排序算法:归并排序(递归和非递归)
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关排序算法的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、

目录
1.归并排序
1.1递归版本
代码演示:
1.2非递归版本
代码演示:
测试排序:
改正代码1:
测试排序:
改正代码2:
1.3递归版本的优化
代码演示:
2.归并排序特性
1.归并排序
基本思想:归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤: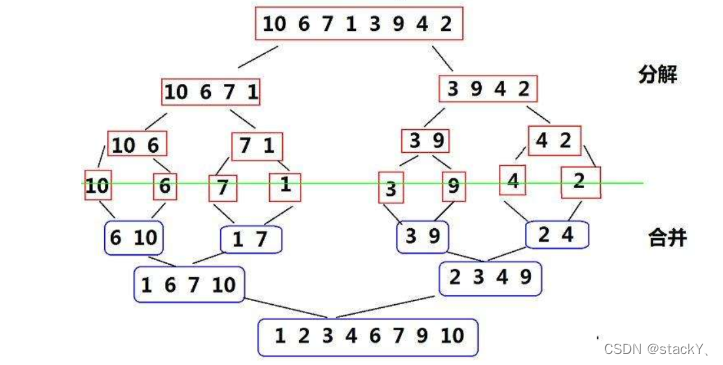
归并排序也分为递归和非递归版本,下面我们就来逐步学习:
1.1递归版本
从上面的图中我们可以看出归并排序是分为两个阶段分解和合并,那么转化为代码的思想就是先划分小区间,然后将区间中最小的单独拿出来在另外的一个数组中进行尾插,等到最后一组数据排完之后,再将尾插排序完的整个数组再拷贝至原数组,这样子就完成了整个数组的排序。
那么通过这个过程可以发现:归并排序是需要单独开一个数组的,所以它的
空间复杂度是O(N),另外归并排序是先划分小区间再进行排序,那么就和二叉树中的后序遍历逻辑类似,先将整个数据一分为二,使得左区间和右区间有序,然后再将左右两个区间进行排序,那么整个数据就有序了,所以需要让左右区间再有序,也需要将做右区间各划分为两个区间,并且让它们的左右区间再有序,以此类推,直到区间内只剩一个数据就不需要再划分了,然后取两个区间小的值尾插到单独的一个数组,最后再次整体拷贝至原数组。
在递归时要注意几个问题:
1. 在递归的时候需要保存两个区间的起始和终止位置,以便访问。
2. 当一个区间已经尾插完毕,那么直接将另外一个区间的数据依次尾插。
3. 两个区间的数据都尾插完毕至tmp数组时,需要将tmp数组的数据再次拷贝至原数组。
4. 在拷贝到原数组时需要注意尾插的哪一个区间就拷贝哪一个区间。
代码演示:
void _MergerSort(int* a, int begin, int end, int* tmp) {//递归截止条件if (begin == end)return;//划分区间int mid = (begin + end) / 2;//[begin,mid] [mid+1,end]//递归左右区间_MergerSort(a, begin, mid, tmp);_MergerSort(a, mid + 1, end, tmp);//将区间保存int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;//取两个区间小的值尾插//一个区间尾插完毕另一个区间直接尾插即可while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//再将剩余数据依次尾插//哪个区间还没有尾插就尾插哪一个while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//再重新拷贝至原数组//尾插的哪个区间就将哪个区间拷贝memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1)); }//归并排序 void MergerSort(int* a, int n) {//先创建一个数组int* tmp = (int*)malloc(sizeof(int) * n);_MergerSort(a, 0, n - 1, tmp);//释放free(tmp); }
归并排序的特性总结:1. 归并的缺点在于需要 O(N) 的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。2. 时间复杂度: O(N*logN)3. 空间复杂度: O(N)4. 稳定性:稳定
1.2非递归版本
由于递归代码在数据太多时可能会因为递归太深出现问题,所以我们也需要写出它们所对应的非递归版本的排序代码:非递归版本的归并排序直接可以使用循环来完成,但是坑点非常多,接下来我们就来慢慢排查。
我们可以先一个数据为一组,然后两两进行排序,然后将排序完的整体结果再重新拷贝至原数组,这样子就完成了一次排序,然后再将排序完的结果两个数据为一组,然后两两排序,然后将排序完的数据再拷贝至原数组,这样子就完成了第二次的排序,然后将数据四个分为一组,两两进行排序,再将排序完的数据拷贝至原数组,直到每组的数据超过或者等于数据的总长度即不需要在进行排序。
首先我们先创建一个开辟一个数组,然后设置一个gap用来分组,然后记录两个区间,对两个区间的数进行比较,小的尾插,再将剩余数据继续尾插,然后完成了一趟排序,再将排完序的数据再拷贝至原数组,再将gap * 2,继续完成剩余的排序,直到划分组的gap大于等于数据总长度即可完成全部的排序:
代码演示:
//归并排序 //非递归 void MergerSortNonR(int* a, int n) {//创建数组int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("tmp");exit(-1);}//划分组数int gap = 1;while (gap < n){int j = 0;for (int i = 0; i < n; i += 2 * gap){//将区间保存int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//取两个区间小的值尾插//一个区间尾插完毕另一个区间直接尾插即可while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}//再将剩余数据依次尾插//哪个区间还没有尾插就尾插哪一个while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}//将数据重新拷贝至原数组memcpy(a, tmp, sizeof(int) * n);//更新gapgap *= 2;}//释放free(tmp); }测试排序:
void PrintArry(int* a, int n) {for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n"); }void TestMergerSortNonR() {int a[] = { 10,6,7,1,3,9,4,2 };PrintArry(a, sizeof(a) / sizeof(int));MergerSortNonR(a, sizeof(a) / sizeof(int));PrintArry(a, sizeof(a) / sizeof(int)); }int main() {TestMergerSortNonR();return 0; }
可以看到排序完成,而且还完成的不错,那么我们再来几组数据进行测试:
在这里我们使用的是8个数据,那如果我们使用9个或者10个数据呢?
void PrintArry(int* a, int n) {for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n"); }void TestMergerSortNonR() {int a[] = { 10,6,7,1,3,9,4,2,8,5 };PrintArry(a, sizeof(a) / sizeof(int));MergerSortNonR(a, sizeof(a) / sizeof(int));PrintArry(a, sizeof(a) / sizeof(int)); }int main() {TestMergerSortNonR();return 0; }
可以看到数据发生错误,那么到底是为什么呢?我们可以来一起观察一下:
随着gap的2倍递增,那么会发生数据区间越界的问题,因为当数据是10个的时候,gap会递增到8,因此在访问数据的时候会发生越界,我们也可以观察一下这个越界的现象:
可以将数据访问的区间打印出来:
那么该怎么解决这个问题呢?
1. 首先不能排完一次序然后将数据整体拷贝,需要排完一组,拷贝一组。
2. 其次当发生越界中的第一、二种时可以直接break。
3. 当发生越界中的第三种时可以将边界进行修正。
改正代码1:
//归并排序 //非递归 void MergerSortNonR(int* a, int n) {//创建数组int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("tmp");exit(-1);}//划分组数int gap = 1;while (gap < n){int j = 0;for (int i = 0; i < n; i += 2 * gap){//将区间保存int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//end1和begin2越界直接跳出if (end1 >= n || begin2 >= n){break;}//end2越界可以进行修正if (end2 >= n){end2 = n - 1;}//取两个区间小的值尾插//一个区间尾插完毕另一个区间直接尾插即可while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}//再将剩余数据依次尾插//哪个区间还没有尾插就尾插哪一个while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}//归并一组,拷贝一组memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}//释放free(tmp); }测试排序:
void PrintArry(int* a, int n) {for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n"); }void TestMergerSortNonR() {int a[] = { 10,6,7,1,3,9,4,2,8,5 };PrintArry(a, sizeof(a) / sizeof(int));MergerSortNonR(a, sizeof(a) / sizeof(int));PrintArry(a, sizeof(a) / sizeof(int));printf("\n");int a2[] = { 10,6,7,1,3,9,4,2 };PrintArry(a2, sizeof(a2) / sizeof(int));MergerSortNonR(a2, sizeof(a2) / sizeof(int));PrintArry(a2, sizeof(a2) / sizeof(int));printf("\n");int a3[] = { 10,6,7,1,3,9,4,2,8 };PrintArry(a3, sizeof(a3) / sizeof(int));MergerSortNonR(a3, sizeof(a3) / sizeof(int));PrintArry(a3, sizeof(a3) / sizeof(int));printf("\n");}int main() {TestMergerSortNonR();return 0; }
改正过后就完全的解决了越界的问题,那么这种改进方法是归并一组,拷贝一组。





