【Python】爬虫基础
爬虫是一种模拟浏览器实现,用以抓取网站信息的程序或者脚本。常见的爬虫有三大类:
通用式爬虫:通用式爬虫用以爬取一整个网页的信息。
聚焦式爬虫:聚焦式爬虫可以在通用式爬虫爬取到的一整个网页的信息基础上只选取一部分所需的信息。
增量式爬虫:增量式爬虫每次只爬取网站中更新的信息。
传输协议
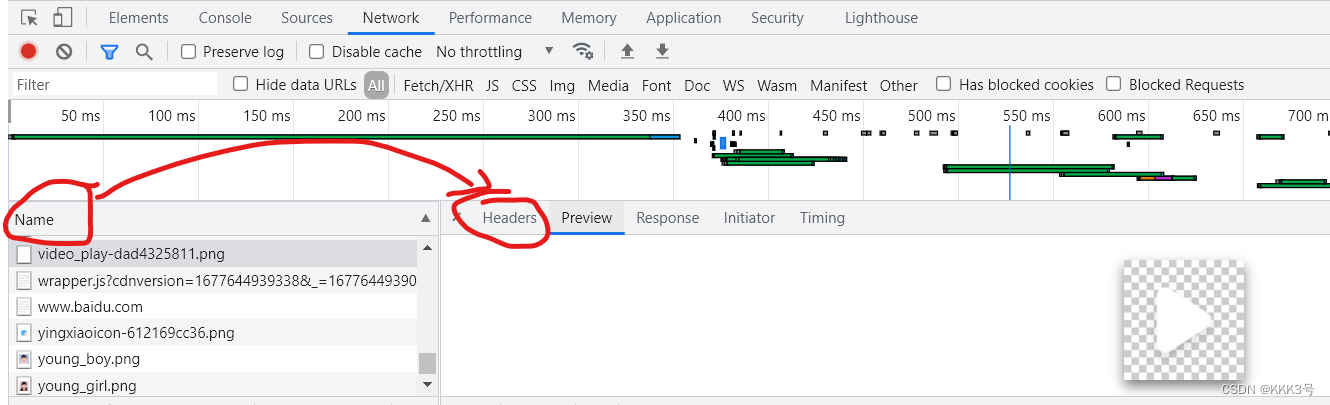
我们知道,当我们点进某个页面时,一般我们的客户端会向服务器发送HTTP请求报文。其中报文里面很重要的一个内容就是报文的头信息(包括请求行、首部行等),它们包含了我们请求的一些基本信息。所以我们有必要了解如何找到客户端和服务器端的相互传输的HTTP报文的头信息:先打开任意一个网址,按下键盘的F12

在打开的窗口中点击network栏,再在Name一栏随意找到该网页中的某个对象,点击后选择右端的headers即可看到我们发送的报文一些头信息。
然而为了防止传输的报文被第三方拦截泄露信息,一般情况下我们的传输过程会加上一些保密协议:例如HTTPS就比HTTP更加安全,因为它采用了证书密钥的加密方式。
requests模块
报文请求过程
因为爬虫是模拟浏览器发送报文,所以我们需要先知道怎么模拟浏览器实现向服务器发送请求功能。正好Python中就为我们提供了相应的功能模块--“requests”。
我们需要明确浏览器发送时它共经历了三个步骤:1、获取URL(点击网址);2、向服务器发送请求报文(等待加载);3、得到、处理响应报文(页面展示),所以我们需要利用requests模块也需要模拟出上面三个过程。(下面以获取百度首页文字为例)
1、获取URL:
导入该模块,并且开辟一个变量来存储目标URL。
import requestsurl = 'https://www.baidu.com'2、发送请求:
这里我们模拟的是使用GET方法的报文,当然我们也可以模拟使用POST、DELETE等方法的报文。具体发送请求就调用requests模块里面的get方法,它常用有三个参数:url、params和headers。我们这里先只传入url。因为我们使用的是get方法,所以它会返回一个响应报文。
import requestsurl = 'https://www.baidu.com/?tn=44004473_52_oem_dg'
response = requests.get(url)3、处理响应报文
我们将得到的响应报文存到变量response里面,并且将其字符编码设置为“utf-8”(防止乱码)。然后我们的目标是获取返回的报文里面的文字信息,所以我们将其文章的文字信息以字符串的形式存储到一个文件里面。
import requestsurl = 'https://www.baidu.com/?tn=44004473_52_oem_dg'
response = requests.get(url)
response.encoding = 'utf-8'
file = open("./myget.html", "w", encoding='utf-8')
file.write(response.text)
file.close()这样我们运行生成的html就可以访问到百度的主页文字了
静态网页采集
之前只是获取一个特定的网页的信息,下面我们以实现采集利用关键词搜索出来的网页内容为例子看如何获取我们想要的网页(搜索):
以百度搜索为例,我们利用百度搜索某个关键词时使用的URL如下:

所以一般搜索类的URL结构如下(百度)
域名+s?wd=“我们的问题”
所以我们在爬取网页内容之前需要模仿关键词搜索,实现URL中包含我们需要搜索的内容。为了实现在URL中插入参数变量,get方法提供了一个params参数,我们只需要向其传入一个需要搜索的关键字即可,这个关键字一般存储于一个字典中。以百度搜索为例,我们的问题对应的键就是’wd‘
import requestsurl = 'https://www.baidu.com/s'
rec = input()
dic = {'wd': rec
}
response = requests.get(url= url, params= dic)
response.encoding = 'utf8'
text = response.text
file = open("./output.html", 'w', encoding='utf8')
file.write(text)
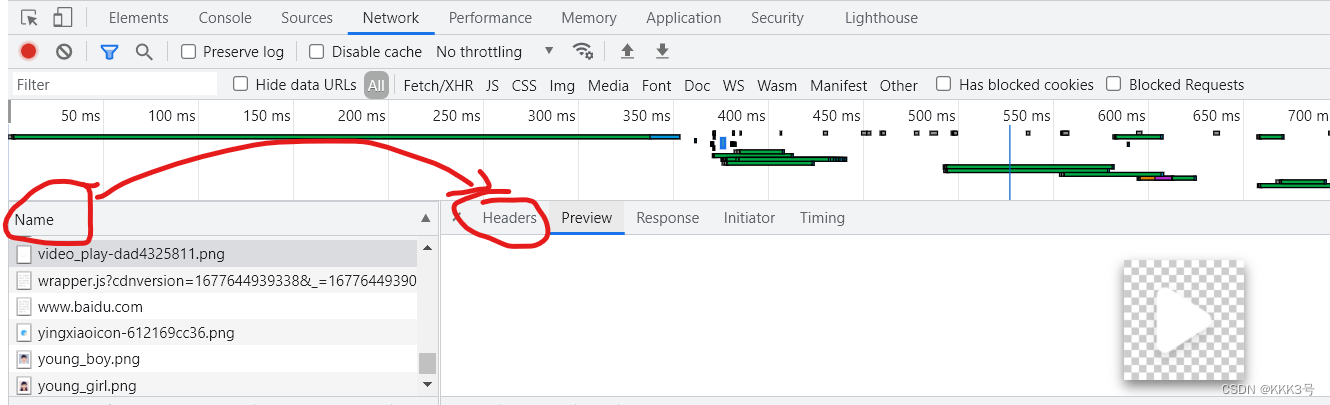
file.close()但是这还不够,我们还需要注意的一点是,我们使用这个方法还不能获取当前的网页,有一网页服务器发现我们不是浏览器发送的请求,会拒绝响应。所以我们需要加上一些伪装信息,绕过一些服务器有反爬机制。所以需要利用get方法的第三个常用参数headers(头信息),假装我们是浏览器发送的报文,而非爬虫程序,一般加入Cookie和Accept即可了。要想知道自己这些信息打开网页按下F12即可看到:
加上我们自己的伪装后的程序可以直接不需要验证就获取网页:
import requestsurl = 'https://www.baidu.com/s'
rec = input()
dic = {'wd': rec
}
headers = {'Accept': ...'User-Agent':...'Cookie':...
}
response = requests.get(url= url, params= dic, headers=headers)
response.encoding = 'utf8'
text = response.text
file = open("./output.html", 'w', encoding='utf8')
file.write(text)
file.close()
动态网页采集
但是并不是所有访问网页上端显示的URL都能获取到对应的完整界面,有时候网页上有一些信息是通过AJAX请求后才返回给我们的,下面是判断信息是否为AJAX请求返回的:
假如我们打开bilibili,找到电影索引的网页,我们目标是想获取所有电影的名字和评分,并将从第一页到第四页的电影名和对应评分都获取下来存到对应的txt文件中,所以需要知道怎么获取其信息。按下F12,我们在All里面找到对应该页面的URL的对象,但是它的response里面没有找到我们需要的数据,那么就证明这些数据不是直接通过访问URL获取的,而是由AJAX请求后再传输给我们的。
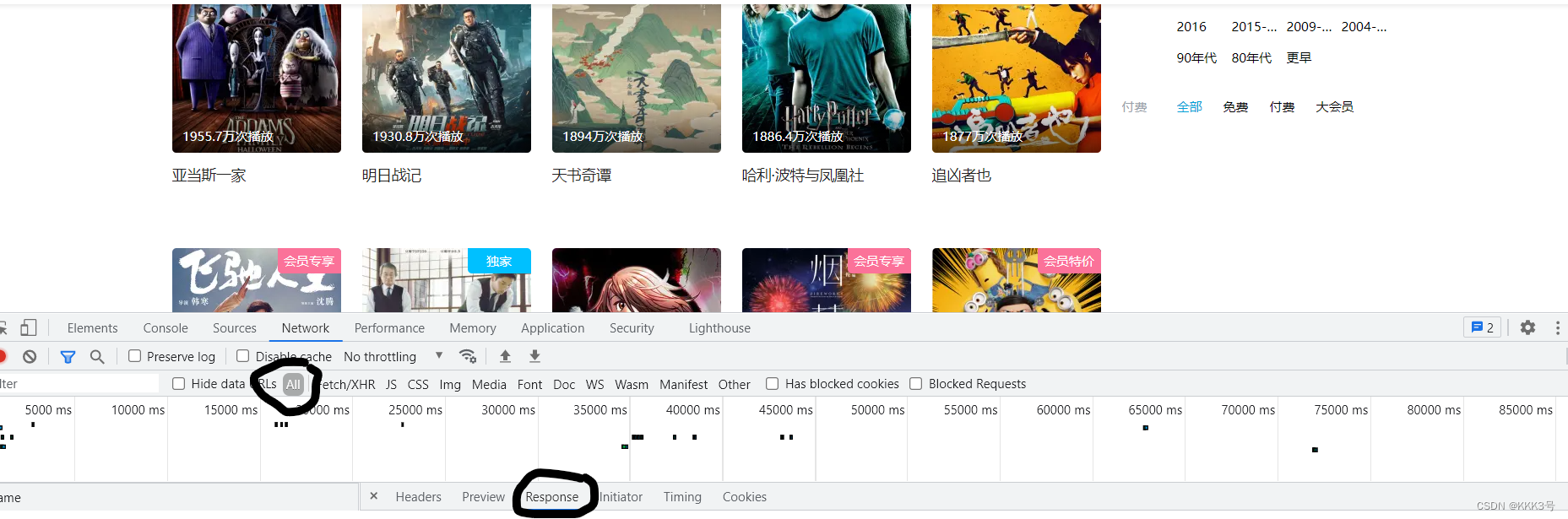
我们可以再次定位到XHR一栏,逐个寻找,找到Response里面包含电影名的那个Name,查看头信息获取其URL和返回的文件类型(json类型)以此来模拟浏览器请求过程。
import json
import requestsurl ='https://api.bilibili.com/pgc/season/index/result'
headers = {'User-Agent':...}
file = open('./output.txt', 'w', encoding='utf8')
for i in range(1,5):params={'st': '2','order': '2','area': '-1','style_id': '-1','release_date': '-1','season_status': '-1','sort': '0','page': i,'season_type': '2','pagesize': '20','type': '1'}response = requests.get(url=url, headers=headers, params=params).json()for p in response['data']['list']:file.write('电影名:'+p['title']+' '+'评分:'+p['score']+'\n')
file.close()数据解析
上面使用到的requests模块主要还是用于获取一整张网页,但是我们很多情况下只需要某部分对应的信息,这时候我们就需要对采集的数据进行解析了,解析位于标签之间的文本内容或文本属性。
所以总结我们数据解析的步骤,可以大致分为两步:1、定位到该信息的标签;2、从该标签中提取该信息。
针对上面的数据解析,我们主要利用bs4和xpath的解析方法。
bs4
bs4的数据解析方法共分为两步:
1、将请求到的页面源码赋予给实例化的对象Beautifulsoup
2、调用Beautifulsoup的属性或者方法来从标签中获取我们所需的内容
在我们使用bs4的方法前,需要先导两个包:bs4包和解释源码用到lxml包:
pip install bs4
pip install lxml
第一步实现:
然后我们既可以实例化出一个BeautifulSoup对象bs了,实例化需要向BeautifulSoup里传入两个参数:1、我们获取的网页源码;2、固定是'lxml'的解析方式。其中所需的源码就是我们曾经使用get方法中的text方式获取到的对应网页的数据。
第二步实现:
1、定位
再者就是如何调用实例化出来的对象bs里面的方法和属性来获取对应标签里面的所需信息了。常见的使用方法或者属性有bs.find()、bs.find_all、bs.tagname。
bs.tagname是获取bs对象里面标签名为tagname的第一个标签的内容,相似地,bs.find('tagname')也是找出第一个标签名为tagname的标签里面的内容,如果想找到更深入,还可以加上属性:bs.find('tagname', class_=‘属性’);要想找到全部标签名为tagmane的标签内容,需要使用find_all,传入标签名即可。
