StreamAPI
StreamAPI
最近开发用上了
Java8的StreamAPI,(咋现在才用?嗯哼,项目需要)自己也不怎么会,来总结一波吧!别认为好抽象!!!干他就完事

一.StreamAPI介绍
就是用来处理集合的数据 其实到后面会发现和SQL的语句是差不多的~哈哈?你不信?往下面看
Stream:英文翻译叫做流
举个粟子:
Stream相当于一条河流,数据相当于里面的水,这条河流里面的水你要饮用还是其他操作叫做Stream的执行数据操作,从而达到你要的目的(比如达成饮用水的目的),在计算机中就是处理达成你要的结果
注意!
Stream不会自己存储元素- 不会改变源对象,只是返回含有结果的一个新
Stream - 延迟执行,在要结果的时候才执行(有点像懒汉模式)

二.流操作的过程
主要就是从生到死周期
- 创建Stream:就是从一个数组或者集合拿取数据(相当于找到水源地)
//主要两种创建方式:
1.Steam()
2.parallelStream() //这个主要返回并行流//eg:List<String> list=new ArrayList<>();Stream<String> s1=list.stream();//
===========================================
//值创建流 Stream.of() 静态方法显示创建 Stream<String> s=Stream.of("a","s","ddddd");s.forEach(System.out::println);==============================================
//创建无限流 Stream.iterate() 和 Stream.generate()两个方法//举例 迭代Steam<Integer> s=Stream.iterate(0,(x)->x>>1);s.limit(10).forEach(System.out::println);//举例 生成Stream.generate(()->Math.random().limit(6)forEach(System.out::println));
- **中间逻辑操作:**就相当于SQL语句中执行条件,处理达到你要的结果和业务数据(比如你要取水去做饮用水啊中间是不是要净化啥的操作)
看下面的主题,太多了,但也是重点
- **结束:**就是终止条件,写结果返回语句,不能无休止啊
三.中间操作
在
终止操作时才会一次性全部处理,就是要到开学了,小学生才会用功写完全部作业~哈哈
filter,limit,skip,distinct
1.筛选切片
Filter:接受
Lambda,进行过滤操作,排除一些不需要的元素
// (1)filter——接收 Lambda , 从流中排除某些元素。@Testpublic void testFilter() {//这里加入了终止操作 ,不然中间操作一系列不会执行//中间操作只有在碰到终止操作才会执行emps.stream().filter((e)->e.getAge()>18) //过滤只要年龄大于18 的.forEach(System.out::println);//终止操作}
limit(n):截取指定n个以内数量的元素
// (2)limit——截断流,使其元素不超过给定数量。@Testpublic void testLimit() {emps.stream().filter((e)->e.getAge()>8).limit(6)//跟数据库中的limit有差不多.forEach(System.out::println);//终止操作}
skip(n):跳过元素,就是前n个元素不要,从第
n+1个数开始,没有,就返回空
// (3)skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补@Testpublic void testSkip() {emps.stream().filter((e)->e.getAge()>8).skip(2)//这里可以查找filter过滤后的数据,前两个不要,要后面的,与limit相反.forEach(System.out::println);//终止操作}
distinct:就是去重,返回不重复的元素
原理:利用
hashCode()和equals()去除重复的元素,
// (4)distinct——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素@Testpublic void testDistinct() {emps.stream().distinct()//去除重复的元素,因为通过流所生成元素的 hashCode() 和 equals() 去除重复元素,所以对象要重写hashCode跟equals方法.forEach(System.out::println);//终止操作}
2.Map映射
- map()
- mapToDouble()
- mapToInt()
- mapToLong()
- flatMap()
map():就是接受一个函数作为参数,该参数会被应用到每个元素上,并且映射成一个新的元素
flatMap():接受一个函数作为参数,并且将流中每个值转换成另一个流,然后把所有的流连成一个流
直接复制了哈,这个代码感觉还是不错的,一起看看吧~哈哈
// map-接收Lambda,将元素转换成其他形式或提取信息。接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。@Testpublic void testMapAndflatMap() {List<String> list=Arrays.asList("aaa","bbb","ccc","ddd");list.stream().map((str)->str.toUpperCase())//里面是Function.forEach(System.out::println);System.out.println("----------------------------------");//这里是只打印名字,map映射,根据Employee::getName返回一个name,映射成新的及结果nameemps.stream().map(Employee::getName).forEach(System.out::println);System.out.println("======================================");//流中流Stream<Stream<Character>> stream = list.stream().map(StreamAPI::filterCharacter);//{{a,a,a},{b,b,b}}//map是一个个流(这个流中有元素)加入流中stream.forEach(sm->{sm.forEach(System.out::println);});System.out.println("=============引进flatMap=============");
