【毕设选题】flink大数据淘宝用户行为数据实时分析与可视化
文章目录
- 0 前言
- 1、环境准备
- 1.1 flink 下载相关 jar 包
- 1.2 生成 kafka 数据
- 1.3 开发前的三个小 tip
- 2、flink-sql 客户端编写运行 sql
- 2.1 创建 kafka 数据源表
- 2.2 指标统计:每小时成交量
- 2.2.1 创建 es 结果表, 存放每小时的成交量
- 2.2.2 执行 sql ,统计每小时的成交量
- 2.3 指标统计:每10分钟累计独立用户数
- 2.3.1 创建 es 结果表,存放每10分钟累计独立用户数
- 2.3.2 创建视图
- 2.3.3 执行 sql ,统计每10分钟的累计独立用户数
- 2.4 指标统计:商品类目销量排行
- 2.4.1 创建商品类目维表
- 2.4.1 创建 es 结果表,存放商品类目排行表
- 2.4.2 创建视图
- 2.4.3 执行 sql , 统计商品类目销量排行
- 3、最终效果与体验心得
- 3.1 最终效果
- 3.2 体验心得
- 3.2.1 执行
- 3.2.2 存储
- 4 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 flink大数据淘宝用户行为数据实时分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
1、环境准备
1.1 flink 下载相关 jar 包
flink-sql 连接外部系统时,需要依赖特定的 jar 包,所以需要事先把这些 jar 包准备好。说明与下载入口
本项目使用到了以下的 jar 包 ,下载后直接放在了 flink/lib 里面。
需要注意的是 flink-sql 执行时,是转化为 flink-job 提交到集群执行的,所以 flink 集群的每一台机器都要添加以下的 jar 包。
| 外部 | 版本 | jar |
|---|---|---|
| kafka | 4.1 | flink-sql-connector-kafka_2.11-1.10.2.jar flink-json-1.10.2-sql-jar.jar |
| elasticsearch | 7.6 | flink-sql-connector-elasticsearch7_2.11-1.10.2.jar |
| mysql | 5.7 | flink-jdbc_2.11-1.10.2.jar mysql-connector-java-8.0.11.jar |
1.2 生成 kafka 数据
用户行为数据来源: 阿里云天池公开数据集
网盘:https://pan.baidu.com/s/1wDVQpRV7giIlLJJgRZAInQ 提取码:gja5
商品类目纬度数据来源: category.sql
数据生成器:datagen.py
有了数据文件之后,使用 python 读取文件数据,然后并发写入到 kafka。
修改生成器中的 kafka 地址配置,然后运行 以下命令,开始不断往 kafka 写数据
# 5000 并发
nohup python3 datagen.py 5000 &
1.3 开发前的三个小 tip
-
生成器往 kafka 写数据,会自动创建主题,无需事先创建
-
flink 往 elasticsearch 写数据,会自动创建索引,无需事先创建
-
Kibana 使用索引模式从 Elasticsearch 索引中检索数据,以实现诸如可视化等功能。
使用的逻辑为:创建索引模式 》Discover (发现) 查看索引数据 》visualize(可视化)创建可视化图表》dashboards(仪表板)创建大屏,即汇总多个可视化的图表
2、flink-sql 客户端编写运行 sql
# 进入 flink-sql 客户端, 需要指定刚刚下载的 jar 包目录
./bin/sql-client.sh embedded -l lib
2.1 创建 kafka 数据源表
-- 创建 kafka 表, 读取 kafka 数据
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3),proctime as PROCTIME(),WATERMARK FOR ts as ts - INTERVAL '5' SECOND
