hive、spark、presto 中的增强聚合-grouping sets、rollup、cube
目录
1、什么是增强聚合和多维分析函数?
2、grouping sets - 指定维度组合
3、with rollup - 上卷维度组合
4、with cube - 全维度组合
5、Grouping__ID、grouping() 的使用场景
6、使用 增强聚合 会不会对查询性能有提升呢?
7、对grouping sets、with cube、with rollup 的优化
1、什么是增强聚合和多维分析函数?
增强聚合指的是:
在SQL中使用分组聚合查询时,使用 grouping sets、rollup、cube 语句进行操作
在常见的数据引擎中都支持这种语法,比如hive、spark、presto、ck、flinkSQL
使用增强聚合不仅可以简化SQL代码,而且还能对SQL语句的性能有所提升
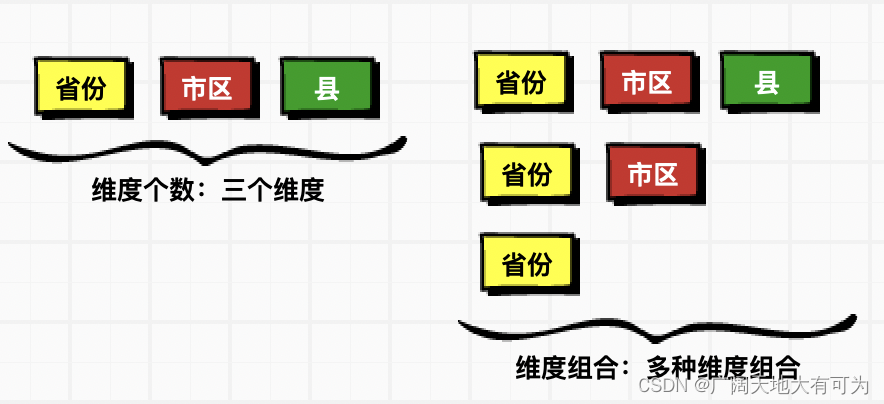
多维分析指的是:
SQL语法中的多维分析指的是 多种维度组合的分析,而不是多种维度的分析
hive官网链接:hive官网
2、grouping sets - 指定维度组合
功能说明:
对指定的分组字段进行多种维度组合的聚合计算
hive-语法:
-- TODO 必须开区map端合并
select 维度A,维度B,维度C,聚合函数(度量字段) ,grouping__id
from 表名 [where ]
group by A,B,C
grouping sets( (A),(A,B),(A,B,C),..维度组合 )
presto、FlinkSQL、SparkSQL-语法:
select 维度A,维度B,维度C,聚合函数(度量字段) ,grouping(A,B,C) as grouping_id
from 表名 [where ]
group by
grouping sets( (A),(A,B),(A,B,C),..维度组合 )语法区别:
1、hiveSQL中 group by 后面必须添加分组的字段
presto、flinksql、sparksql group by 后面不需要指定分组字段
2、hiveSQL中 可以使用 grouping__id字段
presto、flinksql、sparksql 中并没有提供 grouping__id字段,需要使用grouping(a,b,c) 函数来计算
代码示例(HiveSQL):
-- TODO 必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','郑州市','高开区','张3' union all select '河南省','郑州市','高开区','张4' union all select '河南省','郑州市','高开区','张5' union all select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area grouping sets ((prov,city,area),(prov)
)
;代码示例(presto、flinkSQL、sparkSQL):
