【最新面试问题记录持续更新,java,kotlin,android,flutter】
最近找工作,复习了下java相关的知识。发现已经对很多概念模糊了。记录一下。部分是往年面试题重新整理,部分是自己面试遇到的问题。持续更新中~
目录
- java相关
- 1. 面向对象设计原则
- 2. 面向对象的特征是什么
- 3. 重载和重写
- 4. 基本数据类型
- 5. 装箱和拆箱
- 6. final 有什么作用
- 7. String是基本类型吗,可以被继承吗
- 8. String、StringBuffer和StringBuilder的区别?
- 8. 抽象类和接口的区别
- 9. String 类的常用方法都有那些?
- 10. Java 中 IO 流分为几种?
- 11. Java容器有哪些
- 12. Collection 和 Collections 有什么区别?
- 13. HashMap 和 Hashtable 有什么区别?
- 14. 如何决定使用 HashMap 还是 TreeMap?
- 15. 说一下 HashMap 的实现原理?
- 16. equals和 == 的区别
- 17. ConcurrentHashMap如何实现线程安全的
- 18. 说一下 HashSet 的实现原理?
- 19. ArrayList 和 LinkedList 的区别是什么?
- 20. ArrayList 和 Vector 的区别是什么?
- 21. Array 和 ArrayList 有何区别?
- 22. 在 Queue 中 poll()和 remove()有什么区别?
- 多线程
- 23. 并行和并发有什么区别?
- 24. 线程和进程的区别?
- 25. 守护线程是什么?
- 26. 创建线程有哪几种方式?
- 27. 说一下 runnable 和 callable 有什么区别?
- 28. 线程有哪些状态?
- 29. sleep() 和 wait() 有什么区别?
- 30. notify()和 notifyAll()有什么区别?
- 31. 线程的 run() 和 start() 有什么区别?
- 32. 为什么要使用线程池
- 33. 创建线程池有哪几种方式?
- 34. ThreadPoolExecutor了解吗?参数是什么意思
- 35. 线程池中 submit() 和 execute() 方法有什么区别?
- 36. 线程池都有哪些状态?
- 37. 知道线程池中线程复用原理吗?
- 38. 什么是死锁?
- 39. ThreadLocal 是什么?有哪些使用场景?
- 40. 说一下 synchronized 底层实现原理?
- 41. synchronized 和 volatile 的区别是什么?
- 42. synchronized 和 Lock 有什么区别?
- 43. synchronized 和 ReentrantLock 区别是什么?
- 44. 说一下 atomic 的原理?
- 45. 什么是反射?
- 46. 创建对象有几种方式
- 47. 使用过哪些设计模式?
- 48. 线程间如何通信?
- JVM相关
- 1. 简单介绍下jvm虚拟机模型
- 2. 类加载器子系统
- 3.运行时数据区
- 4. 执行引擎
- 5. 了解GC吗
- 6. 了解JMM吗
- 7. 类的加载过程,Person person = new Person();为例进行说明。
- kotlin
- 1. Kotlin如何实现空安全的?
- 2. 谈谈你对协程的理解
- 3. 了解密封类(Sealed Classes)吗
- 3. Kotlin中@JvmOverloads 的作用
- 4.Kotlin实现单例的几种方式
- 5. 了解Data Class吗?
- 6. 了解作用域函数吗?
- 7. 你觉得Kotlin与Java混合开发时需要注意哪些问题?
- 8. 知道什么是inline ,noinline和crossinline函数吗?
- 9. Kotlin中的构造方法
- 10. 说说Kotlin中的Any与Java中的Object有何异同?
- 11. 协程Flow是什么,有哪些应用场景?
- 12. 协程Flow的冷流和热流是什么?
- 13. 谈谈Kotlin中的Sequence,为什么它处理集合操作更加高效?
- android
- 1. Activity启动模式
- 2. Activity生命周期
- 3. 了解Service吗
- 4. 使用过broadcastReceiver吗?
- 5. 说说你对handler的理解
- 如何使用Handler?
- 主线程使用Handler为什么不用Looper.prepare()?
- 简述一下Handler的工作流程
- 一个线程中最多有多少个Handler,Looper,MessageQueue?
- Looper死循环为什么不会导致应用ANR、卡死,会耗费大量资源吗?
- Handler同步屏障了解吗
- Handler 为什么可能导致内存泄露?如何避免?
- Handler是如何实现线程间通讯的
- Handler消息处理的优先级
- 如何正确或Message实例
- Android 为什么不允许并发访问 UI?
- 了解ThreadLocal吗
- ThreadLocal与内存泄漏
- Message 的执行时刻如何管理
- Looper等待如何准确唤醒的?
- Handler机制原理
- 6. 了解View绘制流程吗?
- 7. 自定义View流程是什么
- 8. 了解View事件分发机制吗
- 9. ListVie和RecycleView的区别
- 1. 优化
- 2. 布局不同
- 3. 更新数据
- 4. 自定义适配器
- 5. 绑定事件不同
- 10. 展开讲讲recycleView
- recycleView的缓存了解吗
- 问题1. RecyclerView第一次layout时,会发生预布局pre-layout吗
- 问题2. 如果自定义LayoutManager需要注意什么?
- 问题3. CachedView和RecycledViewPool两者区别
- 问题4. 你是从哪些方面优化RecyclerView的?
- 11. 你知道IPC吗?
- 12. 展开说说Binder
- 问题1. Binder实现原理是什么
- 13. 了解MVC,MVP,MVVM吗?
- 14. 使用过jetpack库吗?
- 1. LifeCycle原理
- 问题 1. LifeCycle怎么做到监听LifecycleOwner(Activity或Fragment)的生命周期的?
- 2. Room
- 3. LiveData
- observe和observeForever区别
- LiveData粘性事件和数据倒灌
- 4. DataBinding
- 15. launcher页面点击app图标启动过程了解吗?以点击淘宝为例。
- 16. 为什么用到socket又用到Binder,为什么不统一用binder呢?
- 17. context 和 activity的区别
- 18. 一个应用程序中有多少个context?
- 开源框架篇
- 1. OKHTTP了解吗?
- 问题 1. 知道OkHttp有几个拦截器以及作用吗吗?
- 问题 2. OkHttp怎么实现连接池
- 问题 3. 简述一下OkHttp的一个工作流程
- 问题 4. Okhttp 如何实现缓存功能?它是如何根据 Cache-Control 首部来判断缓存策略的?
- 问题 5. Okhttp 如何自定义拦截器?你有没有使用过或编写过自己的拦截器?
- 问题 6. Okhttp 如何管理连接池和线程池?它是如何复用和回收连接的?
- 2. Glide了解吗?
- 3. EventBus了解吗?
- 架构方面
- 1. 组件化
- 聊聊你对Arouter的理解
- APT是什么
- 什么是注解?有哪些注解?
- 2. 插件化
- Flutter
- 1. dart中的作用域与了解吗
- 2. dart中. .. ...分别是什么意思?
- 3. Dart 是不是单线程模型?如何运行的?
- 4. Dart既然是单线程模型支持多线程吗?
- 5. Future是什么
- 6. Stream是什么
- 7. Flutter 如何和原生交互
- 8. 说一下 mixin?
- 9. StatefulWidget 的生命周期
- 10. main()和runApp()函数在flutter的作用分别是什么?有什么关系吗?
- 11. 怎么理解Isolate?
- 12. 简单介绍下Flutter框架,以及它的优缺点?
- 12. 简述Widgets、RenderObjects 和 Elements的关系
- 13. 介绍下Widget、State、Context 概念
- 14. 简述Widget的StatelessWidget和StatefulWidget两种状态组件类
- 15. 什么是状态管理,你了解哪些状态管理框架?
- 16. 简述Flutter的绘制流程
- 17. await for 如何使用?
- 18. 介绍下Flutter的架构
- 19. 介绍下Flutter的FrameWork层和Engine层,以及它们的作用
- 20. Dart中var与dynamic的区别
- 21. const关键字与final关键字的区别
- 22. Flutter在Debug和Release下分别使用什么编译模式,有什么区别?
- 23. 什么是Key?
- 24. future 和steam有什么不一样?
- 25. 什么是widget? 在flutter里有几种类型的widget?
- 26. statefulWidget更新流程了解吗
java相关
1. 面向对象设计原则
- 面向对象设计原则
- 单一职责原则——SRP
一个类的职责尽量单一,清晰。即一个类最好专注做一件事情,而不是分散的做好几件事。
每个类都只负责一项任务,可以降低类的复杂性;提高可读性;提高系统可维护性;避免类的臃肿和功能太多太复杂。 - 依赖倒置原则——DIP
实现时尽量依赖抽象,而不依赖于具体实现。
可以减少类间的耦合性,提高系统稳定性
提高代码的可读性,可维护性以及扩展性。 - 接口隔离原则——ISP
即应当为客户端提供尽可能小的单独的接口,而不是大而杂的接口。
也就是要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。依赖几个专用的接口要比依赖一个综合的接口更灵活。 - 里氏替换原则——LSP
即超类存在的地方,子类是可以替换的。
里氏替换原则是实现开闭原则的重要方式之一,由于使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用子类对象来替换父类对象。 - 迪米特原则——LOD
即一个软件实体应当尽可能少的与其他实体发生相互作用。
一个对象对另一个对象知道的越少越好,即一个软件实体应当尽可能少的与其他实体发生相互作用,在一个类里能少用多少其他类就少用多少,尤其是局部变量的依赖类,能省略尽量省略。 - 开闭原则——OCP
面向修改关闭,面向扩展开放。
即一个软件、一套系统在开发完成后,当有增加或修改需求时,应该对拓展代码打开,对修改原有代码关闭
2. 面向对象的特征是什么
- 封装
把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。 - 继承
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。
被继承的类称为“基类”、“父类”或“超类”。
继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。 - 多态
就是指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。
实现多态一般通过重写和重载
封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了——代码重用。而多态则是为了实现另一个目的——接口重用!多态的作用,就是为了类在继承和派生的时候,保证使用“家谱”中任一类的实例的某一属性时的正确调用。
3. 重载和重写
- 重写
是指子类重新定义父类的虚函数的做法。需要保持参数个数,类型,返回类型完全一致。
属于运行时多态的表现 - 重载
是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)
其实,重载的概念并不属于“面向对象编程”,重载的实现是:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数(至少对于编译器来说是这样的)。如,有两个同名函数:function func(p:integer):integer;和function func(p:string):integer;。那么编译器做过修饰后的函数名称可能是这样的:int_func、str_func。对于这两个函数的调用,在编译器间就已经确定了,是静态的(记住:是静态)
4. 基本数据类型
| 数据类型 | 位数 | 默认值 | 取值范围 | 示例 |
|---|---|---|---|---|
| byte | 1字节 | 0 | -2(128~127) | byte a = 10; |
| short | 2字节 | 0 | -2(-32768~32767) | short a = 10; |
| int | 4字节 | 0 | (-2147483648~2147483647) | int a = 10; |
| float | 4字节 | 0.0 | -2(-2147483648~2147483647) | float a = 10; |
| long | 8字节 | 0 | -2(-9223372036854774808~9223372036854774807) | long a = 10; |
| double | 8字节 | 0.0 | -2(-9223372036854774808~9223372036854774807) | char a = 10; |
| char | 2字节 | 空 | -2(128~127) | char a = ‘a’; |
| boolean | 1字节 | false | true、false | booleana = true; |
| 特殊类型void |
对应的包装类
byte——Byte
short——Short
int ——Integer
float——Float
long——Long
double——Double
char——Character
boolean——Boolean
void——Void
包装类出现的原因是Java语言是面对对象的编程语言,而基本数据类型声明的变量并不是对象,为其提供包装类,增强了Java面向对象的性质。
void是一个特殊的类型,有人把它归到Java基本数据类型中,是因为可以通过Class.getPrimitiveClass(“void”)获取对应的原生类型。
void有个对应的类型Void,可以把它看做是void的包装类,Void的作用主要作用有以下2个:
- 泛型占位
当我们定义了泛型时,如果没有写泛型参数,idea等开发工具会给出提醒,建议写上泛型类型,但实际上却是不需要固定的泛型类型,这时候据可以写上Void来消除警告,例如ResponseData - 反射获取void方法
Method[] methods = String.class.getMethods();
for (Method method : methods) {if(method.getGenericReturnType().equals(Void.TYPE)){System.out.println(method.getName());}
}
//输出:
//getBytes
//getChars
//wait
//wait
//wait
//notify
//notifyAll
5. 装箱和拆箱
将基本数据类型转化为包装类就叫做装箱;
调用 包装类.valueOf()方法
int a = 22;//装箱 在实例化时候进行装箱Integer inter1 = new Integer(a);//装箱 调用valueOf方法进行装箱Integer inter2 = Integer.valueOf(a);valueOf 方法是一个静态方法,直接通过类进行调用
拆箱
将包装类转化为基本数据类型;
调用 包装类.parseXXX()方法
int a = Integer.parseInt("3");
6. final 有什么作用
- final 修饰的类叫最终类,该类不能被继承。
- final 修饰的方法不能被重写。
- final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
7. String是基本类型吗,可以被继承吗
String不是基本类型,不可以被继承。因为String被final关键字修饰,不可以被继承
public final class String implements Serializable, Comparable<String>, CharSequence {
8. String、StringBuffer和StringBuilder的区别?
String 大小固定数不可变的。
因为String是字符串常量,是不可变的。实际的拼接操作最后都是产生了一个新的对象并存储这个结果
String str1 = "123";
String str2 = "123"//实际上 "123"这个字符串在常量池中只有一份,str1,str2 两个对象都是指向"123"
str2 = str2 + "45";
实际上是产生了个新的String对象存放"12345"这个结果
查看字节码实际代码是0 ldc #2 <123>2 astore_13 new #3 <java/lang/StringBuilder>6 dup7 invokespecial #4 <java/lang/StringBuilder.<init> : ()V>
10 aload_1
11 invokevirtual #5 <java/lang/StringBuilder.append : (Ljava/lang/String;)Ljava/lang/StringBuilder;>
14 ldc #6 <45>
16 invokevirtual #5 <java/lang/StringBuilder.append : (Ljava/lang/String;)Ljava/lang/StringBuilder;>
19 invokevirtual #7 <java/lang/StringBuilder.toString : ()Ljava/lang/String;>
22 astore_1
23 return
//实际也是通过 StringBuilder.append方法实现拼接,然后toString的性能比较低
//所以字符串拼接直接使用StringBuilder实现效率更高
StringBuffer 大小可变,线程安全(有锁),同步,效率低,适用于多线程,低并发。
StringBuilder 大小可变,线程不安全(无锁),不同步,效率高,适用于单线程,高并发。
8. 抽象类和接口的区别
- 抽象类是对事物属性的抽象,接口是对行为的抽象,是一种规范或者说行为约束。
- 抽象类关键词abstract 接口关键字interface
- 抽象类可以有成员变量,普通方法和抽象方法,接口只能有抽象方法(只有方法定义,无具体函数实现)
- 抽象类可以有构造方法,接口没有构造方法
- 继承了抽象类的子类,要么对父类的抽象方法进行重写,要么自己也是抽象类
- 抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
- 实现数量:类可以实现很多个接口;但是只能继承一个抽象类。
- 访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的方法可以是任意访问修饰符。
-
9. String 类的常用方法都有那些?
- inexOf():返回指定字符的索引。
- charAt():返回指定索引处的字符。
- replace():字符串替换。
- trim():去除字符串两端空白。
- split():分割字符串,返回一个分割后的字符串数组。
- getBytes():返回字符串的 byte 类型数组。
- length():返回字符串长度。
- toLowerCase():将字符串转成小写字母。
- toUpperCase():将字符串转成大写字符。
- substring():截取字符串。
- equals():字符串比较。
-
10. Java 中 IO 流分为几种?
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。11. Java容器有哪些
Java 容器分为 Collection 和 Map 两大类,其下又有很多子类,如下所示: - Collection
- List
- ArrayList
- LinkedList
- Vector
- Stack
- Set
- HashSet
- LinkedHashSet
- TreeSet
- List
- Map
- HashMap
- LinkedHashMap
- TreeMap
- ConcurrentHashMap
- Hashtable
- HashMap
12. Collection 和 Collections 有什么区别?
- Collection 是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的子类,比如 List、Set 等。
- Collections 是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法:Collections. sort(list)。
13. HashMap 和 Hashtable 有什么区别?
- 存储:HashMap 允许 key 和 value 为 null,而 Hashtable 不允许。
- 线程安全:Hashtable 是线程安全的,而 HashMap 是非线程安全的。
- 推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
14. 如何决定使用 HashMap 还是 TreeMap?
对于在 Map 中插入、删除、定位一个元素这类操作,HashMap 是最好的选择,因为相对而言 HashMap 的插入会更快,但如果你要对一个 key 集合进行有序的遍历,那 TreeMap 是更好的选择
15. 说一下 HashMap 的实现原理?
HashMap 基于 Hash 算法实现的,我们通过 put(key,value)存储,get(key)来获取。当传入 key 时,HashMap 会根据 key. hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。当 hash 冲突的个数比较少时,使用链表否则使用红黑树。
jdk1.7以前使用数组+链表实现HashMap,jdk1.8以后用数组+红黑树实现。当链表长度较短时使用链表,长度达到阈值时自动转换为红黑树,提高查询效率。
- 其它问题
- 默认大小 16 ,负载因子0.75 大小到达12时 自动两倍扩容。
16. equals和 == 的区别
- 对于 == 来说:
如果比较的是基本数据类型变量,比较两个变量的值是否相等。(不一定数据类型相同)
如果比较的是引用数据类型变量,比较两个对象的地址值是否相同,即两个引用是否指向同一个地址值 - 对于 equals 来说:
如果类中重写了equals方法,比较内容是否相等。
String、Date、File、包装类都重写了Object类的equals方法。
如果类中没有重写equals方法,比较地址值是否相等(是否指向同一个地址值)。
Student stu1 = new Student(11, "张三");
Student stu2 = new Student(11,"张三");
System.out.println(stu1.equals(stu2));//false
既然equals比较的是内容是否相同,为什么结果还是false呢?
回顾知识:
在Java中我们知道任何类的超类都是Object类,Student类也继承Object类。
查看Object类中的equals方法也是 == 比较(也就是比较地址值),因此结果当然是false。
public boolean equals(Object obj) {return (this == obj);}
既然这样我们如何保证两个对象内容相同呢?
这里就需要我们去重写equals方法?
@Overridepublic boolean equals(Object obj){if (this == obj){return true;}if (obj instanceof Student) {Student stu = (Student)obj;return this.age == stu.age && this.name.equals(stu.name);}return false;}
17. ConcurrentHashMap如何实现线程安全的
-
jdk 1.7以前结构是segment数组 + HashEntry数组 + 链表,使用分段式锁,实现线程安全。容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这 样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的”分段锁”思想,见下图:
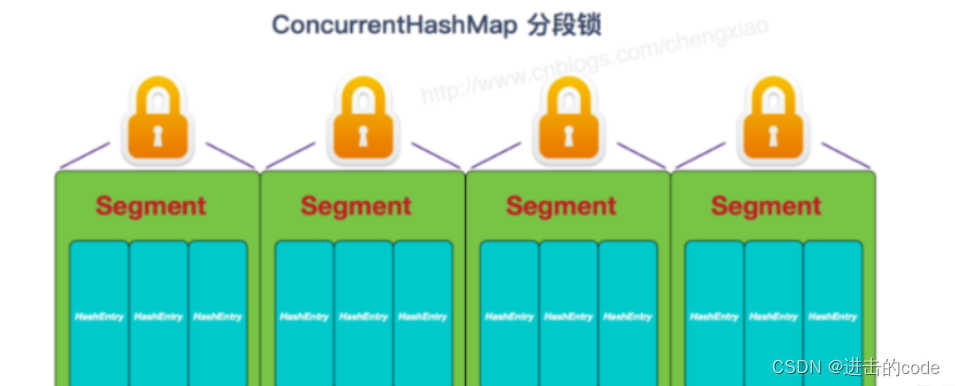
get()操作:
HashEntry中的value属性和next指针是用volatile修饰的,保证了可见性,所以每次获取的都是最新值,get过程不需要加锁。
1.将key传入get方法中,先根据key的hashcode的值找到对应的segment段。
2.再根据segment中的get方法再次hash,找到HashEntry数组中的位置。
3.最后在链表中根据hash值和equals方法进行查找。
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
put()操作:
1.将key传入put方法中,先根据key的hashcode的值找到对应的segment段
2.再根据segment中的put方法,加锁lock()。
3.再次hash确定存放的hashEntry数组中的位置
4.在链表中根据hash值和equals方法进行比较,如果相同就直接覆盖,如果不同就插入在链表中。 -
jdk1.8以后结构是 数组+Node+红黑树实现,采用**Synchronized + CAS(自旋锁)**保证线程安全。Node的val和next都用volatile保证,保证可见性,查找,替换,赋值操作都使用CAS
为什么在有Synchronized 的情况下还要使用CAS
因为CAS是乐观锁,在一些场景中(并发不激烈的情况下)它比Synchronized和ReentrentLock的效率要高,当CAS保障不了线程安全的情况下(扩容或者hash冲突的情况下)转成Synchronized
来保证线程安全,大大提高了低并发下的性能.
锁 :
锁是锁的链表的head的节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写操作(因为扩容的时候使用的是Synchronized锁,锁全表),并发扩容.
读操作无锁 :
-
Node的val和next使用volatile修饰,读写线程对该变量互相可见
-
数组用volatile修饰,保证扩容时被读线程感知
-
get()操作:
get操作全程无锁。get操作可以无锁是由于Node元素的val和指针next是用volatile修饰的。
在多线程环境下线程A修改节点的val或者新增节点的时候是对线程B可见的。
1.计算hash值,定位到Node数组中的位置
2.如果该位置为null,则直接返回null
3.如果该位置不为null,再判断该节点是红黑树节点还是链表节点
如果是红黑树节点,使用红黑树的查找方式来进行查找
如果是链表节点,遍历链表进行查找 -
put()操作:
1.先判断Node数组有没有初始化,如果没有初始化先初始化initTable();
2.根据key的进行hash操作,找到Node数组中的位置,如果不存在hash冲突,即该位置是null,直接用CAS插入
3.如果存在hash冲突,就先对链表的头节点或者红黑树的头节点加synchronized锁
4.如果是链表,就遍历链表,如果key相同就执行覆盖操作,如果不同就将元素插入到链表的尾部, 并且在链表长度大于8, Node数组的长度超过64时,会将链表的转化为红黑树。
5.如果是红黑树,就按照红黑树的结构进行插入。
18. 说一下 HashSet 的实现原理?
- HashSet 是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
19. ArrayList 和 LinkedList 的区别是什么?
- 数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
- 随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数
- 存储方式,所以需要移动指针从前往后依次查找。
- 增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
20. ArrayList 和 Vector 的区别是什么?
- 线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
- 性能:ArrayList 在性能方面要优于 Vector。
- 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
21. Array 和 ArrayList 有何区别?
- Array 可以存储基本数据类型和对象,ArrayList 只能存储对象。
- Array 是指定固定大小的,而 ArrayList 大小是自动扩展的。
- Array 内置方法没有 ArrayList 多,比如 addAll、removeAll、iteration 等方法只有 ArrayList 有。
22. 在 Queue 中 poll()和 remove()有什么区别?
- 相同点:都是返回第一个元素,并在队列中删除返回的对象。
- 不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
多线程
23. 并行和并发有什么区别?
- 并行:多个处理器或多核处理器同时处理多个任务。
- 并发:多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上来看那些任务是同时执行。
24. 线程和进程的区别?
- 进程是cpu资源分配的基本单位
- 线程是cpu调度和执行的最小单位
- 一个程序下至少有一个进程,一个进程下至少有一个线程,一个进程下也可以有多个线程来增加程序的执行速度。
25. 守护线程是什么?
- 守护线程是运行在后台的一种特殊线程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。在 Java 中垃圾回收线程就是特殊的守护线程。
26. 创建线程有哪几种方式?
- 继承 Thread 重写 run 方法;
- 实现 Runnable 接口;
- 实现 Callable 接口。
27. 说一下 runnable 和 callable 有什么区别?
- runnable 没有返回值,callable 可以拿到有返回值,callable 可以看作是 runnable 的补充。
28. 线程有哪些状态?
线程的状态:
- NEW 尚未启动
- RUNNABLE 就绪态
- RUNNING 运行中
- BLOCKED 阻塞的(被同步锁或者IO锁阻塞)
- WAITING 永久等待状态
- TIMED_WAITING 等待指定的时间重新被唤醒的状态
- TERMINATED 执行完成

29. sleep() 和 wait() 有什么区别?
- 类的不同:sleep() 来自 Thread,wait() 来自 Object。
- 释放锁:sleep() 不释放锁;wait() 释放锁。
- 用法不同:sleep() 时间到会自动恢复;wait() 可以使用 notify()/notifyAll()直接唤醒。
30. notify()和 notifyAll()有什么区别?
- notifyAll()会唤醒所有的线程,notify()之后唤醒一个线程。notifyAll() 调用后,会将全部线程由等待池移到锁池,然后参与锁的竞争,竞争成功则继续执行,如果不成功则留在锁池等待锁被释放后再次参与竞争。而 notify()只会唤醒一个线程,具体唤醒哪一个线程由虚拟机控制。
31. 线程的 run() 和 start() 有什么区别?
- start() 方法用于启动线程,run() 方法用于执行线程的运行时代码。run() 可以重复调用,而 start() 只能调用一次。
- 直接调用run方法,不会在线程中执行,只是相当于执行了一个普通的方法。
32. 为什么要使用线程池
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。
33. 创建线程池有哪几种方式?
线程池创建有七种方式,最核心的是最后一种:
- newSingleThreadExecutor():它的特点在于工作线程数目被限制为 1,操作一个无界的工作队列,所以它保证了所有任务的都是被顺序执行,最多会有一个任务处于活动状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目;
- newCachedThreadPool():它是一种用来处理大量短时间工作任务的线程池,具有几个鲜明特点:它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程;如果线程闲置的时间超过 60 秒,则被终止并移出缓存;长时间闲置时,这种线程池,不会消耗什么资源。其内部使用 SynchronousQueue 作为工作队列;
- newFixedThreadPool(int nThreads):重用指定数目(nThreads)的线程,其背后使用的是无界的工作队列,任何时候最多有 nThreads 个工作线程是活动的。这意味着,如果任务数量超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线程退出,将会有新的工作线程被创建,以补足指定的数目 nThreads;
- newSingleThreadScheduledExecutor():创建单线程池,返回 ScheduledExecutorService,可以进行定时或周期性的工作调度;
- newScheduledThreadPool(int corePoolSize):和newSingleThreadScheduledExecutor()类似,创建的是个 ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程;
- newWorkStealingPool(int parallelism):这是一个经常被人忽略的线程池,Java 8 才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序;
- ThreadPoolExecutor():是最原始的线程池创建,上面1-3创建方式都是对ThreadPoolExecutor的封装。
34. ThreadPoolExecutor了解吗?参数是什么意思
- corePoolSize: 线程池中的核心线程数,默认情况下核心线程一直存活在线程池中,如果将ThreadPoolExecutor 的 allowCoreThreadTimeOut 属性设为 true,如果线程池一直闲置并超过了 keepAliveTime 所指定的时间,核心线程就会被终止。
- maximumPoolSize: 最大线程数,当线程不够时能够创建的最大线程数(包含核心线程数)
临时线程数 = 最大线程数 - 核心线程数
- keepAliveTime: 线程池的闲置超时时间,默认情况下对非核心线程生效,如果闲置时间超过这个时间,非核心线程就会被回收。如果 ThreadPoolExecutor 的 allowCoreThreadTimeOut 设为 true 的时候,核心线程如果超过闲置时长也会被回收。
- unit: 配合 keepAliveTime 使用,用来标识 keepAliveTime 的时间单位。
- workQueue: 线程池中的任务队列,使用 execute() 或 submit() 方法提交的任务都会存储在此队列中。
- threadFactory: 为线程池提供创建新线程的线程工厂。
- rejectedExecutionHandler: 线程池任务队列超过最大值之后的拒绝策略, RejectedExecutionHandler 是一个接口,里面只有一个rejectedExecution方法,可在此方法内添加任务超出最大值的事件处理;
ThreadPoolExecutor 也提供了 4 种默认的拒绝策略:
- DiscardPolicy():丢弃掉该任务但是不抛出异常,不推荐这种(导致使用者没觉察情况发生)
- DiscardOldestPolicy():丢弃队列中等待最久的任务,然后把当前任务加入队列中。
- AbortPolicy():丢弃任务并抛出 RejectedExecutionException 异常(默认)。
- CallerRunsPolicy():由主线程负责调用任务的run()方法从而绕过线程池直接执行,既不抛弃任务也不抛出异常(当最大线程数满了,任务队列中也满了,再来一个任务,由主线程执行)

35. 线程池中 submit() 和 execute() 方法有什么区别?
- execute():只能执行 Runnable 类型的任务。
- submit():可以执行 Runnable 和 Callable 类型的任务。
- Callable 类型的任务可以获取执行的返回值,而 Runnable 执行无返回值。
36. 线程池都有哪些状态?
- RUNNING:这是最正常的状态,接受新的任务,处理等待队列中的任务。
- SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
- TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()。
- TERMINATED:terminated()方法结束后,线程池的状态就会变成这个。

