LLVM 与代码混淆技术
项目源码
什么是 LLVM
LLVM 计划启动于2000年,开始由美国 UIUC 大学的 Chris Lattner 博士主持开展,后来 Apple 也加入其中。最初的目的是开发一套提供中间代码和编译基础设施的虚拟系统。
LLVM 命名最早源自于底层虚拟机(Low Level Virtual Machine)的缩写,随着 LLVM 项目的不断发展,原先的全称已不再适用,目前 LLVM 就是该项目的全称。
简单来说,可以将 LLVM 理解为一个现代化、可拓展的编译器。
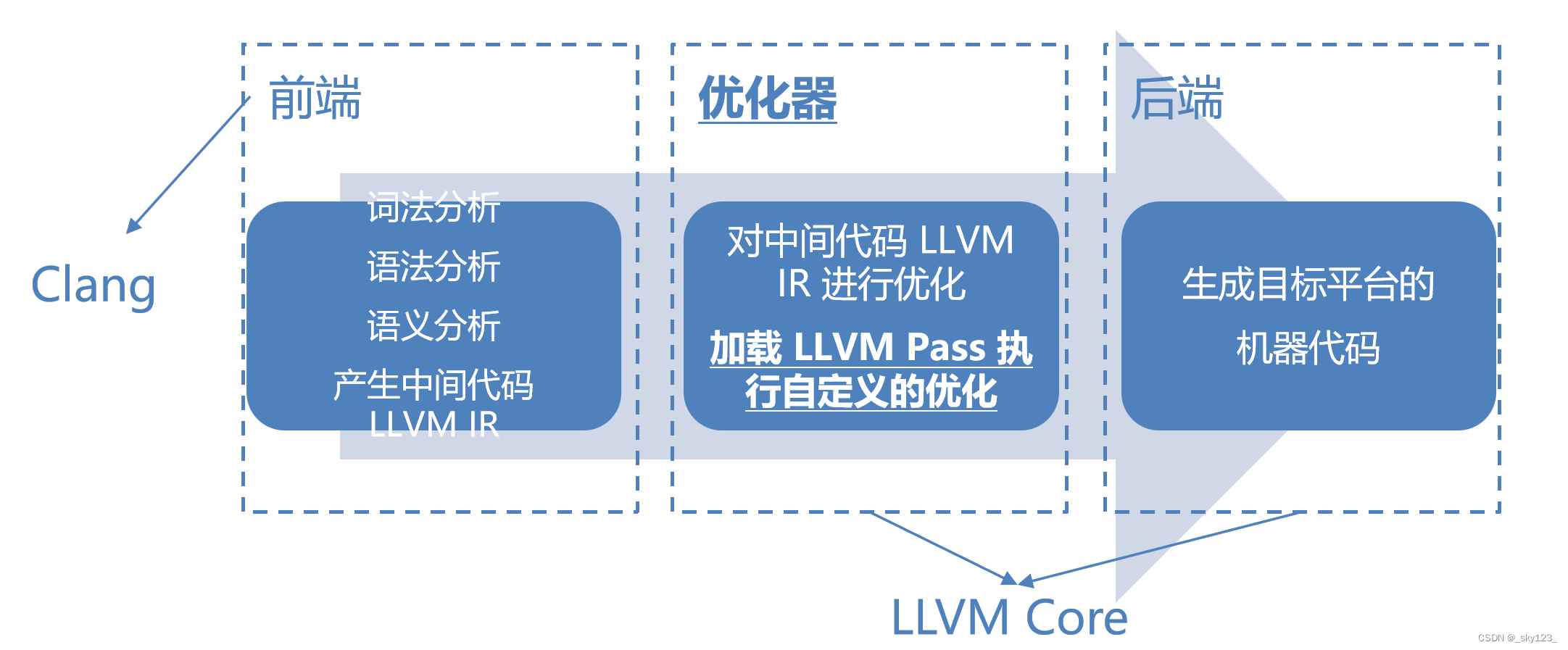
GCC 与 LLVM 编译流程
- GCC 分为三个模块:前端、优化器和后端
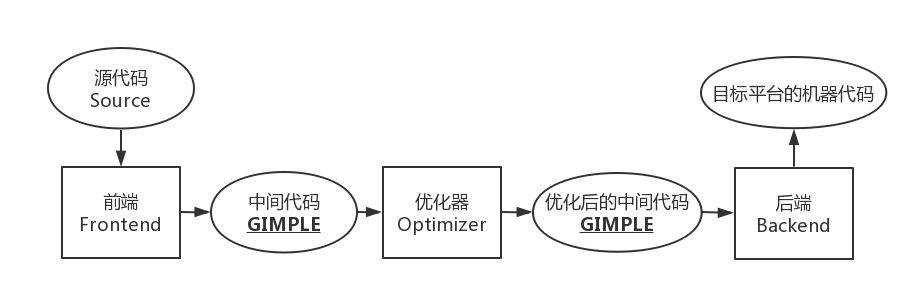
- LLVM 本质上也是三段式:
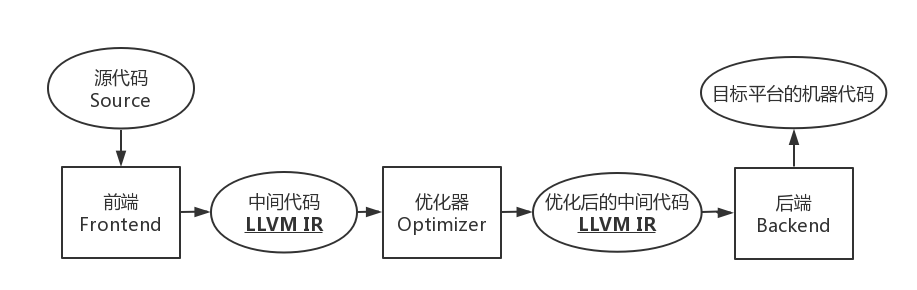
一个具体的例子:

相对于 GCC ,LLVM 有如下优势:
- 模块化:LLVM 是高度模块化设计的,每一个模块都可以从 LLVM 项目中抽离出来单独使用。而 GCC 虽然也是三段式编译,但各个模块之间是难以抽离出来单独使用的。
- 可拓展:LLVM 为开发者提供了丰富的 API ,例如开发者可以通过 LLVM Pass 框架干预中间代码优化过程,并且配备了完善的文档。虽然 GCC 是开源的,但要在 GCC 的基础上进行拓展门槛很高、难度很大。
LLVM 基本用法
对于 C/C++ 程序来说,LLVM 的编译过程如图所示:
第一步:将源代码转化成 LLVM IR
LLVM IR 有两种表现形式,一种是人类可阅读的文本形式,对应文件后缀为 .ll ;另一种是方便机器处
理的二进制格式,对应文件后缀为 .bc 。使用以下命令将源代码转化为 LLVM IR:
clang -S -emit-llvm hello.cpp -o hello.ll
或
clang -c -emit-llvm hello.cpp -o hello.bc
第二步:优化 LLVM IR
使用 opt 指令对 LLVM IR 进行优化
opt -load LLVMObfuscator.so -hlw -S hello.ll -o hello_opt.ll
-load加载特定的 LLVM Pass (集合)进行优化(通常为.so文件)-hlw是 LLVM Pass 中自定义的参数,用来指定使用哪个 Pass 进行优化
第三步:编译 LLVM IR 为可执行文件
这一步我们通过 Clang 完成,从 LLVM IR 到可执行文件中间还有一系列复杂的流程,Clang 帮助我们整
合了这个过程:
clang hello_opt.ll -o hello
LLVM Pass
LLVM Pass 的基本概念
LLVM Pass 框架是整个 LLVM 提供给用户用来干预代码优化过程的框架,也是我们编写代码混淆工具的基础。
编译后的 LLVM Pass 通过优化器 opt 进行加载,可以对 LLVM IR 中间代码进行分析和修改,生成新的中间代码。

LLVM Pass 框架为开发者提供了丰富的 API。开发者可以通过调用 API 方便地实现中间代码的分析和修改。
LLVM 源代码目录结构
llvm/include/llvm文件夹存放了 LLVM 提供的一些公共头文件。即我们在开发过程中可以使用的头文件。llvm/lib文件夹存放了 LLVM 大部分源代码(.cpp文件)和一些不公开的头文件。llvm/lib/Transforms文件夹存放所有 LLVM Pass 的源代码。llvm/lib/Transforms文件夹也存放了一些 LLVM 自带的 Pass。
LLVM Pass 开发环境搭建
为了方便开发我直接搭在 WSL 里面了。
首先安装 llvm 相关开发工具:
sudo apt install llvm
CLion 创建一个项目(最好手动创建然后导入 CMake 项目,因为 CLion 默认项目布局与这里所需的不同),这里命名为 OLLVM 。
➜ OLLVM tree
.
├── Build # 存放编译后 LLVM Pass
├── Test # 存放测试程序 TestProgram.cpp
│ ├── Bin # 用于存放编译好 TestProgram
│ ├── IR # 用于存放生成的 TestProgram.ll
│ └── TestProgram.cpp # 一个简单的 CTF 逆向题
├── Transforms
│ ├── CMakeLists.txt # 整个 CMake 项目的配置文件
│ ├── include # 存放整个 LLVM Pass 项目的头文件
│ └── src # 存放整个 LLVM Pass 项目的源代码
│ └── HelloWorld.cpp # HelloWorld Pass 的源代码,一般来说一个 Pass 使用一个 cpp 文件实现即可。
└── test.sh # 编译 LLVM Pass 并对 Test 文件夹中的代码进行测试5 directories, 4 files
其中 TestProgram.cpp 内容如下:
#include <cstdio>
#include <cstring>char input[100] = {0};
char enc[100] = "\x86\x8a\x7d\x87\x93\x8b\x4d\x81\x80\x8a\x43\x7f\x49\x49\x86\x71\x7f\x62\x53\x69\x28\x9d";void encrypt(unsigned char *dest, char *src) {int len = strlen(src);for (int i = 0; i < len; i++) {dest[i] = (src[i] + (32 - i)) ^ i;}
}//flag{s1mpl3_11vm_d3m0}
int main() {printf("Please input your flag: ");scanf("%s", input);unsigned char dest[100] = {0};encrypt(dest, input);bool result = strlen(input) == 22 && !memcmp(dest, enc, 22);if (result) {printf("Congratulations~\n");} else {printf("Sorry try again.\n");}return 0;
}
其中 CMakeLists.txt 内容如下:
cmake_minimum_required(VERSION 3.16) # 指定 CMake 的最低版本要求
project(OLLVM) # 定义项目名称
set(CMAKE_CXX_STANDARD 20) # C++20
find_package(LLVM REQUIRED CONFIG) # 使用 CMake 的 find_package 命令查找 LLVM ,并加载其配置,也就是后面的 CMake 相关配置参数。
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}") # 将 LLVM 的 CMake 模块路径添加到 CMAKE_MODULE_PATH 中
message("LLVM_CMAKE_DIR: ${LLVM_CMAKE_DIR}")
include(AddLLVM) # 包含 LLVM 提供的 CMake 函数和宏。
separate_arguments(LLVM_DEFINITIONS_LIST NATIVE_COMMAND ${LLVM_DEFINITIONS})
message("LLVM_DEFINITIONS: ${LLVM_DEFINITIONS_LIST}")
add_definitions(${LLVM_DEFINITIONS_LIST}) # 预定义宏定义的定义选项,用于在编译过程中控制编译器的行为。这些宏定义通常用于启用或禁用特定的功能或特性。
message("LLVM_DEFINITIONS_LIST: ${LLVM_DEFINITIONS_LIST}")
include_directories(${LLVM_INCLUDE_DIRS} "./include") # 将 LLVM 的头文件以及项目中的 include 目录添加到项目的包含路径中。
message("LLVM_INCLUDE_DIRS: ${LLVM_INCLUDE_DIRS}")
add_llvm_library(LLVMObfuscator MODULE./src/HelloWorld.cpp
) # 创建一个名为 "LLVMObfuscator" 的模块,也就是最终生成的 ELF 文件名,并将 HelloWorld.cpp 文件作为源文件添加到该模块中。
为了能让 CLion 能够正常分析代码,还需要:
- 设置 --> 构建、执行、部署 --> 工具链创建并选择 WSL 环境。
- 导入 CMakeLists.txt 并重新加载项目的 CMake 文件。
在 HelloWorld.cpp 中编写如下代码,可以看到代码 LLVM 相关变量都能够正常识别。构建项目成功生成 LLVMObfuscator.so 。
#include "llvm/IR/Function.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Pass.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
#include <map>
#include <string>struct Hello : public llvm::FunctionPass {static char ID;Hello() : FunctionPass(ID) {}bool runOnFunction(llvm::Function &F) override {llvm::errs() << "Hello: ";llvm::errs().write_escaped(F.getName()) << '\n';std::map<std::string, int> opCodeMap;int BBsize = 0;int opsize = 0;for (auto &block: F) {// 遍历每个基本块BBsize++;for (auto &opit: block) {// 遍历每条指令opsize++;opCodeMap[opit.getOpcodeName()]++;}}llvm::errs().write_escaped(F.getName()) << " has " << BBsize << " BasicBlocks and " << opsize << " opcode";for (auto &[opt, cnt]: opCodeMap)llvm::errs() << " function totally use " << opt << " " << cnt << " times \n";return false;}
};char Hello::ID = 0;// Register for opt
// 第一个参数是命令行参数,第二个参数是名字
static llvm::RegisterPass <Hello> X("hello", "Hello World Pass");// Register for clang
static llvm::RegisterStandardPasses Y(llvm::PassManagerBuilder::EP_EarlyAsPossible, [](const llvm::PassManagerBuilder &Builder, llvm::legacy::PassManagerBase &PM) { PM.add(new Hello()); });
为了方便,我们直接创建一个测试脚本 test.sh 自动编译和测试 LLVM Pass 。
#!/bin/bashcd ./Build || exit
cmake ../Transforms && make
cd ../Test || exit
clang -S -emit-llvm TestProgram.cpp -o IR/TestProgram.llopt -load ../Build/LLVMObfuscator.so -hello -S IR/TestProgram.ll -o IR/TestProgram_hlw.ll
clang IR/TestProgram_hlw.ll -o Bin/TestProgram_hlw
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_hlw
LLVM Pass 的编写
LLVM Pass 支持三种编译方式:
- 与整个 LLVM 一起重新编译,Pass 代码需要存放在
llvm/lib/Transforms文件夹中。(编译太耗时间) - 通过 CMake 对 Pass 进行单独编译。(推荐使用)
- 使用命令行对 Pass 进行单独编译。(项目越大越不好管理)
clang-15 `llvm-config-15 --cxxflags` -Wl,-znodelete -fno-rtti -fPIC -shared Hello.cpp -o LLVMHello.so `llvm-config-15 --ldflags`
LLVM 有多种类型的 Pass 可供选择,包括:ModulePass 、FuncitonPass 、CallGraphPass 、LoopPass ,这里主要使用 FuncitonPass 。
FunctionPass 以函数为单位进行处理,FunctionPass 的子类必须实现 runOnFunction(Function &F) 函数。在 FunctionPass 运行时,会对程序中的每个函数执行 runOnFunction 函数。
LLVM Pass 的编写有以下步骤:
- 创建一个类(class),继承
FunctionPass父类。 - 在创建的类中实现
runOnFunction(Function &F)函数。 - 向 LLVM 注册我们的 Pass 类。
LLVM IR 指令
LLVM IR 概述
LLVM IR 是一门低级编程语言,语法类似于汇编。任何高级编程语言(如 C++)都可以用 LLVM IR 表示,基于 LLVM IR 可以很方便地进行代码优化。
LLVM IR 共有两种表示方法:
- 第一种是人类可以阅读的文本形式,文件后缀为
.ll - 第二种是易于机器处理的二进制格式,文件后缀为
.bc

源代码被编译为 LLVM IR 后,具有以下结构:

- 模块(Module)
- 一个源代码文件对应 LLVM IR 中的一个模块。
- 头部信息包含程序的目标平台,如X86、ARM等等,和一些其他信息。
- 全局符号包含全局变量、函数的定义与声明。
- 函数(Function)
- LLVM IR 中的函数表示源代码中的某个函数。
- 参数,顾名思义为函数的参数。
- 一个函数由若干基本块组成,其中函数最先执行的基本块为入口块。
- 基本块(BasicBlock)
- 一个基本块由若干个指令和标签组成。
- 正常情况下,基本块的最后一条指令为跳转指令(br 或 switch),或返回指令(retn),也叫作终结指令(Terminator Instruction)。
- PHI 指令是一种特殊的指令。
基于 LLVM 的混淆,通常是以函数或者比函数更小的单位为基本单位进行混淆的,我们通常更关心函数和基本块这两个结构:
- 以函数为基本单位的混淆:控制流平坦化
- 以基本块基本单位的混淆:虚假控制流
- 以指令为基本单位的混淆:指令替代
终结指令 Terminator Instructions
ret 指令
函数的返回指令,对应 C/C++ 中的 return。
ret <type> <value> ; 返回特定类型返回值的return指令
ret void ; 无返回值的return指令
实例:
ret i32 5 ; 返回整数5
ret void ; 无返回值
ret { i32, i8 } { i32 4, i8 2 } ; 返回一个结构体
br 指令
br 是“分支”的英文 branch 的缩写,分为非条件分支和条件分支,对应 C/C++ 的 if 语句。
无条件分支类似于 x86 汇编中的 jmp 指令,条件分支类似于 x86 汇编中的 jnz,je 等条件跳转指令。
br i1 <cond>, label <iftrue>, label <iffalse>
br label <dest> ; 无条件分支
实例:
Test:%cond = icmp eq i32 %a, %bbr i1 %cond, label %IfEqual, label %IfUnequal
IfEqual:ret i32 1
IfUnequal:ret i32 0
switch 指令
分支指令,可看做是 br 指令的升级版,支持的分支更多,但使用也更复杂。对应 C/C++ 中的 switch 。
switch <intty> <value>, label <defaultdest> [ <intty> <val>, label <dest> ... ]
; 与条件跳转等效
%Val = zext i1 %value to i32
switch i32 %Val, label %truedest [ i32 0, label %falsedest ]; 与非条件跳转等效
switch i32 0, label %dest [ ]; 拥有三个分支的条件跳转
switch i32 %val, label %otherwise [ i32 0, label %onzeroi32 1, label %ononei32 2, label %ontwo ]
比较指令
在 x86 汇编中,条件跳转指令(jnz, je 等)通常与比较指令 cmp,test 等一起出现。
在 LLVM IR 中也有这样一类指令,他们通常与条件分支指令 br 一起出现。
icmp 指令
整数或指针的比较指令,条件 cond 可以是 eq(相等), ne(不相等), ugt(无符号大于)等等。
<result> = icmp <cond> <ty> <op1>, <op2> ; 比较整数 op1 和 op2 是否满足条件 cond
实例:
<result> = icmp eq i32 4, 5 ; yields: result=false
<result> = icmp ne ptr %X, %X ; yields: result=false
<result> = icmp ult i16 4, 5 ; yields: result=true
<result> = icmp sgt i16 4, 5 ; yields: result=false
<result> = icmp ule i16 -4, 5 ; yields: result=false
<result> = icmp sge i16 4, 5 ; yields: result=false
fcmp 指令
浮点数的比较指令。条件 cond 可以是 oeq(ordered and equal), ueq(unordered or equal), false(必定不成立)等等。ordered 的意思是,两个操作数都不能为 NAN 。
<result> = fcmp <cond> <ty> <op1>, <op2> ; 比较两个浮点数是否满足条件 cond
实例:
<result> = fcmp oeq float 4.0, 5.0 ; yields: result=false
<result> = fcmp one float 4.0, 5.0 ; yields: result=true
<result> = fcmp olt float 4.0, 5.0 ; yields: result=true
<result> = fcmp ueq double 1.0, 2.0 ; yields: result=false
二元运算 Binary Operations
add 指令
整数加法指令,对应 C/C++ 中的“+”操作符,类似x86汇编中的 add 指令。
<result> = add <ty> <op1>, <op2>
实例:
<result> = add i32 4, %var ; yields i32:result = 4 + %var
sub 指令
整数减法指令,对应 C/C++ 中的“-”操作符,类似x86汇编中的 sub 指令。
<result> = sub <ty> <op1>, <op2>
实例:
<result> = sub i32 4, %var ; yields i32:result = 4 - %var
<result> = sub i32 0, %val ; yields i32:result = -%var
mul 指令
整数乘法指令,对应 C/C++ 中的“*”操作符,类似x86汇编中的 mul 指令。
<result> = mul <ty> <op1>, <op2>
实例:
<result> = mul i32 4, %var ; yields i32:result = 4 * %var
udiv 指令
无符号整数除法指令,对应 C/C++ 中的“/”操作符。如果存在exact关键字,且 op1 不是 op2 的倍数,就会出现错误。
<result> = udiv <ty> <op1>, <op2> ; yields ty:result
<result> = udiv exact <ty> <op1>, <op2> ; yields ty:result
实例:
<result> = udiv i32 4, %var ; yields i32:result = 4 / %var
sdiv 指令
有符号整数除法指令,对应 C/C++ 中的“/”操作符。
<result> = sdiv <ty> <op1>, <op2> ; yields ty:result
<result> = sdiv exact <ty> <op1>, <op2> ; yields ty:result
实例:
<result> = sdiv i32 4, %var ; yields i32:result = 4 / %var
urem 指令
无符号整数取余指令,对应 C/C++ 中的“%”操作符。
<result> = urem <ty> <op1>, <op2> ; yields ty:result
实例:
<result> = urem i32 4, %var ; yields i32:result = 4 % %var
srem 指令
有符号整数取余指令,对应 C/C++ 中的“%”操作符。
<result> = srem <ty> <op1>, <op2> ; yields ty:result
实例:
<result> = srem i32 4, %var ; yields i32:result = 4 % %var
按位二元运算 Bitwise Binary Operations
shl 指令
整数左移指令,对应 C/C++ 中的“<<”操作符,类似x86汇编中的 shl 指令。
<result> = shl <ty> <op1>, <op2>
实例:
<result> = shl i32 4, %var ; yields i32: 4 << %var
<result> = shl i32 4, 2 ; yields i32: 16
<result> = shl i32 1, 10 ; yields i32: 1024
<result> = shl i32 1, 32 ; undefined
<result> = shl <2 x i32> < i32 1, i32 1>, < i32 1, i32 2> ; yields: result=<2 x i32> < i32 2, i32 4>
lshr 指令
整数逻辑右移指令,对应 C/C++ 中的“>>”操作符,右移指定位数后在左侧补 0 。
<result> = lshr <ty> <op1>, <op2>
实例:
<result> = lshr i32 4, 1 ; yields i32:result = 2
<result> = lshr i32 4, 2 ; yields i32:result = 1
<result> = lshr i8 4, 3 ; yields i8:result = 0
<result> = lshr i8 -2, 1 ; yields i8:result = 0x7F
<result> = lshr i32 1, 32 ; undefined
<result> = lshr <2 x i32> < i32 -2, i32 4>, < i32 1, i32 2> ; yields: result=<2 x i32> < i32 0x7FFFFFFF, i32 1>
ashr 指令
整数算数右移指令,右移指定位数后在左侧补符号位(负数的符号位为 1 ,正数的符号位为 0 )。
<result> = ashr <ty> <op1>, <op2>
实例:
<result> = ashr i32 4, 1 ; yields i32:result = 2
<result> = ashr i32 4, 2 ; yields i32:result = 1
<result> = ashr i8 4, 3 ; yields i8:result = 0
<result> = ashr i8 -2, 1 ; yields i8:result = -1
<result> = ashr i32 1, 32 ; undefined
<result> = ashr <2 x i32> < i32 -2, i32 4>, < i32 1, i32 3> ; yields: result=<2 x i32> < i32 -1, i32 0>
and 指令
整数按位与运算指令,对应 C/C++ 中的“&”操作符。
<result> = and <ty> <op1>, <op2>
实例:
<result> = and i32 4, %var ; yields i32:result = 4 & %var
<result> = and i32 15, 40 ; yields i32:result = 8
<result> = and i32 4, 8 ; yields i32:result = 0
or 指令
整数按位或运算指令,对应 C/C++ 中的“|”操作符。
<result> = or <ty> <op1>, <op2>
实例:
<result> = or i32 4, %var ; yields i32:result = 4 | %var
<result> = or i32 15, 40 ; yields i32:result = 47
<result> = or i32 4, 8 ; yields i32:result = 12
xor 指令
整数按位异或运算指令,对应 C/C++ 中的“^”操作符。
<result> = xor <ty> <op1>, <op2>
实例:
<result> = xor i32 4, %var ; yields i32:result = 4 ^ %var
<result> = xor i32 15, 40 ; yields i32:result = 39
<result> = xor i32 4, 8 ; yields i32:result = 12
<result> = xor i32 %V, -1 ; yields i32:result = ~%V
内存访问和寻址操作 Memory Access and Addressing Operations
静态单赋值 (SSA)
在编译器设计中,静态单赋值(Static Single Assignment, SSA),是 IR 的一种属性。简单来说,SSA 的特点是:在程序中一个变量仅能有一条赋值语句。
注意这里说的是静态,也就是程序的所有指令中对同一个变量不能赋值超过 1 次,但在实际运行的过程中可能多次执行同一条赋值语句对一个变量多次赋值。
LLVM IR 正是基于静态单赋值原则设计的。
在下面左边这个程序流程图中,变量 x ,y,w 都被赋值了两次,不满足 SSA。而在下面右边这个程序流程图中,所有变量都只被赋值了一次,满足 SSA 。
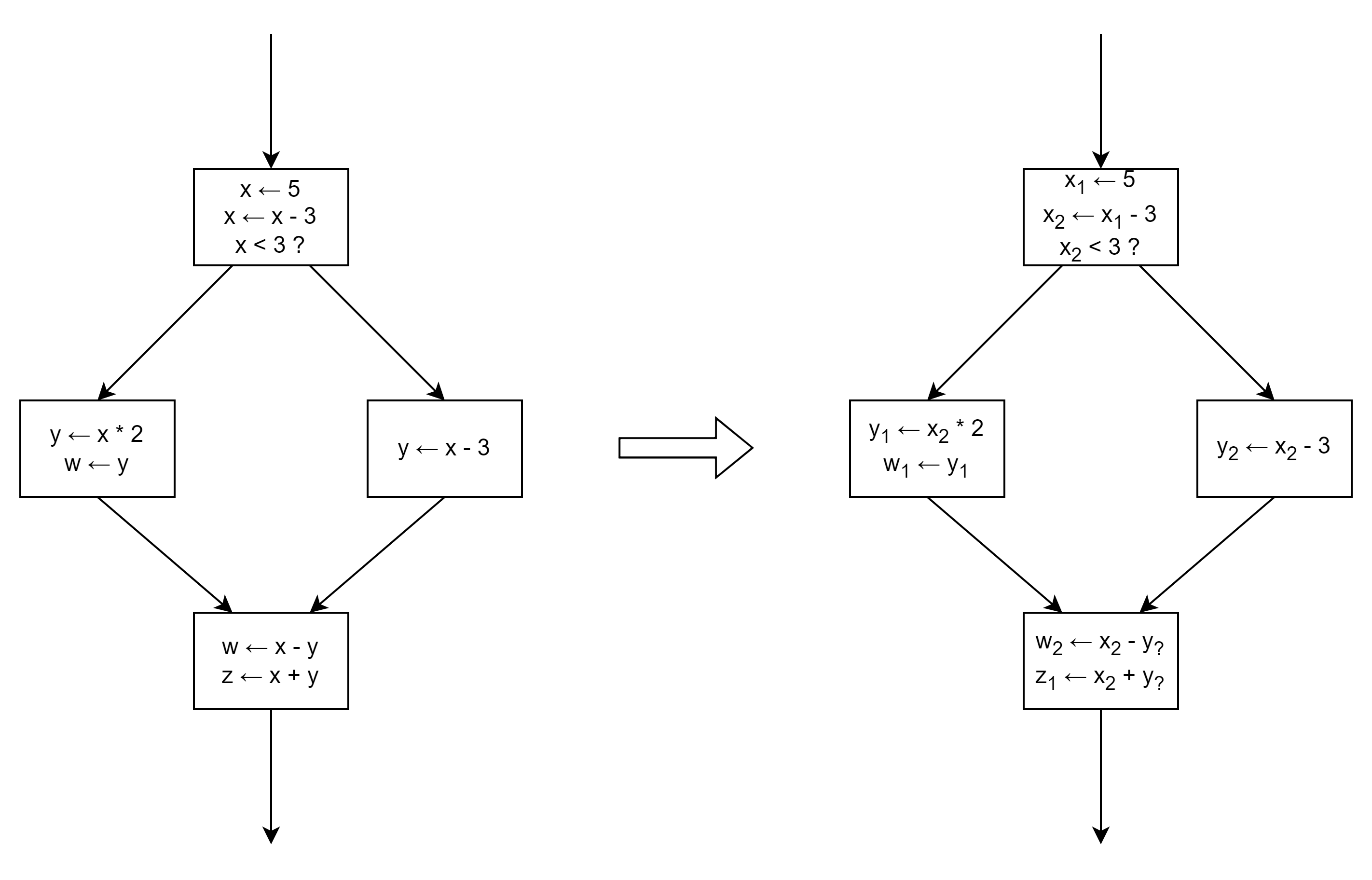
为了实现循环操作,在LLVM IR 中也有类似 malloc 和 指针操作的指令。这个指令申请的内存可以多次赋值,因为申请的内存不被认为是变量,而指向内存的指针认为是变量,指针只被 1 次赋值为内存“地址”。
这里可以把变量理解为寄存器,内存理解为实际内存。
alloca 指令
内存分配指令,在栈中分配一块空间并获得指向该空间的指针,类似于 C/C++ 中的 malloc 函数。
<result> = alloca <type> [, <ty> <NumElements>] [, align <alignment>] [, addrspace(<num>)] ; 分配 sizeof(type)*NumElements 字节的内存,分配地址与 alignment 对齐
实例:
%ptr = alloca i32 ; 分配 4 字节的内存并返回 i32 类型的指针
%ptr = alloca i32, i32 4 ; 分配 4*4 字节的内存并返回 i32 类型的指针
%ptr = alloca i32, i32 4, align 1024 ; 分配 4*4 字节的内存并返回 i32 类型的指针,分配地址与 1024 对齐
%ptr = alloca i32, align 1024 ; 分配 4 字节的内存并返回 i32 类型的指针,分配地址与 1024 对齐
store 指令
内存存储指令,向指针指向的内存中存储数据,类似于 C/C++ 中的指针解引用后的赋值操作。
store <ty> <value>, <ty>* <pointer> ; 向特定类型指针指向的内存存储相同类型的数据
实例:
%ptr = alloca i32 ; yields ptr
store i32 3, ptr %ptr ; yields void
load 指令
内存读取指令,从指针指向的内存中读取数据,类似于 C/C++ 中的指针解引用操作。
<result> = load <ty>, <ty>* <pointer> ; 从特定类型的指针指向的内存中读取特定类型的数据
实例:
%ptr = alloca i32 ; yields ptr
store i32 3, ptr %ptr ; yields void
%val = load i32, ptr %ptr ; yields i32:val = i32 3
类型转换操作 Conversion Operations
trunc … to 指令
截断指令,将一种类型的变量截断为另一种类型的变量。对应 C/C++ 中大类型向小类型的强制转换(比如 long 强转 int)
<result> = trunc <ty> <value> to <ty2> ; 将 ty 类型的变量截断为 ty2 类型的变量
实例:
%X = trunc i32 257 to i8 ; yields i8:1
%Y = trunc i32 123 to i1 ; yields i1:true
%Z = trunc i32 122 to i1 ; yields i1:false
%W = trunc <2 x i16> <i16 8, i16 7> to <2 x i8> ; yields <i8 8, i8 7>
zext … to 指令
零拓展(Zero Extend)指令,将一种类型的变量拓展为另一种类型的变量,高位补0。对应 C/C++ 中小类型向大类型的强制转换(比如 int 强转 long)
<result> = zext <ty> <value> to <ty2> ; 将 ty 类型的变量拓展为 ty2 类型的变量
实例:
%X = zext i32 257 to i64 ; yields i64:257
%Y = zext i1 true to i32 ; yields i32:1
%Z = zext <2 x i16> <i16 8, i16 7> to <2 x i32> ; yields <i32 8, i32 7>
sext … to 指令
符号位拓展(Sign Extend)指令,通过复制符号位(最高位)将一种类型的变量拓展为另一种类型的变量。
<result> = sext <ty> <value> to <ty2> ; 将 ty 类型的变量拓展为 ty2 类型的变量
实例:
%X = sext i8 -1 to i16 ; yields i16 :65535
%Y = sext i1 true to i32 ; yields i32:-1
%Z = sext <2 x i16> <i16 8, i16 7> to <2 x i32> ; yields <i32 8, i32 7>
其他操作 Other Operations
phi 指令:由静态单赋值引起的问题
在前面 SSA 举例中最后一个基本块中,我们不能确定应该使用 y1 变量还是 y2 变量,因此需要通过引入 Φ 函数来解决这个问题,Φ 函数的值由前驱块决定,这里的 Φ 函数对应 LLVM IR 中的 phi 指令:
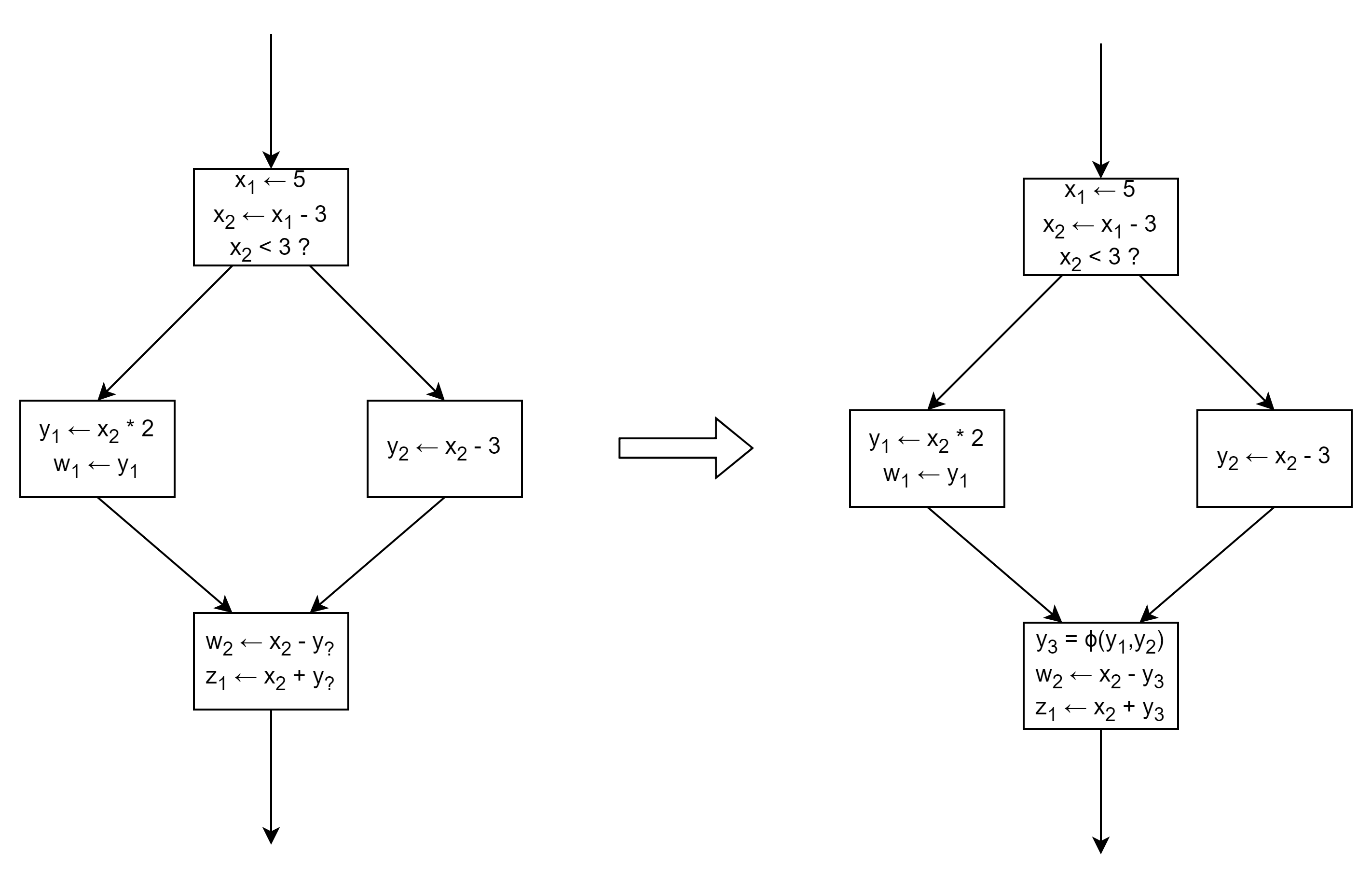
phi 指令可以看做是为了解决 SSA 一个变量只能被赋值一次而引起的问题衍生出的指令。
phi 指令的计算结果由 phi 指令所在的基本块的前驱块确定。
<result> = phi <ty> [ <val0>, <label0>], ... ; 如果前驱块为 label0 ,则 result = val0 ...
以下是一个用 phi 指令实现for循环的实例:
Loop: ; Infinite loop that counts from 0 on up...%indvar = phi i32 [ 0, %LoopHeader ], [ %nextindvar, %Loop ]%nextindvar = add i32 %indvar, 1br label %Loop
select 指令
select 指令类似于 C/C++ 中的三元运算符“… ? … : …”
<result> = select [fast-math flags] selty <cond>, <ty> <val1>, <ty> <val2> ; 如果条件 cond 成立,result = val1 ,否则 result = val2
实例:
%X = select i1 true, i8 17, i8 42 ; yields i8:17
call 指令
call 指令用来调用某个函数,对应 C/C++ 中的函数调用,与 x86 汇编中的 call 指令类似。
<result> = call <ty>|<fnty> <fnptrval>(<function args>) ; 调用函数
实例:
%retval = call i32 @test(i32 %argc) ; 调用 test 函数,番薯为 i32 类型,返回值为 i32 类型
call i32 (ptr, ...) @printf(ptr %msg, i32 12, i8 42) ; 调用 printf 函数,参数可变
LLVM Pass 常用 API
在 LLVM Pass 框架中,三个最核心的类为 Function, BasicBlock, Instruction,分别对应 LLVM IR 中的函数、基本块和指令。
注意这里介绍的只是一小部分,LLVM 的 API 种类繁杂且存在大量重载,因此最好是从代码中学习使用 API。
Function
与 Function 有关的操作主要是获取函数的一些属性,比如名称等等,以及对函数中基本块的遍历。
基本信息获取
F.getName():获取函数名称F.getEntryBlock():获取入口块
函数的创建
创建函数首先要定义函数类型,创建函数类型可以使用 llvm::FunctionType::get 参数来创建
/// This static method is the primary way of constructing a FunctionType.static FunctionType *get(Type *Result,ArrayRef<Type*> Params, bool isVarArg);/// Create a FunctionType taking no parameters.static FunctionType *get(Type *Result, bool isVarArg);
Result:函数的返回类型Params:函数的参数类型,需要传入一个元素类型为Type*的std::vector。isVarArg:是否为可变参数。- 返回值:创建的函数类型
FunctionType*
例如下面这行代码创建了一个参数为空且返回值为空的函数类型。
auto funcType = llvm::FunctionType::get(llvm::Type::getVoidTy(M.getContext()), std::vector<llvm::Type *>{}, false);
之后需要向模块注册函数,注册函数用到的 llvm::Module 的成员函数 getOrInsertFunction 。
FunctionCallee getOrInsertFunction(StringRef Name, FunctionType *T);
Name:函数名称,需要传入一个std::string类型的变量,注意不能与模块中已有的函数名重复,否则会修改模块中已有的函数。T:函数类型,是前面创建的FunctionType *。- 返回值:函数返回一个
llvm::FunctionCallee类,用于表示函数调用的封装。
最后获取函数类,利用 llvm::cast<llvm::Function> 可以将前面获取的 llvm::FunctionCallee 类转换为 llvm::Function* 。
函数中基本块的遍历
在 LLVM 中可以通过 foreach 循环对函数 Function 中的每个基本块 BasicBlock 进行遍历。
// 遍历函数 F 中的基本块 BBbool runOnFunction(llvm::Function &F) override {for (llvm::BasicBlock &BB: F) {// do something whith BB}}
BasicBlock
与 BasicBlcok 有关的操作主要是基本块的克隆、分裂、移动等,以及对基本块中指令的遍历。
基本信息的获取
BB.getName():获取基本块的名称BB.getTreminator():获取基本块的终结指令(llvm::Instruction类型)getParent():返回包含该基本块的函数(llvm::Function类型)
基本块的创建
函数原型如下:
static BasicBlock *Create(LLVMContext &Context, const Twine &Name = "",Function *Parent = nullptr,BasicBlock *InsertBefore = nullptr) {return new BasicBlock(Context, Name, Parent, InsertBefore);}
Context:LLVM 上下文对象,用于创建BasicBlock。Name:基本块的名称,作为一个可选的Twine对象。Parent:所属函数的指针,即将创建的基本块将作为该函数的一个基本块。InsertBefore:将新创建的基本块插入到该参数所指定的基本块之前,作为一个可选的参数。- 返回值:新创建的基本块的指针。
基本块的分裂
函数原型如下:
BasicBlock *splitBasicBlock(iterator I, const Twine &BBName = "");BasicBlock *splitBasicBlock(Instruction *I, const Twine &BBName = "") {return splitBasicBlock(I->getIterator(), BBName);}
I:可以是一个迭代器,也可以是一个指令指针。、BBName:分裂出来的- 返回值:分裂出的后一个基本块。
函数会将指定位置之前的指令保留在原始基本块中,为原始基本块添加一个无条件分支指令,并将原始基本块中指定位置之后的指令移动到新创建的基本块中(包括原始基本块的终止指令)。最后,函数返回新创建的基本块的指针。
基本块的克隆
函数定义:
BasicBlock *CloneBasicBlock(const BasicBlock *BB, ValueToValueMapTy &VMap,const Twine &NameSuffix = "", Function *F = nullptr,ClonedCodeInfo *CodeInfo = nullptr,DebugInfoFinder *DIFinder = nullptr);
const BasicBlock *BB:要克隆的基本块。ValueToValueMapTy &VMap:值映射表,用于记录原基本块和克隆基本块之间的指令和值的对应关系。const Twine &NameSuffix = "":可选参数,用于为克隆基本块的名称添加后缀。Function *F = nullptr:可选参数,用于指定要将克隆基本块插入的函数。如果未指定,则克隆基本块不会自动插入到任何函数中。- 返回值:克隆的基本块。
例如下面这行代码就可以获取基本块 BB 克隆出来的 cloneBB 。
auto cloneBB = llvm::CloneBasicBlock(BB, VMap, "cloneBB", BB->getParent());
基本块的移动
虽然理论上最终代码只与基本块的逻辑关系(分支跳转)有关,但是基本块在 llvm::Function 中的位置关系错误会导致编译错误。因此需要确保基本块的前后顺序与逻辑顺序基本一致(至少保证入口块和返回块在开头和结尾)。
基本块 llvm::BasicBlock 中有如下三个成员函数可以完成基本块的移动。
/// Unlink this basic block from its current function and insert it into/// the function that \p MovePos lives in, right before \p MovePos.void moveBefore(BasicBlock *MovePos);/// Unlink this basic block from its current function and insert it/// right after \p MovePos in the function \p MovePos lives in.void moveAfter(BasicBlock *MovePos);/// Insert unlinked basic block into a function.////// Inserts an unlinked basic block into \c Parent. If \c InsertBefore is/// provided, inserts before that basic block, otherwise inserts at the end.////// \pre \a getParent() is \c nullptr.void insertInto(Function *Parent, BasicBlock *InsertBefore = nullptr);
基本块中指令的遍历
在 LLVM 中可以通过 foreach 循环对基本块 BasickBlock 中的每个指令 Instruction 进行遍历。
// 遍历函数 F 中的基本块 BB 的所有指令 Ibool runOnFunction(llvm::Function &F) override {for (llvm::BasicBlock &BB: F) {for (llvm::Instruction &I: BB) {// do something whith I}}}
Instruction
指令可以有很多种,亦即 Instruction 类可以拥有多个子类,如:BinaryOpterator, AllocaInst, BranchInst 等。与 Instruction 有关的操作主要是指令的创建、删除、修改以及指令中操作数的遍历:
指令的创建
指令的创建方式与具体指令的类型有关,有的指令的创建可以直接通过 new 指令类型创建,有的指令的创建需要调用指令对应的 Create 函数创建。
BranchInst
LLVM 的分支指令通过 Create 函数创建,该函数有多个重载形式的实现。
static BranchInst *Create(BasicBlock *IfTrue,Instruction *InsertBefore = nullptr) {return new(1) BranchInst(IfTrue, InsertBefore);}static BranchInst *Create(BasicBlock *IfTrue, BasicBlock *IfFalse,Value *Cond, Instruction *InsertBefore = nullptr) {return new(3) BranchInst(IfTrue, IfFalse, Cond, InsertBefore);}static BranchInst *Create(BasicBlock *IfTrue, BasicBlock *InsertAtEnd) {return new(1) BranchInst(IfTrue, InsertAtEnd);}static BranchInst *Create(BasicBlock *IfTrue, BasicBlock *IfFalse,Value *Cond, BasicBlock *InsertAtEnd) {return new(3) BranchInst(IfTrue, IfFalse, Cond, InsertAtEnd);}
AllocaInst
AllocaInst 是 LLVM 中用于分配栈内存的指令类。它用于在函数中创建局部变量或数组。常用构造函数如下:
explicit AllocaInst(Type *Ty, unsigned AddrSpace,Value *ArraySize = nullptr,const Twine &Name = "",Instruction *InsertBefore = nullptr);AllocaInst(Type *Ty, unsigned AddrSpace, Value *ArraySize,const Twine &Name, BasicBlock *InsertAtEnd);AllocaInst(Type *Ty, unsigned AddrSpace,const Twine &Name, Instruction *InsertBefore = nullptr);AllocaInst(Type *Ty, unsigned AddrSpace,const Twine &Name, BasicBlock *InsertAtEnd);AllocaInst(Type *Ty, unsigned AddrSpace, Value *ArraySize, MaybeAlign Align,const Twine &Name = "", Instruction *InsertBefore = nullptr);AllocaInst(Type *Ty, unsigned AddrSpace, Value *ArraySize, MaybeAlign Align,const Twine &Name, BasicBlock *InsertAtEnd);
StoreInst
常用的构造函数如下:
StoreInst(Value *Val, Value *Ptr, Instruction *InsertBefore);StoreInst(Value *Val, Value *Ptr, BasicBlock *InsertAtEnd);
LoadInst
常用的构造函数如下:
LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr = "", Instruction *InsertBefore = nullptr);LoadInst(Type *Ty, Value *Ptr, const Twine &NameStr, BasicBlock *InsertAtEnd);
SwitchInst
常用的构造函数如下:
static SwitchInst *Create(Value *Value, BasicBlock *Default,unsigned NumCases,Instruction *InsertBefore = nullptr) {return new SwitchInst(Value, Default, NumCases, InsertBefore);}static SwitchInst *Create(Value *Value, BasicBlock *Default,unsigned NumCases, BasicBlock *InsertAtEnd) {return new SwitchInst(Value, Default, NumCases, InsertAtEnd);}
指令的删除
eraseFromParent() 用于将指令从所在的基本块中删除。
指令中操作数的遍历
在 LLVM 中可以通过 for 循环对指令 Instruction 中的每个操作数 Value* 进行遍历。
// 遍历函数 F 中的基本块 BB 的所有指令 I 的所有操作数 Vbool runOnFunction(llvm::Function &F) override {for (llvm::BasicBlock &BB: F) {for (llvm::Instruction &I: BB) {for (int i = 0; i < I.getNumOperands(); i++) {llvm::Value *V = I.getOperand(i);// do somthing whith V}}}}
Value
所有可以被当做指令操作数的类型都是 Value 的子类,Value 有以下五种类型的子类。
- 常量:Constant
- 参数:Argument
- 指令(的运算结果):Instruction
- 函数(的指针):Function
- 基本块:BasicBlock
输出流
在 C++ 中我们可以通过 cout, cerr, clog 输出流来进行打印,在 LLVM 中则建议使用 outs(), errs(), dbgs() 三个函数来获取输出流,然后打印。
类型相关
isa<>:是一个模板函数,用于判断一个指针指向的数据的类型是不是给定的类型,类似于 Java 中的 instanceof 。cast_retty<>:类型转换,尝试把传入的指针转换为给定类型,如果无法转换则返回nullptr。
其他
llvm::RegisterPass:是 LLVM 中用于注册 Pass 的辅助类。它提供了一种简单的方式来将自定义的 Pass 类注册到 LLVM Pass 管理系统中,以便在编译过程中被正确地加载和使用。RegisterPass 的使用方式如下:static llvm::RegisterPass <Hello> X("hello", "Hello World Pass");Hello:要注册的 PassX:llvm::RegisterPass的实例化,名称X是一种常见的约定,也可以设为其他名称。"hello":Pass 对应参数的命令行标识"Hello World Pass":Pass 的描述
llvm::cl::opt:注册并获取命令行中的可选参数。static llvm::cl::opt<size_t> splitNum("split_num", llvm::cl::init(2), llvm::cl::desc("Split <split_num> time(s) each BB"));size_t:参数类型splitNum:在传入的参数,代码中类型转换一下可以当做一个常量使用。split_num:参数的命令行标识llvm::cl::init(2):参数的默认值,这里是 2llvm::cl::desc("Split <split_num> time(s) each BB"):参数的描述
LLVM 部分官方文档介绍
LLVM 官方文档链接
LLVM Design & Overview
- Introduction to the LLVM Compiler:LLVM 的设计理念,与老编译器相比的优势等等。
- Intro to LLVM:主要是对 LLVM 编译过程的介绍。
- LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation:对 LLVM 的详细介绍(论文)
Documentation
- Getting Started/Tutorials
- Getting Started with the LLVM System:环境搭建和目录结构讲解
- LLVM Programmer’s Manual:一些常用的函数/类的介绍(重要)
- Getting Started with the LLVM System using Microsoft Visual Studio:Windows 下 LLVM 的编译和使用
- User Guides
- LLVM Builds and Distributions:与编译 LLVM 相关的一些教程
- Optimizations
- Writing an LLVM Pass:LLVM Pass 入门教程
- LLVM’s Analysis and Transform Passes:介绍 LLVM 自带的一些优化/分析 Pass
- MergeFunctions pass, how it works:如何使用 LLVM Pass 实现识别并合并相同功能的函数
- MemorySSA:静态单赋值更详细的介绍
- LLVM Loop Terminology (and Canonical Forms):介绍 LLVM 中有关循环的一些术语
- Reference
- Doxygen generated documentation:LLVM API 集大成的文档
- LLVM Command Guide:LLVM 命令行指令介绍
- LLVM Language Reference Manual:LLVM IR 值各种指令的定义,用法以及一些内置函数的介绍
代码混淆基本原理
术语介绍
代码混淆
代码混淆是将计算机程序的代码,转换成一种功能上等价,但是难以阅读和理解的形式的行为。
函数
函数是代码混淆的基本单位,一个函数由若干个基本块组成,有且仅有一个入口块,可能有多个出口块。
一个函数可以用一个控制流图(Control Flow Graph, CFG)表示。
基本块
基本块由一组线性指令组成,每一个基本块都有一个入口点(第一条执行的指令)和一个出口点(最后一条执行的指令,亦即终结指令)。
终结指令要么跳转到另一个基本块(br, switch),要么从函数返回(ret)。
控制流
控制流代表了一个程序在执行过程中可能遍历到的所有路径。
通常情况下,程序的控制流很清晰地反映了程序的逻辑,但经过混淆的控制流会使得人们难以分辨正常逻辑。
不透明谓词
不透明谓词指的是其值为混淆者明确知晓,而反混淆者却难以推断的变量。
例如混淆者在程序中使用一个恒为 0 的全局变量,反混淆者难以推断这个变量恒为 0 。
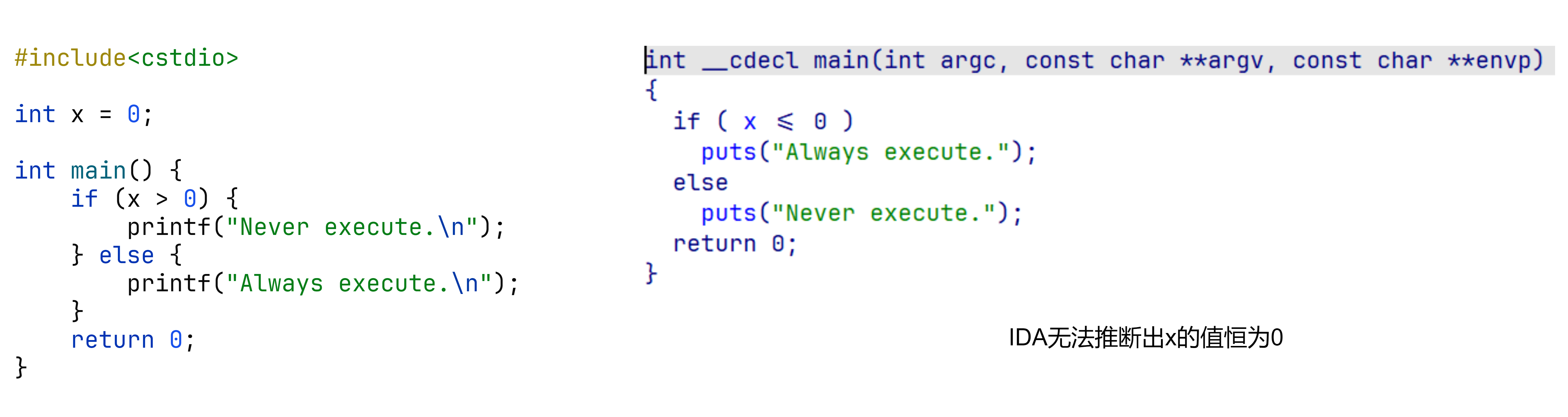
常见混淆思路
符号混淆
将函数的符号,如函数名、全局变量名去除或者混淆。对于 ELF 文件可以通过 strip 指令去除符号表完成。
控制流混淆
控制流混淆指的是混淆程序正常的控制流,使其在功能保持不变的情况下不能清晰地反映原程序的正常逻辑。
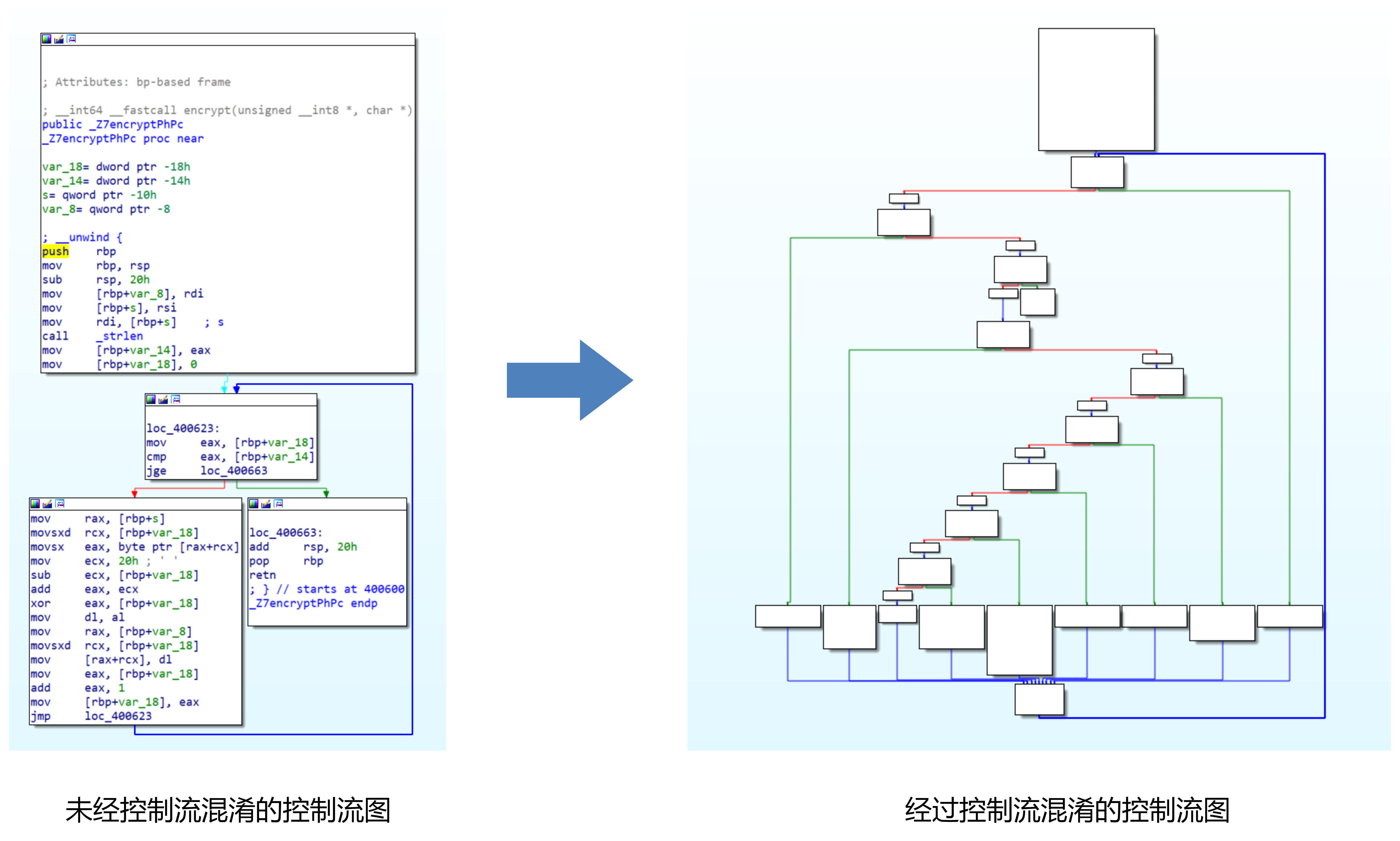
控制流混淆有:控制流平坦化、虚假控制流、随机控制流。
计算混淆
计算混淆指的是混淆程序的计算流程,或计算流程中使用的数据,使分析者难以分辨某一段代码所执行的具体计算。
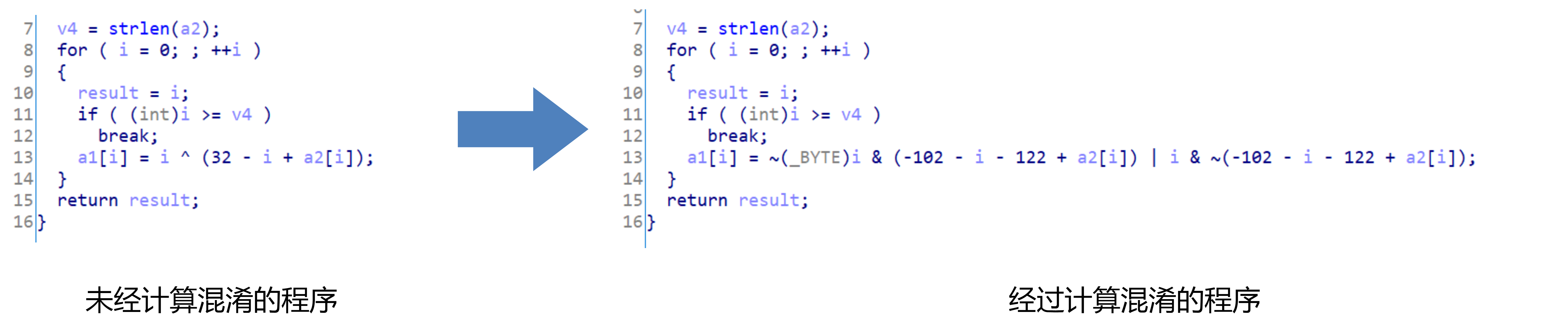
计算混淆有:指令替代、常量替代。
虚拟机混淆
虚拟机混淆的思想是将一组指令集合(如一组 x86 指令),转化为一组攻击者未知的自定义指令集。并用与程序绑定的解释器解释执行。虚拟机混淆代表:VMProtect。
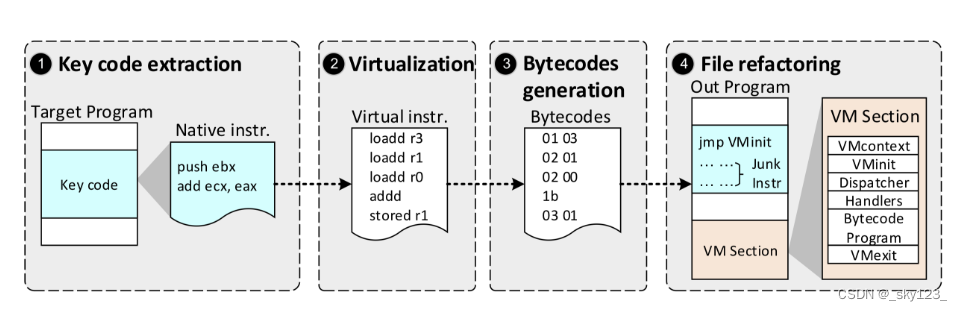
虚拟机混淆是目前最强力的混淆,但也有许多缺点:如性能损耗大、容易被杀毒软件报毒等。
经典代码混淆工具 Ollvm
OLLVM 介绍
Obfuscator-LLVM(简称OLLVM)是2010年6月由瑞士西部应用科学大学(HEIG-VD)的信息安全小组发起的一个项目。 这个项目的目的是提供一个 LLVM 编译套件的开源分支,能够通过代码混淆和防篡改提供更高的软件安全性。
OLLVM 提供了三种经典的代码混淆:
- 控制流平坦化 Control Flow Flattening
- 虚假控制流 Bogus Control Flow
- 指令替代 Instruction Subsititution
OLLVM 在国内移动安全的使用非常广泛,虽然 OLLVM 已于2017年停止更新,并且到目前为止,三种代码混淆方式均已有成熟的反混淆手段 。但是 OLLVM 的各种变体仍然在被开发和使用,OLLVM 至今仍有很大的学习价值。
环境搭建
编译 ollvm
先将 GitHub 上的 ollvm 下载下来。
git clone -b llvm-4.0 https://github.com/obfuscator-llvm/obfuscator.git
创建文件夹,作为编译 ollvm 的目录。
mkdir ollvm
cd ollvm
加载 ollvm 项目。
cmake -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF ~/obfuscator
然后编译项目。
make -j4
ubuntu18.04 我的环境是直接编译成功了,但是对于 ubuntu20.04 ,我这里遇到了两个报错。
第一个报错:

这个错误是因为本机的 gcc 和 g++ 版本是 9.x.x ,改为 8.x.x 就好了。
安装 8.x.x 的编译器
sudo apt-get install gcc-8 g++-8 -y
利用 linux 软件版本管理命令 update-alternatives 更改优先级。
先要在 update-alternatives 工具中注册
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 8
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-8 8
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 9
gcc 切换版本 默认gcc 8
sudo update-alternatives --config gcc

gcc 版本已成功切换

同理, g++ 切换版本 默认g++ 8
sudo update-alternatives --config g++
第二个报错:

貌似也是编译器版本的问题,不过可以通过修改源码解决。
首先找到出错的位置
sudo gedit ~/obfuscator/include/llvm/ExecutionEngine/Orc/OrcRemoteTargetClient.h
修改 char 为 uint8_t 即可。

最后编译生成的 clang 在 bins 目录下。
添加字符串加密模块
这里采用上海交大密码与计算机安全实验室GoSSIP小组设计的基于LLVM 4.0的孤挺花混淆框架。
首先找到字符串加密模块
提取出该文件,放到 obfuscator 相同目录下

在 Obfuscation下的 CMakeLists.txt 将 StringObfuscation.cpp 添加到编译库中
在 include/llvm/Transforms/Obfuscation下增加字符串混淆的头文件 StringObfuscation.h

内容为:
namespace llvm {Pass* createStringObfuscation(bool flag);
}
最后只需要在 /lib/Transforms/IPO 下的 PassManagerBuilder.cpp 将字符串加密的编译选项添加进去即可
-
添加
#include "llvm/Transforms/Obfuscation/StringObfuscation.h"引用 -
在合适的地方插入以下两条函数声明,即编译时的编译参数 -mllvm -sobf :
static cl::opt<std::string> Seed("seed", cl::init(""),cl::desc("seed for the random"));static cl::opt<bool> StringObf("sobf", cl::init(false),cl::desc("Enable the string obfuscation")); -
在 PassManagerBuilder::PassManagerBuilder() 构造函数中添加随机数因子的初始化
//添加随机数因子的初始化 if(!Seed.empty()) {if(!llvm::cryptoutils->prng_seed(Seed.c_str()))exit(1); }

-
最后将该 pass 添加进 void PassManagerBuilder::populateModulePassManager 中即可
MPM.add(createStringObfuscation(StringObf));注意别加到前面的 if 判断中。

