java实现十大排序算法
文章目录
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序
- 归并排序
- 快速排序
- 堆排序
- 桶排序
- 基数排序
- 计数排序
- 验证
- 各个排序的时间复杂度和空间复杂度
冒泡排序
冒泡排序(Bubble Sort)是一种简单的比较排序算法,它的基本思想是重复地交换相邻的两个元素,直到整个数组都是有序的。冒泡排序是一种稳定排序算法,因为它不会改变相等元素的相对顺序。
冒泡排序的基本步骤如下:
- 比较相邻元素: 从数组的第一个元素开始,依次比较相邻的两个元素。
- 交换元素: 如果两个相邻元素的顺序不正确(例如,前一个元素大于后一个元素),则交换它们的位置。
- 重复: 继续重复步骤1和步骤2,直到没有需要交换的元素为止。每一轮都会将最大的元素冒泡到数组的末尾。
- 减少范围: 在每一轮排序后,最大的元素都会冒泡到最后的位置,因此可以减少下一轮的比较范围,不再考虑已排序的部分。
- 完成排序: 当没有需要交换的元素时,数组已经排序完成。
虽然冒泡排序是一种简单的排序算法,但它的时间复杂度较高,为O(n^2),其中n是待排序元素的数量。因此,它对于大规模数据集不太高效。冒泡排序通常用于小规模数据排序。
public class BubbleSort {public static void sort(int[] nums) {for (int i = 0; i < nums.length; i++) {boolean swapped = false;for (int j = 0; j < nums.length - i - 1; j++) {if (nums[j] > nums[j + 1]) {int t = nums[j];nums[j] = nums[j + 1];nums[j + 1] = t;swapped = true;}}if (!swapped) break;}}
}
选择排序
选择排序(Selection Sort)是一种简单的排序算法,它的基本思想是将数组分成已排序和未排序两部分,每次从未排序部分选择最小(或最大)的元素,然后将其放到已排序部分的末尾。选择排序不像冒泡排序那样每次都交换元素,而是只在最后确定了最小元素的位置后进行交换。选择排序也是一种不稳定的排序算法,因为它可能改变相等元素的相对顺序。
以下是选择排序的基本步骤:
- 初始化: 将整个数组视为两部分,已排序部分和未排序部分。一开始,已排序部分为空,而未排序部分包括整个数组。
- 查找最小元素: 从未排序部分中查找最小的元素,并记住其索引。
- 交换元素: 将最小元素与未排序部分的第一个元素交换位置,将最小元素移到已排序部分的末尾。
- 缩小范围: 缩小未排序部分的范围,将已排序部分扩展一个元素,继续重复步骤2和步骤3,直到未排序部分为空。
- 完成排序: 当未排序部分为空时,排序完成。
尽管选择排序在最坏情况下和平均情况下的时间复杂度都是O(n^2),但它不需要额外的存储空间,因此在某些情况下可能是一个有用的排序算法,特别是当内存有限时。
public class SelectionSort {public static void sort(int[] nums) {for (int i = 0; i < nums.length; i++) {int minIndex = i;for (int j = i + 1; j < nums.length; j++) {if (nums[minIndex] > nums[j]) minIndex = j;}int t = nums[minIndex];nums[minIndex] = nums[i];nums[i] = t;}}
}
插入排序
插入排序(Insertion Sort)是一种简单而有效的排序算法。它的基本思想是将数组分成已排序和未排序两部分,从未排序部分选择一个元素,插入到已排序部分的合适位置,重复这个过程,直到整个数组都有序。插入排序是一种稳定排序算法,因为它不会改变相等元素的相对顺序。
以下是插入排序的基本步骤:
- 初始化: 将整个数组视为两部分,已排序部分和未排序部分。一开始,已排序部分只包含数组的第一个元素,而未排序部分包括其余部分。
- 选择未排序部分的元素: 从未排序部分选择一个元素,通常从未排序部分的开头选取。
- 插入元素: 将选取的元素与已排序部分的元素进行比较,找到合适的位置插入选取的元素,以确保已排序部分仍然有序。
- 重复: 继续从未排序部分选择元素,并插入已排序部分,直到未排序部分为空。
- 完成排序: 当未排序部分为空时,排序完成。
插入排序在平均和最坏情况下的时间复杂度都是O(n^2),其中n是待排序元素的数量。然而,在某些情况下,插入排序可能比其他排序算法更加高效,尤其是当待排序的数据集已经基本有序时。
public class InsertionSort {public static void sort(int[] nums) {for (int i = 1; i < nums.length; i++) {int t = nums[i];int j = i - 1;while (j >= 0 && nums[j] > t) {nums[j + 1] = nums[j--];}nums[j + 1] = t;}}
}
希尔排序
希尔排序(Shell Sort)是一种改进的插入排序算法,也称为缩小增量排序。它的基本思想是将整个数组分成多个子序列,对每个子序列进行插入排序,然后逐渐减小子序列的长度,最终使整个数组有序。希尔排序的关键在于选择合适的间隔序列,称为增量序列,以确定子序列的长度。
希尔排序的主要步骤如下:
- 选择增量序列: 首先,选择一个增量序列,这个序列的最后一个元素必须为1,通常以一种特定的方式生成,例如使用 Knuth 序列或者 Sedgewick 序列。
- 按增量分组: 将数组按照增量分成多个子序列。每个子序列包含相距为增量的元素。
- 对每个子序列进行插入排序: 对每个子序列进行插入排序,即将子序列中的元素按照插入排序的方式排序。
- 减小增量: 缩小增量,通常是将增量除以一个固定的因子,继续重复步骤2和步骤3。
- 最后一次排序: 最后一次排序时,增量通常为1,即将整个数组作为一个子序列进行插入排序。
