DQN算法概述及基于Pytorch的DQN迷宫实战代码
一. DQN算法概述
1.1 算法定义
Q-Learing是在一个表格中存储动作对应的奖励值,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。
于是,诞生了DQN算法,即深度Q网络(Deep Q-Network),是指基于深度学习的Q-Learing算法,用来解决连续状态空间和离散动作空间问题。此时的状态-价值函数变为Q(s,a;w),w是神经网络训练的参数矩阵。
DQN算法有两个非常大的优点,分别是经验回放和双Q表,下面详细讲解。
1.2 经验回放
不使用经验回放
DQN算法的缺点:
- 使用完 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)就丢弃,造成经验浪费
- 我们按顺序使用四元组,前后两个
transition四元组相关性很强,这种相关性对学习Q网络是有害的。
经验回放原理
经验回放会构建一个回放缓冲区(replay buffer),存储若干条transition,称为经验区,某一个策略与环境交互,收集很多条transition,放入回放缓冲区,回放缓冲区中的经验transition可能来自不同的策略。回放缓冲区只有在它装满的时候才会把旧的数据丢掉
使用经验回放优点:
- 能够重复使用经验,数据利用率高,对于数据获取困难的情况尤其有用。
- 把序列打散,消除相关性,使得数据满足独立同分布,从而减小参数更新的方差,提高收敛速度。
1.3 目标网络
不使用目标网络
DQN算法的缺点
因为要计算目标网络的目标值target,会使用最大值,这样就会造成计算的结果比真实值要大,用高估的结果再去更新自己,在网络中一次次循环过程,该最大化会越来越大,导致高估。
目标网络原理
使用第二个网络,称为目标网络: Q ( s , a ; w − ) Q(s,a;{w^-}) Q(s,a;w−),网络结构和原来的网络 Q ( s , a ; w ) Q(s,a;{w}) Q(s,a;w)一样,只是参数不同 w − ≠ w {w^-}≠w w−=w,原来的网络称为评估网络
两个网络的作用不一样:
-
评估网络 Q ( s , a ; w ) Q(s,a;{w}) Q(s,a;w)负责控制智能体,收集经验,梯度下降、反向传播
-
目标网络 Q ( s ′ , a ′ ; w − ) Q(s^{\prime},a^{\prime};w^{-}) Q(s′,a′;w−)用于计算下一状态
Q值 -
在更新过程中,只更新评估网络 Q ( s , a ; w ) Q(s,a;{w}) Q(s,a;w)的权重 w w w,目标网络 Q ( s , a ; w − ) Q(s,a;{w^-}) Q(s,a;w−)的权重保持 w − {w^-} w−不变,在更新一定次数后,再将更新过的评估网络的权重复制给目标网络,进行下一批更新,这样目标网络也能得到更新
使用目标网络的优点
利用目标网络可以一定程度避免自举,减缓高估问题;由于在目标网络没有变化的一段时间内回报的目标值是相对固定的,因此目标网络的引入增加了学习的稳定性。
1.4 完整训练过程

- 初始化:初始化深度神经网络 Q Q Q 和目标网络 Q target Q_{\text{target}} Qtarget 的权重 θ \theta θ 和 θ − \theta^- θ−。
- 数据收集: 在环境中与智能体进行交互,执行动作并观察状态转移、奖励和终止状态,将这些经验存储在经验回放缓冲区中。
- 经验回放: 从经验回放缓冲区中随机抽样一批经验,用于更新神经网络。这有助于减少样本之间的相关性,提高训练的稳定性。
- Q值估计: 使用神经网络 Q Q Q 估计当前状态下所有动作的 Q 值。
- 目标计算: 使用目标网络 Q target Q_{\text{target}} Qtarget 估计下一状态的最大 Q 值,即 max a ′ Q target ( s ′ , a ′ ; θ − ) \max_{a'} Q_{\text{target}}(s', a'; \theta^-) maxa′Qtarget(s′,a′;θ−)。
- 更新目标: 使用当前奖励和计算的目标 Q 值更新目标值:
t a r g e t = r + γ ⋅ max a ′ Q t a r g e t ( s ′ , a ′ ; θ − ) \mathrm{target}=r+\gamma\cdot\max_{a^{\prime}}Q_{\mathrm{target}}(s^{\prime},a^{\prime};\theta^{-}) target=r+γ⋅maxa′Qtarget(s′,a′;θ−)
- 计算损失: 使用均方误差损失计算 Q 值估计与目标之间的差异:
L ( θ ) = 1 2 ( target − Q ( s , a ; θ ) ) 2 \mathcal{L}(\theta)=\frac12\left(\text{target}-Q(s,a;\theta)\right)^2 L(θ)=21(target−Q(s,a;θ))2
- 更新网络: 使用梯度下降更新神经网络的权重 θ \theta θ,最小化损失 L ( θ ) \mathcal{L}(\theta) L(θ)。
∇ θ L ( θ ) = − ( t a r g e t − Q ( s , a ; θ ) ) ⋅ ∇ θ Q ( s , a ; θ ) \nabla_\theta\mathcal{L}(\theta)=-\left(\mathrm{target}-Q(s,a;\theta)\right)\cdot\nabla_\theta Q(s,a;\theta) ∇θL(θ)=−(target−Q(s,a;θ))⋅∇θQ(s,a;θ)
