leetcode分类刷题:队列(Queue)(二、优先队列解决TopK简单问题)
1、优先队列好像一般都叫堆,以大顶堆为例,顶部第一个元素最大,底部最后一个元素最小,自顶向底是递减的(更准确的说是非递增的),对外只能访问顶部第一个元素(对应索引为0)和底部最后一个元素(对应索引为-1);在Python中,heapq默认维护小顶堆,构造大顶堆时需要在入堆时添加相反数
2、本次博客总结下用优先队列解决TopK简单问题,比如数组中第K大或小的元素、单个序列里第K大或小的距离、根据元素的出现频率排序的问题
215. 数组中的第K个最大元素
1、TopK简单问题的经典题目:求第K大,直接想到用大顶堆,把数组中所有元素入堆,返回堆中第k个元素作为结果
2、该题也可以用小顶堆,始终维护堆的元素总数为k,那么堆顶元素即为第k个最大元素——这种解法在实际中更合适,好像有一种TopK 大用小顶堆,TopK 小用大顶堆反着来的意思
from typing import List
import heapq
'''
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:输入: [3,2,1,5,6,4], k = 2输出: 5
题眼:Top K
思路1、大顶堆:返回堆中第k个元素作为结果
思路2、小顶堆:始终维护堆的元素总数为k,那么堆顶元素即为第k个最大元素
'''class Solution:def findKthLargest(self, nums: List[int], k: int) -> int:# # 思路1、大顶堆:返回堆中第k个元素作为结果# que = []# for n in nums:# heapq.heappush(que, -n) # 添加相反数:因为python默认维护小顶堆# for _ in range(k - 1):# heapq.heappop(que)# return -que[0]# 思路2、小顶堆:始终维护堆的元素总数为k,那么堆顶元素即为第k个最大元素que = []for n in nums:heapq.heappush(que, n)if len(que) > k:heapq.heappop(que)return que[0]if __name__ == "__main__":obj = Solution()while True:try:in_line = input().strip().split('=')nums = []for n in in_line[0].split('[')[1].split(']')[0].split(','):nums.append(int(n))k = int(in_line[1].strip())print(obj.findKthLargest(nums, k))except EOFError:break
414. 第三大的数
1、TopK简单问题的经典题目:是“215. 数组中的第K个最大元素”的特例,K取3,同时注意这个题有两个细节:一是要把元素去重(使用集合),二是去重后元素总数不足3个时,返回最大值
2、按照上一个题的经验:TopK 大用小顶堆,TopK 小用大顶堆反着来,这道题直接用小顶堆,并始终维护堆的元素总数不超过k
from typing import List
import heapq
'''
414. 第三大的数
给你一个非空数组,返回此数组中 第三大的数 。如果不存在,则返回数组中最大的数。
示例 1:输入:[2, 2, 3, 1]输出:1解释:注意,要求返回第三大的数,是指在所有不同数字中排第三大的数。此例中存在两个值为 2 的数,它们都排第二。在所有不同数字中排第三大的数为 1 。
题眼:Top K
思路:“215. 数组中的第K个最大元素”的扩展,需要先将元素去重复
'''class Solution:def thirdMax(self, nums: List[int]) -> int:nums = set(nums) # 去重# 小顶堆,维持元素总数为3que = []for n in nums:heapq.heappush(que, n)if len(que) > 3:heapq.heappop(que)if len(que) < 3:return que[-1]else:return que[0]if __name__ == "__main__":obj = Solution()while True:try:in_line = input().strip()[1: -1]nums = [int(i) for i in in_line.split(',')]print(obj.thirdMax(nums))except EOFError:break
703. 数据流中的第 K 大元素
1、TopK简单问题的经典题目:是“215. 数组中的第K个最大元素”的扩展,数组会不断的添加新元素进来,并要求添加元素时返回此时新数组的第 K 大元素
2、按照“215. 数组中的第K个最大元素”的经验:TopK 大用小顶堆,TopK 小用大顶堆反着来,这道题直接用小顶堆,并始终维护堆的元素总数不超过K,这样添加新元素时,进行一次入堆和一次出堆就搞定了,用大顶堆就会比较麻烦了
from typing import List
import heapq
'''
703. 数据流中的第 K 大元素
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。
请实现 KthLargest 类:
KthLargest(int k, int[] nums) 使用整数 k 和整数流 nums 初始化对象。
int add(int val) 将 val 插入数据流 nums 后,返回当前数据流中第 k 大的元素。
示例 1:输入:["KthLargest", "add", "add", "add", "add", "add"][[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]输出:[null, 4, 5, 5, 8, 8]解释:KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);kthLargest.add(3); // return 4kthLargest.add(5); // return 5kthLargest.add(10); // return 5kthLargest.add(9); // return 8kthLargest.add(4); // return 8
题眼:Top K(“215. 数组中的第K个最大元素”的扩展)