SELECT prov,city,area,count(1),grouping(prov,city,area) as grouping_id
FROM (VALUES ('河北省','石家庄市','新华区','张1'),('河北省','石家庄市','新华区','张2'),('河南省','郑州市','高开区','张3'),('河南省','郑州市','高开区','张4'),('河南省','郑州市','高开区','张5'),('河南省','新乡市','中华区','张6')) AS person_info_df (prov,city,area,name)
group by grouping sets ((prov,city,area),(prov)
)
;3、with rollup - 上卷维度组合
功能说明:
上卷维度组合,较grouping sets相比,不需要指定维度组合
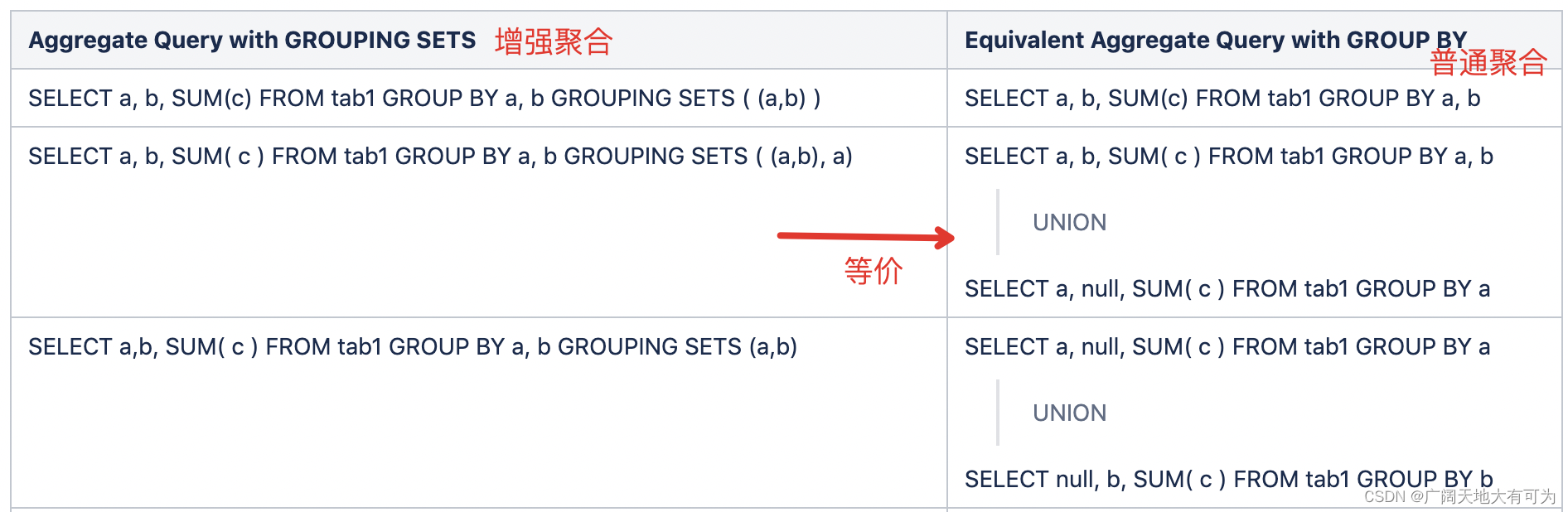
GROUP BY a, b, c, WITH ROLLUP 等价于
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( ))
hive-语法:
-- TODO 必须开区map端合并
select 维度A,维度B,维度C,聚合函数(度量字段) ,grouping__id
from 表名 [where ]
group by A,B,C
with rollup
presto、FlinkSQL、SparkSQL-语法:
select 维度A,维度B,维度C,聚合函数(度量字段) ,grouping(A,B,C) as grouping_id
from 表名 [where ]
group by
rollup(A,B,C) 代码示例(HiveSQL):
-- 1.必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','郑州市','高开区','张3' union all select '河南省','郑州市','高开区','张4' union all select '河南省','郑州市','高开区','张5' union all select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area with rollup
;代码示例(presto、flinkSQL、sparkSQL):
SELECT prov,city,area,count(1),grouping(prov,city,area) as grouping_id
FROM (VALUES ('河北省','石家庄市','新华区','张1'),('河北省','石家庄市','新华区','张2'),('河南省','郑州市','高开区','张3'),('河南省','郑州市','高开区','张4'),('河南省','郑州市','高开区','张5'),('河南省','新乡市','中华区','张6')) AS person_info_df (prov,city,area,name)
group by rollup(prov,city,area)
;4、with cube - 全维度组合
功能说明:
多维度组合,会计算所有分组字段的维度组合,较grouping sets相比,不需要指定维度组合