θ ← θ − α ⋅ ∇ θ L ( θ ) \theta\leftarrow\theta-\alpha\cdot\nabla_\theta\mathcal{L}(\theta) θ←θ−α⋅∇θL(θ)
-
周期性更新目标网络: 每隔一定的时间步骤,将目标网络的权重 θ − \theta^- θ− 更新为当前网络的权重 θ \theta θ。
-
重复步骤2至9: 迭代地进行数据收集、经验回放、更新网络等步骤。
1.5 总结
深度Q网络将Q学习与深度学习结合,用深度网络来近似动作价值函数,而Q学习则是采用表格存储;深度Q网络采用经验回放的训练方式,从历史数据中随机采样,而Q学习直接采用下一个状态的数据进行学习。
二. 基于Pytorch的DQN迷宫实战
直接上GitHub代码吧,注释全部写在里面了,非常详细:
基于Pytorch的DQN迷宫算法
为了防止有小伙伴打不开,还是这里也放一份吧
RL.py:定义DQN网络
'''
@Author :YZX
@Date :2023/8/7 10:21
@Python-Version :3.8
'''import torch
# 用于构建神经网络的各种工具和类
import torch.nn as nn
import numpy as np
# 用于执行神经网络中的各种操作,如激活函数、池化、归一化等
import torch.nn.functional as F
import matplotlib.pyplot as plt# 深度网络,全连接层
class Net(nn.Module):# 输入状态和动作,当前例子中状态有2个表示为坐标(x,y),动作有4个表示为(上下左右)def __init__(self, n_states, n_actions):super(Net, self).__init__()# 创建一个线性层,2行10列self.fc1 = nn.Linear(n_states, 10)# 创建一个线性层,10行4列self.fc2 = nn.Linear(10, n_actions)# 随机初始化生成权重,范围是0-0.1self.fc1.weight.data.normal_(0, 0.1)self.fc2.weight.data.normal_(0, 0.1)# 前向传播(用于状态预测动作的值)def forward(self, state):# 这里以一个动作为作为观测值进行输入(输入张量)# 线性变化后输出给10个神经元,格式:(x,x,x,x,x,x,x,x,x,x,x)state = self.fc1(state)# 激活函数,将负值设置为零,保持正值不变state = F.relu(state)# 经过10个神经元运算过后的数据,线性变化后把每个动作的价值作为输出。out = self.fc2(state)return out# 定义DQN网络class
class DQN:# n_states 状态空间个数;n_actions 动作空间大小def __init__(self, n_states, n_actions):print("<DQN init> n_states=", n_states, "n_actions=", n_actions)# 建立一个评估网络(即eval表示原来的网络) 和 Q现实网络 (即target表示用来计算Q值的网络)# DQN有两个net:target net和eval net,具有选动作、存储经验、学习三个基本功能self.eval_net, self.target_net = Net(n_states, n_actions), Net(n_states, n_actions)# 损失均方误差损失函数self.loss = nn.MSELoss()# 优化器,用于优化评估神经网络更新模型参数(仅优化eval),使损失函数尽量减小self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=0.01)self.n_actions = n_actions # 状态空间个数self.n_states = n_states # 动作空间大小# 使用变量# 用来记录学习到第几步了self.learn_step_counter = 0# 用来记录当前指到数据库的第几个数据了self.memory_counter = 0# 创建一个2000行6列的矩阵,即表示可存储2000行经验,每一行6个特征值# 2*2表示当前状态state(x,y)和下一个状态next_state(x,y) + 1表示选择一个动作 + 1表示一个奖励值self.memory = np.zeros((2000, 2 * 2 + 1 + 1))self.cost = [] # 记录损失值self.steps_of_each_episode = [] # 记录每轮走的步数# 进行选择动作# state = [-0.5 -0.5]def choose_action(self, state, epsilon):# 扩展一行,因为网络是多维矩阵,输入是至少两维# torch.FloatTensor(x)先将x转化为浮点数张量# torch.unsqueeze(input, dim)再将一维的张量转化为二维的,dim=0时数据为行方向扩,dim=1时为列方向扩# 例如 [1.0, 2.0, 3.0] -> [[1.0, 