PyTorch之张量的相关操作大全 ->(个人学习记录笔记)
文章目录
- Torch
- 1. 张量的创建
- 1.1 直接创建
- 1.1.1 `torch.tensor`
- 1.1.2 `torch.from_numpy(ndarray)`
- 1.2 依据数值创建
- 1.2.1 `torch.zeros`
- 1.2.2 `torch.zeros_like`
- 1.2.3 `torch.ones`
- 1.2.4 `torch.ones_like`
- 1.2.5 `torch.full`
- 1.2.6 `torch.full_like`
- 1.2.7 `torch.arange`
- 1.2.8 `torch.linspace`
- 1.2.9 `torch.logspace`
- 1.2.10 `torch.eye`
- 1.3 依概率分布创建张量
- 1.3.1 `torch.normal`
- 1.3.2 `torch.normal`
- 1.3.3 `torch.randn`
- 1.3.4 `torch.rand`
- 1.3.5 `torch.randint`
- 1.3.6 `torch.randperm`
- 1.3.7 `torch.bernoulli`
- 2. 张量的操作
- 2.1 张量拼接与切分
- 2.1.1 `torch.cat`
- 2.1.2 `torch.stack`
- 2.1.3 `torch.chunk`
- 2.1.4 `torch.split`
- 2.2 张量索引
- 2.2.1 `torch.index_select`
- 2.2.2 `torch.masked_select`
- 2.3 张量变换
- 2.3.1 `torch.reshape`
- 2.3.2 `torch.transpose`
- 2.3.3 `torch.t`
- 2.3.4 `torch.squeeze`
- 2.3.5 `torch.unsqueeze`
- 线性回归模型
Torch
1. 张量的创建
1.1 直接创建
1.1.1 torch.tensor
torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False)
- 功能:从data创建tensor
- data: 数据,可以是list,numpy
- dtype: 数据类型,默认与data的一致
- device: 所在设备,cuda/cpu
- requires_grad: 是否需要梯度
- pin_memory: 是否存于锁页内存
样例:
torch.tensor([[0.2, 0.2], [1.2, 2.3], [3.2, 1.3]])
'''
tensor([[0.2, 0.2],[1.2, 2.3],[3.2, 1.3]])
'''
1.1.2 torch.from_numpy(ndarray)
torch.from_numpy(ndarray)
- 功能:从numpy创建tensor
- 注意事项:从torch.from_numpy创建的tensor于原ndarray共享内存,当修改其中一个数据,另一个也将会被改动。
样例:
array = numpy.array([1, 2, 3, 4])
t = torch.from_numpy(array)
1.2 依据数值创建
1.2.1 torch.zeros
torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:依size创建全0张量
- size: 张量的形状,如(3, 3)、(3, 224, 224)
- out: 输出的张量
- layout: 内存中布局形式,有strided, sparse_coo等
- device: 所在设备,gpu/cpu
- requires_grad: 是否需要梯度
样例:
torch.zeros(2, 3) # 2行3列
'''
tensor([[0, 0, 0],[0, 0, 0]])
'''
1.2.2 torch.zeros_like
torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False)
- 功能:依input形状创建全0张量
- input: 创建与input同形状的全0张量
- dtype: 数据类型
- layout: 内存中布局形式
- device: 所在设备,gpu/cpu
- requires_grad: 是否需要梯度
样例:
input = torch.empty(3, 2)
torch.zeros_like(input)
'''
tensor([[0, 0],[0, 0],[0, 0]])
'''
1.2.3 torch.ones
torch.ones(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:依size创建全1张量
- size: 张量的形状,如(3, 3)、(3, 224, 224)
- out: 输出的张量
- layout: 内存中布局形式,有strided, sparse_coo等
- device: 所在设备,gpu/cpu
- requires_grad: 是否需要梯度
样例:
torch.ones(2, 3) # 2行3列
'''
tensor([[1, 1, 1],[1, 1, 1]])
'''
1.2.4 torch.ones_like
torch.ones_like(input, dtype=None, layout=None, device=None, requires_grad=False)
- 功能:依input形状创建全1张量
- input: 创建与input同形状的全0张量
- dtype: 数据类型
- layout: 内存中局形式
- device: 所在设备,gpu/cpu
- requires_grad: 是否需要梯度
样例:
input = torch.empty(2, 3)
torch.ones_like(input)
'''
tensor([[1, 1, 1],[1, 1, 1]])
'''
1.2.5 torch.full
torch.full(size, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:依size创建值全为fill_value的张量
- size: 张量的形状,如(3, 3)、(3, 224, 224)
- fill_value: 张量的值
- out: 输出的张量
- dtype: 数据类型
- layout: 内存中布局形式,有strided, sparse_coo等
- device: 所在设备,gpu/cpu
- requires_grad: 是否需要梯度
样例:
torch.full((3, 2), 1.23)'''
tensor([[1.23, 1.23],[1.23, 1.23],[1.23, 1.23]])
'''
1.2.6 torch.full_like
torch.full_like(input, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:依input形状创建指定数据的张量
- dtype: 数据类型
- layout: 内存中布局形式,有strided, sparse_coo等
- device: 所在设备,gpu/cpu
- requires_grad: 是否需要梯度
1.2.7 torch.arange
torch.arange(start=0, end. step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:创建
等差的1维张量- start: 数列起始值
- end: 数列“结束值”
- step: 数列公差,默认为1
- 注意事项:数值区间为
[𝑠𝑡𝑎𝑟𝑡,𝑒𝑛𝑑)!!!