最后重新进行前面的编译过程即可。
基本用法
控制流平坦化(Control Flow Flattening)
可用选项:
-mllvm -fla:激活控制流平坦化-mllvm -split:激活基本块分割-mllvm -split_num=3:指定基本块分割的数目,这里一个基本款会被分割成 3 个基本块后再进行控制流平坦化混淆
示例:
clang -mllvm -fla -mllvm -split -mllvm -split_num=3 TestProgram.cpp -o TestProgram_fla
注意在编译时可能出现 stddef.h 和 stdarg.h 头文件不存在的错误,可以使用 locate stddef.h 和 locate stdarg.h 指令找到这两个头文件的位置,然后复制到 /usr/include 或 /usr/local/include 目录下。
虚假控制流(Bogus Control Flow)
可用选项:
-mllvm -bcf:激活虚假控制流-mllvm -bcf_loop=3:混淆次数,这里一个函数会被混淆 3 次,默认为 1-mllvm -bcf_prob=40:每个基本块被混淆的概率,这里每个基本块被混淆的概率为 40% ,默认为 30
示例:
clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40 TestProgram.cpp -o TestProgram_bcf
指令替换(Instruction Substitution)
-mllvm -sub:激活指令替代-mllvm -sub_loop=3:混淆次数,这里一个函数会被混淆 3 次,默认为 1
示例:
clang -mllvm -sub -mllvm -sub_loop=3 TestProgram.cpp -o TestProgram_sub
字符串加密
-mllvm -sobf:编译时候添加选项开启字符串加密
示例:
clang -mllvm -sobf TestProgram.cpp -o TestProgram_sobf
开启字符串加密后程序中的字符串被加密并且在 .init_array 中注册了一个 datadiv_decode10546244579238992864 函数用于在 main 函数执行前解密所有的字符串。
__int64 datadiv_decode10546244579238992864()
{__int64 result; // raxunsigned int v2; // [rsp+8h] [rbp-28h]unsigned int v4; // [rsp+14h] [rbp-1Ch]unsigned int v6; // [rsp+20h] [rbp-10h]unsigned int v8; // [rsp+2Ch] [rbp-4h]v8 = 0;doformat[v8] ^= 0xE8u;while ( v8++ < 0x18 );v6 = 0;doasc_4040D9[v6] ^= 0x2Du;while ( v6++ < 2 );v4 = 0;dobyte_4040E0[v4] ^= 0x81u;while ( v4++ < 0x11 );v2 = 0;do{aVjww[v2] ^= 0x25u;result = v2 - 17;}while ( v2++ < 0x11 );return result;
}
基本块分割
基本块分割即将一个基本块分割为等价的若干个基本块,在分割后的基本块之间加上无条件跳转。基本块分割不能算是混淆,因为后续的代码优化会将分割的基本块重新合并,但是由于许多代码混淆是基于基本块的,增加基本块的数量会显著增强代码混淆效果。
这里我们实现一个名为 SplitBasicBlock 的基本块分割 Pass 。
首先我们需要为基本块分割注册
// 可选的参数,指定一个基本块会被分裂成几个基本块,默认值为 2
static llvm::cl::opt<size_t> splitNum("split_num", llvm::cl::init(2), llvm::cl::desc("Split <split_num> time(s) each BB"));
runOnFunction 首先把要分割的基本块的地址事先存放在 origBB 中,因为基本块分割会改变 F 中的基本块,如果直接遍历 F 中的基本块会出问题(例如调用 splitBasicBlock 分割一个基本块,那么遍历的下一个基本块就是分割出来的基本块)。
之后遍历 origBB 中保存的基本块,如果基本块中不含 phi 指令则将该调用 split 函数分割基本块。
bool SplitBasicBlock::runOnFunction(llvm::Function &F) {std::vector < llvm::BasicBlock * > origBB;std::for_each(F.begin(), F.end(), [&](auto &BB) {origBB.emplace_back(&BB);});std::for_each(origBB.begin(), origBB.end(), [&](auto BB) {if (!containsPHI(BB)) {split(BB);}});return true;
}
containsPHI 函数会遍历基本块中的指令,通过 isa<> 判断指令类型是否为 phi 指令。
bool SplitBasicBlock::containsPHI(llvm::BasicBlock *BB) {return std::find_if(BB->begin(), BB->end(), [&](auto &I) {return llvm::isa<llvm::PHINode>(&I);}) != BB->end();
}
split 函数计算出要分割出的基本块的大小,然后调用 splitBasicBlock 函数分割基本块。
void SplitBasicBlock::split(llvm::BasicBlock *BB) {size_t splitSize = std::max(1UL, (BB->size() + splitNum - 1) / splitNum);auto curBB = BB;for (int i = 1; i < (BB->size() + splitSize - 1) / splitSize; i++) {auto it = curBB->begin();std::advance(it, std::min(splitSize, curBB->size()));curBB = curBB->splitBasicBlock(&*it);}
}
test.sh 添加如下命令测试 SplitBasicBlock 的基本块分割效果。
opt -load ../Build/LLVMObfuscator.so -split -split_num=10 -S IR/TestProgram.ll -o IR/TestProgram_split.ll
clang IR/TestProgram_split.ll -o Bin/TestProgram_split
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_split
控制流平坦化
控制流平坦化概述
什么是控制流平坦化
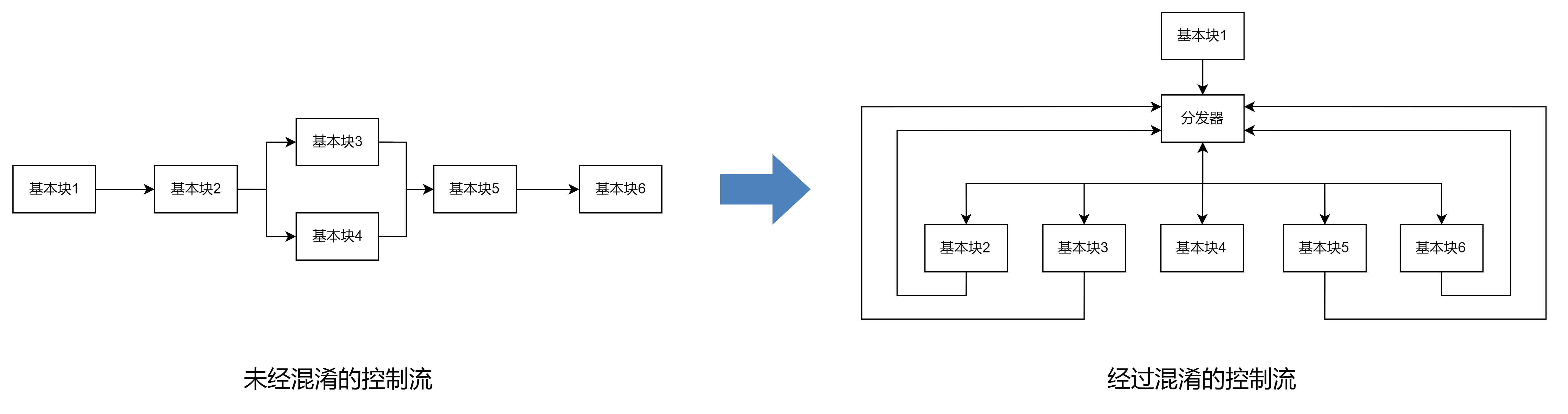
控制流平坦化指的是将正常控制流中基本块之间的跳转关系删除,用一个集中的分发块来调度基本块的执行顺序。
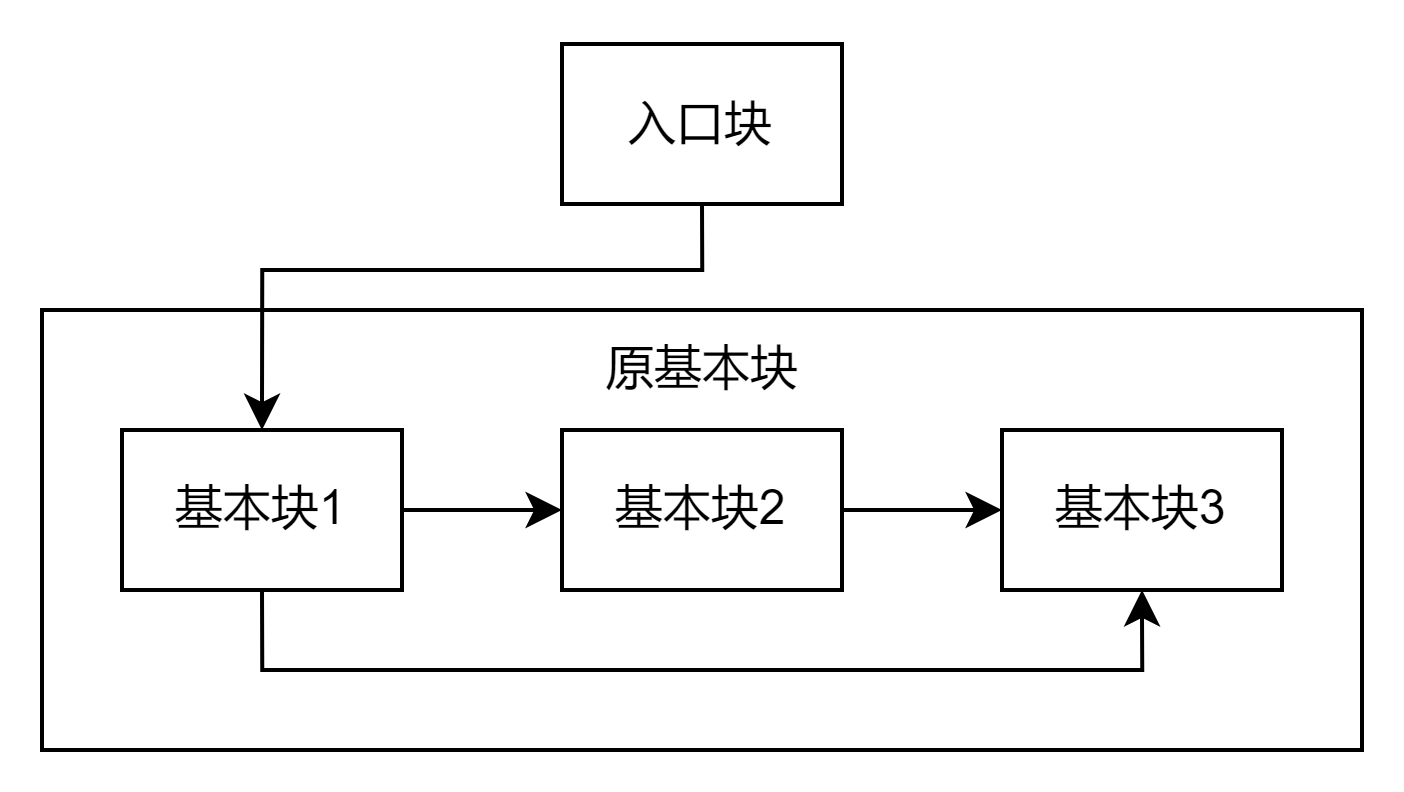
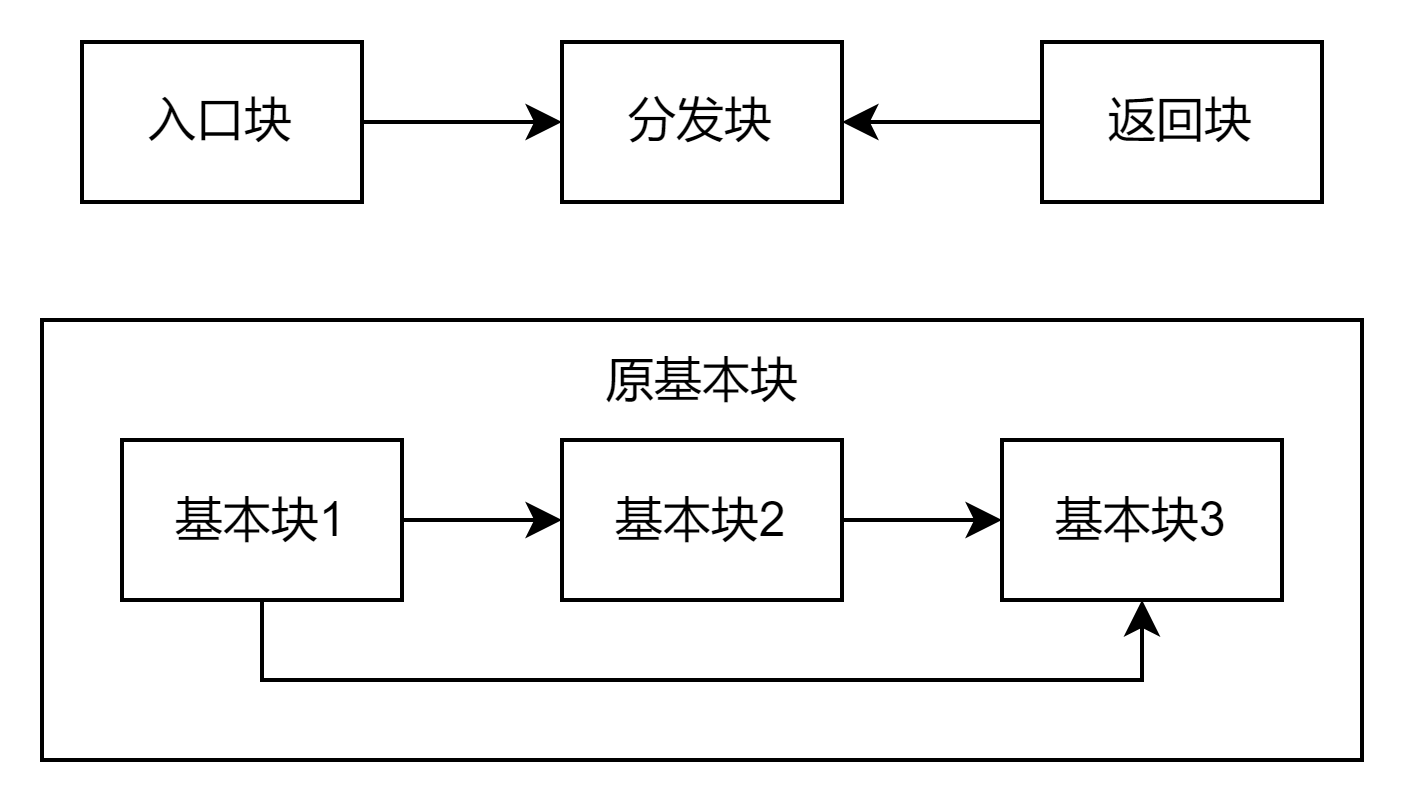
控制流平坦化结构

- 入口块:进入函数第一个执行的基本块。
- 主分发块与子分发块:负责跳转到下一个要执行的原基本块。(本质是一个 swtich,由于 case 值不连续因此被编译器优化为类似平衡树的 if-else 嵌套)
- 原基本块:混淆之前的基本块,真正完成程序工作的基本块。
- 返回块:返回到主分发块。
控制流平坦化的混淆效果
当我们分析正常的控制流时,我们能很容易的分析出程序的执行顺序,以及每一段代码完成的工作(一段代码可能由多个互相关联的基本块组成),进而掌握整个程序的逻辑。
而当我们分析平坦化后的控制流时,在不知道基本块执行顺序的情况下,分别对每一个基本块进行分析是很难的,而如果要得知每一个基本块的执行顺序,必须分析分发块的调度逻辑。
实际上当函数比较复杂的时候,通过手动分析分发块还原原基本块的执行顺序是非常复杂的。
控制流平坦化混淆后的伪代码,while + switch 结构对应平坦化后的控制流结构。

代码实现思路
控制流平坦化是以函数为单位进行混淆的。
第一步:保存原基本块
将除入口块以外的以外的基本块保存到 vector 容器中,方便后续处理。
如果入口块的终结指令是条件分支指令,则将该指令单独分离出来作为一个基本块,加入到 vector 容器的最前面。
// 第一步,保存除入口块以外的基本块。std::vector<llvm::BasicBlock *> origBB;auto enrtyBB = &F.getEntryBlock();for (auto &BB: F) {if (&BB == enrtyBB) {auto br = llvm::dyn_cast<llvm::BranchInst>(BB.getTerminator());if (br && br->isConditional()) {BB.splitBasicBlock(br);}} else {origBB.emplace_back(&BB);}}assert(enrtyBB->getTerminator()->getSuccessor(0) == origBB[0]);
第二步:创建分发块和返回块
除了原基本块之外,我们还要续创建一个分发块来调度基本块的执行顺序。并建立入口块到分发块的绝对跳转。
再创建一个返回块,原基本块执行完后都需要跳转到这个返回块,返回块会直接跳转到分发块。
// 第二步,创建分发块和返回块。auto Context = &F.getContext();auto dispatchBB = llvm::BasicBlock::Create(*Context, "dispatchBB", &F, enrtyBB);auto returnBB = llvm::BasicBlock::Create(*Context, "returnBB", &F, enrtyBB);enrtyBB->moveBefore(dispatchBB);enrtyBB->getTerminator()->eraseFromParent();llvm::BranchInst::Create(dispatchBB, enrtyBB);llvm::BranchInst::Create(dispatchBB, returnBB);
第三步:实现分发块调度
在入口块中创建并初始化 switch 变量,在调度块中插入 switch 指令实现分发功能。
将原基本块移动到返回块之前,并分配随机的 case 值,并将其添加到 switch 指令的分支中。
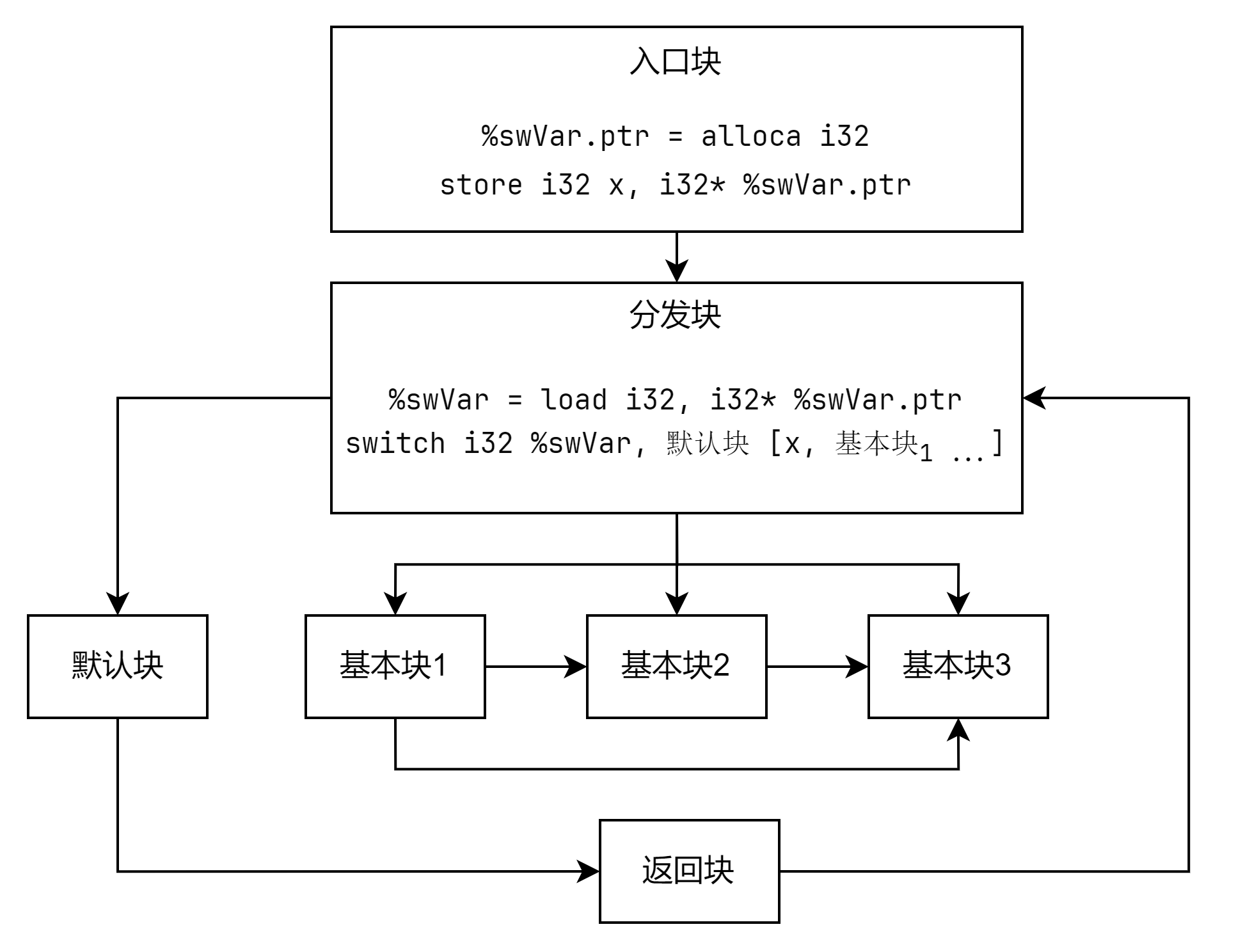
这里默认块实际上是用不到的,但是 switch 指令需要有一个基本块作为默认跳转的目标,为了方便这里创建了一个默认块。
// 第三步,实现分发块的调度功能std::set<uint32_t> set;while (set.size() < origBB.size()) {set.insert(rnd());}int randNumIndex = 0;std::vector<uint32_t> randNumCases{set.begin(), set.end()};std::shuffle(randNumCases.begin(), randNumCases.end(), rnd);auto swVarPtr = new llvm::AllocaInst(llvm::Type::getInt32Ty(*Context), 0, "swVar.ptr", enrtyBB->getTerminator());new llvm::StoreInst(llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), randNumCases[randNumIndex]), swVarPtr, enrtyBB->getTerminator());auto *swVar = new llvm::LoadInst(llvm::Type::getInt32Ty(*Context), swVarPtr, "swVar", dispatchBB);auto defaultBB = llvm::BasicBlock::Create(*Context, "defaultBB", &F, returnBB);llvm::BranchInst::Create(returnBB, defaultBB);auto swInst = llvm::SwitchInst::Create(swVar, defaultBB, 0, dispatchBB);for (auto BB: origBB) {BB->moveBefore(returnBB);swInst->addCase(llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), randNumCases[randNumIndex++]), BB);}
第四步:实现调度变量自动调整
在每个原基本块最后添加修改 switch 变量值的指令,以便返回分发块之后,能够正确执行到下一个基本块。
删除原基本块末尾的跳转,使其结束执行后跳转到返回块。
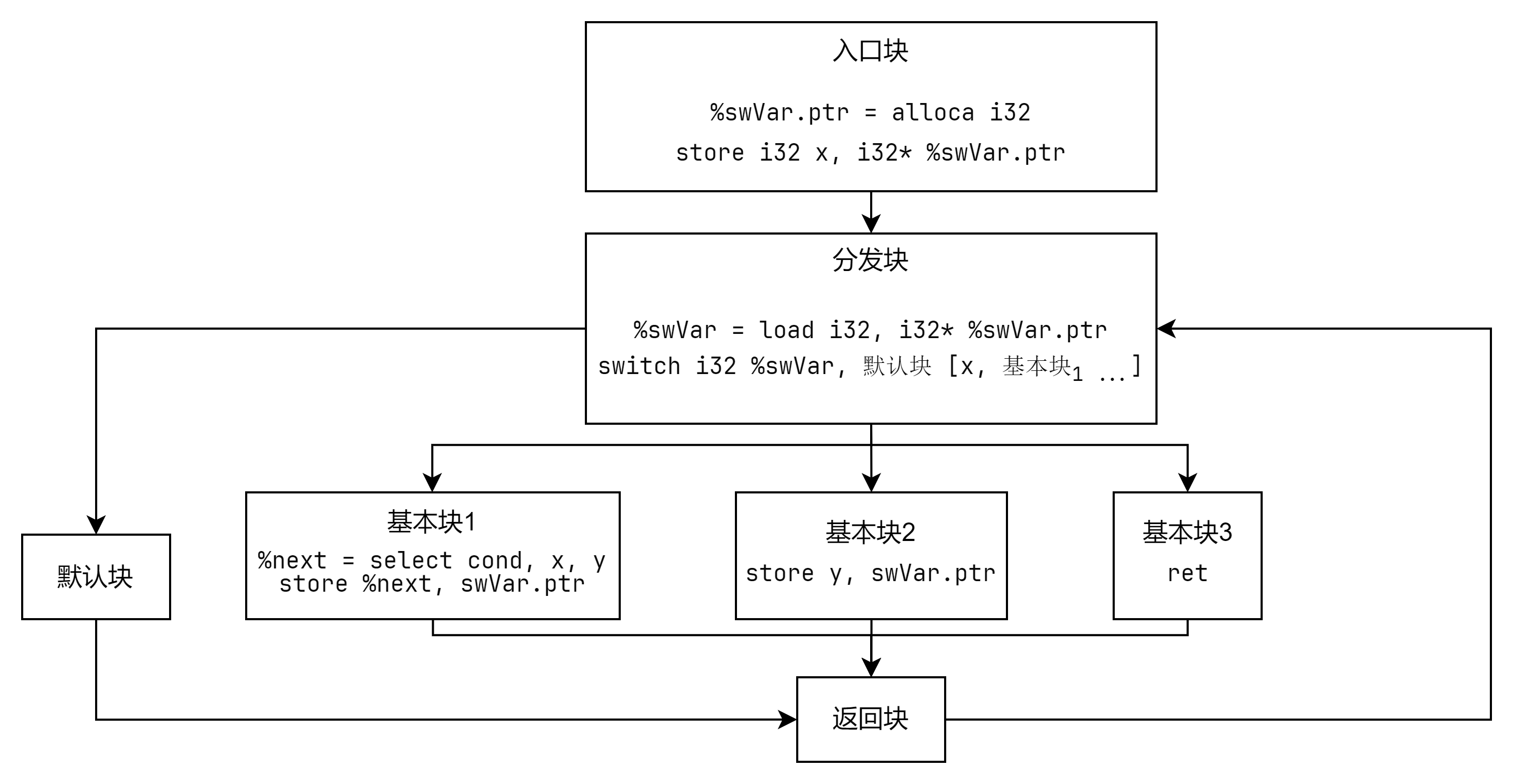
// 第四步,实现 switch 变量的修改for (auto BB: origBB) {if (BB->getTerminator()->getNumSuccessors() == 0) {continue;} else if (BB->getTerminator()->getNumSuccessors() == 1) {auto numCase = swInst->findCaseDest(BB->getTerminator()->getSuccessor(0));new llvm::StoreInst(numCase, swVarPtr, BB->getTerminator());BB->getTerminator()->eraseFromParent();llvm::BranchInst::Create(returnBB, BB);} else if (BB->getTerminator()->getNumSuccessors() == 2) {auto numCase1 = swInst->findCaseDest(BB->getTerminator()->getSuccessor(0));auto numCase2 = swInst->findCaseDest(BB->getTerminator()->getSuccessor(1));auto br = llvm::dyn_cast<llvm::BranchInst>(BB->getTerminator());auto selInst = llvm::SelectInst::Create(br->getCondition(), numCase1, numCase2, "", BB->getTerminator());new llvm::StoreInst(selInst, swVarPtr, BB->getTerminator());BB->getTerminator()->eraseFromParent();llvm::BranchInst::Create(returnBB, BB);} else {assert(false);}}
第五步:修复 PHI 指令和逃逸变量
PHI 指令的值由前驱块决定,平坦化后所有原基本块的前驱块都变成了分发块,因此 PHI 指令发生了损坏。
逃逸变量指在一个基本块中定义,并且在另一个基本块被引用的变量。在原程序中某些基本块可能引用之前某个基本块中的变量,平坦化后原基本块之间不存在确定的前后关系了(由分发块决定),因此某些变量的引用可能会损坏。
判断一个指令是否含有逃逸变量的方法如下:
- 如果一条指令位于入口块并且该指令为
alloca指令则该指令一定不含逃逸变量。这是因为alloca指令用于在函数的栈帧上分配内存,而栈帧是局部于函数的。在函数的入口块中分配的内存不会逃逸到函数外部的作用域,因此这样的指令不会包含逃逸变量。这个条件的目的是排除那些在入口块中分配的局部变量。 - 否则如果该指令在其他基本块中也被使用过则该指令可能含有逃逸变量。因为如果一条指令在其他基本块中被使用,那么它的值可能在函数外部被引用或使用。这意味着该指令的结果可能逃逸到函数外部,因此被使用的指令被认为是含有逃逸变量的。
修复的方法是,将 PHI 指令和逃逸变量都转化为内存存取指令。LLVM 提供了 DemotePHIToStack 和 DemoteRegToStack 函数用于修复上述情况。
void llvm::fixStack(llvm::Function &F) {std::vector < llvm::PHINode * > origPHI;std::vector < llvm::Instruction * > origReg;auto &entryBB = F.getEntryBlock();for (auto &BB: F) {for (auto &I: BB) {if (auto PN = llvm::dyn_cast<llvm::PHINode>(&I)) {origPHI.emplace_back(PN);} else if (!(isa<llvm::AllocaInst>(&I) && I.getParent() == &entryBB) && I.isUsedOutsideOfBlock(&BB)) {origReg.emplace_back(&I);}}}for (auto &PN: origPHI) {llvm::DemotePHIToStack(PN, entryBB.getTerminator());}for (auto &I: origReg) {llvm::DemoteRegToStack(*I, entryBB.getTerminator());}
}
运行测试
LLVM Pass 会根据命令行传入的参数依次调用对应的 Pass 。因此我们可以先传入 -split 参数完成基本块分割,然后传入 -fla 进行控制流平坦化,这样的混淆效果更好。
opt -lowerswitch -S IR/TestProgram.ll -o IR/TestProgram_lowerswitch.ll
opt -load ../Build/LLVMObfuscator.so -split -split_num=10 -fla -S IR/TestProgram_lowerswitch.ll -o IR/TestProgram_fla.ll
clang IR/TestProgram_fla.ll -o Bin/TestProgram_fla
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_fla
效果如下,是一个典型的控制流平坦化结构。
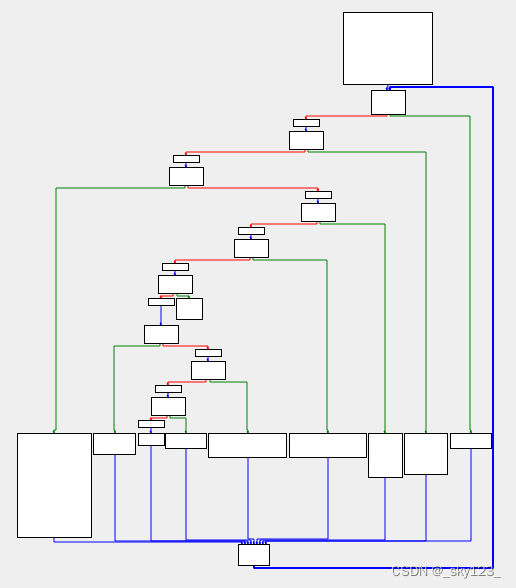
虚假控制流
虚假控制流概述
什么是虚假控制流
虚假控制流指,通过向正常控制流中插入若干不可达基本块(永远不会被执行的基本块)和由不透明谓词造成的虚假跳转,以产生大量垃圾代码干扰攻击者分析的混淆。

