大数据知识合集之预处理方法
数据预处理方法主要有: 数据清洗、数据集成、数据规约和数据变换。
1、数据清洗
数据清洗(data cleaning) :是通过填补缺失值、光滑噪声数据,平滑或删除离群点,纠正数据的不一致来达到清洗的目的。
- 缺失值处理
实际开发获取信息和数据的过程中,会存在各类的原因导致数据丢失和空缺。针对这些缺失值的处理方法,主要是基于变量的分布特性和变量的重要性采用不同的方法。主要分为以下几种:
删除变量: 若变量的缺失率较高(大于80%),覆盖率较低,且重要性较低,可以直接将变量删除;
统计量填充: 若缺失率较低(小于95%)且重要性较低,则根据数据分布的情况用基本统计量填充(最大值、最小值、均值、中位数、众数)进行填充;
插值法填充: 包括随机插值、多重差补法、热平台插补、拉格朗日插值、牛顿插值等;
模型填充: 使用回归、贝叶斯、随机森林、决策树等模型对缺失数据进行预测;
哑变量(虚拟变量)填充: 若变量是离散型,且不同值较少,可转换成哑变量(通常取值0或1);
总结来看,常用的做法是:先用Python中的pandas.isnull.sum() 检测出变量的缺失比例,考虑删除或者填充,若需要填充的变量是连续型,一般采用均值法和随机差值进行填充,若变量是离散型,通常采用中位数或哑变量进行填充。
- 噪声处理
噪声(noise) 是被测量变量的随机误差或方差,是观测点和真实点之间的误差。
通常的处理办法:
分箱法: 对数据进行分箱操作,等频或等宽分箱,然后用每个箱的平均数,中位数或者边界值(不同数据分布,处理方法不同)代替箱中所有的数,起到平滑数据的作用;
回归法: 建立该变量和预测变量的回归模型,根据回归系数和预测变量,反解出自变量的近似值。
- 离群点处理
异常值(离群点)是数据分布的常态,处于特定分布区域或范围之外的数据通常被定义为异常或噪声。异常分为两种:
l “伪异常”,由于特定的业务运营动作产生,是正常反应业务的状态,而不是数据本身的异常;
l “真异常”,不是由于特定的业务运营动作产生,而是数据本身分布异常,即离群点。
主要有以下检测离群点的方法:
简单统计分析:根据箱线图、各分位点判断是否存在异常,例如Python中pandas的describe函数可以快速发现异常值。
基于绝对离差中位数(MAD):这是一种稳健对抗离群数据的距离值方法,采用计算各观测值与平均值的距离总和的方法。放大了离群值的影响。
基于距离: 通过定义对象之间的临近性度量,根据距离判断异常对象是否远离其他对象,缺点是计算复杂度较高,不适用于大数据集和存在不同密度区域的数据集
基于密度: 离群点的局部密度显著低于大部分近邻点,适用于非均匀的数据集
基于聚类: 利用聚类算法,丢弃远离其他簇的小簇。
- 不一致数据处理
实际数据生产过程中,由于一些人为因素或者其他原因,记录的数据可能存在不一致的情况,需要对这些不一致数据在分析前需要进行清理。例如,数据输入时的错误可通过和原始记录对比进行更正,知识工程工具也可以用来检测违反规则的数据。
数据清洗是一项繁重的任务,需要根据数据的准确性、完整性、一致性、时效性、可信性和解释性来考察数据,从而得到标准的、干净的、连续的数据。
2、数据集成
多个数据源集成时会遇到的问题:实体识别问题、冗余问题、数据值的冲突和处理。
- 实体识别问题
匹配来自多个不同信息源的现实世界实体,数据分析者或计算机如何将两个不同数据库中的不同字段名指向同一实体,通常会通过数据库或数据仓库中的元数据(关于数据的数据)来解决这个问题,避免模式集成时产生的错误。
- 冗余问题
如果一个属性能由另一个或另一组属性“导出”,则此属性可能是冗余的。属性或维度命名的不一致也可能导致数据集中的冗余。 常用的冗余相关分析方法有皮尔逊积距系数、卡方检验、数值属性的协方差等。
- 数据值的冲突和处理
不同数据源,在统一合并时,保持规范化,去重。
3、数据规约