37. 知道线程池中线程复用原理吗?
- 线程池将线程和任务进行解耦,线程是线程,任务是任务,摆脱了之前通过 Thread 创建线程时的一个线程必须对应一个任务的限制。
- 在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对 Thread 进行了封装,并不是每次执行任务都会调用 Thread.start() 来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停的检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的 run 方法,将 run 方法当成一个普通的方法执行,通过这种方式将只使用固定的线程就将所有任务的 run 方法串联起来。
38. 什么是死锁?
- 当线程 A 持有独占锁a,并尝试去获取独占锁 b 的同时,线程 B 持有独占锁 b,并尝试获取独占锁 a 的情况下,就会发生 AB 两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。
39. ThreadLocal 是什么?有哪些使用场景?
- ThreadLocal 为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
40. 说一下 synchronized 底层实现原理?
- synchronized 是由一对 monitorenter/monitorexit 指令实现的,monitor 对象是同步的基本实现单元。在 Java 6 之前,monitor 的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作,性能也很低。但在 Java 6 的时候,Java 虚拟机 对此进行了大刀阔斧地改进,提供了三种不同的 monitor 实现,也就是常说的三种不同的锁:偏向锁(Biased Locking)、轻量级锁和重量级锁,大大改进了其性能。
41. synchronized 和 volatile 的区别是什么?
- volatile 是变量修饰符;synchronized 是修饰类、方法、代码段。
- volatile 仅能实现变量的修改可见性,不能保证原子性;而 synchronized 则可以保证变量的修改可见性和原子性。
- volatile 不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
42. synchronized 和 Lock 有什么区别?
- synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
- synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
43. synchronized 和 ReentrantLock 区别是什么?
synchronized 早期的实现比较低效,对比 ReentrantLock,大多数场景性能都相差较大,但是在 Java 6 中对 synchronized 进行了非常多的改进。
主要区别如下:
- ReentrantLock 使用起来比较灵活,但是必须有释放锁的配合动作;
- ReentrantLock 必须手动获取与释放锁,而 synchronized 不需要手动释放和开启锁;
- ReentrantLock 只适用于代码块锁,而 synchronized 可用于修饰方法、代码块等。
44. 说一下 atomic 的原理?
- Atomic包中的类基本的特性就是在多线程环境下,当有多个线程同时对单个(包括基本类型及引用类型)变量进行操作时,具有排他性,即当多个线程同时对该变量的值进行更新时,仅有一个线程能成功,而未成功的线程可以向自旋锁一样,继续尝试,一直等到执行成功。
45. 什么是反射?
- 反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
46. 创建对象有几种方式
- 4种
- new 关键字
Example example = new Example();
- 反射 这是我们运用反射创建对象时最常用的方法。Class类的newInstance使用的是类的public的无参构造器。因此也就是说使用此方法创建对象的前提是必须有public的无参构造器才行,否则报错
// 1.
Example example = Example.class.newInstance();
// 2.Constructor.newInstance
// 本方法和Class类的newInstance方法很像,但是比它强大很多。 java.lang.relect.Constructor类里也有一个newInstance方法可以
//创建对象。我们可以通过这个newInstance方法调用有参数(不再必须是无参)的和私有的构造函数(不再必须是public)。
Constructor<?>[] declaredConstructors = test.class.getDeclaredConstructors();
Constructor<?> noArgsConstructor = declaredConstructors[0];
noArgsConstructor.setAccessible(true); // 非public的构造必须设置true才能用于创建实例
Object test = noArgsConstructor.newInstance();
- 克隆 无论何时我们调用一个对象的clone方法,JVM就会创建一个新的对象,将前面的对象的内容全部拷贝进去,用clone方法创建对象并不会调用任何构造函数。 要使用clone方法,我们必须先实现Cloneable接口并复写Object的clone方法。
public class Test {String b = "123";@Overridepublic Test clone() throws CloneNotSupportedException {return (Test) super.clone();}public Test() {Log.d("TAGGG", "print: init ");}
}public class Main {public static void main(String[] args) throws Exception {Test test= new Test();Object clone = Test.clone();System.out.println(test);System.out.println(clone);System.out.println(test == clone); //false}
}
- 反序列化 当我们序列化和反序列化一个对象,JVM会给我们创建一个单独的对象,在反序列化时,JVM创建对象并不会调用任何构造函数。为了反序列化一个对象,我们需要让我们的类实现Serializable接口。
public class Main {public static void main(String[] args) throws Exception {Test test= new Test();byte[] bytes = SerializationUtils.serialize(test);// 字节数组:可以来自网络、可以来自文件(本处直接本地模拟)Object deserTest = SerializationUtils.deserialize(bytes);System.out.println(test);System.out.println(deserTest);System.out.println(test == deserTest);}
}
47. 使用过哪些设计模式?
- 设计模式可分为三大类
- 创建型模式——对象实例化的模式,创建型模式用于解耦对象的实例化过程。
- 单例模式:某个类只能有一个实例,提供一个全局的访问点。
- 工厂方法模式:一个工厂类根据传入的参量决定创建出哪一种产品类的实例。
- 抽象工厂模式:创建相关或依赖对象的家族,而无需明确指定具体类。
- 建造者模式:封装一个复杂对象的创建过程,并可以按步骤构造。
- 原型模式:通过复制现有的实例来创建新的实例。
- 结构型模式——把类或对象结合在一起形成一个更大的结构。
- 装饰器模式:动态的给对象添加新的功能。
- 代理模式:为其它对象提供一个代理以便控制这个对象的访问。
- 桥接模式:将抽象部分和它的实现部分分离,使它们都可以独立的变化。
- 适配器模式:将一个类的方法接口转换成客户希望的另一个接口。
- 组合模式:将对象组合成树形结构以表示“部分-整体”的层次结构。
- 外观模式:对外提供一个统一的方法,来访问子系统中的一群接口。
- 享元模式:通过共享技术来有效的支持大量细粒度的对象。
- 行为型模式
- 策略模式:定义一系列算法,把他们封装起来,并且使它们可以相互替换。
- 模板方法模式:定义一个算法结构,而将一些步骤延迟到子类实现。
- 命令模式:将命令请求封装为一个对象,使得可以用不同的请求来进行参数化。
- 迭代器模式:一种遍历访问聚合对象中各个元素的方法,不暴露该对象的内部结构。
- 察者模式:对象间的一对多的依赖关系。
- 仲裁者模式:用一个中介对象来封装一系列的对象交互。
- 备忘录模式:在不破坏封装的前提下,保持对象的内部状态。
- 解释器模式:给定一个语言,定义它的文法的一种表示,并定义一个解释器。
- 状态模式:允许一个对象在其对象内部状态改变时改变它的行为。
- 责任链模式:将请求的发送者和接收者解耦,使的多个对象都有处理这个请求的机会。
- 访问者模式:不改变数据结构的前提下,增加作用于一组对象元素的新功能。
- 创建型模式——对象实例化的模式,创建型模式用于解耦对象的实例化过程。
48. 线程间如何通信?
- 使用共享变量:多个线程可以通过共享变量来进行通信。通过对共享变量的读写操作,一个线程可以向另一个线程传递信息。
- 使用wait()和notify()方法:线程可以通过调用wait()方法来等待某个条件的满足,而其他线程可以通过调用notify()方法来通知等待的线程条件已经满足。
- 使用Lock和Condition:Java并发包中的Lock和Condition接口提供了一种更灵活的线程通信机制。通过Lock接口的newCondition()方法可以获得一个Condition对象,线程可以通过调用Condition对象的await()方法等待某个条件的满足,而其他线程可以通过调用Condition对象的signal()或signalAll()方法来通知等待的线程条件已经满足。
- 使用管道(PipedInputStream和PipedOutputStream):管道是一种特殊的流,可以用于在两个线程之间传递数据。一个线程可以将数据写入管道的输出流,而另一个线程可以从管道的输入流中读取数据。
- 使用阻塞队列:Java并发包中的阻塞队列(BlockingQueue)提供了一种线程安全的队列实现,可以用于在多个线程之间传递数据。一个线程可以将数据放入队列中,而另一个线程可以从队列中取出数据。
- 使用信号量(Semaphore):信号量是一种计数器,用于控制同时访问某个资源的线程数。线程可以通过调用信号量的acquire()方法获取一个许可,从而允许同时访问资源的线程数减少;线程可以通过调用信号量的release()方法释放一个许可,从而允许同时访问资源的线程数增加。
- 使用CountDownLatch:CountDownLatch是一种同步工具类,可以用于控制一个或多个线程等待其他线程执行完毕后再继续执行。一个线程可以通过调用CountDownLatch的await()方法等待其他线程执行完毕,而其他线程可以通过调用CountDownLatch的countDown()方法告知自己已经执行完毕。
- 使用CyclicBarrier:CyclicBarrier是一种同步工具类,可以用于控制多个线程在某个屏障处等待,直到所有线程都到达屏障后才继续执行。每个线程可以通过调用CyclicBarrier的await()方法等待其他线程到达屏障,而当所有线程都到达屏障后,屏障会自动打开,所有线程可以继续执行。
JVM相关
1. 简单介绍下jvm虚拟机模型
分为三个部分
- 类加载子系统(Class Loader Sub System)
- 运行时数据区(Runtime Data Area)
- 执行引擎、本地方法接口(本地方法库)(Execution Engine)
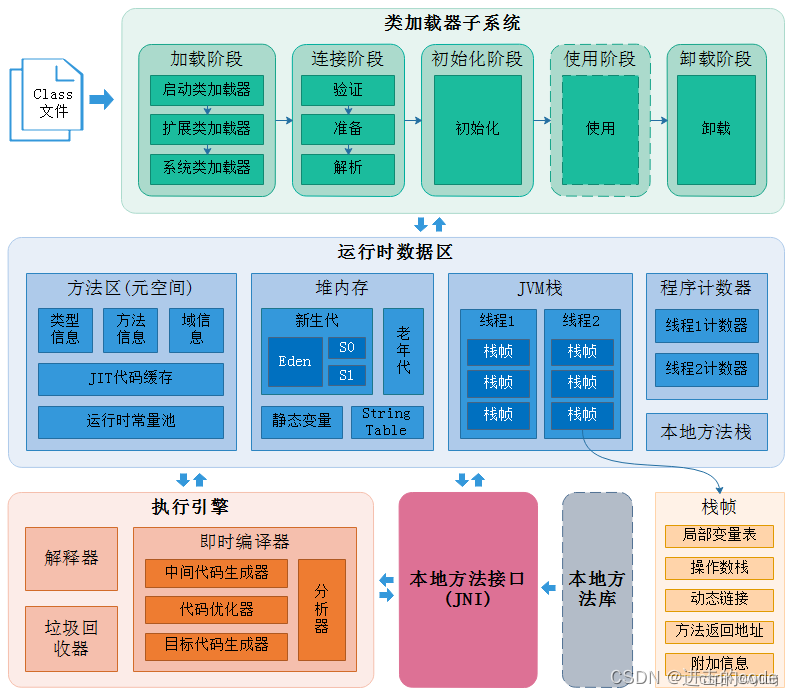
2. 类加载器子系统
Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被称作虚拟机的类加载机制。
-
类加载流程
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载,验证,准备,解析,初始化,使用,卸载这7个阶段,其中其中验证、准备、解析3个部分统称为连接。JVM没有规定类加载的时机,但却严格规定了五种情况下必须立即对类进行初始化,加载自然要在此之前。- 运行JVM必须指定一个含有main方法的主类,虚拟机会先初始化这个类。
- 遇到new、getstatic、putstatic、invokestatic这四条指令时,如果类没有被初始化,则首先对类进行初始化。
- 使用java.lang.reflect包的方法对类进行反射调用时,若类没有进行初始化,则触发其初始化。
- 当初始化一个类时假如该类的父类没有进行初始化,首先触发其父类的初始化。
- 当使用Jdk1.7的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果REF_getstatic、 - REF_putstatic、REF_inokestatic的方法句柄,并且这个方法句柄所对应的类没有进行初始化时,触发该类初始化。
-
1、加载
在加载的过程中,虚拟机会完成以下三件事情:- 通过一个类的全限定名加载该类对应的二进制字节流。
- 将字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区各个类访问该类的入口。
-
2、验证
这一步的目的是为了确保class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。具体验证的东西如下:- 文件格式验证:这里验证的时字节流是否符合Class文件格式的规范,并且能被当前版本的虚拟机处理,例如:是否以 0xCAFEBABE开头、主次版本号是否在当前虚拟机的处理范围之内、常量池中的常量是否有不被支持的类型。
- 元数据的验证:就是对字节码描述的信息进行语义分析,以保证其描述的信息符合Java语言规范的要求,例如:这个类是否有父类,除了 java.lang.Object之外。
- 字节码校验:字节码验证也是验证过程中最为复杂的一个过程。它试图通过对字节码流的分析,判断字节码是否可以被正确地执行。比如:① 在字节码的执行过程中,是否会跳转到一条不存在的指令。② 函数的调用是否传递了正确类型的参数。③ 变量的赋值是不是给了正确的数据类型等。
- 符号引用验证:虚拟机在将符号引用转化为直接引用,验证符号引用全限定名代表的类是否能够找到,对应的域和方法是否能找到,访问权限是否合法,如果一个需要使用类无法在系统中找到,则会抛出NoClassDefFoundError,如果一个 方法无法被找到,则会抛出NoSuchMethodError;这个转化动作将在连接的第三个阶段-解析阶段中发生。
-
3、准备
为类变量(static修饰的变量)分配内存并且设置该类变量的默认初始值,即零值,初始化阶段才会设置代码中的初始值
这里不包含用final修饰的static,因为final在编译的时候就会分配了,准备阶段会显示初始化
这里不会为实例变量分配初始化,类变量会分配在方法区,而实例变量是会随着对象一起分配给Java堆中。 -
4、解析
解析阶段是虚拟机将常量池内的符号引用(类、变量、方法等的描述符 [名称])替换为直接引用(直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄 [地址])的过程,解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。 -
5、初始化
初始化阶段编译器会将类文件声明的静态赋值变量和静态代码块合并生成方法并进行调用。- 初始化阶段就是执行类构造器方法的过程,这个方法不需要定义,只需要类中有静态的属性或者代码块即可,javac编 译器自动收集所有类变量的赋值动作和静态代码块中的语句合并而来
- 构造器方法中指令按照源文件出现的顺序执行
- 如果该类有父类,jvm会保证子类的在执行前,执行父类的
- 虚拟机必须保证一个类的方法在多线程情况下被加锁,类只需要被加载一次
-
类加载器分类
JVM层面支持两种类加载器:启动类加载器和自定义类加载器,启动类加载器由C++编写,属于虚拟机自身的一部分;继承自java.lang.ClassLoader的类加载器都属于自定义类加载器,由Java编写。逻辑上我们可以根据各加载器的不同功能继续划分为:扩展类加载器、应用程序类加载器和自定义类加载器。- 1、启动类加载器
- 由C/C++语言实现,嵌套在JVM内部
- 负责加载Java的核心库(JAVA_HOME/jre/lib/rt.jar、resources.jar或sun.boot.class.path路径下的内容),用于提供JVM自身需要的类
- 没有父加载器,加载扩展类和应用程序类加载器,并作为他们的父类加载器
- 出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类
- 2、扩展类加载器
- 由Java语言实现,派生于ClassLoader类
- 负责加载java.ext.dirs系统属性所指定目录中的类库,或JAVA_HOME/jre/lib/ext目录(扩展目录)下的类库,如果用户创建的jar放在此目录下,也会自动由扩展类加载器加载
- 作为类(在rt.jar中)被启动类加载器加载,父类加载器为启动类加载器
- 3、应用程序类加载器
- 由Java语言实现,派生于ClassLoader类
- 负责加载环境变量classpath或系统属性java.class.path指定路径下的类库
- 作为类被扩展类加载器加载,父类加载器为扩展类加载器
- 该类加载是程序中默认的类加载器,一般来说,Java应用的类都是由它来完成加载
- 通过ClassLoader.getSystemClassLoader()方法可以获取到该类加载器,所以有些场合中也称它为“系统类加载器”
- 4、自定义类加载器
在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,来定制类的加载方式。自定义类加载器作用:- 隔离加载类(相同包名和类名的两个类会冲突,引入自己定义类加载器可以规避冲突问题)
- 修改类加载的方式
- 扩展加载源(默认从jar包、war包等源加载,可以自定义自己的源)
- 防止源码泄漏(对编译后的class字节码进行加密,加载时用自定义的类加载器进行解密后使用)
- 1、启动类加载器
-
类加载器写协作方式
Java虚拟机对class文件采用的是按需加载的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成Class对象,当触发类加载时,JVM并不知道当前类具体由哪个加载器加载,都是先给到默认类加载器(应用程序类加载器),默认类加载器怎么分配到具体的加载器呢,这边使用了一种叫双亲委派模型的加载机制。 -
1、双亲委派模型
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。举例如下:- 当AppClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器ExtClassLoader去完成。
- 当ExtClassLoader加载一个class时,它首先也不会自己去尝试加载这个类,而是把类加载请求委派给BootStrapClassLoader去完成。
- 如果BootStrapClassLoader加载失败(例如在$JAVA_HOME/jre/lib里未查找到该class),会使用ExtClassLoader来尝试加载;
若ExtClassLoader也加载失败,则会使用AppClassLoader来加载,如果AppClassLoader也加载失败,则会报出异常ClassNotFoundException。
-
2、全盘负责
当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。 -
3、缓存机制
缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区寻找该Class,只有缓存区不存在,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓存区。这就是为什么修改了Class后,必须重启JVM,程序的修改才会生效。
使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有使用双亲委派模型,由各个类加载器自行去加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,Java类型体系中最基础的行为也就无法保证,应用程序也将会变得一片混乱。
3.运行时数据区
按照是否线程私有可分为
- 线程共有:方法区,堆
- 线程私有 java虚拟机栈,本地方法栈,程序计数器
1.方法区
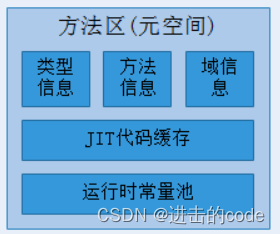
方法区,也称非堆(Non-Heap),是一个被线程共享的内存区域。其中主要存储类的类型信息,方法信息,域信息,JIT代码缓存,运行时常量池等。
-
- 方法区是各个线程共享的内存区域,在虚拟机启动时创建
-
- 虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做Non-Heap(非堆),目的是与Java堆区分开来
-
- 用于存储已被虚拟机加载的类信息、常量、即时编译器编译后的代码等数据。
-
- 当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常
在JDK7之前,习惯把方法区称为永久代,而在JDK8之后,又取消了永久代,改用元空间代替。元空间的本质与方法区类似,都是对JVM规范中方法区这一内存区域的一种实现。不过元空间与永久代的最大区别就是:元空间不在虚拟机设置的内存中,而是直接使用的本地内存。所以元空间的大小并不受虚拟机本身的内存限制,而是受制于计算机的直接内存。
- 当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常
2. 堆 Java堆是Java虚拟机所管理的内存最大的一块区域,Java堆是线程共享的,在虚拟机启动时创建。
-
几乎所有的对象实例都在这里分配内存。
-
字符串常量池(String Table),静态变量也在这里分配内存。
-
Java堆是垃圾收集器管理的内存区域,有些资料称为GC堆,当对象不再使用了,被当做垃圾回收掉后,这些为对象分配的内存又重新回到堆内存中。
-
Java堆在逻辑上应该认为是连续的,但是在具体的物理实现上,可以是不连续的。
-
Java堆可以是固定大小的,也可以是可扩展的。现在主流Java虚拟机都是可扩展的。
-Xmx 最大堆内存
-Xms 最小堆内存 -
如果Java堆没有足够的内存给分配实例,并且也无法继续扩展,则抛出 OutOfMemoryError 异常。
- 1.堆内存结构
- 堆内存从结构上来说分为年轻代(YoungGen)和老年代(OldGen)两部分;
- 年轻代(YoungGen)又可以分为生成区(Eden)和幸存者区(Survivor)两部分;
- 幸存者区(Survivor)又可细分为 S0区(from space)和 S1区 (to space)两部分;
- Eden 区占大容量,Survivor 两个区占小容量,默认比例是 8:1:1;
- 静态变量和字符串常量池在年轻代与老年代之外单独分配空间。
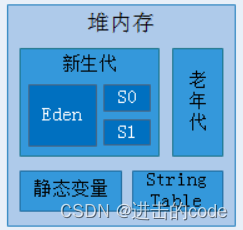
- 1.堆内存结构
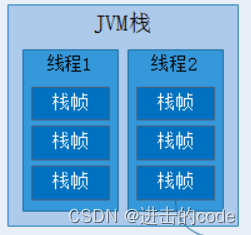
3.Java虚拟机栈 Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的Java方法调用,是线程私有的,因此也是线程安全的。
- Java虚拟机栈是线程私有的,其生命周期和线程相同。
- 虚拟机栈描述的是Java方法执行的线程内存模型,每个方法被执行,都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、参与方法的调用与返回等。
- 每一个方法被调用到执行完成的过程,就对应着一个栈帧在虚拟机栈中出入栈到出栈的过程
- JVM 允许指定 Java 栈的初始大小以及最大、最小容量。
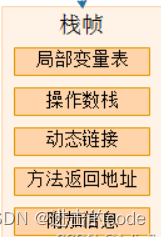
- 1.栈帧
- 定义:栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构。它是虚拟机运行时数据区中的 Java 虚拟机栈的栈元素。栈帧存储了方法的局部变量表、操作数栈、动态链接和方法返回地址等信息。
- 栈帧初始化大小:在编译程序代码的时候,栈帧中需要多大的局部变量表内存,多深的操作数栈都已经完全确定了。 因此一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。
- 栈帧结构:在一个线程中,只有位于栈顶的栈帧才是有效的,称为当前栈帧,与这个栈帧相关联的方法称为当前方法。每一个方法从调用开始至执行完成的过程,都对应着一个栈帧在虚拟机里面从入栈到出栈的过程。
-
4.程序计数器 程序计数器的英文全称是Program Counter Register,又叫程序计数寄存器。Register的命名源于CPU的寄存器,寄存器存储指令相关的现场信息。JVM中的PC寄存器是对 物理PC寄存器的一种抽象模拟。

- 程序计数器其实就是一个指针,它指向了我们程序中下一句需要执行的指令,可以看做当前线程执行的字节码的行数指示器。
- 不管是分支、循环、跳转等代码逻辑,字节码解释器在工作时就是改变程序计数器的值来决定下一条要执行的字节码。
- 每个线程都有一个独立的程序计数器,在任意一个确定的时刻,一个CPU内核都只会执行一条线程中的指令,CPU切换线程后是通过程序计数器来确定该执行哪条指令。
- 程序计数器占用内存空间小到基本可以忽略不计,是唯一一个在虚拟机中没有规定任何OutOfMemoryError 情况的区域。
- 如果正在执行的是Native方法,则这个计数器为空。
5.本地方法栈 本地方法栈与虚拟机栈所发挥的作用是非常相似的。只不过虚拟机栈为虚拟机执行的Java方法(即字节码)服务,本地方法栈为虚拟机执行的本地方法(Native方法、C/C++ 实现)服务。
- 与虚拟机栈一样,当栈深度溢出时,抛出 StackOverFlowError 异常。
- 当栈扩展内存不足时,抛出 OutOfMemoryError 异常。
4. 执行引擎
负责执行class文件中包含的字节码指令;
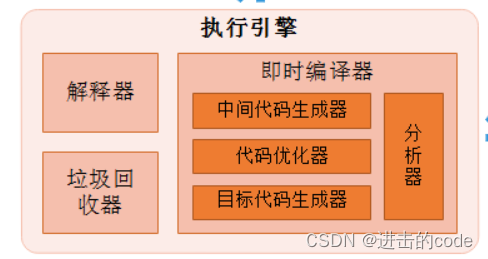
JVM的主要任务之一是负责装载字节码到其内部(运行时数据区),但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只 是一些能够被 JVM 所识别的字节码指令、符号表,以及其他辅助信息。
那么,如果想要让一个 Java 程序运行起来,执行引擎(Execution Engine) 的任务就是将字节码指令解释/编译为对应平台上的本地机器指令才可以。简单来说,JVM 中的执行引擎充当了将高级语言翻译为机器语言的译者。
1. 解释器
当Java虚拟机启动时会根据预定义的规范对字节码采用逐行解释的方式执行,将每条字节码文件中的内容“翻译”为对应平台的本地机器指令然后执行。
JVM 设计者们的初衷仅仅只是单纯地为了满足 Java 程序实现跨平台特性,因此避免采用静态编译的方式由高级语言直接生成本地机器指令,从而诞生了实现解释器在运行时采用逐行解释字节码执行程序的想法。
解释器真正意义上所承担的角色就是一个运行时“翻译者”,将字节码文件中的内容“翻译”为对应平台的本地机器指令执行,执行效率低。
在Java的发展历史里,一共有两套解释执行器,即古老的字节码解释器、现在普遍使用的模板解释器。字节码解释器在执行时通过纯软件代码模拟字节码的执行,效率非常低效。而模板解释器将每一条字节码和一个模板函数性关联,模板函数中直接产生这条字节码执行时的机器码,从而很大程度上提高了解释器的性能。
在Hotspot VM中,解释器主要由Interpreter模块和Code模块构成。
- Interpreter模块:实现了解释器的核心功能。
- Code模块:用于管理Hotspot VM在与运行时生成的本地机器指令。
由于解释器在设计和实现上非常简单,因此除了 Java 语言之外,还有许多高级语言同样也是基于解释器执行的,比如:Python、Perl、Ruby等。但就是因为多了中间这一“翻译”过程,导致代码执行效率低下。
为了解决这个问题,JVM平台支持一种叫做即时编译的的技术。即时编译的目的是为了避免函数被解释执行,而是将整个函数编译成机器码,每次函数执行时,只执行编译后的机器码即可,这种方式可以使执行效率大幅度提升。
2. 即时(JIT)编译器
就是虚拟机将Java字节码一次性整体编译成和本地机器平台相关的机器语言,但并不是马上执行。JIT 编译器将字节码翻译成本地机器指令后,就可以做一个缓存操作,存储在方法区 的 JIT 代码缓存中。JVM真正执行程序时将直接从缓存中获取本地指令去执行,省去了解释器的工作,提高了执行效率高。
HotSpot VM 是目前市面上高性能虚拟机的代表作之一。它采用解释器与及时编辑器并行的结构。在 Java 虚拟机运行时,解释器和即时编译器能够相互协作,各自取长补短,尽力去选择最合适的方式来权衡编译本地代码的时间和直接解释执行代码的时间。
JIT 编译器执行效率高为什么还需要解释器?
- 当程序启动后,解释器可以马上发挥作用,响应速度快,省去编译的时间,立即执行。
- 编译器要想发挥作用,把代码编译成本地代码,需要一定的执行时间,但编译为本地代码后,执行效率高。就需要采用解释器与即时编译器并存的架构来换取 一个平衡点。
是否需要启动JIT编译器将字节码直接编译为对应平台的本地机器指令,则需要根据代码被调用的执行频率而定。关于那些需要被编译成本地代码的字节码,也被称为热点代码,JIT编译器在运行时会对那些频繁被调用的热点代码做出深度优化,将其直接编译成对应平台的本地机器指令,以此提升Java程序的执行性能。
一个被多次调用的方法,或者是一个方法体内部循环次数较多的循环体,都可以被称为热点代码。因此都可以通过JIT编译器编译成本地机器指令。由于这种编译方式发生在方法执行的过程中,因此也被称为栈上替换,或者简称为OSR编译。
一个方法究竟要被调用多少次,或者一个循环体究竟需要执行多少次循环才可以达到这个标准,必然需要一个明确的阈值。JIT编译器才会将这些热点代码编译成本地机器码执行。
5. 了解GC吗
GC是JVM中的垃圾回收机制。主要作用于Java堆区,用于将不再使用的对象回收,释放内存。简单的说垃圾就是内存中不再使用的对象,所谓使用中的对象(已引用对象),指的是程序中有指针指向的对象;而不再使用的对象(未引用对象),则没有被任何指针指向。如果这些不再使用的对象不被清除掉,我们内存里面的对象会越来越多,而可使用的内存空间会越来越少,最后导致无空间可用。
垃圾回收的基本步骤分两步:
- 查找内存中不再使用的对象(GC判断策略)
- 释放这些对象占用的内存(GC收集算法)
1.对象存活判断 即内存中不再使用的对象,判断对象存活一般有两种方式:引用计数算法和可达性分析法
-
1. 引用计数算法 给对象添加一个引用计数器,每当有一个地方引用该对象时,计数器+1,当引用失效时,计数器-1,任何时候当计数器为0的时候,该对象不再被引用。
- 优点:引用计数器这个方法实现简单,判定效率也高,回收没有延迟性。
- 缺点:无法检测出循环引用。 如父对象有一个对子对象的引用,子对象反过来引用父对象。这样,他们的引用计数永远不可能为0,Java的垃圾收集器没有使用这类算法。
-
2. 可达性分析算法 可达性分析算法是目前主流的虚拟机都采用的算法,程序把所有的引用关系看作一张图,从所有的GC Roots节点开始,寻找该节点所引用的节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点,无用的节点将会被判定为是可回收的对象。
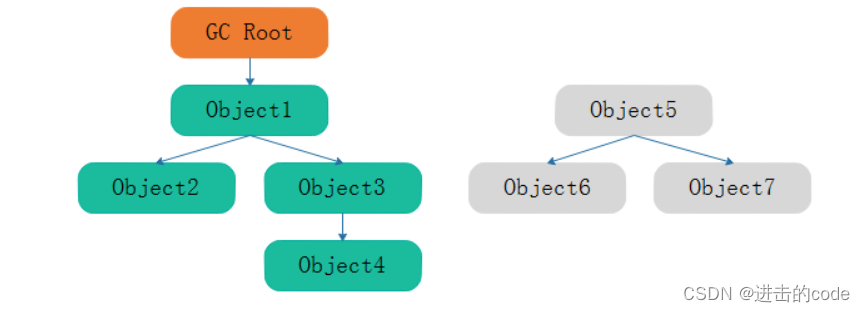
在Java语言中,可作为GC Roots的对象包括下面几种:
- 虚拟机栈中引用的对象(局部变量);
- 方法区中类静态属性引用的对象;
- 方法区中常量引用的对象;
- 本地方法栈中JNI(Native方法)引用的对象
- 所有被同步锁持有的对象;
- 虚拟机的内部引用如类加载器、异常管理对象;
- 反映java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等
2.垃圾回收算法
-
标记-清除算法 标记-清除算法的基本思想就跟它的名字一样,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象
-
标记阶段 标记的过程其实就是前面介绍的可达性分析算法的过程,遍历所有的 GC Roots 对象,对从 GCRoots 对象可达的对象都打上一个标识,一般是在对象的 header 中,将其记录为可达对象;
-
清除阶段清除的过程是对堆内存进行遍历,如果发现某个对象没有被标记为可达对象(通过读取对象header 信息),则将其回收。

标记-清除算法缺点
- 效率问题
标记和清除两个阶段的效率都不高,因为这两个阶段都需要遍历内存中的对象,很多时候内存中的对象实例数量是非常庞大的,这无疑很耗费时间,而且 GC 时需要停止应用程序,这会导致非常差的用户体验。 - 空间问题
标记清除之后会产生大量不连续的内存碎片(从上图可以看出),内存空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾回收动作。
-
2. 复制算法
复制算法是将可用内存按容量划分为大小相等的两块,每次使用其中的一块。当这一块的内存用完了,就将还存活的对象复制到另一块内存上,然后把这一块内存所有的对象一次性清理掉。

复制算法每次都是对整个半区进行内存回收,这样就减少了标记对象遍历的时间,在清除使用区域对象时,不用进行遍历,直接清空整个区域内存,而且在将存活对象复制到保留区域时也是按地址顺序存储的,这样就解决了内存碎片的问题,在分配对象内存时不用考虑内存碎片等复杂问题,只需要按顺序分配内存即可。
复制算法优点
- 复制算法简单高效,优化了标记清除算法的效率低、内存碎片多问题
复制算法缺点
- 将内存缩小为原来的一半,浪费了一半的内存空间,代价太高;
- 如果对象的存活率很高,极端一点的情况假设对象存活率为 100%,那么我们需要将所有存活的对象复制一遍,耗费的时间代价也是不可忽视的。
3. 标记-整理算法
标记-整理算法算法与标记-清除算法很像,事实上,标记-整理算法的标记过程任然与标记-清除算法一样,但后续步骤不是直接对可回收对象进行回收,而是让所有存活的对象都向一端移动,然后直接清理掉端边线以外的内存。
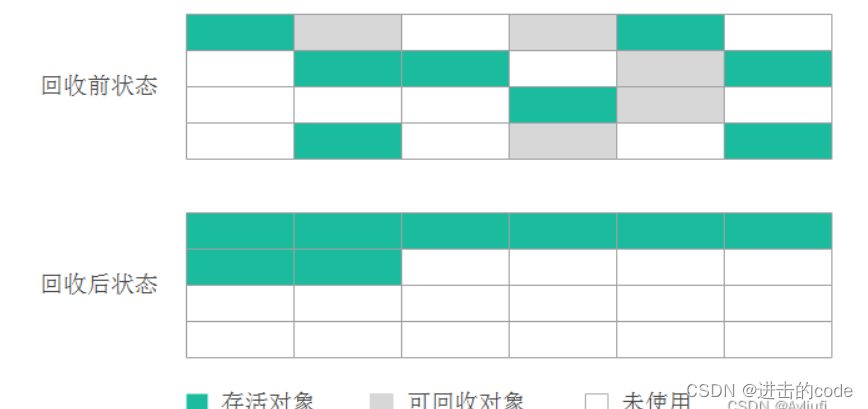
可以看到,回收后可回收对象被清理掉了,存活的对象按规则排列存放在内存中。这样一来,当我们给新对象分配内存时,JVM只需要持有内存的起始地址即可。标记/整理算法弥补了标记/清除算法存在内存碎片的问题消除了复制算法内存减半的高额代价,可谓一举两得。
标记-整理缺点
- 效率不高:不仅要标记存活对象,还要整理所有存活对象的引用地址,在效率上不如复制算法。
4. 分代收集算法
前文介绍JVM堆内存时已经说过了分代概念和对象在分代中的转移,垃圾回收伴随了对象的转移,其中新生代的回收算法以复制算法为主,老年代的回收算法以标记-清除以及标记-整理为主。
5. 方法区的垃圾回收
方法区主要回收的内容有:废弃常量和无用的类。Full GC(Major GC)的时候会触发方法区的垃圾回收。
- 废弃常量
通过可达性分析算法确定的可回收常量 - 无用类
对于无用的类的判断则需要同时满足下面3个条件:
(1)该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例;
(2)加载该类的ClassLoader已经被回收;
(3)该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
6. 了解JMM吗
- JMM 是Java内存模型( Java Memory Model),简称JMM。它本身只是一个抽象的概念,并不真实存在,它描述的是一种规则或规范,是和多线程相关的一组规范。通过这组规范,定义了程序中对各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。需要每个JVM 的实现都要遵守这样的规范,有了JMM规范的保障,并发程序运行在不同的虚拟机上时,得到的程序结果才是安全可靠可信赖的。如果没有JMM 内存模型来规范,就可能会出现,经过不同 JVM 翻译之后,运行的结果不相同也不正确的情况。
- JMM 抽象出 主存储器(Main Memory) 和工作存储器(Working Memory) 两种。
- 主存储器是实例对象所在的区域,所有的实例都存在于主存储器内。比如,实例所拥有的字段即位于主存储器内,主存储器是所有的线程所共享的。
- 工作存储器是线程所拥有的作业区,每个线程都有其专用的工作存储器。工作存储器存有主存储器中必要部分的拷贝,称之为工作拷贝(Working Copy)。
所以,线程无法直接对主内存进行操作,此外,线程A想要和线程B通信,只能通过主存进行。 - JMM的三大特性:原子性、可见性、有序性。
- 一个或多个操作,要么全部执行,要么全部不执行(执行的过程中是不会被任何因素打断的)。
- 只要有一个线程对共享变量的值做了修改,其他线程都将马上收到通知,立即获得最新值。
- 有序性可以总结为:在本线程内观察,所有的操作都是有序的;而在一个线程内观察另一个线程,所有操作都是无序的。前半句指 as-if-serial 语义:线程内似表现为串行,后半句是指:“指令重排序现象”和“工作内存与主内存同步延迟现象”。处理器为了提高程序的运行效率,提高并行效率,可能会对代码进行优化。编译器认为,重排序后的代码执行效率更优。这样一来,代码的执行顺序就未必是编写代码时候的顺序了,在多线程的情况下就可能会出错。
在代码顺序结构中,我们可以直观的指定代码的执行顺序, 即从上到下按序执行。但编译器和CPU处理器会根据自己的决策,对代码的执行顺序进行重新排序,优化指令的执行顺序,提升程序的性能和执行速度,使语句执行顺序发生改变,出现重排序,但最终结果看起来没什么变化(在单线程情况下)。
有序性问题 指的是在多线程的环境下,由于执行语句重排序后,重排序的这一部分没有一起执行完,就切换到了其它线程,导致计算结果与预期不符的问题。这就是编译器的编译优化给并发编程带来的程序有序性问题。
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 是因为其本身包含“禁止指令重排序”的语义,synchronized 是由“一个变量在同一个时刻只允许一条线程对其进行 lock 操作”这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行进入。
7. 类的加载过程,Person person = new Person();为例进行说明。
- 因为new用到了Person.class,所以会先找到Person.class文件,并加载到内存中;
- 执行该类中的static代码块,如果有的话,给Person.class类进行初始化;
- 在堆内存中开辟空间分配内存地址;
- 在堆内存中建立对象的特有属性,并进行默认初始化;
- 对属性进行显示初始化;
- 对对象进行构造代码块初始化;
- 对对象进行与之对应的构造函数进行初始化;
- 将内存地址付给栈内存中的person变量
kotlin
1. Kotlin如何实现空安全的?
- Kotlin 将变量划分为可空和不可空,通过查看字节码可知,声明不可空的变量会加 @NonNull注解,会告诉编译器检查变量是否可空。声明可空的变量会加 @Nullable注解。
- Kotlin 提供了空安全操作符 ?相当于实现了非空判断,当对象不为空时才执行操作,否则不执行。保证了空安全
//场景1,m1方法接收一个不可能为null的字符串
//在其方法体中我们获取了传入字符串的长度
fun m1(str: String) {str.length
}
//场景2,m2方法接收一个可能为null的字符串
//在其方法体中我们采用了安全调用操作符 ?. 来获取传入字符串的长度
fun m2(str: String?) {str?.length
}
//场景3,m3方法接收一个可能为null的字符串
//在其方法体中我们采用了 !! 来获取传入字符串的长度
fun m3(str: String?) {str!!.length
}public final static m1(Ljava/lang/String;)V@Lorg/jetbrains/annotations/NotNull;() // invisible, parameter 0L0ALOAD 0LDC "str"INVOKESTATIC kotlin/jvm/internal/Intrinsics.checkParameterIsNotNull (Ljava/lang/Object;Ljava/lang/String;)VL1LINENUMBER 6 L1ALOAD 0INVOKEVIRTUAL java/lang/String.length ()IPOPL2LINENUMBER 7 L2RETURNL3LOCALVARIABLE str Ljava/lang/String; L0 L3 0MAXSTACK = 2MAXLOCALS = 1// access flags 0x19public final static m2(Ljava/lang/String;)V@Lorg/jetbrains/annotations/Nullable;() // invisible, parameter 0L0LINENUMBER 10 L0ALOAD 0DUPIFNULL L1INVOKEVIRTUAL java/lang/String.length ()IPOPGOTO L2L1POPL2L3LINENUMBER 11 L3RETURNL4LOCALVARIABLE str Ljava/lang/String; L0 L4 0MAXSTACK = 2MAXLOCALS = 1public final static m3(Ljava/lang/String;)V@Lorg/jetbrains/annotations/Nullable;() // invisible, parameter 0L0LINENUMBER 15 L0ALOAD 0DUPIFNONNULL L1INVOKESTATIC kotlin/jvm/internal/Intrinsics.throwNpe ()VL1INVOKEVIRTUAL java/lang/String.length ()IPOPL2LINENUMBER 16 L2RETURNL3LOCALVARIABLE str Ljava/lang/String; L0 L3 0MAXSTACK = 3MAXLOCALS = 1
2. 谈谈你对协程的理解
协程可以看做是官方封装的轻量级线程框架。线程是由系统调度的,线程切换或线程阻塞的开销都比较大。而协程依赖于线程,但是协程挂起时不需要阻塞线程,几乎是无代价的,协程是由开发者控制的。所以协程也像用户态的线程,非常轻量级,一个线程中可以创建任意个协程。
- 协程与线程有什么区别:
·Kotlin协程,不是操作系统级别的概念,无需操作系统支持,线程是操作系统级别的概念,我们开发者通过编程语言(Thread,java)创建的线程,本质还是操作系统内核线程的映射。 - Kotlin协程,是用户态的(userleve),内核对协程无感知;一般情况下,我们说的线程,都是内核线程,线程之间的切换,调
度,都由操作系统负责。 - Kotlin协程,是协作式的,由开发者管理,不需要操作系统进行调度和切换,也没有抢占式的消耗,因比它更加高效;线程,是
抢占式的,它们之间能共享内存资源。 - Kotlin协程,它底层基于状态机实现,多协程之间共用一个实例,资源开销极小,因比它更加轻量;线程会消耗操作系统资源。
- Kotlin协程,本质还是运行于线程之上,它通过协程调度器,可以运行到不同的线程上
优点: - 轻量和高效:协程可以在一个线程中开启1000个协程,也不会有什么影响。
- 简单好用:其实轻量和高效并不是协程的核心竞争力,最主要的还是简化异步并发任务,代码中可以已同步的方式替换异步,去除java中回调地狱问题。
3. 了解密封类(Sealed Classes)吗
可以理解成是Enum枚举类的加强版
- Sealed class(密封类) 是一个有特定数量子类的类,看上去和枚举有点类似,所不同的是,在枚举中,我们每个类型只有一个对象(实例);而在密封类中,同一个类可以拥有几个对象。
- Sealed class(密封类)的所有子类都必须与密封类在同一文件中
- Sealed class(密封类)的子类的子类可以定义在任何地方,并不需要和密封类定义在同一个文件中
- Sealed class(密封类)没有构造函数,不可以直接实例化,只能实例化内部的子类
sealed class SealedClass{class SealedClass1():SealedClass()class SealedClass2():SealedClass()fun hello(){println("Hello World ... ")}
}
fun main(args:Array<String>){var sc:SealedClass = SealedClass()//这里直接编译报错
}
fun main(args:Array<String>){var sc:SealedClass = SealedClass.SealedClass1()//只能通过密封类内部的子类实例化对象,这时就可以执行里面的方法了sc.hello()
}
使用场景:与when表达式搭配
// Result.kt
sealed class Result<out T : Any> {data class Success<out T : Any>(val data: T) : Result<T>()data class Error(val exception: Exception) : Result<Nothing>()
}when(result) {is Result.Success -> { }is Result.Error -> { }}
但是如果有人为 Result 类添加了一个新的类型: InProgress:
sealed class Result<out T : Any> { data class Success<out T : Any>(val data: T) : Result<T>()data class Error(val exception: Exception) : Result<Nothing>()object InProgress : Result<Nothing>()
}
如果想要防止遗漏对新类型的处理,并不一定需要依赖我们自己去记忆或者使用 IDE 的搜索功能确认新添加的类型。使用 when 语句处理密封类时,如果没有覆盖所有情况,可以让编译器给我们一个错误提示。和 if 语句一样,when 语句在作为表达式使用时,会通过编译器报错来强制要求必须覆盖所有选项 (也就是说要穷举):
val action = when(result) {is Result.Success -> { }is Result.Error -> { }
}
当表达式必须覆盖所有选项时,添加 “is inProgress” 或者 “else” 分支。
如果想要在使用 when 语句时获得相同的编译器提示,可以添加下面的扩展属性:
val <T> T.exhaustive: Tget() = this
这样一来,只要给 when 语句添加 “.exhaustive”,如果有分支未被覆盖,编译器就会给出之前一样的错误。
when(result){is Result.Success -> { }is Result.Error -> { }
}.exhaustive
IDE 自动补全
由于一个密封类的所有子类型都是已知的,所以 IDE 可以帮我们补全 when 语句下的所有分支:

当涉及到一个层级复杂的密封类时,这个功能会显得更加好用,因为 IDE 依然可以识别所有的分支:

sealed class Result<out T : Any> {data class Success<out T : Any>(val data: T) : Result<T>()sealed class Error(val exception: Exception) : Result<Nothing>() {class RecoverableError(exception: Exception) : Error(exception)class NonRecoverableError(exception: Exception) : Error(exception)}object InProgress : Result<Nothing>()
}
3. Kotlin中@JvmOverloads 的作用
在Kotlin中@JvmOverloads注解的作用就是:在有默认参数值的方法中使用@JvmOverloadsi注解,则Kotlin就会暴露多个重载方法。如果没有加注解@JvmOverloads则只有一个方法,kotlini调用的话如果没有传入的参数用的是默认值。
@JvmOverloads fun f(a: String, b: Int=0, c:String="abc"){
}
// 相当于Java三个方法 不加这个注解就只能当作第三个方法这唯一一种方法
void f(String a)
void f(String a, int b)
// 加不加注解,都会生成这个方法
void f(String a, int b, String c)
4.Kotlin实现单例的几种方式
- 饿汉式
//Java实现
public class SingletonDemo {private static SingletonDemo instance=new SingletonDemo();private SingletonDemo(){}public static SingletonDemo getInstance(){return instance;}
}
//Kotlin实现
object SingletonDemo
- 懒汉式
//Java实现
public class SingletonDemo {private static SingletonDemo instance;private SingletonDemo(){}public static SingletonDemo getInstance(){if(instance==null){instance=new SingletonDemo();}return instance;}
}
//Kotlin实现
class SingletonDemo private constructor() {companion object {private var instance: SingletonDemo? = nullget() {if (field == null) {field = SingletonDemo()}return field}fun get(): SingletonDemo{//细心的小伙伴肯定发现了,这里不用getInstance作为为方法名,是因为在伴生对象声明时,内部已有getInstance方法,所以只能取其他名字return instance!!}}
}线程安全的懒汉式//Java实现
public class SingletonDemo {private static SingletonDemo instance;private SingletonDemo(){}public static synchronized SingletonDemo getInstance(){//使用同步锁if(instance==null){instance=new SingletonDemo();}return instance;}
}
//Kotlin实现
class SingletonDemo private constructor() {companion object {private var instance: SingletonDemo? = nullget() {if (field == null) {field = SingletonDemo()}return field}@Synchronizedfun get(): SingletonDemo{return instance!!}}}
- 双重校验锁式
//Java实现
public class SingletonDemo {private volatile static SingletonDemo instance;private SingletonDemo(){} public static SingletonDemo getInstance(){if(instance==null){synchronized (SingletonDemo.class){if(instance==null){instance=new SingletonDemo();}}}return instance;}
}
//kotlin实现
class SingletonDemo private constructor() {companion object {val instance: SingletonDemo by lazy(mode = LazyThreadSafetyMode.SYNCHRONIZED) {SingletonDemo() }}
}
- 静态内部类式
//Java实现
public class SingletonDemo {private static class SingletonHolder{private static SingletonDemo instance=new SingletonDemo();}private SingletonDemo(){System.out.println("Singleton has loaded");}public static SingletonDemo getInstance(){return SingletonHolder.instance;}
}
//kotlin实现
class SingletonDemo private constructor() {companion object {val instance = SingletonHolder.holder}private object SingletonHolder {val holder= SingletonDemo()}}
5. 了解Data Class吗?
数据类,相当于MWM模式下的model类,相当于java自动重写了equals/hashCode方法、get()方法、set()方法(如果是可写入的)、
toString方法、componentN方法、copy()方法,注意get/set方法是kotlin中的类都会为属性自动生成的方法,和数据类没关系。
- equals/hashCode:equals方法重写使对象的内容一致则返回true,hashCode方法重写使对象的内容一致则nashCode值也一致。
注意: 在Kotlin中有== 和 ===,==比较的对象内容,===比较的是对象的引用地址
- toString:重写此方法为类和属性值的内容,如:“User(name=John,age=42)”
- componentN:编译器为数据类(data class)自动声明componentN(O函数,可直接用解构Q声明,如下:
var girl1:Girl=Girl("嫚嫚",29,160,"廊坊")
var (a,b,c,d)=girl1
println("$a,$b,c,$d")
在Kotlin中所谓的解构就是将一个类对象中的参数拆开来,成为一个一个单独的变量,从而来使用这些单独的变量进行操作。
copy:复制对象使用,当要复制一个对象,只改变一些属性,但其余不变,copy就是为此而生
6. 了解作用域函数吗?
- wth:不是T的扩展函数,需要传入对象进去,不能判空,最后一行是返回值。
- run:是T的扩展函数,内部使用this,最后一行是返回值。
- apply:是T的扩展函数,内部使用this,返回值是调用本身。
- let:是T的扩展函数,内部使用it,当然可以自定义名称(通过修改ambda表达式参数),最后一行是返回值。
- also:是T的扩展函数,和let一样内部使用it,返回值是调用本身。
使用场景:
- 用于初始化对象或更改对象属性,可使用apply
- 如果将数据指派给接收对象的属性之前验证对象,可使用also
- 如果将对象进行空检查并访问或修改其属性,可使用let
- 如果想要计算某个值,或者限制多个本地变量的范围,则使用run
扩展函数原理:
扩展函数实际上就是一个对应Jva中的静态函数,这个静态函数参数为接收者类型的对象,然后利用这个对象就可以访问这个类
中的成员属性和方法了,并且最后返回一个这个接收者类型对象本身。这样在外部感觉和使用类的成员函数是一样的。
7. 你觉得Kotlin与Java混合开发时需要注意哪些问题?
- kotlin调用java的时候,如果java返回值可能为null那就必须加上@nullable否则kotlin无法识别,也就不会强制你做非空处理,一旦java返回了null那么必定会出现null指针异常,加上@nullable注解之后kotlin就能识别到java方法可能会返回null,编译器就能会知道,并且强制你做非null处理,这也就是kotlin的空安全。
8. 知道什么是inline ,noinline和crossinline函数吗?
- 内联函数 inLine 作用是可以在编译kotlin文件时直接把内联函数执行过程放在调用此内联函数的位置,避免了java中多调用
方法的操作,减少性能消耗。一方面可以减少方法调用栈帧的层级,一方面可以避免lambda表达式和高阶函数运行时的效率损失:每个函数都是一个对象,并且会捕获一个闭包。即那些在函数体内会访问到的变量。
内存分配和虚拟调用(对于函数和类)会引入运行时间开销,但是通过内联化表达式可以消除这类的开销
class TestMain(var a: Int, var b: String) {data class User(var age: Int, var sex: String);fun main() {calculate {System.out.println("调用方法体")}}fun calculate(method: () -> Unit) {System.out.println("calculate 前")method()System.out.println("calculate 后")}查看字节码LINENUMBER 43 L1GETSTATIC java/lang/System.out : Ljava/io/PrintStream;LDC "calculate \u524d"INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)VL2LINENUMBER 44 L2ALOAD 1INVOKEINTERFACE kotlin/jvm/functions/Function0.invoke ()Ljava/lang/Object; (itf) //多了一次方法调用POPL3LINENUMBER 45 L3GETSTATIC java/lang/System.out : Ljava/io/PrintStream;LDC "calculate \u540e"INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)VL4LINENUMBER 46 L4RETURNL5
改为inline后inline fun calculate(method: () -> Unit) {System.out.println("calculate 前")method()System.out.println("calculate 后")}public final main()VL0LINENUMBER 15 L0ALOAD 0ASTORE 1L1ICONST_0ISTORE 2L2LINENUMBER 56 L2GETSTATIC java/lang/System.out : Ljava/io/PrintStream;LDC "calculate \u524d"INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)VL3LINENUMBER 57 L3L4ICONST_0ISTORE 3L5LINENUMBER 16 L5 //直接打印没有方法调用GETSTATIC java/lang/System.out : Ljava/io/PrintStream;LDC "\u8c03\u7528\u65b9\u6cd5\u4f53"INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)VL6LINENUMBER 17 L6NOPL7L8LINENUMBER 58 L8GETSTATIC java/lang/System.out : Ljava/io/PrintStream;LDC "calculate \u540e"INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)VL9LINENUMBER 59 L9NOPL10LINENUMBER 18 L10RETURNL11LOCALVARIABLE $i$a$-calculate-TestMain$main$1 I L5 L7 3LOCALVARIABLE this_$iv Lcom/example/test/TestMain; L1 L10 1LOCALVARIABLE $i$f$calculate I L2 L10 2LOCALVARIABLE this Lcom/example/test/TestMain; L0 L11 0MAXSTACK = 2MAXLOCALS = 4
- noinline noinline 字面意思是“不内联”,用于标记 inline 函数中的函数类型参数。被标记的函数类型参数不会被内联,即不会如上示例所述,进行代码铺平,其依旧是个对象。那么关闭内联优化,有什么用呢?我们可以看下面一个例子:

我们有时会碰到返回值就是函数类型参数这种状况,但是 inline 函数已经将 hello() 中的 block 代码铺平,即本来 block 是个对象,现在被 inline 优化,直接消除了,那还怎么返回呢?所以上述示例是错误的,同时我们也能在 IDE 中发现 return 直接报错了。这时就轮到 noinline 出场,关闭针对函数类型参数的内联优化,使 block 依然作为一个对象被使用,如此就可以正常 return 了。正确示例如下:
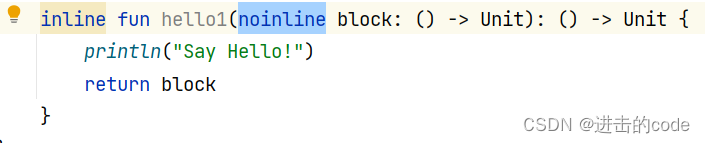
- crossinline crossinline 字面意思是交叉内联,也是作用于内联函数的函数类型参数上,其用途就是强化函数类型参数的内联优化,使之能被间接调用,并且被 crossinline 标记的 Lambda 中不能使用 return。
有这么一个需求,我们需要在UI线程中去执行内联函数中的某个代码块,这个需求应该不过分吧?常规写法一般如下:
// 错误示例
inline fun hello(block: () -> Unit) {println("Say Hello!")runOnUiThread {block()}
}fun main() {hello {println("Bye!")return}println("Continue")
}
这其实就是在内联函数中间接调用函数类型参数,说“间接”是因为本来 block 的控制权是在 hello() 中,其外层是 hello(),这么一写,控制权就被 runOnUiThread 夺走了,外层变成了 runOnUiThread。而如果此时,我们在 hello() 的 Lambda 表达式中加个 return,那么就会出现一个问题, return 无法结束 main()。因为遵循 inline 规则,最后编译出的代码大致是这样的:

非常明显,return 结束的是 runOnUiThread 中的 Runnable 对象,而不是 main()。那这样与之前的规则不就冲突了吗?所以事实上,这种间接调用写法是不被允许的,IDE 会给你一个刺眼的红线。那如果我们一定要间接调用该怎么做呢?这时就轮到 crossinline 出场了,正确示例如下:
// 正确示例
inline fun hello(crossinline block: () -> Unit) {println("Say Hello!")runOnUiThread {block()}
}fun main() {hello {println("Bye!")}
}
我们直接给 block 加上关键字 crossinline,这样就允许间接调用了。
9. Kotlin中的构造方法
-
1.概要简述
- 1.kotlin中构造函数分为主构造和次级构造两类
- 2.使用关键饲constructori标记次级构造函数,部分情况可省略
- 3.init关键词用于初始化代码块,注意与构造函数的执行顺序,类成员的初始化顺序
- 4.继承,扩展时候的构造函数调用逻辑
- 5.特殊的类如data class、.object/,componain object、.sealed classs等构造函数情况与继承问题
- 6.构造函数中的形参声明情况
-
2.详细说明
- 主次构造函数
- 1.kotlin中任何class(包括ob ject/data class/sealed class)都有一个默认的无参构造函数
- 2.如果显式的声明了构造函数,默认的无参构造函数就失效了。
- 3.主构造函数写在classi声明处,可以有访问权限修饰符private,publics等,且可以省略constructor关键字。
- 4.若显式的在class内声明了次级构造函数,就需要委托调用主构造函数。
- 5.若在class内显式的声明处所有构造函数(也就是没有了所谓的默认主构造),这时候可以不用依次调用主构造函
数。例如继承Viw实现自定义控件时,三四个构造函数同时显示声明。
-
init初始化代码块
- kotlin中若存在主构造函数,其不能有代码块执行,init起到类似作用,在类初始化时侯执行相关的代码块。
- 1.init代码块优先于次级构造函数中的代码块执行。
- 2.即使在类的继承体系中,各自的init也是优先于构造函数执行。
- 3.在主构造函数中,形参加有var/val,那么就变成了成员属性的声明。这些属性声明是早于init代码块的。
-
特殊类
- 1.object/companion object是对象示例,作为单例类或者伴生对象,没有构造函数。
- 2.data class要求必须有一个含有至少一个成员属性的主构造函数,其余方面和普通类相同。
- 3.sealed class,只是声明类似以抽象类一般,可以有主构造函数,含参无参以及次级构造等。

10. 说说Kotlin中的Any与Java中的Object有何异同?
- 同:都是顶级父类
- 异:成员方法不同
Any只声明了toString()、hashCode(O和equals()作为成员方法。
我们思考下,为什么Kotlin设计了一个Any?
当我们需要和Java互操作的时候,Kotlin把Java方法参数和返回类型中用到的Object类型看作Any,这个Any的设计是Kotlin兼容
Java时的一种权衡设计。
所有Java引用类型在Kotlin中都表现为平台类型。当在Kotlin中处理平台类型的值的时候,它既可以被当做可空类型来处理,也可以被当做非空类型来操作。
试想下,如果所有来自Jva的值都被看成非空,那么就容易写出比较危险的代码。反之,如果Java值都强制当做可空,则会导致大量的null检查。综合考量,平台类型是一种折中的设计方案。
11. 协程Flow是什么,有哪些应用场景?
- 协程Flow:Kotlin协程中使用挂起函数可以实现非阻塞地执行任务并将结果返回回来,但是只能返回单个计算结果。但是如果希望有多个计算结果返回回来,则可以使用Flow。
应用场景:多个数据流执行的情况下。
12. 协程Flow的冷流和热流是什么?
- 热数据很迫切,它们尽可能快的生产元素并存储它们。它们创造的元素独立于它们的消费者,它们是集合(List、Set)和channel
- 冷数据流是惰性的,它们在终端操作上按需处理元素,所有中间函数知识定义应该做什么(通常是用装饰模式),它们通常不存储元素,而是根据需要创建元素,它们的运算次数很少,可以是无限的,它们创建、处理元素的过程通常和消费过程紧挨着。这些元素是Sequence、Java Stream,Flow和RxJava流(Observable、Single等)
- 协程FIow中的热流是channelFlow,冷流是FIow
fun main() = runBlocking {val time = measureTimeMillis {
// equeneFlow() //同步 1秒左右asyncFlow() //异步700多毫秒}print("cost $time")
}
//异步的
private suspend fun asyncFlow() {channelFlow {for (i in 1..5) {delay(100)send(i)}}.collect {delay(100)println(it)}
}
//同步的
private suspend fun equeneFlow() {flow<Int> {for (i in 1..5) {delay(100)emit(i)}}.collect {delay(100)println(it)}
}
13. 谈谈Kotlin中的Sequence,为什么它处理集合操作更加高效?
集合操作低效在哪?
处理集合时性能损耗的最大原因是循环。集合元素迭代的次数越少性能越好。
list.map { it ++ }.filter { it % 2 == 0 }.count { it < 3 }
反编译一下,你会发现:Kotlin编译器会创建三个while循环。
Sequences减少了循环次数
Sequences提高性能的秘密在于这三个操作可以共享同一个迭代器(iterator),只需要一次循环即可完成。Sequences允许map转换一个元素后,立马将这个元素传递给filter操作,而不是像集合(lists)那样,等待所有的元素都循环完成了map操作后,用一个新的集合存储起来,然后又遍历循环从新的集合取出元素完成filter操作。
Sequences是懒惰的
上面的代码示例,map、filter.、count都是属于中间操作,只有等待到一个终端操作,如打印、sum()、average()、first()时才会开始工作
val list = listOf(1, 2, 3, 4, 5, 6)
val result = list.asSequence().map{ println("--map"); it * 2 }.filter { println("--filter");it % 3 == 0 }
println("go~")
println(result.average())
android
1. Activity启动模式
- standard 标准模式,每次都是新建Activity实例。
- singleTop 栈顶复用。如果要启动的Activity已经处于任务栈顶,则直接复用不会新建Activity实例,此时会调用onNewIntent方法。如果栈内不存在或者不在栈顶。则会新建Activity实例。
- singleTask 栈内单例。如果任务栈内已经存在Activity实例,则直接复用。如果不在栈顶,则把该activity实例之上的全部出栈,让自身位于栈顶。此时会调用onNewIntent方法。
- singleInstance 新建任务栈栈内唯一。应用场景:来电话界面,即使来多个电话也只创建一个Activity;
2. Activity生命周期
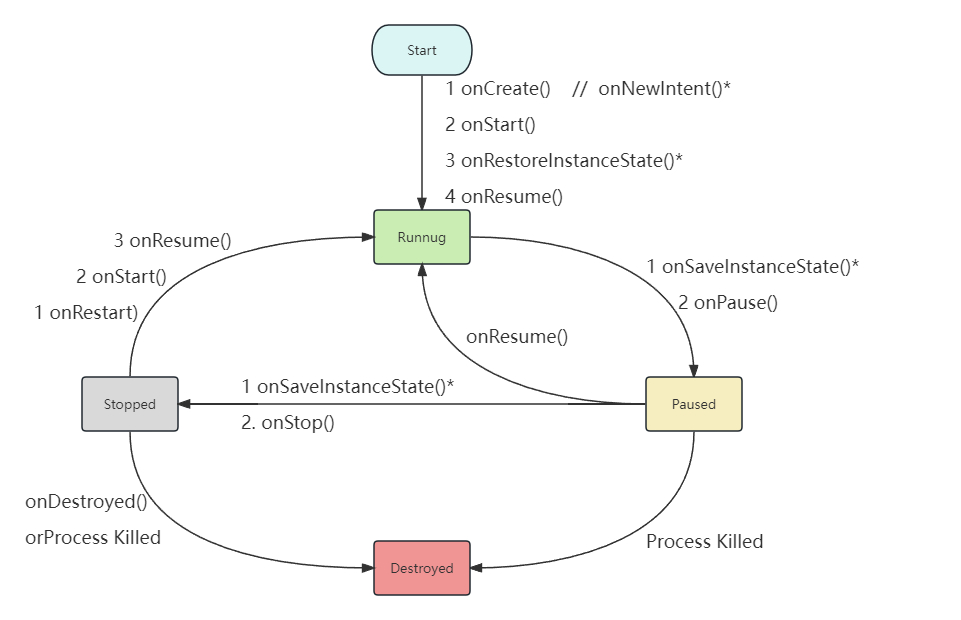
- 启动状态(Starting):Activity的启动状态很短暂,当Activity启动后便会进入运行状态(Running)。
- 运行状态(Running):Activity在此状态时处于屏幕最前端,它是可见、有焦点的,可以与用户进行交互。如单击、长按等事件。即使出现内存不足的情况,Android也会先销毁栈底的Activity,来确保当前的Activity正常运行。
- 暂停状态(Paused):在某些情况下,Activity对用户来说仍然可见,但它无法获取焦点,用户对它操作没有没有响应,此时它处于暂停状态。例如,当前Activity弹出Dialog,或者新启动Activity为透明的Activity等情况。
- 停止状态(Stopped):当Activity完全不可见时,它处于停止状态,但仍然保留着当前的状态和成员信息。如系统内存不足,那么这种状态下的Activity很容易被销毁。
- 销毁状态(Destroyed):当Activity处于销毁状态时,将被清理出内存。
Activity的生命周期
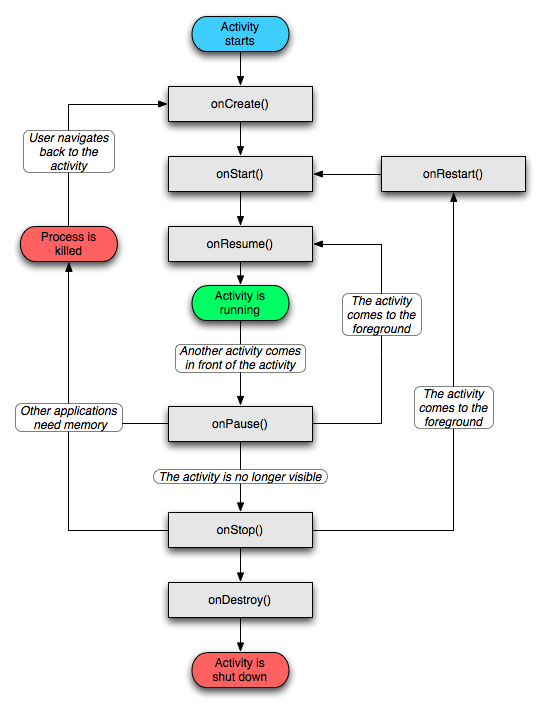
- onCreate() : 在Activity创建时调用,通常做一些初始化设置,不可以执行耗时操作。;
- onNewIntent()*:注意 !!只有当 当前activity实例已经处于任务栈顶,并且使用启动模式为singleTop或者SingleTask再次启动Activity时才会调用此方法。此时不会走OnCreate(),而是会执行onNewIntent()。因为activity不需要创建而是直接复用。
- onStart(): 在Activity即将可见时调用;可以做一些动画初始化的操作。
- onRestoreInstanceState()*:注意 !!当app异常退出重建时才会调用此方法。可以在该方法中恢复以保存的数据。
- onResume(): 在Activity已可见,获取焦点开始与用户交互时调用;当Activity第一次启动完成或者当前Activity被遮挡住一部分(进入了onPause())重新回到前台时调用,比如弹窗消失。当onResume()方法执行完毕之后Activity就进入了运行状态。根据官方的建议,此时可以做开启动画和独占设备的操作。
- onPause(): 在当前Activity被其他Activity覆盖或锁屏时调用;Activity停止但是当前Activity还是处于用户可见状态,比如出现弹窗;在onPause()方法中不能进行耗时操作(当前Activity通过Intent启动另一个Activity时,会先执行当前Activity的onPause()方法,再去执行另一个Activity的生命周期)
- onSaveInstanceState():注意 !! 只有当app可能会异常销毁时才会调用此方法保存activity数据。以便于activity重建时恢复数据
Activity的onSaveInstanceState回调时机,取决于app的targetSdkVersion:
targetSdkVersion低于11的app,onSaveInstanceState方法会在Activity.onPause之前回调;
targetSdkVersion低于28的app,则会在onStop之前回调;
28之后,onSaveInstanceState在onStop回调之后才回调。 - onStop() : 在Activity完全被遮挡对用户不可见时调用(在onStop()中做一些回收资源的操作)
- onDestroy() :在Activity销毁时调用;
- onRestart() : 在Activity从停止状态再次启动时调用;处于stop()状态也就是完全不可见的Activity重新回到前台时调用(重新回到前台不会调用onCreate()方法,因为此时Activity还未销毁)
Activity横竖屏切换生命周期
横竖屏切换涉及到的是Activity的android:configChanges属性;
android:configChanges可以设置的属性值有:
orientation:消除横竖屏的影响
keyboardHidden:消除键盘的影响
screenSize:消除屏幕大小的影响
- 设置Activity的android:configChanges属性为orientation或者orientation|keyboardHidden或者不设置这个属性的时候,横竖屏切换会重新调用各个生命周期方法,切横屏时会执行1次,切竖屏时会执行1次;
- 设置Activity的属性为 android:configChanges=“orientation|keyboardHidden|screenSize” 时,横竖屏切换不会重新调用各个生命周期方法,只会执行onConfigurationChanged方法;
3. 了解Service吗
Service一般用于没有ui界面的长期服务。
Service有两种启动方式
- StartService 这种方式启动的Service生命周期和启动实例无关。启动后会一直存在,直到app退出,或者调用stopService或者stopSelf。生命周期为onCreate-》onStartCommand-》onDestroyed。
- 多次启动StartService。onStartCommand会调用多次
- bindService 这种方式启动的Service和生命周期会和调用者绑定。一旦调用者结束,Service也会一起结束。生命周期为onCreate-》onBind-》onUnbind-》onDestroyed
如何保证Service不被杀死
- onStartCommand方式中,返回START_STICKY或者START_REDELIVER_INTENT
- START_STICKY:如果返回START_STICKY,Service运行的进程被Android系统杀掉之后,Android系统会将该Service依然设置为started状态(即运行状态),会重新创建该Service。但是不再保存onStartCommand方法传入的intent对象
- START_NOT_STICKY:如果返回START_NOT_STICKY,表示当Service运行的进程被Android系统强制杀掉之后,不会重新创建该Service
- START_REDELIVER_INTENT:如果返回START_REDELIVER_INTENT,其返回情况与START_STICKY类似,但不同的是系统会保留最后一次传入onStartCommand方法中的Intent再次保留下来并再次传入到重新创建后的Service onStartCommand方法中
- 提高Service的优先级: 在AndroidManifest.xml文件中对于intent-filter可以通过android:priority = "1000"这个属性设置最高优先级,1000是最高值,如果数字越小则优先级越低,同时适用于广播;
- 在onDestroy方法里重启Service: 当service走到onDestroy()时,发送一个自定义广播,当收到广播 时,重新启动service;
- 提升Service进程的优先级。 进程优先级由高到低:前台进程 一》 可视进程 一》 服务进程 一》 后台进程 一》 空进程
可以使用 startForeground将service放到前台状态,这样低内存时,被杀死的概率会低一些; 系统广播监听Service状态将APK安装到/system/app,变身为系统级应用。
4. 使用过broadcastReceiver吗?
可分为标准广播(无序广播)和有序广播
按照作用范围可分为全局广播和本地广播
按照注册方式可分为静态广播和动态广播
- 标准广播
标准广播(normal broadcasts)是一种完全异步执行的广播,在广播发出之后,所有的BroadcastReceiver几乎都会在同一时刻接收到收到这条广播消息,因此它们之间没有任何先后顺序可言。这种广播的效率会比较高,但同时也意味着它是无法被截断的。 - 有序广播
有序广播(ordered broadcasts)是一种同步执行的广播,在广播发出之后,同一时刻只会有一个BroadcastReceiver能够收到这条广播消息,当这个BroadcastReceiver中的逻辑执行完毕后,广播才会继续传递。所以此时的BroadcastReceiver是有先后顺序的,优先级高的BroadcastReceiver就可以先收到广播消息,并且前面的BroadcastReceiver还可以截断正在传递的广播,这样后面的BroadcastReceiver就无法收到广播消息了。 - 本地广播:发送的广播事件不被其他应用程序获取,也不能响应其他应用程序发送的广播事件。本地广播只能被动态注册,不能静态注册。动态注册或发送时时需要用到LocalBroadcastManager。
- 全局广播:发送的广播事件可被其他应用程序获取,也能响应其他应用程序发送的广播事件(可以通过 exported–是否监听其他应用程序发送的广播 在清单文件中控制) 全局广播既可以动态注册,也可以静态注册。
- 静态广播
静态广播在清单文件AndroidMainfest.xml中注册,生命周期随系统,不受Activity生命周期影响,即使进程被杀死,仍然能收到广播,因此也可以通过注册静态广播做一些拉起进程的事。随着Android版本的增大,Android系统对静态广播的限制也越来越严格,一般能用动态广播解决的问题就不要用静态广播。 - 动态广播
动态广播不需要在AndroidManifest.xml文件中进行注册,动态注册的广播受Activity声明周期的影响,Activity消亡,广播也就不复存在。动态广播在需要接受广播的Activity中进行注册和解注册。
5. 说说你对handler的理解
Handler是Android用来解决线程间通讯问题的消息机制。Handler消息机制分为四个部分。
- Handler 消息的发送者和处理者
- Message 消息实体 消息的载体和携带者。
- MessageQueen 消息队列,使用双向链表实现,是存放消息的队列。
- Looper 消息循环器,不停的从消息队列中中取出消息。
如何使用Handler?
- 使用Handler需要一个Looper环境,在主线程直接新建Handler实例然后实现handleMessage方法,然后在需要发送消息的地方,使用handler.sendMessage等方法即可。
private static class MyHandler extends Handler {private final WeakReference<MainActivity> mTarget;public MyHandler(MainActivity activity) {mTarget = new WeakReference<MainActivity>(activity);}@Overridepublic void handleMessage(@NonNull Message msg) {super.handleMessage(msg);HandlerActivity activity = weakReference.get();super.handleMessage(msg);if (null != activity) {//执行业务逻辑if (msg.what == 0) {Log.e("myhandler", "change textview");MainActivity ma = mTarget.get();ma.textView.setText("hahah");}Toast.makeText(activity,"handleMessage",Toast.LENGTH_SHORT).show();}}}private Handler handler1 = new MyHandler(this);new Thread(new Runnable() {@Overridepublic void run() {handler1.sendEmptyMessage(0);}}).start();
- 在子线程使用需要先创建Looper环境,调用Looper.prepare(),然后再创建Handler。最后在调用Looper.loop()启动消息循环。子线程Handler不使用时要调用handler.getLooper().quitSafely()退出Looper否则会阻塞。
private static class MyHandler extends Handler {@Overridepublic void handleMessage(@NonNull Message msg) {super.handleMessage(msg);if (msg.what == 0) {Log.e("child thread", "receive msg from main thread");}}}private Handler handler1;@Overrideprotected void onCreate(@Nullable Bundle savedInstanceState) { new Thread(new Runnable() {@Overridepublic void run() {Looper.prepare(); //准备Looper环境handler1 = new MyHandler();Looper.loop(); //启动LooperLog.e("child thread", "child thread end");}}).start();handler1.sendEmptyMessage(0);handler1.getLooper().quitSafely();//子线程Handler不用时,退出Looper
}
主线程使用Handler为什么不用Looper.prepare()?
因为在app启动时,ActivityThread的Main方法里帮我们调用了Looper.prepareMainLooper()。并且最后调用了Looper.loop()
启动了主线程。
public static void main(String[] args) {Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ActivityThreadMain");// Install selective syscall interceptionAndroidOs.install();// CloseGuard defaults to true and can be quite spammy. We// disable it here, but selectively enable it later (via// StrictMode) on debug builds, but using DropBox, not logs.CloseGuard.setEnabled(false);Environment.initForCurrentUser();// Make sure TrustedCertificateStore looks in the right place for CA certificatesfinal File configDir = Environment.getUserConfigDirectory(UserHandle.myUserId());TrustedCertificateStore.setDefaultUserDirectory(configDir);// Call per-process mainline module initialization.initializeMainlineModules();Process.setArgV0("<pre-initialized>");Looper.prepareMainLooper();// Find the value for {@link #PROC_START_SEQ_IDENT} if provided on the command line.// It will be in the format "seq=114"long startSeq = 0;if (args != null) {for (int i = args.length - 1; i >= 0; --i) {if (args[i] != null && args[i].startsWith(PROC_START_SEQ_IDENT)) {startSeq = Long.parseLong(args[i].substring(PROC_START_SEQ_IDENT.length()));}}}ActivityThread thread = new ActivityThread();thread.attach(false, startSeq);if (sMainThreadHandler == null) {sMainThreadHandler = thread.getHandler();}if (false) {Looper.myLooper().setMessageLogging(newLogPrinter(Log.DEBUG, "ActivityThread"));}// End of event ActivityThreadMain.Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);Looper.loop();throw new RuntimeException("Main thread loop unexpectedly exited");}
简述一下Handler的工作流程
- Handler使用SendMessage或者post等方法。最终都会调用MessageQueue的enqueueMessage()方法。将消息按照执行时间先后顺序入队。
- Looper里面是个死循环,不停地在队列中通过MessageQueue.next()方法取出消息,取出消息后,通过msg.target.dispatchMessage() 方法分发消息。先交给msg消息的runnable处理,再交给Handler的Callable处理,最后再交给Handler实现的handleMessage方法处理
public void dispatchMessage(@NonNull Message msg) {if (msg.callback != null) {handleCallback(msg);} else {if (mCallback != null) {if (mCallback.handleMessage(msg)) {return;}}handleMessage(msg);}}
一个线程中最多有多少个Handler,Looper,MessageQueue?
- 一个线程可以有多个Handler
- 一个handler只能有一个Looper和一个MessageQueen
因为创建Handler必须有Looper环境,而Looper只能通过Looper.prepare和Looper.prepareMainLooper来创建。同时将Looper实例存放到线程局部变量sThreadLocal(ThreadLocal)中,也就是每个线程有自己的Looper。在创建Looper的时候也创建了该线程的消息队列,prepareMainLooper会判断sMainLooper是否有值,如果调用多次,就会抛出异常,所以主线程的Looper和MessageQueue只会有一个。同理子线程中调用Looper.prepare()时,会调用prepare(true)方法,如果多次调用,也会抛出每个线程只能由一个Looper的异常,总结起来就是每个线程中只有一个Looper和MessageQueue。
public static void prepare() {prepare(true);}private static void prepare(boolean quitAllowed) {if (sThreadLocal.get() != null) {throw new RuntimeException("Only one Looper may be created per thread");}sThreadLocal.set(new Looper(quitAllowed));}
Looper死循环为什么不会导致应用ANR、卡死,会耗费大量资源吗?
线程其实就是一段可执行的代码,当可执行的代码执行完成后,线程的生命周期便该终止了,线程退出。而对于主线程,我们是绝不希望会被运行一段时间,自己就退出,那么如何保证能一直存活呢?简单做法就是可执行代码是能一直执行下去的,死循环便能保证不会被退出
- ANR 产生的原因是主线程没有及时响应用户的操作。也就是主线程执行某个耗时操作来不及处理UI消息。
- 而Looper一直循环,就是在不断的检索消息,与主线程无法响应用户操作没有任何冲突
- Android是基于消息处理机制的,用户的行为都在这个Looper循环中,正是有了主线程Looper的不断循环,才有app的稳定运行。
- 简单来说looper的阻塞表明没有事件输入,而ANR是由于有事件没响应导致,所以looper的死循环并不会导致应用卡死。
主线程的死循环并不消耗 CPU 资源,这里就涉及到 Linux pipe/epoll机制,简单说就是在主线程的 MessageQueue 没有消息时,便阻塞在 loop 的 queue.next() 中的 nativePollOnce() 方法里,此时主线程会释放 CPU 资源进入休眠状态,直到下个消息到达或者有事务发生,通过往 pipe 管道写端写入数据来唤醒主线程工作。这里采用的 epoll 机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。
Handler同步屏障了解吗
同步屏障是为了保证异步消息的优先执行,一般是用于UI绘制消息,避免主线程消息太多,无法及时处理UI绘制消息,导致卡顿。
- 同步消息 一般的handler发送的消息都是同步消息
- 异步消息 Message标记为异步的消息
- 可以调用 Message#setAsynchronous() 直接设置为异步 Message
- 可以用异步 Handler 发送
- 同步屏障 在 MessageQueue 的 某个位置放一个 target 属性为 null 的 Message ,确保此后的非异步 Message 无法执行,只能执行异步 Message。
当 Looper轮循MessageQueue 遍历 Message发现建立了同步屏障的时候,会去跳过其他Message,读取下个 async 的 Message 并执行,屏障移除之前同步 Message 都会被阻塞。
比如屏幕刷新 Choreographer 就使用到了同步屏障 ,确保屏幕刷新事件不会因为队列负荷影响屏幕及时刷新。
注意: 同步屏障的添加或移除 API 并未对外公开,App 需要使用的话需要依赖反射机制
Handler 为什么可能导致内存泄露?如何避免?
持有 Activity 实例的匿名内部类或内部类的 生命周期 应当和 Activity 保持一致,否则产生内存泄露的风险。
如果 Handler 使用不当,将造成不一致,表现为:匿名内部类或内部类写法的 Handler、Handler$Callback、Runnable,或者Activity 结束时仍有活跃的 Thread 线程或 Looper 子线程
具体在于:异步任务仍然活跃或通过发送的 Message 尚未处理完毕,将使得内部类实例的 生命周期被错误地延长 。造成本该回收的 Activity 实例 被别的 Thread 或 Main Looper 占据而无法及时回收 (活跃的 Thread 或 静态属性 sMainLooper 是 GC Root 对象)
建议的做法:
- 无论是 Handler、Handler$Callback 还是 Runnable,尽量采用 静态内部类 + 弱引用 的写法,确保尽管发生不当引用的时候也可以因为弱引用能清楚持有关系
- 另外在 Activity 销毁的时候及时地 终止 Thread、停止子线程的 Looper 或清空 Message ,确保彻底切断 Activity 经由 Message 抵达 GC Root 的引用源头(Message 清空后会其与 Handler 的引用关系,Thread 的终止将结束其 GC Root 的源头)
Handler是如何实现线程间通讯的
- handler是消息的发送者也是处理者。发送消息时,msg.target会标记为自身。插入MessageQueen后,被Looper取出后会通过msg.target.dispatchMessage去分发给对应的Handler去处理。
Handler消息处理的优先级
public void dispatchMessage(@NonNull Message msg) {if (msg.callback != null) {handleCallback(msg);} else {if (mCallback != null) {if (mCallback.handleMessage(msg)) {return;}}handleMessage(msg);}}
可以看出优先级是Message.CallBack->Handler.callback->Handler.handleMessage
有时候面试官也会问Runnable->Callable->handleMessage
post方法就是runnable
Handler构造传入Callback就是Callable
send方法是handleMessage
如何正确或Message实例
- 通过 Message 的静态方法 Message.obtain() 获取;
- 通过 Handler 的公有方法 handler.obtainMessage()
- 默认大小是50
Message使用享元设计模式,里面有一个spool指向一个Message对象,还有一个next指向下一个Message,维护了一个链表实现的对象池,obtain的时候在表头头取Message,在Message回收的时候在表头添加一个Message。
Android 为什么不允许并发访问 UI?
Android 中 UI 非线程安全,并发访问的话会造成数据和显示错乱。
此限制的检查始于ViewRootImpl#checkThread(),其会在刷新等多个访问 UI 的时机被调用,去检查当前线程,非主线程的话抛出异常。(实际上并不是检查主线程。而是检查UI的更新线程是否与UI的创建线程一致,因为UI是在主线程创建的,所以也只能在主线程更新)
而 ViewRootImpl 的创建在 onResume() 之后,也就是说如果在 onResume() 执行前启动线程访问 UI 的话是不会报错的。
了解ThreadLocal吗
- Thread中会维护一个类似HashMap的东西,然后用ThreadLocal对象作为key,value就是要存储的变量值,这样就保证了存储数据的唯一性)
- ThreadLocal为每个线程都提供了变量的副本,使得每个线程在某一时间访问到的并非同一个对象,这样就隔离了多个线程对数据的数据共享。
- ThreadLocal 内部通过 ThreadLocalMap 持有 Looper,key 为 ThreadLocal 实例本身,value 即为 Looper 实例
每个 Thread 都有一个自己的 ThreadLocalMap,这样可以保证每个线程对应一个独立的 Looper 实例,进而保证 myLooper() 可以获得线程独有的 Looper。让每个线程方便程获取自己的 Looper 实例

