Hive 优化建议与策略

目录
编辑
一、Hive优化总体思想
二、具体优化措施、策略
2.1 分析问题得手段
2.2 Hive的抓取策略
2.2.1 策略设置
2.2.2 策略对比效果
2.3 Hive本地模式
2.3.1 设置开启Hive本地模式
2.3.2 对比效果
2.3.2.1 开启前
2.3.2.2 开启后
2.4 Hive并行模式
2.5 Hive严格模式
2.5.1 严格模式实现
2.5.2 严格模式下的限制
2.5.2.1 分区表查询限制
2.5.2.1.1 举证
2.5.2.1.2 查询对比
2.5.2.2 Order by 查询限制
2.5.2.2.1 查询对比
2.5.3 笛卡尔乘积查询限制
2.5.3.1 举证
2.5.3.2 查询对比
2.6 Hive排序
2.6.1 Order By
2.6.2 Sort By
2.6.3 Distribute By
2.6.4 Cluster By
2.7 Hive join
2.7.1 自动JOIN
2.7.1.1 自动JOIN设置
2.7.2 手动JOIN
2.7.2.1 手动JOIN语法
2.7.3 大表join大表
2.7.3.1 空key过滤
2.7.3.2 空key转换
2.8 Map-Side聚合
2.8.1 hive.map.aggr
2.8.2 聚合相关配置参数
2.8.2.1 hive.groupby.mapaggr.checkinterval
2.8.2.2 hive.map.aggr.hash.min.reduction
2.8.2.3 hive.map.aggr.hash.percentmemory
2.8.2.4 hive.groupby.skewindata
2.9 合并小文件
2.9.1 设置合并属性
2.9.1.1 hive.merge.mapfiles
2.9.1.2 hive.merge.mapredfiles
2.9.1.3 hive.merge.size.per.task
2.10 合理设置Map以及Reduce的数量
2.10.1 Map数量相关的参数
2.10.1.1 mapred.max.split.size
2.10.1.2 mapred.min.split.size.per.node
2.10.1.3 mapred.min.split.size.per.rack
2.10.2 Reduce数量相关的参数
2.10.2.1 mapred.reduce.tasks
2.10.2.2 hive.exec.reducers.bytes.per.reducer
2.10.2.3 hive.exec.reducers.max
2.11 JVM重用
2.11.1实现方式
2.11.2 适合场景
2.11.3 缺点
一、Hive优化总体思想
Hive的存储层依托于HDFS,Hive的计算层依托于MapReduce,一般Hive的执行效率主要取决于SQL语句的执行效率,因此,Hive的优化的核心思想是MapReduce的优化。
二、具体优化措施、策略
2.1 分析问题得手段
Hive的SQL语句在执行之前需要将SQL语句转换成MapReduce任务,因此需要了解具体的转换过程,可以在SQL语句中输入如下命令查看具体的执行计划。
语法为:
explain [extended] query例如:
explain extended select * from psn8;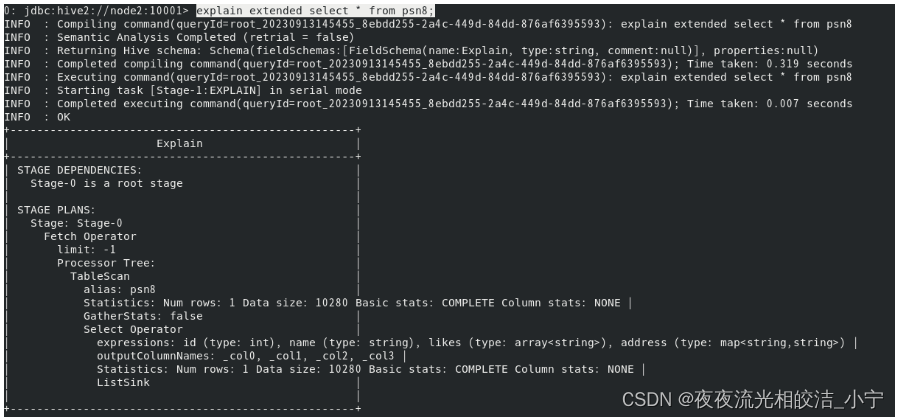
2.2 Hive的抓取策略
Hive的某些SQL语句需要转换成MapReduce的操作,某些SQL语句就不需要转换成MapReduce操作,但是需要注意,理论上来说,所有的SQL语句都需要转换成MapReduce操作,只不过Hive在转换SQL语句的过程中会做部分优化,使某些简单的操作不再需要转换成MapReduce。
2.2.1 策略设置
我们可以通过使用sql语句设置Hive的抓取策略:
set hive.fetch.task.conversion=none/more;或者可以在hive-site.xml配置文件中设置:
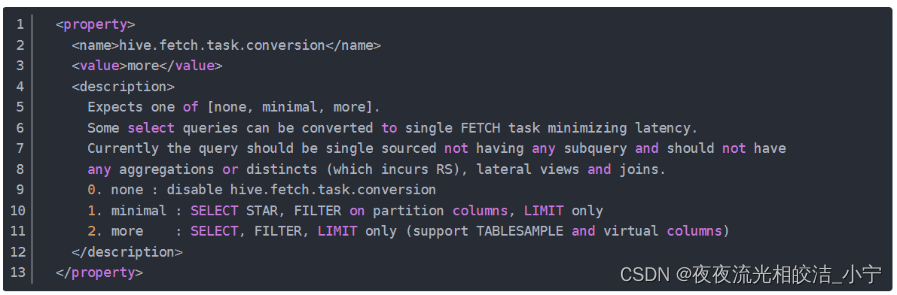
<property><name>hive.fetch.task.conversion</name><value>more</value>
</property>该配置候选值有三个,分别为:
1)none:disable hive.fetch.task.conversion
2)minimal : SELECT STAR, FILTER on partition columns, LIMIT only
3)more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
2.2.2 策略对比效果
我们来看下对比效果:
开启抓取策略前:
关闭一下抓取策略:
set hive.fetch.task.conversion=none;执行查询语句:
select * from psn8;查看执行效果:
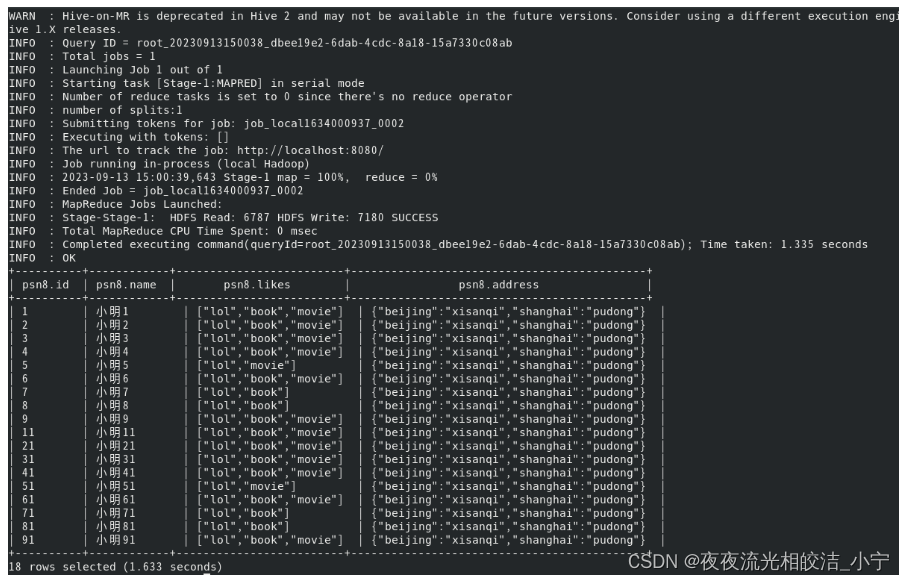
开启抓取策略后:
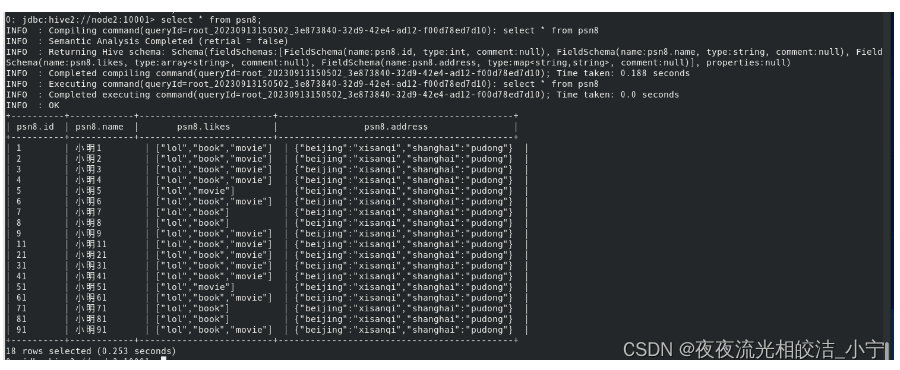
开启抓取策略:
set hive.fetch.task.conversion=more;执行查询语句:
select * from psn8;执行效果:
2.3 Hive本地模式
类似于MapReduce的操作,Hive的运行也分为本地模式和集群模式,在开发阶段可以选择使用本地执行,提高SQL语句的执行效率,验证SQL语句是否正确。
假设你正在运行一些复杂的 Hive 查询,我们都知道这会在后台触发 MapReduce 作业并为你提供输出。如果 Hive 中的数据比较大,这种方法比较有效,但如果Hive 表中的数据比较少,这样会有一些问题。出现此问题的主要原因是 MapReduce 作业被触发,它是在服务器/集群上触发,因此每次运行查询时,它都会上传到服务器并在那里启动 MapReduce,然后输出。因此,为查询触发执行任务的时间消耗可能会比实际作业的执行时间要多的多。
2.3.1 设置开启Hive本地模式
需要满足如下三个配置条件,才能在本地模式下运行 Hive 查询:

| 参数 | 默认值 | 描述 |
| hive.exec.mode.local.auto | false | 让Hive确定是否自动启动本地模式运行 |
| hive.exec.mode.local.auto.inputbytes.max | 134217728(128MB) | 当第一个参数为true时,输入字节小于此值时才能启动本地模式 |
| hive.exec.mode.local.auto.input.files.max | 4 | 当一个参数为true时,任务个数小于此值时才能启动本地模式 |
2.3.2 对比效果
2.3.2.1 开启前
通过命令设置配置:
set hive.exec.mode.local.auto=false;set hive.exec.mode.local.auto.inputbytes.max=134217728;set hive.exec.mode.local.auto.input.files.max=5;执行统计命令:
select count(*) from psn8;查看效果:
我们发现yarn上提交了一个计算任务:
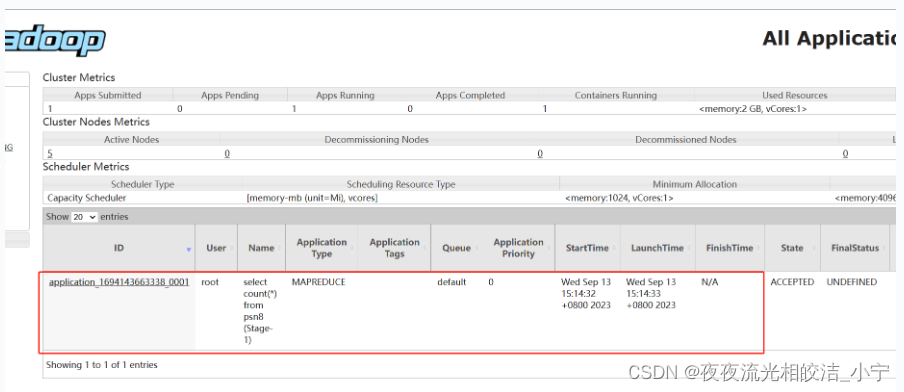
任务执行时间:

我们发现,统计完成花费了54.211秒
2.3.2.2 开启后
通过命令设置配置:
set hive.exec.mode.local.auto=true;执行统计命令:
select count(*) from psn8;查看效果:
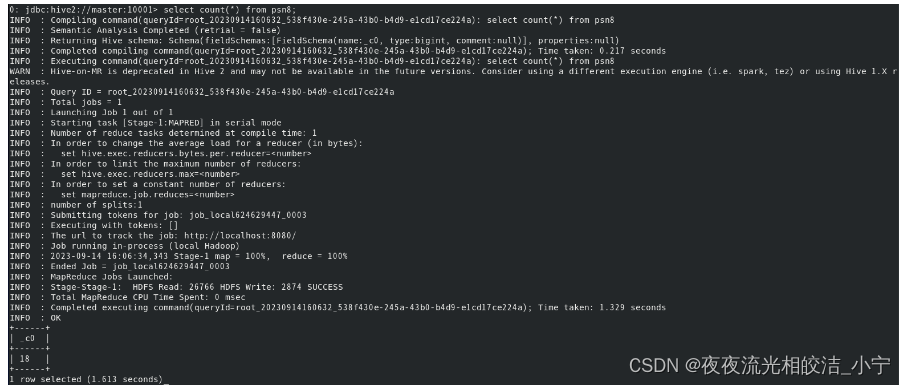
可以看到,设置成本地模式后,耗时1.513秒
2.4 Hive并行模式
在SQL语句足够复杂的情况下,可能在一个SQL语句中包含多个子查询语句,且多个子查询语句之间没有任何依赖关系,此时,可以Hive运行的并行度。
设置命令:
set hive.exec.parallel=true;注意:Hive的并行度并不是无限增加的,在一次SQL计算中,可以通过以下参数来设置并行的job的个数。
设置一次SQL计算允许并行执行的job个数的最大值
设置命令:
set hive.exec.parallel.thread.number2.5 Hive严格模式
Hive中为了提高SQL语句的执行效率,可以设置严格模式,充分利用Hive的某些特点。
2.5.1 严格模式实现
实现命令:
查看当前模式:
set hive.mapred.mode;严格模式:
set hive.mapred.mode=strict;非严格模式:
set hive.mapred.mode=nostrict;2.5.2 严格模式下的限制
2.5.2.1 分区表查询限制
如果在一个分区表执行hive,除非where语句中包含分区字段过滤条件来显示数据范围,否则不允许执行。换句话说, 就是用户不允许扫描所有的分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。
2.5.2.1.1 举证
例子:比如我这里有一张分区表,设置了分区字段age,具体如下:
创建表语句:
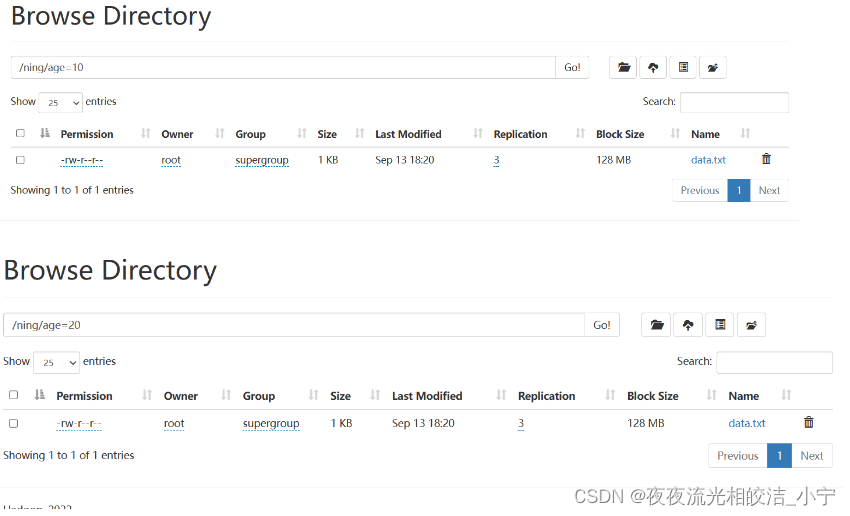
create external table psn11(id int,name string,likes array<string>,address map<string,string>)partitioned by(age int)row format delimitedfields terminated by ','collection items terminated by '-'map keys terminated by ':'location '/ning';在hdfs创建目录并上传文件:
hdfs dfs -mkdir /ning
hdfs dfs -mkdir /ning/age=10
hdfs dfs -mkdir /ning/age=20
hdfs dfs -put /root/data/data /ning/age=10
hdfs dfs -put /root/data/data /ning/age=20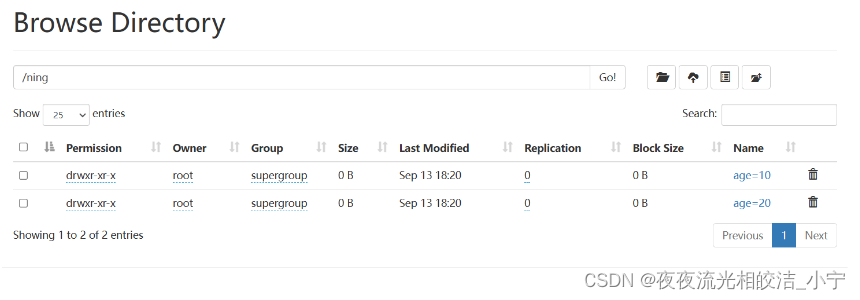
2.5.2.1.2 查询对比
设置严格模式前:
执行命令:
select * from psn11;查询结果:
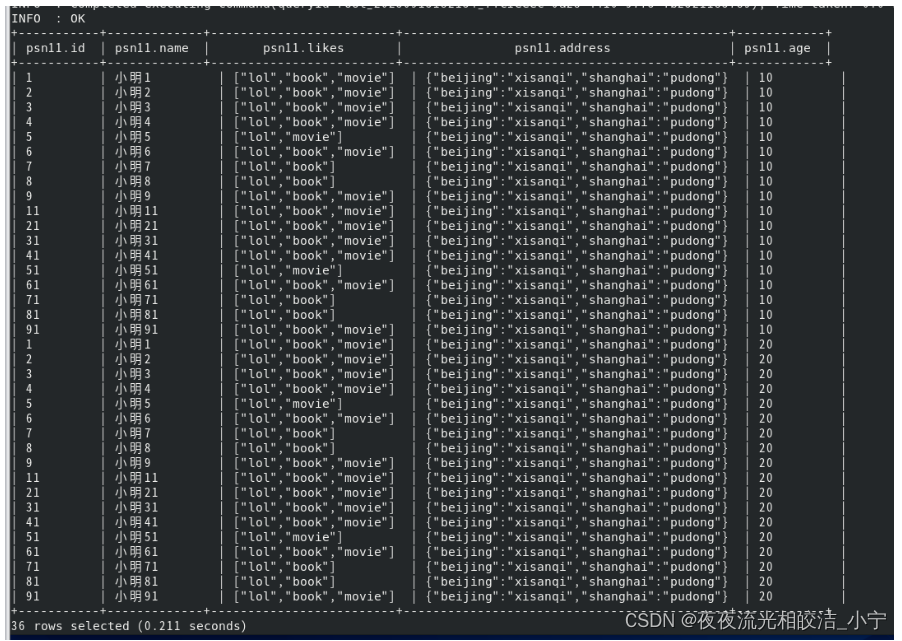
设置严格模式后:
执行命令:
select * from psn11;查询结果:

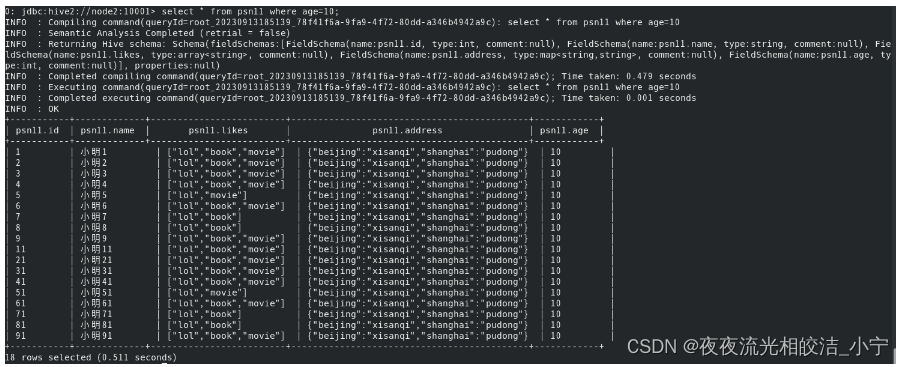
直接报错了,因为严格模式下,不允许扫描所有的分区。
修改后命令:
select * from psn11where age=10;查询结果:
2.5.2.2 Order by 查询限制
对于使用了order by的查询,要求必须有limit语句。因为order by为了执行排序过程会将所有的结果分发到同一个reducer中进行处理,强烈要求用户增加这个limit语句可以防止reducer额外执行很长一段时间。
2.5.2.2.1 查询对比
我们还拿上一小节创建的psn11这张分区表做例子。
在开启严格模式前
执行命令:
select * from psn11 where age=10 order by id;查询效果:
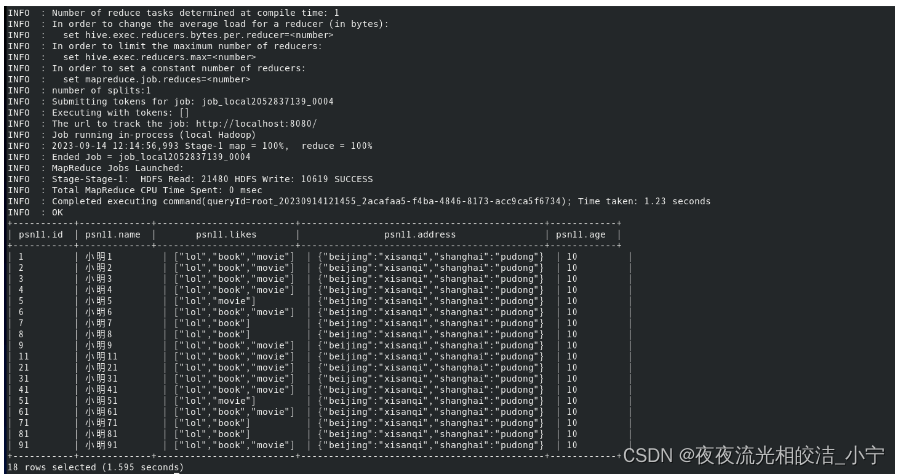
发现查询出了数据。
开启严格模式后:
执行命令:
select * from psn11 where age=10 order by id;查询效果:

开启严格模式后,同样的sql 语句,查询报错了,提示我们需要限制查询数据条数。
修改后指令:
select * from psn11 where age=10 order by id limit 10;查询效果:
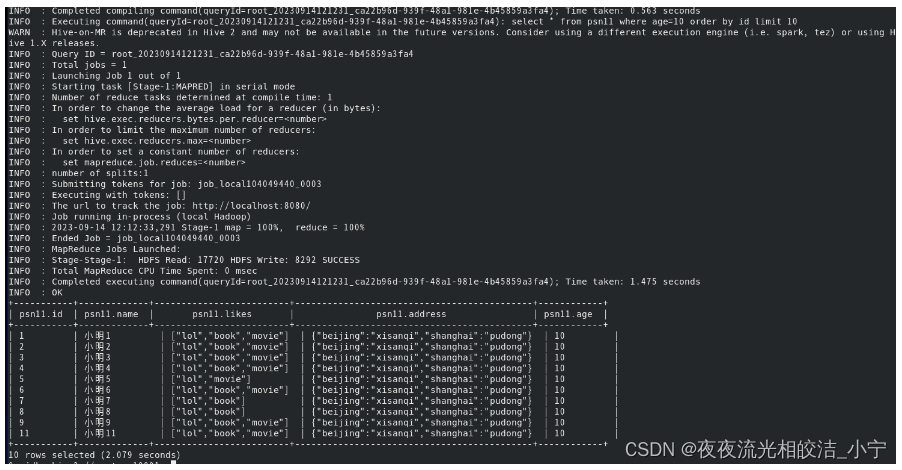
我们加上limit限制查询条数后,发现执行成功了。
2.5.3 笛卡尔乘积查询限制
对关系型数据库非常了解的用户可能期望在执行join查询的时候不使用on语句而是使用where语句,这样关系数据库的执行优化器就可以高效的将where语句转换成那个on语句。but,hive不会执行这种优化,所以如果表足够大,那么这个查询就会出现不可控的情况。
2.5.3.1 举证
我们创建两张表,一张人员表,一张人员课程表
建表语句:
create external table psn14(id int,p_id int,create_time string,name string,number int,learn_time string,)row format delimitedfields terminated by ','location '/data/couses';
create external table psn15(id int,name string,likes array<string>,address map<string,string>)row format delimitedfields terminated by ','collection items terminated by '-'map keys terminated by ':'location '/ning/data';创建目录:
hdfs dfs -mkdir /data/couseshdfs dfs -mkdir /ning/data上传文件:
hdfs dfs -put /opt/hadoop/data/courses1.txt /data/couseshdfs dfs -put /opt/hadoop/data/data1.txt /ning/data2.5.3.2 查询对比
执行笛卡尔乘积
未设置严格模式前:
执行命令:
select * from psn15 JOIN psn14 where1=1;查询结果:
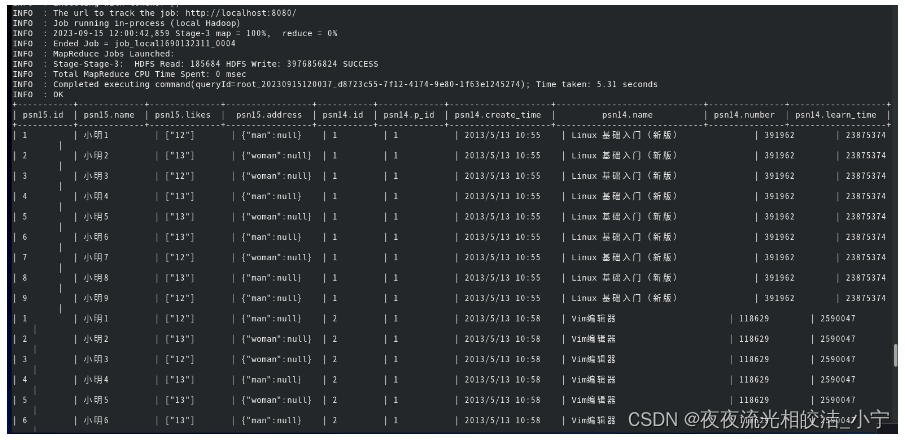
我们发现,查询成功,并且成功关联了数据。
设置严格模式后:
执行命令:
select * from psn15 JOIN psn14 where1=1;查询结果:

开启严格模式后,同样的查询语句,查询报错了。
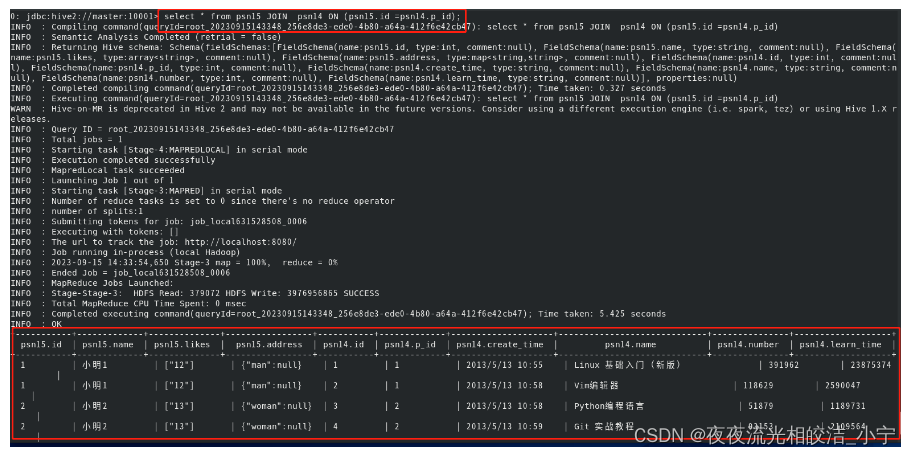
改进查询语句:
select * from psn15 JOIN psn14 ON (psn15.id =psn14.p_id);查询结果:
2.6 Hive排序
在编写SQL语句的过程中,很多情况下需要对数据进行排序操作,Hive中支持多种排序操作适合不同的应用场景。
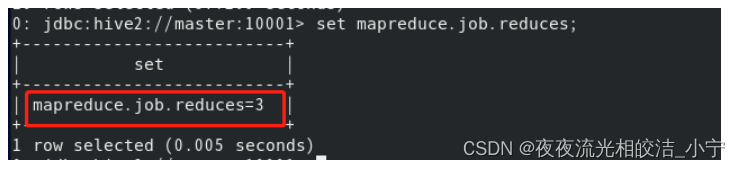
2.6.1 Order By
Order By - 对于查询结果做全排序,只允许有一个reduce处理(当数据量较大时,应慎用。严格模式下,必须结合limit来使用)
我们来验证下:
执行如下语句:
select * from psn14 order by id limit 10;执行结果:
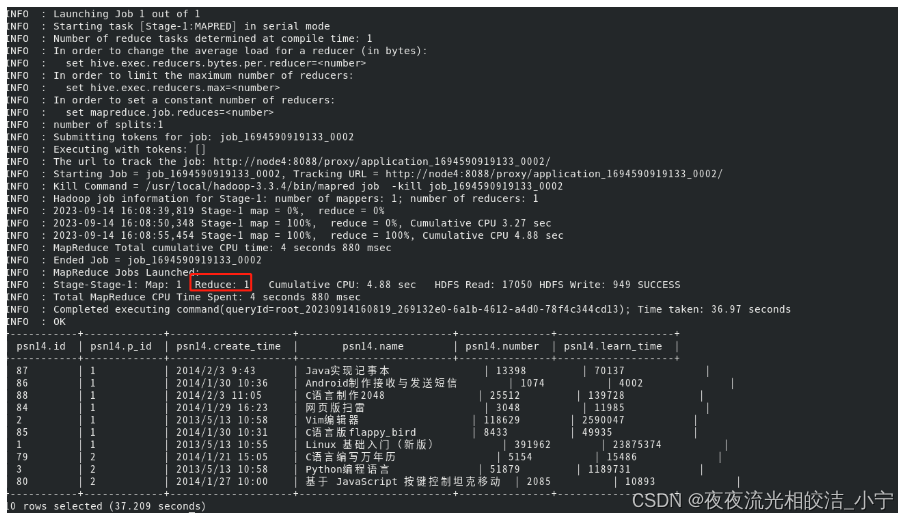
我们可以看到,实际上我们设置了三个reduce,但是order by只是使用了一个reduce计算。
2.6.2 Sort By
对于单个reduce的数据进行排序
我们执行如下语句:
select * from psn14 sort by id;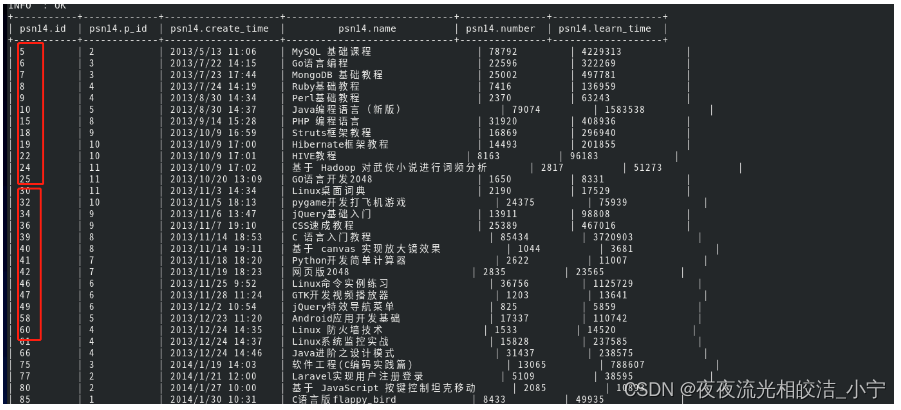
我们可以看到,返回的数据在reduce job中分别进行排序。
2.6.3 Distribute By
有些场景我们需要控制某些特定行应该到同一reducer,做一些聚集操作。
distribute by 类似 MR 中 partition(自定义分区),进行分区,经常结合 sort by 使用。
分区逻辑:根据distribute by 后的字段hash码与reduce 的个数进行模数后,决定分区路由。
我们执行如下语句:
select * from psn14 distribute by p_id sort by number;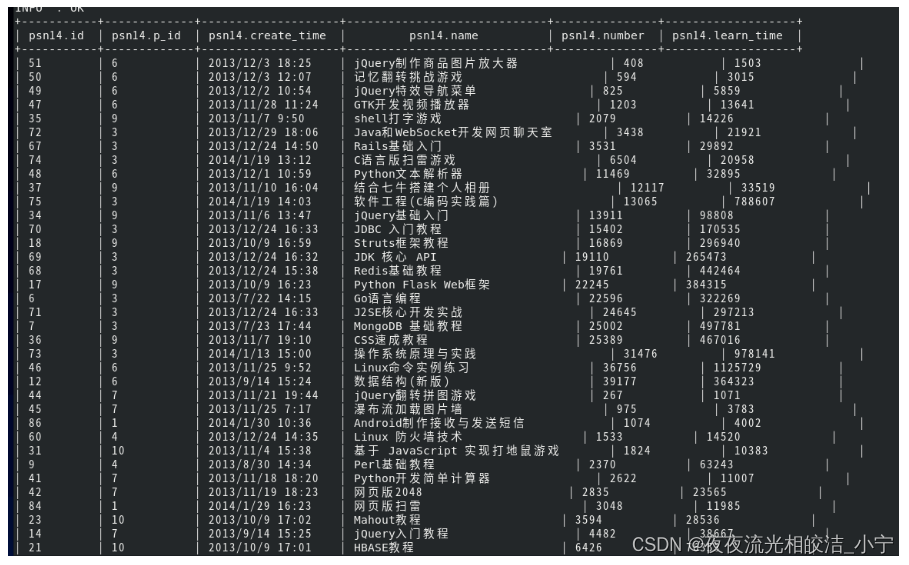
2.6.4 Cluster By
相当于 Sort By + Distribute By(Cluster By不能通过asc、desc的方式指定排序规则;可通过 distribute by column sort by column asc|desc 的方式)。
select * from psn14 cluster by number;执行效果:
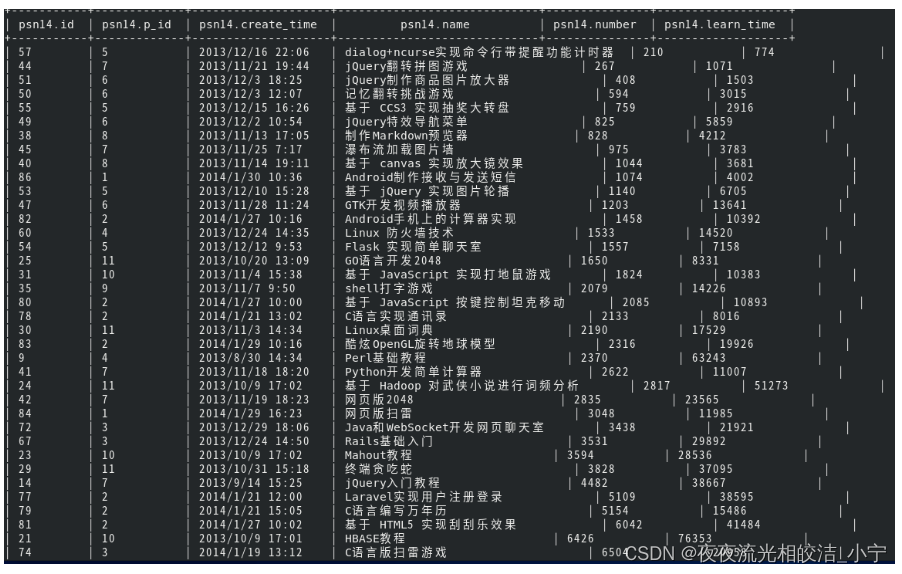
select * from psn14 distribute by number sort by number;执行效果:
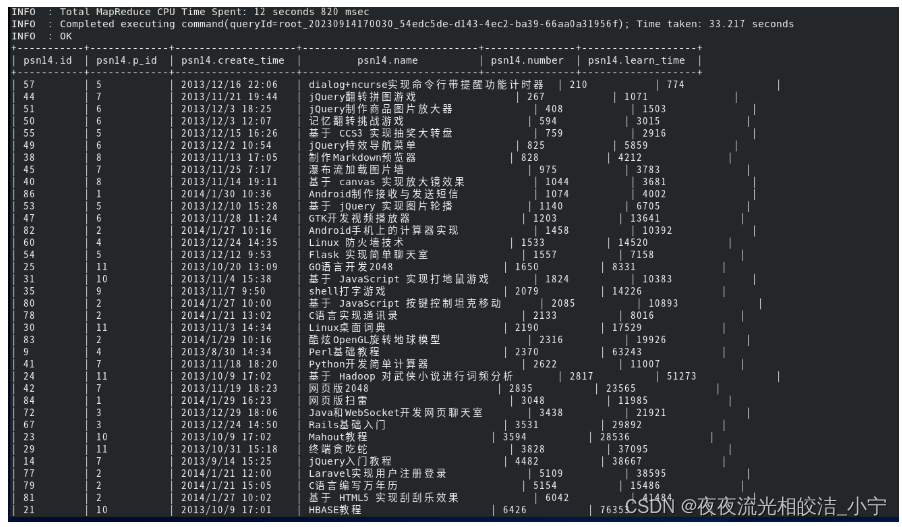
可以看出,两条语句查询的结果是一致的。cluster by 等价于distribute by 和 sort by 字段的升序排序。
2.7 Hive join
小表进行mapjoin,如果在join的表中,有一张表数据量较小,可以存于内存中,这样该表在和其他表join时可以直接在map端进行,省掉reduce过程,效率高。设置方式主要分两种:自动JOIN和手动JOIN。
2.7.1 自动JOIN
2.7.1.1 自动JOIN设置
设置开启自动JOIN:
set hive.auto.convert.join=true;提示:该参数为true时,Hive自动对左边的表统计量,如果是小表就加入内存,即对小表使用Map join。
设置Map JOIN的表的大小(默认为25M):
set hive.mapjoin.smalltable.filesize提示:该参数是大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行。
设置是否忽略mapjoin标记:
set hive.ignore.mapjoin.hint=true;提示:默认值:true;是否忽略mapjoin hint 即mapjoin标记
例子:
select p15.*, p14.* from psn15 p15 JOIN psn14 p14 ON (p15.id =p14.p_id);
2.7.2 手动JOIN
手动Map join在map端完成join操作。
2.7.2.1 手动JOIN语法
SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value
FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key;通过SQL方式,在SQL语句中添加MapJoin标记(mapjoin hint)。
例如:
select /*+ MAPJOIN(p15) */ p15.*,p14.* from psn15 p15 JOIN psn14 p14 ON (p15.id =p14.p_id);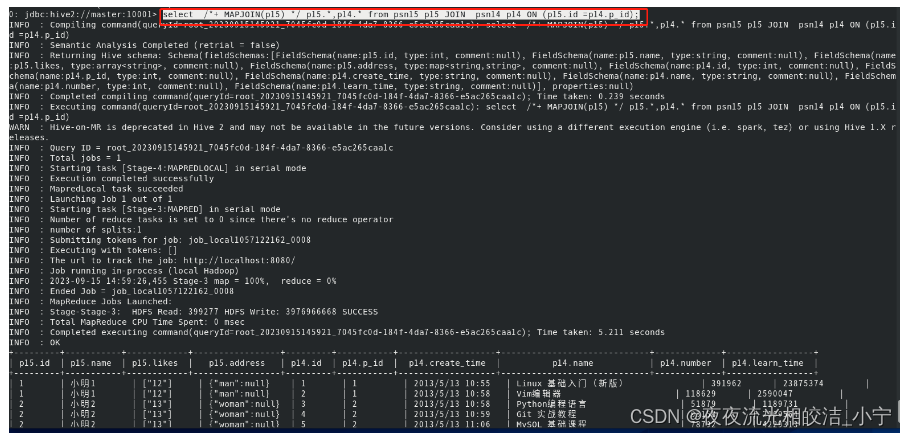
2.7.3 大表join大表
2.7.3.1 空key过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
2.7.3.2 空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。
2.8 Map-Side聚合
Hive的某些SQL操作可以实现map端的聚合,类似于MR的combine操作。
2.8.1 hive.map.aggr
通过设置以下参数开启在Map端的聚合:
set hive.map.aggr=true;2.8.2 聚合相关配置参数
2.8.2.1 hive.groupby.mapaggr.checkinterval
map端group by执行聚合时处理的多少行数据(默认:100000,可根据实际情况修改)
设置命令:
set hive.groupby.mapaggr.checkinterval=100000;2.8.2.2 hive.map.aggr.hash.min.reduction
进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量/100000的值大于该配置0.5,则不会聚合)
设置命令:
set hive.map.aggr.hash.min.reduction=0.5;2.8.2.3 hive.map.aggr.hash.percentmemory
map端聚合使用的内存的最大值(默认值0.5,可根据实际情况修改)
设置命令:
set hive.map.aggr.hash.percentmemory=0.5;2.8.2.4 hive.groupby.skewindata
是否对GroupBy产生的数据倾斜做优化,默认为false
设置命令:
set hive.groupby.skewindata=false;2.9 合并小文件
Hive在操作的时候,如果文件数目小,容易在文件存储端造成压力,给hdfs造成压力,影响效率。
2.9.1 设置合并属性
2.9.1.1 hive.merge.mapfiles
是否合并map输出文件:
set hive.merge.mapfiles=true2.9.1.2 hive.merge.mapredfiles
是否合并reduce输出文件:
set hive.merge.mapredfiles=true;2.9.1.3 hive.merge.size.per.task
合并文件的大小:
set hive.merge.size.per.task=256*1000*10002.10 合理设置Map以及Reduce的数量
2.10.1 Map数量相关的参数
2.10.1.1 mapred.max.split.size
一个split的最大值,即每个map处理文件的最大值
设置命令:
set mapred.max.split.size2.10.1.2 mapred.min.split.size.per.node
一个节点上split的最小值
设置命令:
set mapred.min.split.size.per.node2.10.1.3 mapred.min.split.size.per.rack
一个机架上split的最小值
设置命令:
set mapred.min.split.size.per.rack2.10.2 Reduce数量相关的参数
2.10.2.1 mapred.reduce.tasks
强制指定reduce任务的数量
设置命令:
set mapred.reduce.tasks2.10.2.2 hive.exec.reducers.bytes.per.reducer
每个reduce任务处理的数据量
设置命令:
set hive.exec.reducers.bytes.per.reducer2.10.2.3 hive.exec.reducers.max
每个任务最大的reduce数
设置命令:
set hive.exec.reducers.max2.11 JVM重用
Hadoop的默认配置通常是使用派生JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次。
2.11.1实现方式
执行命令:
set mapred.job.reuse.jvm.num.tasks=n;(n为task插槽个数)2.11.2 适合场景
1)小文件个数过多
2)task个数过多
2.11.3 缺点
开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job中有某几个reduce task执行的时间要比其他Reduce task消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
好了,今天Hive调优的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
相关文章:
Hive 优化建议与策略
目录 编辑 一、Hive优化总体思想 二、具体优化措施、策略 2.1 分析问题得手段 2.2 Hive的抓取策略 2.2.1 策略设置 2.2.2 策略对比效果 2.3 Hive本地模式 2.3.1 设置开启Hive本地模式 2.3.2 对比效果 2.3.2.1 开启前 2.3.2.2 开启后 2.4 Hive并行模式 2.5 Hive…...
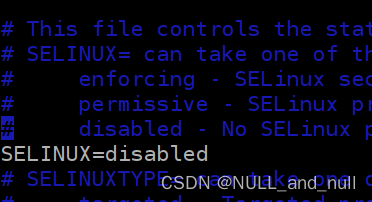
CentOS 7.5 centos failed to load selinux policy 错误解决方法
这是个 selinux 使能导致的, 关闭即可 在进入到内核选中界面,选中要启动的内核, 按键盘 e 就会进入启动参数界面 进入启动参数界面如图,按上下键找到 UTF8 UTF8如图, 添加 selinux0 添加完成如图, 按 ctr…...
注入之SQLMAP(工具注入)
i sqlmap是一个自动化的SQL注入工具,其主要功能是扫描,发现并利用给定的URL和SQL注入漏洞,其广泛的功能和选项包括数据库指纹,枚举,数据库提权,访问目标文件系统,并在获取操作权限时执行任…...

