mybatisplus,jdbc 批量插入

1.测试用例
项目中遇到在做导入号码的时候我们会用到批量导入,提高入库的速度。接下来我们以10000条为测试用例。
1.1 批量执行sql语句
当需要成批插入或者更新记录时,可以采用Java的批量更新机制,这一机制允许多条语句一次性提交给数据库批量处理。通常情况下比单独提交处理更有效率
JDBC的批量处理语句包括下面三个方法:
- addBatch(String):添加需要批量处理的SQL语句或是参数;
- executeBatch():执行批量处理语句;
- clearBatch():清空缓存的数据
通常我们会遇到两种批量执行SQL语句的情况:
- 多条SQL语句的批量处理;
- 一个SQL语句的批量传参;
1.2 导入excell
2.先使用mybatisplus的批量插入
phoneListService.saveBatch(callLists);

感觉插入还是有些慢,查了下文档,需要增加一个参数
Postgres jdbc的连接:
url: jdbc:postgresql://102.2.1.21:5432/postgres?
binaryTransfer=false&forceBinary=false&reWriteBatchedInserts=true
Mysql jdbc连接:
jdbc:mysql://102.2.1.21:3306/demo?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B1&rewriteBatchedStatements=true
增加以下的参数进行优化
rewriteBatchedStatements=true:控制是否将批量插入语句转换成更高效的形式,true表示转换,默认为false
binaryTransfer=false:控制是否使用二进制协议传输数据,false表示不适用,默认为true。
forceBinary=false:控制是否将非 ASCII 字符串强制转换为二进制格式,false表示不强制转换,默认为true

3.用jdbc插入
感觉还是慢,不过不知道是什么原因。后来该用jdbc原生的,每500提交一次
Connection conn = jdbcUtils.getConnection();PreparedStatement ps = null;try {ps = jdbcUtils.createPreparedStatement1(conn, sql);//取消自动提交conn.setAutoCommit(false);for (int i = 0; i < phoneList.size(); i++) {PhoneList call = phoneList.get(i);Long startTime = DateUtils.getSec("00:00");String date1 = phone.getTodayBegin();String date2 = phone.getTodayStop();logger.warn("======date1:{} date2:{}", date1, date2);if (StringUtil.isNotEmpty(date1)) {startTime = DateUtils.getSec(date1.substring(date1.indexOf(":") - 2));}long endTime = DateUtils.getSec("23:58");if (StringUtil.isNotEmpty(date2)) {endTime = DateUtils.getSec(date2.substring(date2.indexOf(":") - 2));}logger.warn("======startTime:{} endTime:{}", startTime, endTime);if (StringUtils.isNotEmpty(sql)) {String startTimeParam = DateUtils.parseDateToStr(DateUtils.YYYY_MM_DD_HH_MM_SS, phone.getStartTime());String endTimeParam = DateUtils.parseDateToStr(DateUtils.YYYY_MM_DD_HH_MM_SS, phone.getEndTime());ps = jdbcUtils.createPreparedStatement2(ps, call.getId(), 2, 1, 0, phone.getRetryCount(), startTime, endTime,112, call.getId(), 0, phone.getPrefix() + call.getCustomerPhone(), 1, phone.getPrefix() + call.getCustomerPhone(),1, phone.getName(), 101, phone.getCampaignId(), phone.getMark(), phone.getIvrProfileUrl(), startTimeParam, endTimeParam);}ps.addBatch();if (i % 500 == 0) {ps.executeBatch();ps.clearBatch();}}ps.executeBatch();ps.clearBatch();//所有语句都执行完毕后才手动提交sql语句conn.commit();} catch (SQLException e) {logger.error("insertBatchSql error:{}", e);} finally {jdbcUtils.close(conn, ps);}jdbcutils工具,也可以自己实现
package com.gary.utils.jdbc;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;/*** JDBC工具类** @author byx*/
