【线性回归、岭回归、Lasso回归分别预测患者糖尿病病情】数据挖掘实验一
Ⅰ、项目任务要求
- 任务描述:将“diabetes”糖尿病患者数据集划分为训练集和测试集,利用训练集分别结合线性回归、岭回归、Lasso回归建立预测模型,再利用测试集来预测糖尿病患者病情并验证预测模型的拟合能力。
- 具体任务要求如下:
- 搜集并加载“diabetes”患者糖尿病指数数据集。
- 定义训练集和测试集(训练集和测试集比例分别为8:2;7:3;6:4)。
- 建立线性回归模型。
- 分别利用可视化方法和交叉验证法确定惩罚参数λ并建立岭回归模型。
- 分别利用可视化方法和交叉验证法确定惩罚参数λ并建立Lasso回归模型。
- 分别用岭回归模型和Lasso回归模型通过测试集预测患者糖尿病病情。
- 利用最小平均均方误差来评估上述三个预测模型的拟合能力。
- 结果分析(上述三种预测模型的对比分析),建议图表结合说明并写出预测模型方程。
参考资料网址:
- 机器学习总结(一):线性回归、岭回归、Lasso回归
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
- Python数据挖掘课程 五.线性回归知识及预测糖尿病实例
- 数据挖掘-diabetes数据集分析-糖尿病病情预测_线性回归_最小平方回归
- 用岭回归和LASSO糖尿病治疗效果好坏
II、数据集描述(10)
。。。。。。(详细描述数据集:如特征属性名称及意义、记录数等)
III、主要算法原理及模型评价方法陈述(15分)
。。。。。。(写出项目中涉及的主要算法原理及模型评价方法)
IV、代码实现(45分)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, model_selection# from sklearn import datasets, linear_model, discriminant_analysis, model_selection# todo: 查看数据(训练集:X_train, y_train; 测试集X_test, y_test)
def check_data():with open("data/X_train.txt", "w") as file:for i in range(len(X_train)):file.write(f"【样本{i+1}】:{X_train[i]}\n")with open("data/y_train.txt", "w") as file:for i in range(len(y_train)):file.write(f"【样本{i+1}】:{y_train[i]}\n")with open("data/X_test.txt", "w") as file:for i in range(len(X_test)):file.write(f"【样本{i+1}】:{X_test[i]}\n")with open("data/y_test.txt", "w") as file:for i in range(len(y_test)):file.write(f"【样本{i+1}】:{y_test[i]}\n")# todo: 可视化展示
def show_plot(alphas, scores):figure = plt.figure()ax = figure.add_subplot(1, 1, 1)ax.plot(alphas, scores)ax.set_xlabel(r"$\alpha$")ax.set_ylabel(r"score")ax.set_xscale("log")ax.set_title("Ridge")plt.show()# Todo: 加载数据