- 完成排序: 当增量减小到1时,继续进行插入排序,最终整个数组将被排序。
希尔排序的关键在于增量序列的选择,不同的增量序列可能导致不同的性能。希尔排序的时间复杂度取决于增量序列的选择,但通常在O(n2)和O(n1.25)之间。希尔排序的优点是可以在不使用额外内存的情况下进行排序,因此适用于对内存限制的情况。
public class ShellSort {public static void sort(int[] nums) {shellSort(nums);}public static void shellSort(int[] nums) {int gap = nums.length / 2;while (gap > 0) {for (int i = gap; i < nums.length; i++) {int t = nums[i];int j = i - gap;while (j >= 0 && nums[j] > t) {nums[j + gap] = nums[j];j -= gap;}nums[j + gap] = t;}gap >>= 1;}}
}
归并排序
归并排序(Merge Sort)是一种经典的分治算法,它的核心思想是将一个大的问题分解成多个小的子问题,解决每个子问题,然后将它们合并起来以得到最终的解决方案。归并排序的主要步骤包括分解、解决和合并。
以下是归并排序的详细步骤:
- 分解(Divide): 将待排序的数组分解为两个子数组,通常是平均分割。这个过程持续递归,直到每个子数组的大小为1或0,即无法再分解为更小的子问题。
- 解决(Conquer): 对每个子数组进行排序,可以使用递归或迭代的方式,这个过程通常采用归并排序本身。
- 合并(Merge): 将已排序的子数组合并成一个有序的数组。合并过程是归并排序的关键步骤,需要合并两个有序的子数组为一个有序的数组。
- 重复合并(Repeat Merge): 重复执行步骤2和步骤3,直到所有的子数组都合并成一个有序的数组为止。
- 得到排序结果(Result): 当所有的子数组都合并完成,得到的就是排序好的数组。
归并排序是一种稳定的排序算法,它的时间复杂度为O(n log n),其中n是数组的大小。这使得归并排序在大多数情况下都比较高效,特别是对于大型数据集。
public class MergeSort {public static void sort(int[] nums) {mergeSort(nums, 0, nums.length - 1);}public static void mergeSort(int[] nums, int left, int right) {if (left < right) {int middle = left + (right - left) / 2;mergeSort(nums, left, middle);mergeSort(nums, middle + 1, right);merge(nums, left, middle, right);}}public static void merge(int[] nums, int left, int middle, int right) {int[] leftNums = new int[middle - left + 1];int[] rightNums = new int[right - middle];int l = 0;int r = 0;for (int i = left; i <= right; i++) {if (i <= middle) leftNums[l++] = nums[i];else rightNums[r++] = nums[i];}l = 0;r = 0;int p = left;while (l < leftNums.length || r < rightNums.length) {if (l == leftNums.length) nums[p++] = rightNums[r++];else if (r == rightNums.length) nums[p++] = leftNums[l++];else if (leftNums[l] <= rightNums[r]) nums[p++] = leftNums[l++];else nums[p++] = rightNums[r++];}}
}
快速排序
快速排序(Quick Sort)是一种常用的排序算法,它也是一种分治算法。它的核心思想是选择一个基准元素(通常是数组的第一个元素),将数组分成两个子数组,其中一个子数组的元素都比基准元素小,另一个子数组的元素都比基准元素大,然后对这两个子数组递归地进行快速排序。
以下是快速排序的主要步骤:
- 选择基准元素(Pivot): 从数组中选择一个元素作为基准元素。通常选择第一个元素,但也可以选择其他位置的元素。
- 分区(Partitioning): 将数组中的元素分成两个子数组,一个子数组包含比基准元素小的元素,另一个子数组包含比基准元素大的元素。基准元素的位置在分区后将是最终排好序的位置。
- 递归排序子数组: 对分区后的两个子数组递归地应用快速排序算法,直到子数组的大小为1或0,即无法再分区。
- 合并结果: 将排序好的子数组合并起来,得到最终的有序数组。
快速排序是一种高效的排序算法,平均情况下的时间复杂度为O(n log n),最坏情况下为O(n^2),但最坏情况很少发生。它通常比其他O(n log n)复杂度的排序算法快,因为它在内部排序中是原地排序(不需要额外的内存),而且适用于大型数据集。
