365天深度学习训练营-第J3周:DenseNet算法实战与解析
目录
一、前言
二、论文解读
1、DenseNet的优势
2、设计理念
3、网络结构
4、与其他算法进行对比
三、代码复现
1、使用Pytorch实现DenseNet
2、使用Tensorflow实现DenseNet网络
四、分析总结
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
● 难度:夯实基础⭐⭐
● 语言:Python3、Pytorch3
● 时间:2月18日-2月14日
🍺要求:1.根据本文的Pytorch代码,编写Tensorflow代码
2.了解DenseNet和ResnetV的区别
3.改进地方可以迁移到哪里呢二、论文解读
论文:Densely Connected Convolutional Networks
众所周知,最近一两年卷积神经网络提高效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而作者则是从特征图入手,通过对特征图的极致利用达到更好的效果和更少的参数。
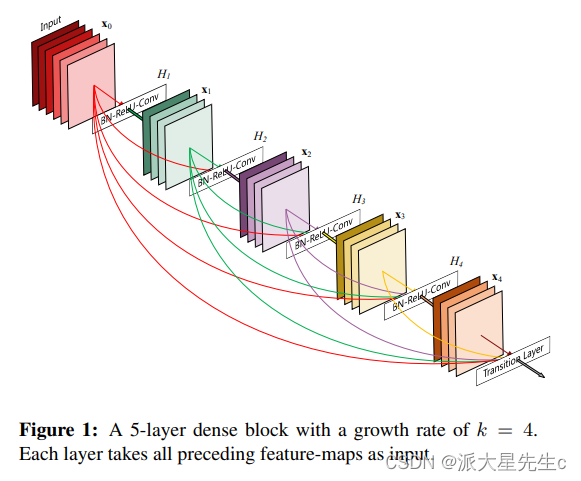
1、DenseNet的优势
- 减轻了vanishing-gradient(梯度消失)
这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。每一层都可以直接利用损失函数的梯度以及最开始的输入信息,相当于是一种隐形的深度监督(implicit deep supervision),这有助于训练更深的网络。前面提到过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种密集连接相当于每一层都直接连接输入和损失,因此就可以减轻梯度消失现象,这样构建更深的网络不是问题。
- 加强了特征的传递,更有效地利用了特征
每层的输出特征图都是之后所有层的输入。
- 一定程度上较少了参数数量
DenseNets的稠密连接模块(dense block)的一个优点是它比传统的卷积网络有更少的参数,因为它不需要再重新学习多余的特征图。传统的前馈结构可以被看成一种层与层之间状态传递的算法。每一层接收前一层的状态,然后将新的状态传递给下一层。它改变了状态,但也传递了需要保留的信息。ResNets将这种信息保留的更明显,因为它加入了自身变换(identity transformations)。最近很多关于ResNets的研究都表明ResNets的很多层是几乎没有起作用的,可以在训练时随机的丢掉。DenseNet结构中,增加到网络中的信息与保留的信息有着明显的不同。DenseNet的dense block中每个卷积层都很窄(例如每一层有12个滤波器),仅仅增加小数量的特征图到网络的“集体知识”(collective knowledge),并且保持这些特征图不变——最后的分类器基于网络中的所有特征图进行预测。
另外作者还观察到这种密集连接有正则化的效果,因此对于过拟合有一定的抑制作用,因为参数减少了,所以过拟合现象减轻。
参考文章
2、设计理念
DenseNet 的想法很大程度上源于一个叫做随机深度网络(Deep networks with stochastic depth)工作。当时我们提出了一种类似于 Dropout 的方法来改进ResNet。我们发现在训练过程中的每一步都随机地「扔掉」(drop)一些层,可以显著的提高 ResNet 的泛化性能。这个方法的成功至少带给我们两点启发:
-
首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征。想像一下在随机深度网络中,当第 l 层被扔掉之后,第 l+1 层就被直接连到了第 l-1 层;当第 2 到了第 l 层都被扔掉之后,第 l+1 层就直接用到了第 1 层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的 DenseNet。
-
其次,我们在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了 ResNet 具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,我们将训练好的 ResNet 随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet 的设计正是基于以上两点观察。我们让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是 DenseNet 与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象,即使 ResNet 也是如此。
3、网络结构
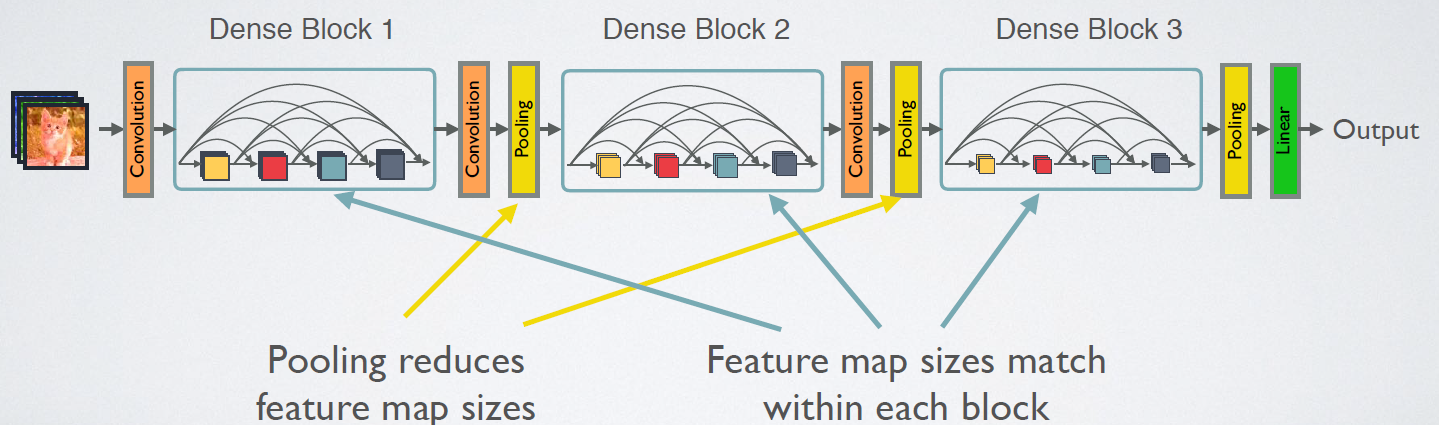
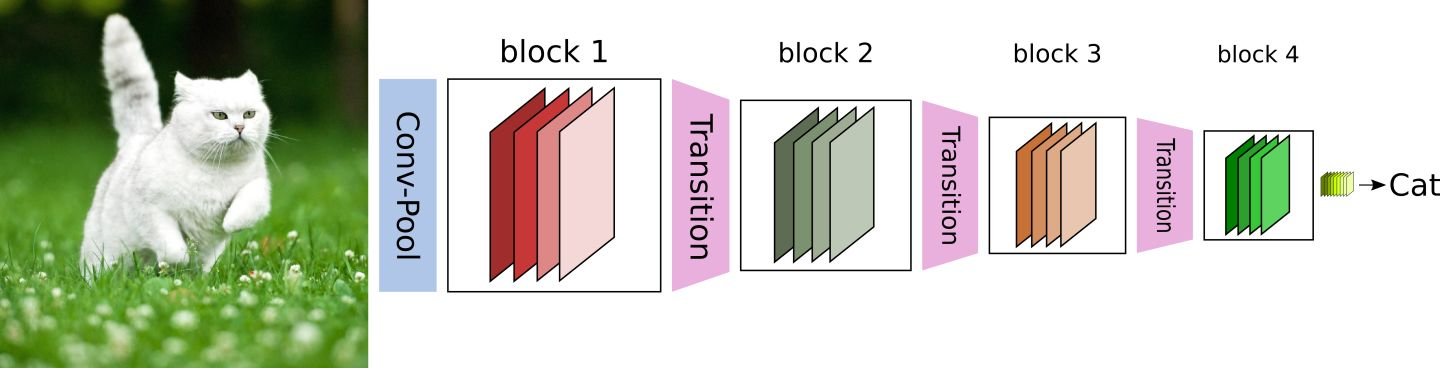
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition层是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图5给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition层连接在一起。
