1_图神经网络GNN基础知识学习
文章目录
- 安装PyTorch Geometric
- 安装工具包
- 在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类
- 两个画图函数
- Graph Neural Networks
- 数据集:Zachary's karate club network.
- PyTorch Geometric
- 数据集介绍
- edge_index
- 使用networkx可视化展示
- Graph Neural Networks 网络定义:
- 输出特征展示
- 训练模型(semi-supervised)
- 回顾
- 综述
- 1. **目标**:
- 2. **数据加载**:
- 3. **数据可视化**:
- 4. **模型定义**:
- 5. **嵌入可视化**:
- 6. **模型训练**:
- 总结:
- 补充
- 在论文引用数据集上使用图卷积网络 (GCN) 进行节点分类
- Cora dataset(数据集描述:[Yang et al. (2016)](https://arxiv.org/abs/1603.08861))
- 试试直接用传统的全连接层会咋样(Multi-layer Perception Network)
- Graph Neural Network (GNN)
安装PyTorch Geometric
安装工具包
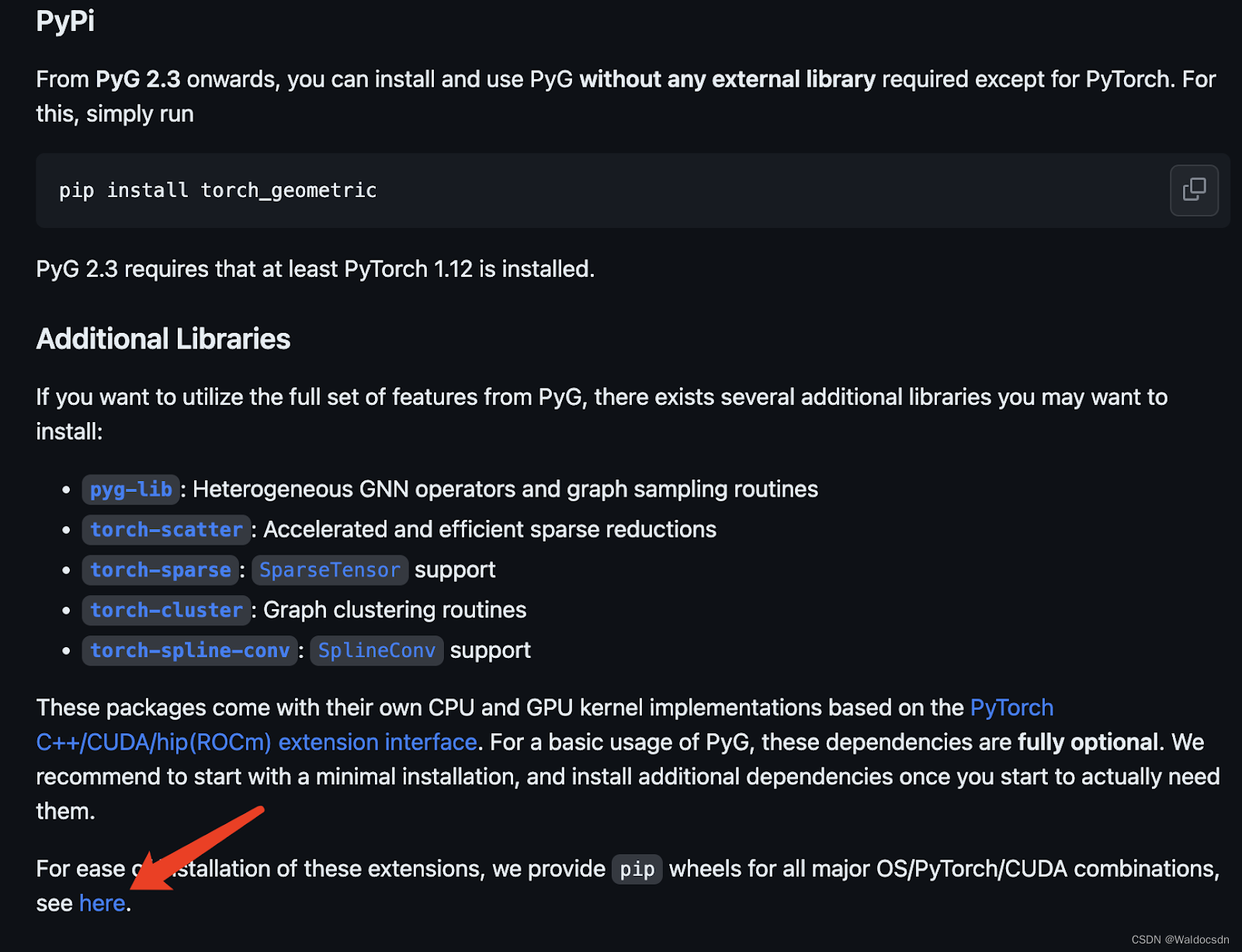
打开链接https://github.com/pyg-team/pytorch_geometric,点击图中箭头处,使用编译好的版本来安装:
使用以下代码片段来查看PyTorch、CUDA和Python的版本:
import torch# 查看PyTorch版本
print("PyTorch版本:", torch.__version__)# 查看CUDA版本(如果使用GPU)
if torch.cuda.is_available():print("CUDA版本:", torch.version.cuda)
else:print("未找到可用的CUDA")# 查看Python版本
import sys
print("Python版本:", sys.version)
运行截图:

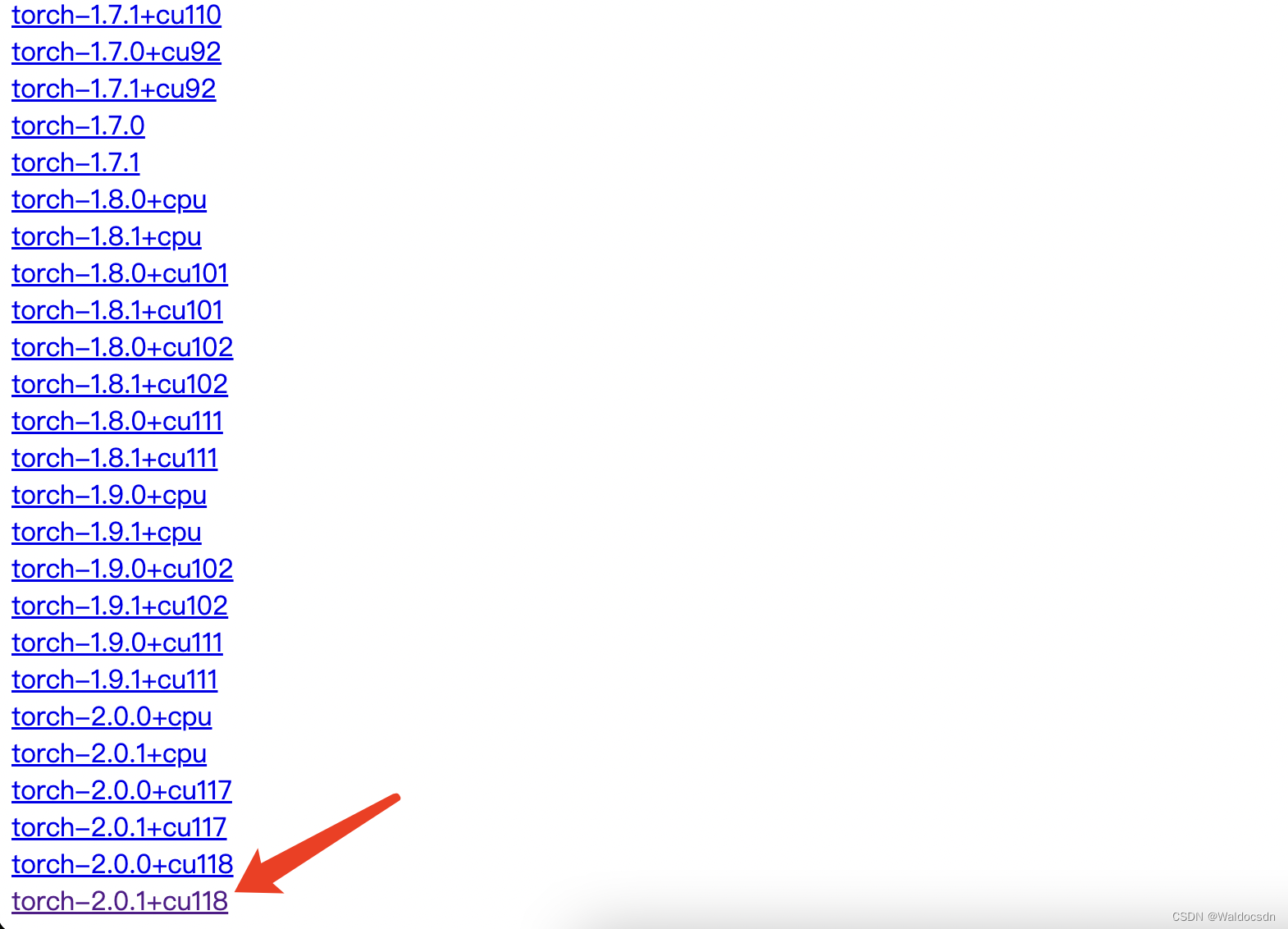
根据版本点击下图中链接:
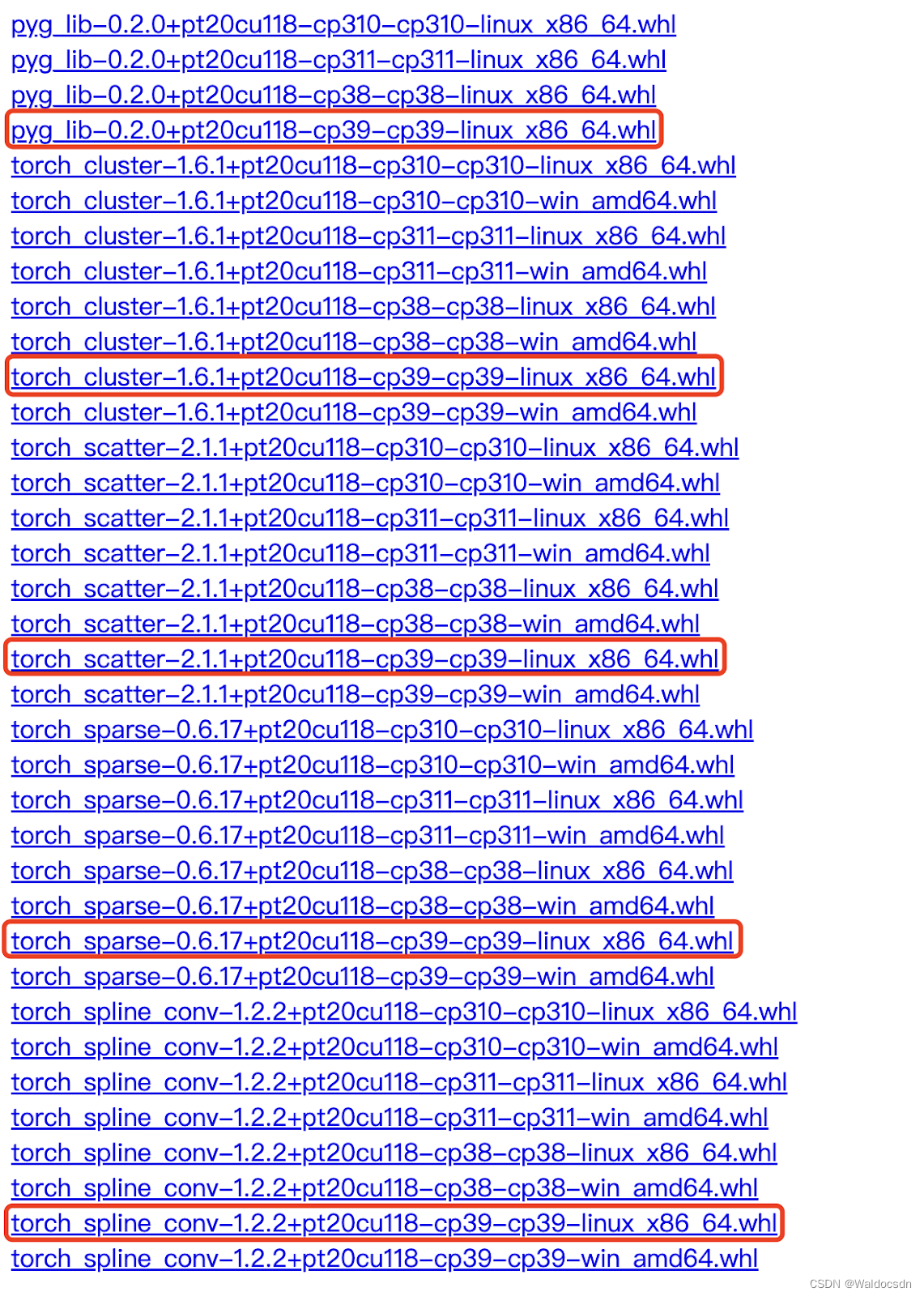
再根据python版本选择安装相应的依赖包,安装命令pip install 包名:
最后执行命令pip install torch_geometric便可
在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类
本部分为代码学习,可以将代码放入Jupyter中运行
两个画图函数
%matplotlib inline
import torch
import networkx as nx
import matplotlib.pyplot as pltdef visualize_graph(G, color):plt.figure(figsize=(7,7))plt.xticks([])plt.yticks([])nx.draw_networkx(G, pos=nx.spring_layout(G, seed=42), with_labels=False,node_color=color, cmap="Set2")plt.show()def visualize_embedding(h, color, epoch=None, loss=None):plt.figure(figsize=(7,7))plt.xticks([])plt.yticks([])h = h.detach().cpu().numpy()plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")if epoch is not None and loss is not None:plt.xlabel(f'Epoch: {epoch}, Loss: {loss.item():.4f}', fontsize=16)plt.show()
