【爬虫基础】万字长文详解XPath
1. 引言
XPath(XML Path Language)是一种在XML和HTML文档中查找和定位信息的强大工具。XPath的重要性在于它允许我们以简洁而灵活的方式导航和选择文档中的元素和属性。本文将深入介绍XPath的基础知识,帮助你掌握这个强大的查询语言,并展示如何在Python中应用它来解析和提取数据。
文章目录
- 1. 引言
- 1.1 XPath简介
- 1.2 本文目标
- 2. XPath基础
- 2.1 XPath的基本概念
- 2.2 XPath语法
- 2.3 节点选择和过滤
- 2.4 轴表达式(Axis Expression)
- 2.5 函数表达式(Function Expression)
- 2.6 示例XPath表达式
- 3. 在Python中使用XPath
- 3.1 安装lxml库
- 3.2 使用XPath进行解析
- 3.3 XPath语法
- 4. XPath在网络爬虫中的应用
- 4.1 示例流程
- 步骤 1: 分析目标网页的结构
- 步骤 2: 使用开发者工具生成XPath路径
- 步骤 3: 使用Python的`requests`库获取网页HTML
- 步骤 4: 使用XPath解析HTML并提取数据
- 步骤 5: 清洗和处理数据
- 4.2 示例代码
- 4.3 XPath与网络爬虫的优势
- 4.4 XPath与Beautiful Soup
- 4.5 注意事项
- 5. XPath与CSS选择器的比较
- 5.1 XPath的优点
- 5.2 XPath的缺点
- 5.3 CSS选择器的优点
- 5.4 CSS选择器的缺点
- 5.5 比较总结
- 6. 高级XPath用法
- 6.1 文本节点和属性节点的处理
- 6.2 多个XPath表达式的组合
- 6.3 错误处理与异常处理
- 7. XPath资源链接
- 8. 总结
1.1 XPath简介
XPath是一种用于在XML和HTML文档中查找和定位信息的查询语言。它允许你按照一定的规则描述路径,以定位文档中的特定元素或节点。XPath不仅用于解析文档,还可用于验证文档的结构、计算节点的值以及执行各种复杂的操作。无论你是在进行数据挖掘、爬虫开发还是测试自动化,XPath都是一个非常有用的工具。
1.2 本文目标
本文的目标是帮助你理解XPath的核心概念、语法和用法。我们将逐步深入,从基础开始,逐渐涵盖高级主题。以下是我们将在本文中探讨的主要内容:
- XPath的基本语法和表达式。
- 在Python中使用lxml、Beautiful Soup和内置xml模块解析文档。
- 如何将XPath与网络爬虫结合使用,从网页中提取所需的数据。
- XPath与CSS选择器的比较,以便你选择适合你项目的工具。
- 高级XPath用法,包括处理文本节点、属性节点以及错误和异常处理。
现在,让我们深入研究XPath的基础知识。
2. XPath基础
在本章中,我们将详细介绍XPath的基本概念和语法。这些基础知识对于理解如何定位和选择文档中的元素至关重要。
2.1 XPath的基本概念
XPath的主要目标是允许我们在XML和HTML文档中定位和选择特定的元素或节点。以下是XPath的一些关键概念:
-
节点(Node):XML和HTML文档中的所有内容都被表示为节点。节点可以是元素、属性、文本或其他类型。
-
元素节点(Element Node):代表文档中的元素,如
<book>或<p>。 -
属性节点(Attribute Node):代表元素的属性,如
class或id。 -
文本节点(Text Node):代表元素内的文本内容。
-
路径表达式(Path Expression):描述了如何从文档的根节点或当前节点导航到目标节点。
2.2 XPath语法
XPath语法由各种表达式和运算符组成,用于定位和选择节点。以下是XPath的一些基本语法元素:
/:从根节点开始选择。//:从当前节点选择文档中的节点,不考虑位置。.:选择当前节点。..:选择当前节点的父节点。@:选择属性。
XPath还包括轴(Axis)和函数(Function),用于更复杂的操作和过滤。在接下来的部分,我们将深入介绍这些语法元素,并提供示例。
2.3 节点选择和过滤
XPath允许我们选择文档中的特定节点,这些节点可以是元素、属性或文本。让我们看一些示例:
/bookstore/book:选择文档中所有bookstore下的book元素。//price:选择文档中的所有price元素。/bookstore/book[1]:选择bookstore下的第一个book元素。
XPath还支持通配符,例如:
*:匹配任何元素节点。@*:匹配任何属性节点。node():匹配任何类型的节点。
XPath的语法和节点选择使其成为处理XML和HTML文档的有力工具。在接下来的章节中,我们将详细介绍如何在Python中应用这些概念。
2.4 轴表达式(Axis Expression)
XPath中的轴表达式用于更明确地定位节点的位置。它们定义了节点之间的关系,如父子关系、兄弟关系等。以下是一些常见的轴:
ancestor:匹配当前节点的所有先辈节点。descendant:匹配当前节点的所有后代节点。following:匹配当前节点之后的所有节点。preceding:匹配当前节点之前的所有节点。self:匹配当前节点本身。
轴表达式可以帮助你更精确地定位节点,特别是在处理复杂的文档结构时非常有用。以下是一些轴表达式的示例:
ancestor::div:选择当前节点的所有先辈div元素。descendant::p:选择当前节点的所有后代p元素。following-sibling::a:选择当前节点之后的所有同级a元素。preceding-sibling::span:选择当前节点之前的所有同级span元素。self::h1:选择当前节点本身,但仅当它是h1元素时才匹配。
轴表达式使XPath更加灵活,可以根据节点之间的关系准确定位所需的元素。
2.5 函数表达式(Function Expression)
XPath内置了多个函数,用于执行各种操作,如字符串处理、数值计算和布尔逻辑。函数表达式通常以函数名开头,后面跟着一对括号,括号中包含函数的参数。以下是一些常用的函数和示例:
-
contains(string, substring):检查一个字符串是否包含另一个字符串,返回布尔值。示例:contains(book/@category, 'web')选择包含’web’的category属性的book元素。 -