GROUP BY a, b, c, WITH CUBE 等价于
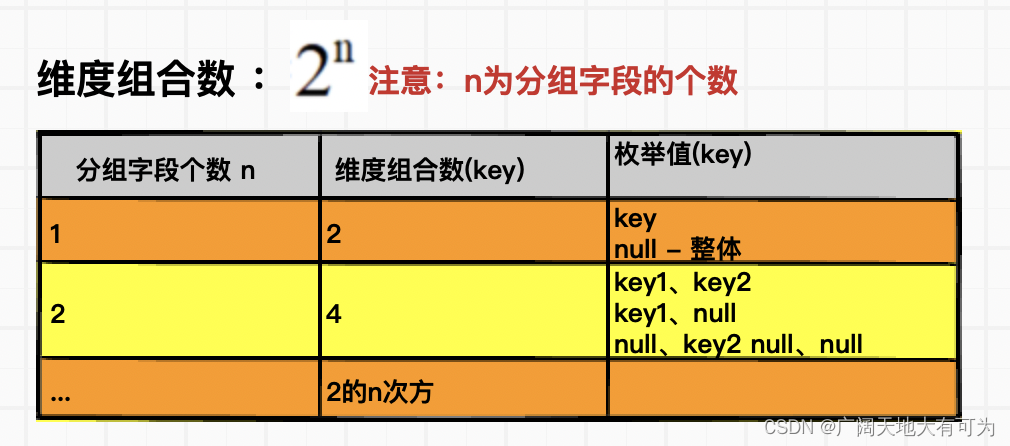
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), ( ))
cube(key1,key2...) 维度组合数:
 hive-语法:
hive-语法:
-- TODO 必须开区map端合并
select 维度A,维度B,维度C,聚合函数(度量字段) ,grouping__id
from 表名 [where ]
group by A,B,C
with cube
presto、FlinkSQL、SparkSQL-语法:
select 维度A,维度B,维度C,聚合函数(度量字段) ,grouping(A,B,C) as grouping_id
from 表名 [where ]
group by
cube(A,B,C) 代码示例(HiveSQL):
-- 1.必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','郑州市','高开区','张3' union all select '河南省','郑州市','高开区','张4' union all select '河南省','郑州市','高开区','张5' union all select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area with cube
;代码示例(presto、flinkSQL、sparkSQL):
SELECT prov,city,area,count(1),grouping(prov,city,area) as grouping_id
FROM (VALUES ('河北省','石家庄市','新华区','张1'),('河北省','石家庄市','新华区','张2'),('河南省','郑州市','高开区','张3'),('河南省','郑州市','高开区','张4'),('河南省','郑州市','高开区','张5'),('河南省','新乡市','中华区','张6')) AS person_info_df (prov,city,area,name)
group by cube(prov,city,area)
;5、Grouping__ID、grouping() 的使用场景
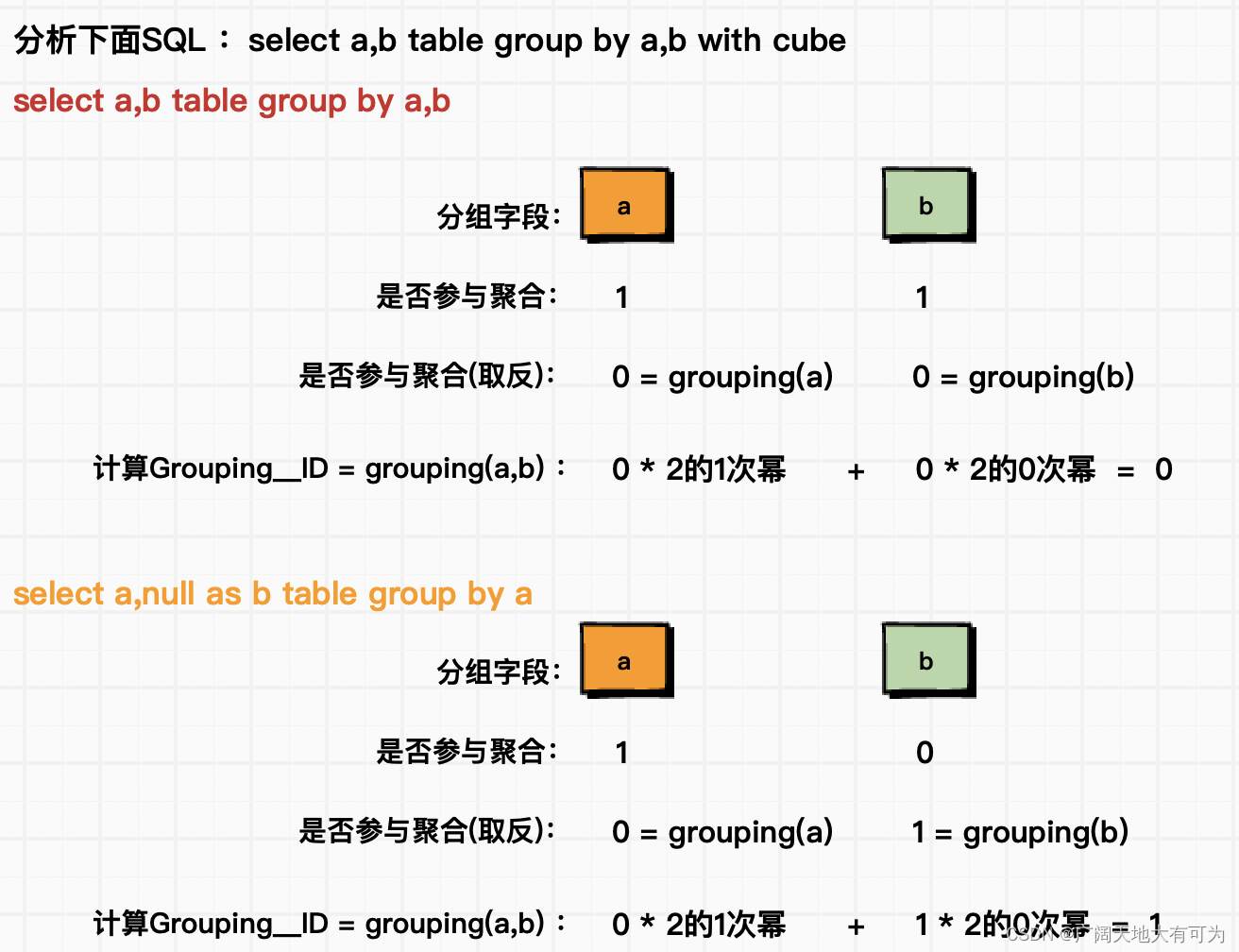
功能说明:
可以用来判断分组字段是否参与聚合,下面为 Grouping__ID 、grouping() 计算逻辑

使用场景:
当使用 grouping sets、with rollup、with cube进行聚合时,对不参与聚合的字段会使用null进行填充,这就导致查询结果中分组字段为null时,无法区分是填充的null还是分组字段本身的null
遇到上述情况,可以使用下面两种解决方式
1、将分组字段中的null进行替换处理,比如9999、other、其他
2、使用 Grouping__ID 或者 grouping() 进行区分

6、使用 增强聚合 会不会对查询性能有提升呢?
