Python爬虫从端到端抓取网页
网页抓取和 REST API 简介
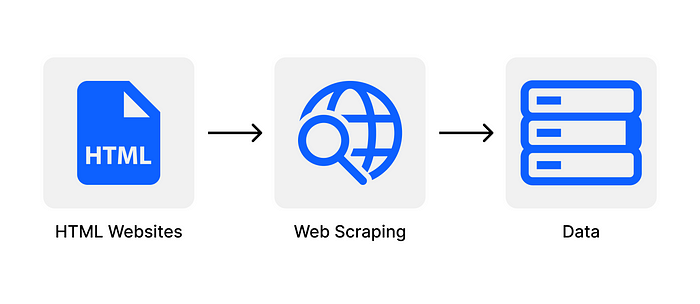
网页抓取是使用计算机程序以自动方式从网站提取和解析数据的过程。这是创建用于研究和学习的数据集的有用技术。虽然网页抓取通常涉及解析和处理 HTML 文档,但某些平台还提供 REST API 来以机器可读格式(如 JSON)检索信息。在本教程中,我们将使用网络抓取和 REST API 创建真实的数据集。
如何运行代码
学习材料的最佳方法是执行代码并亲自进行实验。本教程是一个可执行的 Jupyter 笔记本。
您还可以选择“Run on Colab”或“Run on Kaggle”,但您需要在 Google Colab 或 Kaggle 上创建帐户才能使用这些平台等。
我将在该项目中做什么
1)选择一个网站并描述您的目标
2)使用requests库下载网页
3)使用Beautiful Soup解析和提取信息
4)使用提取的信息创建 CSV 文件
5)编写一个函数:
- 从主题页面获取主题列表
- 从各个主题页面获取顶级存储库列表
- 对于每个主题,创建该主题的顶级存储库的 CSV
GitHub 主题的热门存储库
GitHub URL“ https://github.com/dineshmalappagari/Web-Scraping ”来检查项目。
1)选择一个网站并描述您的目标
——浏览不同的网站并选择进行抓取。查看“项目创意”部分以获取灵感。
— - 确定您想要从网站上抓取的信息。决定输出 CSV 文件的格式。
— -在 Juptyer 笔记本中总结您的项目想法并概述您的策略。使用上面的“新建”按钮。
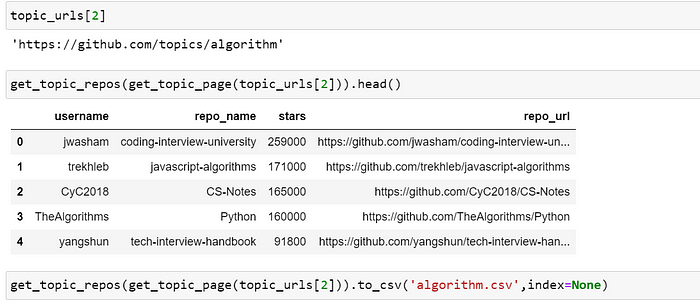
1)我要抓取“ https://github.com/topics”
2)在网站中,我们按字母顺序排列主题。在主题中,我将从主题中选取前 25 个存储库
3)从每个存储库中,我将获取 Repo_name、用户名、Stars 和 URL
2)使用requests库下载网页
— -检查网站的 HTML 源代码并确定要下载的正确 URL。
— -使用requests库将网页下载并保存到本地。
— -创建一个功能来自动下载不同主题/搜索查询。
使用下载网页requests
我们应该安装 !pip 安装请求

requests.get返回一个响应对象,其中包含页面内容和一些使用状态代码指示请求是否成功的信息。在此处了解有关 HTTP 状态代码的更多信息:

让我们将内容保存到具有.html扩展名的文件中。

现在,您可以使用 Jupyter 中的“文件 > 打开”菜单选项并单击显示的文件列表中的3D .html查看该文件。这是打开文件时您将看到的内容:

如果我想编辑文件
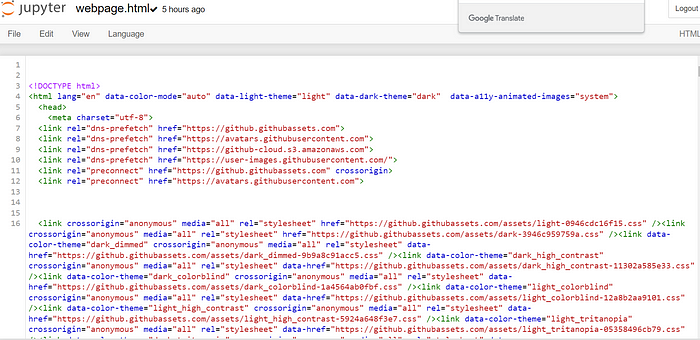
检查网页的 HTML 源代码
正如前面提到的,网页是用一种称为 HTML(超文本标记语言)的语言编写的。HTML 是一种 相 当简单的语言,由标签(也称为节点或元素)组成,例<a href="https://jovian.ai" target="_blank">Go to Jovian</a>。HTML 标 签由三部分组成:
- 名称:(
html、head、body、div等)指示标签代表什么以及浏览器应如何解释其中的信息。 - 属性:(
href、target、class、id等)浏览器使用标签的属性来自定义标签的显示方式并决定用户交互时发生的情况。 - 子级:标签可以在开始段和结束段之间包含一些文本或其他标签或两者都包含,例如
<div>Some content</div>。
HTML 文档内部
这是一个简单的 HTML 文档,其中使用了许多常用标签:
<html><head><title>All About Python</title></head><body><div style="width: 640px; margin: 40px auto"><h1 style="text-align:center;">Python - A Programming Language</h1><img src="https://www.python.org/static/community_logos/python-logo-master-v3-TM.png" alt="python-logo" style="width:240px;margin:0 auto;display:block;"><div><h2>About Python</h2><p>Python is an <span style="font-style: italic">interpreted, high-level and general-purpose</span> programming language. Python's design philosophy emphasizes code readability with its notable use of significant indentation. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects. Visit the <a href="https://docs.python.org/3/">official documentation</a> to learn more.</p></div><div><h2>Some Python Libraries</h2><ul id="libraries"><li>Numpy</li><li>Pandas</li><li>PyTorch</li><li>Scikit Learn</li></ul></div><div><h2>Recent Python Versions</h2><table id="versions-table"><tr><th class="bordered-table">Version</th><th class="bordered-table">Released on</th></tr><tr><td class="bordered-table">Python 3.8</td><td class="bordered-table">October 2019</td></tr><tr><td class="bordered-table">Python 3.7</td><td class="bordered-table">June 2018</td></tr></table><style>.bordered-table { border: 1px solid black; padding: 8px;}</style></div></div></body>
</html>练习:复制上面的 HTML 代码并将其粘贴到名为
webpage.html. 要创建新文件,请从菜单栏中选择“文件 > 打开”,然后选择“新建 > 文本”文件。查看保存的文件。你能看到浏览器如何以不同的方式显示不同的标签吗?

练习:对里面的代码进行一些更改
webpage.html。保存文件并再次查看。您看到自己的改变得到体现了吗?尝试一下文件的结构。尝试打破事物并修复它们!
常用标签和属性
以下是一些最常用的 HTML 标签:
htmlheadtitlebodydivspanh1到h6pimgul,ol和litable,tr,th和tdstyle- ……
每个标签支持多个属性。以下是用于修改标签行为的一些常见属性:
idstyleclasshref(与 一起使用<a>)src(与 一起使用<img>)
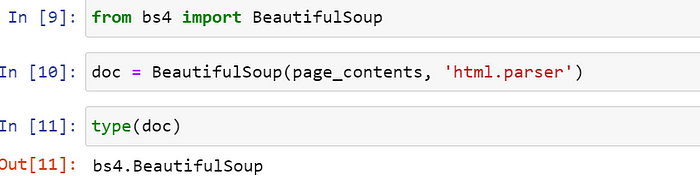
使用 Beautiful Soup 从 HTML 中提取信息
要以编程方式从网页的 HTML 源代码中提取信息,我们可以使用Beautiful Soup库。让我们安装该库并BeautifulSoup从bs4模块导入该类。
3)使用Beautiful Soup解析和提取信息
— -使用 Beautiful soup 解析和探索下载的网页的结构。
——使用正确的属性和方法来提取所需的信息。
— -创建函数以从页面提取到列表和字典中。
— -(可选)如果需要,使用 REST API 获取其他信息。
我想抓取 gitHub 中的所有主题
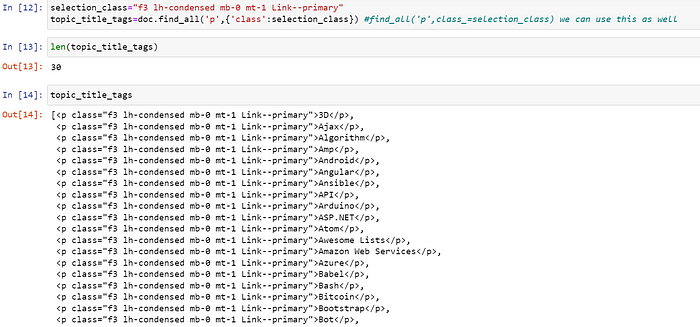
我想获取 gitHub 中所有主题的描述

