Python批处理(一)提取txt中数据存入excel
Python批处理(一)提取txt中数据存入excel
问题描述
现从冠层分析软件中保存了叶面积指数分析的结果,然而软件保存格式为txt,且在不同的文件夹中,每个文件夹的txt文件数量不固定,但是txt文件格式固定。现需要批量处理这些txt文件,获取头三行的数据,并存入excel中。
源代码
def openreadtxt(file_name):data = []file = open(file_name, 'r') # 打开文件file_data = file.readlines() # 读取所有行for row in file_data:tmp_list = row.split(' ') # 按‘,’切分每行的数据# tmp_list[-1] = tmp_list[-1].replace('\n',',') #去掉换行符data.append(tmp_list) # 将每行数据插入data中return dataimport os
import xlrd
# -*- coding: utf-8 -*-
import xlsxwriter as xwdef xw_toExcel(data, fileName): # xlsxwriter库储存数据到excelworkbook = xw.Workbook(fileName) # 创建工作簿worksheet1 = workbook.add_worksheet("sheet1") # 创建子表worksheet1.activate() # 激活表title = ['序号', '叶面积指数', '平均叶倾角','天空散射辐射透过率'] # 设置表头worksheet1.write_row('A1', title) # 从A1单元格开始写入表头i = 2 # 从第二行开始写入数据for j in range(len(data)):insertData = [data[j]["id"], data[j]["lai"], data[j]["angle"],data[j]["sky"]]row = 'A' + str(i)worksheet1.write_row(row, insertData)i += 1workbook.close() # 关闭表# "-------------数据用例-------------"if __name__ == "__main__":DATA=[]list=['A1','A2','A3','A5','A8','A9','AA1','AA2','AA3','AA4','AA5','AA6','AA7','AA8','G1','L1','Q1','R1','R2','RR1','RR2','RR3','RR4','X2','X4','X5','XX1']for