测试用例-grouping sets:
-- TODO 必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area grouping sets ((prov,city,area),(prov,city),(prov)
)
;测试用例-group by + union all:
set hive.map.aggr=true;
SELECT prov,city,area,count(1)
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','新乡市','中华区','张6'
) AS person_info_df
group by prov,city,areaunion all SELECT prov,city,null as area,count(1)
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,cityunion all SELECT prov,null as city,null as area,count(1)
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all select '河北省','石家庄市','新华区','张2' union all select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov对比执行计划:
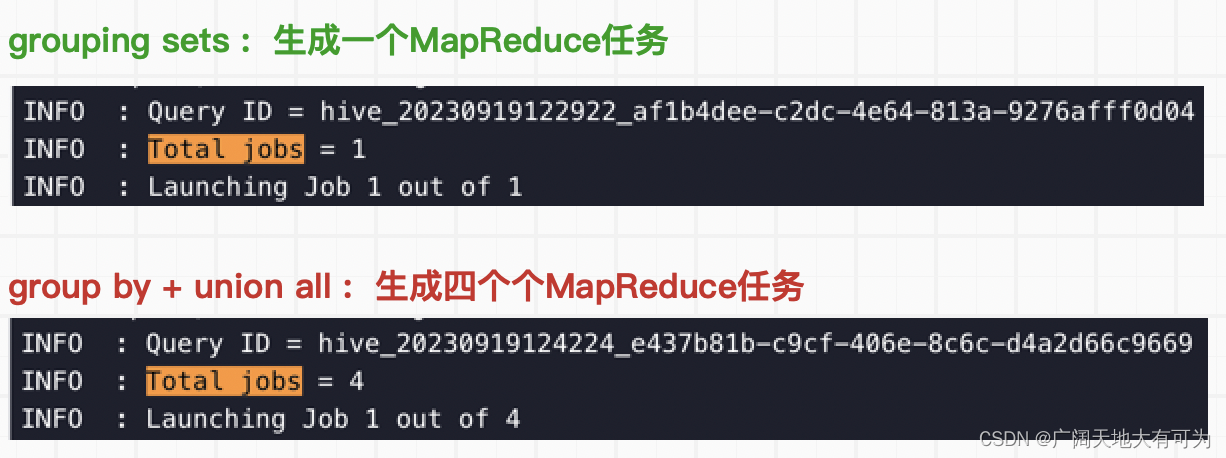
对比运行时长:
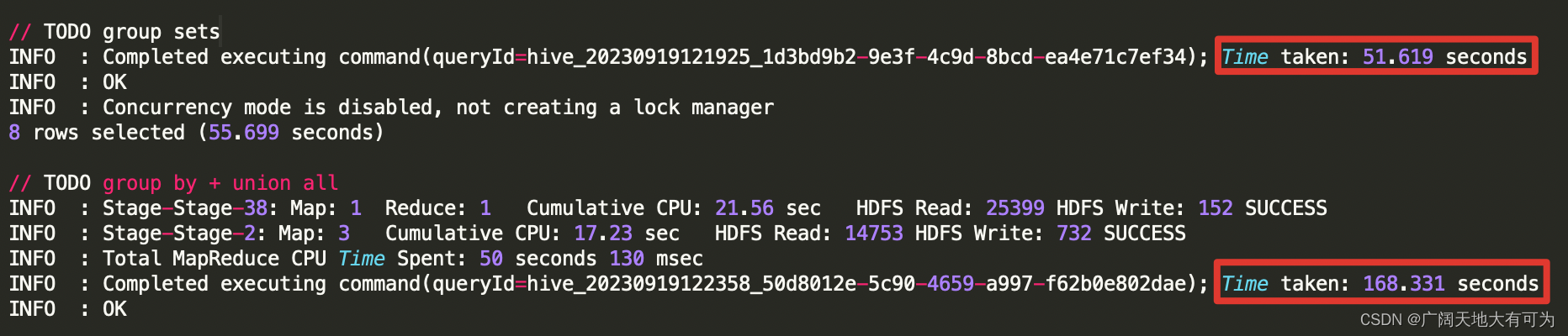
结论:
通过上面执行计划和运行时长的对比,使用 grouping sets、with cube、with rollup 确实比
group by + union all 方式的性能要好,因为 增强group by避免了多次读取底表,降低生成
job的个数,从而减轻了磁盘和网络I/O时的压力。
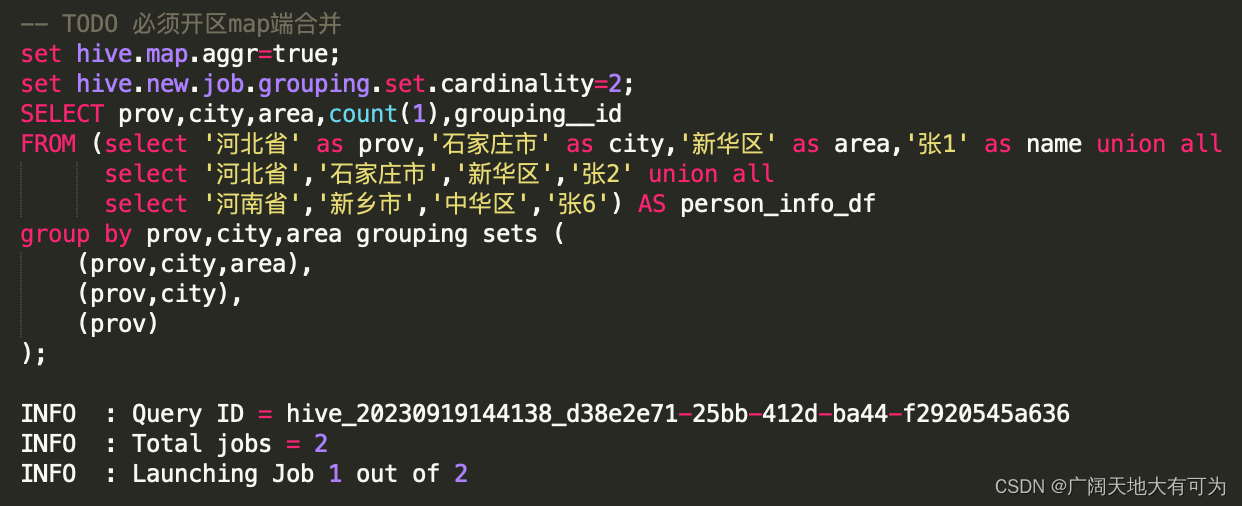
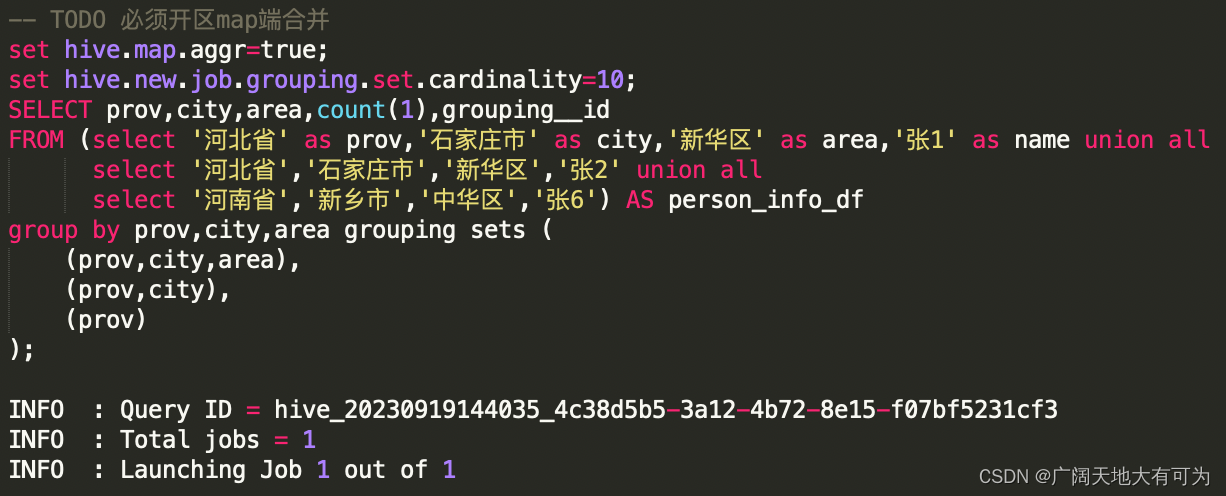
7、对grouping sets、with cube、with rollup 的优化
由于在使用增强group by时,会在同一个job中完成多种维度组合的聚合(2的N次方),当底表数据量太大 或 维度过多时,可能造成计算资源不够而导致任务失败。
在 Hive中可以使用 set hive.new.job.grouping.set.cardinality=30 来对job进行拆分。
参数说明:

验证SQL-实验组:
验证SQL-对照组:
相关文章:
hive、spark、presto 中的增强聚合-grouping sets、rollup、cube
目录 1、什么是增强聚合和多维分析函数? 2、grouping sets - 指定维度组合 3、with rollup - 上卷维度组合 4、with cube - 全维度组合 5、Grouping__ID、grouping() 的使用场景 6、使用 增强聚合 会不会对查询性能有提升呢? 7、对grouping sets、…...
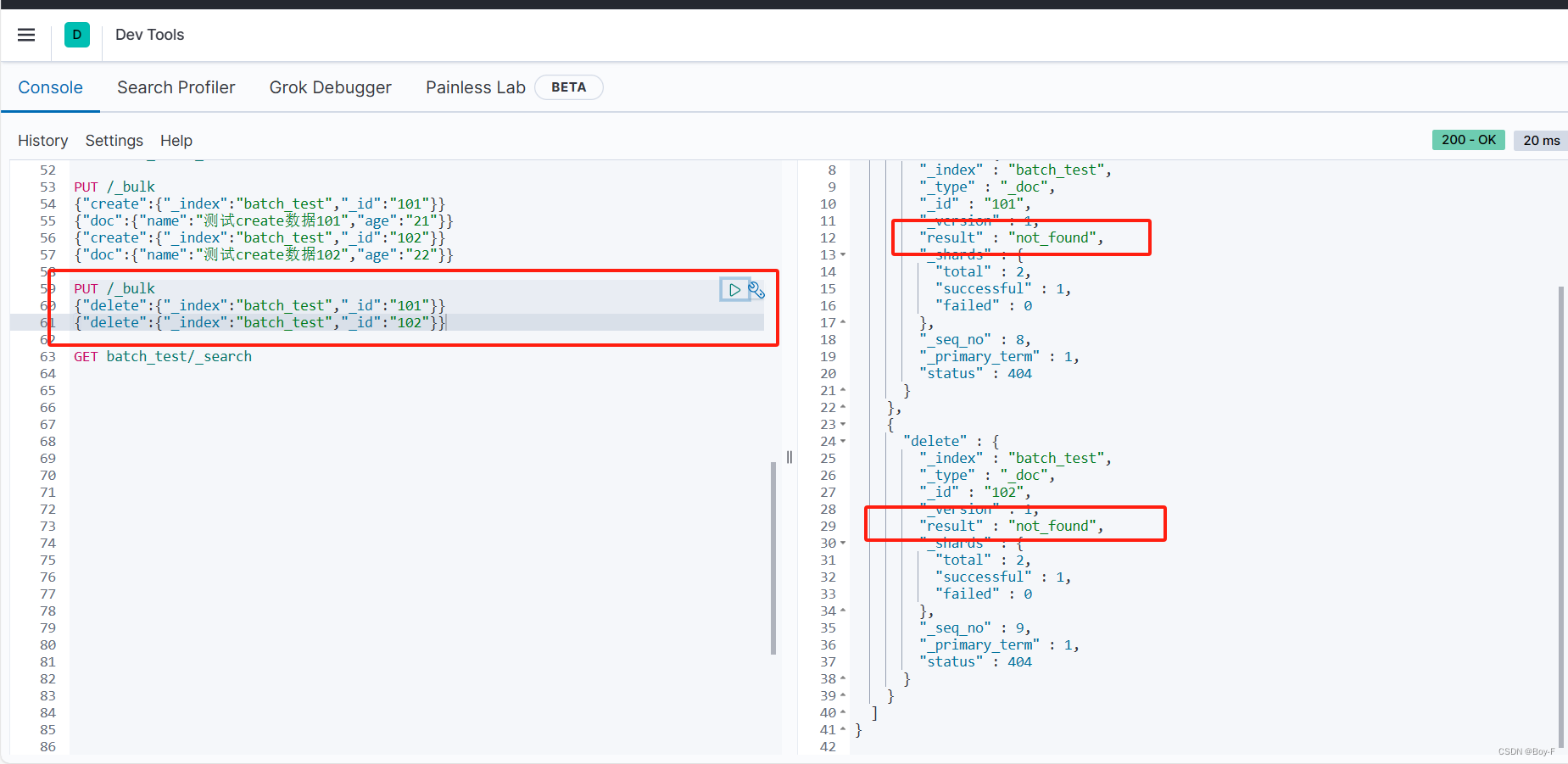
elasticsearch bulk 批量操作