样例;
torch.arange(0, 3, 1)
'''
tensor([0, 1, 2])
'''
1.2.8 torch.linspace
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:创建
均分的1维张量- start: 数列起始值
- end: 数列“结束值”
- step: 数列长度
样例:
torch.linspace(start=-5, end=5, steps=3)
'''
tensor([-5., 0., 5.])
'''
1.2.9 torch.logspace
torch.logspace(start, end, steps=100, base=10.0, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:创建
对数均分的1维张量- start: 数列起始值
- end: 数列“结束值”
- step: 数列长度
- base: 对数函数的底,默认为10
- 注意事项:长度为
steps,底为base
样例:
torch.logspace(start=0.1, end=1, steps=4)
'''
tensor([ 1.2589, 2.5119, 5.0119, 10.0000])
'''
1.2.10 torch.eye
torch.eye(n, m=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:创建
单位对角矩阵(2维张量)- n: 矩阵行数
- m: 矩阵列数
- 注意事项:默认为
方阵
torch.eye(3)
'''
tensor([[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
'''
1.3 依概率分布创建张量
1.3.1 torch.normal
torch.normal(mean, std, out=None)
- 功能:生成
正态分布(高斯分布)- mean: 均值
- std: 标准差
- 四种模式::
- mean为
标量,std为标量- mean为
标量,std为张量- mean为
张量,std为标量- mean为
张量,std为张量
样例:
# 1. mean为标量,std为标量
mean1 = torch.tensor([1.0])
std1 = torch.tensor([2.0])
normal1 = torch.normal(mean=mean1, std=std1)
print(f'mean为标量,std为标量: {normal1}')
# 2. mean为标量,std为张量
mean2 = torch.tensor([1.0])
std2 = torch.arange(1, 0, -0.1)
normal2 = torch.normal(mean=mean2, std=std2)
print(f'mean为标量,std为张量: {normal2}')
# 3. mean为张量,std为标量
mean3 = torch.arange(1, 0, -0.1)
std3 = torch.tensor([1.0])
normal3 = torch.normal(mean=mean3, std=std3)
print(f'mean为张量,std为标量: {normal3}')
# 4. mean为张量,std为张量
mean4 = torch.arange(1., 11.)
std4 = torch.arange(1, 0, -0.1)
normal4 = torch.normal(mean=mean4, std=std4)
print(f'mean为张量,std为张量: {normal4}')
'''
mean为标量,std为标量: tensor([0.8404])
mean为标量,std为张量: tensor([ 1.9674, 0.3015, 1.4441, 1.1592, -0.3160, 0.8436, 1.1548, 1.1149, 0.8569, 0.8924])
mean为张量,std为标量: tensor([-1.1098, 0.0993, 0.7905, 1.5703, -0.2797, -0.5459, -0.7058, -1.1746, 0.1725, 1.2089])
mean为张量,std为张量: tensor([-0.1302, 1.2099, 1.6807, 2.5063, 5.4447, 6.4120, 6.9074, 8.2245, 8.9090, 10.0049])
'''
1.3.2 torch.normal
torch.normal(mean, std, size, out=None)
- 功能:生成一定大小的生成
正态分布(高斯分布)- size: 张量的形状,如(3, 3)、(3, 224, 224)
样例:
torch.normal(3, 2, size=(1, 3))
'''
tensor([[3.6354, 3.2656, 3.2746]])
'''
1.3.3 torch.randn
torch.randn(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:生成
标准正态分布- size: 张量的形状,如(3, 3)、(3, 224, 224)
样例:
torch.randn(3, 2)
'''
tensor([[0.2405, 1.3955],[1.3470, 2.4382],[0.2028, 2.4505]])
'''
1.3.4 torch.rand
torch.rand(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:在区间
[0,1)上,生成均匀分布- size: 张量的形状,如(3, 3)、(3, 224, 224)
样例:
torch.normal(3, 2, size=(1, 3))
'''
tensor([[3.6354, 3.2656, 3.2746]])
'''
1.3.5 torch.randint
torch.randint(low=0, high, size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- 功能:区间
[𝑙𝑜𝑤,ℎ𝑖𝑔ℎ)生成整数均匀分布- size: 张量的形状,如(3, 3)、(3, 224, 224)
样例:
torch.randint(1, 10, (2, 2))
'''
tensor([[8, 6],[1, 3]])
'''
1.3.6 torch.randperm
torch.randperm(n, out=None, dtype=torch.int64, layout=torch.strided, device=None, requires_grad=False)
- 功能:生成从
0到n-1的随机排列- n: 张量的长度
样例:
torch.randperm(6)
'''
tensor([2, 0, 4, 5, 1, 3])
'''
1.3.7 torch.bernoulli
torch.bernoulli(input, *, generator=None, out=None)
- 功能:以
input为概率,生成伯努利分布(0-1分布,两点分布)- input: 概率值
样例:
a = torch.empty(2, 2).uniform_(0, 1) # 生成2×2的概率矩阵
torch.bernoulli(a)
'''
tensor([[0., 1.],[1., 0.]])