# 加载糖尿病数据集
diabetes = datasets.load_diabetes()
# 使用 model_selection.train_test_split() 将数据集分成训练集和测试集,其中训练集占 75%,测试集占 25%(最佳)
# random_state 参数设置了随机种子,以确保结果的可重复性
X_train, X_test, y_train, y_test = model_selection.train_test_split(diabetes.data, diabetes.target, test_size=0.25, random_state=0)
# 查看划分数据(保存至data/*)
check_data()# Todo: 建立线性回归模型
print('========== ※ 线性回归模型 ※ ==========')
# 通过sklearn的 linear_model 创建线性回归对象
linearRegression = linear_model.LinearRegression()
# 进行训练
linearRegression.fit(X_train, y_train)
# 通过LinearRegression的coef_属性获得权重向量,intercept_获得b的值
print("权重向量:%s, b的值为:%.2f" % (linearRegression.coef_, linearRegression.intercept_))
# 计算出损失函数的值
print("损失函数的值: %.2f" % np.mean((linearRegression.predict(X_test) - y_test) ** 2))
# 计算预测性能得分
print("预测性能得分: %.2f" % linearRegression.score(X_test, y_test))# Todo: 分别利用可视化方法和交叉验证法确定惩罚参数λ并建立岭回归模型
print('========== ※ 岭回归模型 ※ ==========')
ridgeRegression = linear_model.Ridge()
ridgeRegression.fit(X_train, y_train)
print("权重向量:%s, b的值为:%.2f" % (ridgeRegression.coef_, ridgeRegression.intercept_))
print("损失函数的值:%.2f" % np.mean((ridgeRegression.predict(X_test) - y_test) ** 2))
print("预测性能得分: %.2f" % ridgeRegression.score(X_test, y_test))# todo: 测试不同的α值对预测性能的影响
alphas = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000]
scores = []
for i, alpha in enumerate(alphas):ridgeRegression = linear_model.Ridge(alpha=alpha)ridgeRegression.fit(X_train, y_train)scores.append(ridgeRegression.score(X_test, y_test))
show_plot(alphas, scores)# Todo: 分别利用可视化方法和交叉验证法确定惩罚参数λ并建立Lasso回归模型
