C++ - 异常介绍和使用
前言
我们在日常编写代码的时候,难免会出现编写错误带来程序的奔溃,或者是用户在使用我们编写的程序时候,使用错误所带来程序的奔溃。
在C++ 当中 可以对你觉得可能发生 错误 的地方在运行之前进行判断,发生错误可以给出提示。
C 语言传统的处理错误的方式
在了解C++ 当中处理错误的异常之前,我们先来了解一下C语言当中处理错误的方式。
终止程序
C 当中有一个 assert()函数,这个函数在 assert.h 这个头文件当中,这个函数的参数是一个 bool 值,我们可以在 ()当中写入判断的表达式,如果是 false 会直接报异常。比如:发生内存错误,除0错误时就会终止程序。
这种方式虽然一定程度上 方便了 程序员 查找报错位置,只需要看 自己 写的 每一个 assert()函数位置,可以更快的找出发生错误的位置。
但是,这种方式对于用户来说非常不友好,用户难以接受。
返回错误码
当发生错误的时候,会报错,但是这个报错需要程序员自己去查找对应的错误。比如系统当中的很多接口函数都是通过把错误码放到 error 当中来表示错误的。
在C语言实际使用当中,返回错误码一直都是其主要的处理错误的方式,只有部分情况下使用终止程序处理非常严重的错误。
但是,错误码的方式还是非常麻烦,比如 有 代码量非常大的工程,有 5 个小组来管理着这个庞大的代码工程,有一天程序报错了,发现在 报错在 第二小组当中输出,但是第二小组经过检查,没有在他们的代码模块当中发现错误,后面才发现,是第一组当中的隐含的错误吗,导致了第二组当中的输出错误。
当代码很多的时候,这种错误码的方式非常的难找错误。
而且,错误码虽然告诉程序员是几号错误,但是我们不可能所以的错误都记得,需要的时候我们还要去查几号错误是什么错误。
所以,在C++当中更新了异常,来更好的解决程序的错误问题。
C++异常
异常是一种处理错误的方式,当一个函数发现自己无法处理的错误时就可以抛出异常,让函数的
直接或间接的调用者处理这个错误。
语法
在异常的使用当中有三大关键字:
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在您想要处理问题的地方,通过异常处理程序捕获异常.catch 关键字用于捕获异常,可以有多个catch进行捕获。
- try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。
如果某一个块当中,抛出了异常,那么,我们可以用 try 和 catch 两个关键字去捕捉这个异常。
在 try 块 当中放置可能会抛出异常的代码,这个 try 块 当中的代码被称为是 保护代码。使用 try 和 catch 语句的语法如下所示:
try
{// 保护的标识代码
}catch( ExceptionName e1 )
{// catch 块
}catch( ExceptionName e2 )
{// catch 块
}catch( ExceptionName eN )
{// catch 块
}一块 try 块 可以使用多个 catch 来对不同异常进行处理。
关于 try/catch 语句执行顺序:
try
{func();
}catch( ExceptionName e1)
{// 异常执行
}上述代码,如果 当 func()函数没有抛出异常,那么就是和没有 try/catch 语句 一样,正常执行。而且没有此时不会去调用catch函数。如果func()函数抛出异常,那么会直接跳到 catch语句执行。
其实,当 try 当中出现异常,直接跳到 catch 语句进行处理是一件非常好的事,因为我们一般在处理异常的时候,把异常都在主函数(main)当中进行处理,或者是同一进行处理,不会单独分开处理的。
直接跳出还有一个好处,当调用链非常深的时候,如果一层一层往外回调的话,非常的麻烦,直接跳到 catch 就很方便。
而且,即使是 直接 跳到 catch 语句,其中应该回调的函数所销毁的函数栈帧也是会销毁的,不会发生 跳到 catch 处在调用链当中还有函数栈帧没有销毁的情况。
异常的使用
异常的抛出和匹配原则:
- 异常是通过抛出对象而引发的,该对象的类型决定了应该激活哪个catch的处理代码。
- 被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那一个。