1:bulk 是 elasticsearch 提供的一种批量增删改的操作API bulk 对 JSON串 有着严格的要求。每个JSON串 不能换行 ,只能放在同一行,同时, 相邻的JSON串之间必须要有换行 (Linux下是\n;Window下是\r\n&#…...

力扣11、 盛最多水的容器
方法一:双指针 考察: 贪心、数组、双指针 说明 本题是一道经典的面试题,最优的做法是使用「双指针」。如果读者第一次看到这题,不一定能想出双指针的做法。 复杂度分析 时间复杂度:O(N),双指针总计最多…...
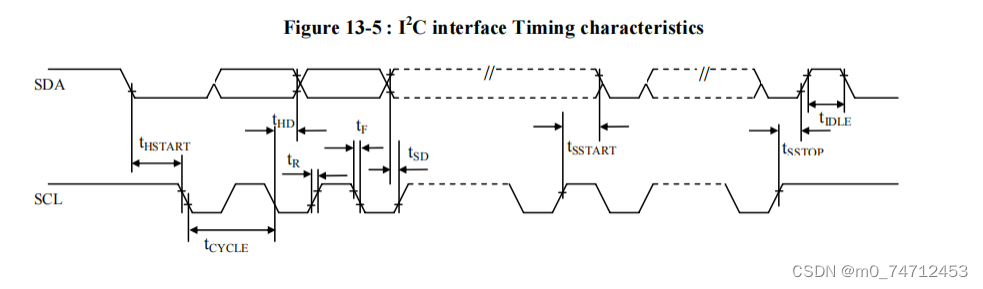
IIC协议详解
目录 1.IIC协议概述 2.IIC总线传输 3.IIC-51单片机应用 1.起始信号 2.终止信号 3.应答信号 4.数据发送 4.IIC-32单片机应用 用到的库函数: 1.IIC协议概述 IIC全称Inter-Integrated Circuit (集成电路总线)是由PHILIPS公司在80年代开发的两线式串行总线&…...

element ui-表头自定义提示框
版本 “element-ui”: “^2.15.5”,需求:鼠标悬浮到该列表头,显示提示框代码 <el-table:data"xxxx"><el-table-column label"序号" width"40" type"index" /><el-table-columnv-for"(ite…...

Python 图形化界面基础篇:创建顶部菜单
Python 图形化界面基础篇:创建顶部菜单 引言 Tkinter 库简介步骤1:导入 Tkinter 模块步骤2:创建 Tkinter 窗口步骤3:创建顶部菜单栏步骤4:处理菜单项的点击事件步骤5:启动 Tkinter 主事件循环 完整示例代码…...