print('========== ※ Lasso归模型 ※ ==========')
lassoRegression = linear_model.Lasso()
lassoRegression.fit(X_train, y_train)
print("权重向量:%s, b的值为:%.2f" % (lassoRegression.coef_, lassoRegression.intercept_))
print("损失函数的值:%.2f" % np.mean((lassoRegression.predict(X_test) - y_test) ** 2))
print("预测性能得分: %.2f" % lassoRegression.score(X_test, y_test))# todo: 测试不同的α值对预测性能的影响
alphas = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000]
lassos_scores = []
for i, alpha in enumerate(alphas):lassoRegression = linear_model.Lasso(alpha=alpha)lassoRegression.fit(X_train, y_train)lassos_scores.append(lassoRegression.score(X_test, y_test))
show_plot(alphas, lassos_scores)V、运行结果截图(15分)
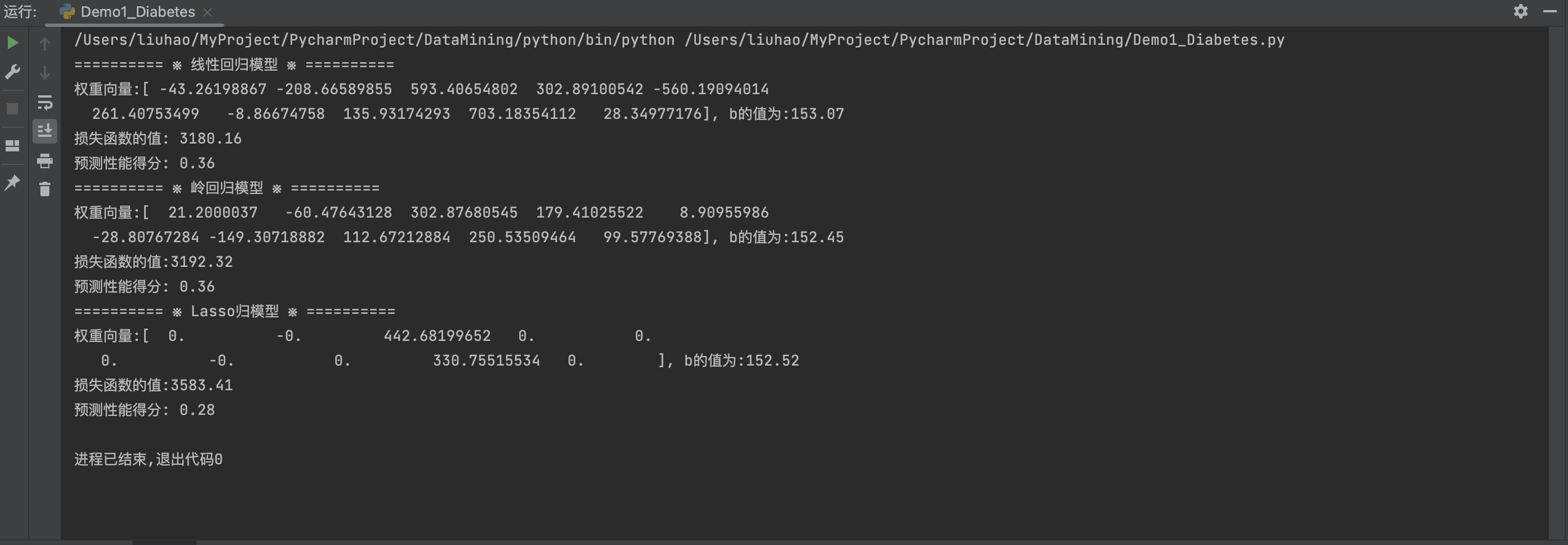
- 岭回归
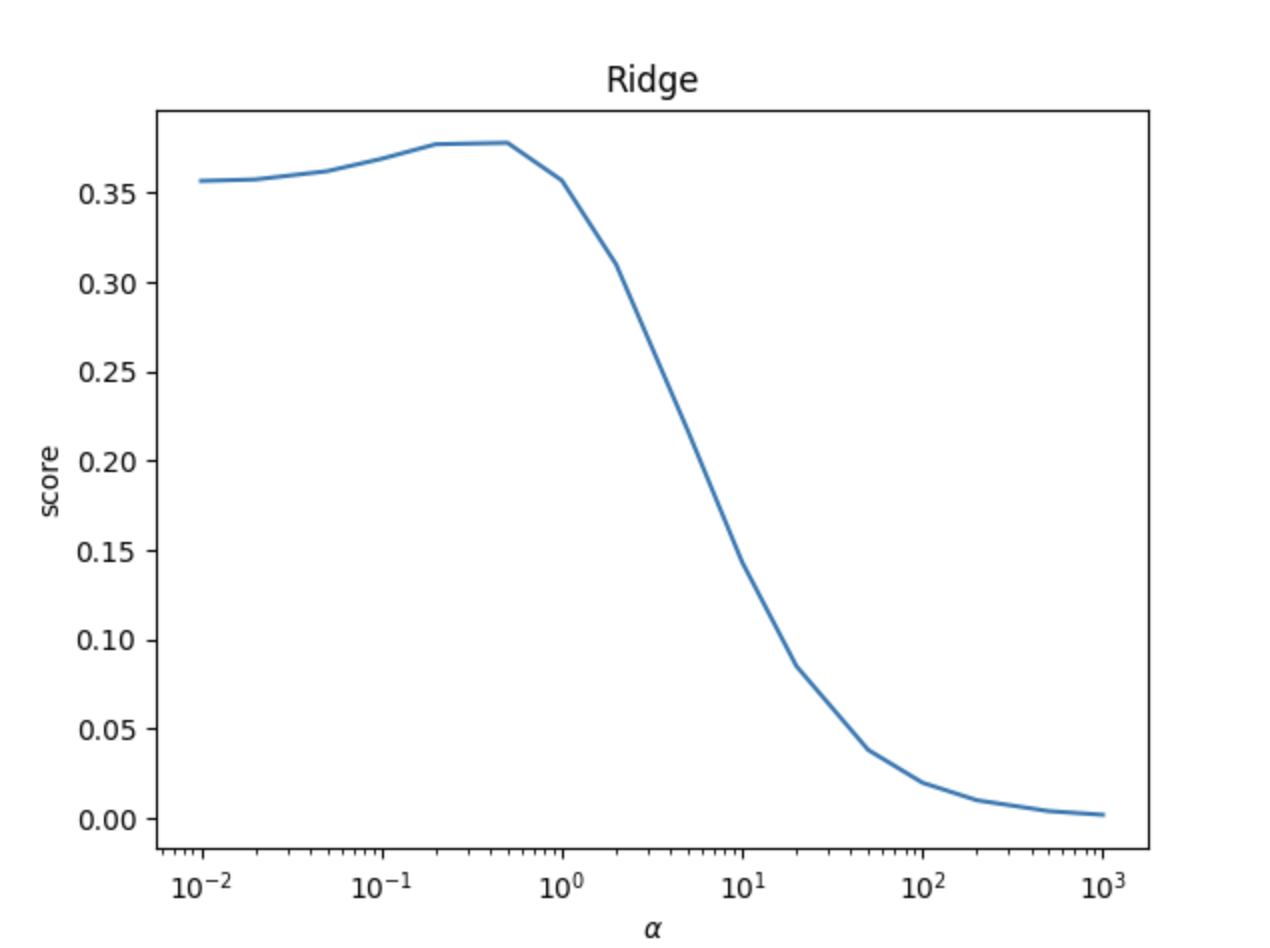
- Lasso回归
VI、结果分析(15分)
。。。。。。(详细分析结果)
VII、小组分工及贡献比
相关文章:
【线性回归、岭回归、Lasso回归分别预测患者糖尿病病情】数据挖掘实验一
Ⅰ、项目任务要求 任务描述:将“diabetes”糖尿病患者数据集划分为训练集和测试集,利用训练集分别结合线性回归、岭回归、Lasso回归建立预测模型,再利用测试集来预测糖尿病患者病情并验证预测模型的拟合能力。具体任务要求如下: …...
037:vue项目监听页面变化,动态设置iframe元素高度
第037个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...

探索前端生成二维码技术:简单实用的实现方式
引言 随着智能手机的普及,二维码已经成为了现代生活中不可或缺的一部分。在许多场景下,我们都需要将某些信息或链接以二维码的形式展示出来。本文将介绍一种简单实用的前端生成二维码的技术,并给出具体的代码示例。 二维码生成原理 首先&a…...
python装13的一些写法
一些当你离职后,让老板觉拍大腿的代码 1. any(** in ** for ** in **) 判断某个集合元素,是否包含某个/某些元素 代码: if __name__ __main__:# 判断 list1 中是否包含某个/某些元素list1 [1,2,3,4]a any(x in [5,4] for x in list1) 输…...
黑马JVM总结(十八)
(1)G1_FullGC的概念辨析 SerialGC:串行的,ParallelGC:并行的 ,CMS和G1都是并发的 这几种垃圾回收器的新生代回收机制时相同的,SerialGC和ParalledGC:老年代内存不足触发的叫FullGC…...
