Elasticsearch:使用 pipelines 路由文档到想要的 Elasticsearch 索引中去

路由文件
当应用程序需要向 Elasticsearch 添加文档时,它们首先要知道目标索引是什么。在很多的应用案例中,特别是针对时序数据,我们想把每个月的数据写入到一个特定的索引中。一方面便于管理索引,另外一方面在将来搜索的时候可以按照每个月的索引来进行搜索,这样速度更快,更便捷。
当你处于某种类型的文档总是转到特定索引的琐碎情况时,这似乎很明显,但当你的索引名称可能根据杂项参数(无论它们是否在你的系统外部 - 当前例如日期 - 或者你尝试存储的文档的固有属性 - 大多数时候是文档字段之一的值)。
当发生最后一种情况时(我们指的是索引名称可以变化的情况),在向 Elasticsearch 发出索引命令之前,你的应用程序需要计算目标索引的名称。
此外 —— 即使一开始这看起来像是一种反模式 —— 你可以有多个应用程序需要在索引中索引相同类型的文档,这些文档的名称可能会发生变化。 现在你必须维护跨多个组件重复的索引名称计算逻辑:就可维护性和敏捷性而言,这不是好消息。
Logstash —— Elastic Stack 的一个知名成员 —— 可以帮助集中这样的逻辑,但代价是维护另一个正在运行的软件,这需要配置、知识等。
我们想要在本文中展示的是通过将索引名称计算委托给 Elasticsearch 而不是我们的应用程序来解决此问题的解决方案。
Date index name processor 介绍
该处理器的目的是通过使用日期数学索引名称支持,根据文档中的日期或时间戳字段将文档指向基于正确时间的索引。
处理器根据提供的索引名称前缀、正在处理的文档中的日期或时间戳字段以及提供的日期舍入,使用日期数学索引名称表达式设置 _index 元数据字段。
首先,此处理器从正在处理的文档中的字段中获取日期或时间戳。 或者,可以根据字段值应如何解析为日期来配置日期格式。 然后这个日期、提供的索引名称前缀和提供的日期舍入被格式化为日期数学索引名称表达式。 此处还可以选择日期格式指定日期应如何格式化为日期数学索引名称表达式。
将文档指向每月索引的示例管道,该索引以基于 date1 字段中的日期的 my-index-prefix 开头:
PUT _ingest/pipeline/monthlyindex
{"description": "monthly date-time index naming","processors" : [{"date_index_name" : {"field" : "date1","index_name_prefix" : "my-index-","date_rounding" : "M"}}]
}使用该管道进行索引请求:
PUT /my-index/_doc/1?pipeline=monthlyindex
{"date1" : "2016-04-25T12:02:01.789Z"
}上面命令运行的结果是:
{"_index": "my-index-2016-04-01","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1
}上面的请求不会将这个文档索引到 my-index 索引中,而是索引到 my-index-2016-04-01 索引中,因为它是按月取整的。 这是因为 date-index-name-processor 覆盖了文档的 _index 属性。
要查看导致上述文档被索引到 my-index-2016-04-01 中的实际索引请求中提供的索引的日期数学(date-math)值,我们可以使用模拟请求检查处理器的效果。
POST _ingest/pipeline/_simulate
{"pipeline" :{"description": "monthly date-time index naming","processors" : [{"date_index_name" : {"field" : "date1","index_name_prefix" : "my-index-","date_rounding" : "M"}}]},"docs": [{"_source": {"date1": "2016-04-25T12:02:01.789Z"}}]
}上面命令返回结果:
{"docs": [{"doc": {"_index": "<my-index-{2016-04-25||/M{yyyy-MM-dd|UTC}}>","_id": "_id","_version": "-3","_source": {"date1": "2016-04-25T12:02:01.789Z"},"_ingest": {"timestamp": "2023-02-23T01:15:52.214364Z"}}}]
}以上示例显示 _index 设置为 <my-index-{2016-04-25||/M{yyyy-MM-dd|UTC}}>。 Elasticsearch 将其理解为 2016-04-01,如日期数学索引名称文档中所述。
日期索引名称选项
以下是使用 date index name 的一些选项
| 名称 | 必要项 | 默认 | 描述 |
|---|---|---|---|
| field | yes | - | 从中获取日期或时间戳的字段。 |
| index_name_prefix | no | - | 要在打印日期之前添加的索引名称的前缀。 支持模板片段。 |
| date_rounding | yes | - | 将日期格式化为索引名称时如何舍入日期。 有效值是:y(年)、M(月)、w(星期)、d(日)、h(小时)、m(分钟)和 s(秒)。 支持模板片段。 |
| date_formats | no | yyyy-MM-dd'T'HH:mm:ss.SSSXX | 用于解析正在预处理的文档中的日期/时间戳的预期日期格式的数组。 可以是 Java 时间模式或以下格式之一:ISO8601、UNIX、UNIX_MS 或 TAI64N。 |
| timezone | no | UTC | 解析日期时使用的时区以及日期数学索引支持的时间将表达式解析为具体的索引名称。 |
| locale | no | ENGLISH | 从正在预处理的文档中解析日期时使用的语言环境,在解析月份名称或工作日时相关。 |
| index_name_format | no | yyyy-MM-dd | 将解析日期打印到索引名称中时使用的格式。 此处需要一个有效的 Java 时间模式。 支持模板片段。 |
| description | no | - | 处理器的描述。 用于描述处理器的用途或其配置。 |
| if | no | - | 有条件地执行处理器。 请参阅有条件地运行处理器。 |
| ignore_failure | no | false | 忽略处理器的故障。 请参阅处理管道故障。 |
| on_failure | no | - | 处理处理器的故障。 请参阅处理管道故障。 |
| tag | no | - | 处理器的标识符。 用于调试和指标 |
使用案例 - 基于时间的时序索引
这是一个众所周知的用例,通常在您要处理日志时发现。这个想法是索引文档,索引的名称由根名称和根据日志事件的日期计算的值组成。 该日期实际上是你要索引的文档的一个字段。
这不是本文的重点,但以这种方式索引文档有几个优点,包括更容易的数据管理、启用冷/暖架构等。让我们举个例子。
假设我们必须处理来自多个来源的数据 —— 例如物联网。 我们的每个对象每分钟都会向不同的后端发送一些数据(是的,这真的很可悲,但我们的对象不通过相同的网络进行通信,因此选择通过多个系统来处理这个问题)。
对象发送的数据被转换成如下所示的 JSON 文档:
POST data/_doc?pipeline=compute-index-name
{"objectId": 1234,"manufacturer": "SHIELD","payload": "some_data","date": "2019-04-01T12:10:30.000Z"
}我们有一个用于传输数据的对象的 UID、一个制造商 ID、一个有效负载部分和一个日期字段。
索引名称计算
假设我们要将对象的数据存储在名为 data-{YYYYMMDD} 的索引中,其中根名称是数据后跟日期模式。基于上面的例子,后端收到这个文档应该怎么办呢?
首先它必须解析它以提取日期字段的值,然后它必须根据它在文档中找到的日期计算目标索引名称。 最后,它向 Elasticsearch 向刚刚计算出名称的索引发出索引请求。
document.date = "2019-04-01T12:10:30Z"
index.name = "data-" + "20190401"在我们的例子中,我们有几个后端必须知道如何计算索引名称,因此必须知道索引的命名逻辑。
如果索引名的计算直接由 Elasticsearch 进行,岂不是更聪明?
Ingest pipeline 的力量