// 只有一个流Stream<Character> flatMap = list.stream().flatMap(StreamAPI::filterCharacter);//flatMap是将一个个流中的元素加入流中//{a,a,a,b,b,b}flatMap.forEach(System.out::println);}/*** 测试map跟flatMap的区别* 有点跟集合中的add跟addAll方法类似 这个就好理解多了* add是将无论是元素还是集合,整体加到其中一个集合中去[1,2,3.[2,3]]* addAll是将无论是元素还是集合,都是将元素加到另一个集合中去。[1,2,3,2,3]* @param str* @return*/public static Stream<Character> filterCharacter(String str){List<Character> list=new ArrayList<>();for (Character character : str.toCharArray()) {list.add(character);}return list.stream();}
3.排序
自然排序:
sorted()定制排序:
sorted(Comparator c): 就是里面写你想添加判断条件
货不多说,看测试代码
@Testpublic void testSorted() {List<String> list=Arrays.asList("ccc","aaa","bbb","ddd","eee");list.stream().sorted().forEach(System.out::println);System.out.println("=======定制排序=========");//=====仔细瞅瞅这边emps.stream().sorted((x, y) -> {if(x.getAge() == y.getAge()){return x.getName().compareTo(y.getName());}else{return Integer.compare(x.getAge(), y.getAge());}}).forEach(System.out::println);}
四.结束
1.查找与匹配
allMatch(): 检查是否匹配所有元素
anyMatch(): 检查是否至少匹配一个元素
noneMatch(): 是否没有匹配的所有元素
findFirst(): 返回第一个元素
findAny(): 返回当前流中的任意元素
count(): 返回流中的元素总数
max(),min(): 返回流中的最大最小值
forEach(): 就是迭代循环,贼常用的
**测试代码:**复制过来的,写的不好,可以留言哈!!!
//3. 终止操作/*查找与匹配allMatch——检查是否匹配所有元素anyMatch——检查是否至少匹配一个元素noneMatch——检查是否没有匹配的元素findFirst——返回第一个元素findAny——返回当前流中的任意元素count——返回流中元素的总个数max——返回流中最大值min——返回流中最小值*/@Testpublic void test() {
// emps.stream():获取串行流
// emps.parallelStream():获取并行流System.out.println("==========allMatch==============");boolean allMatch = emps.stream().allMatch((e)->e.getStatus().equals(Status.BUSY));System.out.println(allMatch);System.out.println("==========anyMatch==============");boolean anyMatch = emps.stream().anyMatch((e)->e.getAge()>10);System.out.println(anyMatch);System.out.println("==========noneMatch==============");boolean noneMatch = emps.stream().noneMatch((e)->e.getStatus().equals(Status.BUSY));System.out.println(noneMatch);System.out.println("==========findFirst==============");Optional<Employee2> findFirst = emps.stream().sorted((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()))//按照工资排序并输出第一个.findFirst(); System.out.println(findFirst);System.out.println("==========findAny==============");Optional<Employee2> findAny = emps.stream().filter((e)->e.getStatus().equals(Status.BUSY)).findAny();System.out.println(findAny);System.out.println("==========count==============");long count = emps.stream().count();System.out.println(count);System.out.println("==========max==============");Optional<Double> max = emps.stream().map(Employee2::getSalary).max(Double::compare);System.out.println(max);System.out.println("==========min==============");Optional<Employee2> min = emps.stream().min((e1,e2)->Double.compare(e1.getSalary(), e2.getSalary()));System.out.println(min);}
2.归纳
reduce(T iden,BinaryOperator b):流中元素反复结合得到一个值,返回T
reduce(BinaryOperator b):流中元素反复结合得到一个值,返回Optional<T>
map-reduce模式感兴趣可以骚操作一波
@Testpublic void testReduce() {List<Integer> list= Arrays.asList(1,2,3,4,5,6,7,8,9,10);Integer sum = list.stream().reduce(0,(x,y)->x+y);System.out.println(sum);Optional<Double> reduce = emps.stream().map(Employee2::getSalary).reduce(Double::sum);System.out.println(reduce.get());}
3.收集
collect():你想收集成啥样的集合返回
Collectors其中主要的方法:
方法名 作用 返回类型 toSet把流中元素收集到set Set toList将流中的元素收集到 ListList toCollection:将流中的元素收集到自己创建的集合中 Collection counting计算流中的元素个数 long summingInt对元素中的整数类型求和 Integer averagingInt求平均值 Double summarizingInt收集流中Integer属性的统计值 IntSummaryStatistics
方法 作用 返回类型 joining连接流中的每个字符串 String maxBy,minBy根据比较器选择最大最小值 Optional reducing归约 归约产生的类型 collectingAndThen包裹另一个收集器并对其结果转换函数 转换函数返回的类型 groupingBy根据某些属性值对流分组,属性为 k,结果为vMap<K,List> partitioningBy根据true或false进行分区 Map<Boolean,List>
测试代码:
//===============
List<String> collect = emps.stream().map(Employee2::getName).collect(Collectors.toList());collect.forEach(System.out::println);
//=====================================================Set<String> collect2 = emps.stream().map(Employee2::getName).collect(Collectors.toSet());collect2.forEach(System.out::println);
//=======================================================
HashSet<String> collect3 = emps.stream().map(Employee2::getName).collect(Collectors.toCollection(HashSet::new));collect3.forEach(System.out::println);
//======================================================Optional<Double> collect = emps.stream().map(Employee2::getSalary).collect(Collectors.maxBy(Double::compare));System.out.println(collect.get());Optional<Employee2> collect2 = emps.stream().collect(Collectors.maxBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));System.out.println(collect2.get());
//=======================================================
Optional<Double> collect4 = emps.stream().map(Employee2::getSalary).collect(Collectors.minBy(Double::compare));System.out.println(collect4);Optional<Employee2> collect3 = emps.stream().collect(Collectors.minBy((e1,e2)->Double.compare(e1.getSalary(),e2.getSalary())));System.out.println(collect3.get());
//====================================================
Double collect5 = emps.stream().collect(Collectors.summingDouble(Employee2::getSalary));System.out.println(collect5);
//========================================================
Double collect6 = emps.stream().collect(Collectors.averagingDouble((e)->e.getSalary()));Double collect7 = emps.stream().collect(Collectors.averagingDouble(Employee2::getSalary));System.out.println("collect6:"+collect6);System.out.println("collect7:"+collect7);
//=======================================================
//总数Long collect8 = emps.stream().collect(Collectors.counting());System.out.println(collect8);
//====================================================
DoubleSummaryStatistics collect9 = emps.stream().collect(Collectors.summarizingDouble(Employee2::getSalary));long count = collect9.getCount();double average = collect9.getAverage();double max = collect9.getMax();double min = collect9.getMin();double sum = collect9.getSum();System.out.println("count:"+count);System.out.println("average:"+average);System.out.println("max:"+max);System.out.println("min:"+min);System.out.println("sum:"+sum);
//=========================================================
//分组@Testpublic void testCollect3() {Map<Status, List<Employee2>> collect = emps.stream().collect(Collectors.groupingBy((e)->e.getStatus()));System.out.println(collect);Map<Status, List<Employee2>> collect2 = emps.stream().collect(Collectors.groupingBy(Employee2::getStatus));System.out.println(collect2);}