解析上面代码:
该代码主要包括两部分功能:使用 networkx 和 matplotlib 来可视化图结构(G)和嵌入向量(h)。
首先,我们逐行解析代码:
-
%matplotlib inline: Jupyter Notebook 的魔术命令,它可以确保在 notebook 内部显示绘制的图形。 -
导入所需的库:
torch: 一个开源的深度学习库。networkx as nx: 一个用于创建、操作和研究复杂网络结构和动态的 Python 库。matplotlib.pyplot as plt: 用于绘图的库。
-
visualize_graph(G, color)函数:- 作用:可视化图
G。 - 参数:
G: 要可视化的图。color: 图中节点的颜色。
- 代码解析:
- 设置图形大小为 7x7。
- 删除 x, y 轴的标签。
- 使用
nx.draw_networkx来绘制图。其中nx.spring_layout是一种布局策略,它会模拟节点之间的弹簧效果,使得布局看起来更为平衡。 - 显示图形。
- 作用:可视化图
-
visualize_embedding(h, color, epoch=None, loss=None)函数:- 作用:可视化嵌入向量
h。 - 参数:
h: 要可视化的嵌入向量。color: 向量的颜色。epoch(可选): 当前的训练迭代次数。loss(可选): 当前的损失值。
- 代码解析:
- 设置图形大小为 7x7。
- 删除 x, y 轴的标签。
- 将嵌入从 GPU 转移到 CPU,并从 PyTorch 张量转换为 numpy 数组。
- 使用
plt.scatter函数在二维空间中绘制每个嵌入。 - 如果提供了
epoch和loss,则在图形的 x 轴标签上显示这些值。 - 显示图形。
- 作用:可视化嵌入向量
简而言之,这段代码提供了两个函数,一个用于可视化图结构,另一个用于可视化嵌入。这在图神经网络的背景下尤为有用,例如当需要查看节点嵌入的演化或与原始图结构进行比较时。
Graph Neural Networks
- 致力于解决不规则数据结构(图像和文本相对格式都固定,但是社交网络与化学分子等格式肯定不是固定的)
- GNN模型迭代更新主要基于图中每个节点及其邻居的信息,基本表示如下:
x v ( ℓ + 1 ) = f θ ( ℓ + 1 ) ( x v ( ℓ ) , { x w ( ℓ ) : w ∈ N ( v ) } ) \mathbf{x}_v^{(\ell + 1)} = f^{(\ell + 1)}_{\theta} \left( \mathbf{x}_v^{(\ell)}, \left\{ \mathbf{x}_w^{(\ell)} : w \in \mathcal{N}(v) \right\} \right) xv(ℓ+1)=fθ(ℓ+1)(xv(ℓ),{xw(ℓ):w∈N(v)})
节点的特征: x v ( ℓ ) \mathbf{x}_v^{(\ell)} xv(ℓ) , v ∈ V v \in \mathcal{V} v∈V 在图中 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G=(V,E) 根据其邻居信息进行更新 N ( v ) \mathcal{N}(v) N(v):
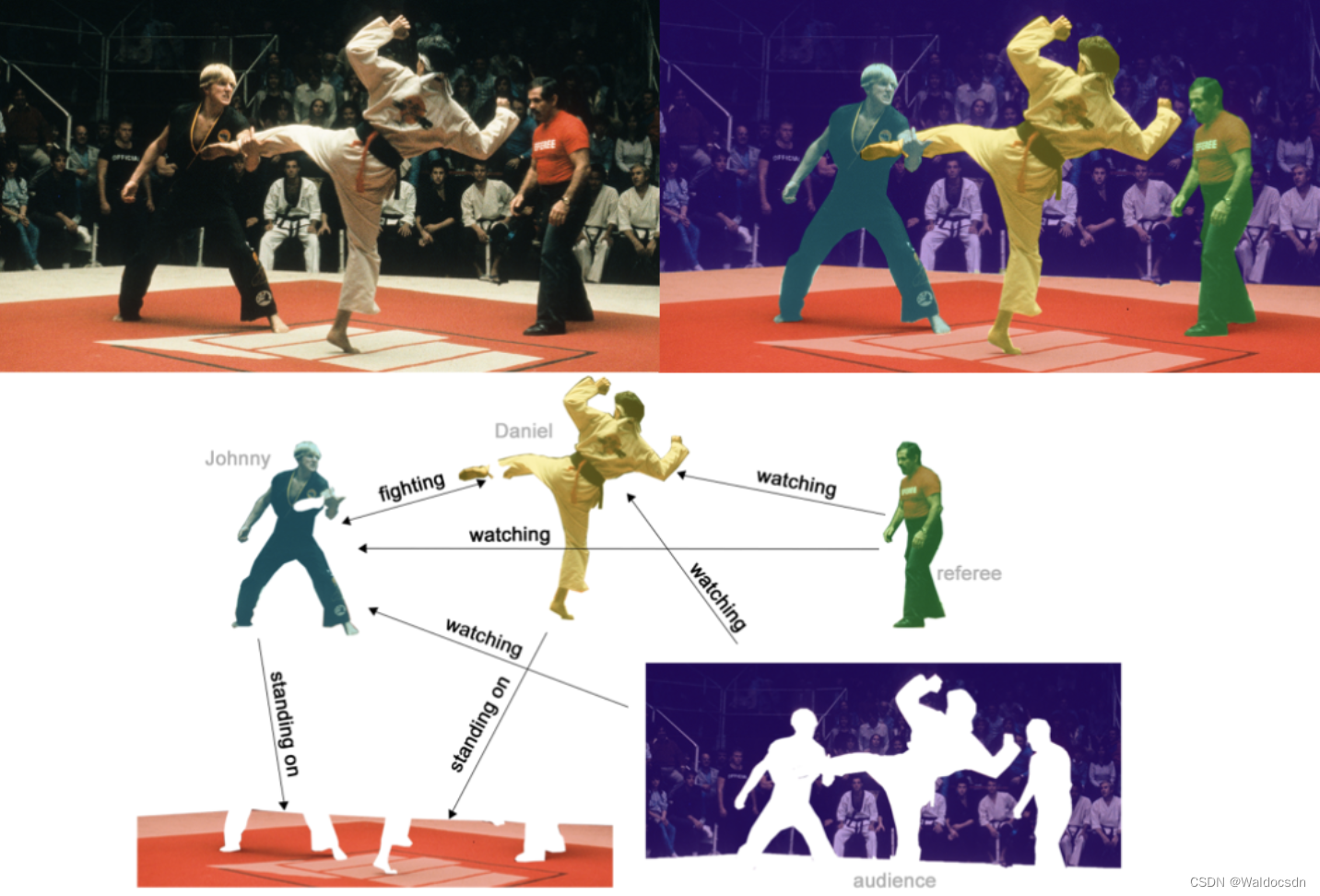
数据集:Zachary’s karate club network.
