【3】单着色器文件读取
Basic.shader文件,可以发现顶点着色器和片段着色器是写在一个文件里的,这里我们将他们读取出来,而不是上一篇使用string的方式。
#shader vertex
#version 330 corelayout(location = 0) in vec4 position;void main()
{gl_Position = position;
};#shader fragment
#version 330 corelayout(location = 0) out vec4 color;void main()
{color = vec4(1.0, 0.0, 0.0, 1.0);
};
主要代码:
//返回的结构体,一个vertex字符串,一个fragment字符串
struct ShaderProgramSource
{std::string VertexSource;std::string FragmentSource;
};static ShaderProgramSource ParseShader(const std::string& filepath) {std::ifstream stream(filepath);/*您提出了一个好问题。从语法角度来分析一下,enum class 为什么被称为"带作用域的枚举类型":- 普通的 enum 定义是:enum EnumName {value1, value2}- 枚举值不加作用域,可以直接使用值名- 而 enum class 定义是:enum class EnumName {value1,value2} - 这里使用了class关键字- 根据C++标准,class关键字会为枚举类型生成一个新的作用域- 枚举值名会放在这个新的作用域中- 所以要使用枚举值名,需要加上作用域操作符::如EnumName::value1- 这样就隔离开其他作用域中的可能重复名称- 并防止枚举值名与其他名称冲突所以,从enum class语法中class关键字产生的作用域来看:- 它为枚举类型值名生成了一个独立的命名空间- 这就产生了"带作用域"的语义希望这个分析可以帮您理解enum class的语法机制!*/enum class ShaderType { /* 带作用域的枚举类型,不是类*/NONE = -1, VERTEX = 0, FRAGMENT = 1};std::string line;std::stringstream ss[2];ShaderType type = ShaderType::NONE;while (getline(stream, line)) {if (line.find("#shader") != std::string::npos) { /* 找到了*/if (line.find("vertex") != std::string::npos) {// set mode to vertextype = ShaderType::VERTEX;}else if (line.find("fragment") != std::string::npos) {// set mode to fragmenttype = ShaderType::FRAGMENT;}}else {ss[(int)type] << line << '\n';}}return { ss[0].str(), ss[1].str() };
}读取结果:通过string打印可以看到成功了。
所有代码:
#include <iostream>
#include <string> #include <GL/glew.h>
#include <GLFW/glfw3.h>
#include <fstream>
#include <sstream>struct ShaderProgramSource
{std::string VertexSource;std::string FragmentSource;
};static ShaderProgramSource ParseShader(const std::string& filepath) {std::ifstream stream(filepath);/*您提出了一个好问题。从语法角度来分析一下,enum class 为什么被称为"带作用域的枚举类型":- 普通的 enum 定义是:enum EnumName {value1, value2}- 枚举值不加作用域,可以直接使用值名- 而 enum class 定义是:enum class EnumName {value1,value2} - 这里使用了class关键字- 根据C++标准,class关键字会为枚举类型生成一个新的作用域- 枚举值名会放在这个新的作用域中- 所以要使用枚举值名,需要加上作用域操作符::如EnumName::value1- 这样就隔离开其他作用域中的可能重复名称- 并防止枚举值名与其他名称冲突所以,从enum class语法中class关键字产生的作用域来看:- 它为枚举类型值名生成了一个独立的命名空间- 这就产生了"带作用域"的语义希望这个分析可以帮您理解enum class的语法机制!*/enum class ShaderType { /* 带作用域的枚举类型,不是类*/NONE = -1, VERTEX = 0, FRAGMENT = 1};std::string line;std::stringstream ss[2];ShaderType type = ShaderType::NONE;while (getline(stream, line)) {if (line.find("#shader") != std::string::npos) { /* 找到了*/if (line.find("vertex") != std::string::npos) {// set mode to vertextype = ShaderType::VERTEX;}else if (line.find("fragment") != std::string::npos) {// set mode to fragmenttype = ShaderType::FRAGMENT;}}else {ss[(int)type] << line << '\n';}}return { ss[0].str(), ss[1].str() };