//=====多级==================================================
//多级分组@Testpublic void testCollect4() {Map<Status, Map<String, List<Employee2>>> collect = emps.stream().collect(Collectors.groupingBy(Employee2::getStatus, Collectors.groupingBy((e)->{if(e.getAge() >= 60)return "老年";else if(e.getAge() >= 35)return "中年";elsereturn "成年";})));System.out.println(collect);}
//===================================================
//多级分组@Testpublic void testCollect4() {Map<Status, Map<String, List<Employee2>>> collect = emps.stream().collect(Collectors.groupingBy(Employee2::getStatus, Collectors.groupingBy((e)->{if(e.getAge() >= 60)return "老年";else if(e.getAge() >= 35)return "中年";elsereturn "成年";})));System.out.println(collect);}
//==========================================================
//多级分组@Testpublic void testCollect4() {Map<Status, Map<String, List<Employee2>>> collect = emps.stream().collect(Collectors.groupingBy(Employee2::getStatus, Collectors.groupingBy((e)->{if(e.getAge() >= 60)return "老年";else if(e.getAge() >= 35)return "中年";elsereturn "成年";})));System.out.println(collect);}
//======================================================
//组接字符串@Testpublic void testCollect6() {String collect = emps.stream().map((e)->e.getName()).collect(Collectors.joining());System.out.println(collect);String collect3 = emps.stream().map(Employee2::getName).collect(Collectors.joining(","));System.out.println(collect3);String collect2 = emps.stream().map(Employee2::getName).collect(Collectors.joining(",", "prefix", "subfix"));System.out.println(collect2);}@Testpublic void testCollect7() {Optional<Double> collect = emps.stream().map(Employee2::getSalary).collect(Collectors.reducing(Double::sum));System.out.println(collect.get());}
//==========================================================总测试代码
/*** collect——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法*/@Testpublic void testCollect() {List<String> collect = emps.stream().map(Employee2::getName).collect(Collectors.toList());collect.forEach(System.out::println);Set<String> collect2 = emps.stream().map(Employee2::getName).collect(Collectors.toSet());collect2.forEach(System.out::println);HashSet<String> collect3 = emps.stream().map(Employee2::getName).collect(Collectors.toCollection(HashSet::new));collect3.forEach(System.out::println);}@Testpublic void testCollect2() {Optional<Double> collect = emps.stream().map(Employee2::getSalary).collect(Collectors.maxBy(Double::compare));System.out.println(collect.get());Optional<Employee2> collect2 = emps.stream().collect(Collectors.maxBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));System.out.println(collect2.get());Optional<Double> collect4 = emps.stream().map(Employee2::getSalary).collect(Collectors.minBy(Double::compare));System.out.println(collect4);Optional<Employee2> collect3 = emps.stream().collect(Collectors.minBy((e1,e2)->Double.compare(e1.getSalary(),e2.getSalary())));System.out.println(collect3.get());System.out.println("=========================================");Double collect5 = emps.stream().collect(Collectors.summingDouble(Employee2::getSalary));System.out.println(collect5);Double collect6 = emps.stream().collect(Collectors.averagingDouble((e)->e.getSalary()));Double