深入理解Linux网络笔记(一):内核是如何接收网络包的
本文为《深入理解Linux网络》学习笔记,使用的Linux源码版本是3.10,网卡驱动是Intel的igb网卡驱动
Linux源码在线阅读:https://elixir.bootlin.com/linux/v3.10/source
1、内核是如何接收网络包的
1)、Linux网络收包总览
在TCP/IP网络分层模型里,整个协议栈被分为了物理层、链路层、网络层、传输层和应用层。应用层对应的是我们常见的Nginx、FTP等各种应用,也包括我们写的各种服务端程序。Liunx内核以及网卡驱动主要实现链路层、网络层和传输层这三层上的功能,内核为更上面的应用层提供socket接口来支持用户进程访问。以Linux的视角看到的TCP/IP网络分层模型如下图所示:

内核和网络设备驱动是通过中断的方式来处理的。当设备上有数据到达时,会给CPU的相关引脚触发一个电压变化,以通知CPU来处理数据。对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)过度占用CPU,使得CPU无法响应其他设备。因此Linux中断处理函数是分上半部和下半部的。上半部只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其他中断进来。将剩下的绝大部分的工作都放到下半部,可以慢慢、从容处理。2.4以后的Linux内核版本采用的下半部实现方式是软中断,由ksoftirqd内核线程全权处理。硬中断是通过给CPU物理引脚施加电压变化实现的,而软中断是通过给内存中的一个变量赋予二进制值以标记有软中断发生
内核收包的路径如下图所示:

当网卡收到数据以后,以DMA的方式把网卡收到的帧写到内存里,再向CPU发起一个中断,以通知CPU有数据到达。当CPU收到中断请求后,会去调用网络设备驱动注册的中断处理函数。网卡的中断处理函数并不做过多工作,发出软中断请求,然后尽快释放CPU资源。ksoftirqd内核线程检测到有软中断请求到达,调用poll开始轮询收包,收到后交由各级协议栈处理。对于TCP包来说,会被放到用户socket的接收队列中
2)、Linux启动
1)创建ksoftirqd线程
Linux软中断由ksoftirqd内核线程处理,该线程数等于CPU核数
系统初始化的时候会执行到spawn_ksoftirqd(位于kernel/softirq.c)来创建出ksoftirqd线程,执行过程如下图所示:

// kernel/softirq.c
static struct smp_hotplug_thread softirq_threads = {.store = &ksoftirqd,.thread_should_run = ksoftirqd_should_run,.thread_fn = run_ksoftirqd,.thread_comm = "ksoftirqd/%u",
};static __init int spawn_ksoftirqd(void)
{register_cpu_notifier(&cpu_nfb);BUG_ON(smpboot_register_percpu_thread(&softirq_threads));return 0;
}
early_initcall(spawn_ksoftirqd);
当ksoftirqd被创建出来以后,它就会进入自己的线程循环函数ksoftirqd_should_run和run_ksoftirqd。接下来判断有没有软中断需要处理
需要注意,软中断不仅有网络软中断,还有其他类型。Linux内核在interrupt.h定义了所有的软中断类型,如下:
// include/linux/interrupt.h
enum
{HI_SOFTIRQ=0,TIMER_SOFTIRQ,NET_TX_SOFTIRQ, // 网络传输发送软中断NET_RX_SOFTIRQ, // 网络传输接收软中断BLOCK_SOFTIRQ,BLOCK_IOPOLL_SOFTIRQ,TASKLET_SOFTIRQ,SCHED_SOFTIRQ,HRTIMER_SOFTIRQ,RCU_SOFTIRQ,NR_SOFTIRQS
};
2)网络子系统初始化
在网络子系统的初始化过程中,会为每个CPU初始化softnet_data,也会为NET_TX_SOFTIRQ和NET_RX_SOFTIRQ注册处理函数,执行过程如下图所示:

Linux内核通过调用subsys_initcall来初始化各个子系统,网络子系统的初始化会执行net_dev_init函数
// net/core/dev.c
static int __init net_dev_init(void)
{...for_each_possible_cpu(i) {struct softnet_data *sd = &per_cpu(softnet_data, i);memset(sd, 0, sizeof(*sd));skb_queue_head_init(&sd->input_pkt_queue);skb_queue_head_init(&sd->process_queue);sd->completion_queue = NULL;INIT_LIST_HEAD(&sd->poll_list);...}...open_softirq(NET_TX_SOFTIRQ, net_tx_action);open_softirq(NET_RX_SOFTIRQ, net_rx_action);...
}subsys_initcall(net_dev_init);
在这个函数里,会为每个CPU都申请一个softnet_data数据结构,这个数据结构里的poll_list用于等待驱动程序将其poll函数注册进来,稍后讲到“网卡驱动初始化”时可以看到这一过程
另外,open_softirq为每一种软中断都注册一个处理函数。NET_TX_SOFTIRQ的处理函数为net_tx_action,NET_RX_SOFTIRQ的处理函数为net_rx_action。继续跟踪open_softirq后发现这个注册的方式是记录在softirq_vec变量里的。后面ksoftirqd线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数
// kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *))
{softirq_vec[nr].action = action;
}
3)协议栈注册
内核实现了网络层的IP协议,也实现了传输层的TCP协议和UDP协议。这些协议对应的实现函数分为是ip_rcv()、tcp_v4_rcv()和udp_rcv()。Linux内核中的fs_initcall和subsys_initcall类似,也是初始化模块的入口。fs_initcall调用inet_init后开始网络协议栈注册,通过inet_init,将这些函数注册到inet_protos和ptype_base数据结构中,如下图所示:

// net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {.type = cpu_to_be16(ETH_P_IP),.func = ip_rcv,
};static const struct net_protocol udp_protocol = {.handler = udp_rcv,.err_handler = udp_err,.no_policy = 1,.netns_ok = 1,
};static const struct net_protocol tcp_protocol = {.early_demux = tcp_v4_early_demux,.handler = tcp_v4_rcv,.err_handler = tcp_v4_err,.no_policy = 1,.netns_ok = 1,
};static int __init inet_init(void)
{...if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)pr_crit("%s: Cannot add UDP protocol\n", __func__);if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)pr_crit("%s: Cannot add TCP protocol\n", __func__);...dev_add_pack(&ip_packet_type);...
}
udp_protocol结构体中的handler是udp_rcv,tcp_protocol结构体中的handler是tcp_v4_rcv,它们通过inet_add_protocol函数被初始化进来
// net/ipv4/protocol.c
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol)
{if (!prot->netns_ok) {pr_err("Protocol %u is not namespace aware, cannot register.\n",protocol);return -EINVAL;}return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],NULL, prot) ? 0 : -1;
}
inet_add_protocol函数将TCP和UDP对应的处理函数都注册到inet_protos数组中
再看net/ipv4/af_inet.c中的dev_add_pack(&ip_packet_type);这一行,ip_packet_type结构体中的type是协议栈名,func是ip_rcv函数,它们在dev_add_pack中被注册到ptype_base哈希表中
// net/core/dev.c
static inline struct list_head *ptype_head(const struct packet_type *pt)
{if (pt->type == htons(ETH_P_ALL))return &ptype_all;elsereturn &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}void dev_add_pack(struct packet_type *pt)
{struct list_head *head = ptype_head(pt);...
}
这里需要记住inet_protos记录着UDP、TCP的处理函数地址,ptype_base存储着ip_rcv()函数的处理地址。后面讲到“ksoftirqd内核线程处理软中断”中会通过ptype_base找到ip_rcv函数地址,进而将IP包正确地发送到ip_rcv()中执行。在ip_rcv中将会通过inet_protos找到TCP或者UDP的处理函数,再把包转发给udp_rcv()或tcp_v4_rcv()函数
4)网卡驱动初始化
每一个驱动程序(不仅仅包括网卡驱动程序)会使用module_init向内核注册一个初始化函数,当驱动程序被加载时,内核会调用这个函数。比如igb网卡驱动程序的代码位于drivers/net/ethernet/intel/igb/igb_main.c中
// drivers/net/ethernet/intel/igb/igb_main.c
static struct pci_driver igb_driver = {.name = igb_driver_name,.id_table = igb_pci_tbl,.probe = igb_probe,.remove = igb_remove,...
};static int __init igb_init_module(void)
{...ret = pci_register_driver(&igb_driver);return ret;
}
驱动的pci_register_driver调用完成后,Linux内核就知道了该驱动的相关信息,比如igb网卡驱动的igb_driver_name和igb_probe函数地址等等。当网卡设备被识别以后,内核会调用其驱动的probe方法(igb_driver的probe方法是igb_probe)。驱动的probe方法执行的目的就是让设备处于ready状态。对于igb网卡,函数igb_probe主要执行的操作如下图所示:

第6步注册net_device_ops用的是igb_netdev_ops变量,其中包含了igb_open,该函数在网卡被启动的时候会被调用
// drivers/net/ethernet/intel/igb/igb_main.c
static const struct net_device_ops igb_netdev_ops = {.ndo_open = igb_open,.ndo_stop = igb_close,.ndo_start_xmit = igb_xmit_frame,.ndo_get_stats64 = igb_get_stats64,.ndo_set_rx_mode = igb_set_rx_mode,.ndo_set_mac_address = igb_set_mac,.ndo_change_mtu = igb_change_mtu,.ndo_do_ioctl = igb_ioctl,...
};
第7步在igb_probe初始化过程中,还调用到了igb_alloc_q_vector。它注册了一个NAPI机制必需的poll函数,对于igb网卡驱动来说,这个函数就是igb_poll
// drivers/net/ethernet/intel/igb/igb_main.c
static int igb_alloc_q_vector(struct igb_adapter *adapter,int v_count, int v_idx,int txr_count, int txr_idx,int rxr_count, int rxr_idx)
{.../* initialize NAPI */netif_napi_add(adapter->netdev, &q_vector->napi,igb_poll, 64);...
}
5)启动网卡
当启动网卡时,net_device_ops变量中定义的ndo_open方法会被调用。对于igb网卡来说,该函数指针指向的是igb_open方法,它主要执行的操作如下图所示:

// drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming)
{...// 分配传输描述符数组err = igb_setup_all_tx_resources(adapter);if (err)goto err_setup_tx;// 分配接收描述符数组err = igb_setup_all_rx_resources(adapter);if (err)goto err_setup_rx;...// 注册中断处理函数err = igb_request_irq(adapter);if (err)goto err_req_irq;...// 启动NAPIfor (i = 0; i < adapter->num_q_vectors; i++)napi_enable(&(adapter->q_vector[i]->napi));...
}
__igb_open函数调用了igb_setup_all_tx_resources和igb_setup_all_rx_resources。在调用igb_setup_all_tx_resources这一步操作中,分配了RingBuffer,并建立内存和Rx队列的映射关系
// drivers/net/ethernet/intel/igb/igb_main.c
static int igb_setup_all_tx_resources(struct igb_adapter *adapter)
{...for (i = 0; i < adapter->num_tx_queues; i++) {err = igb_setup_tx_resources(adapter->tx_ring[i]);...}return err;
}
igb_setup_all_tx_resources函数中通过循环创建了若干个接收队列

// drivers/net/ethernet/intel/igb/igb_main.c
int igb_setup_tx_resources(struct igb_ring *tx_ring)
{struct device *dev = tx_ring->dev;int size;// 申请igb_tx_buffer数组内存size = sizeof(struct igb_tx_buffer) * tx_ring->count;tx_ring->tx_buffer_info = vzalloc(size);if (!tx_ring->tx_buffer_info)goto err;// 申请e1000_adv_tx_desc DMA 数组内存tx_ring->size = tx_ring->count * sizeof(union e1000_adv_tx_desc);tx_ring->size = ALIGN(tx_ring->size, 4096);tx_ring->desc = dma_alloc_coherent(dev, tx_ring->size,&tx_ring->dma, GFP_KERNEL);if (!tx_ring->desc)goto err;// 初始化队列成员tx_ring->next_to_use = 0;tx_ring->next_to_clean = 0;return 0;err:vfree(tx_ring->tx_buffer_info);tx_ring->tx_buffer_info = NULL;dev_err(dev, "Unable to allocate memory for the Tx descriptor ring\n");return -ENOMEM;
}
实际上一个RingBuffer的内部不是仅有一个环形队列数组,而是有两个
- igb_tx_buffer数组:给内核使用,通过vzalloc申请的
- e1000_adv_tx_desc数组:给网卡硬件使用的,通过dma_alloc_coherent分配