2.0, 3.0]]state = torch.unsqueeze(torch.FloatTensor(state), 0)# 在大部分情况,我们选择 去max-valueif np.random.uniform() < epsilon: # greedy # 随机结果是否大于EPSILON(0.9)# 获取动作对应的价值action_value = self.eval_net.forward(state)# torch.max() 返回输入张量所有元素的最大值,torch.max(input, dim),dim是max函数索引的维度0/1,0是每列的最大值,1是每行的最大值# torch.max(a, 1)[1] 代表a中每行最大值的索引# data.numpy()[0] 将Variable转换成tensor# 哪个神经元值最大,则代表下一个动作action = torch.max(action_value, 1)[1].data.numpy()[0]# 在少部分情况,我们选择 随机选择 (变异)else:# random.randint(参数1,参数2)函数用于生成参数1和参数2之间的任意整数,参数1 <= n < 参数2action = np.random.randint(0, self.n_actions)return action# 存储经验# 存储【本次状态,执行的动作,获得的奖励分,完成动作后产生的下一个状态】def store_transition(self, state, action, reward, next_state):# 把所有的记忆捆在一起,以 np 类型# 把 三个矩阵 s ,[a,r] ,s_ 平铺在一行 [a,r] 是因为 他们都是 int 没有 [] 就无法平铺 ,并不代表把他们捆在一起了# np.hstack()是把矩阵按水平方向堆叠数组构成一个新的数组transition = np.hstack((state, [action, reward], next_state))# index 是 这一次录入的数据在 MEMORY_CAPACITY 的哪一个位置# 如果记忆超过上线,我们重新索引。即覆盖老的记忆。index = self.memory_counter % 200self.memory[index, :] = transition # 将transition添加为memory的一行self.memory_counter += 1# 从存储学习数据# target_net是达到次数后更新, eval_net是每次learn就进行更新def learn(self):# 更新 target_net,每循环100次更新一次if self.learn_step_counter % 100 == 0:# 将评估网络的参数状态复制到目标网络中# 即将target_net网络变成eval_net网络,实现模型参数的软更新self.target_net.load_state_dict((self.eval_net.state_dict()))self.learn_step_counter += 1# eval_net是 每次 learn 就进行更新# 从[0,200)中随机抽取16个数据并组成一维数组,该数组表示记忆索引值sample_index = np.random.choice(200, 16)# 表示从 self.memory 中选择索引为 sample_index 的行,: 表示选取所有列# 按照随机获得的索引值获取对应的记忆数据memory = self.memory[sample_index, :]# 从记忆当中获取[0,2)列,即第零列和第一列,表示状态特征state = torch.FloatTensor(memory[:, :2])# 从记忆中获取[2,3)列,即第二列,表示动作特征action = torch.LongTensor(memory[:, 2:3])# 从记忆中获取[3,4)列,即第三列,表示奖励特征reward = torch.LongTensor(memory[:, 3:4])# 从记忆中获取[4,5)列,即第四列和第五列,表示下一个状态特征next_state = torch.FloatTensor(memory[:, 4:6])# 从原来的网络中获得当前状态的动作对应的预测Q值# self.eval_net(state)表示输入当前state,通过forward()函数输出状态对应的Q值估计# .gather(1, action)表示从上述Q值估计的集合中,第一个维度上获取action对应的的Q值# 将Q值赋值给q_eval,表示所采取动作的预测valueq_eval = self.eval_net(state).gather(1, action)# 获得下一步状态的Q值# 把target网络中下一步的状态对应的价值赋值给q_next;此处有时会反向传播更新target,但此处不需更新,故加.detach()q_next = self.target_net(next_state).detach()# 计算对于的最大价值# q_target 实际价值的计算 == 当前价值 + GAMMA(未来价值递减参数) * 未来的价值# max函数返回索引的最大值# unsqueeze(1)将上述计算出来的最大 Q 值的张量在第 1 个维度上扩展一个维度,变为一个列向量。