collect7 = emps.stream().collect(Collectors.averagingDouble(Employee2::getSalary));System.out.println("collect6:"+collect6);System.out.println("collect7:"+collect7);//总数Long collect8 = emps.stream().collect(Collectors.counting());System.out.println(collect8);DoubleSummaryStatistics collect9 = emps.stream().collect(Collectors.summarizingDouble(Employee2::getSalary));long count = collect9.getCount();double average = collect9.getAverage();double max = collect9.getMax();double min = collect9.getMin();double sum = collect9.getSum();System.out.println("count:"+count);System.out.println("average:"+average);System.out.println("max:"+max);System.out.println("min:"+min);System.out.println("sum:"+sum);}//分组@Testpublic void testCollect3() {Map<Status, List<Employee2>> collect = emps.stream().collect(Collectors.groupingBy((e)->e.getStatus()));System.out.println(collect);Map<Status, List<Employee2>> collect2 = emps.stream().collect(Collectors.groupingBy(Employee2::getStatus));System.out.println(collect2);}//多级分组@Testpublic void testCollect4() {Map<Status, Map<String, List<Employee2>>> collect = emps.stream().collect(Collectors.groupingBy(Employee2::getStatus, Collectors.groupingBy((e)->{if(e.getAge() >= 60)return "老年";else if(e.getAge() >= 35)return "中年";elsereturn "成年";})));System.out.println(collect);}//分区@Testpublic void testCollect5() {Map<Boolean, List<Employee2>> collect = emps.stream().collect(Collectors.partitioningBy((e)->e.getSalary()>5000));System.out.println(collect);}//组接字符串@Testpublic void testCollect6() {String collect = emps.stream().map((e)->e.getName()).collect(Collectors.joining());System.out.println(collect);String collect3 = emps.stream().map(Employee2::getName).collect(Collectors.joining(","));System.out.println(collect3);String collect2 = emps.stream().map(Employee2::getName).collect(Collectors.joining(",", "prefix", "subfix"));System.out.println(collect2);}@Testpublic void testCollect7() {Optional<Double> collect = emps.stream().map(Employee2::getSalary).collect(Collectors.reducing(Double::sum));System.out.println(collect.get());}
相关文章:
StreamAPI
StreamAPI 最近开发用上了 Java8的StreamAPI,(咋现在才用?嗯哼,项目需要)自己也不怎么会,来总结一波吧! 别认为好抽象!!!干他就完事 一.StreamAPI介绍 就是用来处理集合的数据 其实到后面会发现和SQL的语句是差不多的~哈哈?你不信?往下面看 Stream:英文翻译叫做流 举个粟子…...
MySQl高可用集群搭建(MGR + ProxySQL + Keepalived)
前言 服务器规划(CentOS7.x) IP地址主机名部署角色192.168.x.101mysql01mysql192.168.x.102mysql02mysql192.168.x.103mysql03mysql192.168.x.104proxysql01proxysql、keepalived192.168.x.105proxysql02proxysql、keepalived 将安装包 mysql_cluster_…...

java+Selenium+TestNg搭建自动化测试架构(3)实现POM(page+Object+modal)
1.Page Object是Selenium自动化测试项目开发实践的最佳设计模式之一,通过对界面元素的封装减少冗余代码,同时在后期维护中,若元素定位发生变化,只需要调整页面元素封装的代码,提高测试用例的可维护性。 PageObject设计…...
oracle11g忘记system密码,重置密码
OPW-00001: 无法打开口令文件 cmd.exe 使用管理员身份登录 找到xxx\product\11.2.0\dbhome_1\database\PWDorcl.ora文件,删除 执行orapwd fileD:\app\product\11.2.0\dbhome_1\database\PWDorcl.ora passwordtiger (orapwd 在\product\11.2.0\dbhome_1\BIN目录下…...
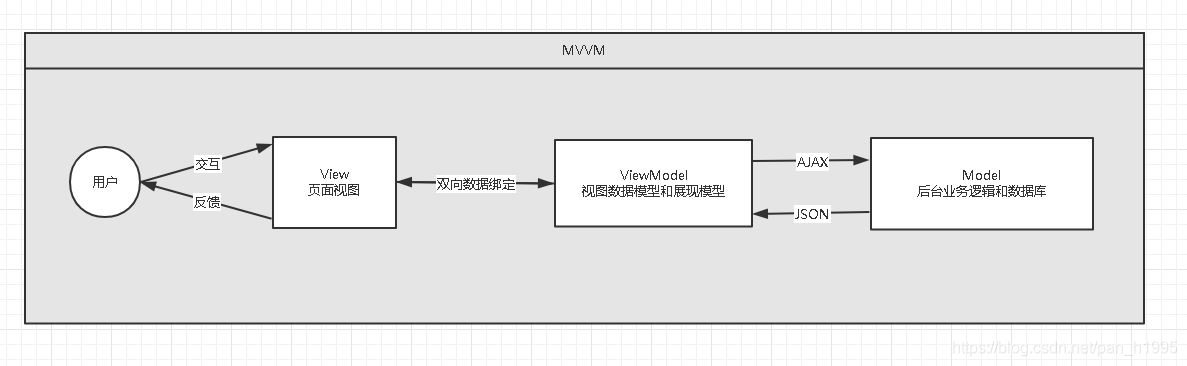
黑马 Vue 快速入门 笔记
黑马 Vue 快速入门 笔记0 VUE相关了解0.1 概述0.2 MVVM0.3 JavaScript框架0.4 七大属性0.5 el:挂载点1 VUE基础1.0 第一个vue代码:Hello,vue1.1 v-bind 设置元素的属性 简写 :1.2 v-if , v-else , v-else-ifv-if , v-e…...