) WITH ('connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.startup-mode' = 'earliest-offset', 'connector.properties.zookeeper.connect' = '172.16.122.24:2181', 'connector.properties.bootstrap.servers' = '172.16.122.17:9092', 'format.type' = 'json'
);
SELECT * FROM user_behavior;
2.2 指标统计:每小时成交量
2.2.1 创建 es 结果表, 存放每小时的成交量
CREATE TABLE buy_cnt_per_hour (hour_of_day BIGINT,buy_cnt BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'buy_cnt_per_hour','connector.document-type' = 'user_behavior','connector.bulk-flush.max-actions' = '1','update-mode' = 'append','format.type' = 'json'
);
2.2.2 执行 sql ,统计每小时的成交量
INSERT INTO buy_cnt_per_hour
SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*)
FROM user_behavior
WHERE behavior = 'buy'
GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);
2.3 指标统计:每10分钟累计独立用户数
2.3.1 创建 es 结果表,存放每10分钟累计独立用户数
CREATE TABLE cumulative_uv (time_str STRING,uv BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'cumulative_uv','connector.document-type' = 'user_behavior', 'update-mode' = 'upsert','format.type' = 'json'
);
2.3.2 创建视图
CREATE VIEW uv_per_10min AS
SELECTMAX(SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0') OVER w AS time_str,COUNT(DISTINCT user_id) OVER w AS uv
FROM user_behavior
WINDOW w AS (ORDER BY proctime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
2.3.3 执行 sql ,统计每10分钟的累计独立用户数
INSERT INTO cumulative_uv
SELECT time_str, MAX(uv)
FROM uv_per_10min
GROUP BY time_str;
2.4 指标统计:商品类目销量排行
2.4.1 创建商品类目维表
先在 mysql 创建一张商品类目的维表,然后配置 flink 读取 mysql。
CREATE TABLE category_dim (sub_category_id BIGINT,parent_category_name STRING
) WITH ('connector.type' = 'jdbc','connector.url' = 'jdbc:mysql://172.16.122.25:3306/flink','connector.table' = 'category','connector.driver' = 'com.mysql.jdbc.Driver','connector.username' = 'root','connector.password' = 'root','connector.lookup.cache.max-rows' = '5000','connector.lookup.cache.ttl' = '10min'
);
2.4.1 创建 es 结果表,存放商品类目排行表
