机器学习简介

引言
为何现在机器学习如此热门?
主要原因是由于“人类无论如何也做不到在短时间内实现从大量的数据中自动的计算出正确的结果操作”。

什么是机器学习?
所谓的机器学习,就是通过对数据进行反复的学习,来找出其中潜藏的规律和模式。
机器学习中所用算法大致分为
- 监督学习(Supervised Learnings)
- 无监督学习(Unsuoervised Learning)
- 强化学习(Reinforcement Learning)
一、各类机器学习算法简介
理解监督学习
所谓监督学习中的“监督”,是指“数据中附带的正确答案标签”。那么,“数据中附带的正确答案标签”指的是什么呢?

如上图,对于表示内容的数据我们称为“正确答案标签”,像①~③这样,最终对数据所属类别进行预测的应用,我们称之为“分类问题”。而数据④是基于面积等量化数据,这种用于对类似房租这样连续变化的数值进行预测,我们将其称为“回归问题”。
简单来说,监督学习的基本原理就是使用大量的数据,通过计算机对数据进行反复处理,最终能够产生接近正确答案标签的输出值。
理解无监督学习
对比监督学习,监督学习包含“正确答案标签”,而“无监督学习”中是不包含“正确答案标签”的,其属于从输入的数据中发现规则,并进行学习的一种方法。监督学习会告诉计算机正确的答案,而无监督学习则是使用计算机去推导答案。因而无监督学习具有不存在所谓正确或者错误答案的特点。
无监督学习多用于热卖商品的推荐、饮食店的推荐菜等应用场合。此外,在对多维数据中的信息进行压缩(又称为主成分分析、数据降维等)。
理解强化学习
“强化学习”也不需要监督,强化学习提供“智能体”和“环境”。配备智能体和环境后,智能体会根据环境的变化采取相应的行动,环境将根据行动的结果给予智能体相应的“报酬”,而智能体根据其获取的报酬,对行动做出“好”或者“不好”的评价,并以此决定下次该如何采取行动。
二、机器学习的流程简介
进行机器学习的整体流程
- 数据收集
- 数据清洗(清洗重复或缺失的数据,以提高数据的精度)
- 运用机器学习算法对数据进行学习(获取基准)
- 使用测试数据进行性能评测
- 将机器学习模型安装到网页等应用环境中
学习数据的使用方法
在机器学习的“监督学习中”,我们将需要处理的数据划分为“训练数据”和“测试数据两种”。其中“训练数据”指的是学习过程中所使用的数据,而“测试数据”是指在学习完成之后对模型精度进行评估时所使用的数据。
之所以将数据分为“训练数据”和“测试数据”,是因为机器学习是以“预测未知数据”为目的的学术体系。而对比统计学是分析数据对产生这一数据的背景进行描述的学术体系。
留出法的理论与实践
所谓留出法,是指将所给的数据集划分为训练数据和测试数据这两种数据的一种简单方法。
接下来将使用第三方软件库Scikit-Learn来进行留出法的实践操作,Scikit-Learn是Python的开源机器学习专用软件库。
- 关于train_test_split()函数介绍:
train_test_split() 是 scikit-learn(sklearn)库中的一个非常重要的函数,它用于将数据集分割成训练集和测试集,以便进行机器学习模型的训练和评估。该函数的主要作用是随机将数据集中的样本按照指定的比例分为两部分,一部分用于训练模型,另一部分用于测试模型的性能。
以下是 train_test_split 函数的一般用法和参数解释:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
参数说明:
- X: 特征矩阵,包含了样本的特征数据。
- y: 目标标签,包含了每个样本对应的目标值(标签)。
- test_size: 测试集的大小,可以是浮点数(表示测试集占总样本的比例)或整数(表示测试集中的样本数量)。例如,test_size=0.2 表示将数据集的20%用于测试,而80%用于训练。
- train_size: 训练集的大小,如果不指定,会自动计算为 1 - test_size。
- random_state: 随机种子,用于控制数据集的随机分割过程。设置相同的随机种子可以确保每次运行代码时得到相同的分割结果,这对于实验的可复现性非常重要。
- shuffle: 默认情况下,数据会被随机打乱(shuffle),以确保分割是随机的。如果希望关闭数据的随机打乱,可以将该参数设置为 False。
函数的返回值包括四个部分:
- X_train: 训练集的特征矩阵。
- X_test: 测试集的特征矩阵。
- y_train: 训练集的目标标签。
- y_test: 测试集的目标标签。
# 读取执行代码所需的模块
from sklearn import datasets
from sklearn.model_selection import train_test_split# 读取名为Iris的数据集
iris = datasets.load_iris() #这一行代码从scikit-learn的datasets模块中加载了鸢尾花数据集,将数据存储在名为iris的变量中。
X = iris.data #这一行代码将鸢尾花数据集中的特征数据存储在名为X的变量中。每行代表一朵鸢尾花,每列代表不同的特征(如花瓣长度、花瓣宽度等)。
y = iris.target #这一行代码将鸢尾花数据集中的目标标签存储在名为y的变量中。每个标签对应于相应鸢尾花的种类# 「X_train, X_test, y_train, y_test」存储数据
#这一行代码使用train_test_split函数将数据集分割成训练集(X_train和y_train)和测试集(X_test和y_test)。
#参数test_size=0.2表示将数据集的20%用于测试,而80%用于训练。random_state参数用于设置随机种子,以确保每次运行代码时都得到相同的随机划分。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=___, random_state=0)# 检查训练数据和测试数据的大小
print ("X_train :", X_train.shape) #表示训练集中特征矩阵的形状(行数和列数
print ("y_train :", y_train.shape) #这表示训练集中目标标签的形状
print ("X_test :", X_test.shape)
print ("y_test :", y_test.shape)
输出结果:
过拟合
在根据数据的模式构建成的计算机中,继续输入新的数据时,只要数据中不存在严重的杂乱成分,计算机就可以正确的根据数据的模型对其进行分类,若我们输入带有严重偏差的数据给计算机,那么会导致模型出现很大的误差。我们通常称计算机对数据进行了过度的学习而产生的状态简称为过拟合。
欠拟合
我们将计算机对数据进行过度学习的学习状态称为过拟合,与之相对,对于数据没有得到充分学习的状态,我们称为欠拟合。此外,我们还将过拟合问题的模型称为方差过高,产生欠拟合问题的模型称为偏置过高。
相关文章:

机器学习简介
引言 为何现在机器学习如此热门? 主要原因是由于“人类无论如何也做不到在短时间内实现从大量的数据中自动的计算出正确的结果操作”。 什么是机器学习? 所谓的机器学习,就是通过对数据进行反复的学习,来找出其中潜藏的规律和模式…...
list事件)
linux之perf(2)list事件
Linux之perf(2)list事件 Author:Onceday Date:2023年9月3日 漫漫长路,才刚刚开始… 参考文档: Tutorial - Perf Wiki (kernel.org)perf-list(1) - Linux manual page (man7.org) 1. 概述 perf list用于列出可用的性能事件,这…...

将多个EXCEL 合并一个EXCEL多个sheet
合并老版本xls using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; using NPOI.HSSF.UserModel; …...

【送书活动】揭秘分布式文件系统大规模元数据管理机制——以Alluxio文件系统为例
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

微信小程序——数据绑定
在微信小程序中,可以通过以下代码实现数据绑定: 在WXML中,使用双大括号{{}}绑定数据,将数据渲染到对应的视图中。 <view>{{message}}</view>在JS中,定义一个数据对象,并将其绑定到页面的data…...

libbpf-bootstrap安卓aarch64适配交叉编译
1.为什么移植 疑惑 起初我也认为,像libbpf-bootstrap这样在ebpf程序开发中很常用的框架,理应支持不同架构的交叉编译。尤其是向内核态的ebpf程序本身就是直接通过clang的-target btf直接生成字节码,各个内核上的ebpf虚拟机大同小异…...

【剑指Offer】24.反转链表
题目 定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL限制: 0 < 节点个数 < 5000 解答 源代码 /*** Defin…...