public class JdbcUtils {private final ConnectionManager connManager;private static Logger logger = LoggerFactory.getLogger(JdbcUtils.class);/*** 创建JdbcUtils** @param dataSource 数据源*/public JdbcUtils(DataSource dataSource) {connManager = new ConnectionManager(dataSource);}public Connection getConnection() {return connManager.getConnection();}public void close(Connection conn, PreparedStatement stmt) {connManager.close(conn, stmt, null);}public PreparedStatement createPreparedStatement1(Connection conn, String sql) throws SQLException {PreparedStatement stmt = conn.prepareStatement(sql);return stmt;}public PreparedStatement createPreparedStatement2(PreparedStatement stmt, Object... params) throws SQLException {for (int i = 0; i < params.length; ++i) {stmt.setObject(i + 1, params[i]);}return stmt;}private PreparedStatement createPreparedStatement(Connection conn, String sql, Object... params) throws SQLException {PreparedStatement stmt = conn.prepareStatement(sql);for (int i = 0; i < params.length; ++i) {stmt.setObject(i + 1, params[i]);}return stmt;}/*** 查询数据库并转换结果集。* 用户可自定义结果集转换器。* 用户也可使用预定义的结果集转换器。** @param sql sql语句* @param resultMapper 结果集转换器* @param params sql参数* @param <T> resultSetMapper返回的结果类型* @return 成功则返回转换结果,失败则抛出DbException,结果为空则返回空列表* @see ResultMapper* @see ListResultMapper* @see SingleRowResultMapper*/public <T> T query(String sql, ResultMapper<T> resultMapper, Object... params) {ResultSet rs = null;PreparedStatement stmt = null;Connection conn = null;try {conn = connManager.getConnection();logger.info("conn:{}", conn);stmt = createPreparedStatement(conn, sql, params);rs = stmt.executeQuery();return resultMapper.map(rs);} catch (SQLException e) {throw new DbException(e.getMessage(), e);} finally {connManager.close(conn, stmt, rs);}}/*** 查询数据库,对结果集的每一行进行转换,然后将所有行封装成列表。* 用户可自定义行转换器。* 用户也可使用预定义的行转换器。** @param sql sql语句* @param rowMapper 行转换器* @param params sql参数* @param <T> rowMapper返回的结果类型* @return 成功则返回结果列表,失败则抛出DbException,结果为空则返回空列表* @see RowMapper* @see BeanRowMapper* @see MapRowMapper* @see SingleColumnRowMapper*/public <T> List<T> queryList(String sql, RowMapper<T> rowMapper, Object... params) {return query(sql, new ListResultMapper<>(rowMapper), params);}/*** 查询数据库,将结果集的每一行转换成JavaBean,然后将所有行封装成列表。** @param sql sql语句* @param type JavaBean类型* @param params sql参数* @param <T> JavaBean类型* @return 成功则返回结果列表,失败则抛出DbException,结果为空则返回空列表*/public <T> List<T> queryList(String sql, Class<T> type, Object... params) {return query(sql, new ListResultMapper<>(new BeanRowMapper<>(type)), params);}/*** 查询数据库,返回结果集中的单个值。* 如果结果集中有多个值,则只返回第一行第一列的值。** @param sql sql语句* @param params sql参数* @param <T> 结果类型* @return 成功则返回结果值,失败则抛出DbException,结果为空则返回null*/public <T> T querySingleValue(String sql, Object... params) {return query(sql, new SingleRowResultMapper<>(new SingleColumnRowMapper<>()), params);}/*** 查询数据库,返回结果集中的单行数据。* 如果结果集中有多行数据,则只返回第一行数据。* 用户可自定义行转换器。* 用户也可使用预定义的行转换器。