【数学建模】数据预处理

为什么需要数据预处理
数学建模是将实际问题转化为数学模型来解决的过程,而数据预处理是数学建模中非常重要的一步。以下是为什么要进行数据预处理的几个原因:
-
数据质量:原始数据往往存在噪声、异常值、缺失值等问题,这些问题会对建模结果产生负面影响。通过数据预处理,可以去除噪声和异常值,填补缺失值,提高数据质量。
-
数据归一化:不同的特征通常具有不同的度量单位和量纲,如果直接将其用于建模,可能会导致模型偏差或失真。数据预处理可以对数据进行归一化或标准化处理,使得不同的特征在数值上具有可比性,减少因量纲不同而引起的问题。
-
特征选择:在建模过程中,往往需要选择最相关的特征用于训练模型。数据预处理可以通过统计分析、相关性分析等方法,帮助识别出最具有代表性和预测能力的特征,提高模型的准确性和泛化能力。
-
数据平衡:在某些问题中,数据的类别分布可能存在不均衡的情况,即某个类别的样本数量远大于其他类别。这样会导致模型对多数类别更加敏感,而对少数类别的预测性能较差。数据预处理可以通过欠采样、过采样等方法,调整数据的类别分布,提高模型对少数类别的预测准确性。
-
数据去除冗余信息:在真实场景中收集到的数据可能包含大量冗余信息,例如重复记录、不相关的特征等。通过数据预处理,可以去除这些冗余信息,简化数据集,提高建模效率和性能。
-
缺失值处理:原始数据中常常存在缺失值,即某些样本的特征数值缺失。如果直接使用带有缺失值的数据进行建模,可能会导致模型训练失败或预测结果不准确。数据预处理可以对缺失值进行处理,例如删除含有缺失值的样本、插补缺失值或使用合适的替代值。
-
数据转换与降维:有时候原始数据的特征维度过高,可能会导致计算复杂度增加、模型泛化能力下降等问题。数据预处理可以通过特征转换(如多项式转换、对数转换)或降维技术(如主成分分析),将高维数据转化为更易处理和理解的低维表示。
-
异常值处理:异常值是指在数据集中与其他观测值显著不同的数据点。这些异常值可能会严重影响模型的训练和预测性能。通过数据预处理,可以检测和处理异常值,提高模型的鲁棒性和准确性。
常见的数学建模数据预处理方法
数学建模中的数据预处理是一个重要的步骤,它有助于清洗和准备原始数据,以便在建模过程中更好地使用。下面是一些常见的数学建模数据预处理方法:
-
数据清洗:检查和处理原始数据中的异常值、缺失值、重复值等。可以使用统计分析、插值、填充等方法来修复缺失值,并根据特定问题和数据集的要求来处理异常值和重复值。
-
数据变换:根据问题的需要对数据进行变换。例如,可以进行对数变换、标准化、归一化或离散化等操作,以改善数据的分布特性或将其转化为更适合建模的形式。
-
特征选择:从原始数据中选择出最相关和最有用的特征变量,以降低维度和减少冗余信息。可以使用统计分析、特征相关性、模型评估等方法来进行特征选择。
-
特征工程:基于原始数据构建新的特征,以提取更有效的信息。这包括生成交互项、多项式特征、指示变量等,以及利用领域知识和专业经验来创建有意义的特征。
-
数据平衡:对于分类问题,如果训练数据的类别分布不平衡,可以采取欠采样、过采样或合成新样本等方法来平衡数据集,以避免对少数类别的训练偏差。
-
数据划分:根据建模需求,将数据集划分为训练集、验证集和测试集,用于模型训练、调优和评估。可以使用随机抽样、时间序列划分或其他合适的方法进行数据集划分。
-
数据压缩和降维:如果数据集较大,可以使用压缩方法(如主成分分析)或降维技术(如特征选择、矩阵分解)来减少数据的维度和存储空间,同时保留尽可能多的有用信息。
缺失值处理