而挑选某个符合条件的信息需要使用select方法,我们向它传递的参数是一个选择器,我们可以选择传递类选择器(标志为 . 号)、id选择器(标志位#号)或者标签名选择器等等...(或者我们还可以传递层选择器“上一级标签 > 次级标签 >最低级标签”、如果有非隶属则>换为空格)。
2、获取
当我们利用定位获取到当前信息存储到标签位置时,我么们就需要考虑如何去获取这些信息了,在BeautifulSoup模块中,其为每一个实例出来的对象都提供了两个属性和一个方法来获取这些信息:我们以bs.tagname为定位标签,则获取信息的方式是bs.tagname.text 、 bs.tagname.get_text() 、 bs.tagname.string。但是这三者中前两者可以获取当前标签下的所有内容,而后者只能获取当前标签下的直隶内容。
import json
import requests
import lxml
from bs4 import BeautifulSoupurl = 'https://blog.csdn.net/m0_61151031'
headers ={'cookie':....、'user-agent': ...
}
param = {'spm': '1011.2415.3001.5343'
}
response = requests.get(url=url, params=param, headers= headers)
response.encoding='utf8'bs = BeautifulSoup(response.text, 'lxml')
title_save = []
URL_save = []
for j in bs.find_all('article' ,class_='blog-list-box'):URL_save.append(j.find('a')['href'])
for i in bs.find_all('h4'):title_save.append(i.text)file= open('./output.txt', 'w', encoding='utf-8')
print(len(title_save))
print(len(URL_save))
for i in range(0,len(title_save)-1):file.write(title_save[i]+' : '+URL_save[i]+'\n')
file.close()
Xpath
在我们使用Xpath之前需要先安装Xpath所需的解释器 lxml 包:
pip install lxml
安装完后,下面我们就可以使用Xpath来捕获网页中某个标签对应的具体信息。整个获取过程总结起来为两步:1、定位到具体存储的标签2、获取该标签下的信息。实际使用Xpath来操作这两个步骤的过程如下:
1、实例化出一个etree对象,并且将网页源码赋予该对象
2、调用etree对象里面的xpath方法,利用xpath表达式定位到我们所需的标签,捕获其内容信息。
下面是作为例子的html文件,我们可以看到信息都是夹杂在一些尖括号括起来的标签里边(类似这样:<XX>信息</XX>):
<html lang="en">
<head><meta charset="UTF-8" /><title>测试bs4</title>
</head>
<body><div><p>百里守约</p></div><div class="song"><p>李清照</p><p>王安石</p><p>苏轼</p><p>柳宗元</p><a href="http://www.song.com/" title="赵匡胤" target="_self"><span>this is span</span>宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a><a href="" class="du">总为浮云能蔽日,长安不见使人愁</a><img src="http://www.baidu.com/meinv.jpg" alt="" /></div><div class="tang"><ul><li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li><li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li><li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li><li><a href="http://www.sina.com" class="du">杜甫</a></li><li><a href="http://www.dudu.com" class="du">杜牧</a></li><li><b>杜小月</b></li><li><i>度蜜月</i></li><li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li></ul></div>
</body>
</html>
第一步实现:
要想定位到具体的标签,首先我们需要有一个etree对象。调用etree的parse方法将本地的html文件传入该方法中(如果是网上的html文件,需要调用etree的HTML方法),该函数会返回一个已解释了html对象:
import requests
from lxml import etreerec_etree = etree.parse('./test.html')然后我们就可以 调用该对象的方法xpath来定位标签,其中xpath方法有多种使用方式,不过具体还是向其传入一个标签位置。
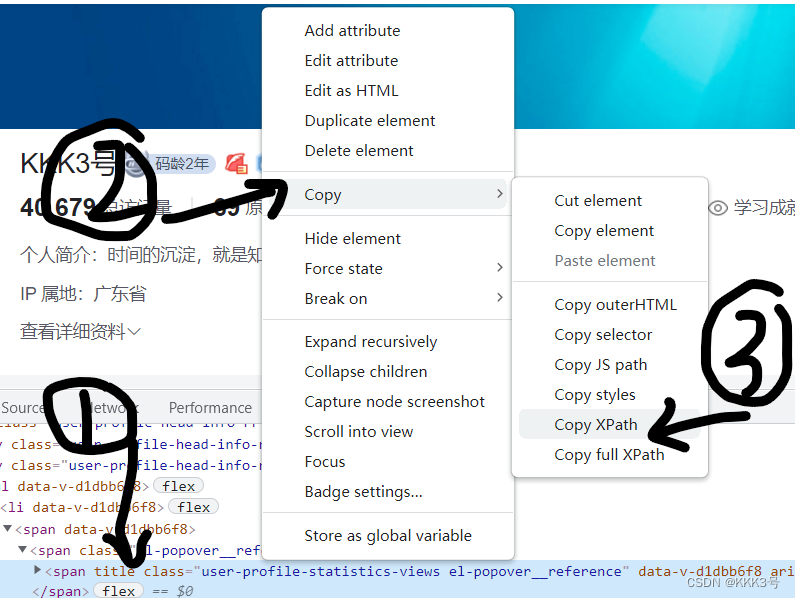
一个标签位置的格式为 :/ 标签名 / 标签名 / 标签名。由 / 符号表示层级关;但是我们还可以利用 // 表示多层级关系,/ 标签名 // 标签名,省略中间的标签名。如果我们以及获取了定位在中间层级的某个对象,那么接下来的位置也可以表示为 ./标签名/标签名,这里的 ./ 就表示从当前位置开始,和Linux系统中用法类似。如果某一层的下一次标签名都相同,那么我们需要在相同的标签后面加上[n](n为数字)来表示是哪一个标签。