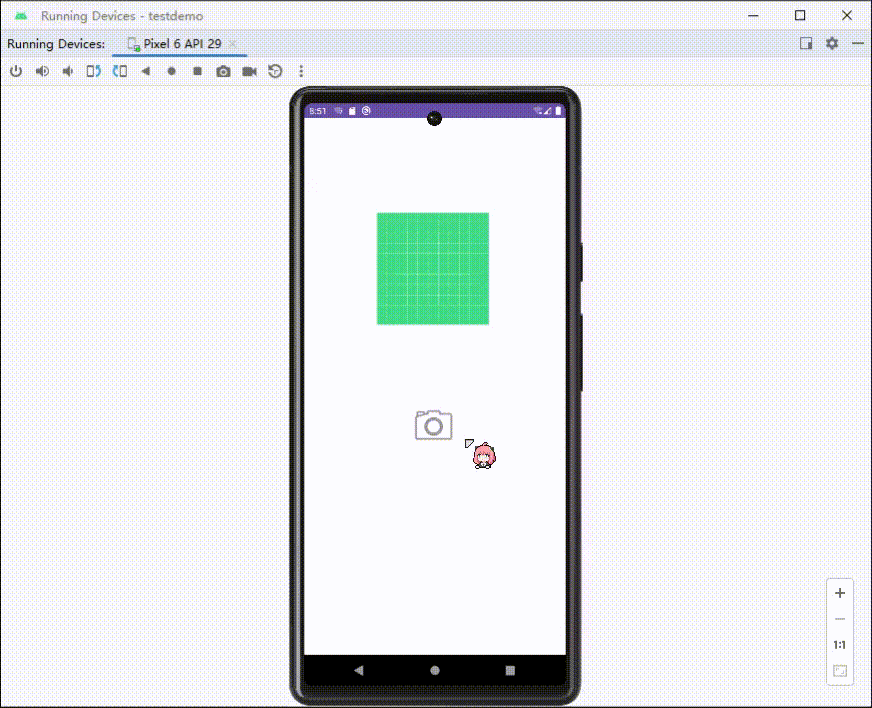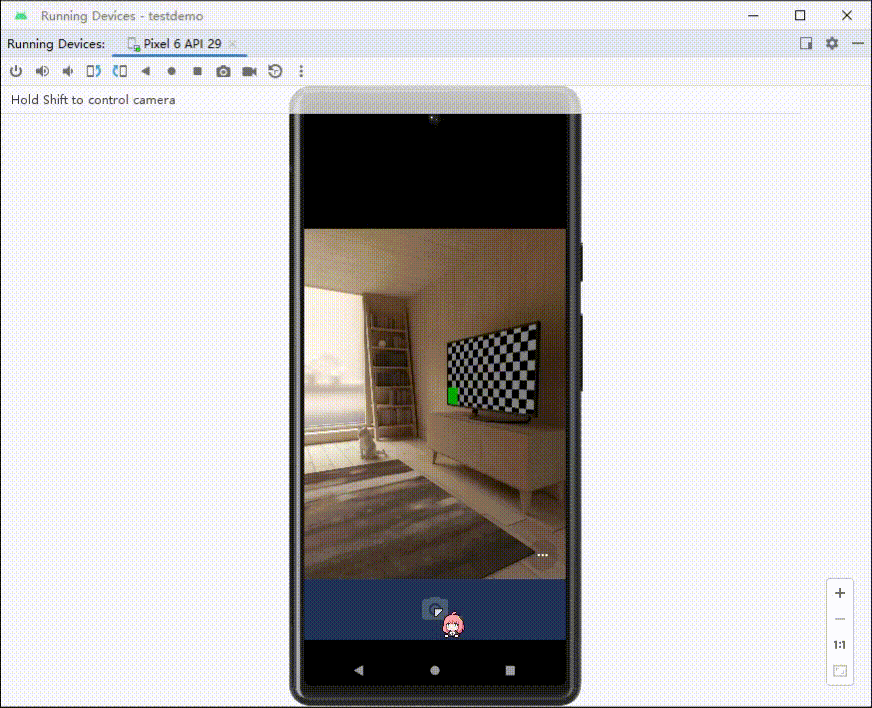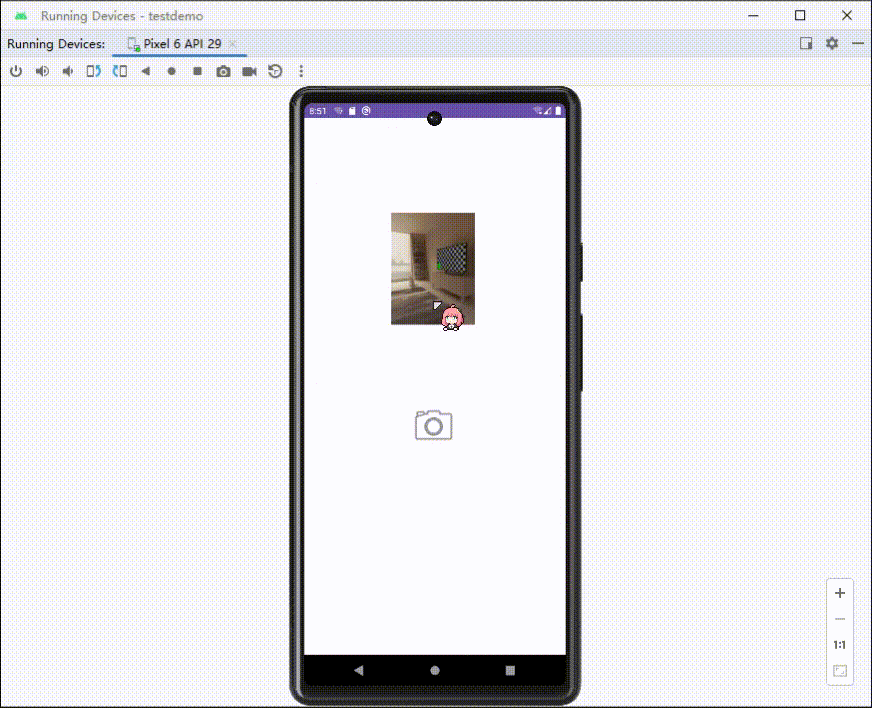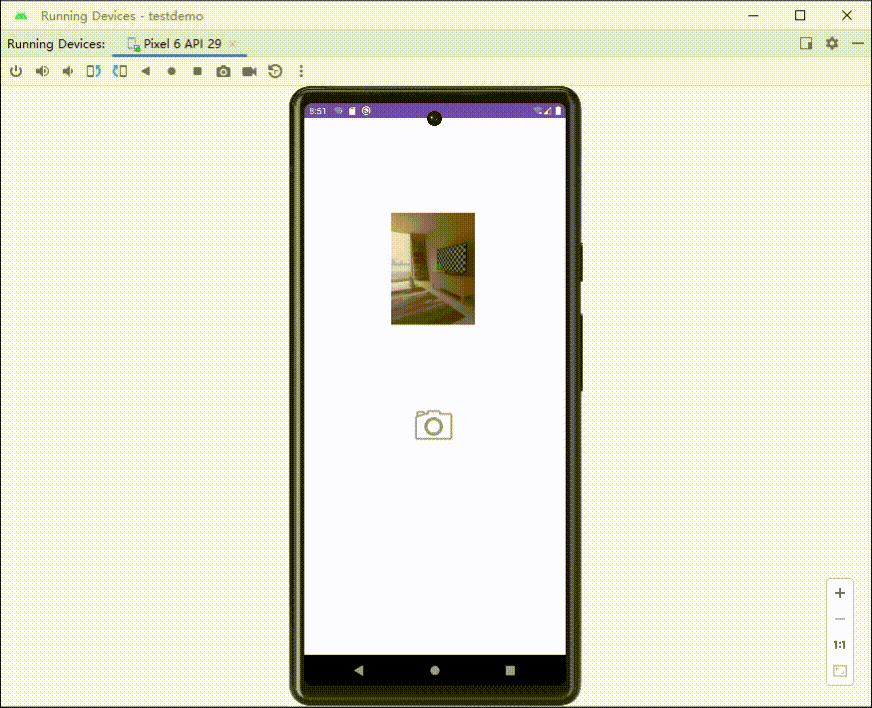
Android调用相机拍照,展示拍摄的图片
调用相机(隐式调用) //自定义一个请求码 这里我设为10010int TAKE_PHOTO_REQUEST 10010;int RESULT_CANCELED 0;//定义取消码//触发监听,调用相机image_camera.setOnClickListener(new View.OnClickListener() {Overridepublic void onCli…...

企业如何找媒体发稿能收录且不被拒稿,媒介盒子无偿分享
媒平台像头条、百家号、微信、微博、搜狐等平台,都支持全自助发稿,拥有庞大的用户群体。也正是因为这些平台的发展,衍生出了一大批自媒体KOL,影响力与传统媒体不相上下甚至更胜。 媒体宣发是企业营销的必要途径之一。软文是成本低…...

利用cms主题构造木马(CVE-2022-26965)
简介 CVE-2022-26965是Pluck CMS 4.7.16版本存在一个远程shell上传执行漏洞。 攻击者可利用此漏洞通过构造恶意的主题包进行上传并执行,未经授权访问服务器,造成潜在的安全隐患。 过程 1.打开环境,查看源码,发现login.php 2.进…...

【MTK】【WFD】手机投屏到投影仪不显示画面
问题分析: 在投屏过程中,有时候会出现WFD sink端回复的video 格式表不正确,sink表示是支持VESA(3fffffff),但是当手机根据协商结果得到最优分辨率并发送给sink端时,sink端看上去没有正常播放,其实实际上应该是不支持的。 比如我们这个问题就是CES表中的0001ffff,最大…...