Linux学习资源Index
由于Linux是支撑“云计算”的最核心、最底层、最重要的技术,持续提升自已的Linux水平是必须的,这里将不断更新的Linux学习索引。 书籍 书籍首页 - Documentation (rockylinux.org) WWW链接 提定发行版 RockyLinux Rocky Linux Download Rocky | R…...

什么是SVG(可缩放矢量图形)?它与普通图像格式有何不同?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 什么是SVG?⭐ 与普通图像格式的不同⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚…...

求生之路2服务器搭建插件安装及详细的游戏参数配置教程windows
求生之路2服务器搭建插件安装及详细的游戏参数配置教程windows 大家好我是艾西,最近研究了下 l4d2(求生之路2)这款游戏的搭建以及架设过程。今天就给喜欢l4d2这款游戏的小伙伴们分享下怎么搭建架设一个自己的服务器。毕竟自己当服主是热爱游…...

React TypeScript 定义组件的各种方式
目录 举例说明1. 使用 class 定义2. 使用函数定义2.1 使用普通函数2.2 使用函数组件 举例说明 比如我们要定义一个计数器 Counter,它包含一个 label 和一个 button,计数器的初始值由外部传入,点击 button 计数加 1: 这虽然是个简单组件&…...
)
互联网摸鱼日报(2023-09-20)
互联网摸鱼日报(2023-09-20) 36氪新闻 国货美妆这五年:押注头部主播,追求极致流量中遭反噬 处于水深火热之中的奈飞该如何自救? 一头“灰犀牛”将冲击美国 年轻人花钱的样子变了 金V之后再推橙V,微博正试图重建创作者生态 …...

AWS入列CNCF基金会
7月27日,IT之家曾经报道,微软加入Linux旗下CNCF基金会,在这之后不到一个月的今天,亚马逊AWS也宣布,以铂金身份加入此基金会。 CNCF,全称Cloud Native Computing Fundation,该基金会旨在使得容器…...

岭回归与LASSO回归:解析两大经典线性回归方法
文章目录 🍋引言🍋岭回归(Ridge Regression)🍋实战---岭回归🍋LASSO回归(LASSO Regression)🍋实战---LASSO回归🍋岭回归和LASSO哪个更容易是直线🍋…...
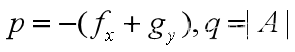
数学建模——微分方程介绍
一、基础知识 1、一阶微分方程 称为一阶微分方程。y(x0)y0为定解条件。 其常规求解方法: (1)变量分离 再两边积分就可以求出通解。 (2)一阶线性求解公式 通解公式: 有些一阶微分方程需要通过整体代换…...