从 Elasticsearch 的第 5 版开始,我们现在有了一种称为摄取的节点。默认情况下,集群的所有节点都具有 ingest 类型。这些节点有权在索引文档之前执行所谓的管道。 管道是一组处理器,每个处理器都可以以某种特定方式转换输入文档。当一个文档被摄入到 Elasticsearch 集群时,它的工作流是这样的。
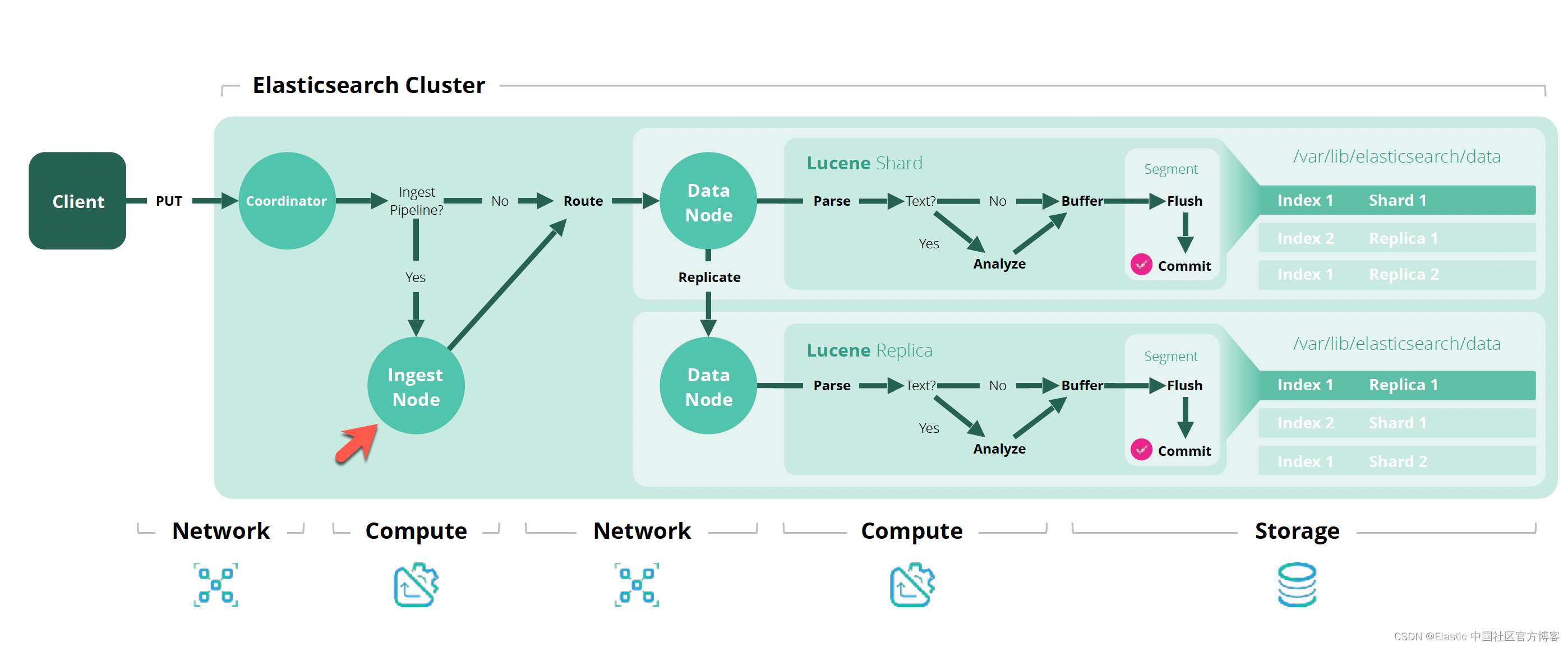
从上面,我们可以看出来,在文档被写入之前,它必须经过 ingest node 进行处理。我们可以通过 date index name processor 来获得我们想要的 index 名称,进而写入到我们想要的索引中去。 这里有用的是,管道不仅可以转换文档的固有数据,还可以修改文档元数据,特别是它的 _index 属性。
现在让我们回到我们的例子。我们建议定义一个管道来完成这项工作,而不是将索引名称计算委托给应用程序。根据文档,此处理器允许你定义包含日期的字段名称、索引的根名称(前缀)以及计算附加到此前缀的日期的舍入方法。
如果我们想将 IoT 数据添加到模式为 data-{YYYYMMDD} 的索引中,我们只需创建如下所示的管道:
PUT _ingest/pipeline/compute-index-name
{"description": "Set the document destination index by appending a prefix and its 'date' field","processors": [{"date_index_name": {"field": "date","index_name_prefix": "data-","date_rounding": "d","index_name_format": "yyyyMMdd"}}]
}一个索引 = 一个管道?
好的,现在我们知道如何定义一个管道来为特定的目标索引建立一个名称。 但是我们可以通过操纵文档元数据来做更多的事情!
假设我们有不同类型的文档,每个文档都有一个日期字段,但需要在不同的索引中进行索引。计算目标索引名称的逻辑对于每种文档类型都是相同的,但使用上述策略将导致创建多个管道。
让我们试着做一些更简单和可重用的东西。
回到我们的示例,我们现在有两种文档类型:一种需要在 adata-{YYYYMMDD} 索引(和以前一样)中建立索引,另一种其目的地是名为 new_data-{YYYYMMDD} 的索引。
目标为 new_data 的文档具有以下结构:
{"newObjectId": 1234,"source": "HYDRA","payload": "some_data","date": "2019-04-02T13:10:30.000Z"
}该结构与标准 IoT 文档略有不同,但重要的是日期字段存在于两个映射中。
现在我们要定义一个管道来计算我们两种文档类型的目标索引。 我们所要做的就是通过分析通过索引 API 发出的请求目的地来构建目的地索引名称。
PUT _ingest/pipeline/compute-index-name
{"description": "Set the document destination index by appending the requested index and its 'date' field","processors": [{"date_index_name": {"field": "date","index_name_prefix": "{{ _index }}-","date_rounding": "d","index_name_format": "yyyyMMdd"}}]
}请注意,索引名称前缀现在位于名为_index 的索引元数据字段中。 通过使用这个字段,我们的管道现在是通用的并且可以与任何索引一起使用 —— 假设目标索引是根据相同的规则计算的。
使用我们的 “路由” 管道
现在我们有了一个能够根据文档的日期字段计算目标索引名称的通用管道,让我们看看如何让 Elasticsearch 使用它。