** @param sql sql语句* @param rowMapper 行转换器* @param params sql参数* @param <T> rowMapper返回的结果类型* @return 成功则返回结果,失败则抛出DbException,结果为空则返回null* @see RowMapper* @see BeanRowMapper* @see MapRowMapper* @see SingleColumnRowMapper*/public <T> T querySingleRow(String sql, RowMapper<T> rowMapper, Object... params) {return query(sql, new SingleRowResultMapper<>(rowMapper), params);}/*** 查询数据库,将结果集中的单行数据转换成JavaBean。** @param sql sql语句* @param type JavaBean类型* @param params sql参数* @param <T> JavaBean类型* @return 成功则返回结果,失败则抛出DbException,结果为空则返回null*/public <T> T querySingleRow(String sql, Class<T> type, Object... params) {return querySingleRow(sql, new BeanRowMapper<>(type), params);}/*** 更新数据库,返回影响行数** @param sql sql语句* @param params sql参数* @return 成功则返回影响行数,失败则抛出DbException*/public int update(String sql, Object... params) {Connection conn = null;PreparedStatement stmt = null;try {conn = connManager.getConnection();stmt = createPreparedStatement(conn, sql, params);return stmt.executeUpdate();} catch (Exception e) {throw new DbException(e.getMessage(), e);} finally {connManager.close(conn, stmt, null);}}/*** 开启事务*/public void startTransaction() {connManager.startTransaction();}/*** 提交事务*/public void commit() {connManager.commit();}/*** 回滚事务*/public void rollback() {connManager.rollback();}/*** 判断当前是否在事务中*/public boolean inTransaction() {return connManager.inTransaction();}
}
Datasource实现
package com.system.modules.utils.jdbc;import com.alibaba.druid.pool.DruidDataSourceFactory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;public class JdbcDataSource {private static Logger logger = LoggerFactory.getLogger(JdbcDataSource.class);// 1. 声明静态数据源成员变量private static DataSource ds;// 2. 创建连接池对象static {logger.info("===数据库初始化====");// 加载配置文件中的数据InputStream is = JdbcUtils.class.getClassLoader().getResourceAsStream("durid.properties");Properties pp = new Properties();try {pp.load(is);logger.info("===数据库初始化====:{}",pp);// 创建连接池,使用配置文件中的参数ds = DruidDataSourceFactory.createDataSource(pp);} catch (IOException e) {logger.info("===数据库初始化====error:{}",e);} catch (Exception e) {logger.info("===数据库初始化====Exception:{}",e);}}// 3. 定义公有的得到数据源的方法public static DataSource getDataSource() {return ds;}
}
durid.propertes 实现:
driverClassName=org.postgresql.Driver url=jdbc:postgresql://100.2.13.2:5432/postgres?reWriteBatchedInserts=true username=root password=123456 initialSize=5 maxActive=50 maxWait=3000
执行时间:

看着速度快了许多。
4.总结
接下来还要研究下,mybatisplus为什么还是慢。
相关文章:
mybatisplus,jdbc 批量插入
1.测试用例 项目中遇到在做导入号码的时候我们会用到批量导入,提高入库的速度。接下来我们以10000条为测试用例。 1.1 批量执行sql语句 当需要成批插入或者更新记录时,可以采用Java的批量更新机制,这一机制允许多条语句一次性提交给数据库…...
如何使用IP归属地查询API来追踪网络活动
引言 在当今数字化世界中,了解网络活动的源头和位置对于网络安全、市场研究和用户体验至关重要。IP归属地查询API是一种强大的工具,可以帮助您追踪网络活动并获取有关IP地址的重要信息。本文将探讨如何使用IP归属地查询API来追踪网络活动,以…...

【SQL】S0 系列博文大纲
系列博文大纲 SQL 学习环境建议系列博文相关书籍系列博文大纲阶段进展 SQL 学习环境建议 对于 SQL 语言的学习,博主本地使用:MySQL DataGrip; MySQL 提供本地数据库服务; DataGrip IDE,承担编程运行测试任务…...
2023年8月体育用品行业数据分析(京东数据产品)
当前,亚运会临近,这也带动了国民对体育消费的热情,体育产品内销逐渐旺盛,“亚运经济”红利开始显现。鲸参谋数据显示,今年8月份,京东平台上体育用品行业的销量为185万,同比增长2%;销…...