随着数据量的增加,基于传统的数据分析变得非常耗时和复杂,往往使得分析不可行。数据归约技术是用来得到数据集的规约表示,在接近或保持原始数据完整性的同时将数据集规模大大减小。对规约后的数据集分析将更有效,并可产生几乎相同的分析结果。常见方法有:维度规约、维度变换、数值规约等。
- 维度规约
用于数据分析的数据可能包含数以百计的属性,其中大部分属性与挖掘任务不相关,是冗余的。维度归约通过删除不相关的属性,来减少数据量,并保证信息的损失最小。
属性子集选择: 目标是找出最小属性集,使得数据类的概率分布尽可能地接近使用所有属性的原分布。在压缩的属性集上挖掘还有其它的优点,它减少了出现在发现模式上的属性的数目,使得模式更易于理解。
单变量重要性: 分析单变量和目标变量的相关性,删除预测能力较低的变量。这种方法不同于属性子集选择,通常从统计学和信息的角度去分析。
如,通过pearson相关系数和卡方检验,分析目标变量和单变量的相关性。
- 维度变换
维度变换是将现有数据降低到更小的维度,尽量保证数据信息的完整性,提高实践中建模的效率。
若维度变换后的数据只能重新构造原始数据的近似表示,则该维度变换是有损的,若可以构造出原始数据而不丢失任何信息,则是无损的。常见有损维度变换方法:主成分分析、因子分析、奇异值分解、聚类、线性组合。
主成分分析(PCA)和因子分析(FA): PCA通过空间映射的方式,将当前维度映射到更低的维度,使得每个变量在新空间的方差最大。FA则是找到当前特征向量的公因子(维度更小),用公因子的线性组合来描述当前的特征向量。
奇异值分解(SVD): SVD的降维可解释性较低,且计算量比PCA大,一般用在稀疏矩阵上降维,例如图片压缩,推荐系统。
聚类: 将某一类具有相似性的特征聚到单个变量,从而大大降低维度。
线性组合: 将多个变量做线性回归,根据每个变量的表决系数,赋予变量权重,可将该类变量根据权重组合成一个变量。
- 数值规约
数值规约通过选择替代的数据表示形式来减少数据量。即用较小的数据表示替换或估计数据。
数值规约技术可以是有参的,也可以是无参的。如参数模型(只需要存放模型参数,而不是实际数据)或非参数方法,如聚类、抽样和直方图。
4、数据变换
数据变换包括对数据进行规范化,离散化,稀疏化处理,达到适用于挖掘的目的。
- 规范化处理
数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,如[-1,1]区间,或[0,1]区间,便于进行综合分析。
- 离散化处理
数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间。分段的原则有基于等距离、等频率或优化的方法。
- 稀疏化处理
针对离散型且标称变量,无法进行有序的LabelEncoder时,通常考虑将变量做0,1哑变量的稀疏化处理,稀疏化处理既有利于模型快速收敛,又能提升模型的抗噪能力。
文章来源:网络 版权归原作者所有
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理
相关文章:

大数据知识合集之预处理方法
数据预处理方法主要有: 数据清洗、数据集成、数据规约和数据变换。 1、数据清洗 数据清洗(data cleaning) :是通过填补缺失值、光滑噪声数据,平滑或删除离群点,纠正数据的不一致来达到清洗的目的。 缺失值处理 实际开发获取信…...
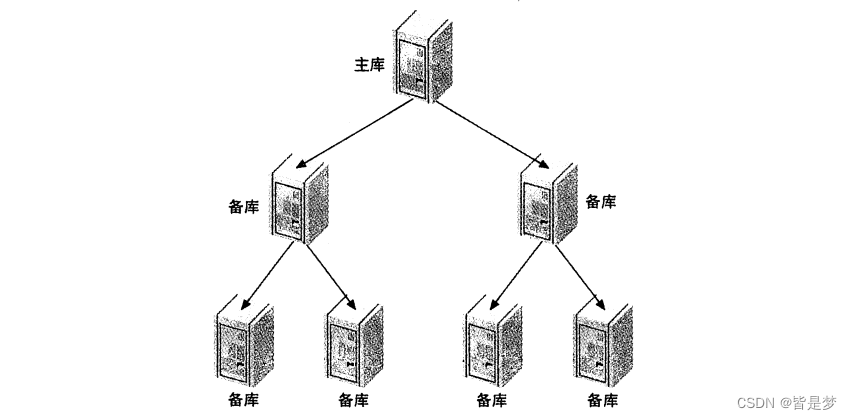
mysql(九)mysql主从复制
目录 前言概述提出问题主从复制的用途工作流程 主从复制的配置创建复制账号配置主库和从库启动主从复制从另一个服务器开始主从复制主从复制时推荐的配置sync_binloginnodb_flush_logs_at_trx_commitinnodb_support_xa1innodb_safe_binlog 主从复制的原理基于语句复制优点&…...