ThreadLocal与内存泄漏
- 在线程池中使用ThreadLocal可能会导致内存泄漏,原因是线程池中线程的存活时间太长,往往和程序都是同生共死的,这就意味着Thread持有的ThreadLocalMap一直都不会被回收,再加上ThreadLocalMap中的Entry对ThreadLocal是弱引用,所以只要ThreadLocal结束了自己的生命周期是可以被回收掉的。但是Entry中的Value却是被Entry强引用的,所以即便Value的生命周期结束了,Value也是无法被回收的,从而导致内存泄漏。
ExecutorService es;
ThreadLocal tl;
es.execute(()->{
//ThreadLocal增加变量
tl.set(obj);
try{
//业务代冯
}finally{
//于动消ThreadLocal
tl.remove();}
});
Message 的执行时刻如何管理
- 发送的 Message 都是按照执行时刻 when 属性的先后管理在 MessageQueue 里
延时 Message 的 when 等于调用的当前时刻和 delay 之和
非延时 Message 的 when 等于当前时刻(delay 为 0) - 插队 Message 的 when 固定为 0,便于插入队列的 head之后 MessageQueue 会根据 读取的时刻和 when 进行比较将 when 已抵达的出队,尚未抵达的计算出 当前时刻和目标 when 的插值 ,交由 Native 等待对应的时长,时间到了自动唤醒继续进行 Message 的读取
- 事实上,无论上述哪种 Message 都不能保证在其对应的 when 时刻执行,往往都会延迟一些!因为必须等当前执行的 Message 处理完了才有机会读取队列的下一个 Message。
比如发送了非延时 Message,when 即为发送的时刻,可它们不会立即执行。都要等主线程现有的任务(Message)走完才能有机会出队,而当这些任务执行完 when 的时刻已经过了。假使队列的前面还有其他 Message 的话,延迟会更加明显!
Looper等待如何准确唤醒的?
读取合适 Message 的 MessageQueue#next() 会因为 Message 尚无或执行条件尚未满足进行两种等的等待:
-
无限等待
尚无 Message(队列中没有 Message 或建立了同步屏障但尚无异步 Message)的时候,调用 Natvie 侧的 pollOnce() 会传入参数 -1 。
Linux 执行 epoll_wait() 将进入无限等待,其等待合适的 Message 插入后调用 Native 侧的 wake() 唤醒 fd 写入事件触发唤醒 MessageQueue 读取的下一次循环 -
有限等待
有限等待的场合将下一个 Message 剩余时长作为参数 交给 epoll_wait(),epoll 将等待一段时间之后 自动返回 ,接着回到 MessageQueue 读取的下一次循环。
Handler机制原理
-
Looper 准备和开启轮循:
尚无 Message 的话,调用 Native 侧的 pollOnce() 进入 无限等待
存在 Message,但执行时间 when 尚未满足的话,调用 pollOnce() 时传入剩余时长参数进入 有限等待
Looper#prepare() 初始化线程独有的 Looper 以及 MessageQueue
Looper#loop() 开启 死循环 读取 MessageQueue 中下一个满足执行时间的 Message -
Message 发送、入队和出队:
Native 侧如果处于无限等待的话:任意线程向 Handler 发送 Message 或 Runnable 后,Message 将按照 when 条件的先后,被插入 Handler 持有的 Looper 实例所对应的 MessageQueue 中 适当的位置 。MessageQueue 发现有合适的 Message 插入后将调用 Native 侧的 wake() 唤醒无限等待的线程。这将促使 MessageQueue 的读取继续 进入下一次循环 ,此刻 Queue 中已有满足条件的 Message 则出队返回给 Looper
Native 侧如果处于有限等待的话:在等待指定时长后 epoll_wait 将返回。线程继续读取 MessageQueue,此刻因为时长条件将满足将其出队 -
handler处理 Message 的实现:
Looper 得到 Message 后回调 Message 的 callback 属性即 Runnable,或依据 target 属性即 Handler,去执行 Handler 的回调。存在 mCallback 属性的话回调 Handler$Callback反之,回调 handleMessage()
6. 了解View绘制流程吗?
Activity启动走完onResume方法后,会进行window的添加。window添加过程会调用**ViewRootImpl的setView()方法,setView()方法会调用requestLayout()方法来请求绘制布局,requestLayout()方法内部又会走到scheduleTraversals()方法,最后会走到performTraversals()**方法,接着到了我们熟知的测量、布局、绘制三大流程了。
- 所有UI的变化都是走到ViewRootImpl的scheduleTraversals()方法。
//ViewRootImpl.javavoid scheduleTraversals() {if (!mTraversalScheduled) {//此字段保证同时间多次更改只会刷新一次,例如TextView连续两次setText(),也只会走一次绘制流程mTraversalScheduled = true;//添加同步屏障,屏蔽同步消息,保证VSync到来立即执行绘制mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();//mTraversalRunnable是TraversalRunnable实例,最终走到run(),也即doTraversal();mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);if (!mUnbufferedInputDispatch) {scheduleConsumeBatchedInput();}notifyRendererOfFramePending();pokeDrawLockIfNeeded();}}final class TraversalRunnable implements Runnable {@Overridepublic void run() {doTraversal();}}final TraversalRunnable mTraversalRunnable = new TraversalRunnable();void doTraversal() {if (mTraversalScheduled) {mTraversalScheduled = false;//移除同步屏障mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);...//开始三大绘制流程performTraversals();...}}
- 首先使用mTraversalScheduled字段保证同时间多次更改只会刷新一次,例如TextView连续两次setText(),也只会走一次绘制流程。
- 然后把当前线程的消息队列Queue添加了同步屏障,这样就屏蔽了正常的同步消息,保证VSync到来后立即执行绘制,而不是要等前面的同步消息。后面会具体分析同步屏障和异步消息的代码逻辑。
- 调用了mChoreographer.postCallback()方法,发送一个会在下一帧执行的回调,即在下一个VSync到来时会执行TraversalRunnable–>doTraversal()—>performTraversals()–>绘制流程。
mChoreographer,是在ViewRootImpl的构造方法内使用Choreographer.getInstance()创建:
Choreographer mChoreographer;
//ViewRootImpl实例是在添加window时创建
public ViewRootImpl(Context context, Display display) {...mChoreographer = Choreographer.getInstance();...
}
public static Choreographer getInstance() {return sThreadInstance.get();}private static final ThreadLocal<Choreographer> sThreadInstance =new ThreadLocal<Choreographer>() {@Overrideprotected Choreographer initialValue() {Looper looper = Looper.myLooper();if (looper == null) {//当前线程要有looper,Choreographer实例需要传入throw new IllegalStateException("The current thread must have a looper!");}Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);if (looper == Looper.getMainLooper()) {mMainInstance = choreographer;}return choreographer;}};
private Choreographer(Looper looper, int vsyncSource) {mLooper = looper;//使用当前线程looper创建 mHandlermHandler = new FrameHandler(looper);//USE_VSYNC 4.1以上默认是true,表示 具备接受VSync的能力,这个接受能力就是FrameDisplayEventReceivermDisplayEventReceiver = USE_VSYNC? new FrameDisplayEventReceiver(looper, vsyncSource): null;mLastFrameTimeNanos = Long.MIN_VALUE;// 计算一帧的时间,Android手机屏幕是60Hz的刷新频率,就是16msmFrameIntervalNanos = (long)(1000000000 / getRefreshRate());// 创建一个链表类型CallbackQueue的数组,大小为5,//也就是数组中有五个链表,每个链表存相同类型的任务:输入、动画、遍历绘制等任务(CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_TRAVERSAL)mCallbackQueues = new CallbackQueue[CALLBACK_LAST + 1];for (int i = 0; i <= CALLBACK_LAST; i++) {mCallbackQueues[i] = new CallbackQueue();}// b/68769804: For low FPS experiments.setFPSDivisor(SystemProperties.getInt(ThreadedRenderer.DEBUG_FPS_DIVISOR, 1));}
安排任务—postCallback
回头看mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null)方法,注意到第一个参数是CALLBACK_TRAVERSAL,表示回调任务的类型,共有以下5种类型:
//输入事件,首先执行
public static final int CALLBACK_INPUT = 0;
//动画,第二执行
public static final int CALLBACK_ANIMATION = 1;
//插入更新的动画,第三执行
public static final int CALLBACK_INSETS_ANIMATION = 2;
//绘制,第四执行
public static final int CALLBACK_TRAVERSAL = 3;
//提交,最后执行,
public static final int CALLBACK_COMMIT = 4;
五种类型任务对应存入对应的CallbackQueue中,每当收到 VSYNC 信号时,Choreographer 将首先处理 INPUT 类型的任务,然后是 ANIMATION 类型,最后才是 TRAVERSAL 类型。
postCallback()内部调用postCallbackDelayed(),接着又调用postCallbackDelayedInternal()
private void postCallbackDelayedInternal(int callbackType,Object action, Object token, long delayMillis) {...synchronized (mLock) {// 当前时间final long now = SystemClock.uptimeMillis();// 加上延迟时间final long dueTime = now + delayMillis;//取对应类型的CallbackQueue添加任务mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);if (dueTime <= now) {//立即执行scheduleFrameLocked(now);} else {//延迟运行,最终也会走到scheduleFrameLocked()Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);msg.arg1 = callbackType;msg.setAsynchronous(true);mHandler.sendMessageAtTime(msg, dueTime);}}}
首先取对应类型的CallbackQueue添加任务,action就是mTraversalRunnable,token是null。CallbackQueue的addCallbackLocked()就是把 dueTime、action、token组装成CallbackRecord后 存入CallbackQueue的下一个节点
然后注意到如果没有延迟会执行scheduleFrameLocked()方法,有延迟就会使用 mHandler发送MSG_DO_SCHEDULE_CALLBACK消息,并且注意到 使用msg.setAsynchronous(true)把消息设置成异步,这是因为前面设置了同步屏障,只有异步消息才会执行。我们看下mHandler的对这个消息的处理:
private final class FrameHandler extends Handler {public FrameHandler(Looper looper) {super(looper);}@Overridepublic void handleMessage(Message msg) {switch (msg.what) {case MSG_DO_FRAME:// 执行doFrame,即绘制过程doFrame(System.nanoTime(), 0);break;case MSG_DO_SCHEDULE_VSYNC://申请VSYNC信号,例如当前需要绘制任务时doScheduleVsync();break;case MSG_DO_SCHEDULE_CALLBACK://需要延迟的任务,最终还是执行上述两个事件doScheduleCallback(msg.arg1);break;}}
}
void doScheduleCallback(int callbackType) {synchronized (mLock) {if (!mFrameScheduled) {final long now = SystemClock.uptimeMillis();if (mCallbackQueues[callbackType].hasDueCallbacksLocked(now)) {scheduleFrameLocked(now);}}}}
private void scheduleFrameLocked(long now) {if (!mFrameScheduled) {mFrameScheduled = true;//开启了VSYNCif (USE_VSYNC) {if (DEBUG_FRAMES) {Log.d(TAG, "Scheduling next frame on vsync.");}//当前执行的线程,是否是mLooper所在线程if (isRunningOnLooperThreadLocked()) {//申请 VSYNC 信号scheduleVsyncLocked();} else {// 若不在,就用mHandler发送消息到原线程,最后还是调用scheduleVsyncLocked方法Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);msg.setAsynchronous(true);//异步mHandler.sendMessageAtFrontOfQueue(msg);}} else {// 如果未开启VSYNC则直接doFrame方法(4.1后默认开启)final long nextFrameTime = Math.max(mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);if (DEBUG_FRAMES) {Log.d(TAG, "Scheduling next frame in " + (nextFrameTime - now) + " ms.");}Message msg = mHandler.obtainMessage(MSG_DO_FRAME);msg.setAsynchronous(true);//异步mHandler.sendMessageAtTime(msg, nextFrameTime);}}}
- 如果系统未开启 VSYNC 机制,此时直接发送 MSG_DO_FRAME 消息到 FrameHandler。注意查看上面贴出的 FrameHandler 代码,此时直接执行 doFrame 方法。
- Android 4.1 之后系统默认开启 VSYNC,在 Choreographer 的构造方法会创建一个 FrameDisplayEventReceiver,scheduleVsyncLocked 方法将会通过它申请 VSYNC 信号。
- isRunningOnLooperThreadLocked 方法,其内部根据 Looper 判断是否在原线程,否则发送消息到 FrameHandler。最终还是会调用 scheduleVsyncLocked 方法申请 VSYNC 信号。
FrameHandler的作用很明显里了:发送异步消息(因为前面设置了同步屏障)。有延迟的任务发延迟消息、不在原线程的发到原线程、没开启VSYNC的直接走 doFrame 方法取执行绘制。
申请和接受VSync
scheduleVsyncLocked 方法是如何申请 VSYNC 信号的。申请 VSYNC 信号后,信号到来时也是走doFrame() 方法:
private void scheduleVsyncLocked() {mDisplayEventReceiver.scheduleVsync();}
调用mDisplayEventReceiver的scheduleVsync()方法,mDisplayEventReceiver是Choreographer构造方法中创建,是FrameDisplayEventReceiver 的实例。 FrameDisplayEventReceiver是 DisplayEventReceiver 的子类,DisplayEventReceiver 是一个 abstract class:
public DisplayEventReceiver(Looper looper, int vsyncSource) {if (looper == null) {throw new IllegalArgumentException("looper must not be null");}mMessageQueue = looper.getQueue();// 注册VSYNC信号监听者mReceiverPtr = nativeInit(new WeakReference<DisplayEventReceiver>(this), mMessageQueue,vsyncSource);mCloseGuard.open("dispose");}
在 DisplayEventReceiver 的构造方法会通过 JNI 创建一个 IDisplayEventConnection 的 VSYNC 的监听者。
FrameDisplayEventReceiver的scheduleVsync()就是在 DisplayEventReceiver中:
public void scheduleVsync() {if (mReceiverPtr == 0) {Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "+ "receiver has already been disposed.");} else {// 申请VSYNC中断信号,会回调onVsync方法nativeScheduleVsync(mReceiverPtr);}}
scheduleVsync()就是使用native方法nativeScheduleVsync()去申请VSYNC信号。这个native方法就看不了了,只需要知道VSYNC信号的接受回调是onVsync()
/*** 接收到VSync脉冲时 回调* @param timestampNanos VSync脉冲的时间戳* @param physicalDisplayId Stable display ID that uniquely describes a (display, port) pair.* @param frame 帧号码,自增*/@UnsupportedAppUsagepublic void onVsync(long timestampNanos, long physicalDisplayId, int frame) {}
具体实现是在FrameDisplayEventReceiver中:
private final class FrameDisplayEventReceiver extends DisplayEventReceiverimplements Runnable {private boolean mHavePendingVsync;private long mTimestampNanos;private int mFrame;public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {super(looper, vsyncSource);}@Overridepublic void onVsync(long timestampNanos, long physicalDisplayId, int frame) {// Post the vsync event to the Handler.// The idea is to prevent incoming vsync events from completely starving// the message queue. If there are no messages in the queue with timestamps// earlier than the frame time, then the vsync event will be processed immediately.// Otherwise, messages that predate the vsync event will be handled first.long now = System.nanoTime();if (timestampNanos > now) {Log.w(TAG, "Frame time is " + ((timestampNanos - now) * 0.000001f)+ " ms in the future! Check that graphics HAL is generating vsync "+ "timestamps using the correct timebase.");timestampNanos = now;}if (mHavePendingVsync) {Log.w(TAG, "Already have a pending vsync event. There should only be "+ "one at a time.");} else {mHavePendingVsync = true;}mTimestampNanos = timestampNanos;mFrame = frame;//将本身作为runnable传入msg, 发消息后 会走run(),即doFrame(),也是异步消息Message msg = Message.obtain(mHandler, this);msg.setAsynchronous(true);mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);}@Overridepublic void run() {mHavePendingVsync = false;doFrame(mTimestampNanos, mFrame);}}
onVsync()中,将接收器本身作为runnable传入异步消息msg,并使用mHandler发送msg,最终执行的就是doFrame()方法了。
注意一点是,onVsync()方法中只是使用mHandler发送消息到MessageQueue中,不一定是立刻执行,如何MessageQueue中前面有较为耗时的操作,那么就要等完成,才会执行本次的doFrame()。
doFrame
VSync信号接收到后确实是走 doFrame()方法,那么就来看看Choreographer的doFrame()
void doFrame(long frameTimeNanos, int frame) {final long startNanos;synchronized (mLock) {if (!mFrameScheduled) {return; // no work to do}...// 预期执行时间long intendedFrameTimeNanos = frameTimeNanos;startNanos = System.nanoTime();// 超时时间是否超过一帧的时间(这是因为MessageQueue虽然添加了同步屏障,但是还是有正在执行的同步任务,导致doFrame延迟执行了)final long jitterNanos = startNanos - frameTimeNanos;if (jitterNanos >= mFrameIntervalNanos) {// 计算掉帧数final long skippedFrames = jitterNanos / mFrameIntervalNanos;if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {// 掉帧超过30帧打印Log提示Log.i(TAG, "Skipped " + skippedFrames + " frames! "+ "The application may be doing too much work on its main thread.");}final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;...frameTimeNanos = startNanos - lastFrameOffset;}... mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);// Frame标志位恢复mFrameScheduled = false;// 记录最后一帧时间mLastFrameTimeNanos = frameTimeNanos;}try {// 按类型顺序 执行任务Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);mFrameInfo.markInputHandlingStart();doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);mFrameInfo.markAnimationsStart();doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos);mFrameInfo.markPerformTraversalsStart();doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);} finally {AnimationUtils.unlockAnimationClock();Trace.traceEnd(Trace.TRACE_TAG_VIEW);}}
void doCallbacks(int callbackType, long frameTimeNanos) {CallbackRecord callbacks;synchronized (mLock) {final long now = System.nanoTime();// 根据指定的类型CallbackkQueue中查找到达执行时间的CallbackRecordcallbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(now / TimeUtils.NANOS_PER_MS);if (callbacks == null) {return;}mCallbacksRunning = true;//提交任务类型if (callbackType == Choreographer.CALLBACK_COMMIT) {final long jitterNanos = now - frameTimeNanos;if (jitterNanos >= 2 * mFrameIntervalNanos) {final long lastFrameOffset = jitterNanos % mFrameIntervalNanos+ mFrameIntervalNanos;if (DEBUG_JANK) {Log.d(TAG, "Commit callback delayed by " + (jitterNanos * 0.000001f)+ " ms which is more than twice the frame interval of "+ (mFrameIntervalNanos * 0.000001f) + " ms! "+ "Setting frame time to " + (lastFrameOffset * 0.000001f)+ " ms in the past.");mDebugPrintNextFrameTimeDelta = true;}frameTimeNanos = now - lastFrameOffset;mLastFrameTimeNanos = frameTimeNanos;}}}try {// 迭代执行队列所有任务for (CallbackRecord c = callbacks; c != null; c = c.next) {// 回调CallbackRecord的run,其内部回调Callback的runc.run(frameTimeNanos);}} finally {synchronized (mLock) {mCallbacksRunning = false;do {final CallbackRecord next = callbacks.next;//回收CallbackRecordrecycleCallbackLocked(callbacks);callbacks = next;} while (callbacks != null);}}}
主要内容就是取对应任务类型的队列,遍历队列执行所有任务,执行任务是 CallbackRecord的 run 方法:
private static final class CallbackRecord {public CallbackRecord next;public long dueTime;public Object action; // Runnable or FrameCallbackpublic Object token;@UnsupportedAppUsagepublic void run(long frameTimeNanos) {if (token == FRAME_CALLBACK_TOKEN) {// 通过postFrameCallback 或 postFrameCallbackDelayed,会执行这里((FrameCallback)action).doFrame(frameTimeNanos);} else {//取出Runnable执行run()((Runnable)action).run();}}}
前面看到mChoreographer.postCallback传的token是null,所以取出action,就是Runnable,执行run(),这里的action就是 ViewRootImpl 发起的绘制任务mTraversalRunnable了,那么这样整个逻辑就闭环了。
那么 啥时候 token == FRAME_CALLBACK_TOKEN 呢?答案是Choreographer的postFrameCallback()方法:
public void postFrameCallback(FrameCallback callback) {postFrameCallbackDelayed(callback, 0);}public void postFrameCallbackDelayed(FrameCallback callback, long delayMillis) {if (callback == null) {throw new IllegalArgumentException("callback must not be null");}//也是走到是postCallbackDelayedInternal,并且注意是CALLBACK_ANIMATION类型,//token是FRAME_CALLBACK_TOKEN,action就是FrameCallbackpostCallbackDelayedInternal(CALLBACK_ANIMATION,callback, FRAME_CALLBACK_TOKEN, delayMillis);}public interface FrameCallback {public void doFrame(long frameTimeNanos);}
可以看到postFrameCallback()传入的是FrameCallback实例,接口FrameCallback只有一个doFrame()方法。并且也是走到postCallbackDelayedInternal,FrameCallback实例作为action传入,token则是FRAME_CALLBACK_TOKEN,并且任务是CALLBACK_ANIMATION类型。
Choreographer的postFrameCallback()通常用来计算丢帧情况,使用方式如下:
//Application.javapublic void onCreate() {super.onCreate();//在Application中使用postFrameCallbackChoreographer.getInstance().postFrameCallback(new FPSFrameCallback(System.nanoTime()));}public class FPSFrameCallback implements Choreographer.FrameCallback {private static final String TAG = "FPS_TEST";private long mLastFrameTimeNanos = 0;private long mFrameIntervalNanos;public FPSFrameCallback(long lastFrameTimeNanos) {mLastFrameTimeNanos = lastFrameTimeNanos;mFrameIntervalNanos = (long)(1000000000 / 60.0);}@Overridepublic void doFrame(long frameTimeNanos) {//初始化时间if (mLastFrameTimeNanos == 0) {mLastFrameTimeNanos = frameTimeNanos;}final long jitterNanos = frameTimeNanos - mLastFrameTimeNanos;if (jitterNanos >= mFrameIntervalNanos) {final long skippedFrames = jitterNanos / mFrameIntervalNanos;if(skippedFrames>30){//丢帧30以上打印日志Log.i(TAG, "Skipped " + skippedFrames + " frames! "+ "The application may be doing too much work on its main thread.");}}mLastFrameTimeNanos=frameTimeNanos;//注册下一帧回调Choreographer.getInstance().postFrameCallback(this);}}
Choreographer的postCallback()、postFrameCallback() 作用理解:发送任务 存队列中,监听VSync信号,当前VSync到来时 会使用mHandler发送异步message,这个message的Runnable就是队列中的所有任务。
7. 自定义View流程是什么
一般需要重写onMeasure,onLayout和onDraw方法。
- onMeasure 测量view的大小,用于确定 View 的测量宽/高。
- Viewgroup先测量所有子View然后再测量自身
- View直接测量自身
- onLayout 布局View,用于确定 View 在父容器中的放置位置。
- ViewGroup先确定自身的位置,再确定自子View的位置
- View直接确定自身的位置
- onDraw 绘制View
- 一般ViewGroup不实现绘制,做容器作用
- View实现一些特殊的绘制功能
- 测量模式
MeasureSpec
MeasureSpec是View的一个公有静态内部类,它是一个 32 位的int值,高 2 位表示 SpecMode(测量模式),低 30 位表示 SpecSize(测量尺寸/测量大小)。
MeasureSpec将两个数据打包到一个int值上,可以减少对象内存分配,并且其提供了相应的工具方法可以很方便地让我们从一个int值中抽取出 View 的 SpecMode 和 SpecSize。
- UNSPECIFIED:表示父容器对子View 未施加任何限制,子View 尺寸想多大就多大。
- EXACTLY:如果子View 的模式为EXACTLY,则表示子View 已设置了确切的测量尺寸,或者父容器已检测出子View 所需要的确切大小。这种模式对应于LayoutParams.MATCH_PARENT和子View 设置具体数值两种情况。
- AT_MOST:表示自适应内容,在该种模式下,View 的最大尺寸不能超过父容器的 SpecSize,因此也称这种模式为 最大值模式。这种模式对应于LayoutParams.WRAP_CONTENT。
// frameworks/base/core/java/android/view/View.java
public static class MeasureSpec {private static final int MODE_SHIFT = 30;private static final int MODE_MASK = 0x3 << MODE_SHIFT;/*** Measure specification mode: The parent has not imposed any constraint* on the child. It can be whatever size it wants.*/public static final int UNSPECIFIED = 0 << MODE_SHIFT;/*** Measure specification mode: The parent has determined an exact size* for the child. The child is going to be given those bounds regardless* of how big it wants to be.*/public static final int EXACTLY = 1 << MODE_SHIFT;/*** Measure specification mode: The child can be as large as it wants up* to the specified size.*/public static final int AT_MOST = 2 << MODE_SHIFT;// 生成测量规格public static int makeMeasureSpec(int size, int mode) {if (sUseBrokenMakeMeasureSpec) {return size + mode;} else {return (size & ~MODE_MASK) | (mode & MODE_MASK);}}// 获取测量模式public static int getMode(int measureSpec) {return (measureSpec & MODE_MASK);}// 获取测量大小public static int getSize(int measureSpec) {return (measureSpec & ~MODE_MASK);}...
}
LayoutParams
对 View 进行测量,最关键的一步就是计算得到 View 的MeasureSpec,子View 在创建时,可以指定不同的LayoutParams(布局参数),LayoutParams的源码主要内容如下所示:
// frameworks/base/core/java/android/view/ViewGroup.java
public static class LayoutParams {.../*** Special value for the height or width requested by a View.* MATCH_PARENT means that the view wants to be as big as its parent,* minus the parent's padding, if any. Introduced in API Level 8.*/public static final int MATCH_PARENT = -1;/*** Special value for the height or width requested by a View.* WRAP_CONTENT means that the view wants to be just large enough to fit* its own internal content, taking its own padding into account.*/public static final int WRAP_CONTENT = -2;/*** Information about how wide the view wants to be. Can be one of the* constants FILL_PARENT (replaced by MATCH_PARENT* in API Level 8) or WRAP_CONTENT, or an exact size.*/public int width;/*** Information about how tall the view wants to be. Can be one of the* constants FILL_PARENT (replaced by MATCH_PARENT* in API Level 8) or WRAP_CONTENT, or an exact size.*/public int height;...
}
- LayoutParams.MATCH_PARENT:表示子View 的尺寸与父容器一样大(注:需要减去父容器padding部分空间,让父容器padding生效)
- LayoutParams.WRAP_CONTENT:表示子View 的尺寸自适应其内容大小(注:需要包含子View 本身的padding空间)
- width/height:表示 View 的设置宽/高,即layout_width和layout_height设置的值,其值有三种选择:LayoutParams.MATCH_PARENT、LayoutParams.WRAP_CONTENT和 具体数值。
LayoutParams会受到父容器的MeasureSpec的影响,测量过程会依据两者之间的相互约束最终生成子View 的MeasureSpec,完成 View 的测量规格。
总之。View 的MeasureSpec受自身的LayoutParams和父容器的MeasureSpec共同决定(DecorView的MeasureSpec是由自身的LayoutParams和屏幕尺寸共同决定,参考后文)。也因此,如果要求取子View 的MeasureSpec,那么首先就需要知道父容器的MeasureSpec,层层逆推而上,即最终就是需要知道顶层View(即DecorView)的MeasureSpec,这样才能一层层传递下来,这整个过程需要结合Activity的启动过程进行分析。
总结
View 的绘制主要有以下一些核心内容:
三大流程:View 绘制主要包含如下三大流程:
- measure:测量流程,主要负责对 View 进行测量,其核心逻辑位于View#measure(…),真正的测量处理由View#onMeasure(…)负责。默认的测量规则为:
- 如果 View 的布局参数为LayoutParams.WRAP_CONTENT或LayoutParams.MATCH_PARENT,那么其测量大小为 SpecSize;如果其布局参数为LayoutParams.UNSPECIFIED,那么其测量大小为android:minWidth/android:minHeight和其背景之间的较大值。
- 自定义View 通常覆写onMeasure(…)方法,在其内一般会对WRAP_CONTENT预设一个默认值,区分WARP_CONTENT和MATCH_PARENT效果,最终完成自己的测量宽/高。而ViewGroup在onMeasure(…)方法中,通常都是先测量子View,收集到相应数据后,才能最终测量自己。
- layout:布局流程,主要完成对 View 的位置放置,其核心逻辑位于View#layout(…),该方法内部主要通过View#setFrame(…)记录自己的四个顶点坐标(记录与对应成员变量中即可),完成自己的位置放置,最后会回调View#onLayout(…)方法,在其内完成对 子View 的布局放置。
注:不同于 measure 流程首先对 子View 进行测量,最后才测量自己,layout 流程首先是先定位自己的布局位置,然后才处理放置 子View 的布局位置。
- draw:绘制流程,就是将 View 绘制到屏幕上,其核心逻辑位于View#draw(…),主要就是对 背景、自身内容(onDraw(…))、子View(dispatchDraw(…))、装饰(滚动条、前景等) 进行绘制。
注:通常自定义View 覆写onDraw(…)方法,完成自己的绘制即可,ViewGroup 一般充当容器使用,因此通常无需覆写onDraw(…)。
- Activity 的根视图(即DecorView)最终是绑定到ViewRootImpl,具体是由ViewRootImpl#setView(…)进行绑定关联的,后续 View 绘制的三大流程都是均有ViewRootImpl负责执行的。
- 对 View 的测量流程中,最关键的一步是求取 View 的MeasureSpec,View 的MeasureSpec是在其父容器MeasureSpec的约束下,结合自己的LayoutParams共同测量得到的,具体的测量逻辑由ViewGroup#getChildMeasureSpec(…)负责。
DecorView的MeasureSpec取决于自己的LayoutParams和屏幕尺寸,具体的测量逻辑位于ViewRootImpl#getRootMeasureSpec(…)。
总结一下 View 绘制的整个流程:
- 首先,当 Activity 启动时,会触发调用到ActivityThread#handleResumeActivity(…),其内部会经历一系列过程,生成DecorView和ViewRootImpl等实例,最后通过**ViewRootImpl#setView(decor,MATCH_PARENT)**设置 Activity 根View。
注:ViewRootImpl#setView(…)内容通过将其成员属性ViewRootImpl#mView指向DecorView,完成两者之间的关联。
- ViewRootImpl成功关联DecorView后,其内部会设置同步屏障并发送一个CALLBACK_TRAVERSAL异步渲染消息,在下一次 VSYNC 信号到来时,CALLBACK_TRAVERSAL就会得到响应,从而最终触发执行ViewRootImpl#performTraversals(…),真正开始执行 View 绘制流程。
- ViewRootImpl#performTraversals(…)内部会依次调用ViewRootImpl#performMeasure(…)、**ViewRootImpl#performLayout(…)和ViewRootImpl#performDraw(…)**三大绘制流程,其中:
- performMeasure(…):内部主要就是对DecorView执行测量流程:DecorView#measure(…)。DecorView是一个FrameLayout,其布局特性是层叠布局,所占的空间就是其 子View 占比最大的宽/高,因此其测量逻辑(onMeasure(…))是先对所有 子View 进行测量,具体是通过ViewGroup#measureChildWithMargins(…)方法对 子View 进行测量,子View 测量完成后,记录最大的宽/高,设置为自己的测量大小(通过View#setMeasuredDimension(…)),如此便完成了DecorView的测量流程。
- performLayout(…):内部其实就是调用DecorView#layout(…),如此便完成了DecorView的布局位置,最后会回调DecorView#onLayout(…),负责 子View 的布局放置,核心逻辑就是计算出各个 子View 的坐标位置,最后通过child.layout(…)完成 子View 布局。
- performDraw():内部最终调用到的是DecorView#draw(…),该方法内部并未对绘制流程做任何修改,因此最终执行的是View#draw(…),所以主要就是依次完成对DecorView的 背景、子View(dispatchDraw(…)) 和 视图装饰(滚动条、前景等) 的绘制。
8. 了解View事件分发机制吗
事件分发机制主要靠三个方法完成dispatchTouchEvent,onInterceptTouchEvent,onTouchEvent
- dispatchTouchEvent(event):用于进行点击事件的分发。
- onInterceptTouchEvent(event):用于进行点击事件的拦截。
- onTouchEvent(event):用于处理点击事件。
三个函数的参数均为even,即上面所说的3种类型的输入事件,返回值均为boolean 类型
三种方法调用关系可以用伪代码表示:
public boolean dispatchTouchEvent(MotionEvent ev) {boolean consume = false;//事件是否被消费if (onInterceptTouchEvent(ev)){//调用onInterceptTouchEvent判断是否拦截事件consume = onTouchEvent(ev);//如果拦截则调用自身的onTouchEvent方法}else{consume = child.dispatchTouchEvent(ev);//不拦截调用子View的dispatchTouchEvent方法}return consume;//返回值表示事件是否被消费,true事件终止,false调用父View的onTouchEvent方法}
整个事件分发到处理可以用一个U形图来表示
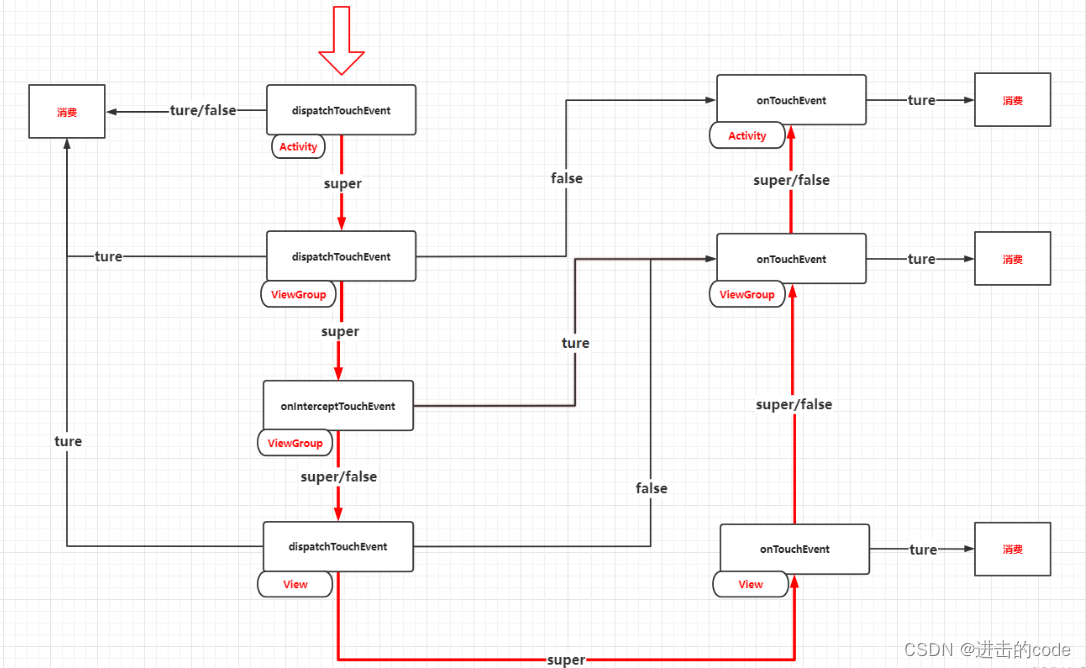
简述流程
从顶层DecorView开始分析
- 点击事件都通过dispatchTouchEvent分发,因为是顶层没有更上层的处理,因此不管返回true或者false都表示事件被消费,不再传递。返回super开始向下传递。
- 交给子View的dispatchTouchEvent,此时因为有上层View。返回true表示事件被消费,返回false交给上层onTouchEvent处理。返回super继续向下传递。因为是ViewGroup有onInterceptTouchEvent实现。onInterceptTouchEvent返回true表示需要拦截交给自身的onTouchEvent处理。返回false或者super则表示继续向下传递。
- 传递到View时,dispatchTouchEvent返回true表示事件被消费,false交给上层处理,因为没有onInterceptTouchEvent实现,所以super就是默认交给自己的onTouchEvent处理
- onTouchEvent 返回true表示被消费不再传递,返回false就交给上层onTouchEvent处理
9. ListVie和RecycleView的区别
1. 优化
ListView优化需要自定义ViewHolder和判断convertView是否为null。 而RecyclerView是存在规定好的ViewHolder。
2. 布局不同
对于ListView,只能在垂直的方向滚动。而对于RecyclerView,他里面的LayoutManager中制定了一套可以扩展的布局排列接口,所以我们可以重写LayoutManager来定制自己需要的布局。RecycleView可以根据LayoutManger有横向,瀑布和表格布局
3. 更新数据
recycleView可以支持在添加,删除或者移动Item的时候,RecyclerView.ItemAnimator添加动画效果,而listview不支持。而且RecyclerView有四重缓存,而ListView只有二重缓存。ListView和RecyclerView最大的区别在于数据源改变时的缓存的处理逻辑,ListView是"一锅端",将所有的mActiveViews都移入了二级缓存mScrapViews,而RecyclerView则是更加灵活地对每个View修改
标志位,区分是否重新bindView。
4. 自定义适配器
ListView的适配器继承ArrayAdapter;RecycleView的适配器继承RecyclerAdapter,并将范类指定为子项对象类.ViewHolder(内部类)。
5. 绑定事件不同
ListView是在主方法中ListView对象的setOnItemClickListener方法;RecyclerView则是在子项具体的View中去注册事件。
10. 展开讲讲recycleView
recycleView以下几个部分
- LayoutManager 布局管理器,实现列表的布局效果
- LinearLayoutManager 线性布局管理器
- StaggeredGridLayoutManager 瀑布流布局管理器
- GridLayoutManager 网格布局管理器
- Adapter 适配器,适配数据如何展示
- ItemDecoration Item 的装饰器,经常用来设置 Item 的分割线。
- ItemAnimator:非必选项,设置 RV 中 Item 的动画。
recycleView会将测量 onMeasure 和布局 onLayout 的工作委托给 LayoutManager 来执行,不同的 LayoutManager 会有不同风格的布局显示,这是一种策略模式。用一张图来描述这段过程如下:
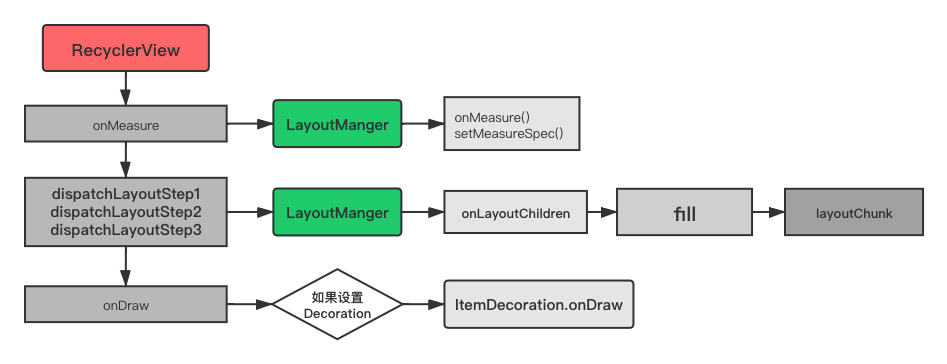
recycleView的缓存了解吗
recycleView分为四级缓存
-
一级缓存 mAttachedScrap&mChangedScrap
这两者主要用来缓存屏幕内的 ViewHolder。主要作用是数据更新时直接复用旧的ViewHolder。
例如下拉刷新时,只需要在原有的 ViewHolder 基础上进行重新绑定新的数据 data 即可,而这些旧的 ViewHolder 就是被保存在 mAttachedScrap 和 mChangedScrap 中。实际上当我们调用 RV 的 notifyXXX 方法时,就会向这两个列表进行填充,将旧 ViewHolder 缓存起来。 -
二级缓存 mCachedViews
它用来缓存移除屏幕之外的 ViewHolder,默认情况下缓存个数是 2个,不过可以通过 setViewCacheSize 方法来改变缓存的容量大小。如果 mCachedViews 的容量已满,则会根据 FIFO 的规则将旧 ViewHolder 抛弃,然后添加新的 ViewHolder,如下所示:

-
三级缓存 ViewCacheExtension
-
这是 RV 预留给开发人员的一个抽象类,在这个类中只有一个抽象方法,如下:
public abstract static class viewCacheExtension{@Nullablepublic abstract view getviewForPositionAndType(@NonNull Recycler recycler,int position,int type);
}
开发人员可以通过继承 ViewCacheExtension,并复写抽象方法 getViewForPositionAndType 来实现自己的缓存机制。只是一般情况下我们不会自己实现也不建议自己去添加缓存逻辑,因为这个类的使用门槛较高,需要开发人员对 RV 的源码非常熟悉。
- 四级缓存 RecycledViewPool
RecycledViewPool 同样是用来缓存屏幕外的 ViewHolder,当 mCachedViews 中的个数已满(默认为 2),则从 mCachedViews 中淘汰出来的 ViewHolder 会先缓存到 RecycledViewPool 中。ViewHolder 在被缓存到 RecycledViewPool 时,会将内部的数据清理,因此从 RecycledViewPool 中取出来的 ViewHolder 需要重新调用 onBindViewHolder 绑定数据。- RecycledViewPool 是根据 type 来获取 ViewHolder,每个 type 默认最大缓存 5 个。
- RecycledViewPool 是一个静态类,因此是可以多个RecycleView共用一个RecycledViewPool 缓存的
- 可以通过RecyclerView.getRecycledViewPool(). setMaxRecycledViews(int viewType, int max) 修改RecycledViewPool的缓存大小;
问题1. RecyclerView第一次layout时,会发生预布局pre-layout吗
第一次布局时,并不会触发pre-layout。pre-layout只会在每次notify change时才会被触发,目的是通过saveOldPosition方法将屏幕中各位置上的ViewHolder的坐标记录下来,并在重新布局之后,通过对比实现Item的动画效果。
问题2. 如果自定义LayoutManager需要注意什么?
在RecyclerView的dispatchLayoutStep1阶段,会调用自定义LayoutManager的 supportsPredictiveItemAnimations 方法判断在某些状态下是否展示predictive animation。以下LinearLayoutManager的实现:
@Override
public boolean supportsPredictiveItemAnimations() {
return mPendingSavedState == null && mLastStackFromEnd == mStackFromEnd;
}
如果 supportsPredictiveItemAnimations 返回true,则LayoutManager中复写onLayoutChildren方法会被调用2次:一次是在pre-layout,另一次是real-layout。
因为会有pre-layout和real-layout,所有在自定义LayoutManager中,需要根据RecyclerView.State中的isPreLayout方法的返回值,在这两次布局中做区分。比如LinearLayoutManager中的onLayoutChildren中有如下判断:
@Overridepublic void onLayoutChildren(RecyclerView.Recycler recycler, RecyclerView.State state) {......if (state.isPreLayout() && mPendingScrollPosition != RecyclerView.NO_POSITION&& mPendingScrollPositionOffset != INVALID_OFFSET) {// if the child is visible and we are going to move it around, we should layout// extra items in the opposite direction to make sure new items animate nicely// instead of just fading infinal View existing = findViewByPosition(mPendingScrollPosition);if (existing != null) {final int current;final int upcomingOffset;if (mShouldReverseLayout) {current = mOrientationHelper.getEndAfterPadding()- mOrientationHelper.getDecoratedEnd(existing);upcomingOffset = current - mPendingScrollPositionOffset;} else {current = mOrientationHelper.getDecoratedStart(existing)- mOrientationHelper.getStartAfterPadding();upcomingOffset = mPendingScrollPositionOffset - current;}if (upcomingOffset > 0) {extraForStart += upcomingOffset;} else {extraForEnd -= upcomingOffset;}}}......}
意思就是如果当前正在update的item是可见状态,则需要在pre-layout阶段额外填充一个item,目的是为了保证处于不可见状态的item可以平滑的滑动到屏幕内。


如果自定义LayoutManager并没有实现pre-layout,或者实现不合理,则当item2移出屏幕时,只会将item3和item4进行平滑移动,而item5只是单纯的appear到屏幕中,如下所示:

问题3. CachedView和RecycledViewPool两者区别
缓存到CachedView中的ViewHolder并不会清理相关信息(比如position、state等),因此刚移出屏幕的ViewHolder,再次被移回屏幕时,只要从CachedView中查找并显示即可,不需要重新绑定(bindViewHolder)。
而缓存到RecycledViewPool中的ViewHolder会被清理状态和位置信息,因此从RecycledViewPool查找到ViewHolder,需要重新调用bindViewHolder绑定数据。
问题4. 你是从哪些方面优化RecyclerView的?
- 尽量将复杂的数据处理操作放到异步中完成。RecyclerView需要展示的数据经常是从远端服务器上请求获取,但是在网络请求拿到数据之后,需要将数据做扁平化操作,尽量将最优质的数据格式返回给UI线程。优化RecyclerView的布局,避免将其与ConstraintLayout使用
- 针对快速滑动事件,可以使用addOnScrollListener添加对快速滑动的监听,当用户快速滑动时,停止加载数据操作。
- 如果ItemView的高度固定,可以使用setHasFixSize(true)。这样RecyclerView在onMeasure阶段可以直接计算出高度,不需要多次计算子ItemView的高度,这种情况对于垂直RecyclerView中嵌套横向RecyclerView效果非常显著。
- 当UI是Tab feed流时,可以考虑使用RecycledViewPool来实现多个RecyclerView的缓存共享。
11. 你知道IPC吗?
IPC 是Inter-Process Communication的缩写,含义为进程间通信或者跨进程通信,是指两个进程之间进行数据交换的过程。
Android中的IPC方式主要有以下几种:
-
使用Bundle
四大组件中的三大组件(Activity、Service、Receiver)都是支持在Intent中传递Bundle数据的,由于Bundle实现了Parcelable接口,所以它可以方便地在不同的进程间传输,这是一种最简单的进程间通信方式, -
使用文件共享
文件共享方式适合在对数据同步要求不高的进程之间进行通信,并且要妥善处理并发读/写的问题。 -
使用Messenger
- Messenger可以翻译为信使,顾名思义,通过它可以在不同进程中传递Message对象,在Message中放入我们需要传递的数据,就可以轻松地实现数据的进程间传递了。
- Messenger是一种轻量级的IPC方案,它的底层实现是AIDL,从构造方法的实现上我们可以明显看出AIDL的痕迹,不管是IMessenger还是Stub.asInterface,这种使用方法都表明它的底层是AIDL。
实现一个Messenger有如下几个步骤,分为服务端和客户端:
1.服务端进程
首先,我们需要在服务端创建一个Service来处理客户端的连接请求,同时创建一个Handler并通过它来创建一个Messenger对象,然后在Service的onBind中返回这个Messenger对象底层的Binder即可。
2.客户端进程
客户端进程中,首先要绑定服务端的Service,绑定成功后用服务端返回的IBinder对象创建一个Messenger,通过这个Messenger就可以向服务端发送消息了,发消息类型为Message对象。如果需要服务端能够回应客户端,就和服务端一样,我们还需要创建一个Handler并创建一个新的Messenger,并把这个Messenger对象通过Message的replyTo参数传递给服务端,服务端通过这个replyTo参数就可以回应客户端。 -
使用AIDL
- 1.服务端服务端首先要创建一个Service用来监听客户端的连接请求,然后创建一个AIDL文件,将暴露给客户端的接口在这个AIDL文件中声明,最后在Service中实现这个AIDL接口即可。
- 2.客户端客户端所要做事情就稍微简单一些,首先需要绑定服务端的Service,绑定成功后,将服务端返回的Binder对象转成AIDL接口所属的类型,接着就可以调用AIDL中的方法了。
- 基本数据类型(int、long、char、boolean、double等);
- String和CharSequence;
- List:只支持ArrayList,里面每个元素都必须能够被AIDL支持;
- Map:只支持HashMap,里面的每个元素都必须被AIDL支持,包括key和value;
- Parcelable:所有实现了Parcelable接口的对象;
- AIDL:所有的AIDL接口本身也可以在AIDL文件中使用。
-
使用ContentProvider
ContentProvider是Android中提供的专门用于不同应用间进行数据共享的方式。和Messenger一样,ContentProvider的底层实现同样也是Binder。虽然ContentProvider的底层实现是Binder,但是它的使用过程要比AIDL简单许多,这是因为系统已经为我们做了封装,使得我们无须关心底层细节即可轻松实现IPC。 -
使用Socket
Socket也称为“套接字”,是网络通信中的概念,它分为流式套接字和用户数据报套接字两种,分别对应于网络的传输控制层中的TCP和UDP协议。
TCP协议是面向连接的协议,提供稳定的双向通信功能,TCP连接的建立需要经过“三次握手”才能完成,为了提供稳定的数据传输功能,其本身提供了超时重传机制,因此具有很高的稳定性;
而UDP是无连接的,提供不稳定的单向通信功能,当然UDP也可以实现双向通信功能。在性能上,UDP具有更好的效率,其缺点是不保证数据一定能够正确传输,尤其是在网络拥塞的情况下。

12. 展开说说Binder
Binder 是一种进程间通信机制,基于开源的 OpenBinder 实现。优点是高性能、稳定性和安全性。
- 性能
- Socket 作为一款通用接口,其传输效率低,开销大,主要用在跨网络的进程间通信和本机上进程间的低速通信。
- 消息队列和管道采用存储-转发方式,即数据先从发送方缓存区拷贝到内核开辟的缓存区中,然后再从内核缓存区拷贝到接收方缓存区,至少有两次拷贝过程。共享内存虽然无需拷贝,但控制复杂,难以使用。
- Binder 只需要一次数据拷贝,性能上仅次于共享内存。
- 共享内存 不需要拷贝数据,但是使用麻烦。
- 稳定性
Binder 基于 C/S 架构,客户端(Client)有什么需求就丢给服务端(Server)去完成,架构清晰、职责明确又相互独立稳定性更好。 - 安全性
Android 为每个安装好的 APP 分配了自己的 UID,故而进程的 UID 是鉴别进程身份的重要标志。传统的 IPC 只能由用户在数据包中填入 UID/PID,但这样不可靠,容易被恶意程序利用。可靠的身份标识只有由 IPC 机制在内核中添加。其次传统的 IPC 访问接入点是开放的,只要知道这些接入点的程序都可以和对端建立连接,不管怎样都无法阻止恶意程序通过猜测接收方地址获得连接。同时 Binder 既支持实名 Binder,又支持匿名 Binder,安全性高。
问题1. Binder实现原理是什么