'''
2. 张量的操作
2.1 张量拼接与切分
2.1.1 torch.cat
torch.cat(tensors, dim=0, out=None)
- 功能:将张量
按维度dim进行拼接- tensors: 张量序列seq
- dim: 要拼接的维度
dim=0按行拼接 dim=1按列拼接 dim=n按维度拼接
x = torch.randn(2, 3)
print(x.shape)
a = torch.cat((x, x, x), 1)
a.shape
'''
torch.Size([2, 3])
torch.Size([2, 9])
'''
2.1.2 torch.stack
torch.stack(tensors, dim=0, out=None)
- 功能:对序列数据内部的张量进行
扩维拼接,指定维度由程序员选择、大小是生成后数据的维度区间。- tensors: 张量序列seq
- dim: 指定扩张的维度
dim=0按行扩张 dim=1按列扩张 dim=n按维度扩张
拼接后的tensor形状,会根据不同的dim发生变化。
参考:pytorch拼接函数:torch.stack()和torch.cat()详解
T1:tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
T2:tensor([[10, 20, 30],[40, 50, 60],[70, 80, 90]])
----------------------------------------------
R0 = torch.stack((T1, T2), dim=0)
'''tensor([[[1, 2, 3],[4, 5, 6],[7, 8, 9]],[[10, 20, 30],[40, 50, 60],[70, 80, 90]]])
torch.Size([2, 3, 3])
----------------------------------------------
'''
R1 = torch.stack((T1, T2), dim=1)
'''tensor([[[1, 2, 3],[10, 20, 30]],[[4, 5, 6],[40, 50, 60]],[[7, 8, 9],[70, 80, 90]]])torch.Size([3, 2, 3])
'''
----------------------------------------------
R2 = torch.stack((T1, T2), dim=2)
'''tensor([[[1, 10],[2, 20],[3, 30]],[[4, 40],[5, 50],[6, 60]],[[7, 70],[8, 80],[9, 90]]])torch.Size([3, 3, 2])
'''R3 = torch.stack((T1, T2), dim=3)
'''
IndexError: Dimension out of range (expected to be in range of [-3, 2], but got 3)
'''2.1.3 torch.chunk
torch.chunk(input, chunks, dim=0)
- 功能:将张量按维度
dim进行平均切分- 返回值: 张量列表
- 注意事项:若不能整除,最后一份张量小于其他张量
- input: 要切分的
张量- chunks: 要切分的
份数- dim: 要切分的
维度0按照列切分 1按照行切分
a = torch.arange(10).reshape(5,2)
torch.chunk(a, 2)
'''
tensor([[0, 1],[2, 3],[4, 5],[6, 7],[8, 9]])
(tensor([[0, 1],[2, 3],[4, 5]]),tensor([[6, 7],[8, 9]]))
'''
---------------------------------------
torch.chunk(a, 2, 1)
'''
(tensor([[0],[2],[4],[6],[8]]),tensor([[1],[3],[5],[7],[9]]))
'''
2.1.4 torch.split
torch.split(tensor, split_size_or_sections, dim=0)
- 功能:将张量按维度
dim进行切分- 返回值: 张量列表
- tensor: 要切分的
张量- split_size_or_sections: 为
int时,表示每一份的长度;为list时,按list元素切分- dim: 要切分的
维度0按照列切分 1按照行切分
a = torch.arange(10).reshape(5,2)
torch.split(a, 2)
'''
tensor([[0, 1],[2, 3],[4, 5],[6, 7],[8, 9]])
(tensor([[0, 1],[2, 3]]),tensor([[4, 5],[6, 7]]),tensor([[8, 9]]))
'''
torch.split(a, [3, 1, 1])
'''
(tensor([[0, 1],[2, 3],[4, 5]]),tensor([[6, 7]]),tensor([[8, 9]]))
'''
2.2 张量索引
2.2.1 torch.index_select
torch.index_select(input, dim, index, out=None)
- 功能:在维度
dim上,按index索引数据- 返回值: 依index索引数据拼接的张量
- input: 要索引的张量
- dim: 要索引的
维度0按照列切分 1按照行切分- index: 要索引数据的序号
x = torch.randn(3, 4)
indices = torch.tensor([0, 2])
torch.index_select(x, 0, indices)
'''
x: tensor([[-0.1468, 0.7861, 0.9468, -1.1143],[ 1.6908, -0.8948, -0.3556, 1.2324],[ 0.1382, -1.6822, 0.3177, 0.1328]])
indices: tensor([0, 2])
tensor([[-0.1468, 0.7861, 0.9468, -1.1143],[ 0.1382, -1.6822, 0.3177, 0.1328]])
'''
2.2.2 torch.masked_select
torch.masked_select(input, mask, out=None)
- 功能:按mask中的True进行索引
- 返回值: 一维张量
- input: 要索引的张量
- mask: 与input同形状的布尔类型张量
x = torch.randn(3, 4)
print('x:',x)
mask = x.ge(0.5)
print('mask:',mask)
torch.masked_select(x, mask)
'''
x: tensor([[ 0.1373, 0.2405, 1.3955, 1.3470],[ 2.4382, 0.2028, 2.4505, 2.0256],[ 1.7792, -0.9179, -0.4578, -0.7245]])
mask: tensor([[False, False, True, True],[ True, False, True, True],[ True, False, False, False]])
tensor([1.3955, 1.3470, 2.4382, 2.4505, 2.0256, 1.7792])
'''
2.3 张量变换
2.3.1 torch.reshape
torch.reshape(input, shape)
- 功能:
变换张量形状- 注意事项: 当张量在内存中是连续时,新张量与input共享数据内存
- input: 要变换的张量
- shape: 新张量的形状
a = torch.arange(4.)
torch.reshape(a, (2, 2))
'''
tensor([0., 1., 2., 3.])
tensor([[0., 1.],[2., 3.]])