public class QuickSort {public static void sort(int[] nums) {quickSort(nums, 0, nums.length - 1);}public static void quickSort(int[] nums, int start, int end) {if (start >= end) return;int pivot = nums[start];int left = start + 1;int right = end;while (true) {while (left <= right && nums[left] <= pivot) left++;while (left <= right && nums[right] >= pivot) right--;if (left <= right) swap(nums, left, right);else break;}swap(nums, start, right);quickSort(nums, start, right - 1);quickSort(nums, right + 1, end);}public static void swap(int[] nums, int x, int y) {int t = nums[x];nums[x] = nums[y];nums[y] = t;}
}
堆排序
堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法。它利用了堆的性质来进行排序,其中堆可以分为最大堆和最小堆。堆排序通常使用最大堆来进行升序排序。
堆排序的主要思想是将待排序的数组构建成一个二叉堆(最大堆),然后不断将堆顶元素(最大元素)与堆的最后一个元素交换,然后将堆的大小减一,再对剩余的元素进行堆的调整,使其满足最大堆的性质,重复这个过程直到整个数组排序完成。
以下是堆排序的主要步骤:
- 构建最大堆(Heapify): 从输入数组构建一个最大堆。这可以通过从最后一个非叶子节点开始,逐步向前进行堆化来实现。堆化的过程是将当前节点与其子节点进行比较,并确保最大堆性质被维护。
- 交换与重建堆: 将堆顶元素(最大元素)与堆的最后一个元素交换,然后减小堆的大小。接着对堆顶元素进行下沉操作,重新调整堆以满足最大堆性质。
- 重复步骤 2 直到堆为空: 重复上述交换和重建堆的过程,直到堆中只剩下一个元素,此时整个数组就已经排序完成。
堆排序的时间复杂度为 O(n log n),并且是一种原地排序算法,因为它不需要额外的存储空间。
public class HeapSort {public static void sort(int[] nums) {heapSort(nums);}public static void heapSort(int[] nums) {for (int i = nums.length / 2 - 1; i >= 0; i--) {heapify(nums, nums.length, i);}for (int i = nums.length - 1; i >= 0; i--) {int t = nums[0];nums[0] = nums[i];nums[i] = t;heapify(nums, i, 0);}}public static void heapify(int[] nums, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && nums[left] > nums[largest]) largest = left;if (right < n && nums[right] > nums[largest]) largest = right;if (largest != i) {int t = nums[i];nums[i] = nums[largest];nums[largest] = t;heapify(nums, n, largest);}}
}
桶排序
桶排序(Bucket Sort)是一种分布式排序算法,它通过将待排序元素分散到多个桶中,然后分别对每个桶中的元素进行排序,最后将所有桶中的元素合并成有序序列。桶排序适用于输入数据均匀分布在某个范围内的情况,例如浮点数排序。
下面是桶排序的基本思想和步骤:
- 确定桶的数量: 首先确定要使用的桶的数量,桶的数量可以根据输入数据的范围和分布情况来决定。
- 将元素分配到桶中: 遍历待排序的元素,将每个元素放入相应的桶中。这可以通过一个映射函数来实现,映射函数将元素映射到桶的索引。
- 对每个桶进行排序: 对每个非空桶中的元素进行排序。可以使用其他排序算法,如插入排序或快速排序,来对每个桶中的元素进行排序。
- 合并桶中的元素: 将排序后的桶依次合并,得到最终的有序序列。
public class BucketSort {public static void sort(int[] nums) {bucketSort(nums, nums.length);}public static void bucketSort(int[] nums, int numBuckets) {if (nums == null || nums.length <= 1) return;int max = nums[0];int min = nums[0];for (int num : nums) {if (num > max) {max = num;}if (num < min) {min = num;}}int bucketSize = (max - min + 1) / numBuckets + 1;List<Integer>[] buckets = new ArrayList[numBuckets];for (int i = 0; i < buckets.length; i++) {buckets[i] = new ArrayList<>();}for (int num : nums) {buckets[(num - min) / bucketSize].add(num);}int p = 0;for (List<Integer> bucket : buckets) {Collections.sort(bucket);for (Integer value : bucket) {nums[p++] = value;}}}
}
基数排序
基数排序(Radix Sort)是一种非比较性的整数排序算法,它通过将待排序的整数按照位数进行排序。基数排序的核心思想是从最低位(个位数)开始,按照位数的顺序依次进行排序,直到最高位(最高位数)。每次排序都是稳定的计数排序或桶排序,保持了元素的相对顺序。这样,多次排序后,最终得到的结果就是整体有序的。
下面是基数排序的基本步骤:
- 确定排序的位数: 首先确定要排序的整数的最高位数,通常是通过找到最大的整数来确定的。