国内高校镜像网站
国内各大高校开源镜像站 排名不分前后 清华大学:https://mirrors.tuna.tsinghua.edu.cn/ 北京大学:https://mirrors.pku.edu.cn/ 北京外国语大学:http:// https://mirrors.bfsu.edu.cn/ 北京理工大学:https://mirrors.bit.e…...
Linux安装kafka-manager
相关链接https://github.com/yahoo/kafka-manager/releases kafka-manager-2.0.0.2下载地址 百度云链接:https://pan.baidu.com/s/1XinGcwpXU9YBF46qkrKS_A 提取码:tzvg 一、安装部署 1.把kafka-manager-2.0.0.2.zip拷贝到目录 /opt/app/elk 2.解压…...

MYSQL索引——B+树讲解
B-/B树看 MySQL索引结构 B-树 B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树.它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图. B-树有如下特点: 所有键值分布在整颗树中; 任何一…...
VB将十进制整数转换成16进制以内的任意进制数
VB将十进制整数转换成16进制以内的任意进制数 数值转换,能够将十进制整数转换成16进制以内的任意进制数 Private Function DecToN(ByVal x%, ByVal n%) As StringDim p() As String, y$, r%p Split("0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F", ",")I…...

基于SpringBoot+Vue的宠物领养饲养交流管理平台设计与实现
前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 👇🏻…...
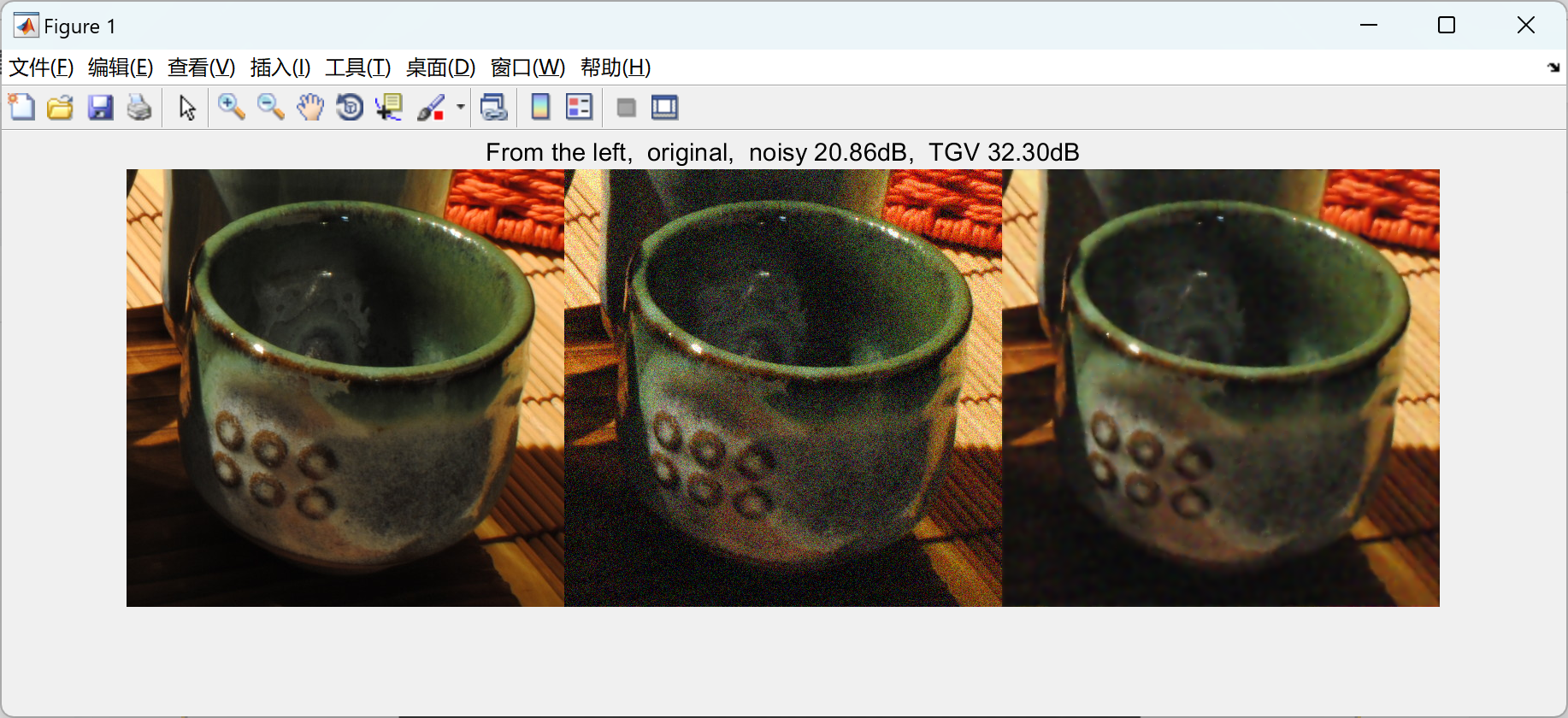