'''
2.3.2 torch.transpose
torch.transpose(input, dim0, dim1)
- 功能:
交换张量的两个维度- input: 要交换的张量
- dim0: 要交换的维度
- dim1: 要交换的维度
x = torch.randn(2, 3)
torch.transpose(x, 0, 1)
'''
x:
tensor([[ 1.2799, -0.9941, 1.8150],[-0.6028, 1.6148, 1.9302]])
torch.Size([2, 3])
tensor([[ 1.2799, -0.6028],[-0.9941, 1.6148],[ 1.8150, 1.9302]])
torch.Size([3, 2])
'''
x = torch.randn(2, 3, 4)
print(x)
print(x.shape)
a = torch.transpose(x, 0, 2)
print(a)
print(a.shape)
'''
tensor([[[ 0.8885, -1.4867, -0.8898, 0.9005],[ 0.2615, -0.1494, 1.1523, -1.1309],[ 1.4025, -0.4167, 0.1655, -0.7157]],[[ 1.2425, -1.3332, 0.2961, -0.0937],[-0.7556, -0.1198, 0.9545, 0.1492],[ 1.6222, 0.1947, -1.5953, 0.5859]]])
torch.Size([2, 3, 4])
tensor([[[ 0.8885, 1.2425],[ 0.2615, -0.7556],[ 1.4025, 1.6222]],[[-1.4867, -1.3332],[-0.1494, -0.1198],[-0.4167, 0.1947]],[[-0.8898, 0.2961],[ 1.1523, 0.9545],[ 0.1655, -1.5953]],[[ 0.9005, -0.0937],[-1.1309, 0.1492],[-0.7157, 0.5859]]])
torch.Size([4, 3, 2])
'''
2.3.3 torch.t
torch.t(input)
- 功能:2维张量转置,对矩阵而言,等价于torch.transpose(input, 0, 1)
x = torch.randn((2, 2))
print(x)
torch.t(x)
'''
tensor([[ 0.5740, -0.0798],[ 0.9674, -0.7761]])
tensor([[ 0.5740, 0.9674],[-0.0798, -0.7761]])
'''
2.3.4 torch.squeeze
torch.squeeze(input, dim=None, out=None)
- 功能:压缩长度为1的维度(轴)
维度压缩- dim: 若为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除
x = torch.zeros(2, 1, 2, 1, 2)
print(x)
print(x.shape)
y = torch.squeeze(x)
print(y)
print(y.shape)
'''
tensor([[[[[0., 0.]],[[0., 0.]]]],[[[[0., 0.]],[[0., 0.]]]]])
torch.Size([2, 1, 2, 1, 2])
tensor([[[0., 0.],[0., 0.]],[[0., 0.],[0., 0.]]])
torch.Size([2, 2, 2])
'''
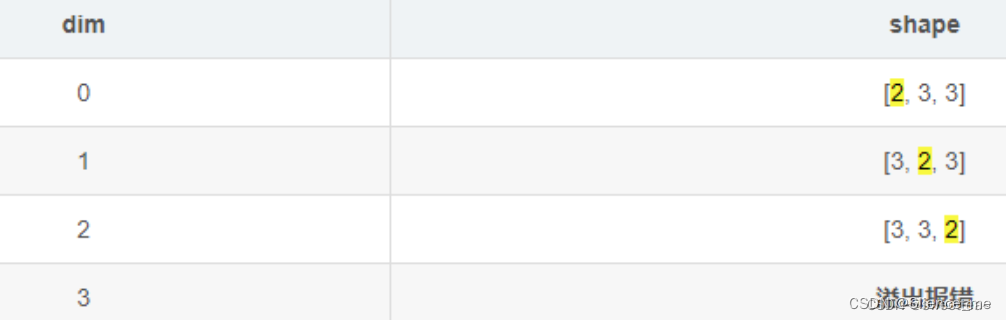
2.3.5 torch.unsqueeze
torch.unsqueeze(input, dim, out=None)
- 功能:依据dim
扩展维度- dim: 扩展的维度 0行扩展 1列扩展 -1最后一个维度扩展
x = torch.tensor([1, 2, 3])
print(x.shape)
t0 = torch.unsqueeze(x, 0)
print(t0.shape)
t1 = torch.unsqueeze(x, 1)
print(t1.shape)
t2 = torch.unsqueeze(x, -1)
print(t2.shape)
t0, t1, t2
'''
x:torch.Size([3])
t0:tensor([[1, 2, 3]])torch.Size([1, 3])
t1: tensor([[1],[2],[3]])torch.Size([3, 1])
t2:tensor([[1],[2],[3]]))torch.Size([3, 1])
'''
线性回归模型
- 线性回归是分析一个变量与另外一(多)个变量之间关系的方法。
- 因变量是 y y y,自变量是 x x x,关系线性: y = w × x + b y=w\times x + b y=w×x+b,任务是求解 w w w, b b b。
- 我们的求解步骤是:
- 确定模型: M o d e l → y = w × x + b Model \to y = w \times x + b Model→y=w×x+b
- 选择损失函数:这里用 M S E : 1 m ∑ i = 1 m ( y i − y ^ i ) 2 MSE:\frac{1}{m}\sum_{i=1}^m(y_i-\hat y_i)^2 MSE:m1∑i=1m(yi−y^i)2
- 求解梯度并更新 w w w, b b b:
w = w − l r × w . g r a d b = b − l r × w . g r a d \begin{array}{lcl} w &=& w - lr \times w.grad \\ b &=& b - lr \times w.grad \end{array} wb==w−lr×w.gradb−lr×w.grad - 下面我们开始写一个线性回归模型:
# 首先我们得有训练样本X,Y, 这里我们随机生成
x = torch.rand(20, 1) * 10
y = 2 * x + (5 + torch.randn(20, 1))# 构建线性回归函数的参数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True) # 这俩都需要求梯度# 设置学习率lr为0.1
lr = 0.1for iteration in range(100):# 前向传播wx = torch.mul(w, x)y_pred = torch.add(wx, b)# 计算loss 均方误差loss = (0.5 * (y-y_pred)**2).mean()# 反向传播loss.backward()# 更新参数b.data.sub_(lr * b.grad) # 这种_的加法操作时从自身减,相当于-=w.data.sub_(lr * w.grad)# 梯度清零w.grad.data.zero_()b.grad.data.zero_()print(w.data, b.data)
部分学习内容来自: 天池实验室
相关文章:
PyTorch之张量的相关操作大全 ->(个人学习记录笔记)
文章目录 Torch1. 张量的创建1.1 直接创建1.1.1 torch.tensor1.1.2 torch.from_numpy(ndarray) 1.2 依据数值创建1.2.1 torch.zeros1.2.2 torch.zeros_like1.2.3 torch.ones1.2.4 torch.ones_like1.2.5 torch.full1.2.6 torch.full_like1.2.7 torch.arange1.2.8 torch.linspace…...

ChatGPT生成内容很难脱离标准化,不建议用来写留学文书
ChatGPT无疑是23年留学届的热门话题,也成为了不少留学生再也离不开的万能工具,从总结文献、润色论文、给教授写email似乎无所不能。 各大高校对于学生使用ChatGPT的态度也有所不同。例如,哈佛大学教育代理院长 Anne Harrington 在内部邮件中…...

sqlserver @@ROWCOUNT的使用
T-SQL是一种用于与关系型数据库(如Microsoft SQL Server)交互的SQL(Structured Query Language)方言。 在T-SQL中,ROWCOUNT是一个系统变量,它返回最后执行的语句影响的行数。你提供的代码检查ROWCOUNT的值…...

Hbase批量删除数据
一、TTL机制 HBase的TTL(Time To Live)是一种用于指定数据存活时间的机制。它允许用户为HBase中的数据设置一个固定的生存时间,在达到指定的时间后,HBase会自动删除这些数据。 具体操作如下: 三步走,先禁用…...

飞行动力学 - 第20节-part2-机翼上反及后掠对横向静稳定性的影响 之 基础点摘要
飞行动力学 - 第20节-part2-机翼上反及后掠对横向静稳定性的影响 之 基础点摘要 1. 上反角贡献2. 后掠角贡献3. 参考资料 1. 上反角贡献 对于无后掠、大展弦比带上反的矩形机翼,飞行状态为 α \alpha α, β \beta β及V。 上反角增加稳定性,…...

力扣 -- 1218. 最长定差子序列
参考代码: class Solution { public:int longestSubsequence(vector<int>& arr, int difference) {int narr.size();unordered_map<int,int> hash;//nums[i]绑定dp[i]hash[arr[0]]1;int ret1;for(int i1;i<n;i){int aarr[i];int ba-difference;…...

【程序员装机】在右键菜单中添加Notepad++选项
文章目录 前言在右键菜单中添加Notepad选项的批处理脚本上述批处理脚本的功能包括 总结 前言 本文将介绍如何通过批处理脚本来在Windows右键菜单中添加Notepad选项,使您能够轻松使用Notepad打开各种文件。 在右键菜单中添加Notepad选项的批处理脚本 以下是一个用于…...