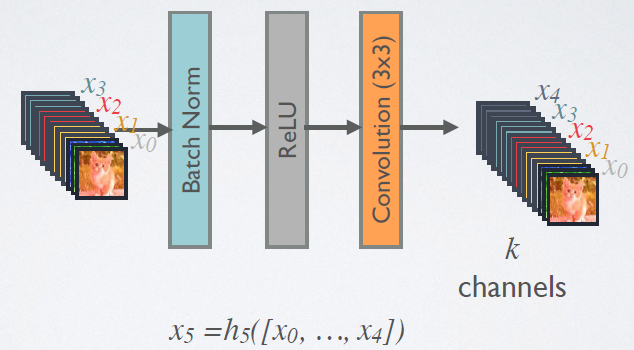
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数H(·)的是 BN+ReLU+3x3 Conv 的结构,如图6所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,或者说采用k个卷积核。k在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为k0,那么l层输入的channel数为![]() ,因此随着层数增加,尽管k设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有k个特征是自己独有的。
,因此随着层数增加,尽管k设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有k个特征是自己独有的。
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图7所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
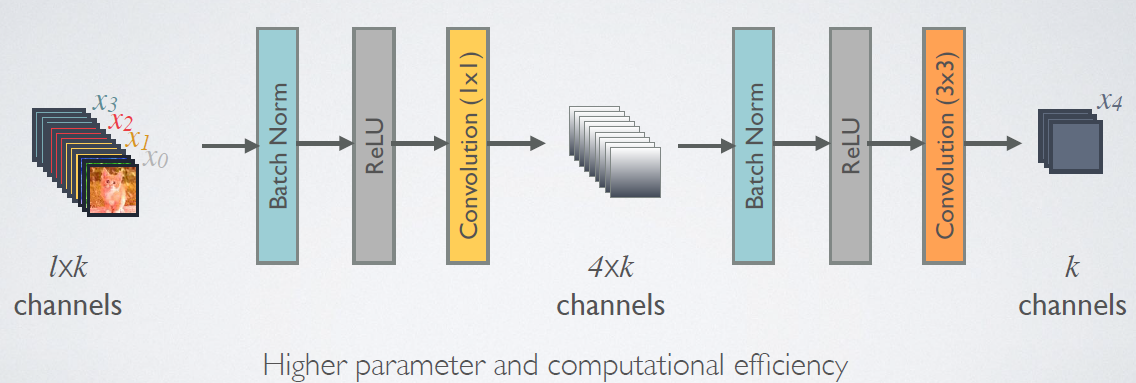
对于Transition层,,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1Conv+2x2AvgPooling。另外,Transition层可以起到压缩模型的作用。假定层的上接DenseBlock得到的特征图channels数为m,Transition层可以产生【θm】个特征(通过卷积层),其中 是压缩系数θ∈(0,1](compression rate)。当 θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用θ=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
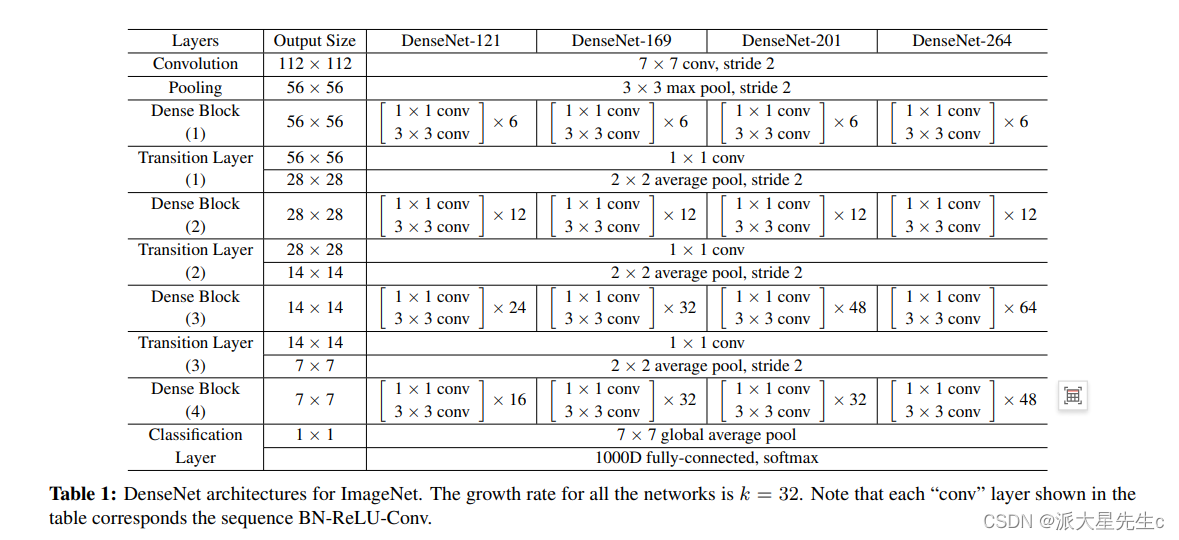
对于ImageNet数据集,图片输入大小为224×224,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层,然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表1所示:
4、与其他算法进行对比
三、代码复现
1、使用Pytorch实现DenseNet
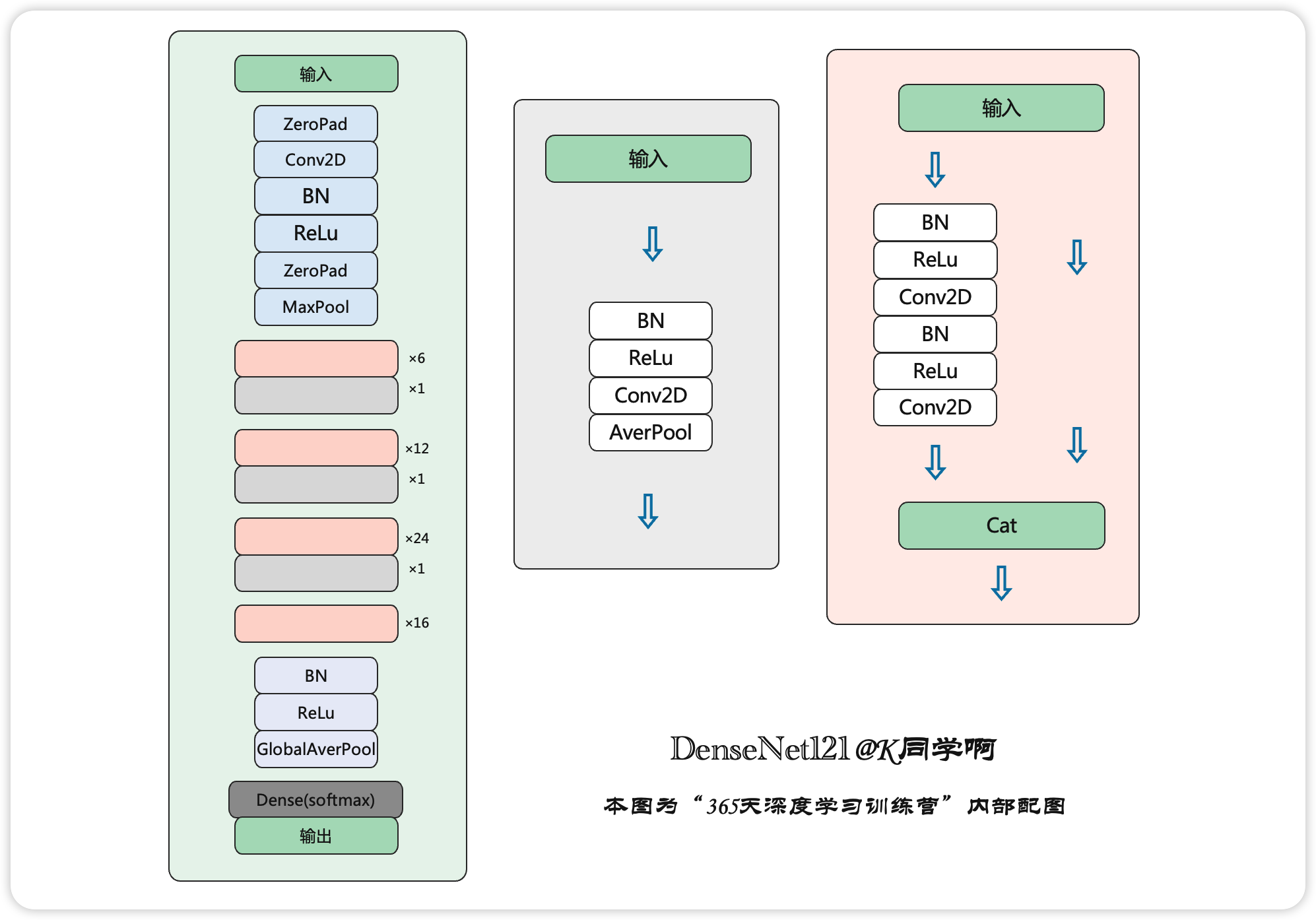
- 这里我们采用了Pytorch的框架来实现DenseNet,首先实现DenseBlock中的内部结构,这里是BN+ReLU+1×1Conv+BN+ReLU+3×3Conv结构,最后也加入dropout层用于训练过程。
class _DenseLayer(nn.Module):def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, efficient=False):super(_DenseLayer, self).__init__()self.add_module('norm1', nn.BatchNorm2d(num_input_features)),self.add_module('relu1', nn.ReLU(inplace=True)),self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate,kernel_size=1, stride=1, bias=False)),self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),self.add_module('relu2', nn.ReLU(inplace=True)),self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,kernel_size=3, stride=1, padding=1, bias=False)),self.drop_rate = drop_rateself.efficient = efficientdef forward(self, *prev_features):bn_function = _bn_function_factory(self.norm1, self.relu1, self.conv1)if self.efficient and any(prev_feature.requires_grad for prev_feature in prev_features):bottleneck_output = cp.checkpoint(bn_function, *prev_features)else:bottleneck_output = bn_function(*prev_features)new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)return new_features- 实现DenseBlock模块,内部是密集连接方式(输入特征数线性增长):