CREATE TABLE top_category (category_name STRING,buy_cnt BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'top_category','connector.document-type' = 'user_behavior','update-mode' = 'upsert','format.type' = 'json'
);
2.4.2 创建视图
CREATE VIEW rich_user_behavior AS
SELECT U.user_id, U.item_id, U.behavior, C.parent_category_name as category_name
FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C
ON U.category_id = C.sub_category_id;
2.4.3 执行 sql , 统计商品类目销量排行
INSERT INTO top_category
SELECT category_name, COUNT(*) buy_cnt
FROM rich_user_behavior
WHERE behavior = 'buy'
GROUP BY category_name;
3、最终效果与体验心得
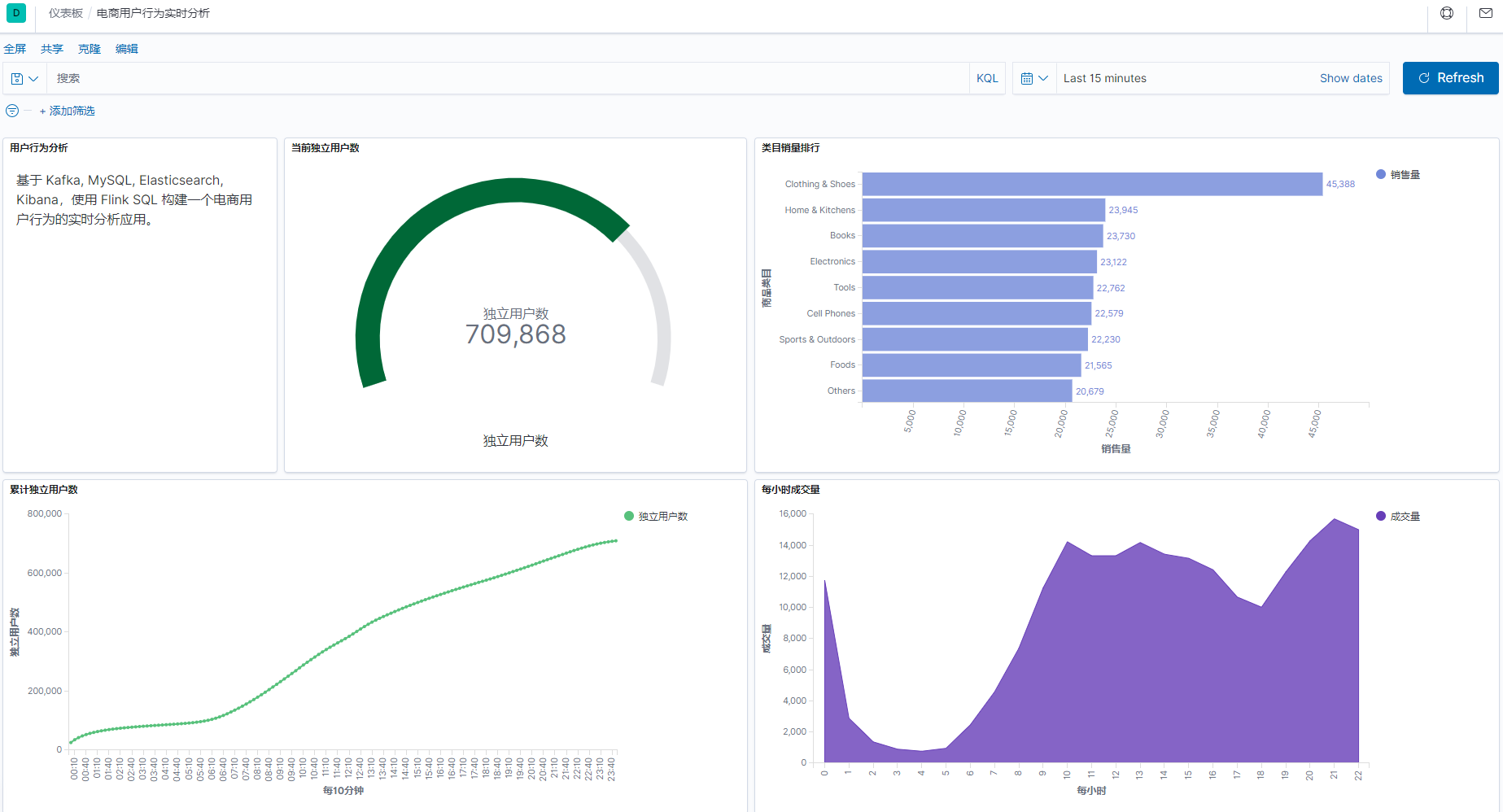
3.1 最终效果
整个开发过程,只用到了 flink-sql ,无需写 java 或者其它代码,就完成了这样一个实时报表。
3.2 体验心得
3.2.1 执行
-
flink-sql 的 ddl 语句不会触发 flink-job , 同时创建的表、视图仅在会话级别有效。
-
对于连接表的 insert、select 等操作,则会触发相应的流 job, 并自动提交到 flink 集群,无限地运行下去,直到主动取消或者 job 报错。
-
flink-sql 客户端关闭后,对于已经提交到 flink 集群的 job 不会有任何影响。
本次开发,执行了 3 个 insert , 因此打开 flink 集群面板,可以看到有 3 个无限的流 job 。即使 kafka 数据全部写入完毕,关闭 flink-sql 客户端,这个 3 个 job 都不会停止。
3.2.2 存储
-
flnik 本身不存储业务数据,只作为流批一体的引擎存在,所以主要的用法为读取外部系统的数据,处理后,再写到外部系统。
-
flink 本身的元数据,包括表、函数等,默认情况下只是存放在内存里面,所以仅会话级别有效。但是,似乎可以存储到 Hive Metastore 中,关于这一点就留到以后再实践。
4 最后
相关文章:
【毕设选题】flink大数据淘宝用户行为数据实时分析与可视化
文章目录 0 前言1、环境准备1.1 flink 下载相关 jar 包1.2 生成 kafka 数据1.3 开发前的三个小 tip 2、flink-sql 客户端编写运行 sql2.1 创建 kafka 数据源表2.2 指标统计:每小时成交量2.2.1 创建 es 结果表, 存放每小时的成交量2.2.2 执行 sql &#x…...
机器学习练习-决策树
机器学习练习-决策树 代码更新地址:https://github.com/fengdu78/WZU-machine-learning-course 代码修改并注释:黄海广,haiguang2000wzu.edu.cn 1.分类决策树模型是表示基于特征对实例进行分类的树形结构。决策树可以转换成一个if…...
分类预测 | Matlab实现基于LFDA-SVM局部费歇尔判别数据降维结合支持向量机的多输入分类预测
分类预测 | Matlab实现基于LFDA-SVM局部费歇尔判别数据降维结合支持向量机的多输入分类预测 目录 分类预测 | Matlab实现基于LFDA-SVM局部费歇尔判别数据降维结合支持向量机的多输入分类预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 基于局部费歇尔判别数据降维的L…...
Say0l的安全开发-代理扫描工具-Sayo-proxyscan【红队工具】
写在前面 终于终于,安全开发也练习一年半了,有时间完善一下项目,写写中间踩过的坑。 安全开发的系列全部都会上传至github,欢迎使用和star。 工具链接地址 https://github.com/SAY0l/Sayo-proxyscan 工具简介 SOCKS4/SOCKS4…...