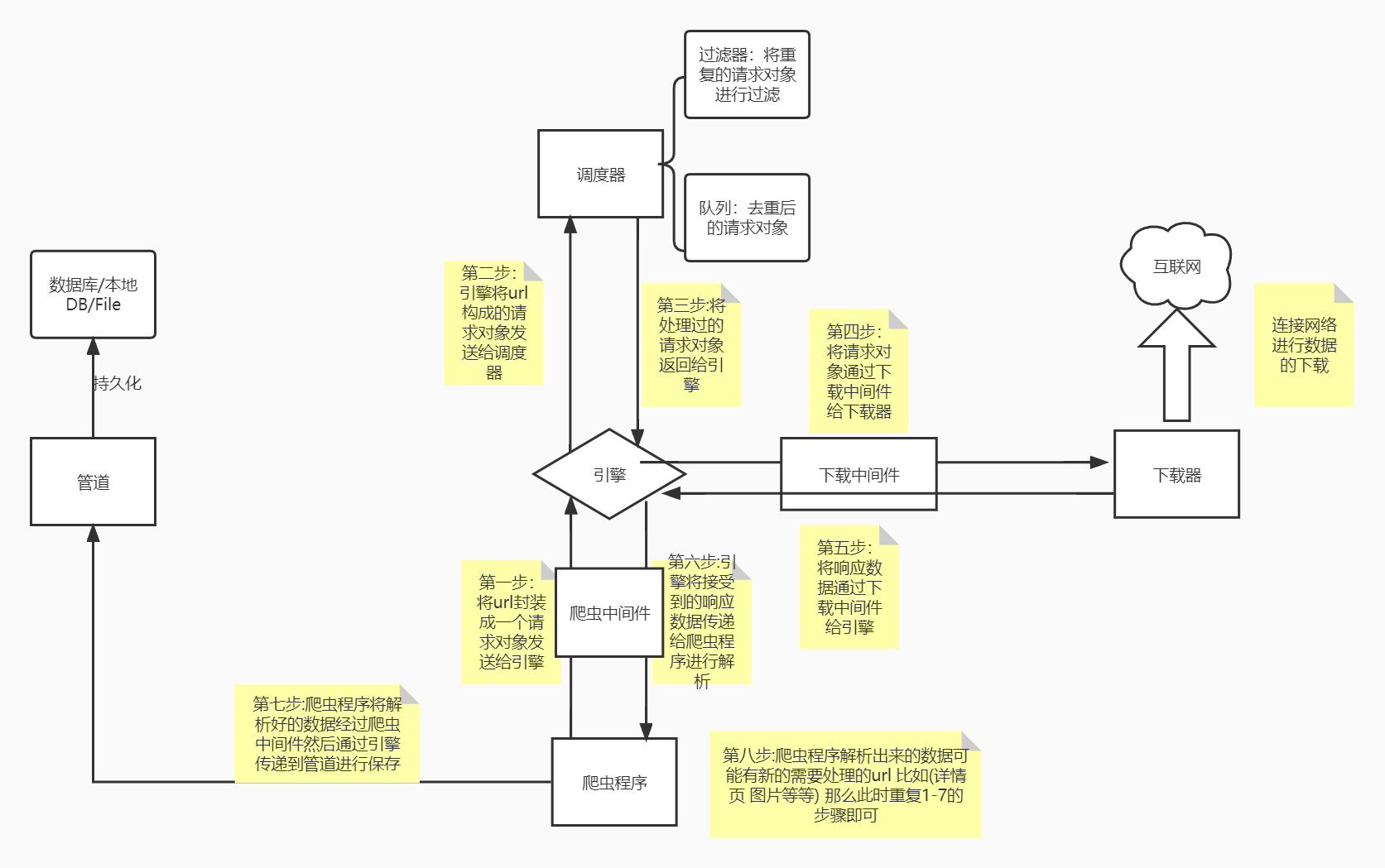
Scrapy的基本介绍、安装及工作流程
一.Scrapy介绍 Scrapy是什么? Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架) 通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。 Scrapy使用了Twisted异步网络框架&…...

CMS 三色标记【JVM调优】
文章目录 1. 垃圾回收器2. CMS 原理3. 三色标记算法 1. 垃圾回收器 ① Serial:最原始的垃圾回收器,用于新生代,是单线程的,GC 时需要停止其它所有的工作,算法简单,但它只能在内存较小时勉强使用;…...
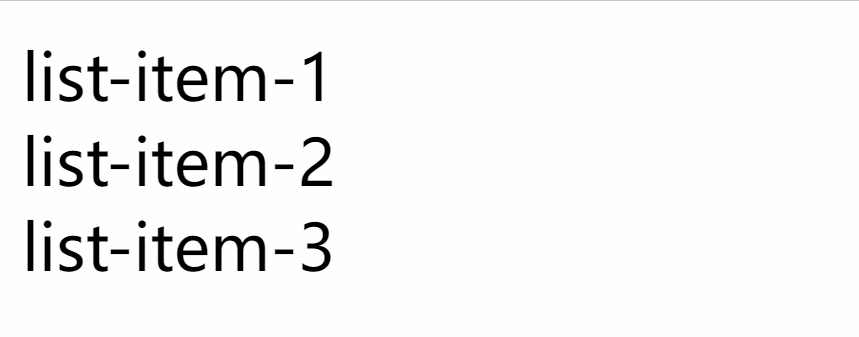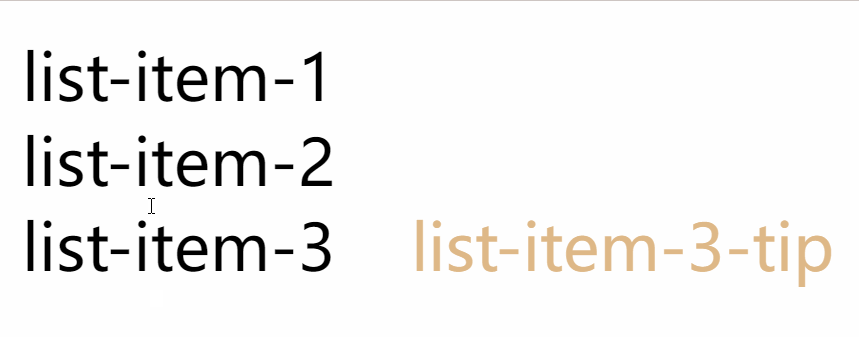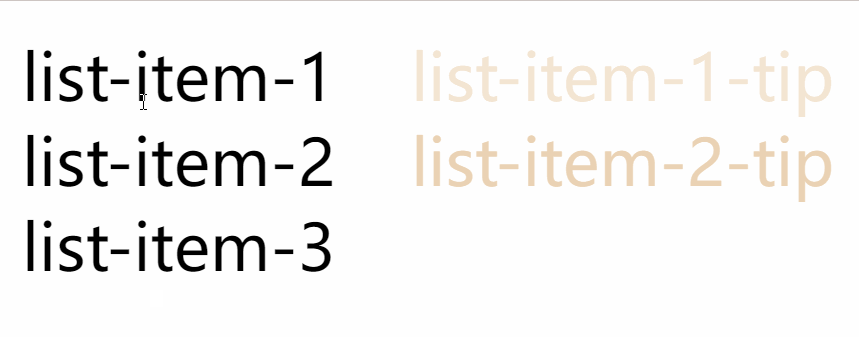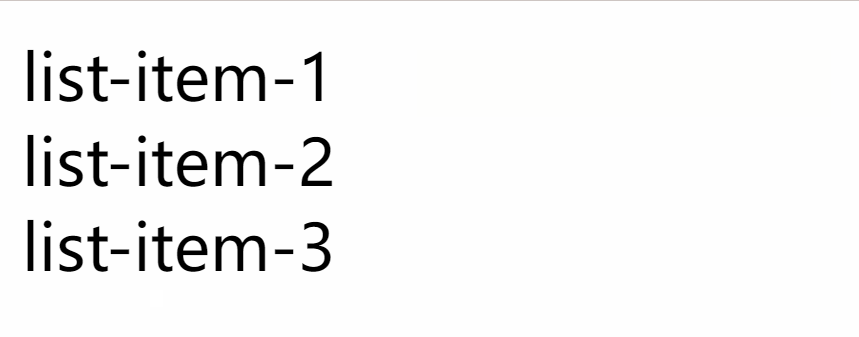
使用 CSS 伪类的attr() 展示 tooltip
效果图: 使用场景: 使用React渲染后台返回的数据, 遍历以列表的形式展示, 可能简要字段内容需要鼠标放上去才显示的 可以借助DOM的自定义属性和CSS伪类的attr来实现 所有代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-…...