我想为主题 3D 创建 URL
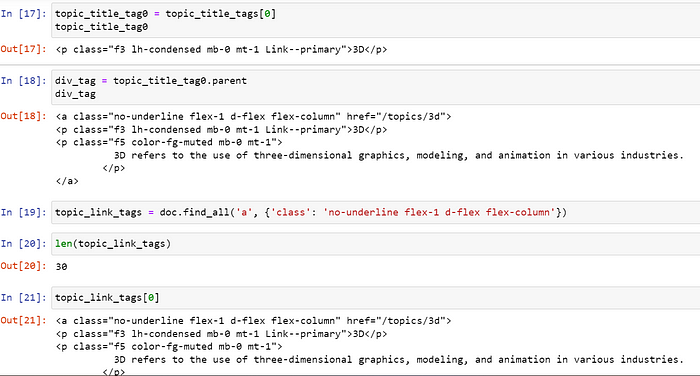
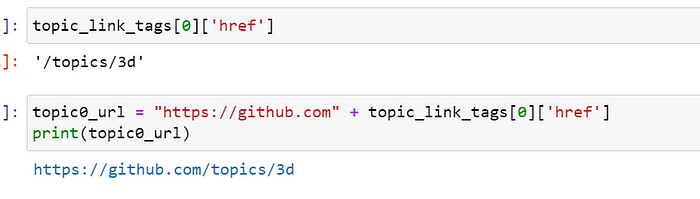
网址已创建
我想创建主题列表

我想创建列表中所有主题的描述

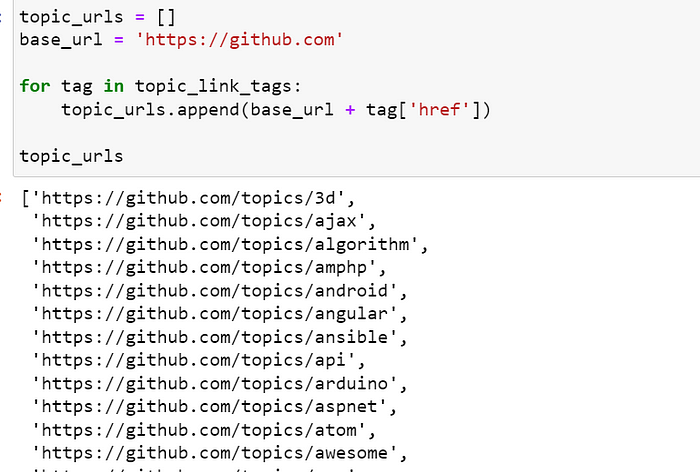
我想为每个主题创建 URL 列表
4)使用提取的信息创建 CSV 文件
— -为下载、解析和保存 CSV 的端到端过程创建函数。
— -使用不同的输入执行该函数以创建 CSV 文件的数据集。
— -使用 Pandas 读回 CSV 文件来验证其中的信息。
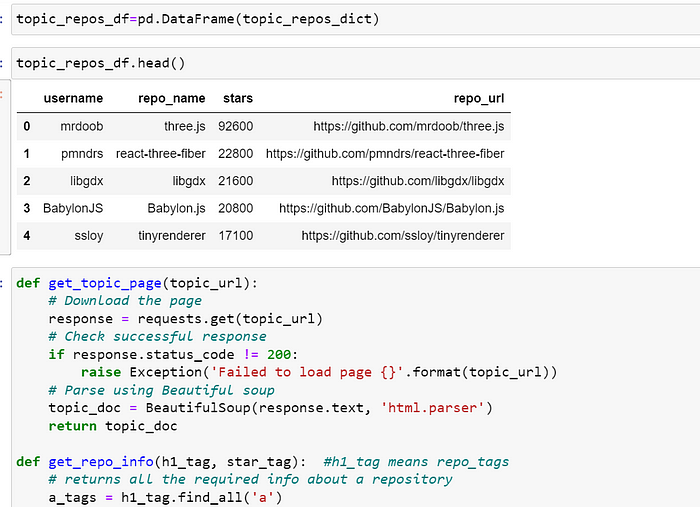
我想为我的信息创建数据框
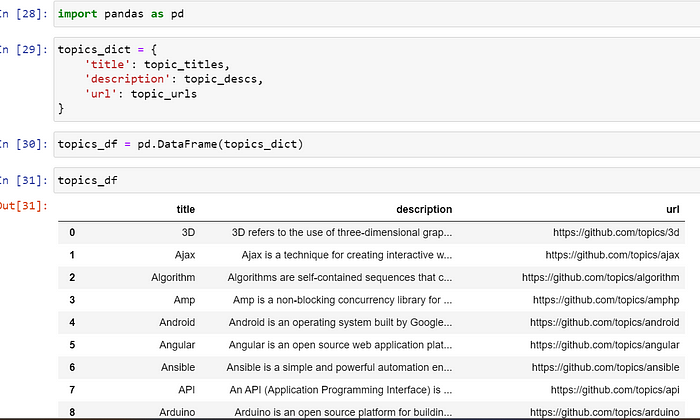
从主题页面获取信息


