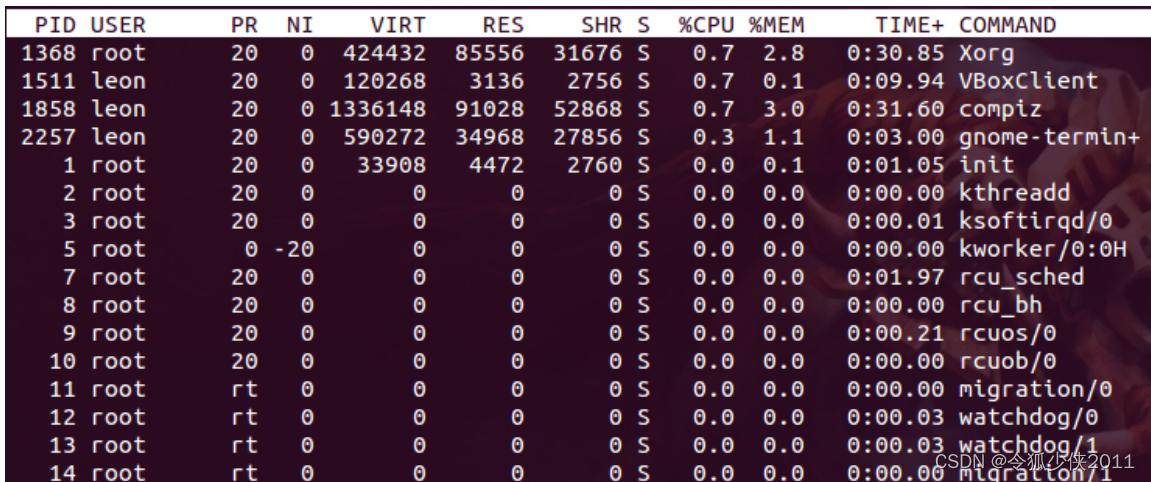
linux运维(二)内存占用分析
一、centos内存高,查看占用内存, top命令详解 1.1: free 命令是 free 单位K free -m 单位M free -h 单位Gfree最常规的查看内存占用情况的命令 1.2: 参数说明 total 总物理内存 used 已经使用的内存 free 没有使用的内存 shared 多进程共享内存 buff/cache 读写…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...
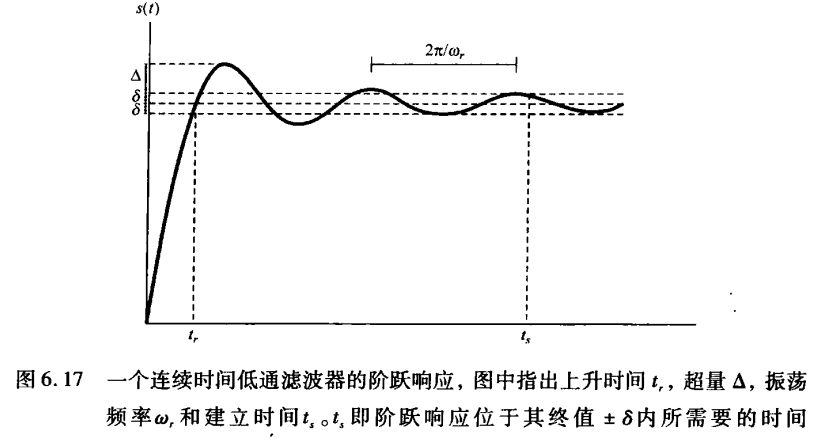
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...
Linux基础开发工具——vim工具
文章目录 vim工具什么是vimvim的多模式和使用vim的基础模式vim的三种基础模式三种模式的初步了解 常用模式的详细讲解插入模式命令模式模式转化光标的移动文本的编辑 底行模式替换模式视图模式总结 使用vim的小技巧vim的配置(了解) vim工具 本文章仍然是继续讲解Linux系统下的…...