思路、小顶堆:始终维护堆的元素总数为k,那么堆顶元素即为第k个频率的元素
'''class KthLargest:def __init__(self, k: int, nums: List[int]):self.que = []self.k = k# 建立小顶堆维护,并保持总的元素数量为k,那么堆顶即为第k个最大的数for n in nums:heapq.heappush(self.que, n)if len(self.que) > k:heapq.heappop(self.que)def add(self, val: int) -> int:heapq.heappush(self.que, val) # 为了防止队列内元素总数不足k个,因此把元素先加进去if len(self.que) > self.k:heapq.heappop(self.que)return self.que[0]if __name__ == "__main__":obj = KthLargest(3, [4, 5, 8, 2])print(obj.add(3))print(obj.add(5))print(obj.add(10))print(obj.add(9))print(obj.add(4))
973. 最接近原点的 K 个点
1、TopK简单问题的经典题目:是“215. 数组中的第K个最大元素”的扩展,只要简单计算下距离就转换为第K小元素了
2、按照“215. 数组中的第K个最大元素”的经验:TopK 大用小顶堆,TopK 小用大顶堆反着来,这道题直接用大顶堆,并始终维护堆的元素总数不超过K,注意用小顶堆在Python中是添加相反数
from typing import List
import heapq
'''
973. 最接近原点的 K 个点
给定一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点,并且是一个整数 k ,返回离原点 (0,0) 最近的 k 个点。
这里,平面上两点之间的距离是 欧几里德距离( √(x1 - x2)2 + (y1 - y2)2 )。
你可以按 任何顺序 返回答案。除了点坐标的顺序之外,答案 确保 是 唯一 的。
示例 1:输入:points = [[1,3],[-2,2]], k = 1输出:[[-2,2]]解释: (1, 3) 和原点之间的距离为 sqrt(10),(-2, 2) 和原点之间的距离为 sqrt(8),由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。
题眼:Top K(“215. 数组中的第K个最大元素”的扩展)
思路、题目是要求k个最小值,大顶堆:始终维护堆的元素总数为k,那么堆内元素即为k个最小值
'''class Solution:def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:# k个最小值,大顶堆:维持元素总数为kresult = []que = []for point in points:x, y = point[0], point[1]d = x * x + y * yheapq.heappush(que, (-d, [x, y])) # 添加相反数:因为python默认维护小顶堆if len(que) > k:heapq.heappop(que)for _ in range(k):result.append(heapq.heappop(que)[1])return resultif __name__ == "__main__":obj = Solution()while True:try:in_line = input().strip().split('=')points = []for row in in_line[1][2: -5].split(']')[: -1]:points.append([int(n) for n in row.split('[')[1].split(',')])k = int(in_line[2].strip())print(obj.kClosest(points, k))except EOFError:break
347. 前 K 个高频元素
1、TopK简单问题的经典题目:是“215. 数组中的第K个最大元素”的扩展,需要先统计元素出现频率的哈希表,然后就是Top K问题的模板了
2、按照“215. 数组中的第K个最大元素”的经验:TopK 大用小顶堆,TopK 小用大顶堆反着来,这道题直接用小顶堆,并始终维护堆的元素总数不超过K,注意入堆的形式为(频率,元素)的元组
from typing import List
import heapq
'''
347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:输入: nums = [1,1,1,2,2,3], k = 2输出: [1,2]
题眼:Top K(“215. 数组中的第K个最大元素”的扩展)
思路1、大顶堆:返回堆中第k个频率的元素作为结果
思路2、小顶堆:始终维护堆的元素总数为k,那么堆顶元素即为第k个频率的元素
'''class Solution:def topKFrequent(self, nums: List[int], k: int) -> List[int]:# # 思路一、大顶堆:返回堆中第k个频率的元素作为结果# # 1、统计数组元素频率# hashTable = {}# for n in nums:# if n not in hashTable:# hashTable[n] = 1# else:# hashTable[n] += 1# # 2、构建大顶堆# que = []# for key in hashTable:# heapq.heappush(que, (-hashTable[key], key)) # 添加相反数:因为python默认维护小顶堆# # 3、输出大顶堆的前k个元素# result = []# for i in range(k):# result.append(heapq.heappop(que)[1])# return result# # 思路二、小顶堆:始终维护堆的元素总数为k,那么堆顶元素即为第k个频率的元素# 1、统计数组元素频率hashTable = {}for n in nums:if n not in hashTable:hashTable[n] = 1else:hashTable[n] += 1# 2、构建小顶堆,并维持其元素数量不多于kque = []for key in