count(node-set):计算一个节点集中节点的数量,返回一个数值。示例:count(//book)计算文档中book元素的数量。 -
concat(string1, string2, ...):将多个字符串连接成一个新的字符串,返回字符串。示例:concat(firstname, ' ', lastname)将firstname和lastname的值连接起来。 -
not(boolean):对布尔值取反,返回相反的布尔值。示例:not(contains(book/title, 'XPath'))检查book元素的title子元素是否不包含’XPath’。 -
position():返回当前节点在其父节点中的位置(索引),返回数值。示例:/bookstore/book[position() < 3]选择bookstore下位置在前两位的book元素。
这些函数增强了XPath的功能,使其能够进行更复杂的操作和条件筛选。你可以根据具体需求选择适当的函数来处理数据。
2.6 示例XPath表达式
为了更好地理解XPath的语法和表达能力,让我们看一些示例:
-
/bookstore/book[1]:选择bookstore下的第一个book元素。 -
/bookstore/book[@category='web']:选择category属性为’web’的book元素。 -
//title[contains(., 'XPath')]:选择文本内容包含’XPath’的title元素,无论它们位于文档的哪个位置。 -
/bookstore/book[position() < 3]:选择bookstore下位置在前两位的book元素。
这些示例展示了XPath的强大功能,你可以根据具体需求构建复杂的查询表达式。XPath的灵活性和功能丰富性使其成为处理XML和HTML文档中数据的强大工具。
3. 在Python中使用XPath
现在我们将深入研究如何在Python中使用XPath来解析XML和HTML文档。我们将介绍几种常见的Python库,包括lxml、Beautiful Soup和Python内置的xml模块,以及它们如何与XPath结合使用。
3.1 安装lxml库
要开始使用XPath,您需要安装lxml库。您可以使用pip来执行安装:
pip install lxml
3.2 使用XPath进行解析
XPath允许您解析和从XML和HTML文档中提取数据。以下是基本的解析过程:
- 实例化一个
etree对象。 - 将要解析的文档的源代码加载到
etree对象中。 - 使用XPath表达式定位并提取文档中的数据。
让我们看看如何在Python中实现:
使用
-
导入lxml.etree
from lxml import etree
-
etree.parse()
解析本地html文件
html_tree = etree.parse(‘XX.html’)
-
etree.HTML()(建议)
解析网络的html字符串
html_tree = etree.HTML(html字符串)
-
html_tree.xpath()
使用xpath路径查询信息,返回一个列表
注意:如果lxml解析本地HTML文件报错可以安装如下添加参数
parser = etree.HTMLParser(encoding="utf-8")
selector = etree.parse('./lol_1.html',parser=parser)
result=etree.tostring(selector)
3.3 XPath语法
XPath使用各种表达式和语法来定位XML和HTML文档中的元素和属性。以下是一些常用的XPath语法:
-
路径表达式
表达式 描述 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 ./ 当前节点再次进行xpath @ 选取属性。 示例
在下面的表格中,我们列出了一些路径表达式以及它们的结果:
路径表达式 结果 /html 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! //li 选取所有li 子元素,而不管它们在文档中的位置。 //ul//a 选择属于 ul元素的后代的所有 li元素,而不管它们位于 ul之下的什么位置。 节点对象.xpath(‘./div’) 选择当前节点对象里面的第一个div节点 //@href 选取名为 href 的所有属性。 -
谓词(Predicates)
谓词用于查找特定节点或包含特定值的节点。
谓词被放置在方括号内。
示例
在下面的表格中,我们列出了带有谓词的一些路径表达式以及它们的结果:
路径表达式 结果 /ul/li[1] 选取属于 ul子元素的第一个 li元素。 /ul/li[last()] 选取属于 ul子元素的最后一个 li元素。 /ul/li[last()-1] 选取属于 ul子元素的倒数第二个 li元素。 //ul/li[position()< 3] 选取最前面的两个属于 ul元素的子元素的 li元素。 //a[@title] 选取所有拥有名为 title的属性的 a元素。 //a[@title=‘xx’] 选取所有 a元素,且这些元素拥有值为 xx的 title属性。 //a[@title>10] > < >= <= !=选取 a元素的所有 title元素,且其中的 title元素的值须大于 10。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 -
通配符(Wildcards)
XPath通配符可用于选取未知的XML元素。
通配符 描述 * 匹配任何元素节点。 一般用于浏览器copy xpath会出现 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 示例
在下面的表格中,我们列出了一些路径表达式以及它们的结果:
路径表达式 结果 /ul/* 选取 bookstore 元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。 //node() 获取所有节点 多路径选择
通过在路径表达式中使用“|”运算符,您可以选择多个路径。
示例
在下面的表格中,我们列出了一些路径表达式以及它们的结果:
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price元素。 -
逻辑运算
-
查找所有id属性等于head并且class属性等于s_down的div标签