class _DenseBlock(nn.Module):def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, efficient=False):super(_DenseBlock, self).__init__()for i in range(num_layers):layer = _DenseLayer(num_input_features + i * growth_rate,growth_rate=growth_rate,bn_size=bn_size,drop_rate=drop_rate,efficient=efficient,)self.add_module('denselayer%d' % (i + 1), layer)def forward(self, init_features):features = [init_features]for name, layer in self.named_children():new_features = layer(*features)features.append(new_features)return torch.cat(features, 1)- 实现Transition层,它主要是一个卷积层和一个池化层:
class _Transition(nn.Sequential):def __init__(self, num_input_features, num_output_features):super(_Transition, self).__init__()self.add_module('norm', nn.BatchNorm2d(num_input_features))self.add_module('relu', nn.ReLU(inplace=True))self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,kernel_size=1, stride=1, bias=False))self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))- 最后我们实现DenseNet网络:
class DenseNet(nn.Module):r"""Densenet-BC model class, based on`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`Args:growth_rate (int) - how many filters to add each layer (`k` in paper)block_config (list of 3 or 4 ints) - how many layers in each pooling blocknum_init_features (int) - the number of filters to learn in the first convolution layerbn_size (int) - multiplicative factor for number of bottle neck layers(i.e. bn_size * k features in the bottleneck layer)drop_rate (float) - dropout rate after each dense layernum_classes (int) - number of classification classessmall_inputs (bool) - set to True if images are 32x32. Otherwise assumes images are larger.efficient (bool) - set to True to use checkpointing. Much more memory efficient, but slower."""def __init__(self, growth_rate=12, block_config=(16, 16, 16), compression=0.5,num_init_features=24, bn_size=4, drop_rate=0,num_classes=10, small_inputs=True, efficient=False):super(DenseNet, self).