hashTable:heapq.heappush(que, (hashTable[key], key))if len(que) > k:heapq.heappop(que)# 3、输出大顶堆的k个元素,逆序放入结果数组result = [0] * kfor i in range(k - 1, -1, -1):result[i] = heapq.heappop(que)[1]return resultif __name__ == "__main__":obj = Solution()while True:try:in_line = input().strip().split('=')nums = [int(i) for i in in_line[1].split('[')[1].split(']')[0].split(',')]k = int(in_line[2].strip())print(obj.topKFrequent(nums, k))except EOFError:break
451. 根据字符出现频率排序
1、TopK简单问题的经典题目:是“215. 数组中的第K个最大元素”的扩展,同样需要先统计元素出现频率的哈希表,
2、这道题是要对所有的字符出现频率进行排序,因此和“215. 数组中的第K个最大元素”的经验:TopK 大用小顶堆,TopK 小用大顶堆不那么一致了,直接用大顶堆,将所有(频率,元素)的元组入堆,然后持续出堆返回结果就可以了
import heapq
'''
451. 根据字符出现频率排序
给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。
返回 已排序的字符串。如果有多个答案,返回其中任何一个。
示例 1:输入: s = "tree"输出: "eert"解释: 'e'出现两次,'r'和't'都只出现一次。因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。
题眼:Top K
思路:这道题是要对所有的字符出现频率进行排序,因此和“215. 数组中的第K个最大元素”的经验:TopK 大用小顶堆,TopK 小用大顶堆不那么一致了,直接用大顶堆,
将所有(频率,元素)的元组入堆,然后持续出堆返回结果就可以了
'''class Solution:def frequencySort(self, s: str) -> str:# 1、统计词频hashTable = {}for ch in s:if ch not in hashTable:hashTable[ch] = 1else:hashTable[ch] += 1# 2、建立大顶堆que = []for k in hashTable:heapq.heappush(que, (-hashTable[k], k))# 3、建立结果字符串result = ''while len(que) > 0:pair = heapq.heappop(que)result += pair[1] * (-pair[0])return resultif __name__ == "__main__":obj = Solution()while True:try:s = input().strip().split('=')[1].strip()[1: -1]print(obj.frequencySort(s))except EOFError:break
692. 前K个高频单词
1、TopK简单问题的经典题目:是“215. 数组中的第K个最大元素”的扩展,同样需要先统计元素出现频率的哈希表,额外增加了对词频相同的元素的排序要求:字典次序小的排前面,因此需要重写<,即__lt__()函数
2、按照“215. 数组中的第K个最大元素”的经验:TopK 大用小顶堆,TopK 小用大顶堆反着来,这道题直接用小顶堆,并始终维护堆的元素总数不超过K,注意入堆的形式为(频率,元素)的元组,
3、由于维护的是小顶堆,那么频率值小的就要排在堆顶,频率值一样时让字典次序大的排在堆顶,这样保留下来的K个元素就满足题意要求的频率值大,字典次序小,最后把这些元素出堆逆序存放到结果数组中
from typing import List
import heapq
'''
692. 前K个高频单词
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2输出: ["i", "love"]解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。注意,按字母顺序 "i" 在 "love" 之前。
题眼:Top K(“215. 数组中的第K个最大元素”的扩展)
思路:题目是要求k个最大值,小顶堆:始终维护堆的元素总数为k,那么堆内元素即为k个最大值
难点:这道题对答案的唯一性进行了限制,因此要重写小于号!
'''class Solution:def topKFrequent(self, words: List[str], k: int) -> List[str]:class Comparer: # 重写小于号:出现次数少的在堆顶、次数一样字典序大的在堆顶def __init__(self, val, key):self.val = valself.key = keydef __lt__(self, other):if self.val != other.val:return self.val < other.valreturn self.key > other.key# 1、统计词频hashTable = {}for n in words:if n not in hashTable:hashTable[n] = 1else:hashTable[n] += 1# 2、建立优先队列:维护元素总数为kque = []for key in hashTable:heapq.heappush(que, Comparer(hashTable[key], key))if len(que) > k:heapq.heappop(que)# 3、输出结果result = ['0'] * kfor i in range(k - 1, -1, -1):result[i] = heapq.heappop(que).keyreturn result
相关文章:
(二、优先队列解决TopK简单问题))
leetcode分类刷题:队列(Queue)(二、优先队列解决TopK简单问题)
1、优先队列好像一般都叫堆,以大顶堆为例,顶部第一个元素最大,底部最后一个元素最小,自顶向底是递减的(更准确的说是非递增的),对外只能访问顶部第一个元素(对应索引为0)…...