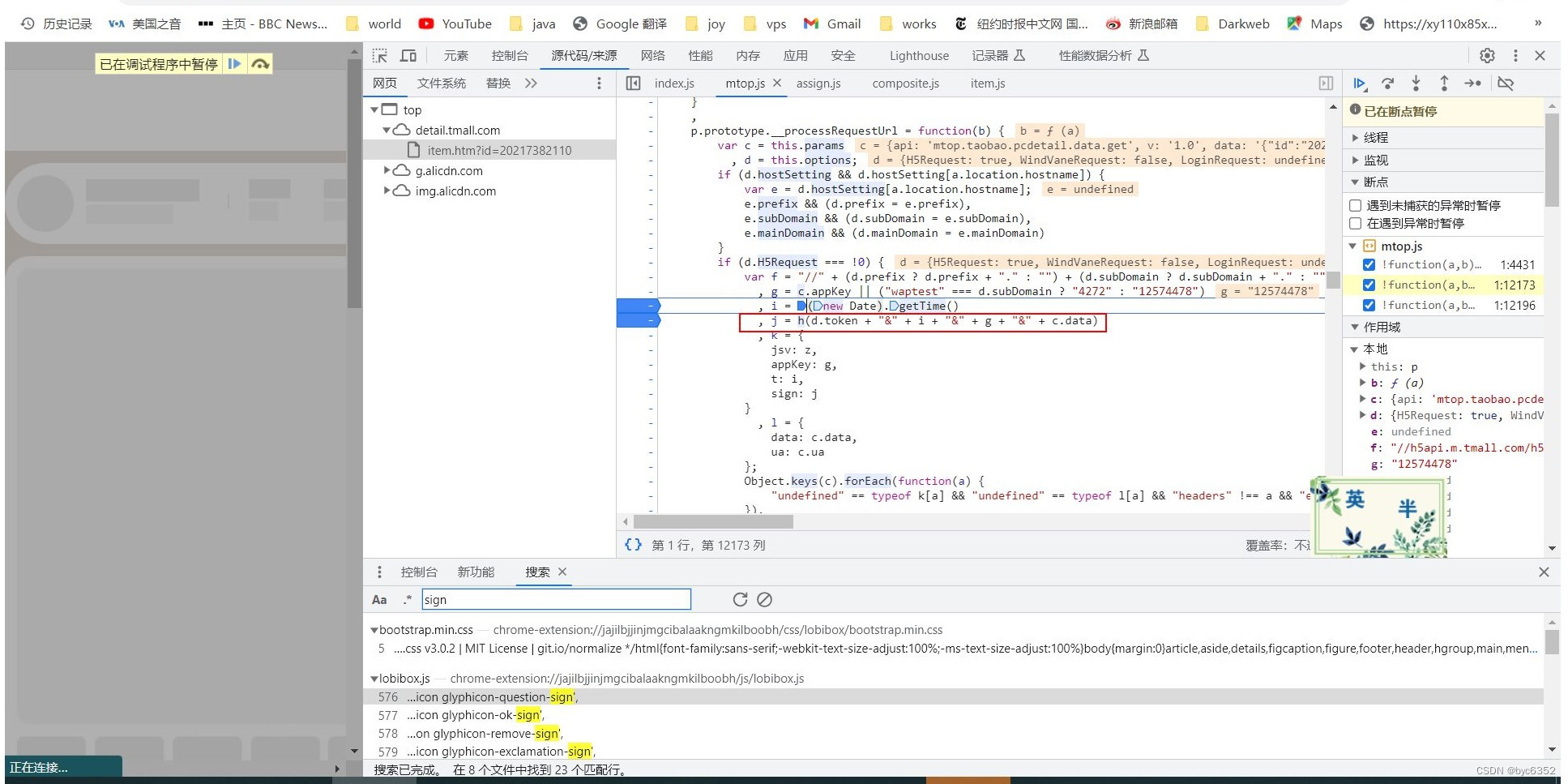
nodejs采集淘宝、天猫网商品详情数据以及解决_m_h5_tk令牌及sign签名验证(2023-09-09)
一、淘宝、天猫sign加密算法 淘宝、天猫对于h5的访问采用了和APP客户端不同的方式,由于在h5的js代码中保存appsercret具有较高的风险,mtop采用了随机分配令牌的方式,为每个访问端分配一个token,保存在用户的cookie中,通…...