使用FFmpeg+ubuntu系统转化flac无损音频为mp3
功能需求如上题,我们来具体的操作一下: 1.先在ubuntu上面安装FFmpeg:sudo apt install ffmpeg 2.进入有flac音频文件的目录使用下述命令: ffmpeg -i test.FLAC -c:a libmp3lame -q:a 2 output.mp3 3.如果没有什么意外的话,你就能看到你的文件夹里面已经有转化好的mp3文件了 批…...

I/O多路复用三种实现
一.select 实现 (1)select流程 基本流程是: 1. 先构造一张有关文件描述符的表; fd_set readfds 2. 清空表 FD_ZERO() 3. 将你关心的文件描述符加入到这…...

DataInputStream数据读取 Vs ByteBuffer数据读取的巨大性能差距
背景: 今天在查找一个序列化和反序列化相关的问题时,意外发现使用DataInputStream读取和ByteBuffer读取之间性能相差巨大,本文就来记录下这两者在读取整数类型时的性能差异,以便在平时使用的过程中引起注意 DataInputStream数据…...

org.apache.flink.table.api.TableException: Sink does not exists
FlinkSQL_1.12_用DDL实现Kafka到MySQL的数据传输_实现按照条件进行过滤写入MySQL_flink从kafka拉取数据并过滤数据写入mysql_旧城里的阳光的博客-CSDN博客 参考这篇文章,写了kafka到mysql的代码例子,因为自己改了表结构,运行下面代码&#x…...
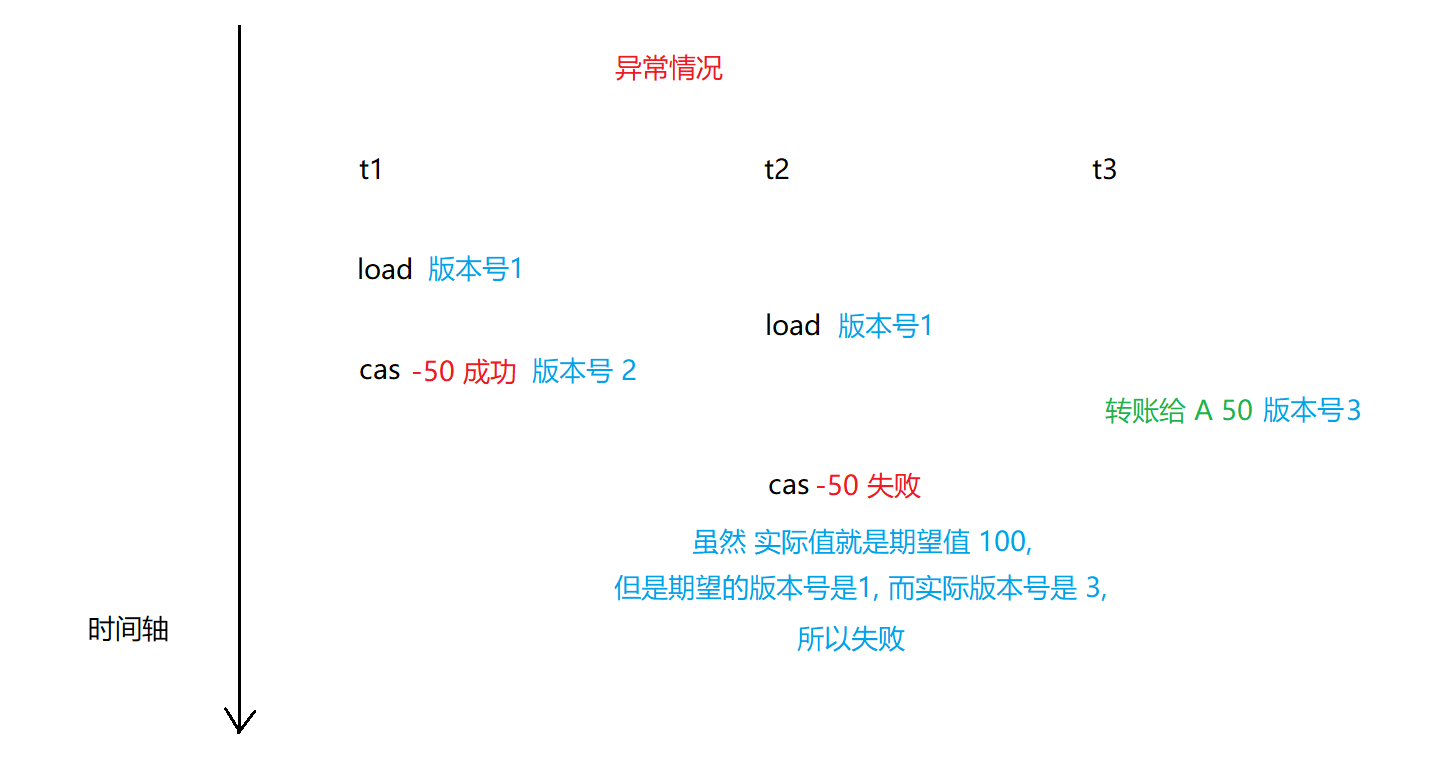
【多线程】CAS 详解
CAS 详解 一. 什么是 CAS二. CAS 的应用1. 实现原子类2. 实现自旋锁 三. CAS 的 ABA 问题四. 相关面试题 一. 什么是 CAS CAS: 全称Compare and swap,字面意思:”比较并交换“一个 CAS 涉及到以下操作: 我们假设内存中的原数据 V,旧的预期值…...