i in list:count = 0for root, dirs, files in os.walk("D:/Learn_Python/数据分析项目/08_叶面积指数批处理/fly/"+str(i)+'/'):for file in files:ext = os.path.splitext(file)[-1].lower()if ext == '.txt':count = count + 1print(i,count)n=0while(n<count):print("正在读取"+i+"下第"+str(n)+"个文件")data = openreadtxt('D:/Learn_Python/数据分析项目/08_叶面积指数批处理/fly/'+i+'/20230905_00'+str(n)+'.txt')newdata={"id":n,"lai":data[2][4],"angle":data[4][4],"sky":data[6][10]}DATA.append(newdata)n=n+1DATA.append({"id":1,"lai":1,"angle":1,"sky":1})print(DATA)xw_toExcel(DATA, 'D:/Learn_Python/数据分析项目/08_叶面积指数批处理/output.xlsx')代码注释
1、file = open(file_name, ‘r’)。使用open()函数打开名为"filename.txt"的文件,并以只读模式(“r”)打开。然后使用read()方法将文件内容读取并赋值给变量file。
2、file_data = file.readlines(),它会从文件中逐行读取数据,并将每一行存储为一个列表中的元素。这样就可以逐行处理文件中的内容了。
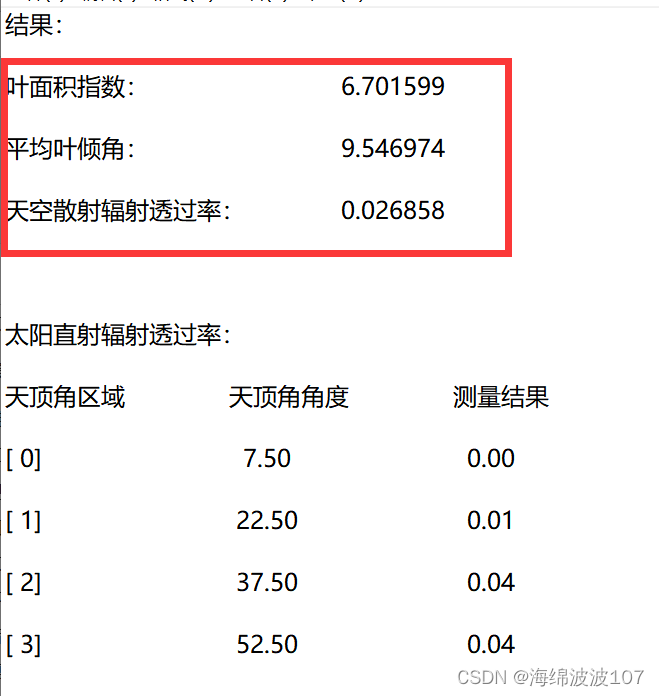
3、 tmp_list = row.split(’ ')。将字符串 row 按空格进行分割,并将分割后的结果存入列表 tmp_list 中。每个空格部分的内容都会成为列表中的一个元素。列表与其中分割的元素如下:
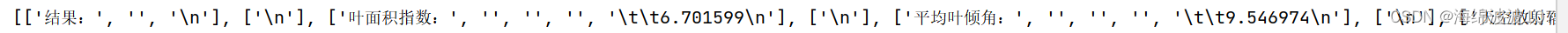
4、workbook = xw.Workbook(fileName) # 创建工作簿
worksheet1 = workbook.add_worksheet(“sheet1”) # 创建子表