}/*方便起见,写成一个函数*/
static unsigned int CompileShader(unsigned int type, const std::string& source) {unsigned int id = glCreateShader(type);/*vertex 或者 fragment */const char* src = source.c_str(); /*或者写 &source[0]*/glShaderSource(id, 1, &src, nullptr);glCompileShader(id);int result;glGetShaderiv(id, GL_COMPILE_STATUS, &result);if (result == GL_FALSE) {int length;glGetShaderiv(id, GL_INFO_LOG_LENGTH, &length);// char message[length]; /*这里会发现因为长度不定,无法栈分配,但你仍要这么做*/char* message = (char*)alloca(length * sizeof(char));glGetShaderInfoLog(id, length, &length, message);std::cout << "Failed to compile " << (type == GL_VERTEX_SHADER ? "vertex":"fragment" )<< "shader!请定位到此行" << std::endl;std::cout << message << std::endl;glDeleteShader(id);return 0;}return id;
}/*使用static是因为不想它泄露到其他翻译单元?
使用string不是最好的选择,但是相对安全, int类型-该着色器唯一标识符,一个ID*/
static unsigned int CreateShader(const std::string& vertexShader, const std::string& fragmentShader) {/*使用unsigned是因为它接受的参数就是这样,或者可以使用 GLuint,但是作者不喜欢这样,因为它要使用多个图像api*/unsigned int program = glCreateProgram();unsigned int vs = CompileShader(GL_VERTEX_SHADER, vertexShader);unsigned int fs = CompileShader(GL_FRAGMENT_SHADER, fragmentShader);glAttachShader(program, vs);glAttachShader(program, fs);glLinkProgram(program);glValidateProgram(program);glDeleteShader(vs);glDeleteShader(fs);return program;
}int main(void)
{GLFWwindow* window;/* Initialize the library */if (!glfwInit())return -1;//if (glewInit() != GLEW_OK)/*glew文档,这里会报错,因为需要上下文,而上下文在后面*/// std::cout << "ERROR!-1" << std::endl;/* Create a windowed mode window and its OpenGL context */window = glfwCreateWindow(640, 480, "Hello World", NULL, NULL);if (!window){glfwTerminate();return -1;}/* Make the window's context current */glfwMakeContextCurrent(window);if (glewInit() != GLEW_OK)/*这里就不会报错了*/std::cout << "ERROR!-2" << std::endl;std::cout << glGetString(GL_VERSION) << std::endl;float positions[6] = {-0.5f, 0.5f,0.0f, 0.0f,0.5f, 0.5f};/*这段代码是创建和初始化顶点缓冲对象(Vertex Buffer Object,简称VBO)。VBO是OpenGL中一个很重要的概念,用于高效渲染顶点数据。它这段代码的作用是:glGenBuffers生成一个新的VBO,ID保存到buffer变量中。glBindBuffer将这个VBO绑定到GL_ARRAY_BUFFER目标上。glBufferData向被绑定的这个VBO中填充实际的顶点数据。通过这三步:我们得到了一个可以存储顶点数据的VBO对象后续绘制调用只需要指定这个VBO就可以加载顶点数据教程强调VBO是因为:相对直接送入顶点更高效绘制调用不再需要每帧重复发送相同顶点提高渲染性能所以总结下VBO可以高效绘制复杂顶点数据至显卡,是OpenGL重要概念glGenBuffers(1, &buffer);
glGenBuffers作用是生成VBO对象的ID编号。第一个参数1表示要生成的VBO数量,这里只生成1个。第二个参数&buffer是用于返回生成的VBO ID编号。glBindBuffer(GL_ARRAY_BUFFER, buffer);