该图描述了一个空手道俱乐部会员的社交关系,以34名会员作为节点,如果两位会员在俱乐部之外仍保持社交关系,则在节点间增加一条边。
每个节点具有一个34维的特征向量,一共有78条边。
在收集数据的过程中,管理人员 John A 和 教练 Mr. Hi(化名)之间产生了冲突,会员们选择了站队,一半会员跟随 Mr. Hi 成立了新俱乐部,剩下一半会员找了新教练或退出了俱乐部。
PyTorch Geometric
- 这个就是咱们的核心了,说白了就是这里实现了各种图神经网络中的方法
- 咱们直接调用就可以了:PyTorch Geometric (PyG) library
数据集介绍
- 可以直接参考其API:https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html#torch_geometric.datasets.KarateClub
from torch_geometric.datasets import KarateClubdataset = KarateClub()
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.
print(data)
输出为:
Dataset: KarateClub():
======================
Number of graphs: 1
Number of features: 34
Number of classes: 4Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])
解析上面代码:
此代码使用 torch_geometric.datasets 中的 KarateClub 数据集,这是一个经常在图神经网络研究中使用的经典数据集。KarateClub 数据集描述了一个学校空手道俱乐部的成员之间的关系,其中成员分为两个派系。
接下来,我们逐步解析代码:
-
导入数据集:
from torch_geometric.datasets import KarateClub -
加载数据集:
dataset = KarateClub()这会实例化
KarateClub数据集,并下载相关数据(如果还没有的话)。 -
打印数据集的一般信息:
print(f'Dataset: {dataset}:'): 打印数据集的描述。print(f'Number of graphs: {len(dataset)}'): 打印数据集中图的数量。输出显示只有一个图。print(f'Number of features: {dataset.num_features}'): 打印每个节点的特征数量。输出显示每个节点有 34 个特征。print(f'Number of classes: {dataset.num_classes}'): 打印数据集中的类别数量。输出显示有 4 个类别(四分类任务)。
-
获取第一个图对象:
data = dataset[0]这会获取数据集中的第一个(也是唯一的)图对象。
torch_geometric中的图数据通常用Data对象表示,它包含节点、边以及其他相关信息。 -
打印图对象的描述:
print(data)输出为
Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])。我们可以从中得知:-
x=[34, 34]: 表示图中有 34 个节点,每个节点有 34 个特征。 -
edge_index=[2, 156]: 描述图的边。它是一个 2x156 的整数张量,其中每列表示一条从源节点到目标节点的边。156 表示图中有 156 条边。 -
y=[34]: 是一个长为 34 的整数张量,表示每个节点的标签。 -
train_mask=[34]: 是一个布尔张量,长度为 34,用于指示哪些节点应该用于训练。这在半监督学习设置中很常见,其中只有一小部分节点的标签是已知的。当我们在图数据中进行学习时,尤其是在半监督学习的情境中,我们可能只有图中部分节点的标签。半监督学习是指我们只有一小部分的数据是带标签的,而大部分数据是不带标签的,目标是使用这少量的标签数据同时学习整个数据的表示。
在图神经网络的上下文中,我们可能只有图中的某些节点是有标签的。因此,为了在训练过程中只考虑这些有标签的节点,我们需要一个方法来区分哪些节点是用于训练的,哪些节点不是。这就是
train_mask的作用。train_mask是一个布尔张量,长度与图中的节点数量相同。如果train_mask中的某个值为True,则表示该位置的节点是用于训练的(即该节点有标签);如果值为False,则表示该节点不用于训练。例如,假设我们有以下
train_mask:train_mask = [True, True, False, False, True]这意味着图中的第一个、第二个和第五个节点有标签,将被用于训练;而第三个和第四个节点没有标签,不会被用于训练。
在图神经网络的训练过程中,我们只会计算并反向传播那些
train_mask值为True的节点的损失,从而使模型能够利用这些已知的标签信息。
-
总的来说,这段代码简单地加载了 KarateClub 数据集并显示了其基本信息。这个数据集是描述一个空手道俱乐部内的关系网络,其中包含 34 个节点(成员)和 156 条边(关系),每个节点有一个 34 维的特征向量和一个类标签。
edge_index
- edge_index:表示图的连接关系(start,end两个序列)
- node features:每个点的特征
- node labels:每个点的标签
- train_mask:有的节点木有标签(用来表示哪些节点要计算损失)
edge_index = data.edge_index
print(edge_index.t())
解析上面代码:
这两行代码主要关注图中的边信息,特别是 edge_index 属性。在 PyTorch Geometric(一个流行的图神经网络库)中,边的信息通常以 edge_index 的形式存储。
-
edge_index = data.edge_index:
这行代码从data对象中取出edge_index属性并将其赋值给一个新的变量edge_index。在 PyTorch Geometric 中,edge_index是一个表示图中所有边的张量。edge_index的维度为[2, E],其中E是图中边的数量。每一列代表一条边,其中第一行的值是边的起始节点,第二行的值是边的终止节点。例如,考虑以下
edge_index:tensor([[0, 2, 2],[1, 0, 3]])这表示图中有三条边:从节点0到节点1、从节点2到节点0、从节点2到节点3。
-
print(edge_index.t()):
这行代码首先使用.t()方法转置edge_index张量,然后打印它。转置操作会将[2, E]维度的张量变成[E, 2]维度。继续上面的例子,转置后的张量为:
tensor([[0, 1],[2, 0],[2, 3]])这使得每一行代表一条边,其中第一个值是边的起始节点,第二个值是边的终止节点。这种表示方式更直观,也更容易阅读,尤其是当边的数量非常多时。
总之,这两行代码从图数据对象中提取边的信息并以更易读的格式打印出来。
使用networkx可视化展示
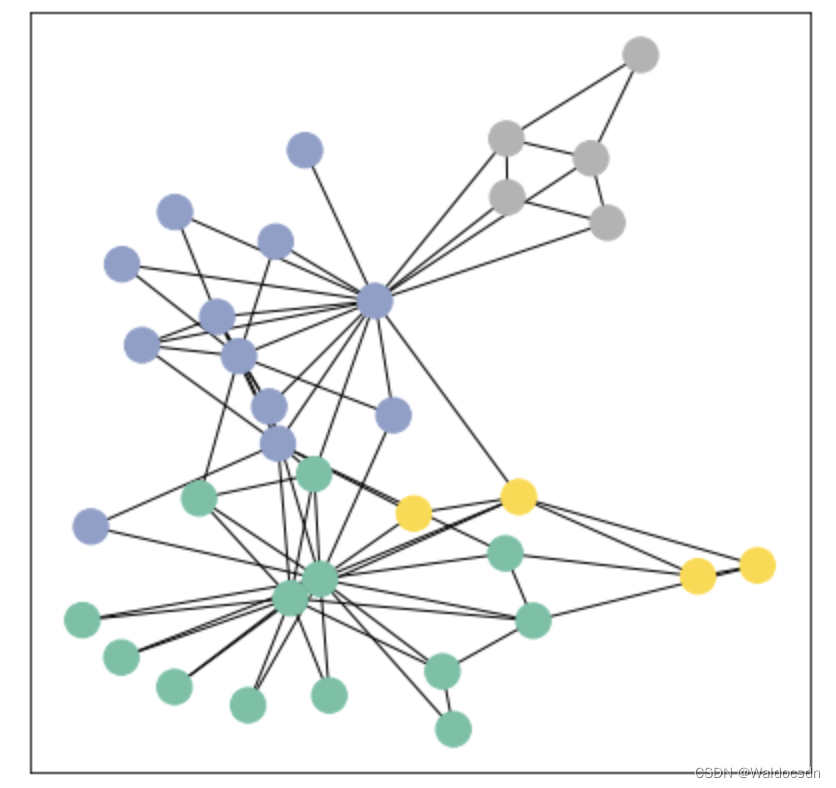
from torch_geometric.utils import to_networkxG = to_networkx(data, to_undirected=True)
visualize_graph(G, color=data.y)
输出如下:
解析上面代码:
这段代码的目的是将 PyTorch Geometric 的图数据转换为 NetworkX 的图格式,并使用前面定义的 visualize_graph 函数将其可视化。以下是对代码的详细解析:
-
导入所需工具:
from torch_geometric.utils import to_networkx这行代码从
torch_geometric.utils中导入了to_networkx函数,这个函数能够将 PyTorch Geometric 的图数据转换为 NetworkX 的图格式。 -
将图数据转换为 NetworkX 格式:
G = to_networkx(data, to_undirected=True)- 这里,
to_networkx(data, to_undirected=True)将 PyTorch Geometric 的图数据data转换为 NetworkX 的图G。参数to_undirected=True表示即使原始图数据可能是有向的,我们也希望得到一个无向图。
- 这里,
-
可视化转换后的图:
visualize_graph(G, color=data.y)- 调用前面定义的
visualize_graph函数来可视化 NetworkX 图G。 - 参数
color=data.y意味着节点的颜色是基于data.y中的标签数据的。这样,不同的节点标签会被赋予不同的颜色,从而在可视化中可以轻松地区分它们。
- 调用前面定义的
综上所述,这段代码首先将 PyTorch Geometric 格式的图数据转换为 NetworkX 格式的图,然后使用给定的节点标签为该图上色并进行可视化。这种可视化通常很有助于理解图的结构和节点间的关系,尤其是当节点标签有意义时(例如,表示不同的社区或类别)。
Graph Neural Networks 网络定义:
- GCN layer (Kipf et al. (2017)) 定义如下:
x v ( ℓ + 1 ) = W ( ℓ + 1 ) ∑ w ∈ N ( v ) ∪ { v } 1 c w , v ⋅ x w ( ℓ ) \mathbf{x}_v^{(\ell + 1)} = \mathbf{W}^{(\ell + 1)} \sum_{w \in \mathcal{N}(v) \, \cup \, \{ v \}} \frac{1}{c_{w,v}} \cdot \mathbf{x}_w^{(\ell)} xv(ℓ+1)=W(ℓ+1)w∈N(v)∪{v}∑cw,v1⋅xw(ℓ)
- PyG 文档
GCNConv
import torch
from torch.nn import Linear
from torch_geometric.nn import GCNConvclass GCN(torch.nn.Module):def __init__(self):super().__init__()torch.manual_seed(1234)self.conv1 = GCNConv(dataset.num_features, 4) # 只需定义好输入特征和输出特征即可self.conv2 = GCNConv(4, 4)self.conv3 = GCNConv(4, 2)self.classifier = Linear(2, dataset.num_classes)def forward(self, x, edge_index):h = self.conv1(x, edge_index) # 输入特征与邻接矩阵(注意格式,上面那种)h = h.tanh()h = self.conv2(h, edge_index)h = h.tanh()h = self.conv3(h, edge_index)h = h.tanh() # 分类层out = self.classifier(h)return out, hmodel = GCN()
