如何进行机器学习
进行机器学习主要包含以下步骤:
获取数据:首先需要获取用于学习的数据,数据的质量和数量都会影响机器学习的效果。如果自己的数据量较少,可以尝试在网上寻找公开数据集进行训练,然后使用自己的数据进行微调。另一种方法是使用对抗网络生成更多的数据。
获取数据是机器学习的重要步骤之一。以下是一些获取数据的途径:
网上寻找公开数据集:这是一个非常常见的数据来源,一些常用的公开数据集包括Kaggle、Open Data、UCI Machine Learning Repository等。这些数据集通常包含大量数据和详细的标签,非常适合用来训练和测试机器学习模型。
自己的数据:如果你在自己的业务中拥有大量数据,那么可以使用这些数据进行训练和微调。这些数据可能包括用户行为数据、交易数据、传感器数据等。不过需要注意的是,自己的数据量可能较少,需要合理利用并选择合适的数据清洗和预处理方法。
生成更多的数据:如果自己的数据量不足或者质量不高,可以使用生成对抗网络(GAN)等技术来生成更多的数据。这些数据可以用来扩充数据集,提高模型的泛化能力。
无论使用哪种方法获取数据,都需要关注数据的质量和数量。好的数据可以训练出更好的模型,提高模型的准确率和泛化能力。同时,不同的数据源也可能需要不同的数据清洗和预处理方法,以确保数据的准确性和可靠性。
数据预处理与特征选择:从原始数据中提取出良好的特征,让机器学习算法能够更好地学习并做出准确的预测。数据预处理包括数据清洗、归一化、离散化、因子化、缺失值处理、去除共线性等步骤。特征选择是关键的一步,需要仔细筛选出与目标任务相关的显著特征,摒弃非显著特征。这需要深入理解业务,并运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
选择合适的算法:根据特定任务的需求,选择合适的机器学习算法。监督学习是机器学习中最常用的方法,其中包括线性回归、逻辑回归、决策树、深度神经网络等算法。
训练模型:使用获取的数据和选择的算法训练模型。训练过程中,通常会使用到各种参数,包括学习率、迭代次数、隐藏层数等。
验证与调整:训练完模型后,需要通过验证数据来评估模型的性能,并根据验证结果对模型进行调整。
应用模型:当模型经过验证并确定达到预期效果后,可以将其应用于实际场景中,例如进行文本分类、图像识别、推荐系统等任务。
以上就是进行机器学习的主要步骤,希望对你有所帮助。如有更深入或具体的需求,建议咨询专业的机器学习工程师或查阅相关文献。
附录:为什么要使用激活函数
激活函数在神经网络中扮演着重要的角色,它的主要作用包括:
增加模型的非线性表达能力:激活函数引入了非线性因素,使得神经网络能够更好地学习和表示复杂的非线性输入输出关系,从而提高了模型的表达能力。
实现隐含层的输出转换:激活函数将隐含层的输出进行非线性转换,将输入数据映射到输出层,这个过程有助于解决各种复杂的分类和回归问题。
增加模型的鲁棒性:加入激活函数可以增加模型的鲁棒性,对于输入数据的小的扰动,模型不会产生太大的误差,提高了模型的鲁棒性。
防止过拟合:激活函数有助于增加模型的复杂度,同时在一定程度上可以防止过拟合问题。
因此,使用激活函数对于神经网络的性能和效果至关重要。
相关文章:

如何进行机器学习
进行机器学习主要包含以下步骤: 获取数据:首先需要获取用于学习的数据,数据的质量和数量都会影响机器学习的效果。如果自己的数据量较少,可以尝试在网上寻找公开数据集进行训练,然后使用自己的数据进行微调。另一种方…...

Vue项目使用axios配置请求拦截和响应拦截以及判断请求超时处理提示
哈喽大家好啊,最近做Vue项目看到axios axios官网:起步 | Axios 中文文档 | Axios 中文网 (axios-http.cn) 重要点: axios是基于Promise封装的 axios能拦截请求和响应 axios能自动转换成json数据 等等 安装: $ npm i…...