//div[@id="head" and @class="s_down"] -
选取文档中的所有 title 和 price 元素。
//title | //price注意:使用“|”运算符时,两边的路径表达式必须是完整的。
-
-
属性查询
-
查找所有包含id属性的div节点
//div[@id] -
查找所有id属性等于maincontent的div标签
//div[@id="maincontent"] -
查找所有的class属性
//@class -
获取属性值
//div/a/@href # 获取a标签的href属性值
-
-
获取特定位置的标签(索引从1开始)
tree.xpath('//li[1]/a/text()') # 获取第一个标签 tree.xpath('//li[last()]/a/text()') # 获取最后一个标签 tree.xpath('//li[last()-1]/a/text()') # 获取倒数第二个标签 -
模糊查询
-
查询所有id属性中包含he的div标签
//div[contains(@id, "he")] -
查询所有id属性以he开头的div标签
//div[starts-with(@id, "he")]
-
-
内容查询
查找所有div标签下的直接子节点h1的内容
//div/h1/text() -
获取所有匹配的节点
//* #获取所有匹配的节点 //*[@class="xx"] #获取所有class属性为xx的节点 -
将节点内容转换为字符串
c = tree.xpath('//li/a')[0] result = etree.tostring(c, encoding='utf-8') print(result.decode('UTF-8'))
4. XPath在网络爬虫中的应用
XPath在网络爬虫中起着重要的作用,它使开发者能够从网页中提取所需的数据。在本节中,我们将讨论如何使用XPath结合Python来编写爬虫,以从网页中抓取信息。
4.1 示例流程
以下是一个使用XPath在网络爬虫中提取数据的示例流程:
步骤 1: 分析目标网页的结构
在开始爬取之前,首先要仔细分析目标网页的HTML结构。使用浏览器开发者工具(例如Chrome的开发者工具)来查看页面的元素和结构,以确定所需数据的位置。
步骤 2: 使用开发者工具生成XPath路径
使用开发者工具中的“检查元素”功能来定位要提取的数据的位置,并生成XPath路径。XPath路径是从根节点到目标元素的唯一描述。
步骤 3: 使用Python的requests库获取网页HTML
使用Python的requests库来获取目标网页的HTML内容。以下是一个示例:
import requestsurl = "https://example.com"
response = requests.get(url)
html = response.text
步骤 4: 使用XPath解析HTML并提取数据
使用XPath表达式解析HTML,并应用之前生成的XPath路径来选择和提取数据。以下是一个示例:
from lxml import etree# 解析HTML
tree = etree.HTML(html)# 使用XPath表达式选择数据
data = tree.xpath("//div[@class='data']/text()")# 处理提取的数据
for item in data:# 处理数据
步骤 5: 清洗和处理数据
在提取数据后,通常需要进行数据清洗和处理,以便进一步分析或存储。
XPath的强大之处在于它可以根据特定的HTML结构精确地定位和提取数据,使爬虫开发变得高效而精确。
4.2 示例代码
以下是一个使用XPath编写的Python爬虫的示例代码:
import requests
from lxml import etreeurl = "https://example.com"
response = requests.get(url)
html = response.text# 解析HTML
tree = etree.HTML(html)# 使用XPath表达式选择数据
data = tree.xpath("//div[@class='data']/text()")# 处理提取的数据
for item in data:# 处理数据
这个示例演示了如何使用XPath结合Python的requests库和lxml来编写简单的网络爬虫,从网页中提取数据。根据实际需求,你可以修改XPath表达式来选择不同的数据元素。
4.3 XPath与网络爬虫的优势
XPath在网络爬虫中具有一些重要的优势:
-
精确定位: XPath可以精确地定位网页中的元素,无论它们在文档中的位置如何。这使得它成为提取特定信息的强大工具。
-
灵活性: XPath支持各种轴(axis)和函数,可以处理各种不同的数据结构和情景。这种灵活性对于处理各种不同结构的网页非常有用。
-
适用性广泛: XPath不仅适用于HTML,还适用于XML和其他标记语言。这使得它成为从各种来源提取数据的通用工具。
-
强大的条件筛选: 你可以使用XPath的条件筛选功能,例如
[@attribute='value'],来选择符合特定条件的元素。这对于从大量数据中提取所需信息非常有帮助。
4.4 XPath与Beautiful Soup
XPath通常与解析库一起使用,例如lxml和Beautiful Soup。虽然Beautiful Soup本身也提供了一种查找HTML元素的方式,但XPath在某些情况下更强大。
XPath的优势在于它可以更精确地定位元素,而且在处理XML文档时更为通用。不过,在某些情况下,特别是在处理简单的HTML文档时,Beautiful Soup可能更易于使用。
以下是一个使用XPath和Beautiful Soup结合的示例:
from bs4 import BeautifulSoup# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html, 'html.parser')# 使用XPath表达式选择数据
data = soup.select("//div[@class='data']")# 处理提取的数据
for item in data:# 处理数据
这种结合使用的方法可以充分发挥XPath的定位能力,同时利用Beautiful Soup的解析功能。
4.5 注意事项
在使用XPath进行网页爬取时,有几个注意事项:
-