q_target = reward + 0.9 * q_next.max(1)[0].unsqueeze(1)# 通过预测值与真实值计算损失 q_eval预测值, q_target真实值loss = self.loss(q_eval, q_target)# 记录损失值self.cost.append(loss.detach().numpy())# 根据误差,去优化我们eval网, 因为这是eval的优化器# 反向传递误差,进行参数更新self.optimizer.zero_grad() # 梯度重置loss.backward() # 反向求导self.optimizer.step() # 更新模型参数# 绘制损失图def plot_cost(self):# np.arange(3)产生0-2数组plt.plot(np.arange(len(self.cost)), self.cost)plt.xlabel("step")plt.ylabel("cost")plt.show()# 绘制每轮需要走几步def plot_steps_of_each_episode(self):plt.plot(np.arange(len(self.steps_of_each_episode)), self.steps_of_each_episode)plt.xlabel("episode")plt.ylabel("done steps")plt.show()
MazeEnv.py:创建环境地图
'''
@Author :YZX
@Date :2023/8/7 16:03
@Python-Version :3.8
'''import tkinter as tk
import numpy as npUNIT = 40 # pixels 像素
MAZE_H = 4 # grid height y轴格子数
MAZE_W = 4 # grid width x格子数# 迷宫
class Maze(tk.Tk, object):def __init__(self):print("<env init>")super(Maze, self).__init__()# 动作空间(定义智能体可选的行为),action=0-3self.action_space = ['u', 'd', 'l', 'r']# 使用变量self.n_actions = len(self.action_space)# 状态空间,state=0,1self.n_states = 2# 配置信息self.title('maze')# 设置屏幕大小self.geometry("160x160")# 初始化操作self.__build_maze()# 渲染画面def render(self):# time.sleep(0.1)self.update()# 重置环境def reset(self):# 智能体回到初始位置# time.sleep(0.1)self.update()self.canvas.delete(self.rect)origin = np.array([20, 20])# 智能体位置,前两个左上角坐标(x0,y0),后两个右下角坐标(x1,y1)self.rect = self.canvas.create_rectangle(origin[0] - 15, origin[1] - 15,origin[0] + 15, origin[1] + 15,fill='red')# return observation 状态# canvas.coords(长方形/椭圆),会得到 【左极值点、上极值点、右极值点、下极值点】这四个点组成的元组,:2表示前2个return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2])) / (MAZE_H * UNIT)# 智能体向前移动一步:返回next_state,reward,terminaldef step(self, action):s = self.canvas.coords(self.rect)base_action = np.array([0, 0])if action == 0: # upif s[1] > UNIT:base_action[1] -= UNITelif action == 1: # downif s[1] < (MAZE_H - 1) * UNIT:base_action[1] += UNITelif action == 2: # rightif s[0] < (MAZE_W - 1) * UNIT:base_action[0] += UNITelif action == 3: # leftif s[0] > UNIT:base_action[0] -= UNITself.canvas.move(self.rect, base_action[0], base_action[1]) # move agentnext_coords = self.canvas.coords(self.rect) # next state# reward functionif next_coords == self.canvas.coords(self.oval):reward = 1print("victory")done = Trueelif next_coords in [self.canvas.coords(self.hell1)]:reward = -1print("defeat")done = Trueelse:reward = 0done = Falses_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2])) / (MAZE_H * UNIT)return