【图像去噪】【TGV 正则器的快速计算方法】通过FFT的总(广义)变化进行图像去噪(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

windbg调试句柄问题
这里写自定义目录标题 winform,句柄资源不够强,程序crash句柄主程序c程序,加载的插件是c# dll,这时候如何用windbg调试dll库如果查看句柄和对象的关系!handle 怎么能知道哪个句柄是Form对话框的句柄如何查看句柄对应的类对象 winf…...
9月13-14日上课内容 第三章 ELK日志分析系统及部署实例
本章结构 ELK日志分析系统简介 ELK日志分析系统分为 Elasticsearch Logstash Kibana 日志处理步骤 1.将日志进行集中化管理 2.将日志格式化(Logstash) 并输出到Elasticsearch 3.对格式化后的数据进行索引和存储 (Elasticsearch) 4.前端数据的展示(Kibana) Elasticsearch介…...

服务器端应用的安装
前言:相信看到这篇文章的小伙伴都或多或少有一些编程基础,懂得一些linux的基本命令了吧,本篇文章将带领大家服务器如何部署一个使用django框架开发的一个网站进行云服务器端的部署。 文章使用到的的工具 Python:一种编程语言&…...

关于硬盘质量大数据分析的思考
近日,看到Backblaze分享了一遍关于硬盘运行监控数据架构的文章,觉得挺有意义的,本文就针对这方面跟大家聊聊。 作为一家在2021年在美国纳斯达克上市的云端备份公司,Backblaze一直保持着对外定期发布HDD和SSD的故障率稳定性质量报告…...
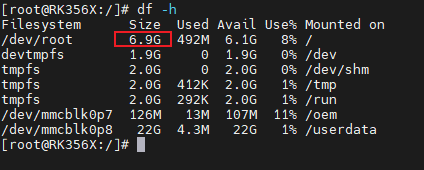
RK3568核心板分区空间不足,如何修改分区大小?
在对评估板进行开发验证时,时常会遇到根目录空间不足的情况,而在其他分区又有冗余空间,这时则需要对分区大小重新进行分配,合理化利用分区空间。 本文将基于HD-RK3568-IOT评估板主要讲解如何修改eMMC分区大小。 1. 分区表介绍…...