- 抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象,所以会生成一个拷贝对象,这个拷贝的临时对象会在被catch以后销毁。(这里的处理类似于函数的传值返回)
- catch(...)可以捕获任意类型的异常,问题是不知道异常错误是什么。
- 实际中抛出和捕获的匹配原则有个例外,并不都是类型完全匹配,可以抛出的派生类对象,使用基类捕获,这个在实际中非常实用。
C++ 当中抛出是通过的 throw 抛出,throw 可以抛出任意类型,无论是 char* ,int,内置类型还是 自定义类型都可以抛出。
而抛出就要使用 catch 捕获,catch 捕获相同 一种类型的由 throw 抛出的异常。
double func(int a, int b)
{if (b == 0)throw "func by zero conditon";elsereturn ((double)a / (double)b);
}int main()
{try{func(1, 2);}catch (int errmsg){cout << errmsg << endl;}return 0;
} 上述 throw 抛出了一个 char* 类型,在 catch 当中就要捕获这个 char*。如在 catch 当中捕获的类型不匹配,比如上述抛出了 char* ,但是我却捕获了 int:
double func(int a, int b)
{if (b == 0)throw "func by zero conditon";elsereturn ((double)a / (double)b);
}int main()
{try{func(1, 2);}catch (int errmsg){cout << errmsg << endl;}return 0;
}我们注意到 当 throw 抛出的类型 和 catch 捕获的类型不匹配是不能捕获到的。而且,抛出异常之后,必须被捕获,如果不被捕获,编译器就会报错。
在函数调用链中异常栈展开匹配原则(也就是检查原则):
- 当 throw 抛出异常之后,先检查 throw 本身是否在 try 内部,如果在,再去看 catch 语句当中是否有匹配的 catch 语句,如果上述两个都有,再调到 对应的 catch 块当中进行处理。
- 如果没有匹配的 catch ,就会退出当前函数栈,继续在调用的栈当中进行查找匹配的 catch。他是层层网上找的,比如现在是 main 函数调用了 func1()函数,func1()调用了 func2()函数,在func2()函数当中抛出了异常,首先会去检查 func2()当中 throw 抛出的异常是否在 func2()函数当中有被 try/catch 内部,如果在 就会去看其中有没有 对应的 catch 块;如果上两个其中一个没有,就会去 上一层函数当中寻找,也就是在 func1()当中寻找,如果还没有找到,再到 main函数当中寻找,如果有多层函数调用,就会这样去寻找,直到找到对应的 catch块。
- 如果到达 main函数的栈当中,依旧没有找到匹配的,则终止程序(debug 和 release都是一样的)。上述沿着调用链查找匹配的 catch 的过程被称为 栈展开。所以,当我们写了 很多个 catch 之后,把我们想到了异常都写出来了,在最后都要加一个任一类型的 catch 来捕获异常,防止程序终止。
- 当编译器找到对应的 catch 语句之后,在指向完当前 catch 语句,会顺序接着执行后面的 代码。
- 当一个 try 当中使用了 多个 throw ,也就是说使用者先抛出多个 异常,这个在语法上是不会报错的,但是除了第一个 throw 之外,后面的 throw 就不会在抛出了,相当于没写。
例1:
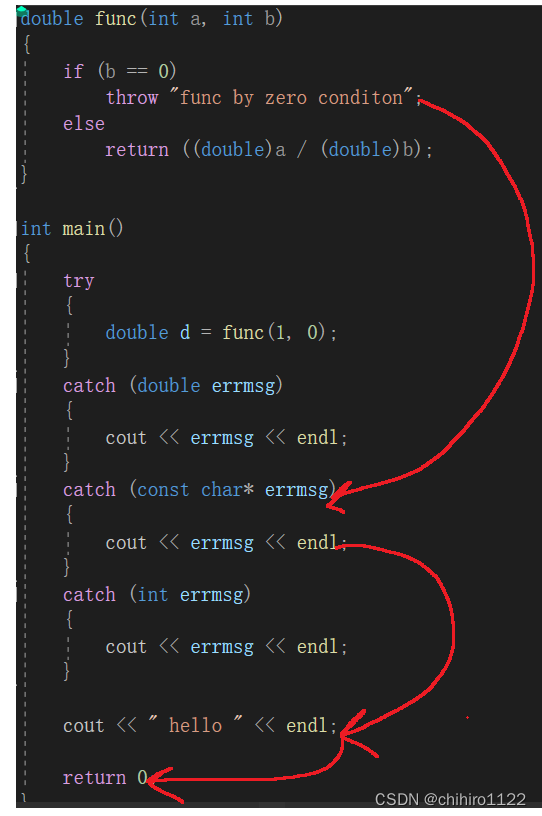
如上述例子,当抛出异常之后,回去 try/catch 当中寻找对应的 catch ,然后接着 程序当中 try/catch 之后的代码顺序执行。
例2:
按照上述这个例子的执行过程,我们来看看下面这个例子的执行过程:
double func2(int a, int b)
{if (b == 0){throw "func by zero conditon";throw 1;}elsereturn ((double)a / (double)b);