多输入多输出 | MATLAB实现PSO-LSSVM粒子群优化最小二乘支持向量机多输入多输出
多输入多输出 | MATLAB实现PSO-LSSVM粒子群优化最小二乘支持向量机多输入多输出 目录 多输入多输出 | MATLAB实现PSO-LSSVM粒子群优化最小二乘支持向量机多输入多输出预测效果基本介绍程序设计往期精彩参考资料 预测效果 基本介绍 MATLAB实现PSO-LSSVM粒子群优化最小二乘支持向…...
scrapyd-完整细节
安装scrapyd服务 pip install scrapyd 安装scrapyd客户端 pip install scrapyd-client 安装好以后重新开启cmd输入命令 scrapyd 出现以下结果代表安装成功 打开浏览器输入网址,即可打开界面客户端 http://127.0.0.1:6800/ 回车后显示一下ok内容代表部署成功 回到服…...
【iOS逆向与安全】插件开发之某音App直播间自动发666
1.目标 由于看直播的时候主播叫我发 666,支持他,我肯定支持他呀,就一直发,可是后来发现太浪费时间了,能不能做一个直播间自动发 666 呢?于是就花了几分钟做了一个。 2.操作环境 越狱iPhone一台 frida ma…...
AI Studio星河社区生产力实践:基于文心一言快速搭建知识库问答
还在寻找基于文心一言搭建本地知识库问答的方案吗?AI Studio星河社区带你实战演练(支持私有化部署)! 相信对于大语言模型(LLM)有所涉猎的朋友,对于“老网红”知识库问答不会陌生。自从大模型爆…...
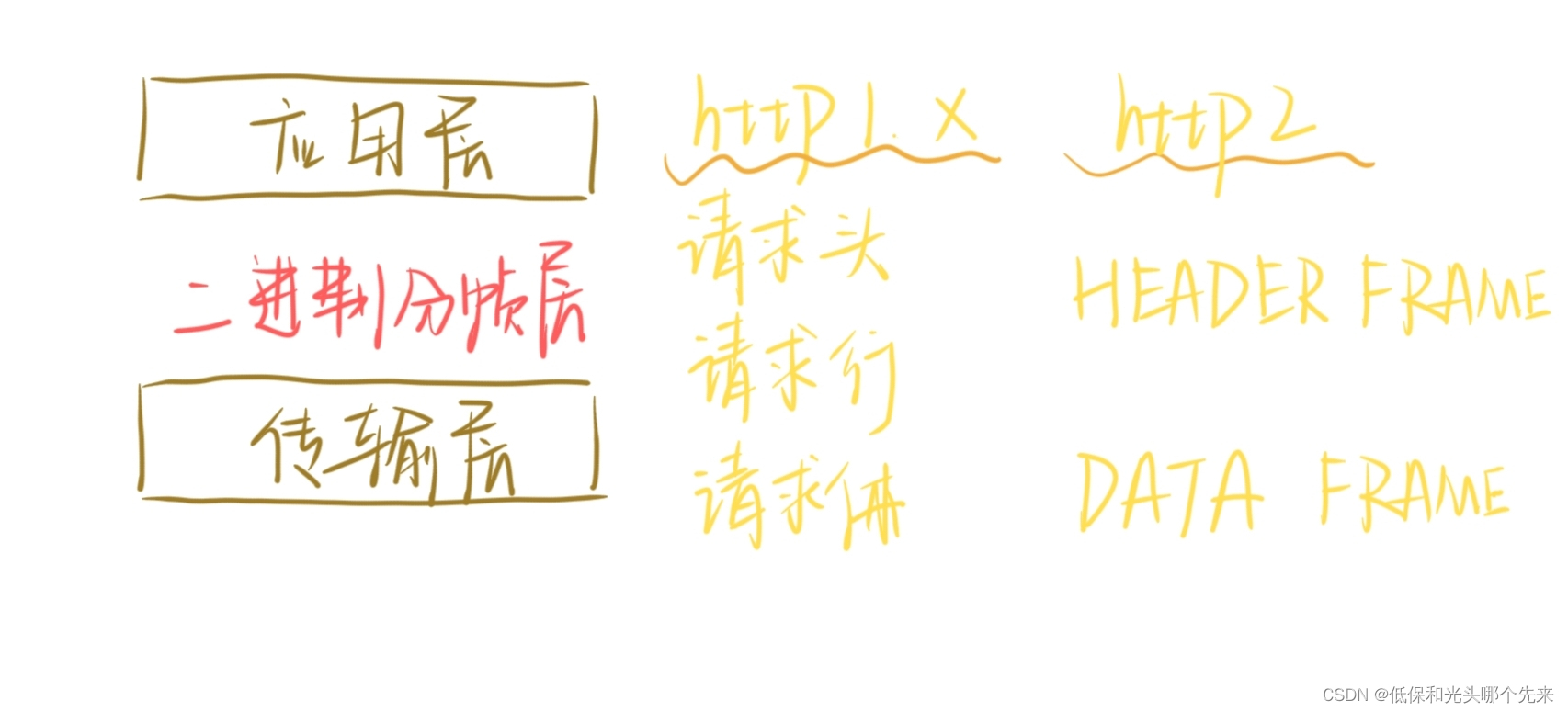
http1和http2的主要区别
主要有四个方面: 二进制分帧多路复用服务器主动推送头部压缩 将前两点结合来说,首先 二进制分帧 帧:HTTP/2 数据通信的最小单位; 消息:HTTP/2 中,例如在请求和响应等操作中,消息由一个或多个…...