HTTP协议知识体系核心重点梳理
HTTP协议知识体系核心重点梳理TCP/IP协议1.四层模型2.通信过程3.tcp三次握手和四次挥手4.tcp安全传输4. 一次HTTP通信流程HTTP协议HTTP/1.1CookieHttp报文格式内容编码分块传输编码HTTP状态码重定向状态码常用的通用首部cache-controlExpiresConnectionTransfer-Encoding常用的…...

Nginx优化与防盗链
Nginx优化与防盗链 📒博客主页: 微笑的段嘉许博客主页 💻微信公众号:微笑的段嘉许 🎉欢迎关注🔎点赞👍收藏⭐留言📝 📌本文由微笑的段嘉许原创! Ὄ…...

自动驾驶路径规划概况
文章目录前言介绍1. 路径规划在自动驾驶系统架构中的位置2. 全局路径规划的分类2.1 基础图搜索算法2.1.1 Dijkstra算法2.1.2 双向搜索算法2.1.3 Floyd算法2.2 启发式算法2.2.1 A*算法2.2.2 D*算法2.3 基于概率采样的算法2.3.1 概率路线图(PRM)2.3.2 快速…...

某某银行行面试题目汇总--HashMap为什么要扩容
一、HashMap啥时候扩容,为什么扩容? HashMap的默认大小是16。在实际开发过程中,我们需要去存储的数据量往往是大于存储容器的默认大小的。所以,出现容量默认大小不能满足需求时,就需要扩容。而这个扩容的动作是由集合自…...
求职者:“我有五年测试经验”面试官: “不,你只是把一年的工作经验用了五年”
最近看到很多软件测试由于公司裁员而需要重新求职的。他们普遍具有4年甚至更长的工作经验。但求职结果往往都不太理想。 我在与部分软件测试求职者交谈的过程中发现,很多人的工作思路不清晰,技能不扎实,没有持续学习的习惯,但对于…...
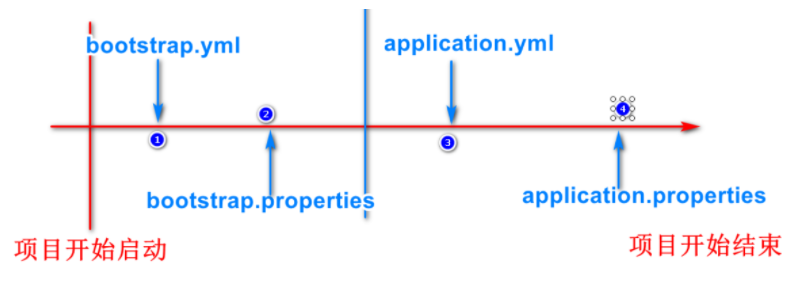
Nacos配置中心
什么是配置中心所谓配置中心:在微服务的环境下,将项目需要的配置信息保存在配置中心,需要读取时直接从配置中心读取,方便配置管理的微服务工具我们可以将部分yml文件的内容保存在配置中心一个微服务项目有很多子模块,这些子模块可能在不同的服务器上,如果有一些统一的修改,我们…...