worksheet1.activate() # 激活表。
首先,我们使用xw.Workbook()方法创建一个名为fileName的工作簿对象。然后,我们使用add_worksheet()方法在工作簿中创建一个名为"sheet1"的子表。最后,我们使用activate()方法激活该子表,使其成为活动表格,以激活后续操作。
5、worksheet1.write_row(row, insertData)。这是一个将数据写入Excel工作表中的代码片段。其中,worksheet1 是对应的工作表对象,row 是要写入的行数,insertData 是要插入的数据。
6、 for root, dirs, files in os.walk()。os.walk()是一个用于遍历目录树并获取目录中所有文件和子目录的函数。它返回一个生成器,可以用于迭代遍历目录结构。这里的root表示当前正在遍历的目录路径,dirs表示当前目录中的子目录列表,files表示当前目录中的文件列表。
7、ext = os.path.splitext(file)[-1].lower()。os.path.splitext(file):这个函数将文件名分割成文件名和扩展名的元组。例如,如果file是"example.txt",那么返回的元组将是(“example”, “.txt”)。
[-1]:这是Python中用于获取列表或元组中最后一个元素的索引。在这种情况下,它用于获取分割后元组中的扩展名(即.txt)。
.lower():这是一个字符串方法,用于将字符串转换为小写。这在这里使用是为了规范化扩展名,以便后续处理不受大小写的影响。
最终,ext变量将包含文件的小写扩展名。
8、newdata={“id”:n,“lai”:data[2][4],“angle”:data[4][4],“sky”:data[6][10]}
DATA.append(newdata)
每次创建一个字典
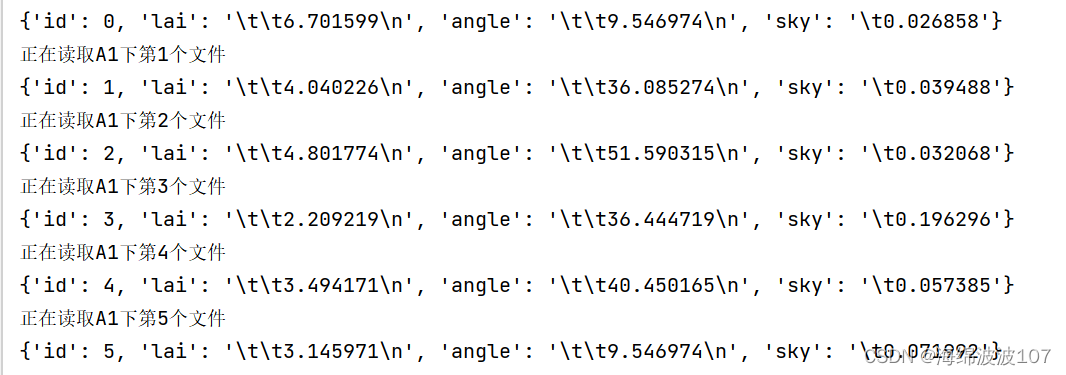
然后在列表中将每次创建的字典添加进去。

最后将字典写入excel中
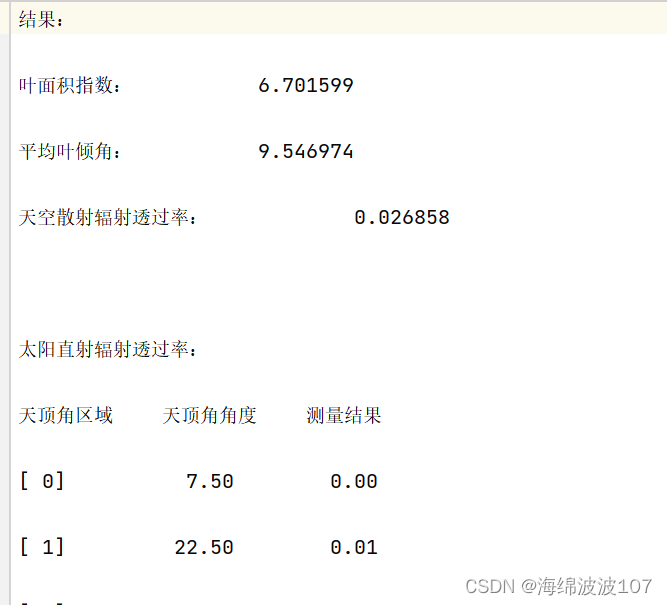
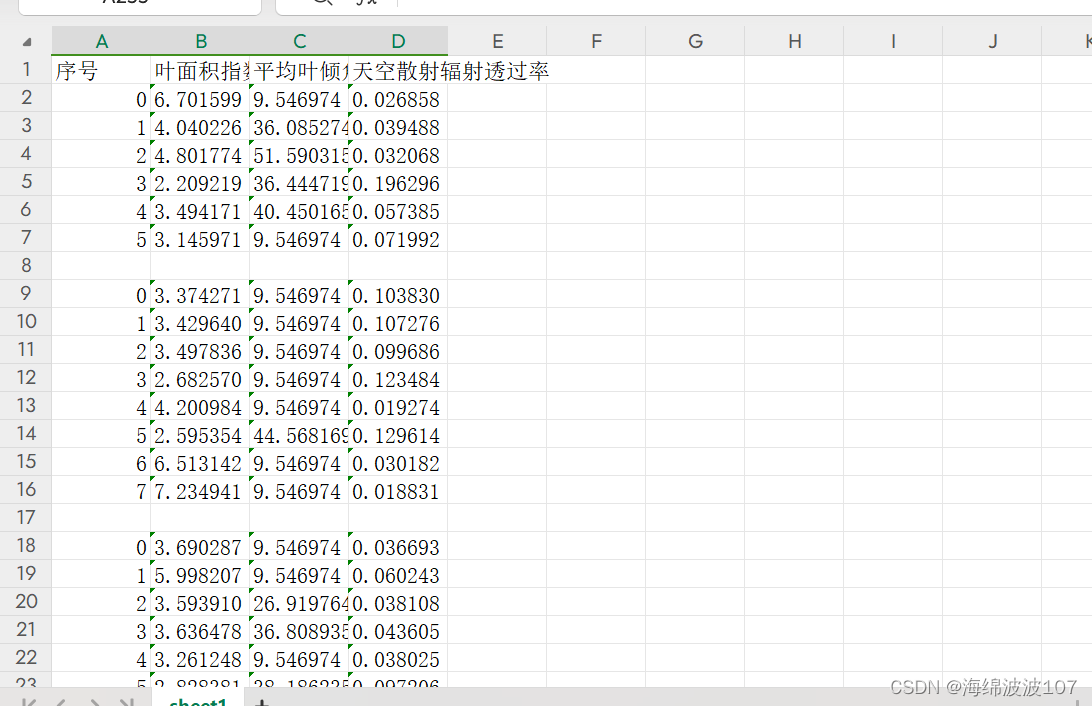
运行结果
相关文章:
Python批处理(一)提取txt中数据存入excel
Python批处理(一)提取txt中数据存入excel 问题描述 现从冠层分析软件中保存了叶面积指数分析的结果,然而软件保存格式为txt,且在不同的文件夹中,每个文件夹的txt文件数量不固定,但是txt文件格式固定。现需…...