网页结构的稳定性: 网站的结构可能会随时间变化,因此XPath路径可能需要定期检查和更新。
-
反爬虫机制: 一些网站采取反爬虫措施,可能会阻止爬虫访问或限制访问频率。爬虫开发者需要注意这些限制。
-
合法性和伦理性: 在进行网页爬取时,请确保你的行为合法和伦理,尊重网站的使用条款和隐私政策。
使用XPath的网络爬虫可以有效地从网页中提取数据,但需要谨慎处理,并遵守相关法律和道德规范。
接下来,我们将探讨XPath与CSS选择器之间的比较,以帮助你选择适合你的数据提取工具。
5. XPath与CSS选择器的比较
XPath和CSS选择器都是用于定位和选择HTML和XML文档中的元素的工具,但它们有不同的语法和应用场景。在本节中,我们将比较这两者,以便你了解何时选择XPath,何时选择CSS选择器。
5.1 XPath的优点
XPath具有以下优点:
-
语法灵活: XPath的语法非常灵活,可以处理各种复杂的查询和选择操作。
-
可读性强: 使用路径表达式描述节点位置,代码更具可读性。
-
支持多种节点类型: XPath不仅可以选择元素节点,还可以选择属性、文本节点等不同类型的节点。
-
功能丰富: XPath内置了丰富的函数,用于字符串处理、数值计算和布尔逻辑。
-
适用于XML和HTML: XPath专门设计用于处理XML和HTML文档,适用性广泛。
5.2 XPath的缺点
XPath也有一些缺点:
-
语法相对复杂: XPath的语法相对较复杂,学习曲线较陡。
-
性能较差: 在处理大型文档时,XPath可能比CSS选择器性能略低。
-
不适合所有场景: 对于简单的选择操作,XPath可能过于强大。
5.3 CSS选择器的优点
CSS选择器具有以下优点:
-
简单直观: CSS选择器的语法简单直观,易于学习和使用。
-
性能较好: 在处理大型文档时,CSS选择器通常具有较好的性能。
-
广泛应用于Web开发: CSS选择器是Web开发中常见的选择元素的方式,可以轻松嵌入到网页样式表中。
5.4 CSS选择器的缺点
CSS选择器也有一些缺点:
-
只能选择元素的文本内容: CSS选择器主要用于选择元素的文本内容,不能直接选择属性、注释等。
-
不支持多种节点类型: CSS选择器只能选择元素节点,无法选择其他类型的节点。
-
无法控制节点关系: CSS选择器无法直接控制节点关系,如父子关系、兄弟关系等。
5.5 比较总结
比较XPath和CSS选择器:
-
选择难度: 如果需要处理复杂的文档结构或选择操作,XPath可能更适合,但对于简单的操作,CSS选择器更直观。
-
性能: 在处理大型文档时,CSS选择器通常具有较好的性能,但XPath在复杂选择操作时性能稍差。
-
适用场景: 如果需要选择和处理多种节点类型,如元素、属性、文本等,XPath更适合。如果只需选择元素的文本内容,CSS选择器足够。
-
使用习惯: 对于Web开发者来说,CSS选择器可能更熟悉,因为它们通常用于样式选择器。
根据你的具体需求和项目背景,可以选择XPath或CSS选择器,或者根据情况混合使用它们来处理Web数据。
6. 高级XPath用法
在这一节中,我们将进一步探讨XPath的高级用法,以帮助你更好地利用XPath处理不同的场景。
6.1 文本节点和属性节点的处理
XPath不仅可以用于选择元素节点,还可以用于处理文本节点和属性节点。以下是一些高级用法示例:
- 选择特定元素的文本内容:
/bookstore/book/title/text()
- 选择具有特定属性值的元素:
/bookstore/book[@category='web']
这些高级用法使XPath能够更精确地选择和处理文档中的数据。
6.2 多个XPath表达式的组合
有时,需要组合多个XPath表达式来选择更复杂的数据结构。XPath支持使用运算符(如|)来合并多个表达式。例如:
//book[@category='web'] | //book[@category='programming']
这将选择所有category属性为’web’或’programming’的book元素。
6.3 错误处理与异常处理
在使用XPath时,应考虑错误处理和异常处理。例如,如果XPath表达式无法找到目标节点,可能会引发异常。你可以使用适当的错误处理机制来应对这些情况,例如使用try和except语句。
以下是一个示例:
try:result = tree.xpath("//nonexistent-element")if result:# 处理结果else:# 处理找不到节点的情况
except Exception as e:# 处理XPath解析错误
这个小节将帮助你更好地理解如何处理XPath中的一些高级用法和错误情况。
7. XPath资源链接
在这一节中,我们将提供一些XPath学习资源的链接,以便你可以进一步深入学习XPath。
-
W3Schools XPath教程: W3Schools提供了关于XPath的详细教程,包括语法和示例。
-
Mozilla Developer Network (MDN) XPath文档: MDN提供了关于XPath的文档和参考资料,适用于Web开发者。
-
XPath and XQuery Functions and Operators 3.1: W3C的官方规范文档,详细介绍XPath的功能和操作。
-
lxml库文档: lxml是一个常用的Python库,用于处理XML和HTML文档,它支持XPath,该文档提供了lxml的详细信息和示例。
-
Beautiful Soup文档: Beautiful Soup是用于解析HTML文档的Python库,文档中包括了与XPath的结合使用示例。
这些资源链接将帮助你深入学习XPath,并获取更多的信息和示例。
8. 总结
在这篇文章中,我们深入探讨了XPath的基本概念、语法、Python中的使用、网络爬虫中的应用、与CSS选择器的比较、高级用法以及错误处理。XPath是一个强大的工具,用于解析和提取XML和HTML文档中的信息,适用于各种Web数据挖掘和爬取任务。
如果你有任何问题、建议或需要进一步了解的内容,请随时联系我。感谢阅读这篇关于XPath的文章!
相关文章:

【爬虫基础】万字长文详解XPath
1. 引言 XPath(XML Path Language)是一种在XML和HTML文档中查找和定位信息的强大工具。XPath的重要性在于它允许我们以简洁而灵活的方式导航和选择文档中的元素和属性。本文将深入介绍XPath的基础知识,帮助你掌握这个强大的查询语言…...