在数据预处理中,处理缺失值是一个重要的步骤,因为缺失值会影响到后续的建模和分析过程。以下是几种常见的缺失值处理方法:
-
删除含有缺失值的样本:最简单的方法是直接删除含有缺失值的样本。这种方法适用于缺失值比例较小的情况,可以保留数据的完整性,但可能会导致数据集减少。
-
插补缺失值:如果删除样本会导致信息损失过大,可以考虑插补缺失值。常见的插补方法有:
- 均值插补:用该特征的均值来填充缺失值。适用于连续型数值特征。
- 中位数插补:用该特征的中位数来填充缺失值。适用于存在极值或异常值的数值特征。
- 众数插补:用该特征的众数来填充缺失值。适用于离散型特征。
- 回归插补:利用其他特征的信息,通过回归模型对缺失值进行预测填充。适用于特征之间存在相关性的情况。
-
使用特殊值填充:对于某些特征,可以使用特殊值(如"未知"、“无效”)来填充缺失值,表示该值是未知的或无效的。这样的处理方法可以保留缺失值的存在,并将其作为一个独立的类别。
-
使用算法进行插补:除了简单的统计插补方法外,还可以利用机器学习算法进行缺失值的预测和插补。常用的算法包括 K-最近邻算法、决策树、随机森林等。这些算法可以基于已有的特征值来推测缺失值,并进行插补。
选择合适的缺失值处理方法需要考虑数据集的大小、缺失值的分布情况以及建模目标等因素。在实际应用中,可以根据具体情况采用单一的插补方法或结合多种方法进行处理,以尽可能减少对数据集的影响,并保持结果的准确性和可靠性。
当处理缺失值时,还有一些其他的方法可以考虑:
-
插值法:插值是根据已知数据点之间的关系来估计缺失值。常见的插值方法包括线性插值、多项式插值、样条插值等。这些方法利用已有数据的趋势和模式来预测缺失值,适用于连续型数据。
-
基于模型的插补:这种方法使用机器学习模型或统计模型来预测缺失值。例如,可以使用线性回归、随机森林、支持向量机等算法来建立模型,并利用模型对缺失值进行预测。这种方法可以更好地利用特征之间的关联性,但需要足够的样本和特征信息。
-
多重插补:多重插补是一种迭代的过程,通过多次模型建立和预测来生成多个可能的填充值,从中选择最符合实际情况的作为最终的填充值。这种方法可以捕捉到缺失值的不确定性,并提供多个候选结果供分析师选择。
-
基于相似性的填充:对于具有相似特征模式的样本,可以采用基于相似性的方法来填充缺失值。例如,可以计算样本之间的相似度,然后使用相似样本的特征值来填充缺失值。这种方法依赖于样本之间的相似性度量,需要考虑特征的重要性和权重。
在选择缺失值处理方法时,需要根据数据的性质、缺失值的类型和分布情况以及建模的要求进行综合考量。同时,为了保证结果的可靠性,应当在处理缺失值前进行数据探索和分析,以了解缺失值的原因和可能的影响。最后,不同的处理方法可能会对建模结果产生不同的影响,因此需要在模型的评估和验证阶段进行比较和选择。
插值方法在处理缺失值时具有一些优点和缺点
优点:
-
保留样本特征:插值方法可以保留样本的其他特征信息,并根据已有的数据点之间的关系来估计缺失值。这样可以最大程度地利用已有数据的信息,避免了删除样本或特征的情况。
-
简单易行:插值方法相对而言比较简单易行,不需要过多的计算和复杂的模型建立过程。一些基本的插值方法如线性插值、多项式插值等都有简单明确的数学原理和实现方式。
-
适用性广泛:插值方法可以适用于各种类型的数据,包括连续型数据和离散型数据。不同的插值方法可以根据数据类型进行选择,例如线性插值适用于连续型数据,多项式插值适用于非线性数据等。
缺点:
-
忽略潜在模式:插值方法只能根据已有数据的趋势和模式进行估计,无法考虑潜在的数据模式和特征之间的关联性。如果缺失值与其他特征存在复杂的关系,插值方法可能无法准确地预测缺失值。
-
引入估计误差:插值方法基于已有数据进行预测,而预测的精度受到已有数据的分布和噪声的影响。这意味着插值方法引入了估计误差,预测的结果可能并不完全准确。
-
可能导致过拟合:某些插值方法,尤其是复杂的插值方法如样条插值、高阶多项式插值等,可能会对数据进行过拟合。过拟合会导致插值结果在训练数据上表现良好,但在新数据上的泛化能力较差。
-
对局部数据敏感:插值方法通常是根据临近的已有数据点进行预测,因此对于缺失值附近的数据点更为敏感。如果缺失值周围的数据点稀疏或存在噪声,插值方法的准确性可能会下降。
总体而言,插值方法是一种简单有效的缺失值处理方法,可以在保留数据完整性的同时估计缺失值。然而,需要注意插值方法的局限性,针对具体情况选择合适的插值方法,并在之后的分析中评估缺失值处理的效果。
拉格朗日插值