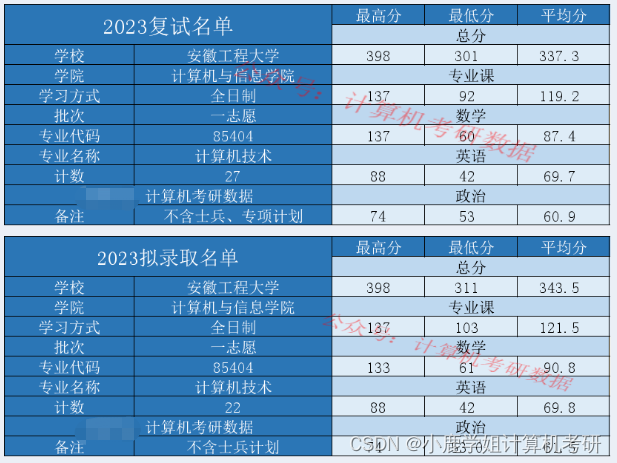
只考一门数据结构!安徽工程大学计算机考研
安徽工程大学 考研难度(☆) 内容:23考情概况(拟录取和复试分析)、院校概况、23专业目录、23复试详情、各专业考情分析、各科目考情分析。 正文992字,预计阅读:3分钟 2023考情概况 安徽工程大…...
Ubuntu 20.04出现蓝牙无法打开的问题(已解决)
安装Ubuntu20.04后,蓝牙无法打开,按钮开启后蓝牙仍处于关闭状态 解决方法(四种方式) 1.卸载并重新加载btusb内核模块(支持蓝牙设备的内核模块) sudo rmmod btusb sleep 1 sudo modprobe btusb2、安装蓝牙工…...
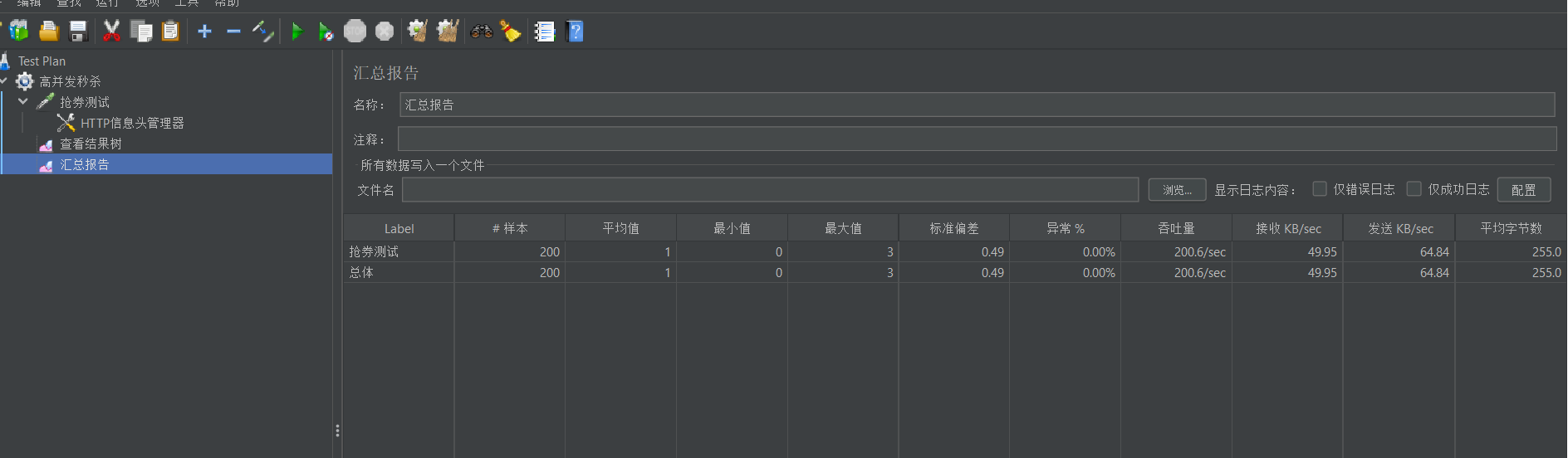
并发测试工具 apache-jmeter使用发送post请求JSON数据
目录 1 下载安装 2 汉化 3 创建高并发测试 配置线程组 创建web请求 创建监听器 结果树 汇总报告 为web请求添加token 添加Content-Type用于发送json 4 启动测试 5 查看结果 1 下载安装 官网Apache JMeter - Download Apache JMeter 解压运行 2 2 汉化 打开软件…...

牛客练习赛115 A Mountain sequence
题目: 样例: 输入 3 5 1 2 3 4 5 3 3 3 3 3 1 2 1 输出 16 1 3 思路: 依据题意,再看数据范围,可以知道暴力肯定是不可能了,然后通过题目意思,我们可以排列模拟一下,这里排列所得结…...

通过git bash激活虚拟环境遇到的问题
直接git bash后用conda activate激活一直报错 报错如下: CommandNotFoundError: Your shell has not been properly configured to use ‘conda activate’. If using ‘conda activate’ from a batch script, change your invocation to ‘CALL conda.bat activa…...