}void func1(int a, int b)
{try{func2(a, b);}catch (const char* e){cout << e << endl;}cout << "world" << endl;
}int main()
{try{func1(1, 0);}catch (const char* errmsg){cout << errmsg << endl;}cout << " hello " << endl;return 0;
}上述这个例子,在 func1 ()函数当中就捕获了 func2()当中的 抛出的异常,也就是说,在main()函数当中捕获 char* 的 catch 没有捕获到,就被 func1()当中的 catch 捕获了,所以main()函数当中的 catch就不会再执行了。
我们还注意到,上述的 func2()当中有两个 throw,他们都位于同一个 try 当中,所以只有第一个 throw 会执行,后面一个 throw 不会执行,第一个 throw 执行就跳到 catch 当中去了,后面的代码就不会执行了。
在 func1()当中捕获到之后,执行完 catch 代码,就会接着这个 catch 执行后面的代码,也就是说输出 “world”,所以上述程序输出:
func by zero conditon
worldhello例3:
当我们抛出一个 string 类的对象,在其他函数的catch 当中捕获这个 string类对象的 异常。我们知道,string对象出了作用域之后,就会调用析构函数销毁,那么我们在 main()函数当中 捕获 这个 string 对象会不会是野指针呢?
double func2(int a, int b)
{if (b == 0){string s("func by zero conditon");throw s;}elsereturn ((double)a / (double)b);
}int main()
{try{func2(1, 0);}catch (const char* errmsg){cout << errmsg << endl;}cout << " hello " << endl;return 0;
}如上述,在 func2()函数当中抛出 string类s 对象,然后在 main()函数当中捕获,其中的errmsg会不会是野指针呢?
不会。可以成功捕获到 s 对象。
因为,这里的返回和 拷贝返回一样,他不会直接返回,而是拷贝一份之后,返回这个拷贝后的对象。这个拷贝的对象,在catch 执行完毕之后才会销毁。
通用类型 catch
在日常当中,我们经常会忘记捕获某个异常,比如在代码量很多的项目当中,可能时不时就忘记某个异常的捕获了。
但是,异常不被捕获程序就直接终止,如果这个异常只是一个小异常,稍微处理一下就可以解决的问题,但是因为异常没有捕获就直接导致程序终止了;这可不是我们希望的。
所以,C++ 当中支持 通用类型的 catch,这个特殊的catch语句可以捕获任意类型的 异常,包括 内置类型 和 自定义类型。
语法:
catch(...)
{}三个 " . " 的意思就是捕获任意类型的异常。
任意类型的捕获一般是放在最后一个 catch 来使用,防止有抛出的异常没有被捕获。
但是,这种通用类型的异常捕获是有弊端的:
通用类型异常捕获,不知道捕获的类型是什么错误,其他catch 还可以通过 类型匹配来知道是什么类型的错误,但是 通用类型catch 不能匹配 类型,所有没有捕获的异常都由 它来捕获。
我们不能把 catch(...) 放到其他 catch 的上面优先捕获,会报错:
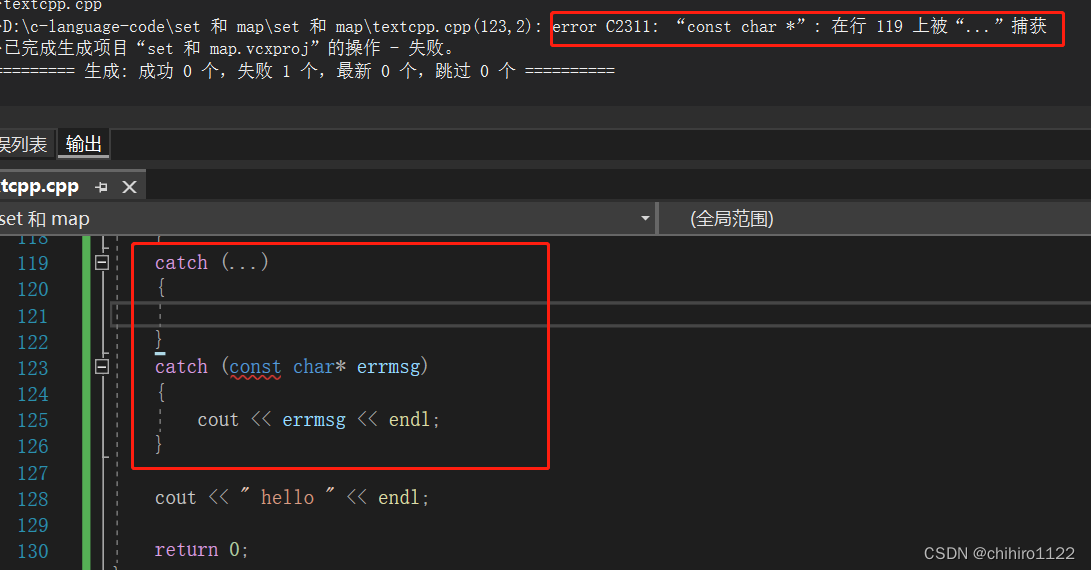
还可以在 catch(...)当中使用 throw;
throw; 代表 捕获什么,抛出什么。
支持可以抛出派生类对象,用基类捕获
例1:
这种在程序日常监控当中多次使用,比如你使用的某一个软件,这个软件当中需要点击来执行下一步操作,那么它怎么知道用户是那个时间点击的呢?不知道,因为用户的点击是有随机性的 。所以,一般是使用一个循环来实时监控用户点击的这一个操作的,如果在点击这一操作当中出现了异常没有被我们写到 catch 当中捕获,此时 catch(...) 就可以帮我们 捕获这个异常,防止程序终止。
例2:

在日常发送消息的过程当中没可能会遇到上述的三个问题,而这些问题我们一般用 id 类辨别存储,在异常类当中,除了会有 string类型的异常信息,还会有一个 id,这个id 代表这是一个什么类型的错误,而且 string 类型的异常表示是记录到日志当中去的。
而且,当抛出异常的时候可能不只是要记录日志,可能还会有其他的处理;比如在隧道里面发送消息,可能就会发送失败,而发送失败的原因是 因为 网络错误,我们回想我们日常使用 微信 或者 qq 发送消息的时候,当网络不好,消息不是 马上就提示 红色感叹号发送失败的,而是先“转圈”。我们看到转圈这个图标的时候,其实就一直在重试发消息。尝试一定次数之后才会 提示发送失败。
- 由上述两个例子,我们发现,异常基本都是要自己针对程序的错误进行记录和处理的,而这就导致不同异常很少有重复的处理方式;虽然C++ 当中支持我们 抛出任意类型的异常,但是,在实际的项目编写当中,异常是不能随便抛出的,抛出一个 没有 进行 处理的异常可能会出现很多问题。
- 一般情况下,都要抛出一个异常的自定义类型,这个自定义类型至少要包含两个错误信息,一个是 string 类异常说明,用于记录日志;另一个是 异常id,id 的本质是错误编号,有了错误的编号才能更好的分辨错误。有些错误需要进行特殊处理,而不是简单的记录日志。
- 在一个大项目当中,可能会分为很多个组来分配实现不同的板块,假设有一组是专门来写异常捕获的,异常处理的,那么其他组如果按照自己处理自己模块异常的方式去抛出异常的话,写异常的那一组人,在其他人每抛出一个异常就要写一个异常重新捕获。异常通常是在最外层进行捕获,如果都是一个异常的话,在外层如何知道是哪一个模块出错了?
- 在比如,数据库模块的人,还希望吧 sql 语句的异常给带出去;网络模块的人,希望把网络模块的异常带出去;可能会带一些信息出来,这样的话,外部的异常类就不满足了,但是如果要各个模块定义各个模块的异常类,机会非常的乱。
- 如果各个模块的人,都定义各自的异常类,在外层捕获异常的人就会非常的繁琐,各种异常都需要写 catch 类捕获,来特殊处理。
基于上述这种问题存储,C++支持抛出派生类对象,用基类捕获。
子类可以切割,兼容赋值给基类,没有类型转换的发生。
所以,一般在公司当中,写出异常基类,和一系列派生类,如果员工想要抛异常,只能抛出基类,和其派生类,或者如果想有自己的东西的话,就自己定义一个集成这个异常基类的派生类,然后抛出这个子类自定义异常类:
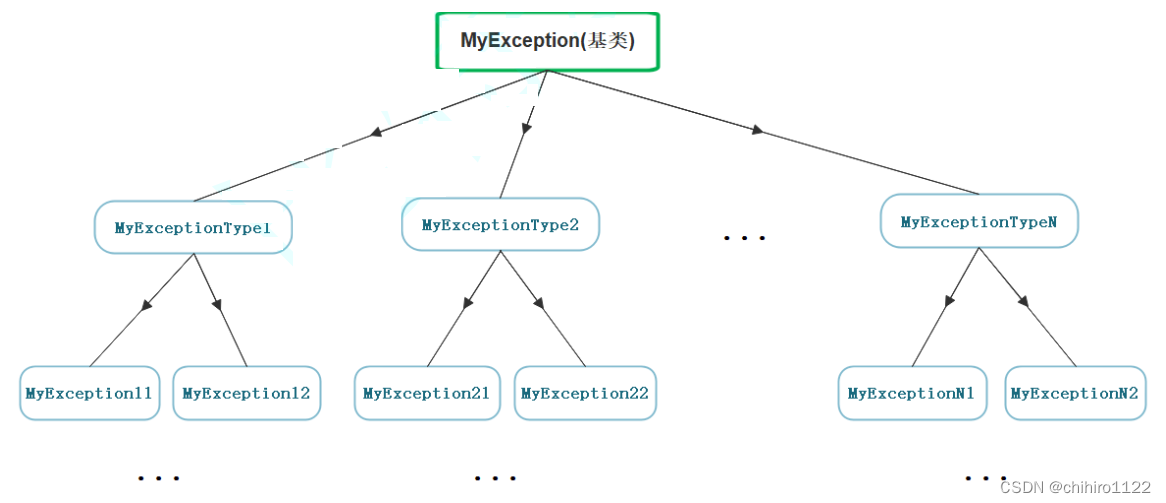
下面是一个 服务器开发当中使用的 异常继承体系 样例:
// 服务器开发中通常使用的异常继承体系
class Exception
{
public:Exception(const string& errmsg, int id):_errmsg(errmsg), _id(id){}virtual string what() const{return _errmsg;}
protected:string _errmsg;int _id;
};class SqlException : public Exception
{
public:SqlException(const string& errmsg, int id, const string& sql):Exception(errmsg, id), _sql(sql){}virtual string what() const{string str = "SqlException:";str += _errmsg;str += "->";str += _sql;return str;}
private:const string _sql;
};
class CacheException : public Exception
{
public:CacheException(const string& errmsg, int id):Exception(errmsg, id){}virtual string what() const{string str = "CacheException:";str += _errmsg;return str;}
};class HttpServerException : public Exception
{
public:HttpServerException(const string& errmsg, int id, const string& type):Exception(errmsg, id), _type(type){}virtual string what() const{string str = "HttpServerException:";str += _type;str += ":";str += _errmsg;return str;}
private:const string _type;
};
void SQLMgr()
{srand(time(0));if (rand() % 7 == 0){throw SqlException("权限不足", 100, "select * from name = '张三'");}//throw "xxxxxx";
}void CacheMgr()
{srand(time(0));if (rand() % 5 == 0){throw CacheException("权限不足", 100);}else if (rand() % 6 == 0){throw CacheException("数据不存在", 101);}SQLMgr();
}void HttpServer()
{// ...srand(time(0));if (rand() % 3 == 0){throw HttpServerException("请求资源不存在", 100, "get");}else if (rand() % 4 == 0){throw HttpServerException("权限不足", 101, "post");}CacheMgr();
}int main()
{while (1){this_thread::sleep_for(chrono::seconds(1));try {HttpServer();}catch (const Exception& e) // 这里捕获父类对象就可以{// 多态cout << e.what() << endl;}catch (...){cout << "Unkown Exception" << endl;}}return 0;
}
捕获的人就解放了,使用捕获父类就行:

而且,在string 类的异常日志当中,不止写异常报错(错误描述),还有写这个异常类的人的编号,让其他人知道,这个异常是公司里面哪一个人写的:

上述的 what()函数是按照库当中的 what()函数样子写的,在父类当中what(),只返回一个错误信息,而在子类当中的what()函数就有了 子类异常类的实现人名称,子类异常类独有的错误信息等等,而且父类当中的what()函数写成了虚函数,这样,子类就可以对 what ()函数进行重写,在外部主函数中调用what()函数就可以使用多态的方式来调用。

向上述子类是 sql 异常类,他还带上了 _sql ,把sql 语句也带上了,除了错误信息,还有出错的sql语句。
在库当中也有what()函数,也是返回错误信息的函数。
C++标准库当中异常类的体系结构

如上述所示,所有的异常子类都继承与一个父类:exception,所以,我们在捕获官方库当中的异常的时候,就可以直接捕获 exception 父类。
各个异常类的说明
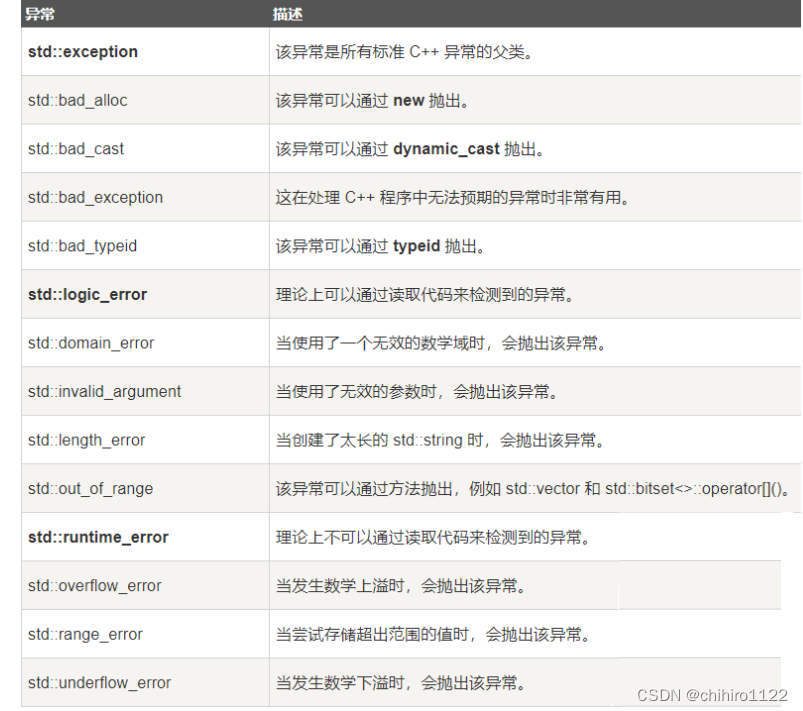
这些子类的捕获方式都可以像上述实现的 服务器 当中的异常体系结构一样,使用多太多方式来实现,库当中异常类也有 what()函数供我们使用。
异常规范
异常其实有一个很大的问题,就是如果抛出异常就会到处乱跳,有时候我们打断点都控制不住,因为我们不清楚哪一个函数可能就抛异常了。
异常规格说明的目的是为了让函数使用者知道该函数可能抛出的异常有哪些。
可以在函数的后面接throw(类型),列出这个函数可能抛掷的所有异常类型:
// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常
void fun() throw(A,B,C,D);
// 这里表示这个函数只会抛出bad_alloc的异常
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数不会抛出异常
void* operator delete (std::size_t size, void* ptr) throw();- 函数的后面接throw(),表示函数不抛异常。
- 若无异常接口声明,则此函数可以抛掷任何类型的异常。
- 如果可能会抛出多个类的异常,在 throw()当中就会 " , " 去分隔。
虽然有规范,但是因为 C++ 兼容C语言,就不能强制去这样写,如果是按照 C 语言的语法来写的函数是没有这样的规范的,但是有不能强制,就不能很好的去控制。
而且,在throw()当中还需要判断这个函数抛出哪几个异常,实际上肯定会有人把抛出的异常种类判断不全。而且 在该函数当中可能还会有其他函数,就算把该函数的异常写完了,其他函数不是我实现的,我不一定能写完;就算那个函数有文档说明,写函数的人也不一定能够把异常写完。
而且,当调用的函数多了之后,我需要把每一个函数的抛出哪一个异常写出来,这样整理是不是太麻烦了,还要一个一个函数抛那些异常整理出来。
所以在C++11 当中简化了上述 繁琐的语法:
使用关键字关键字:noexcept,他的意思和 throw() 一样,表示这个函数不会抛出异常:
thread() noexcept;
thread (thread&& x) noexcept;异常安全
- 构造函数要对对象的进行构造和初始化,最好不要再构造函数当中抛异常,这样可能会导致对象构造不完全。
- 同样的,析构函数要对对象进行销毁,对对象当中动态开辟的空间进行释放等等操作,最好不要再析构函数当中去抛出异常,这样带来的后果更加严重,可能会导致资源泄漏(内存泄漏,句柄未关闭等等)。
- C++ 当中经常会操作 资源泄漏,比如在 new ,delete 当中 抛出异常,在lock和unlock之间抛出了异常导致死锁。在C++ 当中使用 RAII来解决以上问题。
比如下述例子:
void func1()
{}double func1(int a, int b)
{int* array = new int[10];func1();delete[] array;
}int main()
{try{func1(1, 0);}catch ( const char* errmsg){cout << errmsg << endl;}catch (...){}cout << " hello " << endl;return 0;
}假设 func1()当中调用 func2()函数的时候,func2()函数抛出异常了,这会导致在 func1()当中对 array 数组的 delete 操作被直接跳过了,导致内存泄漏。
解决方式:
方式1:把 try/catch 设法移动到 delete 的 上方,使得在 try.catch 执行完之后 顺序执行 delete操作。
方式2: 在 try/catch 的 catch 当中重新把异常抛出:
如果一定想要在外层函数当中对异常进行会处理,因为可能要写入日志等等操作。那么可以在 func1()当中,先把 func2()当中的异常先拦截下来,把 array 数组 delete 之后,再把这个异常给抛出给 外部 的 try/catch :