__init__()assert 0 < compression <= 1, 'compression of densenet should be between 0 and 1'# First convolutionif small_inputs:self.features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, num_init_features, kernel_size=3, stride=1, padding=1, bias=False)),]))else:self.features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),]))self.features.add_module('norm0', nn.BatchNorm2d(num_init_features))self.features.add_module('relu0', nn.ReLU(inplace=True))self.features.add_module('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1,ceil_mode=False))# Each denseblocknum_features = num_init_featuresfor i, num_layers in enumerate(block_config):block = _DenseBlock(num_layers=num_layers,num_input_features=num_features,bn_size=bn_size,growth_rate=growth_rate,drop_rate=drop_rate,efficient=efficient,)self.features.add_module('denseblock%d' % (i + 1), block)num_features = num_features + num_layers * growth_rateif i != len(block_config) - 1:trans = _Transition(num_input_features=num_features,num_output_features=int(num_features * compression))self.features.add_module('transition%d' % (i + 1), trans)num_features = int(num_features * compression)# Final batch normself.features.add_module('norm_final', nn.BatchNorm2d(num_features))# Linear layerself.classifier = nn.Linear(num_features, num_classes)# Initializationfor name, param in self.named_parameters():if 'conv' in name and 'weight' in name:n = param.size(0) * param.size(2) * param.size(3)param.data.normal_().mul_(math.sqrt(2. / n))elif 'norm' in name and 'weight' in name:param.data.fill_(1)elif 'norm' in name and 'bias' in name:param.data.fill_(0)elif 'classifier' in name and 'bias' in name:param.data.fill_(0)def forward(self, x):features = self.features(x)out = F.relu(features, inplace=True)out = F.adaptive_avg_pool2d(out, (1, 1))out = torch.flatten(out, 1)out = self.classifier(out)return 2、使用Tensorflow实现DenseNet网络
- DenseLayer
class DenseLayer(Model):def __init__(self,bottleneck_size,growth_rate):super().__init__()self.filters=growth_rateself.bottleneck_size=bottleneck_sizeself.b1=BatchNormalization()self.a1=Activation('relu')self.c1=Conv2D(filters=self.bottleneck_size,kernel_size=(1,1),strides=1)self.b2=BatchNormalization()self.a2=Activation('relu')self.c2=Conv2D(filters=32,kernel_size=(3,3),strides=1,padding='same')def call(self,*x):x=tf.concat(x,2)x=self.b1(x)x=self.a1(x)x=self.c1(x)x=self.b2(x)x=self.a2(x)y=self.c2(x) return y
- Block