虚假控制流的混淆效果
虚假的跳转和冗余的不可达基本块导致了大量垃圾代码,严重干扰了攻击者的分析:

虚假控制流的结构
与控制流平坦化不同,经过虚假控制流混淆的控制流图呈长条状。

代码实现思路
虚假控制流是以基本块为单位进行混淆的,混淆函数为 bogus ,由于混淆过程中会影响基本块的数量,因此需要提前保存原本的基本块。
bool BogusControlFlow::runOnFunction(llvm::Function &F) {Context = &F.getContext();for (int i = 0; i < obfuTimes; i++) {std::vector < llvm::BasicBlock * > origBB;std::for_each(F.begin(), F.end(), [&](auto &BB) {origBB.emplace_back(&BB);});std::for_each(origBB.begin(), origBB.end(), [&](auto BB) { bogus(BB); });}return true;
}
第一步:基本块拆分
第一步:将基本块拆分成头部、中部和尾部三个基本块。
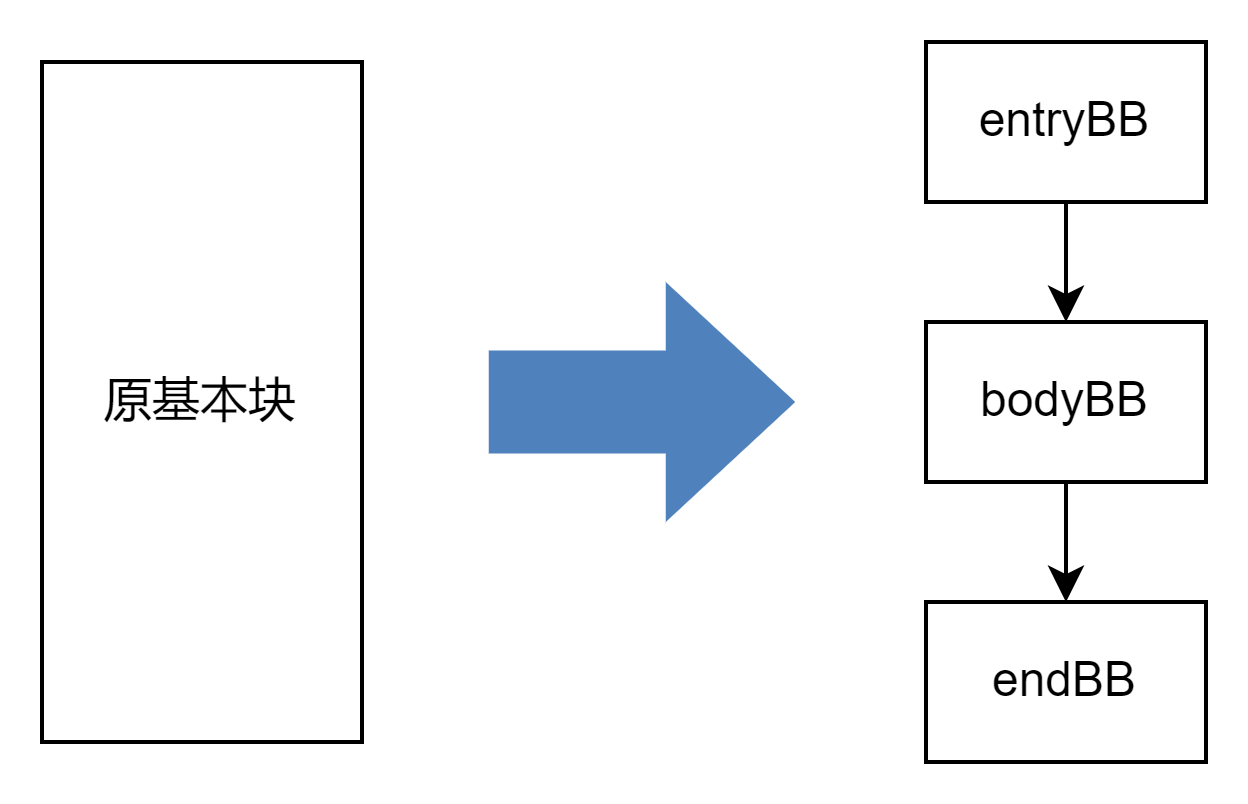
通过 getFirstNonPHI 函数获取第一个不是 PHINode 的指令(我们假定 PHI 指令全部集中在一个基本块的开始处,而事实上代码混淆工具 ollvm 的源码也是这么实现的),以该指令为界限进行分割,得到 entryBB 和 bodyBB 。
以 bodyBB 的终结指令为界限进行分割,最终得到头部、中部和尾部三个基本块,也就是 entryBB, bodyBB 和 endBB 。
// 第一步,将基本块拆分为 entryBB,bodyBB,endBB。auto bodyBB = entryBB->splitBasicBlock(entryBB->getFirstNonPHI(), "bodyBB");auto endBB = bodyBB->splitBasicBlock(bodyBB->getTerminator(), "endBB");
第二步:基本块克隆
第二步,克隆中间的 bodyBB,得到克隆块 cloneBB 。
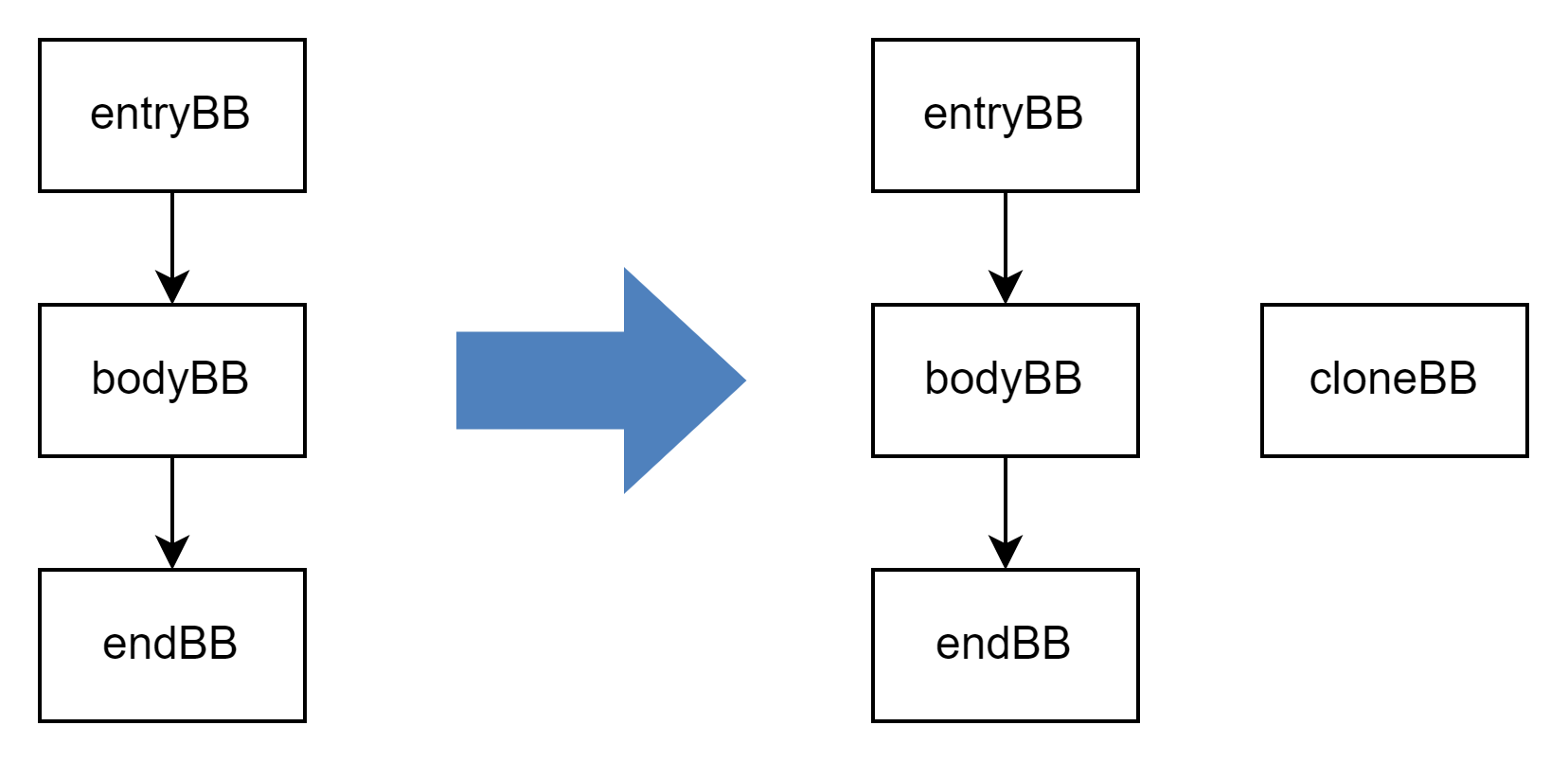
LLVM 自带 CloneBasicBlock 函数,但该函数为不完全克隆,还需要做一些补充处理,我们把基本块的克隆操作写到 createCloneBasicBlock 函数中:
// 第二步,对中间的基本块 bodyBB 进行克隆,得到 cloneBB。auto cloneBB = llvm::createCloneBasicBlock(bodyBB);
在克隆的基本块中,仍然引用了原基本块中的 %a 变量,该引用是非法的,故需要将 %a 映射为 %a.clone:
orig:%a = ...%b = fadd %a, ...clone:%a.clone = ...%b.clone = fadd %a, ... ; Note that this references the old %a and not %a.clone!
不过好在 CloneBasicBkock 函数将待克隆的基本块的变量复制一份,并且会将原变量到复制后的变量的关系以一个 ValueToValueTy 类型的映射返回。因此我们可以通过遍历 cloneBB 中的操作数然后将其中没有转换的操作数进行转换。
llvm::BasicBlock *llvm::createCloneBasicBlock(llvm::BasicBlock *BB) {ValueToValueMapTy VMap;auto cloneBB = llvm::CloneBasicBlock(BB, VMap, "cloneBB", BB->getParent());for (auto &I: *cloneBB) {for (int i = 0; i < I.getNumOperands(); i++) {if (auto v = llvm::MapValue(I.getOperand(i), VMap)) {I.setOperand(i, v);}}}return cloneBB;
}
第三步:构造虚假跳转
构造如下虚假跳转:
- 将
entryBB到bodyBB的绝对跳转改为条件跳转。 - 将
bodyBB到endBB的绝对跳转改为条件跳转。 - 添加
cloneBB到bodyBB的绝对跳转。
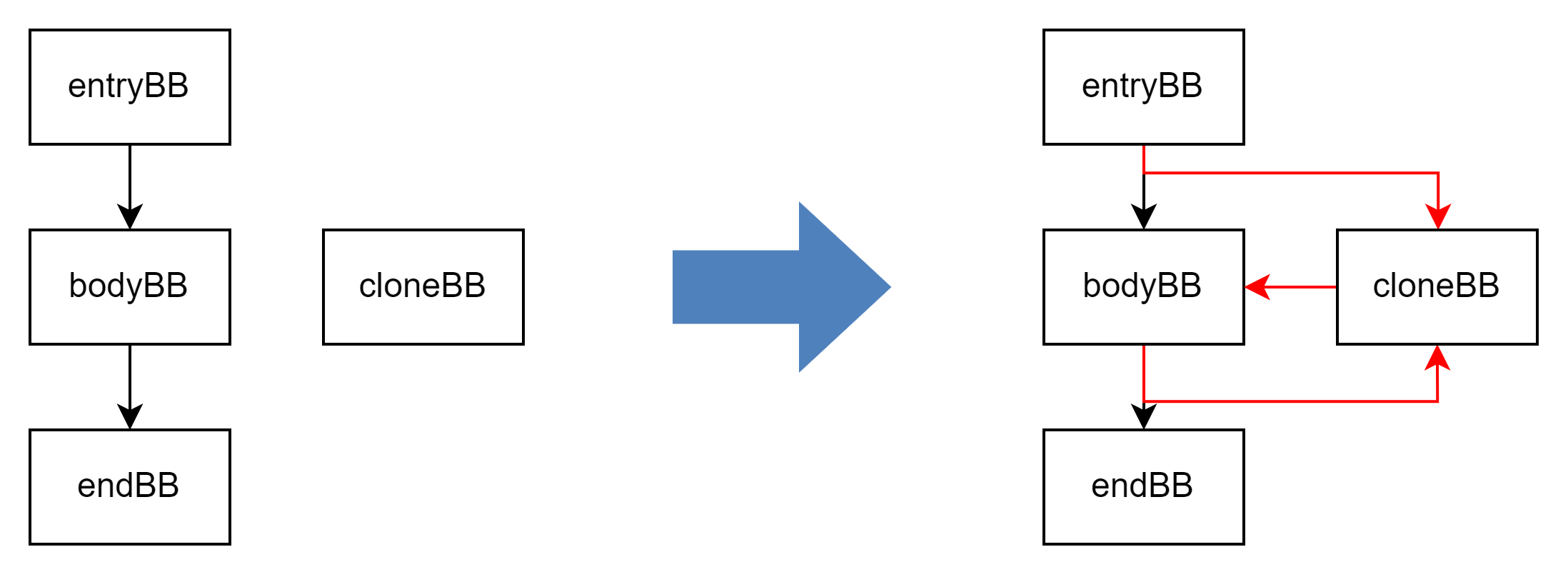
// 第三步,构造虚假跳转。entryBB->getTerminator()->eraseFromParent();bodyBB->getTerminator()->eraseFromParent();cloneBB->getTerminator()->eraseFromParent();auto cond1 = createBogusCmp(entryBB);auto cond2 = createBogusCmp(bodyBB);llvm::BranchInst::Create(bodyBB, cloneBB, cond1, entryBB);llvm::BranchInst::Create(endBB, cloneBB, cond2, bodyBB);llvm::BranchInst::Create(bodyBB, cloneBB);
其中 createBogusCmp 函数用于生成 y < 10 || x * (x + 1) % 2 == 0 条件判断。
llvm::Value *BogusControlFlow::createBogusCmp(llvm::BasicBlock *insertAfter) {// y < 10 || x * (x + 1) % 2 == 0auto M = insertAfter->getModule();auto xptr = new llvm::GlobalVariable(*M, llvm::Type::getInt32Ty(*Context), false, llvm::GlobalValue::PrivateLinkage, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 0), "x");auto yptr = new llvm::GlobalVariable(*M, llvm::Type::getInt32Ty(*Context), false, llvm::GlobalValue::PrivateLinkage, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 0), "y");auto x = new llvm::LoadInst(llvm::Type::getInt32Ty(*Context), xptr, "", insertAfter);auto y = new llvm::LoadInst(llvm::Type::getInt32Ty(*Context), yptr, "", insertAfter);auto cmp1 = new llvm::ICmpInst(*insertAfter, llvm::CmpInst::ICMP_SLT, y, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 10));auto op1 = llvm::BinaryOperator::CreateAdd(x, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 1), "", insertAfter);auto op2 = llvm::BinaryOperator::CreateMul(x, op1, "", insertAfter);auto op3 = llvm::BinaryOperator::CreateSRem(op2, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 2), "", insertAfter);auto cmp2 = new llvm::ICmpInst(*insertAfter, llvm::CmpInst::ICMP_EQ, op3, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 0));return llvm::BinaryOperator::CreateOr(cmp1, cmp2, "", insertAfter);
}
运行测试
这里我们定义了虚假控制流混淆次数的命令行参数为 bcf_loop ,另外还可以与基本块分裂 Pass 结合增加混淆效果。
opt -load ../Build/LLVMObfuscator.so -split -split_num=10 -bcf -bcf_loop=2 -S IR/TestProgram.ll -o IR/TestProgram_bcf.ll
clang IR/TestProgram_bcf.ll -o Bin/TestProgram_bcf
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_bcf
混淆效果如下:

指令替代
指令替代概述
指令替代指将正常的二元运算指令(如加法、减法、异或等等),替换为等效而更复杂的指令序列,以达到混淆计算过程的目的。例如将 a+b 替换为 a - (-b) ,将 a ^ b 替换为 (~a & b) | (a & ~b) 等等。
指令替代仅支持整数运算的替换,因为替换浮点指令会造成舍入的错误和误差。
指令替代后函数的控制流没有发生变化,但是运算过程变得难以分辨。
代码实现思路
控制流平坦化是以指令为单位进行混淆的。混淆函数为 substitute ,由于混淆过程中会影响指令的数量,因此需要提前保存原本的二元运算指令。之后对这些二元运算指令依次随机调用对应的指令替代函数即可。
bool Substitution::runOnFunction(llvm::Function &F) {for (int i = 0; i < obfuTimes; i++) {std::vector<llvm::BinaryOperator *> origBI;for (auto &BB: F) {for (auto &I: BB) {if (auto BI = llvm::dyn_cast<llvm::BinaryOperator>(&I)) {origBI.emplace_back(BI);}}}std::for_each(origBI.begin(), origBI.end(), [&](auto BI) {if (substituteFuncs.contains(BI->getOpcode())) {substituteFuncs[BI->getOpcode()][rnd() % substituteFuncs[BI->getOpcode()].size()](BI);}});}return true;
}
加法替换
substituteFuncs[llvm::BinaryOperator::Add].emplace_back([&](llvm::BinaryOperator *BI) {// a = b + c = (b ^ c) + ((b & c) << 1)auto op1 = llvm::BinaryOperator::CreateXor(BI->getOperand(0), BI->getOperand(1), "", BI);auto op2 = llvm::BinaryOperator::CreateAnd(BI->getOperand(0), BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateShl(op2, llvm::ConstantInt::get(llvm::Type::getInt32Ty(BI->getContext()), 1), "", BI);auto op4 = llvm::BinaryOperator::CreateAdd(op1, op3, "", BI);BI->replaceAllUsesWith(op4);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Add].emplace_back([&](llvm::BinaryOperator *BI) {// a = b + c -> a = b - (-c)auto op1 = llvm::BinaryOperator::CreateNeg(BI->getOperand(1), "", BI);auto op2 = llvm::BinaryOperator::CreateSub(BI->getOperand(0), op1, "", BI);BI->replaceAllUsesWith(op2);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Add].emplace_back([&](llvm::BinaryOperator *BI) {// a = b + c -> a = -(-b + (-c))auto op1 = llvm::BinaryOperator::CreateNeg(BI->getOperand(0), "", BI);auto op2 = llvm::BinaryOperator::CreateNeg(BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateAdd(op1, op2, "", BI);auto op4 = llvm::BinaryOperator::CreateNeg(op3, "", BI);BI->replaceAllUsesWith(op4);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Add].emplace_back([&](llvm::BinaryOperator *BI) {// a = b + c -> r = rand(); a = b + r; a = a + c; a = a - r;auto r = (llvm::ConstantInt *) llvm::ConstantInt::get(BI->getType(), rnd());auto op1 = llvm::BinaryOperator::CreateAdd(BI->getOperand(0), r, "", BI);auto op2 = llvm::BinaryOperator::CreateAdd(op1, BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateSub(op2, r, "", BI);BI->replaceAllUsesWith(op3);BI->eraseFromParent();});
减法替换
substituteFuncs[llvm::BinaryOperator::Sub].emplace_back([&](llvm::BinaryOperator *BI) {// a = b - c -> a = b + (-c)auto op1 = llvm::BinaryOperator::CreateNeg(BI->getOperand(1), "", BI);auto op2 = llvm::BinaryOperator::CreateAdd(BI->getOperand(0), op1, "", BI);BI->replaceAllUsesWith(op2);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Sub].emplace_back([&](llvm::BinaryOperator *BI) {// a = b - c -> a = -(-b - (-c))auto op1 = llvm::BinaryOperator::CreateNeg(BI->getOperand(0), "", BI);auto op2 = llvm::BinaryOperator::CreateNeg(BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateSub(op1, op2, "", BI);auto op4 = llvm::BinaryOperator::CreateNeg(op3, "", BI);BI->replaceAllUsesWith(op4);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Sub].emplace_back([&](llvm::BinaryOperator *BI) {// a = b - c -> r = rand(); a = b + r; a = a - c; a = a - r;auto r = (llvm::ConstantInt *) llvm::ConstantInt::get(BI->getType(), rnd());auto op1 = llvm::BinaryOperator::CreateAdd(BI->getOperand(0), r, "", BI);auto op2 = llvm::BinaryOperator::CreateSub(op1, BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateSub(op2, r, "", BI);BI->replaceAllUsesWith(op3);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Sub].emplace_back([&](llvm::BinaryOperator *BI) {// a = b - c -> r = rand(); a = b - r; a = a - b; a = a + r;auto r = (llvm::ConstantInt *) llvm::ConstantInt::get(BI->getType(), rnd());auto op1 = llvm::BinaryOperator::CreateSub(BI->getOperand(0), r, "", BI);auto op2 = llvm::BinaryOperator::CreateSub(op1, BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateAdd(op2, r, "", BI);BI->replaceAllUsesWith(op3);BI->eraseFromParent();});
与替换
substituteFuncs[llvm::BinaryOperator::And].emplace_back([&](llvm::BinaryOperator *BI) {// a = b & c -> a = (b ^ ~c) & bauto op1 = llvm::BinaryOperator::CreateNot(BI->getOperand(1), "", BI);auto op2 = llvm::BinaryOperator::CreateXor(BI->getOperand(0), op1, "", BI);auto op3 = llvm::BinaryOperator::CreateAnd(op2, BI->getOperand(0), "", BI);BI->replaceAllUsesWith(op3);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::And].emplace_back([&](llvm::BinaryOperator *BI) {// a = b & c -> a = ~(~b | ~c) & (r | ~r)auto r = (llvm::ConstantInt *) llvm::ConstantInt::get(BI->getType(), rnd());auto op1 = llvm::BinaryOperator::CreateNot(r, "", BI);auto op2 = llvm::BinaryOperator::CreateOr(r, op1, "", BI);auto op3 = llvm::BinaryOperator::CreateNot(BI->getOperand(0), "", BI);auto op4 = llvm::BinaryOperator::CreateNot(BI->getOperand(1), "", BI);auto op5 = llvm::BinaryOperator::CreateOr(op3, op4, "", BI);auto op6 = llvm::BinaryOperator::CreateNot(op5, "", BI);auto op7 = llvm::BinaryOperator::CreateAnd(op6, op2, "", BI);BI->replaceAllUsesWith(op7);BI->eraseFromParent();});
或替换
substituteFuncs[llvm::BinaryOperator::Or].emplace_back([&](llvm::BinaryOperator *BI) {// a = b | c -> a = (b & c) | (b ^ c)auto op1 = llvm::BinaryOperator::CreateAnd(BI->getOperand(0), BI->getOperand(1), "", BI);auto op2 = llvm::BinaryOperator::CreateXor(BI->getOperand(0), BI->getOperand(1), "", BI);auto op3 = llvm::BinaryOperator::CreateOr(op1, op2, "", BI);BI->replaceAllUsesWith(op3);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Or].emplace_back([&](llvm::BinaryOperator *BI) {// a = b | c -> a = ~(~b & ~c) & (r | ~r)auto r = (llvm::ConstantInt *) llvm::ConstantInt::get(BI->getType(), rnd());auto op1 = llvm::BinaryOperator::CreateNot(r, "", BI);auto op2 = llvm::BinaryOperator::CreateOr(r, op1, "", BI);auto op3 = llvm::BinaryOperator::CreateNot(BI->getOperand(0), "", BI);auto op4 = llvm::BinaryOperator::CreateNot(BI->getOperand(1), "", BI);auto op5 = llvm::BinaryOperator::CreateAnd(op3, op4, "", BI);auto op6 = llvm::BinaryOperator::CreateNot(op5, "", BI);auto op7 = llvm::BinaryOperator::CreateAnd(op6, op2, "", BI);BI->replaceAllUsesWith(op7);BI->eraseFromParent();});
异或替换
substituteFuncs[llvm::BinaryOperator::Xor].emplace_back([&](llvm::BinaryOperator *BI) {// a = b ^ c -> a = ~b & c | b & ~cauto op1 = llvm::BinaryOperator::CreateNot(BI->getOperand(0), "", BI); // ~bauto op2 = llvm::BinaryOperator::CreateNot(BI->getOperand(1), "", BI); // ~cauto op3 = llvm::BinaryOperator::CreateAnd(op1, BI->getOperand(1), "", BI); // ~b & cauto op4 = llvm::BinaryOperator::CreateAnd(op2, BI->getOperand(0), "", BI); // b & ~cauto op5 = llvm::BinaryOperator::CreateOr(op3, op4, "", BI);BI->replaceAllUsesWith(op5);BI->eraseFromParent();});substituteFuncs[llvm::BinaryOperator::Xor].emplace_back([&](llvm::BinaryOperator *BI) {// a = b ^ c -> r = rand(); a = (b ^ r) ^ (c ^ r) -> r = rand(); a = (~b & r | b & ~r) ^ (~c & r | c & ~r)auto r = (llvm::ConstantInt *) llvm::ConstantInt::get(BI->getType(), rnd());auto op1 = llvm::BinaryOperator::CreateNot(BI->getOperand(0), "", BI);auto op2 = llvm::BinaryOperator::CreateAnd(op1, r, "", BI);auto op3 = llvm::BinaryOperator::CreateNot(r, "", BI);auto op4 = llvm::BinaryOperator::CreateAnd(BI->getOperand(0), op3, "", BI);auto op5 = llvm::BinaryOperator::CreateOr(op2, op4, "", BI);auto op6 = llvm::BinaryOperator::CreateNot(BI->getOperand(1), "", BI);auto op7 = llvm::BinaryOperator::CreateAnd(op6, r, "", BI);auto op8 = llvm::BinaryOperator::CreateNot(r, "", BI);auto op9 = llvm::BinaryOperator::CreateAnd(BI->getOperand(1), op8, "", BI);auto op10 = llvm::BinaryOperator::CreateOr(op7, op9, "", BI);auto op11 = llvm::BinaryOperator::CreateXor(op5, op10, "", BI);BI->replaceAllUsesWith(op11);BI->eraseFromParent();});
运行测试
这里定义了混淆次数参数 sub_loop 。
opt -load ../Build/LLVMObfuscator.so -sub -sub_loop=3 -S IR/TestProgram.ll -o IR/TestProgram_sub.ll
clang IR/TestProgram_sub.ll -o Bin/TestProgram_sub
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_sub
运行效果如下:

随机控制流
随机控制流概述
什么是随机控制流
随机控制流是虚假控制流的一种变体,随机控制流通过克隆基本块,以及添加随机跳转(随机跳转到两个功能相同的基本块中的一个)来混淆控制流。
与虚假控制流不同,随机控制流中不存在不可达基本块和不透明谓词,因此用于去除虚假控制流的手段(消除不透明谓词、符号执行获得不可达基本块后去除)失效。
随机控制流的控制流图与虚假控制流类似,都呈长条形。
随机控制流混淆原理
随机控制流同样是以基本块为单位进行混淆的,每个基本块要经过分裂、克隆、构造随机跳转和构造虚假随机跳转四个操作。
随机控制流的混淆效果
随机的跳转和冗余的不可达基本块导致了大量垃圾代码,严重干扰了攻击者的分析。并且 rdrand 指令可以干扰某些符号执行引擎(如 angr)的分析。

代码实现思路
第一步:基本块拆分
与虚假控制流一样,需要将基本块拆成头部、中部、尾部三个基本块。

// 第一步,将基本块拆分为 entryBB,bodyBB,endBB。auto bodyBB = entryBB->splitBasicBlock(entryBB->getFirstNonPHI(), "bodyBB");auto endBB = bodyBB->splitBasicBlock(bodyBB->getTerminator(), "endBB");
第二步:基本块克隆
将中间的基本块进行克隆,这里可以选择对基本块进行变异,但不能改变基本块的功能。(与虚假控制流不同)
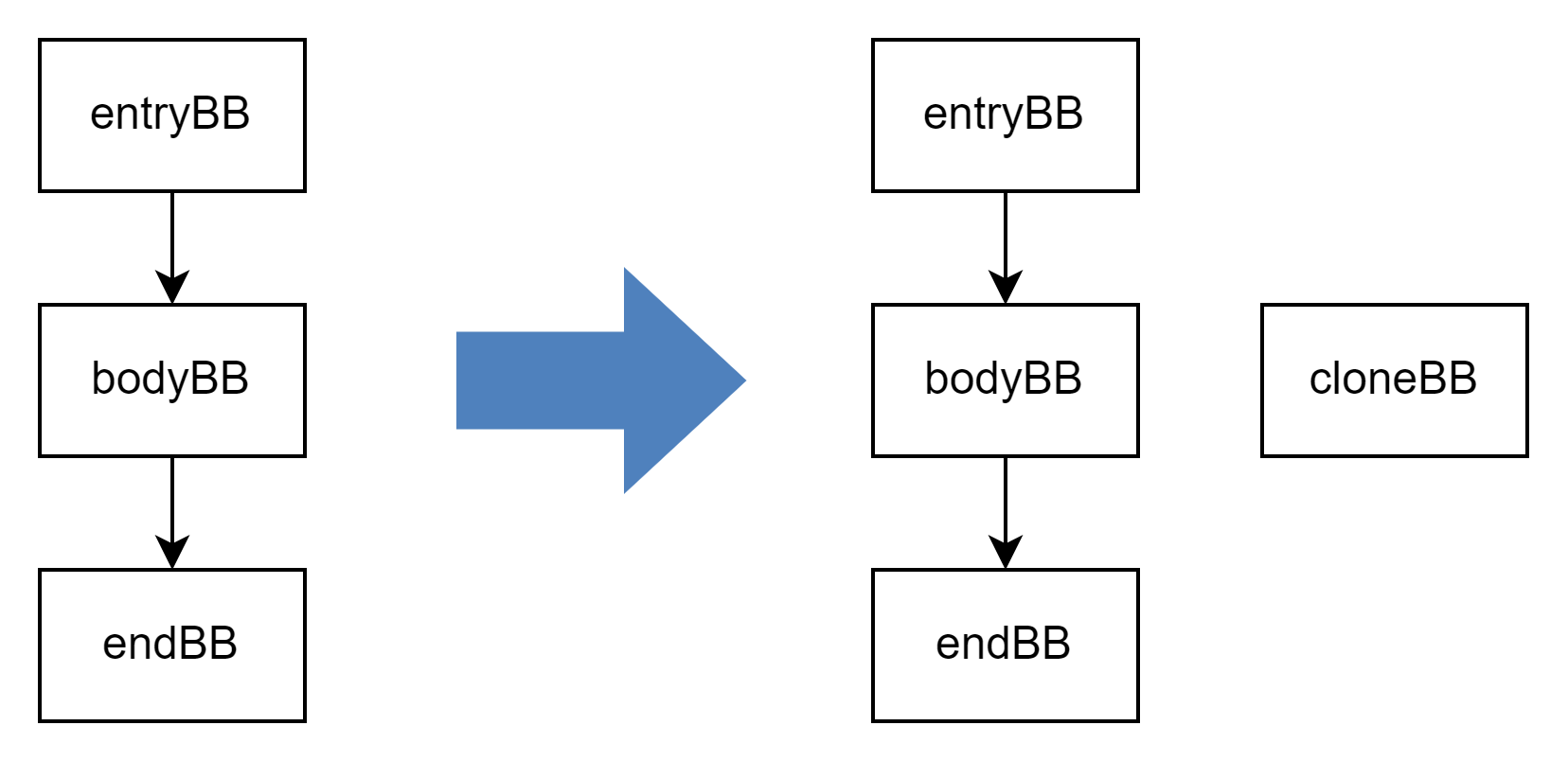
// 第二步,对基本块进行克隆,并修复逃逸变量。auto cloneBB = llvm::createCloneBasicBlock(bodyBB);
在一个基本块中定义的变量,如果在另一个基本块中被引用,那么该变量称为逃逸变量。例如下图中的变量 %a 在原本块和克隆块中都被使用。