void func2()
{}double func1(int a, int b)
{int* array = new int[10];try{func2();}catch (const char* errmsg){delete[] array;throw(errmsg); // 重新抛出异常}}int main()
{try{func1(1, 0);}catch ( const char* errmsg){cout << errmsg << endl;}catch (...){}cout << " hello " << endl;return 0;
}但是上述方式有一个很大的弊端,当 func1()当中的 try 块当中有很多个函数,那么就要对这些个函数都写一个catch 来截取,处理,然后在重新抛出,非常麻烦。
所以我们对上述的方式进行了改进,下述代码只有 func1()部分:
double func1(int a, int b)
{int* array = new int[10];try{func2();}catch (...){delete[] array;throw; // 重新抛出异常}}其中的 throw; 代表 捕获什么,抛出什么。
异常的优缺点
C++异常的优点:
- 异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包含堆栈调用的信息,这样可以帮助更好的定位程序的bug。
- 返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误,最外层才能拿到错误,具体看下面的详细解释。
- 很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们也需要使用异常。
- 部分函数使用异常更好处理,比如构造函数没有返回值,不方便使用错误码方式处理。比如T& operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。
C++异常的缺点:
- 异常会导致程序的执行流乱跳,并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
- 异常会有一些性能的开销。当然在现代硬件速度很快的情况下,这个影响基本忽略不计。
- C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题。学习成本较高。
- C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
- 异常尽量规范使用,否则后果不堪设想,随意抛异常,外层捕获的用户苦不堪言。所以异常规范有两点:一、抛出异常类型都继承自一个基类。二、函数是否抛异常、抛什么异常,都使用 func() throw();的方式规范化。
- 异常规范不强制,也没办法强制。
但是总体而言,C++的异常虽然有很多弊端,但是异常所带来的好处是非常好的,极大的方便了我们寻找bug。
相关文章:
C++ - 异常介绍和使用
前言 我们在日常编写代码的时候,难免会出现编写错误带来程序的奔溃,或者是用户在使用我们编写的程序时候,使用错误所带来程序的奔溃。 在C 当中 可以对你觉得可能发生 错误 的地方在运行之前进行判断,发生错误可以给出提示。 C…...
iText实战--在现有PDF上工作
6.1 使用PdfReader读取PDF 检索文档和页面信息 D:/data/iText/inAction/chapter03/image_direct.pdf Number of pages: 1 Size of page 1: [0.0,0.0,283.0,416.0] Rotation of page 1: 0 Page size with rotation of page 1: Rectangle: 283.0x416.0 (rot: 0 degrees) Is reb…...
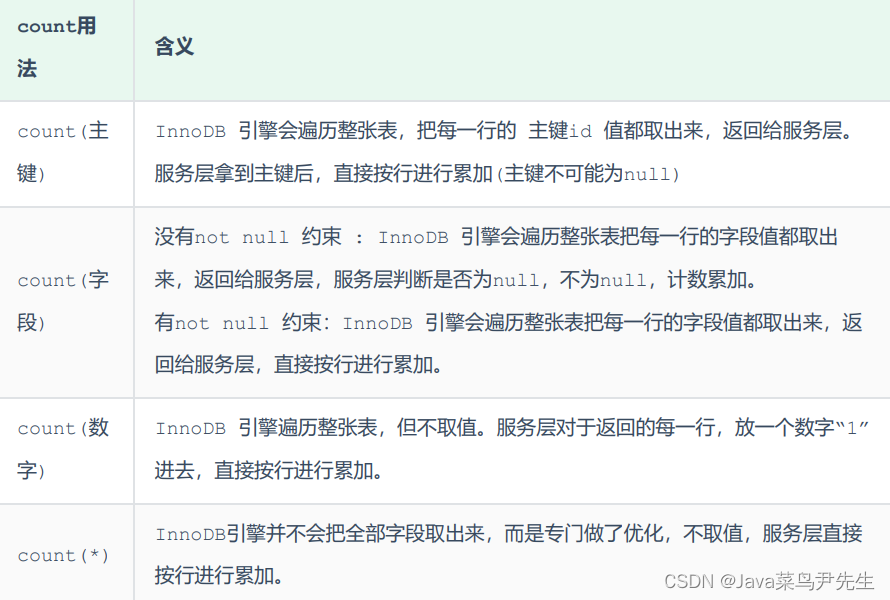
SQL优化--count优化
select count(*) from tb_user ;在之前的测试中,我们发现,如果数据量很大,在执行count操作时,是非常耗时的。 MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很…...
IDEA下使用Spring MVC
<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://ma…...
)
2022基金从业人员资格管理及后续职业培训 部分答案(自答)
2022基金从业人员资格管理及后续职业培训 区块链在金融交易后处理中的应用私募基金行业典型违法案例分析《证券法》修订情况报告《刑法修正案(十一)》金融犯罪条款中国结算港股通结算业务介绍商品投资与商品配置价值气候技术:实现双碳目标的技…...