class DenseBlock(Model):def __init__(self,Dense_layers_num,growth_rate):#Dense_layers_num每个denseblock中的denselayer数,growthsuper().__init__()self.Dense_layers_num=Dense_layers_numself.Dense_layers=[]bottleneck_size=4*growth_ratefor i in range(Dense_layers_num):layer=DenseLayer(bottleneck_size,growth_rate)self.Dense_layers.append(layer)def call(self,input):x=[input]for layer in self.Dense_layers:output=layer(*x)x.append(output)y=tf.concat(x,2)return y
- Transition
class Transition(Model):def __init__(self,filters):super().__init__()self.b=BatchNormalization()self.a=Activation('relu')self.c=Conv2D(filters=filters,kernel_size=(1,1),strides=1)self.p=AveragePooling2D(pool_size=(2,2),strides=2)def call(self,x):x=self.b(x)x=self.a(x)x=self.c(x)y=self.p(x)return y
- DenseNet
class DenseNet(Model):def __init__(self,block_list=[6,12,24,16],compression_rate=0.5,filters=64):super().__init__()growth_rate=32self.padding=ZeroPadding2D(((1,2),(1,2)))self.c1=Conv2D(filters=filters,kernel_size=(7,7),strides=2,padding='valid')self.b1=BatchNormalization()self.a1=Activation('relu')self.p1=MaxPooling2D(pool_size=(3,3),strides=2,padding='same')self.blocks=tf.keras.models.Sequential()input_channel=filtersfor i,layers_in_block in enumerate(block_list):if i<3 :self.blocks.add(DenseBlock(layers_in_block,growth_rate))block_out_channels=input_channel+layers_in_block*growth_rateself.blocks.add(Transition(filters=block_out_channels*0.5))if i==3:self.blocks.add(DenseBlock(Dense_layers_num=layers_in_block,growth_rate=growth_rate))self.p2=GlobalAveragePooling2D()self.d2=Dense(1000,activation='softmax') def call(self,x):x=self.padding(x)x=self.c1(x)x=self.b1(x)x=self.a1(x)x=self.p1(x)x=self.blocks(x)x=self.p2(x)y=self.d2(x)return y
model=DenseNet()
四、分析总结
分析:
该文章提出的DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。
DenseNet具有如下优点:
- 1.信息流通更为顺畅;
- 2.支持特征重用;
- 3.网络更窄
由于DenseNet需要在内存中保存Dense Block的每个节点的输出,此时需要极大的显存才能支持较大规模的DenseNet,这也导致了现在工业界主流的算法依旧是残差网络。
讨论
从表面来看,DenseNets和ResNets很像:方程(2)和方程(1)的不同主要在输入 Hl(*) (进行拼接而不是求和)。然而,这个小的改变却是给这两种网络结构的性能带来了很大的差异。
模型简化性(Model Compactness)。将输入进行连接的直接结果是,DenseNets 每一层学到的特征图都可以被以后的任一层利用。该方式有助于网络特征的重复利用,也因此得到了更简化的模型。
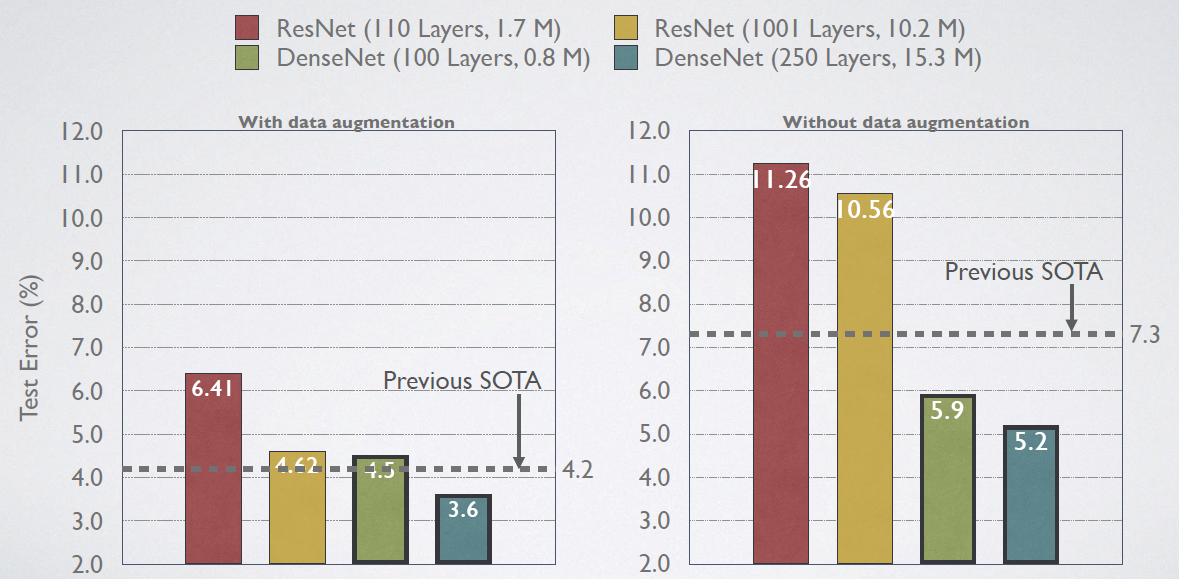
DenseNet-BC 是参数效率最高的一个 DenseNet 版本。此外,DenseNet-BC 仅仅用了大概 ResNets 1/3 的参数量就获得了相近的准确率(中图)。该结果与图3的结果相一致。如图4右图,仅有 0.8M 参数量的 DenseNet-BC 和有 10.2M参数的 101-ResNets 准确率相近。