再接着看中断函数是如何注册的,注册过程见igb_request_irq:
// drivers/net/ethernet/intel/igb/igb_main.c
static int igb_request_irq(struct igb_adapter *adapter)
{...if (adapter->msix_entries) {err = igb_request_msix(adapter);if (!err)goto request_done;...}...
}static int igb_request_msix(struct igb_adapter *adapter)
{...for (i = 0; i < adapter->num_q_vectors; i++) {...err = request_irq(adapter->msix_entries[vector].vector,igb_msix_ring, 0, q_vector->name,q_vector);...}...
}
函数调用顺序为__igb_open => igb_request_irq => igb_request_msix。在igb_request_msix中,对于多队列的网卡,为每一个队列都注册了中断,其对应的中断处理函数是igb_msix_ring。还可以看到,在msix方式下,每个RX队列都有独立的MSI-X中断,从网卡硬件中断的层面就可以设置让收到的包被不同的CPU处理
3)、接收网络数据
1)硬中断处理
首先,当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的RingBuffer中寻找可用的内存位置,找到后DMA引擎会把数据DMA到网卡之前关联的内存里,到这个时候CPU都是无感的。当DMA操作完成以后,网卡会向CPU发起一个硬中断,通知CPU有数据到达。硬中断的处理过程如下图所示:

在前面介绍启动网卡部分,讲到了网卡的硬中断注册的处理函数是igb_msix_ring
// drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(int irq, void *data)
{struct igb_q_vector *q_vector = data;igb_write_itr(q_vector);napi_schedule(&q_vector->napi);return IRQ_HANDLED;
}
其中的igb_write_itr只记录硬件中断频率。顺着napi_schedule调用一路跟踪下去,调用顺序为napi_schedule => __napi_schedule => ____napi_schedule
// net/core/dev.c
static inline void ____napi_schedule(struct softnet_data *sd,struct napi_struct *napi)
{list_add_tail(&napi->poll_list, &sd->poll_list);__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
这里可以看到,list_add_tail修改了每个CPU变量softnet_data里的poll_list,将驱动napi_struct传过来的poll_list添加了进来。softnet_data里的poll_list是一个双向列表,其中的设备都带有输入帧等着被处理。紧接着__raise_softirq_irqoff触发了一个软中断NET_RX_SOFTIRQ,这个所谓的触发过程只是对一个变量进行了一次或运算而已
// kernel/softirq.c
void __raise_softirq_irqoff(unsigned int nr)
{trace_softirq_raise(nr);or_softirq_pending(1UL << nr);
}
// include/linux/interrupt.h
#define or_softirq_pending(x) (local_softirq_pending() |= (x))
// include/linux/irq_cpustat.h
#define local_softirq_pending() \__IRQ_STAT(smp_processor_id(), __softirq_pending)
通过以上代码可以看到,硬中断处理过程真的非常短,只是记录了一个寄存器,修改了一下CPU的poll_list,然后发出一个软中断
2)ksoftirqd内核线程处理软中断
网络包的接收处理过程主要都在ksoftirqd内核线程中完成,软中断都是在这里处理的,流程如下图所示:

在前面介绍内核线程初始化的时候,曾介绍了ksoftirqd中两个线程函数ksoftirqd_should_run和run_ksoftirqd。其中ksoftirqd_should_run函数的代码如下:
// kernel/softirq.c
static int ksoftirqd_should_run(unsigned int cpu)
{return local_softirq_pending();
}
// include/linux/irq_cpustat.h
#define local_softirq_pending() \__IRQ_STAT(smp_processor_id(), __softirq_pending)
该函数和硬中断中调用了同一个函数local_softirq_pending。使用方式不同在于,在硬中断处理中是为了写入标记,这里只是读取。如果硬中断中设置了NET_RX_SOFTIRQ,这里就能读取到。接下来由内核线程处理函数run_ksoftirqd进行处理:
// kernel/softirq.c
static void run_ksoftirqd(unsigned int cpu)
{local_irq_disable();if (local_softirq_pending()) {__do_softirq();...}local_irq_enable();
}
在__do_softirq中,判断根据当前CPU的软中断类型,调用其注册的action方法:
// kernel/softirq.c
asmlinkage void __do_softirq(void)
{...do {if (pending & 1) {unsigned int vec_nr = h - softirq_vec;int prev_count = preempt_count();...trace_softirq_entry(vec_nr);h->action(h);trace_softirq_exit(vec_nr);...}h++;pending >>= 1;} while (pending);...
}
硬中断中的设置软中断标记,和ksoftirqd中的判断是否有软中断到达,都是基于smp_processor_id()的。这意味着只要硬中断在哪个CPU上被响应,那么软中断也是在这个CPU上处理的
NET_RX_SOFTIRQ的处理函数为net_rx_action
// net/core/dev.c
static void net_rx_action(struct softirq_action *h)
{struct softnet_data *sd = &__get_cpu_var(softnet_data);unsigned long time_limit = jiffies + 2;int budget = netdev_budget;void *have;local_irq_disable();while (!list_empty(&sd->poll_list)) {...n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);have = netpoll_poll_lock(n);weight = n->weight;work = 0;if (test_bit(NAPI_STATE_SCHED, &n->state)) {work = n->poll(n, weight);trace_napi_poll(n);}WARN_ON_ONCE(work > weight);budget -= work;local_irq_disable();...}...
}
函数开头的time_limit和budget是用来控制net_rx_action函数主动退出的,目的是保证网络包的接收不霸占CPU不放,等下次网卡再有硬中断过来的时候再处理剩下的接收数据包。这个函数中剩下的核心逻辑是获取当前CPU变量softnet_data,对其poll_list进行遍历,然后执行到网卡驱动注册的poll函数。对于igb网卡来说,就是igb驱动里的igb_poll函数:
// drivers/net/ethernet/intel/igb/igb_main.c
static int igb_poll(struct napi_struct *napi, int budget)
{...if (q_vector->tx.ring)clean_complete = igb_clean_tx_irq(q_vector);if (q_vector->rx.ring)clean_complete &= igb_clean_rx_irq(q_vector, budget);...
}
在读取操作中,igb_poll的重点工作是对igb_clean_rx_irq的调用
// drivers/net/ethernet/intel/igb/igb_main.c
static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{...do {union e1000_adv_rx_desc *rx_desc;/* return some buffers to hardware, one at a time is too slow */if (cleaned_count >= IGB_RX_BUFFER_WRITE) {igb_alloc_rx_buffers(rx_ring, cleaned_count);cleaned_count = 0;}rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean);if (!igb_test_staterr(rx_desc, E1000_RXD_STAT_DD))break;/* This memory barrier is needed to keep us from reading* any other fields out of the rx_desc until we know the* RXD_STAT_DD bit is set*/rmb();/* retrieve a buffer from the ring */skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb);/* exit if we failed to retrieve a buffer */if (!skb)break;cleaned_count++;/* fetch next buffer in frame if non-eop */if (igb_is_non_eop(rx_ring, rx_desc))continue;/* verify the packet layout is correct */if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {skb = NULL;continue;}/* probably a little skewed due to removing CRC */total_bytes += skb->len;/* populate checksum, timestamp, VLAN, and protocol */igb_process_skb_fields(rx_ring, rx_desc, skb);napi_gro_receive(&q_vector->napi, skb);/* reset skb pointer */skb = NULL;/* update budget accounting */total_packets++;} while (likely(total_packets < budget));...
}
igb_fetch_rx_buffer和igb_is_non_eop的作用就是把数据帧从RingBuffer取下来。skb被从RingBuffer取下来以后,会通过igb_alloc_rx_buffers申请新的skb再重新挂上去
为什么需要两个函数呢?因为有可能数据帧要占用多个RingBuffer,所以是在一个循环里获取的,直到帧尾部。获取的一个数据帧用一个sk_buff来表示。收取完数据后,对其进行一些校验,然后开始设置skb变量的timestamp、VLAN id、protocol等字段。接下来进入napi_gro_receive函数
// net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{skb_gro_reset_offset(skb);return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
dev_gro_receive这个函数代表的是网卡GRO特性,可以简单理解成把相关的小包合并成一个大包,目的是减少传给网络栈的包数,有助于减少对CPU的使用量。napi_skb_finish这个函数主要就是调用netif_receive_skb
// net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb)
{switch (ret) {case GRO_NORMAL:if (netif_receive_skb(skb))ret = GRO_DROP;break;...
}
在netif_receive_skb中,数据包将被送到协议栈中
3)网络协议栈处理
netif_receive_skb函数会根据包的协议进程处理,假如是UDP包,将包依次送到ip_rcv、udp_rcv等协议处理函数中进行处理,如下图所示:

// net/core/dev.c
int netif_receive_skb(struct sk_buff *skb)
{// RPS处理逻辑,先忽略...return __netif_receive_skb(skb);
}static int __netif_receive_skb(struct sk_buff *skb)
{int ret;if (sk_memalloc_socks() && skb_pfmemalloc(skb)) {unsigned long pflags = current->flags;current->flags |= PF_MEMALLOC;ret = __netif_receive_skb_core(skb, true);tsk_restore_flags(current, pflags, PF_MEMALLOC);} elseret = __netif_receive_skb_core(skb, false);return ret;
}static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{...// pcap逻辑,这里会将数据送入抓包点.tcpdump就是从这个入口获取包的list_for_each_entry_rcu(ptype, &ptype_all, list) {if (!ptype->dev || ptype->dev == skb->dev) {if (pt_prev)ret = deliver_skb(skb, pt_prev, orig_dev);pt_prev = ptype;}}...type = skb->protocol;list_for_each_entry_rcu(ptype,&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {if (ptype->type == type &&(ptype->dev == null_or_dev || ptype->dev == skb->dev ||ptype->dev == orig_dev)) {if (pt_prev)ret = deliver_skb(skb, pt_prev, orig_dev);pt_prev = ptype;}}...
}
__netif_receive_skb_core函数中取出protocol,它会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表。ptype_base是一个哈希表,在前面的“协议栈注册”部分提到过。ip_rcv函数地址就是存在着哈希表中的
// net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb,struct packet_type *pt_prev,struct net_device *orig_dev)
{...return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
pt_prev->func这一行就调用到了协议层注册的处理函数。对于IP包来说,就会进入ip_rcv(如果是ARP包,会进入arp_rcv)
4)IP层处理
再来看看Linux在IP层都做了什么,包又是怎样进一步被送到UDP或TCP处理函数中的。下面是IP层接收网络包的主入口ip_rcv
// net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{...return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,ip_rcv_finish);...
}
这里的NF_HOOK是一个钩子函数,就是iptables netfilter过滤
当执行完注册的钩子后就会执行到最后一个参数指向的函数ip_rcv_finish
// net/ipv4/ip_input.c
static int ip_rcv_finish(struct sk_buff *skb)
{...if (!skb_dst(skb)) {int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,iph->tos, skb->dev);...}}...return dst_input(skb);...
}
跟踪ip_route_input_noref后看到它又调用了ip_route_input_mc。在ip_route_input_mc中,函数ip_local_deliver被赋值给了dst.input
// net/ipv4/route.c
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev, int our)
{...if (our) {rth->dst.input= ip_local_deliver;rth->rt_flags |= RTCF_LOCAL;}...
}
所以回到ip_rcv_finish中调用的dst_input函数
// include/net/dst.h
static inline int dst_input(struct sk_buff *skb)
{return skb_dst(skb)->input(skb);
}
skb_dst(skb)->input(skb)调用的input方法就是路由子系统赋值的ip_local_deliver
// net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb)
{/** Reassemble IP fragments.*/if (ip_is_fragment(ip_hdr(skb))) {if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))return 0;}return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,ip_local_deliver_finish);
}static int ip_local_deliver_finish(struct sk_buff *skb)
{...{int protocol = ip_hdr(skb)->protocol;const struct net_protocol *ipprot;...ipprot = rcu_dereference(inet_protos[protocol]);if (ipprot != NULL) {int ret;...ret = ipprot->handler(skb);...} else {...}}...
}
如协议栈注册部分所讲,inet_protos中保存着tcp_v4_rcv和udp_rcv的函数地址。这里将会根据包中的协议类型选择转发,在这里skb包将会进一步被派送到更上层的协议中(UDP和TCP)
4)、收包小结
首先在开始收包之前,Linux要做许多的准备工作:
- 创建ksoftirqd线程,为它设置好它自己的线程函数,后面由它来处理软中断
- 协议栈注册,Linux要实现需要协议,比如ARP、ICMP、IP、UDP和TCP,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数
- 网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的DMA准备好,把NAPI的poll函数地址告诉内核
- 启动网卡,分配RX、TX队列,注册中断对应的处理函数
以上是内核准备收包之前的重要工作,当上面这些都准备好之后,就可以打开硬中断,等待数据包的到来了
当数据到来以后,第一个迎接它的是网卡:
- 网卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知
- CPU响应中断请求,调用网卡启动时注册的中断处理函数
- 中断处理函数几乎没干什么,只发起了软中断请求
- 内核线程ksoftirqd发现有软中断请求到来,先关闭硬中断
- ksoftirqd线程开始调用驱动的poll函数收包
- poll函数将收到的包送到协议栈注册的ip_rcv函数中
- 如果是UDP包,ip_rcv函数将包送到udp_rcv函数中(对于TCP包是送到tcp_rcv_v4)
推荐阅读:
Linux中断:Linux 中断(IRQ/softirq)基础:原理及内核实现(2022)
DMA:DMA原理介绍
NAPI机制:Linux网络协议栈:NAPI机制与处理流程分析(图解)
MSI-X中断:PCIe扫盲——两种中断传递方式/三种中断机制(INTx/MSI/MSI-X)
网卡GRO:常见网络加速技术浅谈(二)
RPS处理:一文搞懂内核网络中的GRO/RFS/RPS调优
pcap逻辑:libpcap实现机制及接口函数
相关文章:
深入理解Linux网络笔记(一):内核是如何接收网络包的
本文为《深入理解Linux网络》学习笔记,使用的Linux源码版本是3.10,网卡驱动是Intel的igb网卡驱动 Linux源码在线阅读:https://elixir.bootlin.com/linux/v3.10/source 1、内核是如何接收网络包的 1)、Linux网络收包总览 在TCP/I…...