llvm::BasicBlock *llvm::createCloneBasicBlock(llvm::BasicBlock *BB) {std::vector < llvm::Instruction * > origReg;auto &entryBB = BB->getParent()->getEntryBlock();for (auto &I: *BB) {if (!(isa<llvm::AllocaInst>(&I) && I.getParent() == &entryBB) && I.isUsedOutsideOfBlock(BB)) {origReg.emplace_back(&I);}}for (auto &I: origReg) {llvm::DemoteRegToStack(*I, entryBB.getTerminator());}ValueToValueMapTy VMap;auto cloneBB = llvm::CloneBasicBlock(BB, VMap, "cloneBB", BB->getParent());for (auto &I: *cloneBB) {for (int i = 0; i < I.getNumOperands(); i++) {if (auto v = llvm::MapValue(I.getOperand(i), VMap)) {I.setOperand(i, v);}}}return cloneBB;
}
第三步:构造随机跳转
将生成随机数的指令插入到 entryBB ,将生成的随机数命名为 randVar,并在 entryBB 后插入基于 randVar 的随机跳转指令。
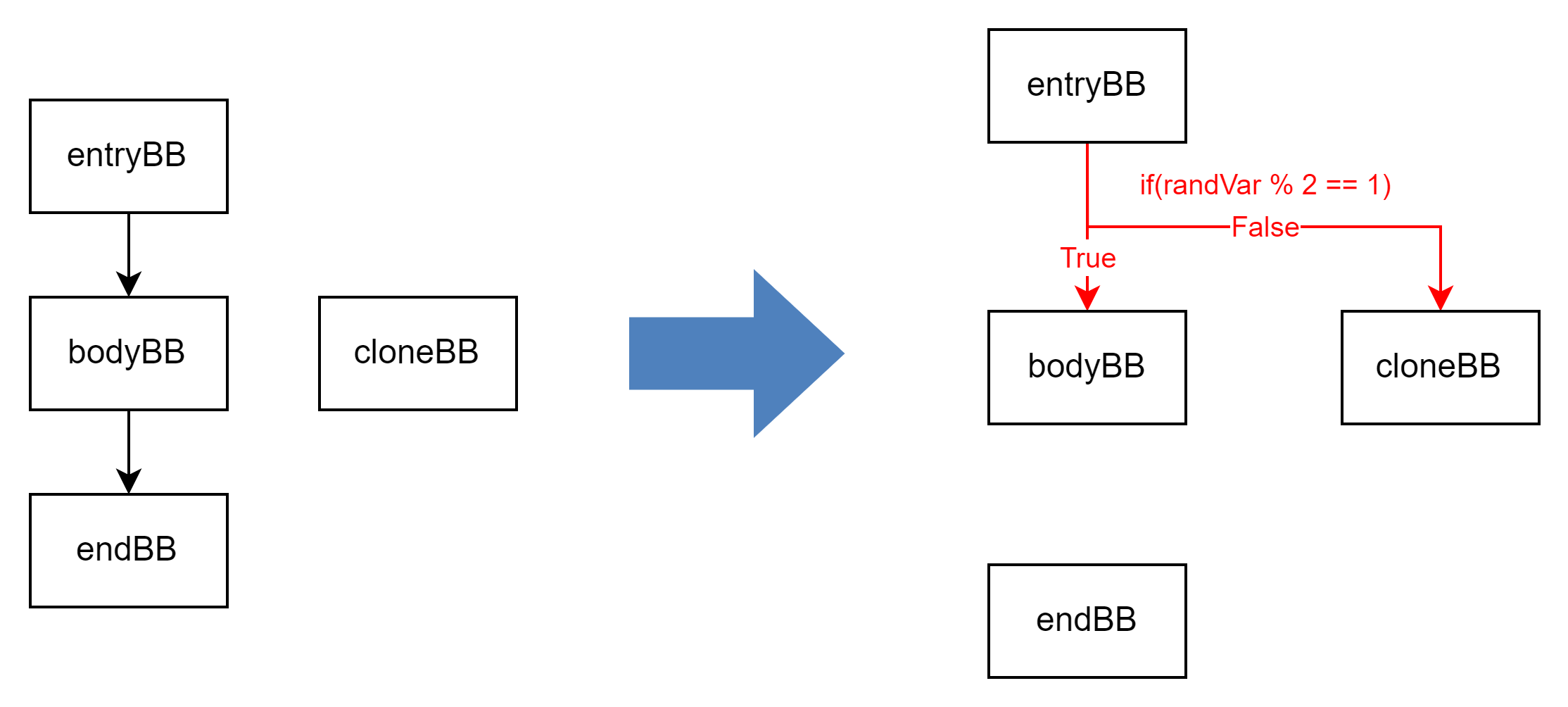
向 entryBB 中插入生成随机数的指令和随机跳转,使其能够随机跳转到 bodyBB 或者 bodyBB 的克隆块。其中随机数指令我们可以使用 LLVM 的内置函数 rdrand。
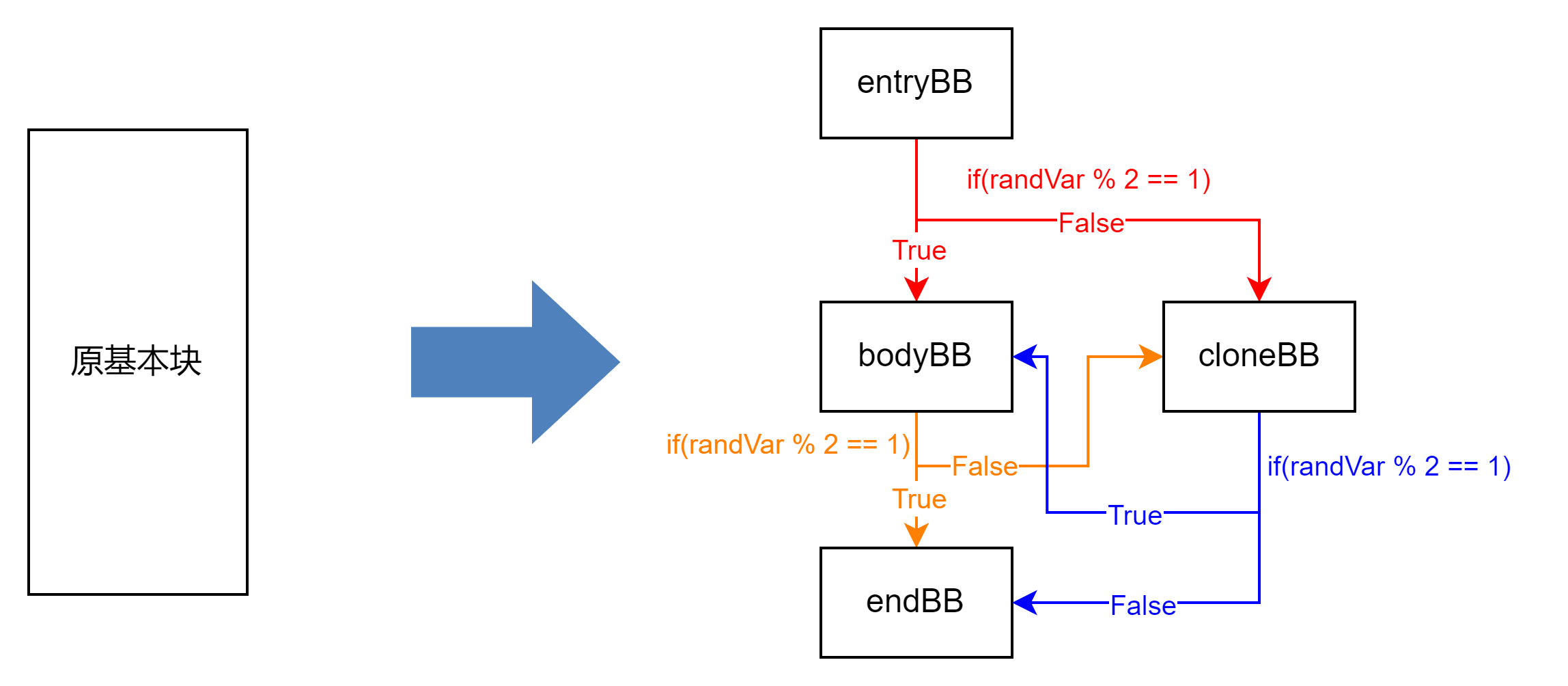
// 插入随机跳转,随机数为 randVar
// 若 randVar % 2 == 1 则跳转到 ifTrue 基本块,否则跳转到 ifFalse 基本块。
void RandomControlFlow::insertRandomBranch(llvm::Value *randVar, llvm::BasicBlock *ifTrue, llvm::BasicBlock *ifFalse, llvm::BasicBlock *insertAfter) {auto alteredRandVar = alterVal(randVar, insertAfter);auto randMod2 = llvm::BinaryOperator::CreateURem(alteredRandVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 2), "", insertAfter);auto icmpInst = new llvm::ICmpInst(*insertAfter, llvm::ICmpInst::ICMP_EQ, randMod2, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 1));llvm::BranchInst::Create(ifTrue, ifFalse, icmpInst, insertAfter);
}// 第三步,构造随机跳转。entryBB->getTerminator()->eraseFromParent();auto randFunc = llvm::Intrinsic::getDeclaration(entryBB->getModule(), llvm::Intrinsic::x86_rdrand_32);auto callInst = llvm::CallInst::Create(randFunc->getFunctionType(), randFunc, "", entryBB);auto randVar = llvm::ExtractValueInst::Create(callInst, 0, "", entryBB);insertRandomBranch(randVar, bodyBB, cloneBB, entryBB);
为了增强混淆的强度,这里将随机数随机进行三种等价变换(不影响判断结果)。
llvm::Value *RandomControlFlow::alterVal(llvm::Value *startVar, llvm::BasicBlock *insertAfter) {uint32_t code = rnd() % 3;if (code == 0) {// x = x * (x + 1) - x^2auto op1 = llvm::BinaryOperator::CreateAdd(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 1), "", insertAfter);auto op2 = llvm::BinaryOperator::CreateMul(startVar, op1, "", insertAfter);auto op3 = llvm::BinaryOperator::CreateMul(startVar, startVar, "", insertAfter);auto op4 = llvm::BinaryOperator::CreateSub(op2, op3, "", insertAfter);return op4;} else if (code == 1) {// x = 3 * x * (x - 2) - 3 * x^2 + 7 * xauto op1 = llvm::BinaryOperator::CreateMul(llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 3), startVar, "", insertAfter);auto op2 = llvm::BinaryOperator::CreateSub(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 2), "", insertAfter);auto op3 = llvm::BinaryOperator::CreateMul(op1, op2, "", insertAfter);auto op4 = llvm::BinaryOperator::CreateMul(startVar, startVar, "", insertAfter);auto op5 = llvm::BinaryOperator::CreateMul(op4, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 3), "", insertAfter);auto op6 = llvm::BinaryOperator::CreateSub(op3, op5, "", insertAfter);auto op7 = llvm::BinaryOperator::CreateMul(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 7), "", insertAfter);auto op8 = llvm::BinaryOperator::CreateAdd(op6, op7, "", insertAfter);return op8;} else {// x = (x - 1) * (x + 3) - (x + 4) * (x - 3) - 9auto op1 = llvm::BinaryOperator::CreateSub(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 1), "", insertAfter);auto op2 = llvm::BinaryOperator::CreateAdd(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 3), "", insertAfter);auto op3 = llvm::BinaryOperator::CreateMul(op1, op2, "", insertAfter);auto op4 = llvm::BinaryOperator::CreateAdd(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 4), "", insertAfter);auto op5 = llvm::BinaryOperator::CreateSub(startVar, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 3), "", insertAfter);auto op6 = llvm::BinaryOperator::CreateMul(op4, op5, "", insertAfter);auto op7 = llvm::BinaryOperator::CreateSub(op3, op6, "", insertAfter);auto op8 = llvm::BinaryOperator::CreateSub(op7, llvm::ConstantInt::get(llvm::Type::getInt32Ty(*Context), 9), "", insertAfter);return op8;}
}
第四步:构造虚假随机跳转
在 bodyBB 和 cloneBB 后插入虚假随机跳转指令(实际上仍会直接跳转到 endBB):
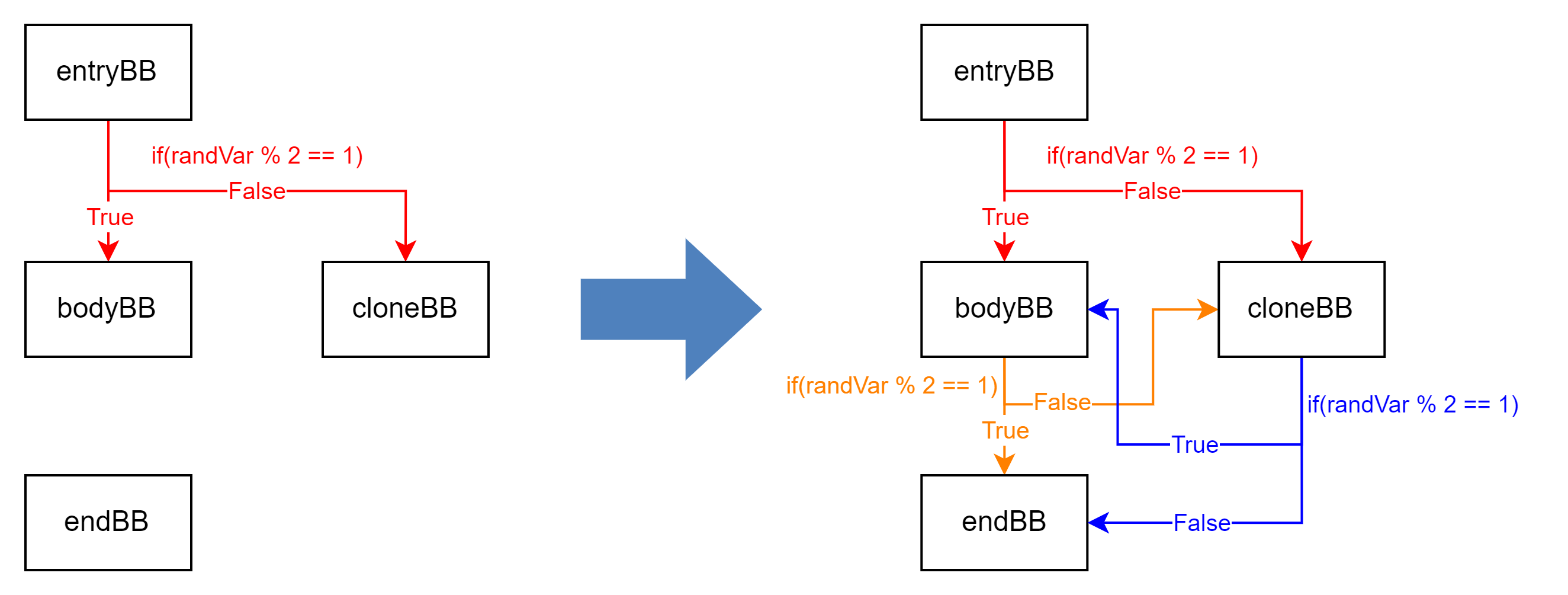
// 第四步,在 bodyBB 和 cloneBB 后插入虚假随机跳转。bodyBB->getTerminator()->eraseFromParent();cloneBB->getTerminator()->eraseFromParent();insertRandomBranch(randVar, endBB, cloneBB, bodyBB);insertRandomBranch(randVar, bodyBB, endBB, cloneBB);
运行测试
由于添加了 rdrnd 指令,直接使用 clang 编译器编译会编译失败,因此这里先使用 llc 并且指定 -mattr=+rdrnd 将进行编译,然后再使用 clang 进行链接。
opt -load ../Build/LLVMObfuscator.so -rcf -rcf_loop=3 -S IR/TestProgram.ll -o IR/TestProgram_rcf.ll
llc -filetype=obj -mattr=+rdrnd IR/TestProgram_rcf.ll -o Bin/TestProgram_rcf.o
clang Bin/TestProgram_rcf.o -o Bin/TestProgram_rcf
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_rcf
混淆效果如下:

常量替代
常量替代概述
什么是常量替代
常量替代指将二元运算指令(如加法、减法、异或等等)中使用的常数,替换为等效而更复杂的表达式,以达到混淆计算过程或某些特殊常量的目的。
例如将 TEA 加密中使用的常量 0x9e3779b 替换为 12167*16715+18858*32146-643678438。不过实际情况为了对抗 IDA 的反编译优化还会利用不透明谓词的思路将部分常量替换为存储常量的全局变量。
常量替代目前仅支持整数常量的替换,因为替换浮点数会造成舍入的错误和误差。且仅支持32位整数的替换,大家课后可以尝试拓展到任意位数整数的替换。
常量替代的混淆效果
类似于指令替代,函数的控制流没有发生变化,但是运算过程变得难以分辨:

进一步拓展
常量替代可进一步拓展为常量数组的替代和字符串替代。
常量数组替代可以抹去 AES, DES 等加密算法中特征数组,字符串替代可以防止攻击者通过字符串定位关键代码。
代码实现思路
常量替代是以指令为单位进行的混淆,因此需要遍历函数的指令对可能存在常量的指令调用 substitute 函数进行常量替代。
bool ConstantSubstitution::runOnFunction(llvm::Function &F) {for (int i = 0; i < obfuTimes; i++) {std::vector<llvm::Instruction *> origInst;for (auto &BB: F) {for (auto &I: BB) {if (isa<llvm::StoreInst>(I) || isa<llvm::CmpInst>(I) || isa<llvm::BinaryOperator>(I)) {origInst.push_back(&I);}}}std::for_each(origInst.begin(), origInst.end(), [&](auto I) { substitute(I); });}return true;
}
substitute 函数随机调用两种常量替代的方法进行混淆,目前实现了线性替换和位运算替换两种替换方法。
void ConstantSubstitution::substitute(llvm::Instruction *I) {for (int i = 0; i < I->getNumOperands(); i++) {if (llvm::isa<llvm::ConstantInt>(I->getOperand(i))) {switch (rnd() % 2) {case 0:linearSubstitute(I, i);break;case 1:bitwiseSubstitute(I, i);break;}}}
}
线性替换
// 线性替换:val -> ax + by + c
// 其中 val 为原常量;a,b 为随机常量;x,y 为随机全局变量;c = val - (ax + by)
void ConstantSubstitution::linearSubstitute(llvm::Instruction *I, int i) {// 第一步,随机生成 x,y,a,buint64_t randX = rnd(), randY = rnd();uint64_t randA = rnd(), randB = rnd();// 第二步,计算 c = val - (ax + by)auto val = cast<llvm::ConstantInt>(I->getOperand(i));auto type = val->getType();auto constA = llvm::ConstantInt::get(type, randA);auto constB = llvm::ConstantInt::get(type, randB);auto constC = llvm::ConstantInt::get(type, val->getValue() - (randA * randX + randB * randY));// 第三步,创建全局变量 x,yauto M = I->getModule();auto x = new llvm::GlobalVariable(*M, type, false, llvm::GlobalValue::PrivateLinkage, llvm::ConstantInt::get(type, randX), "x");auto y = new llvm::GlobalVariable(*M, type, false, llvm::GlobalValue::PrivateLinkage, llvm::ConstantInt::get(type, randY), "y");auto opX = new llvm::LoadInst(type, x, "", I);auto opY = new llvm::LoadInst(type, y, "", I);// 第四步,构造 op = ax + by + c 表达式auto op1 = llvm::BinaryOperator::CreateMul(opX, constA, "", I);auto op2 = llvm::BinaryOperator::CreateMul(opY, constB, "", I);auto op3 = llvm::BinaryOperator::CreateAdd(op1, op2, "", I);auto op4 = llvm::BinaryOperator::CreateAdd(op3, constC, "", I);// 第五步,用 ax + by + c 替换原常量操作数I->setOperand(i, op4);
}
位运算替换
// 按位运算替换:val -> (x << left | y >> right) ^ c
// 其中 val 为原常量;x,y 为随机全局变量;c = val ^ (x << left | y >> right)
void ConstantSubstitution::bitwiseSubstitute(llvm::Instruction *I, int i) {// 第一步,随机生成 x,y,left,rightauto val = cast<llvm::ConstantInt>(I->getOperand(i));auto type = val->getType();uint32_t width = type->getIntegerBitWidth();if (width < 8) { // 不对位数小于8的整数进行替代return;}uint32_t left = rnd() % (width - 1) + 1;uint32_t right = width - left;auto randX = rnd() & type->getBitMask();auto randY = rnd() & type->getBitMask();// 第二步,计算 c = val ^ (x << left | y >> right)auto constC = (llvm::ConstantInt *) llvm::ConstantInt::get(type, val->getValue() ^ (randX << left | randY >> right));// 第三步,创建全局变量 x,yauto M = I->getModule();auto x = new llvm::GlobalVariable(*M, type, false, llvm::GlobalValue::PrivateLinkage, llvm::ConstantInt::get(type, randX), "x");auto y = new llvm::GlobalVariable(*M, type, false, llvm::GlobalValue::PrivateLinkage, llvm::ConstantInt::get(type, randY), "y");auto opX = new llvm::LoadInst(type, x, "", I);auto opY = new llvm::LoadInst(type, y, "", I);// 第四步,构造 op = (x << left | y >> right) ^ c 表达式auto op1 = llvm::BinaryOperator::CreateShl(opX, llvm::ConstantInt::get(type, left), "", I);auto op2 = llvm::BinaryOperator::CreateLShr(opY, llvm::ConstantInt::get(type, right), "", I);auto op3 = llvm::BinaryOperator::CreateOr(op1, op2, "", I);auto op4 = llvm::BinaryOperator::CreateXor(op3, constC, "", I);// 第五步,用 (x << left | y >> right) ^ c 替换原常量操作数I->setOperand(i, op4);
}
运行测试
这里设置混淆次数 csub_loop 为 3 。
opt -load ../Build/LLVMObfuscator.so -csub -csub_loop=3 -S IR/TestProgram.ll -o IR/TestProgram_csub.ll
clang IR/TestProgram_csub.ll -o Bin/TestProgram_csub
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_csub
混淆效果如下:
字符串加密
字符串加密概述
字符串加密指的是将程序中的字符串加密存储,在 main 函数执行前会调用解密函数将字符串解密。
代码实现思路
字符串加密是基于模块的加密,因此这里不再是 FunctionPass 而是 ModulePass 。
第一步:获取字符串变量
遍历 M.getGlobalList() 中的全局变量,如果是字符串类型的就保存下来等待处理。
std::vector<llvm::GlobalVariable *> origGV;for (auto &GV: M.getGlobalList()) {if (GV.hasInitializer() && GV.getName().contains(".str") && !GV.getSection().equals("llvm.metadata")) {origGV.emplace_back(&GV);}}
第二步:加密字符串
遍历获取到的字符串变量,使用 dyn_cast 将变量的 getInitializer() 转换为 ConstantDataSequential 类型,这里 getInitializer() 是获取变量的初始化数据,如果是为初始化的全局变量则返回 nullptr ,另外 ConstantDataSequential 是一个用来处理模块中数组类变量的结构。
之后获取字符串的长度 len 和字符串对应底层存储数据的指针(这个指针指向该字符串存储的内存,修改这块内存也就修改了变量的 getInitializer()),然后加密字符串。
因为原本的全局变量是常量,会存放在只读段中导致解密时访存错误,因此之后需要重新创建一个新的全局变量 dynGV 来替换原来的全局变量。
最后调用 insertModifyFunctions 函数创建对应的解密函数。
for (auto GV: origGV) {if (auto cdata = llvm::dyn_cast<llvm::ConstantDataSequential>(GV->getInitializer())) {uint8_t *data = (uint8_t *) cdata->getRawDataValues().data();uint32_t len = cdata->getNumElements() * cdata->getElementByteSize();uint8_t key = rnd();for (int i = 0; i < len; i++) {data[i] ^= key;}auto dynGV = new llvm::GlobalVariable(M, GV->getType()->getElementType(), false, GV->getLinkage(), GV->getInitializer(), GV->getName(), nullptr, GV->getThreadLocalMode(), GV->getType()->getAddressSpace());GV->replaceAllUsesWith(dynGV);GV->eraseFromParent();insertModifyFunctions(M, {dynGV, key, len});}}
第三步:创建解密函数
首先需要创建函数。由于程序的跳转目标是基本块,因此之后需要创建函数中的基本块,这里我创建了以下基本块:
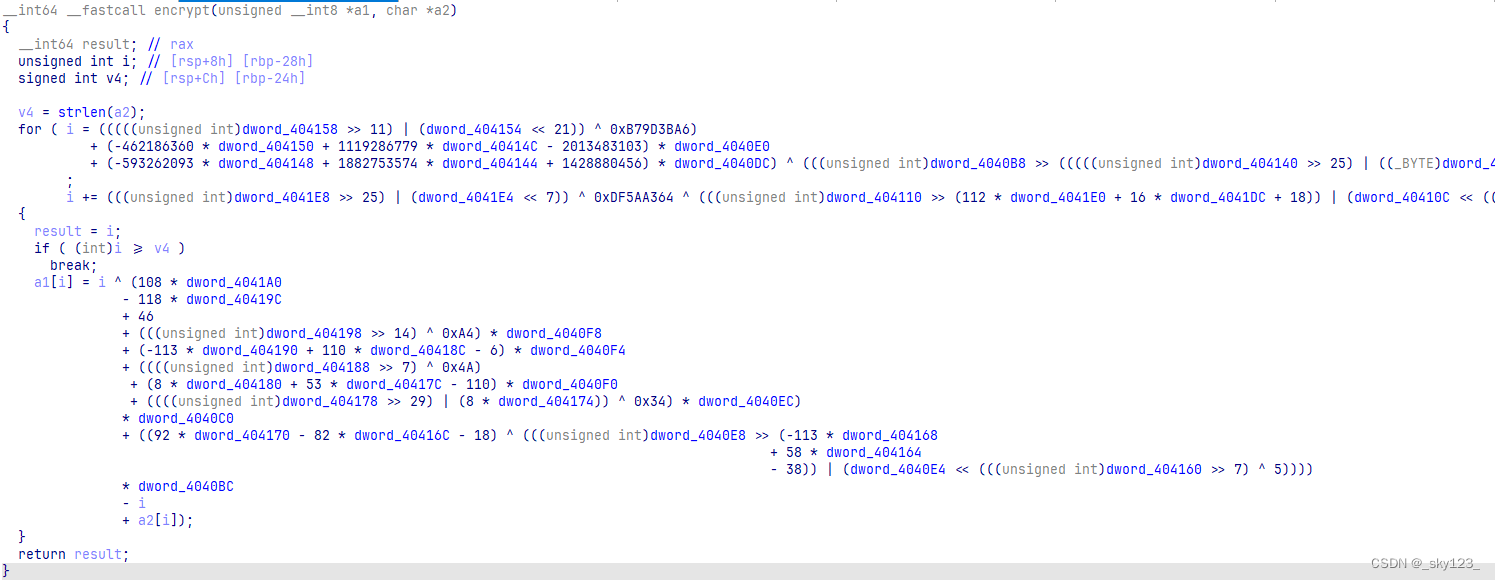
entryBB:创建局部变量i并初始化为 0 作为后面的循环变量。condBB:判断局部变量i是否小于字符串长度,并根据判断结果决定是否结束循环。bodyBB:获取字符串中的第i个元素并解密,之后重新写入字符串中的对应位置。incBB:将局部变量i增加 1 。endBB:函数返回。
这几个基本块的关系如下图所示:
最后调用 appendToGlobalCtors 函数将创建的函数注册到模块的初始化函数,确保其在 main 函数之前调用。
void StringObfuscation::insertModifyFunctions(llvm::Module &M, llvm::EncryptedGV encGV) {auto funcType = llvm::FunctionType::get(llvm::Type::getVoidTy(M.getContext()), std::vector<llvm::Type *>{}, false);auto callee = M.getOrInsertFunction(encGV.GV->getName().str() + "DecFunc", funcType);auto func = llvm::cast<llvm::Function>(callee.getCallee());auto entryBB = llvm::BasicBlock::Create(M.getContext(), "entryBB", func);auto condBB = llvm::BasicBlock::Create(M.getContext(), "condBB", func);auto bodyBB = llvm::BasicBlock::Create(M.getContext(), "bodyBB", func);auto incBB = llvm::BasicBlock::Create(M.getContext(), "incBB", func);auto endBB = llvm::BasicBlock::Create(M.getContext(), "endBB", func);// entryBBauto indexPtr = new llvm::AllocaInst(llvm::Type::getInt32Ty(M.getContext()), 0, llvm::ConstantInt::get(llvm::Type::getInt32Ty(M.getContext()), 1), "i", entryBB);new llvm::StoreInst(llvm::ConstantInt::get(llvm::Type::getInt32Ty(M.getContext()), 0), indexPtr, entryBB);llvm::BranchInst::Create(condBB, entryBB);// condBBauto index = new llvm::LoadInst(indexPtr->getType()->getElementType(), indexPtr, "", condBB);auto cond = new llvm::ICmpInst(*condBB, llvm::ICmpInst::ICMP_SLT, index, llvm::ConstantInt::get(index->getType(), encGV.len));llvm::BranchInst::Create(bodyBB, endBB, cond, condBB);// bodyBBstd::vector<llvm::Value *> indexList{llvm::ConstantInt::get(llvm::Type::getInt32Ty(M.getContext()), 0), index};auto elePtr = llvm::GetElementPtrInst::Create(nullptr, encGV.GV, llvm::ArrayRef<llvm::Value *>(indexList), "", bodyBB);auto ele = new llvm::LoadInst(llvm::Type::getInt8Ty(M.getContext()), elePtr, "", bodyBB);auto encEle = llvm::BinaryOperator::CreateXor(ele, llvm::ConstantInt::get(llvm::Type::getInt8Ty(M.getContext()), encGV.key), "", bodyBB);new llvm::StoreInst(encEle, elePtr, bodyBB);llvm::BranchInst::Create(incBB, bodyBB);// forIncBBauto incIndex = llvm::BinaryOperator::CreateAdd(index, llvm::ConstantInt::get(index->getType(), 1), "", incBB);new llvm::StoreInst(incIndex, indexPtr, incBB);llvm::BranchInst::Create(condBB, incBB);// EndBBllvm::ReturnInst::Create(M.getContext(), endBB);llvm::appendToGlobalCtors(M, func, 0);
}
运行测试
运行脚本:
opt -load ../Build/LLVMObfuscator.so -sob -S IR/TestProgram.ll -o IR/TestProgram_sob.ll
clang IR/TestProgram_sob.ll -o Bin/TestProgram_sob
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_sob
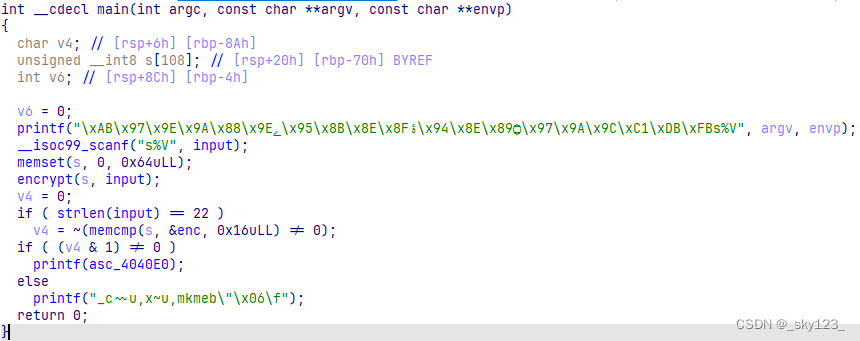
程序中的字符串被加密。
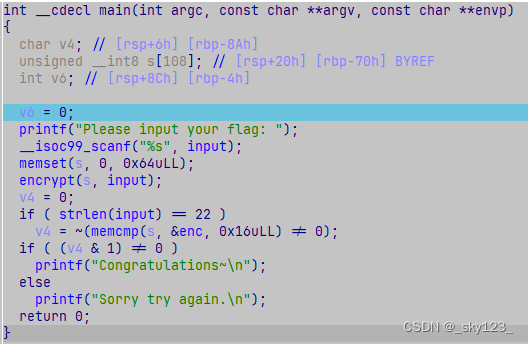
调试状态下字符串被解密。
全局变量加密
全局变量加密概述
全局变量加密本质上是字符串加密的一个更通用的版本,而字符串加密实际上是全局变量加密中数组加密中的一部分。
代码实现思路
全局变量加密按全局变量的类型分为常量加密和数组加密。
数组加密
数组加密和字符串加密的实现无本质区别,这里不做过多解释。
void GVObfuscation::insertModifyArrayFunctions(llvm::Module &M, llvm::EncryptedGV encGV) {auto funcType = llvm::FunctionType::get(llvm::Type::getVoidTy(M.getContext()), std::vector<llvm::Type *>{}, false);auto callee = M.getOrInsertFunction(encGV.GV->getName().str() + "DecFunc", funcType);auto func = llvm::cast<llvm::Function>(callee.getCallee());auto entryBB = llvm::BasicBlock::Create(M.getContext(), "entryBB", func);auto condBB = llvm::BasicBlock::Create(M.getContext(), "condBB", func);auto bodyBB = llvm::BasicBlock::Create(M.getContext(), "bodyBB", func);auto incBB = llvm::BasicBlock::Create(M.getContext(), "incBB", func);auto endBB = llvm::BasicBlock::Create(M.getContext(), "endBB", func);// entryBBauto indexPtr = new llvm::AllocaInst(llvm::Type::getInt32Ty(M.getContext()), 0, llvm::ConstantInt::get(llvm::Type::getInt32Ty(M.getContext()), 1), "i", entryBB);new llvm::StoreInst(llvm::ConstantInt::get(llvm::Type::getInt32Ty(M.getContext()), 0), indexPtr, entryBB);llvm::BranchInst::Create(condBB, entryBB);// condBBauto index = new llvm::LoadInst(indexPtr->getType()->getElementType(), indexPtr, "", condBB);auto cond = new llvm::ICmpInst(*condBB, llvm::ICmpInst::ICMP_SLT, index, llvm::ConstantInt::get(index->getType(), encGV.len));llvm::BranchInst::Create(bodyBB, endBB, cond, condBB);// bodyBBstd::vector<llvm::Value *> indexList{llvm::ConstantInt::get(llvm::Type::getInt32Ty(M.getContext()), 0), index};auto elePtr = llvm::GetElementPtrInst::Create(nullptr, encGV.GV, llvm::ArrayRef<llvm::Value *>(indexList), "", bodyBB);auto eleTyp = cast<llvm::ArrayType>(encGV.GV->getValueType())->getElementType();auto ele = new llvm::LoadInst(eleTyp, elePtr, "", bodyBB);auto decEle = llvm::BinaryOperator::CreateXor(ele, llvm::ConstantInt::get(eleTyp, encGV.key), "", bodyBB);new llvm::StoreInst(decEle, elePtr, bodyBB);llvm::BranchInst::Create(incBB, bodyBB);// forIncBBauto incIndex = llvm::BinaryOperator::CreateAdd(index, llvm::ConstantInt::get(index->getType(), 1), "", incBB);new llvm::StoreInst(incIndex, indexPtr, incBB);llvm::BranchInst::Create(condBB, incBB);// EndBBllvm::ReturnInst::Create(M.getContext(), endBB);llvm::appendToGlobalCtors(M, func, 0);
}auto idata = llvm::dyn_cast<llvm::ConstantInt>(GV->getInitializer());if (cdata && GV->getValueType()->isArrayTy()) {uint8_t *data = (uint8_t *) cdata->getRawDataValues().data();uint64_t key = rnd();uint32_t len = cdata->getNumElements();uint32_t size = cdata->getElementByteSize();if (size > 8) {continue;}for (int i = 0; i < len * size; i++) {data[i] ^= ((uint8_t *) &key)[i % size];}auto dynGV = new llvm::GlobalVariable(M, GV->getType()->getElementType(), false, GV->getLinkage(), GV->getInitializer(), GV->getName(), nullptr, GV->getThreadLocalMode(), GV->getType()->getAddressSpace());GV->replaceAllUsesWith(dynGV);GV->eraseFromParent();insertModifyArrayFunctions(M, {dynGV, key, len});}
常量加密
常量加密比数组加密更容易实现,因为少了循环从数组中获取元素的步骤,只需要读写全局变量即可。
void GVObfuscation::insertModifyIntegerFunctions(llvm::Module &M, llvm::EncryptedGV encGV) {auto funcType = llvm::FunctionType::get(llvm::Type::getVoidTy(M.getContext()), std::vector<llvm::Type *>{}, false);auto callee = M.getOrInsertFunction(encGV.GV->getName().str() + "DecFunc", funcType);auto func = llvm::cast<llvm::Function>(callee.getCallee());auto bodyBB = llvm::BasicBlock::Create(M.getContext(), "bodyBB", func);auto ele = new llvm::LoadInst(encGV.GV, "", bodyBB);auto decEle = llvm::BinaryOperator::CreateXor(ele, llvm::ConstantInt::get(encGV.GV->getValueType(), encGV.key), "", bodyBB);new llvm::StoreInst(decEle, encGV.GV, bodyBB);llvm::ReturnInst::Create(M.getContext(), bodyBB);llvm::appendToGlobalCtors(M, func, 0);
}auto idata = llvm::dyn_cast<llvm::ConstantInt>(GV->getInitializer());...} else if (idata && GV->getValueType()->isIntegerTy()) {uint64_t key = rnd();auto enc = llvm::ConstantInt::get(idata->getType(), key ^ idata->getZExtValue());auto dynGV = new llvm::GlobalVariable(M, GV->getType()->getElementType(), false, GV->getLinkage(), enc, GV->getName(), nullptr, GV->getThreadLocalMode(), GV->getType()->getAddressSpace());GV->replaceAllUsesWith(dynGV);GV->eraseFromParent();insertModifyIntegerFunctions(M, {dynGV, key, 1});}
运行测试
为了体现出全局变量加密的效果,这里与常量替代混淆结合使用,因为常量替代混淆会将部分数据放到全局变量中。
opt -load ../Build/LLVMObfuscator.so -csub -csub_loop=3 -gvo -S IR/TestProgram.ll -o IR/TestProgram_gvo.ll
clang IR/TestProgram_gvo.ll -o Bin/TestProgram_gvo
echo 'flag{s1mpl3_11vm_d3m0}' |./Bin/TestProgram_gvo
运行后可以看到 .init_array 中创建了大量的函数用来解密全局变量。