例如上图中P[1]是李清照、P[2]是王安石...这里要注意下标从1开始。
如果定位时要加上标签的属性,我们则需要在标签后面加上[@class="属性"],例如上面的例子要定位到具有属性song的标签地址就需要写为:
//div[@class="song"]下面以定位信息苏轼的标签p为例可以写出多种定位写法:
print(rec_etree.xpath('/html/body/div/p[3]'))
print(rec_etree.xpath('/html//p[3]'))
print(rec_etree.xpath('//div/p[3]'))
print(rec_etree.xpath('//p[3]'))从上到下我们依次来看:首先第一个是直接完全每一个层级都标清楚的定位;第二个是省略了中间层级的定位;第三个是省略局部前面层级的定位;第四个是省略全部前面层级的定位。
(或者有时候可以直接用右键点击该信息复制...)
第二步实现:
当我们定位到某个标签后,我们得到的还只是给elements对象,我们要想获取里面对应的信息,最简单的方式就是在标签后再加一层/text(),但是这样得出来的还只是一个字典:

为此我们还需要获取其首元素信息
print(rec_etree.xpath('/html/body/div/p[3]/text()')[0])
print(rec_etree.xpath('/html//p[3]/text()')[0])
print(rec_etree.xpath('//div/p[3]/text()')[0])
print(rec_etree.xpath('//p[3]/text()')[0])但是我们仔细看可以看到有时候有些我们需要的信息没有存在标签之间,而是存在了标签里边,作为标签的属性,这时候我们就需要在定位到标签后加上..标签名/@属性名来获取这个属性。
print(rec_etree.xpath('//div[@class="song"]/a[@title="赵匡胤"]/@href')[0])
验证码
验证码是服务器指定的一种反爬机制,当我们登录某些网址时,在输入了账号和密码后系统可能需要我们输入一个随机的验证码,这样可以有效地防止我们的爬虫程序模拟登录,因为程序预先不知道系统会给哪些个验证码,以此来保障反爬。