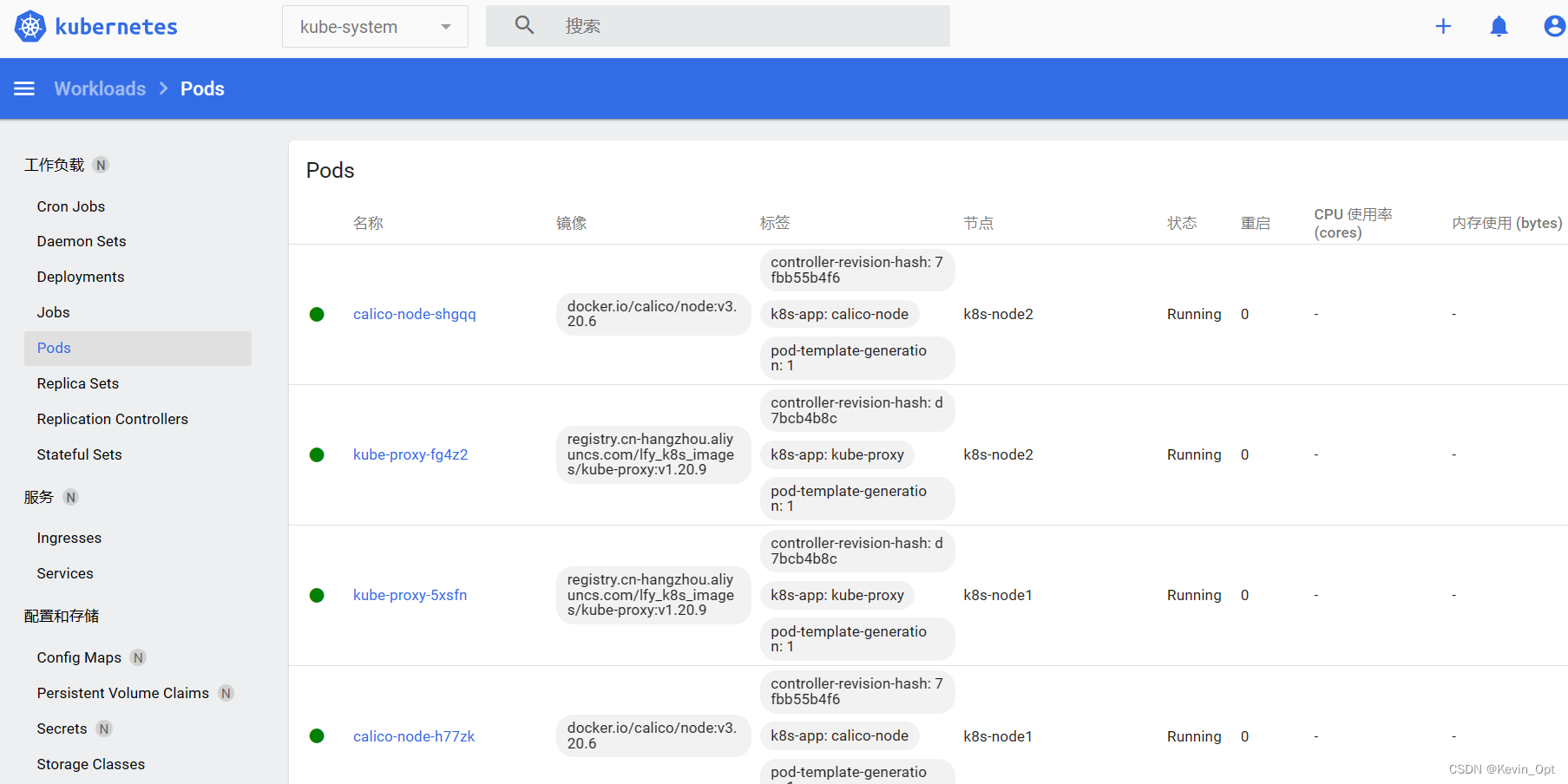
虚拟机上部署K8S集群
虚拟机上部署K8S集群 安装VM Ware安装Docker安装K8S集群安装kubeadm使用kubeadm引导集群 安装VM Ware 参考:http://www.taodudu.cc/news/show-2034573.html?actiononClick 安装Docker 参考:https://www.yuque.com/leifengyang/oncloud/mbvigg#2ASxH …...

设计模式 - 责任链
一、前言 相信大家平时或多或少都间接接触过责任链设计模式,只是可能有些同学自己不知道此处用的是该设计模式,比如说 Java Web 中的 Filter 过滤器,就是非常经典的责任链设计模式的例子。 那么什么是责任链设计模式呢? …...