【排障记录】扩展坞USB 3.0能用而2.0不能用
一、症状表现 日常使用小米的一个扩展坞连接笔记本,平时用来插U盘,没有什么问题,但是今天插了鼠标键盘,发现根本不识别 二、排查过程 目前的连接结构 笔记本C口→type-C延长线→扩展坞A→设备 1.排查笔记本故障 将键盘鼠标插…...

01-从JDK源码级别剖析JVM类加载机制
上一篇:JVM虚拟机调优大全 1. 类加载运行全过程 当我们用java命令运行某个类的main函数启动程序时,首先需要通过类加载器把主类加载到JVM。 public class Math {public static final int initData 666;public static User user new User();public i…...

AI时代:探索机器学习与深度学习的融合之旅
文章目录 1. 机器学习和深度学习简介1.1 机器学习1.2 深度学习 2. 为什么融合是必要的?2.1 数据增强2.2 模型融合 3. 深入分析:案例研究3.1 传统机器学习方法3.2 深度学习方法3.3 融合方法 4. 未来展望结论 🎉欢迎来到AIGC人工智能专栏~AI时代…...
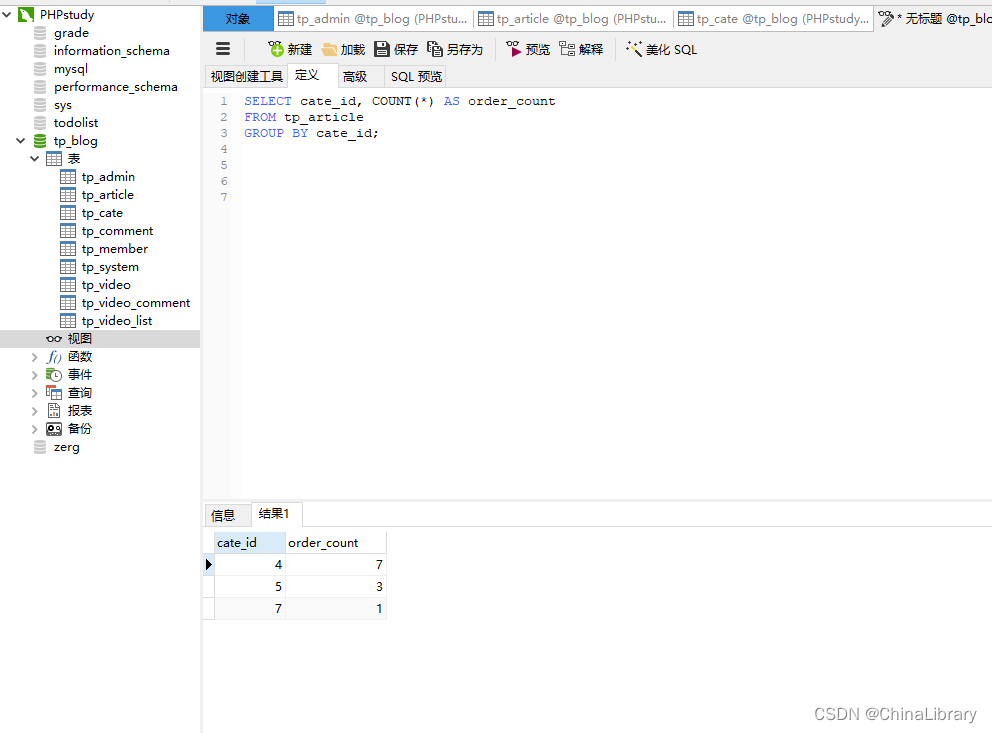
模块化开发_groupby查询think PHP5.1
要求按照分类的区别打印出不同类别的数据计数 如张三,做了6件事情 这里使用原生查询先测试 SELECT cate_id, COUNT(*) AS order_count FROM tp_article GROUP BY cate_id;成功 然后项目中实现 public function ss(){$sql "SELECT cate_id, COUNT(*) AS orde…...
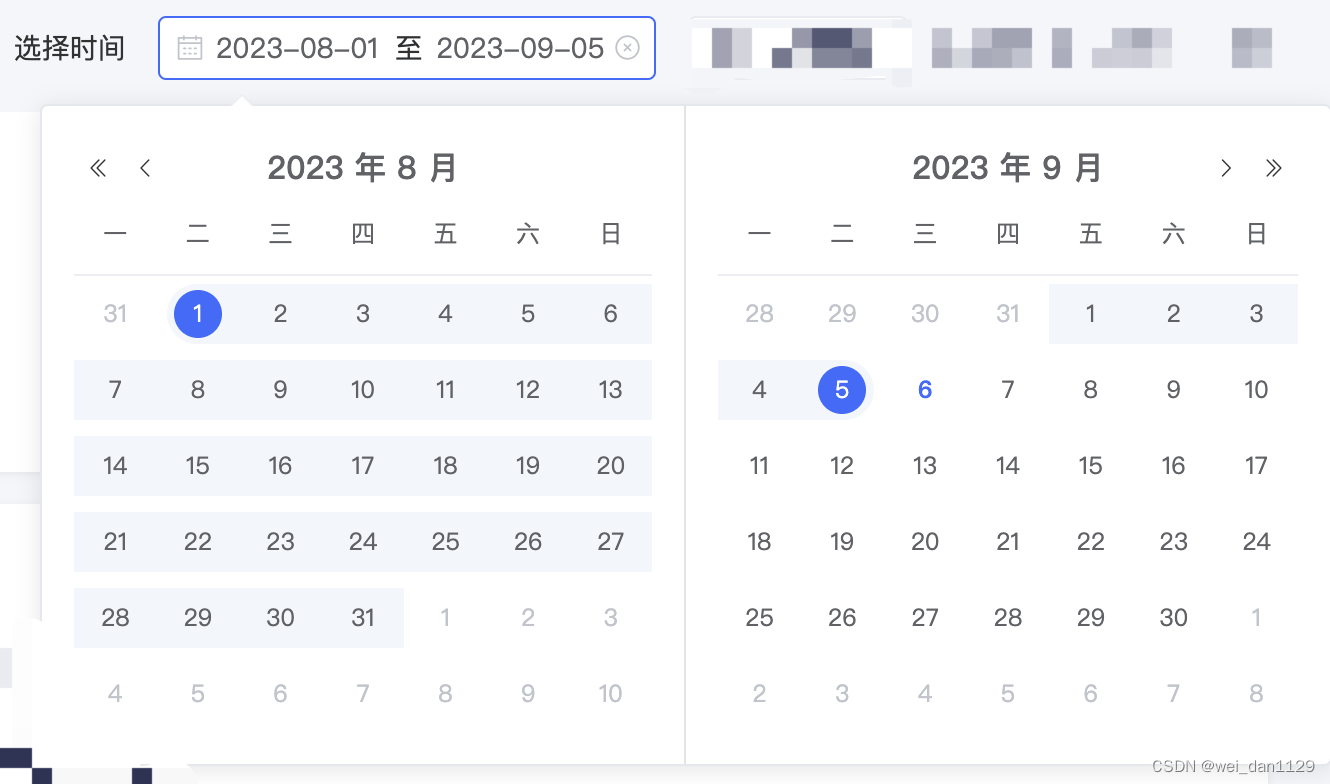
elementUI时间选择器
<template>//月选择器//:clearable"false" 去掉<div class"monthCard"><el-date-picker:clearable"false"v-model"monthValue"type"month"placeholder"选择月"change"handleChangeMonth($eve…...