glBindBuffer用于将VBO对象绑定到指定的目标上。第一个参数GL_ARRAY_BUFFER表示要绑定的目标是顶点属性数组缓冲。GL_ARRAY_BUFFER指定将要保存顶点属性数据如位置、颜色等。第二个参数buffer就是前面glGenBuffers生成的VBO ID。所以总结下:glGenBuffers生成1个VBO对象并获取ID编号glBindBuffer将这个VBO绑定到属性缓冲目标上,作为后续顶点数据的存储对象。glBufferData的作用是向之前绑定的VBO对象中填充实际的顶点数据。参数说明:GL_ARRAY_BUFFER:指定操作目标为顶点属性缓冲(与glBindBuffer一致)6 * sizeof(float):数据大小,这里 positions 数组有6个float数positions:数组指针,提供实际的数据源GL_STATIC_DRAW:数据使用模式GL_STATIC_DRAW:数据不会或很少改变
GL_DYNAMIC_DRAW:数据可能会被修改
GL_STREAM_DRAW:数据每次绘制都会改变
它的功能是:分配指定大小内存给当前绑定的VBO对象将positions数组内容拷贝到VBO对象内存中以GL_STATIC_DRAW模式,显卡知道如何优化分配内存这样一来,positions数组中的顶点数据就上传到GPU中VBO对象里了。OpenGL随后通过该VBO对象来读取顶点数据进行绘制。*/unsigned int buffer;glGenBuffers(1, &buffer);glBindBuffer(GL_ARRAY_BUFFER, buffer);glBufferData(GL_ARRAY_BUFFER, 6 * sizeof(float), positions, GL_STATIC_DRAW);glEnableVertexAttribArray(0);/*index-只有一个属性,填0size-两个数表示一个点,填2stripe-顶点之间的字节数pointer-偏移量好的,我们来用一个例子来解释glVertexAttribPointer的参数含义:假设我们有一个VBO,里面存放3个三维顶点数据,每个顶点由(x,y,z)组成,每个元素类型为float。那么数据在VBO中排列如下:VBO地址 | 数据
0 | x1
4 | y1\
8 | z1
12 | x2
16 | y2
20 | z2
24 | x3
28 | y3
32 | z3现在我们要告诉OpenGL如何解析这些数据:glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 12, 0);- 0:属性为位置数据
- 3:每个位置由3个float组成,(x,y,z)
- GL_FLOAT:数据类型是float
- 12:当前属性到下一个属性的间隔,即一个顶点需要12个字节
- 0:这个属性起始位置就是VBO的开头这样OpenGL就知道:- 从VBO开始地址读取3个float作为第一个顶点的位置
- 下一个顶点偏移12字节再读取3个float最后一个参数0就是告诉OpenGL属性的起始读取偏移是多少。好的,用一个例子来具体说明一下这种情况:假设我们有一个VBO来存储顶点数据,每个顶点包含位置和颜色两个属性。数据在VBO内部的排列方式为:位置x | 位置y | 位置z | 颜色r | 颜色g | 颜色b那么对于第一个顶点来说,它在VBO内的布局是:VBO地址 | 数据
0 | 位置x\
4 | 位置y
8 | 位置z
12 | 颜色r
16 | 颜色g
20 | 颜色b此时,我们设置位置属性和颜色属性的指针:glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 24, 0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 24, 12);可以看到:- 位置属性从0字节处开始读取
- 颜色属性从12字节处开始读取(让出位置数据占用的空间)这就是为什么位置属性的偏移不能写0,需要指定非0偏移量让出给颜色属性存储空间。这样才能正确解析这两个分开但共处一个VBO的数据。*/glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, sizeof(float) * 2, 0);/* (const void)*8//*这里开始使用着色器*/// 测试 ShaderProgramSourceShaderProgramSource source = ParseShader("res/shaders/Basic.shader"); unsigned int shader = CreateShader(source.VertexSource, source.FragmentSource);glUseProgram(shader);/* Loop until the user closes the window */while (!glfwWindowShouldClose(window)){/* Render here */glClear(GL_COLOR_BUFFER_BIT);glDrawArrays(GL_TRIANGLES, 0, 3);// glDrawElements(GL_TRIANGLES, )/* glBegin(GL_TRIANGLES);glVertex2f(-0.5f, 0.5f);glVertex2f(0.0f, 0.0f);glVertex2f(0.5f, 0.5f);glEnd();*//* Swap front and back buffers */glfwSwapBuffers(window);/* Poll for and process events */glfwPollEvents();}glDeleteProgram(shader);glfwTerminate();return 0;
}
相关文章:

【3】单着色器文件读取
Basic.shader文件,可以发现顶点着色器和片段着色器是写在一个文件里的,这里我们将他们读取出来,而不是上一篇使用string的方式。 #shader vertex #version 330 corelayout(location 0) in vec4 position;void main() {gl_Position positio…...

祝贺埃文科技入选河南省工业企业数据安全技术支撑单位
近日,河南省工业信息安全产业发展联盟公布了河南省工业信息安全应急服务支撑单位和河南省工业企业数据安全技术支撑单位遴选结果,最终评选出19家单位作为第一届河南省工业信息安全应急服务支撑单位和河南省工业企业数据安全技术支撑单位。 埃文科技凭借自身技术优势…...

Chinese-LLaMA-Alpaca-2模型的测评
训练生成效果评测 Fastchat Chatbot Arena推出了模型在线对战平台,可浏览和评测模型回复质量。对战平台提供了胜率、Elo评分等评测指标,并且可以查看两两模型的对战胜率等结果。生成回复具有随机性,受解码超参、随机种子等因素影响ÿ…...
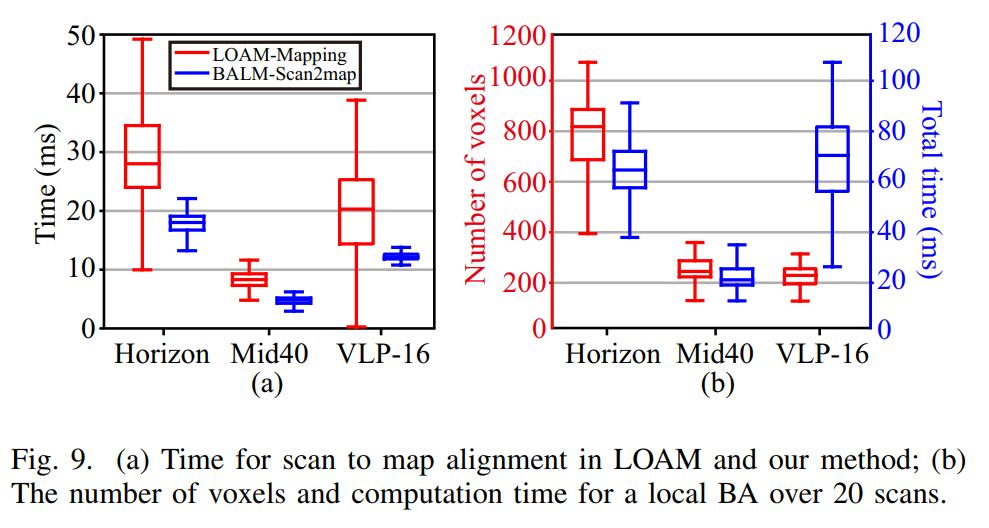
SLAM论文详解(5) — Bundle_Adjustment_LM(BALM)论文详解
目录 1 摘要 2 相关工作 3 BA公式和导数 A. 直接BA公式 B. 导数 C. 二阶近似 4 自适应体素化 5. 将BALM结合进LOAM 6. 实验 7. 算法应用场景解析 1 摘要 Bundle Adjustment是一种用于同时估计三维结构和传感器运动运动的优化算法。在视觉SLAM,三维重建等…...

C语言对单链表所有操作与一些相关面试题
目录 单链表的特性 单链表的所有操作 定义一个单链表 创建一个链表头 插入数据(头插法) 插入数据(尾插法) 查找节点 修改数据节点 删除节点 打印数据 销毁链表 翻转链表 打印链表长度 冒泡排序 快排 堆排 查找倒数第K个节点(双指针法) …...