《DevOps实践指南》- 读书笔记(四)
DevOps实践指南 Part 3 第一步 :流动的技术实践11. 应用和实践持续集成11.1 小批量开发与大批量合并11.2 应用基于主干的开发实践11.3 小结 12. 自动化和低风险发布12.1 自动化部署流程12.1.1 应用自动化的自助式部署12.1.2 在部署流水线中集成代码部署 12.2 将部署…...
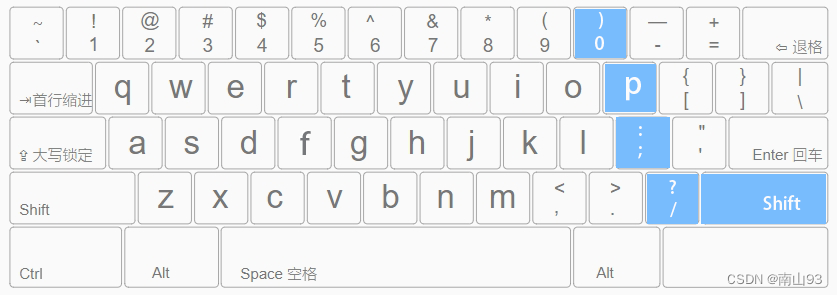
盲打键盘的正确指法指南
简介 很多打字初学者,并不了解打字的正确指法规范,很容易出现只用两根手指交替按压键盘的“二指禅”情况。虽然这样也能实现打字,但是效率极低。本文将简单介绍盲打键盘的正确指法,以便大家在后续的学习和工作中能够提高工作效率…...
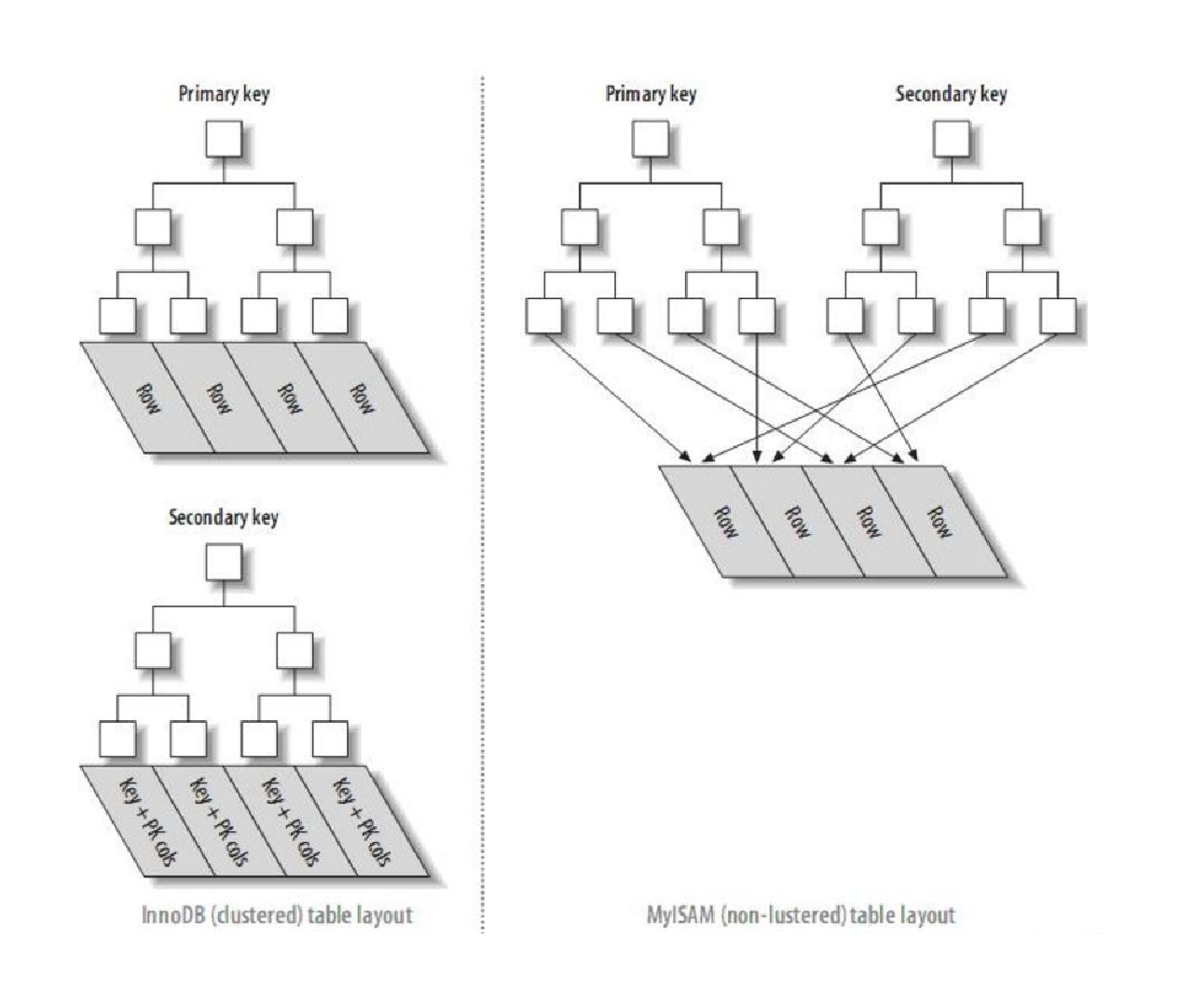
【MySQL】索引 详解