第1章_瑞萨MCU零基础入门系列教程之单片机程序的设计模式
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...
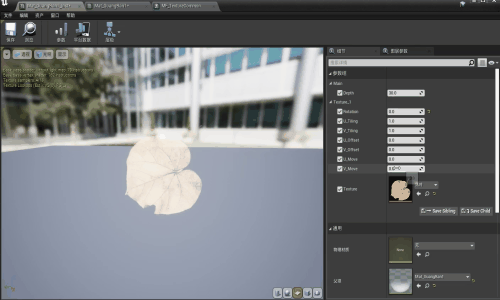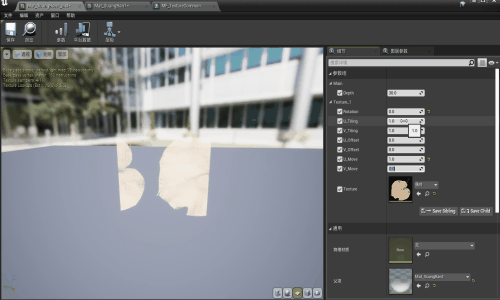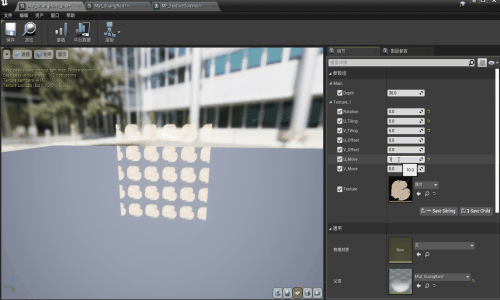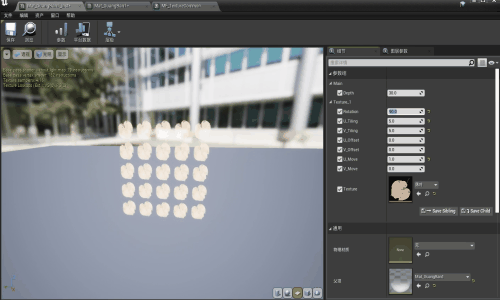
【UE】刀光粒子效果——part2 材质函数部分
效果 步骤 1. 新建一个材质函数,这里命名为“MF_TextureCommon” 2. 新建一个材质,这里命名为“Mat_GuangBan1”,添加如下节点 3. 接下来将该材质的逻辑添加到材质函数上,复制材质“Mat_GuangBan1”中的如下节点,粘贴…...