拉格朗日插值是一种常用的插值方法,可以利用已知数据点之间的关系来估计缺失值。它基于拉格朗日多项式的思想,通过构造一个多项式函数,使得该多项式在已知数据点上与目标函数完全一致。
具体步骤如下:
-
假设已知数据点为 (x₁, y₁), (x₂, y₂), …, (xₙ, yₙ),其中 x₁, x₂, …, xₙ 是已知的自变量值,y₁, y₂, …, yₙ 是对应的因变量值。
-
根据已知数据点构造拉格朗日基函数 Lᵢ(x):
Lᵢ(x) = ∏[(x - xⱼ) / (xᵢ - xⱼ)], j ≠ i其中 i = 1, 2, …, n。这些基函数具有以下特性:
a) 当 x = xᵢ 时,Lᵢ(x) = 1,而在其他已知数据点(xⱼ, j ≠ i)时,Lᵢ(x) = 0。
b) 当 x ≠ xᵢ 时,0 ≤ Lᵢ(x) ≤ 1,且恒有 ∑Lᵢ(x) = 1,即所有基函数的和等于 1。 -
构造拉格朗日插值多项式 P(x):
P(x) = ∑[yᵢLᵢ(x)]其中 i = 1, 2, …, n。该多项式通过已知数据点,可以完全拟合原始函数,并且可以用于估计缺失值。
-
根据插值多项式 P(x),将缺失值的自变量代入,计算对应的因变量值,即得到缺失值的估计结果。
需要注意的是,拉格朗日插值方法的有效性和精度受到以下因素影响:
- 已知数据点的分布情况:数据点之间的间隔大小和分布密度会影响插值结果的准确性。
- 多项式次数的选择:使用更高次数的多项式可以更好地拟合已知数据,但可能导致过拟合和振荡问题。
- 数据噪声的存在:噪声数据对插值结果有较大影响,可能导致插值结果不准确。
当使用拉格朗日插值方法时,需要注意以下几点:
-
数据点选择:选择合适的数据点对于插值结果的准确性至关重要。数据点应该尽可能覆盖整个数据范围,并且在目标函数附近密集分布。缺乏数据点或者数据点分布不均匀可能导致插值结果不准确。
-
多项式次数选择:选择合适的多项式次数可以平衡拟合能力和过拟合的风险。如果选择过低的次数,可能无法捕捉到数据中的复杂模式;而选择过高的次数可能导致插值多项式在数据点之间出现振荡现象,称为龙格现象。一般来说,多项式次数不宜超过数据点个数减一。
-
数据噪声处理:如果数据存在噪声,插值结果可能会受到噪声的影响而产生不准确的估计。在进行插值之前,可以考虑对数据进行平滑处理或噪声去除,以提高插值结果的准确性。
-
结果评估:对插值结果进行评估是很重要的,可以通过与其他已知数据点的比较或与实际情况的对比来验证插值的准确性。如果插值结果与其他数据点或实际情况不一致,则需要重新考虑数据点的选择或使用其他插值方法。
此外,还有其他一些改进和替代的插值方法可供选择,例如样条插值、分段线性插值、Kriging 插值等。根据具体的应用场景和数据特征,可以选择最适合的插值方法来处理缺失值。
牛顿插值
牛顿插值是一种常用的插值方法,它利用数据点的差商来构造插值多项式。以下是使用牛顿插值的一般步骤:
-
数据点的选择:选择合适的数据点对于插值结果的准确性至关重要。数据点应该尽可能覆盖整个数据范围,并且在目标函数附近密集分布。
-
差商的计算:基于选定的数据点,计算差商表。差商是通过递归计算相邻数据点间的斜率得到的。具体地,首先计算一阶差商f[xi, xi+1],然后根据一阶差商计算二阶差商f[xi, xi+1, xi+2],以此类推,直到计算出全部的差商。
-
插值多项式的构造:通过使用差商和对应的节点,可以构造牛顿插值多项式。多项式的形式为:
P(x) = f[x0] + (x - x0)f[x0, x1] + (x - x0)(x - x1)f[x0, x1, x2] + … + (x - x0)(x - x1)…(x - xn-1)f[x0, x1, …, xn]其中 f[xi] 表示第 i 个数据点的函数值,f[xi, …, xj] 表示第 i 到第 j 个数据点间的差商。
-
使用插值多项式进行预测:将待预测的自变量 x 带入插值多项式 P(x) 中,即可得到相应的因变量的预测值。
需要注意的是,牛顿插值对数据点的选取和差商的计算较为敏感,如果数据点选择不合理或差商计算错误,可能会导致插值多项式的精度下降。此外,牛顿插值方法也可以扩展到多维情况下的插值问题,但需要构造对应的多维差商表和多维插值多项式。
当进行牛顿插值时,还有一些进阶技巧和注意事项可以提高插值结果的准确性,包括:
-
数据重心平移:将数据点的横坐标进行平移,使得插值多项式的中心接近待插值的位置。这样可以减小插值误差并提高插值多项式在目标点附近的准确性。
-
非等距节点插值:牛顿插值可以处理等距节点的情况,但对于非等距节点的数据,可以采用更高阶的插值多项式来提高插值效果。通过引入更多的数据点和更高阶的差商,可以增加插值多项式的灵活性。
-
递推计算:对于大规模的插值问题,可以考虑使用递推的方式计算差商表。递推计算可以减少计算量,并且在插值过程中可以方便地添加或删除数据点。
-
限制插值误差:在实际应用中,为了控制插值误差,可以设置一个误差限制条件。当插值误差小于某个特定阈值时,可以停止插值计算,以节省计算资源。
-
数值稳定性考虑:在计算差商时,由于数据点之间的浮点数计算误差,可能会引入数值不稳定性。为了避免这种情况,可以使用秦九韶算法来计算差商,该算法有效地减小了误差累积。
分段插值