s_, reward, donedef __build_maze(self):self.canvas = tk.Canvas(self, bg='white',height=MAZE_H * UNIT,width=MAZE_W * UNIT)# create gridsfor c in range(0, MAZE_W * UNIT, UNIT):x0, y0, x1, y1 = c, 0, c, MAZE_H * UNITself.canvas.create_line(x0, y0, x1, y1)for r in range(0, MAZE_H * UNIT, UNIT):x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, rself.canvas.create_line(x0, y0, x1, y1)origin = np.array([20, 20])hell1_center = origin + np.array([UNIT * 2, UNIT])# 陷阱self.hell1 = self.canvas.create_rectangle(hell1_center[0] - 15, hell1_center[1] - 15,hell1_center[0] + 15, hell1_center[1] + 15,fill='black')oval_center = origin + UNIT * 2# 出口self.oval = self.canvas.create_oval(oval_center[0] - 15, oval_center[1] - 15,oval_center[0] + 15, oval_center[1] + 15,fill='yellow')# 智能体self.rect = self.canvas.create_rectangle(origin[0] - 15, origin[1] - 15,origin[0] + 15, origin[1] + 15,fill='red')self.canvas.pack()Run.py:训练主方法
'''
@Author :YZX
@Date :2023/8/7 16:03
@Python-Version :3.8
'''from MazeEnv import Maze
from RL import DQN
import timedef run_maze():print("====Game Start====")step = 0 # 已进行多少步max_episode = 500 # 总共需要进行多少轮for episode in range(max_episode):# 环境和位置重置,但是memory一直保留state = env.reset()# 本轮已进行多少步step_every_episode = 0# 动态变化随机值epsilon = episode / max_episode# 开始实验循环# 只有env认为 这个实验死了,才会结束循环while True:if episode < 10:time.sleep(0.1)if episode > 480:time.sleep(0.2)# 刷新环境状态,显示新位置env.render()# 根据输入的环境特征 s 输出选择动作 aaction = model.choose_action(state, epsilon) # 根据状态选择行为# 环境根据行为给出下一个状态,奖励,是否结束。next_state, reward, terminal = env.step(action) # env.step(a) 是执行 a 动作# 每完成一个动作,记忆存储数据一次model.store_transition(state, action, reward, next_state) # 模型存储经历# 按批更新if step > 200 and step % 5 == 0:model.learn()# 状态转变state = next_state# 状态是否为终止if terminal:print("episode=", episode, end=",") # 第几轮print("step=", step_every_episode) # 第几步model.steps_of_each_episode.append(step_every_episode) # 记录每轮走的步数breakstep += 1 # 总步数+1step_every_episode += 1 # 当前轮的步数+1# 游戏环境结束print("====Game Over====")env.destroy()if __name__ == "__main__":env = Maze() # 环境# 实例化DQN类,也就是实例化这个强化学习网络model = DQN(n_states=env.n_states,n_actions=env.n_actions)run_maze() # 训练env.mainloop() # mainloop()方法允许程序循环执行,并进入等待和处理事件model.plot_cost() # 画误差曲线model.plot_steps_of_each_episode() # 画每轮走的步数
相关文章:
DQN算法概述及基于Pytorch的DQN迷宫实战代码
一. DQN算法概述 1.1 算法定义 Q-Learing是在一个表格中存储动作对应的奖励值,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情…...