索引 详解 一. 概念二. 作用三. 使用场景四. 操作五. 索引背后的数据结构B-树B树聚簇索引与非聚簇索引 一. 概念 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各…...

怎么通过ip地址连接共享打印机
在现代办公环境中,共享打印机已成为一种常见的需求。通过共享打印机,多个用户可以在网络上共享同一台打印机,从而提高工作效率并减少设备成本。下面虎观代理小二二将介绍如何通过IP地址连接共享打印机。 确定打印机的IP地址 首先࿰…...
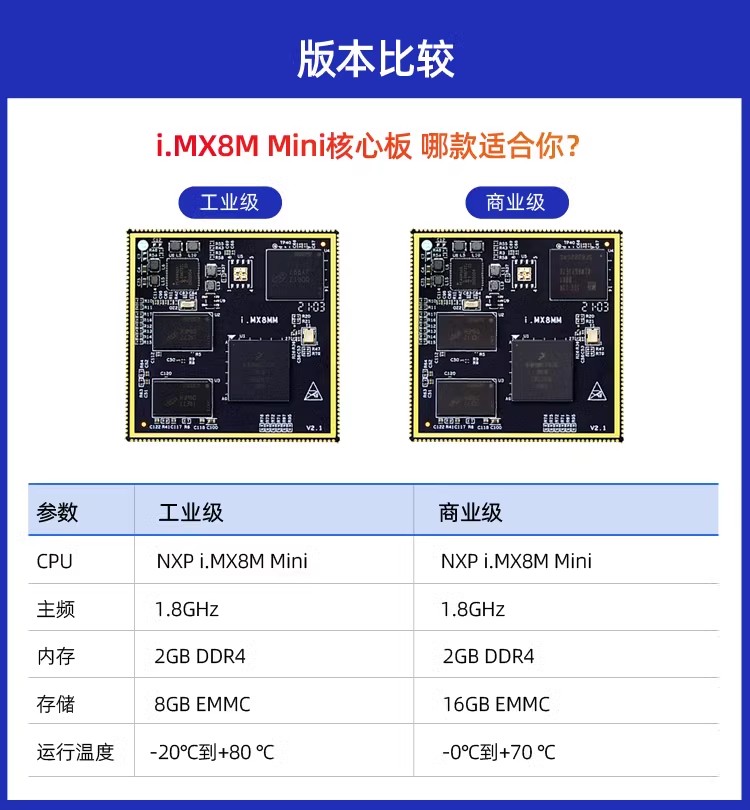
迅为i.MX8mm小尺寸商业级/工业级核心板
尺寸: 50mm*50mm CPU: NXP i.MX8M Mini 主频: 1.8GHz 架构: 四核Cortex-A53,单核Cortex-M4 PMIC: PCA9450A电源管理PCA9450A电源管理NXP全新研制配,iMX8M的电源管理芯片有六个降压稳压器、五…...