【故障】6、yum不可用
文章目录[toc]一、yum命令不能使用1)报错2)问题分析3)完全删除python及yum重新安装1、删除python2、删除yum3、下载Python依赖rpm包4、下载yum依赖rpm包5、强制安装python6、强制安装yum7、测试一、yum命令不能使用 1)报错 Ther…...

深度解读 | 数据资产管理面临诸多挑战,做好这5个措施是关键
日前,大数据技术标准推进委员会(中国通信标准化协会下(CCSA)的专业技术委员会,简称TC601)发布《数据资产管理实践白皮书》(6.0 版)(以下简称:报告)…...
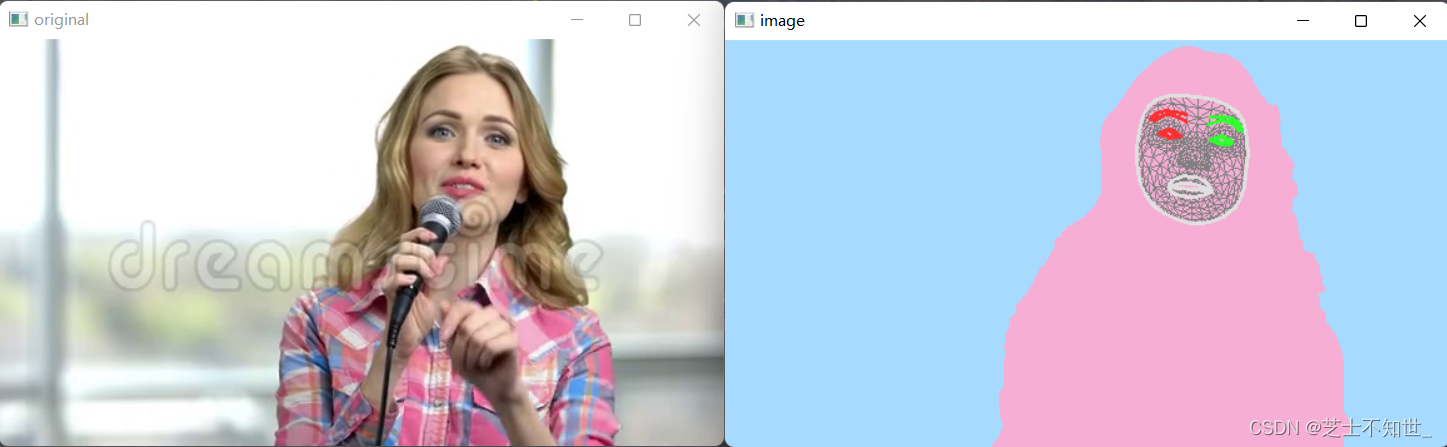
双检测人脸防伪识别方法(活体检测+人脸识别+关键点检测+人像分割)
双检测人脸防伪识别=人脸检测+活体检测+人脸识别 1.人脸关键点+语义分割 使用mediapipe进行视频人脸关键点检测和人像分割: import time import cv2 import mediapipe as mp import numpy as npmp_drawing = mp.solutions.drawing_utils mp_drawing_styles = mp.solution…...

2023年3月 - 笔记
内容已复习 采用下划线标识内容已重写 并补充优化 新建文章并添加超链接 背景颜色 绿色 Python 2023年3月1日 Python 把列表转成元组 # 1、Python 把列表转成元组 使用tuple 即可 list_a [1, 2, 3, 4, 5, 6] list_b tuple(list_a) print(list_b)# 2、如果想把 元组转成列…...
浅谈Redisson实现分布式锁对原理
1.Redisson简介 Redis 是最流行的 NoSQL 数据库解决方案之一,而 Java 是世界上最流行(注意,我没有说“最好”)的编程语言之一。虽然两者看起来很自然地在一起“工作”,但是要知道,Redis 其实并没有对 Java…...

struts1.2升级struts2.5.30问题汇总
严重: 配置应用程序监听器[org.apache.struts2.tiles.StrutsTilesListener]错误java.lang.NoClassDefFoundError: org/apache/tiles/web/startup/AbstractTilesListenerat java.lang.ClassLoader.defineClass1(Native Method)at java.lang.ClassLoader.defineClass(ClassLoader…...