高防服务器如何抵御大规模攻击
高防服务器如何抵御大规模攻击?高防服务器是一种专门设计用于抵御大规模攻击的服务器,具备出色的安全性和可靠性。在当今互联网时代,网络安全问题日益严重,DDOS攻击(分布式拒绝服务攻击)等高强度攻击已成为…...

Go 接口和多态
在讲解具体的接口之前,先看如下问题。 使用面向对象的方式,设计一个加减的计算器 代码如下: package mainimport "fmt"//父类,这是结构体 type Operate struct {num1 intnum2 int }//加法子类,这是结构体…...

Git忽略文件的几种方法,以及.gitignore文件的忽略规则
目录 .gitignore文件Git忽略规则以及优先级.gitignore文件忽略规则常用匹配示例: 有三种方法可以实现忽略Git中不想提交的文件。1、在Git项目中定义 .gitignore 文件(优先级最高,推荐!)2、在Git项目的设置中指定排除文…...
C语言——指针进阶(2)
继续上次的指针,想起来还有指针的内容还没有更新完,今天来补上之前的内容,上次我们讲了函数指针,并且使用它来实现一些功能,今天我们就讲一讲函数指针数组等内容,废话不多说,我们开始今天的学习…...

【汇编中的寄存器分类与不同寄存器的用途】
汇编中的寄存器分类与不同寄存器的用途 寄存器分类 在计算机体系结构中,8086CPU,寄存器可以分为以下几类: 1. 通用寄存器: 通用寄存器是用于存储数据和执行算术运算的寄存器。在 x86 架构中,这些通用寄存器通常包括…...
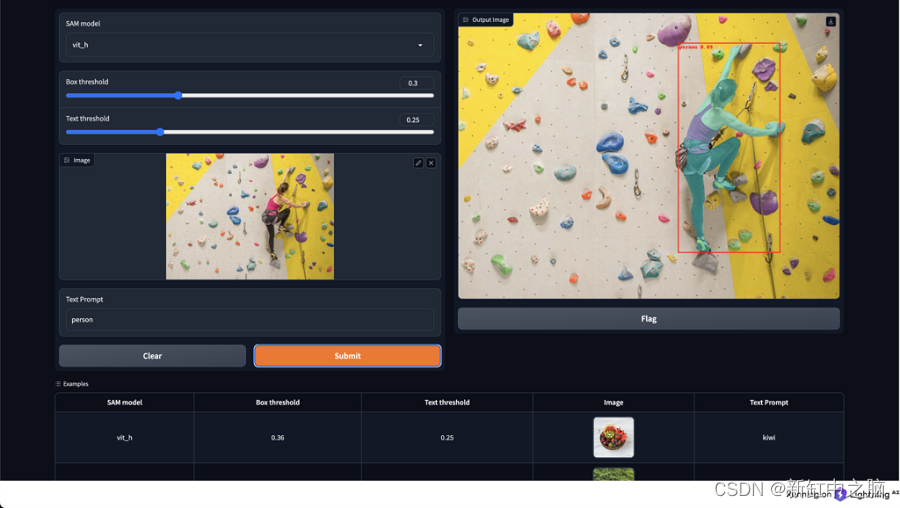
基于文本提示的图像目标检测与分割实践
近年来,计算机视觉取得了显着的进步,特别是在图像分割和目标检测任务方面。 最近值得注意的突破之一是分段任意模型(SAM),这是一种多功能深度学习模型,旨在有效地从图像和输入提示中预测对象掩模。 通过利用…...