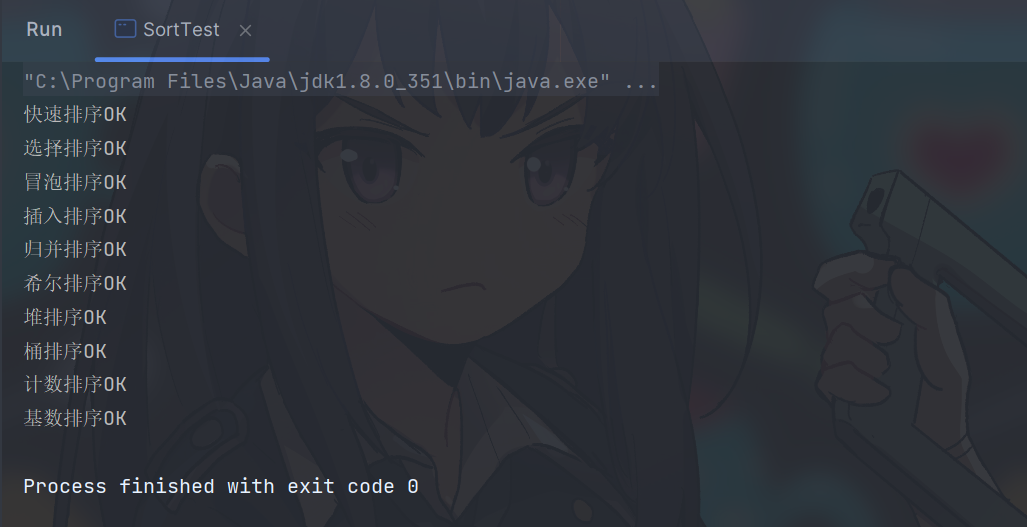
java实现十大排序算法
文章目录 冒泡排序选择排序插入排序希尔排序归并排序快速排序堆排序桶排序基数排序计数排序验证各个排序的时间复杂度和空间复杂度 冒泡排序 冒泡排序(Bubble Sort)是一种简单的比较排序算法,它的基本思想是重复地交换相邻的两个元素&#x…...
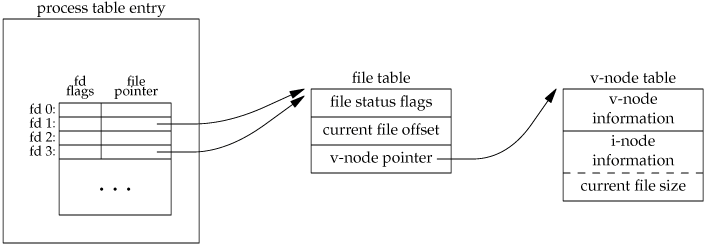
Linux日志管理-logrotate(crontab定时任务、Ceph日志转储)
文章目录 一、logrotate概述二、logrotate基本用法三、logrotate运行机制logrotate参数 四、logrotate是怎么做到滚动日志时不影响程序正常的日志输出呢?Linux文件操作机制方案一方案二 五、logrotate实战--Ceph日志转储参考 一、logrotate概述 logrotate是一个用于…...
用PHP异步协程控制python爬虫脚本,实现多协程分布式爬取
背景 公司需要爬取指定网站的产品数据。但是个人对python的多进程和协程不是特别熟悉。所以,想通过php异步协程,发起爬取url请求控制python爬虫脚本,达到分布式爬取的效果。 准备 1.准备一个mongodb数据库用于存放爬取数据2.引入flask包&a…...
VUE3写后台管理(3)
VUE3写后台管理(3) 1.环境1.node2.vite3.Element-plus4.vue-router5.element icon6.less7.vuex8.vue-demi9.mockjs10.axios11.echarts 2.首页1.布局Main2.头部导航栏CommonHeader3.左侧菜单栏CommonLeft4.首页Home1.从后端获取数据显示到前端table的三种…...
无约束优化问题——共轭梯度法)
机器学习笔记之最优化理论与算法(十二)无约束优化问题——共轭梯度法
机器学习笔记之最优化理论与方法——共轭梯度法 引言回顾:共轭方向法的重要特征线性共轭梯度法共轭方向公式的证明过程 关于线搜索公式中参数的化简关于线搜索公式中步长部分的化简关于线搜索公式中共轭方向系数的化简参数化简的目的 非线性共轭梯度法(FR,PRP方法)关…...

JVM中的java同步互斥工具应用演示及设计分析
1.火车站售票系统仿真 某火车站目前正在出售火车票,共有50张票,而它有3个售票窗口同时售票,下面设计了一个程序模拟该火车站售票,通过实现Runnable接口实现(模拟网络延迟)。 伪代码: Ticket类…...

数据治理-数据质量
实现数据质量的前提就是数据本身是可靠和可信的。 导致数据质量低下的因素 组织缺乏对低质量数据影响的理解,缺乏规划、孤岛式系统设计、不一致的开发过程、不完整的文档、缺乏标准或缺乏治理等。 所有组织都会遇到与数据质量有关的问题。数据质量需要跨职能的承诺…...

[sqoop]hive3.1.2 hadoop3.1.1安装sqoop1.4.7
参考: Hadoop3.2.4Hive3.1.2sqoop1.4.7安装部署_hadoop sqoop安装_alicely07的博客-CSDN博客 一、安装 1、解压 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /home/data_warehouse/module mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.72、配置文件 sqoop-env.s…...