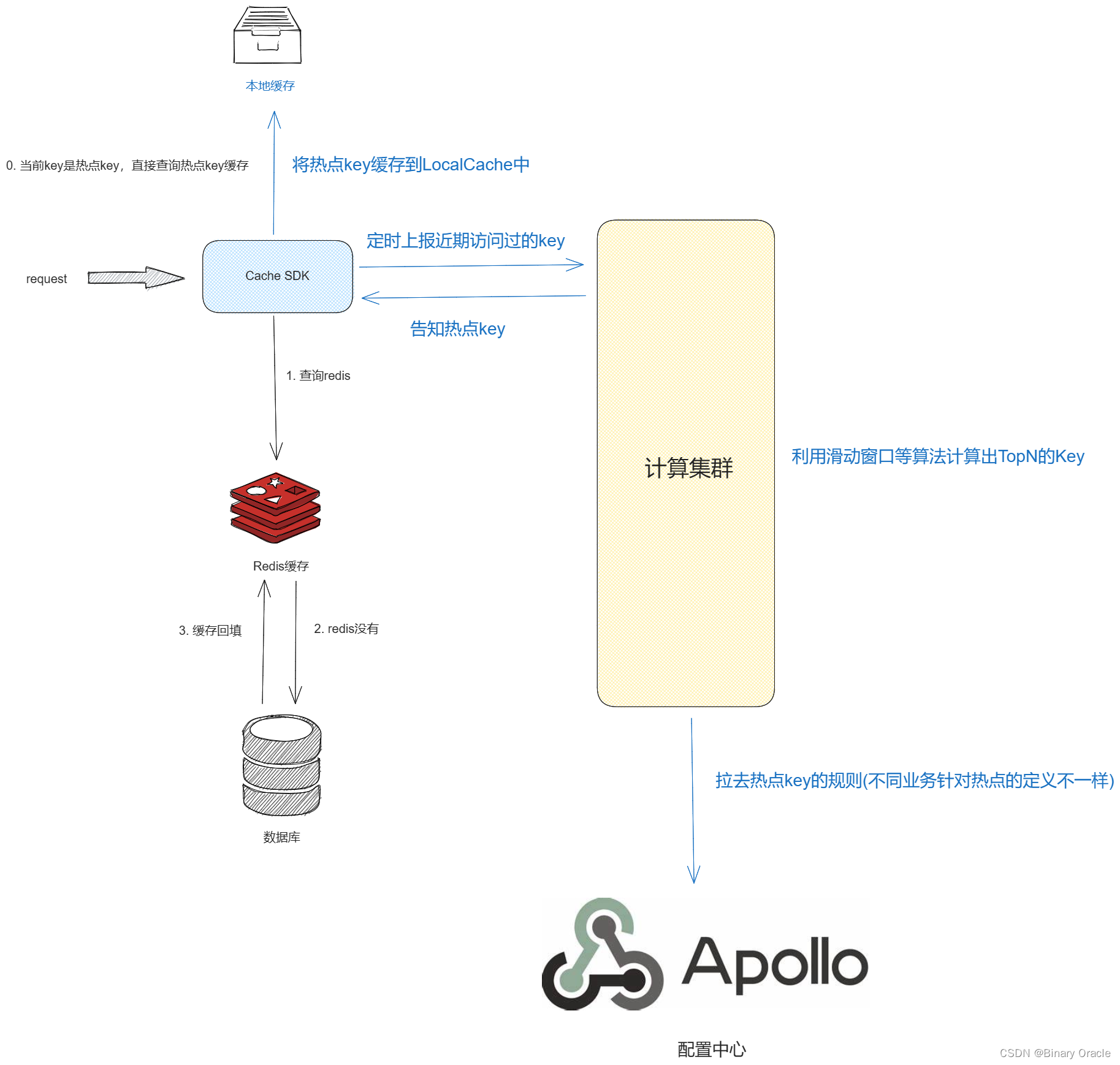
分布式多级缓存SDK设计的思考
分布式多级缓存SDK设计的思考 背景整体架构多层级组装回调埋点分区处理一致性问题缓存与数据库之间的一致性问题不同层级缓存之间的一致性问题不同微服务实例上,非共享缓存之间的一致性问题 小结 之前实习期间编写过一个简单的多级缓存SDK,后面了解到一些…...
)
设计模式:适配器模式(C++实现)
适配器模式(Adapter Pattern)是一种结构设计模式,它允许将一个类的接口转换成客户端所期望的另一个接口。适配器模式通常用于连接两个不兼容的接口或类,使它们能够一起工作。 以下是一个简单的C适配器模式的示例: #in…...
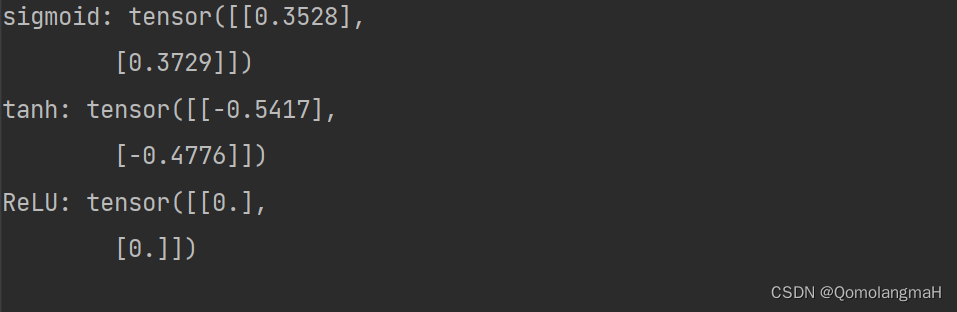
【深度学习实验】前馈神经网络(二):使用PyTorch实现不同激活函数(logistic、tanh、relu、leaky_relu)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 定义激活函数 logistic(z) tanh(z) relu(z) leaky_relu(z, gamma0.1) 2. 定义输入、权重、偏置 3. 计算净活性值 4. 绘制激活函数的图像 5. 应用激活函数并…...