阿里云通义千问向全社会开放,近期将开源更大参数规模大模型
9月13日,阿里云宣布通义千问大模型已首批通过备案,并正式向公众开放,广大用户可登录通义千问官网体验,企业用户可以通过阿里云调用通义千问API。 通义千问在技术创新和行业应用上均位居大模型行业前列。IDC最新的AI大模型评估报告…...

数据结构:二叉查找树
文章目录 二叉查找树一,概述二,添加数据三,删除数据 二叉查找树 一,概述 二叉查找树,也称为二叉搜索树,是一种特殊的二叉树,它或者是一颗空树,或者具有以下性质:对于每…...

Redis的介绍,安装Redis的方式
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Redis 初识Redis1.1 认识Redis1.2 安装Redis的方式…...

深入理解CI/CD流程:改变你的开发生命周期
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
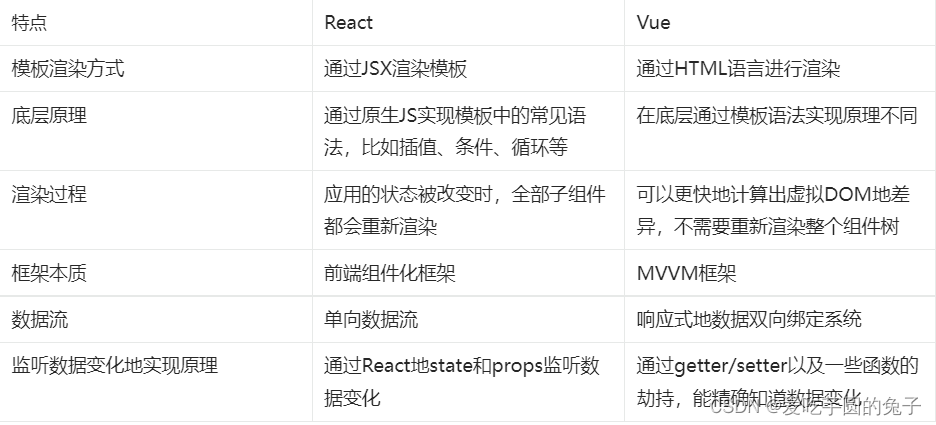
【React】React入门
目录 一、何为React二、React与传统MVC的关系三、React的特性1、声明式编程①、实现标记地图 2、高效灵活3、组件式开发(Component)①、函数式组件②、类组件(有状态组件)③、一个组件该有的特点 4、单向式响应的数据流 四、虚拟DOM1、传统DOM更新①、举…...
面相面试知识--Lottery项目
面相面试知识–Lottery项目 1.设计模式 为什么需要设计模式? (设计模式是什么?优点有哪些?) 设计模式是一套经过验证的有效的软件开发指导思想/解决方案;提高代码的可重用性和可维护性;提高团…...

《Python趣味工具》——自制emoji2(2)
今天,我们将会完成以下2个内容: 绘制静态emoji总结turtle中常用的绘图函数 文章目录 一、绘制静态emoji::sparkles: 画脸::sparkles:绘制嘴巴::sparkles:绘制眼白:绘制眼白-Part1:绘制眼白—pa…...

【面试刷题】——C++四种类型转化
C支持多种类型转换操作,其中包括四种主要类型转换方式: 隐式类型转换(Implicit Conversion): 隐式类型转换是自动发生的类型转换,由编译器自动完成。 它用于处理不同数据类型之间的运算,例如将…...
集成Activiti-Modeler流程设计器
集成Activiti-Modeler流程设计器 Activiti Modeler 是 Activiti 官方提供的一款在线流程设计的前端插件,可以方便流程设计与开发人员绘制流程图,保存流程模型,部署至流程定义等等。 1、材料准备 首先我们需要获取activiti-explorer.zip&…...
【深度学习】 Python 和 NumPy 系列教程(十一):NumPy详解:3、数组数学(元素、数组、矩阵级别的各种运算)
目录 一、前言 二、实验环境 三、NumPy 0、多维数组对象(ndarray) 多维数组的属性 1、创建数组 2、数组操作 3、数组数学 1. 元素级别 a. 直接运算 b. 加法:np.add()函数 c. 减法:np.subtract()函数 d. 乘法…...
python难题切片处理
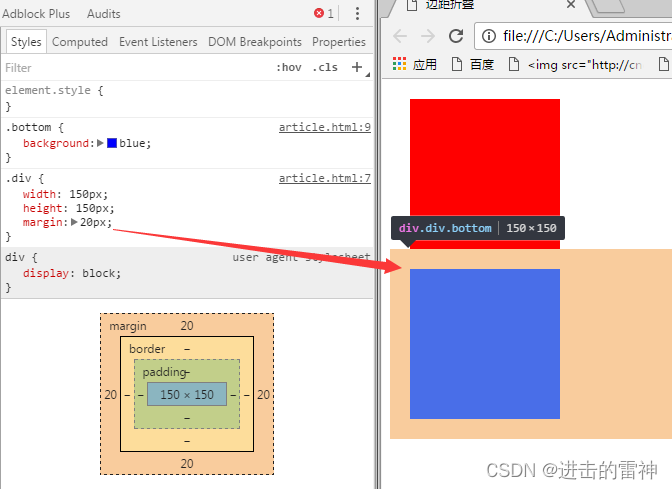
边距折叠 Html经常出现的一个外边距折叠,可能有人的不太理解,或者说不知道怎么解决、我们来着重来看下: 当两个div盒子模型连续出现的时候并且同时应用了一个margin外边距,会出现边距重叠的现象: .Div {width:150px; #定义公共的盒子样式 Height:150px; Margin:20p…...