Pytorch学习整理笔记(一)
文章目录 数据处理DatasetTensorboard使用Transformstorchvision数据集使用DataLoader使用nn.Module的使用神经网络 数据处理Dataset 主要是对Dataset的使用: 继承 Dataset实现init方法,主要是进行一些全局变量的定义,在对其初始化时需要赋…...

paddlespeech asr脚本demo
概述 paddlespeech是百度飞桨平台的开源工具包,主要用于语音和音频的分析处理,其中包含多个可选模型,提供语音识别、语音合成、说话人验证、关键词识别、音频分类和语音翻译等功能。 本文介绍利用ps中的asr功能实现批量处理音频文件的demo。…...

算法分析与设计编程题 递归与分治策略
棋盘覆盖 题目描述 解题代码 // para: 棋盘,行偏移,列偏移,特殊行,特殊列 void dividedCovering(vector<vector<int>>& chessBoard, int dr, int dc, int sr, int sc, int size) {if (size 1) return;size / 2…...

Java的XWPFTemplate工具类导出word.docx的使用
依赖 <!-- word导出 --><dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.7.3</version></dependency><!-- 上面需要的依赖--><dependency><groupId>org.ap…...

Science adv | 转录因子SPIC连接胚胎干细胞中的细胞代谢与表观调控
代谢是生化反应网络的结果,这些反应吸收营养物质并对其进行处理,以满足细胞的需求,包括能量产生和生物合成。反应的中间体被用作各种表观基因组修饰酶的底物和辅助因子,因此代谢与表观遗传密切相关。代谢结合表观遗传涉及疾病&…...
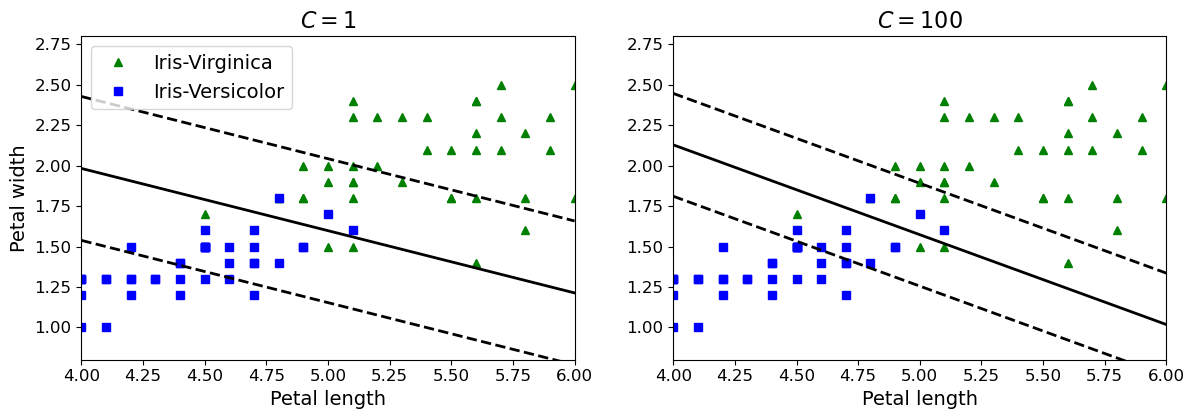
机器学习实战-系列教程7:SVM分类实战2线性SVM(鸢尾花数据集/软间隔/线性SVM/非线性SVM/scikit-learn框架)项目实战、代码解读
🌈🌈🌈机器学习 实战系列 总目录 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 SVM分类实战1之简单SVM分类 SVM分类实战2线性SVM SVM分类实战3非线性SVM 3、不同软间隔C值 3.1 数据标准化的影响 如图左边是没…...

DOM渲染与优化 - CSS、JS、DOM解析和渲染阻塞问题
文章目录 DOM渲染面试题DOM的渲染过程DOM渲染的时机与渲染进程的概述浏览器的渲染流程1. 解析HTML生成DOM树:遇到<img>标签加载图片2. 解析CSS生成CSSOM(CSS Object Model): 遇见背景图片链接不加载3. 将DOM树和CSSOM树合并生成渲染树:加载可视节点…...