我们可以通过两种方式告诉 Elasticsearch 使用管道,让我们评估一下。
Index API 调用
第一个 —— 也是直接的解决方案——是使用 Index API 的管道参数。
换句话说:每次你想索引一个文档,你必须告诉 Elasticsearch 要使用的管道。
POST data/_doc?pipeline=compute-index-name
{"objectId": 1234,"manufacturer": "SHIELD","payload": "some_data","date": "2019-04-01T12:10:30.000Z"
}现在,每次我们通过指示 compute-index-name 管道将文档添加到索引中时,该文档将被添加到正确的基于时间的索引中。 在此示例中,目标索引将为 data-20190401 。
我们提供给 Index API 的 data 索引名称呢? 它可以被看作是一个假索引:它只是用来执行 API 调用并且是真正目标索引的根,它不一定存在!
默认管道:引入 “虚拟索引”
索引默认管道(default pipeline)是使用管道的另一种有用方式:当你创建索引时,有一个名为 index.default_pipeline 的设置可以设置为管道的名称,只要你将文档添加到相应的索引就会执行该管道并且没有管道被添加到 API 调用中。 你还可以在索引文档时使用特殊管道名称 _none 来绕过此默认索引。 通过使用此功能,你可以定义我称之为 “虚拟索引” 的内容,并将其与默认管道相关联,该默认管道将充当我们上面看到的路由管道。
让我们将其应用到我们的示例中。
我们假设我们的通用路由管道 compute-index-name 已经创建。 我们现在可以创建一个名为 data 的索引,它将使用此管道作为其默认管道。
PUT data
{"settings" : {"index" : {"number_of_shards" : 3, "number_of_replicas" : 1,"default_pipeline" : "compute-index-name"}}
}现在,每次我们要求 Elasticsearch 为数据索引中的文档编制索引时,计算索引名称管道将负责该文档的实际路由。 因此,数据索引中永远不会有单个文档被索引,但我们将调用管道的责任完全委托给 Elasticsearch。
运行完上面的命令后,我们来尝试写入一个文档:
POST data/_doc
{"objectId": 1234,"manufacturer": "SHIELD","payload": "some_data","date": "2019-04-01T12:10:30.000Z"
}上面的命令返回的结果是:
{"_index": "data-20190401","_id": "2DMGfIYBaog4blQ55Qr7","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1
}结论
我们刚刚在这里看到了如何利用 Elasticsearch 中的管道功能根据文档的固有属性来路由文档。Ingest pipeline 不仅仅可以替代 Logstash 过滤器:你可以定义复杂的管道,使用多个处理器(一个特定的处理器甚至允许你调用另一个管道)、条件等。有关 ingest pipeline 的更多文章,请参阅 “Elastic:开发者上手指南” 文章中的 “Ingest pipeline” 章节。
在我看来,本文末尾看到的 “虚拟索引” 非常有趣。 包含创建这样一个并非真正的索引的索引只是为了创建路由管道的入口点的功能甚至可以成为 Elasticsearch 的一个新的和有用的功能,为什么不呢?
相关文章:
Elasticsearch:使用 pipelines 路由文档到想要的 Elasticsearch 索引中去
路由文件 当应用程序需要向 Elasticsearch 添加文档时,它们首先要知道目标索引是什么。在很多的应用案例中,特别是针对时序数据,我们想把每个月的数据写入到一个特定的索引中。一方面便于管理索引,另外一方面在将来搜索的时候可以…...