我们也可以将全部越界的区间进行修正,然后排序完一次将整个数据拷贝。
改正代码2:
将越界区间全部修正也是可以达到改进的目的,我们就以归并数据的逻辑为基础,然后修改区间,因此需要将越界的区间改为不存在的区间即可:
//归并排序 //非递归 //改进代码2: void MergerSortNonR(int* a, int n) {//创建数组int* tmp = (int*)malloc(sizeof(int) * n);//划分组数int gap = 1;while (gap < n){int j = 0;for (int i = 0; i < n; i += 2 * gap){//将区间保存int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//将越界的区间修改为不存在的区间if (end1 >= n){end1 = n - 1;//修改为不存在的区间begin2 = n;end2 = n - 1;}else if (begin2 >= n){//不存在的区间begin2 = n;end2 = n - 1;}else if (end2 >= n){end2 = n - 1;}//取两个区间小的值尾插//一个区间尾插完毕另一个区间直接尾插即可while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}//再将剩余数据依次尾插//哪个区间还没有尾插就尾插哪一个while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}//整体拷贝memcpy(a, tmp, sizeof(int) * n);gap *= 2;}//释放free(tmp); }
1.3递归版本的优化
当数据量非常多的时候使用递归版本可以进行一个优化,当递归到小区间的时候,我们可以采用插入排序来进行优化,这个优化只限于递归版本,在进行小区间中的插入排序时需要注意在前面的步骤递归到了哪个区间就使用插入排序排序哪个区间,所以在进行插入排序的时候需要注意排序的区间。
代码演示:
void _MergerSort(int* a, int begin, int end, int* tmp) {//递归截止条件if (begin == end)return;小区间优化//区间过小时直接使用插入排序,减少递归损耗if (end - begin + 1 < 10){// 注意排序的区间InsertSort(a + begin, end - begin + 1); return;}//划分区间int mid = (begin + end) / 2;//[begin,mid] [mid+1,end]//递归左右区间_MergerSort(a, begin, mid, tmp);_MergerSort(a, mid + 1, end, tmp);//将区间保存int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;//取两个区间小的值尾插//一个区间尾插完毕另一个区间直接尾插即可while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//再将剩余数据依次尾插//哪个区间还没有尾插就尾插哪一个while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//再重新拷贝至原数组//尾插的哪个区间就将哪个区间拷贝memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1)); }//归并排序 void MergerSort(int* a, int n) {//先创建一个数组int* tmp = (int*)malloc(sizeof(int) * n);_MergerSort(a, 0, n - 1, tmp);//释放free(tmp); }
2.归并排序特性
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。2. 时间复杂度:O(N*logN)3. 空间复杂度:O(N)4. 稳定性:稳定
朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!
相关文章:

排序算法:归并排序(递归和非递归)
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关排序算法的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入门到精通…...
数据可视化
一、Flask介绍 #通过访问路径,获取用户的字符串参数 app.route(/user/<name>) def welcome(name):return "你好,%s"%nameapp.route(/user/<int:id>) def welcome2(id):return "你好,%d号的会员"%id能够自动…...
Go并发可视化解释 – select语句
上周,我发布了一篇关于如何直观解释Golang中通道(Channel)的文章。如果你对通道仍然感到困惑,请先查看那篇文章。 Go并发可视化解释 — Channel 作为一个快速复习:Partier、Candier和Stringer经营着一家咖啡店。Partie…...
http的网站进行访问时候自动跳转至https
通常情况下我们是用的都是http的路径,对于https的使用也很少,但是随着https的普及越来越多的域名访问需要用到https的,这个我们就演示怎么设置在我们对一个http的网站进行访问时候自动跳转至https下。 用到的工具及软件: 系统:wi…...

realloc
目录 前提须知: 函数介绍: 函数原型: 使用realloc: realloc在调整内存空间的是存在两种情况/使用realloc为扩大空间的两种情况 1.是剩下的没有被分配的空间足够 2 .剩下没有被分配的空间不够了 注意事项: rea…...
Windows AD域使用Linux Samba
Windows AD域使用Linux Samba 1. 初始化配置 1.1 初始化配置 配置服务器名 hostnamectl set-hostname samba.sh.pana.cnhosts文件配置,确保正常解析到本机和域控 [rootcentos7 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.loc…...

Scrapy+Selenium自动化获取个人CSDN文章质量分
前言 本文将介绍如何使用Scrapy和Selenium这两个强大的Python工具来自动获取个人CSDN文章的质量分数。我们将详细讨论Scrapy爬虫框架的使用,以及如何结合Selenium浏览器自动化工具来实现这一目标。无需手动浏览每篇文章,我们可以轻松地获取并记录文章的…...