- 按位数排序: 从最低位(个位数)开始,对整数进行稳定的排序(通常使用计数排序或桶排序)。按照当前位数的值,将整数分配到对应的桶中。
- 依次处理高位数: 继续对下一位数进行排序,直到处理完最高位数。这个过程是递归的,每次排序都是以前一轮排序的结果为基础。
- 合并结果: 经过多轮排序后,最终得到的结果就是整体有序的。
public class RadixSort {public static void sort(int[] nums) {radixSort(nums);}public static void radixSort(int[] nums) {int max = Arrays.stream(nums).max().getAsInt();int exp = 1;int[] bucket = new int[nums.length];while (max / exp > 0) {int[] count = new int[10];for (int num : nums) {count[(num / exp) % 10]++;}for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}for (int i = nums.length - 1; i >= 0; i--) {bucket[--count[(nums[i] / exp) % 10]] = nums[i];}System.arraycopy(bucket, 0, nums, 0, nums.length);exp *= 10;}}
}
计数排序
计数排序(Counting Sort)是一种非比较性的整数排序算法,它通过统计待排序整数中每个整数出现的次数,然后按照整数的值顺序输出排好序的结果。计数排序适用于整数排序,特别是当待排序的整数范围相对较小时(不过这个范围不能太大,否则需要大量的内存来存储计数数组)。
以下是计数排序的基本思想和步骤:
- 找出待排序的整数范围: 首先确定待排序整数的最小值(min)和最大值(max),以便确定计数数组的大小。
- 创建计数数组: 创建一个大小为
max - min + 1的计数数组,用于存储每个整数出现的次数。数组的索引对应于整数的值,数组的值表示该整数出现的次数。 - 统计整数出现次数: 遍历待排序的整数数组,对每个整数进行统计,增加相应值的计数器。
- 生成排序结果: 遍历计数数组,按照整数的值和出现次数,将整数输出到排序结果数组中。
计数排序的时间复杂度是 O(n+k),其中 n 是待排序整数的个数,k 是整数范围。在整数范围不大的情况下,计数排序可以非常高效。
public class CountingSort {public static void sort(int[] nums) {countingSort(nums);}public static void countingSort(int[] nums) {if (nums == null || nums.length <= 1) return;int max = nums[0];int min = nums[0];for (int num : nums) {if (num > max) {max = num;}if (num < min) {min = num;}}int k = max - min + 1;int[] countArr = new int[k];for (int num : nums) {countArr[num - min]++;}for (int i = 1; i < countArr.length; i++) {countArr[i] += countArr[i - 1];}int[] temp = new int[k];for (int i = nums.length - 1; i >= 0; i--) {temp[--countArr[nums[i] - min]] = nums[i];}System.arraycopy(temp, 0, nums, 0, nums.length);}
}
验证
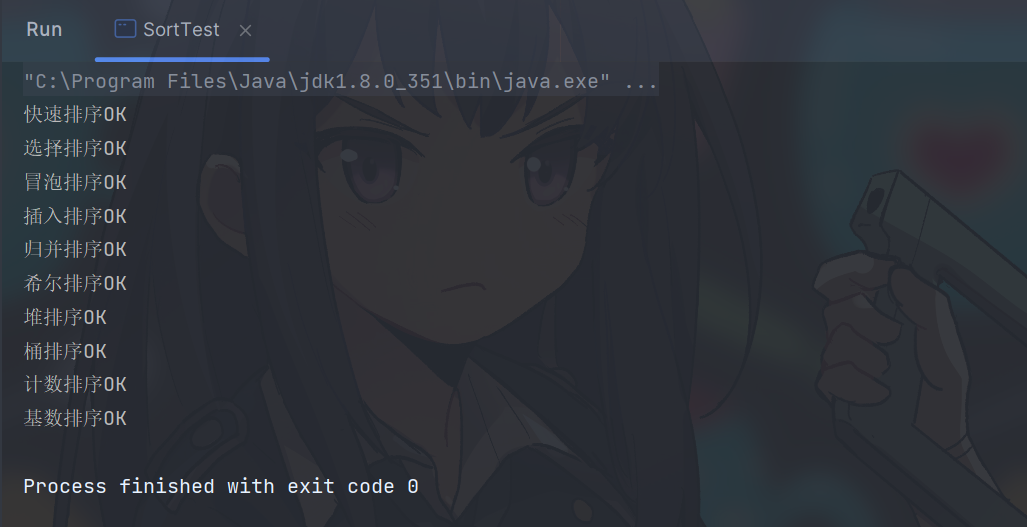
上面排序算法可以使用下面代码进行验证
public class SortTest {public static void test(Class aclass, Method method, String name) {int count = 1000;while (count-- > 0) {int[] nums1 = new int[1000];for (int i = 0; i < nums1.length; i++) {nums1[i] = (int) (Math.random() * 10000);}int[] nums2 = Arrays.copyOf(nums1, nums1.length);Arrays.sort(nums1);try {method.invoke(aclass, nums2);} catch (IllegalAccessException | InvocationTargetException e) {throw new RuntimeException(e);}boolean flag = Arrays.equals(nums1, nums2);if (!flag) {System.out.println("=========================================");System.out.println(name + "排序错误");System.out.println(Arrays.toString(nums1));System.out.println(Arrays.toString(nums2));System.out.println("=========================================");return;}}System.out.println(name + "OK");}public static void main(String[] args) throws NoSuchMethodException {test(QuickSort.class, QuickSort.class.getMethod("sort", int[].class), "快速排序");test(SelectionSort.class, SelectionSort.class.getMethod("sort", int[].class), "选择排序");test(BubbleSort.class, BubbleSort.class.getMethod("sort", int[].class), "冒泡排序");test(InsertionSort.class, InsertionSort.class.getMethod("sort", int[].class), "插入排序");test(MergeSort.class, MergeSort.class.getMethod("sort", int[].class), "归并排序");test(ShellSort.class, ShellSort.class.getMethod("sort", int[].class), "希尔排序");test(HeapSort.class, HeapSort.class.getMethod("sort", int[].class), "堆排序");test(BucketSort.class, BucketSort.class.getMethod("sort", int[].class), "桶排序");test(CountingSort.class, CountingSort.class.getMethod("sort", int[].class), "计数排序");test(RadixSort.class, RadixSort.class.getMethod("sort", int[].class), "基数排序");}
}
上面代码会随机生成1000个[0,9999]的数,然后进行排序,重复1000次来验证代码的正确性,上面代码输入如下
各个排序的时间复杂度和空间复杂度
以下是十大常见排序算法的平均时间复杂度、最坏时间复杂度、最好时间复杂度、空间复杂度以及是否稳定的表格展示:
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 是否稳定排序 |
|---|---|---|---|---|---|
| 冒泡排序 (Bubble Sort) | O(n^2) | O(n^2) | O(n) | O(1) | 是 |
| 选择排序 (Selection Sort) | O(n^2) | O(n^2) | O(n^2) | O(1) | 否 |
| 插入排序 (Insertion Sort) | O(n^2) | O(n^2) | O(n) | O(1) | 是 |
| 希尔排序 (Shell Sort) | O(n1.3-2) | O(n^2) | O(n log n) | O(1) | 否 |
| 归并排序 (Merge Sort) | O(n log n) | O(n log n) | O(n log n) | O(n) | 是 |
| 快速排序 (Quick Sort) | O(n log n) | O(n^2) | O(n log n) | O(log n) | 否 |
| 堆排序 (Heap Sort) | O(n log n) | O(n log n) | O(n log n) | O(1) | 否 |
| 计数排序 (Counting Sort) | O(n + k) | O(n + k) | O(n + k) | O(k) | 是 |
| 桶排序 (Bucket Sort) | O(n + k) | O(n^2) | O(n) | O(n + k) | 是 |
| 基数排序 (Radix Sort) | O(n * k) | O(n * k) | O(n * k) | O(n + k) | 是 |
说明:
- “n” 表示输入数据的规模。
- “k” 表示输入数据中的最大值和最小值之差(数字的范围),基数排序中k可以理解为最大值的位数,但更准确地说,它表示每个数字的进制。
相关文章:
java实现十大排序算法
文章目录 冒泡排序选择排序插入排序希尔排序归并排序快速排序堆排序桶排序基数排序计数排序验证各个排序的时间复杂度和空间复杂度 冒泡排序 冒泡排序(Bubble Sort)是一种简单的比较排序算法,它的基本思想是重复地交换相邻的两个元素&#x…...
Linux日志管理-logrotate(crontab定时任务、Ceph日志转储)
文章目录 一、logrotate概述二、logrotate基本用法三、logrotate运行机制logrotate参数 四、logrotate是怎么做到滚动日志时不影响程序正常的日志输出呢?Linux文件操作机制方案一方案二 五、logrotate实战--Ceph日志转储参考 一、logrotate概述 logrotate是一个用于…...
用PHP异步协程控制python爬虫脚本,实现多协程分布式爬取
背景 公司需要爬取指定网站的产品数据。但是个人对python的多进程和协程不是特别熟悉。所以,想通过php异步协程,发起爬取url请求控制python爬虫脚本,达到分布式爬取的效果。 准备 1.准备一个mongodb数据库用于存放爬取数据2.引入flask包&a…...
VUE3写后台管理(3)
VUE3写后台管理(3) 1.环境1.node2.vite3.Element-plus4.vue-router5.element icon6.less7.vuex8.vue-demi9.mockjs10.axios11.echarts 2.首页1.布局Main2.头部导航栏CommonHeader3.左侧菜单栏CommonLeft4.首页Home1.从后端获取数据显示到前端table的三种…...
无约束优化问题——共轭梯度法)
机器学习笔记之最优化理论与算法(十二)无约束优化问题——共轭梯度法
机器学习笔记之最优化理论与方法——共轭梯度法 引言回顾:共轭方向法的重要特征线性共轭梯度法共轭方向公式的证明过程 关于线搜索公式中参数的化简关于线搜索公式中步长部分的化简关于线搜索公式中共轭方向系数的化简参数化简的目的 非线性共轭梯度法(FR,PRP方法)关…...