前端开发常用的18个JavaScript框架和库
JavaScript 可以说是最流行的编程语言之一,也是Web 开发人员必须学习的 3 种语言之一,JavaScript 几乎可以做任何事情,更可以在包括物联网在内的多个平台和设备上运行。在WebGL库和SVG/Canvas元素的支持下,JavaScript变得惊人的强…...

理解、总结重点知识
一、常见的数据结构 1、数组结构 数组结构: 存储区间连续、内存占用严重、空间复杂度大 优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)缺点:插入和删除数据效率低&a…...

记一次从文件备份泄露到主机上线
前言 记录下某个测试项目中,通过一个文件备份泄露到主机上线的过程。 文件备份泄露 对于测试的第一项当然是弱口令,bp跑了一通词典,无果。目录又爆破了一通,发现一个web.rar可通,赶紧下载看看,如下图所示…...

8年测开经验面试28K公司后,吐血整理出1000道高频面试题和答案
1、python的数据类型有哪些 答:Python基本数据类型一般分为:数字、字符串、列表、元组、字典、集合这六种基本数据类型。 浮点型、复数类型、布尔型(布尔型就是只有两个值的整型)、这几种数字类型。列表、元组、字符串都是序列。 2、列表和元组的区别 答…...

Linux 基础知识之权限管理
目录一、权限的认识二、用户切换三、文件权限1.三类文件访问者2.文件权限类型3.文件访问权限4.文件权限值表示一、权限的认识 权限是对用户所能进行的操作的限制,如果不对用户作出限制,那么碰到恶意用户,就会损害其他用户的利益。 Linux是多用…...

百度LAC分词
对应数据的链接放这里了 import pandas as pd from util.logger import Log import os from util.data_dir import root_dir from LAC import LAC os_file_name os.path.split(os.path.realpath(__file__))[-1]# 加载LAC模型 lac LAC(mode"lac") # 载入自定义词典 …...