print(model)
输出如下:
GCN((conv1): GCNConv(34, 4)(conv2): GCNConv(4, 4)(conv3): GCNConv(4, 2)(classifier): Linear(in_features=2, out_features=4, bias=True)
)
解析上面的代码:
代码定义了一个简单的图卷积网络(GCN)模型。详细分析这段代码:
-
导入必要的库和模块:
import torch from torch.nn import Linear from torch_geometric.nn import GCNConv这些库和模块是构建模型所必需的。
-
定义 GCN 类:
class GCN(torch.nn.Module):通过继承
torch.nn.Module,我们定义了一个新的神经网络模型类GCN。 -
初始化方法:
def __init__(self):super().__init__()torch.manual_seed(1234)...- 使用
super().__init__()调用父类的初始化方法。 torch.manual_seed(1234)设置随机种子,以确保模型的权重初始化是确定的。
- 使用
-
定义图卷积层和分类器:
self.conv1 = GCNConv(dataset.num_features, 4): 定义第一个图卷积层,它将输入特征(即图中节点的特征数,这里为34)映射到4个特征。- 接下来的两个图卷积层
self.conv2和self.conv3进一步对特征进行转换。 self.classifier = Linear(2, dataset.num_classes): 这是一个线性分类层,用于将最后一个图卷积层的输出(2个特征)映射到目标类别的数量(这里是4)。
-
定义前向传播方法:
def forward(self, x, edge_index):...return out, h- 这定义了如何对输入数据进行操作以获得模型的输出。
- 数据通过三个图卷积层,并在每层后应用双曲正切激活函数
tanh。 - 输出经过分类器并返回。
-
实例化模型并打印:
model = GCN() print(model)这些行实例化上面定义的
GCN类并打印模型的结构。输出显示了模型包含的各个层及其配置。
输出的解析:
GCN((conv1): GCNConv(34, 4)(conv2): GCNConv(4, 4)(conv3): GCNConv(4, 2)(classifier): Linear(in_features=2, out_features=4, bias=True)
)
这个输出描述了 GCN 模型的结构。它有三个图卷积层和一个线性分类器。例如,(conv1): GCNConv(34, 4) 表示第一个图卷积层接受34个特征作为输入并输出4个特征。最后,线性分类器将2个特征映射到4个输出类别。
总体而言,这段代码定义了一个三层的图卷积网络,并为每个节点生成分类分数。
输出特征展示
- 最后不是输出了两维特征嘛,画出来看看长啥样
- 但是,但是,现在咱们的模型还木有开始训练。。。
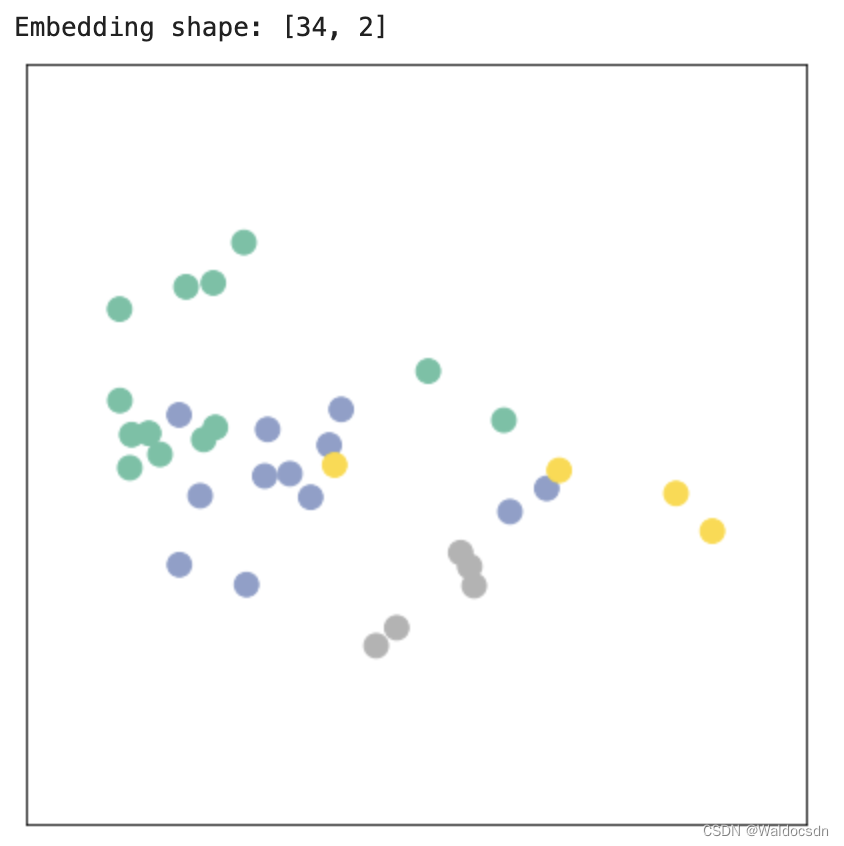
model = GCN()_, h = model(data.x, data.edge_index)
print(f'Embedding shape: {list(h.shape)}')visualize_embedding(h, color=data.y)
输出如下:
解析上面的代码:
这段代码主要关注了两件事:首先,它在一个图上运行定义的 GCN 模型来获取节点嵌入;然后,它使用一个可视化函数来显示这些嵌入。以下是对代码的详细解析:
-
模型实例化:
model = GCN()这行代码创建了
GCN类的一个新实例。该模型已经在前面的代码中被定义,并且它包含了三个图卷积层和一个线性分类器。 -
模型前向传播:
_, h = model(data.x, data.edge_index)这行代码调用了
GCN模型的前向传播方法,传入节点特征data.x和边索引data.edge_index作为参数。这两个参数来源于data,这是一个 PyTorch Geometric 图数据对象。输出是一个元组,其中第一个元素
_是模型的主要输出(分类得分),而第二个元素h是模型的最后一个图卷积层的输出,代表节点的嵌入。 -
打印嵌入的形状:
print(f'Embedding shape: {list(h.shape)}')这行代码将嵌入张量
h的形状打印出来。这有助于我们了解嵌入的维度,通常这是[节点数, 嵌入维度]。 -
可视化嵌入:
visualize_embedding(h, color=data.y)使用之前定义的
visualize_embedding函数,这行代码将嵌入h可视化为一个散点图。这个散点图中的每个点都代表一个节点,位置由其嵌入决定。点的颜色基于data.y,这通常代表节点的标签或类别。
总结:这段代码运行了一个图卷积网络模型,取得了节点的嵌入,并将这些嵌入可视化。这种可视化有助于我们理解模型如何将节点分布在嵌入空间中,以及节点间的相似性和差异性。
训练模型(semi-supervised)
import timemodel = GCN()
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Define optimizer.def train(data):optimizer.zero_grad() out, h = model(data.x, data.edge_index) #h是两维向量,主要是为了咱们画个图 loss = criterion(out[data.train_mask], data.y[data.train_mask]) # semi-supervisedloss.backward() optimizer.step() return loss, hfor epoch in range(401):loss, h = train(data)if epoch % 10 == 0:visualize_embedding(h, color=data.y, epoch=epoch, loss=loss)time.sleep(0.3)
解析上面的代码:
这段代码定义了训练流程并执行了400个训练周期。接下来,我们将逐步解析代码的每一部分。
-
初始化模型和工具:
model = GCN() criterion = torch.nn.CrossEntropyLoss() # Define loss criterion. optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Define optimizer.model = GCN(): 创建GCN类的一个新实例,之前已经定义。criterion: 定义了损失函数,这里使用的是交叉熵损失,适用于分类问题。optimizer: 定义了优化器,用于更新模型的权重。这里使用的是Adam优化器,学习率设为0.01。
-
定义训练函数:
def train(data):...return loss, h这个函数定义了模型的一次训练步骤,并返回损失和节点嵌入。具体步骤如下:
optimizer.zero_grad(): 清除之前梯度的残留。out, h = model(data.x, data.edge_index): 对模型进行前向传播。loss = criterion(out[data.train_mask], data.y[data.train_mask]): 计算损失。由于这是一个半监督学习任务,我们只在具有标签的节点上计算损失,这些节点由train_mask指示。loss.backward(): 基于计算的损失进行反向传播,计算梯度。optimizer.step(): 使用优化器更新模型的权重。
-
训练循环:
for epoch in range(401):loss, h = train(data)...这个循环执行了401个训练周期。在每个周期,它都会调用上面定义的
train函数,获取损失和嵌入。 -
可视化:
if epoch % 10 == 0:visualize_embedding(h, color=data.y, epoch=epoch, loss=loss)time.sleep(0.3)每10个周期,代码会调用之前定义的
visualize_embedding函数,显示节点的嵌入。time.sleep(0.3)意味着每次可视化之间会有0.3秒的暂停,使得可视化的变化不会过于迅速,这样我们可以更容易地观察节点嵌入的变化情况。
总的来说,这段代码定义了图卷积网络模型的训练过程,并在每10个训练周期后进行嵌入可视化,这样我们可以看到模型是如何逐渐学习将相似的节点放在嵌入空间的相近位置的。
回顾
综述
在训练开始时,嵌入(由h表示)可能是随机的或是在嵌入空间中均匀分布的。这意味着,在散点图中,具有不同标签的节点可能会混在一起,没有明显的聚类。
随着训练的进行,模型会尝试将相似的节点(基于它们的特征和它们在图中的位置)放在嵌入空间中的相近位置,并将不相似的节点分开。这在可视化中表现为:
- 具有相同标签的节点开始聚集在一起。
- 不同的聚类或类别之间形成了明确的边界。
在多次迭代之后,如果模型被成功地训练,我们应该能看到几个清晰的聚类,其中每个聚类代表一种类别的节点。在KarateClub数据集中,由于有4个类,我们期望看到4个聚类。
回顾和总结上面的代码和实践。
1. 目标:
在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类。
2. 数据加载:
首先加载了KarateClub数据集,这是一个经典的小型图数据集。它描述了一个空手道俱乐部中34个成员之间的关系,目标是根据其社交网络关系预测每个成员的团体归属。
3. 数据可视化:
利用networkx库和提供的工具函数,将图数据可视化为网络结构图。
4. 模型定义:
定义了一个简单的GCN模型,它包括三个GCNConv层,用于学习图中节点的嵌入表示,以及一个线性分类器,用于将这些嵌入映射到预测的类别。
5. 嵌入可视化:
在模型定义后,立即进行了一次前向传播,并使用提供的工具函数可视化了初始的节点嵌入。这提供了一个参考点,了解模型训练前节点嵌入的初始状态。
6. 模型训练:
- 设定了交叉熵损失和Adam优化器。
- 定义了一个
train函数来描述单次训练迭代的流程。 - 在400个周期中进行了模型的训练,并每10个周期可视化节点嵌入,以观察模型是如何逐步更新和优化嵌入的。
总结:
我们成功地将图神经网络应用于KarateClub数据集的节点分类任务。首先加载和可视化数据,然后定义了一个GCN模型,之后可视化了初始的节点嵌入。在接下来的训练过程中,观察了随着训练的进行,嵌入如何逐渐形成聚类,以便使具有相同标签的节点更接近。这个实践展示了图神经网络在节点分类任务上的工作方式和其效果。
补充
关于嵌入(由h表示):