为此,我们要想爬取需要验证码的网址,需要借助一些第三方验证码识别工具进行验证码破解或者人工识别图片或者用专门的AI图片识别算法。
多线程
现在我们需要考虑一种情况,如果我们一次性需要请求很多的URL,那么系统会如何去执行我们的代码呢?下面是一次模拟请求情况的代码:
import requestsurl =['url1''url2''url3'...
]
headers = {...
}def get_status(each_url):response = requests.get(url=url, headers=headers)return response.status_codefor each_url in url:ret = get_status(each_url)print(ret)我们将输出每一个请求的URL的返回状态码。系统会将我们的URL通过GET函数一次一次地串行发送过去,这样也就表面,如果GET函数发送请求一个报文并获得响应需要1s,那么100个URL请求将要花费100s,更多情况下花费地时间将更长!
其实我们回过头来看,问题主要还是出在了每一次GET只发送一个URL的请求,下面为串行通信的示意:
 为了解决这个问题,人们提出的方案为开辟多个进程进行发送,也就是使用并行的通信方式,这种方式的示意图如下,虽然多线程的通信可以大大减少发送的时间,但是每次调用就开辟一个进程,用完就关掉的往复操作却增大了CPU的工作量!所以每一个方法都会有副作用!
为了解决这个问题,人们提出的方案为开辟多个进程进行发送,也就是使用并行的通信方式,这种方式的示意图如下,虽然多线程的通信可以大大减少发送的时间,但是每次调用就开辟一个进程,用完就关掉的往复操作却增大了CPU的工作量!所以每一个方法都会有副作用!
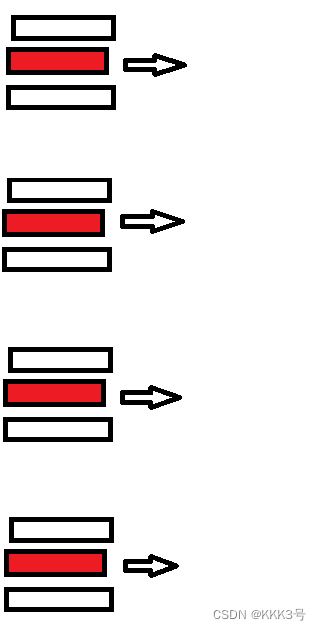
除了上面的两种方法,聪明的人们还想出了另外一种方法:线程池,它在多线程的基础上进行修改,基本原理为一次开辟多个进程,然后用这些有限的线程池来进行数据传输,这样可以有效地避免了多线程情况下线程使用的开关开关操作导致的消耗。下面我们来做两个例子对比一下:
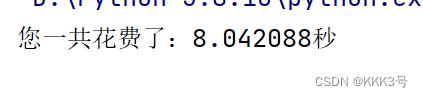
首先是模拟单线程,模拟的例子的思路是用一个函数operation,这个函数将期待我们发送报文的函数,其中每次get函数所导致的阻塞时间就由sleep函数来模拟,每次的url就由一个elements列表来表示。
from time import *start = time()
def operation(element):sleep(2)elements = [1, 2, 3, 4]
for i in elements:operation(i)
end = time()
print('您一共花费了:'+'%lf'%(end-start)+'秒')通过测试上面的代码我们可以得到共花费的时间:
然后我们来使用多线程传输。要想实现多线程传输我们首先需要导入一个包,这个包里面的Pool类将帮助我们创建一个多线程对象,其中初始化对象时传进去的参数就是未来我们将开辟的线程池的总线程数:
from time import *
from multiprocessing.dummy import Poolstart = time()
def operation(element):sleep(2)elements = [1, 2, 3, 4]
pool = Pool(4)
pool.map(operation, elements)end = time()
print('您一共花费了:'+'%lf'%(end-start)+'秒')然后调用实例化出来的多线程对象的map方法,向其传入产生通信阻塞的操作(这里是operation函数)和需要向该操作传递的参数。它就会帮助我们使用多线程的动作来实现这个操作,并且如果该操作本身有返回值那么它也会向我们返回某些数值。 所以使用了多线程那么理论上消耗时间将变为原来的1/4:
当然,如果使用3个线程,那么类似木桶理论,传输时间取最大的值,也就是先用三进程传输3个,再用三进程中其中一个传输第四个数,所以共消耗4s左右:
协程
协程的定义及其实现过程
在我们学习协程之前首先需要理解协程的定义,下面的解释来自百度百科:
协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。
总的来说,协程是运行在线程之上的函数调用操作,之所以选择这么做,是因为有时候即使我们开启了线程池,同时阻塞的情况也是可能存在,线程之间由于阻塞而等待切换的过程会导致时间以及空间上的浪费。所以发明一种协程可以单独运行在堵塞的线程之上,当一个协程完成后另一个可以补上,并且它还不会增加线程的数量。
下面我们来看看如何用Python实现协程:
协程对象及事件循环
因为协程本质是一个函数调用,所以我们首先需要定义一个函数,并且为其加上关键字async,这就表明这个函数不再是一个简单的函数,它会会返回一个协程对象,并且当我们再次调用这个函数时,函数里面的语句不会被执行!
当我们利用async修饰一个函数后,调用该函数会返回一个协程对象,并且如果我们想去使用这个协程对象,需要先创建一个事件循环,我们只有将协程对象注册进事件循环里面其才能被执行,这个过程就像先烧一锅开水(事件循环),然后才能放方便面(协程对象)下去焖(执行)。而创建一个事件循环就是调用asyncio里面的方法,并且还需要启动它和放入协程对象。
import asyncioasync def func1():print("函数已调用!")ret = func1()
loop = asyncio.get_event_loop()
loop.run_until_complete(ret)
基于事件循环创建任务对象
关于函数func1返回的协程对象ret,我们还可以将其封装成一个任务对象,它在原来协程对象的基础上会增加一些对象的状态,而封装的方法就是调用loop里面的方法,方法调用完后会返回一个新的任务对象,它具有大部分协程对象的性质:
import asyncioasync def func1():print("函数已调用!")ret = func1()
loop = asyncio.get_event_loop()
task = loop.create_task(ret)
loop.run_until_complete(task)
print(task)
下面就是task对象所附带的状态信息的输出
基于asyncio创建任务对象
除了上面利用loop创建任务对象的方法,我们还可以利用一种别的方式来创建任务对象,具体是直接调用asyncio里面的ensure_future方法向其传入协程对象即可创建出一个任务对象:
import asyncioasync def func1():print("函数已调用!")ret = func1()
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(ret)
loop.run_until_complete(task)
print(task)![]() 回调函数
回调函数
如果我们想在函数执行完后绑定一个回调函数,只需要调用下面的方法将task和该回调函数绑定即可,这样在事件循环中凡是执行了task任务对象后它会调用这个回调函数!
import asyncioasync def func1():print("函数已调用!")return 'a'def show_ret(task):print(task.result())
ret = func1()
loop = asyncio.get_event_loop()
task = loop.create_task(ret)
task.add_done_callback(show_ret)
loop.run_until_complete(task)协程的优势测试
下面我们就一个具体的例子来看看协程的优势:
下面是一组测试代码,具体的意思是我们先创建一个协程对象,然后在这个协程对象里面写一个睡眠函数,让函数执行停止2秒模仿等待过程(注意这里要用asyncio里面的sleep函数,因为time包里面的sleep函数是基于同步(线程如果堵塞会等待当前任务响应才继续处理下一个任务)实现的,而我们的多任务协程的实现方式是异步(线程如果堵塞将任务挂起直到收到回应才重新处理,不阻碍线程),这里如果调用基于同步实现的函数会失效。同时注意在前面加上一个await的挂起操作)然后使用一个for循环来模仿多任务的情况,每一次循环都会创建一个协程对象并且基于其来创建一个任务对象。最后将存储任务的任务列表注册到事件循环中,这里注意要调用因为是任务列表所以要使用wait。
import asyncio
from time import *
start = time()async def func():print("调用该函数!")await asyncio.sleep(2)task_list=[]
loop = asyncio.get_event_loop()
for i in range(0,3):ret = func()task = loop.create_task(ret)task_list.append(task)loop.run_until_complete(asyncio.wait(task_list))
end = time()
print(end-start) 
协程的具体实现
接下来我们就可以直接来看看如何使用协程进行多任务异步实现,我们一次性爬取百度搜索的搜狗、360和猎豹页面。按照上面的使用方法,我们先创建一个URL的元组,然后定义一个请求该URL内容的函数,并且将加上async的定义关键字,此时这个函数将会返回一个协程对象。然后创建一个事件循环并且每一次都将协程对象创建出来的任务对象放进事件循环中执行。
import requests
import asyncio
import time
start = time.time()
urls = ['https://www.baidu.com/s?wd=%E6%90%9C%E7%8B%97','https://www.baidu.com/s?wd=360','https://www.baidu.com/s?wd=%E7%8C%8E%E8%B1%B9']
headers = {'Accept': ...'User-Agent':'...'Cookie': ...
}async def get_content(url):ret = requests.get(url=url, headers=headers)print("success!")loop = asyncio.get_event_loop()
tasks=[]
for url in urls:ret_ = get_content(url)task = loop.create_task(ret_)tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(end-start)虽然这样看起来好像实现了异步多任务处理,但是实际上requests里面的get函数是一个基于同步处理的函数,也就是说我们根本没有利用协程实现异步多任务的处理!为了解决这个问题我们需要利用基于异步而写的请求函数,为此我们需要使用到aiohttp模块。我们首先需要获取一个请求对象session,这个对象将会帮助我们发送请求报文,我们会调用aiohttp里面的CilentSession方法来创建一个对象,然后类似于requests一样调用对象里面的get方法来获取响应(注意这里获取字符串需要使用到text是一个方法而非属性),而且请求函数和获取响应报文内容等操作是都需要进行挂起(使用await)。
async def get_content(url):ret = requests.get(url=url, headers=headers)print("success!")||V
async def get_content(url):async with aiohttp.ClientSession() as session:async with await session.get(url=url, headers=headers) as response:print('success!')//ret = await response.text()使用协程:

不使用协程:

我们可以明显看出使用了协程的速度比不使用要快!
Selenium
因为Selenium的内容有很多,所以我另外写了一篇博客来记录我的Selenium学习过程👉
代理
代理就是我们在客户端和服务器之间构建一个中间桥梁,我们可以通过代理服务器来向目标服务器发送请求。这样可以在我们IP被目标服务器封的时候还能够请求到目标服务器的内容,或者可以让我们不想直接使用自己的以IP的身份直接请求某个服务器而隐藏起自己的IP。
其中代理IP有三种类型:透明、匿名和高匿。
使用透明的代理IP服务器会知道你在使用代理IP并且也知道你的真实IP;
使用匿名的代理IP服务器会知道你在使用代理IP但不知道你的真实IP;
使用高匿的代理IP服务器不知道你在使用代理IP更不会知道你的真实IP。
参考资料:
什么是协程? - 知乎
Day1 - 1.爬虫简介-爬虫的概念和价值_哔哩哔哩_bilibili
相关文章:
【Python】爬虫基础
爬虫是一种模拟浏览器实现,用以抓取网站信息的程序或者脚本。常见的爬虫有三大类: 通用式爬虫:通用式爬虫用以爬取一整个网页的信息。 聚焦式爬虫:聚焦式爬虫可以在通用式爬虫爬取到的一整个网页的信息基础上只选取一部分所需的…...
(三、优先队列用于归并排序))
leetcode分类刷题:队列(Queue)(三、优先队列用于归并排序)
1、当TopK问题出现在多个有序序列中时,就要用到归并排序的思想了 2、将优先队列初始化为添加多个有序序列的首元素的形式,再循环K次优先队列的出队和出队元素对应序列下个元素的入队,就能得到TopK的元素了 3、这些题目好像没有TopK 大用小顶堆…...

无线窨井水位监测仪|排水管网智慧窨井液位计安装案例
城市窨井在城市排水、雨水、污水输送等方面发挥着重要作用,是污水管网、排水管网 建设重要的组成部分。随着城镇精细化建设及人民安全防范措施水平的提高,对窨井内水位的监测提出了更高的要求,他是排水管网问题的晴雨表,窨井信息化…...

024 - STM32学习笔记 - 液晶屏控制(一) - LTDC与DMA2D初始
024- STM32学习笔记 - LTDC控制液晶屏 在学习如何控制液晶屏之前,先了解一下显示屏的分类,按照目前市场上存在的各种屏幕材质,主要分为CRT阴极射线管显示屏、LCD液晶显示屏、LED显示屏、OLED显示屏,在F429的开发板上,…...
)
Python数据容器:dict(字典、映射)
1、什么是字典 Python中的字典是通过key找到对应的Value(相当于现实生活中通过“字”找到“该字的含义” 我们前面所学习过的列表、元组、字符串以及集合都不能够提供通过某个东西找到其关联的东西的相关功能,字典可以。 例如 这里有一份成绩单…...
2023年基因编辑行业研究报告
第一章 行业发展概况 1.1 定义 基因编辑(Gene Editing),又称基因组编辑(Genome Editing)或基因组工程(Genome Engineering),是一项精确的科学技术,可以对含有遗传信息的…...
Spring MVC:请求转发与请求重定向
Spring MVC 请求转发请求重定向附 请求转发 转发( forward ),指服务器接收请求后,从一个资源跳转到另一个资源中。请求转发是一次请求,不会改变浏览器的请求地址。 简单示例: 1.通过 String 类型的返回值…...

按键灯待机2秒后灭掉
修改文件:/device/mediatek/mt6580/init.mt6580.rc chown system system /sys/class/leds/red/triggerchown system system /sys/class/leds/green/triggerchown system system /sys/class/leds/blue/triggerchown system system sys/devices/platform/device_info/…...

SpringBoot通过自定义注解实现日志打印
目录 前言: 正文 一.Spring AOP 1.JDK动态代理 2.Cglib动态代理 使用AOP主要的应用场景: SpringBoot通过自定义注解实现日志打印 一.Maven依赖 二.ControllerMethodLog.class自定义注解 三.Spring AOP切面方法的执行顺序 四.ControllerMethodL…...