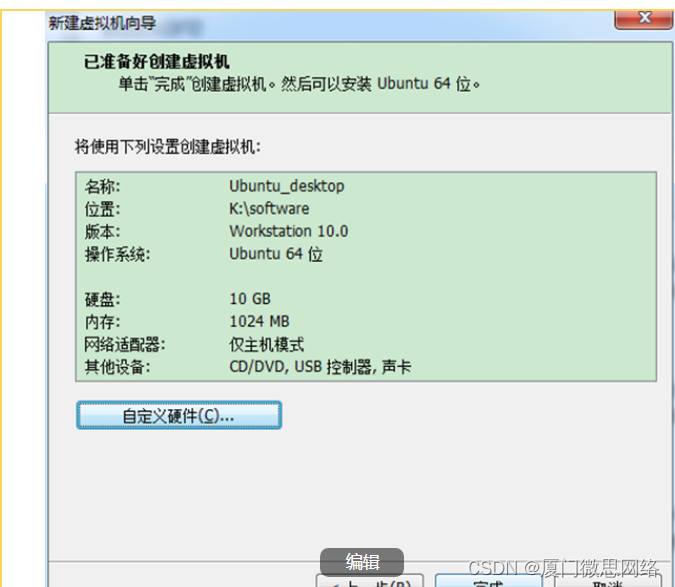
Linux系统怎么修改主机名
【微|信|公|众|号:厦门微思网络】 1.备份主机名文件 首先redhat修改主机名,在进行任何修改之前,请务必备份主机名文件。这样,即使出现意外情况,你也能够轻松恢复到原始状态。使用以下命令备份主机名文件࿱…...

BroadcastChannel方法跨浏览器窗口通信
1. 描述 同源 的不同浏览器窗口,Tab 页,frame 或者 iframe 下的不同文档之间可以通过 BroadcastChannel 相互通信。 2. 构造函数 通过 BroadcastChannel 类传入的参数创建实例,传入的参数将指定通道名称,在同源环境下该通道可以…...
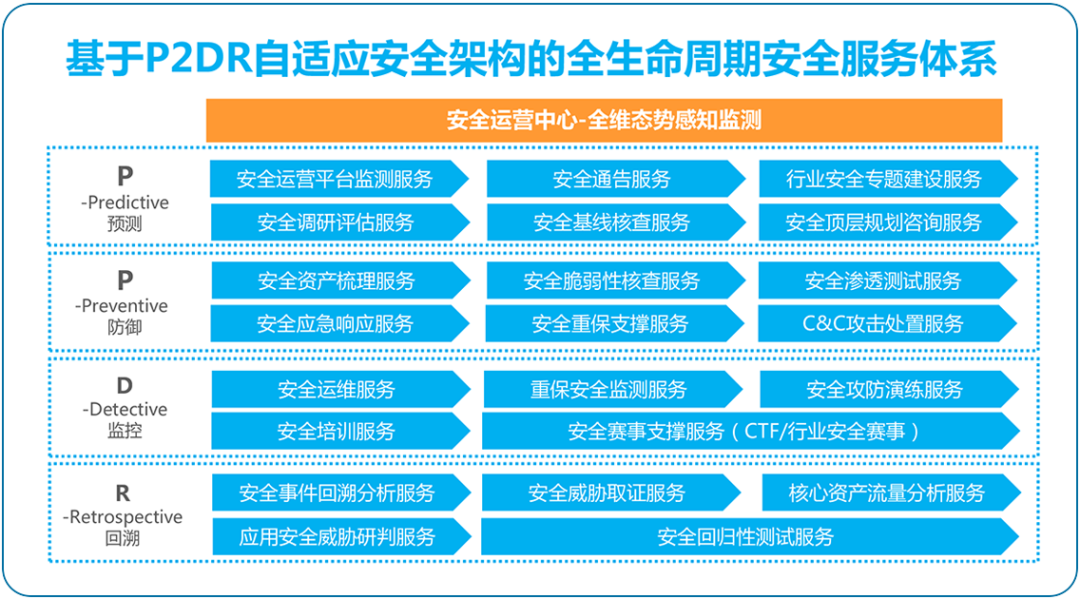
山石网科国产化防火墙,打造全方位边界安全解决方案
互联网的快速发展促进了各行各业的信息化建设,但也随之带来了诸多网络安全风险。大部分组织机构采用统一互联网接入方案,互联网出口承担着内部用户访问互联网的统一出口和对外信息服务的入口,因此在该区域部署相匹配的安全防护手段必不可少。…...