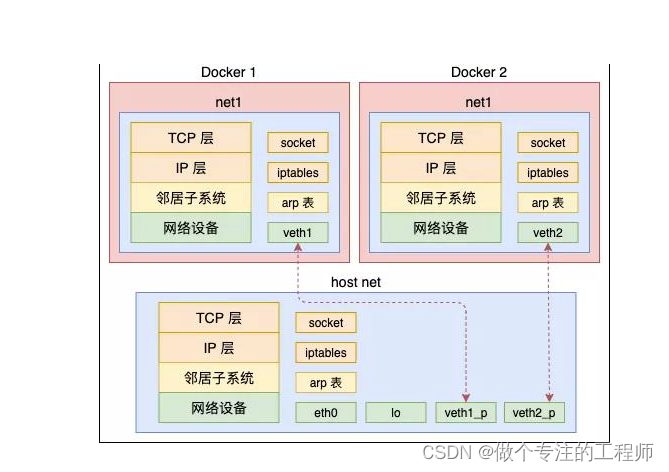
容器技术所涉及Linux内核关键技术
一、容器技术前世今生 1.1 1979年 — chroot 容器技术的概念可以追溯到1979年的UNIX chroot。 它是一套“UNIX操作系统”系统,旨在将其root目录及其它子目录变更至文件系统内的新位置,且只接受特定进程的访问。 这项功能的设计目的在于为每个进程提供…...
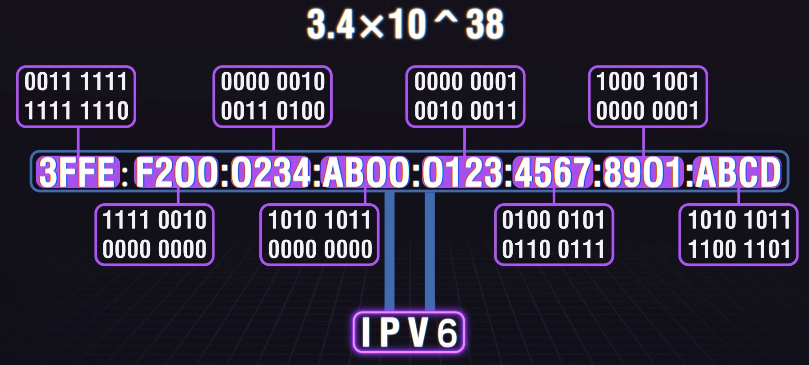
IPV4和IPV6,公网IP和私有IP有什么区别?
文章目录 1、什么是IP地址?1.1、背景1.2、交换机1.3、局域网1.4、广域网1.5、ISP 互联网服务提供商 2、IPV42.1、什么是IPV4?2.2、IPV4的组成2.3、NAT 网络地址转换2.4、端口映射 3、公网IP和私有IP4、IPV6 1、什么是IP地址? 1.1、背景 一台…...
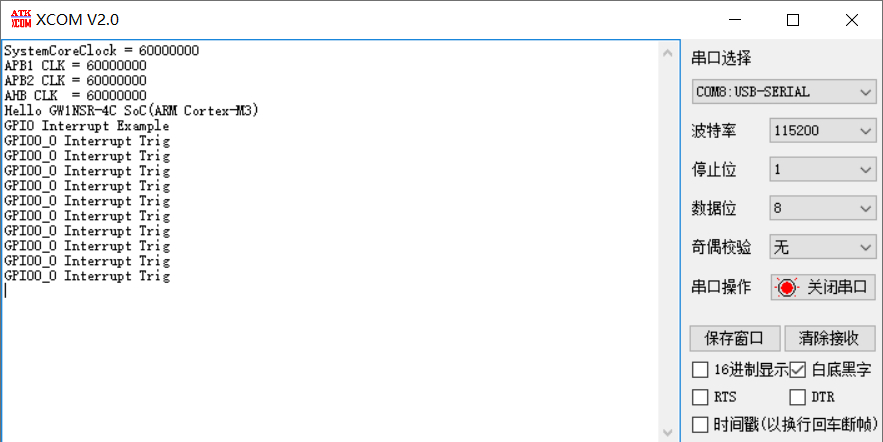
高云FPGA系列教程(7):ARM GPIO外部中断
文章目录 [toc]GPIO中断简介FPGA配置常用函数MCU程序设计工程下载 本文是高云FPGA系列教程的第7篇文章。 本篇文章介绍片上ARM Cortex-M3硬核处理器GPIO外部的使用,演示按键中断方式来控制LED亮灭,基于TangNano 4K开发板。 参考文档:Gowin_E…...

Python爬虫:动态获取页面
动态网站根据用户的某些操作产生一些结果。例如,当网页仅在向下滚动或将鼠标移动到屏幕上时才完全加载时,这背后一定有一些动态编程。当您将鼠标指针悬停在某些文本上时,它会为您提供一些选项,它还包含一些动态.这是是一篇关于动态…...