为什么项目经理的时间观念这么重?
项目经理的时间观念强是因为项目管理涉及到时间、成本和质量的平衡。 项目经理需要按时按质地交付项目,这不仅关乎项目本身的质量和进度,还关乎团队的士气和客户的满意度。 在项目管理过程中,存在大量的时间浪费现象,也可以把它…...
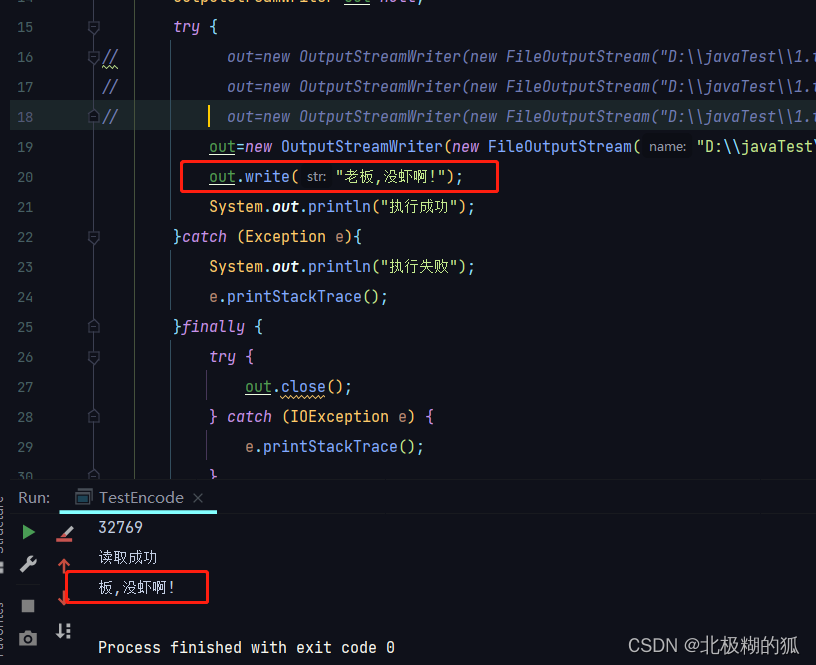
编码转换流
同理,创建f1和f2方法,分别测试OutputStreamWriter和InputStreamReader 也是主要分三步,即1创建流 2使用流 3关流 OutputStreamWriter f1方法 因为要操作流,所以先创建一个try-catch-finally结构,创建流对象Out…...
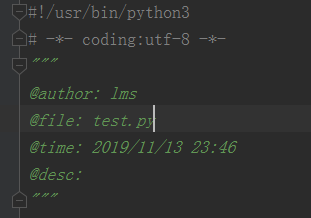
Pycharm创建项目时如何自动添加头部信息
1.打开PyCharm,选择File--Settings 2.依次选择Editor---Code Style-- File and Code Templates---Python Script 3..添加头部内容 可以根据需要添加相应的信息 #!/usr/bin/python3可用的预定义文件模板变量为:$ {PROJECT_NAME} - 当前项目的名称。$ {NAM…...