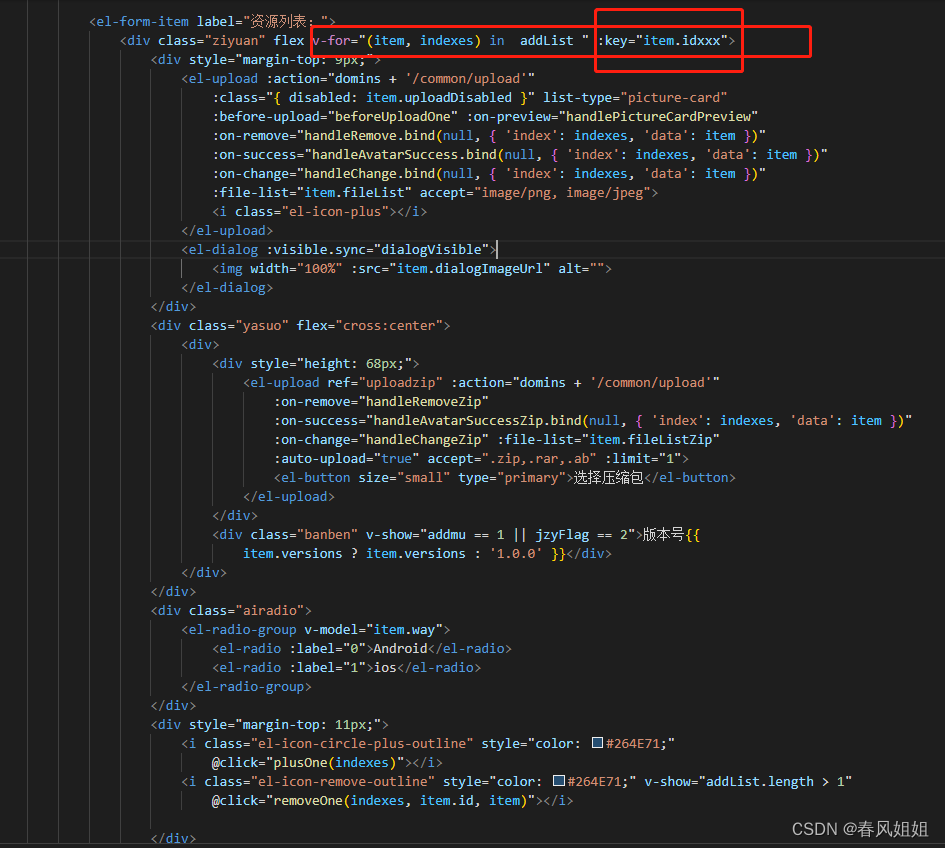
vue中v-for循环数组使用方法中splice删除数组元素(错误:每次都删掉点击的下面的一项)
总结:平常使用v-for的key都是使用index,这里vue官方文档也不推荐,这个时候就出问题了,我们需要key为唯一标识,这里我使用了时间戳(new Date().getTime())处理比较复杂的情况, 本文章…...

Python用GAN生成对抗性神经网络判别模型拟合多维数组、分类识别手写数字图像可视化...
全文链接:https://tecdat.cn/?p33566 生成对抗网络(GAN)是一种神经网络,可以生成类似于人类产生的材料,如图像、音乐、语音或文本(点击文末“阅读原文”获取完整代码数据)。 相关视频 最近我们…...

嵌入式Linux驱动开发(LCD屏幕专题)(一)
一、LCD简介 总的分辨率是 yres*xres。 1.1、像素颜色的表示 以下三种方式表示颜色 1.2、如何将颜色数据发送给屏幕 每个屏幕都有一个内存(framebuffer)如下图,内存中每块数据对用屏幕上的一个像素点,设置好LCD后ÿ…...

uniapp搜索功能
假设下方数据是我们从接口中获取到的,我们需要通过name来搜索,好我们看下一步。 data: [{"id": 30,"category_id": 3,"name": "日常家居名称","goods_num": 20,"integral_num": 20,&q…...

iframe 实现跨域,两页面之间的通信
一、 背景 一个项目为vue2,一个项目为vue3,两个不同的项目实现iframe嵌入,并实现通信 二、方案 iframe跨域时,iframe组件之间常用的通信,主要是H5的possmessage方法 三、案例代码 父页面-vue2(端口号为…...