嵌入(Embedding)在深度学习和自然语言处理中是一个非常常见的概念。嵌入是将某种类型的数据(如单词、节点、用户或其他实体)转换为固定大小的向量,这样机器学习模型可以更容易地处理它。
代码中,嵌入(由h表示)特指图的节点嵌入。这意味着每个图中的节点都被转换为一个向量。这些向量捕捉了节点的特征和其在图中的结构位置。
以下是关于嵌入的一些详细点:
-
捕捉信息:嵌入向量通常被设计为捕捉关于原始数据的有意义的信息。例如,在词嵌入中,相似的单词会有相似的嵌入。
-
固定大小:不论原始数据的大小或形式如何,嵌入向量都有固定的长度。这对于机器学习模型非常有用,因为它们需要固定大小的输入。
-
图节点嵌入:在图神经网络(如GCN)中,节点嵌入捕捉了节点的特征信息以及其在图中的邻接关系。相邻或相似的节点可能会有相似的嵌入。
-
可视化:由于嵌入是高维数据的向量表示,它们可以用于可视化。在代码中,
h的每个节点嵌入是一个二维向量,这使得它们可以直接在平面上绘制。这种可视化有助于我们理解模型是如何在嵌入空间中组织节点的。
在上下文中,h是图卷积网络(GCN)的输出,它为图中的每个节点提供一个二维嵌入。这些嵌入向量随着模型的训练而更新,以更好地反映节点的特征和其在图中的位置。
在论文引用数据集上使用图卷积网络 (GCN) 进行节点分类
点分类任务学习
Cora dataset(数据集描述:Yang et al. (2016))
- 论文引用数据集,每一个点有1433维向量
- 最终要对每个点进行7分类任务(每个类别只有20个点有标注)
from torch_geometric.datasets import Planetoid#下载数据集用的
from torch_geometric.transforms import NormalizeFeaturesdataset = Planetoid(root='data/Planetoid', name='Cora', transform=NormalizeFeatures())#transform预处理print()
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.print()
print(data)
print('===========================================================================================================')# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')
输出如下:
Dataset: Cora():
======================
Number of graphs: 1
Number of features: 1433
Number of classes: 7Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
===========================================================================================================
Number of nodes: 2708
Number of edges: 10556
Average node degree: 3.90
Number of training nodes: 140
Training node label rate: 0.05
Has isolated nodes: False
Has self-loops: False
Is undirected: True
解析以上代码:
Planetoid数据集是一个经常用于图神经网络研究的数据集。然后加载了Cora数据,这是一个大型图,主要用于文献分类任务。在Cora数据集中,每个节点代表一篇文献,每个边表示文献之间的引用关系,而节点的特征是文献中单词的存在(或词袋表示)。
以下是代码的详细分析:
数据加载和预处理:
Planetoid:用于下载并加载Planetoid数据集(Cora、CiteSeer和PubMed)。NormalizeFeatures:这是一个预处理步骤,它将节点特征标准化。
数据统计:
接着,打印了关于数据的一些统计信息:
-
数据集信息:
Number of graphs: 数据集中图的数量。Cora只有一个图,所以这个数字是1。Number of features: 每个节点的特征数量。在Cora中,这表示文献的词袋表示。Number of classes: 需要分类的类别数量。这是文献分类任务的类别数量。
-
图数据:
Data(...): 显示了图的主要属性。
这个输出描述了Cora数据集中的一个图结构,其中包含了图的节点特征、边、节点标签和其他信息。下面逐一进行解析:
-
x=[2708, 1433]:
- 这是一个节点特征矩阵,其中包含了2708个节点。
- 每个节点有1433个特征。这些特征是基于文献的词袋表示。换句话说,每篇文献(节点)都用一个1433维的向量表示,每维代表一个词汇表中的单词,其值表示该词在文献中的出现次数或重要性。
-
edge_index=[2, 10556]:
- 这是一个定义图中边的张量。
- “2”表示张量的行数,每行都是一个连接的节点对。这种方式用于定义图中的边。第一行包含源节点的索引,而第二行包含目标节点的索引。
- “10556”表示图中总共有10556条边。
-
y=[2708]:
- 这是节点标签的向量。
- 它包含2708个标签,对应于2708个节点。每个标签可能是一个整数值,表示所属的类别。
-
train_mask=[2708], val_mask=[2708], test_mask=[2708]:
- 这些是布尔掩码,用于分隔数据集中的节点为训练、验证和测试集。
- 这三个掩码都有2708个布尔值。如果
train_mask[i]为True,则表示第i个节点应用于训练;同理,val_mask和test_mask则分别用于验证和测试。 - 这种分隔方法是为了半监督学习设置,其中只有部分节点的标签是已知的,并用于训练,而其余节点的标签则用于验证和测试。
综上所述,Cora数据集包含一个大图,这个图中有2708个节点,10556条边。每个节点有1433个基于词袋模型的特征,并分为7个类别。为了进行机器学习任务(如节点分类),这些节点被分为训练、验证和测试集。
-
图统计:
Number of nodes: 图中的节点数量。Number of edges: 图中的边数量。Average node degree: 平均节点度数,表示每个节点平均连接的边数。Number of training nodes: 用于训练的节点数量。Training node label rate: 用于训练的节点所占的比例。Has isolated nodes: 图中是否有孤立的节点。Has self-loops: 图中是否有自循环,即一个节点是否有指向自己的边。Is undirected: 图是否是无向的。
输出分析:
从输出中,我们可以看到Cora数据集的以下信息:
- 它由一个大型图组成,其中有2708个节点,10556条边。
- 每个节点有1433个特征,这些特征基于文献的词袋表示。
- 需要将文献分类为7个不同的类别。
- 平均每个节点有3.90条边。
- 仅有140个节点的标签用于训练,这意味着大部分节点的标签是隐藏的,这种设置模拟了半监督学习的情景。
- 该图没有孤立节点和自循环,且是无向的。
总的来说,这段代码加载了Cora数据集,进行了预处理,并获取了有关图结构和其属性的详细统计信息。
解释——“每个节点有1433个特征,这些特征基于文献的词袋表示”
“每个节点有1433个特征,这些特征基于文献的词袋表示”这句话涉及到两个重要概念:节点特征和词袋表示法(Bag-of-Words, BoW)。我们逐一解析:
-
节点特征: 在图中,每个节点可以有一个或多个属性或特征。在许多图神经网络任务中,这些特征用于预测节点的标签、分类等。例如,在社交网络中,一个节点可能代表一个人,而节点特征可能包括该人的年龄、性别、职业等。
-
词袋表示法 (BoW): BoW是一种将文本数据(如句子、段落或整篇文档)转化为数值特征的技术。具体来说,它是一种文本模型,其中每个文档表示为一个固定长度的向量。这个向量的长度通常与词汇表(或所有考虑的单词的集合)的大小相同。每个向量的元素表示词汇表中对应单词在文档中出现的次数。
在Cora数据集的上下文中:
-
每个节点代表一篇文献:Cora数据集中的节点代表学术文献。
-
1433个特征:意味着考虑了1433个不同的单词(或可能是由其他文本处理技术,如TF-IDF,提取的1433个特征)。
-
基于文献的词袋表示:每个节点(或文献)的1433个特征值是根据文献内容创建的。特定的特征值表示文献中对应单词的出现次数或其他相关度量。
例如,假设我们的词汇表只有三个词:[“apple”, “banana”, “cherry”]。一个文献中提到"apple" 10次、“banana” 5次,但没有提到"cherry",那么这篇文献的BoW表示将是[10, 5, 0]。
在Cora的实际情境中,每篇文献都被转化为一个1433维的向量,每维代表词汇表中的一个单词,并且数值表示该单词在文献中的重要性或出现次数。
# 可视化部分
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.manifold import TSNEdef visualize(h, color):z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())plt.figure(figsize=(10,10))plt.xticks([])plt.yticks([])plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")plt.show()
解析以上代码:
这段代码的目的是为了可视化高维数据。为了方便在二维空间中进行观察,代码使用了t-SNE(t-分布式随机邻域嵌入)算法将高维数据映射到二维空间。下面是对每一部分的详细解析:
-
导入相关的库:
%matplotlib inline import matplotlib.pyplot as plt from sklearn.manifold import TSNE%matplotlib inline: 是一个Jupyter Notebook的特殊指令,使得生成的图像能直接在notebook中显示。import matplotlib.pyplot as plt: 导入matplotlib的绘图模块,常用于数据的可视化。from sklearn.manifold import TSNE: 导入sklearn库中的t-SNE实现。
-
定义可视化函数
visualize:def visualize(h, color):z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())...visualize函数有两个参数:h和color.h是需要可视化的高维数据,而color是一个列表,用于为每一个数据点指定颜色。
-
使用t-SNE进行数据映射:
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())- t-SNE是一种非线性降维方法,经常用于可视化高维数据。这里,我们将数据降到2维。
h.detach().cpu().numpy(): 由于h可能是一个PyTorch的张量,所以先使用detach()分离它,使其不再具有梯度信息;然后用cpu()确保它在CPU上;最后,转换为numpy数组。
-
绘图设置:
plt.figure(figsize=(10,10)) plt.xticks([]) plt.yticks([])plt.figure(figsize=(10,10)): 定义图像的大小为10x10单位。plt.xticks([])和plt.yticks([]): 隐藏x和y轴的刻度。
-
绘制散点图:
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")-
z[:, 0]和z[:, 1]: 表示t-SNE算法映射后的二维数据的x和y坐标。 -
s=70: 指定散点的大小为70。 -
c=color: 指定每个散点的颜色。color是传递给visualize函数的参数,通常是一个与数据点数量相等的列表或数组,表示每个数据点的颜色或类别。 -
cmap="Set2": 定义了一个颜色映射,确保散点图的颜色是从“Set2”调色板中选取的。
-
-
显示图形:
plt.show()- 使用
plt.show()来展示之前定义和配置的图像。在Jupyter Notebook中,这会直接在单元格下方显示图像。
- 使用
总的来说,这段代码定义了一个名为 visualize 的函数,该函数接受高维数据和颜色信息,然后使用t-SNE算法将高维数据降至二维,并在散点图中进行可视化。通过这种可视化,我们可以观察数据点在低维空间中的分布和聚类趋势,从而获得对数据结构和模式的直观了解。
试试直接用传统的全连接层会咋样(Multi-layer Perception Network)
import torch
from torch.nn import Linear
import torch.nn.functional as Fclass MLP(torch.nn.Module):def __init__(self, hidden_channels):super().__init__()torch.manual_seed(12345)self.lin1 = Linear(dataset.num_features, hidden_channels)self.lin2 = Linear(hidden_channels, dataset.num_classes)def forward(self, x):x = self.lin1(x)x = x.relu()x = F.dropout(x, p=0.5, training=self.training)x = self.lin2(x)return xmodel = MLP(hidden_channels=16)
print(model)
输出如下:
MLP((lin1): Linear(in_features=1433, out_features=16, bias=True)(lin2): Linear(in_features=16, out_features=7, bias=True)
)
解析以上代码:
这段代码定义了一个简单的多层感知器(MLP),并基于给定的数据集初始化了它。以下是对代码的详细分析:
-
导入必要的库和模块:
import torch from torch.nn import Linear import torch.nn.functional as Ftorch: PyTorch库,用于张量计算和神经网络。Linear: 一个模块,表示全连接的线性层。F: 这是PyTorch中的功能模块,其中包含了ReLU和dropout等各种神经网络操作。
-
定义MLP类:
class MLP(torch.nn.Module):这个类继承了
torch.nn.Module,表示它是一个PyTorch模型。 -
构造函数 (
__init__):def __init__(self, hidden_channels):super().__init__()torch.manual_seed(12345)self.lin1 = Linear(dataset.num_features, hidden_channels)self.lin2 = Linear(hidden_channels, dataset.num_classes)hidden_channels: 这是MLP的隐藏层的大小。torch.manual_seed(12345): 设置随机种子以确保模型的权重初始化是可重复的。self.lin1和self.lin2: 定义了两个线性层。第一个线性层将输入特征映射到隐藏层,第二个线性层将隐藏层映射到输出层。
-
前向传播 (
forward方法):def forward(self, x):x = self.lin1(x)x = x.relu()x = F.dropout(x, p=0.5, training=self.training)x = self.lin2(x)return x- 输入
x首先通过lin1线性层。 - 然后应用ReLU激活函数。
- 接着应用了50%的dropout。Dropout是一种正则化技术,它在训练期间随机关闭一些神经元以防止过拟合。
- 最后,数据通过
lin2线性层。
- 输入
-
模型实例化:
model = MLP(hidden_channels=16)这里创建了一个新的MLP模型实例,其隐藏层大小为16。
-
打印模型:
print(model)当你打印模型时,PyTorch会显示模型的结构。对于这个特定的模型,输出如下:
MLP((lin1): Linear(in_features=1433, out_features=16, bias=True)(lin2): Linear(in_features=16, out_features=7, bias=True) )这表示MLP有两个线性层。第一个线性层接受1433个特征作为输入,并输出16个隐藏通道。第二个线性层从16个隐藏通道接受输入并输出7个结果,这7个结果对应于数据集中的7个类别。
model = MLP(hidden_channels=16)
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4) # Define optimizer.def train():model.train()optimizer.zero_grad() # Clear gradients.out = model(data.x) # Perform a single forward pass.loss = criterion(out[data.train_mask], data.y[data.train_mask]) # Compute the loss solely based on the training nodes.loss.backward() # Derive gradients.optimizer.step() # Update parameters based on gradients.return lossdef test():model.eval()out = model(data.x)pred = out.argmax(dim=1) # Use the class with highest probability.test_correct = pred[data.test_mask] == data.y[data.test_mask] # Check against ground-truth labels.test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # Derive ratio of correct predictions.return test_accfor epoch in range(1, 201):loss = train()print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
解析以上代码:
这段代码描述了使用多层感知器(MLP)在图数据上进行训练和测试的过程。以下是代码的详细分析:
-
模型初始化:
model = MLP(hidden_channels=16)这里创建了一个
MLP模型实例,其隐藏层大小为16。 -
损失函数定义:
criterion = torch.nn.CrossEntropyLoss()这定义了交叉熵损失函数,它在多分类任务中常用。
-
优化器定义:
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)使用Adam优化器来训练模型,学习率设置为0.01,同时应用了权重衰减,这有助于防止模型过拟合。
-
训练函数:
def train():这个函数定义了模型的训练步骤:
model.train(): 将模型设置为训练模式。optimizer.zero_grad(): 在每一次的训练迭代开始时清除梯度。out = model(data.x): 通过模型进行一次前向传播。loss = criterion(...): 仅基于训练节点计算损失。loss.backward(): 计算损失的梯度。optimizer.step(): 更新模型的参数。
-
测试函数:
def test():这个函数定义了测试步骤:
model.eval(): 将模型设置为评估模式,这意味着例如dropout和batch normalization等层会在推理模式下运行。pred = out.argmax(dim=1): 对每个节点的输出类概率取最大值,从而得到预测的类别。test_correct = ...: 检查预测值与真实标签是否相等。test_acc = ...: 计算正确预测的比率。
-
训练循环:
for epoch in range(1, 201):loss = train()print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')该循环进行200个训练周期。在每个周期中,模型在训练数据上进行一次训练,并打印出该周期的损失值。
总结:这段代码描述了如何使用一个简单的多层感知器来训练和评估图数据。它首先定义了模型、损失函数和优化器,然后通过训练和测试函数执行模型的训练和评估,最后在200个训练周期中训练模型。
Graph Neural Network (GNN)
将全连接层替换成GCN层
from torch_geometric.nn import GCNConvclass GCN(torch.nn.Module):def __init__(self, hidden_channels):super().__init__()torch.manual_seed(1234567)self.conv1 = GCNConv(dataset.num_features, hidden_channels)self.conv2 = GCNConv(hidden_channels, dataset.num_classes)def forward(self, x, edge_index):x = self.conv1(x, edge_index)x = x.relu()x = F.dropout(x, p=0.5, training=self.training)x = self.conv2(x, edge_index)return xmodel = GCN(hidden_channels=16)