分段插值是一种常用的插值方法,它将整个插值区间分割为多个小区间,并在每个小区间内使用不同的插值函数进行插值。这样可以根据数据的特点,在不同区间内使用不同的插值函数,从而提高整体插值结果的准确性。以下是分段插值的一般步骤:
-
数据点的选择:选择合适的数据点对于分段插值结果的准确性很重要。数据点应该尽可能覆盖整个数据范围,并且在目标函数附近密集分布。
-
区间划分:将整个插值区间划分为多个小区间,每个小区间由相邻的数据点确定。区间的划分可以根据数据的特点来确定,例如可以按照等距离划分或者依据数据密度来划分。
-
插值函数的选择:针对每个小区间,选择合适的插值函数进行插值。常用的插值函数包括线性插值、拉格朗日插值、牛顿插值等。根据不同的函数选择,可以得到不同的精度和平滑性。
-
在每个小区间进行插值:在每个小区间内利用选定的插值函数进行插值计算。具体的插值方法和计算步骤将根据选择的插值函数而有所不同。
-
连接各个小区间:将每个小区间内得到的插值结果进行连接,形成整体的分段插值函数。可以通过确保不同区间之间的连续性来获得平滑的插值曲线。
需要注意的是,分段插值可以在局部区间内提供更高的插值精度,尤其适用于数据分布不均匀或者函数在不同区间内变化较大的情况。然而,分段插值可能会引入插值节点处的跳跃或不连续现象,因此在应用阶段需要根据具体需求进行评估和调整,以获得最佳的插值效果。
当进行分段插值时,还有一些进阶技巧和注意事项可以提高插值结果的准确性,包括:
-
区间选择:对于分段插值,区间的选择对最终结果影响很大。可以根据数据的变化趋势选择不同长度的区间,以便更好地捕捉函数的变化特征。在数据变化较快的区域可以使用更短的区间,而在变化较慢的区域可以使用更长的区间。
-
插值方法选择:不同的插值方法在分段插值中的表现也会有所不同。除了线性插值、拉格朗日插值和牛顿插值,还有其他的插值方法如分段线性插值、样条插值等。根据数据的特点选择合适的插值方法,以获得更精确的插值结果。
-
节点筛选:在分段插值中,节点的选择非常重要。过多的节点可能导致插值函数过度拟合,而过少的节点则可能导致插值函数无法准确描述数据。可以通过节点筛选方法,如剔除冗余节点或添加缺失节点,来优化插值结果。
-
插值误差控制:为了控制插值误差,可以在分段插值中设置误差限制条件。当插值误差小于某个特定阈值时,可以停止插值计算或者进行其他优化处理,可以提高插值结果的准确性。
-
平滑处理:在分段插值中,由于每个区间内使用不同的插值函数,可能会导致插值函数之间的连接处存在不连续性。为了获得平滑的插值曲线,可以使用平滑技术,如样条插值或者分段多项式拟合,并确保在连接处有连续的梯度。
以上是一些常见的分段插值的进阶技巧和注意事项。选择合适的区间、插值方法和节点,控制插值误差,并进行平滑处理,可以提高分段插值的准确性和稳定性。根据具体的数据和问题需求,可以灵活应用这些技巧,以获得更好的分段插值结果。
异常值检测和处理
异常值(Outliers)是指在数据集中与其他观测值明显不同的数值。异常值可能是由于测量误差、数据录入错误、自然变异或者其他未知原因引起的。检测和处理异常值的目的是确保数据分析和建模的准确性和可靠性,避免异常值对结果产生过大的影响。
以下是异常值检测和处理的一般步骤:
-
数据可视化:首先,对数据进行可视化分析,例如绘制直方图、散点图或箱线图等。这可以帮助我们观察数据的分布情况和异常值的存在。
-
统计方法:使用统计方法来检测异常值。常见的统计方法包括基于均值和标准差的Z分数方法、基于四分位数的箱线图方法等。通过计算观测值与数据集的平均值或中位数之间的偏差,可以确定是否存在异常值。
-
领域知识:结合领域知识来判断是否存在异常值。根据对所研究问题的了解,判断某些数值是否合理,并结合实际背景对其进行评估。
-
异常值处理:一旦发现异常值,可以选择采取以下策略之一进行处理:
- 删除异常值:若异常值显然是由于数据录入错误等人为因素引起,可以安全地删除这些异常值。
- 替换异常值:使用合理的替代值来代替异常值。可以选择使用数据集的平均值、中位数或者通过插值等方法进行替换。
- 分析异常值:对于潜在的异常值,可以单独分析,并考虑它们是否包含有价值的信息。有时候,异常值可能对我们的分析提供重要见解,因此不一定都需要处理。
需要注意的是,异常值处理要结合具体问题和领域知识进行判断和决策。处理异常值时应保持谨慎,并在处理前进行充分的分析和评估。同时,处理异常值也要注意记录处理过程和原因,以便后
续分析和解释。
-
使用离群点检测算法:离群点检测算法可以帮助自动识别异常值。常见的离群点检测算法包括基于统计方法的Z-score、箱线图方法以及基于距离的DBSCAN和LOF算法等。这些算法能够根据数据的密度、距离或者分布特征来识别异常值。
-
采用异常值标记:将异常值标记为特殊值或者缺失值可以使其在后续的数据处理和分析中得到特殊处理。这样可以避免直接删除数据,同时保留异常值的存在。
-
分组处理异常值:在某些情况下,可以根据特定的属性或条件将数据集分成多个子集,并对每个子集独立处理异常值。这样可以更准确地处理不同子集中的异常值,而不会对整个数据集产生过大的影响。
-
验证处理结果:在处理异常值后,应该验证处理的效果。可以重新可视化数据并进行描述性统计,以确保异常值没有引入新的偏差或问题。如果处理结果不符合预期,可能需要重新评估方法或尝试其他异常值处理策略。
-
注意上下文和领域知识:在处理异常值时,始终要考虑数据所属的上下文和相关领域知识。某些数值在特定领域中可能是合理的,因此需要谨慎处理这些值,避免错误地将其视为异常值。
-
文档记录:在处理异常值的过程中,及时记录处理的方法、原因和结果。这对于其他人阅读和理解数据集以及后续分析工作都非常重要。
以上是处理异常值的一些常用方法和技巧。在实际应用中,需要根据具体情况选择合适的方法,并结合领域知识进行决策。处理异常值的目标是保持数据的准确性和可靠性,以提高后续分析和建模的质量和稳定性。