卷积神经网络实现咖啡豆分类 - P7
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 目录 环境步骤环境设置包引用全局设备对象 数据准备查看图像的信息制作数据集 模型设…...

C++之默认与自定义构造函数问题(二百一十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
Docker从认识到实践再到底层原理(五)|Docker镜像
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...

【Flowable】任务监听器(五)
前言 之前有需要使用到Flowable,鉴于网上的资料不是很多也不是很全也是捣鼓了半天,因此争取能在这里简单分享一下经验,帮助有需要的朋友,也非常欢迎大家指出不足的地方。 一、监听器 在Flowable中,我们可以使用监听…...

spring-kafka中ContainerProperties.AckMode详解
近期,我们线上遇到了一个性能问题,几乎快引起线上故障,后来仅仅是修改了一行代码,性能就提升了几十倍。一行代码几十倍,数据听起来很夸张,不过这是真实的数据,线上错误的配置的确有可能导致性能…...
)
【rpc】Dubbo和Zookeeper结合使用,它们的作用与联系(通俗易懂,一文理解)
目录 Dubbo是什么? 把系统模块变成分布式,有哪些好处,本来能在一台机子上运行,为什么还要远程调用 Zookeeper是什么? 它们进行配合使用时,之间的关系 服务注册 服务发现 动态地址管理 Dubbo是…...

ChatGPT的未来
随着人工智能的快速发展,ChatGPT作为一种自然语言生成模型,在各个领域都展现出了巨大的潜力。它不仅可以用于日常对话、创意助手和知识查询,还可以应用于教育、医疗、商业等各个领域,为人们带来更多便利和创新。 在教育领域&#…...