Minio入门系列【7】Spring Boot集成Minio
1 前言 之前介绍了如何使用Minio提供的JAVA SDK进行上传和下载文件,在此基础上,我们可以使用spring boot集成Minio JAVA SDK,添加自动配置、装配、客户端管理等功能,简化开发 2 Spring Boot集成Minio 2.1 环境搭建 首先我们搭…...
)
抖音视频下载.py(23年9月份可用)
声明:仅供学习交流使用!!! 抖音无水印视频下载; 首先登录抖音网页端 打开要下载的视频userId 然后编码实现下载 最后是完整代码,拿走就能用那种: # _*_ coding:utf-8 _*_import json import requests import time import randomheaders = """Accept: a…...

项目基本搭建流程
项目创立:webapp 设置maven 的和settings.xml 的地址 手动建立java文件夹和resource文件夹 一.分层 二.使用generator 来自动建立实体类dao 和dao接口,存放sql文件的xml;并复制到项目中(路径可能可以直接设置) 三. 配置文件&…...
学习pytorch11 神经网络-非线性激活
神经网络-非线性激活 官网文档常用1 ReLUinplace 常用2 Sigmoid 代码logs B站小土堆学习pytorch视频 非常棒的up主,讲的很详细明白 官网文档 https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity 常用1 ReLU 对输入做截断…...
Jenkins学习笔记2
Jenkins下载安装: 从清华源开源镜像站上下载jenkins的安装包: 安装的是这个版本。 关于软件的版本,尽量使用LTS,长期支持。 首先是安装openjdk: yum install fontconfig java-11-openjdk[rootlocalhost soft]# java …...

自动化测试:yaml结合ddt实现数据驱动!
在pythonunittestseleniumddt的框架中,数据驱动常见有以下几种方式实现: Csv/txtExcelYAML 本文主要给大家介绍测试数据存储在YAML文件中的使用场景。首先先来简单介绍一下YAML。 1. 什么是YAML 一种标记语言类似YAML,它实质上是一种通用…...
高效管理,轻松追踪——Chrono Plus for Mac任务管理工具
Chrono Plus for Mac是一款专注于任务管理和跟踪的应用程序。它提供了一种直观、清晰的界面,使您能够轻松创建、安排和分类任务。无论是个人项目还是团队合作,Chrono Plus都能为您提供一种有效组织和管理任务的方式。 这个应用程序具有多种强大的功能&a…...

python项目2to3方案预研
目录 官方工具2to3工具安装参数解释基本使用工具缺陷 future工具安装参数解释基本使用工具缺陷 python-modernize工具安装参数解释基本使用工具缺陷 pyupgrade工具安装参数解释基本使用工具缺陷 对比 官方工具2to3 2to3 是Python官方提供的用于将Python 2代码转换为Python 3代…...

MongoDB 是什么和使用场景概述(技术选型)
一、从NOSQL(Not Only SQL)说起 常见的数据库可以分为下面的两种类型: RDBMS(关系型数据库):常见的关系型数据库有 Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL;NoSQL(非关系型数据库&a…...

BusyBox实战案例:构建救援磁盘和Live CD系统
BusyBox实战案例:构建救援磁盘和Live CD系统 【免费下载链接】busybox BusyBox mirror 项目地址: https://gitcode.com/gh_mirrors/bu/busybox BusyBox是一款集成了数百个Linux常用命令的工具集合,被广泛称为"嵌入式Linux的瑞士军刀"。…...

TermuxBlack故障排除:常见安装问题和解决方案完整清单
TermuxBlack故障排除:常见安装问题和解决方案完整清单 【免费下载链接】TermuxBlack Termux repository for hacking tools and packages 项目地址: https://gitcode.com/gh_mirrors/te/TermuxBlack TermuxBlack是一个专注于提供黑客工具和软件包的Termux仓库…...

gh_mirrors/in/invoice图像预处理技术:从原始图片到可识别文本
gh_mirrors/in/invoice图像预处理技术:从原始图片到可识别文本 【免费下载链接】invoice Collaboration with wangxupeng(https://github.com/wangxupeng) 项目地址: https://gitcode.com/gh_mirrors/in/invoice gh_mirrors/in/invoice项目是一款专注于发票图…...

设计稿自动化解析:从Figma到代码的设计令牌提取实战
1. 项目概述:从设计稿到代码的自动化提取 最近在跟一个前端团队合作,他们被一个老生常谈但又极其消耗人力的环节卡住了脖子:UI设计稿的还原。设计师在Figma或Sketch里交付了精美的界面,但前端工程师需要手动测量间距、提取颜色值、…...

AI代码助手本地部署指南:从原理到实践,打造专属编程副驾驶
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的项目,叫skibidiskib/ai-codex。光看这个名字,可能有点抽象,但点进去研究了一下,发现它本质上是一个围绕AI代码生成与辅助编程的工具集或框架。这类项目…...

AI代理成本管理:基于MCP协议构建成本监控与预算控制系统
1. 项目概述:一个为AI代理成本管理而生的MCP服务器最近在折腾AI应用开发,特别是基于大语言模型的智能代理(Agent)时,发现一个挺头疼的问题:成本不可控。你给Agent接上各种工具,让它去调用搜索引…...
)
TypeScript 对列,实现消息队列(FIFO显示+定时清理)
使用对列实现消息接收显示与清除, 根据消息的【显示时间】来清除,显示超过 10 秒的自动清理,未显示、显示不足 10 秒的都保留线程安全 Queue/*** 纯先进先出(FIFO)队列独立实现* 支持:入队、出队、查看队头…...

向AI证明“我不是AI”?2026年毕业生必须搞懂的降重降AIGC问题,今天交给宏智树AI一次说清
宏智树AI官网:www.hzsxueshu.com | 微信公众号搜一搜:宏智树AI 大家好,我是你们的论文科普博主,专门帮大家攻克论文写作的各种疑难杂症。 如果你正在经历毕业季,一定听说过这样的场景:有人把《滕王阁序》…...

Zotero Style插件终极指南:5个简单步骤打造个性化文献管理系统
Zotero Style插件终极指南:5个简单步骤打造个性化文献管理系统 【免费下载链接】zotero-style Ethereal Style for Zotero 项目地址: https://gitcode.com/GitHub_Trending/zo/zotero-style 还在为海量文献管理而烦恼吗?Zotero Style插件正是你需…...

AD8232开源心电监测系统:从传感器到可视化平台的完整技术架构
AD8232开源心电监测系统:从传感器到可视化平台的完整技术架构 【免费下载链接】AD8232_Heart_Rate_Monitor AD8232 Heart Rate Monitor 项目地址: https://gitcode.com/gh_mirrors/ad/AD8232_Heart_Rate_Monitor AD8232开源心电监测系统构建了一个从生物电信…...