【4-5章】Spark编程基础(Python版)
课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili 第4章 RDD编程(21节) Spark生态系统: Spark Core:底层核心(RDD编程是针对这个)Spark SQL:…...
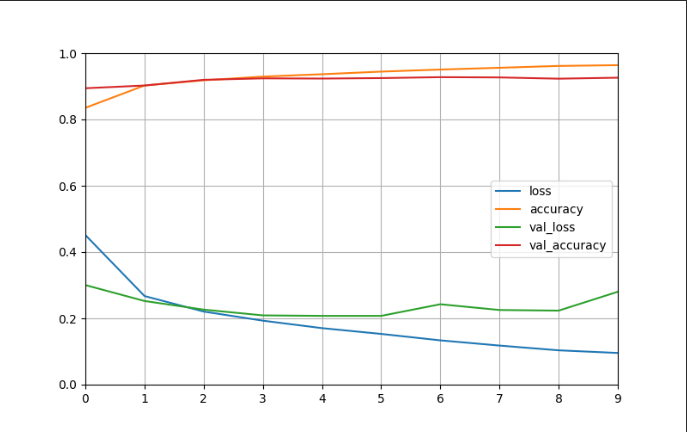
04 卷积神经网络搭建
一、数据集 MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。 MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图…...

【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述 在hadoop3.0.3集群上执行hive3.1.2的任…...
)
数据结构--6.5二叉排序树(插入,查找和删除)
目录 一、创建 二、插入 三、删除 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树: ——若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值…...
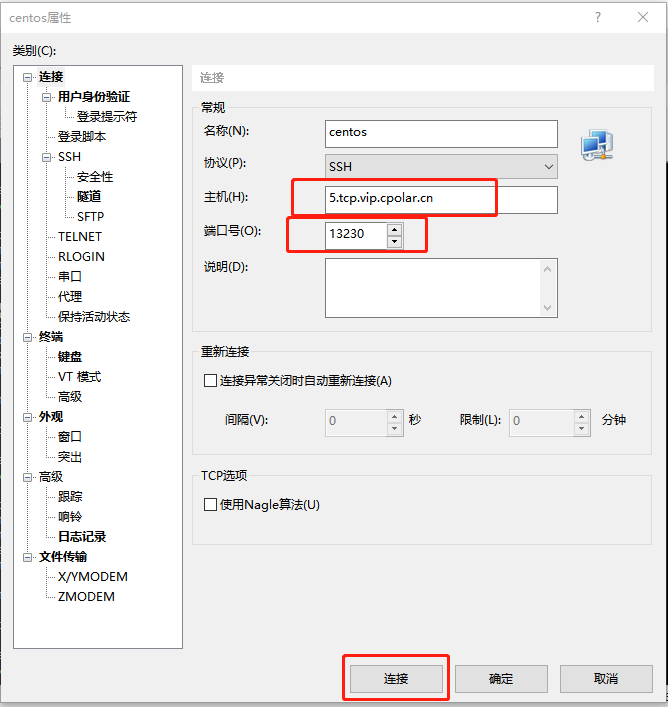
无需公网IP,在家SSH远程连接公司内网服务器「cpolar内网穿透」
文章目录 1. Linux CentOS安装cpolar2. 创建TCP隧道3. 随机地址公网远程连接4. 固定TCP地址5. 使用固定公网TCP地址SSH远程 本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。…...

Java工具类
一、org.apache.commons.io.IOUtils closeQuietly() toString() copy() toByteArray() write() toInputStream() readLines() copyLarge() lineIterator() readFully() 二、org.apache.commons.io.FileUtils deleteDirectory() readFileToString() de…...

makefile之使用函数wildcard和patsubst
Makefile之调用函数 调用makefile机制实现的一些函数 $(function arguments) : function是函数名,arguments是该函数的参数 参数和函数名用空格或Tab分隔,如果有多个参数,之间用逗号隔开. wildcard函数:让通配符在makefile文件中使用有效果 $(wildcard pattern) 输入只有一个参…...

算法通关村第十八关——排列问题
LeetCode46.给定一个没有重复数字的序列,返回其所有可能的全排列。例如: 输入:[1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 元素1在[1,2]中已经使…...

基于STM32设计的生理监测装置
一、项目功能要求 设计并制作一个生理监测装置,能够实时监测人体的心电图、呼吸和温度,并在LCD液晶显示屏上显示相关数据。 随着现代生活节奏的加快和环境的变化,人们对身体健康的关注程度越来越高。为了及时掌握自身的生理状况,…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...