隐含的深度监督(implicit deep supervision)。稠密卷积网络可以提升准确率的一个解释是,由于更短的连接,每一层都可以从损失函数中获得监督信息。可以将 DenseNets 理解为一种“深度监督”(Deep supervision)。深度监督的好处已经在之前的深度监督网络(DSN)中说明,该网络在每一隐含层都加了分类器,迫使中间层也学习判断特征(discriminative features)。
DenseNet和深度监督网络相似:网络最后的分类器通过最多两个或三个过度层为所有层提供监督信息。然而,DenseNets的损失含数字和梯度不是很复杂,这是因为所有层之间共享了损失函数。
随机 VS 确定连接。稠密卷积网络与残差网络的随机深度正则化(stochastic depth regularzaion)之间有着有趣的关系。在随机深度中,残差网络随机丢掉一些层,直接将周围的层进行连接。因为池化层没有丢掉,所以该网络和DenseNet有着相似的连接模式:以一定的小概率对相同池化层之间的任意两层进行直接连接——如果中间层随机丢掉的话。尽管这两个方法在根本上是完全不一样的,但是 DenseNet 关于随机深度的解释会给该正则化的成功提供依据。
总结一下:DenseNet和stochastic depth的关系,在 stochastic depth中,residual中的layers在训练过程中会被随机drop掉,其实这就会使得相邻层之间直接连接,这和DenseNet是很像的。
特征重复利用。根据设计来看,DenseNets 允许每一层获得之前所有层(尽管一些是通过过渡层)的特征图。我们做了一个实验来判断是否训练的网络可以重复利用这个机会。我们首先在 C10+ 数据上训练了 L=40, k=12 的 DenseNet。对于每个 block的每个卷积层 l,我们计算其与 s 层连接的平均权重。三个 dense block 的热度图如图 5 所示。平均权重表示卷积层与它之前层的依赖关系。位置(l, s)处的一个红点表示层 l 充分利用了前 s 层产生的特征图。由图中可以得到以下结论:
- 1,在同一个 block 中,所有层都将他的权重传递给其他层作为输入。这表明早期层提取的特征可以被同一个 dense block 下深层所利用
- 2,过渡层的权重也可以传递给之前 dense block 的所有层,也就是说 DenseNet 的信息可以以很少的间接方式从第一层流向最后一层
- 3,第二个和第三个 dense block 内的所有层分配最少的权重给过渡层的输出,表明过渡层输出很多冗余特征。这和 DenseNet-BC 强大的结果有关系
- 4,尽管最后的分类器也使用通过整个 dense block 的权重,但似乎更关注最后的特征图,表明网络的最后也会产生一些高层次的特征。
相关文章:
365天深度学习训练营-第J3周:DenseNet算法实战与解析
目录 一、前言 二、论文解读 1、DenseNet的优势 2、设计理念 3、网络结构 4、与其他算法进行对比 三、代码复现 1、使用Pytorch实现DenseNet 2、使用Tensorflow实现DenseNet网络 四、分析总结 一、前言 🍨 本文为🔗365天深度学习训练营 中的学习…...

Parisland NFT 作品集
该作品集用来自 Parisland 体验,共包含 11 个 NFT 资产,把你的土地装扮成一个眼花缭乱的热带天堂吧! 登上芭黎丝的爱情船和戴上豪华的螺旋爱情戒指,成为她在数位世界举办的真人秀的一部分吧!该系列还包含两个传奇级别的…...

uniapp: 基础开发官网文档
1、uniapp官网文档:https://uniapp.dcloud.net.cn/component/2、uView跨端UI组件库:http://v1.uviewui.com/components/intro.html3、lunch-request(类似axios的请求库):https://www.quanzhan.co/luch-request/handboo…...

mybatis中配置连接池的原理介绍分析
1.连接池:我们在实际开发中都会使用连接池。因为它可以减少我们获取连接所消耗的时间。2、mybatis中的连接池mybatis连接池提供了3种方式的配置:配置的位置:主配置文件SqlMapConfig.xml中的dataSource标签,type属性就是表示采用何…...
二叉树——路径总和
路径总和 链接 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。 叶子节点…...

WebDAV之π-Disk派盘+文件管理器
文件管理器 支持WebDAV方式连接π-Disk派盘。 推荐一款iOS上的免费文件管理器新秀。 文件管理器这是一款功能强大的文件管理工具,支持zip,rar,7z等压缩包的解压和压缩,支持小说,漫画,视频下载及播,极大提升日常办公,娱乐,文件管理的工作效率,使得文档的归档和管理随心…...

form表单单输入框回车提交事件处理
问题 form表单中如果只有一个输入框,在输入时按Enter回车键会出发默认事件自动提交表单,该交互是同步发生的,会导致页面刷新。 解决思路 有三种解决思路: 1. 增加input输入框的数量 如果form表单中不止一个input输入框&#…...