大数据平台迁移后yarn连接zookeeper 异常分析
大数据平台迁移后yarn连接zookeeper 异常分析 XX保险HDP大数据平台机房迁移异常分析。 异常现象: 机房迁移后大部分组件都能正常启动Yarn 启动后8088 8042等端口无法访问Hive spark 作业提交到yarn会出现卡死。 【备注】虽然迁移,但IP不变。 1. Yarn连…...

Ubuntu Nginx 配置 SSL 证书
首先需要在 Ubuntu 中安装 Nginx 服务, 打开终端执行以下命令: $ sudo apt update $ sudo apt install nginx -y然后启动 Nginx 服务并设置为开机时自动启动, 执行以下命令: $ sudo systemctl start nginx $ sudo systemctl enable nginx最后再验证一下 Nginx 服务的当前状态…...
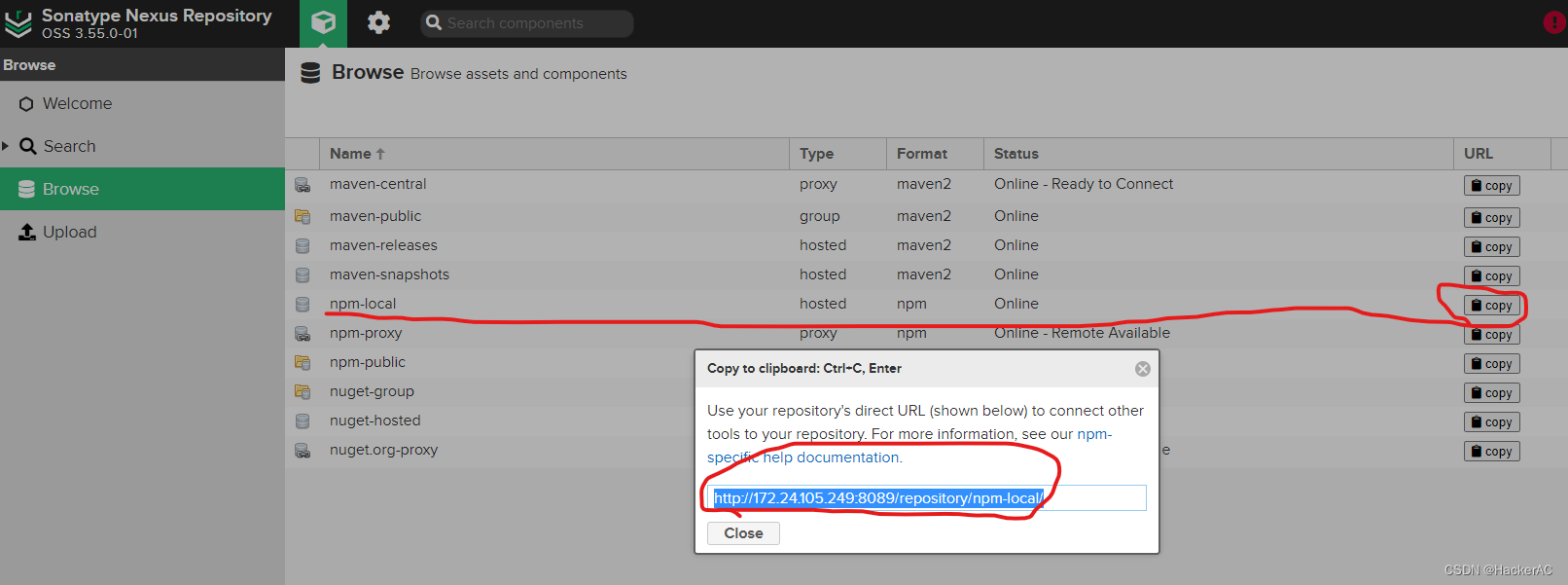
将本地前端工程中的npm依赖上传到Nexus
【问题背景】 用Nexus搭建了内网的依赖仓库,需要将前端工程中node_modules中的依赖上传到Nexus上,但是node_modules中的依赖已经是解压后的状态,如果直接机械地将其简单地打包上传到Nexus,那么无法通过npm install下载使用。故有…...
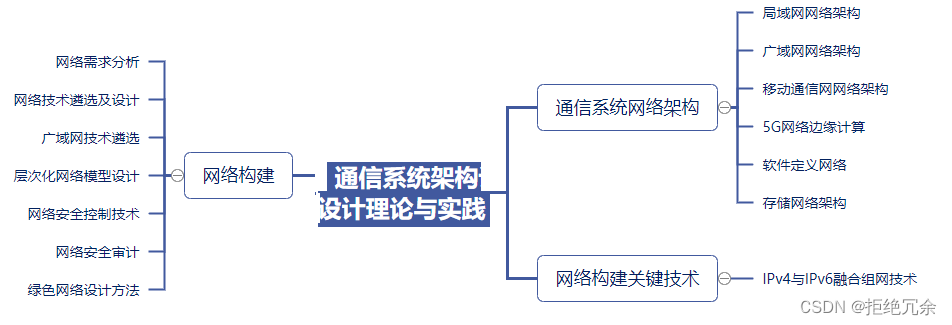
软考高级架构师下篇-16通信系统架构设计理论与实践
目录 1. 引言2. 通信系统网络架构3. 网络构建关键技术4. 网络构建5. 前文回顾1. 引言 此章节主要学习通信系统架构设计的理论和工作中的实践。根据新版考试大纲,本节知识点会涉及案例分析题(25分),而在历年考试中,案例题对该部分内容的考查并不多,虽在综合知识选择题目中…...

国庆中秋特辑(二)浪漫祝福方式 使用生成对抗网络(GAN)生成具有节日氛围的画作
要用人工智能技术来庆祝国庆中秋,我们可以使用生成对抗网络(GAN)生成具有节日氛围的画作。这里将使用深度学习框架 TensorFlow 和 Keras 来实现。 一、生成对抗网络(GAN) 生成对抗网络(GANs,…...