EasyAVFilter代码示例之将摄像机RTSP流转成RTMP推流输出
以下是一套完整的RTSP流转RTMP推流功能的开发源码,就简简单单几行代码,就可以完成原来ffmpeg很复杂的调用流程,而且还可以集成在自己的应用程序中调用,不需要再单独一个ffmpeg的进程来调用,方法很简单: #i…...

【【C语言康复训练-4】】
C语言康复训练-4 head.h #pragma once #define ROWS 11 #define COLS 11 #define ROW 9//为什么会在头文件中定义两个 因为1到9是我们想要实现的标准单元 #define COL 9 //但是对于我们幕后调控者,对边角上并不能和其他一样方便操作,所以我们向外拓展了…...
[DM8] DM-DM DBLINK DPI方式
前言 对于DM与DM之间的DBLINK,三种方式中,使用DPI方式配置上最为方便,ODBC方式需要安装ODBC包并配置ODBC数据源,dmmal方式需要设置MAL_INI数据库参数、配置dmmal.ini文件并需要重启数据库服务。 dpi类型的dblink,达梦…...

创建了一个名为nums_list的vector容器,其中存储了一系列的pair<int, int>
vector<pair<int, int>> nums_list;for (int i 0; i < nums.size(); i) {nums_list.emplace_back(i, nums[i]);}这段代码创建了一个名为nums_list的vector容器,其中存储了一系列的pair<int, int>。代码的逻辑如下:1. 创建一个空的…...

SpringMVC文件上传、文件下载多文件上传及jrebel的使用与配置
一.文件上传 1.导入依赖 <dependency><groupId>commons-fileupload</groupId><artifactId>commons-fileupload</artifactId><version>1.3.3</version> </dependency> 2.配置文件上传解析器 在spring-mvc.xml文件中添加文件…...

Leetcode143. 重排链表
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个单链表 L 的头节点 head ,单链表 L 表示为: L0 → L1 → … → Ln - 1 → Ln请将其重新排列后变为: L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → … 不能只…...
Git 回顾小结
Git是一个免费开源,分布式的代码版本控制系统,版主开发团队维护代码 作用:记录代码内容,切换代码版本,多人开发时高校合并代码内容 Git常用命令 命令作用注意git -v查看Git版本git init初始化本地Git仓库git add 文件…...

响应式布局(3种) + flex计算
响应式布局 1.媒体查询2.使用百分比、rem、vw、vh等相对单位来设置元素的宽度、高度、字体大小等1.rem与em2.vw、vh、vmax、vmin 3.Flexboxflexbox计算题 响应式布局是指同一个页面在不同屏幕尺寸下有不同的布局。 1.媒体查询 媒体查询是最基础的实现响应式的方式 使用media关键…...
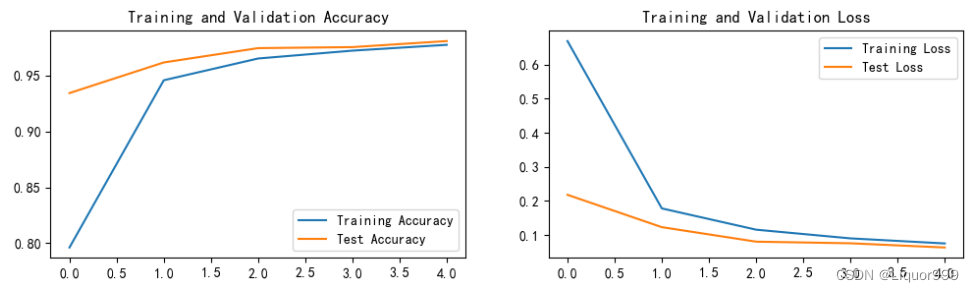
Pytorch从零开始实战01
Pytorch从零开始实战——MNIST手写数字识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——MNIST手写数字识别环境准备数据集模型选择模型训练可视化展示 环境准备 本系列基于Jupyter notebook,使用Python3.7.12,Py…...