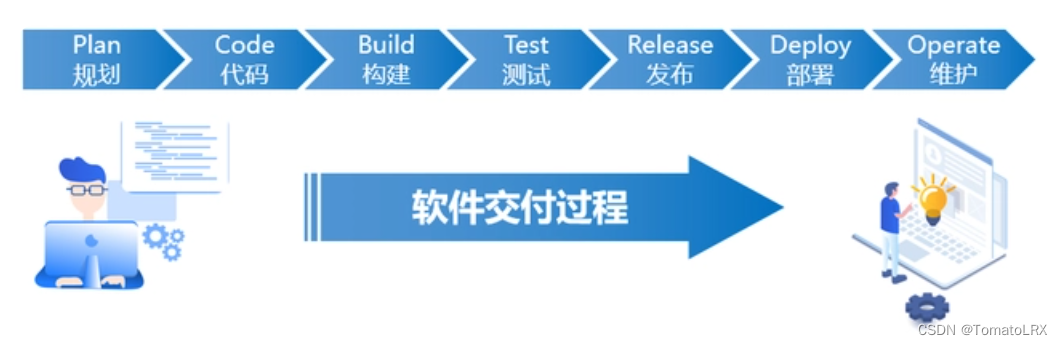
DevOps到底是什么意思?
前言: 当我们谈到 DevOps 时,可能讨论的是:流程和管理,运维和自动化,架构和服务,以及文化和组织等等概念。那么,到底什么是"DevOps"呢? 那么,DevOps是什么呢? 有人说它是一种方法,也有人说它是一种工具,还有人说它是一种思想。更有甚者,说它是一种哲学…...
03JVM_类加载
一、类加载与字节码技术 1.类文件结构 2.字节码指令 3.编译期处理 4.类加载阶段 5.类加载器 6.运行期优化 1.类文件结构 类文件结构 1.1 魔数magic 介绍 每个java class文件的前4个字节是魔数:0x CAFEBABE。魔数作用在于分辨出java class文件和非java clas…...
)
Mysql如何对null进行排序(mysql中null排序)
来源:Mysql如何对null进行排序(mysql中null排序) Mysql如何对null进行排序 Mysql是一种开源的关系型数据库管理系统,经常被用于Web开发和应用程序中。在使用Mysql进行数据处理的过程中,很多时候都会遇到需要对null进行…...
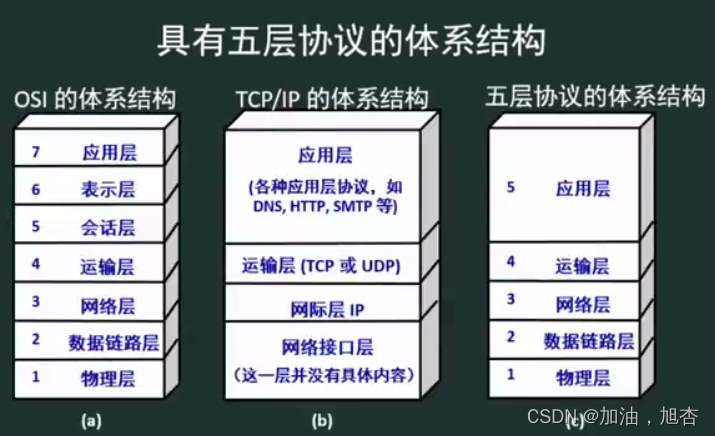
【基础计算机网络1】认识计算机网络体系结构,了解计算机网络的大致模型(下)
前言 在上一篇我们主要介绍了有关计算机网络概述的内容,下面这一篇我们将来介绍有关计算机网络体系结构与参考模型的内容。这一篇博客紧紧联系上一篇博客。 这一篇博客主要内容是:计算机网络体系结构与参考模型,主要是计算机网络分层结构、协…...

vscode 画流程图
文章目录 1、安装插件 draw2、新建文件3、开始画图4、另存为图片 vscode可以画流程图了,只需要安装插件就可以了。 1、安装插件 draw 2、新建文件 3、开始画图 4、另存为图片...

uniapp-一些实用的api接口
唤起导航 调用后可以跳转到地图页 uni.openLocation({latitude: res.data.data.latitude, //到达的纬度longitude: res.data.data.longitude, //到达的经度name: res.data.data.address, // 到达的名字scale: 12, // 缩放倍数success() { // 成功回调console.log(success) }…...