04-docker compose容器编排
Docker Compose简介 Docker Compose是什么 Compose 是Docker公司推出的一个工具软件,可以管理多个Dokcer容器组成一个应用。你需要定义一个YAML格式的配置文件 docker-compose.yml,写好多个容器之间的调用关系。然后,只要一个命令&#…...

通过位运算打多个标记
通过位运算打多个标记 如何在一个字段上,记录多个标记? 如何在一个字段上,记录不同类型的多个标记? 如何用较少的字段,记录多个标记? 如何在不增加字段的要求下,记录新增的标记? 在实…...
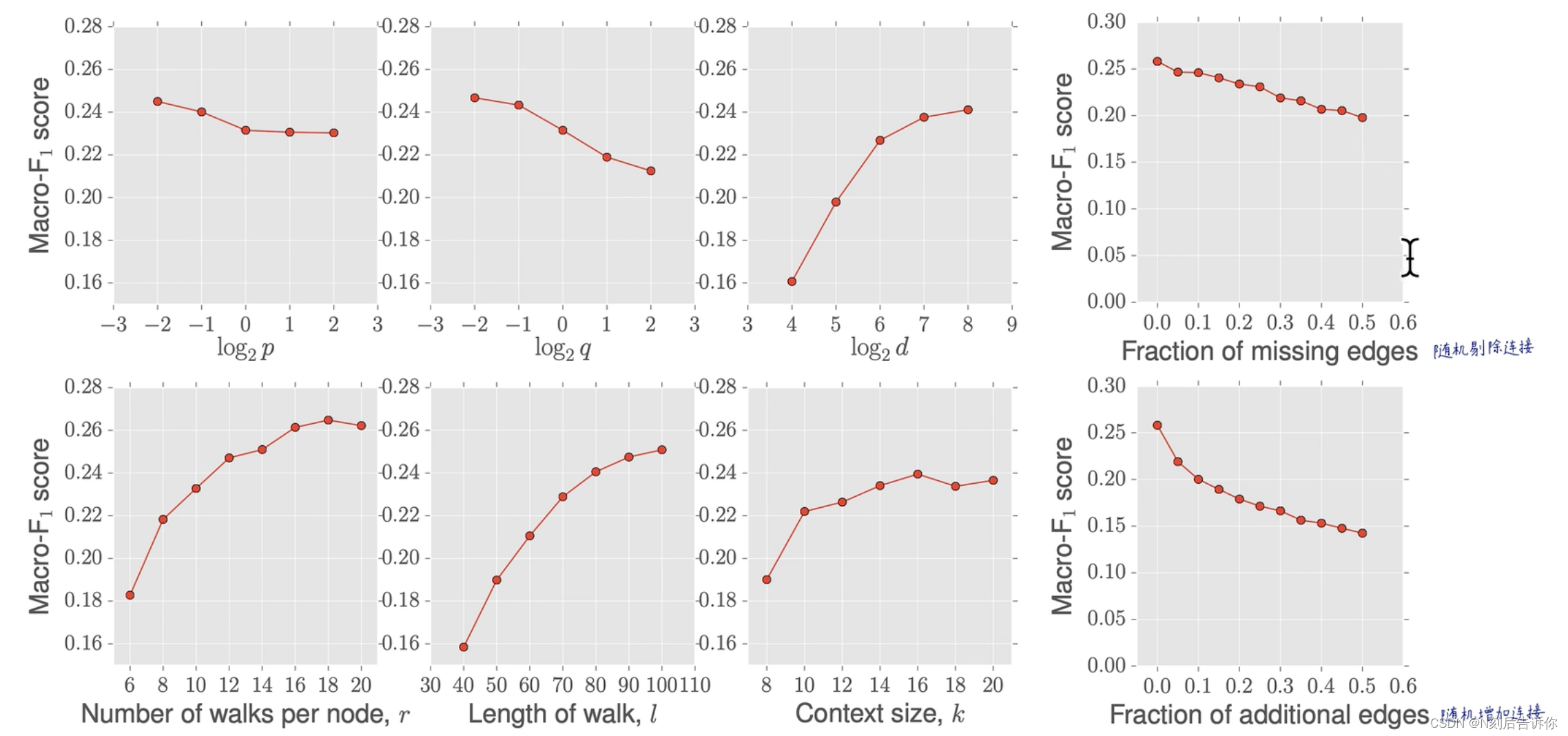
[学习笔记]Node2Vec图神经网络论文精读
参考资料:https://www.bilibili.com/video/BV1BS4y1E7tf/?p12&spm_id_frompageDriver Node2vec简述 DeepWalk的缺点 用完全随机游走,训练节点嵌入向量,仅能反应相邻节点的社群相似信息,无法反映节点的功能角色相似信息。 …...