JVM中的java同步互斥工具应用演示及设计分析
1.火车站售票系统仿真 某火车站目前正在出售火车票,共有50张票,而它有3个售票窗口同时售票,下面设计了一个程序模拟该火车站售票,通过实现Runnable接口实现(模拟网络延迟)。 伪代码: Ticket类…...

数据治理-数据质量
实现数据质量的前提就是数据本身是可靠和可信的。 导致数据质量低下的因素 组织缺乏对低质量数据影响的理解,缺乏规划、孤岛式系统设计、不一致的开发过程、不完整的文档、缺乏标准或缺乏治理等。 所有组织都会遇到与数据质量有关的问题。数据质量需要跨职能的承诺…...

[sqoop]hive3.1.2 hadoop3.1.1安装sqoop1.4.7
参考: Hadoop3.2.4Hive3.1.2sqoop1.4.7安装部署_hadoop sqoop安装_alicely07的博客-CSDN博客 一、安装 1、解压 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /home/data_warehouse/module mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.72、配置文件 sqoop-env.s…...

js事件的详细介绍
11.事件 1.什么是事件 js属于事件驱动编程,把驱动,执行,调用通过一些交互,触发一些函数事件:发起-->执行绑定事件-->触发事件on 绑定 emit触发 off解绑2.事件分类 鼠标事件 点击事件 onclick 双击事件 ondblclick 按下事件 onmousedown 抬起事件 onmouseup 鼠标进…...
虚幻4学习笔记(12)操控导入的角色、动画蓝图、播放蒙太奇和打包、角色重定向
虚幻4学习笔记 操控导入的角色设置鼠标旋转关掉动态模糊 动画蓝图、播放蒙太奇和打包角色走路奔跑动画shift 奔跑F 跳舞移动打断 跳舞 打包角色重定向姿势调整解决跑步 腿分太开隐藏剑 B站UP谌嘉诚课程:https://www.bilibili.com/video/BV164411Y732 操控导入的角色…...