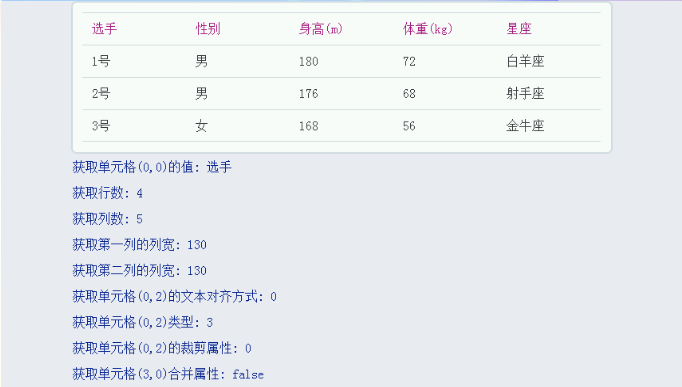
合宙Air724UG LuatOS-Air LVGL API控件-表格(Table)
表格(Table) 示例代码 --创建表格Table1 lvgl.table_create(lvgl.scr_act(),nil)--设置表格为4行5列lvgl.table_set_row_cnt(Table1,4)lvgl.table_set_col_cnt(Table1,5)--给每个单元格赋值lvgl.table_set_cell_value(Table1, 0, 0, "选手")l…...
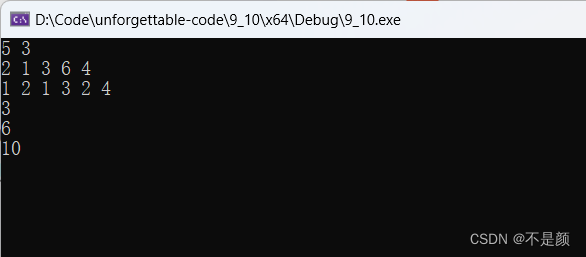
前缀和思想
何为前缀和 有一个数组a, 为 ...... 前缀和 ...... 有两个问题: 1.如何求? 只需要从前往后遍历,令 就可以了,最开始是 ,定义 0 2. 有什么用? 能够快速地求出原数组中某一段的和,预处理的…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...
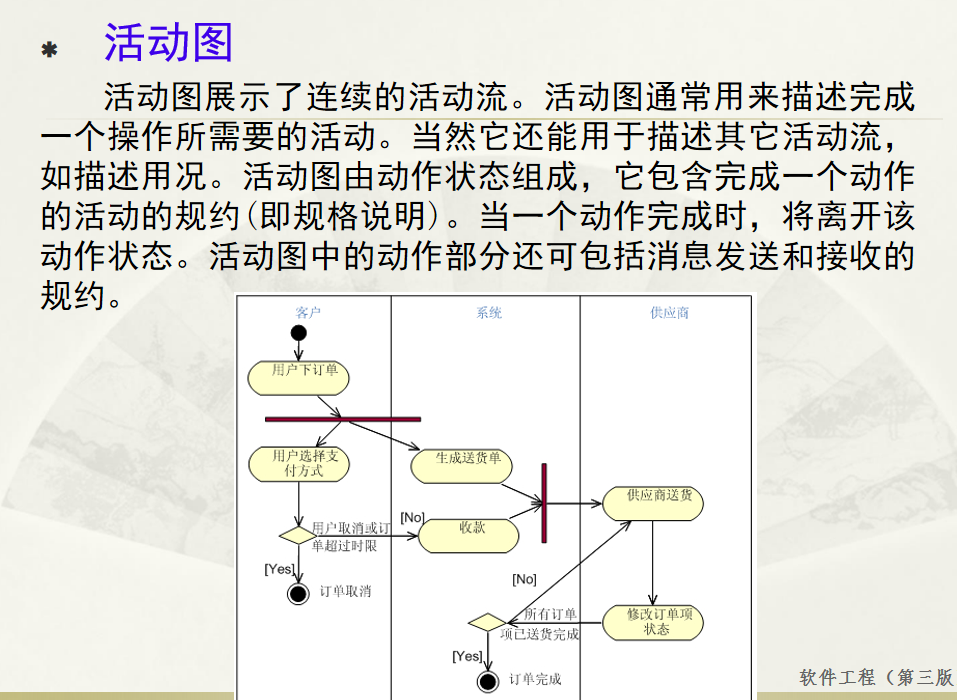
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...