- Linux系统将进程空间划分为用户空间和内核空间
- 进程与进程之间是相互隔离的,进程间需要进行数据交互就需要采用IPC
传统 IPC 通信原理
- 消息发送方将要发送的数据存放在内存缓存区中,通过系统调用进入内核态。
- 然后内核程序在内核空间分配内存,开辟一块内核缓存区,调用 copyfromuser() 函数将数据从用户空间的内存缓存区拷贝到内核空间的内核缓存区中。
- 同样的,接收方进程在接收数据时在自己的用户空间开辟一块内存缓存区,然后内核程序调用 copytouser() 函数将数据从内核缓存区拷贝到接收进程的内存缓存区。这样数据发送方进程和数据接收方进程就完成了一次数据传输,我们称完成了一次进程间通信。
这种传统的 IPC 通信方式有两个问题:
- 性能低下,一次数据传递需要经历:内存缓存区 --> 内核缓存区 --> 内存缓存区,需要 2 次数据拷贝;
- 接收数据的缓存区由数据接收进程提供,但是接收进程并不知道需要多大的空间来存放将要传递过来的数据,因此只能开辟尽可能大的内存空间或者先调用 API 接收消息头来获取消息体的大小,这两种做法不是浪费空间就是浪费时间。
Binder 跨进程通信原理
跨进程通信是需要内核空间做支持的。传统的 IPC 机制如管道、Socket 都是内核的一部分,可以通过内核支持来实现进程间通信。但是 Binder 并不是 Linux 系统内核的一部分。如何实现呢?利用了Linux系统的动态内核可加载模块和内存映射
- 动态内核可加载模块(Loadable Kernel Module,LKM)机制
模块是具有独立功能的程序,它可以被单独编译,但是不能独立运行。它在运行时被链接到内核作为内核的一部分运行。这样,Android 系统通过动态添加一个内核模块运行在内核空间,用户进程之间通过这个内核模块作为桥梁来实现通信。也就是Binder 驱动(Binder Dirver) - 内存映射
内存映射通过 mmap() 来实现,mmap() 是操作系统中一种内存映射的方法。内存映射简单的讲就是将用户空间的一块内存区域映射到内核空间。映射关系建立后,用户对这块内存区域的修改可以直接反应到内核空间;反之内核空间对这段区域的修改也能直接反应到用户空间。
一次完整的 Binder IPC 通信过程通常是这样:
- 首先 Binder 驱动在内核空间创建一个数据接收缓存区;
- 接着在内核空间开辟一块内核缓存区,建立内核缓存区和内核中数据接收缓存区之间的映射关系,以及内核中数据接收缓存区和接收进程用户空间地址的映射关系;
- 发送方进程通过系统调用 copyfromuser() 将数据 copy 到内核中的内核缓存区,由于内核缓存区和接收进程的用户空间存在内存映射,因此也就相当于把数据发送到了接收进程的用户空间,这样便完成了一次进程间的通信。
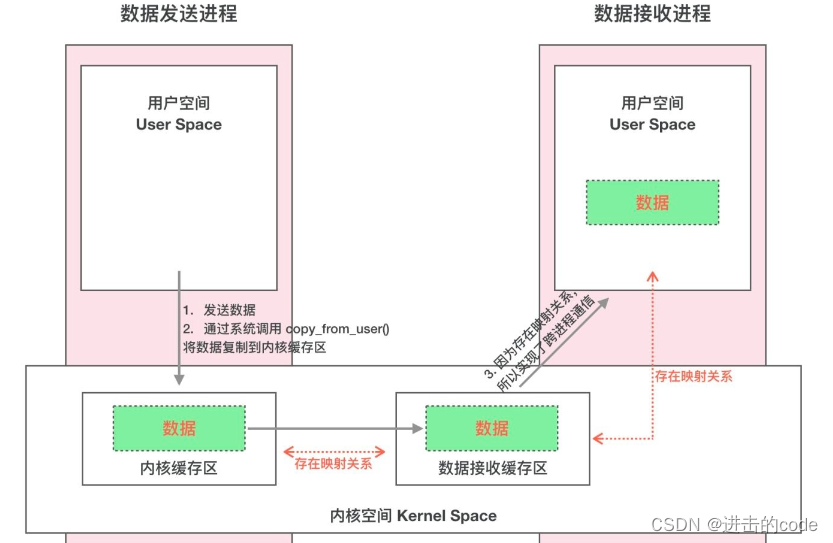
13. 了解MVC,MVP,MVVM吗?
-
MVC是 模型 - 视图 - 控制器 MVC的目的就是将M和V的代码分离,且MVC是单向通信,必须通过Controller来承上启下。
- Model:模型层,数据模型及其业务逻辑,是针对业务模型建立的数据结构,Model与View无关,而与业务有关。
- View:视图层,用于与用户实现交互的页面,通常实现数据的输入和输出功能。
- controller:控制器,用于连接Model层和View层,完成Model层和View层的交互。还可以处理页面业务逻辑,它接收并处理来自用户的请求,并将Model返回给用户。
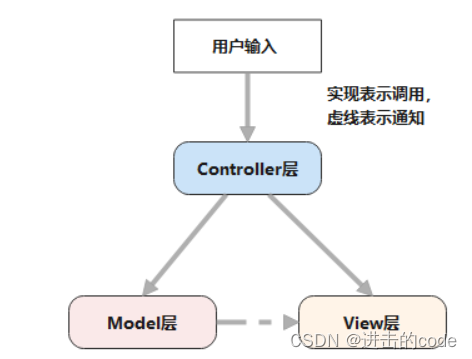
-
MVP是 模型 - 视图 - 表示器
- Model:模型层,用于数据存储以及业务逻辑。
- View:视图层,用于展示与用户实现交互的页面,通常实现数据的输入和输出功能。
- Presenter:表示器,用于连接M层、V层,完成Model层与View层的交互,还可以进行业务逻辑的处理。
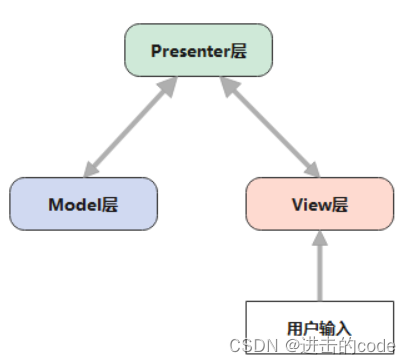
-
MVVM是 模型 - 视图 - 视图模型 MVVM与MVP框架区别在于:MVVM采用双向绑定:View的变动,自动反映在ViewModel,反之亦然。
Model:数据模型(数据处理业务),指的是后端传递的数据。
View:视图,将Model的数据以某种方式展示出来。
ViewModel:视图模型,数据的双向绑定(当Model中的数据发生改变时View就感知到,当View中的数据发生变化时Model也能感知到),是MVVM模式的核心。ViewModel 层把 Model 层和 View 层的数据同步自动化了,解决了 MVP 框架中数据同步比较麻烦的问题,不仅减轻了 ViewModel 层的压力,同时使得数据处理更加方便——只需告诉 View 层展示的数据是 Model 层中的哪一部分即可。
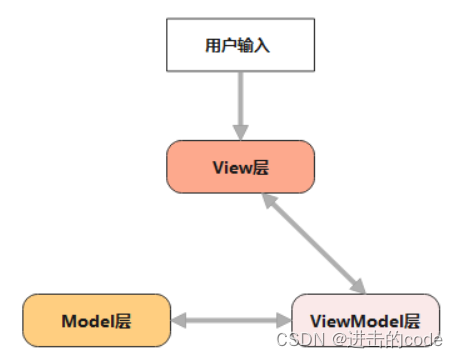
14. 使用过jetpack库吗?
1. LifeCycle原理
Lifecycle是一个管理生命周期的工具类,Lifecycle是一个抽象类,它通过Event枚举类型维护了生命周期分别对应的状态,通过State维护了执行了某一个生命周期函数后和在执行下一个生命周期函数前被观察者(Activity或Fragment)处于什么状态
问题 1. LifeCycle怎么做到监听LifecycleOwner(Activity或Fragment)的生命周期的?
Lifecycle是通过在Activity中绑定了一个空的fragment来实现监听Activity的生命周期的,因为如果在Activity中添加一个fragment 那在fragment的生命周期执行的时候 就能知道宿主对应的生命周期执行了
在ComponentActivity的onCreate方法中添加一个名字为ReportFragment空Fragment
ComponentActivity@Overrideprotected void onCreate(@Nullable Bundle savedInstanceState) {super.onCreate(savedInstanceState);mSavedStateRegistryController.performRestore(savedInstanceState);ReportFragment.injectIfNeededIn(this);if (mContentLayoutId != 0) {setContentView(mContentLayoutId);}}
@Overridepublic void onActivityCreated(Bundle savedInstanceState) {super.onActivityCreated(savedInstanceState);dispatchCreate(mProcessListener);dispatch(Lifecycle.Event.ON_CREATE);}@Overridepublic void onStart() {super.onStart();dispatchStart(mProcessListener);dispatch(Lifecycle.Event.ON_START);}@Overridepublic void onResume() {super.onResume();dispatchResume(mProcessListener);dispatch(Lifecycle.Event.ON_RESUME);}@Overridepublic void onPause() {super.onPause();dispatch(Lifecycle.Event.ON_PAUSE);}@Overridepublic void onStop() {super.onStop();dispatch(Lifecycle.Event.ON_STOP);}@Overridepublic void onDestroy() {super.onDestroy();dispatch(Lifecycle.Event.ON_DESTROY);// just want to be sure that we won't leak reference to an activitymProcessListener = null;}private void dispatch(Lifecycle.Event event) {Activity activity = getActivity();if (activity instanceof LifecycleRegistryOwner) {((LifecycleRegistryOwner) activity).getLifecycle().handleLifecycleEvent(event);return;}if (activity instanceof LifecycleOwner) {Lifecycle lifecycle = ((LifecycleOwner) activity).getLifecycle();if (lifecycle instanceof LifecycleRegistry) {((LifecycleRegistry) lifecycle).handleLifecycleEvent(event);}}}
-
ComponentActivity 实现了 LifecycleOwner ,所以可以添加观察者,并且自己的onCreate 方法中,创建并添加了一个ReportFragment ,用来感应自身的生命周期的回调, 并进行对应分发。
-
在分发过程中,Lifecycle 通过内部维护的状态机 将生命周期事件转化为State状态,并进行存储,在 分发过程中,通过状态比较来判断 当前过程是正在可见还是正在不可见,不同过程采用不同策略。最后通过调用 LifecycleEventObserver 的 onStateChanged 方法 来进行回调。
2. Room
Room 是 Google 官方推出的数据库 ORM 框架。ORM:即 Object Relational Mapping,即对象关系映射为面向对象的语言。
Room 包含三个组件:Entity、DAO 和 Database。
- Entity:实体类,数据库中的表(table),保存数据库并作为应用持久性数据底层连接的主要访问点。
- DAO:数据库访问对象,提供访问 DB 的 API,如增删改查等方法。
- Database:访问底层数据库的入口,管理着真正的数据库文件。
原理分析
Room 在编译期通过 kapt 处理 @Dao 和 @Database 注解,通过注解在运行时生成代码和SQL语句,并生成 DAO 和 Database 的实现类:TestRoomDataBase_Impl 和 UserDao_Impl。
- createFromAsset()/createFromFile():从 SD 卡或者 Assets 的 DB 文件创建 RoomDatabase 实例
- addMigrations():添加一个数据库迁移(migration),当进行数据版本升级时需要
- allowMainThreadQueries():允许在 UI 线程进行数据库查询,默认是不允许的
- fallbackToDestructiveMigration():如果找不到 migration 则重建数据库表(会造成数据丢失)
3. LiveData
LiveData 是 Jetpack 推出的基于观察者的消息订阅/分发的可观察数据组件,具有宿主(Activity、Fragment)生命周期感知能力,这种感知能力可确保 LiveData 仅分发消息给处于活跃状态的观察者,即只有处于活跃状态的观察者才能收到消息。
事件注册流程
- 首先会将Observer与其宿主包装成一个WrapObserver,继承自LifecycleObserver
- 宿主将WrapObserver注册到Lifecycle监听自身状态,此时会触发Lifecycle的事件回调
- 判断监听的宿主当前状态,是否已经销毁,如果是的话则进行反注册
- 如果不是,则进行至少一次的状态对齐,如果当前监听的宿主是活跃的则继而触发事件分发逻辑
- 如果版本号不一致,则进行触发监听器,同步数据源(粘性事件)
事件分发流程
postValue自带切换主线程的能力
public abstract class LiveData<T> {static final Object NOT_SET = new Object();//用于线程切换时,暂存Data用的变量volatile Object mPendingData = NOT_SET;protected void postValue(T value) {boolean postTask;synchronized (mDataLock) {//1.判断是否为一次有效的postValuepostTask = mPendingData == NOT_SET;//2.暂存对象到mPendingData中mPendingData = value;}//3.过滤无效postValueif (!postTask) {return;}//4.这里通过ArchTaskExecutor切换线程,其实ArchTaskExecutor切换线程的核心靠一个掌握着MainLooper的Handler切换ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);}//用于给Handler执行切换线程的Runnableprivate final Runnable mPostValueRunnable = new Runnable() {@SuppressWarnings("unchecked")@Overridepublic void run() {Object newValue;synchronized (mDataLock) {//5.从缓存中获得DatanewValue = mPendingData;mPendingData = NOT_SET;}//6.通过setValue设置数据setValue((T) newValue);}};
}
setValue(T data)
事件分发的关键函数,主要做了三件事
1、版本+1,LiveData的mVersion变量表示的是发送数据的版本,每次发送一次数据, 它都会+1;
2、将值赋值给全局变量mData;
3、调用dispatchingValue方法分发数据,dispatchingValue方法中主要调用的是considerNotify方法
@MainThreadprotected void setValue(T value) {//1.判断当前是否主线程,如果不是则报错(因为多线程会导致数据问题)assertMainThread("setValue");//2.版本号自增mVersion++;//3.数据源更新mData = value;//4.分发事件逻辑dispatchingValue(null);} //事件分发的函数@SuppressWarnings("WeakerAccess") /* synthetic access */void dispatchingValue(@Nullable ObserverWrapper initiator) {//5.判断是否分发中,如果是的话,忽略这次分发if (mDispatchingValue) {mDispatchInvalidated = true;return;}//6.设置表示mDispatchingValue = true;do {mDispatchInvalidated = false;//7.判断参数中,有没指定Observer,如果有则只通知指定Observer,没有的话则遍历全部Observer通知if (initiator != null) {//7.0 considerNotify(initiator);initiator = null;} else {//7.1 遍历全部Observer通知更新for (Iterator<Map.Entry<Observer<? super T>, ObserverWrapper>> iterator =mObservers.iteratorWithAdditions(); iterator.hasNext(); ) {considerNotify(iterator.next().getValue());if (mDispatchInvalidated) {break;}}}} while (mDispatchInvalidated);mDispatchingValue = false;} //分发函数private void considerNotify(ObserverWrapper observer) {//8. 判断如果当前监听器不活跃,则不分发if (!observer.mActive) {return;}//9. 二次确认监听器所在宿主是否活跃,如果不活跃,则证明Observer中的mActive状态并非最新的,调用activeStateChanged更新状态if (!observer.shouldBeActive()) {observer.activeStateChanged(false);return;}//10. 判断版本号是否一致,如果一致则不需要分发if (observer.mLastVersion >= mVersion) {return;}//11. 对齐版本号observer.mLastVersion = mVersion;//12. 通知监听器observer.mObserver.onChanged((T) mData);}
observe和observeForever区别
observer会自动监听生命周期,当是STARTED和RESUMED的时候才会触发订阅,而observeForever则是会一直检测数据变化,只要数据变化了就会触发订阅。
@MainThread
public void observeForever(@NonNull Observer<? super T> observer) {assertMainThread("observeForever");// 会创建一个总是活动的观察者LiveData<T>.AlwaysActiveObserver wrapper = new LiveData.AlwaysActiveObserver(observer);......
如源码所示,observeForever会创建一个总是活动的观察者AlwaysActiveObserver,改类继承ObserverWrapper,并实现了shouldBeActive方法,而且始终返回true,所以只要数据一改变,会触发onChanged方法。
private class AlwaysActiveObserver extends LiveData<T>.ObserverWrapper {AlwaysActiveObserver(Observer<? super T> observer) {super(observer);}// 一直返回trueboolean shouldBeActive() {return true;}
}
LiveData粘性事件和数据倒灌
- 粘性事件:先setValue/postValue,后调用observe(),如果成功收到了回调,即为粘性事件。
- 数据倒灌:先setValue/postValue,后调用observe(new Obs()),至此收到了回调。然后再第二次调用observe(new anotherObs()),如果还能收到第一次的回调,则为“数据倒灌”。
4. DataBinding
15. launcher页面点击app图标启动过程了解吗?以点击淘宝为例。
- 点击桌面launcher的淘宝图标时,会调用桌面程序的onClick方法,调用startActivity方法启动app
- 启动新app,属于跨进程启动。跨进程通信用到AMS(activity Manager Service),ActivityManagerNative.getDefault返回ActivityManagerService的远程接口,即ActivityManagerProxy接口,
通过Binder驱动程序,ActivityManagerProxy与AMS服务通信,则实现了跨进程到System进程。AMS响应Launcher进程。在AMS的onTransact方法里面会获取到请求的Activity - 处理启动的activity的参数,判断是否需要新建task启动Activity
- ApplicationThread对象的远程接口,通过调用这个远程接口的schedulePauseActivity,通知launcher进程进入Paused状态,
此时AMS对Launcher的请求已经响应,这时我们又通过Binder通信回调至Launcher进程。
Launcher进程挂起Launcher,再次通知AMS。 - AMS知道了Launcher已经挂起之后,就可以放心的为新的Activity准备启动工作了,首先,APP肯定需要一个新的进程去运行,所以需要创建一个新进程,AMS通过Socket去和Zygote协商,如果需要创建进程,那么就会fork自身,创建一个进程,新的进程会导入ActivityThread类,这就是每一个应用程序都有一个ActivityThread与之对应的原因;
- 启动目标进程
创建新进程的时候,AMS会保存一个ProcessRecord信息,如果应用程序中的AndroidManifest.xml配置文件中,我们没有指定Application标签的process属性,系统就会默认使用package的名称。每一个应用程序都有自己的uid,因此,这里uid + process的组合就可以为每一个应用程序创建一个ProcessRecord。
新的进程会导入android.app.ActivityThread类,并且执行它的main函数 - 绑定新进程
在AMS中注册应用进程,启动栈顶页面
此时在App进程,经过一些列的调用链最终调用至MainActivity:onCreate函数,之后会调用至onResume,而后会通知AMS该MainActivity已经处于resume状态。至此,整个启动流程完成。
流程分析
16. 为什么用到socket又用到Binder,为什么不统一用binder呢?
- 先后时序问题
安卓中一般使用的binder引用,都是保存在ServiceManager进程中的,而如果想从ServiceManager中获取到对应的binder引用,前提是需要注册,而注册的行为是在对应的逻辑代码执行时才会去注册的。
流程上,是Init产生Zygote进程和ServiceManager进程,然后Zygote进程产生SystemServer进程。如果AMS想通过binder向Zygote发送信号,必须向ServiceManager获取Zygote的binder引用,而前提是Zygote进程中必须提前注册好才行。
而实际上,Init进程是先创建ServiceManager,后创建Zygote进程的。虽然Zygote更晚创建,但是并不能保证Zygote进程去注册binder的时候,ServiceManager已经初始化好了,因为两者属于两个进程,是并行的。 - 多线程问题
Linux中,fork进程其实并不是完美的fork,linux设计之初只考虑到了主线程的fork,也就是说如果主进程中存在子线程,那么fork进程中,其子线程的锁状态,挂起状态等等都是不可恢复的,只有主进程的才可以恢复。
而binder作为典型的CS模式,其在Server是通过线程来实现的,Server等待请求状态时,必然是处于一种挂起的状态。所以如果使用binder机制,zygote进程fork子进程后,子进程的binder的Server永远处于一种挂起不可恢复的状态,这样的设计无疑是非常差的。
所以,zygote如果使用binder,会导致子进程中binder线程的挂起和锁状态不可恢复, - 效率问题
Binder基于mmap机制,只会进行一次拷贝,所以效率是很高的。那么Socket就一定低吗?
其实答案也许会出乎你的意料。如果这个问题你问GPT,GPT会告诉你,localsocket的效率是高于binder的。其原因,是虽然binder只有一次拷贝,比socket的两次更少,但是拷贝次数只是一个很重要的原因,但并不是所有影响的因素。binder因为涉及到安全验证等等环节,所以实际上效率反而没有localsocket高。据说腾讯小程序跨进程通讯使用的就是LocalSocket的方式。
所以,LocalSocket效率其实并不低。 - 安全问题 普遍认为Socket是不安全的,因为它缺乏PID校验,所以导致任何进程都可以访问。但是LocalSocket是安全的。
代码如下,我们尝试直接给zygote的进程发送socket消息,看zygote进程是否可以接受。如果可以接受的话,那么我们只要发送指定格式的字符串,APP也能启动其它应用进程了。相关代码是直接拷贝AMS中的。
val localSocket = LocalSocket()val localSocketAddress =LocalSocketAddress("zygote", LocalSocketAddress.Namespace.RESERVED)localSocket.connect(localSocketAddress)val outputStream = localSocket.outputStreamoutputStream.write(1)outputStream.flush()
实验下来LocalSocket也是有权限验证的。
connectLocal在native层的实现是socket_connect_local方法。
socket_connect_local(JNIEnv *env, jobject object,jobject fileDescriptor, jstring name, jint namespaceId)
{int ret;int fd; if (name == NULL) {jniThrowNullPointerException(env, NULL);return;} fd = jniGetFDFromFileDescriptor(env, fileDescriptor); if (env->ExceptionCheck()) {return;} ScopedUtfChars nameUtf8(env, name);ret = socket_local_client_connect(fd,nameUtf8.c_str(),namespaceId,SOCK_STREAM);if (ret < 0) {jniThrowIOException(env, errno);return;}
}
所以最终的校验逻辑应该在Linux层的socket_local_client_connect方法。
socket_connect_local(JNIEnv *env, jobject object,jobject fileDescriptor, jstring name, jint namespaceId)
{int ret;int fd;if (name == NULL) {jniThrowNullPointerException(env, NULL);return;} fd = jniGetFDFromFileDescriptor(env, fileDescriptor);if (env->ExceptionCheck()) {return;} ScopedUtfChars nameUtf8(env, name); ret = socket_local_client_connect(fd,nameUtf8.c_str(),namespaceId,SOCK_STREAM); if (ret < 0) {jniThrowIOException(env, errno);return;}
}
LocalSocket其实也有权限校验,并不意味着可以被所有进程随意调用。
5. Binder拷贝问题
进程的fork,是拷贝一个和原进程一摸一样的进程,其中的各种内存对象自然也会被拷贝。所以用来接收消息去fork进程的binder对象自然也会被拷贝。但是这个拷贝对于APP层有用吗?那自然是没用的,所以就凭白多占用了一块无用的内存区域。
说到这你自然想问,如果通过socket的方式,不也平白无故的多占用一块Socket内存区域吗?是的,确实是,但是fork出APP进程之后,APP进程会去主动的关闭掉这个socket,从而释放这块区域。相关代码在ZygoteConnection的processCommand方法中:
try {if (pid == 0) {// in childzygoteServer.setForkChild(); zygoteServer.closeServerSocket();IoUtils.closeQuietly(serverPipeFd);serverPipeFd = null; return handleChildProc(parsedArgs, childPipeFd,parsedArgs.mStartChildZygote);} else {// In the parent. A pid < 0 indicates a failure and will be handled in// handleParentProc.IoUtils.closeQuietly(childPipeFd);childPipeFd = null;handleParentProc(pid, serverPipeFd);return null;}}
17. context 和 activity的区别
Context是个抽象类,通过类的结构可以知道:Activity、Service、Application都是Context的子类;从Android系统的角度来理解:Context是一个场景,描述的是一个应用程序环境的信息,即上下文,代表与操作系统的交互的一种过程。
Activity和Application都是Context的子类,他们维护的生命周期不一样。前者维护一个Acitivity的生命周期,所以其对应的Context也只能访问该activity内的各种资源。后者则是维护一个Application的生命周期。
- Activity继承自ContextThemeWrapper类其内部包含了与主题相关的接口。主题就是清单文件中android:theme为Application或Activity元素指定的主题。(Activity才需要主题,Serviceu不需要,因为服务是没有界面的后台场景,所以服务直接继承ContextWrapper。Application同理。)
18. 一个应用程序中有多少个context?
看完以上分析答案显而易见:总Context实例个数 = Service个数 + Activity个数 + 1(Application对应的Context实例)
开源框架篇
1. OKHTTP了解吗?
OkHttp 是一套处理 HTTP 网络请求的开源框架
OkHttpclient client new OkHttpclient();
Requestrequest new Request.Builder()
.url(url)
.build();
client.newcall(request).enqueue(new Callback(){
@Override
public void onFailure(Call call,IOException e){}
@Override
public void onResponse(Call call,Response response) throws IOException{};
- 一般使用异步请求enqueue(),会交给内部RealCall实际上是RealCall.enqueue()
- 然后会交给调度器Dispatcher执行入队方法,最终请求操作是委托给 Dispatcher的enqueue 方法内实现的
- Dispatcher 是 OkHttpClient 的调度器,是一种门户模式。主要用来实现执行、取消异步请求操作。本质上是内部维护了一个线程池去执行异步操作,
并且在 Dispatcher 内部根据一定的策略,保证最大并发个数、同一 host 主机允许执行请求的线程个数等。
synchronized void enqueue(AsyncCall call){
if (runningAsyncCalls.size()<maxRequests &runningCallsForHost(call)<maxRequestsPerHost){
runningAsyncCalls.add(call);
executorService().execute(call);
}else{readyAsyncCalls.add(call);}
}
线程池执行了一个 AsyncCall,而 AsyncCall 实现了 Runnable 接口,因此整个操作会在一个子线程(非 UI 线程)中执行。
AsyncCall 中的 run
final class AsyncCall extends NamedRunnable {
......@Override protected void execute() {boolean signalledCallback = false;try {Response response = getResponseWithInterceptorChain();if (retryAndFollowUpInterceptor.isCanceled()) {signalledCallback = true;responseCallback.onFailure(RealCall.this, new IOException("Canceled"));} else {signalledCallback = true;responseCallback.onResponse(RealCall.this, response);}} catch (IOException e) {if (signalledCallback) {// Do not signal the callback twice!Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);} else {responseCallback.onFailure(RealCall.this, e);}} finally {client.dispatcher().finished(this);}}}
最后response是通过getResponseWithInterceptorChain()中获取的,内部是一个拦截器的调用链
Response getResponseWithInterceptorChain() throws IOException {// Build a full stack of interceptors.List<Interceptor> interceptors = new ArrayList<>();interceptors.addAll(client.interceptors());interceptors.add(retryAndFollowUpInterceptor);interceptors.add(new BridgeInterceptor(client.cookieJar()));interceptors.add(new CacheInterceptor(client.internalCache()));interceptors.add(new ConnectInterceptor(client));if (!forWebSocket) {interceptors.addAll(client.networkInterceptors());}interceptors.add(new CallServerInterceptor(forWebSocket));Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0, originalRequest);return chain.proceed(originalRequest);}
问题 1. 知道OkHttp有几个拦截器以及作用吗吗?
八大拦截器
- client.interceptors() 自定义拦截器,开发者设置的,会按照开发者的要求,在所有的拦截器处理之前进行最早的拦截处理,比如一些公共参数,Header都可以在这里添加。
- retryAndFollowUpInterceptor 重试拦截器,这里会对连接做一些初始化工作,以及请求失败的重试工作,重定向的后续请求工作。跟他的名字一样,就是做重试工作还有一些连接跟踪工作
- BridgeInterceptor 桥接连接器。主要是进行请求前的一些操作,将我们的请求设置成服务器能识别的请求,比如设置一系列头部信息,比如设置请求内容长度,编码,gzip压缩,cookie等。
- CacheInterceptor:缓存拦截器。作用是缓存请求和响应,比如同一个请求之前发生过,这次就不需要重新构建了,直接从缓存取;响应同理
- ConnectInterceptor:连接拦截器,为当前请求找到一个合适的连接,比如如果从连接池中可以找到能复用的连接,就不要再创建新的连接了。这里主要就是负责建立连接了,会建立TCP连接或者TLS连接,以及负责编码解码的HttpCodec
- networkInterceptors 网络拦截器。这里也是开发者自己设置的,所以本质上和第一个拦截器差不多,但是由于位置不同,所以用处也不同。这个位置添加的拦截器可以看到请求和响应的数据了,所以可以做一些网络调试。
- CallServerInterceptor:连接服务器拦截器,负责向服务器发送真正的请求,接受服务器的响应
问题 2. OkHttp怎么实现连接池
为什么需要连接池?
频繁的进行建立Sokcet连接和断开Socket是非常消耗网络资源和浪费时间的,所以HTTP中的keepalive连接对于降低延迟和提升速度有非常重要的作用。keepalive机制是什么呢?也就是可以在一次TCP连接中可以持续发送多份数据而不会断开连接。所以连接的多次使用,也就是复用就变得格外重要了,而复用连接就需要对连接进行管理,于是就有了连接池的概念。
OkHttp中使用ConectionPool实现连接池,默认支持5个并发KeepAlive,默认链路生命为5分钟。
怎么实现的?
- 首先,ConectionPool中维护了一个双端队列Deque,也就是两端都可以进出的队列,用来存储连接。
- 然后在ConnectInterceptor,也就是负责建立连接的拦截器中,首先会找可用连接,也就是从连接池中去获取连接,具体的就是会调用到ConectionPool的get方法。也就是遍历了双端队列,如果连接有效,就会调用acquire方法计数并返回这个连接。
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {assert (Thread.holdsLock(this));for (RealConnection connection : connections) {if (connection.isEligible(address, route)) {streamAllocation.acquire(connection, true);return connection;}}return null;}
- 如果没找到可用连接,就会创建新连接,并会把这个建立的连接加入到双端队列中,同时开始运行线程池中的线程,其实就是调用了ConectionPool的put方法。
public final class ConnectionPool {void put(RealConnection connection) {if (!cleanupRunning) {//没有连接的时候调用cleanupRunning = true;executor.execute(cleanupRunnable);}connections.add(connection);}
}
- ConectionPool有一个线程,是用来清理连接的,也就是cleanupRunnable
private final Runnable cleanupRunnable = new Runnable() {@Overridepublic void run() {while (true) {//执行清理,并返回下次需要清理的时间。long waitNanos = cleanup(System.nanoTime());if (waitNanos == -1) return;if (waitNanos > 0) {long waitMillis = waitNanos / 1000000L;waitNanos -= (waitMillis * 1000000L);synchronized (ConnectionPool.this) {//在timeout时间内释放锁try {ConnectionPool.this.wait(waitMillis, (int) waitNanos);} catch (InterruptedException ignored) {}}}}}};
也就是当如果空闲连接maxIdleConnections超过5个或者keepalive时间大于5分钟,则将该连接清理掉。
long cleanup(long now) {synchronized (this) {//遍历连接for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {RealConnection connection = i.next(); //检查连接是否是空闲状态,//不是,则inUseConnectionCount + 1//是 ,则idleConnectionCount + 1if (pruneAndGetAllocationCount(connection, now) > 0) {inUseConnectionCount++;continue;} idleConnectionCount++; // If the connection is ready to be evicted, we're done.long idleDurationNs = now - connection.idleAtNanos;if (idleDurationNs > longestIdleDurationNs) {longestIdleDurationNs = idleDurationNs;longestIdleConnection = connection;}}//如果超过keepAliveDurationNs或maxIdleConnections,//从双端队列connections中移除if (longestIdleDurationNs >= this.keepAliveDurationNs|| idleConnectionCount > this.maxIdleConnections) { connections.remove(longestIdleConnection);} else if (idleConnectionCount > 0) { //如果空闲连接次数>0,返回将要到期的时间// A connection will be ready to evict soon.return keepAliveDurationNs - longestIdleDurationNs;} else if (inUseConnectionCount > 0) {// 连接依然在使用中,返回保持连接的周期5分钟return keepAliveDurationNs;} else {// No connections, idle or in use.cleanupRunning = false;return -1;}}closeQuietly(longestIdleConnection.socket());// Cleanup again immediately.return 0;}
怎样属于空闲连接?
public void acquire(RealConnection connection, boolean reportedAcquired) {assert (Thread.holdsLock(connectionPool));if (this.connection != null) throw new IllegalStateException();this.connection = connection;this.reportedAcquired = reportedAcquired;connection.allocations.add(new StreamAllocationReference(this, callStackTrace));}
在RealConnection中,有一个StreamAllocation虚引用列表allocations。每创建一个连接,就会把连接对应的StreamAllocationReference添加进该列表中,如果连接关闭以后就将该对象移除。
其实可以这样理解,在上层反复调用acquire和release函数,来增加或减少connection.allocations所维持的集合的大小,到最后如果size大于0,则代表RealConnection还在使用连接,如果size等于0,那就说明已经处于空闲状态了
问题 3. 简述一下OkHttp的一个工作流程
- 异步请求会交给调度器Dispatcher入队,
- Dispatcher内部维护了一个线程池ExecutorService和三个队列 readyAsyncCalls ,runningAsyncCalls,runningSyncCalls
- readyAsyncCalls 待请求队列,里面存储准备执行的异步请求。
- runningAsyncCalls 异步请求队列,里面存储正在执行,包含已经取消但是还没有结束的请求。
- runningSyncCalls 同步请求队列,正在执行的请求,包含已经取消但是还没有结束的请求。
- 判断正在进行异步请求队列长度是否小于64,且单个Host正在执行的请求数小于5;如果满足,将请求添加到runningAsyncCalls队列,同时使用内部线程池执行该请求
- 如果条件不满足就将请求添加到readyAsyncCalls队列
- 然后调用 promoteAndExecute(),从readyAsyncCalls中取出符合条件的请求到runningAsyncCalls,并执行。
- 调用拦截器链拿到服务器响应
同步请求
- 首先出现一个同步代码块,对当前对象加锁,通过一个标志位executed判断该对象的execute方法是否已经执行过,如果执行过就抛出异常;这也就是同一个Call只能执行一次的原因
- 第二步:调用Dispatcher的executed方法,将请求放入分发器,这是非常重要的一步
- 第三步:通过拦截器连获取返回结果Response
- 第四步:调用dispatcher的finished方法,回收同步请求
问题 4. Okhttp 如何实现缓存功能?它是如何根据 Cache-Control 首部来判断缓存策略的?
-
Okhttp 实现缓存功能是通过 CacheInterceptor 拦截器和 Cache 类来实现的。
在创建 OkHttpClient 对象时,可以指定一个 Cache 对象,用于存储缓存的响应。
CacheInterceptor 拦截器会根据请求和响应的 Cache-Control 首部来判断是否使用缓存或网络,以及更新缓存。
Cache-Control 首部是用于控制缓存行为的指令,它有以下几种常见的值:- no-cache:表示不使用本地缓存,必须向服务器验证缓存是否有效。
- no-store:表示不使用本地缓存,也不更新本地缓存。
- only-if-cached:表示只使用本地缓存,不使用网络。
- max-age=n:表示本地缓存在 n 秒内有效,超过 n 秒后需要向服务器验证或重新获取。
- must-revalidate:表示本地缓存必须向服务器验证是否有效,如果无效则重新获取。
• CacheInterceptor 拦截器的工作流程大致如下:
- 根据请求查找是否有匹配的缓存响应,如果没有,则直接使用网络,并将响应写入缓存(如果满足条件)。
- 如果有匹配的缓存响应,判断是否过期或需要再验证,如果是,则向服务器发送带有验证首部的请求,并根据服务器的响应来决定是否使用缓存或更新缓存。
- 如果不过期或不需要再验证,则直接使用缓存,并添加 Age 首部来表示缓存的新鲜度。
问题 5. Okhttp 如何自定义拦截器?你有没有使用过或编写过自己的拦截器?
通过实现 Interceptor 接口,Interceptor 接口只有一个方法 intercept,该方法接收一个 Chain 参数,表示拦截器链。在 intercept 方法中,可以对请求或响应进行修改或转发,并且可以决定是否继续传递给下一个拦截器。在创建 OkHttpClient 对象时,可以通过 addInterceptor 或 addNetworkInterceptor 方法来添加自定义的应用拦截器或网络拦截器。
我有使用过或编写过自己的拦截器
- 一个日志拦截器,用于打印请求和响应的信息,方便调试和监控。
- 一个加密拦截器,用于对请求参数进行加密,保证数据的安全性。
- 一个认证拦截器,用于对请求添加认证信息,如 token、签名等,实现用户的身份验证。
问题 6. Okhttp 如何管理连接池和线程池?它是如何复用和回收连接的?
-
Okhttp 管理连接池和线程池是通过 ConnectionPool 类和 Dispatcher 类来实现的。
-
ConnectionPool 类表示一个连接池,它维护了一个双端队列,用于存储空闲的连接。
它有一个清理线程,用于定期检查连接是否过期或超过最大空闲数,并将其移除。 -
Dispatcher 类表示一个调度器,它维护了三个双端队列,分别用于存储同步任务、异步任务和等待执行的异步任务。
它有一个线程池,用于执行异步任务,并根据最大并发数和主机数来调度任务执行。
-
-
Okhttp 复用和回收连接是通过 StreamAllocation 类和 RealConnection 类来实现的。
- StreamAllocation 类表示一个流分配器,它负责管理连接的分配和释放。
- RouteSelector 对象,用于寻找最优的路由和地址。
- RealConnection 对象,用于表示当前分配的连接。
- release 方法,用于释放连接,并根据连接是否空闲或是否可以复用来决定是否将其加入到连接池中。
RealConnection 类表示一个真实的连接,它封装了一个 Socket 对象,用于建立 TCP 连接,并通过 Okio 获取输入流和输出流。
allocationLimit 属性,用于表示该连接可以分配给多少个流。
noNewStreams 属性,用于表示该连接是否可以创建新的流。
onStreamFinished 方法,用于在流结束时减少 allocationLimit 的值,并根据情况释放或回收连接。
2. Glide了解吗?
Glide是Google推荐的一套快速高效的图片加载框架功能强大且使用方便。
优点
- 使用方便,API简洁。with、load、into三步就可以加载图片
- 生命周期自动绑定,根据绑定的Activity或者Fragment生命周期管理图片请求
- 高效的缓存策略,三级缓存策略
- A. 支持Memory和Disk图片缓存
- B. Picasso 只会缓存原始尺寸的图片,而 Glide 缓存的是多种规格,也就意味着 Glide 会根据你 ImageView 的大小来缓存相应大小的图片尺寸.
- C. 内存开销小
默认的 Bitmap 格式是 RGB_565 格式,而 Picasso 默认的是 ARGB_8888 格式,这个内存开销要小一半。
Glide生命周期,**with()**方法就是用于绑定生命周期,
- 传入Application参数 Glide生命周期和应用程序的生命周期同步。
- 传入非Application参数 不管传入的是Activity、FragmentActivity、Fragment 最终的流程都是一样的,那就是会向当前的Activity当中添加一个隐藏的Fragment,用于同步生命周期
- 如果我们是在非主线程当中使用的Glide,那么不管你是传入的Activity还是Fragment,都会被强制当成Application来处理。
Glide图片缓存
- Glide的缓存功能设计成 二级缓存:内存缓存 & 硬盘缓存 缓存读取顺序:内存缓存 --> 磁盘缓存 --> 网络
- 内存缓存:防止应用重复将图片数据 读取到内存当中。内存缓存又分为2种,弱引用和Lrucache
- 弱引用:弱引用的对象具备更短生命周期,因为当JVM进行垃圾回收时,一旦发现弱引用对象,都会进行回收(无论内存充足否)
- LruCache算法原理:将 最近使用的对象用强引用的方式存储在LinkedHashMap中 ;当缓存满时 ,将最近最少使用的对象从内存中移除
- 硬盘缓存:防止应用重复从网络或其他地方重复下载和读取数据。磁盘缓存就是DiskLrucache
- 内存缓存:防止应用重复将图片数据 读取到内存当中。内存缓存又分为2种,弱引用和Lrucache