hive with tez:无法从链中的任何提供者加载aws凭据
环境信息 hadoop 3.1.0 hive-3.1.3 tez 0.9.1 问题描述 可以从hadoop命令行正确地访问s3a uri。我可以创建外部表和如下命令: create external table mytable(a string, b string) location s3a://mybucket/myfolder/; select * from mytable limit 20; 执行正…...
Ubuntu修改静态IP、网关和DNS的方法总结
Ubuntu修改静态IP、网关和DNS的方法总结 ubuntu系统(其他debian的衍生版本好像也可以)修改静态IP有以下几种方法。(搜索总结,可能也不太对) /etc/netplan (use) Ubuntu 18.04开始可以使用netplan配置网络࿰…...
Eureka服务器注册
一。Eureka服务器注册 1.pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mav…...

Windows安装GPU版本的pytorch详细教程
文章目录 chatGLM2-6B安装教程正式安装 chatGLM2-6B ChatGLM2-6B版本要装pytorch2.0,而且要2.0.1 ,因此CUDA不能用12.0 ,也不能用10.0,只能用11.x 版本。 安装教程 pip install直接下载安装 官网: https://pytorch.…...

理解Kruskal算法的前提----深入理解并查集【超简单~】
并查集的实现思路 并查集主要分为两个部分:第一部分就是需要找到点对应的祖宗节点,第二部分,是要将属于同一个集合节点的祖宗节点进行统一,也就是结合操作。 Find函数实现 // parent数组用来存储下标值所对应的父节点值 // 比如…...
Jenkins+Gitee+Docker+Ruoyi项目前后端分离部署
前言 描述:本文主要是用来记录 如何用标题上的技术,部署到云服务器上通过ip正常访问。 一、总览 1.1、Docker做的事 拉取 mysql 镜像拉取 redis 镜像拉取 jdk 镜像拉取 nginx 镜像 解释说明:前端项目的打包文件放在 nginx容器运行。后端…...
)
笙默考试管理系统-MyExamTest----codemirror(23)
笙默考试管理系统-MyExamTest----codemirror(23) 目录 笙默考试管理系统-MyExamTest----codemirror(23) 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙…...
 泛型)
重学Java (一) 泛型
1. 前言 泛型编程自从 Java 5.0 中引入后已经超过15个年头了。对于现在的 Java 码农来说熟练使用泛型编程已经是家常便饭的事情了。所以本文就在不对泛型的基础使用在做说明了。 如果你还不会使用泛型的话,可以参考下面两个链接 Java 泛型详解The Java™ Tutorial…...