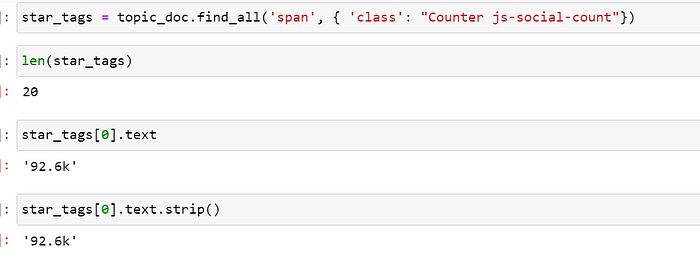
我想将 '92.6k' 转换为 '92600'
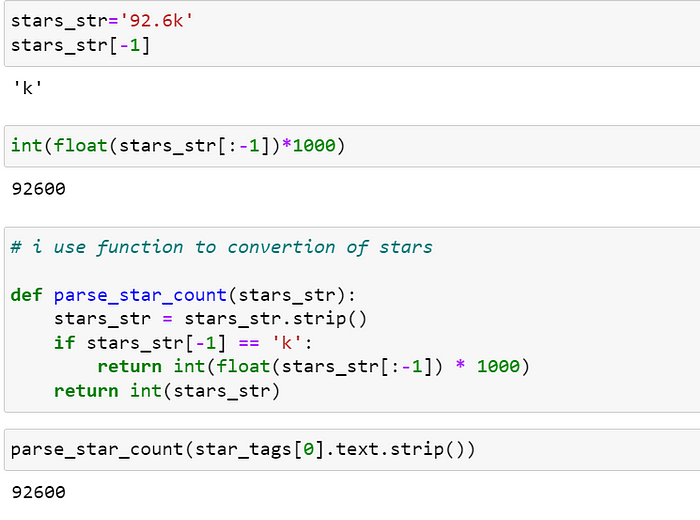
我想使用函数添加我的所有数据