去除重复数据

要去除重复数据,可以遵循以下步骤:
-
导入数据:将包含重复数据的数据集导入到适当的数据分析工具中,如Python的pandas库或SQL数据库等。
-
检测重复数据:使用工具提供的功能或方法来检测数据集中的重复数据。在pandas中,可以使用
duplicated()方法来识别重复的行,返回一个布尔值的Series。 -
去除重复数据:根据检测结果,可以使用工具提供的相应方法将重复数据从数据集中删除。在pandas中,可以使用
drop_duplicates()方法来删除重复的行。 -
确认处理结果:删除重复数据后,可以再次检查数据集以确保重复数据已经被成功去除。可以使用
duplicated()方法验证是否还存在重复数据。
以下是一些示例代码,在Python的pandas库中演示如何去除重复数据:
import pandas as pd# 导入数据
df = pd.read_csv("data.csv")# 检测重复数据
duplicate_rows = df.duplicated()# 去除重复数据
df = df.drop_duplicates()# 确认处理结果
updated_duplicate_rows = df.duplicated()
这些步骤将帮助你验证和去除数据集中的重复数据。但请注意,去除重复数据可能会导致数据集内容的丢失,请在操作前提前备份数据,以便需要时可以恢复原始数据。
如果你想进一步定制化去除重复数据的过程,可以考虑以下方法和注意事项:
-
指定列:默认情况下,重复数据是根据所有列的数值进行比较和判断的。如果你只希望根据特定列或一组列来判断重复数据,可以在去除重复数据时指定这些列。在pandas的
drop_duplicates()方法中,可以使用subset参数指定要考虑的列。 -
保留第一个/最后一个:默认情况下,
drop_duplicates()方法会保留第一个出现的重复数据行,而删除后续出现的重复行。如果你希望保留最后一个出现的重复行,可以设置keep参数为"last"。这在某些场景下可能更合适,例如按时间顺序排序的数据集。 -
自定义条件:有时候,你可能需要根据自定义条件来判断重复数据。例如,你可能希望仅将相邻行之间满足特定条件的重复数据视为重复。在这种情况下,你可以使用
subset参数指定要考虑的列,并结合自定义的条件来判断是否为重复数据。 -
处理缺失值:在去除重复数据之前,你可能需要处理数据集中的缺失值。缺失值可能会被视为不同的数值,从而导致误判重复数据。你可以选择填充缺失值或删除包含缺失值的行,然后再进行去重操作。
-
注意性能:对于大型数据集,去除重复数据可能需要较长的计算时间和更多的内存。在处理大型数据时,可以考虑使用更高效的算法或分块处理技术,以提高处理速度和节省资源。
记住,去除重复数据是为了确保数据的准确性和一致性。根据数据集的特点和需求,灵活运用这些方法和注意事项,可以更好地完成去重操作。
以下是一个示例代码,演示如何使用pandas库去除重复数据:
import pandas as pd# 导入数据
df = pd.read_csv("data.csv")# 检测并删除重复数据
df.drop_duplicates(inplace=True)# 确认处理结果
print(df)
在这个示例中,我们假设数据保存在名为"data.csv"的CSV文件中。首先,我们使用pd.read_csv()方法将数据导入到DataFrame对象df中。然后,通过调用drop_duplicates()方法,并将参数inplace设置为True,来直接在原始DataFrame上修改并去除重复数据。最后,我们打印处理后的DataFrame以确认去重操作的结果。
你可以根据实际情况修改代码,例如指定特定列进行去重、设置keep参数来保留第一个或最后一个重复行等。
数据变换