【Android Framework系列】第15章 Fragment+ViewPager与Viewpager2相关原理
1 前言 上一章节【Android Framework系列】第14章 Fragment核心原理(AndroidX版本)我们学习了Fragment的核心原理,本章节学习常用的FragmentViewPager以及FragmentViewPager2的相关使用和一些基本的源码分析。 2 FragmentViewPager 我们常用的两个Page…...

typeof的作用
typeof 是 JavaScript 中的一种运算符,用于获取给定值的数据类型。 它的作用是返回一个字符串,表示目标值的数据类型。通过使用 typeof 运算符,我们可以在运行时确定一个值的类型,从而进行相应的处理或逻辑判断。 常见的数据类型…...

性能测试 —— Tomcat监控与调优:status页监控
Tomcat服务器是一个免费的开放源代码的Web 应用服务器,Tomcat是Apache 软件基金会(Apache Software Foundation)Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。 Tomcat是一个轻量级应用服务器,在中小型系统…...

Ubuntu 安装 CUDA 与 CUDNN GPU加速引擎
一、NVIDIA(英伟达)显卡驱动安装 NVIDIA显卡驱动可以通过指令sudo apt purge nvidia*删除以前安装的NVIDIA驱动版本,重新安装。 1.1. 关闭系统自带驱动nouveau 注意!在安装NVIDIA驱动以前需要禁止系统自带显卡驱动nouveau…...
pdf文件太大如何处理?教你pdf压缩简单方法
PDF文件过大,是很多人在使用PDF文件时都遇到过的一个常见问题,过大的PDF文件不仅会占用大量的存储空间,还会影响文件传输和处理效率,下面给大家总结了几个方法,帮助大家解决PDF文件过大的问题。 方法一:嗨格…...
——nacos注册中心(1))
Nacos使用教程(二)——nacos注册中心(1)
文章目录 Nacos vs Eureka介绍架构设计Nacos架构Eureka架构 功能特性服务注册与发现配置管理健康检查 生态系统支持可用性与稳定性总结 Nacos中的CAP原则介绍CAP原则一致性(Consistency)可用性(Availability)分区容错性࿰…...