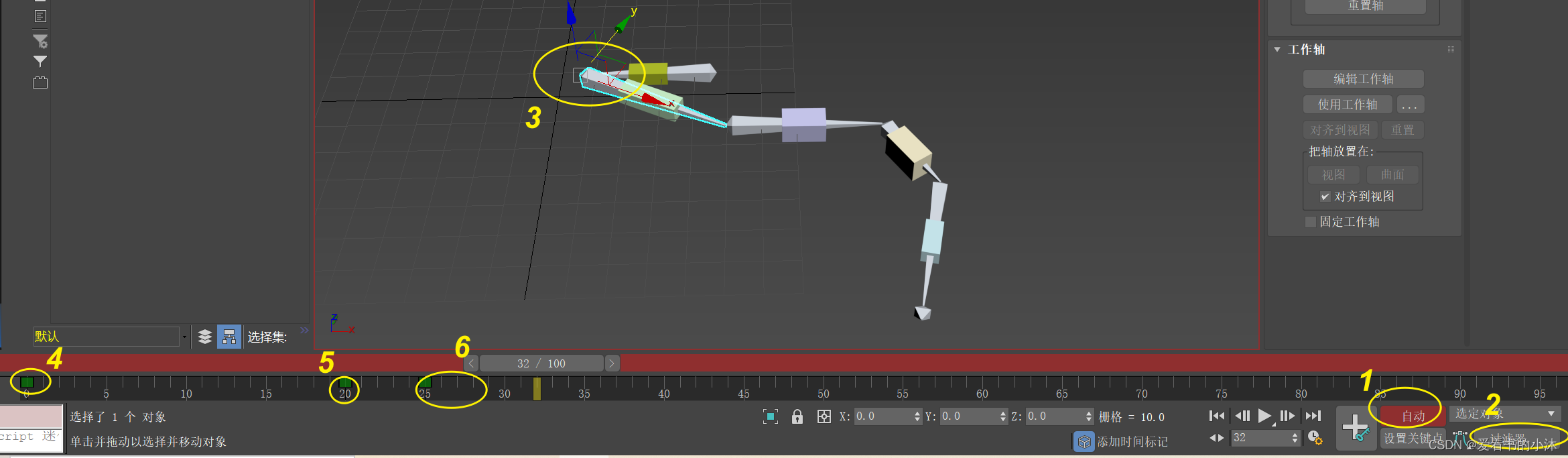
【小沐学Unity3d】3ds Max 骨骼动画制作(CAT、Character Studio、Biped、骨骼对象)
文章目录 1、简介2、 CAT2.1 加载 CATRig 预设库2.2 从头开始创建 CATRig 3、character studio3.1 基本描述3.2 Biped3.3 Physique 4、骨骼系统4.1 创建方法4.2 简单示例 结语 1、简介 官网地址: https://help.autodesk.com/view/3DSMAX/2018/CHS https://help.aut…...
CUDA说明和安装[window]
文章目录 1、查看版本信息查看GPU查看cuda版本其他方法 2区分 了解cudaCUDA ToolkitNVCCcuDNN 3/ 安装过程4/版本的问题CUDA Toolkit和 显卡驱动 的版本对应CUDA / CUDA Toolkit和cuDNN的版本对应 5/关于CUDA和Cudnn**5.1 CUDA的命名规则****5.2 如何查看自己所安装的CUDA的版本…...
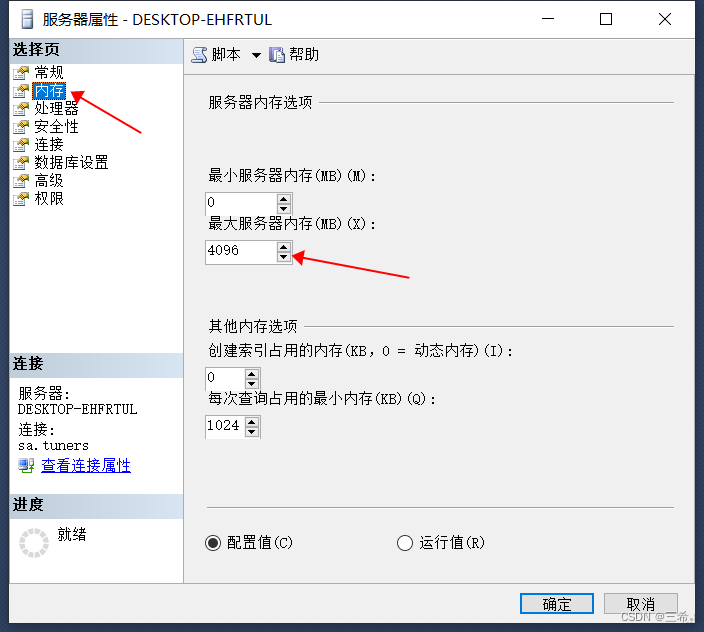
sqlserver2012性能优化配置:设置性能相关的服务器参数
前言 sqlserver2012 长时间运行的话会将服务器的内存占满 解决办法 通过界面设置 下图中设置最大服务器内存 通过执行脚本设置 需要先开发开启高级选项配置才能设置成功 设置完成之后将高级选择配置关闭,还原成跟之前一样 --可以配置高级选项 EXEC sp_conf…...