数据变换是指对原始数据进行一系列操作以创建新的特征或转换数据的形式。以下是一些常见的数据变换技术:
-
标准化(Normalization):将数值特征缩放到相似的范围,通常采用Z-score标准化或最小-最大缩放。标准化可以确保不同特征具有可比性,并且能够更好地适应某些机器学习算法。
-
分类编码(Categorical Encoding):将分类变量转换为数值表示形式,以便在机器学习算法中使用。常见的分类编码方法包括独热编码(One-Hot Encoding)、标签编码(Label Encoding)等。
-
特征合成(Feature Engineering):通过从现有特征中提取、组合、转换信息来创建新的特征。例如,可以通过从日期中提取年份、月份和季节来创建新的时间特征,或者通过计算两个数值特征之间的差异来创建一个新的特征。
-
对数转换(Log Transformation):将数据的对数应用于偏态分布的数值特征,以使其更加接近正态分布。对数转换可用于降低数据的右偏性或左偏性。
-
平滑处理(Smoothing):平滑处理可以帮助去除数据中的噪声和离群值,常见的平滑方法包括移动平均、加权平均等。
-
归一化(Normalization):将数值特征缩放到固定的范围,例如[0, 1]或[-1, 1]。归一化可以确保不同尺度的特征对模型的影响相对均衡。
以上只是一些常见的数据变换技术,根据具体问题和数据的特点,你可以选择适合的数据变换方法。在进行数据变换时,记得要在处理前分析数据的分布、异常值以及需要解决的问题,并进行适当的预处理和清洗。
在数学建模中,数据变换是非常重要的一步,它可以使原始数据更适合用于模型分析和建立。以下是几个可能用到的数据变换举例:
-
对数变换:例如,在一些情况下,数据的数值大小差异很大,这会影响模型的预测效果。此时,可以将数据进行对数变换,以平滑数值之间的差异。常见例子包括GDP数据,因为经济增长率通常采用增长率取对数来比较。
-
归一化/标准化:在一些情况下,不同特征的量纲或单位不同,这会影响模型的预测结果。因此,可以使用归一化或标准化技术对数据进行处理,使得所有特征都处于相似的范围内。例如,人口出生率和死亡率在数量级上相差很大,用归一化或标准化可以使它们更容易进行比较。
-
缺失值填充:现实数据中,常常会存在某些数据缺失的情况。如果直接忽略缺失值,可能会导致模型预测结果的偏差。因此,可以尝试通过一个填充函数,使用相邻数据的平均值、插值法等方式,将缺失值填充或者删除缺失值。例如,在预测某一城市的人口增长时,如有过往年份缺失数据,可以通过插值法来填充缺失值。
-
独热编码:在建立分类模型时,需要将分类变量转换为数值特征。但是,使用简单的数字表示可能会影响模型预测精度,因为经常让计算机误以为它们是重要程度关联。因此,可以采用独热编码来对分类变量进行处理。例如,在某人口普查数据中,学历有高中、大专和本科三种情况,可以通过独热编码将分类变量转换为三个数值特征,每个特征仅表明一个分类的二值化(0/1)信息。
好的,让我给你更具体的实例。
- 对数变换:
假设你在研究城市人口增长与年份之间的关系。由于城市发展的非线性特征,你决定对人口数据进行对数变换。你有如下原始数据:
| 年份 | 人口 |
|---|---|
| 2000 | 100000 |
| 2005 | 120000 |
| 2010 | 150000 |
你可以对人口数据应用对数变换,得到如下结果:
| 年份 | 对数人口 |
|---|---|
| 2000 | 11.51 |
| 2005 | 11.70 |
| 2010 | 11.92 |
通过对数变换,你平滑了人口增长的差异,并使其更适合进行模型分析。
- 归一化/标准化:
假设你正在观察城市的平均气温和降水量,并希望将它们归一化或标准化,使得它们在相似的范围内。你有如下原始数据:
| 城市 | 平均气温(摄氏度) | 降水量(毫米) |
|---|---|---|
| 北京 | 25 | 80 |
| 上海 | 30 | 120 |
| 广州 | 28 | 100 |
你可以使用最小-最大缩放方法将数据归一化到区间[0, 1],得到如下结果:
| 城市 | 归一化平均气温 | 归一化降水量 |
|---|---|---|
| 北京 | 0.333 | 0.250 |
| 上海 | 1.000 | 1.000 |
| 广州 | 0.667 | 0.625 |
通过归一化,你确保了不同城市的平均气温和降水量在相似的范围内,以便在模型中比较它们的影响。
这些是数学建模中数据变换的实例。根据具体问题和数据特点,你可以选择适当的数据变换方法以提高模型的准确性和可解释性。
相关文章:
【数学建模】数据预处理
为什么需要数据预处理 数学建模是将实际问题转化为数学模型来解决的过程,而数据预处理是数学建模中非常重要的一步。以下是为什么要进行数据预处理的几个原因: 数据质量:原始数据往往存在噪声、异常值、缺失值等问题,这些问题会对…...
VMware 安装 黑群晖7.1.1-42962 DS918+
本例的用的文件 1、ARPL 1.0beat 引导文件 vmdk格式: https://download.csdn.net/download/mshxuyi/88309308 2、DS918_42962.pat:https://download.csdn.net/download/mshxuyi/88309383 一、引导文件 1、创建一个虚拟机 2、下一步,选稍后…...
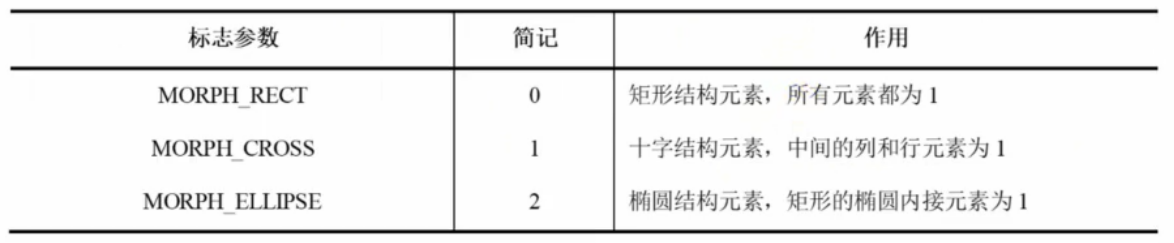
OpenCV(二十九):图像腐蚀
1.图像腐蚀原理 腐蚀操作的原理是将一个结构元素(也称为核或模板)在图像上滑动,并将其与图像中对应位置的像素进行比较。如果结构元素的所有像素与图像中对应位置的像素都匹配,那么该位置的像素值保持不变。如果结构元素的任何一个…...
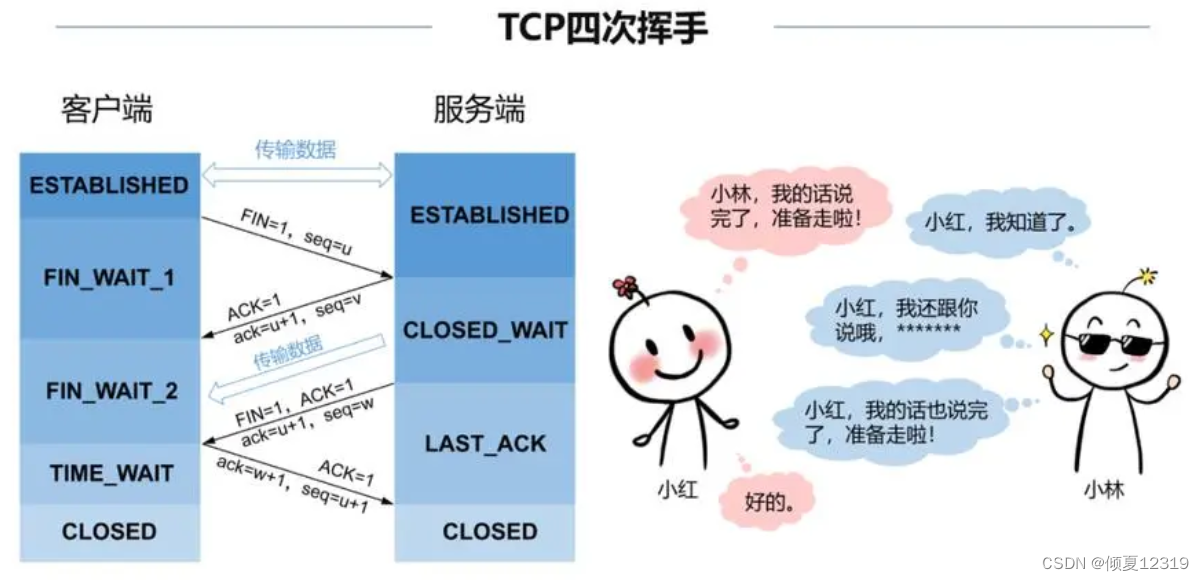
【网络知识点】三次握手和四次挥手
文章目录 一、三次握手二、四次挥手 一、三次握手 三次握手的原理如下: 客户端向服务器发送一个SYN(同步)包,其中包含一个随机生成的初始序列号(ISN)。 服务器收到SYN包后,会发送一个SYNACK&…...