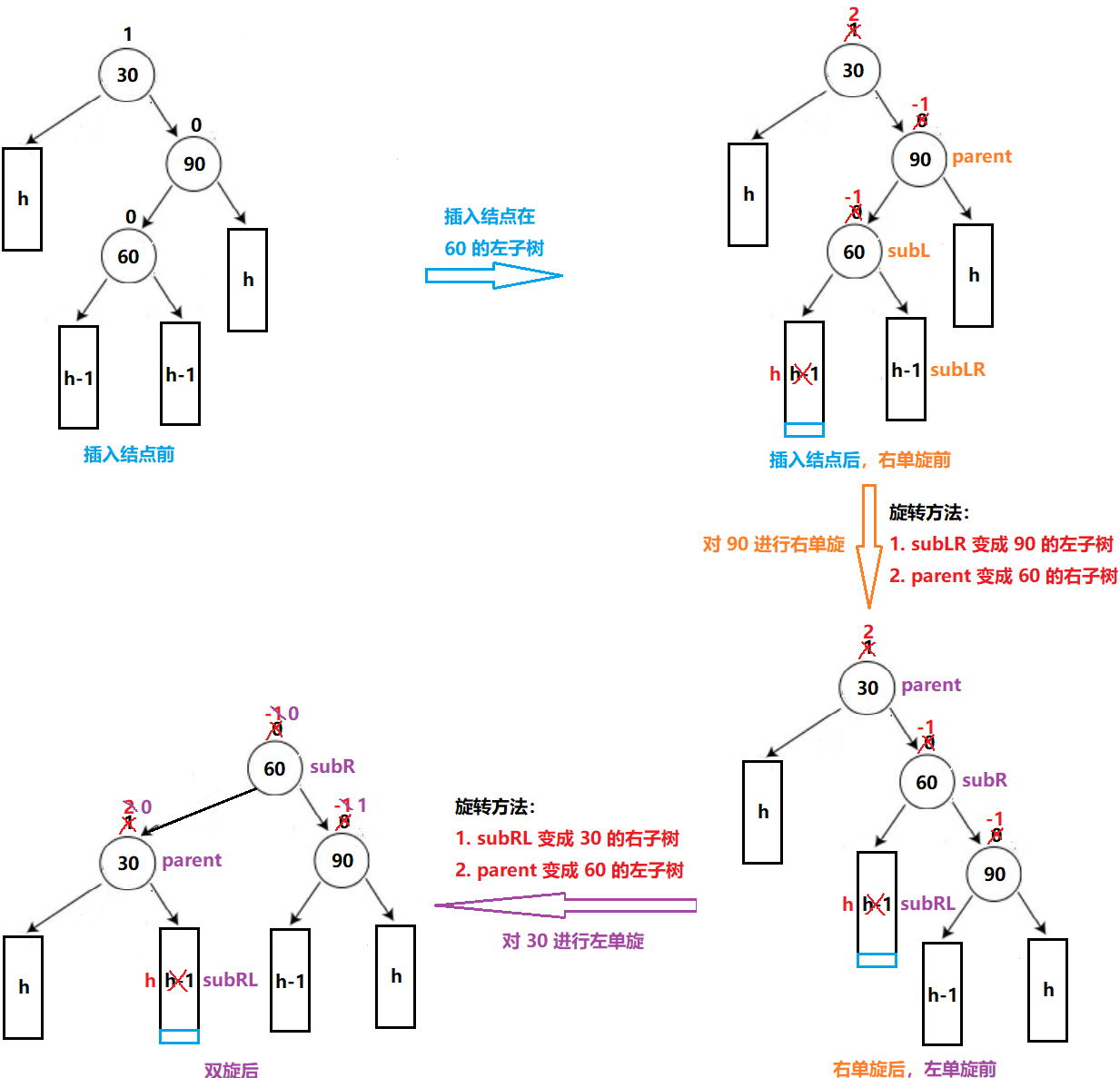
AVL 树
文章目录 一、AVL 树的概念二、AVL 树的实现1. AVL 树的存储结构2. AVL 树的插入 一、AVL 树的概念 在 二叉搜索树 中,当我们连续插入有序的数据时,二叉搜索树可能会呈现单枝树的情况,此时二叉搜索树的查找效率为 O(N) 俄罗斯的两位数学家 …...