print(model)
输出如下:
GCN((conv1): GCNConv(1433, 16)(conv2): GCNConv(16, 7)
)
解析以上代码:
这段代码描述了使用图卷积网络(GCN)模型在图数据上进行操作的定义。以下是代码的详细分析:
-
模型定义:
class GCN(torch.nn.Module):定义了一个基于
torch.nn.Module的GCN类,这意味着它是一个PyTorch的模型类。 -
构造函数初始化:
def __init__(self, hidden_channels):GCN的构造函数接受一个参数hidden_channels,它定义了隐藏层的大小。 -
层定义:
torch.manual_seed(1234567): 设置随机种子以确保实验的可重复性。self.conv1 = GCNConv(dataset.num_features, hidden_channels): 第一层是一个图卷积层,它将节点特征从原始特征大小(dataset.num_features,在这里是1433)转换为hidden_channels大小(在这里是16)。self.conv2 = GCNConv(hidden_channels, dataset.num_classes): 第二层将隐藏层的输出转换为类别数大小,这在本例中为7。
-
前向传播:
def forward(self, x, edge_index):定义了模型的前向传播过程:
x = self.conv1(x, edge_index): 通过第一层图卷积。x = x.relu(): 对输出应用ReLU激活函数。x = F.dropout(x, p=0.5, training=self.training): 应用dropout以防止过拟合,dropout率为0.5。x = self.conv2(x, edge_index): 通过第二层图卷积。
-
模型初始化:
model = GCN(hidden_channels=16)这行代码创建了一个
GCN模型实例,其隐藏层大小为16。 -
输出:
GCN((conv1): GCNConv(1433, 16)(conv2): GCNConv(16, 7) )这是模型的打印输出。它显示了模型的两个图卷积层,第一层接受1433个特征并输出16个特征,而第二层接受这16个特征并输出7个类别。
总结:这段代码描述了一个基于图卷积的简单神经网络模型。它由两个图卷积层组成,其中第一个图卷积层负责特征转换,而第二个图卷积层产生最终的类别输出。这个模型为每个节点在图中生成一个类别输出,可以用于图中节点的分类任务。
可视化时由于输出是7维向量,所以降维成2维进行展示
model = GCN(hidden_channels=16)
model.eval()out = model(data.x, data.edge_index)
visualize(out, color=data.y)
输出如下:

训练GCN模型
model = GCN(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()def train():model.train()optimizer.zero_grad() out = model(data.x, data.edge_index) loss = criterion(out[data.train_mask], data.y[data.train_mask]) loss.backward() optimizer.step() return lossdef test():model.eval()out = model(data.x, data.edge_index)pred = out.argmax(dim=1) test_correct = pred[data.test_mask] == data.y[data.test_mask] test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) return test_accfor epoch in range(1, 101):loss = train()print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
解析以上代码:
这段代码实现了基于图数据的GCN模型的训练过程,同时还提供了测试函数来评估模型的性能。下面我会详细地解析这段代码:
-
模型初始化:
model = GCN(hidden_channels=16)这里创建了一个新的GCN模型实例,其中隐藏层的大小为16。
-
优化器初始化:
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)使用Adam优化器来更新模型的权重。学习率设置为0.01,权重衰减(用于正则化)为5e-4。
-
定义损失函数:
criterion = torch.nn.CrossEntropyLoss()选择交叉熵损失函数,这在多分类问题中是常用的。
-
定义训练函数:
model.train(): 设置模型为训练模式。optimizer.zero_grad(): 清除所有优化的梯度。out = model(data.x, data.edge_index): 使用模型进行前向传播。loss = criterion(...): 计算使用训练节点的损失。loss.backward(): 进行反向传播以计算梯度。optimizer.step(): 使用优化器更新模型参数。
-
定义测试函数:
model.eval(): 设置模型为评估模式。out = model(...): 进行前向传播。pred = out.argmax(dim=1): 对每个节点的输出获取最大值的索引,这代表预测的类别。test_correct = ...: 检查预测的类别是否与真实类别匹配。test_acc = ...: 计算测试集上的准确率。
-
训练循环:
for epoch in range(1, 101):loss = train()print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')对模型进行100轮的训练,并在每轮结束后打印当前的损失。
总之,这段代码描述了如何使用GCN模型、Adam优化器和交叉熵损失函数进行图数据的训练。定义了train和test两个函数来分别实现训练和测试的逻辑,并在主循环中进行了模型的训练。
# 准确率计算
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
输出如下:
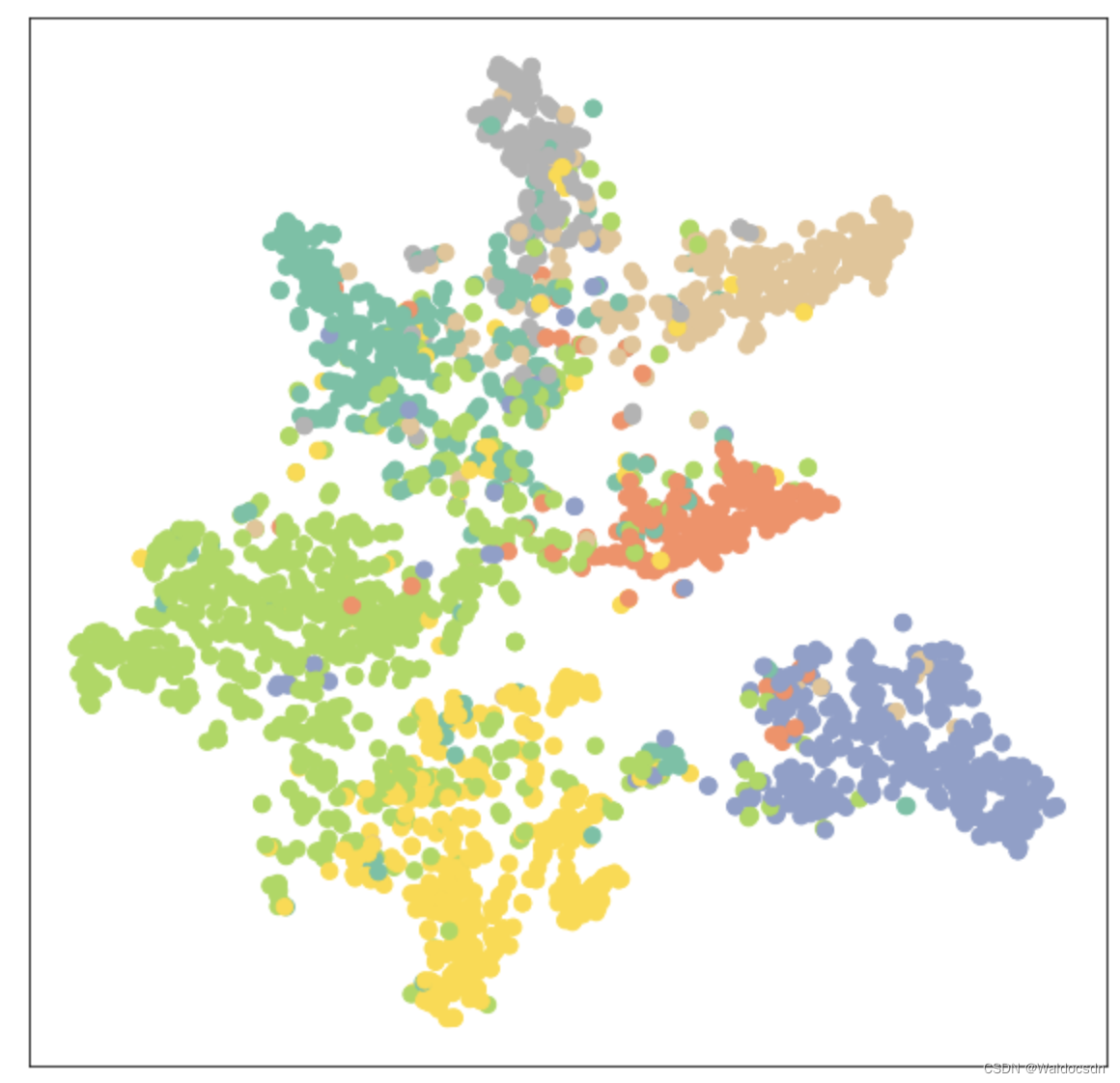
Test Accuracy: 0.8150
从59%到81%,这个提升还是蛮大的;训练后的可视化展示如下:
model.eval()out = model(data.x, data.edge_index)
visualize(out, color=data.y)
输出如下:
相关文章:
1_图神经网络GNN基础知识学习
文章目录 安装PyTorch Geometric安装工具包 在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类两个画图函数Graph Neural Networks数据集:Zacharys karate club network.PyTorch Geometric数据集介绍 edge_index使用networkx可视化展示 Graph Neural Networks…...
瑞芯微:基于RK3568的ocr识别
光学字符识别(Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。OCR的应用场景 卡片证件识别类:大陆、港澳…...

C++真的是 C加加
📝个人主页:夏目浅石. 📌博客专栏:C的故事 🏠学习社区:夏目友人帐. 文章目录 前言Ⅰ. 函数重载0x00 重载规则0x01 函数重载的原理名字修饰 Ⅱ. 引用0x00 引用的概念0x01 引用和指针区分0x03 引用的本质0x04…...
)
java学习--day5 (java中的方法、break/continue关键字)
文章目录 day4作业今天的内容1.方法【重点】1.1为什么要有方法1.2其实已经见过方法1.3定义方法的语法格式1.3.1无参无返回值的方法1.3.2有参无返回值的方法1.3.3无参有返回值的方法1.3.4有参有返回值的方法 2.break和continue关键字2.1break;2.2continue; 3.案例关于方法的练习…...
MFC主框架和视类PreCreateWindow()函数学习
在VC生成的单文档应用程序中,主框架类和视类均具有PreCreateWindow函数; 从名字可知,可在此函数中添加一些代码,来控制窗口显示后的效果; 并且它有注释说明, Modify the Window class or styles here by…...

for forin forof forEach map区别
一、总结 相同点:都是串行遍历。不同点: 二、for of循环 设计目的:遍历所有数据结构的统一方法。原理:会调用数据结构的Symbol.iterator方法。 只要数据结构定义了Symbol.iterator属性,就能用for of遍历它的成员。…...
)
特殊时间(蓝桥杯)
特殊时间 问题描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 2022年2月22日22:20 是一个很有意义的时间, 年份为 2022 , 由 3 个 2 和 1 个 0 组成, 如果将月和日写成 4 位, 为 0222 , 也是由 3 个 2 和 1 个 0 组 成…...
VUE路由与nodeJS环境搭建
VUE路由 Vue路由是Vue.js提供的路由管理工具,它允许我们在应用程序中实现页面之间的导航,从而使单页面应用程序的开发更加方便。通过Vue路由,我们可以轻松地创建和管理多个视图,并在这些视图之间导航。 Vue路由使用HTML5的Histo…...
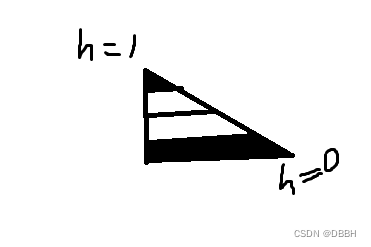
抗锯齿的线
抗锯齿的线 右下角的时候h是0,到顶部 h是1,然后中间y相距4个像素,那dy就是0.25 如果让h abs(fract(h - 0.5) - 0.5) 中间一行0.5,第一行 第三行都是0.25,两端都是0 根据插值来看 这里是 如果用h/dy 那么第一行以上࿰…...

如何使用高压放大器驱动高容性负载
使用高压放大器驱动高容性负载是一个具有挑战性的任务,需要仔细考虑电路设计和操作技巧。下面西安安泰Aigtek将为您介绍一些关于如何使用高压放大器驱动高容性负载的方法和注意事项。 首先,让我们了解一下高容性负载。高容性负载通常指电容值较大的负载元…...