一文了解水雨情在线监测站的优势
随着全球气候变化的加剧,水雨情的监测变得越来越重要。水雨情监测站作为现代环境监测系统的重要组成部分,其优势在实现环境智能监控方面得到了充分体现。 实时监测,数据准确 水雨情监测站通过先进的技术设备和智能传感器,能够实时…...

windows11中安装curl
windows11中安装curl 1.下载curl curl 下载地址:curl 2.安装curl 2.1.解压下载的压缩包 解压文件到 C:\Program Files\curl-8.3.0_1-win64-mingw 目录 2.2.配置环境变量 WINS 可打开搜索栏,输入“编辑系统环境变量” 并按回车。 3.可能遇到的问题 3…...
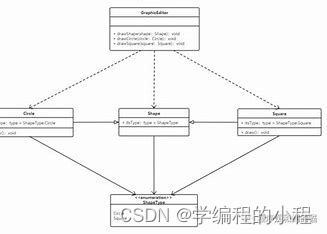
小谈设计模式(5)—开放封闭原则
小谈设计模式(5)—开放封闭原则 专栏介绍专栏地址专栏介绍 开放封闭原则核心思想关键词概括扩展封闭 解释抽象和接口多态 代码示例代码解释 优缺点优点可扩展性可维护性可复用性高内聚低耦合 缺点抽象设计的复杂性需要预留扩展点可能引入过度设计 总结 专…...

计算机视觉与深度学习-全连接神经网络-训练过程-欠拟合、过拟合和Dropout- [北邮鲁鹏]