我想将信息存储到我指定列名称的列中
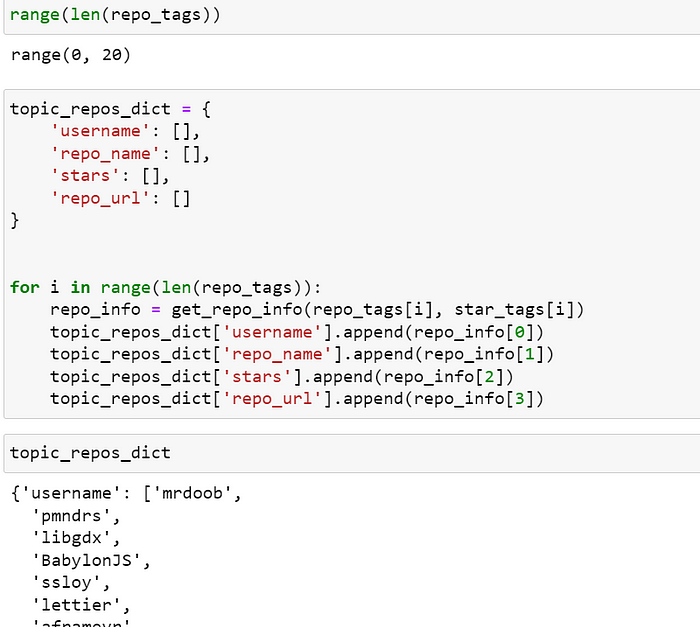

我想检查我的代码如何工作

我们检查一下我们的代码在一行中是如何工作的
我要为文件写的代码不应该重复
os.path 模块始终是适合 Python 运行的操作系统的路径模块,因此可用于本地路径。
最终代码
导入操作系统
def scrape_topic(topic_url, path):
if os.path.exists(path):
print(“文件 {} 已存在。正在跳过…”.format(path))
return
topic_df = get_topic_repos(get_topic_page(topic_url))
topic_df.to_csv (路径,索引=无)
5)编写一个函数:
- 从主题页面获取主题列表
- 从各个主题页面获取顶级存储库列表
- 对于每个主题,创建该主题的顶级存储库的 CSV


相关文章:
Python爬虫从端到端抓取网页
网页抓取和 REST API 简介 网页抓取是使用计算机程序以自动方式从网站提取和解析数据的过程。这是创建用于研究和学习的数据集的有用技术。虽然网页抓取通常涉及解析和处理 HTML 文档,但某些平台还提供 REST API 来以机器可读格式(如 JSON)检…...

这10款类似Stable Diffusion的ai绘图软件,你了解多少?
Stable Diffusion这款ai软件有哪些可以替代的软件?好用的类似Stable Diffusion的ai软件推荐,那么今天就跟着赞奇云工作站小编一起来看看吧。 什么是Stable Diffusion? 称为“Stable Diffusion”的文本到图像模型可以将任何文本转换为逼真、…...
部署ik分词器
部署ik分词器 案例版本:elasticsearch-analysis-ik-8.6.2 ES默认自带的分词器对中文处理不够友好,创建倒排索引时可能达不到我们想要的结果,然而IK分词器能够很好的支持中文分词 因为是集群部署,所以每台服务器中的ES都需…...
基于STM32+华为云IOT设计的智能垃圾桶
一、项目介绍 在商业街、小吃街和景区等人流密集的场所,垃圾桶的及时清理对于提供良好的游客体验至关重要。然而,传统的垃圾桶清理方式通常是定时或定期进行,无法根据实际情况进行及时响应,导致垃圾桶溢满,影响环境卫…...

板子接线图
1.ST-LINK V2接线 2.对抗板子刷蓝牙固件 接USB转TTL,用镊子短接两个孔 2.对抗板子用串口测试蓝牙AT命令 短接白色箭头,接TX,RX,电源...

Python练习之选择与循环
目录 1、编写程序,运行后用户输入4位整数作为年份,判断其是否为闰年。提示:如果年份能被400整除,则为闰年;如果年份能被4整除但不能被100整除也为闰年。2、编写程序,用户从键盘输入小于 1000 的整数&#x…...

MySQL5.7开启通用日志功能
起因: 因项目数据库占用异常,查询数据库有哪些IP地址连接使用(Windows环境下)。 操作步骤: 1、修改MySQL服务的my.ini 文件 # 开启通用查询日志 general_log 1 log_output …...

WPF控件模板
在过去,Windows开发人员必须在方便性和灵活性之间做出选择。为得到最大的方便性,他们可以使用预先构建好的控件。这些控件可以工作的足够好,但可定制性十分有限,并且几乎总是具有固定的可视化外观。偶尔,某些控件提供了…...
vue移动端页面适配
页面的适配,就是一个页面能在PC端正常访问,同时也可以在移动端正正常访问。 现在我们可以通过弹性布局【Flexible布局】、媒体查询和响应式布局。除此之外,还可以通过rem和vw针对性地解决页面适配问题。 响应式布局 响应式布局的核心&…...