Pytorch模型转ONNX部署
开始以为会很困难,但是其实非常方便,下边分两步走:1. pytorch模型转onnx;2. 使用onnx进行inference 0. 准备工作 0.1 安装onnx 安装onnx和onnxruntime,onnx貌似是个环境。。倒是没有直接使用,onnxruntim…...

k8s优雅停服
在应用程序的整个生命周期中,正在运行的 pod 会由于多种原因而终止。在某些情况下,Kubernetes 会因用户输入(例如更新或删除 Deployment 时)而终止 pod。在其他情况下,Kubernetes 需要释放给定节点上的资源时会终止 po…...

面试题五:computed的使用
题记 大部分的工作中使用computed的频次很低的,所以今天拿出来一文对于computed进行详细的介绍,因为Vue的灵魂之一就是computed。 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护…...
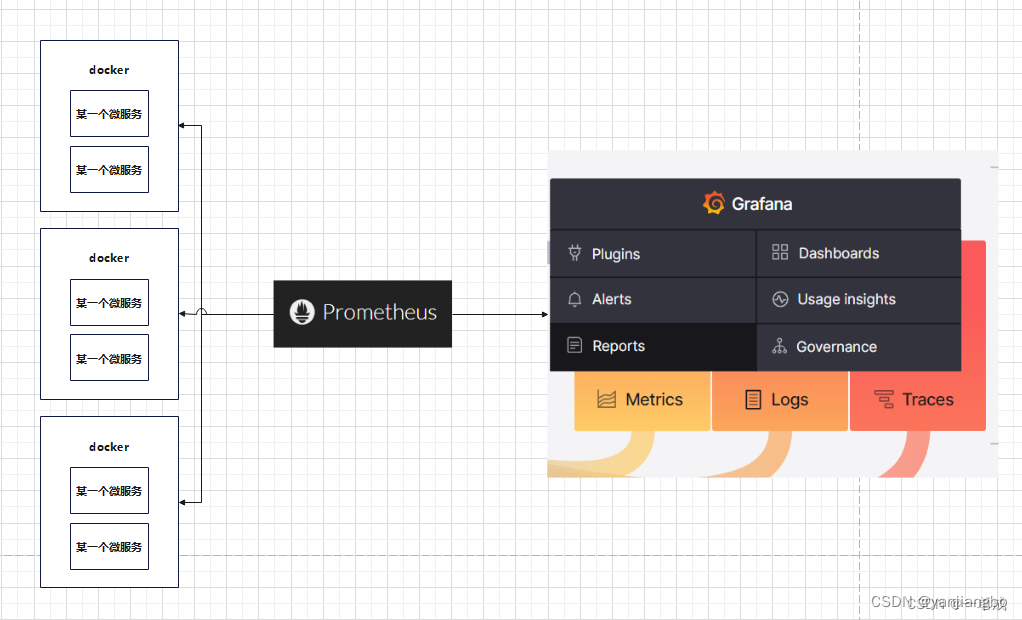
完美的分布式监控系统 Prometheus与优雅的开源可视化平台 Grafana
1、之间的关系 prometheus与grafana之间是相辅相成的关系。简而言之Grafana作为可视化的平台,平台的数据从Prometheus中取到来进行仪表盘的展示。而Prometheus这源源不断的给Grafana提供数据的支持。 Prometheus是一个开源的系统监控和报警系统,能够监…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...
从“安全密码”到测试体系:Gitee Test 赋能关键领域软件质量保障
关键领域软件测试的"安全密码":Gitee Test如何破解行业痛点 在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的"神经中枢"。从国防军工到能源电力,从金融交易到交通管控,这些关乎国计民生的关键领域…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...

深入浅出WebGL:在浏览器中解锁3D世界的魔法钥匙
WebGL:在浏览器中解锁3D世界的魔法钥匙 引言:网页的边界正在消失 在数字化浪潮的推动下,网页早已不再是静态信息的展示窗口。如今,我们可以在浏览器中体验逼真的3D游戏、交互式数据可视化、虚拟实验室,甚至沉浸式的V…...