每个解密函数都会解密一个全局变量。
__int64 x_177DecFunc()
{__int64 result; // raxresult = dword_407114 ^ 0x85920896;dword_407114 ^= 0x85920896;return result;
}
相关文章:
LLVM 与代码混淆技术
项目源码 什么是 LLVM LLVM 计划启动于2000年,开始由美国 UIUC 大学的 Chris Lattner 博士主持开展,后来 Apple 也加入其中。最初的目的是开发一套提供中间代码和编译基础设施的虚拟系统。 LLVM 命名最早源自于底层虚拟机(Low Level Virtu…...

R语言---使用runway进行机器学习模型性能的比较
R语言—使用runway进行机器学习模型性能的比较 #dataloadrm(list=ls())#librarylibrary(dcurves)library(gtsummary)library(tidyverse)library(mlr3verse)library(tidyverse)library(data.table)</...
C++斩题录|递归专题 | leetcode50. Pow(x, n)
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...

详解Redis之Lettuce实战
摘要 是 Redis 的一款高级 Java 客户端,已成为 SpringBoot 2.0 版本默认的 redis 客户端。Lettuce 后起之秀,不仅功能丰富,提供了很多新的功能特性,比如异步操作、响应式编程等,还解决了 Jedis 中线程不安全的问题。 …...

【3】单着色器文件读取
Basic.shader文件,可以发现顶点着色器和片段着色器是写在一个文件里的,这里我们将他们读取出来,而不是上一篇使用string的方式。 #shader vertex #version 330 corelayout(location 0) in vec4 position;void main() {gl_Position positio…...

祝贺埃文科技入选河南省工业企业数据安全技术支撑单位
近日,河南省工业信息安全产业发展联盟公布了河南省工业信息安全应急服务支撑单位和河南省工业企业数据安全技术支撑单位遴选结果,最终评选出19家单位作为第一届河南省工业信息安全应急服务支撑单位和河南省工业企业数据安全技术支撑单位。 埃文科技凭借自身技术优势…...

Chinese-LLaMA-Alpaca-2模型的测评
训练生成效果评测 Fastchat Chatbot Arena推出了模型在线对战平台,可浏览和评测模型回复质量。对战平台提供了胜率、Elo评分等评测指标,并且可以查看两两模型的对战胜率等结果。生成回复具有随机性,受解码超参、随机种子等因素影响ÿ…...
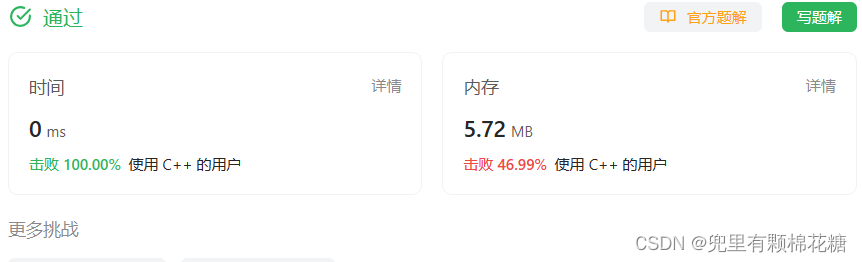
SLAM论文详解(5) — Bundle_Adjustment_LM(BALM)论文详解
目录 1 摘要 2 相关工作 3 BA公式和导数 A. 直接BA公式 B. 导数 C. 二阶近似 4 自适应体素化 5. 将BALM结合进LOAM 6. 实验 7. 算法应用场景解析 1 摘要 Bundle Adjustment是一种用于同时估计三维结构和传感器运动运动的优化算法。在视觉SLAM,三维重建等…...

C语言对单链表所有操作与一些相关面试题
目录 单链表的特性 单链表的所有操作 定义一个单链表 创建一个链表头 插入数据(头插法) 插入数据(尾插法) 查找节点 修改数据节点 删除节点 打印数据 销毁链表 翻转链表 打印链表长度 冒泡排序 快排 堆排 查找倒数第K个节点(双指针法) …...

高防服务器如何抵御大规模攻击
高防服务器如何抵御大规模攻击?高防服务器是一种专门设计用于抵御大规模攻击的服务器,具备出色的安全性和可靠性。在当今互联网时代,网络安全问题日益严重,DDOS攻击(分布式拒绝服务攻击)等高强度攻击已成为…...

Go 接口和多态
在讲解具体的接口之前,先看如下问题。 使用面向对象的方式,设计一个加减的计算器 代码如下: package mainimport "fmt"//父类,这是结构体 type Operate struct {num1 intnum2 int }//加法子类,这是结构体…...

Git忽略文件的几种方法,以及.gitignore文件的忽略规则
目录 .gitignore文件Git忽略规则以及优先级.gitignore文件忽略规则常用匹配示例: 有三种方法可以实现忽略Git中不想提交的文件。1、在Git项目中定义 .gitignore 文件(优先级最高,推荐!)2、在Git项目的设置中指定排除文…...
C语言——指针进阶(2)
继续上次的指针,想起来还有指针的内容还没有更新完,今天来补上之前的内容,上次我们讲了函数指针,并且使用它来实现一些功能,今天我们就讲一讲函数指针数组等内容,废话不多说,我们开始今天的学习…...

【汇编中的寄存器分类与不同寄存器的用途】
汇编中的寄存器分类与不同寄存器的用途 寄存器分类 在计算机体系结构中,8086CPU,寄存器可以分为以下几类: 1. 通用寄存器: 通用寄存器是用于存储数据和执行算术运算的寄存器。在 x86 架构中,这些通用寄存器通常包括…...
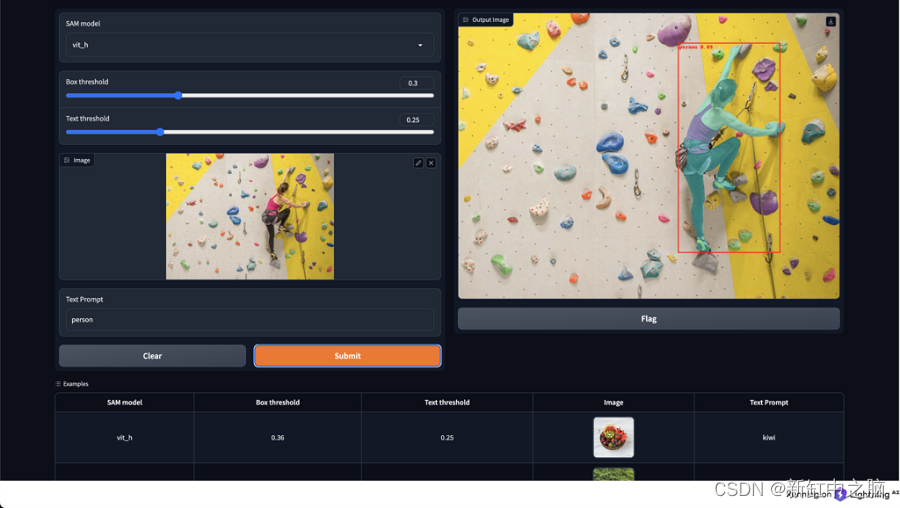
基于文本提示的图像目标检测与分割实践
近年来,计算机视觉取得了显着的进步,特别是在图像分割和目标检测任务方面。 最近值得注意的突破之一是分段任意模型(SAM),这是一种多功能深度学习模型,旨在有效地从图像和输入提示中预测对象掩模。 通过利用…...

【4-5章】Spark编程基础(Python版)
课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili 第4章 RDD编程(21节) Spark生态系统: Spark Core:底层核心(RDD编程是针对这个)Spark SQL:…...
04 卷积神经网络搭建
一、数据集 MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。 MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图…...

【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述 在hadoop3.0.3集群上执行hive3.1.2的任…...
)
数据结构--6.5二叉排序树(插入,查找和删除)
目录 一、创建 二、插入 三、删除 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树: ——若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值…...
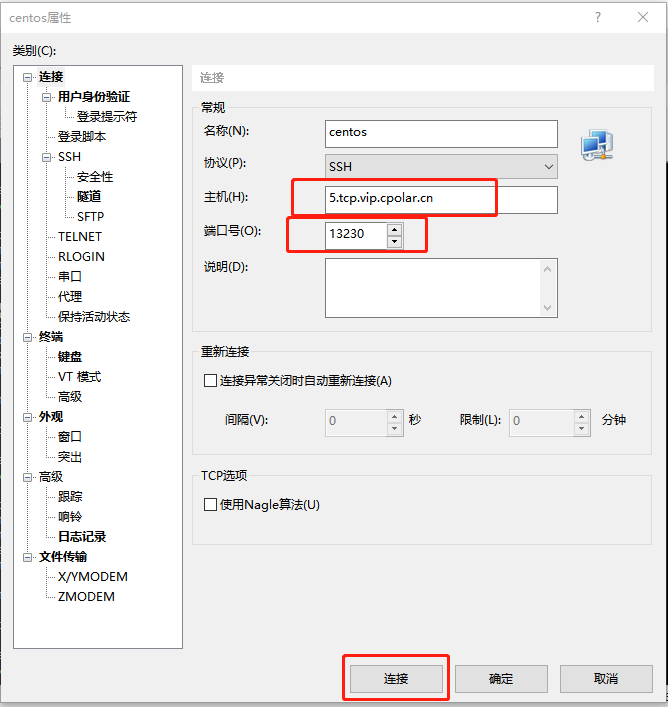
无需公网IP,在家SSH远程连接公司内网服务器「cpolar内网穿透」
文章目录 1. Linux CentOS安装cpolar2. 创建TCP隧道3. 随机地址公网远程连接4. 固定TCP地址5. 使用固定公网TCP地址SSH远程 本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...
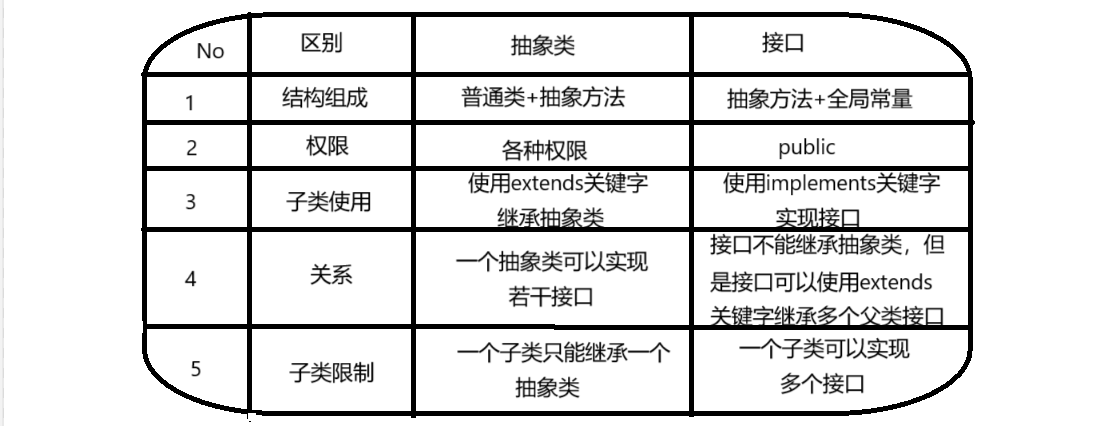
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...
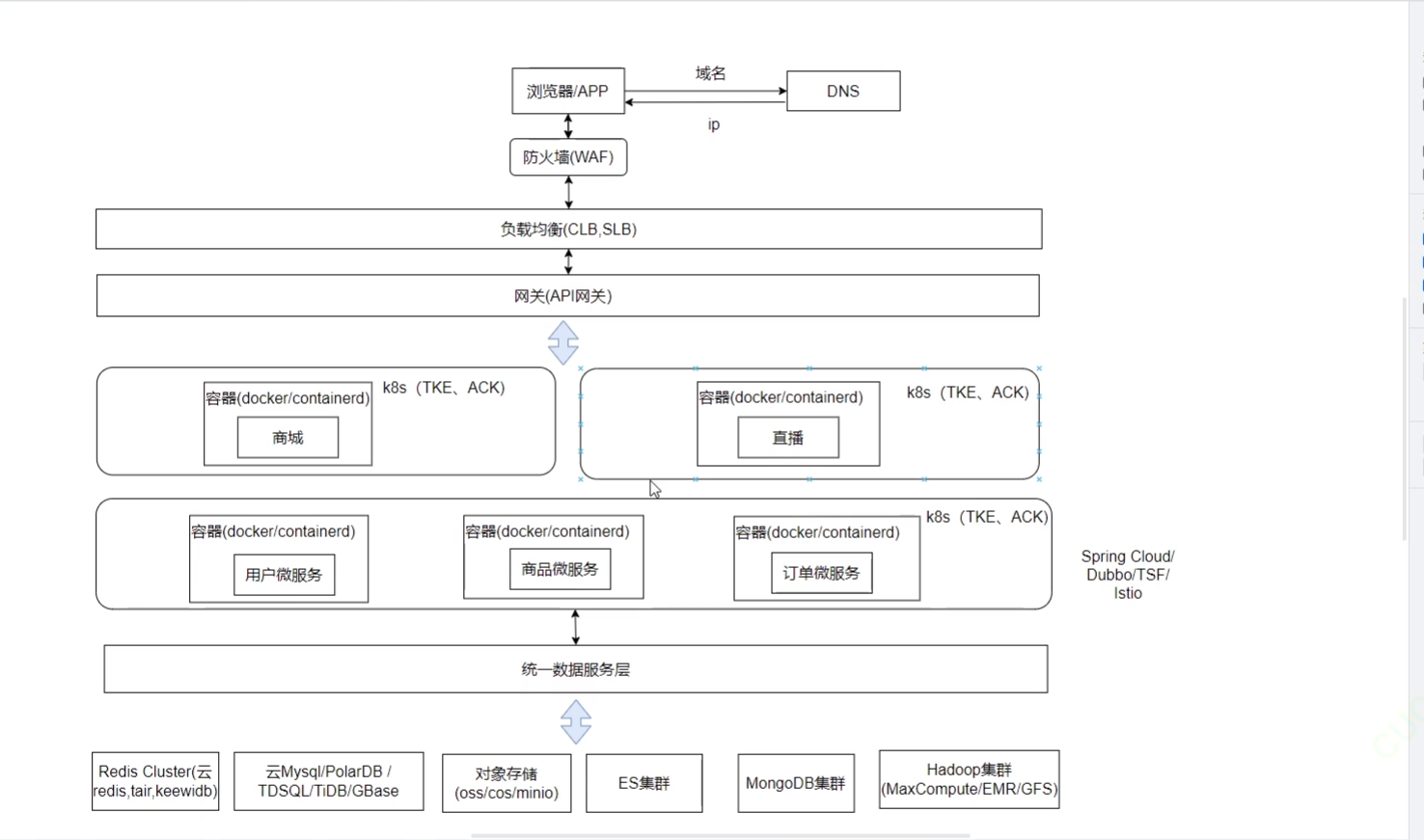
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...