android系统目录结构
文章目录 android系统目录结构问答偏好设置保存在哪里在应用设置中点击清除数据,清除的是什么在应用设置中点击清除缓存,清除的是什么 参考 android系统目录结构 /- system (一般只有root权限才能访问)- data- app (存放应用程序的 APK 文件…...
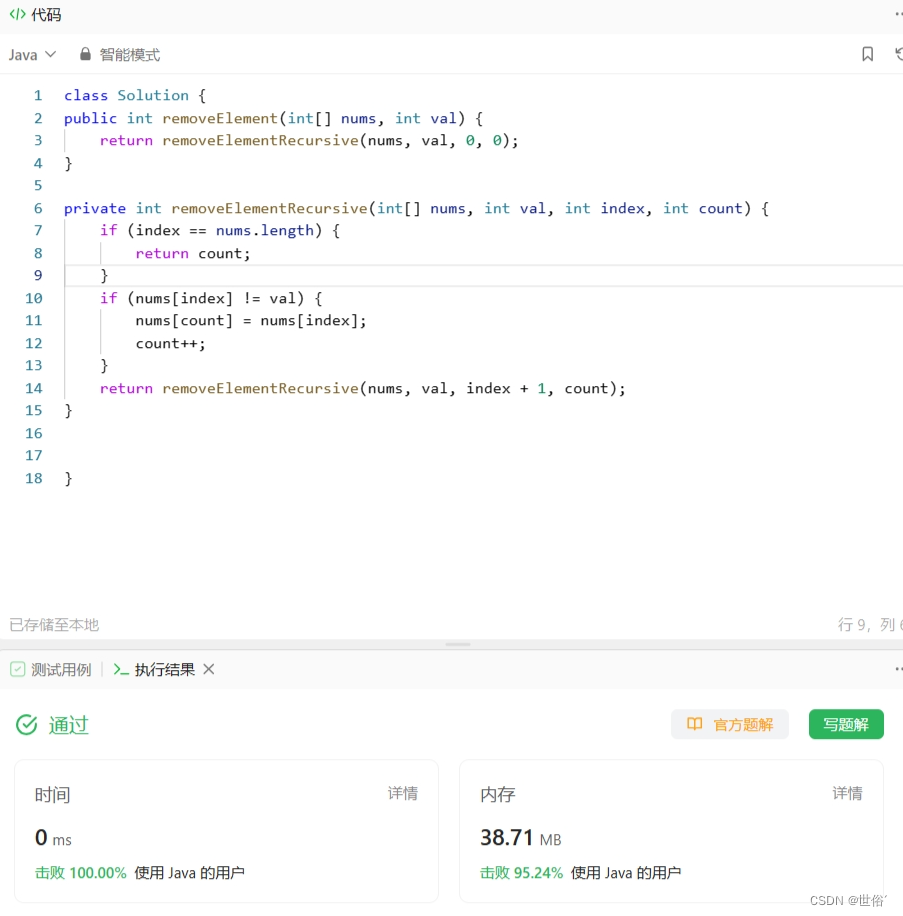
怒刷LeetCode的第11天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:迭代 方法二:递归 方法三:指针转向 第二题 题目来源 题目内容 解决方法 方法一:快慢指针 方法二:Arrays类的sort方法 方法三:计数器 方法四…...

CentOS LVM缩容与扩容步骤
为VM打快照;备份home数据;# yum install xfsdump -y [root@testCentos7 home]# xfsdump -f /dev/home.dump /home xfsdump: using file dump (drive_simple) strategy xfsdump: version 3.1.7 (dump format 3.0) - type ^C for status and control ===================…...