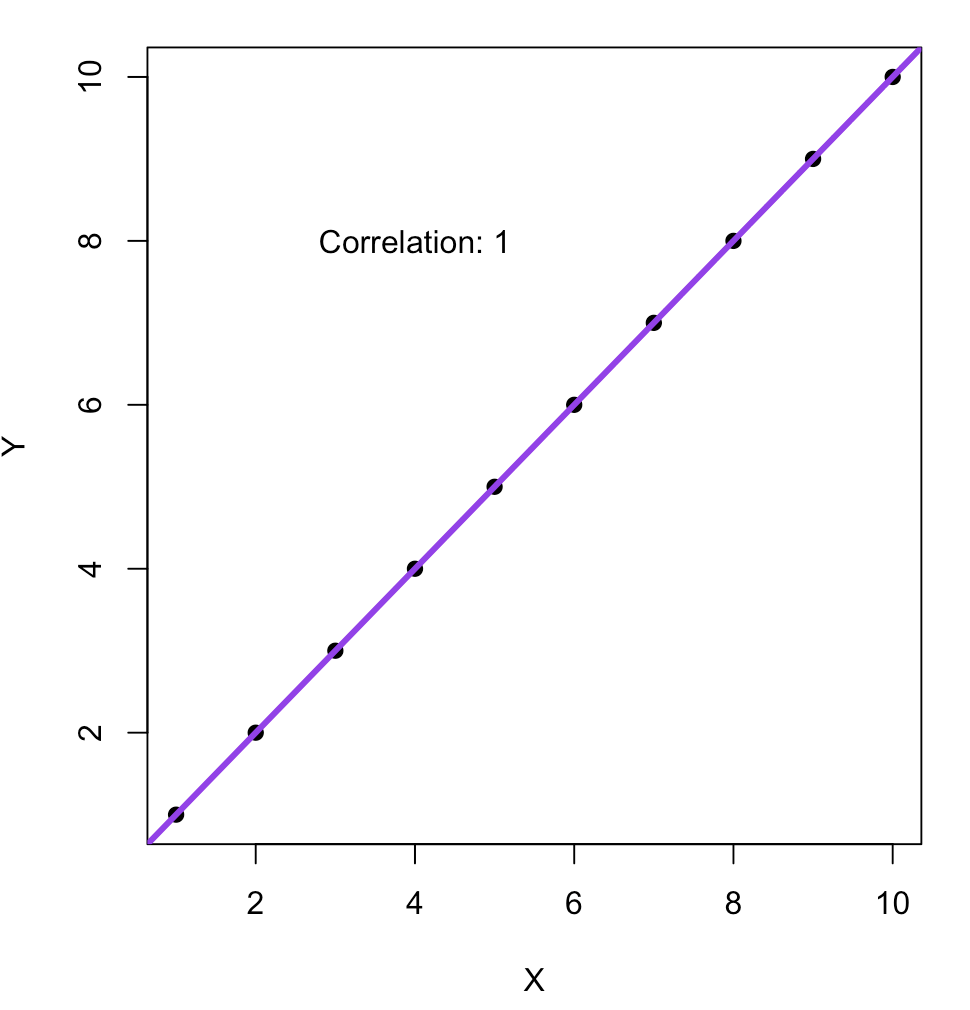
ggplot2做图(填坑中)
数据 df <- data.frame(x 1:10, y 1:10, f c(rep("A", 5), rep("B", 5))) 做图 1. 散点图 (scatter plot) # scatter plot scatter_plot <- function(df, metadata) {identical(rownames(df), rownames(metadata))data <- cbind(df, metada…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...