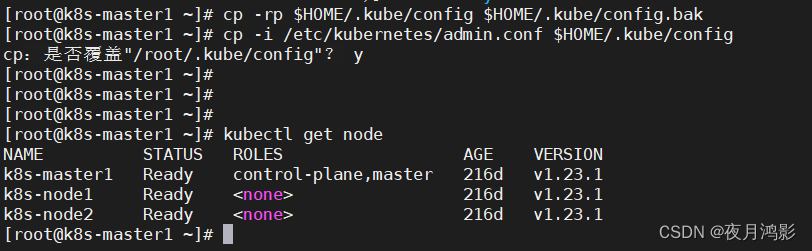
kubernetes集群证书过期启动失败问题解决方法
1、问题现象 执行kubectl命令异常报告 [rootk8s-master1 ~]# kubectl get node The connection to the server 192.168.227.131:6443 was refused - did you specify the right host or port? [rootk8s-master1 ~]# 查看etcd的日志,报错信息如下 {"level&…...

nvm使用的注意事项和常用命令。
nvm官网下载地址:nvm文档手册 - nvm是一个nodejs版本管理工具 - nvm中文网 (uihtm.com) 参考网址:(14 封私信 / 80 条消息) 如何通过 nvm 安装多版本 nodejs?npm 安装失败了怎么办? - 知乎 (zhihu.com) nvm目录下,修…...
)
代码大全阅读随笔(七)
循环控制 循环控制会出现什么样的错误,任何一种答案都可以归结到下面所说的问题之一:忽略或者错误的对循环执行初始化,忽略了对累加变量或者其他与循环有关变量执行初始化,不正确的嵌套,不正确的循环终止,忽…...
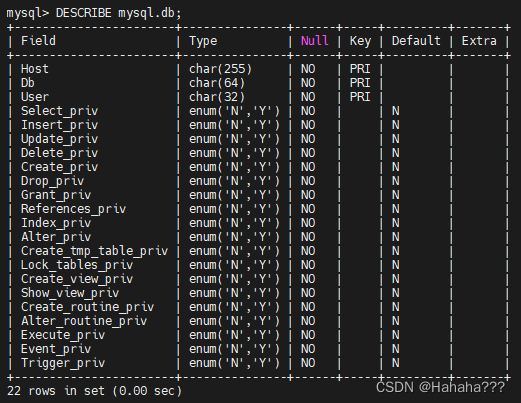
用户与权限管理
文章目录 用户与权限管理1. 用户管理1.1 MYSQL用户1.2 登录MySQL服务器1.3 创建用户1.4 修改用户1.5 删除用户1.6 修改密码1. 修改当前用户密码2. 修改其他用户密码 1.7 MYSQL8密码管理 2. 权限管理2.1 权限列表2.2 授予权限的原则2.3 授予权限2.4 查看权限2.5 收回权限 3. 权限…...
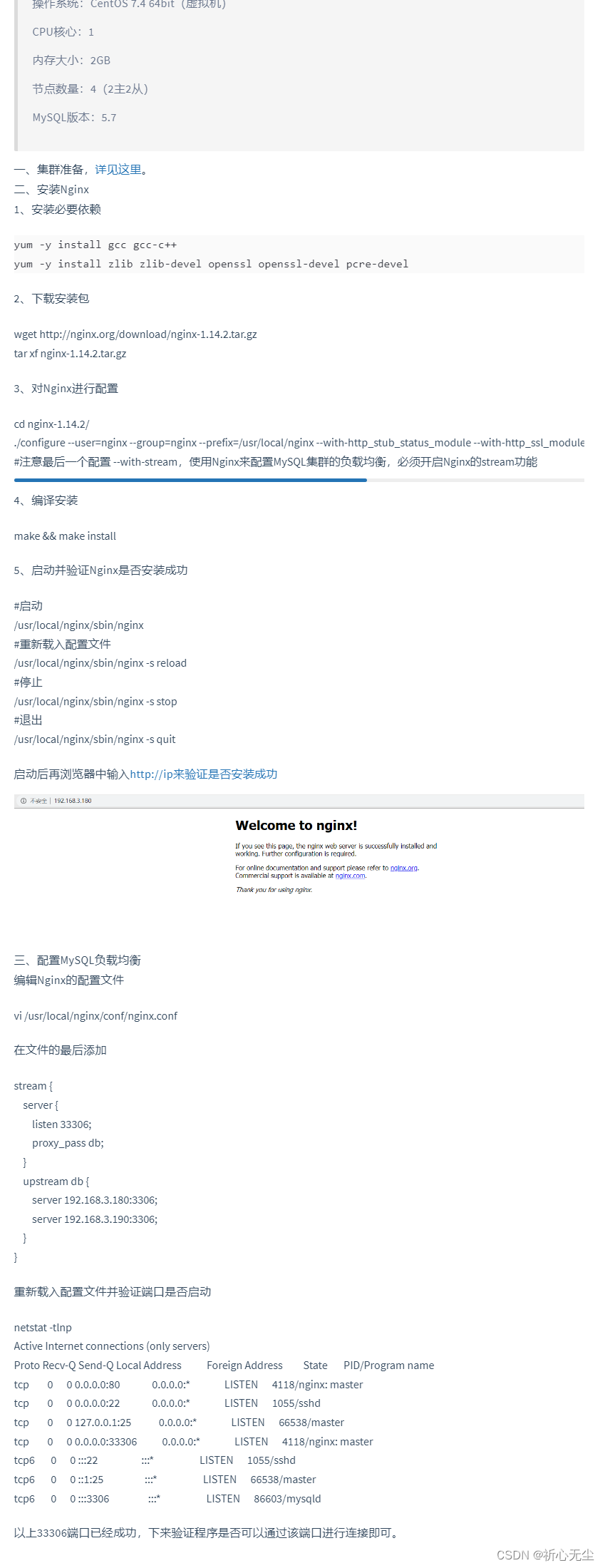
mysql集群使用nginx配置负载均衡
参考链接:https://mu-sl.com//archives/mysql%E9%9B%86%E7%BE%A4%E4%BD%BF%E7%94%A8nginx%E9%85%8D%E7%BD%AE%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1 配置文件nginx_tcp.conf 示例 load_module modules/ngx_stream_module.so;stream{upstream tcpssh{hash $remote_…...

蓝桥杯每日一题2023.9.21
蓝桥杯2021年第十二届省赛真题-异或数列 - C语言网 (dotcpp.com) 题目描述 Alice 和 Bob 正在玩一个异或数列的游戏。初始时,Alice 和 Bob 分别有一个整数 a 和 b,有一个给定的长度为 n 的公共数列 X1, X2, , Xn。 Alice 和 Bob 轮流操作࿰…...

知识联合——函数指针数组
前言:小伙伴们又见面啦,今天我们来讲解一个将函数,指针,数组这三个C语言大将整合在一起的知识——函数指针数组。同时来告诉小伙伴们我们上一篇文章的伏笔——函数指针的具体用法。 目录 一.什么是函数指针数组 二.函数指针数组…...

【Nginx26】Nginx学习:日志与镜像流量复制
Nginx学习:日志与镜像流量复制 总算到了日志模块,其实这个模块的指令之前我们就用过了,而且也是是非常常见的指令。相信这一块的学习大家应该不会有什么难度。另一个则是镜像功能,这个估计用过的同学就比较少了,不过也…...
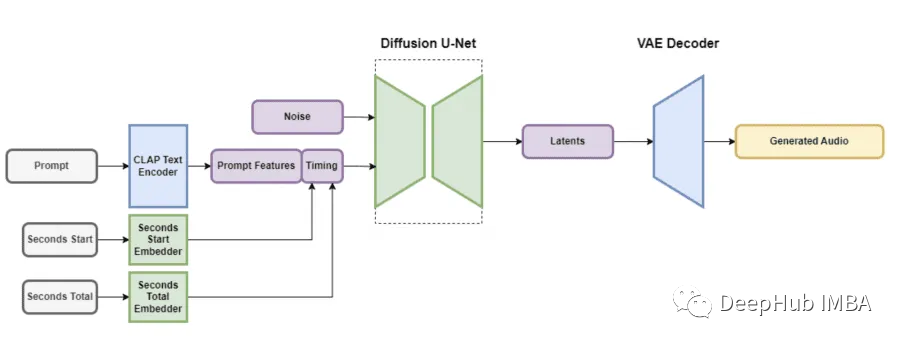
Stability AI发布基于稳定扩散的音频生成模型Stable Audio
近日Stability AI推出了一款名为Stable Audio的尖端生成模型,该模型可以根据用户提供的文本提示来创建音乐。在NVIDIA A100 GPU上Stable Audio可以在一秒钟内以44.1 kHz的采样率产生95秒的立体声音频,与原始录音相比,该模型处理时间的大幅减少…...

华为OD机试 - 计算面积 - 逻辑分析(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、解题思路五、Java算法源码六、效果展示1、输入2、输出3、说明 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷&#…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...
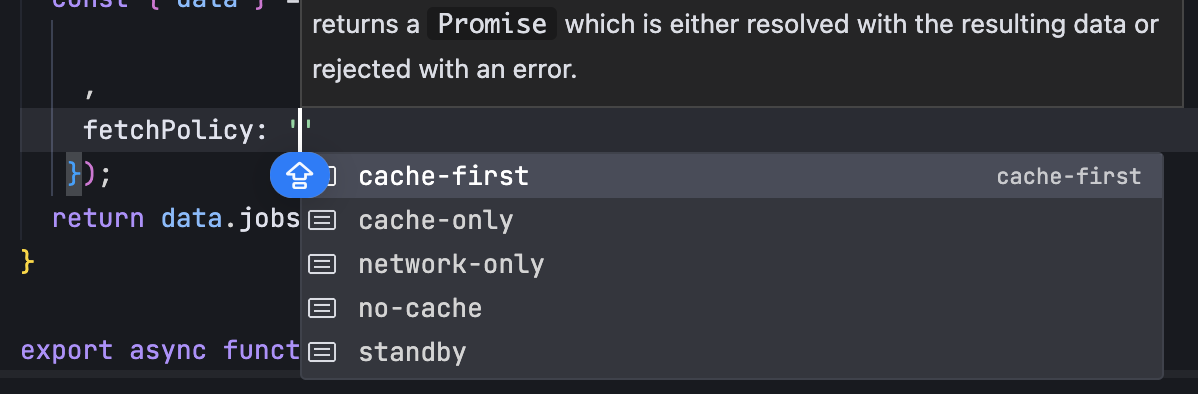
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...