C# Linq源码分析之Take(五)
概要 本文在C# Linq源码分析之Take(四)的基础上继续从源码角度分析Take的优化方法,主要分析Where.Select.Take的使用案例。 Where.Select.Take的案例分析 该场景模拟我们显示中将EF中与数据库关联的对象进行过滤,然后转换成Web…...
性能监控-grafana+prometheus+node_exporter
Prometheus是一个开源的系统监控和报警工具。它由SoundCloud开发并于2012年发布,后来成为了一个独立的开源项目,并得到了广泛的应用和支持。 Prometheus的主要功能包括采集和存储各种系统和应用程序的监控数据,并提供强大的查询语言PromQL来…...
(STM32H5系列)STM32H573RIT6、STM32H573RIV6、STM32H573ZIT6嵌入式微控制器基于Cortex®-M33内核
一、应用 工业(PLC、工业电机控制、泵和压缩机) 智能家居(空调、冰箱、冰柜、中央警报系统、洗衣机) 个人电子产品(键盘、智能手机、物联网标签、跟踪设备) 智能城市(工业通信、照明控制、数字…...

mysql配置bind-address不生效
1、前言 因为要ip直接访问mysql,故去修改bind-address参数,按照mysql配置文件查找顺序是:/etc/my.cnf、/etc/mysql/my.cnf、~/.my.cnf,服务器上没有 /etc/my.cnf文件,故去修改 /etc/mysql/my.cnf文件,但是一…...