js事件的详细介绍
11.事件 1.什么是事件 js属于事件驱动编程,把驱动,执行,调用通过一些交互,触发一些函数事件:发起-->执行绑定事件-->触发事件on 绑定 emit触发 off解绑2.事件分类 鼠标事件 点击事件 onclick 双击事件 ondblclick 按下事件 onmousedown 抬起事件 onmouseup 鼠标进…...
虚幻4学习笔记(12)操控导入的角色、动画蓝图、播放蒙太奇和打包、角色重定向
虚幻4学习笔记 操控导入的角色设置鼠标旋转关掉动态模糊 动画蓝图、播放蒙太奇和打包角色走路奔跑动画shift 奔跑F 跳舞移动打断 跳舞 打包角色重定向姿势调整解决跑步 腿分太开隐藏剑 B站UP谌嘉诚课程:https://www.bilibili.com/video/BV164411Y732 操控导入的角色…...

hive with tez:无法从链中的任何提供者加载aws凭据
环境信息 hadoop 3.1.0 hive-3.1.3 tez 0.9.1 问题描述 可以从hadoop命令行正确地访问s3a uri。我可以创建外部表和如下命令: create external table mytable(a string, b string) location s3a://mybucket/myfolder/; select * from mytable limit 20; 执行正…...
Ubuntu修改静态IP、网关和DNS的方法总结
Ubuntu修改静态IP、网关和DNS的方法总结 ubuntu系统(其他debian的衍生版本好像也可以)修改静态IP有以下几种方法。(搜索总结,可能也不太对) /etc/netplan (use) Ubuntu 18.04开始可以使用netplan配置网络࿰…...
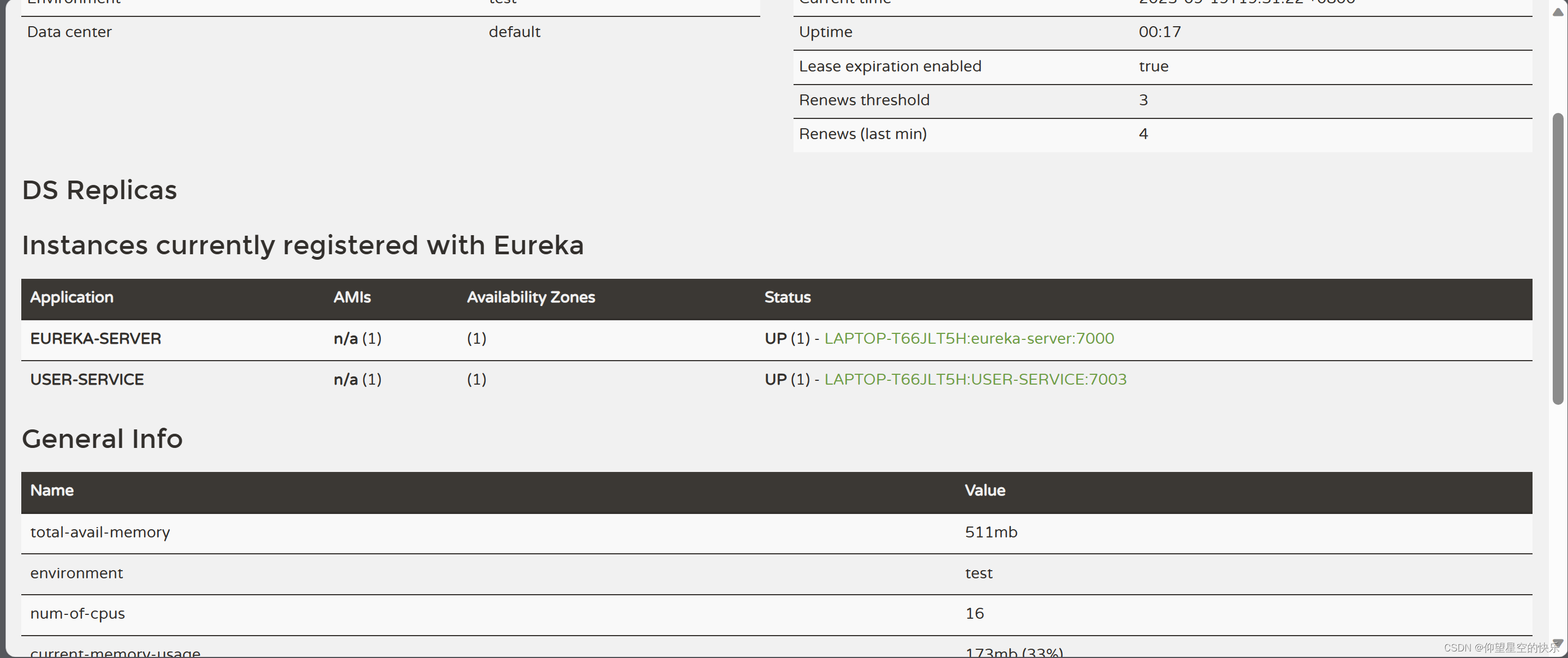
Eureka服务器注册
一。Eureka服务器注册 1.pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mav…...

Windows安装GPU版本的pytorch详细教程
文章目录 chatGLM2-6B安装教程正式安装 chatGLM2-6B ChatGLM2-6B版本要装pytorch2.0,而且要2.0.1 ,因此CUDA不能用12.0 ,也不能用10.0,只能用11.x 版本。 安装教程 pip install直接下载安装 官网: https://pytorch.…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...