开发者福利!李彦宏将在百度世界大会手把手教你做AI原生应用
目录 一、写在前面 二、大模型社区 2.1 加入频道 2.2 创建应用 一、写在前面 1. “把最先进的技术用到极致,把最先进的应用做到极致。” 2. “每个产品都在热火朝天地重构,不断加深对AI原生应用的理解。” 3. “这就是真正的AI原生应用,这…...
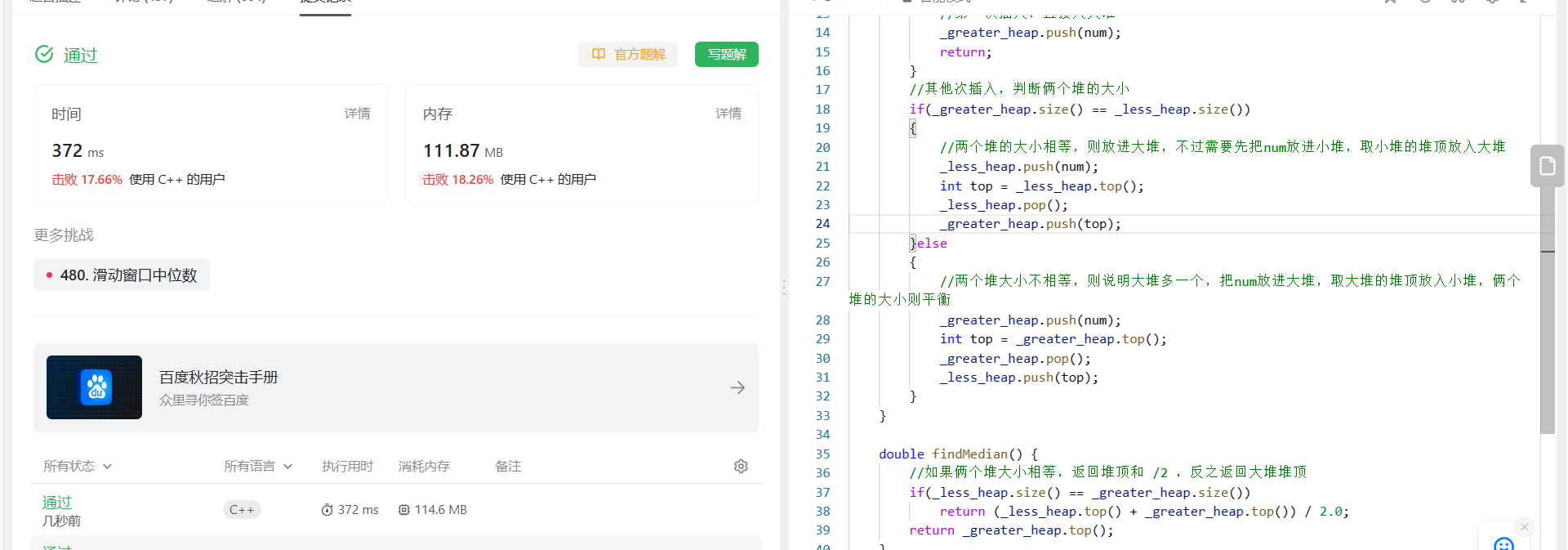
堆的OJ题
🔥🔥 欢迎来到小林的博客!! 🛰️博客主页:✈️林 子 🛰️博客专栏:✈️ 小林的算法笔记 🛰️社区 :✈️ 进步学堂 &am…...

物联网网关:连接设备与云端的桥梁
物联网网关作为连接设备与云端的桥梁,承担着采集数据、设备远程控制、协议转换、数据传输等重要任务。物联网网关是一种网络设备,它可以连接多个物联网设备,实现设备之间的数据传输和通信。物联网网关通常具有较高的网络带宽和处理能力&#…...

ChatGPT企业版来了,速度翻倍,无使用限制
美国时间8月28日,OpenAI宣布了自ChatGPT推出以来最重大的新闻:将推出ChatGPT企业版,企业版ChatGPT将直接对接GPT-4,提供无限制访问、高级数据分析功能、定制服务等服务,并支持处理更长文本输入的长上下文窗口。 OpenAI…...