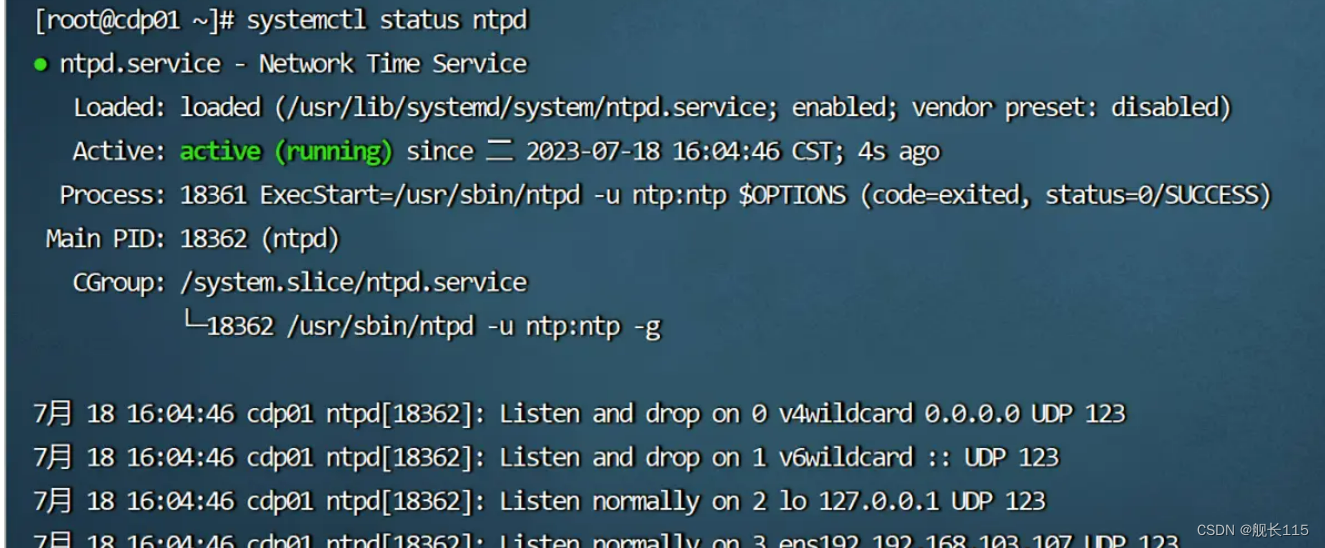
inappropriate address 127.0.0.1 for the fudge command, line ignored 时间同步的时候报错
1、安装ntp服务后,启动ntpd正常,但是在查看ntpd服务状态时,有一个红色的报错,报错信息如下: inappropriate address 127.0.0.1 for the fudge command, line ignored 2、解决方法:编辑ntp配置文件…...
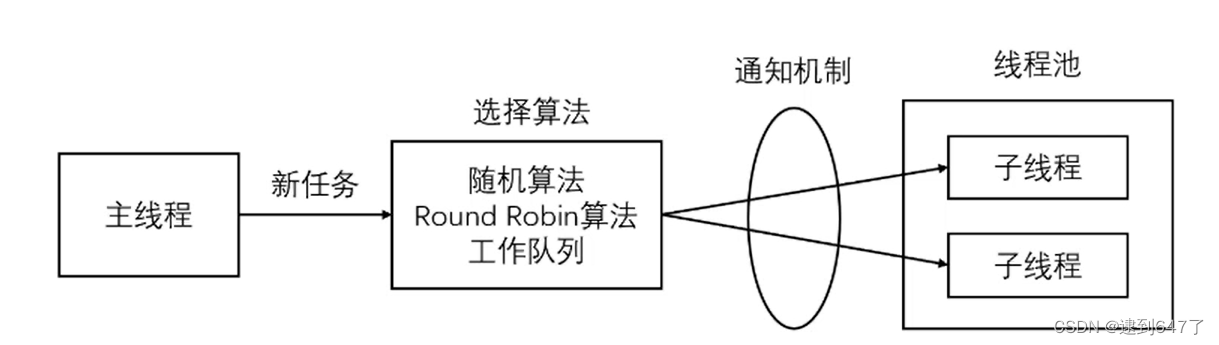
linux并发服务器 —— 项目实战(九)
阻塞/非阻塞、同步/异步 数据就绪 - 根据系统IO操作的就绪状态 阻塞 - 调用IO方法的线程进入阻塞状态(挂起) 非阻塞 - 不会改变线程的状态,通过返回值判断 数据读写 - 根据应用程序和内核的交互方式 同步 - 数据的读写需要应用层去读写 …...