DAY48
#ifndef QUEUE_H #define QUEUE_H#include<iostream>using namespace std;#define MAX 10typedef int datatype;template <typename T> class queue {T data[MAX];T front;T tail;public:queue();~queue();queue(const T &other);//创建循环队列T *queue_crea…...

光栅和矢量图像处理:Graphics Mill 11.4.1 Crack
Graphics Mill 是适用于 .NET 和 ASP.NET 开发人员的最强大的成像工具集。它允许用户轻松向 .NET 应用程序添加复杂的光栅和矢量图像处理功能。 光栅图形 加载和保存 JPEG、PNG 和另外 8 种图像格式 调整大小、裁剪、自动修复、色度键和 30 多种其他图像操作 可处理任何尺寸&am…...

vue3中组件没有被调用,没进去也没报错
在父页面引用了一个组件,然后父级调用子组件方法,但是根本没进去,也不报错 父级页面挂载组件 <!-- 视频插件组件 --> <div><VideoPluginView ref"video_perview_ref"></VideoPluginView> </div> …...

Postgresql中ParamListInfoData的作用
ParamListInfoData是参数的统一抽象,例如 在pl中执行raise notice %, n;n的值会拼成select n到SQL层取值,但值在哪呢,还是在pl层。对sql层来说,n的一种可能性是参数,在这种可能性中,n的数据放在ParamListI…...
)
《计算机视觉中的多视图几何》笔记(1)
1 Introduction – a Tour of Multiple View Geometry 本章介绍了本书的主要思想。 1.1 Introduction – the ubiquitous projective geometry 为了了解为什么我们需要射影几何,我们从熟悉的欧几里得几何开始。 欧几里得几何在二维中认为平行线是不会相交的&…...

YOLO目标检测——火焰检测数据集+已标注xml和txt格式标签下载分享
实际项目应用:火灾预警系统、智能监控系统、工业安全管理、森林火灾监测以及城市规划和消防设计等应用场景中具有广泛的应用潜力,可以提高火灾检测的准确性和效率,保障人员和财产的安全。数据集说明:YOLO火焰目标检测数据集&#…...

tkinter四大按钮:Button,Checkbutton, Radiobutton, Menubutton
文章目录 四大按钮Button连击MenubuttonCheckbuttonRadiobutton tkinter系列: GUI初步💎布局💎绑定变量💎绑定事件💎消息框💎文件对话框控件样式扫雷小游戏💎强行表白神器 四大按钮 tkinter中…...