代码随想录算法训练营第七天 |151.翻转字符串里的单词
今天是代码随想录的第七天,写了力扣的151.翻转字符串里的单词; 之后或许还要再琢磨琢磨 代码随想录链接 力扣链接 151.翻转字符串里的单词,代码如下: # class Solution: # def reverseWords(self, s: str) -> str: # …...
WEBRTC 发送视频RTP包)
【WebRTC---源码篇】(十:一)WEBRTC 发送视频RTP包
RTPSenderVideo在整个框架中起到重要的作用,它把采集的数据进行编码,并且在流程中会进行将编码后的数据进行RTP打包,最后发送到网络层 RTPSenderVideo::SendVideo //对编码数据打包 bool RTPSenderVideo::SendVideo(int payload_type,absl::optional<VideoCodecType>…...

cmd 90 validate error!(达梦数据库日志报错)
达梦数据库报错 error-cmd 90 validate error! 环境介绍1 解决办法 环境介绍 某生产环境数据库启动后,dm_实例名_202309.log,偶尔报错cmd 90 validate error! 1 解决办法 接口用错了,消息非法,比如用 6 的 JDBC 连 7 或 7 的 …...
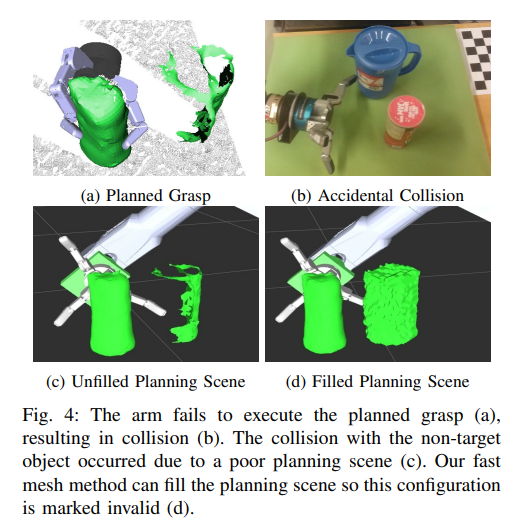
Shape Completion Enabled Robotic Grasping
摘要-这项工作提供了一个架构,使机器人能够通过形状完成抓取规划。形状完成是通过使用3D卷积神经网络(CNN)来完成的。该网络是在我们自己的新的开源数据集上训练的,该数据集包含了从不同视角捕获的超过44万个3D样本。运行时,从单个视角捕获的…...
【C++】构造函数意义 ( 构造函数显式调用与隐式调用 | 构造函数替代方案 - 初始化函数 | 初始化函数缺陷 | 默认构造函数 )
文章目录 一、构造函数意义1、类的构造函数2、构造函数显式调用与隐式调用3、构造函数替代方案 - 初始化函数4、初始化函数缺陷5、默认构造函数6、代码示例 - 初始化函数无法及时调用 一、构造函数意义 1、类的构造函数 C 提供的 构造函数 和 析构函数 作为 类实例对象的 初始化…...
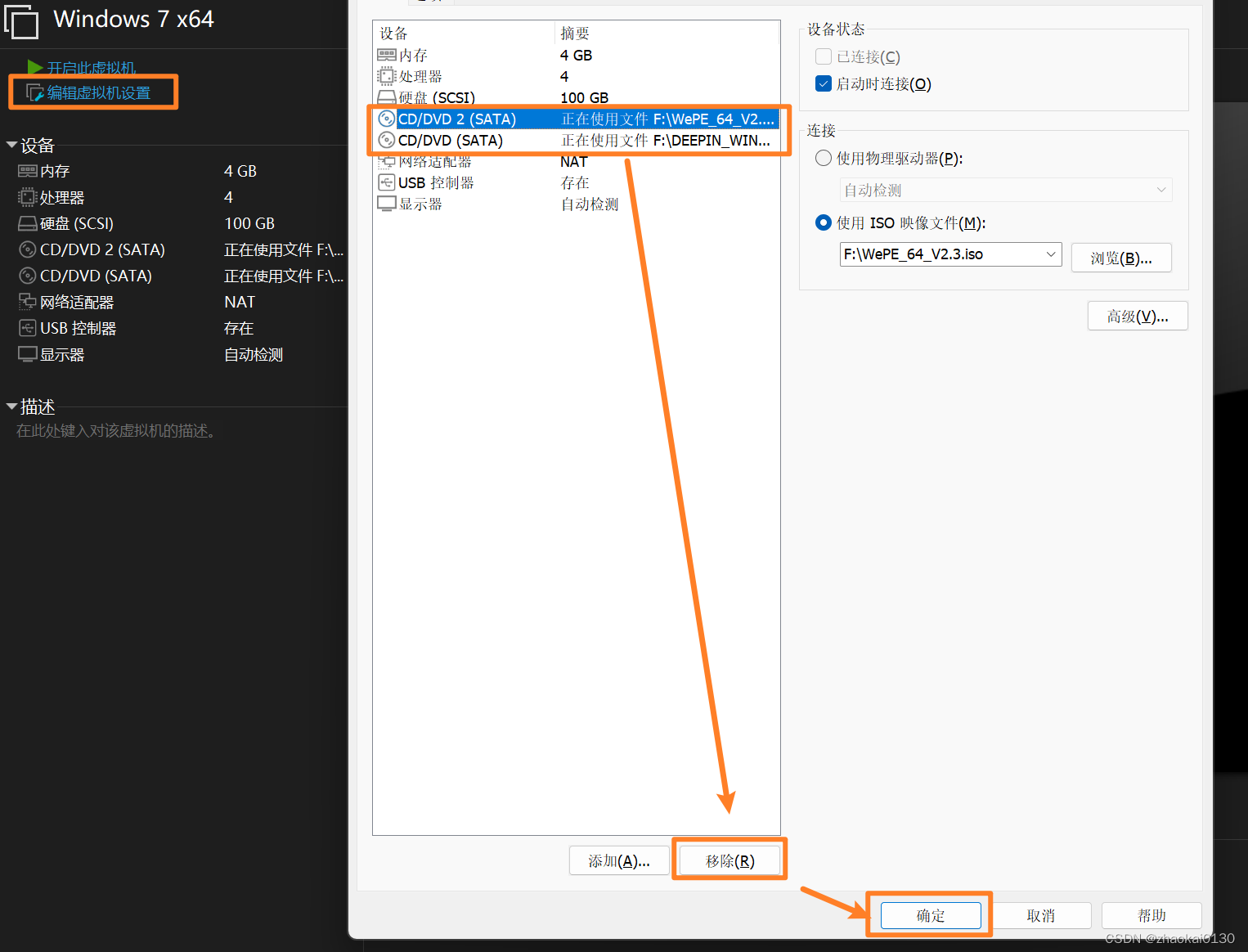
VMware16安装ghost版win7
文章目录 准备工作GHO 文件装机工具 新建虚拟机配置虚拟机还需要一个 CD/DVD PE 安装步骤分区还原挂载 CD/DVD开始还原 还原之后 准备工作 GHO 文件 可以去百度搜索这种文件,我这里是从系统之家下载的deepin win7 ghost 系统 装机工具 因为下载的 ghost 版的 w…...