介绍 dubbo-go 并在Mac上安装,完成一次自己定义的接口RPC调用
目录 RPC 远程调用的说明作用:像调用本地方法一样调用远程方法和直接HTTP调用的区别:调用模型图示: Dubbo 框架说明Dubbo Go 介绍应用 Dubbo Go环境安装(Mac 系统)安装 Go语言环境安装 序列化工具protoc安装 dubbogo-c…...
)
目标检测数据集:摄像头成像吸烟检测数据集(自己标注)
1.专栏介绍 ✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨ 本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的…...
Unity的UI管理器
1、代码 public class UIManager {private static UIManager instance new UIManager();public static UIManager Instance > instance;//存储显示着的面板脚本(不是面板Gameobject),每显示一个面板就存入字典//隐藏的时候获取字典中对…...

Mp4文件提取详细H.264和MP3文件
文章目录 Mp4文件提取为H.264和MP3文件**提取视频为H.264:****提取音频为MP3:** 点赞收藏加关注,追求技术不迷路!!!欢迎评论区互动。 Mp4文件提取为H.264和MP3文件 要将视频分开为H.264(视频编…...
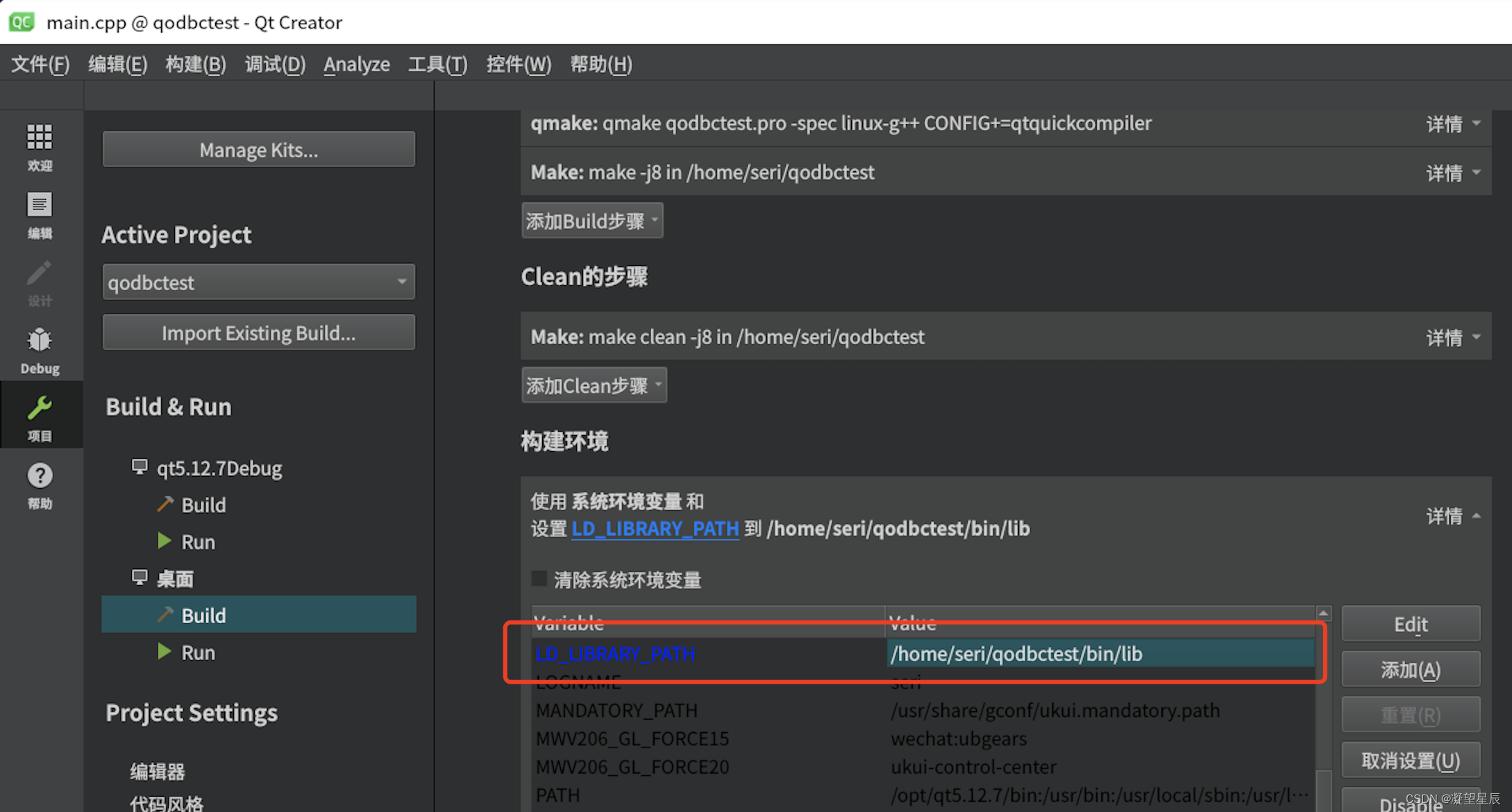
Qt应用程序连接达梦数据库-飞腾PC麒麟V10
目录 前言1 安装ODBC1.1 下载unixODBC源码1.2 编译安装1.4 测试 2 编译QODBC2.1 修改 qsqldriverbase.pri 文件2.2 修改 odbc.pro 文件2.3 编译并安装QODBC 3 Qt应用程序连接达梦数据库测试4 优化ODBC配置,方便程序部署4.1 修改pro文件,增加DESTDIR 变量…...