目录标题 机器学习的根本问题过拟合overfitting泛化能力差。应对过拟合最优方案次优方案调节模型大小约束模型权重,即权重正则化(常用的有L1、L2正则化)L1 正则化L2 正则化对异常值的敏感性随机失活(Dropout)随机失活的问题 欠拟合 机器学习的根本问题 机器学习的根…...
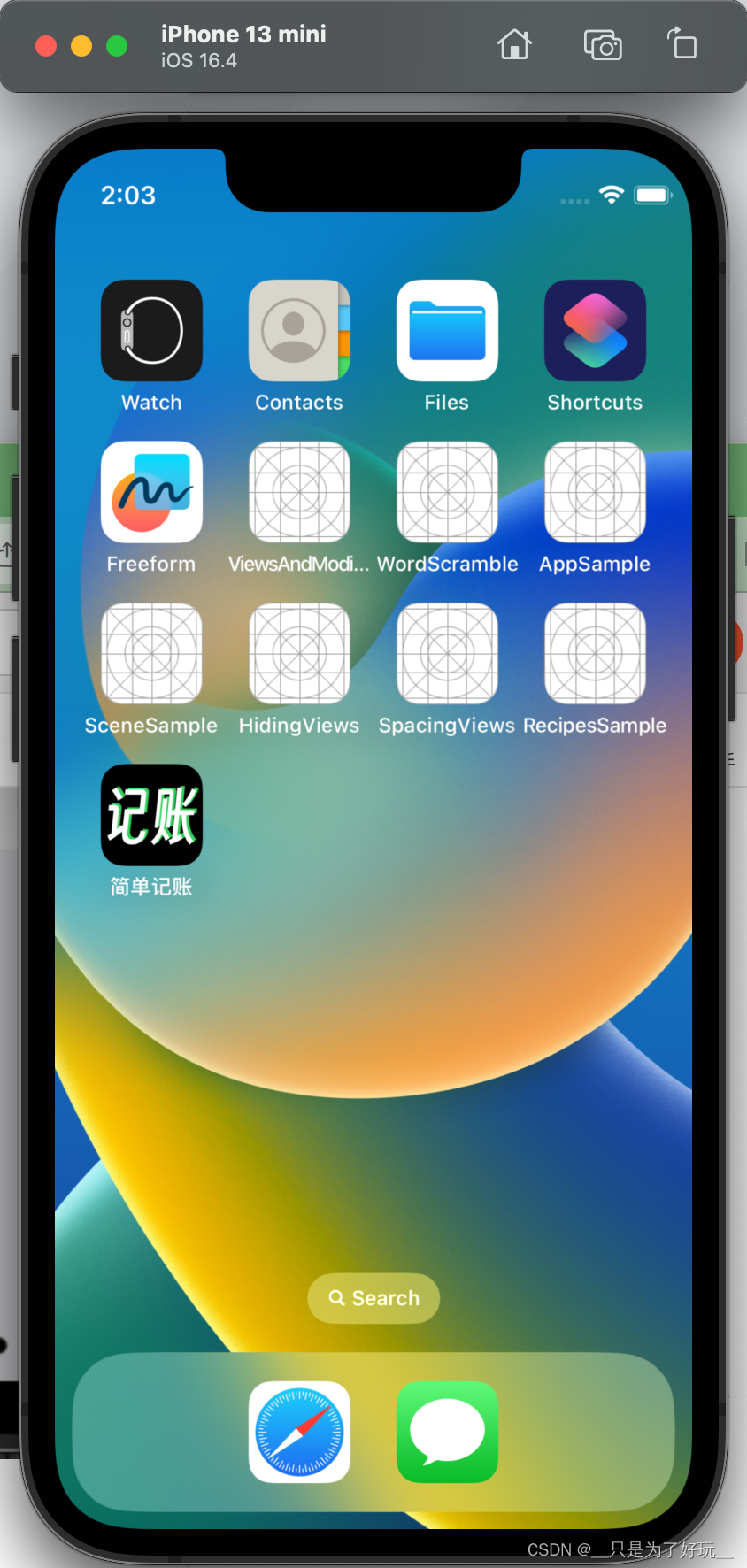
SwiftUI Swift iOS iPadOS 实现更改 App 图标
Xcode: 14.3.1 更改 App 图标 淘宝,支付宝,有道翻译有时候会随着运营活动去调整图标,比如 双 11。(这个很简单,替换一下 AppIcon 就可以了)Github App 提供了多套图标可以修改。(需要配置 &…...
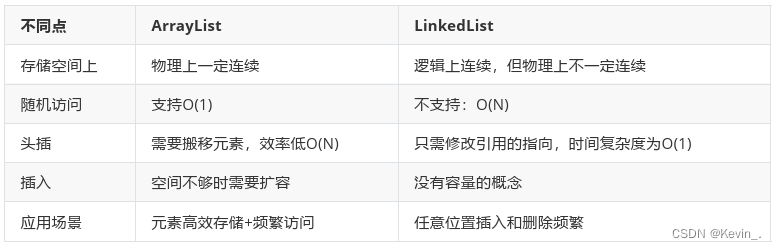
Java————List
一 、顺序表和链表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构, 常见的线性表:顺序表、链表、栈、队列… 线性表在逻辑上是线性结构,也就说是连续的一条直…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...
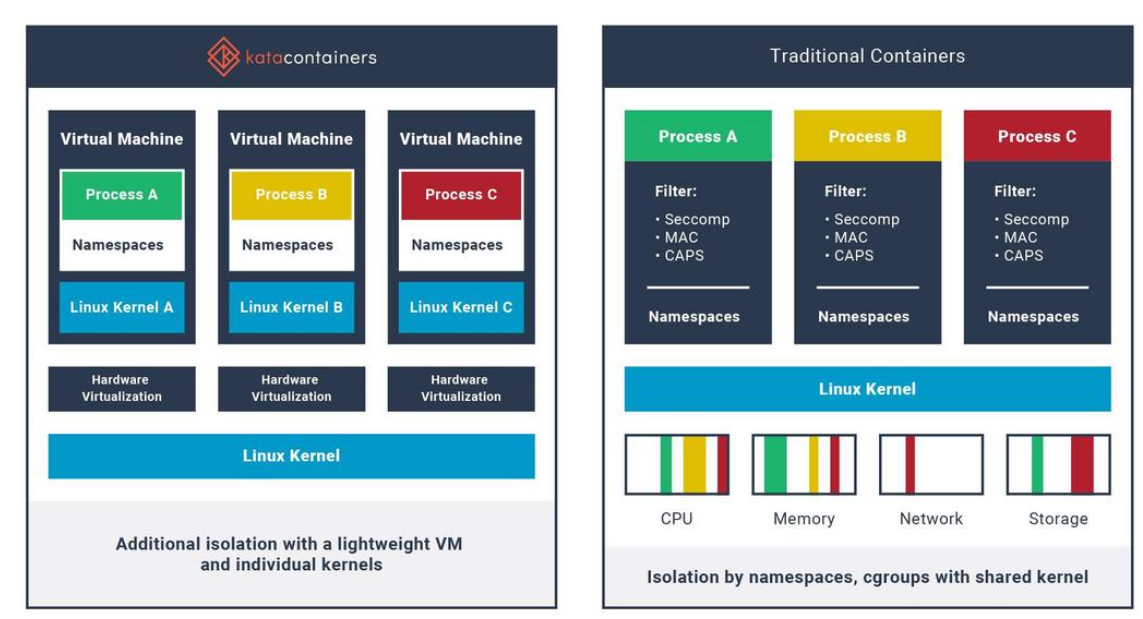
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...