软件测试面试题 —— 整理与解析(1)
😏作者简介:博主是一位测试管理者,同时也是一名对外企业兼职讲师。 📡主页地址:🌎【Austin_zhai】🌏 🙆目的与景愿:旨在于能帮助更多的测试行业人员提升软硬技能…...

深入浅出C++ ——红黑树模拟实现STL中的set与map
文章目录一、红黑树二、用泛型红黑树模拟实现set三、用泛型红黑树模拟实现map一、红黑树 红黑树作为set和map的底层容器,既要实现插入key又要实现插入pair,所以做了稍许的改动,使其成为一颗泛型结构的红黑树,通过不同的实例化参数…...

自动化测试框架设计
大数据时代,多数的web或app产品都会使用第三方或自己开发相应的数据系统,进行用户行为数据或其它信息数据的收集,在这个过程中,埋点是比较重要的一环。 埋点收集的数据一般有以下作用: 驱动决策:ABtest、漏…...
【虚拟仿真】Unity3D中实现鼠标的单击、双击、拖动的不同状态判断
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 这篇文章分享一下虚拟仿真项目中经常碰到鼠标事件控制代码。 …...
【2023】Prometheus-相关知识点(面试点)
目录1.Prometheus1.1.什么是Prometheus1.2.Prometheus的工作流程1.3.Prometheus的组件有哪些1.4.Prometheus有什么特点1.5.Metric的几种类型?分别是什么?1.6.Prometheus的优点和缺点1.7.Prometheus怎么采集数据1.8.Prometheus怎么获取采集对象1.9.Promet…...
英语二-电子邮件邀请短文写作
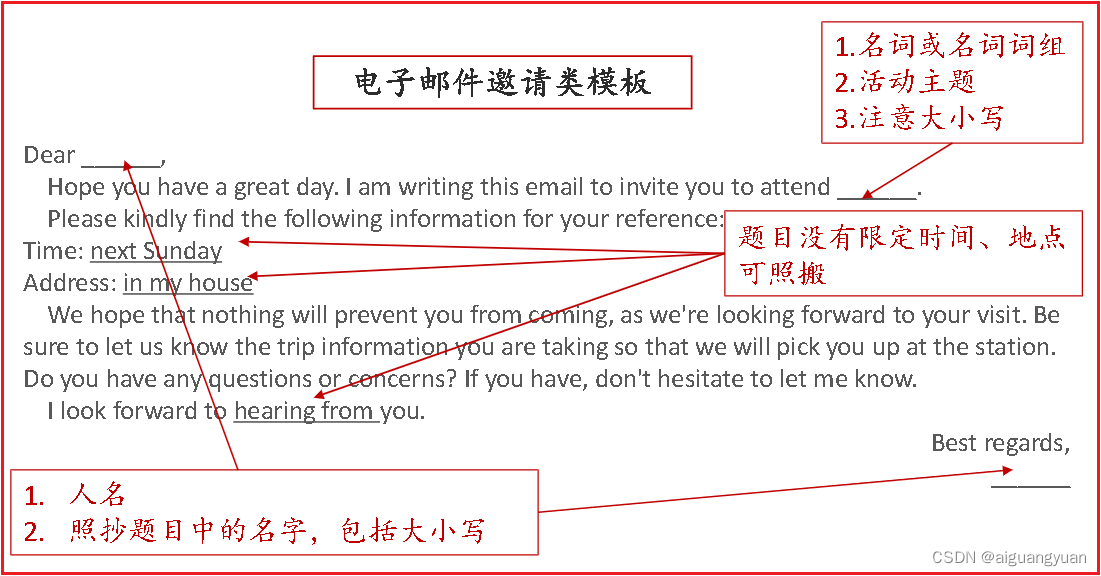
1. 邮件模板 Dear 邀请人, Hope you have a great day. I am writing this email to invite you to attend 主题. Please kindly find the following information for your reference: Time: 时间 Address: 地点 We hope that nothing will prevent you from coming, as…...