基于小程序的理发店预约系统
一、项目背景及简介 现在很多的地方都在使用计算机开发的各种管理系统来提高工作的效率,给人们带来很多的方便。计算机技术从很大的程度上解放了人们的双手,并扩大了人们的活动范围,是人们足不出户就可以通过电脑进行各种事情的管理。信息系…...

MD5 算法流程
先通过下面的命令对 md5算法有个感性的认识: $ md5sum /tmp/1.txt 1dc792fcaf345a07b10248a387cc2718 /tmp/1.txt$ md5sum // 从键盘输入,ctrl-d 结束输入 hello, world! 910c8bc73110b0cd1bc5d2bcae782511 -从上面可以看到,一个文件或一…...

TCP/IP协议详解
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网协议)是互联网的基本协议,也是国际互联网络的基础。 TCP/IP 不是指一个协议,也不是 TCP 和 IP 这两个协议的合称,而是一个协…...
SSM SpringBoot vue快递柜管理系统
SSM SpringBoot vue快递柜管理系统 系统功能 登录 注册 个人中心 快递员管理 用户信息管理 用户寄件管理 配送信息管理 寄存信息管理 开发环境和技术 开发语言:Java 使用框架: SSM(Spring SpringMVC Mybaits)或SpringBoot 前端: vue 数据库:Mys…...

期权交易保证金比例一般是多少?
期权交易是一种非常受欢迎的投资方式之一,它为期权市场带来了更为多样化和灵活化的交易形式。而其中的期权卖方保证金比例是期权交易中的一个重要指标,直接关系到投资者的风险与收益,下文介绍期权交易保证金比例一般是多少?本文来…...

029:vue项目,勾选后今天不再弹窗提示
第029个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...

Unet语义分割-语义分割与实例分割概述-001
文章目录 前言1、图像分割和图像识别1.语义分割2.实例分割 2、分割任务中的目标函数定义3.IOU 前言 大纲目录 1、图像分割和图像识别 下面是图像识别和图像分割的区别,图像识别就是识别出来,画个框,右边的是图像分割。 1.语义分割 两张图把…...

Linux常用命令字典篇
Linux命令 1. 翻页查看文件 less [-N] 文件名:可以向后翻页,也可以向前翻页,-N表示显示行号 more 文件名:仅可以向后翻页 2. 端口占用信息查看 netstat -tunlp | grep 端口号:查看端口号对应的信息 lsof i: 端口号…...
 在C++)
__declspec(novtable) 在C++
__declspec(novtable) 在C中接口中广泛应用. 不容易看到它是因为在很多地方它都被定义成为了宏. 比如说ATL活动模板库中的ATL_NO_VTABLE, 其实就是__declspec(novtable). __declspec(novtable) 就是让类不要有虚函数表以及对虚函数表的初始化代码, 这样可以节省运行时间和空间.…...

ChatGPT充值,银行卡被拒绝
目录 前言步骤1. 魔法地址选择2. 选择手机号码(归属地)3. 勾选,服从协议4. 填写信息5. 完善账单地址6. 订阅成功 前言 大家好,今天我在订阅ChatGPT4时,遭遇了银行卡被拒绝的尴尬境地。这里有个技巧,我来给…...
算法通过村第七关-树(递归/二叉树遍历)白银笔记|递归实战
文章目录 前言1. 深入理解前中后序遍历从小到大递推分情况讨论,明确结束条件组合出完整的方法:从大到小 画图推演 总结 前言 提示:没有客观公正的记忆这回事,所有的记忆都是偏见,都是为自己的存活而重组过的经验。--国…...
- 抖音小程序高级功能)
抖音小程序开发教学系列(6)- 抖音小程序高级功能
第六章:抖音小程序高级功能 6.1 抖音小程序的支付功能6.1.1 接入流程6.1.2 注意事项 6.2 抖音小程序的地理位置和地图功能6.2.1 接入流程6.2.2 使用方法 6.3 抖音小程序的实时音视频功能6.3.1 接入流程6.3.2 使用方法 6.4 抖音小程序的小游戏开发6.4.1 基本流程6.4.…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...