opencv图像像素类型转换与归一化
文章目录 opencv图像像素类型转换与归一化1、为什么对图像像素类型转换与归一化2、在OpenCV中,convertTo() 和 normalize() 是两个常用的图像处理函数,用于图像像素类型转换和归一化;(1)convertTo() 函数用于将一个 cv…...
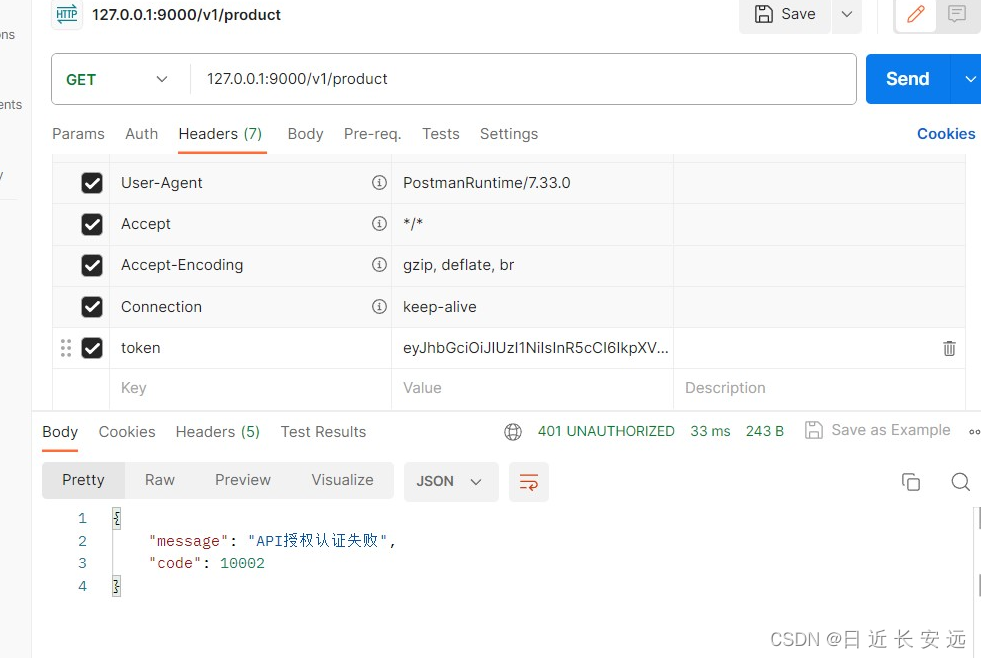
【自学开发之旅】Flask-前后端联调-异常标准化返回(六)
注册联调: 前端修改: 1.修改请求向后端的url地址 文件:env.development修改成VITE_API_TARGET_URL http://127.0.0.1:9000/v1 登录:token验证 校验forms/user.py from werkzeug.security import check_password_hash# 登录校验…...
springcloud3 分布式事务解决方案seata之XA模式4
一 seata的模式 1.1 seata的几种模式比较 Seata基于上述架构提供了四种不同的分布式事务解决方案: XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入 TCC模式:最终一致的分阶段事务模式,有…...
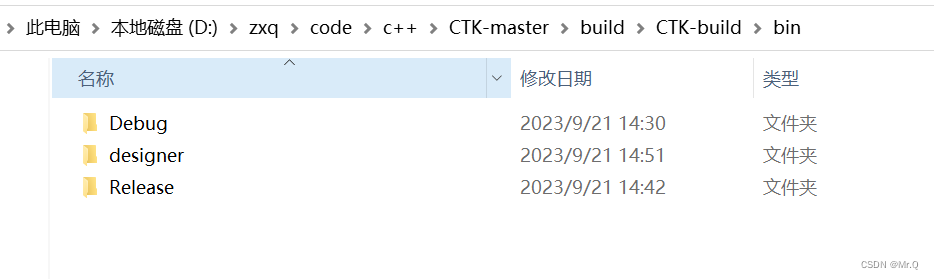
编译ctk源码
目录 前景介绍 下载The Common Toolkit (CTK) cmake-gui编译 vs2019生成 debug版本 release版本 前景介绍 CTK(Common Toolkit)是一个用于医学图像处理和可视化应用程序开发的工具集,具有以下特点: 基于开源和跨平台的Qt框…...
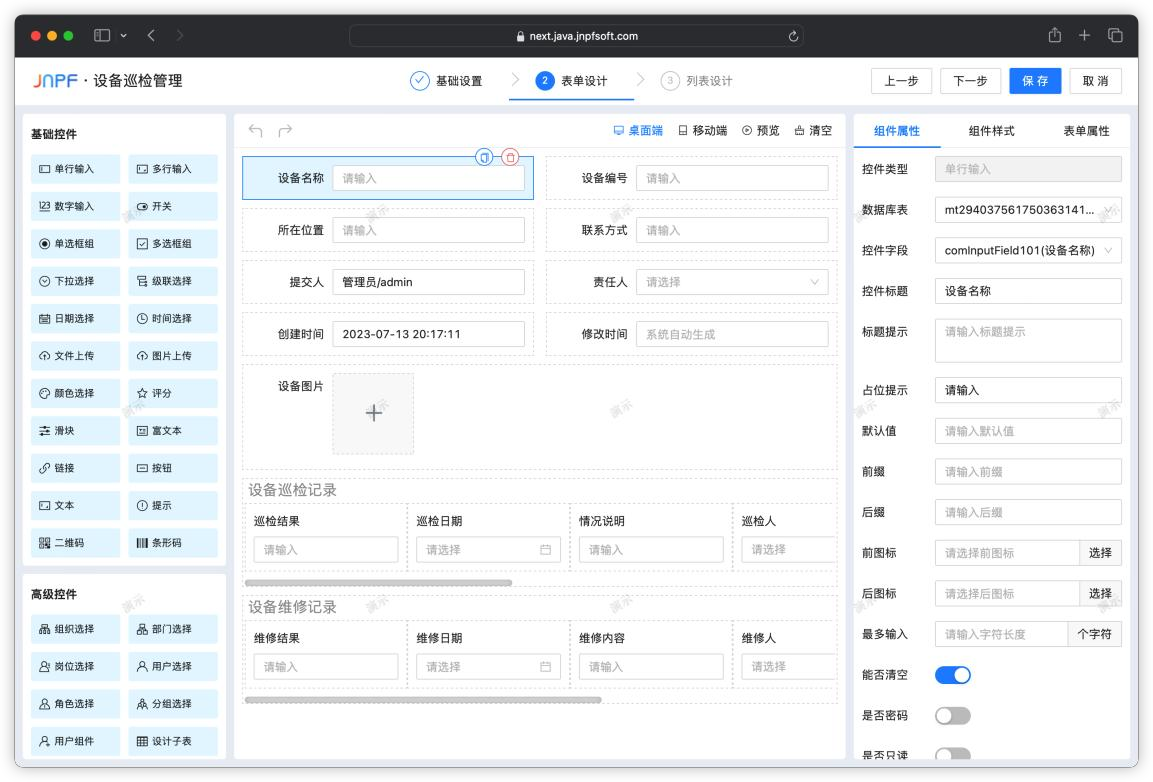
前后端分离的低代码快速开发框架
低代码开发正逐渐成为企业创新的关键工具。通过提高开发效率、降低成本、增强灵活性以及满足不同用户需求,低代码开发使企业能够快速响应市场需求,提供创新解决方案。选择合适的低代码平台,小成本组建一个专属于你的应用。 项目简介 这是一个…...

【Java 基础篇】Java同步代码块解决数据安全
多线程编程是现代应用程序开发中的常见需求,它可以提高程序的性能和响应能力。然而,多线程编程也带来了一个严重的问题:数据安全。在多线程环境下,多个线程同时访问和修改共享的数据可能导致数据不一致或损坏。为了解决这个问题&a…...