电动汽车充放电的优化调度(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
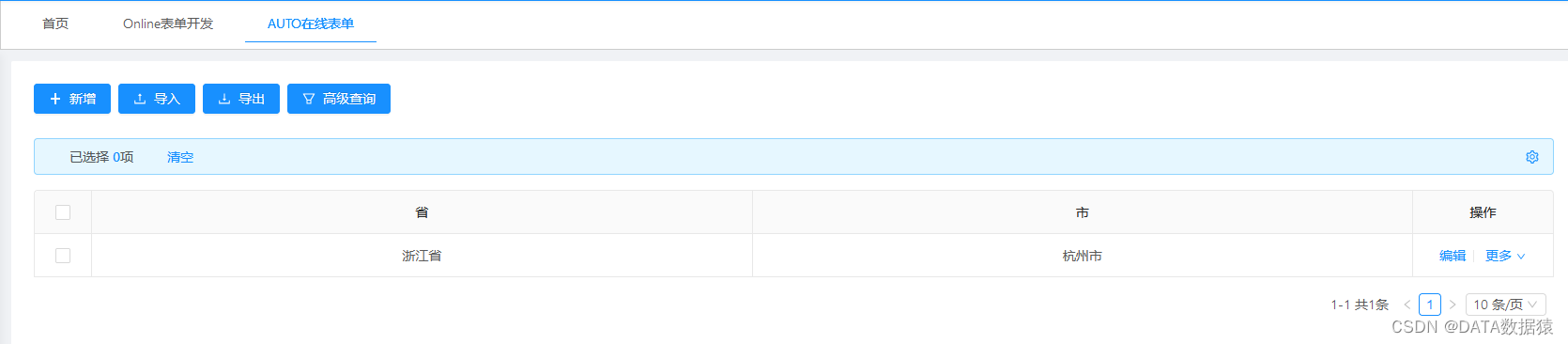
《JeecgBoot系列》 如何设计表单实现“下拉组件二级联动“ ? 以省市二级联动为例
《JeecgBoot系列》 如何设计表单实现"下拉组件二级联动" ? 以省市二级联动为例 一、准备字典表 1.1 创建字典表 CREATE TABLE sys_link_table ( id int NULL, pid int NULL, name varchar(64) null );1.2 准备数据 idpidname1全国21浙江省32杭州市42宁波市51江苏…...
数学小课堂:数学的线索(从猜想到定理再到应用的整个过程)
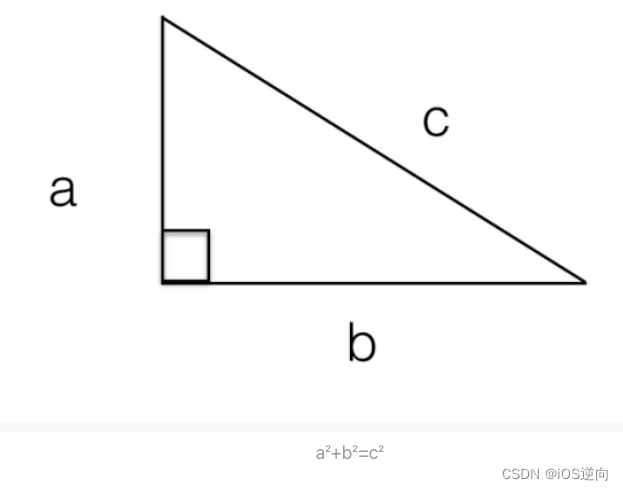
文章目录 引言I 勾股定理1.1 勾三股四弦五1.2 数学和自然科学的三个本质差别1.3 总结引言 从猜想到定理再到应用的整个过程是数学发展和体系构建常常经历的步骤。 I 勾股定理 勾股定理: 直角三角形两条直角边的平方之和等于斜边的平方,这个定理在国外都被称为毕达哥拉斯定理…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...