Ei Scopus 双检索 |第三届信息与通信工程国际会议国际会议(JCICE 2024)
会议简介 Brief Introduction 2024年第三届信息与通信工程国际会议国际会议(JCICE 2024) 会议时间:2024年5月10日-12日 召开地点:中国福州 大会官网:JCICE 2024-2024 International Joint Conference on Information and Communication Engin…...
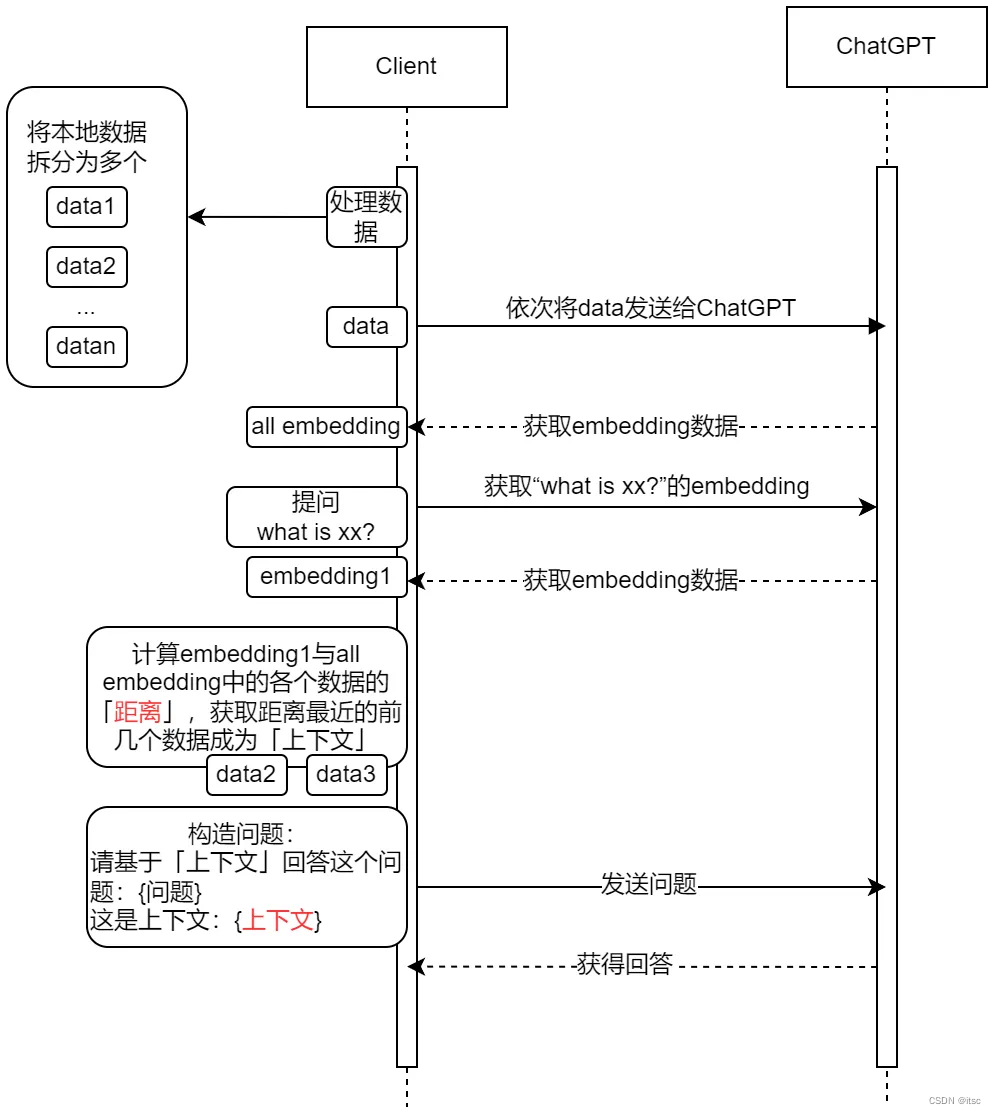
ChatGPT实战-Embeddings打造定制化AI智能客服
本文介绍Embeddings的基本概念,并使用最少但完整的代码讲解Embeddings是如何使用的,帮你打造专属AI聊天机器人(智能客服),你可以拿到该代码进行修改以满足实际需求。 ChatGPT的Embeddings解决了什么问题? …...