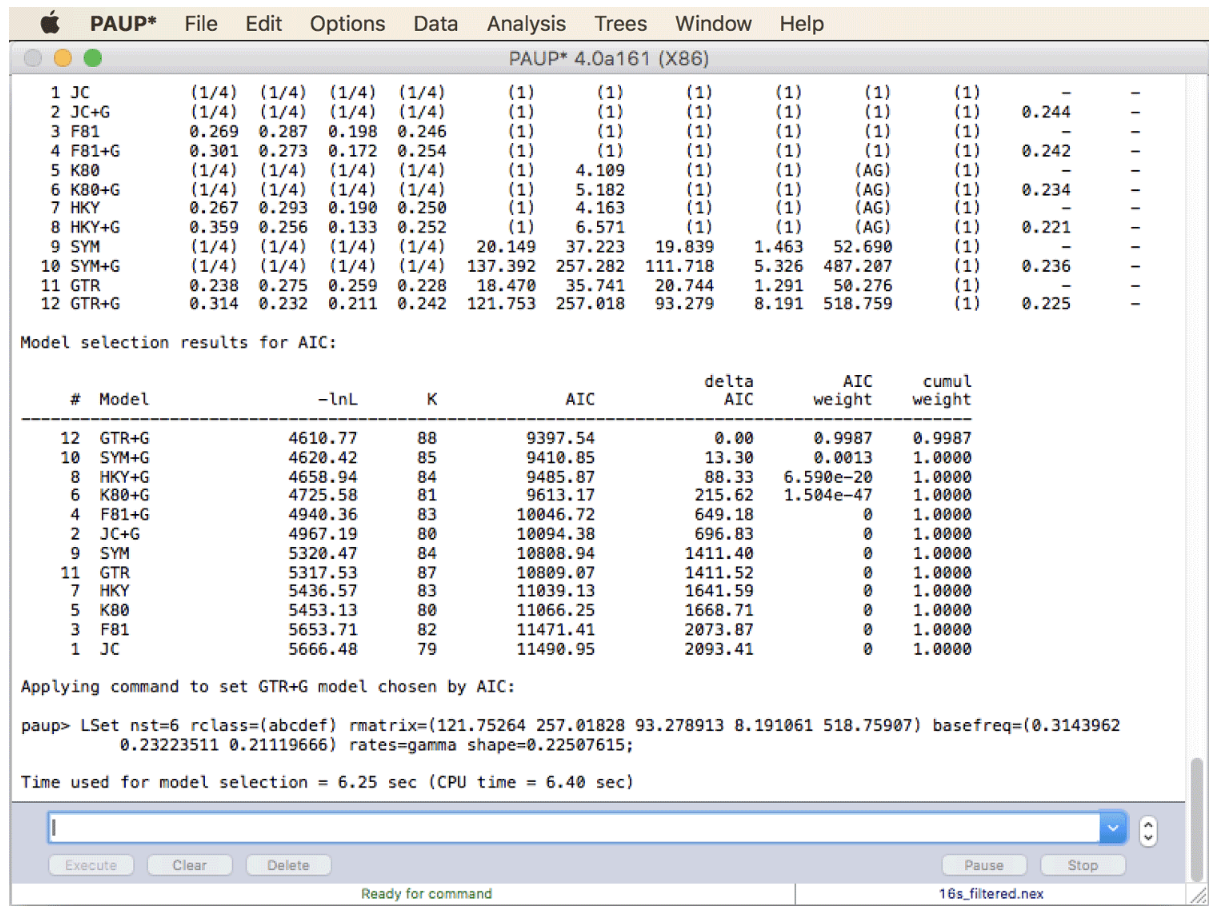
生信教程|替代模型选择
摘要 由于教程时间比较久远,因此不建议实操,仅阅读以了解学习。 在运行基于可能性的系统发育分析之前,用户需要决定模型中应包含哪些自由参数:是否应该为所有替换假设单一速率(如序列进化的 Jukes-Cantor 模型…...