CSS整理
目录 CSS中的& 弹性(display:flex)布局 flex的对齐方式 justify-content align-items flex-wrap 弹性盒换行 flex:1 flex属性 flex-grow:项目的放大比例 flex-shrink:收缩 flex-basis:初始值ÿ…...

OpenCV 06(图像的基本变换)
一、图像的基本变换 1.1 图像的放大与缩小 - resize(src, dsize, dst, fx, fy, interpolation) - src: 要缩放的图片 - dsize: 缩放之后的图片大小, 元组和列表表示均可. - dst: 可选参数, 缩放之后的输出图片 - fx, fy: x轴和y轴的缩放比, 即宽度和高度的缩放比. - …...

Java 中的日期时间总结
前言 大家好,我是 god23bin,在日常开发中,我们经常需要处理日期和时间,日期和时间可以说是一定会用到的,现在总结下 Java 中日期与时间的基本概念与一些常用的用法。 基本概念 日期(年月日,某…...
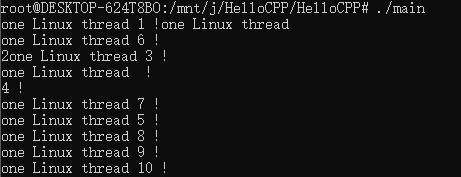
创建10个线程并发执行(STL/Windows/Linux)
C并发编程入门 目录 STL 写法 #include <thread> #include <iostream> using namespace std;void thread_fun(int arg) {cout << "one STL thread " << arg << " !" << endl; }int main(void) {int thread_count 1…...

三、创建各个展示模块组件
简介 在文件 components 中创建轮播模块组件,引入App.vue展示。欢迎访问个人的简历网站预览效果 本章涉及修改与新增的文件:First.vue、Second.vue、Third.vue、Fourth.vue、Fifth.vue、App.vue、vite-env.d.ts、assets 一、修改vite-env.d.ts文件 /// <reference type…...

推荐一款程序员截图神器!
快来看一下程序员必备的一款截图工具 今天就来和大家说一下作为程序员必备截图神器,几乎每一个程序员都会设置开机自启,因为这个截图功能太太太好用了!!!只要你在键盘上按下F1就可以轻松截取整个屏幕,然后…...

无涯教程-JavaScript - IMCSC函数
描述 IMCSC函数以x yi或x yj文本格式返回复数的余割。 复数的余割定义为正弦的倒数。即 余割(z) 1 /正弦(z) 语法 IMCSC (inumber)争论 Argument描述Required/OptionalInumberA complex number for which you want the cosecant.Required Notes Excel中的复数只是简单…...

Ubuntu22.04 LTS 显卡相关命令
第一部分查看驱显卡信息 一、查看显卡型号 # -i表示不区分大小写 lspci | grep -i nvidia # 必须安装好nvidia驱动 nvidia-smi -L 二、查看显卡驱动版本 cat /proc/driver/nvidia/version 三、查看CUDA、cuDNN版本 # 或者 nvcc -V(两个显示的版本一致…...

《TCP/IP网络编程》阅读笔记--基于 TCP 的半关闭
目录 1--基于TCP的半关闭 1-1--TCP单方面完全断开的问题 1-2--shutdown()函数 1-3--半关闭的必要性 2--基于半关闭的文件传输程序 1--基于TCP的半关闭 1-1--TCP单方面完全断开的问题 Linux 系统中的 close 函数会将 TCP Socket 的连接完全断开,这意味着不能收…...

Rust的模块化
Rust的模块化要从Rust的入口文件谈起。 Rust的程序的入口文件有两个 如果程序类型是可执行应用,入口文件是main.rs;如果程序类型是库,入口文件是lib.rs; 入口文件中,必须声明本地模块,否则编译器在编译过…...

vmware设置桥接模式后ip设置
网络连接方式设置 找到虚拟机里机器的网络设置 左边是宿主机,右边是虚拟机,按照这个设置就可以上网了(IP指定一个没有占用的值,子网掩码和网关设置成一样的)就可以联网了。 over~~...
算法通关村第十七关:白银挑战-贪心高频问题
白银挑战-贪心高频问题 1. 区间问题 所有的区间问题,参考下面这张图 1.1 判断区间是否重叠 LeetCode252 https://leetcode.cn/problems/meeting-rooms/ 思路分析 因为一个人在同一时刻只能参加一个会议,因此题目的本质是判断是否存在重叠区间 将区…...