《研发效能(DevOps)工程师(中级)认证》证书查询方式和路径丨IDCF
由国家工业和信息化部教育与考试中心颁发的职业技术证书,也是国内首个《研发效能(DevOps)工程师国家职业技术认证》,IDCF社区作为官方指定培训中心,邀请了多位业界知名专家讲师(部分专家讲师名单:王立杰、杜伟忠、陈老…...

NVR添加rtsp流模拟GB28181视频通道
一、海康、大华监控摄像头和硬盘录像机接入GB28181平台配置 1、海康设备接入配置 通过web登录NVR管理系统,进入网络,高级配置界面,填入GB28181相关参数。 将对应项按刚才获取的配置信息填入即可,下面的视频通道的编码ID可以保持…...

浅谈C++|文件篇
引子: 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放通过文件可以将数据持久化。C中对文件操作需要包含头文件< fstream > 。 C提供了丰富的文件操作功能,你可以使用标准库中的fstream库来进行文件的读取、写入和定位…...
C++ QT qml 学习之 做个登录界面
最近在学习QT,也初探到qml 做ui 的灵活性与强大,于是手痒痒,做个demo 记录下学习成果 主要内容是如何自己编写一个按钮以及qml多窗口。 参考WX桌面版,做一个登录界面,这里面按钮是写的一个组合控件,有 按…...

如何使用HyperUI打造无缝第三方集成:支付网关、地图与社交登录组件全指南
如何使用HyperUI打造无缝第三方集成:支付网关、地图与社交登录组件全指南 【免费下载链接】hyperui Free Tailwind CSS components for application UI, ecommerce and marketing with support for dark mode, RTL and Alpine JS 🚀 项目地址: https:/…...
轻量化适配可行性分析)
StructBERT情感分析部署案例:边缘设备(Jetson)轻量化适配可行性分析
StructBERT情感分析部署案例:边缘设备(Jetson)轻量化适配可行性分析 1. 引言:当情感分析遇上边缘计算 想象一下,一个智能客服机器人正在处理海量的用户咨询,它需要实时判断每一条消息背后的情绪是愤怒、满…...

浏览器音频处理与前端音频编码:基于LAMEJS的实现教程与优化策略
浏览器音频处理与前端音频编码:基于LAMEJS的实现教程与优化策略 【免费下载链接】lamejs mp3 encoder in javascript 项目地址: https://gitcode.com/gh_mirrors/la/lamejs 在现代Web应用开发中,音频处理已成为提升用户体验的关键环节。然而&…...

EPLAN2022 3D宏文件创建全流程:从模型导入到安装面定义的一站式教程
EPLAN2022 3D宏文件创建全流程:从模型导入到安装面定义的一站式教程 在电气工程设计领域,EPLAN作为行业标杆软件,其3D宏功能正在彻底改变工程师的工作方式。想象一下,当您能够将机械部件精准地映射到电气设计中,实现真…...

Nunchaku-flux-1-dev快速体验:无需安装,在线教程即刻生成第一张图
Nunchaku-flux-1-dev快速体验:无需安装,在线教程即刻生成第一张图 想试试最近挺火的Nunchaku-flux-1-dev模型,但又觉得本地部署太麻烦,光是装环境、配依赖就能劝退一大半人?别担心,今天带你体验一个完全不…...

LFM2.5-1.2B进阶技巧:3个方法控制AI写作长度、语气和角色
LFM2.5-1.2B进阶技巧:3个方法控制AI写作长度、语气和角色 你已经用Ollama把LFM2.5-1.2B-Thinking模型装进了电脑,也用它写过几篇文案。但有没有遇到过这种情况:让它“写一段简短介绍”,结果它洋洋洒洒写了三百字;让它…...
)
基于智慧校园的大学生综合能力测评系统毕业论文+PPT(附源代码+演示视频)
文章目录 一、项目简介1.1 运行视频1.2 🚀 项目技术栈1.3 ✅ 环境要求说明 前台运行截图后台运行截图项目部署源码下载 一、项目简介 项目基于SpringBoot框架,前后端分离架构,后端为SpringBoot前端Vue。本研究旨在设计并实现一个基于智慧校园…...

Windows下Vivim环境搭建实战:causal_conv1d与mamba_ssm的避坑指南
1. Windows下Vivim环境搭建全攻略 最近在复现Vivim这个基于Mamba的医疗视频分割模型时,发现很多小伙伴在Windows环境下配置causal_conv1d和mamba_ssm这两个核心库时频频踩坑。作为一个在Windows平台折腾过无数次环境搭建的老司机,今天我就把实战中积累的…...

Idea高效开发秘籍:从快捷键到性能优化全解析
1. 快捷键操作:指尖飞舞的代码艺术 第一次用Idea时,我被同事行云流水的操作惊呆了——他几乎不用鼠标,光靠键盘就能在几秒内完成类创建、方法跳转、代码重构。后来才发现,这都归功于精准的快捷键组合。比如用CtrlAltV提取变量时&a…...
如何通过HSTracker提升炉石传说对战效率:从入门到精通
如何通过HSTracker提升炉石传说对战效率:从入门到精通 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 你是否曾在炉石传说对战中因记不清对手已使用的卡牌而…...