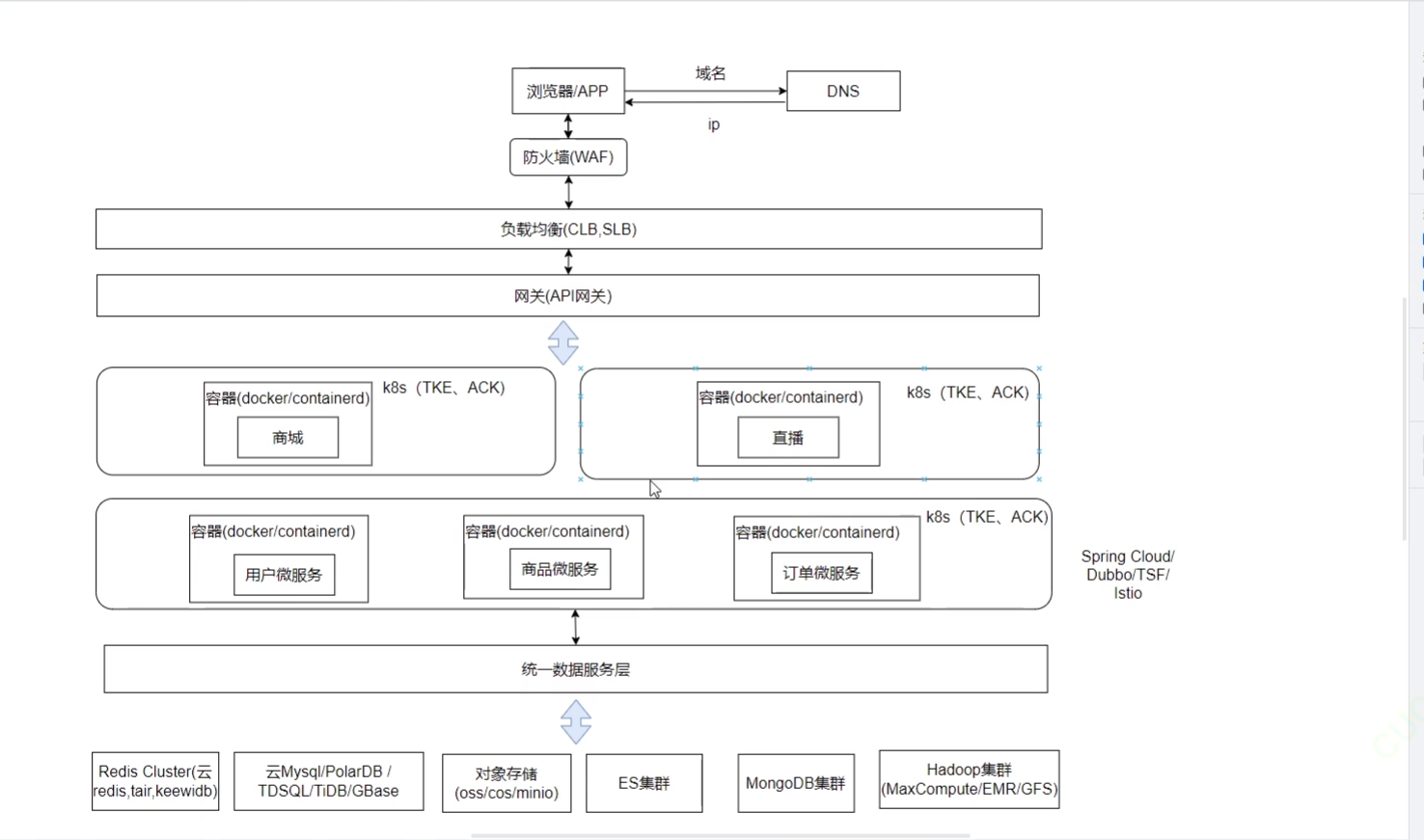
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...