Sudowrite:基于人工智能的AI写作文章生成工具
【 产品介绍】 名称 Sudowrite 成立/上线时间 2023年 具体描述 Sudowrite是一个基于GPT-3的人工智能写作工具,可以帮助你快速生成高质量的文本内容, 无论是小说、博客、营销文案还是学术论文。 Sudowrite可以根据你的输入和指…...

加密狗软件有什么作用?
加密狗软件是一种用于加密和保护计算机软件和数据的安全设备。它通常是一个硬件设备,可以通过USB接口连接到计算机上。加密狗软件的作用主要体现在以下几个方面: 软件保护:加密狗软件可以对软件进行加密和授权,防止未经授权的用户…...
告别嘈杂录音:用ClearerVoice-Studio一键清除背景噪音实战教程
告别嘈杂录音:用ClearerVoice-Studio一键清除背景噪音实战教程 1. 为什么你需要专业的语音降噪工具 在远程会议、线上课程、播客录制等场景中,背景噪音是影响语音质量的常见问题。传统音频编辑软件如Audacity虽然功能强大,但操作复杂&#…...
)
山东大学项目实训-大数据租房推荐智能体(一)
整体任务搭建完整的agent框架,设计项目结构,agent工作流程,编写prompt和重试机制约束LLM输出,实现多轮对话管理,让agent能够理解当下环境和用户意图,编排正确的工具调用顺序。(一)第…...

开源工具助力音频内容管理:打破平台限制的跨平台解决方案
开源工具助力音频内容管理:打破平台限制的跨平台解决方案 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 你是否曾遇到…...

EPON OLT光模块RSSI精度优化方案解析
1. EPON OLT光模块基础原理 EPON(以太网无源光网络)系统中,OLT(光线路终端)光模块扮演着核心角色。简单来说,它就像小区宽带的总闸门,负责把数据分发给各家各户的ONU(光网络单元&…...

OpenEMS终极指南:三步构建你的智能能源管理系统
OpenEMS终极指南:三步构建你的智能能源管理系统 【免费下载链接】openems OpenEMS - Open Source Energy Management System 项目地址: https://gitcode.com/gh_mirrors/op/openems 还在为高额电费账单发愁吗?是否羡慕别人家的太阳能系统能智能调…...

郭老师-人生四次开悟:错过一次,代价沉重
人生四次开悟 ——错过一次,可能一生难返“人这一生,大约只有四次开悟的机会。 开悟不了的人,就‘玩完了’。”🌿 开悟不是玄学, 而是—— 在关键年龄点上, 看清世界、认清自己、与道合一。🌱 第…...

Spring AI 快速入门教程:基于VUE3与Spring AI技术实现的“流式聊天““打字机效果“功能
目录 前言 一、Spring AI 核心认知 1.1 技术定位与核心价值 1.2 版本支持与生态兼容性 1.3 与其他 AI 集成框架对比 二、效果展示 三、快速入门 3.1 环境准备 JDK 配置 AI 服务密钥准备 3.2 后端项目创建 主要技术栈 pom.xml 配置 application.yml 配置 Java 主…...

从5V电源到485通信:一个工业级PT100温度变送器的全链路DIY搭建实录
从5V电源到485通信:一个工业级PT100温度变送器的全链路DIY搭建实录 在工业自动化领域,温度监测的可靠性和精度往往直接关系到生产安全与质量控制。传统温度变送器虽然成熟稳定,但对于需要定制化功能或特殊安装环境的场景,自主搭建…...

云容笔谈·东方红颜影像生成系统Python爬虫数据驱动创作实战
云容笔谈东方红颜影像生成系统Python爬虫数据驱动创作实战 最近在尝试用AI绘画工具“云容笔谈”来创作一些古风角色,效果确实惊艳。但有个问题一直困扰我:每次想画一个新角色,都得绞尽脑汁去想外貌、服饰、神态的描述词,效率很低…...

千问3.5-2B轻量部署最佳实践:Docker容器资源限制+GPU显存预分配配置
千问3.5-2B轻量部署最佳实践:Docker容器资源限制GPU显存预分配配置 1. 千问3.5-2B模型简介 千问3.5-2B是Qwen系列中的轻量级视觉语言模型,具备图片理解与文本生成能力。这个2B参数规模的模型在保持较高性能的同时,显著降低了部署门槛和资源…...