亿纬锦能项目总结
项目名称:亿纬锦能 项目链接:https://www.evebattery.com 项目概况: 此项目用到了 wow.js/slick.js/swiper-bundle.min.js/animate.js/appear.js/fullpage.js以及 slick.css/animate.css/fullpage.css/swiper-bundle.min.css/viewer.css 本项目是一种…...
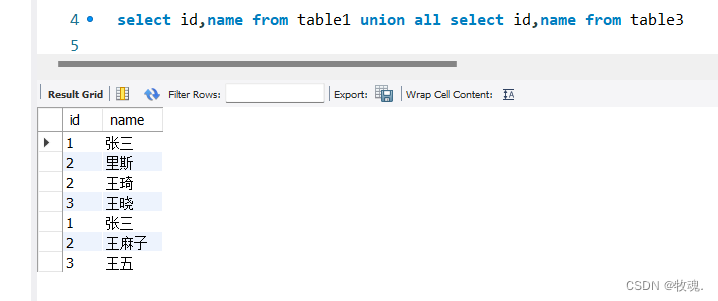
简明 SQL 组合查询指南:掌握 UNION 实现数据筛选
在SQL中,组合查询是一种将多个SELECT查询结果合并的操作,通常使用UNION和UNION ALL两种方式。 UNION 用于合并多个查询结果集,同时去除重复的行,即只保留一份相同的数据。UNION ALL 也用于合并多个查询结果集,但不去除…...

【springMvc】自定义注解的使用方式
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》 ⛺️ 生活的理想,为了不断更新自己 ! 1.前言 1.1.什么是注解 Annontation是Java5开始引入的新特征,中文名称叫注解。 它提供了一种安全…...
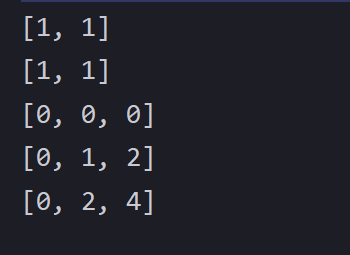
求二维子数组的和(剖析)
文章目录 🐒个人主页🏅JavaSE系列专栏📖前言:本篇剖析一下二维子数组求和规则: 🐒个人主页 🏅JavaSE系列专栏 📖前言:本篇剖析一下二维子数组求和 规则: 这…...
代码开发思路介绍)
无(低)代码开发思路介绍
无代码或者低代码开发的思路,是通过非编程代码,而是基于页面拖拉拽的方式来实现创建web应用的功能。 作为程序员我们知道私有云公有云已经实现了基础设施的web方式管理。DEVOPS把代码发布,管理也实现了web方式管理。那么我们很容易能够想到,只要把拖拉拽出来的项目自动化部…...

代码随想录刷题 Day14
144.二叉树的前序遍历(opens new window) 要注意下创建函数参数传递不是很理解 class Solution { public:void tranversal(TreeNode* s, vector<int> &b) {if (s NULL) {return;}b.push_back(s->val);tranversal(s->left, b);tranversal(s->right, b);}v…...

革新性植物大战僵尸全能修改工具:重定义游戏体验
革新性植物大战僵尸全能修改工具:重定义游戏体验 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 植物大战僵尸辅助工具PVZ Toolkit是一款专为经典游戏《植物大战僵尸》PC版设计的开源修…...

如何一站式管理Mac周边所有设备的电池电量:AirBattery终极指南
如何一站式管理Mac周边所有设备的电池电量:AirBattery终极指南 【免费下载链接】AirBattery Get the battery level of all your devices on your Mac and put them on the Dock / Status Bar / Widget! && 在Mac上获取你所有设备的电量信息并显示在Dock / …...

MOOTDX终极指南:Python通达信数据接口让量化分析变得简单高效
MOOTDX终极指南:Python通达信数据接口让量化分析变得简单高效 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 你是否曾为获取股票数据而烦恼?面对复杂的API接口和繁琐的数据…...

手把手教你用Llama-3.2V-11B-cot:像聊天一样轻松实现图片智能分析
手把手教你用Llama-3.2V-11B-cot:像聊天一样轻松实现图片智能分析 1. 引言:当视觉大模型遇上聊天式交互 想象一下,你正面对一张复杂的医学影像或工程图纸,需要快速理解其中的关键信息。传统方法可能需要专业培训或反复查阅资料&…...

三步打造清爽Mac菜单栏:Dozer终极隐藏方案
三步打造清爽Mac菜单栏:Dozer终极隐藏方案 【免费下载链接】Dozer Hide menu bar icons on macOS 项目地址: https://gitcode.com/gh_mirrors/do/Dozer 还在为Mac菜单栏上拥挤不堪的图标感到困扰吗?想要一个简洁高效的工作界面?Dozer正…...
)
别光看公式了!用Multisim 14.0手把手仿真这8个经典运放电路(附工程文件)
别光看公式了!用Multisim 14.0手把手仿真这8个经典运放电路(附工程文件) 在电子工程的学习过程中,运算放大器(Op-Amp)无疑是一个让人又爱又恨的存在。爱的是它强大的功能和广泛的应用,恨的是那些…...
)
H3C交换机vlan隔离常见配置错误排查指南(附HCL模拟器案例)
H3C交换机VLAN隔离配置实战:从原理到排错的深度指南 在当今企业网络架构中,VLAN隔离技术已经成为网络分段和安全策略的基础支柱。作为网络管理员,我们经常需要在H3C交换机上配置VLAN隔离来实现不同部门或业务单元之间的逻辑隔离。然而&#…...

nlp_structbert_sentence-similarity_chinese-large赋能微信小程序:实现文本查重功能
nlp_structbert_sentence-similarity_chinese-large赋能微信小程序:实现文本查重功能 最近和一位做在线教育的朋友聊天,他提到一个挺头疼的问题:批改学生作文时,经常发现不同学生提交的作业内容高度相似,甚至有大段雷…...

Nunchaku FLUX.1-dev 文生图技术解析:卷积神经网络在图像生成中的角色
Nunchaku FLUX.1-dev 文生图技术解析:卷积神经网络在图像生成中的角色 最近在尝试各种文生图模型时,Nunchaku FLUX.1-dev 的表现让我印象深刻。它生成的图片不仅细节丰富,而且风格多样,从写实到抽象都能驾驭得很好。这让我不禁好…...

LeetCode 1089 复写零:用双指针从后往前填,保姆级图解避坑指南
LeetCode 1089 复写零:双指针逆向填充的视觉化拆解与实战避坑 当你第一次看到LeetCode 1089题时,可能会觉得"复写零"这个操作听起来简单——不就是遇到0就多写一个吗?但真正动手实现时,很多人会在指针移动、边界处理和数…...