C语言指针,深度长文全面讲解
指针对于C来说太重要。然而,想要全面理解指针,除了要对C语言有熟练的掌握外,还要有计算机硬件以及操作系统等方方面面的基本知识。所以本文尽可能的通过一篇文章完全讲解指针。 为什么需要指针? 指针解决了一些编程中基本的问题。…...

云桌面打开部署在linux的服务特别卡 怎么解决
云桌面打开部署在 Linux 服务器上的服务卡顿可能是由多种因素引起的,包括服务器性能、网络连接、应用程序配置等。以下是一些可能的解决方法,可以帮助您缓解云桌面访问部署在 Linux 服务器上的服务时的卡顿问题: 优化服务器性能: …...
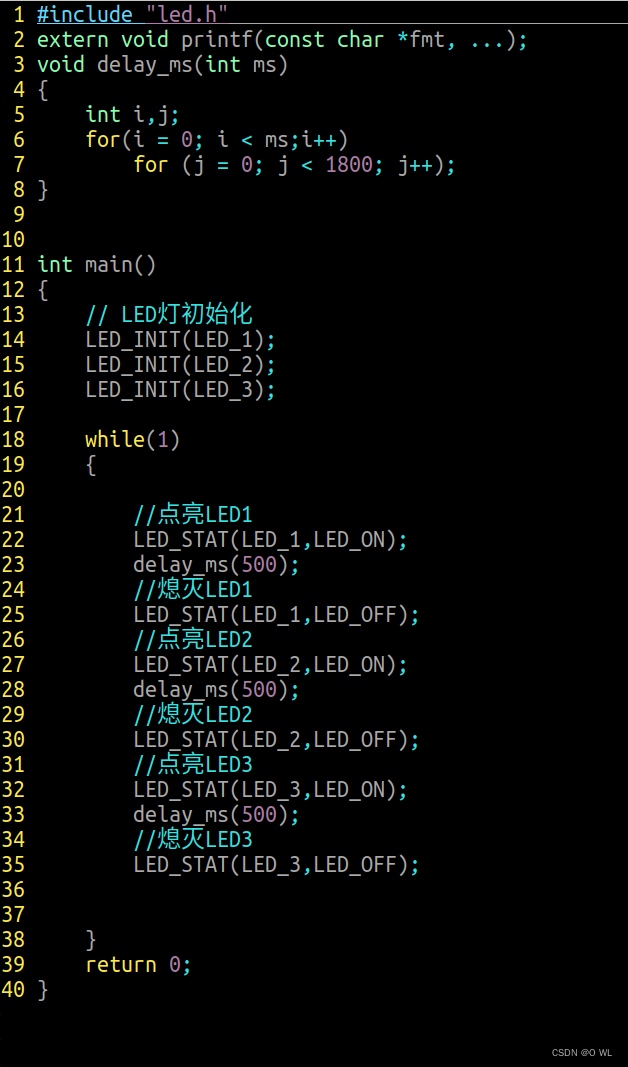
day5ARM
循环点亮三个led灯 方法1 ------------------led.h---------------- #ifndef __LED_H__ #define __LED_H__#define RCC (*(volatile unsigned int *)0x50000A28) #define GPIOE ((GPIO_t *)0x50006000) #define GPIOF ((GPIO_t *)0x50007000)//结构体封装 typedef struct {vo…...
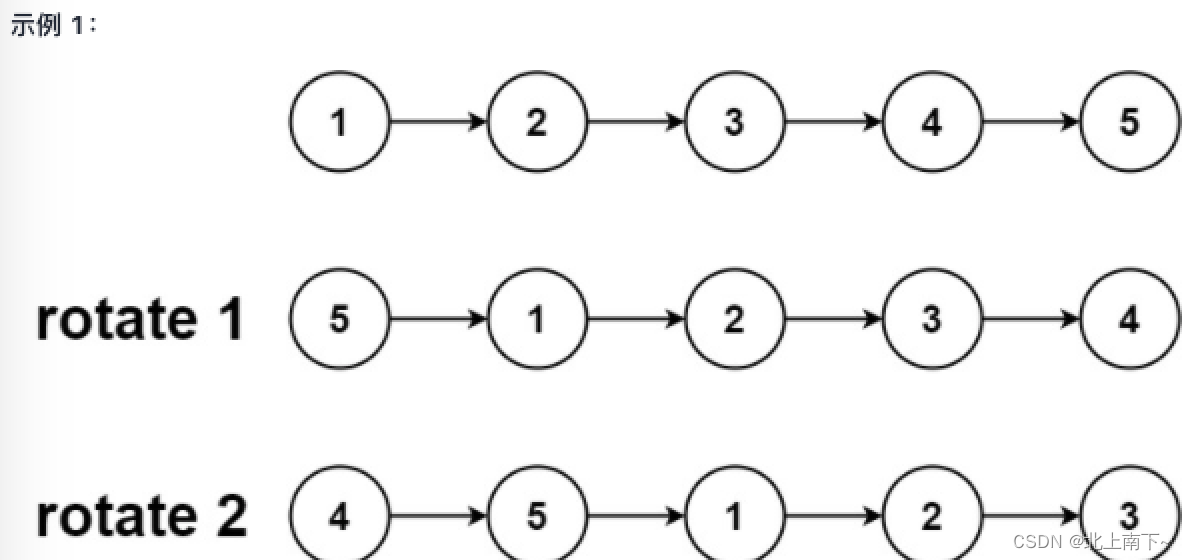
旋转链表-双指针思想-LeetCode61
题目要求:给定链表的头结点,旋转链表,将链表每个节点向右移动K个位置。 示例: 输入:head [1,2,3,4,5], k2 输出:[4,5,1,2,3] 双指针思想: 先用双指针策略找到倒数K的位置,也就是(…...