蓝桥杯2023年第十四届省赛真题-买瓜--C语言题解
目录 蓝桥杯2023年第十四届省赛真题-买瓜 题目描述 输入格式 输出格式 样例输入 样例输出 提示 【思路解析】 【代码实现】 蓝桥杯2023年第十四届省赛真题-买瓜 时间限制: 3s 内存限制: 320MB 提交: 796 解决: 69 题目描述 小蓝正在一个瓜摊上买瓜。瓜摊上共有 n 个…...
R语言进行孟德尔随机化+meta分析(1)---meta分析基础
目前不少文章用到了孟德尔随机化meta分析,今天咱们也来介绍一下,孟德尔随机化meta其实主要就是meta分析的过程,提取了孟德尔随机化文章的结果,实质上就是个meta分析,不过多个孟德尔随机化随机化的结果合并更加加强了结…...
网络安全第一次作业
1、什么是防火墙 防火墙是一种网络安全系统,它根据预先确定的安全规则监视和控制传入和传出的网络流量。其主要目的是阻止对计算机或网络的未经授权的访问,同时允许合法通信通过。 防火墙可以在硬件、软件或两者的组合中实现,并且可以配置为根…...
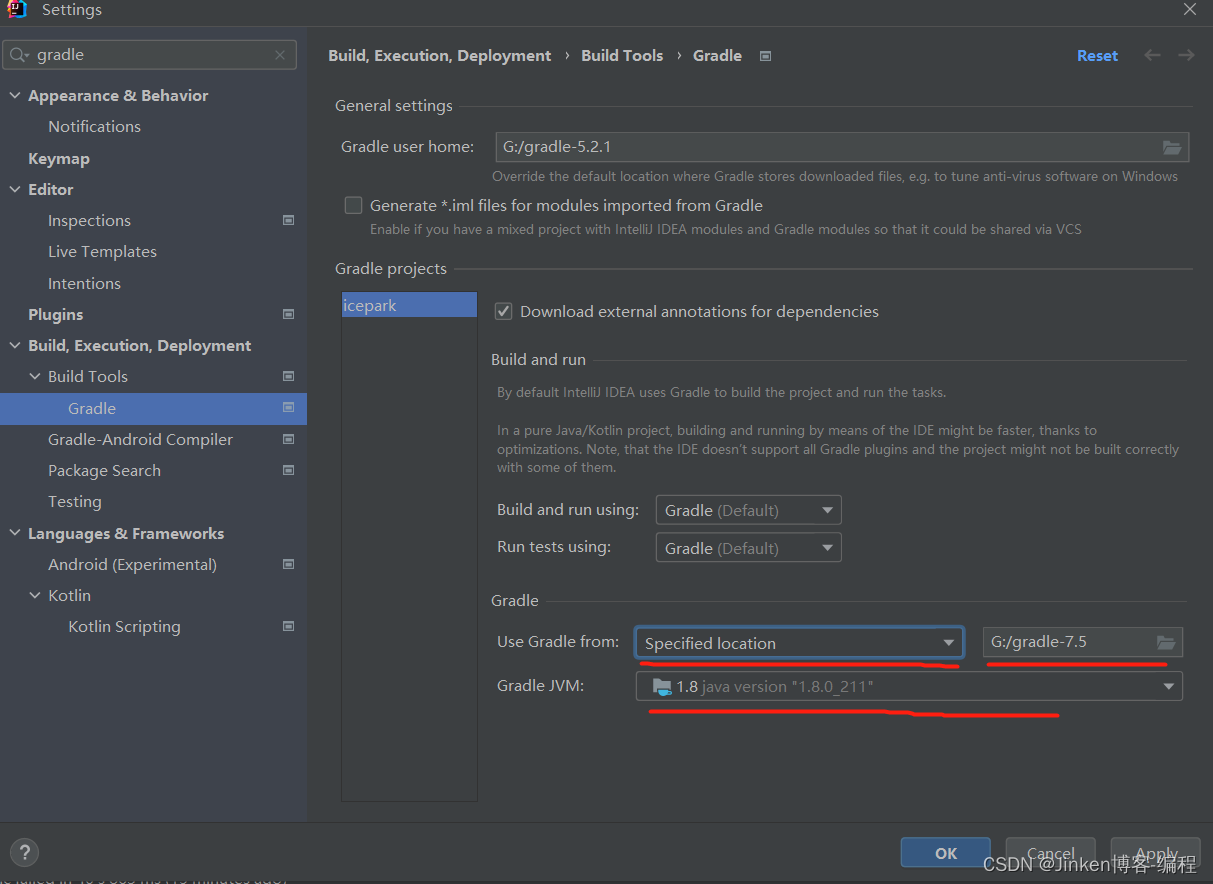
idea设置gradle
1、不选中 2、下面选specified location 指定gradle目录...
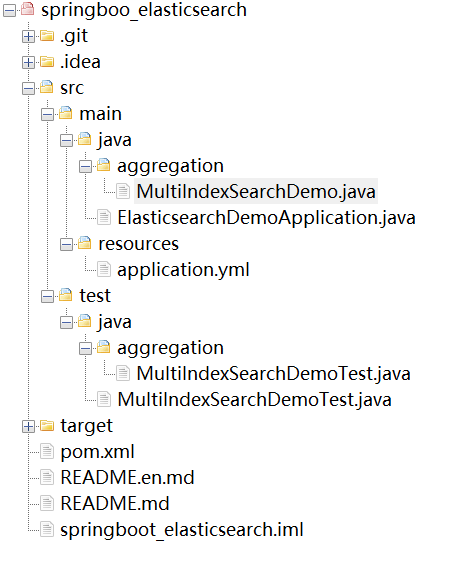
基于Elasticsearch的多文档检索 比如 商品(goods)、案例(cases)
概述 Elasticsearch多文档聚合检索 详细 记得把这几点描述好咯:需求(要做什么) 代码实现过程 项目文件结构截图 演示效果 应用场景 我们需要在五种不同的文档中检索数据。 比如 商品(goods)、案例(ca…...