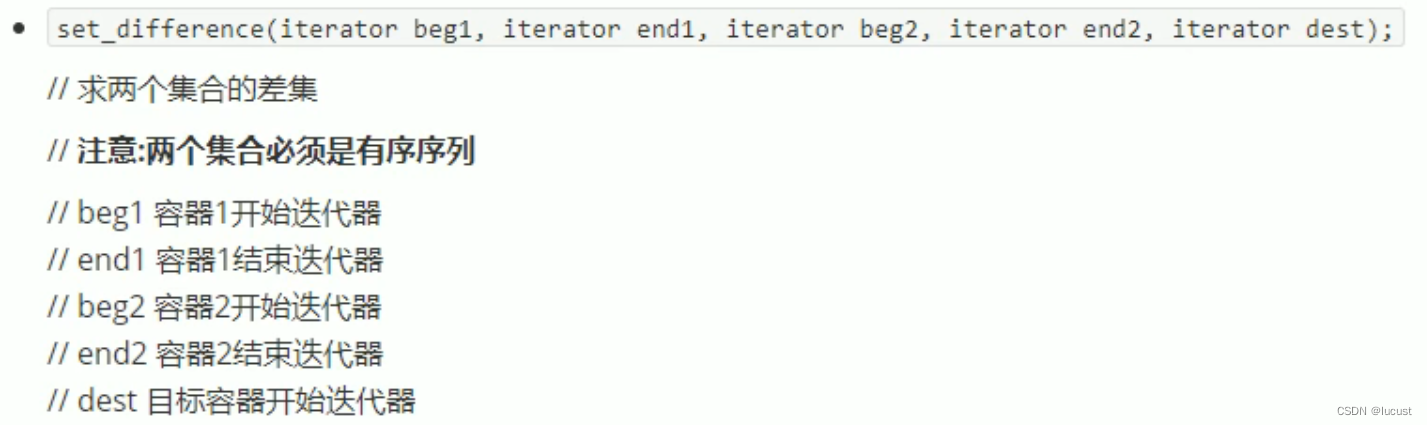
c++常用stl算法
1、头文件 这些算法通常包含在头文件<algorithm> <functional> <numeric>中。 2、常用遍历算法 for_each(v.begin(),v.end(), 元素处理函数/仿函数) 注意:在使用transform转存时,目标容器需要提取开辟合适的空间。 void printfunc(…...
非对称密钥PKCS#1和PKCS#8格式互相转换(Java)
目录一、序言二、代码示例1、Maven依赖2、工具类封装三、测试用例1、密钥文件2、公私钥PKCS1和PKCS8格式互相转换一、序言 之前在 《前后端RSA互相加解密、加签验签、密钥对生成》 中提到过PKCS#1格式和PKCS#8格式密钥的区别以及如何生成密钥。实际有些场景中有可能也会涉及到…...

java获取当前时间的方法:LocalDateTime、Date、Calendar,以及三者的比较
文章目录前言一、LocalDateTime1.1 获取当前时间LocalDate.now()1.2 获取当前时间的年、月、日、时分秒localDateTime.getYear()……1.3 给LocalDateTime赋值LocalDateTime.of()1.4 时间与字符串相互转换LocalDateTime.parse()1.5 时间运算——加上对应时间LocalDateTime.now()…...
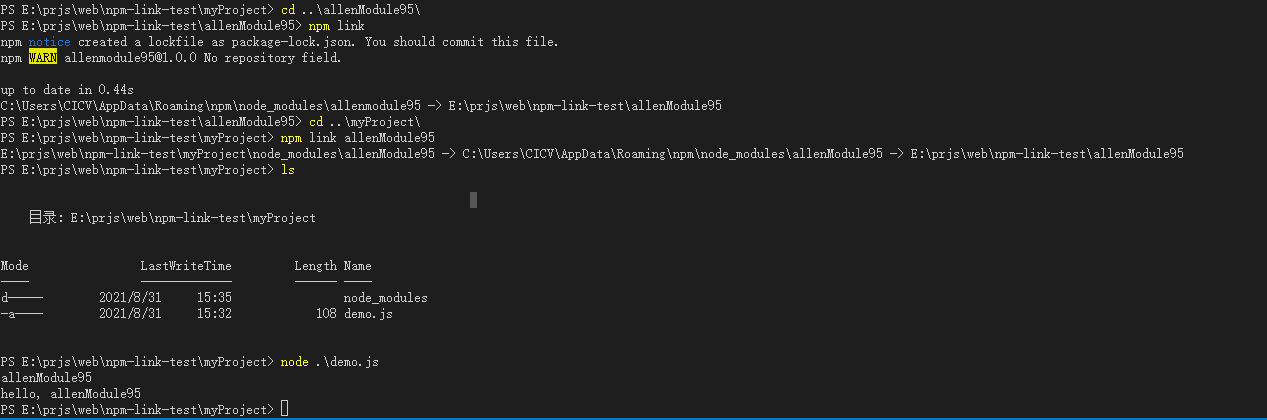
npm link
正文npm link的用法假如我们想自己开发一个依赖包,以便在多个项目中使用。一种可行的方法,也是npm给我们提供的标准做法,那就是我们独立开发好这个 "依赖包",然后将它直接发布到 npm镜像站 上去,等以后想在其…...