目标检测评估指标mAP:从Precision,Recall,到AP50-95
1. TP, FP, FN, TN True Positive 满足以下三个条件被看做是TP 1. 置信度大于阈值(类别有阈值,IoU判断这个bouding box是否合适也有阈值) 2. 预测类型与标签类型相匹配(类别预测对了) 3. 预测的Bouding Box和Ground …...
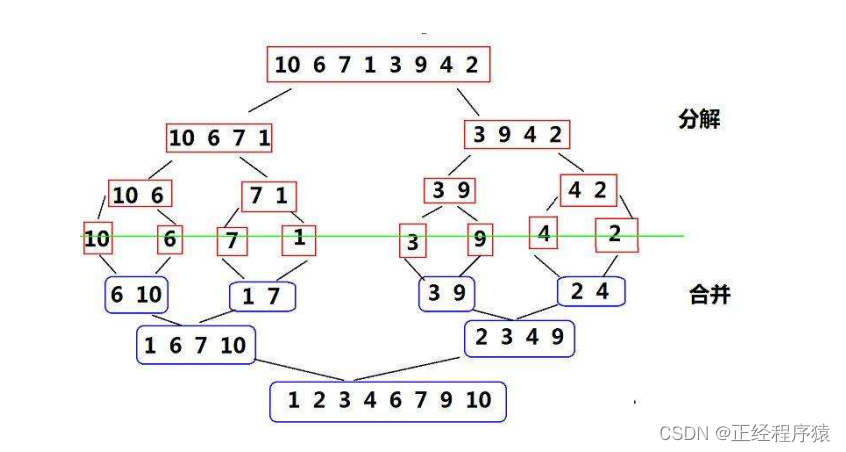
七大排序算法
目录 直接插入排序 希尔排序 直接选择排序 堆排序 冒泡排序 快速排序 快速排序优化 非递归实现快速排序 归并排序 非递归的归并排序 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作. 常见的排序算法有插入排序(直接插入…...

GitHub two-factor authentication
1. 介绍 登录 GitHub 官网,会提示要开启双因子认证。 但推荐的 APP 都是国外了,国内用不了。 可以使用 “腾讯身份验证器” 微信小程序。 2. 操作 开启双因子认证: 打开 “腾讯身份验证器” 微信小程序,扫描 GitHub 那个二维…...
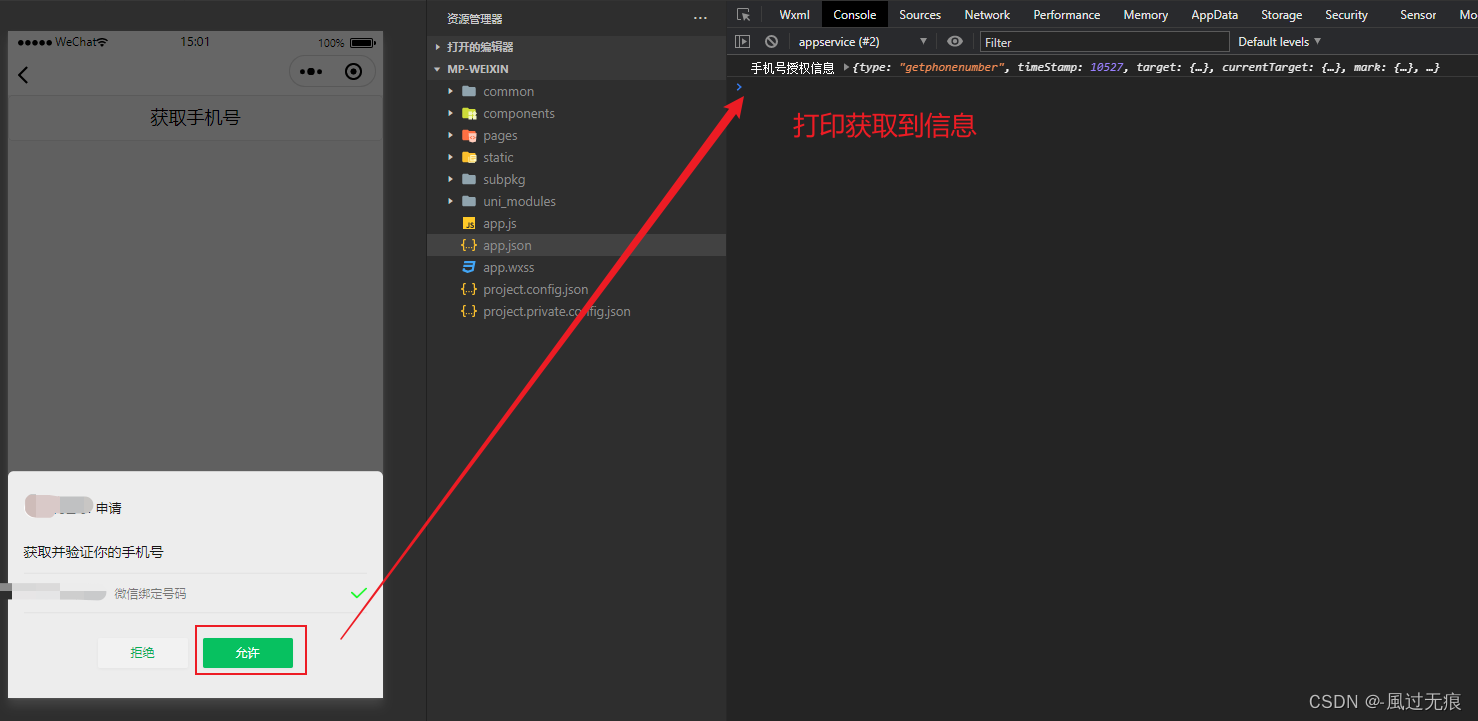
un-app-手机号授权登录-授权框弹不出情况
前言 手机号授权是获取用户信息api停用之后,经常使用的api。但是此api也是有很多坑 手机号授权会出现调用不起来的情况,这是因为小程序后台没有进行微信认证导致的 手机号授权调用不起来-没有微信认证 来到小程序后台-设置-基本设置-下拉找到微信认证…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...