9月18日,每日信息差
今天是2023年09月19日,以下是为您准备的11条信息差 第一、江苏无锡首次获得6000年前古人类DNA 第二、全球天然钻石价格暴跌。数据显示,国际钻石交易所钻石价格指数在2022年3月达到158的历史峰值,之后一路下跌到目前的110左右,创…...
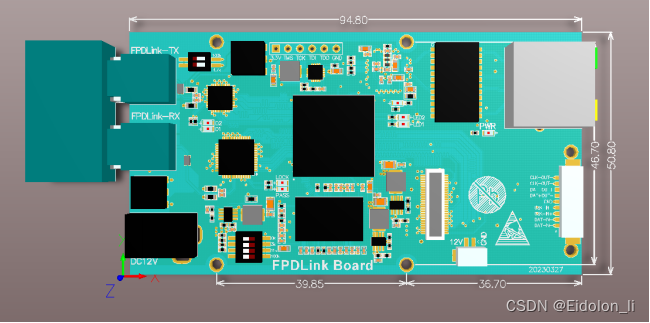
基于FPGA实现FPDLINK III
功能概述 本模块主要包含FPDLINKIII/CML收发信号与HDMI/SDI/USB信号、千兆网络信号,支持客户按照按照指定功能定制 当前默认功能为FPD LINK III/CML转为HDMI/SDI/UVC信号 性能参数 名称 描述 供电接口 DC12V FPD LINK RX GM8914 FPD LINK TX GM8913 千兆网…...
ANSYS Box Color 和 Transparent 应变为可编辑状态 无法选中 解决办法
取消勾选 Material Appearance 即可恢复编辑。...

RWKV7-1.5B-g1a实操手册:Web界面操作截图+curl API调用+日志分析三位一体
RWKV7-1.5B-g1a实操手册:Web界面操作截图curl API调用日志分析三位一体 1. 平台介绍 rwkv7-1.5B-g1a是基于新一代RWKV-7架构的多语言文本生成模型,特别适合中文场景下的轻量级应用。这个1.5B参数的版本在单张24GB显存的GPU上就能流畅运行,模…...

乙巳马年·皇城大门春联生成终端W前端交互:JavaScript实现动态预览与编辑
乙巳马年皇城大门春联生成终端W前端交互:JavaScript实现动态预览与编辑 最近在捣鼓一个挺有意思的小项目,想做一个能在线生成和编辑春联的网页工具。想象一下,你只需要输入几个关键词,比如“马年”、“吉祥”、“丰收”ÿ…...

AcousticSense AI真实案例:民谣与乡村音乐在ViT-B/16特征空间中的聚类效果
AcousticSense AI真实案例:民谣与乡村音乐在ViT-B/16特征空间中的聚类效果 1. 引言:当AI“看见”民谣与乡村的旋律 你有没有想过,AI是怎么“听”音乐的?它怎么知道一首歌是民谣还是乡村,是摇滚还是爵士?今…...
Transformer的自注意力机制原理
Transformer的自注意力机制(Self-Attention Mechanism)是模型的核心组件,它允许模型在处理序列数据时,动态地关注序列中不同位置的信息,从而捕捉序列内部的复杂依赖关系。以下是自注意力机制的详细原理:一、…...

手把手教你用Ollama+Continue搭建本地AI编程环境:完全替代Augment Code的免费方案
手把手教你用OllamaContinue搭建本地AI编程环境:完全替代Augment Code的免费方案 1. 为什么选择本地化AI编程环境? 在AI辅助编程工具爆发的时代,Augment Code凭借其强大的代码理解能力赢得了不少开发者的青睐。但商业产品往往存在隐私顾虑、…...

093华为黄大年茶思屋第3期·难题一:AI大模型训练 – 多维度混合并行策略的自动搜索算法
华为黄大年茶思屋第3期难题一:AI大模型训练 – 多维度混合并行策略的自动搜索算法 双思路解题方案:常规行业解法 本源动态原点解法,双框架对照,专家级可落地、可验证 核心亮点:直击大模型并行策略搜索产业卡点&#x…...

Umi-OCR Rapid引擎参数配置实战指南
Umi-OCR Rapid引擎参数配置实战指南 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/GitHub_Trending/um/Umi-OCR …...

【69页PPT】“1+2+M+N”数字农业农村解决方案:整体解决方案框架、农业数字大脑、AI平台、区块链平台、金融平台、云码、交易平台...
该方案以“12MN”架构为核心,通过农业产业互联网平台整合金融、农资、服务等资源,构建数据中台、物联网、区块链等数字大脑能力,推动资源数字化、产业数字化与运营数字化,实现生产智能化、管理高效化、服务便捷化,赋能…...

突破三大系统壁垒:跨平台视频播放器如何重新定义多端体验
突破三大系统壁垒:跨平台视频播放器如何重新定义多端体验 【免费下载链接】zyfun 跨平台桌面端视频资源播放器,免费高颜值. 项目地址: https://gitcode.com/gh_mirrors/zy/zyfun 在数字娱乐日益碎片化的今天,用户面临着一个普遍痛点:同…...