在命令窗口便捷快速复制输出结果到剪贴板
在macOS上,将命令的输出结果复制到剪贴板 在日常的工作中, 经常使用命令的小伙伴可能会遇到一个场景, 就是把命令执行的结果复制出来另作它用. 每次都需要通过鼠标进行选择然后复制, 虽然 macOS 的命令行的复制快捷键和普通的复制是一样的, 非常友好, 但是还要选择…...
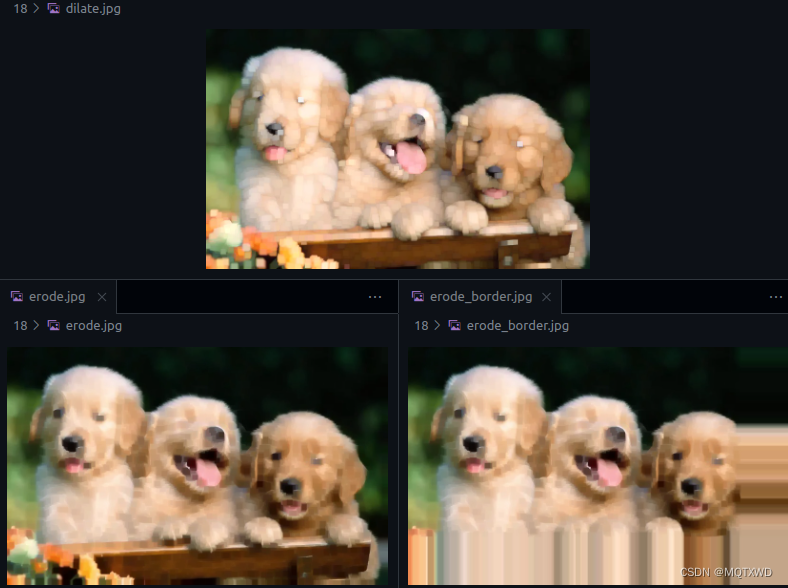
CUDA小白 - NPP(8) 图像处理 Morphological Operations
cuda小白 原始API链接 NPP GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》 常见的NppStatus…...

java获取音频,文本准转语音时长
jar 以上传到资源中 <dependency><groupId>it.sauronsoftware</groupId><artifactId>jave</artifactId><version>1.0.2</version></dependency> mvn install:install-file -DfileD:\xxx\xxx\jave-1.0.2.jar -DgroupIdit.sauro…...