2023-09-03 LeetCode每日一题(消灭怪物的最大数量)
2023-09-03每日一题 一、题目编号 1921. 消灭怪物的最大数量二、题目链接 点击跳转到题目位置 三、题目描述 你正在玩一款电子游戏,在游戏中你需要保护城市免受怪物侵袭。给你一个 下标从 0 开始 且长度为 n 的整数数组 dist ,其中 dist[i] 是第 i …...

绘图 | MATLAB
目的语法注意事项图片中出现网格grid on放在plot后面在同一图片中绘制多个图例hold on在图形中添加图例legend LineSpec 线性 线型描述线型描述" - "实线" : "点线" - - "虚线" -. "点划线 标记 标记描述标记描述“o”圆圈“squa…...
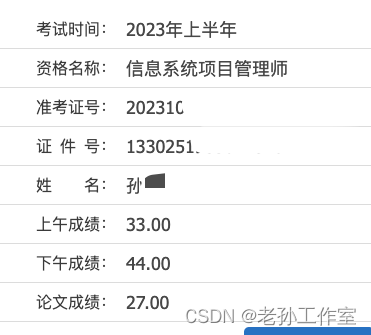
2023年下半年高项考试学习计划
之前总结 2023年上半年的考试,对于我自己,就是虎头蛇尾,也谈不上太过自信,好好学习了一段时间之后,也就是不再发博文,截止到2022年11月的时候,自己就算是放弃了,没有再主动学习。 结…...

SpringBoot中CommandLineRunner的使用
开发中,你有没有遇到这样的场景,项目启动后,立即需要进行一些操作。比如:加载一些初始化数据、执行一段逻辑代码。你可以使用SpringBoot中CommandLineRunner。它可以在项目启动后,执行CommandLineRunner接口实现类的相…...
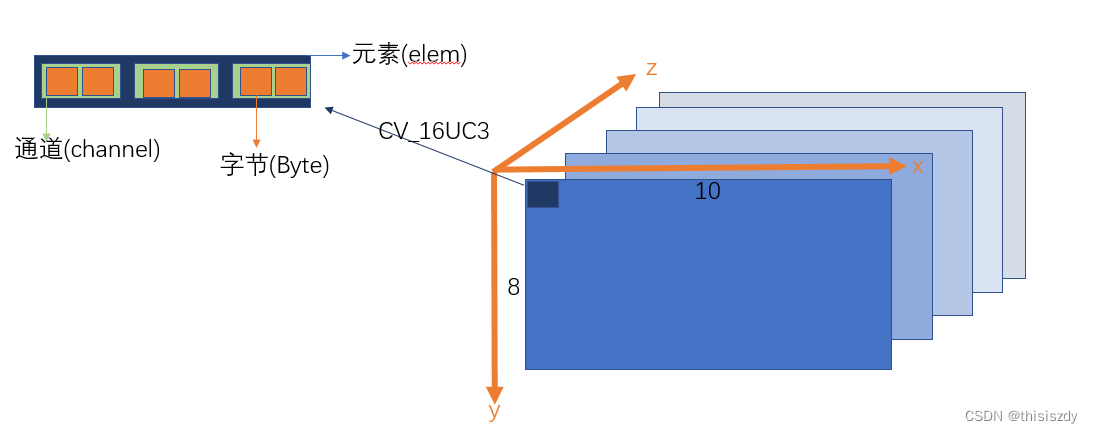
<OpenCV> Mat属性
OpenCV的图像数据类型可参考之前的博客:https://blog.csdn.net/thisiszdy/article/details/120238017 OpenCV-Mat类型的部分属性如下: size:矩阵的大小, s i z e ( c o l s , r o w s ) size(cols,rows) size(cols,rows)…...