Docker 部署 Redis 服务
拉取最新版本的 Redis 镜像: $ sudo docker pull redis:latest在本地预先创建好 data 目录和 conf/redis.conf 文件。 使用以下命令来运行 Redis 容器: $ sudo docker run -itd --name redis --privilegedtrue -p 6379:6379 -v /home/ubuntu/docker/redis/data:/data -v /ho…...
阿里云产品试用系列-负载均衡 SLB
阿里云负载均衡(Server Load Balancer,简称SLB)是云原生时代应用高可用的基本要素。通过将流量分发到不同的后端服务来扩展应用系统的服务吞吐能力,消除单点故障并提升应用系统的可用性。阿里云SLB包含面向4层的网络型负载均衡NLB…...

一次会员积分系统改造复盘:从同步阻塞到异步解耦的演进与多级缓存一致性保障
2026年4月,我们的会员积分系统在经历一次大促后频繁告警。起初只是零星的用户投诉积分未到账,但随着流量攀升,积分服务响应时间从平均 80ms 飙升至 1.2s,数据库连接池被打满,甚至触发了熔断机制。我们意识到࿰…...

PHP支付配置安全加固指南:从SSL证书到PCI DSS合规,7步实现生产环境零漏洞上线
第一章:PHP支付配置安全加固的核心原则与风险全景在现代Web应用中,PHP支付模块常因配置疏忽成为攻击者突破口。密钥硬编码、环境变量泄露、未校验回调签名、调试模式残留等隐患,极易导致资金盗刷、订单篡改或敏感信息外泄。安全加固并非仅依赖…...

大数据专业如何补齐实战型数据分析能力?从工具、项目到求职一文讲清
大数据专业如何补齐实战型数据分析能力大数据专业学生在理论学习之外,需通过工具熟练度提升、实战项目积累和求职策略优化三方面构建核心竞争力。以下为具体实施路径:工具技能矩阵大数据分析需掌握的工具可分为数据处理、可视化、编程语言三类࿰…...

YOLO + SubspaceAD:一张良品图,检出所有未知缺陷
YOLO + SubspaceAD:一张良品图,检出所有未知缺陷 当YOLO遇上CVPR 2026子空间建模,工业缺陷检测迎来质变 一、痛点直击:缺陷检测的“三座大山” 第一座山:缺陷样本少,种类严重失衡。 工业生产追求“零缺陷”,导致真实缺陷样本极度稀缺,每十万件产品中往往仅出现3—5件次…...

Agentic AI 深度解析:当人工智能学会“动手”
从“回答问题”到“完成任务”,Agentic AI 正在重新定义人工智能的边界。它不是“更大的聊天机器人”,而是能够自主规划、调用工具、执行多步任务并持续迭代的智能体系统。一、什么是 Agentic AI?——重新定义“智能” Agentic AI(…...

为什么83%的PHP项目AI检测失败:深度拆解Tokenization偏差、框架上下文缺失与Composer依赖盲区
第一章:PHP AI代码检测的现状与核心挑战当前,PHP作为全球广泛部署的Web后端语言,其生态中存在大量历史遗留代码、动态类型特性及弱类型隐式转换机制,为AI驱动的静态/动态代码检测带来了独特复杂性。主流工具链(如PHPSt…...

FreakStudio缮
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try: ks Ks(KS_ARCH_X86, KS_MODE_64) encoding, count ks.…...

如何用DoubleQoLMod在30分钟内让你的工业帝国效率翻倍?
如何用DoubleQoLMod在30分钟内让你的工业帝国效率翻倍? 【免费下载链接】DoubleQoLMod-zh 项目地址: https://gitcode.com/gh_mirrors/do/DoubleQoLMod-zh 想象一下,你的工厂正在全速运转,但资源采集却像蜗牛一样缓慢;你的…...

颠覆式OpenCore自动化配置:5分钟完成黑苹果EFI构建的终极解决方案
颠覆式OpenCore自动化配置:5分钟完成黑苹果EFI构建的终极解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore-Simplify是一款专…...

kill-doc:让文档下载回归简单的智能工具
kill-doc:让文档下载回归简单的智能工具 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您的烦恼而…...