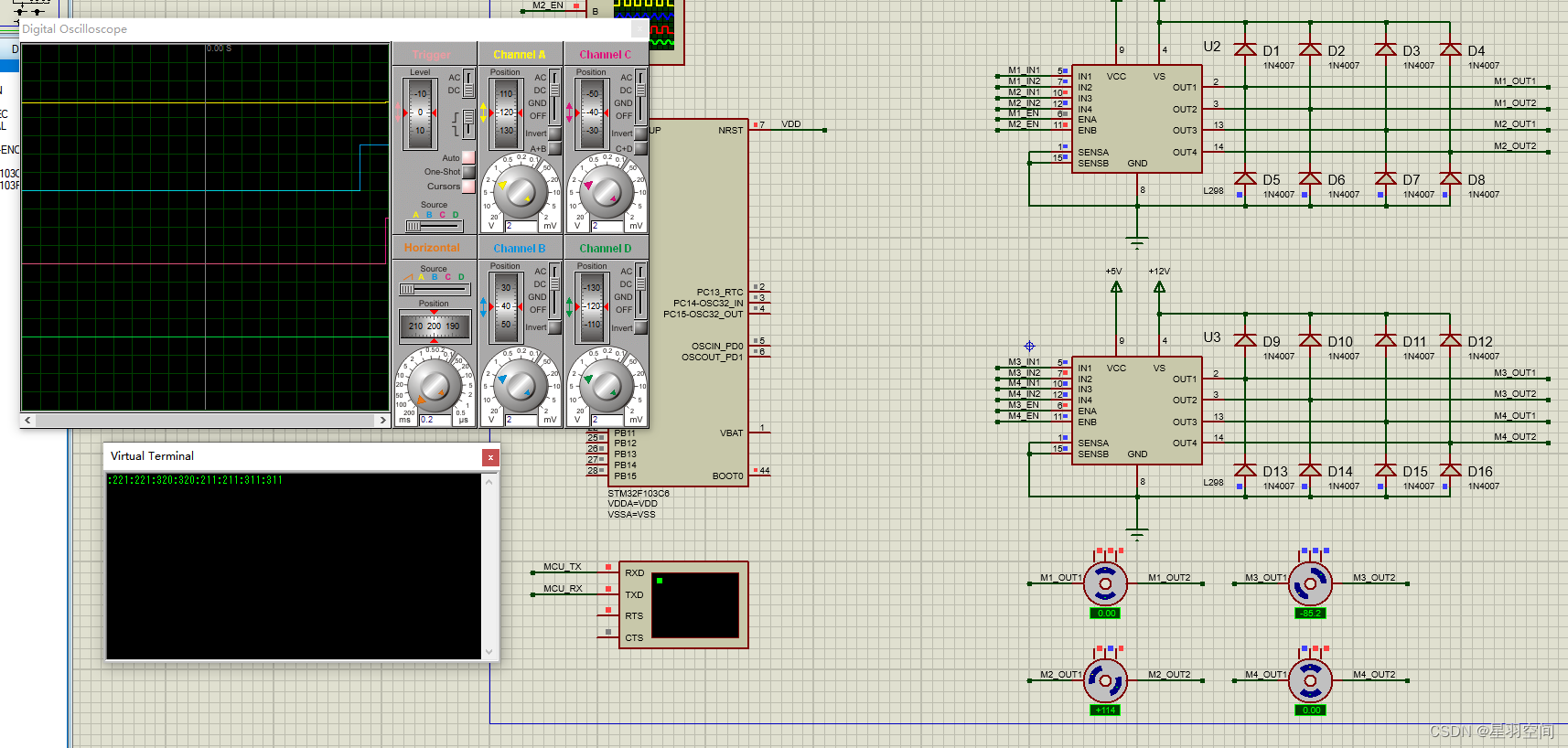
基于串口通讯的多电机控制技术研究
基于STM32CubeMX生成keil工程 基于proteus 8.7版本进行程序验证 采用了简单的串口通讯协议 基本效果如图 先对电机旋转方向进行指令设置 :221 :320 分别实现对第二个电机正转、第三个电机反转设置 为了方便观测,程序对接受到的串口数据会进行回显。 然后使能电…...
【深入解读Redis系列】(五)Redis中String的认知误区,详解String数据类型
有时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,请认准https://blog.zysicyj.top 首发博客地址 系列文章地址 需求描述 现在假设有这样一个需求,我们要开发一个图像存储系统。要求如下: 该系统能快…...

段指导-示例
RDBMS 19.20 参考文档: Database Administrator’s Guide 19 Managing Space for Schema Objects 19.3.2.4 Running the Segment Advisor Manually 针对表SOE.CUSTOMERS进行段指导 -- 创建段指导 variable id number; begindeclarename varchar2(100);descr …...

LeetCode 面试题 04.02. 最小高度树
文章目录 一、题目二、C# 题解 一、题目 给定一个有序整数数组,元素各不相同且按升序排列,编写一个算法,创建一棵高度最小的二叉搜索树。 点击此处跳转题目。 示例: 给定有序数组: [-10,-3,0,5,9], 一个可能的答案是:[0,-3,9,-10…...

华为云云耀云服务器L实例评测|初始化centos镜像到安装nginx部署前端vue、react项目
文章目录 ⭐前言⭐购买服务器💖 选择centos镜像 ⭐在控制台初始化centos镜像💖配置登录密码 ⭐在webstorm ssh连接 服务器⭐安装nginx💖 wget 下载nginx💖 解压运行 ⭐添加安全组⭐nginx 配置⭐部署vue💖 使用默认的ng…...
python项目制作docker镜像,加装引用模块,部署运行!
一、创建Dockerfile # 基于python:3.10.4版本创建容器 FROM python:3.10.4 # 在容器中创建工作目录 RUN mkdir /app # 将当前Dockerfile目录下的所有文件夹和文件拷贝到容器/app目录下 COPY . /app# 由于python程序用到了requests模块和yaml模块, # python:3.10.4基…...
Redis缓存设计与性能优化
多级缓存架构 缓存设计 缓存穿透 缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储层查不到数据则不写入缓存层。缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...