LAMP 综合实验
LAMP 综合实验 一.实验目标 实验目标如下: 实现 LAMP 架构 实现数据库主从复制 实现 NFS 服务器存储 wordpress 文件 实现备份服务器实时备份 NFS 服务器文件 实现日志集中存储 实现 loganalyzer 分析展示日志 二.实验准备 2.1 实验环境 实验环境: 虚拟机版本: VM…...

JavaScript发展历程
目录 一、起源(1995-1997) 二、发展(1997-2005) 三、进化——Ajax与Web 2.0(2005-2010年) 四、移动互联网与现代化(2010年至今) 结论 JavaScript是一种广泛使用的网络编程语言&…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...
智警杯备赛--excel模块
数据透视与图表制作 创建步骤 创建 1.在Excel的插入或者数据标签页下找到数据透视表的按钮 2.将数据放进“请选择单元格区域“中,点击确定 这是最终结果,但是由于环境启不了,这里用的是自己的excel,真实的环境中的excel根据实训…...
Axure Rp 11 安装、汉化、授权
Axure Rp 11 安装、汉化、授权 1、前言2、汉化2.1、汉化文件下载2.2、windows汉化流程2.3、 macOs汉化流程 3、授权 1、前言 Axure Rp 11官方下载链接:https://www.axure.com/downloadthanks 2、汉化 2.1、汉化文件下载 链接: https://pan.baidu.com/s/18Clf…...
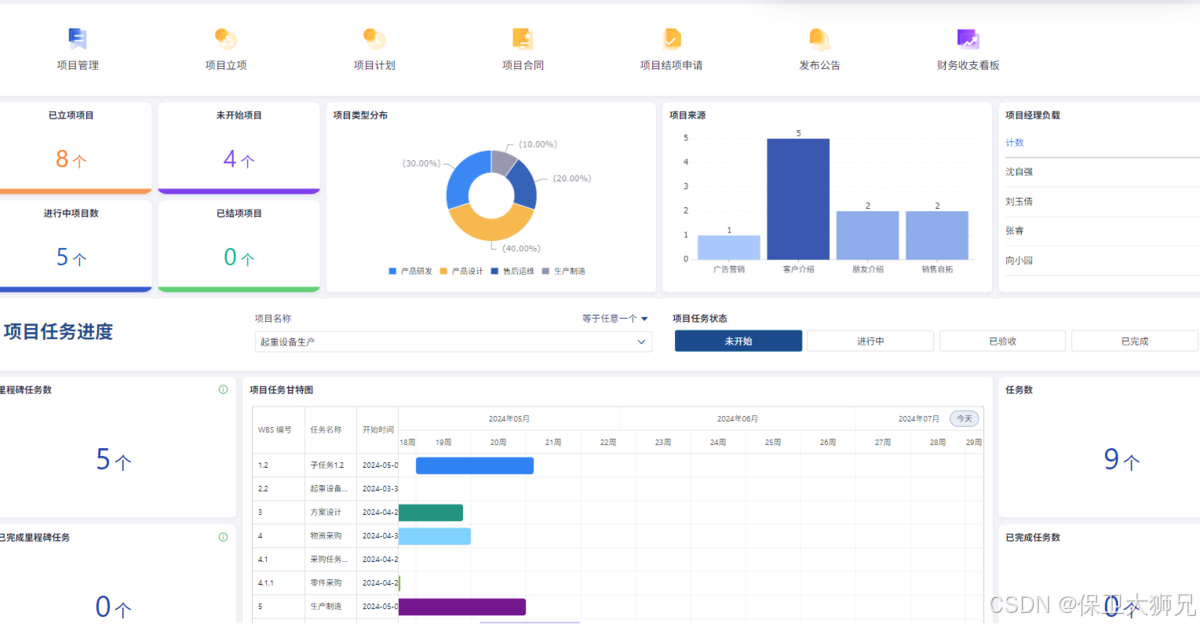
项目进度管理软件是什么?项目进度管理软件有哪些核心功能?
无论是建筑施工、软件开发,还是市场营销活动,项目往往涉及多个团队、大量资源和严格的时间表。如果没有一个系统化的工具来跟踪和管理这些元素,项目很容易陷入混乱,导致进度延误、成本超支,甚至失败。 项目进度管理软…...

codeforces C. Cool Partition
目录 题目简述: 思路: 总代码: https://codeforces.com/contest/2117/problem/C 题目简述: 给定一个整数数组,现要求你对数组进行分割,但需满足条件:前一个子数组中的值必须在后一个子数组中…...