stm32 串口发送和接收
串口发送 #include "stm32f10x.h" // Device header #include <stdio.h> #include <stdarg.h>//初始化串口 void Serial_Init() {//开启时钟RCC_APB2PeriphClockCmd(RCC_APB2Periph_USART1,ENABLE);RCC_APB2PeriphClockCmd(RCC_APB2Pe…...

Vite + Vue3 实现前端项目工程化
通过官方脚手架初始化项目 第一种方式,这是使用vite命令创建,这种方式除了可以创建vue项目,还可以创建其他类型的项目,比如react项目 npm init vitelatest 第二种方式,这种方式是vite专门为vue做的配置,…...

Java动态代理Aop的好处
1. 预备知识-动态代理 1.1 什么是动态代理 动态代理利用Java的反射技术(Java Reflection)生成字节码,在运行时创建一个实现某些给定接口的新类(也称"动态代理类")及其实例。 1.2 动态代理的优势 动态代理的优势是实现无侵入式的代…...
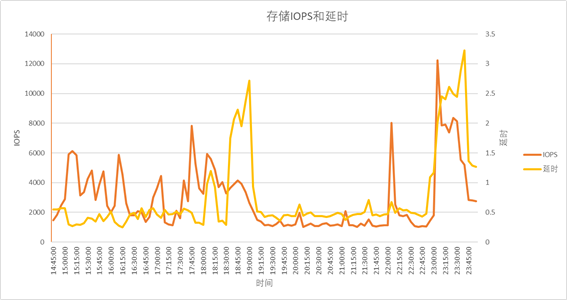
各种存储性能瓶颈如何分析与优化?
【摘要】本文结合实践剖析存储系统的架构及运行原理,深入分析各种存储性能瓶颈场景,并提出相应的性能优化手段,希望对同行有一定的借鉴和参考价值。 【作者】陈萍春,现就职于保险行业,拥有多年的系统、存储以及数据备…...
Android StateFlow初探
Android StateFlow初探 前言: 最近在学习StateFlow,感觉很好用,也很神奇,于是记录了一下. 1.简介: StateFlow 是一个状态容器式可观察数据流,可以向其收集器发出当前状态更新和新状态更新。还可通过其 …...
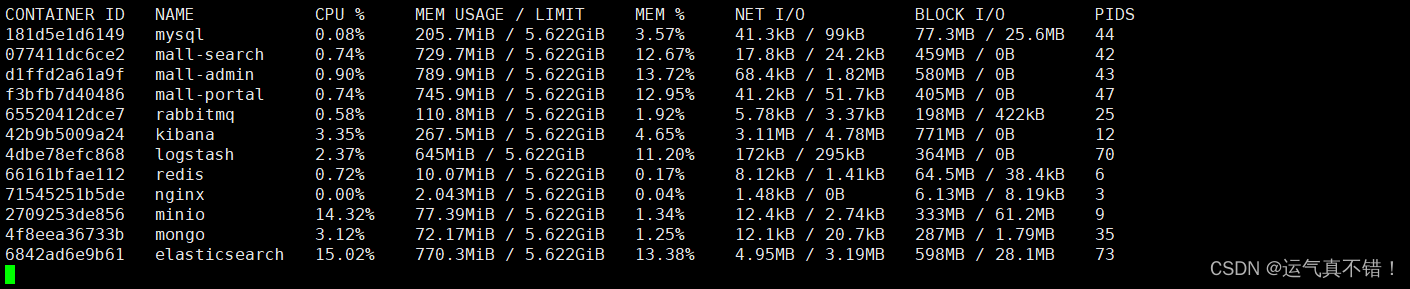
Docker Compose初使用
简介 Docker-Compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。 Docker-Compose将所管理的容器分为三层,分别是 工程(project),服务(service)以及容器(cont…...
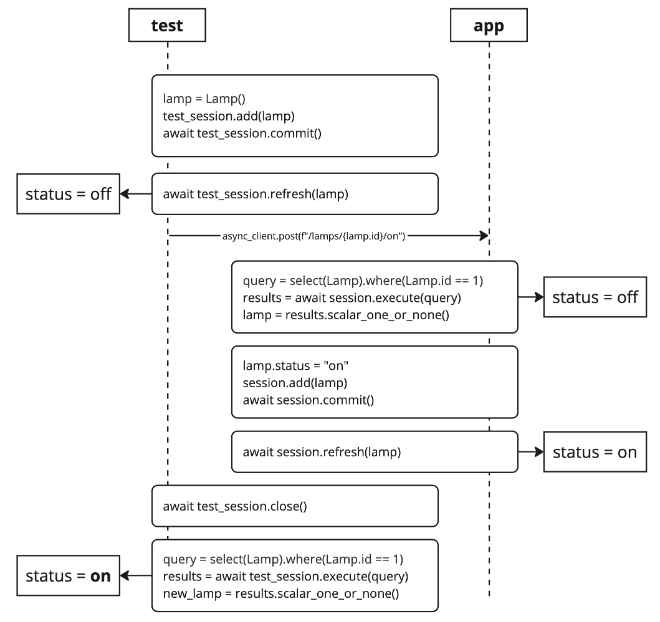
测试与FastAPI应用数据之间的差异
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等 当使用两个不同的异步会话来测试FastAPI应用程序与数据库的连接时,可能会出现以下错误: 在测试中,在数据库中创建了一个对象&#x…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...