如何快速一次性通过pmp考试?
我们就从三个方向进行了解 1.PMP考试难不难? 2.PMP如何备考? 3.考试过程中需要注意什么? 一,PMP考试难不难? 首先关注的问题是,PMP考试难吗?我想全球55%的通过率和学会这边93.9%的通过率&a…...

1-Linux 保存kernel panic信息到flash
在系统运行过程中,如果内核发生了panic,那么开发人员需要通过内核报错日志来进行定位问题。但是很多时候出现问题的时候没有接调试串口,而报错日志是在内存里面的,重启后就丢失了。所以需要一种方法,可以在系统发生crash时&#x…...

linux基本功系列-top命令实战
文章目录一. top命令介绍二. 语法格式及常用选项三. 参考案例3.1 显示进程信息3.2 显示完整的进程命令3.3 以批处理的形式展示3.4 设置信息更新频次3.5 显示指定进程号的信息3.6 top面板中常用参数3.7 其他用法四. top的相关说明4.1 交互命令介绍4.2 top面板每行信息的含义4.2.…...

6.5 拓展:如何实现 Web API 版本控制,同时兼容无版本控制的原始接口?
第6章 构建 RESTful 服务 6.1 RESTful 简介 6.2 构建 RESTful 应用接口 6.3 使用 Swagger 生成 Web API 文档 6.4 实战:实现 Web API 版本控制 6.5 拓展:如何实现 Web API 版本控制,同时兼容无版本控制的原始接口? 6.5 拓展&#…...

Springboot依赖注入Bean的三种方式,final+构造器注入Bean
文章目录Springboot依赖注入Bean的方式一、Field 注入/属性注入二、set注入三、构造器注入Springboot依赖注入Bean的方式 一、Field 注入/属性注入 Autowired注解的一大使用场景就是Field Injection。 Controller public class UserController {Autowiredprivate UserServic…...
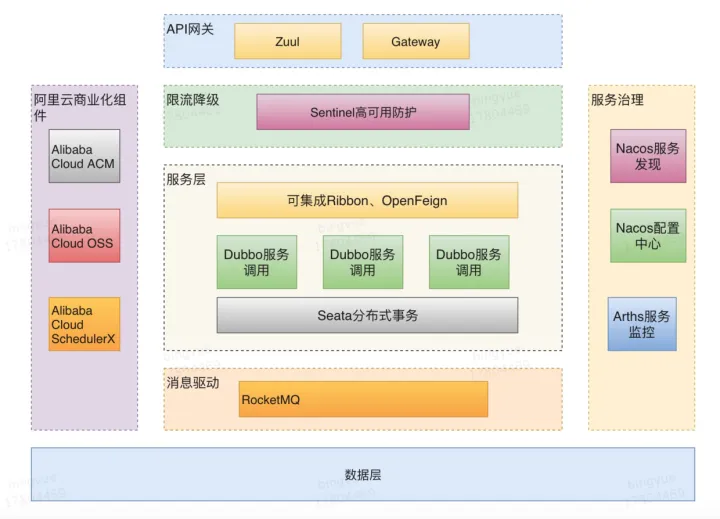
【java】Spring Cloud --Spring Cloud Alibaba 微服务解决方案
文章目录1、Spring Cloud Alibaba 是什么先说说 Spring CloudSpring Cloud Alibaba和Spring Cloud 的区别和联系Spring Cloud Alibaba2、Spring Cloud Alibaba 包含组件阿里开源组件阿里商业化组件集成 Spring Cloud 组件3、Spring Cloud Alibaba 功能服务注册与发现支持多协议…...
)
CSS 6种选择器(超详细)
CSS6大种选择器(超详细) 一、常用的css基本选择器(4种) 1、标签选择器 结构: 标签名{css属性名:属性值} 作用:通过标签名,找到页面中所有的这类标签,设置样式 注意:1.标签选择器选择的是一类标签&#…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...