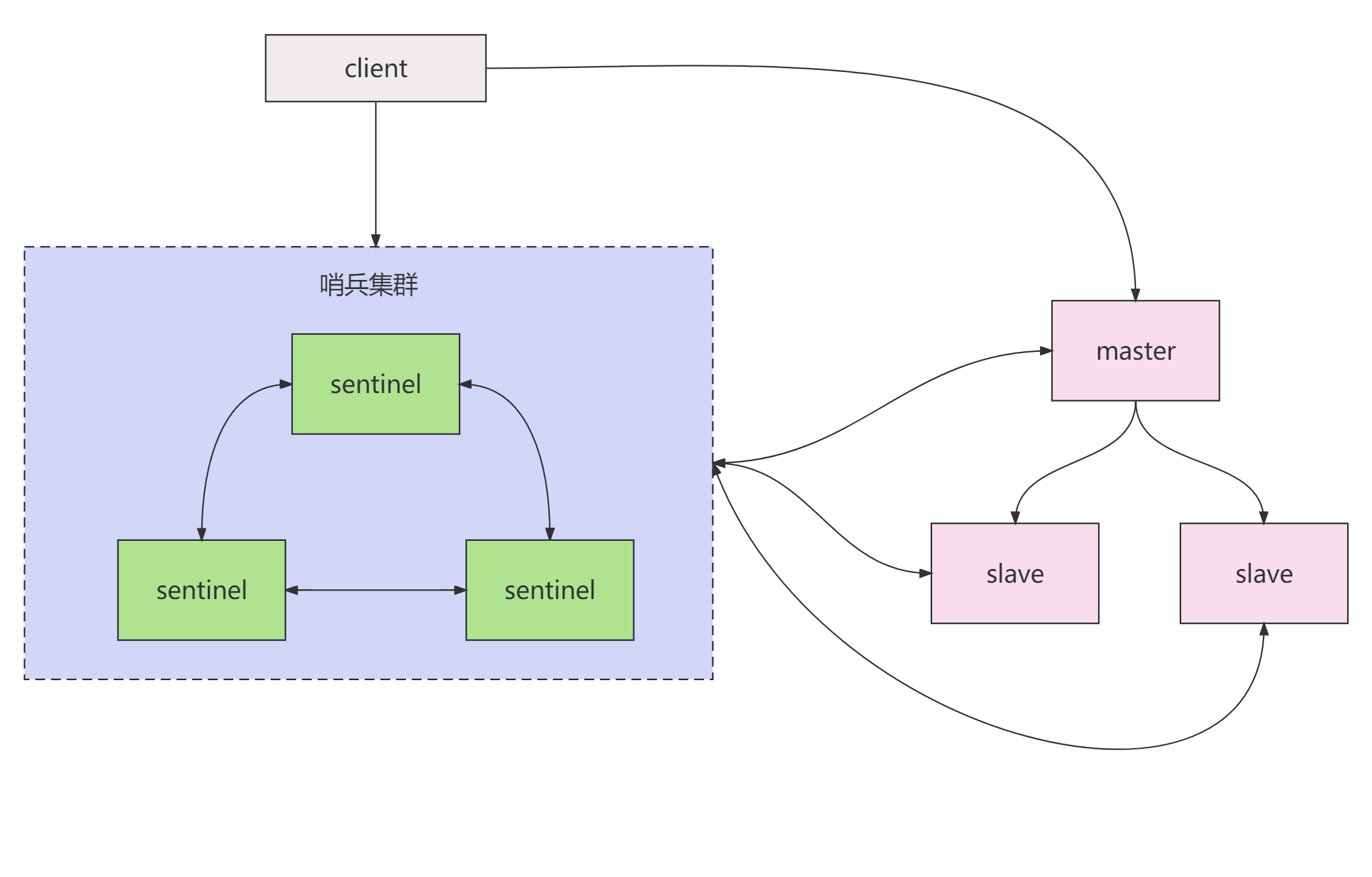
redis持久化、主从和哨兵架构
一、redis持久化 1、RDB快照(snapshot) redis配置RDB存储模式,修改redis.conf文件如下配置: # 在300s内有100个或者以上的key被修改就会把redis中的数据持久化到dump.rdb文件中 # save 300 100# 配置数据存放目录(现…...

Python 连接 Oracle 详解
文章目录 1 首先,安装第三方库 cx_Oracle2 其次,配置命令 1 首先,安装第三方库 cx_Oracle 参考 CSDN 博客:Python 安装第三方库详解(含离线) 2 其次,配置命令 import cx_Oracle# 1.数据库连接…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...

命令行关闭Windows防火墙
命令行关闭Windows防火墙 引言一、防火墙:被低估的"智能安检员"二、优先尝试!90%问题无需关闭防火墙方案1:程序白名单(解决软件误拦截)方案2:开放特定端口(解决网游/开发端口不通)三、命令行极速关闭方案方法一:PowerShell(推荐Win10/11)方法二:CMD命令…...