写入磁盘缓存
- Glide将图片写入磁盘缓存的时机:获取图片资源后 、图片加载完成前
- 写入磁盘缓存又分为:将 原始图片 写入或将 转换后的图片写入磁盘缓存
写入内存缓存
Glide 将图片写入 内存缓存的时机:图片加载完成后 、图片显示出来前
-
当 acquired 变量 >0 时,说明图片正在使用,即该图片缓存继续存放到activeResources弱引用缓存中
-
当 acquired变量 = 0,即说明图片已经不再被使用,就将该图片的缓存Key从 activeResources弱引用缓存中移除,并存放到LruResourceCache缓存中实现了:
- 正在使用中的图片 采用 弱引用 的内存缓存
- 不在使用中的图片 采用 LruCache算法 的内存缓存
Glide5大磁盘缓存策略
- DiskCacheStrategy.DATA: 只缓存原始图片;
- DiskCacheStrategy.RESOURCE: 只缓存转换过后的图片;
- DiskCacheStrategy.ALL: 既缓存原始图片,也缓存转换过后的图片;对于远程图片,缓存 DATA和 RESOURCE;对于本地图片,只缓存 RESOURCE;
- DiskCacheStrategy.NONE:不缓存任何内容;
- DiskCacheStrategy.AUTOMATIC:默认策略,尝试对本地和远程图片使用最佳的策略。当下载网络图片时,使用DATA;对于本地图片,使用RESOURCE;
3. EventBus了解吗?
EventBus是一个开源库,是用于Android开发的 “事件发布—订阅总线”, 用来进行模块间通信、解藕。它可以使用很少的代码,来实现多组件之间的通信。
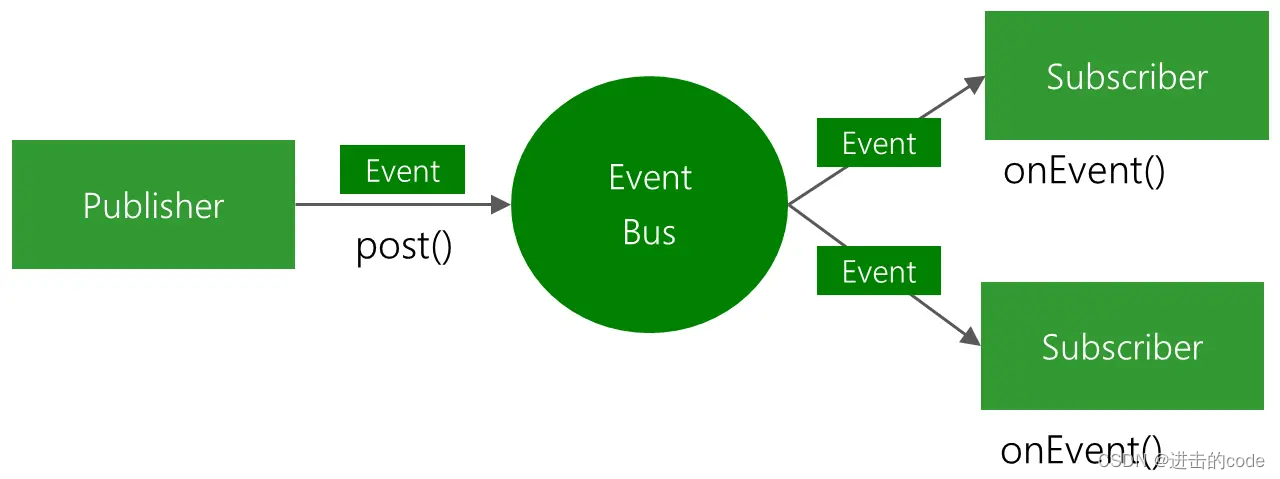
EventBus的优势
1,简化组件之间的通讯方式
2,对通信双方进行解藕
3,使用ThreadMode灵活切换工作线程
5,库比较小,不占内存
EentBus缺点
1、使用的时候有定义很多event类。
2、event在注册的时候会调用反射去遍历注册对象的方法在其中找出带有@subscriber标签的方法,性能不高。
3、需要自己注册和反注册,如果忘了反注册就会导致内存泄漏。
4、造成代码逻辑不清晰,出现bug不容易溯源
- ThreadMode.POSTING,默认的线程模式,在那个线程发送事件就在对应线程处理事件,避免了线程切换,效率高。
- ThreadMode.MAIN,如在主线程(UI线程)发送事件,则直接在主线程处理事件;如果在子线程发送事件,则先将事件入队列,然后通过 Handler 切换到主线程,依次处理事件。
- ThreadMode.MAIN_ORDERED,无论在那个线程发送事件,都先将事件入队列,然后通过 Handler 切换到主线程,依次处理事件。
- ThreadMode.BACKGROUND,如果在主线程发送事件,则先将事件入队列,然后通过线程池依次处理事件;如果在子线程发送事件,则直接在发送事件的线程处理事件。
- ThreadMode.ASYNC,无论在那个线程发送事件,都将事件入队列,然后通过线程池处理。
流程
- 注册
EventBus.getDefault().register(this);
register()方法主要分为查找和注册两部分,
查找 的过程 findSubscriberMethods() 先从缓存中查找,如果找到则直接返回,否则去做下一步的查找过程,然后缓存查找到的集合然后调用findUsingInfo() 会在当前要注册的类以及其父类中查找订阅事件的方法,这里出现了一个FindState类,它是SubscriberMethodFinder的内部类,用来辅助查找订阅事件的方法,具体的查找过程在findUsingReflectionInSingleClass()方法,它主要通过反射查找订阅事件的方法
注册 subscribe()方法主要是得到了subscriptionsByEventType、typesBySubscriber两个 HashMap。我们在发送事件的时候要用到subscriptionsByEventType,完成事件的处理。当取消 EventBus 注册的时候要用到typesBySubscriber、subscriptionsByEventType,完成相关资源的释放。
取消注册
EventBus.getDefault().unregister(this);
public synchronized void unregister(Object subscriber) {// 得到当前注册类对象 对应的 订阅事件方法的参数类型 的集合List<Class<?>> subscribedTypes = typesBySubscriber.get(subscriber);if (subscribedTypes != null) {// 遍历参数类型集合,释放之前缓存的当前类中的Subscriptionfor (Class<?> eventType : subscribedTypes) {unsubscribeByEventType(subscriber, eventType);}// 删除以subscriber为key的键值对typesBySubscriber.remove(subscriber);} else {logger.log(Level.WARNING, "Subscriber to unregister was not registered before: " + subscriber.getClass());}}private void unsubscribeByEventType(Object subscriber, Class<?> eventType) {// 得到当前参数类型对应的Subscription集合List<Subscription> subscriptions = subscriptionsByEventType.get(eventType);if (subscriptions != null) {int size = subscriptions.size();// 遍历Subscription集合for (int i = 0; i < size; i++) {Subscription subscription = subscriptions.get(i);// 如果当前subscription对象对应的注册类对象 和 要取消注册的注册类对象相同,则删除当前subscription对象if (subscription.subscriber == subscriber) {subscription.active = false;subscriptions.remove(i);i--;size--;}}}}
unregister()方法中,释放了typesBySubscriber、subscriptionsByEventType中缓存的资源。
发送事件
EventBus.getDefault().post("Hello World!")public void post(Object event) {// currentPostingThreadState是一个PostingThreadState类型的ThreadLocal// PostingThreadState类保存了事件队列和线程模式等信息PostingThreadState postingState = currentPostingThreadState.get();List<Object> eventQueue = postingState.eventQueue;// 将要发送的事件添加到事件队列eventQueue.add(event);// isPosting默认为falseif (!postingState.isPosting) {// 是否为主线程postingState.isMainThread = isMainThread();postingState.isPosting = true;if (postingState.canceled) {throw new EventBusException("Internal error. Abort state was not reset");}try {// 遍历事件队列while (!eventQueue.isEmpty()) {// 发送单个事件// eventQueue.remove(0),从事件队列移除事件postSingleEvent(eventQueue.remove(0), postingState);}} finally {postingState.isPosting = false;postingState.isMainThread = false;}}}
所以 post() 方法先将发送的事件保存到事件队列,然后通过循环出队列,将事件交给postSingleEvent()处理:
private void postSingleEvent(Object event, PostingThreadState postingState) throws Error {Class<?> eventClass = event.getClass();boolean subscriptionFound = false;// eventInheritance默认为true,表示是否向上查找事件的父类if (eventInheritance) {// 查找当前事件类型的Class,连同当前事件类型的Class保存到集合List<Class<?>> eventTypes = lookupAllEventTypes(eventClass);int countTypes = eventTypes.size();// 遍历Class集合,继续处理事件for (int h = 0; h < countTypes; h++) {Class<?> clazz = eventTypes.get(h);subscriptionFound |= postSingleEventForEventType(event, postingState, clazz);}} else {subscriptionFound = postSingleEventForEventType(event, postingState, eventClass);}if (!subscriptionFound) {if (logNoSubscriberMessages) {logger.log(Level.FINE, "No subscribers registered for event " + eventClass);}if (sendNoSubscriberEvent && eventClass != NoSubscriberEvent.class &&eventClass != SubscriberExceptionEvent.class) {post(new NoSubscriberEvent(this, event));}}}
postSingleEvent()方法中,根据eventInheritance属性,决定是否向上遍历事件的父类型,然后用postSingleEventForEventType() 方法进一步处理事件:
private boolean postSingleEventForEventType(Object event, PostingThreadState postingState, Class<?> eventClass) {CopyOnWriteArrayList<Subscription> subscriptions;synchronized (this) {// 获取事件类型对应的Subscription集合subscriptions = subscriptionsByEventType.get(eventClass);}// 如果已订阅了对应类型的事件if (subscriptions != null && !subscriptions.isEmpty()) {for (Subscription subscription : subscriptions) {// 记录事件postingState.event = event;// 记录对应的subscriptionpostingState.subscription = subscription;boolean aborted = false;try {// 最终的事件处理postToSubscription(subscription, event, postingState.isMainThread);aborted = postingState.canceled;} finally {postingState.event = null;postingState.subscription = null;postingState.canceled = false;}if (aborted) {break;}}return true;}return false;}
postSingleEventForEventType() 方法核心就是遍历发送的事件类型对应的Subscription集合,然后调用postToSubscription() 方法处理事件。
处理事件
postToSubscription() 内部会根据订阅事件方法的线程模式,间接或直接的以发送的事件为参数,通过反射执行订阅事件的方法。
private void postToSubscription(Subscription subscription, Object event, boolean isMainThread) {// 判断订阅事件方法的线程模式switch (subscription.subscriberMethod.threadMode) {// 默认的线程模式,在那个线程发送事件就在那个线程处理事件case POSTING:invokeSubscriber(subscription, event);break;// 在主线程处理事件case MAIN:// 如果在主线程发送事件,则直接在主线程通过反射处理事件if (isMainThread) {invokeSubscriber(subscription, event);} else {// 如果是在子线程发送事件,则将事件入队列,通过Handler切换到主线程执行处理事件// mainThreadPoster 不为空mainThreadPoster.enqueue(subscription, event);}break;// 无论在那个线程发送事件,都先将事件入队列,然后通过 Handler 切换到主线程,依次处理事件。// mainThreadPoster 不为空case MAIN_ORDERED:if (mainThreadPoster != null) {mainThreadPoster.enqueue(subscription, event);} else {invokeSubscriber(subscription, event);}break;case BACKGROUND:// 如果在主线程发送事件,则先将事件入队列,然后通过线程池依次处理事件if (isMainThread) {backgroundPoster.enqueue(subscription, event);} else {// 如果在子线程发送事件,则直接在发送事件的线程通过反射处理事件invokeSubscriber(subscription, event);}break;// 无论在那个线程发送事件,都将事件入队列,然后通过线程池处理。case ASYNC:asyncPoster.enqueue(subscription, event);break;default:throw new IllegalStateException("Unknown thread mode: " + subscription.subscriberMethod.threadMode);}}
postToSubscription() 方法就是根据订阅事件方法的线程模式、以及发送事件的线程来判断如何处理事件,至于处理方式主要有两种:
一种是在相应线程直接通过invokeSubscriber()方法,用反射来执行订阅事件的方法,这样发送出去的事件就被订阅者接收并做相应处理了:
void invokeSubscriber(Subscription subscription, Object event) {try {subscription.subscriberMethod.method.invoke(subscription.subscriber, event);} catch (InvocationTargetException e) {handleSubscriberException(subscription, event, e.getCause());} catch (IllegalAccessException e) {throw new IllegalStateException("Unexpected exception", e);}}
另外一种是先将事件入队列(其实底层是一个List),然后做进一步处理,以**mainThreadPoster.enqueue(subscription, event)**为例简单的分析下,其中mainThreadPoster是HandlerPoster类的一个实例
public class HandlerPoster extends Handler implements Poster {private final PendingPostQueue queue;private boolean handlerActive;......public void enqueue(Subscription subscription, Object event) {// 用subscription和event封装一个PendingPost对象PendingPost pendingPost = PendingPost.obtainPendingPost(subscription, event);synchronized (this) {// 入队列queue.enqueue(pendingPost);if (!handlerActive) {handlerActive = true;// 发送开始处理事件的消息,handleMessage()方法将被执行,完成从子线程到主线程的切换if (!sendMessage(obtainMessage())) {throw new EventBusException("Could not send handler message");}}}}@Overridepublic void handleMessage(Message msg) {boolean rescheduled = false;try {long started = SystemClock.uptimeMillis();// 死循环遍历队列while (true) {// 出队列PendingPost pendingPost = queue.poll();......// 进一步处理pendingPosteventBus.invokeSubscriber(pendingPost);......}} finally {handlerActive = rescheduled;}}
}
HandlerPoster的enqueue()方法主要就是将subscription、event对象封装成一个PendingPost对象,然后保存到队列里,之后通过Handler切换到主线程,在handleMessage()方法将中将PendingPost对象循环出队列,交给invokeSubscriber()方法进一步处理:
void invokeSubscriber(PendingPost pendingPost) {Object event = pendingPost.event;Subscription subscription = pendingPost.subscription;// 释放pendingPost引用的资源PendingPost.releasePendingPost(pendingPost);if (subscription.active) {// 用反射来执行订阅事件的方法invokeSubscriber(subscription, event);}}
从pendingPost中取出之前保存的event、subscription,然后用反射来执行订阅事件的方法,又回到了第一种处理方式。所以mainThreadPoster.enqueue(subscription, event)的核心就是先将将事件入队列,然后通过Handler从子线程切换到主线程中去处理事件。

架构方面
1. 组件化
一、优点
- 基础功能复用,节省开发时间
在项目初期框架搭建的时候,基础功能可直接搬移复用,日积月累,每个人/公司应该都会有一套自己的Base。 - 业务拆分,便于分工,实现解耦
单独的业务模块抽取成一个独立的Module,不同人员在各自的模块实现自己的业务代码,实现业务拆解、人员拆解,从而实现真正解耦。 - 支持单/组合模块编译,提升编译速度,便于开发调试
当项目随着版本的不断迭代,随之增加的功能会越来越多,业务也会变得越来越复杂,最终会导致代码量急剧上升,相关的三方sdk也会不断的涌入,以至于,更改一处,就要全量编译运行,有时候甚至会出现,改一行而等10分钟的情况,非常的耗时,大大降低了开发效率。而采取了组件化的方式后,相关业务模块,进行单独抽取,使得每个业务模块可以独立当做App存在,和其他模块,互不关联影响,在编译运行时期,只考虑本模块即可,从而减少了代码的编译量,提高了编译运行速度,节约了开发时间。
组件之间数据交互怎么实现?
- Broadcastreceiver
- EventBus
- Arouter
聊聊你对Arouter的理解
ARouter是阿里巴巴的一个组件化开源的路由框架。
ARouter通过 APT 技术,生成 保存路径(路由path) 和 被注解(@Router)的组件类 的映射关系的类,利用这些保存了映射关系的类,Arouter根据用户的请求 postcard(明信片) 寻找到要跳转的 目标地址(class) ,使用 Intent跳转。原理很简单,框架的核心是利用APT生成的映射关系。
流程
通过APT技术,寻找到所有带有注解@Router的组件,将其注解值path和对应的Activity保存到一个map。
然后在初始化的时候将这个map加载到内存中,需要的时候直接get(path)就可以了。
这样,两个模块不用相互有任何直接的依赖,就可以进行转跳,模块与模块之间就相互独立了。
优化
利用APT、JavaPoet完成了代码生成的工作,对于一个大型项目,组件数量会很多,可能会有一两百或者更多,把这么多组件都放到这个Map里,显然会对内存造成很大的压力,因此,Arouter采用的方法就是“分组+按需加载”,分组还带来的另一个好处是便于管理。
解决步骤一:分组
Arouter在一层map之外,增加了一层map,WareHouse这个类,里面有两个静态Map:
static Map<String, Class<? extends IRouteGroup>> groupsIndex = new HashMap<>();
static Map<String, RouteMeta> routes = new HashMap<>();
-
groupsIndex 保存了 group 名字到 IRouteGroup 类的映射,这一层映射就是Arouter新增的一层映射关系。
-
routes 保存了路径 path 到 RouteMeta 的映射,其中,RouteMeta是目标地址的包装。这一层映射关系跟我门自己方案里的map是一致的,我们路径跳转也是要用这一层来映射。
IRouteGroup和RouteMeta,后者很简单,就是对跳转目标的封装,我们后续称其为“目标”,其内包含了目标组件的信息,比如Activity的Class。那IRouteGroup是个什么东西?
public interface IRouteGroup {/*** Fill the atlas with routes in group.*/void loadInto(Map<String, RouteMeta> atlas);
}
Arouter通过apt技术,为每个组生成了一个以Arouter$$Group开头的类,这个类负责向atlas这个Hashmap中填充组内路由数据
IRouteGroup正如其名字,它就是一个能装载该组路由映射数据的类,其实有点像个工具类,为了方便后续讲解,我们姑且称上面这样一个实现了IRouteGroup的类叫做“组加载器”
for (String className : routerMap) {if (className.startsWith(ROUTE_ROOT_PAKCAGE + DOT + SDK_NAME + SEPARATOR +SUFFIX_ROOT)) {((IRouteRoot) (Class.forName(className).getConstructor().newInstance())).loadInto(Warehouse.groupsIndex);}
}
public interface IRouteRoot {/*** Load routes to input* @param routes input*/void loadInto(Map<String, Class<? extends IRouteGroup>> routes);
}
这个类实现了IRouteRoot,在loadInto方法中,他将组名和组对应的“组加载器”保存到了routes这个map中。也就是说,这个类将所有的“组加载器”给索引了下来,通过任意一个组名,可以找到对应的“组加载器”,我们再回到前面讲的初始化Arouter时候的方法中:
((IRouteRoot) (Class.forName(className).getConstructor().newInstance())).loadInto(Warehouse.groupsIndex);
WareHouse中的groupsIndex保存的是组名到“组加载器”的映射关系
Arouter的分组设计:Arouter在原来path到目标的map外,加了一个新的map,该map保存了组名到“组加载器”的映射关系。其中“组加载器”是一个类,可以加载其组内的path到目标的映射关系。
解决步骤二:按需加载
Arouter.getInstance().build("main/hello").navigation;
最终走到
protected Object navigation(final Context context, final Postcard postcard, final int requestCode, final NavigationCallback callback) {try {//请关注这一行LogisticsCenter.completion(postcard);} catch (NoRouteFoundException ex) {logger.warning(Consts.TAG, ex.getMessage());....//简化代码}//调用Intent跳转return _navigation(context, postcard, requestCode, callback)
//从缓存里取路由信息
RouteMeta routeMeta = Warehouse.routes.get(postcard.getPath());
//如果为空,需要加载该组的路由
if (null == routeMeta) {Class<? extends IRouteGroup> groupMeta = Warehouse.groupsIndex.get(postcard.getGroup());IRouteGroup iGroupInstance = groupMeta.getConstructor().newInstance();iGroupInstance.loadInto(Warehouse.routes);Warehouse.groupsIndex.remove(postcard.getGroup());
}
//如果不为空,走后续流程
else {postcard.setDestination(routeMeta.getDestination());...
}
- 首先从Warehouse.routes(前面说了,这里存放的是path到目标的映射)里拿到目标信息,如果找不到,说明这个信息还没加载,需要加载,实际上,刚开始这个routes里面什么都没有。
- 加载流程:首先从Warehouse.groupsIndex里获取“组加载器”,组加载器是一个类,需要通过反射将其实例化,实例化为iGroupInstance,接着调用组加载器的加载方法loadInto,将该组的路由映射关系加载到Warehouse.routes中,加载完成后,routes中就缓存下来当前组的所有路由映射了,因此这个组加载器其实就没用了,为了节省内存,将其从Warehouse.groupsIndex移除。
- 如果之前加载过,则在Warehouse.routes里面是可以找到路有映射关系的,因此直接将目标信息routeMeta传递给postcard,保存在postcard中,这样postcard就知道了最终要去哪个组件了。
APT是什么
APT(Annotation Processing Tool) 即注解处理器 可以在编译期扫描注解帮我们提前生成类
实现流程
- 添加autoService和JavaPoet依赖
- 创建两个JavaLibrary,一个用来定义注解,一个用来扫描注解
- 动态生成类和方法用IO生成文件
1. 注解Lib中创建一个注解类
@Retention(RetentionPolicy.CLASS)
@Target(ElementType.FIELD)
public @interface Print {}
2. 扫描注解的Lib添加依赖
dependencies {//自动注册,动态生成 META-INF/...文件implementation 'com.google.auto.service:auto-service:1.0-rc6'annotationProcessor 'com.google.auto.service:auto-service:1.0-rc6'//依赖apt-annotationimplementation project(path: ':apt-annotation')
}
3. 创建扫描注解的类
添加 @AutoService (Processor.class) 注解
继承AbstractProcessor
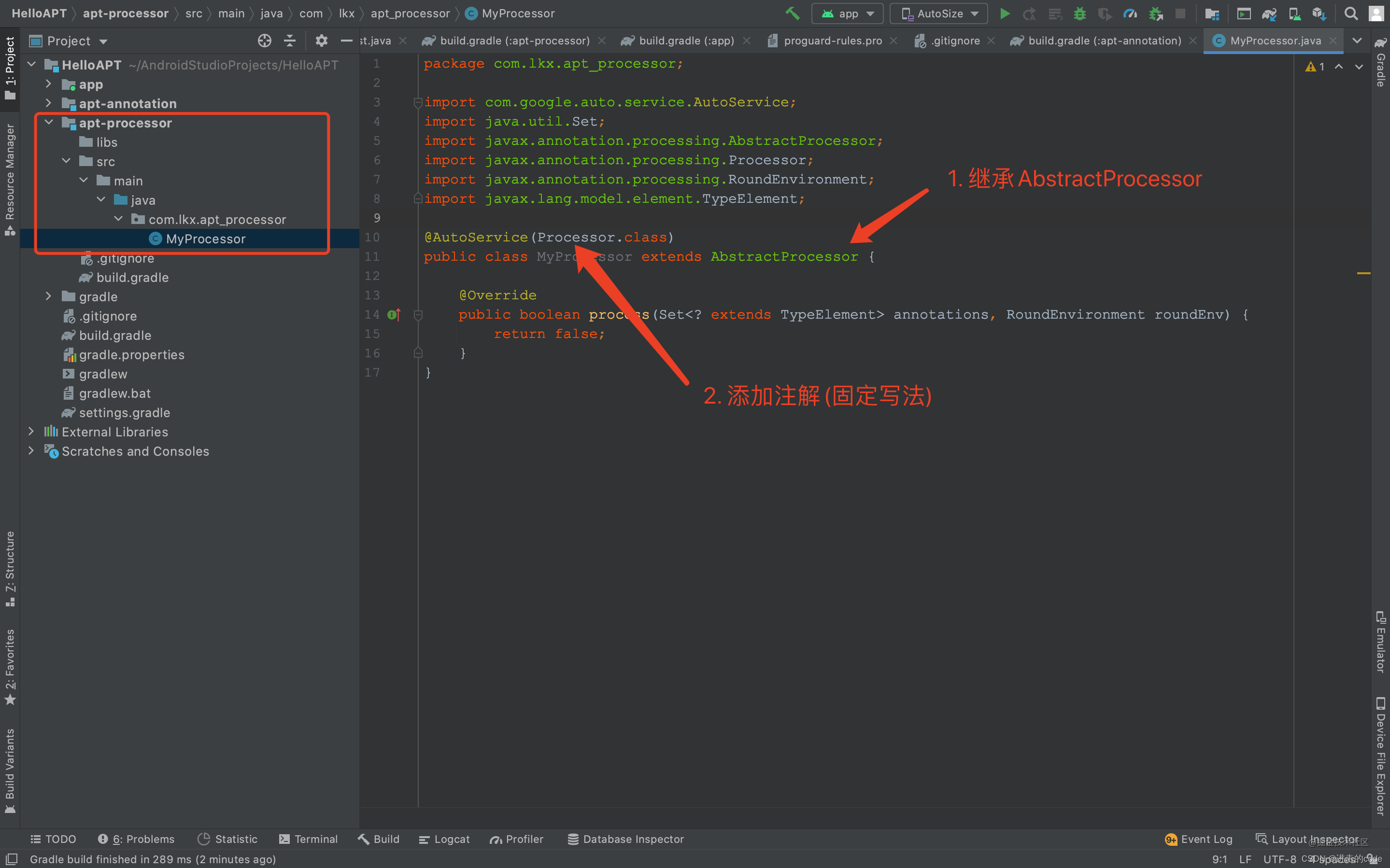
4. 解析注解
真正解析注解的地方是在process方法
/*** 扫描注解回调*/
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {//拿到所有添加Print注解的成员变量Set<? extends Element> elements = roundEnv.getElementsAnnotatedWith(Print.class);for (Element element : elements) {//拿到成员变量名Name simpleName = element.getSimpleName();//输出成员变量名processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE,simpleName);}return false;
}
5. 生成类
用字符串拼出来一个工具类,然后用IO流写到本地就ok了,或者使用JavaPoet提供的方法生成类
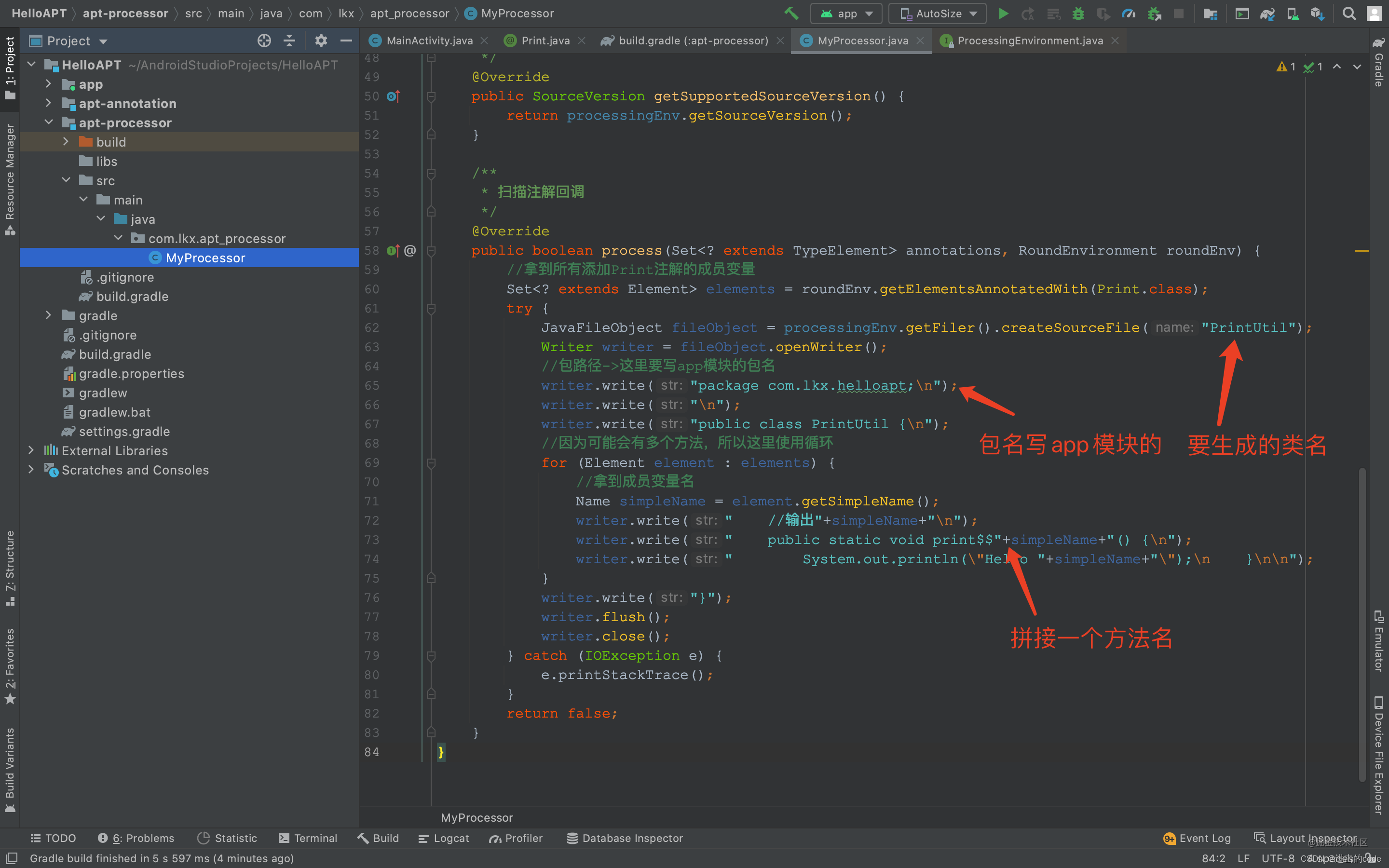
总结
- JavaPoet可以帮我们优雅的生成类,再也不用拼接了
- APT最主要的功能就是可以替代反射的一些功能,避免降低性能
- APT只会在编译时影响一点点速度,在运行期不会,而反射刚好相反
什么是注解?有哪些注解?
Java注解是一种元数据,它们可以在Java源代码中添加额外的信息,这些信息可以被编译器、工具和运行时环境使用。Java注解可以用来提供类、方法、字段或其他程序元素的附加信息,以及在编译时执行某些任务。
Java注解有三种类型:预定义注解、元注解和自定义注解。
-
预定义注解
Java中有三种内置注解,这些注解用来为编译器提供指令,它们是:-
@Deprecated
这个元素是用来标记过时的元素,想必大家在日常开发中经常碰到。编译器在编译阶段遇到这个注解时会发出提醒警告,告诉开发者正在调用一个过时的元素比如过时的方法、过时的类、过时的成员变量
可以用来标记类,方法,属性; -
@Override
用来修饰对父类进行重写的方法。如果一个并非重写父类的方法使用这个注解,编译器将提示错误。
实际上在子类中重写父类或接口的方法,@Overide并不是必须的。但是还是建议使用这个注解,在某些情况下,假设你修改了父类的方法的名字,那么之前重写的子类方法将不再属于重写,如果没有@Overide,你将不会察觉到这个子类的方法。有了这个注解修饰,编译器则会提示你这些信息 -
@SuppressWarnings
用来抑制编译器生成警告信息
可以修饰的元素为类,方法,方法参数,属性,局部变量
当我们一个方法调用了弃用的方法或者进行不安全的类型转换,编译器会生成警告。我们可以为这个方法增加@SuppressWarnings注解,来抑制编译器生成警告。
注意:使用@SuppressWarnings注解,采用就近原则,比如一个方法出现警告,我们尽量使用@SuppressWarnings注解这个方法,而不是注解方法所在的类。虽然两个都能抑制编译器生成警告,但是范围越小越好,因为范围大了,不利于我们发现该类下其他方法的警告信息
-
-
元注解
java.lang.annotation提供了四种元注解,专门注解其他的注解(在自定义注解的时候,需要使用到元注解).-
1.@Documented - 注解是否将包含在JavaDoc中
一个简单的Annotations标记注解,表示是否将注解信息添加在javadoc文档中 -
2.@Retention –什么时候使用该注解
Retention 的英文意为保留期的意思。当 @Retention 应用到一个注解上的时候,它解释说明了这个注解的的存活时间- RetentionPolicy.SOURCE 注解只在源码阶段保留,在编译器进行编译时它将被丢弃忽视。
- RetentionPolicy.CLASS 注解只被保留到编译进行的时候,它并不会被加载到 JVM 中。
- RetentionPolicy.RUNTIME 注解可以保留到程序运行的时候,它会被加载进入到 JVM 中,所以在程序运行时可以获取到它们。
-
3.@Target– 注解用于什么地方
默认值为任何元素,表示该注解用于什么地方。可用的ElementType参数包括- ElementType.CONSTRUCTOR:用于描述构造器
- ElementType.FIELD:成员变量、对象、属性(包括enum实例)
- ElementType.LOCAL_VARIABLE:用于描述局部变量
- ElementType.METHOD:用于描述方法
- ElementType.PACKAGE:用于描述包
- ElementType.PARAMETER:用于描述参数
- ElementType.TYPE:用于描述类、接口(包括注解类型) 或enum声明
-
4.@Inherited – 定义该注释和子类的关系
-
Inherited 是继承的意思,但是它并不是说注解本身可以继承,而是说如果一个超类被 @Inherited 注解过的注解进行注解的话,那么如果它的子类没有被任何注解应用的话,那么这个子类就继承了超类的注解
-
自定义注解
自定义注解类编写的一些规则:1. Annotation型定义为@interface, 所有的Annotation会自动继承java.lang.Annotation这一接口,并且不能再去继承别的类或是接口.2. 参数成员只能用public或默认(default)这两个访问权修饰3. 参数成员只能用基本类型byte,short,char,int,long,float,double,boolean八种基本数据类型和String、Enum、Class、annotations等数据类型,以及这一些类型的数组.4. 要获取类方法和字段的注解信息,必须通过Java的反射技术来获取 Annotation对象,因为你除此之外没有别的获取注解对象的方法5. 注解也可以没有定义成员, 不过这样注解就没啥用了
@Target(ElementType.FIELD)//可以用来修饰对象,属性
@Retention(RetentionPolicy.RUNTIME)//什么时候都不丢弃
@Documented//用于生成javadoc文档
public @interface FruitName {String value() default "";
}
@Target(ElementType.FIELD)//可以用来修饰对象,属性
@Retention(RetentionPolicy.RUNTIME)//什么时候都不丢弃
@Documented//用于生成javadoc文档
public @interface FruitColor {public enum Color{RED,GREEN,BLUE};Color fc() default Color.GREEN;
}
创建一个工具类用来处理注解
package cn.sz.gl.test07;
import java.lang.reflect.Field;
public class AnnotationUtil {public static Object findInfo(Class clazz) throws IllegalArgumentException, IllegalAccessException, InstantiationException{Object obj = clazz.newInstance();Field fs [] = clazz.getDeclaredFields();for (int i = 0; i < fs.length; i++) {//判断该属性上是否有FruitName类型的注解if(fs[i].isAnnotationPresent(FruitName.class)){FruitName fn = fs[i].getAnnotation(FruitName.class);//为属性赋值fs[i].setAccessible(true);fs[i].set(obj, fn.value());}if(fs[i].isAnnotationPresent(FruitColor.class)){FruitColor fc = fs[i].getAnnotation(FruitColor.class);fs[i].setAccessible(true);fs[i].set(obj, fc.fc().toString());}}return obj;}
}
2. 插件化
所谓插件化,是实现动态化的一种具体的技术手段。
- 布局动态化。通过下发配置,再由客户端映射为具体的原生布局,实现动态化。这种方案的性能还不错,但只适合布局动态化,更新业务逻辑则较为困难。
- H5容器。其实webview就是一个天然可实现动态化的方案。这种方案的稳定性和动态化能力都不错,主要缺陷是性能较差,毕竟js是解释型语言,终究比不过原生。
- 虚拟运行环境。如Flutter。Flutter所使用的Dart语言既是解释型语言,又是编译型语言,解决了上面提到的性能问题。但这种方案往往需要在apk中依赖一个sdk,增加了包大小。
- 插件化。插件化通过动态下发部分代码,来实现动态的功能更新。前几年,插件化是较火的方案,近些年受制于系统的限制,变得越来越难以实现。
Shadow
通过运用AOP思想,利用字节码编辑工具,在编译期把插件中的所有Activity的父类都改成一个普通类,然后让壳子持有这个普通类型的父类去转调它就不用Hack任何系统实现了。虽然说是非常简单的事,实际上这样修改后还带来一些额外的问题需要解决,比如getActivity()方法返回的也不是Activity了。不过Shadow的实现中都解决了这些问题。
Flutter
1. dart中的作用域与了解吗
默认是public,如需私有只需要在变量名或者方法名前加_
例如
var user = "小王"; //是public
var _user= "小王"; //是private
2. dart中. … …分别是什么意思?
一个点 .
是正常的对象访问
两个点 . .
意思是 「级联操作符」,为了方便配置而使用。「…」和「.」不同的是 调用「…」后返回的相当于是 this, 可以实现对一个对象的连续调用
Paint()..color = thumbColor..style = PaintingStyle.stroke..strokeCap = StrokeCap.round..strokeWidth = tempWidth);
三个点 … 用来拼接集合,如List,Map等
class TestDemo { TestDemo() { var list2 = ['d', 'e', 'f'];var list = ['a', 'b', 'c', ...list2];// 打印结果:// 这里组合后 list就变成[ 'a', 'b', 'c','d', 'e', 'f']var map2 = {'a': 'a', 'b': 'b'};var map = {...map2, 'c': 'c', 'd': 'd'};// 打印结果:// 这里组合后map就变成{'a': 'a', 'b': 'b','c': 'c', 'd': 'd'}}
}
3. Dart 是不是单线程模型?如何运行的?
Dart是单线程模型
Dart在单线程中是以消息循环机制来运行的,其中包含两个任务队列,一个是 “微任务队列” microtask queue,另一个叫做 “事件队列” event queue。微任务队列的执行优先级高于 事件队列。
Dart大致运行原理:先开启app执行入口函数main(),执行完成之后,消息机制启动,先是会按照先进先出的顺序逐个执行微任务队列中的任务microtask,事件任务eventtask 执行完毕后便会退出,但是,在事件任务执行的过程中也可以插入新的微任务和事件任务,在这种情况下,整个线程的执行过程便是一直在循环,不会退出,而Flutter中,主线程的执行过程正是如此,永不终止。
在事件循环中,当某个任务发生异常并没有被捕获时,程序并不会退出,而直接导致的结果是当前任务的后续代码就不会被执行了,也就是说一个任务中的异常是不会影响其它任务执行的。
Dart 中事件的执行顺序:Main > MicroTask > EventQueue
- 通常使用 scheduleMicrotask(…) 或者 Future.microtask(…) 方法向微任务队列插入一个任务。
- 通常使用 Future 向 EventQueue加入事件,也可以使用 async 和 await 向 EventQueue 加入事件。
4. Dart既然是单线程模型支持多线程吗?
多线程语言如Java实现异步的方式是将耗时操作新开子线程去执行。Dart是单线程模型,没有多线程的概念,他是通过Future和Stream来实现异步的。
5. Future是什么
Future是异步函数,它可以在不阻塞当前任务的情况下执行一个任务,并在任务完成后获得相应的结果。
Future实际上是将其中的事件放入到了Event Queue事件队列中执行。
常与async一起使用
Async是Dart中的一个关键字,用于标记异步函数。async函数返回一个Future对象,并且可以使用await关键字来等待函数的执行结果。例如:
Future<String> getData(String url) async {
var response = await http.get(url);
return response.body;
}
6. Stream是什么
Stream 流是一个异步的事件队列。分为单订阅流和广播订阅
- 单订阅流
默认情况下创建的流都是单订阅流,单订阅流只能被订阅一次,第二次监听会报错!监听开始之前的元素不会被订阅。但 Stream 可以通过 transform() 方法(返回另一个 Stream)进行连续调用。通过 Stream.asBroadcastStream() 可以将一个单订阅模式的 Stream 转换成一个多订阅模式的 Stream.isBroadcast 属性可以判断当前 Stream 所处的模式。 - 广播订阅
广播流允许存在任意数量的 listener,并且无论是否存在 listener,它都能产生事件,所以中途加入的 listener 不会侦听到已发生的事件。
单订阅流常用于数据的传递,广播流用于事件的分发。
StreamController 是流控制器的核心接口,包含了流控制器该有的大多数接口方法。其中
- stream 用于向外提供创建的Stream。
- sink 是该控制器关联的流的数据来源。可以使用sink.add 方法向流中添加数据。
- onListen, 当控制器中的流被监听的时候,会回调该方法。
- onPause, 当流的监听主动暂停的时候,会回调该方法。
- onResume, 当流的监听主动恢复监听的时候,会回调该方法。
- onCancel,当流的监听取消监听的时候,会回调该方法。
7. Flutter 如何和原生交互
Flutter 与原生交互使用Platform Channel。Flutter定义了三种不同类型的Channel
- BasicMessageChannel 用于传递字符串和半结构化的信息,可持续通信,收到消息后可以回复此次消息。场景:消息互发(双向有返回值,可持续通信)
- MethodChannel 用于传递方法调用。场景:native与flutter的方法调用(双向有返回值,一次性通信)
- EventChannel 用于事件型的通信,仅支持 native 到 Flutter 的单向传递。场景:通常用于状态端监听,比如网络变化、传感器数据、电量更新或声音改变(仅支持数据单向传递,无返回值)
8. 说一下 mixin?
- mixin 可以理解为对类的一种“增强”,但它与单继承兼容,因为它的继承关系是线性的。
- with 后面的类会覆盖前面的类的同名方法
- 当我们想要在不共享相同类层次结构的多个类之间共享行为时,可以使用 mixin
- on限定了使用mixin组块的宿主必须要继承于某个特定的类;在mixin中可以访问到该特定类的成员和方法。
- 作为mixin的类不能有自定义构造方法
9. StatefulWidget 的生命周期