Linux相关指令(下)
cat指令 查看目标文件的内容 常用选项: -b 对非空输出行编号 -n 对输出的所有行编号 -s 不输出多行空行 一个重要思想:linux下一切皆文件,如显示器文件,键盘文件 cat默认从键盘中读取数据再打印 退出可以ctrlc 输入重定向<…...
(A - F))
Codeforces Round 855 (Div 3)(A - F)
Codeforces Round 855 (Div. 3)(A - F) Codeforces Round 855 (Div. 3) A. Is It a Cat?(思维) 思路:先把所有字母变成小写方便判断 , 然后把每一部分取一个字母出来 , 判断和‘meow’是否相同即可。 复杂度 O ( n…...
:社交媒体金融的未来,真的如此美好吗?)
Friend.tech(FT):社交媒体金融的未来,真的如此美好吗?
Friend.tech(FT)是一个在2023年8月10日正式推出的社交金融平台,它的特点在于允许用户购买和出售创作者的股票(shares),这些股票赋予用户访问创作者内容的权利。FT的推出引发了广泛的关注,吸引了…...
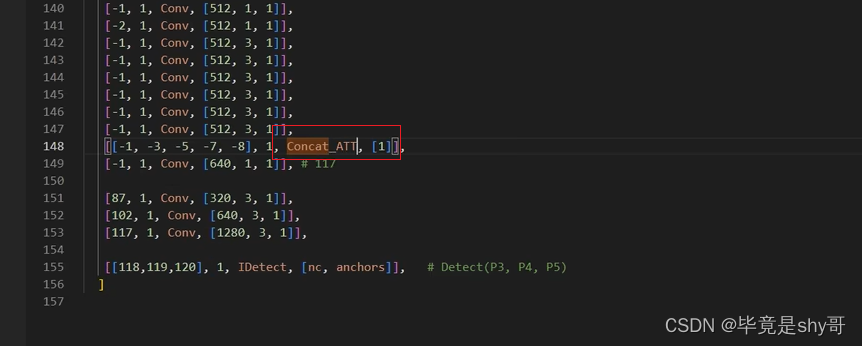
yolov7中Concat之后加注意力模块(最复杂的情况)
1、common.py中找到Concat模块,复制一份 2、要传参进来,dim通道数 3、然后找yolo.py模块,添加 4、yaml里替换 5、和加的位置也有关系...
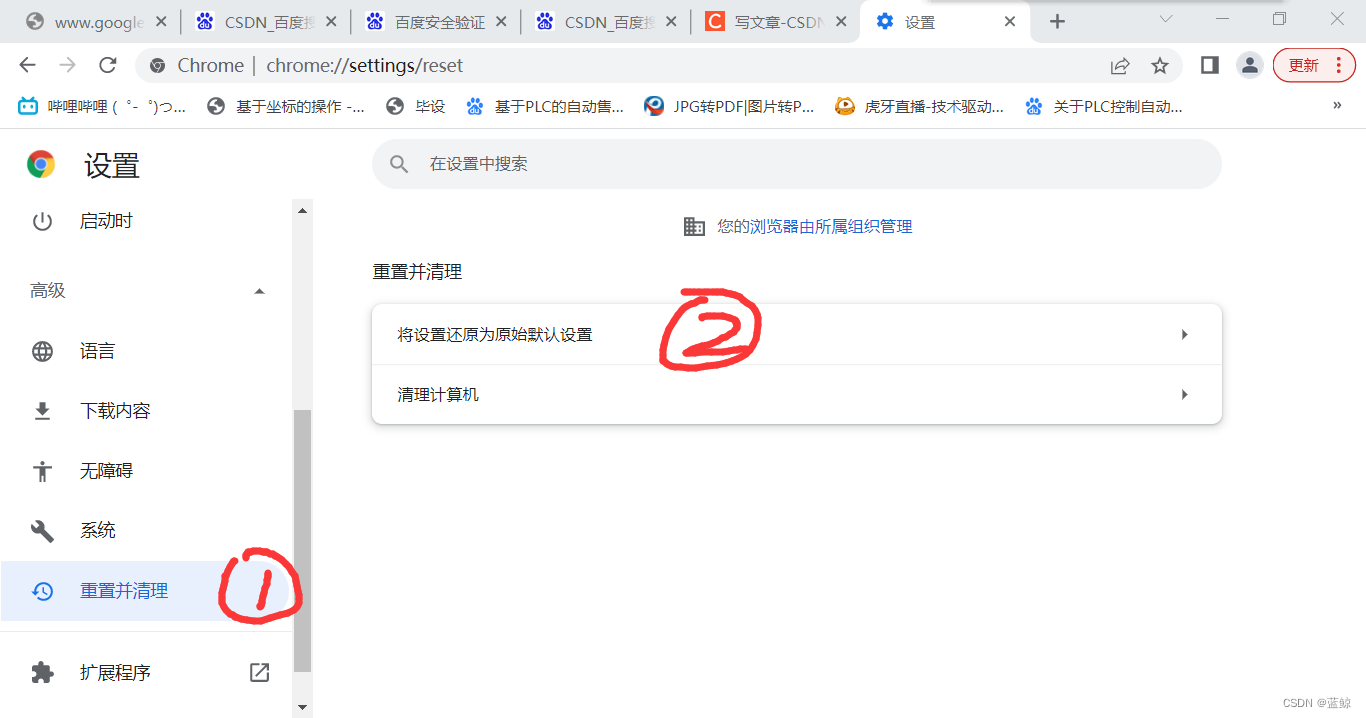
解除百度安全验证
使用chrome浏览器用百度浏览时,一直弹百度安全验证: 在设置里进行重置: 然后重启浏览器就可以了。...
(A - F))
Codeforces Round 731 (Div 3)(A - F)
Codeforces Round 731 (Div. 3)(A - F) Dashboard - Codeforces Round 731 (Div. 3) - Codeforces A. Shortest Path with Obstacle(思维) 思路:显然要计算 A → B 之间的曼哈顿距离 , 要绕开 F 当且仅当 AB形成的直线平行于坐…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...