使用自定义XML配置文件在.NET桌面程序中保存设置
本文将详细介绍如何在.NET桌面程序中使用自定义的XML配置文件来保存和读取设置。除了XML之外,我们还将探讨其他常见的配置文件格式,如JSON、INI和YAML,以及它们的优缺点和相关的NuGet类库。最后,我们将重点介绍我们为何选择XML作为…...
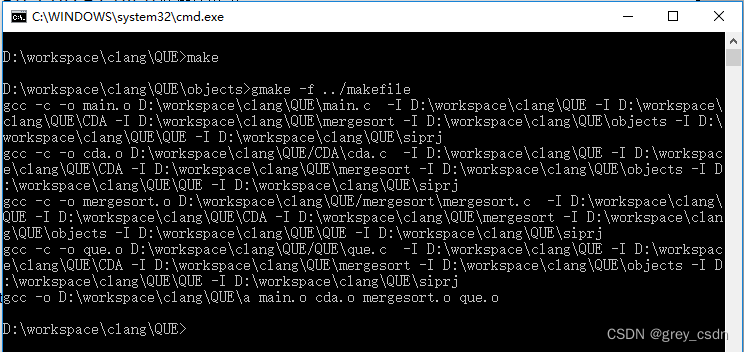
1787_函数指针的使用
全部学习汇总:GitHub - GreyZhang/c_basic: little bits of c. 前阵子似乎写了不少错代码,因为对函数指针的理解还不够。今天晚上似乎总算是梳理出了一点眉目,在先前自己写过的代码工程中做一下测试。 先前实现过一个归并排序算法,…...

解决nomachine扫描不出ip问题
IP扫描工具Advanced IP Scanner 快速的扫描局域网中存在ip地址以及pc机的活跃状态,还能列出局域网计算机的相关信息。并且ip扫描工具(Advanced IP Scanner)还能够单击访问更多有用的功能- 远程关机和唤醒 软件下载地址...

Web 3.0 发展到什么水平了?
最初,有互联网:电线和服务器的物理基础设施,让计算机和它们前面的人相互交谈。美国政府的阿帕网在1969年发出了第一条消息,但我们今天所知道的网络直到1991年才出现,当时HTML和URL使用户可以在静态页面之间导航。将此视…...

大模型:如何利用旧的tokenizer训练出一个新的来?
背景: 我们在用chatGPT或者SD的时候,发现如果使用英语写提示词得到的结果比我们使用中文得到的结果要好很多,为什么呢?这其中就有一个叫做tokenizer的东西在作怪。 训练一个合适的tokenizer是训练大模型的基础,我们既…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...