项目集成swagger,访问不到swagger页面
项目集成swagger 文章目录 前言一、背景二、问题复现1.Full authentication is required to access this resource2.Illegal DefaultValue null for parameter type integer 总结 前言 项目集成swagger这个没啥好整的,maven项目就在pom文件导入依赖,ser…...
变透明的解决方案)
微信小程序怎么隐藏顶部导航栏(navigationBar)变透明的解决方案
怎么隐藏小程序顶部导航栏(navigationBar)? 官网说:Navigation是小程序的顶部导航组件,当页面配置 navigationStyle 设置为 custom 的时候可以使用此组件替代原生导航栏。 那么,我们就知道这种效果是可以…...
RabbitMQ基础概念-02
RabbitMQ是基于AMQP协议开发的一个MQ产品, 首先我们以Web管理页面为 入口,来了解下RabbitMQ的一些基础概念,这样我们后续才好针对这些基础概念 进行编程实战。 可以参照下图来理解RabbitMQ当中的基础概念: 虚拟主机 virtual hos…...

从构建者到设计者的低代码之路
低代码开发技术,是指无需编码或通过少量代码就可以快速生成应用程序的工具,一方面可降低企业应用开发人力成本和对专业软件人才的需求,另一方面可将原有数月甚至数年的开发时间成倍缩短,帮助企业实现降本增效、灵活迭代。那么&…...

Linux创建进程 及父子进程虚拟空间 多进程GDB调试
父子进程的资源是读时共享,写时拷贝,用到某一个资源,比如说改变变量的值的时候才去拷贝这个变量到一个独立的空间 父子进程的关系: 区别: 1.fork()函数的返回值不同 父进程中:>…...

YOLO-v8.3实战:用AI识别图片中的物体,5分钟完成你的第一个检测项目
YOLO-v8.3实战:用AI识别图片中的物体,5分钟完成你的第一个检测项目 你是否曾经好奇,那些能自动识别照片中物体的人工智能是如何工作的?想象一下,你拍了一张街景照片,AI不仅能告诉你照片里有汽车、行人和红…...

Wan2.2-I2V-A14B效果展示:复杂提示词‘雨夜霓虹街道行人撑伞行走’生成效果
Wan2.2-I2V-A14B效果展示:复杂提示词雨夜霓虹街道行人撑伞行走生成效果 1. 模型能力概览 Wan2.2-I2V-A14B是一款专为高质量视频生成设计的先进模型,能够将文字描述转化为生动的动态画面。这款模型特别擅长处理复杂场景和细腻氛围的渲染,在以…...
,大模型调优从入门到精通,收藏这一篇就够了!)
工具调用准确率飙到95%!Qwen-7B解耦微调实战实录(非常详细),大模型调优从入门到精通,收藏这一篇就够了!
用Qwen-7B做Agent,本来信心满满,结果MCP一跑,选工具选不对、参数填得稀巴烂,准确率惨不忍睹,最高也就60%徘徊。 后来我发现:普通LoRA根本救不了复杂工具调用。 真正能救命的,是2026年最火的解…...

Google 地图事件:探索、挑战与未来展望
Google 地图事件:探索、挑战与未来展望 引言 Google 地图作为全球最受欢迎的地图服务之一,自2005年推出以来,已经深入到人们生活的方方面面。然而,在这段时间里,Google 地图也经历了一系列事件,包括技术挑战、政策争议以及市场竞争等。本文将围绕这些事件,对 Google 地…...

Joy-Con Toolkit终极指南:快速解锁Switch手柄隐藏功能
Joy-Con Toolkit终极指南:快速解锁Switch手柄隐藏功能 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款专为任天堂Switch手柄设计的开源控制软件,为游戏玩家提供前所…...

别再手动测试了!教你用ThinkPHP6+Workerman/MQTT搭建一个本地MQTT消息调试台
基于ThinkPHP6与Workerman/MQTT构建物联网调试平台的完整指南 物联网开发中,MQTT协议因其轻量级和高效性成为设备通信的首选方案。但调试MQTT消息往往依赖命令行工具或第三方平台,效率低下且缺乏灵活性。本文将展示如何利用ThinkPHP6框架配合Workerman/M…...
)
提升开发效率:IntelliJ IDEA必备插件推荐与安装指南(2023最新版)
2023年IntelliJ IDEA插件生态深度解析:从效率工具到全栈开发支持 JetBrains家族的IntelliJ IDEA早已超越普通代码编辑器的范畴,成为现代开发者手中的瑞士军刀。但鲜有人意识到,真正让这把军刀所向披靡的,是背后超过5000个官方认证…...

学术论文解析神器!OpenDataLab MinerU智能文档理解实测体验
学术论文解析神器!OpenDataLab MinerU智能文档理解实测体验 1. 前言:当AI遇见学术论文 对于每一位科研工作者、学生或技术从业者来说,阅读和整理学术论文都是一项既基础又繁重的工作。你是否也曾经历过这样的场景:面对一篇几十页…...

Vue3+ECharts水球图实战:手把手教你打造个性化数据展示组件
Vue3与ECharts水球图深度整合:打造企业级数据可视化组件 在数据驱动的时代,可视化呈现已成为现代Web应用的核心竞争力。水球图(Liquid Fill Chart)作为一种直观展示百分比数据的可视化形式,在仪表盘、进度监控和数据看…...

事务失效十大场景分析
1. 方法不是 public(最经典失效) 代码示例 Service public class UserService {Autowiredprivate UserMapper userMapper;// 非 public → 事务失效Transactionalprivate void addUser() {userMapper.insert(new User("张三"));// 模拟异常int…...