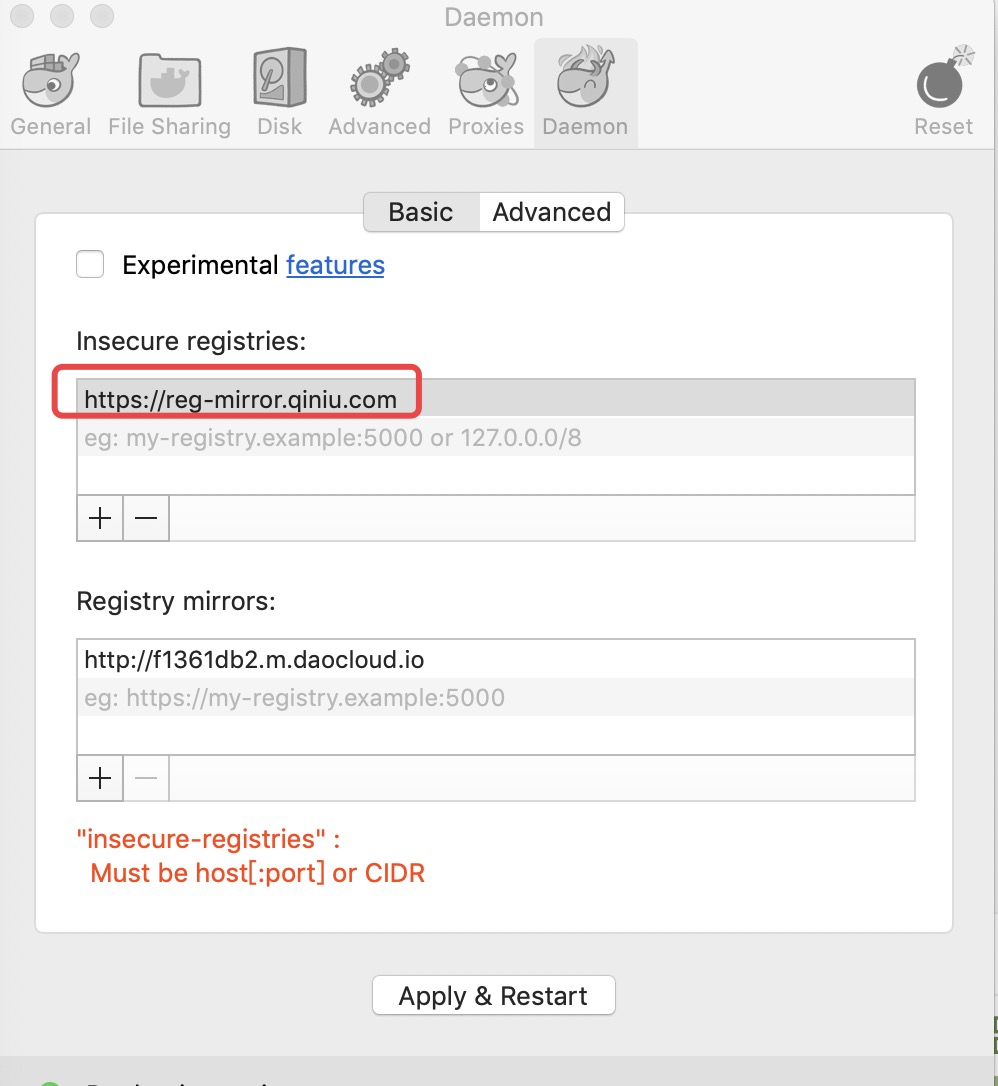
Docker 如何配置镜像加速
Docker 镜像加速 国内从 DockerHub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。Docker 官方和国内很多云服务商都提供了国内加速器服务,例如: 科大镜像:https://docker.mirrors.ustc.edu.cn/网易:https://hub-…...
阅读笔记7——Focal Loss
一、提出背景 当前一阶的物体检测算法,如SSD和YOLO等虽然实现了实时的速度,但精度始终无法与两阶的Faster RCNN相比。是什么阻碍了一阶算法的高精度呢?何凯明等人将其归咎于正、负样本的不平衡,并基于此提出了新的损失函数Focal L…...

ZCMU--5009: 龙虎斗
轩轩和开开正在玩一款叫《龙虎斗》的游戏,游戏的棋盘是一条线段,线段上有n个兵营(自左至右编号1~n),相邻编号的兵营之间相隔1厘米,即棋盘为长度为n-1厘米的线段。i号兵营里有ci位工兵。 下面图1为n 6的示例: 轩轩在左侧…...
创建项目(React+umi+typeScript)
项目框架搭建的方式react脚手架Ant-design官网一、安装方式npm二、安装方式yarn三、安装方式umi devreact脚手架 命令行: npx create-react-app myReactName项目目录结构: 浏览器运行,端口号3000: Ant-design官网 一、安装方…...
FISCO BCOS(二十七)———java操作WeBase
一、搭建fiscobcos环境 1.1、安装jdk1.8 https://blog.csdn.net/weixin_46457946/article/details/1232435131.2、安装mysql https://blog.csdn.net/weixin_46457946/article/details/1232447361.3、安装python https://blog.csdn.net/weixin_46457946/article/details/123…...

失眠时还在吃它?有风险,你了解过吗
失眠,是当代人的通病。所以解决失眠也成了刚需,市面上开始出现各种助眠产品。有商业机构调查发现,62%的90后消费者曾买过助眠产品,其中人气选手就是褪黑素。褪黑素本身就是人体天然存在的,与睡眠有关的物质,…...
星戈瑞收藏Sulfo-CY7 amine/NHS ester/maleimide小鼠活体成像染料标记反应
关于小鼠活体成像,就一定要提到CY活性染料标记反应: 用不同的活性基团的Cyanine菁染料和相应的活性基团的生物分子或小分子药物发生反应,链接到一起。 根据需要标记的抗原、抗体、酶、多肽等分子所带的可标记基团的种类(氨基、醛…...

守护最后一道防线:Coremail邮件安全网关推出邮件召回功能
根据Coremail邮件安全大数据中心2022年Q4季报显示,2021年CAC识别钓鱼邮件1.81亿,2022年上升至2.25亿,增幅高达24.1%。 这表明2022年平均每天有61万7088封钓鱼邮件被接收及发出,企业用户面临潜在经济损失不可估量。 尤其是活跃至今…...

Python实战之小说下载神器(二)整本小说下载:看小说不用这个程序,我实在替你感到可惜*(小说爱好者必备)
前言 这次的是一个系列内容给大家讲解一下何一步一步实现一个完整的实战项目案例系列之小说下载神器(二)(GUI界面化程序) 单章小说下载保存数据——整本小说下载 你有看小说“中毒”的经历嘛?小编多多少少还是爱看小说…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...