- initState 初始化阶段回调
- didUpdateWidget build阶段回调 当Widget配置发生变化时,比如父Widget触发重建(即父Widget的状态发生变化时),热重载,系统会调用这个函数。
- didChangeDependencies build阶段回调 state对象依赖关系发生变化后,flutter会进行回调。
- deactivate 不可见时回调
- dispose 销毁时回调
10. main()和runApp()函数在flutter的作用分别是什么?有什么关系吗?
main函数是程序执行的入口。
runApp是Flutter应用启动的入口。runApp中启动了Flutter FrameWork并且完成根widget树的渲染
在runApp中 初始化了WidgetsFlutterBinding这个类混入了七个BindingBase子类。同时调用WidgetsFlutterBinding 将Flutter Framework绑定到Flutter Engine上面
- GestureBinding:绑定手势系统。
- ServicesBinding:主要作用与defaultBinaryMessenger有关,用于和native通讯相关。
- SchedulerBinding:该类主要用于调度帧渲染相关事件。
- PaintingBinding:和painting库绑定,处理图片缓存。
- SemanticsBinding:将语义层和Flutter Engine绑定起来。
- RendererBinding:将渲染树与Flutter Engine绑定起来。
- WidgetsBinding:将Widget层与Flutter Engine绑定起来。
11. 怎么理解Isolate?
isolate 意思是隔离。它可以理解为 Dart 中的线程。isolate与线程的区别就是线程与线程之间是共享内存的,而 isolate 和 isolate 之间是不共享的。因此也不存在锁竞争问题,两个Isolate完全是两条独立的执行线,且每个Isolate都有自己的事件循环,它们之间只能通过发送消息通信,它的资源开销低于线程。
每个 isolate 都拥有自己的事件循环及队列(MicroTask 和 Event)。这意味着在一个 isolate 中运行的代码与另外一个 isolate 不存在任何关联。
isolate之间的通信
由于isolate之间没有共享内存,他们之间的通信唯一方式只能是通过Port进行,而且Dart中的消息传递总是异步的。
- 两个Isolate是通过两对Port对象通信,一对Port分别由用于接收消息的ReceivePort对象,和用于发送消息的SendPort对象构成。
- Flutter 中可以使用compute函数来创建Isolate
- compute中运行的函数,必须是顶级函数或者是static函数,
- compute传参,只能传递一个参数,返回值也只有一个
12. 简单介绍下Flutter框架,以及它的优缺点?
Flutter 是Google开发的一款跨平台方案的开源框架。
优点
- 高性能:自带绘制系统,让Flutter拥有原生级别的性能。
RN、Weex等跨平台开发框架,都选择将绘制任务交给了平台原生的绘制引擎。因此,这些框架在规避了重新开发一套图形机制的同时,也从底层机制上带来了无法调和的性能问题。 - 因为Flutter底层使用和Android原生一样的Skia引擎,所以保证了android和ios两端的UI一致性
- 拥有热更新机制,开发效率比原生更高
- Dart语言比较简单,而且Flutter语法与JectPack库中的Compose接近,容易上手。
缺点
- 生态还不够丰富
- 缺少动态性
12. 简述Widgets、RenderObjects 和 Elements的关系
- Widget :仅用于存储渲染所需要的信息。Widget只是配置信息,相当于Android里的XML布局文件
- RenderObject :负责管理布局、绘制等操作。保存了元素的大小,布局等信息.
- Element :是这颗巨大的控件树上的实体。通过 Widget 的 createElement() 方法,根据 Widget数据生成。如果 widget 有相同的 runtimeType 并且有相同的 key, Element 可以根据新的 widget 进行 update.
Widget会被inflate(填充)到Element,并由Element管理底层渲染树。Widget并不会直接管理状态及渲染,而是通过State这个对象来管理状态。Flutter创建Element的可见树,相对于Widget来说,是可变的,通常界面开发中,我们不用直接操作Element,而是由框架层实现内部逻辑。就如一个UI视图树中,可能包含有多个TextWidget(Widget被使用多次),但是放在内部视图树的视角,这些TextWidget都是填充到一个个独立的Element中。Element会持有renderObject和widget的实例。记住,Widget 只是一个配置,RenderObject 负责管理布局、绘制等操作。
在第一次创建 Widget 的时候,会对应创建一个 Element, 然后将该元素插入树中。如果之后 Widget 发生了变化,则将其与旧的 Widget 进行比较,并且相应地更新 Element。重要的是,Element 不会被重建,只是更新而已。
- 一个Widget一定对应一个Element,但是不一定会有RenderObject
- 只有当Widget被渲染显示出来时才会有RenderObject
13. 介绍下Widget、State、Context 概念
- Widget:在Flutter中,几乎所有东西都是Widget。将一个Widget想象为一个可视化的组件(或与应用可视化方面交互的组件),当你需要构建与布局直接或间接相关的任何内容时,你正在使用Widget。
- Widget树:Widget以树结构进行组织。包含其他Widget的widget被称为父Widget(或widget容器)。包含在父widget中的widget被称为子Widget。
- Context:仅仅是已创建的所有Widget树结构中的某个Widget的位置引用。简而言之,将context作为widget树的一部分,其中context所对应的widget被添加到此树中。一个context只从属于一个widget,它和widget一样是链接在一起的,并且会形成一个context树。
- State:定义了StatefulWidget实例的行为,它包含了用于”交互/干预“Widget信息的行为和布局。应用于State的任何更改都会强制重建Widget。
14. 简述Widget的StatelessWidget和StatefulWidget两种状态组件类
-
StatelessWidget: 一旦创建就不关心任何变化,在下次构建之前都不会改变。它们除了依赖于自身的配置信息(在父节点构建时提供)外不再依赖于任何其他信息。比如典型的Text、Row、Column、Container等,都是StatelessWidget。它的生命周期相当简单:初始化、通过build()渲染。
-
StatefulWidget: 在生命周期内,该类Widget所持有的数据可能会发生变化,这样的数据被称为State,这些拥有动态内部数据的Widget被称为StatefulWidget。比如复选框、Button等。State会与Context相关联,并且此关联是永久性的,State对象将永远不会改变其Context,即使可以在树结构周围移动,也仍将与该context相关联。当state与context关联时,state被视为已挂载。StatefulWidget由两部分组成,在初始化时必须要在createState()时初始化一个与之相关的State对象。
15. 什么是状态管理,你了解哪些状态管理框架?
Flutter中的状态和前端React中的状态概念是一致的。React框架的核心思想是组件化,应用由组件搭建而成,组件最重要的概念就是状态,状态是一个组件的UI数据模型,是组件渲染时的数据依据。
Flutter的状态可以分为全局状态和局部状态两种。常用的状态管理有GetX和Provider
16. 简述Flutter的绘制流程
Flutter只关心向 GPU提供视图数据,GPU的 VSync信号同步到 UI线程,UI线程使用 Dart来构建抽象的视图结构,这份数据结构在 GPU线程进行图层合成,视图数据提供给 Skia引擎渲染为 GPU数据,这些数据通过 OpenGL或者 Vulkan提供给 GPU。

17. await for 如何使用?
await for是不断获取stream流中的数据,然后执行循环体中的操作。它一般用在直到stream什么时候完成,并且必须等待传递完成之后才能使用,不然就会一直阻塞。
Stream<String> stream = new Stream<String>.fromIterable(['开心', '面试', '过', '了']);
main() async{await for(String s in stream){print(s);}
18. 介绍下Flutter的架构
Flutter框架自下而上分为Embedder、Engine和Framework三层。
- Embedder是操作系统适配层,实现了渲染 Surface设置,线程设置,以及平台插件等平台相关特性的适配;
- Engine层负责图形绘制、文字排版和提供Dart运行时,Engine层具有独立虚拟机,正是由于它的存在,Flutter程序才能运行在不同的平台上,实现跨平台运行;
- Framework层则是使用Dart编写的一套基础视图库,包含了动画、图形绘制和手势识别等功能,是使用频率最高的一层。
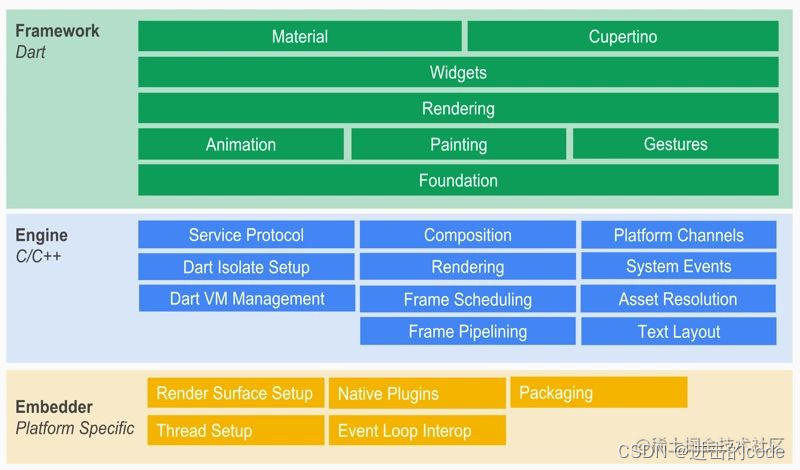
19. 介绍下Flutter的FrameWork层和Engine层,以及它们的作用
- Flutter的FrameWork层是用Drat编写的框架(SDK),它实现了一套基础库,包含Material(Android风格UI)和Cupertino(iOS风格)的UI界面,下面是通用的Widgets(组件),之后是一些动画、绘制、渲染、手势库等。这个纯 Dart实现的 SDK被封装为了一个叫作 dart:ui的 Dart库。我们在使用 Flutter写 App的时候,直接导入这个库即可使用组件等功能。
- Flutter的Engine层是Skia 2D的绘图引擎库,其前身是一个向量绘图软件,Chrome和 Android均采用 Skia作为绘图引擎。Skia提供了非常友好的 API,并且在图形转换、文字渲染、位图渲染方面都提供了友好、高效的表现。Skia是跨平台的,所以可以被嵌入到 Flutter的 iOS SDK中,而不用去研究 iOS闭源的 Core Graphics / Core Animation。Android自带了 Skia,所以 Flutter Android SDK要比 iOS SDK小很多。
20. Dart中var与dynamic的区别
var 和 dynamic 可以用来声明一个可以接受任何类型的变量
- var 是编译时确定类型,一旦赋值,类型推断就会确定这个变量的类型 ,由于Dart是个强类型语言,所以不能在以后的赋值中变更其类型。
- dynamic 是运行时确定类型,且在后续赋值中可以改变类型。
21. const关键字与final关键字的区别
- final 用来修饰变量,运行时赋值、只能被赋值一次。
- const 只可以修饰变量,常量构造函数,编译时确定。
- final 修饰的对象内容一样会指向不同的地址,const 修饰的对象内容一样会指向相同的地址
22. Flutter在Debug和Release下分别使用什么编译模式,有什么区别?
Flutter在Debug下使用JIT模式即Just in time(即时编译),在Release下使用AOT模式即Ahead of time(提前编译)
- JIT模式因为需要边运行边编译,所以会占用运行时内存,导致卡顿现象,但是有动态编译效果对于开发者来说非常方便调试。
- AOT模式提前编译不会占用运行时内存,相对来说运行流畅,但是会导致编译时间增加。
23. 什么是Key?
Flutter key子类包含 LocalKey 和 GlobalKey 。在Flutter中,Key是不能重复使用的,所以Key一般用来做唯一标识。组件在更新的时候,其状态的保存主要是通过判断组件的类型或者key值是否一致。
- GlobalKey 能够跨 Widget 访问状态。在整个APP范围内唯一
- LocalKey,在兄弟节点中唯一
Widget相当于配置文件,是不可变的,想改变只能重建,而Element是Widget实体,创建后只会更新不会重建。
Widget可以通过Key来更新Element
24. future 和steam有什么不一样?
在 Flutter 中有两种处理异步操作的方式 Future 和 Stream,Future 用于处理单个异步操作,Stream 用来处理连续的异步操作。
25. 什么是widget? 在flutter里有几种类型的widget?
widget在flutter里基本是一些UI组件
有两种类型的widget,分别是statefulWidget 和 statelessWidget两种
- statelessWidget不会自己重新构建自己
- statefulWidget会重新构建自己
26. statefulWidget更新流程了解吗
- 触发setState方法:当调用setState方法时会在State类中调用setState方法
@protected
void setstate(VoidCallback fn){
final dynamic result fn()as dynamic;
_element.markNeedsBuild();
}
- element标脏:StatefulElement中执行的markNeedsBuild方法。在markNeedsBuild函数中将当前树进行标脏(标记为dirty),如果己经是脏树,那么直接返回。owner:是BuildOwner,BuildOwner是element的管理类,主要负责dirtyElement、ina
ctiveElement、globalkey关联的element的管理。
void markNeedsBuild(){
if (!_active)
return;
if (dirty)
return;
_dirty true;
owner.scheduleBuildFor(this);
}
- 将element添加到脏列表_dirtyElements中,并触发WidgetsBindingl的回调。
scheduleBuildFor方法在BuildOwner中执行。onBuildScheduled()回调在WidgetsBinding类中执行。BuildOwner对象执行onBuildScheduled() 回调时,会去执行WidgetsBinding类中的handleBuildScheduled() 方法。
final List_dirtyElements [];
......
void scheduleBuildFor(Element element){
......
if (element._inDirtyList){
_dirtyElementsNeedsResorting true;
return;
}
if (!_scheduledFlushDirtyElements && onBuildScheduled !=null){
_scheduledFlushDirtyElements true;
//是一个回调方法
onBuildScheduled();
}
dirtyElements.add(element);
element._inDirtyList true;
}
- 在WidgetsBinding中触发onBuildScheduled的回调,执行ensurevisualUpdate
方法。
mixin WidgetsBinding on BindingBase, ServicesBinding, SchedulerBinding, GestureBinding, RendererBinding, SemanticsBinding {@overridevoid initInstances() {super.initInstances();_instance = this;assert(() {_debugAddStackFilters();return true;}());_buildOwner = BuildOwner();buildOwner!.onBuildScheduled = _handleBuildScheduled;platformDispatcher.onLocaleChanged = handleLocaleChanged;SystemChannels.navigation.setMethodCallHandler(_handleNavigationInvocation);assert(() {FlutterErrorDetails.propertiesTransformers.add(debugTransformDebugCreator);return true;}());platformMenuDelegate = DefaultPlatformMenuDelegate();}
.....void _handleBuildScheduled() {
....ensureVisualUpdate();}
- 在SchedulerBinding中触发ensureVisualUpdate的方法,根据不同的调度任务执
行不同的操作。
void ensurevisualUpdate()
switch (schedulerPhase){
//没有正在处理的帧,可能正在执行的是WidgetsBinding.scheduleTask,
//scheduleMicrotask,Timer,事件handlers,或者其他回调等
case SchedulerPhase.idle:
//主要是清理和计划执行下一帧的工作
case SchedulerPhase.postFrameCallbacks:
scheduleFrame();//清求新的贞渲染。
return;
//SchedulerBinding.handleBeginFrame过程,
处理动画状态更新
case SchedulerPhase.transientCallbacks:
//处理transientCal1 backs阶段触发的微任务(Microtasks)
case SchedulerPhase.midFrameMicrotasks:
//WidgetsBinding.drawFrame和SchedulerBinding.handleDrawFrame过程,
//bui1d/1 ayout/paint流水线江作
case SchedulerPhase.persistentCallbacks:
return;
}
- 在SchedulerBinding请求新的frame,注册Vsync信号。Flutter在window上注册一个onBeginFrame和一个onDrawFrame回调,在onDrawFrame回调中最终会调用drawFrame。
当我们调用window.scheduleFrame() 方法之后,Flutter引擎会在合适的时机(可
以认为是在屏幕下一次刷新之前,具体取决于Flutter引擎的实现)来调用onBeginFrame和onDrawFrame。
void scheduleFrame()
if (_hasScheduledFrame!framesEnabled)
return;
//确保渲染的回调已经被注册
ensureFrameCallbacksRegistered();
//windowi调度帧
window.scheduleFrame();
_hasScheduledFrame true;
}
@protected
void ensureFrameCallbacksRegistered(){
/处理渲染前的任务
window.onBeginFrame ??=_handleBeginFrame;
//核心渲染流程
window.onDrawFrame ??_handleDrawFrame;}
- 当下一次刷新之前,会调用onBeginFrame和onDrawFrame方法。
handleBeginFrame () - 调用RendererBinding和drawFrame方法。
相关文章:
【最新面试问题记录持续更新,java,kotlin,android,flutter】
最近找工作,复习了下java相关的知识。发现已经对很多概念模糊了。记录一下。部分是往年面试题重新整理,部分是自己面试遇到的问题。持续更新中~ 目录 java相关1. 面向对象设计原则2. 面向对象的特征是什么3. 重载和重写4. 基本数据类型5. 装箱和拆箱6. …...

面试:经典问题解决思路
1. 秒杀系统架构 参考:秒杀系统架构优化思路 2. 如何防止订单重复提交 重复提交原因: 一种是由于用户在短时间内多次点击下单按钮,或浏览器刷新按钮导致。另一种则是由于Nginx或类似于SpringCloud Gateway的网关层,进行超时重试造成的。 方案…...

CG MAGIC分享3ds Max卡顿未保存处理方法有哪些?
3ds Max进行建模、渲染这一系列过程中,大家使用中都会遇到各种原因导致软件卡顿或崩溃是很常见的情况。 可以说卡机没关系,可是卡顿发生时,如果之前的工作没有及时保存,可能会导致数据的丢失和时间的浪费。这就是最让人烦躁的了&…...

[python 刷题] 238 Product of Array Except Self
[python 刷题] 238 Product of Array Except Self 题目: Given an integer array nums, return an array answer such that answer[i] is equal to the product of all the elements of nums except nums[i]. The product of any prefix or suffix of nums is guar…...
UG NX二次开发(C#)-计算直线到各个坐标系轴向的投影角度
文章目录 1、前言2、需求分析3、NXOpen方法实现3.1 创建基准坐标系3.2 然后计算直线到基准坐标系的轴向角度3.3 代码调用4、测试效果为:1、前言 最近有个粉丝问我如何计算直线到坐标系各个轴向的角度,这里用UG NX二次开发(C#)实现。当然,这里的内容是经验之谈,如果有更好的…...
相互关联)
C# ComboBox 和 枚举类型(Enum)相互关联
C# ComboBox 和 枚举类型(Enum)相互关联 目的 在C# Winform面板上的ComboBox选择项,由程序填写某个Enum的各个枚举项目。 在运行中读取ComboBox的选择项,返回Enum数值。 非编程方法 低阶做法可以在winform设计窗口手动填写,但是不会自动跟…...
Linux CentOS7 tree命令
tree就是树,是文件或文件名输出到控制台的一种显示形式。 tree命令作用:以树状图列出目录的内容,包括文件、子目录及子目录中的文件和目录等。 我们使用ll命令显示只能显示一个层级的普通文件和目录的名称。而使用tree则可以树的形式将指定…...

软件设计模式系列之九——桥接模式
1 模式的定义 桥接模式是一种结构型设计模式,它用于将抽象部分与其实现部分分离,以便它们可以独立地变化。这种模式涉及一个接口,它充当一个桥,使得具体类可以在不影响客户端代码的情况下改变。桥接模式将继承关系转化为组合关系…...

构造函数的调用规则
#include <iostream> #include <string> using namespace std; class person{ public:int m_age; // person(){ // cout<<"默认构造的调用"<<endl; // } // person(int age){ // m_ageage; // cout<<"有参构造的调用"<…...

第十章:枚举类与注解
10.1:枚举类的使用 当需要定义一组常量时,建议使用枚举类(前提:类的对象只有有限个,确定的) eg: 星期:Mondey、.....、Sunday 性别:Man、.....、Woman 线程状态ÿ…...

ChatGPT:字符串操作问题——提取包含括号的字符串中的题干内容
ChatGPT:字符串操作问题——提取包含括号的字符串中的题干内容 String title p.text().split(“(”)[0];为什么会报错 ChatGPT: 在这段代码中,您正在使用Java处理一个字符串(假设是HTML或文本),尝试将其分…...
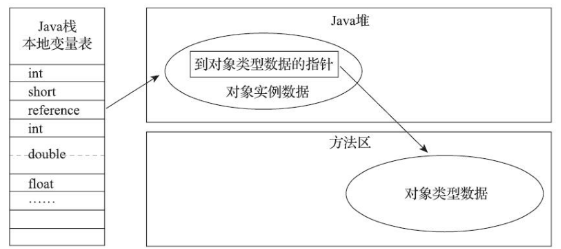
jvm中对象创建、内存布局以及访问定位
对象创建 Java语言层面,创建对象通常(例外:复制、反序列化)仅仅是一个new关键字即可,而在虚拟机中,对象(限于普通Java对象,不包括数组和Class对象等)的创建又是怎样一个过…...

C基础-操作符详解
操作符分类: 算数操作符: - * / % //算数操作符 // int main() // { // // /除法 1.整数除法(除号两端都是整数) 2浮点数除法,除号的两端只要有一个小数就执行小数除法 // // 除法中,除数为0 // int a 7 / 2; /…...

时序预测 | MATLAB实现BO-BiGRU贝叶斯优化双向门控循环单元时间序列预测
时序预测 | MATLAB实现BO-BiGRU贝叶斯优化双向门控循环单元时间序列预测 目录 时序预测 | MATLAB实现BO-BiGRU贝叶斯优化双向门控循环单元时间序列预测效果一览基本介绍模型搭建程序设计参考资料 效果一览 基本介绍 MATLAB实现BO-BiGRU贝叶斯优化双向门控循环单元时间序列预测。…...
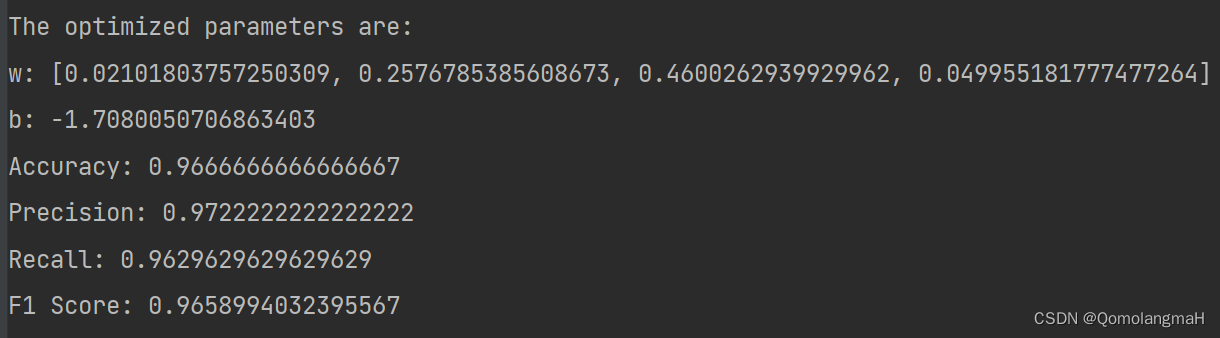
【深度学习实验】线性模型(五):使用Pytorch实现线性模型:基于鸢尾花数据集,对模型进行评估(使用随机梯度下降优化器)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入库 1. 线性模型linear_model 2. 损失函数loss_function 3. 鸢尾花数据预处理 4. 初始化权重和偏置 5. 优化器 6. 迭代 7. 测试集预测 8. 实验结果评估 9. 完整代码 一、实验介…...
ADB底层原理
介绍 adb的全称为Android Debug Bridge,就是起到调试桥的作用。通过adb我们可以在Eclipse/Android Studio中方便通过DDMS来调试Android程序,说白了就是debug工具。adb是android sdk里的一个工具, 用这个工具可以直接操作管理android模拟器或者真实的and…...

etcd之读性能主要影响因素
1、Raft模块-线性读ReadIndex-节点之间的RTT延时、磁盘IO 线性读时Follower节点首先会向Raft 模块发送ReadIndex请求,此时Raft模块会先向各节点发送心跳确认,一半以上节点确认 Leader 身份后由leader节点将已提交日志索引 (committed index) 封装成 Rea…...
【Stable Diffusion】安装 Comfyui 之 window版
序言 由于stable diffusion web ui无法做到对流程进行控制,只是点击个生成按钮后,一切都交给AI来处理。但是用于生产生活是需要精细化对各个流程都要进行控制的。 故也就有个今天的猪脚:Comfyui 步骤 下载comfyui项目配置大模型和vae下载…...
Ansys Zemax | 如何建立二向分色分光镜
分光镜(Beam splitter)可被运用在许多不同的场合。一般而言,入射光抵达二向分色分光镜(dichroic beam splitter)时,会根据波长的差异产生穿透或反射的现象。这篇文章将说明如何在OpticStudio的非序列模式(non-sequential mode)中建立二向分色分光镜&…...
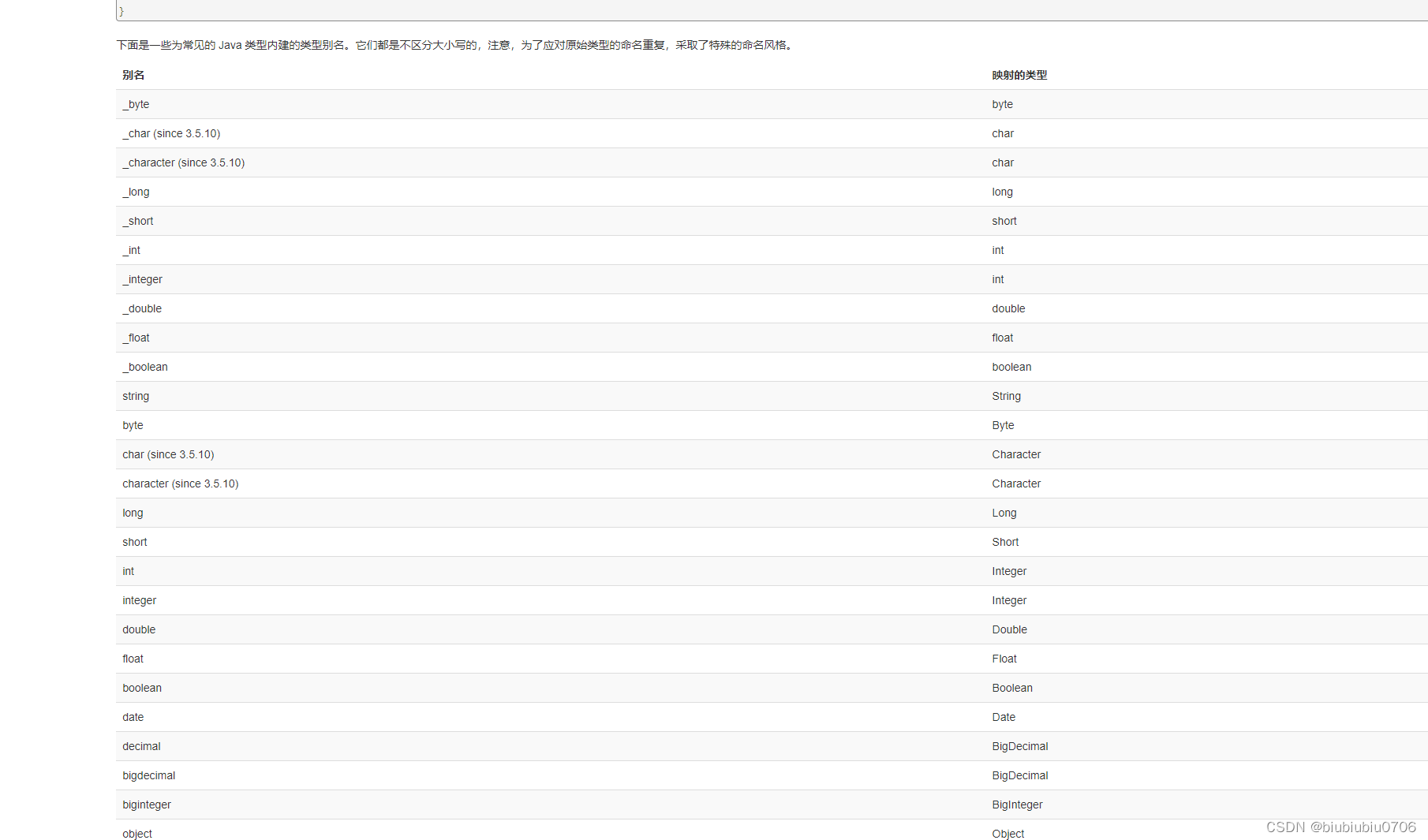
Mybatis学习笔记8 查询返回专题
1.返回实体类 2.返回List<实体类> 3.返回Map 4.返回List<Map> 5.返回Map<String,Map> 6.resultMap结果集映射 7.返回总记录条数 新建模块 依赖 目录结构 1.返回实体类 如果返回多条,用单个实体接收会出异常 2.返回List<实体类> 即使返回一条记…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...