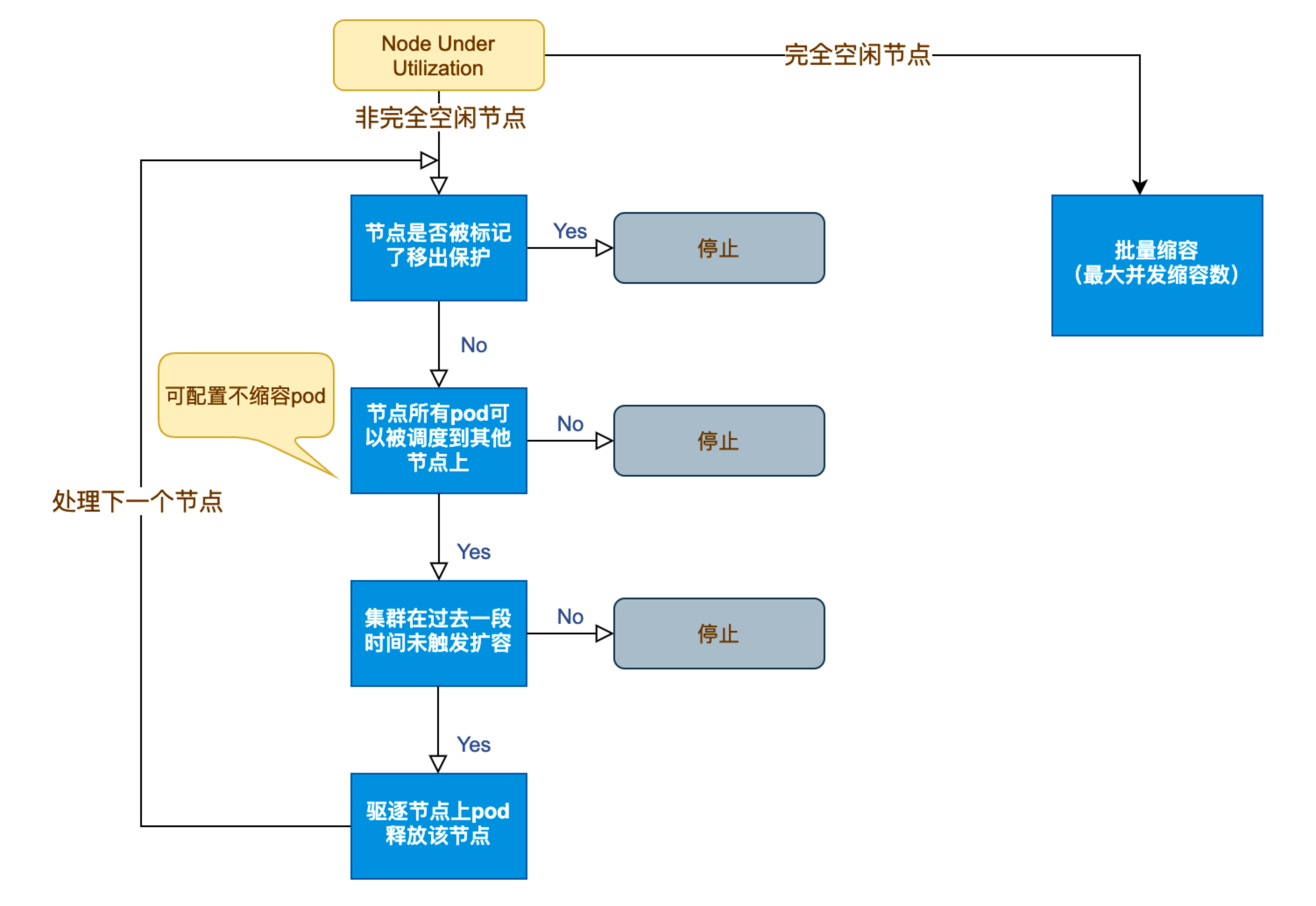
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...